
BAB III OBJEK DAN METODOLOGI PENELITIAN 3
37
28 BAB III OBJEK DAN METODOLOGI PENELITIAN 3.1 Objek Penelitian Penelitian ini menggunakan pendekatan manajemen pemasaran khususnya mengenai intention to online shopping. Variabel adalah segala sesuatu yang memiliki perbedaan atau variasi nilai. Nilai nilai tersebut dapat berbeda untuk berbagai objek atau orang yang sama, atau pada waktu ang sama untuk objek atau orang yang berbeda. Penelitian ini terdapat dua variabel eksogen dan variaebel endogen. Variable eksogen dalam penelitian ini adalah social media influencer (X) yang terdiri dari adalah attractiveness (X1), content (X2), relevant (X3), interaction (X4), expertise (X5), credibility (X6), trust (X7), influence (X8). Variabel endogen dalam penelitian ini adalah intention to online shopping (Y). Objek yang dijadikan responden dalam penelitian ini adalah Perusahaan Focallure. Penelitian ini dilakukan pada kurun waktu kurang dari satu tahun, maka penelitian ini menggunakan teknik data cross-sectional. Menurut Sekaran & Bougie (2016) cross sectional study adalah sebuah studi yang dapat dilakukan dimana data dikumpulkan hanya sekali, dalam periode bulan Februari sampai dengan bulan April, untuk menjawab pertanyaan penelitian. 3.2 Metode Penelitian 3.2.1 Jenis Penelitian dan Metode yang digunakan Berdasarkan pertimbangan tujuan penelitian, maka jenis penelitian yang digunakan adalah penelitian deskriptif dan verifikatif. Menurut (Uma Sekaran & Bougie, 2016) penelitian deskriptif adalah jenis penelitian konklusif yang memiliki tujuan utama mendeskripsikan sesuatu. Penelitian deskritif dilakukan untuk mendapatkan deskripsi secara terperinci mengenai gambaran social media influencer yang terdiri dari 1) atttractiveness 2) content 3) relevant 4) interaction 5) expertise 6) credibility 7) trust 8) influence. Penelitian verifikatif menurut (Cooper & Schindler, 2014) adalah suatu penelitian yang mencoba untuk mengungkapkan hubungan kausal antara variabel. Menurut (Sekaran & Bougie, 2016:44) penelitian verifikatif adalah sebuah penelitian yang dilakukan untuk membangun hubungan sebab dan akibat antar variabel. Penelitian verifikatif dilakukan untuk menguji hipotesis dilapangan untuk
Transcript of BAB III OBJEK DAN METODOLOGI PENELITIAN 3

28
BAB III
OBJEK DAN METODOLOGI PENELITIAN
3.1 Objek Penelitian
Penelitian ini menggunakan pendekatan manajemen pemasaran khususnya
mengenai intention to online shopping. Variabel adalah segala sesuatu yang memiliki
perbedaan atau variasi nilai. Nilai nilai tersebut dapat berbeda untuk berbagai objek
atau orang yang sama, atau pada waktu ang sama untuk objek atau orang yang berbeda.
Penelitian ini terdapat dua variabel eksogen dan variaebel endogen. Variable eksogen
dalam penelitian ini adalah social media influencer (X) yang terdiri dari adalah
attractiveness (X1), content (X2), relevant (X3), interaction (X4), expertise (X5),
credibility (X6), trust (X7), influence (X8). Variabel endogen dalam penelitian ini
adalah intention to online shopping (Y).
Objek yang dijadikan responden dalam penelitian ini adalah Perusahaan
Focallure. Penelitian ini dilakukan pada kurun waktu kurang dari satu tahun, maka
penelitian ini menggunakan teknik data cross-sectional. Menurut Sekaran & Bougie
(2016) cross sectional study adalah sebuah studi yang dapat dilakukan dimana data
dikumpulkan hanya sekali, dalam periode bulan Februari sampai dengan bulan April,
untuk menjawab pertanyaan penelitian.
3.2 Metode Penelitian
3.2.1 Jenis Penelitian dan Metode yang digunakan
Berdasarkan pertimbangan tujuan penelitian, maka jenis penelitian yang
digunakan adalah penelitian deskriptif dan verifikatif. Menurut (Uma Sekaran &
Bougie, 2016) penelitian deskriptif adalah jenis penelitian konklusif yang memiliki
tujuan utama mendeskripsikan sesuatu. Penelitian deskritif dilakukan untuk
mendapatkan deskripsi secara terperinci mengenai gambaran social media influencer
yang terdiri dari 1) atttractiveness 2) content 3) relevant 4) interaction 5) expertise 6)
credibility 7) trust 8) influence. Penelitian verifikatif menurut (Cooper & Schindler,
2014) adalah suatu penelitian yang mencoba untuk mengungkapkan hubungan kausal
antara variabel. Menurut (Sekaran & Bougie, 2016:44) penelitian verifikatif adalah
sebuah penelitian yang dilakukan untuk membangun hubungan sebab dan akibat antar
variabel. Penelitian verifikatif dilakukan untuk menguji hipotesis dilapangan untuk

29
memperoleh gambaran mengenai pengaruh social media influencer dan gambaran
mengenai intention to online shopping pada pengikut Focallure di Instagram.
Metode penelitian pada dasarnya merupakan cara ilmiah untuk mendapatkan
data dengan tujuan dan kegunaan memecahkan suatu masalah. (Uma Sekaran &
Bougie, 2016) mendefinisikan metode penelitian sebagai suatu pendekatan umum
untuk mengumpukan data yang menentukan apakah kesimpulan kausal dapat ditarik.
Berdasarkan jenis penelitiannya yaitu verifikatif yang dilaksanakan melalui
pengumpulan data dilapangan, maka metode penelitian ini adalah metode explanatory
survey. Menurut (Malhotra, 2013:250) explanatory survey dilakukan untuk
mengeksplorasi situasi masalah, yaitu untuk mendapatkan ide-ide dan wawasan ke
dalam masalah yang dihadapi manajemen atau para peneliti tersebut. Penelitian yang
menggunakan metode ini, informasi dari seluruh populasi dikumpulkan langsung di
tempat kejadian dengan tujuan untuk mengetahui pendapat dari seluruh populasi
terhadap objek yang sedang diteliti.

30
3.2.2 Operasional Variabel
Operasional variabel adalah proses pengubahan atau penguraian konsep atau konstruk menjadi variabel terukur yang sesuai untuk
pengujian (Cooper & Schindler, 2014). Penelitian ini terdapat variabel yang diteliti yang diantaranya social media influencer sebagai
variabel bebas (X) dengan sub variable Attractiveness (𝑋1), Content (𝑋2), Relevant (𝑋3), Interaction (𝑋4), Expertise (𝑋5), Credibility (𝑋6)
, Trust (𝑋7), Influence (𝑋8) serta intention to online shopping (Y) dengan sub variabel Website Design (𝑌1), Convenience (𝑌2), Enjoyment
(𝑌3), Time Saving (𝑌4), Security (𝑌5), Price (𝑌6) , Product Quality (𝑌7). Secara lengkap dalam penelitian ini, disajikan pada Tabel 3.1 di
bawah ini.
TABEL 3.1
OPERASIONAL VARIABEL
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
Sosial Media Influencer adalah bentuk pemasaran yang mengidentifikasi dan menargetkan individu yang memiliki
pengaruh terhadap pembeli potensial untuk mempengaruhi konsumen lain agar percaya dan ikut melakukan pembelian
yang sama (Pang & a, 2016).
Social Media
Influencer
(X1)14
Attractiveness
(X1)
Daya tarik SMI dalam iklan
dapat mempengaruhi
konsumen untuk merasa
seperti dia dapat mencapai
tampilan yang sama dengan
SMI dengan memiliki produk
yang sama. (Forbes, 2016)
Interest Tingkat ketertarikan
visual pada social media Interval 1
Information
Tingkat kemenarikan
pesan dalam menggali
kaingintahuan
konsumen
Interval 2
Creatif
Tingkat kreatifitas
dalam menarik
perhatian calon
konsumen
3
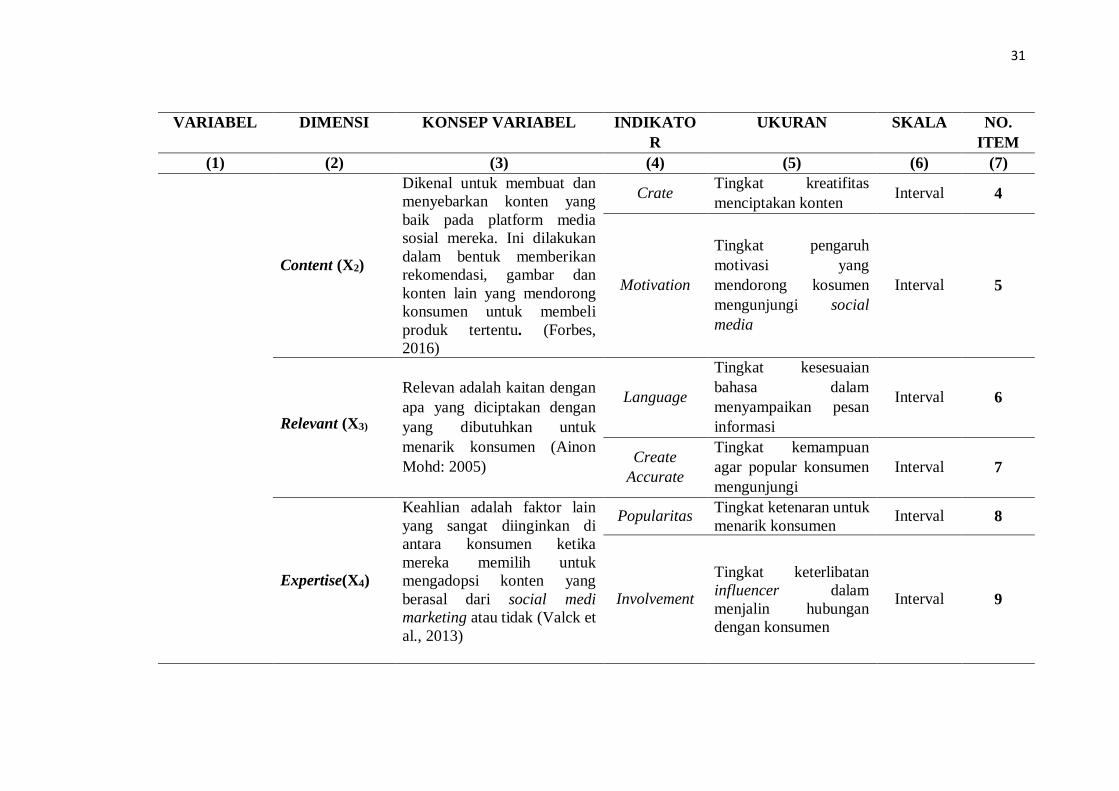
31
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
Content (X2)
Dikenal untuk membuat dan
menyebarkan konten yang
baik pada platform media
sosial mereka. Ini dilakukan
dalam bentuk memberikan
rekomendasi, gambar dan
konten lain yang mendorong
konsumen untuk membeli
produk tertentu. (Forbes,
2016)
Crate Tingkat kreatifitas
menciptakan konten Interval 4
Motivation
Tingkat pengaruh
motivasi yang
mendorong kosumen
mengunjungi social
media
Interval 5
Relevant (X3)
Relevan adalah kaitan dengan
apa yang diciptakan dengan
yang dibutuhkan untuk
menarik konsumen (Ainon
Mohd: 2005)
Language
Tingkat kesesuaian
bahasa dalam
menyampaikan pesan
informasi
Interval 6
Create
Accurate
Tingkat kemampuan
agar popular konsumen
mengunjungi
Interval 7
Expertise(X4)
Keahlian adalah faktor lain
yang sangat diinginkan di
antara konsumen ketika
mereka memilih untuk
mengadopsi konten yang
berasal dari social medi
marketing atau tidak (Valck et
al., 2013)
Popularitas Tingkat ketenaran untuk
menarik konsumen Interval 8
Involvement
Tingkat keterlibatan
influencer dalam
menjalin hubungan
dengan konsumen
Interval 9
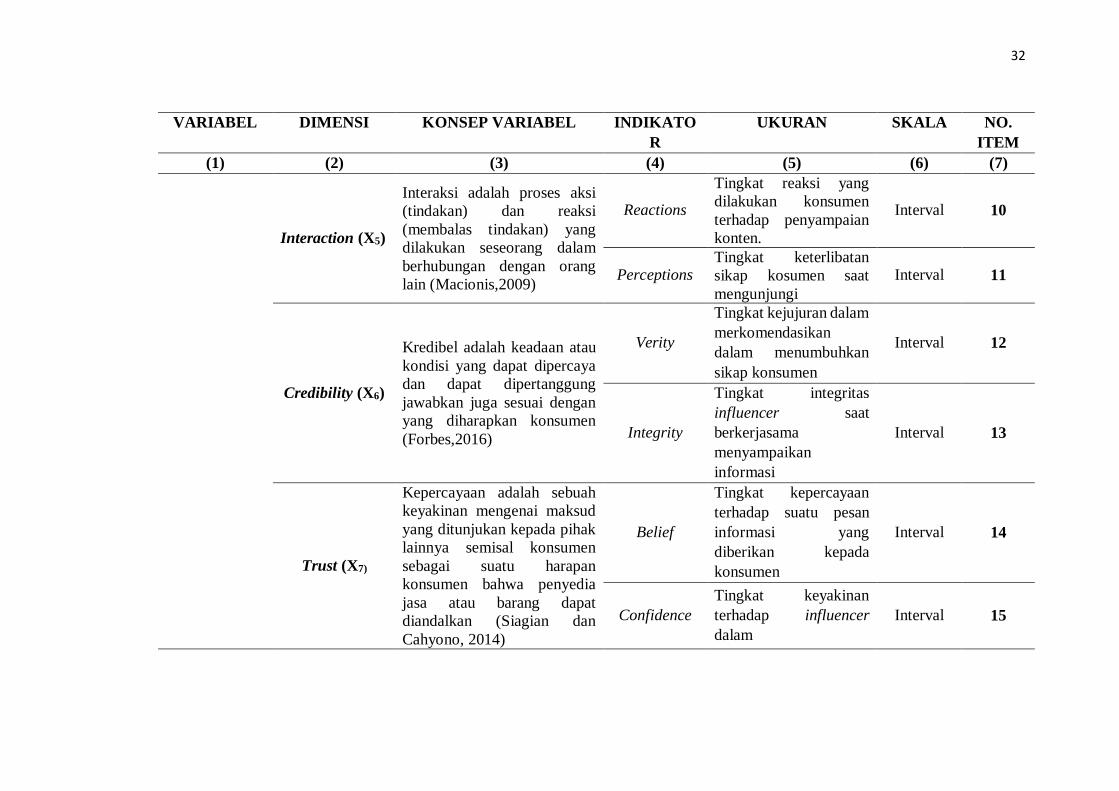
32
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
Interaction (X5)
Interaksi adalah proses aksi
(tindakan) dan reaksi
(membalas tindakan) yang
dilakukan seseorang dalam
berhubungan dengan orang
lain (Macionis,2009)
Reactions
Tingkat reaksi yang
dilakukan konsumen
terhadap penyampaian
konten.
Interval 10
Perceptions Tingkat keterlibatan
sikap kosumen saat
mengunjungi
Interval 11
Credibility (X6)
Kredibel adalah keadaan atau
kondisi yang dapat dipercaya
dan dapat dipertanggung
jawabkan juga sesuai dengan
yang diharapkan konsumen
(Forbes,2016)
Verity
Tingkat kejujuran dalam
merkomendasikan
dalam menumbuhkan
sikap konsumen
Interval 12
Integrity
Tingkat integritas
influencer saat
berkerjasama
menyampaikan
informasi
Interval 13
Trust (X7)
Kepercayaan adalah sebuah
keyakinan mengenai maksud
yang ditunjukan kepada pihak
lainnya semisal konsumen
sebagai suatu harapan
konsumen bahwa penyedia
jasa atau barang dapat
diandalkan (Siagian dan
Cahyono, 2014)
Belief
Tingkat kepercayaan
terhadap suatu pesan
informasi yang
diberikan kepada
konsumen
Interval 14
Confidence
Tingkat keyakinan
terhadap influencer
dalam
Interval 15
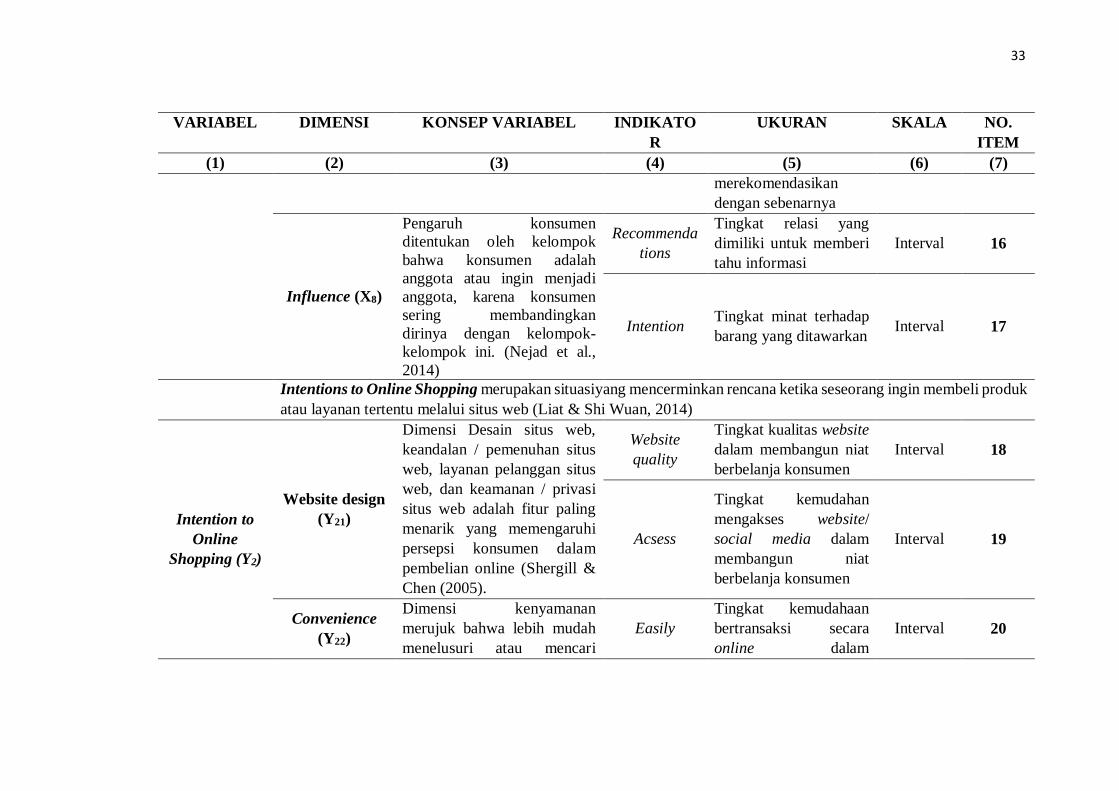
33
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
merekomendasikan
dengan sebenarnya
Influence (X8)
Pengaruh konsumen
ditentukan oleh kelompok
bahwa konsumen adalah
anggota atau ingin menjadi
anggota, karena konsumen
sering membandingkan
dirinya dengan kelompok-
kelompok ini. (Nejad et al.,
2014)
Recommenda
tions
Tingkat relasi yang
dimiliki untuk memberi
tahu informasi
Interval 16
Intention Tingkat minat terhadap
barang yang ditawarkan Interval 17
Intentions to Online Shopping merupakan situasiyang mencerminkan rencana ketika seseorang ingin membeli produk
atau layanan tertentu melalui situs web (Liat & Shi Wuan, 2014)
Intention to
Online
Shopping (Y2)
Website design
(Y21)
Dimensi Desain situs web,
keandalan / pemenuhan situs
web, layanan pelanggan situs
web, dan keamanan / privasi
situs web adalah fitur paling
menarik yang memengaruhi
persepsi konsumen dalam
pembelian online (Shergill &
Chen (2005).
Website
quality
Tingkat kualitas website
dalam membangun niat
berbelanja konsumen
Interval 18
Acsess
Tingkat kemudahan
mengakses website/
social media dalam
membangun niat
berbelanja konsumen
Interval 19
Convenience
(Y22)
Dimensi kenyamanan
merujuk bahwa lebih mudah
menelusuri atau mencari
Easily
Tingkat kemudahaan
bertransaksi secara
online dalam
Interval 20

34
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
informasi melalui online lebih
mudah daripada berbelanja
eceran tradisional.
membangun niat
berbelanja konsumen
Flexibility Tingkat kelenturan
informasi pada website. Interval 21
Enjoyment
(Y23)
Kesenangan adalah kegiatan
atau kondisi yang dianggap
menyenangkan dalam dirinya
dan sensasi secara holistic
Good system
Tingkat kemudahan
dalam mencari variasi
yang menarik dalam
membangun minat beli
Interval 22
Selection
Tingkat kesenangan
karena sistem yang
bagus tidak buffering
Interval 23
Time saving
(Y24)
Dimensi penghematan waktu
adalah salah satu dimensi yang
paling merujuk terhadap minat
belanja online. Menelusuri
atau mencari katalog online
dapat menghemat waktu dan
kesabaran.
Less Time
Tingkat efisien waktu
dengan menghemat
waktu konsumen.
Interval 24
Time during
Insensitas waktu yang
efisien untuk kecepatan
waktu pengiriman
Interval 25
Security (Y25) Dimensi keamanan adalah
salah satu atribut yang Protected
Tingkat perlindungan
informasi konsumen Interval 26

35
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
membatasi pembelian di web
karena mereka mengklaim
bahwa ada segmen besar
pembeli internet yang tidak
suka membeli secara online
karena pemikiran mereka
tentang keamanan sensitif
mereka. Informasi (Bhatnagar
dan Ghose, 2004
untuk berbelanja secara
online
Safety
Tingkat keamanan atas
konsumen dalam berniat
untuk membeli online
Interval 27
Price (Y26)
Harga adalah sejumlah uang
yang harus di bayarkan sesuai
dengan masing masing produk
(moenroe,1990)
Affordable
Tingkat harga yang
terjangkau bagi
konsumen dalam
membangun niat beli
online
Interval 28
Discount
Tingkat perusahaan
memberikan diskon
yang menarik bagi
konusumen
Interval 29
Product Quality
(Y27)
Kualitas Produk adalah
kemampuam suatu produk
untuk
melaksanakannfungsinya
dalam keandalan, ketepatan
serta atribut bernilai lainnya
(Kotler,2009)
Performance
Tingkat kualitas produk
yang di sajikan dalam
menarik minat beli
konsumen
Interval 30
Suitability Tingkat kesesuaian
dalam memenuhi Interval 31

36
VARIABEL DIMENSI KONSEP VARIABEL INDIKATO
R
UKURAN SKALA NO.
ITEM
(1) (2) (3) (4) (5) (6) (7)
kebutuhan konsumen
dalam berniat membeli

37
3.2.3 Jenis dan Sumber Data
Untuk kepentingan penelitian ini, jenis dan sumber data diperlukan
dikelompokan ke dalam 2 golongan yaitu:
1. Data Primer
Menurut McDaniel dan Gates (2015) menyatakan bahwa data primer adalah
data baru yang dikumpulkan untuk membantu memecahkan masalah dalam
penyelidikan/penelitian. Terdapat menurut Uma Sekaran dan Roger (2016)
mendefinisikan data primer sebagai data yang dikumpulkan langsung untuk analisis
selanjutnya untuk mencari solusi terhadap masalah yang diteliti. Dari penelitian ini
data yang akan diambil yaitu data berupa tanggapan dari peserta mengenai pengaruh
Attractivness (𝑋1), Content (𝑋2), Relevant (𝑋3), Expertise (𝑋4), Interaction (𝑋5),
Credibility (𝑋6), Trust (𝑋7),Influence (𝑋8) serta intention to online shopping (Y)
dengan sub dimensi Website Design (𝑌1), Convenience (𝑌2), Enjoyment (𝑌3), Time
Saving (𝑌4), Security (𝑌5), Price (𝑌6), Product Quality (𝑌7).
2. Data Sekunder
Data sekunder merupakan data yang telah dikumpulkan berupa variabel,
simbol atau konsep yang bisa mengasumsikan salah satu dari seperangkat nilai
(McDaniel & Gates, 2015). Terdapat menurut Uma Sekaran dan Roger (2016) data
sekunder adalah data yang sudah ada dan tidak dikumpulkan oleh peneliti secara
langsung. Untuk lebih jelasnya mengenai data dan sumber data yang digunakan dalam
penelitian ini, maka peneliti mengumpulkan dan menyajikannya dalam bentuk Tabel
3.2 berikut.
TABEL 3.2
JENIS DAN SUMBER DATA
NO. JENIS DATA SUMBER DATA JENIS
DATA
1. Cosmetic Usage Rank www.similarweb.com Sekunder
2. Website Engagement Financial
Cosmetic www.similarweb.com Sekunder
3 Rating Kepuasan Penggunaan
Cosmetic www.easycounter.com Sekunder
4
Klasifikasi Tingkat Intention to Online
Shopping Followers Instagram Resmi
Focallure Indonesia
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer

38
NO. JENIS DATA SUMBER DATA JENIS
DATA
5
Profil Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Jenis Kelamin dan Usia
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
6
Keterkaitan Tingkat Intention to Online
Shopping Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Usia dan Jenis Kelamin
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
7
Keterkaitan Tingkat Intention to Online
Shopping Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Usia dan Status Pekerjaan
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
8
Keterkaitan Tingkat Intention to Online
Shopping Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Pendidikan Terakhir dan Status
Pekerjaan
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
9
Keterkaitan Tingkat Intention to Online
Shopping Akun Instagram Resmi
Focallure Indonesia Berdasarkan
Pendapatan/Uang Saku dan Status
Pekerjaan
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
10
Keterkaitan Tingkat Intention to Online
Shopping Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Pendapatan/Uang Saku dan Kategori
Produk
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
11
Keterkaitan Tingkat Intention to Online
Shopping Followers Akun Instagram
Resmi Focallure Indonesia Berdasarkan
Tempat Membeli Produk dan Kategori
Produk yang akan Dibeli
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
12
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Website Design Pada Intention
to Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
13
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Convenience Pada Intention to
Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
14
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Enjoyment Pada Intention to
Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer

39
NO. JENIS DATA SUMBER DATA JENIS
DATA
15
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Time Saving Pada Intention to
Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
17
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Security Pada Intention to
Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
18
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Price Pada Intention to Online
Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
19
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Product Quality Pada
Intention to Online Shopping
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
20
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Attractivness Pada Social
Media Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
21
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Content Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
22
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Relevant Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
23
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Expertise Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
24
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Interaction Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
25
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Credibility Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
26 Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Hasil Pengolahan Data
Followers akun Primer

40
NO. JENIS DATA SUMBER DATA JENIS
DATA
Dimensi Trust Pada Social Media
Influencer
instagram Resmi
Focallure Indonesia
27
Tanggapan Followers Akun Instagram
Resmi Focallure Indonesia Terhadap
Dimensi Influence Pada Social Media
Influencer
Hasil Pengolahan Data
Followers akun
instagram Resmi
Focallure Indonesia
Primer
Sumber: Hasil Pengolahan Data, 2020
3.2.4 Populasi, Sampel dan Teknik Sampling
3.2.4.1 Populasi
Populasi adalah total dari semua elemen yang terbagi dalam beberapa
seperangkat karakteristik. Populasi diartikan sebagai kumpulan seluruh unit-unit
pengamatan yang menjadi objek penelitian (Asra & Prasetyo, 2015). Tujuan dari
sebagian besar proyek riset adalah untuk memperoleh informasi tentang karakteristik
suatu populasi dengan cara mengambil sensus ataupun sampel (Malhotra, 2015).
Populasi berkaitan dengan seluruh kelompok orang, peristiwa, benda gejala,
fenomena, atau kejadian-kejadian yang menjadi pusat perhatian peneliti untuk diteliti
(Hermawan, 2006).
Populasi perlu diidentifikasi secara tepat dan akurat sejak awal penelitian.
Populasi yang tidak diidentifikasikan dengan baik, memungkinkan akan menghasilkan
sebuah kesimpulan penelitian yang keliru. Hasil penelitian tersebut kemungkinan tidak
akan memberikan informasi yang relevan karena tidak tepatnya penentuan populasi
(Hermawan, 2006). Berdasarkan pengertian mengenai populasi, maka populasi dalam
penelitian ini adalah followers Instagran resmi Focallure Indonesia sebesar 88.200 per
bulan Februari 2020.
3.2.4.2 Sampel
Masalah pokok dari sampel adalah menjawab pertanyan, apakah sampel yang
diambil benar-benar mewakili populasi. Indikator penting dalam pengujian desain
sampel adalah seberapa baik sampel tersebut mewakili karakteristik populasi. Sampel
adalah bagian dari populasi (Uma Sekaran & Bougie, 2016). Sedangkan menurut
McDaniel & Gates (2015) sampel dapat didefinisikan sebagai bagian dari semua
anggota populasi yang diminati. Menurut Donald & Pamela (2014) sampel adalah

41
sekelompok kasus, peserta, peristiwa atau catatan yang terdiri dari populasi sasaran,
dipilih dengan cermat untuk mewakili populasi tersebut.
Penelitian ini mengambil sampel berdasarkan pada acuan ukuran sampel
minimal untuk model persamaan struktural (SEM) yang diungkapkan Kelloway
(1998) yaitu paling sedikit 200 responden. Secara teori, untuk model-model yang
memiliki 10 sampai 15 variabel manifes ukuran sampelnya berkisar 200-400 (Sarjono
& Julianita, 2015). Pengambilan sampel sebanyak 200 responden karena SEM
bergantung pada pengujian-pengujian yang sifatnya sensitif terhadap ukuran sampel
dan besarnya perbedaan di antara matriks kovarians (Sarjono & Julianita, 2015). Selain
itu juga untuk mengantisipasi adanya ouliers data setelah pengambilan sampel
dilakukan.
Penelitian ini melakukan kajian terhadap industri cosmetic Indonesia, dengan
objek penelitian pada Followers Akun Instagram Focallure Indonesia berjumlah
88.200 orang akun pada Februari 2020, dapat diketahui bahwa jumlah sampel yang
digunakan pada penelitian ini ditentukan sebanyak 200 orang atau responden.
3.2.4.3 Teknik Sampling
Teknik sampling merupakan teknik pengambilan sampel untuk menentukan
sampel yang akan digunakan dalam penelitian, sehingga dapat diperoleh nilai
karakteristik perkiraan (estimate value). Uma dan Roger (2016:240) sampling adalah
proses pemilihan jumlah elemen yang tepat dari populasi, sehingga sampel penelitian
dan pemahaman tentang sifat atau karakteristik memungkinkan baru kita untuk
menggeneralisasi sifat atau karakteristik tersebut pada elemen populasi. Terdapat tipe
teknik sampling yaitu probability sampling dan nonprobability sampling.
Probability sampling merupakan teknik pengambilan sampel dimana setiap
elemen atau anggota populasi memiliki peluang atau kemungkinan yang diketahui
untuk dipilih sebagai sampel. Probability sampling terdiri dari simple random
sampling, systematic random sampling, stratification sampling, dan cluster sampling.
Sedangkan nonprobability sampling merupakan teknik pengambilan sampel dimana
setiap elemen atau anggota dalam populasi tidak memiliki peluang yang diketahui atau
telah ditentukan sebelumnya untuk dipilih sebagai sampel. Nonprobability sampling
terdiri dari convenience sampling, purposive sampling, judgement sampling dan quota
sampling (Sekaran & Bougie, 2016:240).

42
Teknik pengambilan sampel yang digunakan dalam penelitian ini adalah
probability sampling karena setiap elemen populasi penelitian memiliki peluang atau
probability yang sama untuk dipilih sebagai sampel. Metode yang digunakan yaitu
metode penarikan sampel acak sederhana atau simple random sampling dimana
memberikan kesempatan yang sama kepada populasi untuk dijadikan sampel. Cara
pengambilan sampel dengan simple random sampling dapat dilakukan dengan metode
undian, ordinal, maupun tabel bilangan random. Semua populasi dari pengikut
Focallure Indonesia di Instagram memiliki kesempatan yang sama untuk menjadi
sampel terpilih oleh peneliti.
3.2.5 Teknik Pengumpulan Data
Teknik pengumpulan data merupakan cara mengumpulkan data yang
dibutuhkan untuk menjawab rumusan masalah penelitian. Menurut Uma Sekaran
(2016:24) teknik pengumpulan data merupakan bagian yang tidak terpisahkan dari
desain penelitian. Adapun teknik pengumpulan data yang digunakan penulis dalam
penelitian ini adalah:
1. Studi literatur, yaitu pengumpulan data dengan cara mempelajari buku,
makalah, jurnal maupun homepage/website guna memperoleh informasi yang
berhubungan dengan teori-teori dan konsep-konsep yang berkaitan dengan
masalah penelitian atau variabel yang diteliti yaitu social media influencer dan
intention to online shopping.
2. Observasi merupakan metode pengumpulan data dengan melakukan
pengamatan terhadap objek penelitian yaitu jumlah followers Focallure di
Instagram.
3. Wawancara adalah kegiatan pengumpulan data dan fakta dengan cara
melakukan tanya jawab yang berkaitan dengan penelitian. Teknik wawancara
dilakukan dengan maksud mendapatkan informasi mengenai implementasi
social media influencer kepada pihak Followers Focallure di Instagram.
4. Kuisioner merupakan teknik pengumpulan data primer yang dilakukan dengan
cara menyebarkan seperangkat daftar pertanyaan atau pernyataan tertulis
mengenai karaketeristik responden, pengalaman responden setelah berkunjung
dan pelaksanaan implementasi social media influencer serta intention to online
shopping. Kuisioner akan ditujukan kepada sampel dari followers Focallure di

43
Instagram secara online melalui google form yang dikirim secara langsung
melalui direct message responden.
Untuk mengetahui lebih jelas bagaimana teknik pengumpulan data dalam
penelitian ini, maka peneliti mengumpulkan dan menyajikan dalam Tabel 3.3 berikut:
TAHUN 3.3
TEKNIK PENGUMPULAN DATA
No. Teknik Pengumpulan Data Sumber Data
1 Wawancara Followers Focallure di Instagram
2 Observasi Pelaksanaan implementasi social media
influencer Focallure.
3 Kuesioner Followers Focallure di Instagram
4 Studi Literatur Teori social media influencer dan intention
to online shopping
Sumber: Hasil Pengolahan Data Sekunder dan Primer, 2020
3.2.6 Pengujian Validitas dan Realibilitas
Setelah data yang diperoleh dari responden melalui kuesioner terkumpul,
selanjutnya adalah mengolah dan menafsirkan data sehingga dari hasil tersebut dapat
dilihat apakah antara social media influencer (X) ada pengaruhnya atau tidak terhadap
variabel intention to online shopping (Y). Sebelum melakukan analisis data, dan juga
untuk menguji layak atau tidaknya kuesioner yang disebarkan kepada responden,
terlebih dahulu dilakukan uji validitas dan uji reliabilitas untuk melihat tingkat
kebenaran serta kualitas data.
3.2.6.1 Pengujian Validitas
Validitas berkaitan dengan ketepatan penggunaan indikator untuk
menjelaskan arti konsep yang sedang diteliti, sedangkan reliabilitas berkaitan dengan
konsistensi suatu indikator (Priyono, 2016).
Jenis validitas yang digunakan dalam penelitian ini adalah validitas konstruk
yang akan membuktikan seberapa baik hasil dari penggunaan yang diperoleh sesuai
dengan teori-teori di sekitar yang dirancang dalam tes (Sekaran, 2003). Hal ini dinilai
melalui konvergen dan diskriminan validitas, yang menentukan validitas dengan cara
mengkorelasikan antar skor yang diperoleh dari masing-masing item berupa
pertanyaan dengan skor totalnya. Skor total ini merupakan nilai yang diperoleh dari
penjumlahan semua skor item. Berdasarkan ukuran statistik, bila ternyata skor semua
item yang disusun menurut dimensi konsep berkorelasi dengan skor totalnya, maka
dapat dikatakan bahwa alat ukur tersebut mempunyai validitas. Kevalidan suatu

44
instrumen dihitung menggunakan rumus korelasi product moment, yang dikemukakan
oleh Pearson sebagai berikut:
rxy =Nxy − (x)(y)
√{Nx2 − (x)2}{Ny2 − (y)2}(3.1)
Sumber: (Sugiyono, 2002:248)
Keterangan:
rxy = Koefisien korelasi antara variabel X dan variabel Y
X = Skor yang diperoleh subjek seluruh item
Y = Skor total
∑X = Jumlah skor dalam distribusi X
∑Y = Jumlah skor dalam distribusi Y
∑XY = Jumlah perkalian faktor korelasi variabel X dan Y
∑X2 = Jumlah kuadrat dalam skor distribusi X
∑Y2 = Jumlah kuadrat dalam skor distribusi Y
N = Banyaknya responden
Langkah selanjutnya perlu diuji apakah koefisien validitas tersebut signifikan
terhadap taraf signifikan tertentu, artinya ada koefisien validitas tersebut bukan karena
faktor kebetulan, diuji dengan rumus statistik t sebagai berikut :
t = r√n−2
√1−r2 (3.2)
Sumber : (Sugiyono, 2002)
Keputusan pengujian validitas responden menggunakan taraf signifikan
sebagai berikut:
1. Nilai t dibandingkan dengan harga rtabel dengan dk = n-2 dan taraf signifikasi
α = 0.05
2. Item pertanyaan-pertanyaan responden penelitian dikatakan valid jika rhitung
lebih besar atau sama dengan rtabel (rhitung ≥ rtabel)
3. Item pertanyaan-pertanyaan responden penelitian dikatakan tidak valid jika
rhitung lebih kecil dari rtabel (rhitung< rtabel)
Pengujian validitas diperlukan untuk mengetahui apakah instrument yang
digunakan untuk mencari data primer dalam sebuah penelitian dapat digunakan untuk
mengukur apa yang seharusnya terukur. Penelitian ini akan diuji validitas dari

45
instrument hubungan social media influencer sebagai variabel X sebanyak 17 item dan
intention to online shopping sebagai variabel Y sebanyak 14 item.
Berdasarkan kuesioner yang diuji pada 200 responden dengan tingkat
signifikansi 5% dan derajat bebas (df=n-2) (200-2=198), maka diperoleh nilai r tabel
sebesar 0.1166 dari tabel hasil pengujian validitas diketahui bahwa pernyataan-
pernyataan yang diajukan kepada respondenseluruhnya dinyatakan valid karena rhitung
lebih besar dari rtabel sehingga pernyataan pernyataan tersebut dapat dijadikan alat ukur
terhadap semua konsep seharusnya diukur. Variabel sosial media influencer semua
item valid, hasil uji validitas tersebut dapat dilihat pada Tabel 3.4 berikut:
TABEL 3.4
HASIL UJI VALIDITAS VARIABEL X (SOCIAL MEDIA INFLUENCER)
No Pernyataan r
hitung
r
tabel
Ket
Attractivness
1 Kemenarikan visual Instagram dalam
mempengaruhi aktifitas pencarian informasi
0,682 0.1166 Valid
2 Kemenarikan feeds dalam mempengaruhi kesan
pertama konsumen
0,583 0.1166 Valid
3 Pesan informasi yang menarik dalam
mempengaruhi rasa ingin tahu konsumen
0,679 0.1166 Valid
Content
4 Kreatifitas fitur yang diciptakan Focallure
dalam menarik target konsumen
0,800 0.1166 Valid
5 Kehandalan menciptakan konten dalam
merekomendasikan Focallure
0,789 0.1166 Valid
Relevant
6 Kemenarikan informasi keunggulan Focallure
dalam mempengaruhi persepsi konsumen
0,714 0.1166 Valid
7 Ketertarikan konsumen dalam bahasa yang
tepat untuk menyampaikan pesan
0,622 0.1166 Valid
Expertise
8 Popularitas Instagram dalam menarik
konsumen berkunjung secara rutin
0,374 0.1166 Valid
9 Keterlibatan influencer (Tasha Farasya) dengan
Focallure di Instagram
0,610 0.1166 Valid
Interaction
10 Keterlibatan konsumen memberikan like,
comment pada posting-an social media
0,661 0.1166 Valid
11 Keterlibatan Focallure menanggapi persepsi
dari konsumen
0,841 0.1166 Valid
Credibility
12 Kejujuran informasi yang diberikan kepada
konsumen dalam menawarkan Focallure
0,730 0.1166 Valid

46
No Pernyataan r
hitung
r
tabel
Ket
13 Integritas Influencer (Tasya Farasya) yang
terpilih dalam membangun Focallure
0,652 0.1166 Valid
Trust
14 Kepercayaan konsumen dalam memahami
informasi mengenai Focallure
0,735 0.1166 Valid
15 Keyakinan terhadap influencer (Tasya Farasya)
yang memiliki pengaruh terhadap konsumen
0,628 0.1166 Valid
Influence
16 Keinginan konsumen merekomendasikan
Focallure kepada orang lain
0,848 0.1166 Valid
17 Konsumen terpengaruh untuk melakukan
pembelian produk Focallure
0,788 0.1166 Valid
Sumber: Hasil Pengolahan Data 2020 (Menggunakan SPSS 22.0 for windows)
Berdasarkan Tabel 3.4 Pengujian Validitas Social media influencer dapat
diketahui bahwa nilai yang tertinggi terdapat pada dimensi influence dengan
pernyataan keinginan konsumen merekomendasikan Focallure kepada orang lain yang
bernilai sebesar 0,848. Sementara nilai terendah terdapat pada dimensi expertise
dengan pernyataan popularitas Instagram dalam menarik konsumen berkunjung secara
rutin bernilai sebesar 0,374.
Hasil uji coba penelitian untuk variable X1 social media influencer berdasarkan
hasil perhitungan validitas item penelitian yang dilakukan dengan menggunakan
bantuan SPSS 22.0 for windows, menunjukan bahwa item-item pernyataan dalam
kuesioner dinyatakan valid katena rhitung lebih besar dibandingkan denga rtabel yang
bernilai 0,1166.
Selanjutnya, hasil uji coba penelitian untuk variabel X2 Intention to Online
Shopping berdasarkan hasil perhitungan validitas item penelitian yang dilakukan
dengan menggunakan bantuan SPSS 22.0 for windows, menunjukkan bahwa item-item
pernyataan dalam kuesioner dinyatakan valid karena rhitung lebih besar dibandingkan
dengan rtabel yang bernilai 0.1166. Berikut ini Tabel 3.5 Hasil Pengujian Validitas
intention to Online Shopping.
TABEL 3.5
HASIL PENGUJIAN VALIDITAS INTENTION TO ONLINE SHOPPING
No Pernyataan r
hitung
r
tabel
Ket
Website Design

47
No Pernyataan r
hitung
r
tabel
Ket
1 Minat berbelanja online pada Focallure karena
tampilan yang menarik
0,773 0.1166 Valid
2 Minat pembelian pada Focallure karena website
yang mudah untuk diakses
0,713 0.1166 Valid
Convenience
3 Minat berbelanja online karena mudah dalam
bertransaksi secara online
0,756 0.1166 Valid
4 Konsumen memiliki minat beli karena
informasi yang mudah dicari
0,765 0.1166 Valid
Enjoyment
5 Minat pembelian konsumen pada Focallure
karena produk yang diinginkan tersedia
variasinya
0,791 0.1166 Valid
6 Konsumen berniat membeli Focallure karena
layanan yang tidak buffering
0,731 0.1166 Valid
Time Saving
7 Minat berbelanja online karena dapat
menghemat waktu konsumen
0,712 0.1166 Valid
8 Minat berbelanja online karena pelayanan
dalam ketepatan waktu pengiriman
0,762 0.1166 Valid
Security
9 Minat pembelian online pada Focallure karena
terdapat jaminan atas keamanan konsumen
0,749 0.1166 Valid
10 Minat pembelian online karena kerahasiaan
tentang konsumen terlindungi
0,758 0.1166 Valid
Price
11 Minat pembelian online Focallure karena harga
yang terjangkau
0,636 0.1166 Valid
12 Minat pembelian online Focallure karena
diskon yang selalu diberikan
0,692 0.1166 Valid
Product Quality
13 Minat pembelian konsumen karena kualitas
produk Focallure
0,749 0.1166 Valid
14 Minat pembelian Focalure karena produk
memenuhi kebutuhan minat konsumen
0,794 0.1166 Valid
Sumber: Hasil Pengolahan Data, 2020
3.2.6.2 Hasil Pengujian Realibilitas
Reliabilitas menunjukkan sejauh yang mana data bebas dari kesalahan
sehingga dapat menjamin pengukuran yang konsisten sepanjang waktu dalam seluruh
instrumen. Dengan kata lain, reliabilitas adalah indikasi stabilitas dan konsistensi
instrumen untuk mengukur konsep dan membantu untuk menilai kebaikan dari ukuran
(Sekaran, 2003:203). 55

48
Malhotra (2015:226) mendefinisikan reliabilitas sebagai sejauh mana suatu
ukuran bebas dari kesalahan acak. Reliabilitas dinilai dengan cara menentukan
hubungan antara skor yang diperoleh dari skala administrasi yang berbeda. Jika
asosiasi tinggi, maka skala akan menghasilkan hasil yang konsisten sehingga dapat
dikatakan reliabel.
Pegujiuan instrumen dilakukan dengan internal consistency dengan teknik
belah dua (split half) yang dianalisis dengan rumus Spearman Brown yaitu:
r1=2𝑟𝑏
1+𝑟𝑏 (3.3)
sumber: (Sugiyono, 2002:190)
Keputusan uji reliabilitas ditentukan dengan kriteria sebagai berikut:
1. Jika koefisien internal seluruh item (ri) ≥ rtabel dengan tingkat signifikansi 5%
maka item pertanyaan dikatakan reliabel.
2. Jika koefisien internal seluruh item (ri) < rtabel dengan tingkat signifikansi 5%
maka item pertanyaan dikatakan reliabel.
Pengujian realibilitas tersebut menurut Sugiyono (2002:190) dilaksanakan
dengan langkah-langkah sebagai berikut:
1. Butir-butir instrumen dibelah menjadi dua kelompok, yaitu kelompok instumen
ganjil dan genap.
2. Skor data dari tiap kelompok disusun sendiri dan kemudian skor total antara
kelompok gajil dan genap dicari korelasinya.
Berdasarkan jumlah angket yang diuji kepada sebanyak 200 responden dengan
tingkat signifikansi 5% dengan derajat bebas (df) n-2 (200-2=192, maka didapat nilai
r tabel sebesar 0,1166. Hasil pengujian reliabilitas penelitian yang dilakukan dengan
menggunakan bantuan program SPSS 22.0 for windows diketahui semua variabel
reliabel, hal ini disebabkan nilai rhitung lebih besar jika dibandingkan dengan nilai
rtabel, maka dapat dilihat pada Tabel 3.6 Hasil Uji Reliabilitas sebagai berikut:
TABEL 3.6
HASIL UJI RELIABILITAS
No Variabel r Hitung r Tabel Keterangan
1 Attractivness 0,834 0.1166 reliabel
2 Content 0,871 0.1166 reliabel
3 Relevant 0,789 0.1166 reliabel

49
No Variabel r Hitung r Tabel Keterangan
4 Expertise 0,633 0.1166 reliabel
5 Interaction 0,783 0.1166 reliabel
6 Credibility 0,718 0.1166 reliabel
7 Trust 0,713 0.1166 reliabel
8 Influence 0,840 0.1166 reliabel
9 Intention to Online Shopping 0,946 0.1166 reliabel
Sumber: Hasil Pengolahan Data 2020 (Menggunakan SPSS 22,0 for Windows)
3.2.7 Teknik Analisis Data
Analisis data merupakan langkah untuk menganalisis data yang telah
dikumpulkan secara statistik untuk melihat apakah hipotesis yang dihasilkan telah
didukung oleh data (Sekaran, 2003:32). Tujuan pengolahan data adalah untuk
memberikan keterangan yang berguna, serta untuk menguji hipotesis yang telah
dirumuskan dalam penelitian sehingga teknik analisis data diarahkan pada
pengujian hipotesis serta menjawab masalah yang diajukan. Alat penelitian yang
digunakan dalam penelitian ini adalah angket atau kuesioner. Angket ini disusun
oleh penulis berdasarkan variabel yang terdapat dalam penelitian. Pada penelitian
kuantitatif analisis data dilakukan setelah data seluruh responden terkumpul.
Kegiatan analisis data dalam penelitian dilakukan melalui tahapan:
1. Menyusun data, kegiatan ini dilakukan untuk memeriksa kelengkapan identitas
responden, kelengkapan data serta isian data yang sesuai dengan tujuan
penelitian.
2. Menyeleksi data, kegiatan ini dilakukan untuk memeriksa kesempurnaan dan
kebenaran data yang sudah terkumpul.
3. Tabulasi data, penelitian ini melakukan tabulasi data dengan langkah-langkah
sebagai berikut:
a. Memasukan data ke program Miscrosoft Office Excel
b. Memberi skor pada setiap item
c. Menjumlahkan skor pada setiap item
d. Menyusun rangking skor pada setiap variabel penelitian
Pada penelitian ini akan diteliti pengaruh social media influencer terhadap
intention to online shoppimg, Penelitian ini menggunakan skala semantic

50
differential scale dimana biasanya menunjukkan skala tujuh poin dengan atribut
bipolar untuk mengukur arti suatu objek atau konsep bagi responden. Data yang
diperoleh adalah data interval. Rentang dalam penelitian ini yaitu sebanyak 7 angka
seperti pada Tabel 3.7 Skor Alternatif berikut ini.
TABEL 3.7
PEDOMAN NILAI ANGKET
Alternatif
Jawaban
Sangat
Tinggi
Rentang Jawaban Sangat
Rendah
7 6 5 4 3 2 1
Positif 7 6 5 4 3 2 1 Negatif
Sumber: Ridwan (2013:91)
3.2.7.1 Teknik Analisis Data Deskriptif
Analisis deskriptif digunakan untuk mencari adanya suatu hubungan antara
variabel melalui analisis korelasi dan membuat perbandingan rata-rata data sampel
atau populasi tanpa perlu diuji signifikasinya. Alat penelitian yang digunakan dalam
penelitian ini adalah angket atau kuesioner yang disusun berdasarkan variabel yang
terdapat pada data penelitian, yaitu memberikan keterangan dan data mengenai
pengaruh social media influencer terhadap intention to online shopping. Pengolahan
data yang terkumpul dari hasil kuesioner dapat dikelompokkan kedalam tiga langkah,
yaitu persiapan, tabulasi dan penerapan data pada pendekatan penelitian.
Langkah-langkah yang digunakan untuk melakukan analisis deskriptif pada
ketiga variabel penelitian tersebut sebagai berikut:
1. Analisis Tabulasi Silang (Cross Tabulation)
Metode cross tabulation merupakan analisis yang dilakukan untuk melihat
apakah terdapat hubungan deskriptif antara dua variabel atau lebih dalam data yang
diperoleh (Malhotra, 2015). Analisis ini pada prinsispnya menyajikan data dalam
bentuk tabulasi yang meliputi baris dan kolom. Data yang digunakan untuk penyajian
cross tabulation merupakan data berskala nominal atau kategori (Ghozali, 2014).
Cross tabulation merupakan metode yang menggunakan uji statistik untuk
mengidentifikasi dan mengetahui korelasi antar dua variabel atau lebih, apabila
terdapat hubungan antara variabel tersebut, maka terdapat tingkat ketergantungan yang
saling mempengaruhi yaitu perubahan variabel yang satu ikut dalam mempengaruhi
variabel lain.

51
TABEL 3.8
TABEL TABULASI SILANG (CROSS TABULATION)
Variabel
Kontrol
Judul
(Identitas/Karakteri
stik/Pengalaman)
Judul (Identitas/Kareakteristik/
Pengalaman)
Tota
l
Klasifikasi Identitas/
Karakteristik/Pengalaman
Total
TOTAL
2. Skor Ideal
Skor ideal merupakan skor yang secara ideal diharapkan untuk jawaban dari
pertanyaan yang terdapat pada angket kuesioner yang akan dibandingkan dengan
perolehan skor total untuk mengetahui hasil kinerja dari variabel. Penelitian atau survei
membutuhkan instrumen atau alat yang digunakan untuk melakukan pengumpulan
data seperti kuesioner. Kuesioner berisikan pertanyaan yang diajukan kepada
responden atau sampel dalam suatu proses penelitian atau survei. Jumlah pertanyaan
yang dimuat dalam penelitian cukup banyak sehingga membutuhkan scoring untuk
memudahkan dalam proses penilaian dan untuk membantu dalam proses analisis data
yang telah ditemukan. Rumus yang digunakan dalam skor ideal yaitu sebagai berikut:
Skor Ideal = Skor Tertinggi x Jumlah Responden
3. Tabel Analisis Deskriptif
Penelitian ini menggunakan analisis deskriptif untuk mendeskripsikan variabel-
variabel penelitian, diantaranya yaitu: 1) Analisis Deskriptif Variabel Y (Intention to
Online Shopping), dimana variabel Y terfokus pada penelitian Intention to Online
Shopping melalui website design, convenience, enjoyment time saving, security,
price dan product quality; 2) Analisis Deskriptif Variabel X (Social Media
Influencer), dimana variabel X terfokus pada penelitian terhadap Social Media
Influencer melalui attractiveness, content, relevant, expertise, interaction,
credibility, trust,, dan influence. Untuk mengkategorikan hasil perhitungan,
digunakan kriteria penafsiran persentase yang diambil 0% sampai 100%.
TABEL 3.9
ANALISIS DESKRIPTIF
No Pernyataan Alternatif Jawaban Total Skor
Ideal
TotalSkor
per-
Tahun
%
Skor 1 2 3 4 5 6 7
Skor

52
Total Skor
Langkah selanjutnya yang dilakukan setelah mengkategorikan hasil
perhitungan berdasarkan kriteria penafsiran, maka dibuat garis kontinum yang
dibedakan menjadi tujuh tingkatan diantaranya sangat rendah, rendah, cukup rendah,
sedang, cukup tinggi, tinggi, dan sangat tinggi. Garis kontinum dibuat untuk
membandingkan setiap skor total pada setiap variabel untuk memperoleh gambaran
variabel Intention to Online Shopping Y dan Social Media Influencer X. Rancangan
langkah-langkah pembuatan garis kontinumdi jelaskan sebagai berikut.
1. Menentukan kontinum tertinggi dan terendah
Kontinum Tertinggi = Skor tertinggi x Jumlah butir item x Jumlah responden
Kontinum Terendah = Skor terendah x Jumlah butir item x Jumlah responden
2. Menentukan selisih skor kontinum dari setiap tingkatan
Skor setiap tingkat = Kontinum tertinggi − Kontinum terendah
3. Membuat garis kontinum dan menentukan daerah letak skor hasil penelitian
menentukan persentase letak skor hasil penelitian (rating scale) dalam garis
kontinum (skor maksimal x 100%)
Sangat
Rendah
Rendah Cukup
Rendah
Sedang Cukup
Tinggi
Tinggi Sangat
Tinggi
a b N
GAMBAR 3.1
GARIS KONTINUM PENELITIAN SOCIAL MEDIA INFLUENCER DAN
INTENTION TO ONLINE SHOPPING
Keterangan:
a : Skor minimum
b : Jarak Interval
∑ : Jumlah perolehan skor
N : Skor ideal Teknik analisis data verifikatif
3.2.7.2 Teknik Analisis Data Verifikatif
Setelah keseluruhan data yang diperoleh dari responden telah terkumpul dan
dilakukan analisis deskriptif, maka dilakukan analisis berikutnya yaitu analisis data
verifikatif. Penelitian verifikatif merupakan penelitian yang dilaksanakan untuk
menguji kebenaran ilmu-ilmu yang telah ada, berupa konsep, prinsip, prosedur,
maupun praktek dari ilmu itu sendiri sehinggan tujuan dari penelitian verifikatif dalam

53
penelitian ini untuk memperoleh kebenaran dari sebuah hipotesis yang dilaksanakan
melalui pengumpulan data di lapangan (Arifin, 2011:17).
Teknik analisis data verifikatif dalam penelitian ini digunakan untuk melihat
pengaruh social media influencer (X) terhadap intention to online shopping (Y).
Teknik analisis data verifikatif yang digunakan untuk mengetahui hubungan korelatif
dalam penelitian ini yaitu teknik analisis Structure Equation Model (SEM) atau
Pemodelan Persamaan Struktural.
Structure Equation Model (SEM) merupakan teknik analisis data yang
bertujuan untuk menjelaskan secara menyeluruh hubungan antar variabel yang ada
dalam penelitian. SEM digunakan bukan untuk merancang suatu teori, tetapi lebih
ditujukan untuk memeriksa dan membenarkan suatu model. Syarat utama
menggunakan SEM adalah membangun suatu model hipotesis yang terdiri dari model
struktural dan model pengukuran yang berdasarkan justifikasi teori.
SEM merupakan sekumpulan teknik-teknik statistik yang memungkinkan
pengujian sebuah rangkaian hubungan secara simultan. Structural Equation Modeling
memungkinkan dilakukannya analisis terhadap serangkaian hubungan secara simultan
sehingga memberikan efisiensi secara statistik.
Structural Equation Modeling memiliki karakteristik utama yang yang dapat
membedakan dengan teknik analisis multivariat lainnya. Teknik analisis data SEM
memiliki estimasi hubungan ketergantungan ganda (multiple dependence relationship)
dan juga memungkinkan mewakili konsep yang sebelumnya tidak teramati
(unobserved concept) dalam hubungan yang ada dan memperhitungkan kesalahan
pengukuran (measurement error).
Ada beberapa asumsi yang harus dipenuhi dalam pengujian SEM, asumsi-
asumsi tersebut adalah sebagai berikut:
1. Ukuran sampel
Ukuran sampel yang harus dipenuhi dalam SEM minimal berukuran 200 yang
akan memberikan dasar untuk mengestimasi sampling error. Sampel dalam
penelitian ini berjumlah 200.
2. Normalitas Data
Syarat dalam melakukan pengujian berbasis SEM yaitu melakukan uji asumsi
data dan variabel yang diteliti dengan uji normalitas. Sebaran data harus

54
dianalisis untuk melihat apakah asumsi normalitas dipenui sehingga data dapat
diolah lebih lanjut untuk pemodelan.
3. Outliers Data
Outliers data adalah observasi data yang nilainya jauh di atas atau di bawah
rata-rata nilai (nilai ekstrim) baik secara univariate maupun multivariate
karena kombinasi karakteristik unik yang dimilikinya sehingga jauh berbeda
dari observasi lainnya. Pemeriksaan outliers dapat dilakukan dengan
membandingkan nilai Mahalanobis d-squared dengan chi square dt. Nilai
Mahalanobis d-squared < chisquare dt.
4. Multikolinearitas
Multikolinearitas dapat dideteksi dari determinan matrik kovarians. Nilai
matriks kovarians yang sangat kecil memberikan indikasi adanya masalah
multikolinearitas atau singularitas. Multikolinearitas menunjukkan kondisi
dimana antar variabel penyebab terdapat hubungan linier yang sempurna,
eksak, perfectly predicted atau singularity.
3.2.7.3 Tahapan Pengujian Structural Equation Model
Setelah semua asumsi terpenuhi, maka langkah selanjutnya yaitu terdapat
beberapa prosedur yang harus dilewati dalam teknik analisis data menggunakan SEM
yang secara umum terdiri dari tahap-tahap sebagai berikut (Bollen dan Long, 1993):
1. Spesifikasi Model (Model Specification)
Tahap ini berkaitan dengan pembentukan model awal persamaan struktural,
sebelum dilakukan estimasi. Model awal ini diformulasikan berdasarkan suatu teori
atau penelitian sebelumnya.
Berikut merupakan langkah-langkah untuk mendapatkan model yang tepat
dalam tahap spesifikasi model sebagai berikut (Wijanto, 2008).
a. Spesifikasi model pengukuran
1) Mendefinisikan variabel-variabel laten yang ada dalam penelitian
2) Mendefinisikan variabel-variabel yang teramati
3) Mendefinisikan suatu hubungan antara variabel laten dengan variabel yang
teramati
b. Spesifikasi model struktural, yaitu mendefinisikan hubungan diantara variable
variabel laten tersebut.

55
c. Menggambarkan diagram jalur dengan hybrid model yang merupakan kombinasi
dari model pengukuran dan model struktural, jika diperlukan yang bersifat opsional.
2. Identifikasi (Identification)
Tahap ini berkaitan dengan pengkajian tentang kemungkinan diperolehnya
nilai yang unik untuk setiap parameter yang ada di dalam model dan kemungkinan
persamaan simultan tidak ada solusinya
Ada terdapat 3 kategori dalam persamaan secara simultan, diantaranya yaitu
(Santoso, 2015).
a. Under-identified model, merupakan model dengan jumlah parameter yang
diestimasi lebih besar dari jumlah data yang diketahui. Dimana keadaan ini terjadi
pada saat nilai degree of freedom/df menunjukkan angka negatif, pada keadaan ini
estimasi dan penilaian model tidak bisa dilakukan.
b. Just-identified model, merupakan model dengan jumlah parameter yang estimasi
sama dengan jumlah data yang diketahui. Dimana keadaan ini terjadi pada saat nilai
degree of freedom/df berada pada angka 0, keadaan tersebut disebut dengan istilah
saturated. Jika terjadi just identified maka estimasi dan penilaian model tidak perlu
dilakukan
c. Over-identified model, merupakan model dengan jumlah parameter yang estimasi
nya lebih kecil dari jumlah data yang diketahui. Keadaan tersebut terjadi saat nilai
degree of freedom/df menunjukkan angka nol, dimana keadaan ini estimasi dan
penilaian model dapat dilakukan.
Besarnya degree of freedom/df pada SEM yaitu besarnya jumlah data yang
diketahui dikurangi jumlah parameter yang diestimasi yang nilainya kurang dari nol
(df = (jumlah data yang diketahui – jumlah parameter yang diestimasi)
3. Estimasi (estimation)
Pemilihan metode estimasi yang digunakan seringkali ditentukan berdasarkan
karakteristik dari variabel-variabel yang dianalisis. Tahap ini berkaitan dengan
estimasi terhadap model untuk menghasilkan nilai-nilai parameter dengan
menggunakan salah satu metode estimasi yang tersedia. Metode estimasi model
didasarkan pada asumsi sebaran dari data, jika asumsi normalitas multivariate dipenuhi
maka estimasi model dapat dilakukan dengan metode Maximum Likelihood (ML).
Namun, jika multivariate tidak terpenuhi maka metode estimasi yang dapat digunakan

56
yaitu Robust Maximum Likelihood (RML) atau Weighted Least Squares (WLS)
(Ghozali, 2014). Penelitian ini akan dilihat apakah model menghasilkan sebuah
estimated population covariance matrix yang konsisten dengan sampel covariance
matrix. Tahap ini dilakukan untuk pemeriksaan kecocokan beberapa model tested
(model yang memiliki bentuk yang sama tetapi berbeda baik dalam jumlah atau tipe
hubungan kausal mempresentasikan model) yang secara subjektif mengindentifikasi
apakah data sesuai atau cocok dengan model teoritis atau tidak.
4. Uji Kecocokan (testing fit)
Tahap ini berkaitan dengan pengujian kecocokan antara model dengan data.
Uji kecocokan model dilakukan untuk menguji apakah model yang dihipotesiskan
merupakan model yang baik untuk mempresentasikan hasil penelitian. Ada tiga jenis
ukuran goodness of fit yaitu: 1) absolute fit measures, yaitu mengukur model fit 64
secara keseluruhan, 2) incremental fit measures, yaitu membandingkan model dengan
model lain yang dispesifikasi oleh peneliti, dan 3) parsimonious fit measures, yaitu
melakukan adjustment terhadap pengukuran model fit untuk dapat diperbandingkan
antar model dengan jumlah koefisien yang berbeda (Ghozali, 2014). Pengujian
validitas measuremen model untuk menguji kesesuaian model atau dapat disebut
Goodness of Fit (GOF). Adapun indikator pengujian goodness of fit dan nilai cut-off
(cut-off value) yang digunakan dalam kesesuaian model ini menurut Yvonne & Robert
(2013:182), adalah sebagai berikut:
1. Chi Square (X2)
Ukuran yang mendasari pengukuran secara keseluruhan (overall) yaitu likelihood
ratio change. Ukuran ini merupakan ukuran utama dalam pengujian measurement
model, yang menunjukkan apakah model merupakan model overall fit. Pengujian
ini bertujuan untuk mengetahui matriks kovarian sampel berbeda dengan matriks
kovarian hasil estimasi. Oleh karena itu, chi-square bersifat sangan sensitif
terhadap besarnya sampel yang digunakan. Kriteria yang digunakan adalah
apabila matriks kovarian sampel tidak berbeda dengan matriks hasil estimasi,
maka dikatakan data fit dengan data yang dimasukkan. Model dianggap baik jika
nilai chi-square rendah.
Meskipun chi-square merupakan alat pengujian utama, namun tidak dianggap
sebagai satu-satunya dasar penentuan untuk menentukan model fit, untuk

57
memperbaiki kekurangan pengujian chi-square digunakan χ2/df (CMIN/DF),
dimana model dapat dikatakan fit apabila nilai CMIN/DF < 2,00.
2. GFI (Goodness of Fit Index) dan AGFI (Adjusted Goodness of Fit Index)
GFI bertujuan untuk menghitung proporsi tertimbang varians dalam matriks
sampel yang dijelaskan oleh matrik kovarians populasi yang diestimasi. Nilai
Good of Fit Index berukuran antara 0 (poor fit) sampai dengan 1 (perfect fit). Oleh
karena itu, semakin tinggi nilai GIF, maka menunjukkan model semakin fit
dengan data. Cut-off value GFI adalah ≥ 0,90 dianggap sebagai nilai yang baik
(perfect fit).
3. Root Mean Square Error of Approximation (RMSEA)
RMSEA adalah indeks yang digunakan untuk mengkompensasi kelemahan chi-
square (X2) pada sampel yang besar. nilai RMSEA yang semakin rendah,
mengindikasikan model semaikin fit d dengan data. Ukuran cut-off-value RMSEA
adalah ≤ 0,08 dianggap sebagai model yang diterima.
4. Adjusted Goodness of Fit Indices (AGFI)
AGFI merupakan GFI yang disesuaikan terhadap degree of freedom, analog
dengan R2 dan regresi berganda. GFI maupun AGFI merupakan criteria yang
memperhitungkan proporsi tertimbang dari varians dalam sebuah matriks kovarian
sampel. cut-off-value dari AGFI adalah ≥0,90 sebagai tingkatan yang baik. Kriteria
ini dapat diinterpretasikan jika nilai ≥0,95 sebagai good overall model fit. Jika nilai
berkisar antara 0,90-0,95 sebagai tingkatan yang cukup dan jika besarnya nilai
0,80-0,90 menunjukan marginal fit.
5. Tucker Lewis Index (TLI)
TLI merupakan alternative incremental fit Index yang membandingkan sebuah
model yang diuji terhadap basedline model. Nilai yang direkomendasikan sebagai
acuan untuk diterima sebuah model adalah ≥0,90.
6. Comparative Fit Index (CFI)
Keunggulan dari model ini adalah uji kelayakan model yang tidak sensitive
terhadap besarnya sampel dan kerumitan model, sehingga sangat baik untuk
mengukur tingkat penerimaan sebuah model. Nilai yang direkomendasikan untuk
menyatakan model SEM adalah ≥ 0,90.
7. Parsimonious Normal Fit Index (PNFI)

58
PNFI merupakan modifikasi dari NFI. PNFI memasukkan jumlah degree of
freedom yang digunakan untuk mencapai level fit. Semakin tinggi nilai PNFI
semakin baik. Kegunaan utama dari PNFI yaitu untuk membandingkan model
dengan degree of freedom yang berbeda. Jika perbedaan PNFI 0.60 sampai 0.90
menunjukkan adanya perbedaan model yang signifikan (Ghozali, 2014).
8. Parsimonious Goodnees of Fit Index (PGFI) PGFI merupakan modifikasi GFI
atas dasar parsimony estimated model. Nilai PGFI berkisar antara 0 sampai 1.0
dengan nilai semakin tinggi menunjukkan model lebih parsimony (Ghozali,
2014).
TABEL 3.10
KRITEA EVALUASI MODEL DENGAN GOODNESS OF FIT
MEASURE
No Goodness-of-Fit Measures Tingkat Penerimaan
Absolute Fit Measures
1 Statistic Chi-square (X2) Mengikuti uji statistik yang berkaitan
dengan persyaratan signifikan semakin
kecil semakin baik
2 Goodness-of-Fit-Index (GFI) Nilai berkisar antara 0-1, dengan nilai
lebih tinggi adalah lebih baik. GFI ≥ 0.90
adalah good fit, sedang 0.80 ≤ GFI < 0.90
adalah marginal fit.
3 Root Mean Square Error of
Approximation (RMSEA)
RMSEA yang semakin rendah,
mengindikasikan model semakin fit
dengan data. Ukuran cut-offvalue
RMSEA < 0,05 dianggap close fit, dan
0,05 ≤ RMSEA ≤ 0,08 dikatakan good fit
sebagai model yang diterima.
Incremental Fit Measure
1 Trucker-Lewis Index (TLI) Nilai berkisar antara 0-1. Dengan nilai
lebih tinggi adalah lebih baik. TLI ≥ 0.90
adalah good fit, sedang 0.80 ≤ TLI < 0.90
adalah marginal fit
2 Adjusted Goodness of Fit
Index (AGFI)
Cut-off-value dari AGFI adalah ≥ 0.90
3 Comparative Fit Index (CFI) Nilai berkisar antara 0-1, dengan nilai
lebih tinggi adalah lebih baik. CFI ≥ 0.90
adalah good fit, sedang 0.80 ≤ CFI < 0.90
adalah marginal fit.
Parsmonious Fit Measure
1 Parsimonious Goodness of fit
Index (PGFI)
PGFI<GFI, semakin rendah semakin
baik
2 Parsimonious Normed-Fit
Index (PNFI)
Nilai tinggi menunjukan kecocokan lebih
baik hanya digunakan untuk perbandingan

59
No Goodness-of-Fit Measures Tingkat Penerimaan
antara model alternatif. Semakin tinggi
nilai PNFI, maka kecocokan suatu model
akan semakin baik.
Sumber: Y vonne and Robert (2013, hal 182) dan Wijianto (2007)
5. Respesifikasi (respicification)
Tahap ini berkaitan dengan respesifikasi model berdasarkan atas hasil uji
kecocokan tahap sebelumnya. Pelaksanaan respesifikasi sangat tergantung pada
strategi pemodelan yang digunakan. Suatu model struktural yang secara statistik dapat
dibuktikan fit dan antar variabel mempunyai hubungan yang signifikan, tidaklah
kemudian dikatakan sebagai satu-satunya model terbaik. Model tersebut merupakan
satu diantara sekian banyak kemungkinan bentuk model lain yang dapat diterima
secara statistik. Maka dalam praktik seseorang tidak berhenti setelah menganalisis satu
model. Peneliti cenderung akan melakukan respesifikasi model untuk menyajikan
alternatif dalam menguji bentuk model yang lebih baik
Tujuan modifikasi yaitu untuk menguji apakah modifikasi yang dilakukan
dapat menurunkan nilai chi-square atau tidak, yang mana semakin kecil angka chi-
square maka model tersebut semakin fit dengan data yang ada. Adapun langkah-
langkah dari modifikasi ini sebenarnya sama dengan pengujian yang telah dilakukan
sebelumnya, hanya saja sebelum dilakukan perhitungan ada beberapa modifikasi yang
dilakukan pada model berdasarkan kaidah yang sesuai dengan penggunaan AMOS.
Adapun modifikasi yang dapat dilakukan pada AMOS terdapat pada output
modification indices (M.I) yang terdiri dari tiga kategori yaitu covariances, variances
dan regressions weight. Modifikasi yang umum dilakukan mengacu pada tabel
covariances, yaitu dengan membuat hubungan covariances pada variabel/indikator
yang disarankan pada tabel tersebut yaitu hubungan yang memiliki nilai M.I paling
besar. Sementara modifikasi dengan menggunakan regressions weight harus dilakukan
berdasarkan teori tertentu yang mengemukakan adanya hubungan antar variabel yang
disarankan pada output modification indices (Santoso, 2015).
3.2.7.4 Spesifikasi Model dalam SEM
Terdapat dua jenis dalam sebuah model perhitungan SEM, yaitu terdiri dari
model pengukuran dan model struktural sebagai berikut.

60
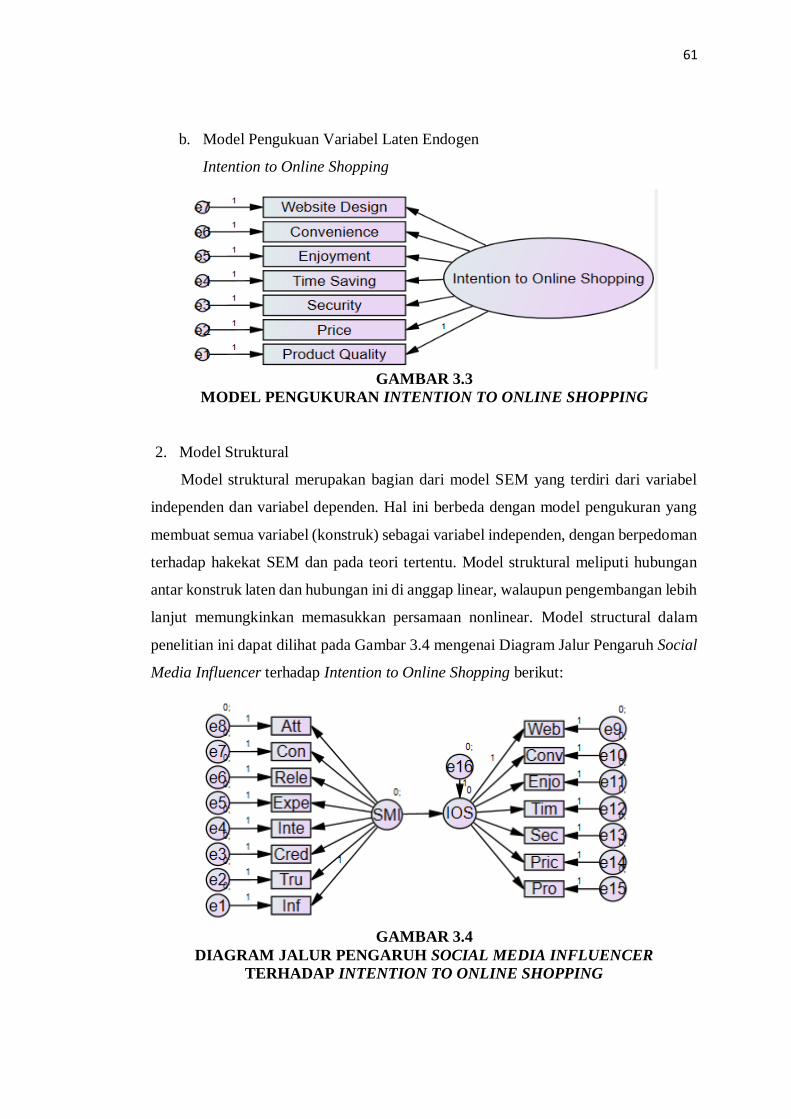
1. Model Pengukuran
Model pengukuran merupakan bagian dari suatu model SEM yang berhubungan
dengan variabel-variabel laten dan indikator-indikatornya. Model pengkuran sendiri
digunakan untuk menguji validitas konstruk dan reliabilitas instrumen. Model
pengukuran murni disebut model analisis faktor konfirmatori atau confirmatory factor
analysis (CFA) dimana terdapat kovarian yang tidak terukur antara masing-masing
pasangan variabel-variabel yang memungkinkan. Model pengukuran dievaluasi
sebagaimana model SEM lainnya dengan menggunakan pengukuran uji keselarasan.
Proses analisis hanya dapat dilanjutkan jika model pengukuran valid (Sarwono, 2010).
Pada penelitian ini, variabel laten eksogen terdiri dari social media influencer,
sedangkan keseluruhan variabel-variabel tersebut mempengaruhi variabel laten
endogen yaitu intention to online shopping baik secara langsung maupun tidak
langsung. Spesifikasi model pengukuran model variabel adalah sebagi berikut:
a. Model Pengukuran Variabel Laten Eksogen
Social Media Influencer
GAMBAR 3.2
MODEL PENGUKURAN SOCIAL MEDIA INFLUENCER
61
b. Model Pengukuan Variabel Laten Endogen
Intention to Online Shopping
GAMBAR 3.3
MODEL PENGUKURAN INTENTION TO ONLINE SHOPPING
2. Model Struktural
Model struktural merupakan bagian dari model SEM yang terdiri dari variabel
independen dan variabel dependen. Hal ini berbeda dengan model pengukuran yang
membuat semua variabel (konstruk) sebagai variabel independen, dengan berpedoman
terhadap hakekat SEM dan pada teori tertentu. Model struktural meliputi hubungan
antar konstruk laten dan hubungan ini di anggap linear, walaupun pengembangan lebih
lanjut memungkinkan memasukkan persamaan nonlinear. Model structural dalam
penelitian ini dapat dilihat pada Gambar 3.4 mengenai Diagram Jalur Pengaruh Social
Media Influencer terhadap Intention to Online Shopping berikut:
GAMBAR 3.4
DIAGRAM JALUR PENGARUH SOCIAL MEDIA INFLUENCER
TERHADAP INTENTION TO ONLINE SHOPPING

62
3.2.7.5 Pengujian Hipotesis
Hipotesis merupakan proposisi yang akan diuji keberlakuannya, atau
merupakan suatu jawaban sementara atas pertanyaan penelititi. Hipotesis dalam
penelitian kuantitatif dapat berupa hipotesis satu variabel dan hipotesis dua atau lebih
variabel yang dikenal sebagai hipotesis ka ketika usal (Priyono, 2016:66).
Pengujian hipotesis adalah sebuah cara pengujian jika pernyataan yang
dihasilkan dari kerangka teoritis yang berlaku mengalami pemeriksaan ketat (Sekaran,
2003:418). Rancangan analisis untuk menguji hipotesis yang telah dirumuskan harus
menggunakan uji statistik yang tepat. Untuk mencari antara hubungan dua variabel
atau lebih dapat dilakukan dengan menghitung korelasi antar variabel yang akan dicari
hubungannya. Korelasi merupakan angka yang menunjukan arah dan kuatnya
hubungan antar dua variabel atau lebih.
Objek penelitian yang menjadi variabel bebas atau variabel independen yaitu
social media influencer (X), sedangkan variabel dependen adalah intention to online
shopping (Y) dengan memperhatikan karakteristik variabel yang akan diuji, maka uji
statistik yang digunakan adalah melalui perhitungan analisis SEM untuk ke dua
variabel tersebut.
Secara statistik, hipotesis yang akan diuji dalam rangka pengambilan
keputusan penerimaan atau penolakan hipotesis dapat dirumuskan sebagai berikut:
1. Ho: 𝜌 ≤0, artinya tidak terdapat pengaruh dari social media influencer terhadap
intention to online shopping
2. Ha: 𝜌> 0, artinya terdapat pengaruh positif dari social media influencer
terhadap intention to online shopping
Pada penelitian ini pengujian hipotesis dilakukan dengan menggunakan
program IBM SPSS AMOS versi 22 untuk menganalisis hubungan dalam model
struktural yang diusulkan. Adapun model struktural yang diusulkan untuk menguji
hubungan kausalitas antara dimensi Social Media Influencer (X) terhadap Intention to
Online Shopping (Y). Pengujian hipotesis dilakukan dengan menggunakan t-value
dengan tingkat signifikansi 0,05 dan derajat kebebasan sebesar n (sampel). Nilai t-
value dalam program IBM SPSS AMOS versi 22 merupakan nilai Critical Ratio (C.R.)
(Siswono, 2012:316). H0 ditolak dan hipotesis penelitian yang telah dirumuskan

63
diterima. Kriteria penerimaan atau penolakan hipotesis utama pada penelitian ini dapat
ditulis sebagai berikut:
Hipotesis 1:
H0 c.r ≤ 0,05 artinya tidak terdapat pengaruh antara social media
influencer dengan intention to online shopping
H1c.r ≥ 0,05 artinya terdapat pengaruh antara social media influencer
dengan intention to online shopping
Hipotesis 2:
Penelitian ini bertujuan untuk membuktikan adanya hubungan antara faktor
social media influencer terhadap intention to online shopping. Hipotesis konseptual
yang diajukan dapat dilihat pada Gambar 3.1 berikut ini:
Keterangan
SMI = Social Media Influencer
IOS = Intention to Online Shopping
GAMBAR 3.4
DIAGRAM JALUR SEM STRUKTUR HIPOTESIS
Pengujian hipotesis dilakukan dengan menggunakan t-value dengan tingkat
signifikansi 0,05. Nilai t-value dalam program IBM SPSS AMOS versi 22 merupakan
nilai Critical Ratio (C.R.). Apabila nilai Critical Ratio (C.R.) ≥ 1,967 atau nilai
Attractivness
Content
Interaction
Relevant
SMI IOS
Credibility
Trust
Influence
Enjoyment
Convenience
Website Design
Time Saving
Security
Product Quality
ξ
γ
ε Price

64
probabilitas (P) ≤ 0,05 maka H0 ditolak (hipotesis penelitian diterima. Untuk
mengetahui besar tidaknya pengaruh hubungan variabel terhadap variabel lain, AMOS
menyajikan pengaruh setiap variabel yang dirangkum dalam efek langsung (direct
effect), efek tidak langsung (indirect effect) dan efek total (total effect). Adapun SEM
sendiri yang terdiri dari analisis jalur memiliki beberapa simbol untuk mewakili
pengaruh tersebut yaitu (Sugiyono,2013:328):
a. ξ (ksi) = mewakili variabel laten eksogen;
b. ε (eta) = mewakili variabel laten endogen;
c. λ (lambda) = nilai factor loading;
d. β (beta) = koefisien pengaruh variabel endogen terhadap variable
endogen;
e. γ (gamma) = koefisien pengaruh variabel eksogen terhadap variable
endogen;
f. φ (phi) = koefisien pengaruh variabel eksogen terhadap variable
eksogen;
g. δ (zeta) = peluang galat model;
h. ε (epsilon) = kesalahan pengukuran variabel manifes untuk variabel laten
endogen;
i. δ (delta) = kesalahan pengukuran variabel manifes untuk variabel laten
eksogen


















