
Automated Patent Classification By Yu Hu. Class 706 Subclass 12.
12
Automated Patent Classification By Yu Hu
-
Upload
joanna-lee -
Category
Documents
-
view
215 -
download
0
Transcript of Automated Patent Classification By Yu Hu. Class 706 Subclass 12.

Automated Patent Classification
By Yu Hu

Class 706
Subclass 12

Patent Classifier
• Input: descriptions of the invention(abstracts)• Output: US Classification • Data from USPTO Full-text database• Extract abstracts and classifications

Abstract of US8452718
• Automated determination of a number of profiles for a training data set to be used in training a machine learning system for generating target function information from modeled profile parameters. In one embodiment, a first principal component analysis (PCA) is performed on a training data set, and a second PCA is performed on a combined data set which includes the training data set and a test data set. A test data set estimate is generated based on the first PCA transform and the second PCA matrix. The size of error between the test data set and the test data set estimate is used to determine whether a number of profiles associated with the training data set is sufficiently large for training a machine learning system to generate a library of spectral information.

Bag of Words
• Automated determination of a number of profiles for a training data set to be used in training a machine learning system for generating target function information from modeled profile parameters. In one embodiment, a first principal component analysis (PCA) is performed on a training data set, and a second PCA is performed on a combined data set which includes the training data set and a test data set. A test data set estimate is generated based on the first PCA transform and the second PCA matrix. The size of error between the test data set and the test data set estimate is used to determine whether a number of profiles associated with the training data set is sufficiently large for training a machine learning system to generate a library of spectral information

K Nearest Neighbor

Data
• 631 most recently filed patent application of Apple Inc.• Preprocessing: Remove html tags, punctuation, stopwords, (numbers)• Extract abstracts and classifications
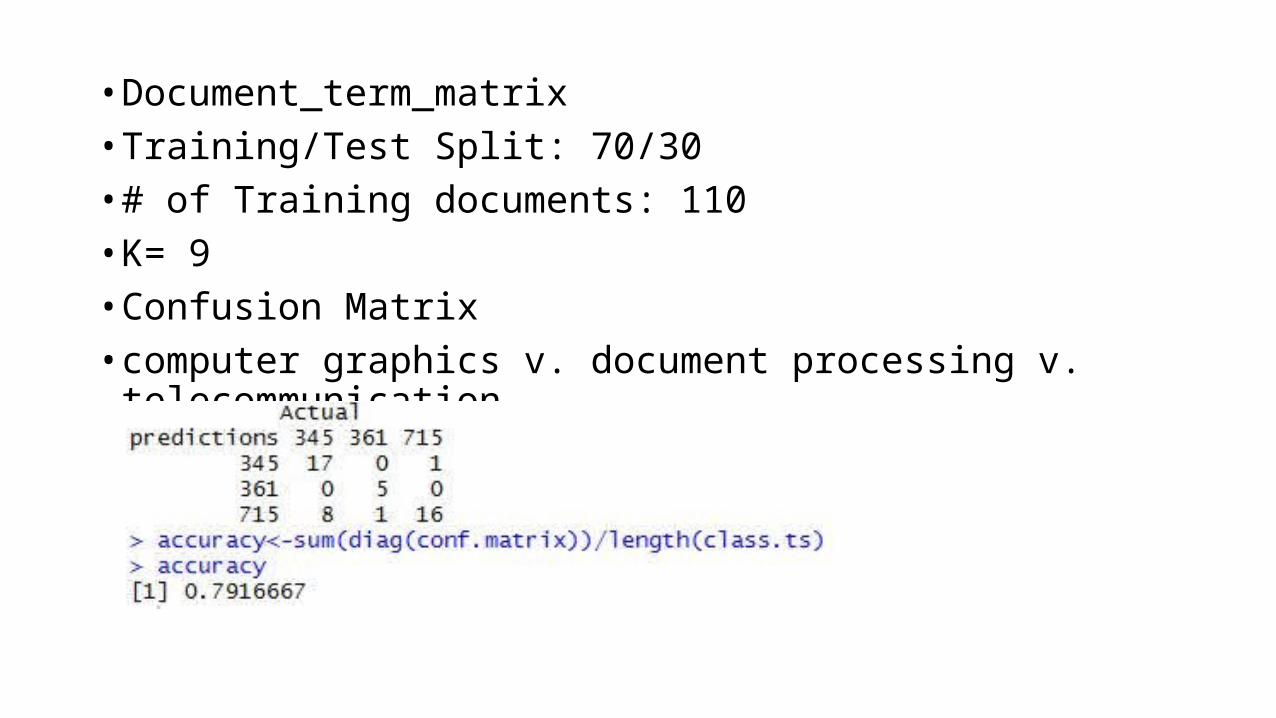
• Document_term_matrix• Training/Test Split: 70/30• # of Training documents: 110 • K= 9• Confusion Matrix• computer graphics v. document processing v. telecommunication

382 Image Analysis v. 435 Chemistry: molecular biology and microbiologyTraining documents: ~ 400; 80% split
382:Precision = 86.4%Recall = 97.4%
435:Precision = 81.8%Recall = 96.4%

Subclasses of Image Analysis Overlap

Subclass classification of 382 Image Analysis
382/181: Pattern Recognition382/232: Image Compression
If-Idf: term frequency-inverse document frequencyThis weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus.
181:Precision = 83.7%Rrecall = 75%
232:Precision = 67.5%Recall = 78.1%

• Thank you!• Questions?


















