
Asynchronous Stochastic Gradient Descent on GPU: Is It...
36
Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU? Florin Rusu Yujing Ma, Martin Torres (Ph.D. students) University of California Merced
Transcript of Asynchronous Stochastic Gradient Descent on GPU: Is It...

Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU?
Florin Rusu
Yujing Ma, Martin Torres (Ph.D. students)
University of California Merced

Machine Learning (ML) Boom
• Two SIGMOD 2017 tutorials

ML Systems
General purpose (databases) • BIDMach • Bismarck • Cumulon • DeepDive • DimmWitted • GLADE • GraphLab • MADlib • Mahout • MLlib (MLbase) • SimSQL (BUDS) • SystemML • Vowpal Wabbit • …
Deep learning
• Caffe (con Troll)
• CNTK
• DL4J
• Keras
• MXNet
• SINGA
• TensorFlow
• Theano
• Torch
• …
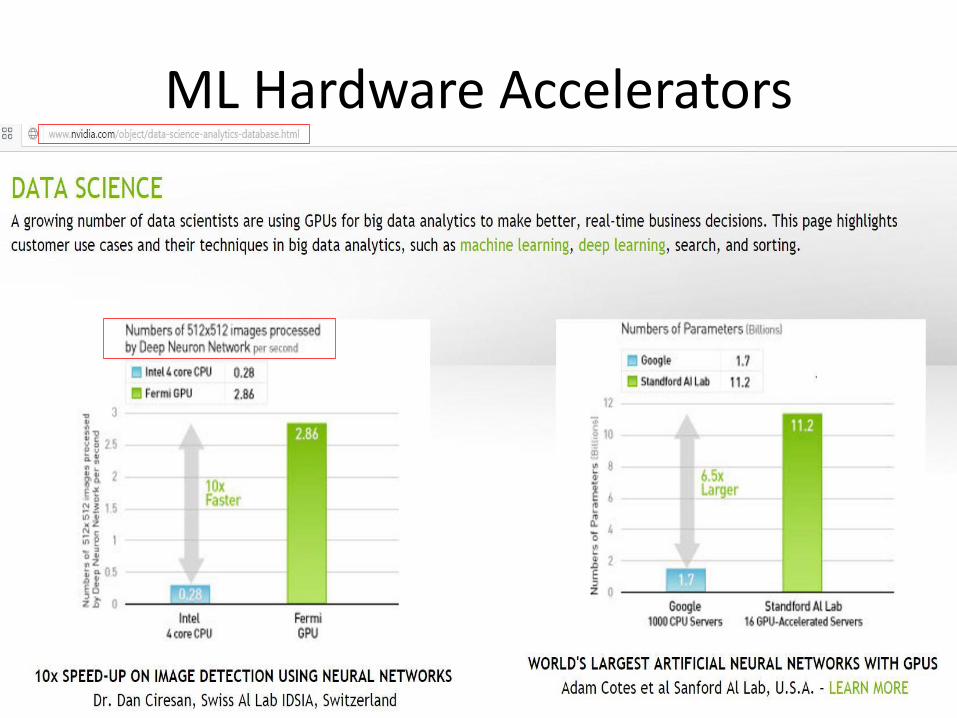
ML Hardware Accelerators

ML Systems with GPU Acceleration
General purpose • BIDMach • Bismarck • Cumulon • DeepDive • DimmWitted • GLADE • GraphLab • MADlib • Mahout • MLlib (MLbase) • SimSQL (BUDS) • SystemML • Vowpal Wabbit • …
Deep learning
• Caffe
• CNTK
• DL4J
• Keras
• MXNet
• SINGA
• TensorFlow
• Theano
• Torch
• …

ML in Databases
• It is not so much about deep learning – Regression (linear, logistic) – Classification (SVM) – Recommendation (LMF)
• Mostly about training – Inside DB, close to data – Over joins or factorized databases – Compressed data, (compressed) large models
• Selection of optimization algorithm and hyper-parameters – BGD vs. SGD vs. SCD

Classification Tasks
• Logistic regression (LR)
• Support Vector Machines (SVM)

Datasets and Platforms
S. Sallinen et al: “High Performance Parallel Stochastic Gradient Descent in Shared Memory” in IPDPS 2016.
• CPU: Intel Xeon E5-2660 (14 cores, 28 threads)
• GPU: Tesla K80 (use only one multiprocessor)

Experiments • Stochastic gradient descent (SGD) optimizer: mini-batch with 4096 batch size • Average time per iteration over 100 iterations (measure only the iteration time) • TensorFlow and MXNet support only dense data: covtype and w8a are “densified”;
others do not fit in GPU memory
LR
SVM

Research Questions
• Why is GPU not significantly better than CPU on LR and SVM models?
– The gain in deep nets seems to come mostly from convolutions, not gradient computations
– SparseMatrix-Vector (SpMV) and SparseMatrix-Matrix (SpMM) are harder to optimize
• Can we improve the GPU performance?

Gradient Descent

(Mini-)Batch Gradient Descent (BGD)
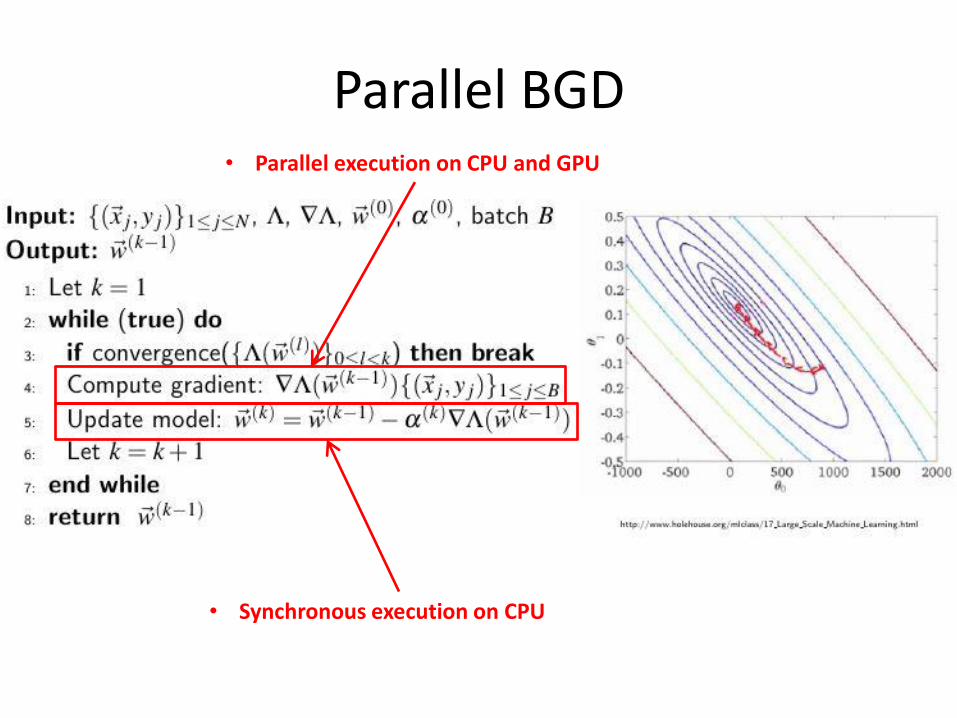
Parallel BGD • Parallel execution on CPU and GPU
• Synchronous execution on CPU
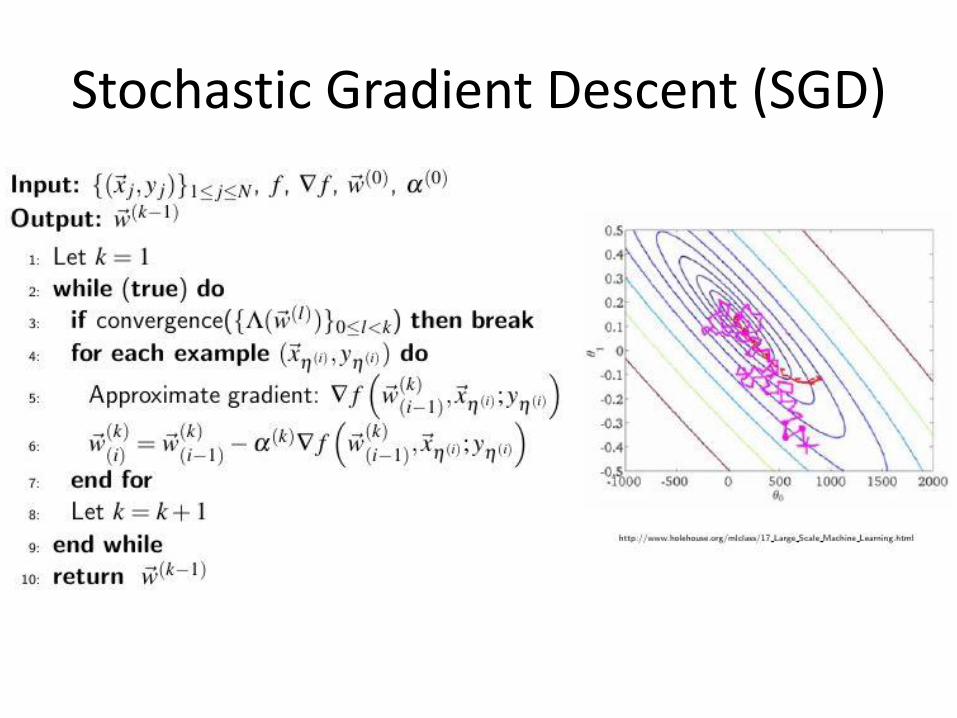
Stochastic Gradient Descent (SGD)

Parallel SGD (Hogwild)
• No synchronization or locks
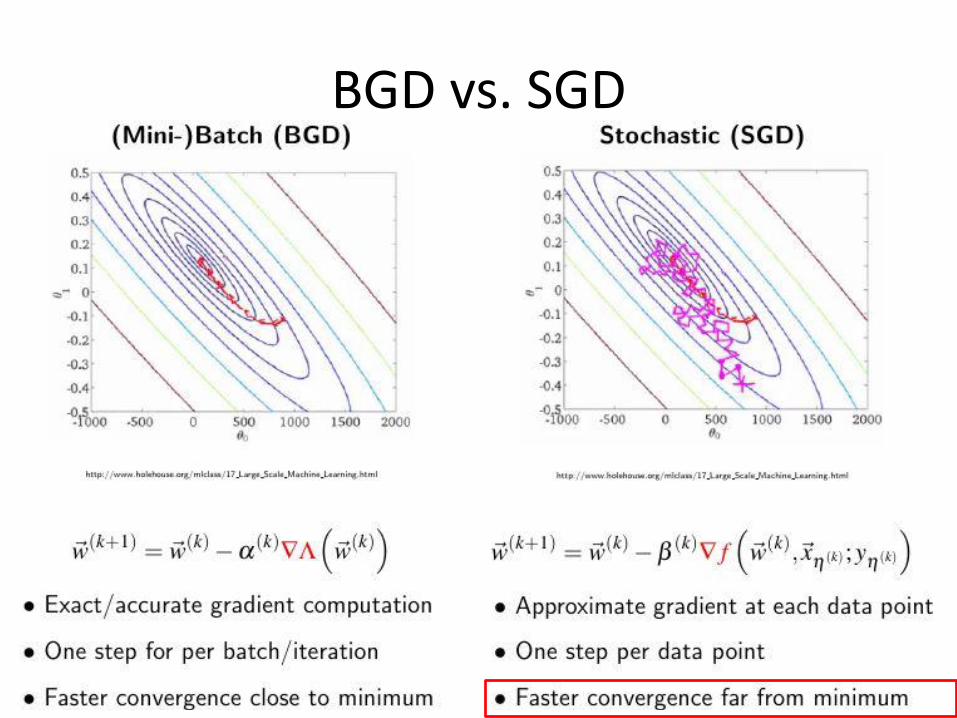
BGD vs. SGD
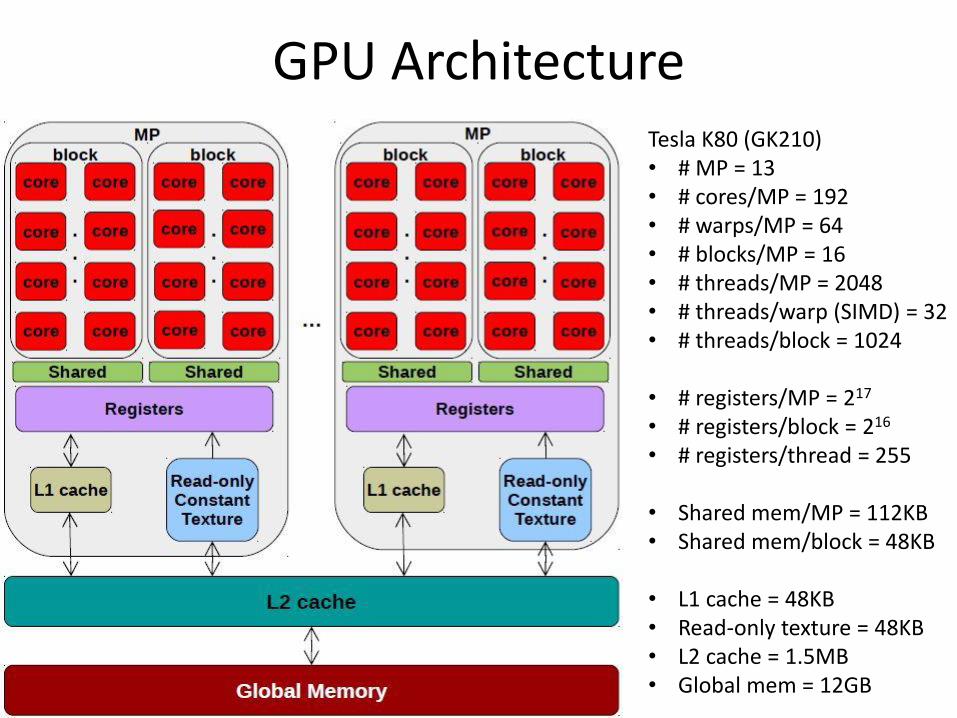
GPU Architecture Tesla K80 (GK210) • # MP = 13 • # cores/MP = 192 • # warps/MP = 64 • # blocks/MP = 16 • # threads/MP = 2048 • # threads/warp (SIMD) = 32 • # threads/block = 1024
• # registers/MP = 217
• # registers/block = 216 • # registers/thread = 255
• Shared mem/MP = 112KB • Shared mem/block = 48KB
• L1 cache = 48KB • Read-only texture = 48KB • L2 cache = 1.5MB • Global mem = 12GB

Map Hogwild to GPU
Algorithm 1. Copy data and model to GPU 2. While not converge do
1. Execute kernel update_model that implements Hogwild
3. End while

Design Space
Data access • Storage scheme
• Row-store • Column-store
• Partitioning • Round-robin • Chunking
Data replication • Number of threads
accessing an example • 1-way • K-way
Model replication • Where is model stored on GPU
memory hierarchy • Per thread (registers) • Per block (shared memory) • Per kernel (global memory)

Evaluation Metrics
• DimmWitted by Zhang and Re in PVLDB 2014
• Hardware efficiency
– Time to convergence
• Statistical efficiency
– Number of iterations to convergence
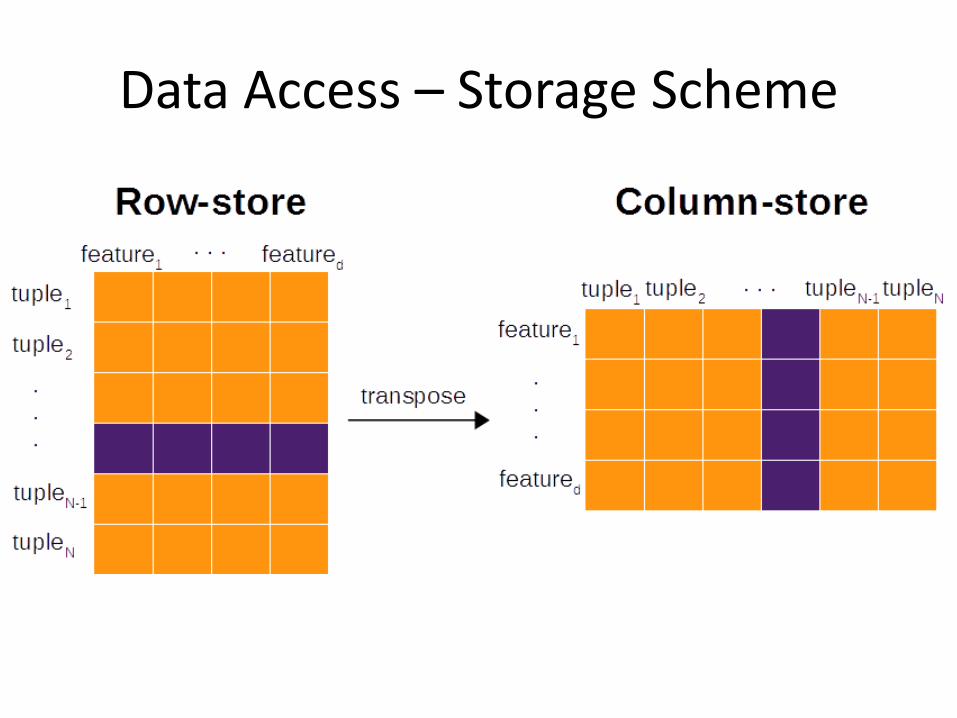
Data Access – Storage Scheme
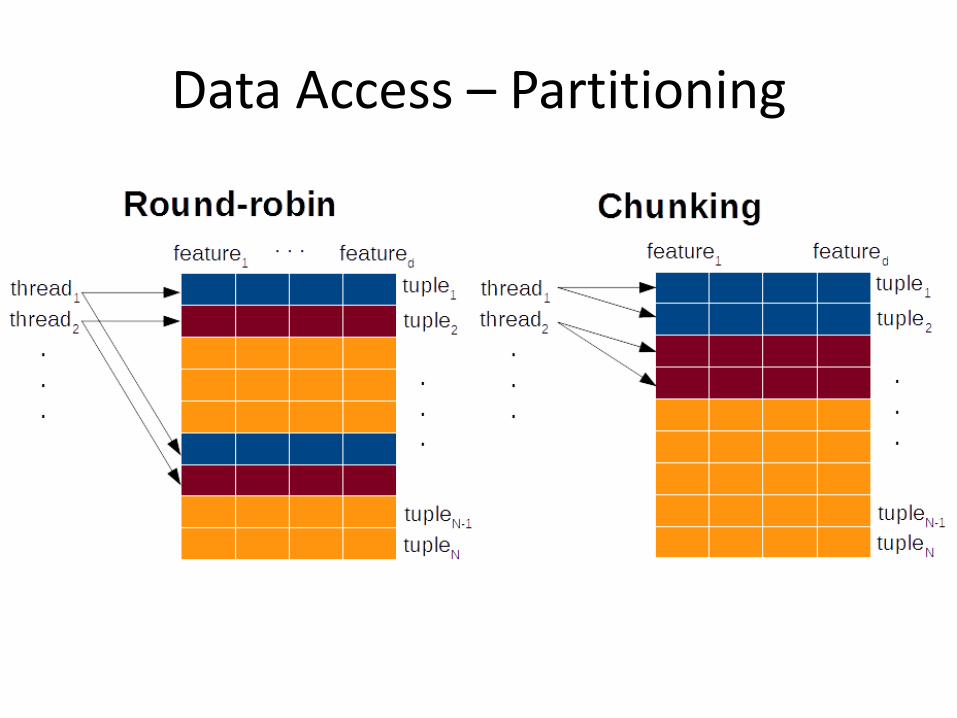
Data Access – Partitioning

Evaluation – Dense Data (covtype)
Hardware efficiency Statistical efficiency
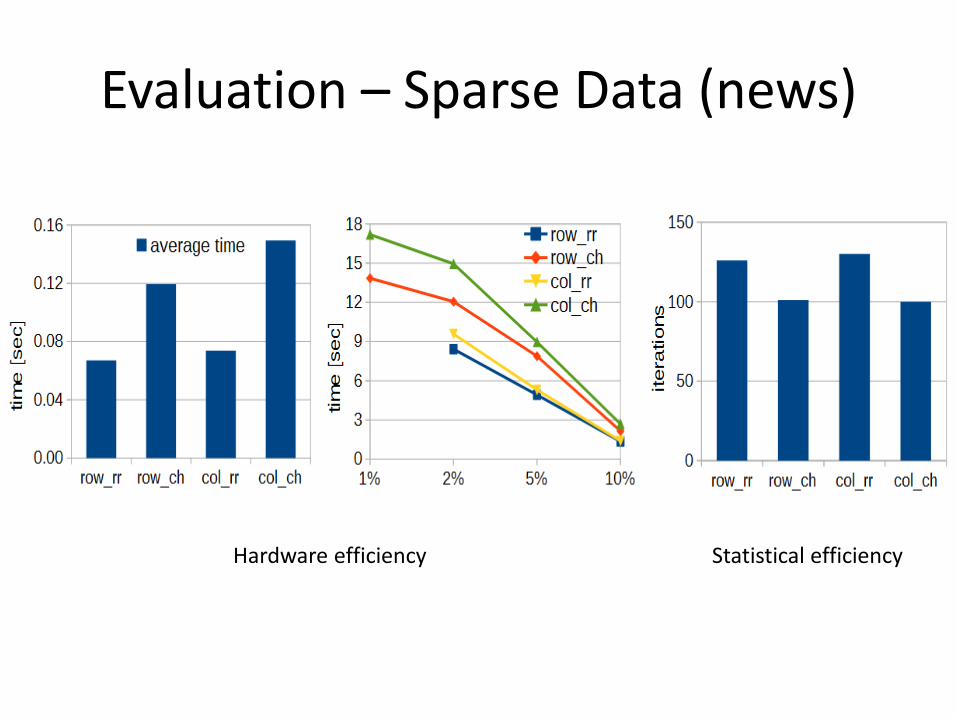
Evaluation – Sparse Data (news)
Hardware efficiency Statistical efficiency

Data Replication

Evaluation – Dense Data (covtype)
Hardware efficiency Statistical efficiency
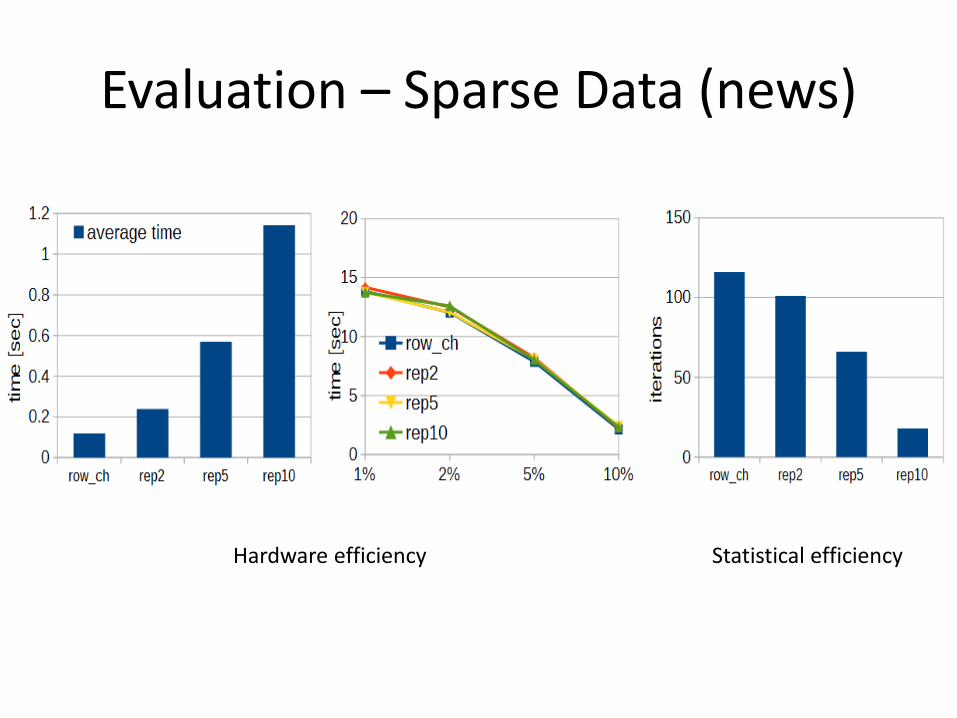
Evaluation – Sparse Data (news)
Hardware efficiency Statistical efficiency
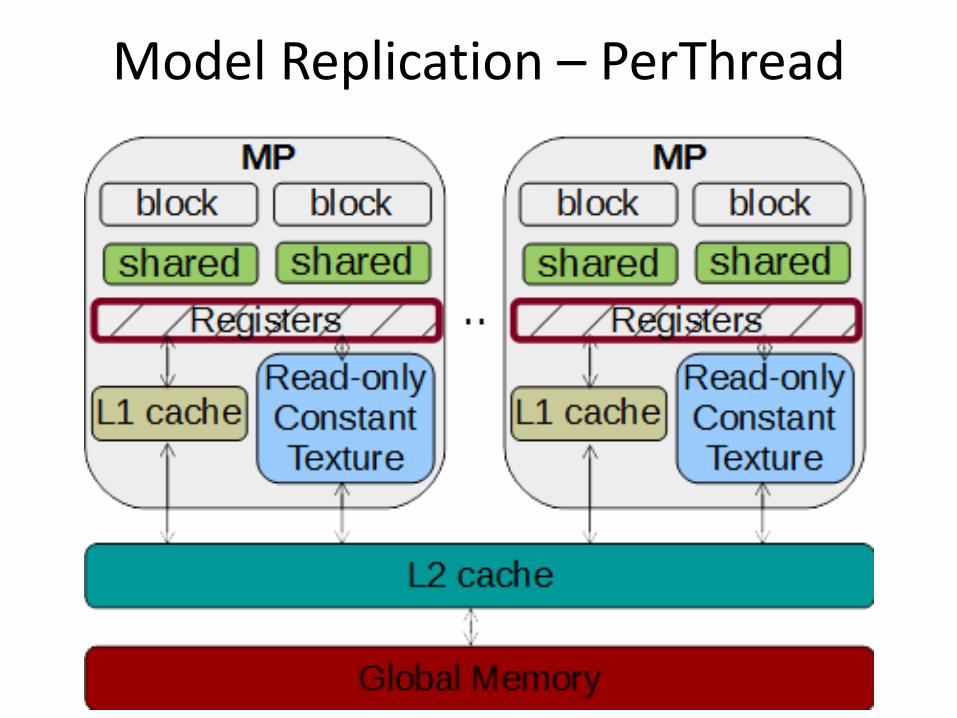
Model Replication – PerThread
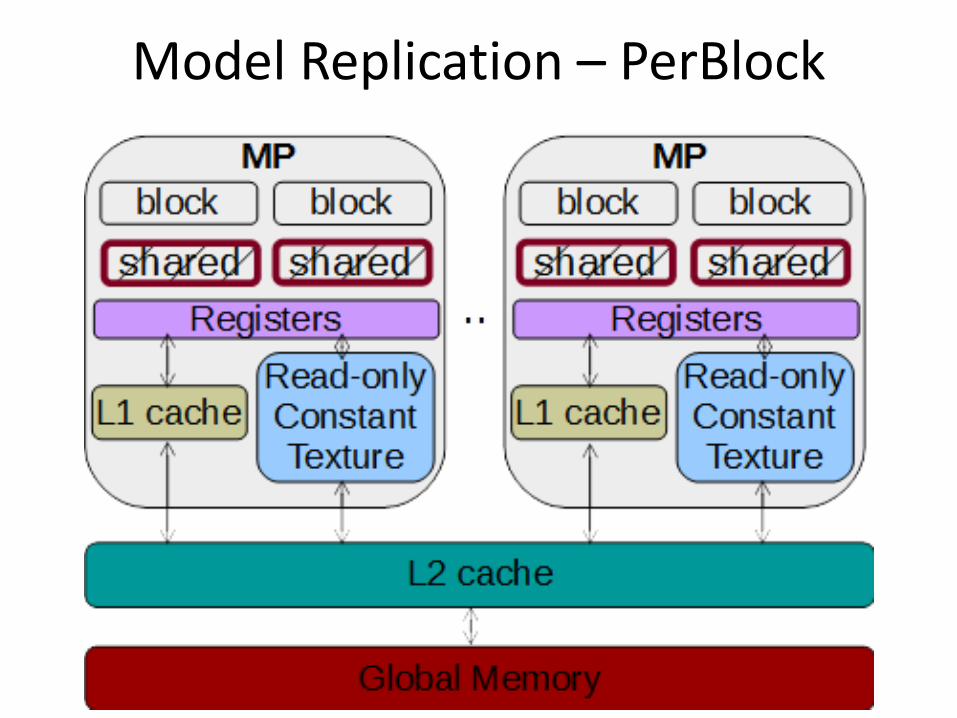
Model Replication – PerBlock

Model Replication – PerKernel
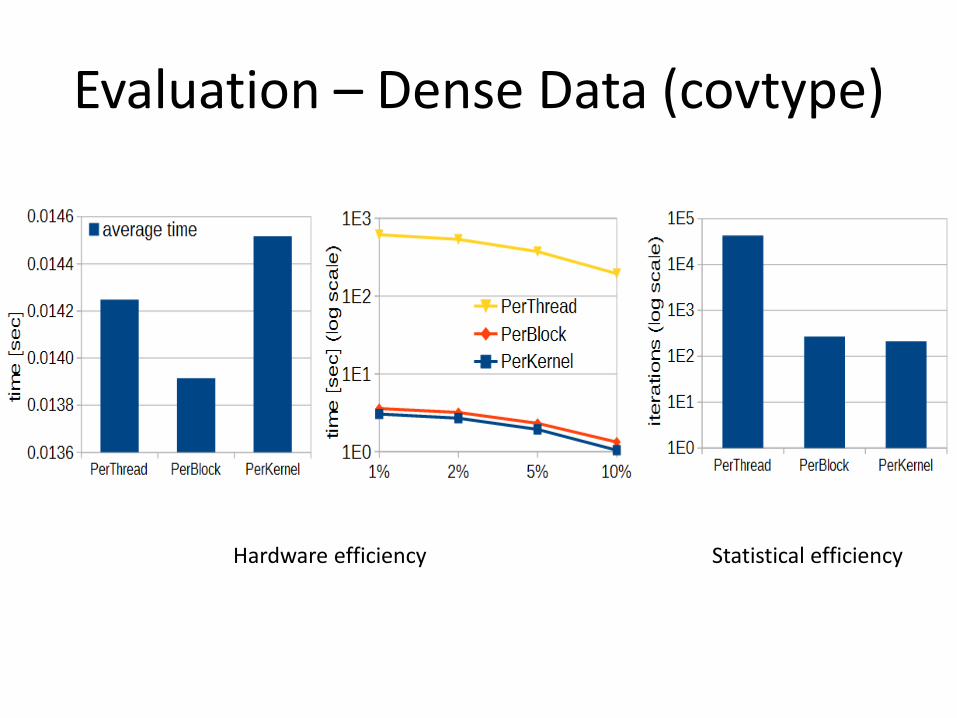
Evaluation – Dense Data (covtype)
Hardware efficiency Statistical efficiency

Evaluation – Sparse Data (news)
Hardware efficiency Statistical efficiency
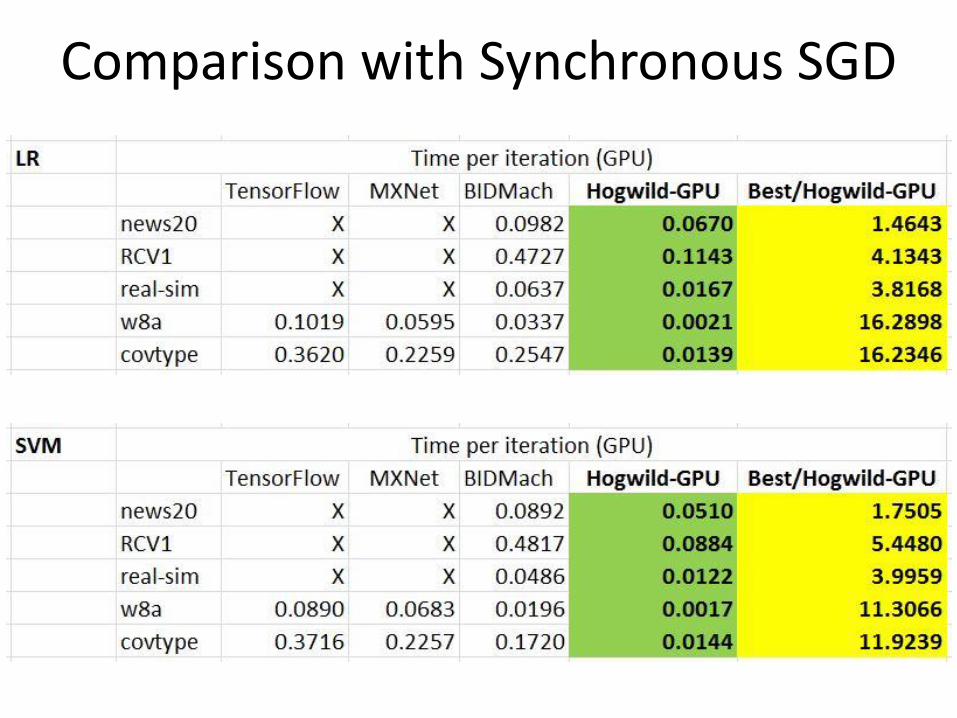
Comparison with Synchronous SGD

CPU vs. GPU

Conclusions
• Synchronous mini-batch in deep learning systems is rarely faster in convergence on GPU than on CPU
• Asynchronous SGD on GPU is always faster in time per iteration than synchronous mini-batch on GPU
• Asynchronous SGD on GPU is sometimes faster in convergence than asynchronous SGD on CPU

Thank you.
Questions ???


















