
Association Analysis (2). Example TIDList of item ID’s T1I1, I2, I5 T2I2, I4 T3I2, I3 T4I1, I2, I4...
31
Association Analysis (2)
-
Upload
cristian-osler -
Category
Documents
-
view
232 -
download
2
Transcript of Association Analysis (2). Example TIDList of item ID’s T1I1, I2, I5 T2I2, I4 T3I2, I3 T4I1, I2, I4...

Association Analysis (2)

Example
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset
{I5}
{I4}
{I3}
{I2}
{I1}
C1
Sup. count
Itemset
2{I5}
2{I4}
6{I3}
7{I2}
6{I1}
F1

Generate C2 from F1F1
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset Sup. count
{I1} 6
{I2} 7
{I3} 6
{I4} 2
{I5} 2
F1
{I4,I5}
{I3,I5}
{I3,I4}
{I2,I5}
{I2,I4}
Itemset
{I2,I3}
{I1,I5}
{I1,I4}
{I1,I3}
{I1,I2}
C2
Itemset Sup. C
{I1,I2} 4
{I1,I3} 4
{I1,I4} 1
{I1,I5} 2
{I2,I3} 4
{I2,I4} 2
{I2,I5} 2
{I3,I4} 0
{I3,I5} 1
{I4,I5} 0

Generate C3 from F2F2
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset Sup. C
{I1,I2} 4
{I1,I3} 4
{I1,I5} 2
{I2,I3} 4
{I2,I4} 2
{I2,I5} 2
F2
Itemset
{I1,I2,I3}
{I1,I2,I5}
{I1,I3,I5}
{I2,I3,I4}
{I2,I3,I5}
{I2,I4,I5}
Prune
Itemset
{I1,I2,I3}
{I1,I2,I5}
{I1,I3,I5}
{I2,I3,I4}
{I2,I3,I5}
{I2,I4,I5}
Itemset Sup. C
{I1,I2,I3} 2
{I1,I2,I5} 2
F3

Generate C4 from F3F3
TID List of item ID’s
T1 I1, I2, I5
T2 I2, I4
T3 I2, I3
T4 I1, I2, I4
T5 I1, I3
T6 I2, I3
T7 I1, I3
T8 I1, I2, I3, I5
T9 I1, I2, I3
Min_sup_count = 2
Itemset Sup. C
{I1,I2,I3,I5} 2
C4
{I1,I2,I3,I5} is pruned because {I2,I3,I5} is infrequent
Itemset Sup. C
{I1,I2,I3} 2
{I1,I2,I5} 2
F3

Candidate support counting• Scan the database of transactions to determine the support of
each candidate itemset
• Brute force: Match each transaction against every candidate. – Too many comparisons!
• Better method: Store the candidate itemsets in a hash structure– A transaction will be tested for match only against candidates
contained in a few buckets
TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
N
Transactions Hash Structure
k
Buckets
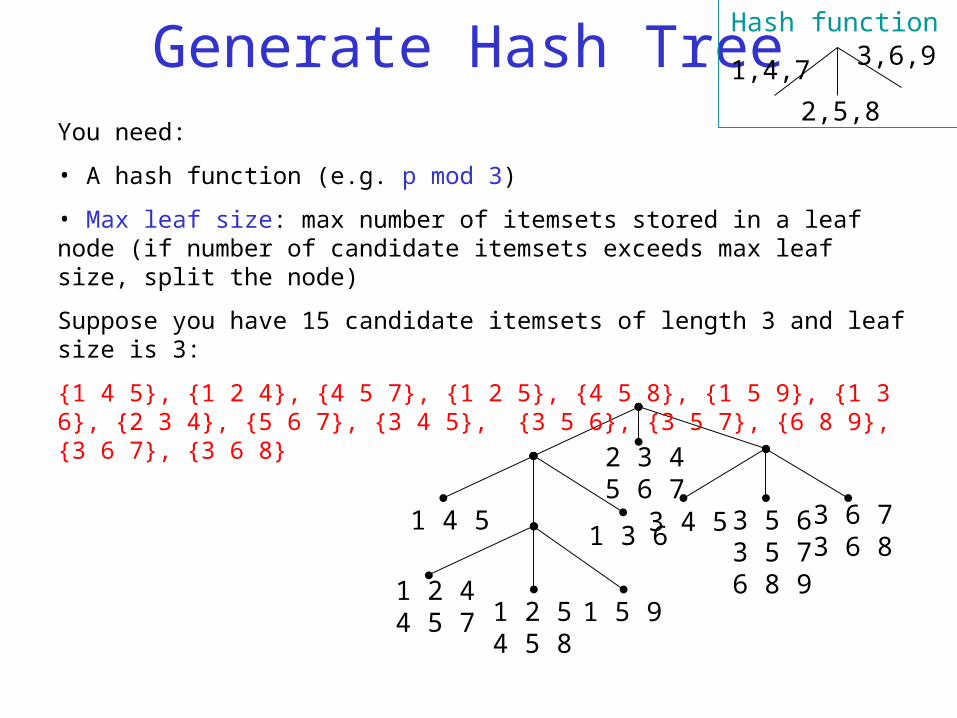
Generate Hash Tree
2 3 45 6 7
1 4 51 3 6
1 2 44 5 7 1 2 5
4 5 81 5 9
3 4 5 3 5 63 5 76 8 9
3 6 73 6 8
1,4,7
2,5,8
3,6,9Hash function
You need:
• A hash function (e.g. p mod 3)
• Max leaf size: max number of itemsets stored in a leaf node (if number of candidate itemsets exceeds max leaf size, split the node)
Suppose you have 15 candidate itemsets of length 3 and leaf size is 3:
{1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7}, {3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8}

Generate Hash Tree
1,4,7
2,5,8
3,6,9Hash function
Suppose you have 15 candidate itemsets of length 3 and leaf size is 3:
{1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7}, {3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8}
2 3 45 6 7
1 4 51 3 61 2 44 5 71 2 54 5 81 5 9
3 5 63 5 76 8 93 4 53 6 73 6 8
Split nodes with more than 3 candidates
using the second item

Generate Hash Tree
1,4,7
2,5,8
3,6,9Hash function
Suppose you have 15 candidate itemsets of length 3 and leaf size is 3:
{1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7}, {3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8}
2 3 45 6 7 3 5 6
3 5 76 8 93 4 53 6 73 6 8
1 2 44 5 71 2 54 5 81 5 9
1 4 51 3 6
Now split nodesusing the third item

Generate Hash Tree
1,4,7
2,5,8
3,6,9Hash function
Suppose you have 15 candidate itemsets of length 3 and leaf size is 3:
{1 4 5}, {1 2 4}, {4 5 7}, {1 2 5}, {4 5 8}, {1 5 9}, {1 3 6}, {2 3 4}, {5 6 7}, {3 4 5}, {3 5 6}, {3 5 7}, {6 8 9}, {3 6 7}, {3 6 8}
2 3 45 6 7 3 5 6
3 5 76 8 93 4 53 6 73 6 8
1 4 51 3 6
1 2 44 5 7 1 2 5
4 5 81 5 9
Now, split this similarly.

Subset Operation
1 2 3 5 6
Transaction, t
2 3 5 61 3 5 62
5 61 33 5 61 2 61 5 5 62 3 62 5
5 63
1 2 31 2 51 2 6
1 3 51 3 6
1 5 62 3 52 3 6
2 5 6 3 5 6
Subsets of 3 items
Level 1
Level 2
Level 3
63 5
Given a (lexicographically ordered) transaction t, say {1,2,3,5,6} how can we enumerate the possible subsets of size 3?

Subset Operation Using Hash Tree
1 5 9
1 4 5 1 3 63 4 5 3 6 7
3 6 8
3 5 6
3 5 7
6 8 9
2 3 4
5 6 7
1 2 4
4 5 71 2 5
4 5 8
1 2 3 5 6
1 + 2 3 5 63 5 62 +
5 63 +
1,4,7
2,5,8
3,6,9
Hash Functiontransaction

Subset Operation Using Hash Tree
1 5 9
1 4 5 1 3 63 4 5 3 6 7
3 6 8
3 5 6
3 5 7
6 8 9
2 3 4
5 6 7
1 2 4
4 5 71 2 5
4 5 8
1,4,7
2,5,8
3,6,9
Hash Function1 2 3 5 6
3 5 61 2 +
5 61 3 +
61 5 +
3 5 62 +
5 63 +
1 + 2 3 5 6
transaction

Subset Operation Using Hash Tree
1 5 9
1 4 5 1 3 63 4 5 3 6 7
3 6 8
3 5 6
3 5 7
6 8 9
2 3 4
5 6 7
1 2 4
4 5 71 2 5
4 5 8
1,4,7
2,5,8
3,6,9
Hash Function1 2 3 5 6
3 5 61 2 +
5 61 3 +
61 5 +
3 5 62 +
5 63 +
1 + 2 3 5 6
transaction
Match transaction against 7 out of 15 candidates

Rule Generation• An association rule can be extracted by partitioning a frequent itemset Y into
two non empty subsets, X and Y -X, such that XY-X
satisfies the confidence threshold.
• Each frequent k-itemset, Y, can produce up to 2k-2 association rules
– ignoring rules that have empty antecedents or consequents.Example Let Y = {1, 2, 3} be a frequent itemset. Six candidate association rules can be generated from Y: {1, 2} {3}, {1, 3}{2}, {2, 3} {1}, {1}{2, 3}, {2} {1, 3}, {3} {1, 2}.
Computing the confidence of an association rule does not require additional scans of the transactions. Consider {1, 2}{3}. The confidence is
({1, 2, 3}) / ({1, 2}) Because {1, 2, 3} is frequent, the anti monotone property of support ensures that {1, 2} must be frequent, too, and we know the supports of frequent itemsets.

Confidence-Based Prunning ITheorem.
If a rule XY – X does not satisfy the confidence threshold,
then any rule X ’Y – X ’, where X ’ is a subset of X, cannot satisfy the confidence threshold as well.
Proof.
Consider the following two rules: X ’ Y – X ’ and X Y – X, where X ’ X.
The confidence of the rules are (Y ) / (X ’) and (Y ) / (X), respectively.
Since X ’ is a subset of X, (X ’) (X).
Therefore, the former rule cannot have a higher confidence than the latter rule.

Confidence-Based Prunning II• Observe that:
X ’ X implies that Y – X ’ Y – X
Y
X
X’

Confidence-Based Prunning III• Initially, all the high confidence rules that have only one item in
the rule consequent are extracted.
• These rules are then used to generate new candidate rules.
• For example, if – {acd} {b} and {abd} {c} are high confidence rules, then the
candidate rule {ad} {bc} is generated by merging the consequents of both rules.

Confidence-Based Prunning IV
{Bread,Milk}{Diaper} (confidence = 3/3) threshold=50%
{Bread,Diaper}{Milk} (confidence = 3/3)
{Diaper,Milk}{Bread} (confidence = 3/3)
Item CountBread 4Coke 2Milk 4Beer 3Diaper 4Eggs 1
Itemset Count{Bread,Milk} 3{Bread,Beer} 2{Bread,Diaper} 3{Milk,Beer} 2{Milk,Diaper} 3{Beer,Diaper} 3
Itemset Count {Bread,Milk,Diaper} 3
Items (1-itemsets)
Pairs (2-itemsets)
Triplets (3-itemsets)

Confidence-Based Prunning VMerge:
{Bread,Milk}{Diaper}
{Bread,Diaper}{Milk}
{Bread}{Diaper,Milk} (confidence = 3/4)
…

Compact Representation of Frequent Itemsets
• Some itemsets are redundant because they have identical support as their supersets
• Number of frequent itemsets
• Need a compact representation
TID A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 B1 B2 B3 B4 B5 B6 B7 B8 B9 B10 C1 C2 C3 C4 C5 C6 C7 C8 C9 C101 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 02 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 03 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 04 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 05 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 06 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 07 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 08 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 09 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 010 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 011 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 112 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 113 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 114 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 115 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
456,435
103
10
1
k k
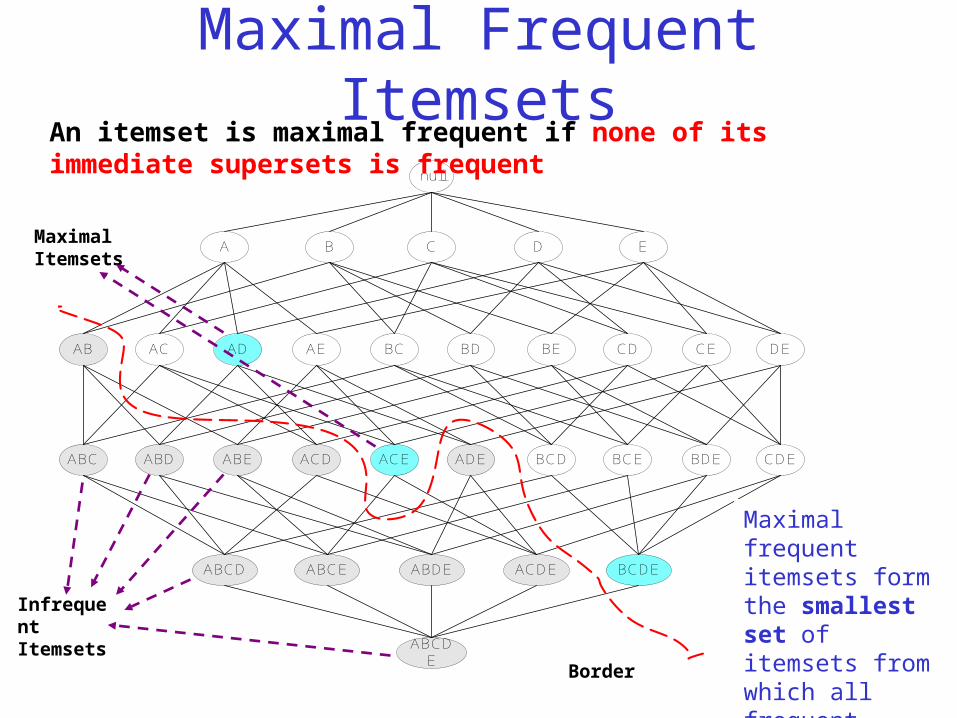
Maximal Frequent Itemsets
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
Border
Infrequent Itemsets
Maximal Itemsets
An itemset is maximal frequent if none of its immediate supersets is frequent
Maximal frequent itemsets form the smallest set of itemsets from which all frequent itemsets can be derived.

Maximal Frequent Itemsets• Despite providing a compact representation, maximal frequent
itemsets do not contain the support information of their subsets. – For example, the support of the maximal frequent itemsets
{a, c, e}, {a, d}, and {b,c,d,e} do not provide any hint about the support of their subsets.
• An additional pass over the data set is therefore needed to determine the support counts of the non maximal frequent itemsets.
• It might be desirable to have a minimal representation of frequent itemsets that preserves the support information. – Such representation is the set of the closed frequent itemsets.

Closed Itemset• An itemset is closed if none of its immediate supersets has the same support
as the itemset.
– Put another way, an itemset X is not closed if at least one of its immediate supersets has the same support count as X.
• An itemset is a closed frequent itemset if it is closed and its support is greater than or equal to minsup.
TID Items1 {A,B}2 {B,C,D}3 {A,B,C,D}4 {A,B,D}5 {A,B,C,D}
Itemset Support{A} 4{B} 5{C} 3{D} 4
{A,B} 4{A,C} 2{A,D} 3{B,C} 3{B,D} 4{C,D} 3
Itemset Support{A,B,C} 2{A,B,D} 3{A,C,D} 2{B,C,D} 3
{A,B,C,D} 2

LatticeTID Items
1 ABC
2 ABCD
3 BCE
4 ACDE
5 DE
null
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
124 123 1234 245 345
12 124 24 4 123 2 3 24 34 45
12 2 24 4 4 2 3 4
2 4
Transaction Ids
Not supported by any transactions

Maximal vs. Closed Itemsetsnull
AB AC AD AE BC BD BE CD CE DE
A B C D E
ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE
ABCD ABCE ABDE ACDE BCDE
ABCDE
124 123 1234 245 345
12 124 24 4 123 2 3 24 34 45
12 2 24 4 4 2 3 4
2 4
Minimum support = 2
# Closed = 9
# Maximal = 4
Closed and maximal
Closed but not maximal

Maximal vs Closed Itemsets
FrequentItemsets
ClosedFrequentItemsets
MaximalFrequentItemsets
All maximal frequent itemsets are closed because none of the maximal frequent itemsets can have the same support count as their immediate supersets.

Deriving Frequent Itemsets From Closed Frequent Itemsets
• Consider {a, d}.
– It is frequent because {a, b, d} is. – Since it isn't closed, its support count must be identical to one of its immediate
supersets. – The key is to determine which superset among {a, b, d}, {a, c, d}, or {a, d, e} has
exactly the same support count as {a, d}.
• The Apriori principle states that:
– Any transaction that contains the superset of {a, d} must also contain {a, d}. – However, any transaction that contains {a, d} does not have to contain the
supersets of {a, d}. – So, the support for {a, d} must be equal to the largest support among its
supersets. – Since {a, c, d} has a larger support than both {a, b, d} and {a, d, e}, the support
for {a, d} must be identical to the support for {a, c, d}.

AlgorithmLet C denote the set of closed frequent itemsets
Let kmax denote the maximum length of closed frequent itemsets
Fkmax ={f | f C, | f | = kmax } {Find all frequent itemsets of size kmax}
for k = kmax – 1 downto 1 do
Set Fk to be all sub-itemsets of length k from the frequent itemsets in Fk+1 plus the closed frequent itemsets of size k.
for each f Fk do if f C then
f.support = max{f’.support | f’ Fk+1, f f’} end if
end for end for

ExampleC = {ABC:3, ACD:4, CE:6, DE:7}
kmax=3
F3 = {ABC:3, ACD:4}
F2 = {AB:3, AC:4, BC:3, AD:4, CD:4, CE:6, DE:7}
F1 = {A:4, B:3, C:6, D:7, E:7}

Computing Frequent Closed Itemsets• How?
• Use the Apriori Algorithm.
• After computing, say Fk and Fk+1, check whether there is some itemset in Fk which has a support equal to the support of one of its supersets in Fk+1. Purge all such itemsets from Fk.


















