
Artificial Neural Networks - University of Minnesota...
37
CS 5751 Machine Learning Chapter 4 Artificial Neural Networks 1 Artificial Neural Networks • Threshold units • Gradient descent • Multilayer networks • Backpropagation • Hidden layer representations • Example: Face recognition • Advanced topics
Transcript of Artificial Neural Networks - University of Minnesota...

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 1
Artificial Neural Networks • Threshold units
• Gradient descent
• Multilayer networks
• Backpropagation
• Hidden layer representations
• Example: Face recognition
• Advanced topics

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 2
Connectionist ModelsConsider humans• Neuron switching time ~.001 second• Number of neurons ~1010
• Connections per neuron ~104-5
• Scene recognition time ~.1 second• 100 inference step does not seem like enoughmust use lots of parallel computation!Properties of artificial neural nets (ANNs):• Many neuron-like threshold switching units• Many weighted interconnections among units• Highly parallel, distributed process• Emphasis on tuning weights automatically

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 3
When to Consider Neural Networks• Input is high-dimensional discrete or real-valued (e.g., raw
sensor input)• Output is discrete or real valued• Output is a vector of values• Possibly noisy data• Form of target function is unknown• Human readability of result is unimportant
Examples:• Speech phoneme recognition [Waibel]• Image classification [Kanade, Baluja, Rowley]• Financial prediction

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 4
ALVINN drives 70 mph on highways
4 HiddenUnits
30x32 SensorInput Retina
SharpLeft
SharpRight
StraightAhead
CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 5
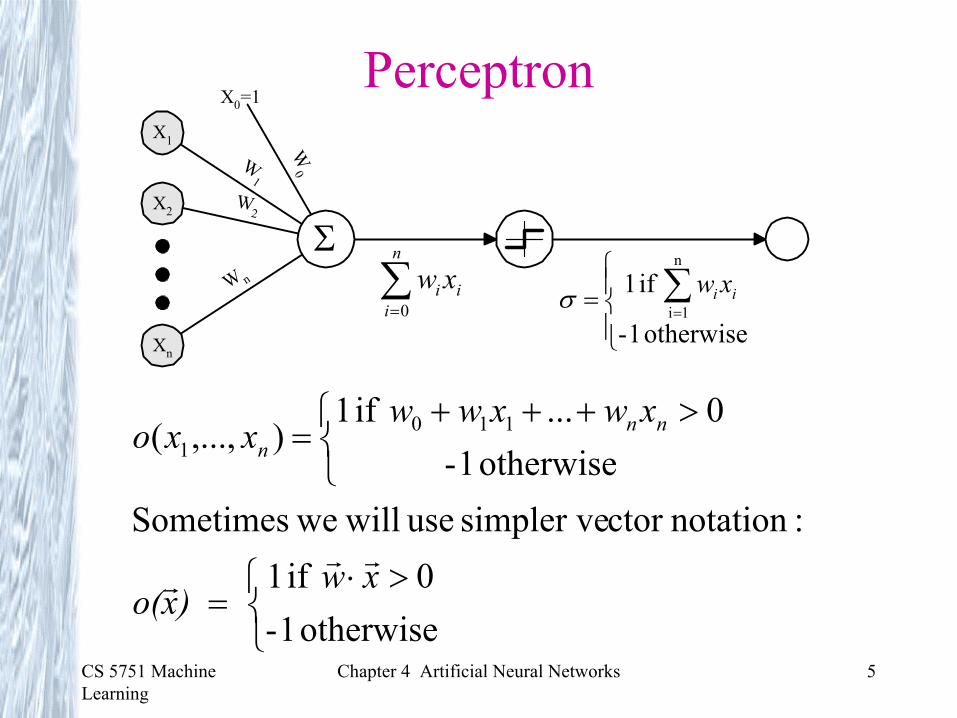
Perceptron
W n
W2
W0W
1
X1
ΣX2
Xn
X0=1
i
n
ii xw∑
=0
= ∑=
otherwise 1-
if 1n
1iii xwσ
>⋅
=
>+++
=
otherwise 1-0 if 1
:notationctor simpler ve use will weSometimesotherwise 1-
0... if 1),...,( 110
1
xw ) xo(
xwxwwxxo nn
n
rrr

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 6
Decision Surface of Perceptron
X2
X1
X2
X1
Represents some useful functions• What weights represent g(x1,x2) = AND(x1,x2)?But some functions not representable• e.g., not linearly separable• therefore, we will want networks of these ...

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 7
Perceptron Training Rule•
smallly sufficient is and separablelinearly is data trainingIf
converge it will proveCan
rate learning called .1) (e.g.,constant small is output perceptron is
lue target vais )( )(
where
η
η
η
••
••
=•−=∆
∆+←
oxct
xotw
www
ii
iii
r

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 8
Gradient Descent
[ ]
examples trainingofset theis Where
)(
error squared theminimize that s'learn :Idea
where, simpleconsider ,understand To
221
110
D
otwE
wxw...xwwo
tlinear uni
Dddd
i
nn
∑∈
−≡
+++=
r

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 9
Gradient Descent

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 10
Gradient Descent
ii
i
n
wEw
wEwwE
wE
wEwE
∂∂
−=∆
∇−=∆
∂∂
∂∂
∂∂
≡∇
i.e.,
][ :rule Training
,...,,][ Gradient 10
η
η r
r

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 11
Gradient Descent
))((
)()(
)()(221
)(21
)(21
,
2
2
∑
∑
∑
∑
∑
−−=∂∂
⋅−∂∂
−=
−∂∂
−=
−∂∂
=
−∂∂
=∂∂
ddidd
i
ddd i
dd
ddd i
dd
ddd i
ddd
ii
xotwE
xwtw
ot
otw
ot
otw
otww
E
rr

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 12
Gradient Descent
iii
iii
i
i
i
www
xotwww
oxexamplestraining,tx
w
w). (e.g., .rning rateis the leavalue. et output s the tes and t iinput valu
ctor of is the vexwhere ,,txe form pair of thples is a ining exam Each traexamplestraining
∆+←
−+∆←∆
∗><∆
••
><−
do t w,unit weighlinear each For -
)( do ,t unit weighlinear each For *
output compute and instance Input the do ,_in each For -
zero. toeach Initialize - do met, iscondition on terminati the Until valuerandom small some toeach Initialize
05 arg
) ,_(DESCENTGRADIENT
η
η
η
r
r
rr

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 13
SummaryPerceptron training rule guaranteed to succeed if• Training examples are linearly separable• Sufficiently small learning rate η
Linear unit training rule uses gradient descent• Guaranteed to converge to hypothesis with
minimum squared error• Given sufficiently small learning rate η• Even when training data contains noise• Even when training data not separable by H

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 14
Incremental (Stochastic) Gradient DescentBatch mode Gradient Descent:Do until satisfied:
][ 2.gradient theCompute .1
wEww]w[E
D
Drrr
r
∇−←∇
η
Incremental mode Gradient Descent:Do until satisfied:- For each training example d in D
][ 2.gradient theCompute .1
wEww]w[E
d
drrr
r
∇−←∇
η
221 )(][ d
DddD otwE −≡ ∑
∈
r
221 )(][ ddd otwE −≡
r
Incremental Gradient Descent can approximate Batch GradientDescent arbitrarily closely if η made small enough

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 15
Multilayer Networks of Sigmoid Units
d1
d0 d2
d3
d1
d0
d2
d3
h1h2
x1 x2
h1 h2
o

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 16
Multilayer Decision Space

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 17
Sigmoid Unit
W n
W2
W0W
1
X1
ΣX2
Xn
X0=1
i
n
ii xwnet ∑
=
=0
neteneto −+
==1
1)(σ
ationBackpropag networksMultilayer
xxdx
xde
x
-x
units sigmoid of unit sigmoid One
train torulesdescent gradient derivecan We
))( 1)(( )( :property Nice
11
functionsigmoid theis )(σ
→••
−=
+
σσσ
CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 18
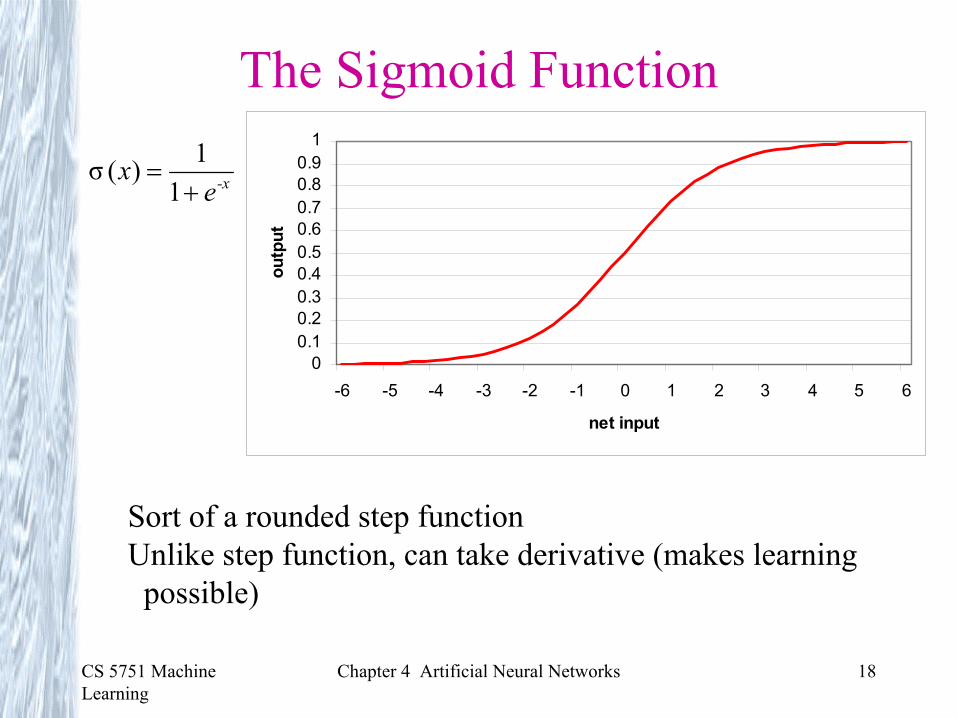
The Sigmoid Function
00.10.20.30.40.50.60.70.80.9
1
-6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6
net input
outp
ut
-xex
+=
11)(σ
Sort of a rounded step functionUnlike step function, can take derivative (makes learningpossible)

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 19
Error Gradient for a Sigmoid Unit
i
d
d
d
ddd
d i
ddd
dd
di
dd
dd
di
dDd
dii
wnet
netoot
woot
otw
ot
otw
otww
E
∂∂
∂∂
−=
∂∂
−−=
−∂∂
−=
−∂∂
=
−∂∂
=∂∂
∑
∑
∑
∑
∑∈
)(-
)(
)()(221
)(21
)(21
2
2
didddDd
di
dii
d
i
d
ddd
d
d
d
xoootwE
xw
xww
net
oonetnet
neto
,
,
)1()(
:So
)(
)1()(
:know But we
−−−=∂∂
=∂⋅∂
=∂∂
−=∂
∂=
∂∂
∑∈
rr
σ

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 20
Backpropagation Algorithm
jijji
jijiji
ji
koutputsk
khhhk
kkkkk
xw
www
w
woohotoo
k
,,
,,,
,
,
ere wh
ight network weeach Update4.
)1( unit hidden each For 3.
))(1( unit output each For 2.
outputs thecompute and example trainingInput the 1. do example, ingeach trainFor
do satisfied, Untilnumbers. random small to weightsall Initialize
δη
δδ
δ
=∆
∆+←
−←
−−←
•
∑∈

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 21
More on Backpropagation• Gradient descent over entire network weight vector
• Easily generalized to arbitrary directed graphs
• Will find a local, not necessarily global error minimum– In practice, often works well (can run multiple times)
• Often include weight momentum α
• Minimizes error over training examples
• Will it generalize well to subsequent examples?
• Training can take thousands of iterations -- slow!– Using network after training is fast
)1( )( ,,, −∆+=∆ nwxnw jijijji αδη

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 22
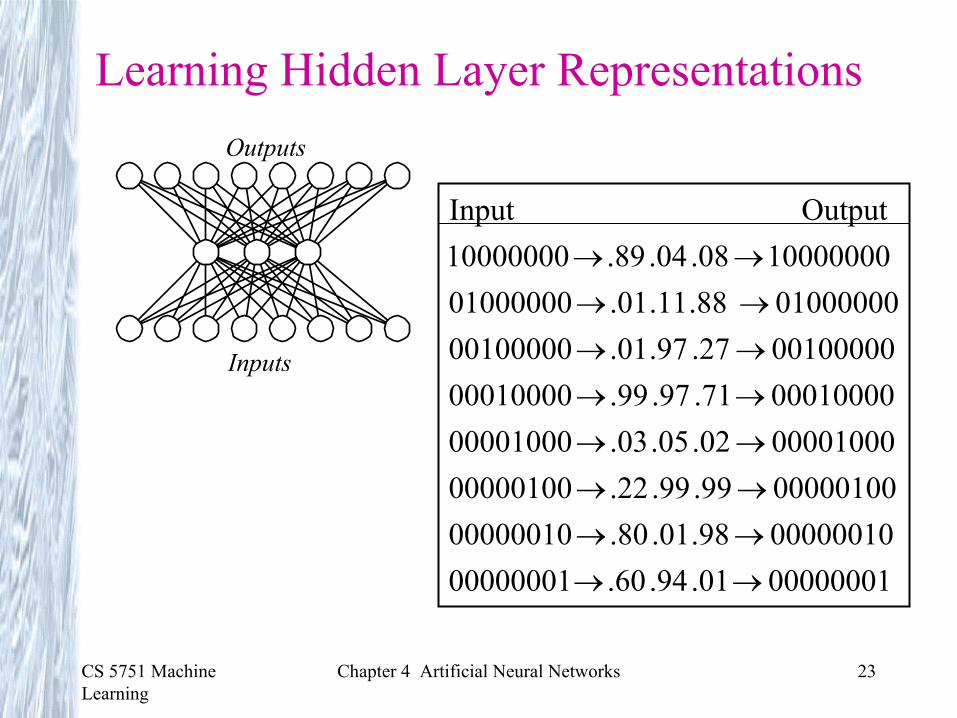
Learning Hidden Layer Representations
00000001 0000000100000010 0000001000000100 0000010000001000 0000100000010000 0001000000100000 0010000001000000 0100000010000000 10000000
Output Input
→→→→→→→→
Inputs
Outputs
CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 23
Learning Hidden Layer Representations
Inputs
Outputs
00000001 .01 .94 .60 0000000100000010 .98 .01 .80 0000001000000100 .99 .99 .22 0000010000001000 .02 .05 .03 0000100000010000 .71 .97 .99 0001000000100000 .27 .97 .01 0010000001000000 .88 .11 .01 01000000
10000000 .08 .04 .89 10000000Output Input
→→→→→→→→→→→→→→→→

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 24
Output Unit Error during Training
Sum of squared errors for each output unit
00.10.20.30.40.50.60.70.80.9
0 500 1000 1500 2000 2500
CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 25
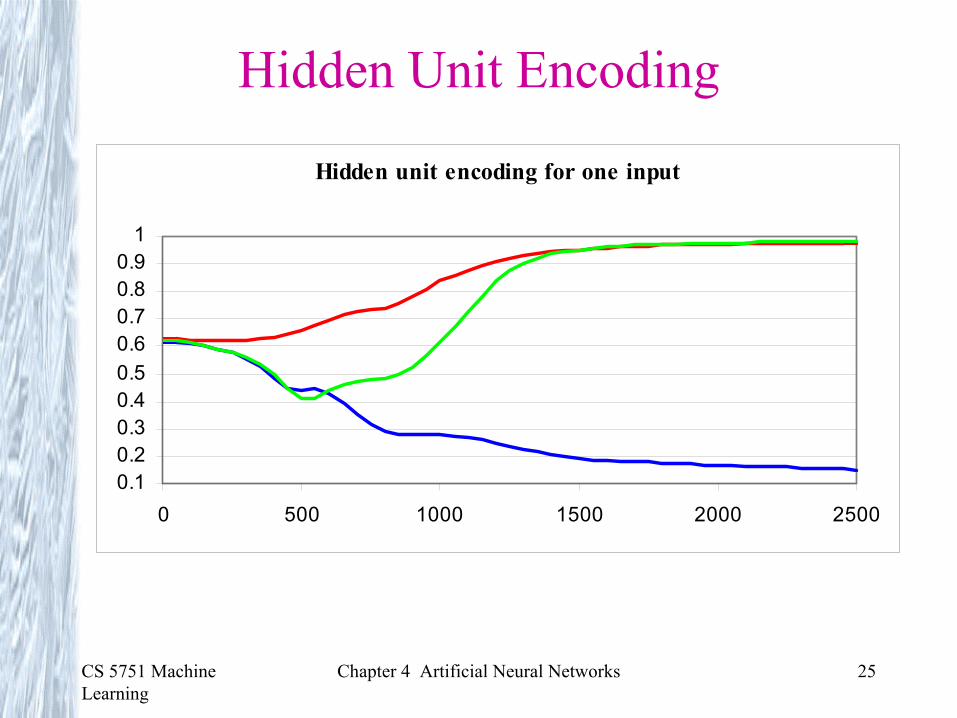
Hidden Unit Encoding
Hidden unit encoding for one input
0.10.20.30.40.50.60.70.80.9
1
0 500 1000 1500 2000 2500
CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 26
Input to Hidden WeightsWeights from inputs to one hidden unit
-5-4-3-2-101234
0 500 1000 1500 2000 2500

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 27
Convergence of BackpropagationGradient descent to some local minimum• Perhaps not global minimum• Momentum can cause quicker convergence• Stochastic gradient descent also results in faster
convergence• Can train multiple networks and get different results (using
different initial weights)
Nature of convergence• Initialize weights near zero• Therefore, initial networks near-linear• Increasingly non-linear functions as training progresses

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 28
Expressive Capabilities of ANNsBoolean functions:• Every Boolean function can be represented by network
with a single hidden layer• But that might require an exponential (in the number of
inputs) hidden units
Continuous functions:• Every bounded continuous function can be approximated
with arbitrarily small error by a network with one hidden layer [Cybenko 1989; Hornik et al. 1989]
• Any function can be approximated to arbitrary accuracy by a network with two hidden layers [Cybenko 1988]

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 29
Overfitting in ANNs
Error versus weight updates (example 1)
0.0020.0030.0040.0050.0060.0070.0080.009
0.01
0 5000 10000 15000 20000
Number of weight updates
Erro
r
Training setValidation set

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 30
Overfitting in ANNs
Error versus weight updates (Example 2)
00.010.020.030.040.050.060.070.08
0 1000 2000 3000 4000 5000 6000
Number of weight updates
Erro
r
Training setValidation set

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 31
Neural Nets for Face Recognition
30x32inputs
left strt rgt up
Typical Input Images
90% accurate learninghead pose, and recognizing1-of-20 faces

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 32
Learned Network Weights
Typical Input Images
30x32inputs
left strt rgt upLearned Weights

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 33
Alternative Error Functions
nrecognitio phonemein e.g., :weights together Tie
)()(
: valuesas wellas slopeson target Train
)()( : weightslarge Penalize
22
21
ji,
2221
•
∂∂
−∂∂
+−≡
+−≡
∑ ∑
∑∑ ∑
∈ ∈
∈ ∈
Dd outputsk djkd
dj
kdkdkd
jikdDd outputsk
kd
xo
xtotwE
wotwE
µ
γ
r
r

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 34
Recurrent Networks
FeedforwardNetwork
y(t+1)
x(t)
RecurrentNetwork
y(t+1)
x(t)
y(t+1)
x(t)
y(t)
x(t-1)
y(t-1)
x(t-2)
Recurrent Networkunfolded in time

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 35
Neural Network Summary• physiologically (neurons) inspired model• powerful (accurate), slow, opaque (hard to
understand resulting model)• bias: preferential
– based on gradient descent– finds local minimum– effect by initial conditions, parameters
• neural units– linear– linear threshold– sigmoid

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 36
Neural Network Summary (cont)• gradient descent
– convergence
• linear units– limitation: hyperplane decision surface– learning rule
• multilayer network– advantage: can have non-linear decision surface– backpropagation to learn
• backprop learning rule
• learning issues– units used

CS 5751 Machine Learning
Chapter 4 Artificial Neural Networks 37
Neural Network Summary (cont)• learning issues (cont)
– batch versus incremental (stochastic)– parameters
• initial weights• learning rate• momentum
– cost (error) function• sum of squared errors• can include penalty terms
• recurrent networks– simple– backpropagation through time


















