
Arquitecturas Paralelas Introducción - UNLP · Topologías para pasaje de mensajes. Redes de...
41
Arquitecturas Paralelas Introducción William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo. Andrew S. Tanenbaum, Organización de Computadoras 4ta. ed., Capítulo 8: Arquitecturas de computadoras paralelas. Hesham El-Rewini & Mostafa Abd-El-Barr, Advanced Computer Architecture and Parallel Processing. Willey.
Transcript of Arquitecturas Paralelas Introducción - UNLP · Topologías para pasaje de mensajes. Redes de...

Arquitecturas ParalelasIntroducción
William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo.
Andrew S. Tanenbaum, Organización de Computadoras 4ta. ed., Capítulo 8: Arquitecturas de computadoras paralelas.
Hesham El-Rewini & Mostafa Abd-El-Barr, Advanced Computer Architecture and Parallel Processing. Willey.
Contexto
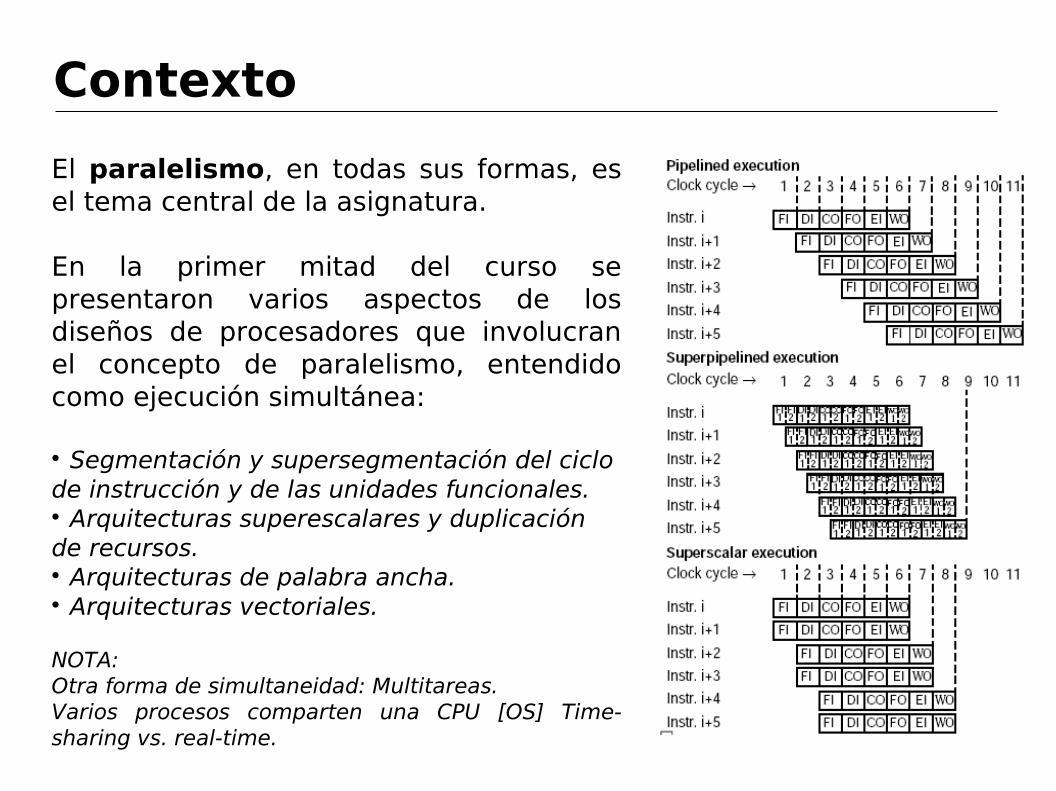
El paralelismo, en todas sus formas, es el tema central de la asignatura.
En la primer mitad del curso se presentaron varios aspectos de los diseños de procesadores que involucran el concepto de paralelismo, entendido como ejecución simultánea:
Segmentación y supersegmentación del ciclo de instrucción y de las unidades funcionales. Arquitecturas superescalares y duplicación de recursos. Arquitecturas de palabra ancha. Arquitecturas vectoriales.
NOTA:Otra forma de simultaneidad: Multitareas.Varios procesos comparten una CPU [OS] Time-sharing vs. real-time.

Paralelismo a nivel de instrucciones (ILP)Existe ILP cuando las instrucciones que componen un programa son independientes. En ese caso el código puede ser reordenado sin alterar el resultado. Por lo tanto existe la posibilidad de ejecutar las instrucciones en paralelo. Las dependencias de datos son críticas en este contexto.Ejemplo operaciones independientes: for(i=0;i<1000;i++) x[i]=x[i]+y[i];Ejemplo operaciones dependientes: for(i=1;i<1000;i++) x[i]=(x[i]+x[i-1])/2;
Paralelismo de la máquina (MLP)Es una medida de la capacidad del procesador para sacar partido del ILP. Depende del número de instrucciones que puedan captarse y ejecutarse simultáneamente (número de cauces paralelos). Existen dos aproximaciones:
− Scheduling Dinámico (HW): P4, UltraSPARCIII. SUPERESCALAR. Paralelismo implícito.
− Scheduling Estático (SW): IA-64, Transmeta. VLIW. Paralelismo explícito.
El punto es detectar el ILP y explotarlo con MLP
Alteramos la secuencialidad de las instrucciones del programa
Contexto

Contexto
Se presentaron los limites para la construcción de procesadores:
La disipación de potencia limita el tamaño de los transistores La velocidad de la luz limita la velocidad de reloj
Utilizando diseños RISC profundamente segmentados con características superescalares, puede conseguirse hasta un factor 10 de aceleración respecto de los diseños tradicionales, pero no más que eso.Pero qué sucede si una aplicación necesita 1012 instrucciones por segundo? Puede especularse sobre la futura existencia de un período de reloj de 0.001 ns? Casi imposible (la luz recorre 0.3 mm en 1 ps). Puede pensarse en 1000 computadoras de 1 ns trabajando simultáneamente? Puede ser...Si se desea un factor 1000 no alcanza con extender el concepto superescalar, agregando unidades funcionales, o pensar en aumentar 1000 veces la frecuencia de trabajo. La única solución es repetir CPUs enteras y lograr una colaboración eficiente entre ellas.

Contexto
Avances importantes en microprocesadores desde von Neumann (1950)
Unidad de control microprogramada y el concepto de familia (1964) Compatibilidad ISA con diferentes implementaciones [IBM 360].
Memoria cache (1968) [IBM 360]. Arquitecturas RISC (1982) Involucra la mayoría de los asuntos
importantes de arquitectura y organización: Segmentación de cauce (pipeline) y diseño superescalar.
No existe en la actualidad una tecnología que haga prever un impacto semejante.
Múltiples procesadores?

MotivaciónLas computadoras con una única CPU no son suficientes para satisfacer los requerimientos de algunas áreas de aplicación, a pesar de los avances tecnológicos y arquitectónicos de los procesadores modernos.
Simulaciones y modelado de sistemas complicados. Problemas que dependan de la manipulación/cómputo de grandes
cantidades de datos Los grandes problemas físicos, económicos, biológicos, climatológicos.
Estas aplicaciones se caracterizan por manejar cantidades enormes de datos y/o realizar grandes cantidades de cálculos numéricos.
Grand Challenge Problems (los grandes desafíos)
Problemas que tienen solución, pero que no pueden resolverse en una cantidad de tiempo razonable utilizando las computadoras actuales. Dinámica de fluídos, modelado ambiental, biología molecular. Ejemplo: pronostico meteorológico.
Una posible solución para las necesidades de alta performance es utilizar sistemas con varias CPUs para resolver una determinada aplicación.
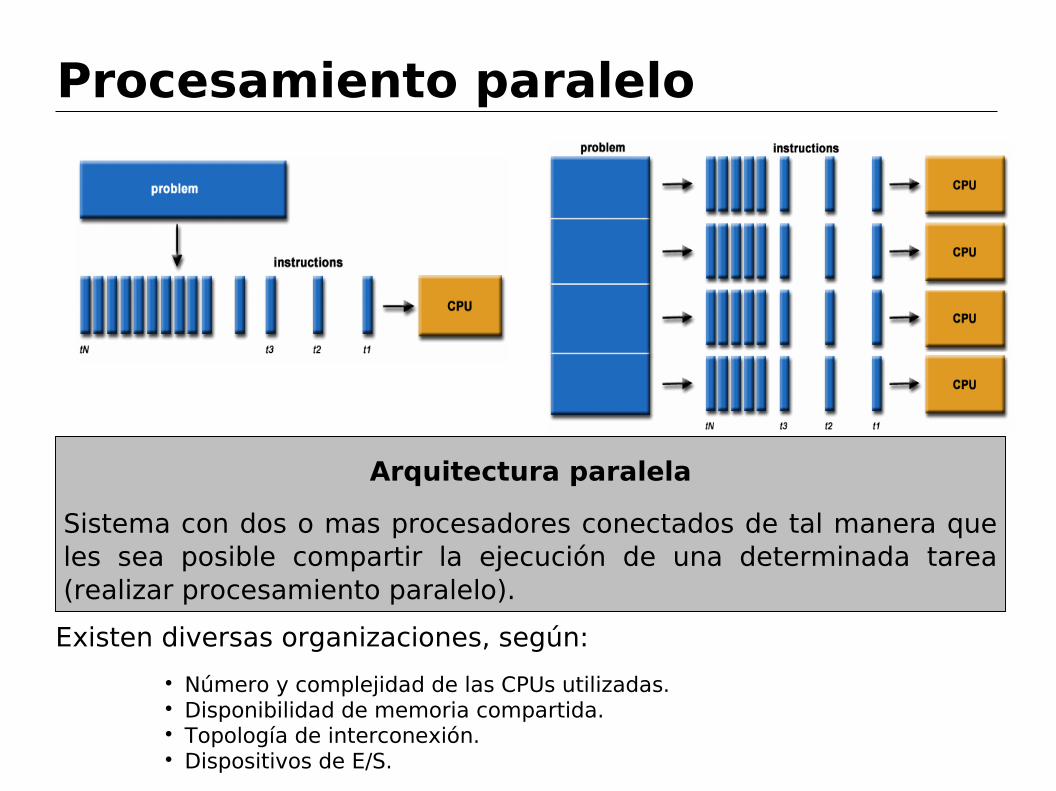
Procesamiento paralelo
Arquitectura paralela
Sistema con dos o mas procesadores conectados de tal manera que les sea posible compartir la ejecución de una determinada tarea (realizar procesamiento paralelo).
Existen diversas organizaciones, según:
Número y complejidad de las CPUs utilizadas. Disponibilidad de memoria compartida. Topología de interconexión. Dispositivos de E/S.

Paralelización de programas
La estrategia para la construcción de un programa paralelo (paralelización) consiste en descomponer el problema en tareas de menor complejidad que puedan ejecutarse simultáneamente.
El paralelismo se consigue:
Descomponiendo el problema en tareas menores.
Asignando las tareas a procesadores que puedan ejecutar en
paralelo.
Coordinando las tareas simultáneas.
Analogía con la industria automotriz y otros problemas complejos.

Programas paralelos - CondicionesSe necesitan dos condiciones en los programas de aplicación para hacer un uso eficiente de los procesadores:
1) Poca comunicación entre los procesadores mientras ejecutan la tarea compartida.
2) Un cierto grado de paralelismo inherente en la tarea a realizar.
Generalmente, la resolución de un problema puede ser dividida en tareas de menor complejidad, las cuales pueden ser ejecutadas simultáneamente con una cierta coordinación. Pero puede suceder que el esfuerzo de coordinación supere los beneficios del procesamiento simultáneo.
No todas las aplicaciones se benefician
Problemas “Embarrassingly parallel” Problemas en los cuales no hay que hacer ningún esfuerzo para paralelizar, pues no existe comunicación entre procesadores.
Fractales (cada punto puede calcularse en forma independiente) Animación (cada cuadro se renderiza en forma independiente de los
demás) Simulaciones y reconstrucciones en física de partículas.
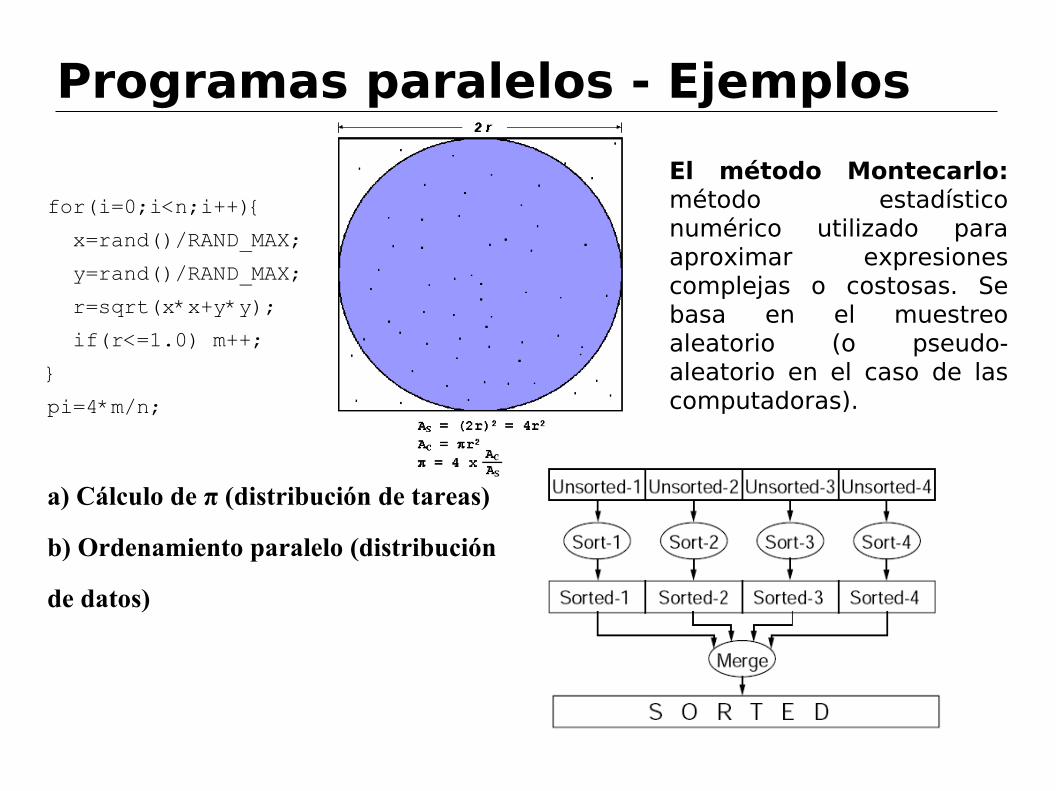
Programas paralelos - Ejemplos
for(i=0;i<n;i++){
x=rand()/RAND_MAX;
y=rand()/RAND_MAX;
r=sqrt(x*x+y*y);
if(r<=1.0) m++;
}
pi=4*m/n;
a) Cálculo de π (distribución de tareas)
b) Ordenamiento paralelo (distribución
de datos)
El método Montecarlo: método estadístico numérico utilizado para aproximar expresiones complejas o costosas. Se basa en el muestreo aleatorio (o pseudo-aleatorio en el caso de las computadoras).

Tipos de paralelismo
PARALELISMO EN LOS DATOSDiferentes datos, misma tarea (SIMD)
program:...if CPU="a" then low_limit=1 upper_limit=50else if CPU="b" then low_limit=51 upper_limit=100end ifdo i = low_limit , upper_limit Task on d(i)end do...end program
PARALELISMO EN LAS TAREASDiferentes datos, diferentes tareas (MIMD)
program:...if CPU="a" then do task "A"else if CPU="b" then do task "B"end if...end program
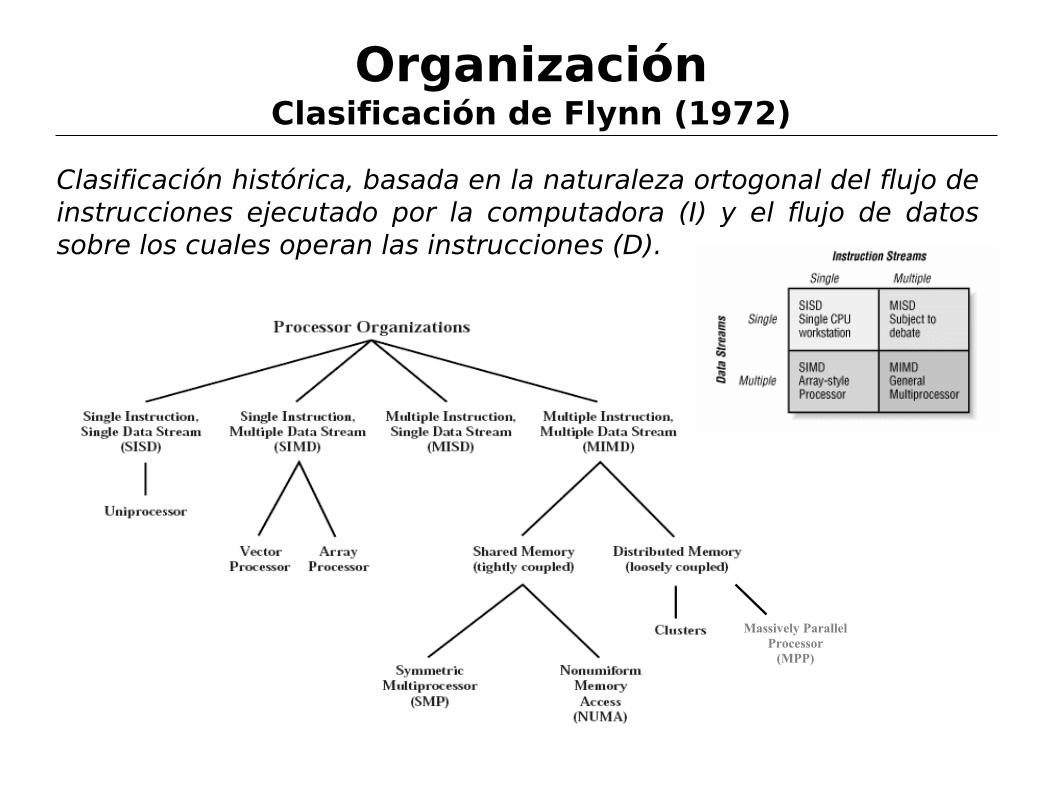
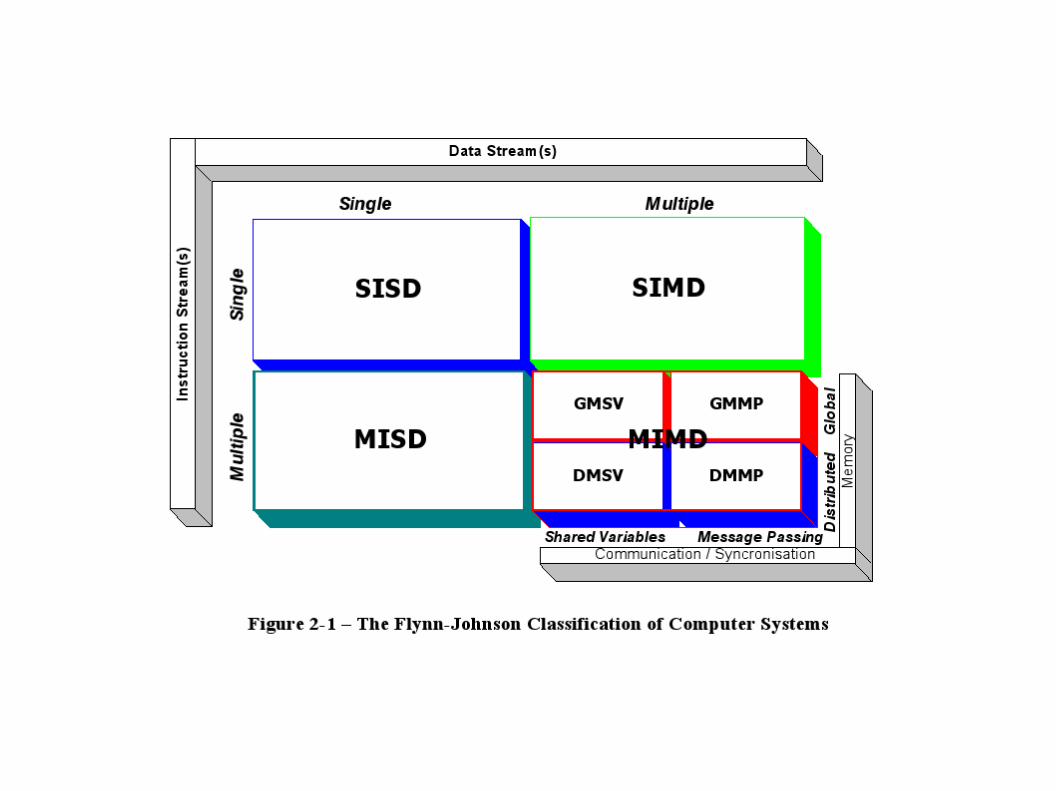
OrganizaciónClasificación de Flynn (1972)
Clasificación histórica, basada en la naturaleza ortogonal del flujo de instrucciones ejecutado por la computadora (I) y el flujo de datos sobre los cuales operan las instrucciones (D).
Massively ParallelProcessor
(MPP)
(Tanenbaum)
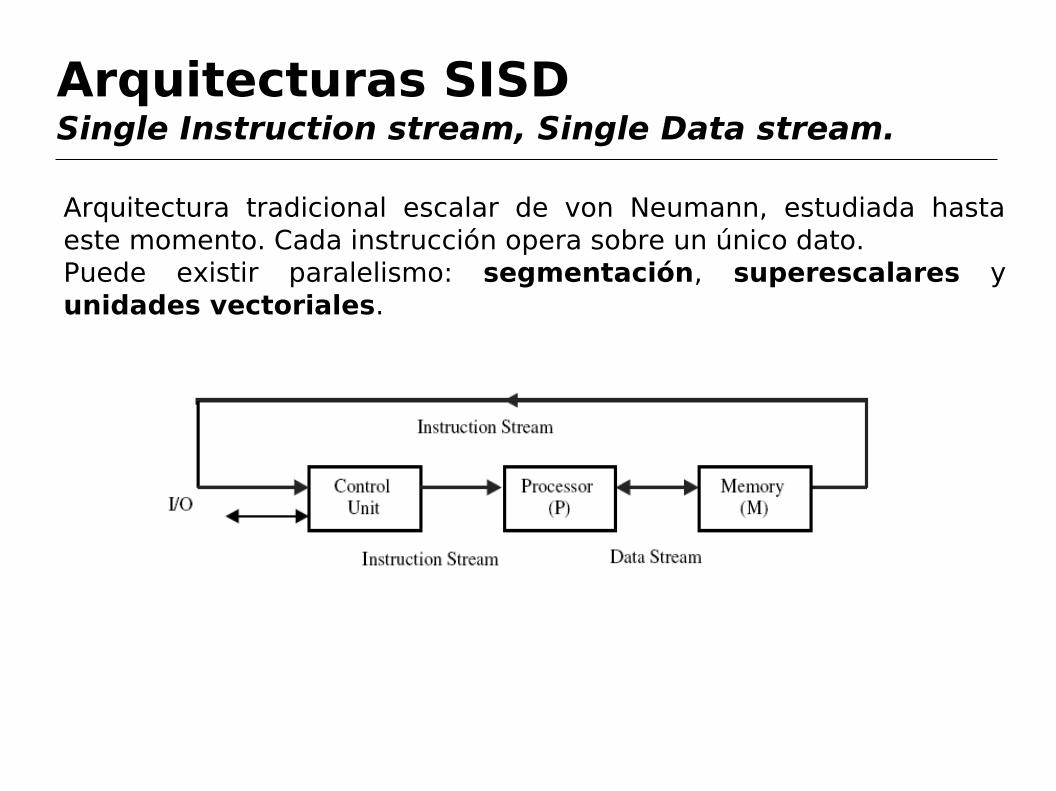
Arquitecturas SISDSingle Instruction stream, Single Data stream.
Arquitectura tradicional escalar de von Neumann, estudiada hasta este momento. Cada instrucción opera sobre un único dato.Puede existir paralelismo: segmentación, superescalares y unidades vectoriales.
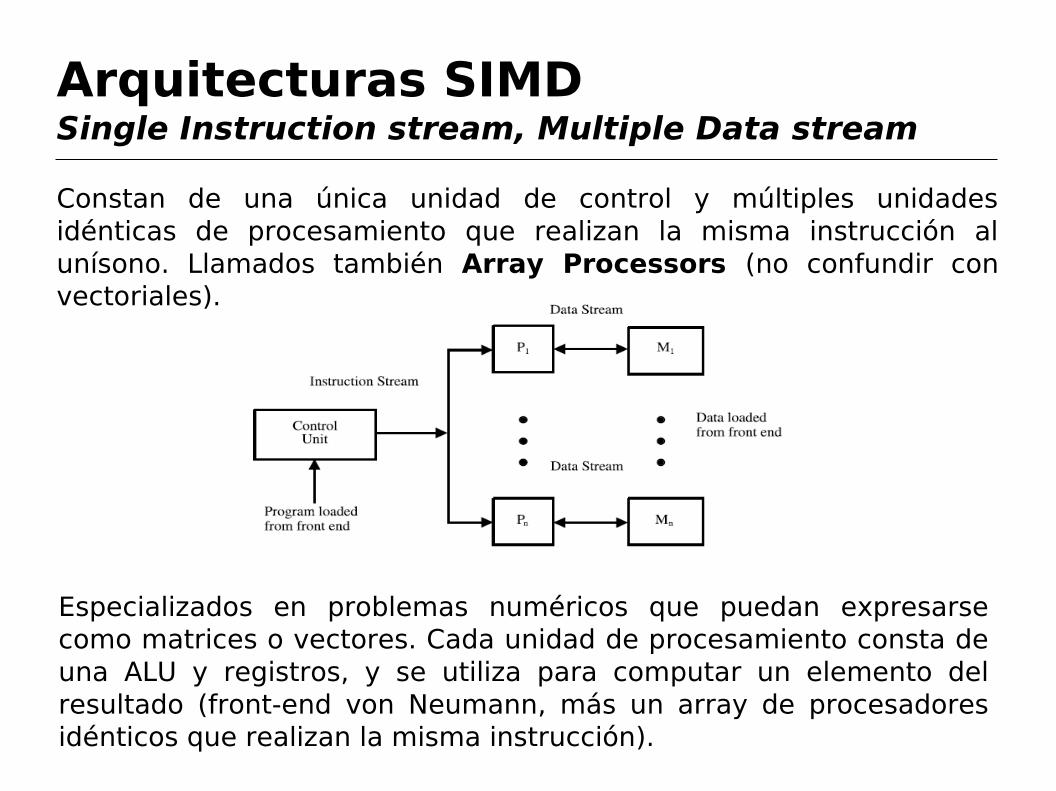
Arquitecturas SIMDSingle Instruction stream, Multiple Data stream
Constan de una única unidad de control y múltiples unidades idénticas de procesamiento que realizan la misma instrucción al unísono. Llamados también Array Processors (no confundir con vectoriales).
Especializados en problemas numéricos que puedan expresarse como matrices o vectores. Cada unidad de procesamiento consta de una ALU y registros, y se utiliza para computar un elemento del resultado (front-end von Neumann, más un array de procesadores idénticos que realizan la misma instrucción).
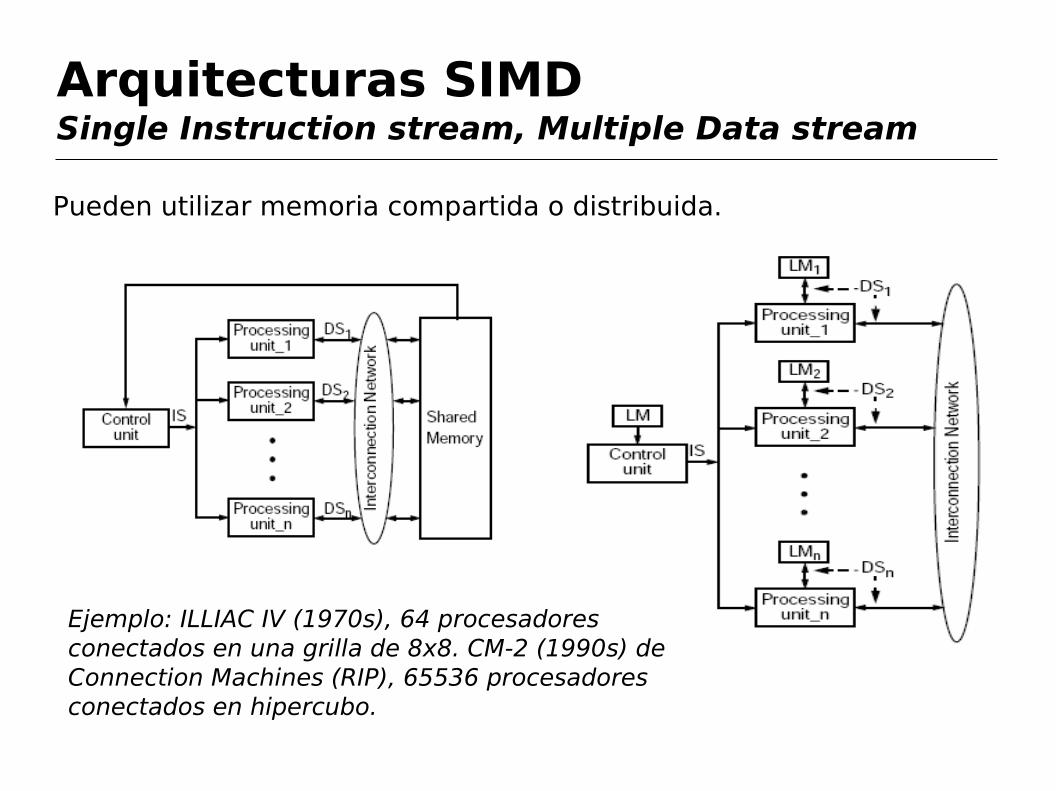
Pueden utilizar memoria compartida o distribuida.
Ejemplo: ILLIAC IV (1970s), 64 procesadores conectados en una grilla de 8x8. CM-2 (1990s) de Connection Machines (RIP), 65536 procesadores conectados en hipercubo.
Arquitecturas SIMDSingle Instruction stream, Multiple Data stream
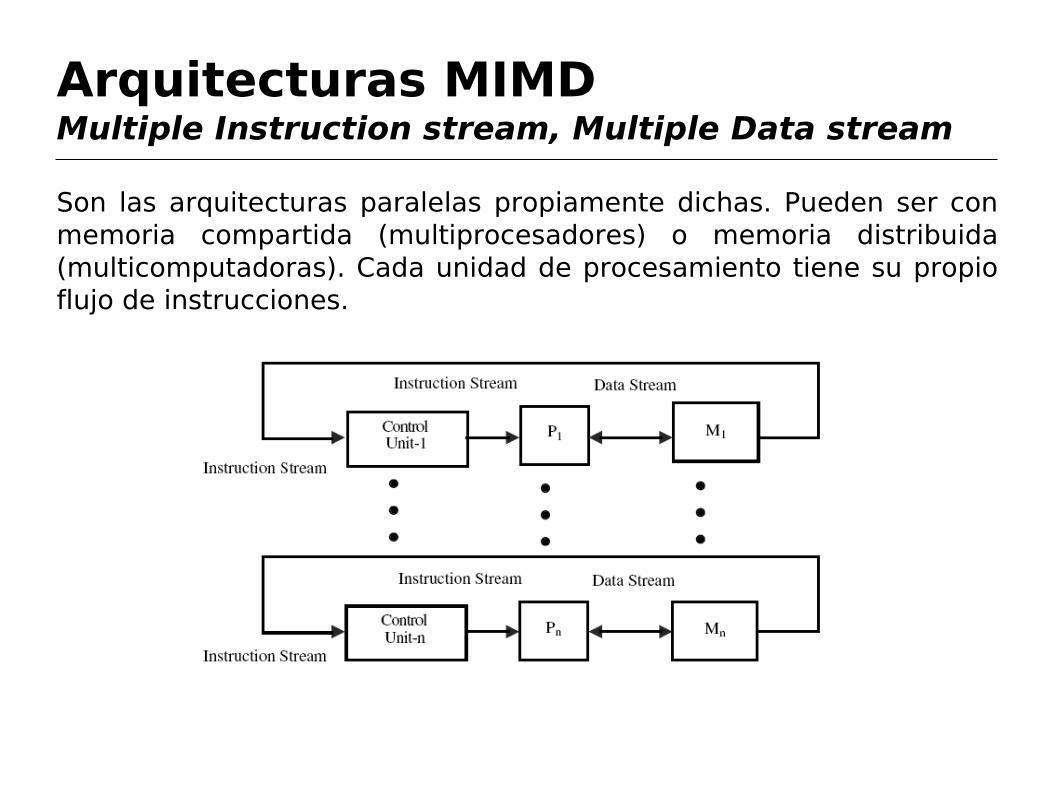
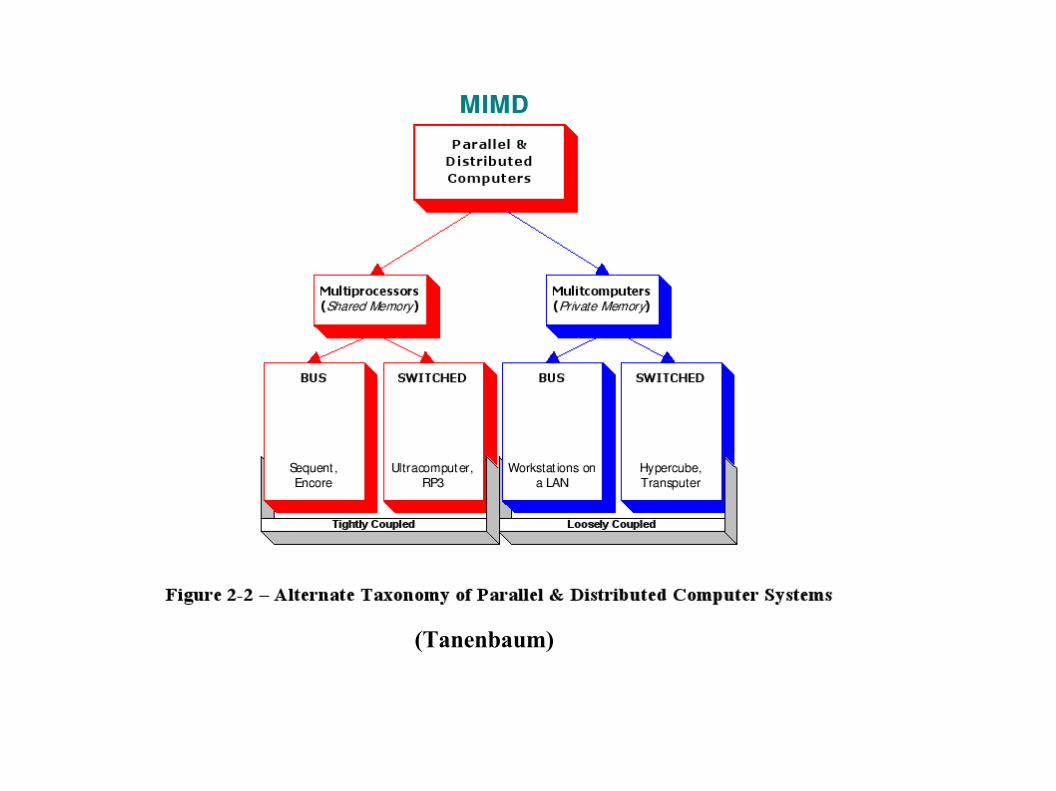
Arquitecturas MIMDMultiple Instruction stream, Multiple Data stream
Son las arquitecturas paralelas propiamente dichas. Pueden ser con memoria compartida (multiprocesadores) o memoria distribuida (multicomputadoras). Cada unidad de procesamiento tiene su propio flujo de instrucciones.
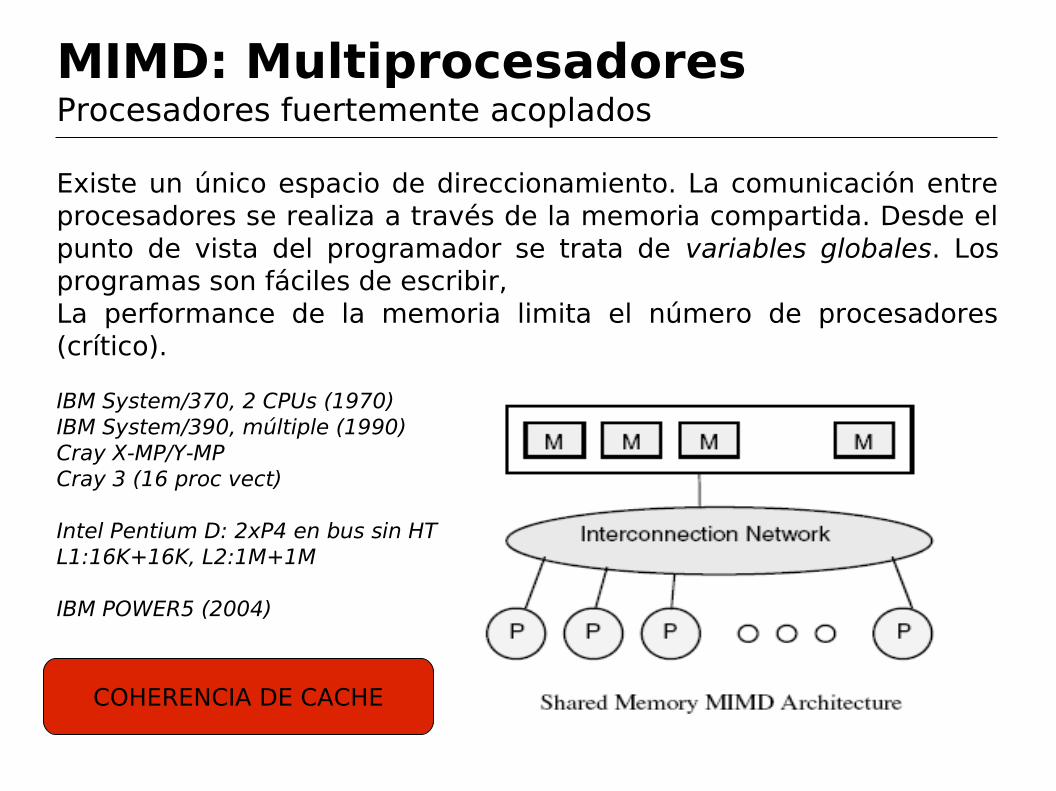
MIMD: MultiprocesadoresProcesadores fuertemente acoplados
Existe un único espacio de direccionamiento. La comunicación entre procesadores se realiza a través de la memoria compartida. Desde el punto de vista del programador se trata de variables globales. Los programas son fáciles de escribir,La performance de la memoria limita el número de procesadores (crítico).
IBM System/370, 2 CPUs (1970)IBM System/390, múltiple (1990)Cray X-MP/Y-MPCray 3 (16 proc vect)
Intel Pentium D: 2xP4 en bus sin HTL1:16K+16K, L2:1M+1M
IBM POWER5 (2004)
COHERENCIA DE CACHE
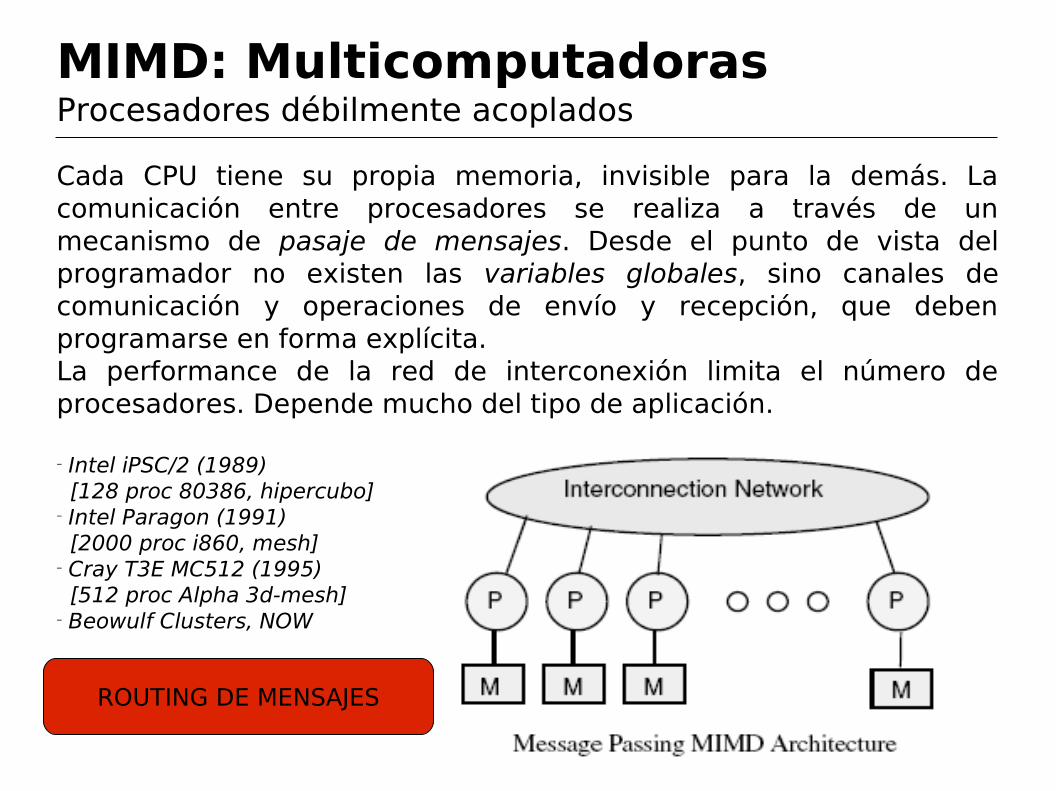
MIMD: MulticomputadorasProcesadores débilmente acoplados
Cada CPU tiene su propia memoria, invisible para la demás. La comunicación entre procesadores se realiza a través de un mecanismo de pasaje de mensajes. Desde el punto de vista del programador no existen las variables globales, sino canales de comunicación y operaciones de envío y recepción, que deben programarse en forma explícita.La performance de la red de interconexión limita el número de procesadores. Depende mucho del tipo de aplicación.
− Intel iPSC/2 (1989) [128 proc 80386, hipercubo]− Intel Paragon (1991) [2000 proc i860, mesh]− Cray T3E MC512 (1995) [512 proc Alpha 3d-mesh]− Beowulf Clusters, NOW
ROUTING DE MENSAJES

Redes de interconexión para arquitecturas paralelas
Pueden clasificarse según diferentes criterios:
Modo de operación: sincrónico vs. asincrónico.
Estrategia de control: centralizado vs. descentralizado.
Técnica de conmutación: circuitos vs. conmutación de paquetes.
Topología: cómo se conectan procesadores y memorias entre sí.
Balance entre performance (ancho de banda) y costo.
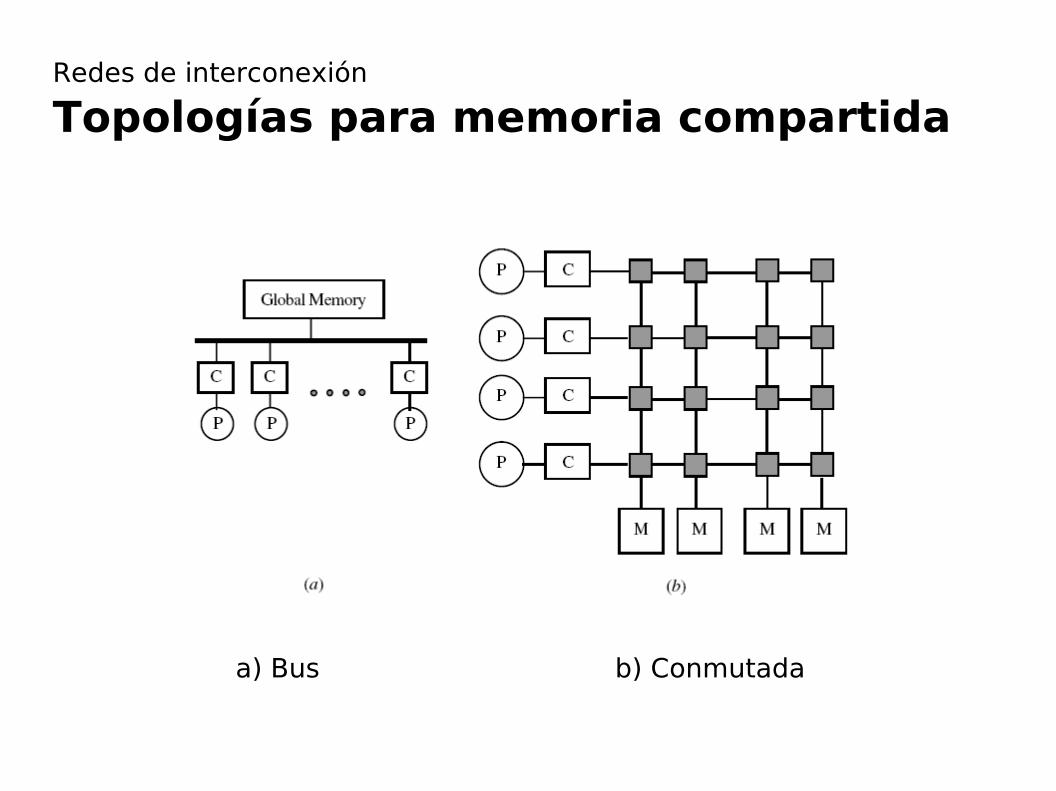
Redes de interconexión
Topologías para memoria compartida
a) Bus b) Conmutada
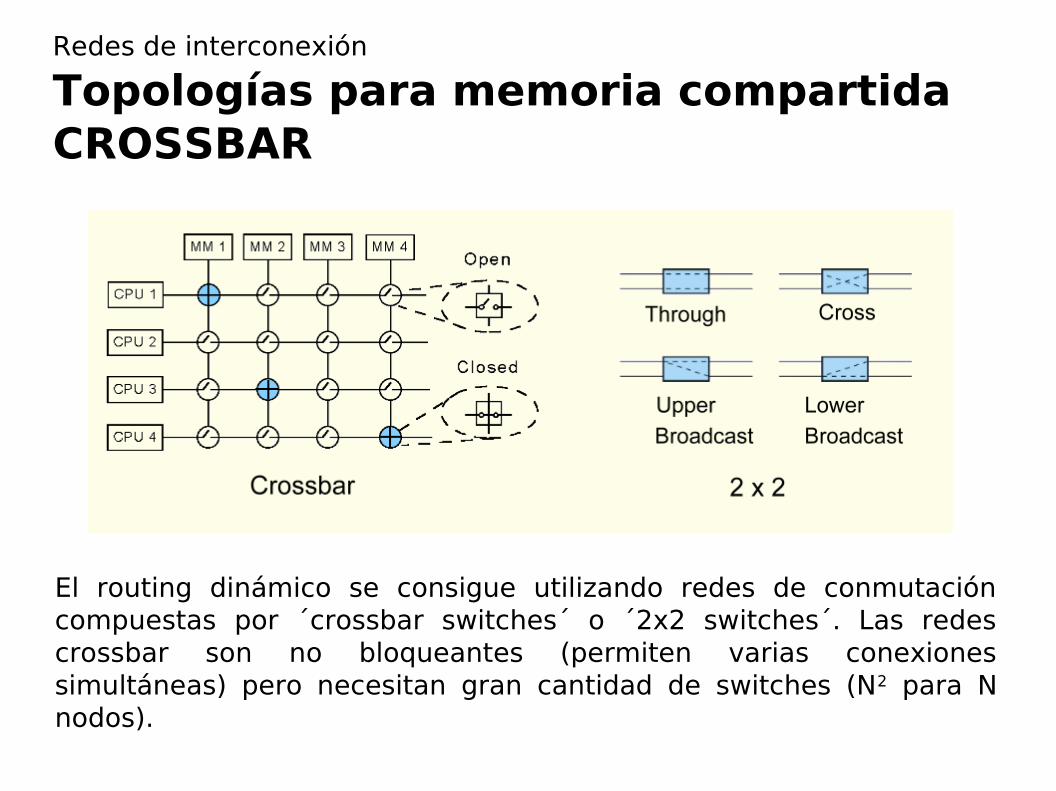
El routing dinámico se consigue utilizando redes de conmutación compuestas por ´crossbar switches´ o ´2x2 switches´. Las redes crossbar son no bloqueantes (permiten varias conexiones simultáneas) pero necesitan gran cantidad de switches (N2 para N nodos).
Redes de interconexión
Topologías para memoria compartidaCROSSBAR
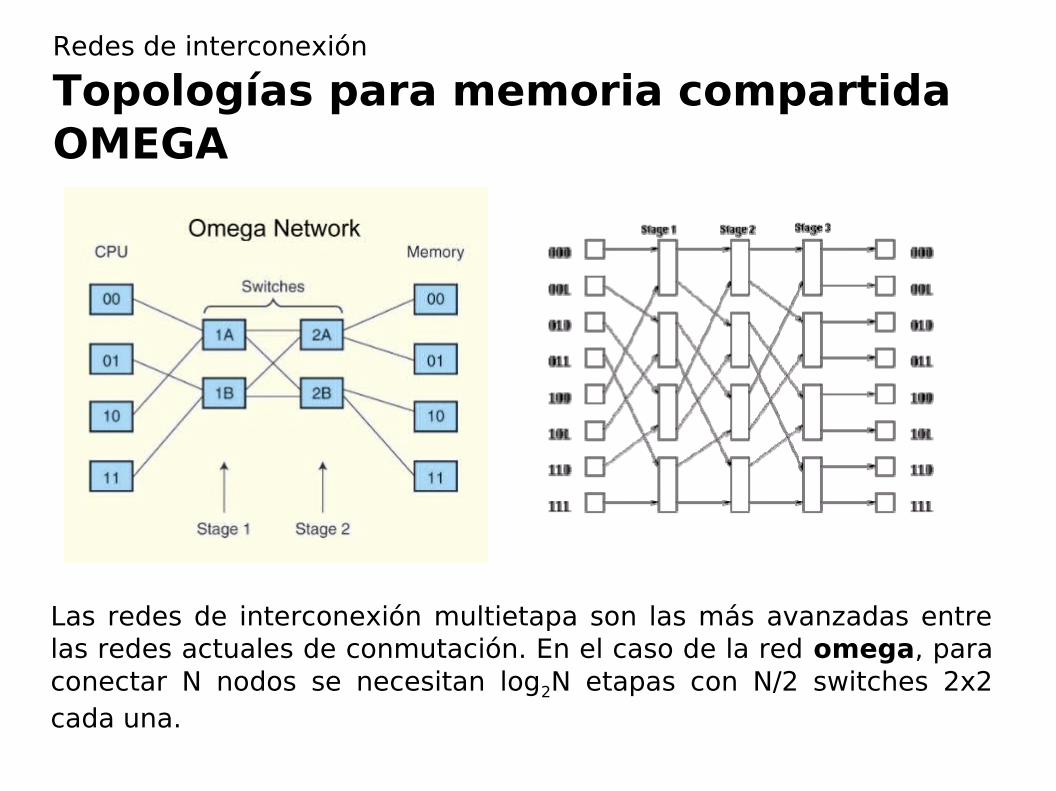
Las redes de interconexión multietapa son las más avanzadas entre las redes actuales de conmutación. En el caso de la red omega, para conectar N nodos se necesitan log2N etapas con N/2 switches 2x2 cada una.
Redes de interconexión
Topologías para memoria compartidaOMEGA

Ventajas y desventajas de las diferentes topologías:
Las redes tipo bus son económicas pero pueden transformarse en el cuello de botella del sistema.
Los buses paralelos mejoran la performance, pero son costosos.
Las redes crossbar son no bloqueantes, pero requieren un gran número de switches.
Las redes omega son bloqueantes en menor grado. Presentan mejor performance que los buses y son más económicas que las crossbar.
Redes de interconexión
Topologías para memoria compartidaSumario
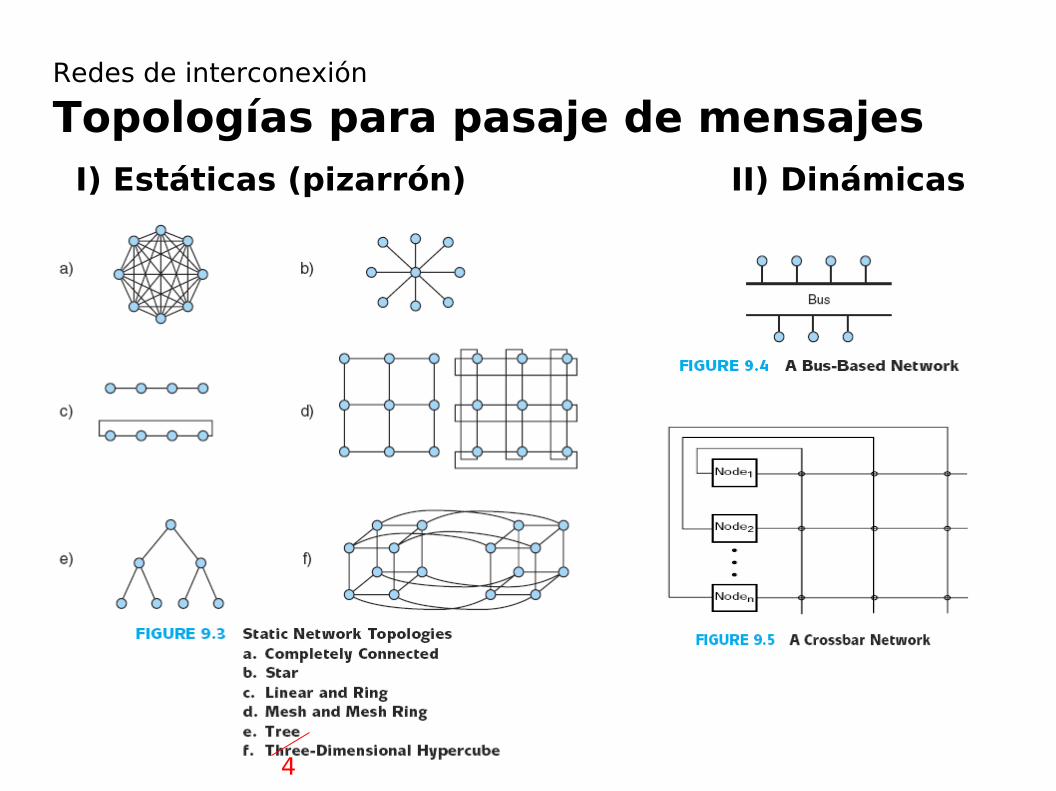
I) Estáticas (pizarrón) II) Dinámicas
4
Redes de interconexión
Topologías para pasaje de mensajes
Redes de interconexión
Topologías para pasaje de mensajes
10-cube 4-cube

Análisis de performance enArquitecturas Paralelas
Hesham El-Rewini & Mostafa Abd-El-Barr, Advanced Computer Architecture and Parallel Processing. Willey.Capítulo 3 completo.
Peak rate (no muy útil, marketing)
Mejora y Eficiencia [S=Ts/Tp, ξ=S/n]
Equal duration model: caso ideal [S=n, ξ=1]
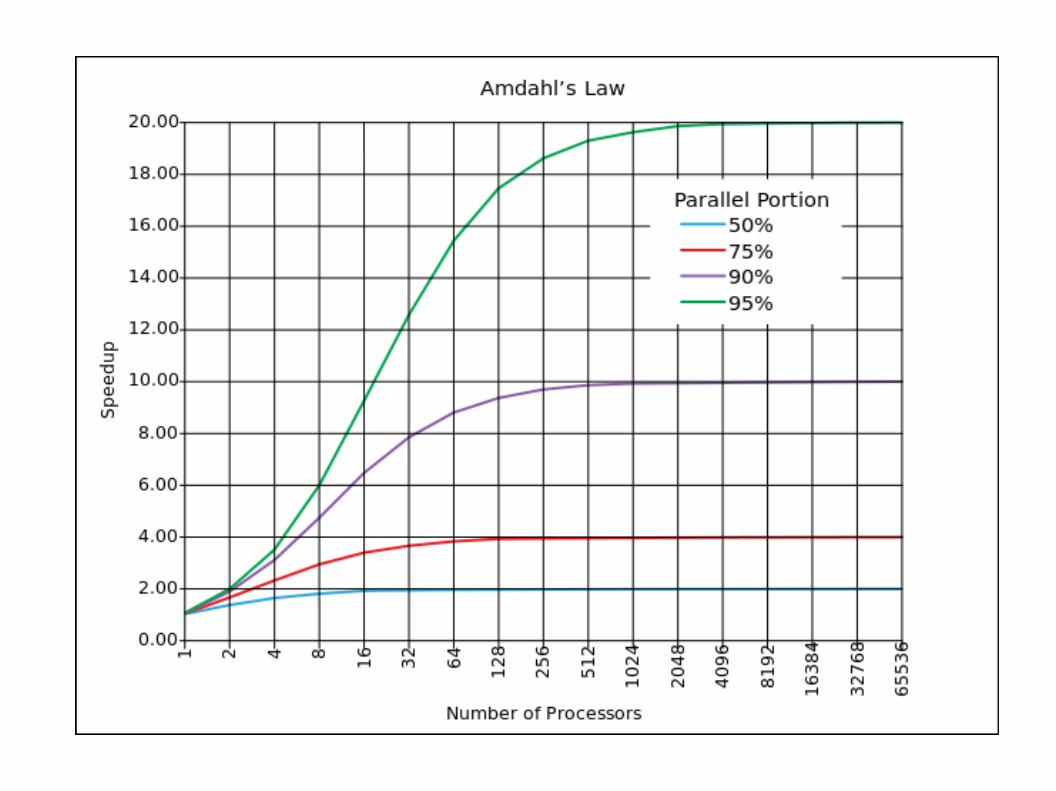
Serial section model: ley de Amdahl [S=n/(f(n-1)+1)]
Amdahl vs. Gustafson-Barsis [SS=n-f(n-1)]
Efecto del tiempo de comunicación [S=Ts/(Tp+Tc), fc=nTc/Ts]
Escalabilidad

ξ= 1
ξ=SnS=
t s
tm
Equal duration model
Fractional communication overhead
Definición de mejora y eficiencia

Serial section model

Serial section model with communication overhead

Métrica de Karp-FlattDespejando f de Amdhal y midiendo la aceleración S que se obtiene para un
dado problema (utilizando n procesadores), resulta que f es una medida
experimental de cuán paralelizable es el problema. Puede utilizarse para
predecir cómo se comportará el sistema al variar el número de
procesadores).
f=
1S
+1n
1−1n
Amdhal vs. Gustafson-BarsisAlgunos problemas no se comportan en forma tan pesimista como
predice Amdhal. A veces el tamaño del problema escala con el número
de procesadores. SS(f) es una recta y no presenta el límite en 1/f. Es
como si f se fuera achicando, en proporción, al aumentar el orden del
problema (en la práctica sucede)
SS
1
n
1f
SS ( n )=f+(1− f )×n
f+(1− f )
n×n
lim SS (n )n →∞=∞
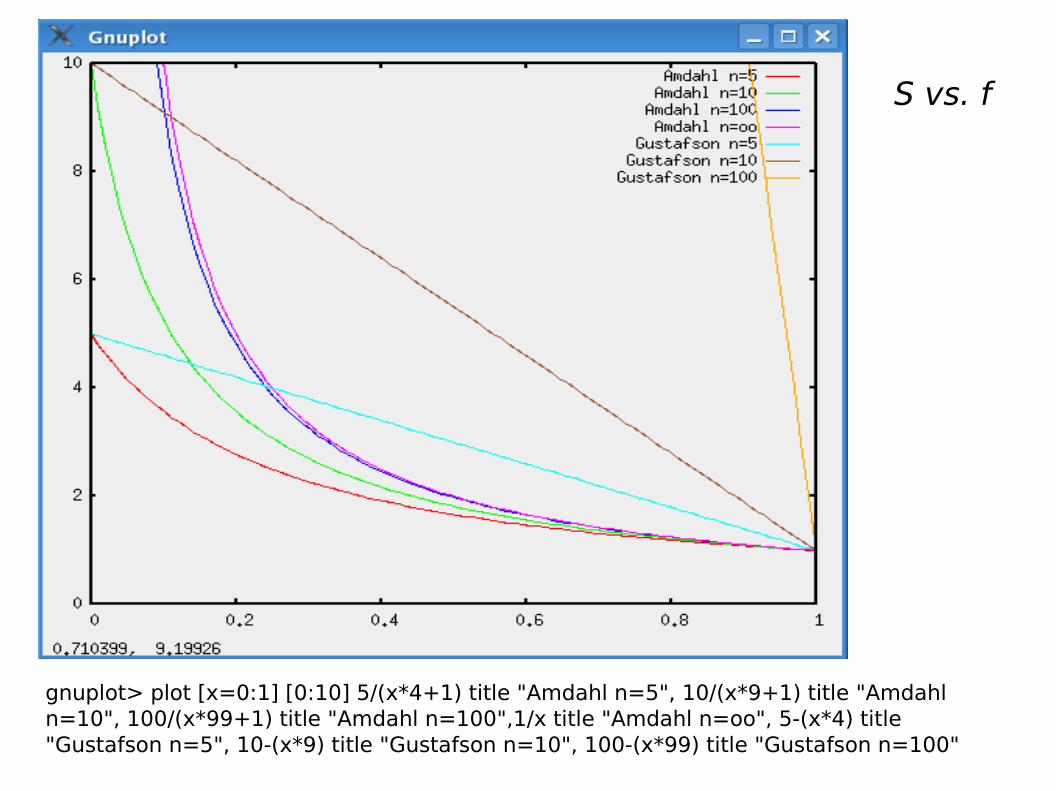
S vs. f
gnuplot> plot [x=0:1] [0:10] 5/(x*4+1) title "Amdahl n=5", 10/(x*9+1) title "Amdahl n=10", 100/(x*99+1) title "Amdahl n=100",1/x title "Amdahl n=oo", 5-(x*4) title "Gustafson n=5", 10-(x*9) title "Gustafson n=10", 100-(x*99) title "Gustafson n=100"
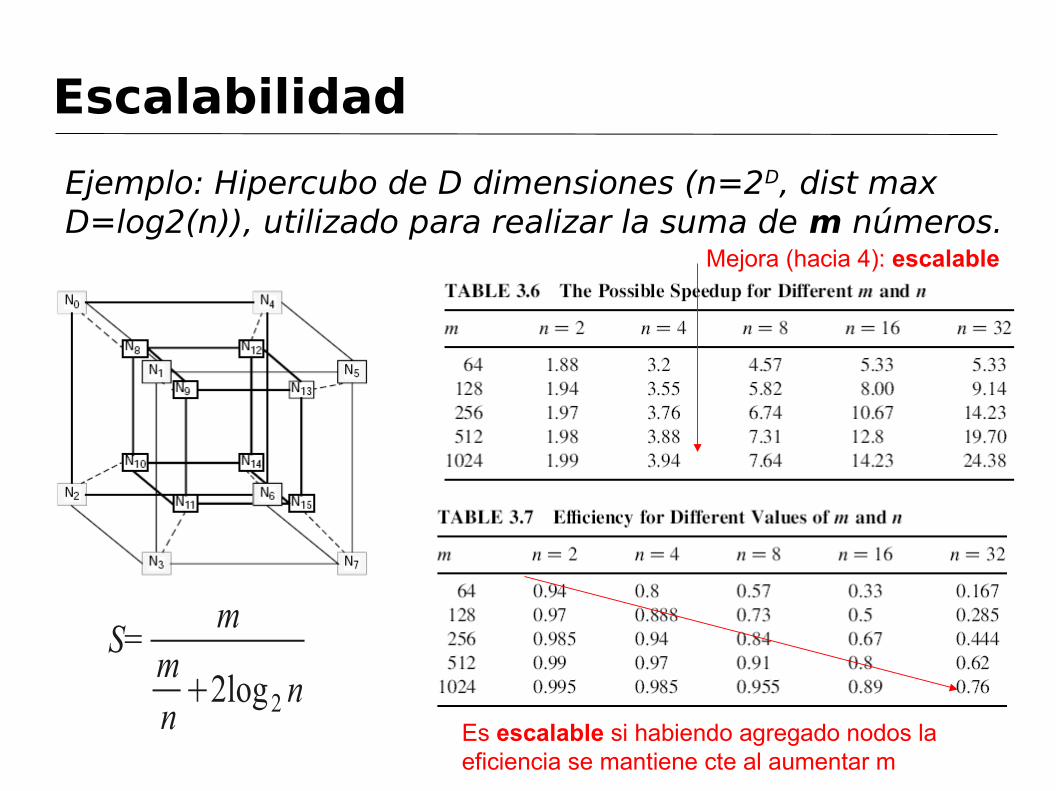
Escalabilidad
Ejemplo: Hipercubo de D dimensiones (n=2D, dist max D=log2(n)), utilizado para realizar la suma de m números.
S=m
mn
+2log2 n
Mejora (hacia 4): escalable
Es escalable si habiendo agregado nodos la eficiencia se mantiene cte al aumentar m
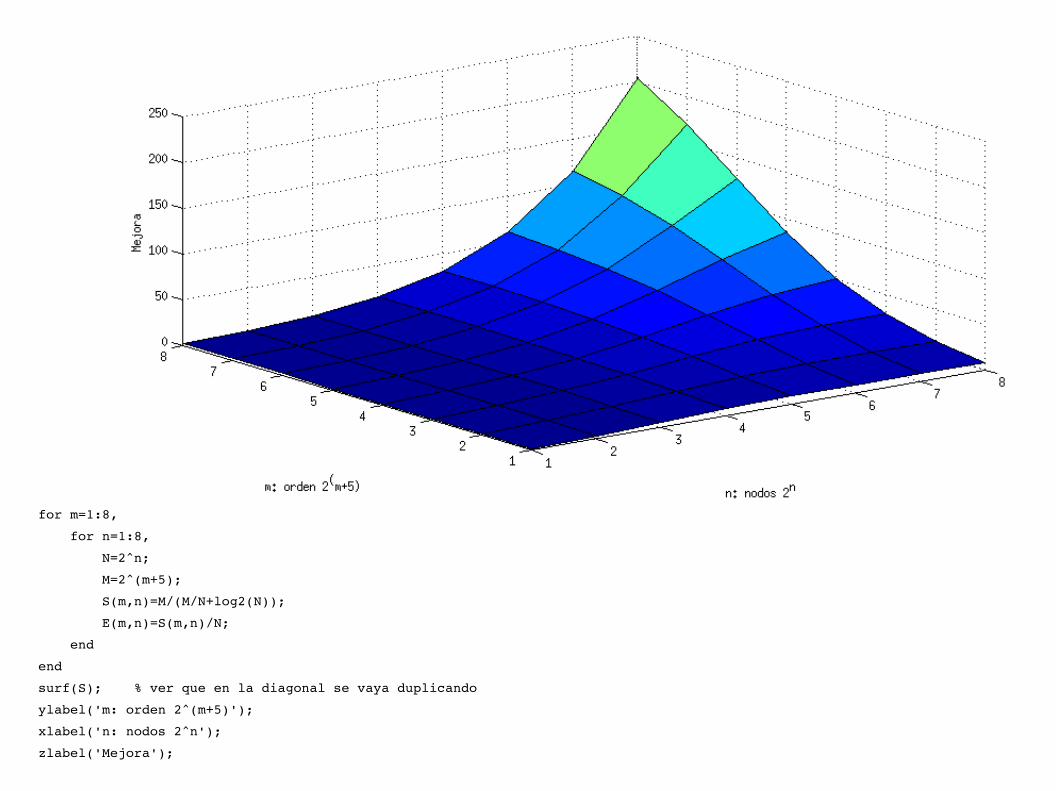
for m=1:8,
for n=1:8,
N=2^n;
M=2^(m+5);
S(m,n)=M/(M/N+log2(N));
E(m,n)=S(m,n)/N;
end
end
surf(S); % ver que en la diagonal se vaya duplicando
ylabel('m: orden 2^(m+5)');
xlabel('n: nodos 2^n');
zlabel('Mejora');
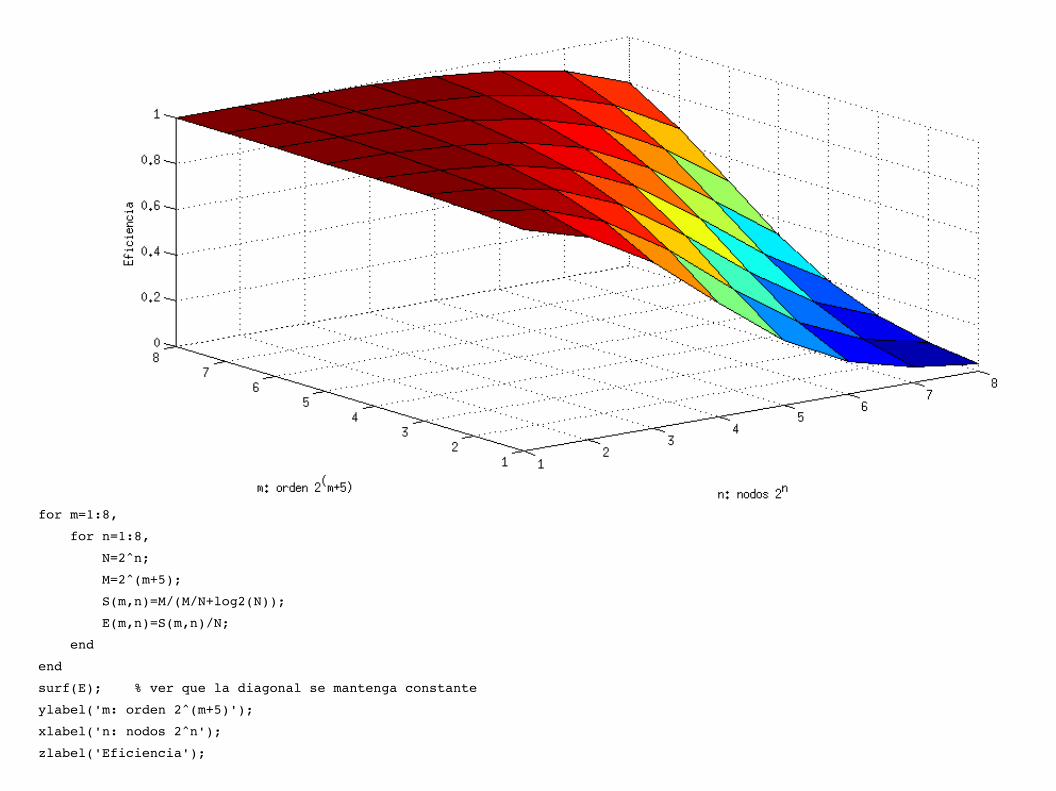
for m=1:8,
for n=1:8,
N=2^n;
M=2^(m+5);
S(m,n)=M/(M/N+log2(N));
E(m,n)=S(m,n)/N;
end
end
surf(E); % ver que la diagonal se mantenga constante
ylabel('m: orden 2^(m+5)');
xlabel('n: nodos 2^n');
zlabel('Eficiencia');

Escalabilidad
El grado de escalabilidad de un sistema paralelo se determina por la relación en que el problema debe incrementarse respecto del número de procesadores (n), para mantener una eficiencia constante cuando el número de procesadores aumenta.
Por ejemplo, en un sistema paralelo altamente escalable el tamaño del problema deberá crecer linealmente con respecto de n a fin de mantener la eficiencia constante.
En un sistema poco escalable el tamaño del problema necesitará crecer exponencialmente con respecto de n para mantener la eficiencia constante.

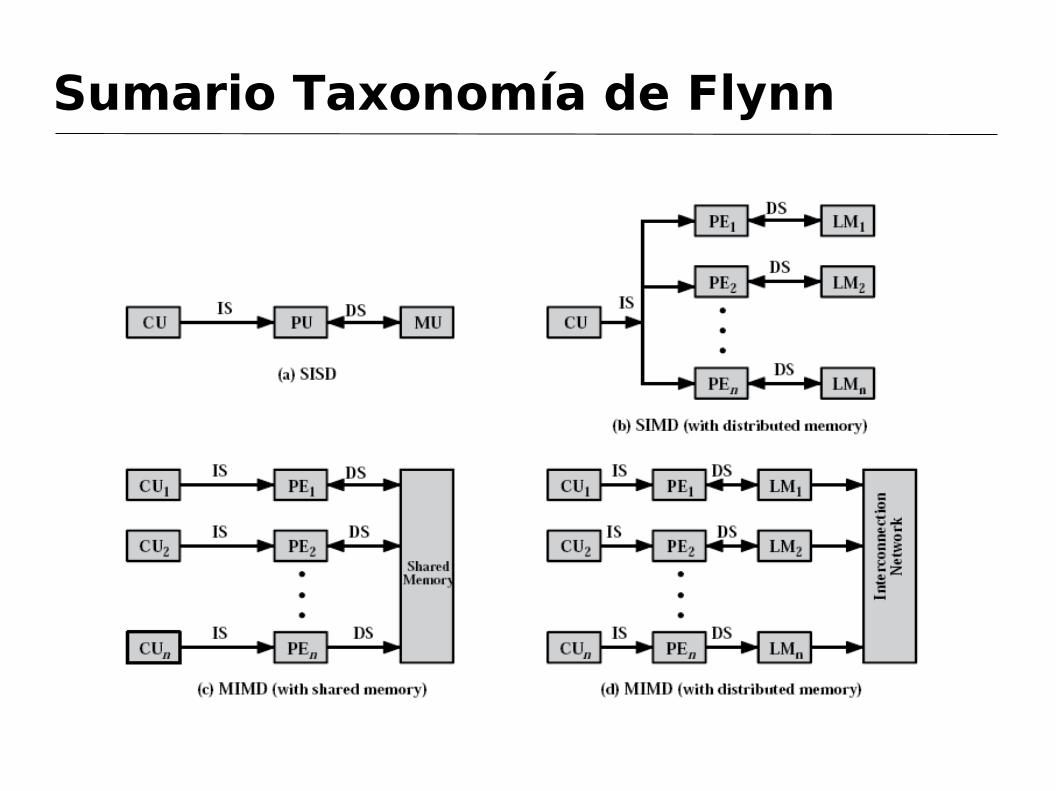
Sumario Taxonomía de Flynn
SISD: Single Processor, von Neumann
SIMD: Array Processors
MISD: ????
MIMD:
Memoria compartida: Multiprocesadores (SMP y NUMA)
Memoria distribuida: Multicomputadoras (MPP y Clusters)
Sumario Taxonomía de Flynn

SumarioLas arquitecturas para procesamiento paralelo, en sus diversas variantes, son el tema central de la materia.
Las técnicas superescalares y de segmentación utilizan conceptos de paralelismo con el objetivo de incrementar el desempeño de los diseños clásicos. Estas encuentran rápidamente limitaciones prácticas en el momento de la implementación.
Existen problemas que no pueden solucionarse utilizando un único procesador, dado el actual estado de la tecnología, por lo que se presenta la necesidad de utilizar varios de ellos trabajando en forma coordinada. Pero no todos los problemas pueden sacar partido de esta estrategia. Los programas deben cumplir con algunas condiciones.
Existen dos tipos de organizaciones con diferentes objetivos: los diseños SIMD explotan el paralelismo en los datos, y los MIMD el paralelismo en las instrucciones.
Estos últimos se dividen en multiprocesadores y multicomputadoras, según dispongan o no de memoria compartida. Estas son las dos grandes categorías actuales de arquitectutas paralelas. Ambas utilizan modelos de programación diferentes.
Los grandes sistemas de cómputo utilizan hoy una combinación de ambas arquitecturas.


















