
ARQUITECTURA ALGORÍTMICA PARA ELrepository.udistrital.edu.co/bitstream/11349/4473/1... · Speech...
122
ARQUITECTURA ALGORÍTMICA PARA EL RECONOCIMIENTO DE PATRONES FONÉTICOS DEL HABLA SUB-VOCAL EN EL ESPAÑOL. OLGA LUCÍA RAMOS SANDOVAL UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS FACULTAD DE INGENIERÍA PROGRAMA DE DOCTORADO EN INGENIERÍA ÉNFASIS EN CIENCIAS DE LA INFORMACIÓN Y EL CONOCIMIENTO BOGOTÁ, D.C. 2016
Transcript of ARQUITECTURA ALGORÍTMICA PARA ELrepository.udistrital.edu.co/bitstream/11349/4473/1... · Speech...

ARQUITECTURA ALGORÍTMICA PARA EL RECONOCIMIENTO DE PATRONES FONÉTICOS
DEL HABLA SUB-VOCAL EN EL ESPAÑOL.
OLGA LUCÍA RAMOS SANDOVAL
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERÍA PROGRAMA DE DOCTORADO EN INGENIERÍA
ÉNFASIS EN CIENCIAS DE LA INFORMACIÓN Y EL CONOCIMIENTO
BOGOTÁ, D.C. 2016

ARQUITECTURA ALGORITMICA PARA EL RECONOCIMIENTO DE PATRONES FONÉTICOS
DEL HABLA SUB-VOCAL EN EL ESPAÑOL.
OLGA LUCÍA RAMOS SANDOVAL
Tesis de grado para optar por el título de Doctor en Ingeniería
Director:
JORGE ENRIQUE SABY BELTRÁN, Ph.D.
Co-Director:
DARÍO AMAYA HURTADO, Ph.D.
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE
CALDAS FACULTAD DE INGENIERÍA
PROGRAMA DE DOCTORADO EN INGENIERÍA ÉNFASIS EN CIENCIAS DE LA INFORMACIÓN Y EL
CONOCIMIENTO BOGOTÁ, D.C.
2016

Comisión de Doctorado Esta tesis, titulada “Arquitectura Algorítmica para el Reconocimiento de Patrones Fonéticos del Habla Sub-Vocal en el Español”, escrita por Olga Lucia Ramos Sandoval, ha sido aprobada en cuanto a estilo y contenido intelectual. Hemos leído esta tesis y la aprobamos, ______________________________________ Doctor João Mauricio Rosário Jurado 1 ______________________________________ Doctor Oscar Fernando Avilés Sánchez Jurado 2 ______________________________________ Doctor Giovanny Mauricio Tarazona Bermúdez Jurado 3 ______________________________________ Doctor Jorge Enrique Saby Beltrán Director ______________________________________ Doctor Darío Amaya Hurtado Codirector Fecha de la defensa: 28 de octubre de 2016

DEDICATORIA
A Dios por mi familia, a mis amados hijos Daniela y Kamilo, por darme
fortaleza siempre y todo su amor. A mi amado esposo por su
persistencia y por enseñarme a luchar por las metas trazadas. A mis
padres y hermanos por su apoyo.

AGRADECIMIENTOS
El autor expresa sus agradecimientos a:
A los Doctores Jorge Enrique Saby y Darío Amaya Hurtado, por sus
enseñanzas, sus orientaciones su y acompañamiento en los momentos
difíciles.
Al Doctor Giovanny Mauricio Tarazona, por su apoyo y persistencia
Al Ingeniero Juan Pablo Ramírez, por toda su colaboración

CONTENIDO
1. INTRODUCCIÓN ...................................................................................... 16
1.1. FORMULACIÓN DEL PROBLEMA ............................................ 18
1.2. PREGUNTA DE INVESTIGACIÓN ........................................... 18
1.3. OBJETIVOS ......................................................................................... 19
1.3.1. General .......................................................................................... 19
1.3.2. Específicos ................................................................................... 19
1.4. MARCO METODOLÓGICO ......................................................... 19
1.5. HIPÓTESIS DE SOLUCIÓN .......................................................... 19
2. MARCO TEÓRICO Y REFERENCIAL ................................................ 21
2.1. Marco teórico ........................................................................................ 21
2.1.1. Sistema de reconocimiento automático de habla subvocal .. 21
2.1.2. Adquisición de datos .................................................................. 21
2.1.3. Micrófono tipo NAM ................................................................. 22
2.1.4. Preprocesamiento ........................................................................ 23
2.1.5. Extracción de características...................................................... 25
2.1.6. Dynamic Time Warping (DTW) .................................................... 32
2.1.7. Reconocimiento de patrones ..................................................... 35
2.2. MARCO REFERENCIAL ................................................................ 37
2.2.1. Imágenes ....................................................................................... 37
2.2.2. Electromiografía .......................................................................... 38
2.2.3. Murmuro no Audible .................................................................. 39
2.2.4. Detección de voz ......................................................................... 41
3. CONSIDERACIONES FONOLÓGICAS ............................................. 42
3.1.1. Fonética y fonología. .................................................................. 42
3.1.2. La lingüística y el reconocimiento de habla. ........................... 42
3.1.3. Unidades lingüísticas para el reconocimiento. ........................ 43
3.1.4. Características fonéticas de las unidades lingüísticas. ............ 45

4. DESARROLLO DE LA INVESTIGACIÓN ........................................ 51
4.1. Adquisición de la señal ........................................................................ 51
4.1.1. Muestra poblacional .................................................................... 51
4.1.2. Micrófono Tipo NAM ............................................................... 53
4.1.3. Pre-procesamiento ...................................................................... 54
El pre-procesamiento se utiliza para estandarizar las características de
las señales adquiridas, garantizando su uniformidad al momento de
implementar los métodos de extracción de características. A
continuación, se realiza una breve descripción de las técnicas utilizadas
en el pre- procesamiento. ............................................................................. 54
4.1.3.1. Eliminación de Silencios ........................................................ 54
4.2. Extracción de Características .............................................................. 56
4.2.1. Software ........................................................................................ 56
4.2.2. Descomposición por paquetes de Wavelet ............................... 56
4.2.3. Codificación predictiva lineal (LPC) ........................................ 64
4.3. Coeficientes Cepstrales en Frecuencia Mel (MFCC) ...................... 68
4.3.1. Pre-énfasis: ................................................................................... 70
4.3.2. Ventaneo de la señal: .................................................................. 71
4.3.3. Cálculo de la FFT ........................................................................ 71
4.3.4. Banco de filtros de Mel y logaritmo: ........................................ 75
4.3.5. Transformada discreta de Coseno ............................................ 77
4.4. Algoritmo de Inteligencia Artificial ................................................... 81
4.4.1. Clasificador para Descomposición por paquetes de Wavelet 84
4.4.2. Clasificador para Codificación Predictiva Lineal.................... 86
4.4.3. Clasificador para Coeficientes Ceptrales en Frecuecias Mel 86
5. ANÁLISIS DE RESULTADOS Y APORTES ....................................... 89
6. CONCLUSIONES ....................................................................................... 96
7. TRABAJOS FUTUROS .............................................................................. 98
8. REFERENCIAS ........................................................................................... 99
ANEXO 1. Generalidades de los sistemas de captura y micrófono utilzado
para la adquisición de la señal subvocal NAM ................................................. 106

ANEXO 2. Código Embebido para método MFCC ..................................... 108
ANEXO 3. Recognition of Spanish Vowels through Imagined ................... 119
Speech by Using Spectral Analysis and SVM ................................................... 119
ANEXO 4. Embedded MFCC feature extraction system for speech
processing .............................................................................................................. 120
ANEXO 5. Comparative Analysis of the MFCC coefficients for voiced and
silent speech ........................................................................................................... 121
ANEXO 6. Embedded Wavelet Analysis of Non-Audible Signal ............... 122

NOMENCLATURA
𝜔 Frecuencia. Angular
𝑎𝑘 Coeficientes del denominador del filtro digital
𝑏𝑘 Coeficientes del numerador del filtro digital
𝐹 Tranformada de Fourier
𝜓 Wavelet madre
𝜑 Función de escala para la Wavelet madre
ℎ(𝑛) Vector de coeficientes para el filtro pasa alto en la descomposición wavelet
𝑔(𝑛) Vector de coeficientes para el filtro pasa bajo en la descomposición wavelet
𝜃𝑘 Polos del modelo discreto del tracto vocal
𝛼𝑘 Coeficientes del predictor lineal
𝑅(𝑘) Coeficientes de autocorrelación

LISTA DE TABLAS Tabla 1. Filtros digitales IIR. ................................................................................. 24
Tabla 2. Wavelets de tiempo continúo. ............................................................... 28
Tabla 3. Punto de articulación y modo de articulación de los fonemas
consonánticos. ......................................................................................................... 44
Tabla 4. Selección de muestras. ............................................................................ 52
Tabla 5. Coeficientes en el sistema embebido. ................................................... 78
Tabla 6. Coeficientes calculados en Matlab ........................................................ 78
Tabla 7. Porcentaje de patrones identificados erróneamente. ......................... 89
Tabla 8. Respuesta de la red neuronal entrenada con los datos de entropía. 89
Tabla 9. Porcentaje de patrones identificados erróneamente. ......................... 90
Tabla 10. Respuesta de la red neuronal entrenada con los datos de la media
aritmética. ................................................................................................................. 90
Tabla 11. Porcentaje de patrones identificados erróneamente. ....................... 91
Tabla 12. Respuesta de la red neuronal entrenada con los datos de desviación
estándar. ................................................................................................................... 91
Tabla 13. Porcentaje de patrones identificados erróneamente. ....................... 92
Tabla 14. Respuesta de la red neuronal entrenada con los datos LPC........... 93
Tabla 15. Porcentaje de patrones identificados erróneamente. ....................... 93
Tabla 16. Respuesta de la red neuronal entrenada con los datos MFCCs ..... 94
Tabla 17. Producción científica derivada del proyecto. .................................... 95

LISTA DE FIGURAS Figura 1. Esquema de un micrófono NAM. ...................................................... 22
Figura 2. Watchdog del conversor analogo – digital. ........................................... 23
Figura 3. Señal original (a) y señal contaminada con ruido de media cero (b).
................................................................................................................................... 26
Figura 4. Espectros de amplitud para las señal original y contaminada. ........ 27
Figura 5. Transformada de Wavelet continua para una señal no estacionaria. 29
Figura 6. Resolución de tiempo y frecuencia. .................................................... 29
Figura 7. Procesos involucrados en el cálculo de MFCCs ............................... 30
Figura 8. Operación de ventaneo. ........................................................................ 31
Figura 9. Coeficientes de Mel para las dos primeras ventanas de los fonemas
/a/, /e/ y /o/. ........................................................................................................ 32
Figura 10. Conjunto de señales a comparar. ...................................................... 33
Figura 11. Cálculo de distancias euclidianas. ...................................................... 33
Figura 12. Matriz de costo acumulado. ............................................................... 34
Figura 13. Camino óptimo. ................................................................................... 35
Figura 14. Visualización de la envolvente entre las dos señales. ..................... 35
Figura 15. Topología de la red neuronal utilizada ............................................. 36
Figura 16. Modelo conceptual de la producción del habla. ............................. 43
Figura 17. Espectrograma de la señal de habla subvocal para el fonema /ta/.
................................................................................................................................... 47
Figura 18. Espectrograma de la señal de habla subvocal para el fonema /te/.
................................................................................................................................... 48
Figura 19. Espectrograma de la señal de habla subvocal para el fonema /ti/.
................................................................................................................................... 48
Figura 20. Espectrograma de la señal de habla subvocal para el fonema /to/.
................................................................................................................................... 49
Figura 21. Espectrograma de la señal de habla subvocal para el fonema /tu/.
................................................................................................................................... 49
Figura 22. Arquitectura algorítmica propuesta. .................................................. 51
Figura 23. Estructura y ubicación del micrófono tipo NAM. ......................... 53
Figura 24. Señales de audio de habla normal y habla sub-vocal. ..................... 54
Figura 25. Eliminación de silencio y normalización de la señal. ..................... 55
Figura 26. Árbol de descomposición para tres niveles. .................................... 57
Figura 27. Paquetes Wavelets para la función Daubechie # 8. ......................... 58
Figura 28. Descomposición de la señal capturada para el fonema /ta/. ....... 60
Figura 29. Distribución de los coeficientes para 6 niveles de descomposición.
................................................................................................................................... 60
Figura 30. Diagrama de bloques del sistema de reconocimiento propuesto. 61
Figura 31. Entropías para los tres primeros niveles del fonema /ta/. ........... 62

Figura 32. Calculo de las Entropías de Shannon para cada fonema y nivel. . 62
Figura 33. Cálculo de la media aritmética para los coeficientes de detalle y
aproximación. .......................................................................................................... 63
Figura 34. Cálculo de la desviación estándar de los coeficientes de detalle y
aproximación. .......................................................................................................... 63
Figura 35. Ventano de una señal. ......................................................................... 65
Figura 36. Estimación del espectro para la pronunciación del fonema /te/. 67
Figura 37. Reconstrucción de los espectros para distintos fonemas vocálicos.
................................................................................................................................... 67
Figura 38. Algoritmo para el cálculo de los coeficientes predictivos lineales 68
Figura 39. Partes del sistema de procesamiento. ............................................... 68
Figura 40. Representación de la señal NAM del fonema /te/. ....................... 69
Figura 41. Diagrama de flujo de proceso de pre-énfasis embebido en la
tarjeta. ....................................................................................................................... 70
Figura 42. Cálculo de FFT..................................................................................... 72
Figura 43. Espectro de magnitud para la primera ventana de la señal. .......... 73
Figura 44. Espectro de magnitud para la segunda ventana de la señal. ......... 74
Figura 45. Espectro de magnitud para la tercera ventana de la señal. ............ 74
Figura 46. Espectro de magnitud para la cuarta ventana de la señal. ............. 75
Figura 47. Banco de filtros de Mel. ...................................................................... 76
Figura 48. Gráfica de los coeficientes embebidos. ............................................ 79
Figura 49. Coeficientes calculados en Matlab .................................................... 80
Figura 50. MFCCs para diferentes fonemas vocálicos. .................................... 80
Figura 51. Algoritmo para la extracción de coeficientes cepstrales en
frecuencia Mel. ........................................................................................................ 81
Figura 52. Algoritmo desarrollado para la red neuronal. .................................. 82
Figura 53. Estructura general de la red neuronal. .............................................. 82
Figura 54. Diagrama de bloques para la capa oculta. ........................................ 83
Figura 55. Diagrama de bloques para la capa de salida. .................................... 84
Figura 56. Proceso de entrenamiento de la red las características de entropía.
................................................................................................................................... 85
Figura 57. Proceso de entrenamiento de la red con los datos de la media
aritmética. ................................................................................................................. 85
Figura 58. Proceso de entrenamiento de la red con la desviación estándar de
los coeficientes. ....................................................................................................... 86
Figura 59.Entrenamiento de la red neuronal para los espectros ajustados con
LPC. .......................................................................................................................... 86
Figura 60. Diagrama de la metodología propuesta. ........................................... 87
Figura 61. Error de la red en función de la cantidad de neuronas en la capa
oculta......................................................................................................................... 87

Figura 62. Comportamiento de la red neuronal durante el entrenamiento. 88
Figura 63. Trabajos con clasificación SCIMAGO. ............................................ 95
Figura 64. Trabajos indexados en Publindex. .................................................... 95

RESUMEN
El habla sub-vocal, es una técnica de reciente investigación, que puede ser
aplicada para habilitar formas alternas de comunicación en diferentes
escenarios como, ambientes de alta contaminación auditiva, personas con
discapacidad en el aparato fonador, comunicación subacuática, entre otros.
Esta técnica se fundamenta, en la información que se produce al intentar
pronunciar un vocablo o una palabra, pero no se ve representada en una señal
sonora. Es decir, estas señales representan la intención del habla antes de ser
articulada. En este trabajo, se presenta una arquitectura algorítmica, para el
reconocimiento de patrones de fonemas del idioma español, que permite
instanciar dicha habla sub-vocal. Se realizó una adquisición de las señales
producidas por el habla silenciosa, utilizando un micrófono de Murmuro No
Audible (NAM), diseñado para tal propósito. Posteriormente, las muestras
capturadas fueron procesadas y analizadas utilizando técnicas de análisis
frecuencial y temporal. Además, se utilizaron métodos de algoritmos basados
en inteligencia artificial, para desarrollar una arquitectura de identificación de
patrones, que permitió realizar la identificación de fonemas del idioma
español. Como aporte de este trabajo, se obtuvieron diferentes resultados a
partir de la implementación de distintas técnicas de análisis y extracción de
características, así como, de clasificación y reconocimiento, haciendo uso de
aprendizaje de máquina y un sistema digital para su ejecución en tiempo real,
consiguiendo una identificación cercana al 90%.

ABSTRACT
Silent speech is a recent subject in research. The objective is to allow the
communication within high-noise environments, help people with language
and speech disorders and under-water communication. Silent Speech is based
on the information produced when a word is thought by a speaker-person but
sonorous response is not produced. It means that the produced signals
represent the intention of speak before the overt production (sonorous
production). In this work is described the process of design and
implementation of a recognition process for silent phonemes of the Spanish
language. First was performed the acquisition of silent speech signals which
were processed in further steps for feature extraction, using methodologies
based in time and frequency representations. For the pattern recognition
phase, algorithms based on Artificial Intelligence were implemented to
perform the identification and classification of the silent speech signals. As
result of this work were evaluated different processing and classification
techniques with recognition indices near from 90%.

16
1. INTRODUCCIÓN
La comunicación, es una herramienta de uso cotidiano para el ser humano que le
permite interactuar con otras personas en una sociedad o ambiente especifico
(Watzlawick, Bavelas, Jackson, & O’Hanlon, 2011) y puede dividirse en dos grandes
categorías, la primera es la comunicación verbal (Gärdenfors & Warglien, 2013), que
se refiere a la divulgación de información a través de signos lingüísticos característicos
de una cultura, y pueden ser orales o escritos. Por otro lado, se encuentra la
comunicación no verbal (Knapp, Hall, & Horgan, 2013), que es la transmisión de
mensajes sin el uso de palabras, es decir, indicios, gestos, o señales como el lenguaje
facial o corporal.
De las dos categorías anteriores, el tipo de comunicación más común es el habla, que
está basada en la combinación de léxico y nombres extraídos de un grupo de palabras
denominado vocabulario. La producción del habla, a nivel lingüístico describe como
se ubican los labios, mandíbula y lengua para lograr emitir un sonido, y depende de
dos procesos fundamentales, la percepción, por medio de la cual se interpretan y
entienden los sonidos propios de un lenguaje, y la repetición, que es cuando un
sonido se trasforma en un movimiento inconsciente volviendo el habla un
movimiento mecánico.
El habla, involucra tres etapas en su producción, la primera es la intención de generar
un sonido relacionado a un concepto en particular, la segunda, incluye la codificación
gramatical, morfo-fonológica y fonética para generar la activación correspondiente
en los órganos que conforman el aparato fonador, y por último, se realiza la
articulación o producción de voz (Levelt, 1999). Estos procesos, han sido de gran
interés en las últimas décadas para la comunidad científica, la cual a partir de los
últimos desarrollos tecnológicos han hecho de las técnicas de procesamiento digital
de señales, métodos más eficientes y eficaces para construir sistemas de
reconocimiento de voz cada vez más complejos.
Actualmente, existen desarrollos de carácter tecnológico capaces de procesar,
interpretar y generar el habla, conocidos como sistemas ASR (Automatic Speech
Recognition), (L. Rabiner & Schafer, 2011) ,que basan su funcionamiento en la acústica
de las señales de voz por lo cual poseen ciertas limitaciones, como la susceptibilidad
al ruido presente en el medio de transmisión del mensaje y además dependen de la
amplitud de las señales vocales, por lo que patologías, como la disfonía y afonía que
afectan la correcta producción de voz del usuario tienen una incidencia directa en el
desempeño del sistema.
Como una posible solución a las limitaciones mencionadas anteriormente, se
propone el uso del habla sub-vocal, ya que esta no depende de la producción de voz

17
audible, en lugar de esto utiliza señales adquiridas de los procesos bio-eléctricos que
controlan los órganos que componen el aparato fonador. A partir de este concepto
surgen desarrollos como las interfaces de habla silenciosa o por sus siglas en inglés
SSI (Silent Speech Interface) (Denby et al., 2010). Sin embargo, estos sistemas aún se
encuentran en etapa experimental.
Algunos trabajos han realizado acercamientos al procesamiento y clasificación de este
tipo de señales, utilizando diferentes medios para la adquisición de las mismas, como
es el caso de (Wand, Janke, & Schultz, 2014) donde emplean sensores para
electromiografía de superficie capaces de registrar la actividad muscular generada al
momento de la producción de sonido, obteniendo un error de reconocimiento en
palabras pronunciadas de 16.8% y murmuradas de 34.8%, de la misma manera en (L.
Mendoza, Peña, Muñoz-Bedoya, & Velandia-Villamizar, 2013) utilizan sensores
similares, pero para el procesamiento de las señales utilizan Wavelet Packets,
obteniendo un rango de reconocimiento entre 74% y 76%.
En otros trabajos se observan desarrollos basados en el comportamiento de órganos
pertenecientes al tracto vocal, como la glotis a través del análisis de vibraciones (Patil
& Hansen, 2010) o electromagnetismo (Quatieri et al., 2006), donde se llega a la
conclusión que los dos sistemas tienen un amplio potencial en la detección de
estímulos sub-vocales, también se han elaborado trabajos con sensores ultrasónicos
y procesamiento de imágenes para analizar el movimiento de la lengua como se
aprecia en (Hueber et al., 2010), donde alcanzan una tasa de reconocimiento del 60%
para fonemas del idioma inglés utilizando PCA (Principal Component Analysis) y HMM
(Hidden Markov Models).
Otro dispositivo de captura, ampliamente utilizado para registrar señales de este tipo,
son los micrófonos de murmullo no audible NAM, con el cual se han elaborado
numerosos trabajos, además de obtenerse resultados significativos tal cual se muestra
en (Nakajima, Kashioka, Shikano, & Campbell, 2003) y (Hirahara et al., 2010),
además utilizando técnicas como LAD (Linear Discriminant Analysis) y GMM (Gaussian
Mixture Models) se obtuvo un porcentaje de identificación superior a 60% como se
presenta en (V.-A. Tran, Bailly, Lœvenbruck, & Toda, 2010).
Por último en (Ramos, Gamma, & Hurtado, 2015), fue elaborada una revisión de los
diferentes dispositivos mencionados con anterioridad, concluyendo que el micrófono
de tipo NAM presenta una serie de ventajas frente a los demás dispositivos de
adquisición, debido a que es cómodo para el usuario, su uso es comercial y es cercano
a la independencia del hablante.

18
1.1. FORMULACIÓN DEL PROBLEMA
Un aspecto relevante en los seres vivos es la comunicación, específicamente en el
humano, el medio más utilizado para comunicarse, es el habla, que le permite
intercambiar información con sus semejantes. Para algunas personas, la posibilidad
de comunicarse a través del habla, es nula, por diversos problemas. Por ejemplo, por
dificultades fisiológicas, que le impide reproducir las señales enviadas desde el
cerebro. Para el último censo en Colombia, (DANE, 2005), se registraron 157417
personas con limitaciones con el habla. Otros escenarios donde la alteración de la
comunicación humana se hace presente, es en lugares que poseen alta contaminación
auditiva también denominados ambientes ruidosos. En el mismo sentido, en los
ámbitos subacuáticos, se hace necesario contar con un sistema que permita la
comunicación humana.
Una alternativa de comunicación para los escenarios expuestos, es el habla sub-vocal
o lenguaje silencioso. Éste consiste en la transferencia de señales neurológicas
generadas por el cerebro, cuando se tiene la intención de pronunciar una palabra, que
luego son enviadas a los músculos de la garganta, aun existiendo algún daño o
parálisis en el aparato fonador.
Investigaciones recientes han dado como resultado las llamadas interfaces de lenguaje
silencioso, que consisten en proceso de adquisición y reconocimiento de fonemas,
sílabas o palabras para lograr trasmitir el mensaje que se tiene la intención de decir,
sin que llegue realmente a ser expresado como una señal sonora. A pesar de ello, y
que en los últimos tiempos se han realizado trabajos significativos para el
reconocimiento automático del habla sonora, son mínimas las investigaciones
encontradas en función de la identificación de patrones del idioma español utilizando
habla sub-vocal y sus resultados alcanzan un reconocimiento del 76% (L. Mendoza
et al., 2013), haciendo poco factible la construcción de un sistema en tiempo real
debido a la margen de error presente.
1.2. PREGUNTA DE INVESTIGACIÓN
¿Cuál es la arquitectura del algoritmo que permita la discriminación y el
reconocimiento de patrones de fonemas del idioma español utilizando el habla sub-
vocal?
En esta investigación, se plantea y evalúa una arquitectura algorítmica que logra la
discriminación de patrones de fonemas del idioma español, basados en las señales
provenientes del habla sub-vocal, permitiendo identificar dichos fonemas, a través
del análisis con diferentes técnicas para su procesamiento, y la aplicación de métodos
basados inteligencia artificial.

19
1.3. OBJETIVOS
1.3.1. General
Diseñar y evaluar el desempeño de una arquitectura algorítmica para la
discriminación y el reconocimiento de patrones de cinco fonemas del idioma
español, basado en el habla sub-vocal, aplicando técnicas de procesamiento de
señales e inteligencia artificial en tiempo real.
1.3.2. Específicos
Diseñar y desarrollar un sistema de adquisición de las señales generadas
por el cerebro bajo el concepto del habla sub-vocal, utilizando la técnica de
murmuro no audible.
Realizar el procesamiento digital de las señales del habla sub-vocal, para
realizar la extracción de características y la posterior identificación de
patrones asociados a fonemas del español.
Diseñar un modelo computacional de aprendizaje para la interpretación
de patrones en tiempo real de las señales obtenidas a través del habla sub-
vocal.
1.4. MARCO METODOLÓGICO
Con el propósito de dar cumplimiento a los objetivos propuestos, el marco
metodológico, se desarrolló inicialmente con una etapa de captura de la señal del habla
sub-vocal, utilizando como elemento primario un sensor tipo NAM. Posterior a esto,
se realizó una etapa de pre-procesamiento a la señal adquirida, donde se diseñaron
filtros digitales que eliminaron ruidos asociados a la señal capturada. Se continuó con
la etapa de extracción de características, aplicando técnicas de transformación de
dominio temporal y frecuencial, con el propósito de implementar una etapa de
identificación de patrones de fonemas del idioma español, empleando algoritmos de
inteligencia artificial. Finalmente, los pasos descritos fueron implementados en un
sistema embebido para su operación en tiempo real. La metodología utilizada en el
desarrollo del proyecto se basó en el método experimental.
1.5. HIPÓTESIS DE SOLUCIÓN
Una arquitectura algorítmica, con fundamento en inteligencia artificial, basado en
el procesamiento de señales del habla sub-vocal, puede l legar a discriminar
patrones lingüísticos, que permitan la identificación de fonemas del español, en

20
tiempo real. Convirtiéndose en una herramienta que permite la comunicación en
ambientes con contaminación auditiva.
El presente documento está distribuido de la siguiente manera: el capítulo uno,
introducción contiene lo referente a la formulación de la propuesta de investigación.
El capítulo dos, presenta los referentes teóricos y el marco referencial en las temáticas
de desarrollo de la investigación. El capítulo tres, describe el desarrollo de la
investigación. En el capítulo cuatro, se expone los resultados y los principales aportes.
Por último, se presentan las conclusiones y trabajos futuros.

21
2. MARCO TEÓRICO Y REFERENCIAL
2.1. Marco teórico
2.1.1. Sistema de reconocimiento automático de habla subvocal
La comunicación es una herramienta de uso diario para el ser humano, debido a que
ésta es el proceso a través del cual se generan señales o indicios con la intención de
enviar o transmitir información (Lasswell, 1948), y para que sea exitosa, tanto el
emisor como el receptor deben tener el conocimiento o las habilidades necesarias
para decodificar correctamente los elementos que componen el mensaje. Una de las
formas de comunicación más comunes y naturales para el ser humano es el habla, la
cual involucra tres etapas en su producción, la primera es la intención de generar un
sonido que se relacione con algún objeto o concepto, la segunda es la codificación
gramatical y por último la articulación de voz.
En la actualidad existen desarrollos de carácter tecnológico que son capaces de
procesar, interpretar y generar el habla, que basan su operación en las señales
acústicas producidas por el discurso en voz alta, por lo cual poseen ciertas
limitaciones, como la alta susceptibilidad al ruido del ambiente y patologías que
afectan la articulación de palabras como la afonía. Como una posible solución a las
limitaciones mencionadas, se propone la elaboración de un sistema de
reconocimiento de habla sub-vocal, debido a que este no depende en gran medida de
la generación de voz audible, sino que utiliza señales provenientes de los procesos
bioeléctricos generados antes de la producción de voz. En los apartados siguientes se
exponen y explican algunos de los conceptos y fundamentos teóricos tenidos en
cuenta para la realización del sistema propuesto.
2.1.2. Adquisición de datos
Para la adquisición de datos, es importante tener en cuenta que la producción de voz
involucra diferentes procesos controlados por el cerebro y el sistema nervioso
central, en los cuales se involucran la actividad muscular asociada en el aparato
fonador. Cuando un músculo es activado por el sistema nervioso central, se genera
un flujo de impulsos bioeléctricos que pueden ser registrados por electrodos de
superficie u otros sensores para su posterior procesamiento.
Aunque existen en la actualidad diversas tecnologías y sensores para desarrollar
sistemas conocidos como Interfaces de habla silente, algunos ejemplos son los
sensores de articulografía electromagnética, electrodos de superficie(Wand et al.,
2014), ultrasonido (Hueber et al., 2010) y el micrófono tipo NAM (Yang, Brown, Lu,
Yamagishi, & King, 2012), que fue utilizado en el desarrollo de este trabajo.

22
2.1.3. Micrófono tipo NAM
Los micrófonos NAM en sistemas de reconocimiento de habla sub-vocal son algunos
de los sensores más prometedores debido a sus características, como lo son la
portabilidad y facilidad de instalación, es cercano a la independencia con respecto al
hablante, además es de uso comercial y su fabricación es sencilla. El murmullo no
audible, hace referencia a los sonidos de inferiores a 30 dB (Darbyshire & Young,
2013), producidos en el aparato fonador por el paso de aire en la laringe, de acuerdo
a lo anterior, un micrófono NAM está diseñado para detectar y registrar exitosamente
las vibraciones generadas por los sonidos de baja intensidad mencionados
anteriormente.
El micrófono NAM utilizado para el desarrollo de este trabajo está conformado por
un sensor MEMS ADMP401 que se encuentra instalado dentro de una cubierta
específicamente diseñada para sujetar el micrófono, además de permitir la conexión
de éste con el dispositivo de adquisición. El extremo del contenedor que tiene el
micrófono está cubierto por una capa de caucho siliconado, con el fin de imitar la
textura de la piel humana y facilitar la propagación de las vibraciones o señales
generadas antes de la producción de sonido hasta el micrófono. En la Figura 1, se
muestra la posición ideal del micrófono para registrar correctamente las señales, así
como un esquema de su estructura.
Figura 1. Esquema de un micrófono NAM.
La adquisición y procesamiento de señales, son dos de las etapas más importantes de
todo el sistema, debido a que una buena adquisición entrega señales crudas con una
alta cantidad de información y a partir del procesamiento, se obtienen características
relevantes de las señales capturadas. Para realizar lo dicho previamente, se debe
contar con un hardware capaz de adquirir y procesar de manera adecuada las señales
provenientes del dispositivo de captura. El elemento seleccionado fue un sistema
embebido de STM Electronics, la tarjeta de desarrollo STM34F407 cuyos componentes
cuentan con las siguientes características:

23
2.1.3.1. Micro-procesador
Este sistema de desarrollo cuenta con un procesador ARM Cortex/M4 de 32 bits,
con unidad de coma flotante y está desarrollado para proveer una plataforma de bajo
costo que afronte los requerimientos actuales para un microprocesador, a través de
un número reducido de pines y bajo consumo de energía. El procesador soporta una
seria de instrucciones de procesamiento digital para el análisis de señales y el cálculo
de algoritmos complejos.
2.1.3.2. Conversor análogo digital
El sistema de desarrollo cuenta con tres módulos de conversión análoga-digital
embebidos, y cada uno tiene hasta 16 canales externos, lo que permite la adquisición
individual o un modo scan donde la conversión es automática para un rango de
canales escogidos. La adquisición puede alcanzar una tasa de hasta 2.4 millones de
muestras por segundo. El ADC de este sistema embebido, puede ser configurado
para que se active un watchdog, que activa un bit de estado, que permite determinar si
la señal de entrada está en una ventana acotada por un límite inferior y un límite
superior, como se presenta en la Figura 2. Los límites de esta ventana pueden ser
configurados de manera independiente a través de dos registros de 16 bits, en un
rango de entrada de 0 a 3 V.
Figura 2. Watchdog del conversor analogo – digital.
2.1.4. Preprocesamiento
Debido a las características inherentes de las señales producidas por el habla sub-
vocal, como baja amplitud y perdida de componentes frecuenciales, que se deben a
la composición de los órganos que conforman el aparato fonador, además de los
factores externos que se involucran en su adquisición, como ruido causado por la
presencia de individuos ajenos a la captura en el ambiente, o variaciones en la señal
Límite Superior de guarda
Límite Inferior de guarda
Señal Análoga (mV)
0
3000
Zona de Interrupción

24
debido al sensor y elementos conductores de la misma, se hace necesaria la
elaboración de una etapa de pre-procesamiento con operaciones de filtrado y
amplificación.
La amplificación se realiza, con la finalidad de realzar las características de la señal en
un rango desde 0 hasta 3.3V y mejorar su adquisición al momento de ingresarla en el
sistema embebido, por otro lado, el filtrado se implementa con el objetivo de
seleccionar o eliminar datos de la señal que no aportan datos relevantes para permitir
una caracterización e identificación adecuada. Con el uso del sistema embebido
STM32F407 resulta factible la implementación de filtros digitales, que son una
versión computarizada de los filtros análogos y tienen una serie de ventaja frente a
éstos, como su estabilidad a lo largo del tiempo, debido a que no sufren desgaste y
solo requieren operaciones aritméticas.
Los filtros digitales se dividen en dos categorías según su repuesta al impulso, si ésta
cae después de pasar un tiempo 𝑡 se dice que es un filtro FIR (Finite Impulse Response),
por otro lado, si se mantiene de manera indefinida es un filtro IIR (Infinite Impulse
Response). La principal diferencia entre estos dos es su programación, porque el filtro
FIR solamente depende del valor de las entradas, mientras que el IIR depende de las
entradas y salidas. Los filtros IIR requieren menos coeficientes, por lo tanto, su
tiempo de ejecución es menor, no obstante, su comportamiento en fase no es lineal.
En la Tabla 1 se muestran algunos de los filtros establecidos bajo estas características
y un breve resumen de sus características.
Tabla 1. Filtros digitales IIR.
Nombre Características Ecuación
Butterworth
No tiene oscilación en la banda de
paso. Se caracteriza por tener una
respuesta suave en la banda de paso.
𝐻(𝜔) = √1
1 + (𝜔𝜔𝑐)2𝑁
Chebyshev
Menor zona de transición. Posee ripple
en la zona de paso. Su mayor ventaja
es su rápida respuesta en la zona de
transición.
𝐻(𝜔) =1
√1 + 휀2𝑇𝑛2(𝜔𝜔0)
Elípticos
Posee ripple en las bandas de paso y de
transición.
Su zona de transición es la más rápida.
𝐻(𝜔) =1
√1 +1
𝛼2𝑇𝑛2(1𝜔)
Por otro lado, los filtros FIR son de fácil implementación y se diseñan para ser
estables y alcanzar un comportamiento lineal en fase. Su complejidad precisamente
radica en el diseño, debido a que se debe escoger una frecuencia ideal de trabajo,

25
calcular su respuesta al impulso y cuando el filtro llegue a la respuesta deseada se
detiene para almacenar los coeficientes obtenidos. Su implementación se realiza a
través de las ecuaciones en diferencias que definen el comportamiento de los filtros,
como se ve en las ecuaciones (1) y (2) para filtros FIR e IIR respectivamente.
𝑦[𝑛] = ∑𝑏𝑘𝑥[𝑛 − 𝑘]
𝑀
𝑘=0
( 1 )
𝑦[𝑛] = ∑𝑏𝑘𝑥[𝑛 − 𝑘] −
𝑀
𝑘=0
∑𝑎𝑘𝑦[𝑛 − 𝑘]
𝑁
𝑘=0
( 2 )
Donde 𝑏𝑘 y 𝑎𝑘 son los coeficientes de los valores de entrada y salida, M y N definen
el orden de los filtros, así como la cantidad de ceros y polos del filtro.
2.1.5. Extracción de características
En procesamiento de señales enfocado a la elaboración de algoritmos de inteligencia
artificial y reconocimiento de patrones, las técnicas de extracción de características
son todas aquellas, que a partir de un conjunto inicial de datos pueden calcular valores
nuevos (características) para proveer información relevante y no redundante del
conjunto original, con el fin de facilitar y reducir el tiempo de entrenamiento en los
algoritmos de inteligencia artificial, además de estar relacionadas con la reducción
dimensional de los datos.
Cuando los datos de entrada para un algoritmo de clasificación e identificación son
demasiado grandes para ser procesados de manera eficaz, se pueden transformar en
un grupo reducido de características que generalicen y mantengan la información más
importante del conjunto original. En esta sección, se describen algunas de las técnicas
utilizadas para extraer información a partir de las señales adquiridas utilizando el
micrófono NAM, unas de estas convierten los datos de un dominio a otro para
facilitar su manipulación, y otras simplemente aprovechan las características
inherentes de la señal para obtener datos discriminantes a la hora de realizar el
reconocimiento.
2.1.5.1. Transformada de Fourier
Esta transformada, denominada así por el matemático Joseph Fourier, es una
operación matemática de transformación de dominios, para convertir los datos de
una señal en el dominio del tiempo al dominio de la frecuencia y tiene un sin número
de aplicaciones en la ingeniería, física, química y demás campos de la ciencia, además
esta transformación es reversible, pudiendo pasar de un dominio al otro sin ningún
problema.
En ingeniería se utiliza para obtener información de una señal, que no es visible en
el dominio del tiempo, con lo cual se estaría hablando de una extracción de

26
características y reducción de dimensión, debido a que la cantidad de datos que arroja
la FT puede ser configurado independientemente del tamaño temporal de la señal.
En la ecuación (3) se encuentra la expresión que representa la Transformada de
Fourier en tiempo continuo (CFT), donde 𝜔 es la frecuencia angular, y 𝑓(𝑡) la señal
en el dominio temporal.
𝐹[𝑓(𝑡)] = ∫ 𝑓(𝑡)𝑒−𝑗𝜔𝑡𝑑𝑡
∞
−∞
( 3 )
No obstante, el uso de la CFT en aplicaciones de procesamiento digital de señales
debe realizarse a través de su versión discreta, la Transformada de Fourier en tiempo
Discreto (DFT). Esta versión de la CFT, requiere que la señal de entrada sea una
secuencia discreta y de una duración determinada, lo cual se logra con el muestreo de
una señal continua, como se ilustra en la ecuación (4), donde k representa los
coeficientes de la transformada y j el valor de la señal temporal que está siendo tenido
en cuenta en el cálculo.
𝑋[𝑘] =∑𝑥[𝑗]𝑒−2𝜋𝑖[𝑗−1][𝑘−1]
𝑁
𝑁
𝑗=1
( 4 )
En la práctica el cálculo de la DFT se realiza utilizando un algoritmo de optimización
computacional conocido como la Transformada Rápida de Fourier (FFT), que
disminuye el tiempo de cálculo de la transformada, pasando de realizar 𝑁2
operaciones a 𝑛 log (𝑛), pero pone ciertas limitaciones a la señal y el espectro
resultante, por ejemplo, es obligatorio que la duración de la señal en termino de
muestras debe ser un valor potencia de 2 (128, 256, 512, 1024). Existen diferentes
metodologías para el cálculo de la FFT, como la FFT del factor primo, algoritmo de
Bruun, algoritmo de Rader, y el más usado, algoritmo de Colley-Tukey que divide la
señal en dos hasta obtener pares de muestras y aplicar de manera recursiva la
transformada a cada par de datos. Para mostrar la capacidad de análisis que ofrece
una trasformación de dominio como la FFT, se tiene la señal 𝑦(𝑡) =
2𝑆𝑒𝑛(2𝜋50𝑡) + 0.8𝐶𝑜𝑠(2𝜋100𝑡) como se muestra en la Figura 3.
Figura 3. Señal original (a) y señal contaminada con ruido de media cero (b).

27
En la Figura 4, se aprecia la señal escogida para ejemplificar el comportamiento de
este algoritmo, la cual fue corrupta con ruido de media cero alterando notablemente
su comportamiento en el dominio del tiempo al cambiar su amplitud y forma, sin
embargo, en el dominio de la frecuencia que es obtenido tras aplicar la trasformada
rápida de Fourier, se puede observar que la distribución de frecuencias, así como los
dos valores de amplitud más altos no cambian drásticamente su comportamiento.
Figura 4. Espectros de amplitud para las señal original y contaminada.
2.1.5.2. Transformada Wavelet
Un método para analizar cualquier señal y disminuir los problemas de resolución
relacionados las trasformaciones de dominios es el MRA (MultiResolution Analysis),
utilizando esta metodología es posible analizar la señal en diferentes frecuencias y
resoluciones, y su diseño está concebido para obtener datos relevantes del tiempo en
las altas frecuencias y de frecuencia en las bajas, sin embargo, esta aproximación
tiene sentido si las altas frecuencias se presentan en periodos de corta duración, y las
bajas durante un tiempo más prolongado.
Una de las técnicas incluidas en este grupo de herramientas analíticas es la
Transformada Wavelet, que es muy similar a la transformada de Fourier en tiempo
corto, pero solo porque se debe multiplicar la señal por una función ventana y la
transformada se calcula para diferentes secciones de tiempo, sin embargo existen dos
grandes diferencias, la primera es que la transformada Wavelet no computa frecuencias
negativas, y el ancho de la ventana va cambiando cada vez que la transformada se
calcula para cada componente espectral, siendo esta la característica más importante
de este algoritmo. La transformada Wavelet de tiempo continuo se define según la
expresión mostrada en la ecuación (5).
𝐶𝑊𝑇𝜒𝜓(𝜏, 𝑠) =
1
√𝑠∫ 𝑥(𝑡)𝜓∗ (
𝑡 − 𝜏
𝑠)𝑑𝑡
∞
−∞
( 5 )
Donde 𝑠 es el parámetro de escala, 𝜏 es la constante de traslación, 𝜓 es la función
“transformante”, y se le conoce como wavelet madre y 𝑥(𝑡) es la señal a transformar.

28
El nombre wavelet significa literalmente onda pequeña, donde pequeño significa que
el tamaño de la ventana es finito, y onda es debido a que la ventana es oscilatoria. La
traslación es la propiedad de desplazamiento temporal de la ventana, pero a diferencia
de la FFT, la ecuación (5) no está en términos de frecuencia sino de escala.
Esta escala se puede comparar con la misma que es utilizada en cartografía, a menor
escala se obtienen datos más detallados. En términos de frecuencia, las bajas
frecuencias son una escala grande, lo que corresponde con información global de la
señal, mientras que las altas frecuencias a una escala pequeña, son información
detallada de un patrón particular en la señal, en otros términos, la escala dilata o
contrae la señal si esta estuviera en el numerador de la expresión, pero como se
encuentra en el denominador el comportamiento de la escala es como se explica en
la ecuación (6).
𝑓(𝑡) = 𝑓(𝑠𝑡) {𝑠 > 1𝑠 < 1
𝐷𝑖𝑙𝑎𝑡𝑎𝐶𝑜𝑛𝑡𝑟𝑎𝑒
( 6 )
Para el cálculo de la CWT (Continuous Wavelet Transform) primero se debe escoger una
wavelet madre como prototipo para las funciones ventana. En la Tabla 2, se presentan
algunas de las expresiones de las funciones wavelet existentes.
Tabla 2. Wavelets de tiempo continúo.
Nombre Función
Mexican Hat 𝜓(𝑡) =2
√3𝜎𝜋1/4(1 −
𝑡2
𝜎2) 𝑒
−𝑡2
2𝜎2
Meyer 𝜓(𝑡) =
{
1
√2𝜋𝑆𝑖𝑛 (
𝜋
2𝜐 (3|𝑡|
2𝜋− 1))𝑒𝑗𝜔/2 𝑠𝑖 2𝜋 3⁄ < |𝑡| < 4𝜋 3⁄
1
√2𝜋𝐶𝑜𝑠 (
𝜋
2𝜐 (3|𝑡|
2𝜋− 1))𝑒𝑗𝜔/2 𝑠𝑖 4𝜋 3⁄ < |𝑡| < 8𝜋 3⁄
0 𝑑𝑒 𝑜𝑡𝑟𝑜 𝑚𝑜𝑑𝑜
Poisson 𝜓(𝑡) = {(𝑡 − 𝑛
𝑛!) 𝑡𝑛−1𝑒−𝑡 𝑝𝑎𝑟𝑎 𝑡 ≥ 0
0 𝑝𝑎𝑟𝑎 𝑡 < 0
Hermitian 𝜓𝑛(𝑡) = (2𝑛)−𝑛2𝑐𝑛𝐻𝑛 (
𝑡
√𝑛) 𝑒−
12𝑛𝑡2
Shannon 𝜓(𝑡) =∏(𝑡 − 3𝜋 2⁄
𝜋) +∏(
𝑡 + 3𝜋 2⁄
𝜋)
Morlet 𝜓𝑐(𝑡) = 𝑐𝜎𝜋−14𝑒−
12𝑡2(𝑒𝑖𝜎 − 𝜅𝜎)
Una vez se ha seleccionado la wavelet madre, esta se inicia con un valor de escala igual
a 1, y a medida que se ve ejecutando la transformada se va cambiando la escala por

29
valores más bajos o altos. La ventana se ubica al inicio de la señal, es decir en 𝑡 = 0
y con un valor de escala igual a 1 se multiplica por la señal para luego integrarse.
Como resultado final de incrementar la traslación y escala, se obtienen datos en un
plano tiempo-escala, en donde cada valor computado para la escala seleccionada
forma una fila en el plano, y las columnas irán siendo formadas a medida que la escala
también lo hace como se ve en la Figura 5.
Figura 5. Transformada de Wavelet continua para una señal no estacionaria.
Para explicar mejor el funcionamiento de la transformada wavelet, se tiene el gráfico
que muestra la Figura 6. Asumiendo que cada uno de los rectángulos tiene la misma
área, cada una representa una porción del plano tiempo-frecuencia, pero con
diferentes proporciones, lo cual indica que para bajas frecuencias se tiene un rango
de información temporal más amplio, y para las altas la información que predomina
es de frecuencia. La diferencia y eficacia de la transformada depende en gran medida
de la wavelet madre utilizada, debido a que esta puede variar las dimensiones de las
áreas, por lo cual se debe buscar un balance en la relación frecuencia-tiempo, en otras
palabras, realizar la selección de una función wavelet que permita obtener los datos
que se quieren calcular.
Figura 6. Resolución de tiempo y frecuencia.

30
2.1.5.3. Coeficientes cepstrales de las frecuencias de Mel (MFCC)
Los MFCC son valores que representan las señales de audio provenientes del habla,
teniendo en cuenta los límites de percepción para la audición humana y es una de las
herramientas más utilizada en el desarrollo de trabajos relacionados con señales
pertenecientes al habla (Zhou, Garcia-Romero, Duraiswami, Espy-Wilson, &
Shamma, 2011). En la Figura 7 se muestra un esquema que muestra en orden los
procesos que deben realizarse para calcular de manera adecuada los coeficientes.
Figura 7. Procesos involucrados en el cálculo de MFCCs
Pre-énfasis
La primera etapa para el cálculo de los coeficientes de Mel, es el pre-énfasis, cuyo
objetivo es incrementar la cantidad de energía presente en las altas frecuencias de la
señal, para hacer de ésta, información detectable y útil en el procesamiento de voz.
Las ventajas de su implementación no se ven reflejadas sino hasta etapas posteriores,
como el reconocimiento de patrones donde el aumento de las altas frecuencias es
proporcional a la tasa de reconocimiento. Para el caso de estudio, el pre-énfasis se
realiza utilizando un filtro pasa alto de primer orden, como se expresa en la ecuación
(7), cuyo valor de multiplicación para el valor del atraso a la salida varía entre 0.95 y
0.98.
sf[n] = s[n] − 0.97s[n − 1] ( 7 )
Ventaneo
En el procesamiento de señales de voz, debe tenerse en cuenta que una de sus
propiedades es que son no estacionarias., es decir, la frecuencia de éstas varia con
respecto al tiempo y por ende sus características no son constantes. Esto implica un
problema al momento de implementar técnicas clásicas de procesamiento, como la
Transformada de Fourier y otros análisis temporales, no obstante, estas variaciones
son lentas con respecto al tiempo dada la estructura del tracto vocal (L. R. Rabiner &
Schafer, 2011). De acuerdo a lo anterior, si se realiza una segmentación de la señal en
divisiones lo suficientemente pequeñas para asumir que son estacionarias, pero aun
así del tamaño adecuado para considerar que son información importante, es posible
aplicar las técnicas clásicas. (Jurafsky & Martin, 2009). Algunas de los factores a tener
en cuenta en el ventaneo de la señal son:
Ancho y desplazamiento de la ventana
Forma de la ventana

31
En la Figura 8 se muestra la operación de ventaneo para una señal proveniente de la
pronunciación del fonema vocálico /e/, para habla normal.
Figura 8. Operación de ventaneo.
La forma de ventana escogida, fue de tipo Hamming como se expresa en la ecuación
(8).
𝑤[𝑛] = {0.54 − 0.46 cos[2𝜋 𝑛 𝑁⁄ ]
0
0 ≤ 𝑛 ≤ 𝐿 − 1
𝑝𝑜𝑟 𝑙𝑜 𝑑𝑒𝑚á𝑠 ( 8 )
Periodograma
La tercera fase del cálculo de los coeficientes es la estimación de la energía que hay
en cada una de las ventanas de la señal, esto se realza utilizando el periodograma, el
cual se calcula obteniendo la transformada de Fourier para cada una de los segmentos
realizados en la etapa de ventaneo y es expresado en la ecuación (9).
𝑃𝑖[𝑘] =1
𝑁|𝑆𝑖[𝑘]|
2 ( 9 )
Donde, 𝑆𝑖[𝑘] es la DFT de un segmento de la señal y 𝑘 es la resolución de la
trasformada. A partir del periodograma, se tiene una representación del espectro de
potencia de la señal, con el cual se estima la potencia presente en todas y cada una de
las divisiones de la señal, teniendo información de la señal completa.
Banco de filtros de Mel y operación Logaritmo
El filtrado de los datos obtenidos en el periodograma se elabora con un banco de
filtros triangulares, en donde por encima de 1KHz, el filtro se relaciona de manera
logarítmica y por debajo de éste valor lo hace de manera lineal. La escala de Mel fue
desarrollada a partir de la percepción que posee el oído humano para los
componentes frecuenciales del sonido, cuyo comportamiento es no lineal (Hossan,
Memon, & Gregory, 2010). Para convertir los valores de frecuencia a la escala de Mel

32
se utiliza la función descrita en la ecuación (10), donde 𝑓 es la frecuencia lineal, y el
número de filtros varía entre 20 y 40 (Huang, Acero, Hon, & Reddy, 2001).
𝑚𝑒𝑙(𝑓) = 2595 ln (1 +𝑓
700) ( 10 )
Transformada discreta de coseno (TDC)
Para finalizar el cómputo de los coeficientes, se aplica la transformada discreta de
coseno a los datos obtenidos tras la implementación del banco de filtros. A diferencia
de otras metodologías, la implementación de la TDC permite realizar una correlación
entre la energía de la señal, esto se debe a que en primer lugar la TDC es
computacionalmente más cómoda, y segundo, debido a la forma triangular de los
filtros, estos se traslapan en ciertas zonas dando una relación muy marcada en esas
intersecciones, por lo cual se debe aplicar un método de correlación que disminuya
ese fenómeno, siendo la TDC una herramienta muy útil.
En la Figura 9 se muestra una gráfica con el valor de los coeficientes calculados para
los fonemas /a/, /e/ y /o/.
Figura 9. Coeficientes de Mel para las dos primeras ventanas de los fonemas /a/, /e/ y /o/.
2.1.6. Dynamic Time Warping (DTW)
DTW es una técnica de procesamiento que permite realizar análisis sobre series
temporales que pueden variar en tiempo y velocidad a través de la cuantificación de
diferencias con el fin de encontrar un alineamiento óptimo entre las dos secuencias
bajo ciertas condiciones. En un principio, ésta técnica fue concebida como un
complemento parar procesar señales de voz en sistemas de reconocimiento
automático de habla, sin embargo, también ha sido utilizada con éxito en otros
campos como la minería de datos. En el procesamiento de señales de audio resulta
útil debido a la naturaleza de éstas, debido a que por lo general dos señales de voz
nunca tienen la misma pronunciación ni duración. (Deng & Leung, 2015)

33
Esta técnica tiene tres etapas de operación, en la primera se realiza el cálculo de las
distancias euclidianas para todos los puntos de las señales, luego, se realiza el mapeo
de la función de costo calculada con los valores de las distancias previamente
obtenidas, y por último hace la búsqueda del camino más corto dentro de la matriz
de costo, que permita la comparación entre las dos señales (Müller, 2007). Para
ejemplificar el funcionamiento de este algoritmo se van a utilizar el par de señales
mostradas en la Figura 10.
Figura 10. Conjunto de señales a comparar.
El par de señales sinusoidales que tienen un comportamiento similar en cuanto a
velocidad, pero tienen distinta duración en término de muestras y tiempo. En la
primera etapa del cómputo de DTW se deben hallar las distancias de todas las parejas
de puntos existentes en la pareja de señales, para hacer esto se ubican las dos señales
sobre ejes coordenados y se consignan en una matriz los datos de las distancias
euclidianas calculadas punto a punto. Para el caso de ejemplo se ubicó la señal 1 sobre
el eje horizontal y la señal 2 sobre el eje vertical obteniendo la matriz de distancias
mostrada en la Figura 11.
Figura 11. Cálculo de distancias euclidianas.

34
Se puede observar que los valores más pequeños de las distancias calculadas en la
primera etapa presentan patrones diagonales, esto significa que las distancias son
menores entre aquellas muestras que poseen índices similares. Para crear una
correlación entre las dos señales, hay que calcular un camino en el gráfico de la Figura
11. Cálculo de distancias euclidianas. Figura 12, que permita llegar desde el punto
𝑃(0,0) hasta 𝑃(𝐴, 𝐵), donde 𝐴y 𝐵 son las longitudes de las señales en términos de
muestras con la menor distancia posible. El objetivo de este algoritmo es encontrar
dicho camino teniendo en cuenta las siguientes condiciones:
1) El camino debe comenzar en 𝑃(0,0)y terminar en 𝑃(𝐴, 𝐵).
2) No es posible retroceder, por lo cual el camino solo puede ir hacia adelante, es decir,
a partir de un punto 𝑃(𝑥, 𝑦), solo se puede girar hacia arriba 𝑃(𝑥, 𝑦 + 1), hacia la
izquierda 𝑃(𝑥 + 1, 𝑦) o en diagonal 𝑃(𝑥 + 1, 𝑦 + 1)
Con estas condiciones se impide que se presente un problema combinatorio, y en
lugar de esto se convierte en un problema de programación dinámica que puede
resolverse en (𝐴 ∗ 𝐵) operaciones. Para facilitar la búsqueda del camino óptimo se
utiliza algo conocido como matriz de costos acumulados, la cual va acumulando las
distancias euclidianas para formar un nuevo set de datos, y sobre éste realizar la
búsqueda. En la Figura 12 se encuentra la matriz de costo acumulado.
Figura 12. Matriz de costo acumulado.
El cálculo del camino óptimo 𝑊 = (𝑤1, …… ,𝑤𝐿) se realiza en reversa, es decir, se
inicia por el punto 𝑊𝐿 = 𝑃(𝐴, 𝐵) hasta llegar al punto 𝑊0 = 𝑃(𝐴, 𝐵) siguiendo las
expresiones de la ecuación (11).
𝑊𝐿−1 = {
(1, 𝑏 − 1),(𝑎 − 1,1),
min{𝑃(𝑎 − 1, 𝑏 − 1), 𝑃(𝑎 − 1, 𝑏). 𝑃(𝑎, 𝑏 − 1)}
𝑠𝑖 𝑎 = 1𝑠𝑖 𝑏 = 1
, 𝑑𝑒 𝑜𝑡𝑟𝑜 𝑚𝑜𝑑𝑜
( 11 )

35
Las distancias que están consignadas en la Figura 13, y es en esta matriz de datos
donde se debe realizar la búsqueda del camino óptimo que minimice el error a la hora
de comparar las dos señales.
Figura 13. Camino óptimo.
En la Figura 14, se muestra la gráfica de los puntos que conectan las dos señales al
recorrer el camino que produce el costo mínimo, y por lo tanto permite comparar las
dos señales obteniendo un error mínimo al momento de realizarlo.
Figura 14. Visualización de la envolvente entre las dos señales.
2.1.7. Reconocimiento de patrones
Es una rama de la ingeniería y computación que se encarga de describir y clasificar
objetos, representaciones y/o señales. Los patrones son obtenidos a través de
procesos de adquisición, partición, extracción de características y descripción. Esta
ciencia funciona gracias a un conjunto de datos con todos los posibles patrones a
reconocer debidamente discriminados.
El reconocimiento trabaja en función de un conjunto previo con todos los posibles
patrones a identificar debidamente etiquetados y separados según sus características.
El rango de acción que tiene sus aplicaciones es muy amplio, como por ejemplo
previsión de condiciones meteorológicas, reconocimiento de huellas dactilares,

36
rostros y voz, así como detección de irregularidades en imágenes médicas, sin
embargo, las más importantes se relacionan con la audición y visión de máquina.
Algunos de los algoritmos más utilizados para llevar a cabo esta tarea, son los
asociados al aprendizaje de máquina como las redes neuronales y máquinas de
soporte vectorial (Duda, Hart, & Stork, 2012).
2.1.7.1. Redes neuronales artificiales
Las redes neuronales con un modelo de aprendizaje de máquina y procesamiento
automático de datos que fueron concebidas como una simulación del sistema
nervioso animal, que está constituido por unidades funcionales llamadas neuronas.
El primer modelo fue propuesto en 1943, el cual era un modelo binario donde cada
neurona tenía un único valor de umbral configurado, y sirvió como base para todos
los desarrollos realizados hasta el día de hoy.
Algunas de las características que hacen de las redes neuronales algoritmos muy útiles,
son su capacidad de procesamiento no lineal y paralelo, además son adaptables y
auto-organizables dependiendo del problema requiera ser resuelto. En cuanto a sus
aplicaciones se encuentran el ajuste de datos, clustering, control, optimización,
identificación de sistemas y reconocimiento de patrones.También existe una amplia
variedad en la construcción o arquitectura de este tipo de modelos, desde el más
sencillo conocido como perceptrón, hasta las redes MLP (Multi Layer Perceptron)
(Kruse, Borgelt, & Klawonn, 2013), redes de Hopfield (Anand, Hephzibah, &
Anandan, 2014), mapas de Kohonen (Angeli, Quesney, & Gross, 2012), etc.
La arquitectura de red utilizada para el reconocimiento de patrones es un perceptrón
multicapa Feed-forward, el cual está conformado por tres capas, la primera para ingresar
los patrones, la segunda, conocida como la capa oculta que se encarga de todo el
procesamiento de datos, y por último la capa de salida, que ajusta los valores
procesados para arrojar una respuesta coherente con la cantidad y características de
las clases tenidas en cuenta. En la Figura 15 se muestra el esquema de una red
neuronal de tipo feed-forward configurada para realizar un reconocimiento de patrones.
Figura 15. Topología de la red neuronal utilizada

37
En este desarrollo en concreto se utilizaron las funciones de activación tangente
sigmoidal y la función de clasificación denominada softmax como se muestra en las
ecuaciones (12) y (13) respectivamente, donde 𝑥, es el valor de salida para cada capa.
𝑇𝑎𝑛𝑠𝑖𝑔(𝑥) =2
1 + 𝑒−2𝑥− 1 ( 12 )
𝑆𝑜𝑓𝑡𝑚𝑎𝑥(𝑥) =𝑒𝑥
∑ 𝑒𝑥𝑛𝑖=1
( 13 )
Una vez establecida la estructura de la red, se debe implementar el algoritmo de
aprendizaje para la red neuronal, para que sea capaz de distinguir las características
existentes en los diferentes patrones. El entrenamiento utilizando el algoritmo
backpropagation (Lin Wang, Zeng, & Chen, 2015), y como parámetros para detener el
aprendizaje se tienen el error, las épocas, el tiempo, y el valor del gradiente o la
dirección en la que el error está variando. Para la mayoría de las aplicaciones se utiliza
éste entrenamiento variando el tipo de error, por ejemplo, para ajuste de datos se
utiliza el error cuadrático medio, mientras que para tareas de reconocimiento de
patrones se recomienda el uso del error por entropía cruzada (EEC) (Saric & Xiao,
2011), como se ilustra en la ecuación (14).
𝐸𝐸𝐶 = −1
𝑁∑[𝑦𝑛 ∙ log [�̂�𝑛] + [1 − �̂�𝑛] ∙ log [1 − �̂�𝑛]]
𝑁
𝑛=1
( 14 )
En esta expresión, 𝑦𝑛es la salida deseada y �̂�𝑛 la salida obtenida.
2.2. MARCO REFERENCIAL
2.2.1. Imágenes
(Ahmadi, McLoughlin, & Sharifzadeh, 2010) hacen un análisis de las características
de adquisición de señales de la voz en tracto vocal, a través de sensores ultrasónicos
de baja frecuencia. Este análisis da como resultado que en frecuencias comprendidas
entre 20 y 100 KHz la adquisición de estas señales es buena.
(Srinivasan, Raj, & Ezzat, 2010) realizan el reconocimiento de los dígitos del 0 al 9
del idioma inglés, utilizando sensores ultrasónicos, con seis hablantes. El algoritmo
de reconocimiento utiliza Cadenas Ocultas de Markov, y obtuvieron el 33% de
exactitud en el resultado.
(Hueber et al., 2010) Realizaron una interfaz de habla silenciosa, a través de captura
de imágenes ultrasónicas de la lengua y los labios. El sistema se basa en un
diccionario audiovisual que asocia a las observaciones visuales a la pronunciación
acústica de diferentes fonemas. El algoritmo de discriminación está basado en

38
modelos ocultos de Markov. Los movimientos de la boca son registrados por una
cámara de video y son procesados con técnicas de análisis de imágenes para
identificar letras o fonemas, alcanzaron el 60% de la identificación.
(Kalgaonkar, Hu, & Raj, 2007) propusieron un algoritmo en tiempo real que realiza
un análisis frecuencial a las señales de voz captadas a través de sensores ultrasónicos.
La muestra se realizó con 4 hablantes, tres hombres y una mujer, con 30 frases
diferentes, bajo diversas condiciones. El algoritmo desarrollado digitaliza la señal y la
demodula, luego hace una aproximación por Euler y aplican algoritmo de Görtzel.
El algoritmo les permitió determinar que le método basado en el efecto Doppler es
mucho más eficiente que un método acústico debido que puede aislar regiones de
actividad de voz en muy altas condiciones de ruido.
(Hasegawa & Ohtani, 1992) realizaron un sistema de interpretación de movimientos
de la boca. Estos son registrados por una cámara de video y son procesados por
técnicas de análisis de imágenes para identificar letras o fonémas. Permitido
identificar la pronunciación de letras como las vocales, para esto el sistema se vale de
las condiciones dimensionales de la boca como alto (H), ancho (W), área(A), y
contorno de los labios. La investigación dio como resultado identificar los
movimientos de la boca para las cinco vocales del idioma Japonés, con un 91%, de
exactitud.
2.2.2. Electromiografía
En el trabajo presentado por (Meltzner, Colby, Deng, & Heaton, 2011), se realizó
una descripción de un método de adquisición y procesamiento para el
reconocimiento del habla basado en señales generadas el lenguaje silencioso. Para la
adquisición de las señales, se utilizó una técnica electromiografía. Fueron empleados
8 electrodos, colocados sobre la superficie facial y acorde a los músculos del habla,
Las señales de electromiografía adquiridas, son procesadas por medio de una
máquina de estados finita, donde se identifica el inicio del habla y posteriormente se
realizan análisis de identificación a través de modelos de Markov.
Otro trabajo basado en electromiografía es el realizado en (Wand et al., 2014), donde
hicieron un trabajo orientado al reconocimiento del habla silenciosa. Los sensores
fueron ubicados en los músculos faciales, con ello consiguieron registran la actividad
del aparato fonador humano, procesándola con distintas wavelets, alcanzado una tasa
de error inferior al 10%.
(Jorgensen & Dusan, 2010) utilizó en sensores electromiograficos, con el propósito
de realizar reconocimiento de patrones del habla silenciosa. Los sensores fueron
colocados en la laringe y en áreas sublinguales, debajo de la mandíbula. Las señales
adquiridas fueron filtradas a través de un filtro notch, para eliminar la frecuencia de la
red eléctrica. Para el procesamiento de la señal, se muestreó a una frecuencia de 2000
Hz y se utilizó como estrategia de reconocimiento arboles de transformadas Wavelets.

39
Esta investigación, ha sido aplicada a tecnologías de comunicación hombre máquina,
con amplias afinidades en el campo de la robótica y el reconocimiento de palabras.
2.2.3. Murmuro no Audible
Para la captura de la señal originada por el habla silenciosa, (Nakajima et al., 2003)
utilizó como sensor un micrófono NAM. Los autores, presentan la manera como se
puede llegar a implementar este tipo de sensor. Además, estudiaron la posición que
debe tener este sobre la piel, para obtener la una señal más precisa. En este se propone
un algoritmo de reconocimiento, basado en cadena Markov. En sus pruebas
obtuvieron el 90% de precisión en ambientes con contaminación auditiva. Otro
trabajo relacionado con la identificación de habla a través del murmuro no audible,
es el realizado por (P. Heracleous, Nakajima, Lee, Saruwatari, & Shikano, 2003),
donde proponen un modelo de reconocimiento basado en cadenas de Markov
mejorando las distancias del modelo.
La investigación realizada por (V. A. Tran, Bailly, Lœvenbruck, & Jutten, 2008) con
la captura de señales NAM, plantea la importancia del habla silenciosa asociada a los
sistemas de comunicación celular, resaltando las restricciones que estos equipos
tienen en lugares públicos y la aplicación de los NAM como sistemas manos libres.
En él se analiza el reconocimiento de fonémas del alfabeto en lengua francesa,
mostrando como una prioridad detectar la frecuencia fundamental de la voz. Esta
condición mejora los resultados obtenidos sobre el proceso de identificación con
modelos de Markov y sus distribuciones gaussianas. Para determinar la frecuencia
fundamental, se aplica una red neuronal artificial. Las actividades de investigación se
realizaron con las vocales /a/, /e/, /i/, /o/, /u/ y las consonantes, /p/, /pj/, /b/,
/bj/, /m/, /mj/ con pronunciación bilabial. /d/, /t/, /s/, /ts/, /z/, /j/, /n/, con
pronunciación alveolar. /k/, /kj/, /g/, /gj/, con pronunciación palatal. /f/, /∫/,
/t∫/, /ƺ/, con pronunciación fricativa, entre otras. Dentro de los resultados, se
presentan tablas comparativas donde muestran índices de confusión entre
pronunciaciones. Estos indicadores son mostrados de forma porcentual. De este
análisis, se puede resaltar que las transiciones de pronunciación del mismo tipo,
presentan los mayores índices de error.
En la investigación realizada por (Panikos Heracleous, Tran, Nagai, & Shikano,
2010), plantea un sistema de reconocimiento de fonemas vocales, los cuales son
adquiridos por medio de un micrófono NAM. El desarrollo, además de analizar la
información del micrófono por medio de los modelos ocultos de Markov, se apoya
en análisis de imágenes sobre fotogramas que representan los espectrogramas del
micrófono. El espectrograma presenta en función del tiempo las componentes de
frecuencia de la señal de carácter instantáneo. En (Panikos Heracleous et al., 2010),
se muestra una representación de los fonemas japoneses /a/, /e/, /i/, /o/, /u/, en
un espacio tridimensional, contemplando los principales componentes de frecuencia
presentes en la señal de NAM. La investigación (Panikos Heracleous et al., 2010)

40
,también demuestra las diferencias de posición con respecto a una adquisición de
audio sonora normal.
La investigación de (Toda, 2012) ilustra cómo los sonidos o ruidos naturales del
cuerpo humano, afectan la calidad del habla capturada por los micrófonos NAM.
Como método de mejora, esta investigación y la realizada también por (Toda,
Nakagiri, & Shikano, 2012) plantean el uso de un algoritmo de estimación de máxima
verosimilitud, por sus siglas en inglés MLE. Utiliza modelos gaussianos de Markov,
determina la frecuencia fundamental del fono parlante. Este sistema termina con el
reconocimiento de los fonemas, para hacer una conversión a voz. En síntesis, el
sistema reconoce las intenciones de habla del fono parlante y las reproduce como
habla sonora.
La investigación de (Miyamoto, Nakamura, Toda, Saruwatari, & Shikano, 2009)
ilustran métodos para mejorar las características del micrófono NAM. La
propagación del murmuro a través de los tejidos del sistema fonador, provocan
cambios y ruidos sobre las señales de NAM. Como estrategias para reducir esta
condición de ruido, se propone compensar las señales por medio de técnicas
matemáticas como diferencia de la media espectral (CMS), regresión lineal de máxima
verosimilitud restringida (CMLLR) y máximo con restricciones de regresión lineal
(CSMAPLR). El uso del método CMS, compensa eficazmente componentes estáticas
de audio y se caracteriza por las distorsiones múltiples o armónicas. La
implementación de CMLLR, reduce la diferencia entre un modelo y su adaptación a
los datos adquiridos. Este método estima múltiples transformaciones lineales
regresivas que permiten organizar grupos o clases, de acuerdo a la forma de
adaptación que se presente, el método asume un árbol de regresión. El método de
CSMAPLR, es en resumen una versión más robusta, pero a su vez mas difícil de
implementar. Dentro de los resultados y las comparaciones hechas en la investigación
se puede resaltar, que la ubicación del micrófono NAM, ofrece diferentes niveles de
distorsión en las señales acústicas adquiridas. Esta investigación concluye que la
implementación de un método de compensación, en el algoritmo, mejora las
condiciones de habla y reconocimiento con sistemas NAM. Dados los resultados se
estima como mejor técnica la CSMAPLR.
La investigación planteada por (Babani, Toda, Saruwatari, & Shikano, 2011) se
propone la identificación del habla utilizando, la transformada normal (SAT). La
búsqueda de los coeficientes y características del sistema SAT, son realizados con la
implementación de una función objetivo y un criterio de optimización en el algoritmo
de reconocimiento. Para el proceso de optimización, se usan varias muestras de habla
por medio de micrófonos NAM y micrófonos de habla sonora normal. Las dos
lecturas de señal, son implementadas para hacer la búsqueda del vector óptimo del
SAT. Los resultados que evidencia la investigación muestran que es posible mejorar
el sistema de identificación del habla NAM, en un 2%.

41
La investigación planteada por (Ishii, Toda, Saruwatari, Sakti, & Nakamura, 2011),
presenta una técnica para reducir el ruido ciego. Este es producido por características
naturales del organismo como, movimientos musculares, respiración y latidos del
corazón. De forma adicional, aparecen otros ruidos producidos por factores
externos, como el movimiento de las extremidades y la fricción de las prendas de
vestir con la piel. La investigación (Ishii et al., 2011), propone la implementación de
dos micrófonos NAM, produciendo un efecto de adquisición sonora en estéreo. El
modelo planteado por el autor en (Ishii et al., 2011), toma las frecuencias estáticas de
las dos señales de audio, y por medio de un proceso de filtrado se estiman las
componentes de ruido en la señal estéreo. Posteriormente, una etapa de reducción
del ruido se aplica, con el análisis de las potencias presentes en las componentes
espectrales. Esto implica hacer una trasformación de Fourier, directa e inversa.
2.2.4. Detección de voz
Investigación de (Lopez-Larraz, Mozos, Antelis, & Minguez, 2010) plantea cómo
reconocer silabas del idioma español a través de electromiografía colocando
electrodos de superficie en la cara, tomaron como base un vocabulario que albergara
todas las vocales combinadas con una consonante para producir sonidos de
diferentes tipos labiales, dentales, palatales, velares y alveolares, utilizaron algoritmos
de Matlab, para el reconocimiento lograron un 33% de precisión.
(Hassan, Mohamad, Kalil, & Murah, 2011) buscaban cómo realizar un algoritmo de
reconocimiento de voz para el control de movimiento en robots a través del uso de
algoritmos de reconocimiento de Microsoft. En su trabajo, (Ettaouil, Lazaar, & En-
Naimani, 2013) propusieron una investigación para realizar un sistema de
reconocimiento de dígitos arábigos en idioma árabe, Implementaron una red
neuronal óptima con procesamiento de cadenas ocultas de Markov, modelo hibrido,
obtuvieron 84% en el resultado con una red neuronal de T=34 y el 86% con T=48.
(Lei Wang, Liu, Wei, & Hu, 2013) buscan mejorar los sistemas de reconocimiento de
fonemas del idioma Mandarín implementaron filtros Gabo para el procesamiento de
las señales, diseñaron un sistema tándem que integra diferentes características de
fonemas del idioma mandarín con la implementación de los filtros lograron
identificar vocales sordas del idioma mandarín y algunas consonantes.
(Varsavsky & McDermott, 2013), plantearon un algoritmo para aumentar la precisión
en el reconocimiento de pablaras en personas que utilizan implante coclear. Ajustaron
de manera automática los electrodos para generar los estímulos de forma simultánea.
El algoritmo tuvo en cuenta un procesamiento para la puntuación. Realizaron prueba
de con seis implantes dando mejor rendimiento que los procesos estándar. Se utilizó
una interfaz realizada en Matlab & Simulink ®.

42
3. CONSIDERACIONES FONOLÓGICAS
El enfoque práctico de esta investigación se encuentra particularmente
fundamentado en el análisis de las señales de murmuro no audible. Las características
que definen la naturaleza de la producción de estas formas de onda, claramente
difieren de aquellas que distinguen a las de las señales generadas en la acción de habla
sonora. Sin embargo, la concepción lingüística, vista desde los rasgos fonéticos y
fonológicos, es un punto común que comparten y que dada la importancia de la voz
silente, es necesario analizar con el fin de fundamentar el método y las características
procedimentales, en los algoritmos de extracción y clasificación, como fin último de
esta investigación. De acuerdo a lo anterior, es necesario definir dichos aspectos
lingüísticos, por lo que a continuación se definirán en términos de la fonética y
fonología.
3.1.1. Fonética y fonología.
La fonética y la fonología dentro de la lingüística, respectivamente, se encargan del
estudio de las características de los sonidos del habla cuando estos son articulados a
través del aparato fonador, y la codificación de las unidades lingüísticas que dichas
formas de onda representan (Gleason & Ratner, 2010). Mientras la fonética trata la
naturaleza de la producción de los sonidos, comprometiendo el análisis acústico en
términos de sus propiedades físicas, que se podría extender al dominio
suprasegmental de acuerdo a su definición (Saby Beltrán, 2002) y la variación
articulatoria en el tracto vocal, la fonología se ocupa de la organización lingüística de
los sonidos que son producidos y percibidos en el habla (Gil Fernández, 2007).
De acuerdo a dichas definiciones, la fonética y fonología se encuentran ligadas al
análisis de los sonidos y su utilización dentro del lenguaje. A partir de esta relación,
es posible caracterizar los lazos entre las diferentes unidades lingüísticas para definir
su aporte y comportamiento en el lenguaje. Los Fonemas son definidos como dichas
unidades representativas de los sonidos en el habla, y marcan los rasgos distintivos
en el significado de los mensajes comunicados a través de este proceso comunicativo
(Ávila, 2007). El estudio fonético del habla, del cual es basado el análisis de los
fonemas, tiene dos objetivos principales: El primero hace referencia a la
caracterización de los mecanismos involucrados en la producción y percepción del
habla, y el segundo se encarga de la explicación del proceso codificación-
decodificación de la información lingüística, contenida en las señales de voz en la
comunicación oral (Llisterri, 2010).
3.1.2. La lingüística y el reconocimiento de habla.
Tal y como se describieron los objetivos del estudio fonético, la base de la
formulación de los procesos involucrados en el habla son relacionados con la
concepción y diseño metodológico de los sistemas de reconocimiento de voz
(Rabiner & Schafer, 2011). La Figura 16 muestra el modelo conceptual de la

43
producción del habla, el cual es el resultado del estudio fonético del habla y
modificado para su interpretación, validación e implementación como base de los
sistemas de reconocimiento de voz.
Figura 16. Modelo conceptual de la producción del habla.
El modelo conceptual de la Figura 16, permite relacionar el fundamento fonético
descrito anteriormente con el contexto metodológico de los sistemas de
reconocimiento de habla. A partir de este modelo, es posible esbozar y proponer
metodologías que se adapten a su fundamento en términos lingüísticos e ingenieriles,
donde el objetivo es reconocer el mensaje que el hablante (emisor), transmite a través
de las ondas sonoras y cuyo sentido se obtiene a través de la intención que comunica.
De acuerdo al modelo de producción de habla, es posible reconocer dos importantes
elementos a tener en cuenta en el diseño de las metodologías de análisis, extracción
y reconocimiento de señales de voz (sea sonora o silente). Por un lado, se tiene el
modelo del hablante, que en un caso generalizado corresponde a cualquier persona
involucrada en el proceso comunicativo oral y que participa activamente a través de
la producción de habla. Por el otro, se tiene el reconocimiento de habla que es
realizado por la persona receptora del mensaje, la cual efectúa un proceso de
decodificación, en el que analiza y procesa el significado del mensaje enmarcado
dentro la señal de voz producida por el emisor, como método de comprensión de la
información comunicada. En estos términos, el sistema de recepción es el que es
analizado para construir dispositivos de reconocimiento de habla.
El análisis fonético de las señales de voz, corresponde al primer paso en el desarrollo
de sistemas de reconocimiento de habla. Con una descripción teórica detallada de
estos elementos característicos en señales de voz, es posible fundamentar y proponer
las unidades lingüísticas a reconocer por el sistema.
3.1.3. Unidades lingüísticas para el reconocimiento.
El conjunto de unidades lingüísticas para la identificación, conforma el grupo de
elementos de interés del cual se basará el sistema de reconocimiento. Teniendo en
mente esto, una correcta caracterización de dichos elementos, así como la
diferenciación en términos de extensión, se hace necesaria. De acuerdo a que el
sistema está orientado al procesamiento de señales de habla subvocal, se opta por el
análisis de fonemas consecutivos representados por grafemas derivados de
estructuras silábicas tal y como se definen en (Hidalgo Navarro & Quilis Merín,
2012).

44
En primer lugar, se analizaron las características fonéticas y fonológicas de los
elementos consonánticos en cuanto al punto de articulación y modo de articulación.
La Tabla 3, muestra la relación entre la descripción modal y de punto al articular las
consonantes en según el Alfabeto Fonético Internacional (AFI).
Tabla 3. Punto de articulación y modo de articulación de los fonemas consonánticos.
Para escoger las estructuras silábicas como elementos objetivo de clasificación, se
tuvo en cuenta la definición de las señales de habla subvocal producidas a partir del
murmuro-no-audible (NAM). De acuerdo a (Heracleous, Nakajima, Saruwatari, &
Shikano, 2005), las señales NAM son sonidos de baja intensidad que se producen
cuando se realiza la pronunciación de unidades lingüísticas definidas en forma de
susurro. Teniendo en cuenta lo anterior, estas señales objetivo de habla subvocal,
corresponden a sonidos sordos dentro de la representación fonética internacional.
Es por eso que, para garantizar la integridad de las señales, y la clasificación de la
información importante derivada de los fonemas vocálicos de las palabras. Se optó
por tomar fonemas consonánticos sordos que los acompañen. A partir de la
información suministrada en (Gil Fernández, 2007; Quilis, 2002), los fonemas /p/,
/t/ y /k/, corresponden a unidades lingüísticas con un modo de articulación de tipo
oclusivo, y puntos de articulación de tipo bilabial, dental y velar respectivamente.
El punto de articulación de cada fonema, hace referencia a las zonas de la cavidad
bucal en las que los órganos articulatorios se unen para producir el sonido asociado.
En el caso de la /p/ es llamado bilabial, por su punto de articulación, que se realiza
al juntar los labios en la pronunciación. Para la /t/ la articulación es dental debido
que la punta de la lengua, hace contacto con los dientes del maxilar superior. Por
último, el fonema /k/ se lleva a cabo en la zona linguovelar. El modo de articulación
es definido como la forma en que el aire sale de los órganos articulatorios, y para los
tres fonemas es denominado oclusivo, porque el aire sale de golpe, produciendo una
pequeña explosión que es posible de caracterizar en términos temporales y de
frecuencia dentro del sistema de reconocimiento.

45
De acuerdo a estas características lingüísticas, se optó por escoger el fonema
consonántico /t/, debido a que para esta unidad, se garantiza una mejor
discriminación de acuerdo a sus aportes en la producción de habla subvocal. Esta
unidad fonológica acompañada de los fonemas vocálicos /a/, /e/, /i/, /o/ y /u/,
forma así el grupo de clasificación /ta/, /te/, /ti/, /to/ y /tu/, que es caracterizado
en términos de tiempo y frecuencia para posteriores tareas de reconocimiento, tal y
como se explica más adelante.
3.1.4. Características fonéticas de las unidades lingüísticas.
La construcción de un sistema de reconocimiento automático del habla, se basa en la
conceptualización del modelo comunicativo que se ve en la Figura 16. A partir de él,
es posible definir ciertos elementos característicos que representan la base del sistema
a desarrollar. Como bien se explicó anteriormente, los fonemas que se plantearon
analizar en esta investigación corresponden a compuestos de elementos fonológicos
mínimos entre consonantes y vocales.
Cada uno de estos elementos corresponde a la unidad de reconocimiento mínima, la cual
es definida como el elemento indivisible en la tarea de reconocimiento; y que difiere
de la unidad fonológica mínima (i.e. fonema). De acuerdo a esto, a partir de los
requerimientos y características propias del sistema de reconocimiento de voz, es
posible definir diferentes unidades de reconocimiento, las cuales pueden variar desde
unidades fonológicas mínimas y sus compuestos, hasta palabras (Rabiner & Schafer,
2011). El grupo de unidades de reconocimiento, es denominado vocabulario de
reconocimiento, y detalla el alcance del sistema de reconocimiento, y su aplicación
específica.
A partir de estas consideraciones, se realiza un análisis específico sobre las
características fonéticas del vocabulario de reconocimiento. En este caso orientado a
los fonemas compuestos del grupo: /ta/, /te/, /ti/, /to/ y /tu/. La fonética acústica
en este caso permite realizar tal análisis, con el que es posible establecer los primeros
parámetros de caracterización en posteriores etapas de extracción de características.
Las señales de habla subvocal, difieren en varios sentidos a las señales de voz sonora.
Sin embargo, se mantienen las características de punto y modo de articulación cuando
estas son producidas, por lo que es posible encontrar similitudes en las formas de
onda producto de la articulación sonora y silente de las señales analizadas.
En el habla sonora, existen características fonéticas específicas que son propias de
algunos de los fonemas vocálicos analizados. En general, para una señal de voz
sonora debido a sus características no-estacionarias, hacen que no posean elementos
característicos propios en su representación en frecuencia, lo cual sumado a la
dependencia que existe con la persona que produce el sonido, hacen que se dificulte
el proceso de extracción de características; por esta razón se han desarrollado otras

46
metodologías que explotan las representaciones temporales y de frecuencia de
manera integral para cumplir con la tarea de extracción.
Sin embargo, existen posiciones relativas típicas que ayudan a caracterizar y/o
analizar el comportamiento de la señal de voz sin importar la persona, entonación,
potencia, lugar de origen, o tipo de lengua utilizada al realizar la pronunciación de las
unidades de (Fernando Trujillo Sáez, Antonio González Vázquez, Pablo Cobo
Martínez, & Elisabel Cubillas Casas, 2002; Fujisaki & Kawashima, 1968).
Estas variables acústicas son denominadas Formantes, y corresponden a frecuencias
que están contenidas en el espectro de amplitud de las señales analizadas, en donde
existe una mayor concentración de energía en la señal (Fernández, 1988; Fernando
Trujillo Sáez et al., 2002). De acuerdo a esto, es necesario realizar un análisis
estadístico de estas propiedades, como forma de caracterización fonética del habla
subvocal. Sin embargo, dado que un desarrollo de tales alcances va más allá del
objetivo de esta investigación, se limita a la presentación de algunos ejemplos de los
espectros de potencia, que evidencian la posible presencia de los formantes en señales
de habla silente.
Para los fonemas vocálicos, los formantes se pueden distinguir de acuerdo a la
llamada Correlación articulatoria-acústica, con la cual de acuerdo a la abertura de la
mandíbula, la posición horizontal de la lengua y la labialización, determinan la
frecuencia distintiva de los formantes para los fonemas vocálicos. La Figura 17,
muestra esta representación a través del trapecio vocálico.
Figura 17. Correlación articulatoria-acústica de las vocales en el español.
2500 2000 1500 1000200
300
400
500
600
700
[i][u]
[e][o]
[a]
Segundo
Formante F2 (Hz)
Prim
er F
orm
an
te
F1
(Hz)
Cerrada
Media
Abierta
Anterior Central Posterior

47
La transcripción fonética del español con el alfabeto fonético internacional para las
vocales en el español, relaciona la naturaleza oscilatoria en el dominio de la frecuencia
denotada por las características de los formantes de estos fonemas sonoros, con la
ubicación de la lengua al momento de la producción de voz (anterior, central o
posterior) y posición de la mandíbula (cerrada, semi-abierta o media y abierta). De
esta forma, se contruye la relación de la articulación con las frecuencias comunes para
la /a/, /e/, /i/, /o/ y /u/, tal y como se observa en la Figura 17.
Las Figuras 18-22, corresponden a los espectrogramas de las señales de habla silente
para los fonemas /ta/, /te/, /ti/, /to/ y /tu/ respectivamente. En ellas se puede
observar claramente algunas regiones en donde existe mayor representación de
energía en algunos rangos de frecuencia (en su mayoría correspondientes a los
primeros 2 kHz), durante todo el rango de tiempo de la señal.
Figura 18. Espectrograma de la señal de habla subvocal para el fonema /ta/.
La Figura 18, muestra el espectrograma de la señal correspondiente a la
pronunciación del fonema /ta/, se puede observar en esta figura, (así como en las
Figuras 19-22), que para los primeros 50 ms de la señal, toda la banda de frecuencia
registra valores altos de energía en la señal. Esto es debido al sobrepico que se
evidencia en la forma de onda al inicio de la grabación. Particularmente para la Figura
17, existen amplitudes de energía altos para el rango de frecuencias de 0-2600 Hz, el
cual se debe a las características de ruido que poseen las señales de habla subvocal.

48
Figura 19. Espectrograma de la señal de habla subvocal para el fonema /te/.
Para la Figura 19, la banda de frecuencia en la que la señal contiene información espectral relevante, se encuentra enmarcada de 1 a 2 kHz, lo cual se evidencia en el espectro de amplitud representado a través del código de color de la gráfica. Estas franjas de potencia que se reflejan sobre las bandas específicas de frecuencia, podrían ayudar a caracterizar las señales de habla subvocal para el fonema /te/.
Figura 20. Espectrograma de la señal de habla subvocal para el fonema /ti/.
De manera similar, la Figura 20 (espectrograma del fonema /ti/) muestra un rango de frecuencias característico que va desde un poco más de los 500 Hz hasta los 2000 Hz, esta característica diferenciable permitiría encontrar componentes específicas relacionadas con los formantes para las señales de voz sonora.

49
Figura 21. Espectrograma de la señal de habla subvocal para el fonema /to/.
Para el fonema /to/ representado a través de la Figura 21, hay un marcado retraso
en relación a los demás espectros de los otros fonemas, en este caso, el rango de
frecuencias está mucho mejor definido entre los 1200 Hz y los 2000 Hz,
expandiéndose su banda de frecuencia al final de la producción de esta señal.
Figura 22. Espectrograma de la señal de habla subvocal para el fonema /tu/.
Por último, el espectrograma de la Figura 22 muestra similitudes con el generado para
la señal del fonema /te/, lo cual evidencia características de tiempo-frecuencia que
pueden servir para la identificación de patrones en posteriores etapas de clasificación.

50
Herramientas matemáticas como las que se mostraron anteriormente, basadas en la
aplicación de la transformada en tiempo corto de Fourier, ayudan al análisis de señales
no estacionarias como las de habla sonora y silente, además permiten encontrar
valores de frecuencia predominantes en términos de potencia, que ayudan a
caracterizar su comportamiento y su naturaleza de producción.

51
4. DESARROLLO DE LA INVESTIGACIÓN
El presente capitulo describe el desarrollo de la investigación. Obedeciendo a la
arquitectura algorítmica que se ilustra en la Figura 23, donde se distinguen tres
grandes bloques. El primero es la adquisición de la señal, donde se realiza el proceso
de captura de la señal, propia del habla sub-vocal, a la que se aplican técnicas de pre-
procesamiento que permiten la preparación de dicha señal para la etapa posterior. El
siguiente bloque es la extracción de características, proceso de máxima importancia
en esta investigación. La extracción de las características de la señal sub-vocal, se
realizó a través de tres métodos: Descomposición por Paquetes de Wavelet (DWPT),
Codificación Predictiva Lineal (LPC) y Coeficientes Cepstrales en Frecuencia Mel
(MFCC). La parte final del capítulo, describe el entrenamiento de la red neuronal
desarrollada para cada uno de los métodos de extracción y sus resultados.
Figura 23. Arquitectura algorítmica propuesta.
4.1. Adquisición de la señal
Es este apartado, se describe la adquisición de la señal de habla subvocal, realizando
captura de la señal del murmuro no audible, a través de un elemento primario que
detecta la vibración en el apófisis mastoideo.
4.1.1. Muestra poblacional
Para la selección de la muestra poblacional, se toma en cuenta el universo de la
problemática, donde el escenario más asequible son los ambientes con contaminación

52
auditiva o ambientes ruidosos. Aunque las leyes (Resolución 627 de 2006 del
Ministerio de Ambiente) tengan establecidos los niveles máximos de ruidos para
vecindarios residenciales y comerciales, la contaminación sigue en aumento (Pacheco,
Pacheco, Franco, & Behrentz, 2009). La metodología utilizada en la selección de la
muestra poblacional, inicio con la definición de la población objeto, continuando con
la delimitación de la población, la elección del tipo de muestra y finalmente, se
definido el tamaño muestra, en función de los datos requeridos (Iza Alcívar &
Fabricio, 2016).
La población objeto fue seleccionada de acuerdo a la problemática planteada, donde
la unidad de análisis, corresponde con personas que están en contacto con un
ambiente ruidoso. En la delimitación de la población, se tuvo en cuenta la diferencia
entre las características fonéticas y fonológicas entre hombres y mujeres, que aunque
no presenta grandes factores diferenciadores, se puede distinguir que los rasgos
lingüísticos, tiene mayor acentuación en el sexo masculino que en el femenino, al
igual que se observan propiedades similares por grupos de edades (Rissel, 1981). La
delimitación de la población para esta investigación se definió para un grupo de 30
individuos masculinos con edades entre 21 y 35 años.
Las muestras se clasifican en dos grupos, muestras probabilísticas y no probabilísticas
(Hidalgo & Ramírez, 2009). Las muestras no probabilísticas, denominadas muestras
dirigidas, hacen una selección informal. La ventaja de este tipo de muestras, radica en
su aplicabilidad en estudios que requieran una selección de la población con
características relevantes, que identifiquen el problema a investigar (Meiriño, Brea,
Vila, & López, 2016). Finalmente, el tamaño de las muestras para el desarrollo de esta
investigación, fue de 1500 registros, donde se realizaron 10 registros para cada
persona y 300 capturas por fonema. La Tabla 4 ilustra en resumen la selección de las
muestras. Para el entrenamiento de los algoritmos de clasificación e identificación
basados en inteligencia artificial, se utilizó el 60% de los datos o 900 muestras, y los
600 datos restantes se utilizaron para validar el desempeño del algoritmo con
muestras no presentes al momento de entrenarlo.
Tabla 4. Selección de muestras.
Definición de la población Personas que se encuentren en ambientes ruidoso
Delimitación de la población 30 individuos masculinos, con edades entre 21 y 35 años
Tipo de muestra No probabilística
Tamaño de la muestra 1500 registros
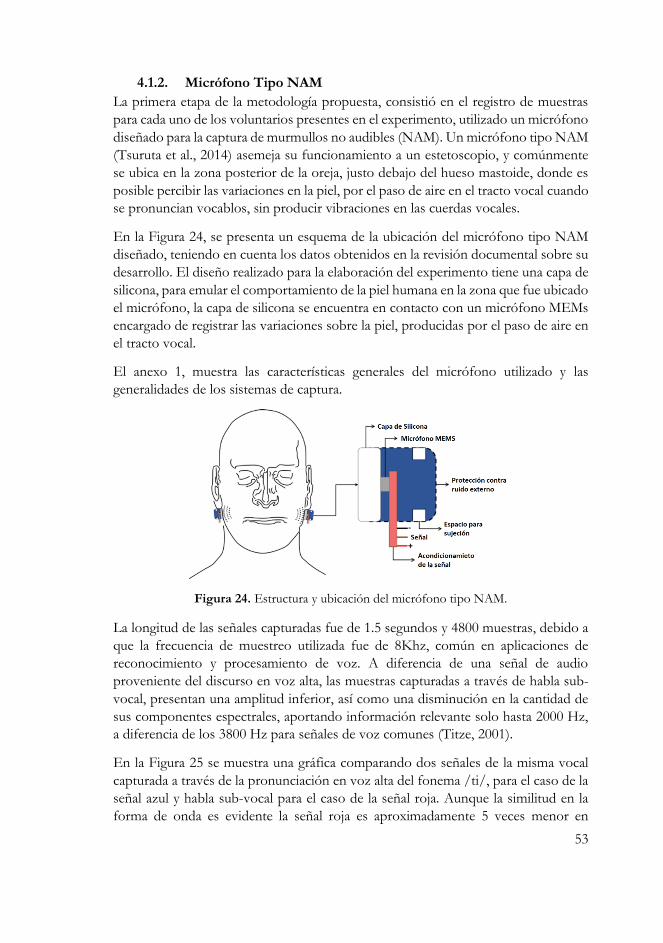
53
4.1.2. Micrófono Tipo NAM
La primera etapa de la metodología propuesta, consistió en el registro de muestras
para cada uno de los voluntarios presentes en el experimento, utilizado un micrófono
diseñado para la captura de murmullos no audibles (NAM). Un micrófono tipo NAM
(Tsuruta et al., 2014) asemeja su funcionamiento a un estetoscopio, y comúnmente
se ubica en la zona posterior de la oreja, justo debajo del hueso mastoide, donde es
posible percibir las variaciones en la piel, por el paso de aire en el tracto vocal cuando
se pronuncian vocablos, sin producir vibraciones en las cuerdas vocales.
En la Figura 24, se presenta un esquema de la ubicación del micrófono tipo NAM
diseñado, teniendo en cuenta los datos obtenidos en la revisión documental sobre su
desarrollo. El diseño realizado para la elaboración del experimento tiene una capa de
silicona, para emular el comportamiento de la piel humana en la zona que fue ubicado
el micrófono, la capa de silicona se encuentra en contacto con un micrófono MEMs
encargado de registrar las variaciones sobre la piel, producidas por el paso de aire en
el tracto vocal.
El anexo 1, muestra las características generales del micrófono utilizado y las
generalidades de los sistemas de captura.
Figura 24. Estructura y ubicación del micrófono tipo NAM.
La longitud de las señales capturadas fue de 1.5 segundos y 4800 muestras, debido a
que la frecuencia de muestreo utilizada fue de 8Khz, común en aplicaciones de
reconocimiento y procesamiento de voz. A diferencia de una señal de audio
proveniente del discurso en voz alta, las muestras capturadas a través de habla sub-
vocal, presentan una amplitud inferior, así como una disminución en la cantidad de
sus componentes espectrales, aportando información relevante solo hasta 2000 Hz,
a diferencia de los 3800 Hz para señales de voz comunes (Titze, 2001).
En la Figura 25 se muestra una gráfica comparando dos señales de la misma vocal
capturada a través de la pronunciación en voz alta del fonema /ti/, para el caso de la
señal azul y habla sub-vocal para el caso de la señal roja. Aunque la similitud en la
forma de onda es evidente la señal roja es aproximadamente 5 veces menor en

54
amplitud y posee menos componentes espectrales, lo que reduce drásticamente su
calidad, no obstante, para realizar un reconocimiento de habla ésta similitud resulta
suficiente realizando ajustes en los procesos siguientes para abarcar los componentes
frecuenciales que arrojen información relevante del habla sub-vocal.
Figura 25. Señales de audio de habla normal y habla sub-vocal.
Una vez adquirida la señal pura se hace necesario realizar un pre-procesamiento que
involucra los sub-procesos de eliminación de silencios, normalización y filtrado.
4.1.3. Pre-procesamiento
El pre-procesamiento se utiliza para estandarizar las características de las señales
adquiridas, garantizando su uniformidad al momento de implementar los métodos
de extracción de características. A continuación, se realiza una breve descripción de
las técnicas utilizadas en el pre- procesamiento.
4.1.3.1. Eliminación de Silencios:
Se denomina eliminación de silencios a desechar las señales que no tienen contenido
de información. Para este efecto se pueden aplicar, tradicionalmente, tres métodos:
cálculo de potencia, detección de cruce por cero y cálculo de la frecuencia central.
Para esta investigación el proceso utilizado fue el cálculo de potencia, con umbral de
2%. Las señales por debajo de ello fueron desechadas por considerarlas sordas.

55
4.1.3.2. Normalización:
Debido a que no existe igual aprehensión lingüística para todos los individuos y a las
características propias de la señal subvocal, se hace necesario realizar una
normalización de la señal. Esta investigación realizó una normalización entre valores
de -1 y 1.
La Figura 26 ,muestra la señal pura y las respectivas señales después de aplicados los
procesos anteriormente descritos.
Figura 26. Eliminación de silencio y normalización de la señal.
4.1.3.3. Filtrado
El proceso de filtrado, se hace necesario para realizar la eliminación de señales
espurias que pueden provenir de cualquier órgano componente del aparato fonador.
Para contrarrestar esto, se desarrolló un filtro pasabajas Butterworth de tercer orden,
con frecuencia de corte en 2200Hz, que permite determinar los componentes
frecuenciales que llevan información del habla subvocal.
Terminando el proceso de adquisición de da cumplimiento al primer objetivo
específico, planteado en esta investigación. A través de la adquisición de la señal
subvocal, gráficamente se puede observar que se disminuye la amplitud de esta señal,
respecto a la l de habla sonora. Sin embargo, se conservan las características generales
de la señal de voz.

56
Luego de realizar el proceso de pre-procesamiento, la señal está preparada para
realizar la extracción de sus características, que se abordara en el siguiente capítulo.
4.2. Extracción de Características
La extracción de características es un factor de alta relevancia en los sistemas de
reconocimiento de voz. Por lo tanto, para esta investigación, también constituye un
componente indispensable, a pesar de que no se produce habla sonora. Este
apartado, presenta los métodos de extracción de características desarrollados en
cumplimiento al segundo objetivo propuesto.
La extracción de características se realizó a través de tres métodos: Descomposición
por paquetes de wavelet, Codificación Predictiva Lineal (LPC) y Coeficientes
Cepstrales en Frecuencias Mel (MFCC).
4.2.1. Software
Para la implementación de la adquisición de datos, las diferentes técnicas de
extracción utilizadas en este documento y el entrenamiento de los algoritmos de
inteligencia artificial, para la tarea de clasificación de patrones se utilizó el software
de programación matricial MATLAB® de MathWorks® en su versión 8.5. La
programación del sistema embebido, para la implementación física y en tiempo real
del sistema de reconocimiento, fue elaborada en el compilador para dispositivos
ARM , Keil de uVision en su versión 5.21a.
Para realizar el sistema de reconocimiento automático de fonemas del idioma español
mediante habla sub-vocal, se probaron diferentes metodologías para la extracción de
características, así como la programación de los coeficientes cepstrales de las
frecuencias de Mal en el sistema embebido, para su operación en tiempo real.
4.2.2. Descomposición por paquetes de Wavelet
Este método, es una generalización de la descomposición de señales realizada con la
transformada discreta de wavelet (DWT), pero permite realizar un análisis más
profundo de la señal original, al dividirla en una mayor cantidad de secciones. El
análisis tradicional consiste en dividir la señal en dos partes iguales, una de
aproximación y otra de detalle, luego el proceso es repetido para la sección que
contiene los datos de aproximación, hasta alcanzar el nivel de descomposición
deseado. La división de la señal es realizada mediante dos filtros, un filtro pasa alto y
un filtro pasa bajo que, para el caso práctico en el análisis con wavelets, son la función
wavelet madre (𝜓) y la función de escala (𝜑). El análisis por medio de paquetes wavelets,
utiliza formas de onda dependientes de tres parámetros, tiempo, escala y frecuencia.
Dada una función wavelet que cumpla con la condición de ortogonalidad presente en
la expresión de la ecuación (16), se puede generar un grupo de funciones conocidas
como paquetes base de wavelet.

57
∫ 𝜓𝑎,𝑏(𝑡) ∙
∞
−∞
𝜓𝑎′,𝑏′∗ (𝑡)𝑑𝑡 = 𝛿(𝑎 − 𝑎′)𝛿(𝑏 − 𝑏′) {1 𝑠𝑖 𝑎 = 𝑎′ ∧ 𝑏 = 𝑏′
0 𝑒𝑛 𝑜𝑡𝑟𝑜 𝑐𝑎𝑠𝑜 ( 16 )
Esta expresión, indica que el resultado del producto punto de una wavelet madre
escalada y trasladada es un impulso unitario. Una propiedad interesante de las wavelets
que cumplen el criterio de ortogonalidad, es que los filtros de análisis o
descomposición, y síntesis o reconstrucción son los mismos, y si además son
ortonormales, es posible elaborar una descomposición sin pérdida global de energía,
sin información redundante y reconstruir completamente la señal, en caso de ser
necesario. (Chan, 1995)
El proceso de análisis mencionado para la DWT solamente tiene en cuenta el vector
de coeficientes de aproximación, y la información perdida entre dos niveles sucesivos
es almacenada en los coeficientes de detalle, sin que dicha información sea re-
analizada. El actual método de descomposición por paquetes, divide de nuevo los
coeficientes de detalle, de la misma manera que ocurre con los de aproximación, lo
cual ofrece un análisis más profundo del comportamiento temporal y frecuencial de
la señal. La idea de este análisis es iniciar con la división de la señal orientada hacia el
factor de escala, y luego obtener información de las frecuencias presentes en cada
nivel. En la Figura 27, se ilustra la estructura obtenida al utilizar los paquetes de
wavelets para descomponer una señal en tres niveles.
Figura 27. Árbol de descomposición para tres niveles.
La generación de los paquetes de wavelets es factible cuando se realiza la selección de
una wavelet que cumple con los criterios de ortogonalidad para la ecuación (16),
algunos tipos de onda que cumplen esas características son las wavelets Haar, Symlet,
Coiflet, Meyer y Daubechie. El proceso se inicia utilizando dos filtros de longitud total
2𝑁, donde ℎ(𝑛) será el filtro pasa alto y 𝑔(𝑛) es el filtro pasa bajo, correspondientes
a la forma de la wavelet utilizada. Definiendo la secuencia de funciones de acuerdo al
número de descomposición requerido, las funciones de los filtros son obtenidas de
la siguiente manera:

58
𝜑(𝑥) = 𝑊2𝑛(𝑥) = √2 ∑ ℎ[𝑛]
2𝑁−1
𝑛=0
∙ 𝑊𝑛[2𝑥 − 𝑛], 𝑛 ∈ ℤ+ ( 17 )
La ecuación (17) pertenece al filtro pasa alto o la función de escala que entrega los
coeficientes de detalle, y su contraparte, que actúa como filtro pasa-bajo o función
wavelet para la obtención de los coeficientes de aproximación, se muestra en la
ecuación 18.
𝜓(𝑥) = 𝑊2𝑛+1(𝑥) = √2 ∑ 𝑔[𝑛]
2𝑁−1
𝑛=0
∙ 𝑊𝑛[2𝑥 − 𝑛], 𝑛 ∈ ℤ+ ( 18 )
De esta manera se obtienen los paquetes de wavelets requeridos para representar una
función los niveles de descomposición deseados.
Para el caso de estudio, se dividió la señal en 6 niveles de descomposición, utilizando
las funciones wavelets mostradas en la Figura 28.
Figura 28. Paquetes Wavelets para la función Daubechie # 8.
En las gráficas de la Figura 28, se puede apreciar que, a distintos niveles la función
presenta valores de traslación y escala diferentes, lo cual es un comportamiento
esperado en el método de descomposición por paquetes. Como ha sido mencionado
anteriormente, fue utilizada una función wavelet de la familia Daubechie, en primer
lugar, por sus propiedades ortogonales y ortonormales, y en segunda instancia porque

59
son funciones que se caracterizan por tener un número máximo de momentos de
desvanecimiento.
Esta última característica, es un indicador de la calidad con la que los distintos
paquetes pueden realizar la descomposición y representación de la señal, es decir,
mientras mayor sea el número de momentos de desvanecimiento, mejor será el
análisis de la señal. Por ejemplo, la función Daubechie # 8 tiene 4 momentos de
desvanecimiento, que resultan suficientes para analizar por completo el ancho de
banda de una señal de habla sub-vocal. Para los paquetes de funciones Wavelet de la
familia Daubechie, los coeficientes de los filtros deben cumplir las siguientes
condiciones.
∑ ℎ[𝑛] ∙ ℎ∗[𝑚 + 2𝑘] = 𝛿[𝑘, 0] = {∑|ℎ[𝑚]|2 𝑠𝑖 𝑘 = 0,
𝑁−1
𝑚=0
0 𝑠𝑖 𝑘 ≠ 0
𝑁−1
𝑚=0
( 19 )
∑ℎ[𝑛] =
𝑁−1
𝑛=0
√2 ( 20 )
∑[−1]𝑛 ∙ 𝑛𝑘 ∙ ℎ[𝑁 − 1 − 𝑛] = 0, 𝑝𝑎𝑟𝑎 0 ≤ 𝑘 ≤𝑁
2− 1
𝑁−1
𝑛=0
( 21 )
Con estas condiciones, se pueden hallar las funciones base Daubechie, sin embargo,
encontrar esas funciones base definidas en una expresión cerrada o de forma analítica
resulta complicado e innecesario, debido a que existen tablas que indican los valores
de los coeficientes, dependiendo de la wavelet a ser utilizada (Strang, 1992). Dentro de
este grupo de wavelets, existen un amplio rango de funciones, desde aquellas que son
altamente localizadas o concentradas, y otras altamente suavizadas o dilatadas. La
expresión que se utiliza para aplicar la transformada wavelet a la señal, de acuerdo al
nivel de descomposición, es como se muestra en la ecuación (22).
𝑊[2𝑗 , 2𝑗𝑛] =1
√2𝑗∑𝜓𝑛
𝑗′[𝑘
2𝑖− 𝑛] ∙ 𝑊[𝑘]
𝑘
( 22 )
En la ecuación anterior 𝑗, hace referencia al nivel de descomposición, 𝑘 y 𝑛 son los
factores de expansión y traslación respectivamente. De igual manera, el superíndice
𝑗, que acompaña la función wavelet 𝜓, indica la función que se debe aplicar para
realizar la transformada, siguiendo la secuencia que se encuentra ilustrada en la Figura
28. En la Figura 29, se presentan los primeros dos niveles de descomposición para la
señal de habla sub-vocal, adquirida al momento de pronunciar el fonema /ta/,
después de implementar las técnicas de pre-procesamiento, como la eliminación de

60
silencio y el realce de altas frecuencias. Las señales de color azul, representan los
coeficientes de aproximación y las verdes los coeficientes de detalle. Es importante
mencionar que los valores de cada grupo de coeficientes son adimensionales.
Figura 29. Descomposición de la señal capturada para el fonema /ta/.
Para la extracción de características fueron utilizados 2𝑗+1 − 1 grupos de
coeficientes, divididos en los 6 niveles de descomposición. Esto quiere decir, que los
127 grupos de coeficientes fueron reducidos a 6 características para los coeficientes
de aproximación y 6 características para los coeficientes de detalle. La Figura 30,
ilustra de manera gráfica la descomposición de la señal original, y la cantidad de
coeficientes que se obtiene cuando se alcanza el máximo nivel deseado. Cada nuevo
grupo de coeficientes de aproximación y detalle, divide a la mitad la señal de la cual
fueron extraídos, debido a la operación de diezmado que se realiza después de aplicar
la transformada wavelet con la función correspondiente.
Figura 30. Distribución de los coeficientes para 6 niveles de descomposición.
Para cualquier sistema o algoritmo relacionado al reconocimiento de patrones, en
este caso de haba sub-vocal, la selección y extracción de características es una etapa
crítica y fundamental para el resultado final del sistema, porque, sin importar lo
sofisticado, complejo o eficiente que sea el algoritmo clasificador, éste tendrá un bajo
rendimiento creo si las características no definen lo suficientemente bien el
comportamiento de los patrones a reconocer.

61
Los métodos para extracción de características, no solamente deben ser capaces de
representar y condensar la información de una señal, sino que además deben hacerlo
utilizando una menor cantidad de datos. En la Figura 31, se encuentra descrita la
metodología llevada a cabo para realizar la extracción de características de las señales
de habla sub-vocal mediante los paquetes wavelet de la función Daubechie #8. Se
inició con la descomposición de las señales en seis niveles, posteriormente los
coeficientes de aproximación y detalle se almacenaron por nivel para obtener
parámetros estadísticos, como la media aritmética, desviación estándar y entropía,
que fueron utilizados para el entrenamiento y comprobación del algoritmo
clasificador.
Figura 31. Diagrama de bloques del sistema de reconocimiento propuesto.
Para clasificar los patrones extraídos de los fonemas de habla sub-vocal, se
entrenaron tres redes neuronales, una para cada parámetro estadístico calculado. El
primer parámetro fue la Entropía de Shannon, como se ve en la ecuación (23), donde
𝑖 es el índice del coeficiente, y 𝑠 es el valor del coeficiente.
𝐸𝑛𝑡𝑟𝑜𝑝𝑖𝑎 = −∑𝑠𝑖2 ∙ log (𝑠𝑖
2)
𝑖
( 23 )
Este valor es un indicador de la incertidumbre existente en una fuente de
información, se dice que si la información es insuficiente su entropía será mayor, por
lo tanto, se puede afirmar que, para una mayor profundidad o mayor nivel de
descomposición, el valor de entropía obtenido será cada vez menor. El diagrama de
la Figura 32 presenta la distribución de entropías para los coeficientes de las señales
presentes en la Figura 27, incluyendo un nivel más de descomposición. Como se
esperaba, al aumentar el nivel de descomposición, el valor de la entropía disminuye,

62
siendo para el nivel 3 evidentemente inferior al valor que tienen los coeficientes de
aproximación y detalle en el nivel 1.
Figura 32. Entropías para los tres primeros niveles del fonema /ta/.
Al final de este proceso, se obtuvo un vector de características con una longitud de
12 valores, 6 entropías para los coeficientes de aproximación y 6 entropías para los
coeficientes de detalle, como se aprecia en la Figura 33.
Figura 33. Calculo de las Entropías de Shannon para cada fonema y nivel.
En esta figura, se aprecia que la forma de los datos concatenados es similar para los
coeficientes de aproximación, especialmente para los primeros dos niveles de
descomposición. No obstante, el valor de las entropías es diferente para cada uno de
los fonemas a identificar (/ta/, /te/, /ti/, /to/ y /tu/). La señal de color verde, y
cuyos valores de entropías son mayores a los demás fonemas vocálicos, pertenecen
a la señal de habla sub-vocal asociada con la pronunciación del fonema /to/, lo cual
indicia que la información contenida en su registro, no es relevante.
El siguiente parámetro estadístico es la media aritmética de los coeficientes, permite
obtener información de la distribución de las frecuencias de la señal en cada sub-
banda o nivel de descomposición como se aprecia en la Figura 34. En este caso los

63
patrones no tuvieron un comportamiento homogéneo, sino que su distribución
coincide con la agrupación lingüística entre de vocablos abiertos y cerrados. Los
fonemas /ta/, /te/ y /to/ se agruparon en la zona inferior de la gráfica, y los fonemas
/ti/ y /tu/ en la parte superior.
Figura 34. Cálculo de la media aritmética para los coeficientes de detalle y aproximación.
El último parámetro estadístico tenido en cuenta para condensar la información de
los coeficientes de aproximación y detalle, es la desviación estándar, que proporciona
información sobre cambio en la distribución de frecuencias en cada nivel. Con este
parámetro, lo que se pretende es encontrar un indiciador de la variación de los
coeficientes de acuerdo al nivel de descomposición, en otras palabras, conocer de
manera indirecta el comportamiento de los componentes frecuenciales a medida que
la señal va siendo analizada. La Figura 35, condensa en una gráfica el comportamiento
de la desviación estándar de los coeficientes para cada nivel.
Figura 35. Cálculo de la desviación estándar de los coeficientes de detalle y aproximación.

64
Para los resultados obtenidos de los métodos del promedio aritmético y la desviación
estándar, se puede concluir que la distribución de las frecuencias, cumplen con las
características fonológicas de los fonemas. La agrupación de los fonemas que
contienen vocales abiertas y semi-abiertas presentan una distribución frecuencial
cercana. En el mismo sentido, se observa la agrupación y distribución frecuencial, de
los fonemas cuya composición silábica está dada por las vocales cerradas (ti y tu).
4.2.3. Codificación predictiva lineal (LPC)
El análisis predictivo lineal, es una de las técnicas ampliamente utilizadas en el
procesamiento de señales de voz, convirtiéndose en un método popular para la
estimación de parámetros en la producción de voz, y por lo tanto resulta factible su
aplicación en señales de habla sub-vocal (L. R. Rabiner & Schafer, 2011). Además,
esta técnica permite representar almacenar y transmitir los datos de señales de habla
sub-vocal utilizando una menor tasa de bits, al reducir la dimensión de los mismos,
haciendo posible el desarrollo de sistemas de reconocimiento de habla automático
eficiente a nivel computacional. El cálculo de los coeficientes predictivos lineales se
realizó en tres etapas diferentes, como se explica a continuación:
4.2.3.1. Filtrado
La primera etapa para la formulación de los coeficientes predictivos lineales consiste
en filtrar la señal, para remover el silencio presente, y realzar algunas características a
través del pre-énfasis (Loweimi, Ahadi, Drugman, & Loveymi, 2013). La eliminación
de silencio se realiza retirando las muestras con un nivel de energía inferior al
promedio de la señal, utilizando un umbral para no retirar información con
características relevantes. Por otro lado, el pre-énfasis tiene la función de incrementar
la magnitud de las frecuencias más altas de la señal mediante un filtro pasa altos de
primer orden, igual al de la ecuación (7).
Este procedimiento realza las frecuencias altas, haciéndolas detectables y
normalizando la señal en términos de amplitud, con lo cual se mejora la extracción
de los coeficientes predictivos lineales, así como su posterior clasificación e
identificación.
4.2.3.2. Segmentación y ventaneo
La segmentación, consiste en dividir una señal en fragmentos iguales, utilizando un
intervalo de tiempo fijo y un corrimiento temporal constante. Para este caso, el
segmento fue de 40 ms, con un corrimiento de 10 ms hasta completar el total de la
señal. Cada segmento fue procesado con la función de ventana Hamming, para evitar
distorsiones al inicio y final de cada segmento. En la Figura 36, se presenta un ejemplo
gráfico de la operación de segmentación y ventaneo.

65
Figura 36. Ventano de una señal.
4.2.3.3. Análisis de autocorrelación
De las distintas formulaciones que existen para encontrar los coeficientes predictivos
lineales, fue escogido el método por autocorrelación, debido a que es una forma
conveniente de representar características temporales de la señal, asociadas con la
periodicidad, además, resulta computacionalmente sencilla de calcular (Bansal, Dev,
& Jain, 2010). En la expresión de la ecuación (24), se presenta de forma general la
definición para la autocorrelación de una señal.
∅[𝑘] = ∑𝜃𝑘 𝑌[𝑛 − 𝑘]
𝑝
𝑘=1
( 24 )
Para realizar el análisis predictivo lineal, se tomó como referencia el modelo discreto
del tracto vocal en la producción de audio, que describe su funcionamiento como un
filtro digital variante en el tiempo representado por la función de transferencia de la
ecuación (25) (Schafer & Rabiner, 1975).
𝑌[z]
𝑈[z]=
𝐴
1 − ∑ 𝜃𝑘 𝑧−𝑘𝑝
𝑘=1
( 25 )
En la ecuación (25), 𝑌[𝑧] hace referencia a la señal de voz, 𝑈[z], es la excitación de
los órganos que componen el aparato fonador y 𝜃𝑘 son los polos del filtro digital,
que reflejan el comportamiento del espectro compuesto por las distintas frecuencias
que se encuentran en tracto vocal. Es importante destacar, que el modelo de la
ecuación (25) es un modelo simplificado, que solamente comprende sonidos no
nasales, como los de habla sub-vocal. De la ecuación (25), se obtiene ecuación en
diferencias de la expresión (26) para representan el comportamiento del sonido
obtenido en función de la excitación 𝑈[𝑛].
𝑌[n] = ∑𝜃𝑘 𝑌[𝑛 − 𝑘]
𝑝
𝑘=1
+ A ∙ 𝑈[n] ( 26 )

66
Teniendo presente, que A solamente existe en los instantes que hay excitación de los
órganos productores de sonido, es posible obviar su aporte en los instantes que hay
entre cada excitación, reescribiendo la expresión como se muestra en (27).
𝑌[n] = ∑𝜃𝑘 𝑌[𝑛 − 𝑘]
𝑝
𝑘=1
( 27 )
La metodología LPC, busca encontrar un predictor lineal que se ajuste al
comportamiento de la señal descrita en (27), aproximando el valor de los coeficientes
𝜑𝑘 . En la ecuación (28) se muestra la forma general que tiene el predictor lineal,
donde �̂�[n] es la señal predicha.
�̂�[n] = ∑𝛼𝑘 �̂�[n − k]
𝑝
𝑘=1
( 28 )
Para conseguir un ajuste apropiado, se debe minimizar el error de predicción, dado
por la expresión de la ecuación (29). Sí no es tenido en cuenta el aporte realizado cada
vez que la excitación se produce en el tracto vocal, el error puede acercarse bastante
a cero, en caso contrario, el ajuste del predictor será únicamente aproximado.
𝐸 =∑[𝑌[n] − �̂�[n]]2
𝑁
𝑛=1
( 29 )
El error varía en función de los coeficientes de predicción 𝛼𝑘 , por lo tanto, se deben
encontrar los valores de 𝛼𝑘 , tales que el error de la ecuación (29) tienda a cero. Lo
anterior resulta ser una derivada del error en función de la variación de los
coeficientes 𝛼𝑘 , como se muestra en la ecuación (30).
𝜕𝐸
𝜕𝛼𝑘 = 0, para 𝑘 = 1,2,3, … . . p ( 30 )
Resolviendo la derivada, se obtiene una solución similar a la función de
autocorrelación mostrada en la ecuación (31), pero multiplicada por los coeficientes
predictivos lineales.
𝜕𝐸
𝜕𝛼𝑘 = 𝛼𝑘 ∑𝑌[n]𝑌[n + k]
𝑁−1
𝑛=0
= 𝛼𝑘 𝑅[k] ( 31 )
Utilizando los términos de autocorrelación, el problema de encontrar los coeficientes
se reduce a solucionar el sistema de ecuaciones lineales mostrado en (32) y (33).
[ 𝑅(0) 𝑅(1) … 𝑅(𝑝 − 2) 𝑅(𝑝 − 1)𝑅(1) 𝑅(0) ⋮ ⋮ 𝑅(𝑝 − 2)
⋮ 𝑅(1) ⋮ ⋮ ⋮𝑅(𝑝 − 2) ⋮ ⋮ 𝑅(0) 𝑅(1)
𝑅(𝑝 − 2) 𝑅(𝑝 − 2) … 𝑅(1) 𝑅(0) ]
[ 𝛼1𝛼2⋮⋮𝛼𝑝]
=
[ 𝑟(1)𝑟(2)⋮⋮
𝑟(𝑝)]
( 32 )
𝛼 = 𝑅−1𝑟 ( 33 )

67
Como se aprecia en la expresión número (32), la matriz que contienen los coeficientes
de auto correlación 𝑅 es simétrica, por lo tanto, encontrar su inversa y coeficientes
predictivos lineales, se vuelve una tarea iterativa y computacionalmente eficiente. En
la Figura 37, se muestra la estimación del espectro para la pronunciación del fonema
vocálico /te/.
Figura 37. Estimación del espectro para la pronunciación del fonema /te/.
La metodología LPC fue utilizada para obtener la reconstrucción o ajuste del espectro
de frecuencias para cada muestra, utilizando un predictor lineal de 7 coeficientes. La
Figura 38, muestra los espectros suavizados para la pronunciación de los fonemas
vocálicos que acompañan la consonante /t/.
Figura 38. Reconstrucción de los espectros para distintos fonemas vocálicos.
Para este método de clasificación, los resultados presentan que se realizó la
predicción que arrojo un patrón que distingue a cada uno de los fonemas. Las señales
originales utilizan 1024 puntos para su representación, utilizando la predicción, los
patrones se obtienen con 128 puntos. De igual manera, las características lingüísticas
se agrupan de acuerdo al vocablo de la estructura silábica, es decir abierto o cerrado.
Se distingue además que la información relevante del habla sub-vocal está alrededor

68
de los 2000Hz. El algoritmo aplicado para desarrollar este método de extracción de
características se muestra en la Figura 39.
Figura 39. Algoritmo para el cálculo de los coeficientes predictivos lineales
4.3. Coeficientes Cepstrales en Frecuencia Mel (MFCC)
La metodología utilizada para obtener los coeficientes cepstrales, involucra la
transformada de Fourier para encontrar el periodograma de la señal. Por lo tanto, en
la primera parte de esta sección se describen las etapas correspondientes a la
adquisición, pre-énfasis, segmentación y cálculo del espectro de magnitud de señales
de habla sub-vocal utilizando la transformada rápida de Fourier. Estas etapas son
embebidas en una tarjeta de desarrollo, a fin de construir un sistema portable para el
procesamiento de habla sub-vocal. El diagrama de la Figura 40, muestra la
representación gráfica del sistema de procesamiento hasta el cálculo de la FFT.
Figura 40. Partes del sistema de procesamiento.

69
Después de ubicar el micrófono NAM en la apófisis mastoides para la adquisición de
las señales, se continúa con el acondicionamiento de esta señal, en este caso, a través
de una etapa de amplificación por medio de un transistor, el cual entrega la señal
acondicionada para ser tratada digitalmente en la tarjeta de desarrollo.
El sistema embebido al cual ingresa la señal acondicionada, es la tarjeta
STM32F4Discovery de la marca STMicroelectronics®, la cual es trabajada a una
frecuencia de reloj de 8 MHz, junto con las librerías HAL (Hardware Abstraction Layer)
de ST®, y la CMSIS de ARM®.
Los principales módulos del microcontrolador involucrados para el desarrollo que se
plantea en este documento, son: El módulo ADC (Analog to Digital Converter), DAC
(Digital to Analog Converter), y el de comunicación UART (Universal Asynchronous Receiver
Transmitter).
La digitalización de la señal de habla sub-vocal, se realiza utilizando el módulo ADC
del microcontrolador, el cual es configurado a una resolución de 12 bits y a un tiempo
de muestreo aproximado de 125 µs. La señal de voz escogida para su procesamiento,
en este caso corresponde a la de la pronunciación del fonema /te/, cuya duración
neta aproximada es de 600 ms.
Los 600 ms de la señal, corresponden a 4800 muestras de acuerdo al tiempo de
muestreo alcanzado por el MCU, sin embargo, definir un arreglo de entrada limitado
exactamente a esta cantidad de muestras, representaría problemas a la hora de
capturar la señal sin que existan corrimientos en la adquisición. Es por esto que se
define un vector de entrada de 4000 muestras, que corresponde a 600 ms para la
adquisición de la señal NAM, con lo cual se mitiga esta condición. La Figura 41,
muestra la señal NAM de la pronunciación del fonema /te/.
Figura 41. Representación de la señal NAM del fonema /te/.

70
4.3.1. Pre-énfasis:
El pre-énfasis para esta metodología, se realiza con el filtro pasa alto de primer orden,
presentado en la ecuación 5. Las N muestras de información de la señal, fueron
almacenados en la memoria de programa, como elementos de un arreglo de N datos
de tipo float32_t. A este vector de datos fue aplicado el filtro de primer orden para
el pre-énfasis de la señal, tal y como se muestra en el diagrama de bloques de la Figura
42. El nuevo vector 𝑠𝑓[𝑛], representa la señal 𝑠[𝑛] al aplicarle el filtro pasa altos, sin
embargo, su notación en términos de 𝑖, se realiza para representar el proceso iterativo
en el algoritmo.
Figura 42. Diagrama de flujo de proceso de pre-énfasis embebido en la tarjeta.
Hay N
muestras?
Conversión análoga-digital
Almacenar en el vector s[n]
No
sf[i]=s[i]-0,97s[i-1]
i=i+1
i==N?
Siguiente etapa

71
4.3.2. Ventaneo de la señal:
Las señales de habla sub-vocal, hacen parte del grupo de formas de onda del tipo no
estacionarias, en pocas palabras, esto quiere decir que su frecuencia varía en el
tiempo, y por ende sus características estadísticas no son constantes. Esto representa
problemas a la hora de realizar análisis clásicos de la señal (i.e. Fourier, o análisis
temporales), sin embargo existe la ventaja de que estas variaciones de la frecuencia
en relación al tiempo, son bastante lentas, debido a las propiedades del sistema del
tracto vocal (L. R. Rabiner & Schafer, 2011).
De acuerdo a esto, si se realiza la segmentación de una señal, en ventanas de tiempo
lo suficientemente cortas como para considerarse estacionarias, y lo suficientemente
largas como para encontrar características importantes en la señal, es posible
continuar con el tratamiento clásico de señales, sin inconvenientes debidos a la no-
estacionariedad de estas formas de onda (Jurafsky & Martin, 2009).
Se deben tener en cuenta varios parámetros al momento de realizar el ventaneo de la
señal a través de los frames resultantes. El primero de ellos, es el ancho de la ventana
(𝑓𝑤), que para este caso es de 40 ms y corresponde a la duración total del frame, el
desplazamiento (𝑓𝑠) es de 10 ms, y marca el tiempo muerto que existe entre el inicio
de uno de los frames, con el siguiente, y por último, se define la forma de la ventana.
Al igual que en la implementación de la codificación predictiva lineal, se utiliza una
forma de ventana del tipo Hamming, dado que evita discontinuidades al momento
del cálculo de la transformada de Fourier de los segmentos de la señal, al limitar los
valores frontera de la ventana de la señal a cero. El ancho de la ventana se escogió de
40 ms, ya que se encuentra dentro del rango recomendado para esta clase de
aplicaciones [20 40] ms y además, porque de acuerdo al tiempo de muestreo, este
ancho de ventana corresponde a 320 datos de la señal filtrada 𝑠𝑓[𝑛]. Por último, el
desplazamiento entre las muestras se tomó de 10 ms, a razón de los criterios de
recomendación que se resumen en (Huang et al., 2001).
Para embeber el proceso de segmentación en la tarjeta, se definió un arreglo
bidimensional como matriz contenedora de los datos a guardar. Este arreglo fue
definido en relación al número de ventanas obtenidas en la señal 𝑠𝑓[𝑛].
4.3.3. Cálculo de la FFT
El proceso de segmentación de la señal, permitió dividir en ventanas de igual
duración el vector de datos que representa la señal NAM en tiempo discreto. Esto
permite realizar tareas de procesamiento específico, como la de la extracción de
características a partir de la representación en frecuencia de la señal. Así, se hace
necesario realizar el cálculo de la transformada de Fourier para hallar las
componentes en frecuencia que caracterizan a las formas de onda analizadas.

72
Orientándose en la implementación de un algoritmo para esta tarea, utilizando la
tarjeta de desarrollo, se utilizó la librería DSP de CMSIS, para calcular la FFT de los
segmentos de la señal digitalizada. Para calcular correctamente esta información, se
realizó la estimación de la magnitud de la transformada de Fourier para una secuencia
real, como la de los segmentos resultantes en el ventaneo. El diagrama de la Figura
43, muestra el procedimiento seguido para esta tarea.
Figura 43. Cálculo de FFT.
Como se puede observar en la Figura 43, después de realizar el cálculo de la FFT, se
visualizan los datos en un osciloscopio como método de verificación del
procesamiento realizado. Esto es logrado a partir del módulo DAC del sistema
embebido, el cual es configurado para esta tarea.
La metodología propuesta resumida en la Figura 40, fue aplicada con éxito a la señal
de habla sub-vocal del fonema /te/, que se muestra en la Figura 41. De esta forma,
y como resultado final, fue posible obtener el espectro de magnitud de cada uno de
los segmentos de la señal.
La Figura 41, muestra la representación en el dominio temporal de la señal analizada.
En esta captura tomada del osciloscopio, se puede ver claramente que el contenido
de información relevante en la señal, inicia aproximadamente a los 70 ms, por lo que
los segmentos de fuera de este umbral de tiempo fueron descartados. A partir de esto,
el primer segmento de señal inicia en el dato número 896 del vector de adquisición
(equivalente a 70 ms). Y el último segmento, se ubica a los 390 ms del inicio de la
señal. Con estos datos, es posible hallar el número de segmentos por analizar en los
360 𝑚𝑠 de duración neta de la señal de habla sub-vocal, a partir de la ecuación 38.
Final del vector?
Cálculo FFT
Conversión Digital - Análoga
No
Return
Osciloscopio

73
𝑁𝑓 =𝑁𝑠 −𝑤𝑓
𝑠𝑓+ 1 ( 37 )
Donde 𝑁𝑓 es el número de segmentos contenidos en la señal, 𝑁𝑠 corresponde al
número de muestras de la señal, el valor de 𝑤𝑓 equivale al ancho de la ventana en
número de muestras y 𝑠𝑓 al valor de corrimiento en número de muestras. Con
propósitos de explicación, solo se tendrán en cuenta las 4 primeras ventanas de la
señal, cuyos espectros se muestran a continuación.
La Figura 44, muestra el espectro de magnitud de la primera ventana, y que
corresponde a un ancho de segmento igual a 40 ms (320 muestras). Se puede notar
claramente en el espectro que, debido a los efectos de normalización, aplicados a
través de la etapa de pre-énfasis, los picos de amplitud presentes en las frecuencias
altas de la señal, son dominantes con respecto a los valores en las bajas frecuencias,
sin embargo, hay un valor dominante que se presenta aproximadamente a los 3200
Hz en la señal, valor importante que puede ser utilizado para caracterizar la señal en
etapas siguientes.
Figura 44. Espectro de magnitud para la primera ventana de la señal.
Para el caso de la segunda ventana en la Figura 45, en su espectro de magnitud se
puede ver una variación con respecto al espectro anterior, en donde se aprecia una
componente en baja frecuencia, cuyo valor es importante por la magnitud que posee,
esta componente de baja frecuencia, se ubica en aproximadamente 400 Hz, y como
se puede observar en las siguientes figuras, se mantiene. Esto se debe a que la
definición de este segmento de ventana, al utilizar la FFT, se encuentra ubicado en
un intervalo de la señal, donde hay mayor información sobre las características de
frecuencia.

74
Figura 45. Espectro de magnitud para la segunda ventana de la señal.
Para la tercera ventana, el espectro de la Figura 46 condensa mejores resultados con
respecto a las frecuencias altas de la señal, aunque manteniendo el valor de baja
frecuencia en 400 Hz, como se mencionó anteriormente. El pico prominente en alta
frecuencia, se ubica al igual que para las primeras dos ventanas en una frecuencia de
aproximadamente 3200 Hz, convirtiéndose este valor en un elemento dominante en
la representación en frecuencia de la señal.
Figura 46. Espectro de magnitud para la tercera ventana de la señal.
Mientras que el número de ventanas va aumentando, también lo hace el intervalo en
el que se encuentra definida, y por ende se encuentra mayor información que define
el comportamiento de la señal en frecuencia. Este comportamiento se puede notar

75
claramente en la Figura 47, donde la ventana definida en el mantiene una frecuencia
baja con una alta cantidad de energía en el valor de 400 Hz, y además componentes
de alta frecuencia en diferentes puntos; en 3200 Hz, 3400 Hz y 3800 Hz
aproximadamente.
Figura 47. Espectro de magnitud para la cuarta ventana de la señal.
Una vez realizada la transformada rápida de Fourier, el cálculo de los coeficientes
cepstrales en las frecuencias de Mel, es un proceso que se compone de 4 pasos como
se ilustra en la Figura 7. Debido a que la implementación de la transformada rápida
de Fourier, incluye los procesos de preénfasis y ventaneo, el siguiente paso para
estimar los MFCC, es el cálculo del periodograma. Este proceso es aplicado al
segmento de la señal adquirido en la etapa anterior, y de esta forma es posible obtener
una estimación de la energía presente en las frecuencias que definen la señal en
cuestión. Esta tarea, también fue embebida en el MCU haciendo uso de la librería
DSP de CMSIS, la cual es diseñada para los dispositivos ARM®, como el que se
utiliza en este caso. La ecuación (4) y (9), muestran la estimación del periodograma
de la señal segmentada 𝑥𝑖[𝑛].
4.3.4. Banco de filtros de Mel y logaritmo:
El siguiente paso de estimación de los coeficientes de Mel, es el filtrado del espectro
de potencia, a partir de una serie de funciones triangulares denominadas filtros de
Mel. Los filtros de Mel, son funciones definidas dentro de pequeños intervalos
definidos en vectores de igual longitud al de la mitad de los datos de salida del
periodograma de la señal, en este caso, este valor corresponde a 256. La Figura 48,
corresponde a 26 filtros de Mel superpuestos.

76
Figura 48. Banco de filtros de Mel.
A partir de la longitud de los datos, es posible realizar la definición de las funciones
que representan los filtros de Mel, para esto, se realiza primero una conversión al
espacio de frecuencias de Mel, de las frecuencias específicas que definen los picos
máximos de las funciones triangulares. Para esto, se utiliza la ecuación (10).
Los valores en términos de frecuencias de Mel, son calculados a partir del ancho de
banda que se desea trabajar, para este caso, el rango se define desde 0 hasta la
frecuencia máxima detectable por el sistema, es decir 4000 Hz. Estos valores de
frecuencia máximo y mínimo son convertidos a través de 41, y después son definidos
los frequency bins de cada uno de los filtros, espaciando linealmente los rangos de
frecuencia y definiendo en total 26 filtros, de los cuales son utilizados solo 13 para
abarcar el ancho de banda de la señal de habla sub-vocal. La función por partes que
se define en la ecuación (38), muestra el proceso de cálculo de los rangos de
frecuencia para los 26 vectores que integran el banco de filtros de Mel.
𝐻𝑚(𝑘) =
{
0𝑘 − 𝑓(𝑚 − 1)
𝑓(𝑚) − 𝑓(𝑚 − 1)
𝑓(𝑚 + 1) − 𝑘
𝑓(𝑚 + 1) − 𝑓(𝑚)
0
𝑘 < 𝑓(𝑚 − 1)
𝑓(𝑚 − 1) ≤ 𝑘 ≤ 𝑓(𝑚)
𝑓(𝑚) ≤ 𝑘 ≤ 𝑓(𝑚 + 1)
𝑘 > 𝑓(𝑚 + 1)
( 38 )
Donde,𝐻𝑚(𝑘), es la matriz contenedora de los filtros de Mel, 𝑚 hace referencia al
filtro que se calcula en determinado instante, y 𝑓 es el vector que contiene los
frequency bins en términos de las frecuencias de Mel, y 𝑘 es el índice del vector que
está siendo calculado. Este proceso da como resultado, un arreglo de dimensiones
13x256 datos de tipo float32_t, que para este caso y teniendo en cuenta su carácter
estático, fueron almacenados en la memoria ROM del MCU, para disminuir el uso
de memoria de programa.
Después cada filtro definido en la matriz 𝐻𝑚(𝑘), es multiplicado término a término
con el periodograma del segmento de señal que se está procesando en ese instante,

77
de esta forma se obtienen nuevos vectores que contienen la estimación de la energía,
en los rangos de frecuencia definidos por los filtros. Por último, los valores
contenidos en cada uno de los 13 vectores, son sumados entre sí para obtener los
coeficientes de energía que finalmente son guardados como valores de un arreglo de
13 posiciones. Como último paso, es aplicado la operación de logaritmo, para realizar
el mapeo en términos cepstrales de la energía que definen los coeficientes.
4.3.5. Transformada discreta de Coseno
El último paso para estimar los MFCC de la ventana de la señal, es la aplicación de la
DCT como método de de-correlación de las energías estimadas a través del
periodograma. Para este caso, se aplicó la DCT tipo II, de forma ortogonal, para
normalizar y realizar la de-correlación que se presenta gracias al traslapamiento
debido a la aplicación del banco de filtros en la señal. La ecuación (39), define la DCT
embebida en el MCU.
𝑀𝐹𝐶𝐶𝑘 = √2
𝑁∑ 𝐸𝑛 cos [
𝑘𝜋
𝑁(𝑛 +
1
2)] ,
𝑁−1
𝑛=0
𝑘 = 0, … , 𝑁 − 1.
( 39 )
Donde 𝑀𝐹𝐶𝐶𝑘 es el coeficiente calculado en la iteración, 𝐸, es la estimación de la
energía en términos de cepstrum calculada anteriormente, y 𝑁 es el número de datos
del arreglo contenedor de los coeficientes, que para este caso es de 13. Los
coeficientes de Mel, para cada ventana, por último, son almacenados en un arreglo
bidimensional para su posterior análisis. Cada uno de los procesos que se explicaron
anteriormente, fueron embebidos en la tarjeta de desarrollo STM32F4Discovery. Así
mismo, las características de implementación de los algoritmos, fueron las que se
tuvieron en cuenta en el análisis metodológico. Como forma de análisis de este
trabajo, se realizó una comparación de los resultados obtenidos al calcular los MFCC.
Dicha comparación, fue realizada entre los coeficientes de salida del sistema
embebido, y el mismo algoritmo de estimación de los coeficientes de Mel,
implementado en Matlab ®.
Como aspecto a tener en cuenta, primero se debe notar que este desarrollo depende
en gran medida del proceso de filtrado en términos de las frecuencias de Mel. El
banco de filtros de Mel, como se explicó anteriormente, se trata de una serie de
vectores cuyos valores en su mayoría son 0 pero que, en ciertos intervalos, dichas
magnitudes aumentan su valor hasta llegar a la unidad para después volver a 0,
formando así un filtro triangular, el cual, al multiplicarse término a término con la

78
ventana de trabajo, se estima el rango de energías presente en el intervalo específico
definido por el filtro.
El número de filtros que se definen para esta tarea, depende en gran medida del
criterio que se tenga presente para el desarrollo de la aplicación que se desee realizar.
En este caso, el número de filtros diseñado, fue de 26, de los cuales solo fueron
tenidos en cuenta 13, lo cual, en términos de frecuencia, permiten encontrar
información relevante en una señal dentro del intervalo [0 1000] Hz
aproximadamente. A partir de estas restricciones, se maneja entonces un rango de
frecuencias limitado con el cual trabajar. Las Tabla 5 y Tabla 6, condensan los
coeficientes cepstrales en frecuencias de Mel, para las señales que ingresan al
algoritmo embebido y Matlab® respectivamente.
Tabla 5. Coeficientes en el sistema embebido.
Índice del coeficiente
Muestra 1 2 3 4 5 6 7 8 9 10 11 12
#1 -0,47 -0,57 -0,39 0,11 -0,10 -0,21 -0,33 -0,15 -0,18 0,14 0,04 0,00
#2 -0,44 -0,61 -0,38 0,09 -0,04 -0,20 -0,36 -0,22 -0,15 0,20 0,03 -0,01
#3 -0,39 -0,62 -0,35 0,06 -0,08 -0,19 -0,34 -0,20 -0,13 0,18 0,04 0,01
#4 -0,34 -0,69 -0,26 0,00 -0,02 -0,22 -0,27 -0,24 -0,12 0,22 0,02 0,05
#5 -0,38 -0,63 -0,26 0,01 -0,06 -0,22 -0,27 -0,25 -0,15 0,24 0,02 0,03
Tabla 6. Coeficientes calculados en Matlab
Índice del coeficiente
Muestra 1 2 3 4 5 6 7 8 9 10 11 12
#1 -0,23 -0,83 -0,31 -0,04 -0,07 -0,33 -0,15 -0,42 0,07 0,23 -0,05 0,10
#2 -0,19 -0,78 -0,29 -0,01 -0,06 -0,36 -0,13 -0,38 0,08 0,20 -0,03 0,12
#3 -0,17 -0,78 -0,30 0,03 -0,07 -0,33 -0,18 -0,34 0,10 0,17 -0,04 0,14
#4 -0,15 -0,86 -0,24 0,01 -0,08 -0,23 -0,21 -0,32 0,09 0,14 -0,03 0,09
#5 -0,15 -0,86 -0,17 -0,02 -0,06 -0,23 -0,13 -0,34 0,06 0,14 -0,02 0,09
Cada una de las tablas, lista los coeficientes de Mel para las señales de habla subvocal.
La Figura 49 y Figura 50 muestran gráficamente los coeficientes. Estas magnitudes,
se han superpuesto para evidenciar la variación presente en cada una, y se identifican
a partir de los símbolos de cruz (+).

79
Como se puede notar, existe una correlación marcada entre los coeficientes para cada
ventana, en donde se demarca un patrón determinado para cada señal, en cada
algoritmo. Estos patrones, si se observa con detenimiento, a su vez presentan una
relación en cuanto a la forma en que varían los coeficientes entre sí. A pesar de que
las magnitudes obtenidas no son las mismas, al graficarlos, se observa claramente que
la variación entre los MFCC es proporcional para los dos algoritmos. A excepción
del coeficiente 7 representado en la Figura 50, el patrón seguido por las magnitudes
de los MFCC se mantiene en los dos casos.
Dado que se pretende hacer una comparación en términos de resultados obtenidos
entre el algoritmo embebido en la tarjeta de desarrollo, y el realizado en Matlab, es
necesario tener en cuenta que para los dos casos no se contó con la misma señal para
realizar el procesamiento. El algoritmo de Matlab, es una señal sinusoidal generada
en un estudio profesional de audio, y la señal de entrada al sistema embebido proviene
de un generador de señales. Esto evidencia que a pesar de que, para el sistema
embebido, haya presencia de ruido, el algoritmo es capaz de caracterizar
correctamente la señal de entrada.
La Figura 49, muestra los coeficientes de Mel estimados por el algoritmo embebido,
en esta figura, se observa que el valor más alto corresponde al coeficiente 9 de las
ventanas de tiempo, esto corresponde a los valores de frecuencia de la señal junto
con la definición del banco de filtros de Mel, en donde la energía representada a
través del cálculo de la transformada discreta de coseno, entrega el valor más alto en
donde el filtro triangular definido para la frecuencia de 1 kHz se encuentra definido.
Figura 49. Gráfica de los coeficientes embebidos.
Los coeficientes obtenidos con el algoritmo de Matlab, mostrados de la Figura 50,
muestran un patrón similar que presentan los coeficientes embebidos mostrados en

80
la figura anterior. Sin embargo, los valores de magnitud para las frecuencias por
debajo de 1kHz (Índice 4 y 6). Este comportamiento no se encuentra en algoritmo
embebido, y puede ocurrir debido al uso de funciones predefinidas en Matlab. A
pesar del comportamiento de los componentes de bajas frecuencias, el
comportamiento de los patrones es constante, y responde adecuadamente ante el
ingreso de nuevas señales. Lo anterior también aplica para el sistema embebido.
Figura 50. Coeficientes calculados en Matlab
Al terminar el desarrollo del algoritmo, se procesaron las muestras almacenadas
obteniendo para cada una, un conjunto de coeficientes cepstrales, como se ilustra en
la Figura 51. En esta figura, es evidente el cambio existente en el comportamiento de
los patrones, a pesar de que algunas señales tengan comportamientos similares en
algunos coeficientes, como son los casos de las señales /te/ y /ti/.
Figura 51. MFCCs para diferentes fonemas vocálicos.

81
Para este método, solo se puede observar que se generan patrones para cada uno de los fonemas. Debido a que los coeficientes están en la escala Mel, no se distinguen sus características lingüísticas. La Figura 52 resume el algoritmo desarrollado para la extracción de los coeficientes cepstrales en frecuencia Mel.
Figura 52. Algoritmo para la extracción de coeficientes cepstrales en frecuencia Mel.
Finalizados todos los procesos de extracción de características, se pueden concluir que en general, cada uno de los métodos, entrega un patrón para cada uno de los fonemas y que sus características lingüísticas se cumplen, de acuerdo a su estructura silábica. En el siguiente aparte, se describe los entrenamientos de los algoritmos de inteligencia artificial desarrollados para la obtención de los patrones de los cinco fonemas.
4.4. Algoritmo de Inteligencia Artificial
Al finalizar cada método de extracción de características se aplicó un algoritmo de
inteligencia artificial. La Figura 53, muestra el algoritmo desarrollado en cada uno de
los métodos para la obtención de los patrones de cada uno de los fonemas.

82
Figura 53. Algoritmo desarrollado para la red neuronal.
Para esta investigación, se diseñó y desarrolló una red neuronal perceptrón multicapa,
entrenada por retro propagación. Cálculo de error por entropía cruzada, debido al
tipo de etiquetas (1,0) en las clases y la actualización de los pesos se realizó a través
del algoritmo de direcciones conjugadas. La Figura 54 , ilustra la estructura general
de la red neuronal implementada.
Figura 54. Estructura general de la red neuronal.
El algoritmo de entrenamiento fue backpropagation, cuya implementación tiene ciertas
variantes cuando la tarea que debe realizar la red está asociada con el reconocimiento
de patrones. En la ecuación (34) se encuentra la función de actualización de pesos a
través de la regla delta, con una dirección de búsqueda αi, y un ajuste de gradiente
Ai.
xi+1 = xi + αiAi ( 34 )
A diferencia de la actualización de pesos para una red de ajuste o predicción, en el
reconocimiento de patrones se suele utilizar el descenso de gradiente conjugado
(Hager & Zhang, 2006), que básicamente desplaza el error en dos direcciones, la
primera desplaza el error hasta alcanzar un mínimo global, luego se calcula la segunda
dirección o dirección conjugada, que no varía en dirección, únicamente en magnitud,

83
facilitando la consecución de un mínimo global. En las ecuaciones (34) y (35), se
encuentra las expresiones de la primera dirección, y la dirección conjugada
respectivamente, donde J(w), es el gradiente del error en función de los pesos de la
red.
Ai = −J(w)i + Bi ∙ Ai−1 ( 35 )
Bi =J(w)i
𝑇 ∙ J(w)i
J(w)i−1𝑇 ∙ J(w)i−1
( 36 )
El valor de la ecuación (36), es la tasa entre la norma cuadrática del gradiente actual
y el gradiente pasado, realizando la actualización de los pesos relacionados con la
segunda dirección de descenso. Otro elemento que presenta una variación al
momento de realizar el entrenamiento de la red neuronal es el cálculo de error que,
en lugar de utilizar el error cuadrático medio, se emplea el error calculado por
entropía cruzada, como se presentan en la ecuación (40). (Saric & Xiao, 2011). Donde
𝑦𝑛, es la salida deseada y �̂�𝑛 es la salida obtenida.
𝐸𝑟𝑟𝑜𝑟 = −1
𝑁∑[𝑦𝑛log [�̂�𝑛] + (1 − 𝑦𝑛)log (1 − �̂�𝑛)]
𝑁
𝑛=1
( 40 )
El entrenamiento en su totalidad fue realizado antes de ingresar la estructura de la
red en el sistema embebido. El proceso de embeber la red fue dividido en dos etapas,
de las cuales la primera tuvo en consideración los valores de entrada, pesos y bias de
la capa oculta, así como la función de activación tangente sigmoide como se muestra
en la Figura 55.
Figura 55. Diagrama de bloques para la capa oculta.
Para programar el proceso mostrado en la Figura 55 en el sistema embebido se
utilizaron las matrices, vectores y operaciones presentadas en la ecuación (41).
[𝐻𝐿𝑜1⋮
𝐻𝐿𝑜𝑚
] = 𝐴𝐹𝐻𝐿 ([
𝑊ℎ𝑙1,1 ⋯ 𝑊ℎ𝑙1,𝑛⋮ ⋱ ⋮
𝑊ℎ𝑙𝑚,1 ⋯ 𝑊ℎ𝑙𝑚,𝑛
] [𝐼1⋮𝐼𝑛
] + [𝐵ℎ𝑙1⋮
𝐵ℎ𝑙𝑚
]) ( 41 )
Donde,
𝐼= Entrada de la red neuronal
𝑊ℎ𝑙= Pesos de la capa oculta
𝐵ℎ𝑙= Bias de la capa oculta

84
𝐻𝐿𝑜 = Salida de la capa oculta
𝐴𝐹𝐻𝐿=Función de activación para la capa oculta, específicamente la función tangente sigmoide (Namin, Leboeuf, Muscedere, Wu, & Ahmadi, 2009), cuya expresión se muestra en la ecuación (12). La segunda parte involucra los valores provenientes de la capa oculta para realizar la implementación de la capa de salida como se muestra en la Figura 56.
Figura 56. Diagrama de bloques para la capa de salida.
En este diagrama se tienen en cuenta los valores de los pesos y bias calculados para
el funcionamiento de la capa de salida, así como la programación de la función
exponencial normalizada (Tuske, Tahir, Schluter, & Ney, 2015) para finalizar la tarea
de clasificación. La expresión mostrada en la ecuación (43), resume las operaciones
necesarias para que la red neuronal funcione de manera adecuada en el sistema
embebido.
[𝑁𝑁𝑜1⋮
𝑁𝑁𝑜𝑚
] = 𝐴𝐹𝑂𝐿 ([
𝑊𝑜𝑙1,1 ⋯ 𝑊𝑜𝑙1,𝑛⋮ ⋱ ⋮
𝑊𝑜𝑙𝑚,1 ⋯ 𝑊𝑜𝑙𝑚,𝑛
] [𝐻𝐿𝑜1⋮
𝐻𝐿𝑜𝑛
] + [𝐵𝑜𝑙1⋮
𝐵𝑜𝑙𝑚
]) ( 43 )
Donde,
𝑊𝑜𝑙= Pesos de la capa de salida
𝐵𝑜𝑙= Bias de la capa de salida
𝑁𝑁𝑜= Salida y respuesta de la red neuronal.
𝐴𝐹𝑂𝐿=Función de activación de la capa oculta, conocida como exponencial
normalizada y se expresa en la ecuación (13).
A continuación, se describe el desarrollo del clasificador para cada método.
4.4.1. Clasificador para Descomposición por paquetes de Wavelet
Para clasificar la información de las entropías, se utilizó una red neuronal con
perceptrón multicapa, debido a que los patrones no son linealmente separables, con
37 neuronas en la capa oculta, cuyo proceso de entrenamiento puede verse en la
Figura 57.

85
Figura 57. Proceso de entrenamiento de la red las características de entropía.
En el caso de las entropías, el entrenamiento no se detuvo por épocas, valor de error
o entropía cruzada, el criterio de detención fue la validación del descenso del
gradiente. En este caso el entrenamiento se detiene cuando el gradiente presenta un
comportamiento estático por más de 7 épocas, como se aprecia en la Figura 57.
Después de 85 épocas el error permaneció estático en 0.053673. La red fue
almacenada para su comparación con las otras, y así determinar que valores
estadísticos describen mejor el comportamiento de los patrones a reconocer.
Debido a la naturaleza de los patrones obtenidos con el promedio aritmético, se
necesitaron más neuronas y épocas para separar las clases. En este caso, el algoritmo
clasificador necesitó 47 neuronas y 213 épocas para detener el entrenamiento del
algoritmo, como se muestra en la Figura 58. La diferencia con el anterior es evidente,
y aunque se trate de un cálculo estadístico de los mismos coeficientes, los resultados
cambian drásticamente. Aunque el valor de error es inferior al clasificador anterior,
no necesariamente es un indiciador confiable del desempeño de la red ante nuevos
patrones, debido a que puede tratarse de un sobre aprendizaje en la red, con lo cual
se ve limitada su capacidad de generalización, y por lo tanto, en su tarea de
clasificación para nuevos patrones no utilizados para el aprendizaje.
Figura 58. Proceso de entrenamiento de la red con los datos de la media aritmética.
Por último, para los valores relacionados con la desviación estándar, la estructura de
la red necesitó de 68 neuronas en la capa oculta y 188 épocas para llegar a un valor

86
de error lo suficientemente bajo para detener el algoritmo de aprendizaje. Aunque el
error alcanzado fue de 6.571𝑒−7 unidades, el verdadero desempeño se mide con los
patrones no tenidos en cuenta al momento de entrenar la red. El proceso de
entrenamiento de esta red para el último parámetro calculado a partir de la
descomposición wavelet se presenta en la Figura 59.
Figura 59. Proceso de entrenamiento de la red con la desviación estándar de los coeficientes.
4.4.2. Clasificador para Codificación Predictiva Lineal
Para la clasificación y reconocimiento de patrones obtenidos con el algoritmo LPC,
también se utilizó una red neuronal multicapa entrenada con el 60% de las muestras,
con el fin de realizar pruebas sobre el algoritmo con el 20% restante.
Para realizar la clasificación de las características extraídas con la metodología LPC,
se utilizó una red neuronal con 25 neuronas en la capa oculta, y fueron necesarias 70
épocas como lo ilustra la gráfica de la Figura 60.
Figura 60.Entrenamiento de la red neuronal para los espectros ajustados con LPC.
4.4.3. Clasificador para Coeficientes Ceptrales en Frecuecias Mel
Para desarrollar el algoritmo de reconocimiento en el sistema embebido, se llevaron
a cabo los procesos mostrados en el esquema de la Figura 61. En este diagrama se

87
incluyen las etapas de adquisición de señales y el procesamiento de las mismas, la
implementación de las técnicas de extracción de características, y por último el
entrenamiento, evaluación y embebido de la red.
Figura 61. Diagrama de la metodología propuesta.
Siguiendo la metodología expuesta en la Figura 61, los MFFCs calculados
anteriormente se utilizaron como material de entrenamiento y validación de una red
neuronal. De acuerdo a los datos presentados en la Figura 62, se escogió el valor de
32 neuronas para realizar la implementación en el sistema embebido, lo anterior
obedece a que el comportamiento de la red no mejoró significativamente para valores
de neuronas superiores al escogido. En la Figura 62, se muestra el comportamiento
del error de entrenamiento al aumentar la cantidad de neuronas en la capa oculta.
Figura 62. Error de la red en función de la cantidad de neuronas en la capa oculta.

88
De acuerdo a los datos presentados en la Figura 62, se escogió el valor de 32 neuronas
para realizar la implementación en el sistema embebido, lo anterior obedece a que el
comportamiento de la red no mejoró significativamente para valores de neuronas
superiores al escogido. En la Figura 63, se puede observar el proceso de
entrenamiento de la red neuronal, el cual necesitó 237 épocas para alcanzar un valor
lo suficientemente bajo para detener el aprendizaje. El código desarrollado para la
validación en el sistema embebido se presenta en el anexo 2.
Figura 63. Comportamiento de la red neuronal durante el entrenamiento.
La Tabla 7 resume el proceso de clasificación aplicado a la identificación de
patrones de habla sub-vocal.
Tabla 7. Resumen de la red neuronal aplicada en cada método de extracción de características.
Método de Extracción
Datos de la red neuronal
No. de datos del
vector de entrada
No. de
neuronas
capa oculta
Iteraciones o
épocas
Wavelet
Entropía 12 37 85
Promedio 12 47 213
Desviación Estándar 12 48 188
Codificación
Predictiva Lineal
128 35 70
Coeficientes Cepstrales de las
Frecuencias de Mel 104 32 237

89
5. ANÁLISIS DE RESULTADOS Y APORTES
El apartado de resultados, se encuentra enfocado a los valores obtenidos del
algoritmo de clasificación y reconocimiento de patrones. Primero se realizó la
evaluación de los algoritmos entrenados con la transformada Wavelet, y los tres
parámetros estadísticos hallados, Entropía, Promedio y Desviación Estándar. En la
Tabla 8 se condensan los resultados de evaluar los datos adquiridos para las etapas
de extracción de características.
Tabla 8. Porcentaje de patrones identificados erróneamente.
Observación Fonema vocálico
/ta/ /te/ /ti/ /to/ /tu/
# Muestras mal clasificadas 68 53 63 93 85
Porcentaje 11,333% 8,833% 10,500% 15,500% 14,167%
Los valores porcentuales para las todas las tablas presentes se encuentran sobre una
base de 600 muestras. La tasa promedio de reconocimiento fallido para la red
entrenada con los datos relacionados al cálculo de las entropías para los coeficientes
de aproximación y detalle, fue de 12.067%. Esto indica que, para las 600 muestras de
prueba, el algoritmo no fue capaz de reconocer adecuadamente alrededor de 72
muestras. De igual manera, el algoritmo fue validado con nuevas muestras en
condiciones diferentes a las presentadas en el momento de la adquisición, los
resultados de estas nuevas 5 muestras para cada fonema se encuentran en la Tabla 9
Tabla 9. Respuesta de la red neuronal entrenada con los datos de entropía.
# Muestra Fonema
Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
1
0,7517 1,81E-09 2,58E-17 1,36E-10 0,0002 /ta/
6,40E-06 0,9967 1,49E-07 0,3087 0,0266 /te/
2,05E-10 2,77E-11 0,9962 3,49E-06 0,1311 /ti/
0,2483 9,02E-06 1,96E-08 0,6798 0,0260 /to/
2,06E-06 3,56E-11 0,0038 0,0115 0,8161 /tu/
2
0,9966 5,90E-06 3,12E-18 1,72E-06 0,0003 /ta/
2,24E-10 0,9985 0,0040 2,03E-06 0,0349 /te/
1,37E-19 8,29E-08 0,9960 0,0028 0,0002 /ti/
0,0034 2,98E-06 1,68E-15 0,8023 0,4324 /to/
5,32E-10 3,17E-07 5,56E-10 0,1949 0,5322 /tu/
3
0,9998 6,01E-05 1,29E-09 0,0433 0,0015 /ta/
2,82E-09 0,7951 3,52E-05 0,0136 1,17E-05 /te/
2,59E-19 4,42E-07 0,9905 1,90E-06 3,66E-07 /ti/
0,0002 0,1466 0,0005 0,7775 0,9805 /to/
2,97E-11 0,0583 0,0090 0,1656 0,0180 /tu/
4
0,4473 0,0445 1,81E-10 0,0006 6,83E-07 /ta/
2,51E-07 0,8546 0,0008 0,7234 5,15E-08 /te/
8,20E-12 0,0312 0,9992 0,0018 1,44E-05 /ti/

90
# Muestra Fonema
Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
0,5490 0,0403 1,58E-08 0,0515 0,4081 /to/
0,0037 0,0293 1,88E-06 0,2227 0,5918 /tu/
5
0,8989 1,56E-07 2,63E-17 0,4708 0,0002 /ta/
0,0173 0,9900 0,1624 0,0003 0,0021 /te/
2,04E-07 0,0012 0,8376 1,14E-06 3,17E-05 /ti/
0,0817 0,0003 2,20E-10 0,4218 0,2145 /to/
0,0021 0,0085 1,01E-06 0,1072 0,7832 /tu/
Los resultados mostrados, revelan la confusión existente en el reconocimiento de los
fonemas /ta/ y /to/, que obedece en gran medida a la cercanía de las frecuencias, y
que ambos fonemas están acompañados de una vocal cuya pronunciación es abierta.
El siguiente parámetro estadístico, es el promedio aritmético de los coeficientes por
cada nivel. Los resultados de la evaluación de las 600 muestras se muestran en la
Tabla 10, donde el porcentaje de muestras calcificadas incorrectamente aumento
hasta un 20.433 %, evidenciando que este parámetro estadístico no es un valor
adecuado para realizar el reconocimiento. La mayoría de muestras mal clasificadas
fueron para el fonema /to/.
Tabla 10. Porcentaje de patrones identificados erróneamente.
Observación Fonema vocálico /ta/ /te/ /ti/ /to/ /tu/
# Muestras Mal clasificadas 75 155 83 195 105
Porcentaje 12,500% 25,833% 13,833% 32,500% 17,500%
La mala clasificación de las muestras provenientes de la pronunciación del fonema
/to/, tuvo un impacto negativo en el reconocimiento de las nuevas muestras, como
se ve en la Tabla 11.
Tabla 11. Respuesta de la red neuronal entrenada con los datos de la media aritmética.
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
1
0,9544 0,9997 5,65E-50 1,84E-14 4,87E-39 /ta/
3,3273E-23 3,E-15 8,09E-13 6,98E-18 5,45E-22 /te/
1,5927E-37 1,41E-26 0,9991 0,0335 0,0103 /ti/
4,5567E-06 2,15E-32 5,45E-36 9,11E-12 4,42E-29 /to/
2,2188E-16 3,56E-30 0,0009 0,9665 0,9833 /tu/
2
0,9928 7,81E-17 1,26E-22 4,02E-07 4,70E-25 /ta/
1,54E-17 0,9920 1,66E-08 5,56E-13 5,57E-23 /te/
1,41E-27 6,74E-07 0,9978 3,54E-22 2,98E-12 /ti/
5,77E-07 5,63E-08 5,20E-13 0,9598 5,66E-17 /to/
2,81E-16 0,0080 0,0002 2,67E-17 0,99702 /tu/
3
2,81E-14 2,30E-19 3,35E-49 8,69E-08 0,0122 /ta/
0,2345 0,9875 9,28E-12 5,03E-13 4,96E-15 /te/
9,51E-28 0,0007 0,9273 7,06E-09 3,34E-15 /ti/

91
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
0,7648 1,51E-08 4,42E-29 0,9906 0,9999 /to/
3,55E-11 0,0119 0,0727 3,71E-10 8,61E-16 /tu/
4
0,9890 0,9997 9,46E-27 1,04E-18 4,44E-13 /ta/
1,46E-27 3,35E-15 0,9949 0,7794 4,23E-24 /te/
1,25E-36 1,41E-26 0,0003 1,00E-12 6,35E-21 /ti/
1,10E-06 2,15E-32 1,49E-16 0,0016 0,29073396 /to/
9,43E-16 3,56E-30 1,17E-08 0,2190 0,70926604 /tu/
5
0,9025 3,70E-07 4,88E-29 1,72E-24 1,27E-02 /ta/
1,93E-24 0,99469 1,05E-07 5,19E-15 1,08E-18 /te/
1,17E-20 4,12E-06 0,99584 1,01E-04 0,9080 /ti/
9,75E-07 1,28E-10 3,04E-17 5,42E-07 3,87E-07 /to/
4,15E-12 1,93E-11 6,43E-07 0,9995 0,0793 /tu/
Aunque la columna que contiene los resultados para el fonema /to/, presento 3
resultados incorrectos de 5, el desempeño en general de la red neuronal entrenada
con éstos patrones no fue satisfactorio, comparado con los datos de la Tabla 9. De
manera similar a los resultados anteriores, los patrones obtenidos con la desviación
estándar de los coeficientes mostraron un desempeño deficiente, en este caso las
muestras mal clasificadas tuvieron un promedio de 21.833%, y de nuevo, los patrones
del fonema /to/ fueron los que más error presentaron, aumentando de 195 a 215
muestras mal clasificadas, como se aprecia en la Tabla 12.
Tabla 12. Porcentaje de patrones identificados erróneamente.
Observación Fonema vocálico /ta/ /te/ /ti/ /to/ /tu/
# Muestras Mal clasificadas 84 162 81 215 113
Porcentaje 14,000% 27,000% 13,500% 35,833% 18,833%
Para este caso, el desempeño fue peor para las nuevas muestras. Todos los fonemas
fallaron en al menos una muestra, con un margen de error más elevado, comparando
la Tabla 13 con la Tabla 11, no solo hubo mayor cantidad de muestras identificadas
erróneamente, los errores para cada intento de clasificación fueron mayores, como
lo es el caso de la tercera muestra del fonema /ta/, y en su mayoría para el fonema
/to/.
Tabla 13. Respuesta de la red neuronal entrenada con los datos de desviación estándar.
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
1
0,9954 0,9887 6,E-53 2,25E-33 0,0127 /ta/
3,33E-23 0,0113 7,87E-16 4,75E-16 1,08E-18 /te/
1,59E-37 2,41E-16 0,9608 2,58E-18 0,9080 /ti/

92
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
5,E-06 9,83E-10 1,09E-41 1,08E-05 3,87E-07 /to/
2,22E-16 6,69E-13 0,0392 0,9594 0,07934517 /tu/
2
0,9903 2,28E-21 5,65E-50 1,84E-14 4,12E-18 /ta/
1,93E-24 0,9962 8,E-13 6,98E-18 1,93E-16 /te/
1,17E-20 5,63E-07 0,9991 0,0335 1,12E-06 /ti/
8,72,E-07 8,23E-10 5,45E-36 9,11E-12 6,45E-11 /to/
4,15E-12 3,82E-10 0,0009 0,9268 1,0000 /tu/
3
3,E-14 1,88E-12 8,74E-10 1,72E-24 4,87E-39 /ta/
1,50E-19 1,58E-05 2,71E-25 5,19E-15 5,45E-22 /te/
9,51E-28 0,9682 0,9921 0,0101 0,0103 /ti/
1,0000 3,94E-18 1,31E-34 5,00E-07 4,42E-29 /to/
3,55E-11 6,11E-08 3,52E-12 0,9182 0,9897 /tu/
4
0,9666 2,66E-31 1,89E-33 8,69E-08 0,0022 /ta/
1,55E-25 0,9977 0,9711 5,03E-13 4,96E-15 /te/
1,54E-36 1,71E-14 3,33E-07 7,06E-09 3,34E-15 /ti/
3,E-11 9,40E-11 4,12E-11 0,9957 0,9999 /to/
7,E-17 5,25E-12 0,0289 3,71E-10 8,61E-16 /tu/
5
0,9928 2,00E-46 3,35E-49 1,04E-18 3,21E-21 /ta/
3,E-38 1,69E-07 9,28E-12 0,7794 6,27E-41 /te/
8,53E-33 0,9307 0,9273 1,00E-12 4,70E-14 /ti/
9,E-21 3,64E-26 4,42E-29 0,0016 0,99951 /to/
7,E-13 1,30E-10 0,07269887 0,2190 2,27E-15 /tu/
Con la tabla anterior, se termina la evaluación de parámetros estadísticos para la
descomposición por paquetes Wavelet. Las siguientes tablas contienen los datos de
entrenar redes neuronales con los otros métodos de extracción de características
mencionados. En la Tabla 14 están los resultados de evaluar las 600 muestras,
utilizando la red que fue entrenada con los patrones obtenidos al implementa la
codificación predictiva lineal. Para este caso, el porcentaje de muestras mal
clasificadas fue de 10.833%, el cual resulta ser inferior a los resultados obtenidos con
los métodos previos.
Tabla 14. Porcentaje de patrones identificados erróneamente.
Observación Fonema vocálico /ta/ /te/ /ti/ /to/ /tu/
# Muestras Mal clasificadas 49 48 52 93 83
Porcentaje 8,167% 8,000% 8,667% 15,500% 13,833%
Aunque el desempeño general fue mejor, no significa que todas las nuevas muestras
serán reconocidas adecuadamente, como se demuestra con los datos consignados en
la Tabla 15. El hecho de obtener una mejor clasificación general, con respecto a los
métodos anteriores, no es garantía del correcto reconocimiento para las nuevas

93
muestras. Por ejemplo, dos de las nuevas muestras para los fonemas /ti/, /to/ y
/tu/, arrojaron identificaciones erróneas al evaluar el algoritmo de clasificación.
Tabla 15. Respuesta de la red neuronal entrenada con los datos LPC
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
1
0,98674636 4,634E-05 1,0398E-14 1,36E-07 1,39E-12 /ta/
1,43E-10 0,9890 2,2915E-06 1,22E-11 3,27E-07 /te/
2,38E-16 6,337E-09 0,9977 0,6421 1,10E-06 /ti/
1,44E-09 6,761E-11 2,3699E-09 0,3575 2,02E-07 /to/
1,31E-07 1,506E-05 1,0317E-09 0,0004 0,9688 /tu/
2
0,99803728 0,0073 8,1087E-11 1,37E-06 2,35E-08 /ta/
3,77E-10 8,886E-07 0,0181 7,44E-13 2,65E-11 /te/
2,39E-07 0,9992 0,9819 4,88E-10 2,22E-06 /ti/
0,0020 0,0010 1,0909E-07 1,0000 3,37E-08 /to/
1,33E-07 1,527E-09 6,2471E-10 1,29E-06 0,9968 /tu/
3
0,08754429 3,047E-08 4,4036E-09 0,1013 0,9609 /ta/
0,25267195 0,9995 0,9948 3,76E-09 2,30E-08 /te/
1,14E-06 3,252E-06 0,0010 2,91E-07 1,36E-06 /ti/
0,65978262 1,150E-07 0,0043 0,7645 4,51E-06 /to/
3,89E-10 0,0005 6,0547E-07 0,1342 2,03E-05 /tu/
4
0,995948 0,0006 1,1161E-12 0,0013 6,12E-07 /ta/
7,88E-10 0,9994 0,0022 1,63E-07 1,09E-13 /te/
2,76E-15 8,895E-15 0,0511 0,0043 7,92E-05 /ti/
1,04E-08 2,092E-11 0,9487 0,9944 1,01E-07 /to/
1,51E-10 1,010E-12 0,0066 1,86E-08 0,9386 /tu/
5
0,995651 3,538E-10 2,3021E-10 1,11E-10 1,21E-11 /ta/
1,45E-11 0,9987 1,3055E-09 5,46E-10 2,31E-13 /te/
1,40E-15 2,031E-11 0,9933 0,9994 2,19E-07 /ti/
3,64E-09 1,773E-09 0,0007 0,0006 0,7891 /to/
1,39E-09 6,891E-07 0,0059 4,84E-07 0,2109 /tu/
La última metodología para extracción de características evaluada fueron los
coeficientes cepstrales de las frecuencias de Mel. Éste último método presento los
mejores resultados, tanto en la clasificación de las 600 muestras para la validación del
entrenamiento del algoritmo de clasificación, como para nuevas muestras capturadas
en condiciones diferentes. En la Tabla 16 se resumen los datos para la clasificación
de los datos de validación, alcanzado un error promedio igual a 9.96%.
Tabla 16. Porcentaje de patrones identificados erróneamente.
Observación Fonema vocálico /ta/ /te/ /ti/ /to/ /tu/
# Muestras mal clasificadas 41 46 55 82 75
Porcentaje 6,833% 7,667% 9,167% 13,667% 12,500%

94
En este caso, no solo disminuyó el error general, sino que el algoritmo mostro
mejores resultados ante nuevas muestras como se ve en la Tabla 17. A diferencia de
los métodos anteriores, las muestras de lo fonemas /ta/ y /ti/ fueron identificadas
correctamente en su totalidad, los demás fonemas solo presentaron errores en una
de las muestras, y con valores de error en la identificación bajos si se comparan con
los datos mostrados previamente
Tabla 17. Respuesta de la red neuronal entrenada con los datos MFCCs
# Muestra
Fonema vocálico Clase o Grupo /ta/ /te/ /ti/ /to/ /tu/
1
0,7721 4,28E-10 8,84E-15 5,37E-07 1,46E-11 /ta/
0,2356 0,93118 4,83E-07 7,46E-10 4,64E-12 /te/
7,8967E-15 3,98E-07 0,9909 9,06E-10 2,53E-07 /ti/
1,2258E-06 1,79E-07 2,54E-07 0,9428 3,39E-07 /to/
1,7455E-09 1,02E-12 1,88E-07 3,33E-08 0,9079 /tu/
2
0,8947 1,56E-10 2,46E-15 2,27E-06 1,28E-06 /ta/
0,1254 0,58160 1,03E-06 4,33E-06 6,05E-12 /te/
4,20E-14 4,29E-01 0,9758 4,44E-11 2,71E-07 /ti/
1,76E-06 9,55E-08 1,51E-08 0,9997 7,83E-11 /to/
9,84E-09 2,23E-09 9,55E-07 3,85E-10 0,9534 /tu/
3
0,9907 1,39E-10 0,3354 2,08E-06 1,63E-11 /ta/
5,12E-08 0,99762 8,97E-07 1,33E-07 2,07E-12 /te/
2,00E-14 2,82E-07 0,7755 5,48E-13 4,54E-07 /ti/
1,32E-06 3,78E-08 7,82E-09 0,9976 1,40E-06 /to/
2,20E-09 2,23E-09 1,80E-07 1,68E-07 0,9936 /tu/
4
0,9955 1,19E-12 6,27E-14 2,27E-06 5,68E-12 /ta/
1,86E-08 0,99902 1,85E-06 4,33E-06 1,22E-12 /te/
7,89E-15 2,61E-06 0,9974 0,5432 3,20E-07 /ti/
1,19E-06 8,92E-07 2,36E-06 0,4671 1,63E-07 /to/
1,69E-09 3,05E-11 1,45E-08 3,85E-10 0,9971 /tu/
5
0,5291 1,78E-06 2,34E-10 9,04E-07 6,61E-12 /ta/
0,4801 0,99954 1,02E-06 1,66E-07 1,60E-12 /te/
8,77E-15 1,70E-06 0,9905 1,50E-12 0,7236 /ti/
1,15E-06 1,96E-09 4,05E-11 0,9106 1,42E-07 /to/
2,59E-09 1,50E-13 7,94E-09 2,20E-07 0,2865 /tu/
El comportamiento del algoritmo de reconocimiento, con lo patrones obtenidos al
utilizar MFCC fue el factor determinante al momento de seleccionar la metodología
a implementar en el sistema embebido para su operación en tiempo real.
Los principales resultados reflejados en producción científica publicada, se
condensan en la Tabla 18

95
Tabla 18. Producción científica derivada del proyecto.
Nombre Revista/Evento/
Institución Clasificación
Scimago Clasificación
Publindex
Imagined speech of Spanish vowels through spectral analysis and support vector machine. El
anexo 3, muestra la primera hoja del artículo JIHMSP Q1 A1
Embedded MFCC feature extraction system for speech processing. El anexo 4, muestra la primera
hoja del artículo IRECOS Q2 A2
Analysis of the MFCC coefficients for voiced and silent speech. . El anexo 5, muestra la primera
hoja del artículo IRECAP Q2 A2
Embedded Wavelet Analysis of Non-Audible Signal. . El anexo 6, muestra la primera hoja del
artículo TECNURA ---------- A2
En la Figura 64 se presenta la proporción de artículos publicados en revistas
indexadas en la base científica SCIMAGO.
Figura 64. Trabajos con clasificación SCIMAGO.
En la Figura 65 se relacionan los trabajos indexados en la base de datos nacional
PUBLINDEX.
Figura 65. Trabajos indexados en Publindex.
1; 25%
2; 50%
1; 25%
SCIMAGO
Q1 Q2 NA
2; 50%2; 50%
PUBLINDEX
A1 A2

96
6. CONCLUSIONES
Esta investigación presenta una alternativa desde la ingeniería y la lingüística
a una problemática de la sociedad, como es la comunicación en ambientes
con contaminación auditiva. Además, los resultados obtenidos, son un
punto de partida y se convierten en una opción de solución de la
problemática de comunicación, en personas con dificultades en su aparato
fonador.
El habla subvocal es un proceso lingüístico, debido que sigue el as fonético,
la estructura silábica y en general el comportamiento prosódico y fonológico
de los fonemas identificados, de acuerdo con los resultados obtenidos por
los métodos utilizados en la extracción de características.
Los coeficientes cepstrales de las frecuencias de Mel, demuestran ser los
principales entes de información en el desarrollo de aplicaciones como las
planteadas en esta investigación. Los datos representativos extraídos por este
método, son relevantes para condensar los patrones variables de la señal del
habla subvocal. Esto se evidencio, al utilizar los 13 primeros coeficientes,
que resultaron suficientes para identificar los fonemas /ta/, /te/, /ti/, /to/,
y /tu/, a través de algoritmo de identificación de patrones.
Los cambios de la señal con respecto al tiempo, demuestran que los
coeficientes dinámicos, son características importantes a tener en cuenta,
dado que contienen información sobre la variación de la señal, cuando esta
es producida por el sistema característico variante en el tiempo, del tracto
vocal. La diferencia más importante en los coeficientes de Mel, se
fundamenta, en que para el habla silente, no hay vibración de las cuerdas
vocales, lo cual significa una ausencia importante de la energía en la acción
de habla, en comparación con las señales de voz.
De acuerdo a la arquitectura algorítmica utilizada, el grado de
reconocimiento obtenido en el desarrollo de esta investigación, alcanzo una
tasa de identificación de 85 %, lo que representa un avance respecto al
alcanzado por (P. Heracleous, 2003) en Japón y (L. E. Mendoza, Peña, &
Ramón Valencia, 2015) en Colombia.
Los sistemas para reconocimiento de patrones como las redes neuronales,
son algoritmos de inteligencia artificial muy eficaces en el cumplimiento de
su labor, pero computacionalmente costosos al momento de entrenarlos, sin
embargo, una vez se han calculado los parámetros adecuados para su
correcto funcionamiento, estos pueden ser almacenados para su posterior
uso sin la necesidad de ser entrenados de nuevo. Por lo anterior, el uso de
sistemas embebidos para su implementación permite elaborar aplicaciones

97
versátiles, como el prototipo de sistema de reconocimiento de habla sub-
vocal planteado a lo largo de esta investigación.

98
7. TRABAJOS FUTUROS
Realizar algoritmos para la identificación de patrones de palabras, lo cual
constituye una solución definitiva, a las problemáticas de comunicación de
personas con discapacidad en el aparato fonador, comunicación en
ambientes ruidosos, misiones especiales policiacas, comunicación
subacuática entre otros.
Utilización de nuevas técnicas de reconocimiento de patrones y algoritmos
de optimización, para mejorar el nivel de reconocimiento del algoritmo
inteligente.
Diseñar un sistema cómodo y eficiente para la captura, procesamiento y
reconocimiento de los patrones de la señal del habla subvocal, que sea lo
menos incómodo para el usuario. Esto permitirá que, al utilizarlo, lo pueda
hacer con discreción, sin el temor a juzgamientos sociales.

99
8. REFERENCIAS
Ahmadi, F., McLoughlin, I. V., & Sharifzadeh, H. R. (2010). Linear predictive analysis for ultrasonic speech. Electronics Letters, 46(6), 387–388. http://doi.org/10.1049/el.2010.3521
Anand, M., Hephzibah, S., & Anandan, S. (2014). IMPLEMENTATION OF ANALOG TO DIGITAL CONVERSION BY HOP FIELD NEURAL NETWORKS. Retrieved from http://ijrcar.com/Volume_2_Issue_9/v2i922.pdf
Angeli, S., Quesney, A., & Gross, L. (2012). Image Simplification Using Kohonen Maps: Application to Satellite Data for Cloud Detection and Land Cover Mapping. Retrieved from http://cdn.intechopen.com/pdfs-wm/38176.pdf
Ávila, R. (2007). La lengua y los hablantes (4a ed.). México.
Babani, D., Toda, T., Saruwatari, H., & Shikano, K. (2011). Acoustic model training for non-audible murmur recognition using transformed normal speech data. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 5224–5227). IEEE. http://doi.org/10.1109/ICASSP.2011.5947535
Bansal, P., Dev, A., & Jain, S. (2010). Role of different order ranges of autocorrelation sequence on the performance of speech recognition. WSEAS Transactions on Systems, 9(1), 1–9. Retrieved from http://www.wseas.us/e-library/transactions/systems/2010/32-109.pdf
Chan, Y. T. (1995). Wavelet basics. Transform, 99(2), 1–26. http://doi.org/10.1121/1.414569
Darbyshire, J. L., & Young, J. D. (2013). An investigation of sound levels on intensive care units with reference to the WHO guidelines. Critical Care (London, England), 17(5), R187. http://doi.org/10.1186/cc12870
Denby, B., Schultz, T., Honda, K., Hueber, T., Gilbert, J. M., & Brumberg, J. S. (2010). Silent speech interfaces. Speech Communication, 52(4), 270–287. http://doi.org/10.1016/j.specom.2009.08.002
Deng, J. J., & Leung, C. H. C. (2015). Dynamic Time Warping for Music Retrieval Using Time Series Modeling of Musical Emotions. IEEE Transactions on Affective Computing, 6(2), 137–151. http://doi.org/10.1109/TAFFC.2015.2404352
Duda, R., Hart, P., & Stork, D. (2012). Pattern classification. John Wiley & Sons.
Ettaouil, M., Lazaar, M., & En-Naimani, Z. (2013). A hybrid ANN/HMM models for arabic speech recognition using optimal codebook. In 2013 8th International

100
Conference on Intelligent Systems: Theories and Applications, SITA 2013 (pp. 1–5). IEEE. http://doi.org/10.1109/SITA.2013.6560806
Gärdenfors, P., & Warglien, M. (2013). The development of semantic space for pointing and verbal communication. … Evidence from Human Communication, 29–42. http://doi.org/10.1093/acprof:oso/9780199641635.003.0003
Gil Fernández, J. (2007). Fonética para profesores de español: de la teoría a la práctica. Arco Libros.
Gleason, J. B., & Ratner, N. B. (2010). El desarrollo del lenguaje. Prentice Hall Pearson
Educacio ́n.
Hager, W. W., & Zhang, H. (2006). A New Conjugate Gradient Method with Guaranteed Descent and an Efficient Line Search. http://dx.doi.org/10.1137/030601880, 16(1), 170–192. http://doi.org/http://dx.doi.org/10.1137/030601880
Hasegawa, T., & Ohtani, K. (1992). Oral image to voice converter-image input microphone. [Proceedings] Singapore ICCS/ISITA `92, 617–620. http://doi.org/10.1109/ICCS.1992.255190
Hassan, Z., Mohamad, A. R., Kalil, M. R., & Murah, M. Z. (2011). Evaluation of Microsoft speech recognition in controlling robot soccer. In Proceedings of the 2011 International Conference on Pattern Analysis and Intelligent Robotics, ICPAIR 2011 (Vol. 1, pp. 114–118). IEEE. http://doi.org/10.1109/ICPAIR.2011.5976922
Heracleous, P., Nakajima, Y., Lee, a., Saruwatari, H., & Shikano, K. (2003). Accurate hidden Markov models for non-audible murmur (NAM) recognition based on iterative supervised adaptation. 2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No.03EX721), 5–8. http://doi.org/10.1109/ASRU.2003.1318406
Heracleous, P., Nakajima, Y., Saruwatari, H., & Shikano, K. (2005). A tissue-conductive acoustic sensor applied in speech recognition for privacy. In Joint Conference on Smart Objects and Ambient Intelligence: Innovative Context-Aware Services: Usages And Technologies (pp. 93–97). http://doi.org/10.1145/1107548.1107577
Heracleous, P., Tran, V. A., Nagai, T., & Shikano, K. (2010). Analysis and recognition of NAM speech using HMM distances and visual information. IEEE Transactions on Audio, Speech and Language Processing, 18(6), 1528–1538. http://doi.org/10.1109/TASL.2009.2037398
Hidalgo, F. K., & Ramírez, J. C. R. (2009). Aplicación de las técnicas de muestreo en los negocios y la industria. Ingeniería Industrial, (27), 11–40.
Hidalgo Navarro, A., & Quilis Merín, M. (2012). La voz del lenguaje: fonética y fonología

101
del español. Tirant Humanidades.
Hirahara, T., Otani, M., Shimizu, S., Toda, T., Nakamura, K., Nakajima, Y., & Shikano, K. (2010). Silent-speech enhancement using body-conducted vocal-tract resonance signals. Speech Communication, 52(4), 301–313. http://doi.org/10.1016/j.specom.2009.12.001
Hossan, M. A., Memon, S., & Gregory, M. A. (2010). A novel approach for MFCC feature extraction. In 2010 4th International Conference on Signal Processing and Communication Systems (pp. 1–5). IEEE. http://doi.org/10.1109/ICSPCS.2010.5709752
Huang, X., Acero, A., Hon, H.-W., & Reddy, R. (2001). Spoken Language Processing: A Guide to Theory, Algorithm, and System Development. Prentice Hall PTR.
Hueber, T., Benaroya, E.-L., Chollet, G., Denby, B., Dreyfus, G., & Stone, M. (2010). Development of a silent speech interface driven by ultrasound and optical images of the tongue and lips. Speech Communication, 52(4), 288–300. http://doi.org/10.1016/j.specom.2009.11.004
Ishii, S., Toda, T., Saruwatari, H., Sakti, S., & Nakamura, S. (2011). Blind noise suppression for Non-Audible Murmur recognition with stereo signal processing. In 2011 IEEE Workshop on Automatic Speech Recognition and Understanding, ASRU 2011, Proceedings (pp. 494–499). IEEE. http://doi.org/10.1109/ASRU.2011.6163981
Iza Alcívar, W. F., & Fabricio, W. (2016). Desarrollo de un sistema informático que permita automatizar una metodología y de un modelo matemático para evaluar y calificar el riesgo del sector financiero público.
Jorgensen, C., & Dusan, S. (2010). Speech interfaces based upon surface electromyography. Speech Communication, 52(4), 354–366. http://doi.org/10.1016/j.specom.2009.11.003
Jurafsky, D., & Martin, J. H. (2009). Speech and language processing : An introduction to natural language processing, computational linguistics, and speech recognition (2nd ed.). Prentice Hall.
Kalgaonkar, K., Hu, R., & Raj, B. (2007). Ultrasonic Doppler Sensor for Voice Activity Detection. IEEE Signal Processing Letters, 14(10), 754–757. http://doi.org/10.1109/LSP.2007.896450
Knapp, M., Hall, J., & Horgan, T. (2013). Nonverbal Communication in Human Interaction (Eighth Edi). Wadsworth.
Kruse, R., Borgelt, C., & Klawonn, F. (2013). Multi-Layer Perceptrons. Computational …. Retrieved from http://link.springer.com/chapter/10.1007/978-1-4471-5013-8_5
Lasswell, H. D. (1948). The structure and function of communication in society.

102
The Communication of Ideas, (1948), 37–52.
Levelt, W. J. M. (1999). Models of word production. Trends in Cognitive Sciences, 3(6), 223–232. http://doi.org/10.1016/S1364-6613(99)01319-4
Llisterri, J. (2010). Las aplicaciones de la fonética.
Lopez-Larraz, E., Mozos, O. M., Antelis, J. M., & Minguez, J. (2010). Syllable-based speech recognition using EMG. In 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBC’10 (pp. 4699–4702). IEEE. http://doi.org/10.1109/IEMBS.2010.5626426
Loweimi, E., Ahadi, S. M., Drugman, T., & Loveymi, S. (2013). On the Importance of Pre-emphasis and Window Shape in Phase-Based Speech Recognition. In Advances in Nonlinear Speech Processing (pp. 160–167). Springer Berlin Heidelberg. http://doi.org/10.1007/978-3-642-38847-7_21
Meiriño, R. C., Brea, J. A. F., Vila, N. A., & López, E. R. (2016). Segmentación del mercado de un destino turístico de interior. El caso de A Ribeira Sacra (Ourense). PASOS. Revista de Turismo Y Patrimonio Cultural, 14(2), 369–383.
Meltzner, G. S., Colby, G., Deng, Y., & Heaton, J. T. (2011). Signal acquisition and processing techniques for sEMG based silent speech recognition. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS (pp. 4848–4851). IEEE. http://doi.org/10.1109/IEMBS.2011.6091201
Mendoza, L. E., Peña, J., & Ramón Valencia, J. L. (2015). Electro-myographic patterns of sub-vocal Speech: Records and classification. Revista de Tecnología, 12(2). http://doi.org/10.18270/rt.v12i2.758
Mendoza, L., Peña, J., Muñoz-Bedoya, L., & Velandia-Villamizar, H. (2013). Procesamiento de Señales Provenientes del Habla Subvocal usando Wavelet Packet y Redes Neuronales. Tecno Lógicas, 655–667. Retrieved from http://bibliotecadigital.itm.edu.co/jspui/handle/123456789/304
Miyamoto, D., Nakamura, K., Toda, T., Saruwatari, H., & Shikano, K. (2009). Acoustic compensation methods for body transmitted speech conversion. In ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings (pp. 3901–3904). IEEE. http://doi.org/10.1109/ICASSP.2009.4960480
Müller, M. (2007). Dynamic time warping. Information Retrieval for Music and Motion. Retrieved from http://link.springer.com/chapter/10.1007/978-3-540-74048-3_4
Nakajima, Y., Kashioka, H., Shikano, K., & Campbell, N. (2003). Non-audible murmur recognition input interface using stethoscopic microphone attached to the skin. In 2003 IEEE International Conference on Acoustics, Speech, and Signal

103
Processing, 2003. Proceedings. (ICASSP ’03). (Vol. 5, p. V-708-11). IEEE. http://doi.org/10.1109/ICASSP.2003.1200069
Namin, A. H., Leboeuf, K., Muscedere, R., Wu, H., & Ahmadi, M. (2009). Efficient hardware implementation of the hyperbolic tangent sigmoid function. In 2009 IEEE International Symposium on Circuits and Systems (pp. 2117–2120). IEEE. http://doi.org/10.1109/ISCAS.2009.5118213
Pacheco, J., Pacheco, J., Franco, J. F., & Behrentz, E. (2009). Caracterización de los niveles de contaminación auditiva en Bogotá: Estudio piloto. Revista de Ingeniería, 0(30), 72–80. http://doi.org/10.16924/riua.v0i30.230
Patil, S. A., & Hansen, J. H. L. (2010). The physiological microphone (PMIC): A competitive alternative for speaker assessment in stress detection and speaker verification. Speech Communication, 52(4), 327–340. http://doi.org/10.1016/j.specom.2009.11.006
Quatieri, T. F., Brady, K., Messing, D., Campbell, J. P., Campbell, W. M., Brandstein, M. S., … Gatewood, P. D. (2006). Exploiting Nonacoustic Sensors for Speech Encoding. IEEE Transactions on Audio, Speech and Language Processing, 14(2), 533–544. http://doi.org/10.1109/TSA.2005.855838
Rabiner, L. R., & Schafer, R. W. (2011). Theory and Applications of Digital Speech Processing (1st ed.). Pearson.
Rabiner, L., & Schafer, R. (2011). Digital Speech Processing. Journal of Telecommunications, 6, 237.
Ramos, O., Gamma, N., & Hurtado, D. (2015). Revisión de las tecnologías y aplicaciones del habla sub-vocal. Ingeniería, 20(2). Retrieved from http://revistas.udistrital.edu.co/ojs/index.php/reving/article/view/8513
Reddy, V. R., & Rao, K. S. (2013). Two-stage intonation modeling using feedforward neural networks for syllable based text-to-speech synthesis. Computer Speech & Language, 27(5), 1105–1126. http://doi.org/10.1016/j.csl.2013.02.003
Rissel, D. A. (1981). Diferencias entre el habla femenina y la masculina en español. Thesaurus: Boletín Del Instituto Caro Y Cuervo, 36(2), 305–322.
Saby Beltrán, J. E. (2002). FONÉTICA Y FONOLOGÍA AUTOSEGAMENTAL. Seminario, Universidad del Valle, Instituto de Educación y Pedagogía.
Saric, A., & Xiao, J. (2011). Efficient Levenberg-Marquardt minimization of the cross-entropy error function. In The 2011 International Joint Conference on Neural Networks (pp. 1–8). California: IEEE. http://doi.org/10.1109/IJCNN.2011.6033191
Schafer, R. W., & Rabiner, L. R. (1975). Digital representations of speech signals. Proceedings of the IEEE, 63(4), 662–677.

104
http://doi.org/10.1109/PROC.1975.9799
Srinivasan, S., Raj, B., & Ezzat, T. (2010). Ultrasonic sensing for robust speech recognition. In ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings (pp. 5102–5105). IEEE. http://doi.org/10.1109/ICASSP.2010.5495039
Strang, G. (1992). The optimal coefficients in Daubechies wavelets. Physica D: Nonlinear Phenomena, 60(1), 239–244. http://doi.org/10.1016/0167-2789(92)90240-N
Titze, I. R. (2001). Acoustic interpretation of resonant voice. Journal of Voice, 15(4), 519–528. http://doi.org/10.1016/S0892-1997(01)00052-2
Toda, T. (2012). Statistical approaches to enhancement of body-conducted speech detected with non-audible murmur microphone. In 2012 ICME International Conference on Complex Medical Engineering, CME 2012 Proceedings (pp. 623–628). IEEE. http://doi.org/10.1109/ICCME.2012.6275604
Toda, T., Nakagiri, M., & Shikano, K. (2012). Statistical voice conversion techniques for body-conducted unvoiced speech enhancement. IEEE Transactions on Audio, Speech and Language Processing, 20(9), 2505–2517. http://doi.org/10.1109/TASL.2012.2205241
Tran, V.-A., Bailly, G., Lœvenbruck, H., & Toda, T. (2010). Improvement to a NAM-captured whisper-to-speech system. Speech Communication, 52(4), 314–326. http://doi.org/10.1016/j.specom.2009.11.005
Tran, V. A., Bailly, G., Lœvenbruck, H., & Jutten, C. (2008). Improvement to a NAM captured whisper-to-speech system. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 52, 1465–1468. http://doi.org/10.1016/j.specom.2009.11.005
Tsuruta, S., Tanaka, K., Toda, T., Neubig, G., Sakti, S., & Nakamura, S. (2014). An evaluation of target speech for a nonaudible murmur enhancement system in noisy environments. In Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific (pp. 1–4). Cambodia: IEEE. http://doi.org/10.1109/APSIPA.2014.7041618
Tuske, Z., Tahir, M. A., Schluter, R., & Ney, H. (2015). Integrating Gaussian mixtures into deep neural networks: Softmax layer with hidden variables. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4285–4289). IEEE. http://doi.org/10.1109/ICASSP.2015.7178779
Varsavsky, A., & McDermott, H. J. (2013). Application of real-time loudness models can improve speech recognition for cochlear implant users. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 21(1), 81–87. http://doi.org/10.1109/TNSRE.2012.2213841

105
Wand, M., Janke, M., & Schultz, T. (2014). Tackling Speaking Mode Varieties in EMG-Based Speech Recognition. Biomedical Engineering, IEEE …, 61(10), 2515–2526. http://doi.org/10.1109/TBME.2014.2319000
Wang, L., Liu, S., Wei, M., & Hu, X. F. (2013). Time-frequency analysis of nonlinear and non-stationary weak signals of corona discharge. Journal of Physics: Conference Series, 418, 12081. http://doi.org/10.1088/1742-6596/418/1/012081
Wang, L., Zeng, Y., & Chen, T. (2015). Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Systems with Applications, 42(2), 855–863. http://doi.org/10.1016/j.eswa.2014.08.018
Watzlawick, P., Bavelas, J., Jackson, D., & O’Hanlon, B. (2011). Pragmatics of human communication: A study of interactional patterns, pathologies and paradoxes. (W. N. & Company., Ed.). London: WW Norton & Company.
Yang, C.-Y., Brown, G., Lu, L., Yamagishi, J., & King, S. (2012). Noise-robust whispered speech recognition using a non-audible-murmur microphone with VTS compensation. In 2012 8th International Symposium on Chinese Spoken Language Processing (pp. 220–223). IEEE. http://doi.org/10.1109/ISCSLP.2012.6423522
Zhou, X., Garcia-Romero, D., Duraiswami, R., Espy-Wilson, C., & Shamma, S. (2011). Linear versus mel frequency cepstral coefficients for speaker recognition. In 2011 IEEE Workshop on Automatic Speech Recognition & Understanding (pp. 559–564). IEEE. http://doi.org/10.1109/ASRU.2011.6163888

106
ANEXO 1. Generalidades de los sistemas de captura y
micrófono utilzado para la adquisición de la señal
subvocal NAM
Generalidades del sensor
Característica Descripción
Tipo de señal Murmuro No Audible
(NAM)
Ancho de banda 300Hz-2000Hz
Material Caja de Sonoridad Ácido Poli Láctico (PLA)
Micrófono MEMS
Especificaciones del Micrófono
Característica Valor
Relación señal ruido 64 dB
Ancho de banda 100 – 15000 Hz
Voltaje de alimentación 1,5 – 3,3 V
Impedancia de salida 200 Ω

107
Especificaciones de los sistemas de adquisición
Característica Computador Sistema embebido
Amplitud de
la señal 0-2 V 0-3,3 V
Frecuencia de
muestreo 8000 Hz 8000 Hz
Resolución 16 bits 12 bits

108
ANEXO 2. Código Embebido para método MFCC
/////----------------CODIGO PARA CALCULO DE MFCC #include <stdio.h> #include <string.h> #include "stm32f4xx_hal.h" // Keil::Device:STM32Cube HAL:Common #include "cmsis_os.h" // ARM::CMSIS:RTOS:Keil RTX #include "stm32f4xx_hal_conf.h" // Keil::Device:STM32Cube #include "RTE_Components.h" // Component selection #include "RTE_Device.h" // Keil::Device:STM32Cube #include "Board_LED.h" // ::Board Support:LED #include "Board_ADC.h" #include "Board_Buttons.h" // ::Board Support:Buttons #include "stm32f4xx.h" // Device header #include "stm32f4xx_hal_adc.h" // Keil::Device:STM32Cube HAL:Common //------------------------------------------ //DSP configuration #include "arm_math.h" #include "arm_const_structs.h"/ //------------- #define VECTOR_LENGTH 1024 #define NSamples 12000 //0.11 SEGUNDOS Duración de señal (D) float32_t buffer_input[VECTOR_LENGTH]; float32_t buffer_output[VECTOR_LENGTH]; float32_t buffer_output_mag[VECTOR_LENGTH]; uint8_t FFT_8[VECTOR_LENGTH]; float32_t maxvalue; uint32_t maxvalueindex; uint8_t mode; arm_rfft_instance_f32 S; arm_cfft_radix4_instance_f32 S_CFFT; /////ADC-UART-CLOCK-CONFIG ADC_HandleTypeDef AdcHandle; ADC_ChannelConfTypeDef sConfig; GPIO_InitTypeDef GPIO_InitStruct;

109
//Definición para GPIOA GPIO_InitTypeDef GPIO_ADC; GPIO_InitTypeDef GPIO_UART; //Definición para ADC-PC0-PC1-PC2 UART_HandleTypeDef UartHandle; //Declaración de variables de trabajo unsigned int i,j,h,l,q,p,Y,windows,counter=0; float32_t CONVERSION = 0; //Variable de conversión ADC uint16_t Conv8b = 0; uint8_t ADC_Trans; //Declaración de vectores para Windowing float32_t senal[9600]; float32_t Fsenal[2048]; float32_t Hamming[512]; float32_t MFCCout [13][8]; float32_t O[1280]={-0.2017822265625, -0.271514892578125, -0.369537353515625, -0.445892333984375}; uint8_t NeuralNet [13][5]; void uart_config(){ //Configuración de puerto rs232 USART3 (TX=PB10, RX=PB11)// UartHandle.Instance = USART3; __USART3_CLK_ENABLE(); //Habilitación USART3 CLOCK __GPIOB_CLK_ENABLE(); GPIO_UART.Pin = GPIO_PIN_10|GPIO_PIN_11; //Conf-Pines de ADC GPIO_UART.Mode = GPIO_MODE_AF_PP; //Conf- pines como analogos GPIO_UART.Pull = GPIO_PULLUP; GPIO_UART.Speed = GPIO_SPEED_FAST;

110
GPIO_UART.Alternate = GPIO_AF7_USART3; HAL_GPIO_Init(GPIOB, &GPIO_UART); UartHandle.Init.BaudRate = 115200; UartHandle.Init.WordLength = UART_WORDLENGTH_8B; UartHandle.Init.StopBits = UART_STOPBITS_1; UartHandle.Init.Parity = UART_PARITY_NONE; UartHandle.Init.HwFlowCtl = UART_HWCONTROL_NONE; UartHandle.Init.Mode = UART_MODE_TX_RX; UartHandle.Init.OverSampling = UART_OVERSAMPLING_16; HAL_UART_Init(&UartHandle); } void adc_config(){ //Configuración de ADC para trabajar a una //frecuencia de muestreo = 8000 Hz //Tiempo de muestreo = 1/8000 s //Prescaler/8 //#Cycles = 144 AdcHandle.Instance = ADC1; __ADC1_CLK_ENABLE(); //Habilitación de reloj para ADC1 __GPIOC_CLK_ENABLE(); //Habilitación de reloj para puerto C GPIO_ADC.Pin = GPIO_PIN_0| GPIO_PIN_1|GPIO_PIN_2; //Conf-Pines de ADC GPIO_ADC.Mode = GPIO_MODE_ANALOG; //Conf- pines como analogos HAL_GPIO_Init(GPIOC, &GPIO_ADC); //Inicialización de pines //CONFIGIGURACIÓN DE MODULO ADC// AdcHandle.Init.ClockPrescaler = ADC_CLOCKPRESCALER_PCLK_DIV8; AdcHandle.Init.Resolution = ADC_RESOLUTION_12B; AdcHandle.Init.ScanConvMode = DISABLE; AdcHandle.Init.ContinuousConvMode = ENABLE; AdcHandle.Init.DiscontinuousConvMode = DISABLE; AdcHandle.Init.NbrOfDiscConversion = 0; AdcHandle.Init.ExternalTrigConv = ADC_EXTERNALTRIGCONV_T1_CC1; AdcHandle.Init.DataAlign = ADC_DATAALIGN_RIGHT;

111
AdcHandle.Init.NbrOfConversion = 1; AdcHandle.Init.DMAContinuousRequests = DISABLE; AdcHandle.Init.EOCSelection = DISABLE; HAL_ADC_Init(&AdcHandle); //Inicialización de Modulo ADC sConfig.Channel = ADC_CHANNEL_12; //Pin de conversion sConfig.Rank = 1; sConfig.SamplingTime = ADC_SAMPLETIME_144CYCLES; sConfig.Offset = 0; HAL_ADC_ConfigChannel(&AdcHandle, &sConfig); //PIN } int adc_convert(){ for (h = 0; h < 14; h++); //Retardo para Fs=8000 HAL_ADC_Start(&AdcHandle); //Start the conversion HAL_ADC_PollForConversion(&AdcHandle,10); //Processing the
conversion CONVERSION=HAL_ADC_GetValue(&AdcHandle); Conv8b = CONVERSION*255/4095; ADC_Trans = Conv8b&0xff; return (ADC_Trans); } ///Filter bank static float32_t H[13][256]; float32_t Frame_Flt[13][256]; float32_t FIL[13]; float32_t MFCC[13]; static uint16_t WdwL=512, ShftS=128; static uint8_t Nfilas=0; static uint8_t M=26; static uint16_t fl=0; static uint16_t fh=6400; static float32_t Mel[28]; static float32_t filter[28]; float32_t FilterBank(){ Mel[0]=2595*log(1+(fl/700)); Mel[M+2]=2595*log(1+(fh/700)); for(i=1;i<=M+1;i++){

112
Mel[i]=Mel[i-1]+(Mel[M+2]-Mel[0])/(M+1); } for(i=0;i<=M+1;i++){ Mel[i]=700*exp(Mel[i]/2595)-700; } for(i=0;i<=M+1;i++){ filter[i]=floor((256*Mel[i])/fh); } for(i=1;i<=M/2;i++){ for(h=1;h<=255;h++){ if(h<filter[i-1]){ H[i-1][h]=0*255; }else if(h >= filter[i-1] && h <= filter[i]){ H[i-1][h]=((h-filter[i-1])/(filter[i]- filter[i-1])); }else if(h >= filter[i] && h <= filter[i+1]){ H[i-1][h]=((filter[i+1]-h)/(filter[i+1]- filter[i])); }else if(h>filter[i+1]){ H[i-1][h]=0*255; } } } } int k=0; int contador=-1; ///Variables red unsigned int a,b,c,i; #define PO_LENGTH_SAMPLES (5*2) //Tamaños de las matrices iniciales //Matriz de los pesos de la capa oculta #define m0 10 #define n0 104 //Matriz de entrada #define m1 104 #define n1 1 //Matriz S0 #define m2 10 #define n2 1 //Matriz Bias Oculta #define m3 10

113
#define n3 1 //Matriz S1 #define m4 10 #define n4 1 //Matriz S2 #define m5 10 #define n5 1 //Matriz pesos de salida #define m6 3 #define n6 10 //Matriz S3 #define m7 3 #define n7 1 //Matriz Bias salida #define m8 3 #define n8 1 //Matriz S4 #define m9 3 #define n9 1 //Matriz de resultados #define m10 3 #define n10 1 //Entrada para una E float32_t Entrada [m1][n1]; float32_t PesosOcultos[m0][n0] ={ {-0.035979663,-0.073589896,-0.015968615,0.031598316,-0.078149746}; {0.023407347,0.001113942,-0.188938014,-0.060281308,-0.200052673}; {-0.034406504,-0.270509315,-0.086179234,0.139866805,-0.091542076}; {-0.077516188,-0.173514632,-0.048156738,-0.004724049,0.13243002}; {-0.193686966,-0.176483362,0.074109997,0.123956414,0.118548376}; {-0.005119343,0.031994199,-0.009919398,0.10043974,0.018296128}; {0.01049271,-0.029180476,0.021977611,-0.030006445,-0.128230217}; {-0.012884671,0.070672109,0.030084125,0.016171817,-0.121152824}; {0.000404429,-0.070698755,0.036217074,-0.051968928,-0.081230242}; {-0.011278216,-0.011128468,-0.031136563,0.044607801,0.114686665}; }; float32_t BiasOculto[m3][n3] ={ {-8.64814115822036}, {-1.61279516547541}, {-3.54082518599055}, {0.349430553960645}, {0.120035127773977},

114
{2.75674313259088}, {-2.6320891074238}, {-4.85651008883633}, {-7.81951176392393}, {3.84918703452075} }; float32_t PesosSalida[m6][n6] ={ {-0.611252205,-4.601711487,-2.560730244,1.943044124,1.911848916,-0.556677965,0.102946094,0.454311,0.212346379,0.39357485}, {-0.494581374,1.911523252,-1.590518953,-1.738760415,-3.349223396,-0.268353155,-0.316488117,0.307766765,-0.116861865,1.132665503}, {-0.494581374,1.911523252,-1.590518953,-1.738760415,-3.349223396,-0.268353155,-0.316488117,0.307766765,-0.116861865,1.132665503} }; float32_t BiasSalida[m8][n8] ={ {0.896714721512725}, {-0.166419793904853}, {0.678207948881287} }; float32_t maxvalue=0; uint32_t maxvalueindex=0; float32_t S0[m2][n2]; float32_t S1[m4][n5]; float32_t S2[m5][n5]; float32_t S3[m7][n7]; float32_t S4[m9]; float32_t Salida[m10]; float32_t SumSoft=0; int32_t main(void) { HAL_Init(); LED_Initialize(); Buttons_Initialize(); adc_config(); uart_config(); arm_rfft_init_f32(&S, &S_CFFT, 512, 0, 1); FilterBank();

115
for (i=0;i<512;i++){ Hamming[i]=0.54-0.46*cos(2*PI*i/512); } while(1){ if (Buttons_GetState() & (1 << 0)){ for (i=0;i<NSamples;i++){ adc_convert(); senal[i]=(float32_t)(ADC_Trans-128); } Fsenal[0]=senal[0]; for (i=1;i<NSamples;i++){ Fsenal[i]=senal[i]-0.97*senal[i-1]; } Nfilas=((NSamples-WdwL)/ShftS)+1; h=0; for (l=0;l<Nfilas;l++){ h=128*l; for(j=h;j<h+512;j++){ buffer_input[q]=(float32_t)Fsenal[j]; q=q+1; } q=0; for(i=0;i<512;i++){ buffer_input[i]=buffer_input[i]*Hamming[i]; } arm_rfft_f32(&S, buffer_input, buffer_output); arm_cmplx_mag_f32(buffer_output, buffer_output_mag, 512); arm_max_f32(buffer_output_mag, 512, &maxvalue, &maxvalueindex); for(i=0; i<512; ++i){

116
buffer_output_mag[i] = buffer_output_mag[i]/maxvalue; } for(i=0; i<512;++i){ buffer_output_mag[i]=(((buffer_output_mag[i])*buffer_output_mag[i])/512); } for (i=0;i<=12;i++){ FIL[i]=0; MFCC[i]=0; } for(i=0;i<=12;i++){ for(j=0;j<256;j++){ Frame_Flt[i][j]=(H[i][j])*buffer_output_mag[j]; FIL[i]=FIL[i]+Frame_Flt[i][j]; } } for (i=0;i<=12;i++){ FIL[i]=log(FIL[i]); } for(i=0;i<13;i++){ for(j=0;j<13;j++){ MFCC[i]=MFCC[i]+(float32_t)((FIL[j]*cos((PI/13)*(j+(1/2))*i))*0.392232); } } contador++; if (contador < 8){ for(j=0;j<13;j++){ MFCCout[j][contador]= (float32_t)(MFCC[j]); } }else contador=-1; counter=0; for(windows=0;windows<8;windows++){ for(i=0;i<13;i++){

117
Entrada[counter][0]=MFCCout[i][windows]; counter=counter+1; } } } //*************RED NEURONAL**************** //Multiplicacion Pesos Capa Oculta (PCO) * Entradas (E) for(a=0;a<m0;a++){ for(b=0;b<n1;b++){ for(c=0;c<n0;c++){ S0[a][b]=S0[a][b]+PesosOcultos[a][c]*Entrada[c][b]; } } } //Suma (PCO*E)+Bias Capa Oculta for(a=0;a<m2;a++){ S1[a][0]=S0[a][0]+BiasOculto[a][0]; } //Tansig Manual Salida de la Capa Oculta for (a=0;a<m5;a++){ S2[a][0]=2/(1+exp(-2*S1[a][0]))-1; } //Multiplicacion for(a=0;a<m6;a++){ for(b=0;b<n5;b++){ for(c=0;c<n6;c++){ S3[a][b]=S3[a][b]+PesosSalida[a][c]*S2[c][b]; } } } //Suma Manual for(a=0;a<m8;a++){ S4[a]=S3[a][0]+BiasSalida[a][0]; } SumSoft=0; //Softmax Manual for (a=0;a<m9;a++){ SumSoft=SumSoft+exp(S4[a]); } for (a=0;a<m10;a++){

118
Salida[a]=exp(S4[a])/SumSoft; } arm_max_f32(Salida, m10, &maxvalue, &maxvalueindex); LED_On(maxvalueindex); // Turn specified LED on for (i = 0; i < 100000; i++); LED_Off(maxvalueindex); // Turn specified LED off for (i = 0; i < 100000; i++); } }; }

119
ANEXO 3. Recognition of Spanish Vowels through Imagined
Speech by Using Spectral Analysis and SVM

120
ANEXO 4. Embedded MFCC feature extraction system for speech
processing

121
ANEXO 5. Comparative Analysis of the MFCC coefficients for
voiced and silent speech

122
ANEXO 6. Embedded Wavelet Analysis of Non-Audible Signal


















