
Apache spark - Spark's distributed programming model
27
Spark’s distributed programming model Martin Zapletal Cake Solutions Apache Spark
-
Upload
martin-zapletal -
Category
Software
-
view
1.147 -
download
1
Transcript of Apache spark - Spark's distributed programming model

Spark’s distributed programming model
Martin Zapletal Cake Solutions
Apache Spark

Apache Spark and Big Data
1) History and market overview2) Installation3) MLlib and machine learning on Spark4) Porting R code to Scala and Spark5) Concepts - Core, SQL, GraphX, Streaming6) Spark’s distributed programming model

Table of Contents
● Distributed programming introduction● Programming models● Datafow systems and DAGs● RDD● Transformations, Actions, Persistence, Shared variables

Distributed programming
● reminder○ unreliable network○ ubiquitous failures○ everything asynchronous○ consistency, ordering and synchronisation expensive○ local time○ correctness properties safety and liveness○ ...

Two armies (generals)● two armies, A (Red) and B (Blue)● separated parts A1 and A2 of A army must synchronize attack to win● consensus with unreliable communication channel● no node failures, no byzantine failures, …● designated leader

Parallel programming models● Parallel computing models
○ Different parallel computing problems ■ Easily parallelizable or communication needed
○ Shared memory■ On one machine
● Multiple CPUs/GPUs share memory■ On multiple machines
● Shared memory accessed via network● Still much slower compared to memory
■ OpenMP, Global Arrays, …○ Share nothing
■ Processes communicate by sending messages■ Send(), Receive()■ MPI
○ usually no fault tolerance

Dataflow system
● term used to describe general parallel programming approach● in traditional von Neumann architecture instructions executed sequentially by a
worker (cpu) and data do not move
● in Dataflow workers have different tasks assigned to them and form an assembly line
● program represented by connections and black box operations - directed graph● data moves between tasks● task executed by worker as soon as inputs available● inherently parallel● no shared state● closer to functional programming
● not Spark specific (Stratosphere, MapReduce, Pregel, Giraph, Storm, ...)

MapReduce
● shows that Dataflow can be expressed in terms of map and reduce operations
● simple to parallelize● but each map-reduce is separate from the rest

Directed acyclic graph● Spark is a Dataflow execution engine that supports cyclic data flows● whole DAG is formed lazily● allows global optimizations● has expresiveness of MPI● lineage tracking

Optimizations
● similar to optimizations of RDBMS (operation reordering, bushy join-order enumeration, aggregation push-down)
● however DAGs less restrictive than database queries and it is difficult to optimize UDFs (higher order functions used in Spark, Flink)
● potentially major performance improvement● partially support for incremental algorithm optimization (local
change) with sparse computational dependencies (GraphX)

Optimizations
sc .parallelize(people) .map(p => Person(p.age, p.height * 2.54)) .filter(_.age < 35)
sc .parallelize(people) .filter(_.age < 35) .map(p => Person(p.age, p.height * 2.54))
case class Person(age: Int, height: Double)
val people = (0 to 100).map(x => Person(x, x))
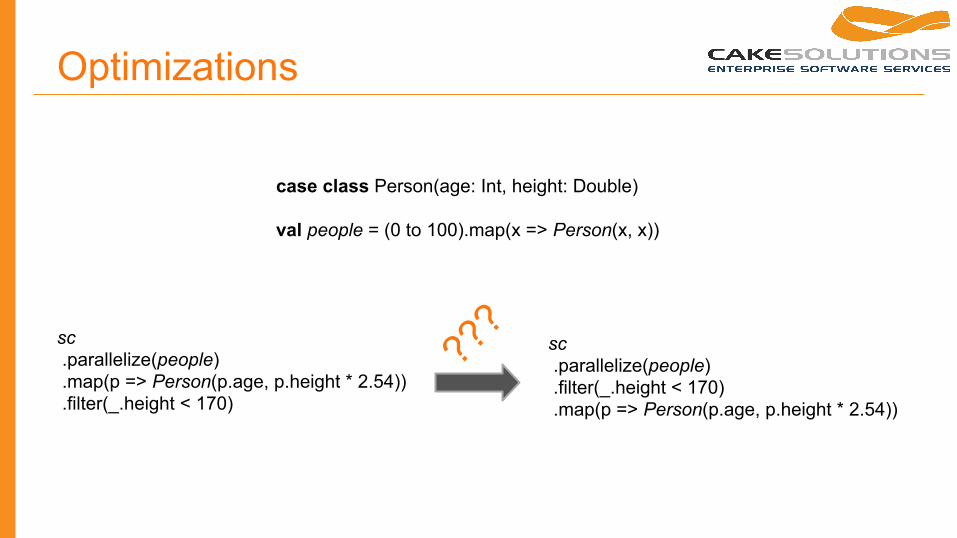
Optimizations
sc .parallelize(people) .map(p => Person(p.age, p.height * 2.54)) .filter(_.height < 170)
sc .parallelize(people) .filter(_.height < 170) .map(p => Person(p.age, p.height * 2.54))
case class Person(age: Int, height: Double)
val people = (0 to 100).map(x => Person(x, x))
???
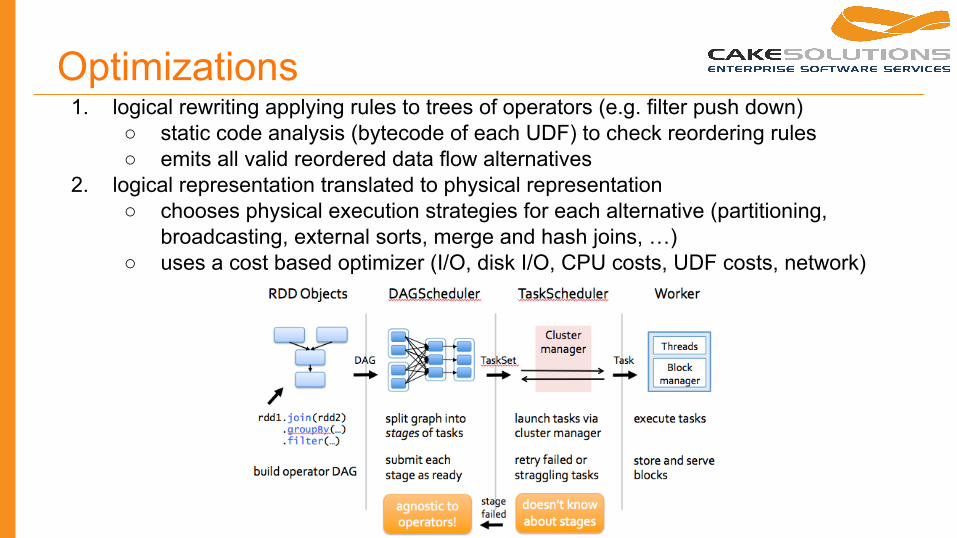
Optimizations1. logical rewriting applying rules to trees of operators (e.g. filter push down)
○ static code analysis (bytecode of each UDF) to check reordering rules○ emits all valid reordered data flow alternatives
2. logical representation translated to physical representation ○ chooses physical execution strategies for each alternative (partitioning,
broadcasting, external sorts, merge and hash joins, …)○ uses a cost based optimizer (I/O, disk I/O, CPU costs, UDF costs, network)

Stream optimizations
● similar, because in Spark streams are just mini batches● a few extra window, state operations
pageViews = readStream("http://...", "1s")
ones = pageViews.map(event => (event.url, 1))
counts = ones.runningReduce((a, b) => a + b)

Performance
Hadoop Spark Spark
Data size 102.5 TB 100 TB 1000 TB
Time [min] 72 23 234
Nodes 2100 206 190
Cores 50400 6592 6080
Rate/node [GB/min] 0.67 20.7 22.5
Environment dedicated data center EC2 EC2
● fastest open source solution to sort 100TB data in Daytona Gray Sort Benchmark (http://sortbenchmark.org/)
● required some improvements in shuffle approach● very optimized sorting algorithm (cache locality, unsafe off-heap memory structures, gc, …) ● Databricks blog + presentation

Spark programming model
● RDD● parallelizing collections● loading external datasets● operations
○ transformations○ actions
● persistence● shared variables

RDD● transformations
○ lazy, form the DAG○ map, filter, flatMap, mapPartitions, mapPartitionsWithIndex, sample, union,
intersection, distinct, groupByKey, reduceByKey, sortByKey, join, cogroup, repatition, cartesian, glom, ...
● actions○ execute DAG○ retrieve result○ reduce, collect, count, first, take, foreach, saveAs…, min, max, ...
● different categories of transformations with different complexity, performance and sematics
● e.g. mapping, filtering, grouping, set operations, sorting, reducing, partitioning● full list https://spark.apache.org/docs/1.3.0/api/scala/index.html#org.apache.spark.
rdd.RDD

Transformations with narrow deps
● map
● union
● join with copartitioned inputs

Transformations with wide deps
● groupBy
● join without copartitioned inputs

Actions collect
● retrieves result to driver program● no longer distributed

Actions reduction
● associative, commutative operation

Cache
● cache partitions to be reused in next actions on it or on datasets derived from it
● snapshot used instead of lineage recomputation● fault tolerant● cache(), persist()● levels
○ memory○ disk○ both○ serialized○ replicated○ off-heap
● automatic cache after shuffle

Shared variables - broadcast
● usually all variables used in UDF are copies on each node● shared r/w variables would be very inefficient
● broadcast○ read only variables○ efficient broadcast algorithm, can deliver data cheaply to all nodes
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value

Shared variables - accumulators
● accumulators○ add only○ use associative operation so efficient in parallel○ only driver program can read the value○ exactly once semantics only guaranteed for actions (in case of failure
and recalculation)
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
accum.value

Shared variables - accumulators
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}

Conclusion
● expressive and abstract programming model● user defined functions● based on research● optimizations
● constraining in certain cases (spanning partition boundaries, functions of multiple variables, ...)

Questions


















