
Apache Spark for Big Data Processing
58
Unless otherwise indicated, these slides are © 2013-2015 Pivotal Software, Inc. and licensed under a Creative Commons Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/ SPRINGONE2GX WASHINGTON, DC Spark meets Spring Ludwine Probst @nivdul Ilayaperumal Gopinathan @ilayaperumalg
-
Upload
spring-io -
Category
Technology
-
view
1.514 -
download
4
Transcript of Apache Spark for Big Data Processing

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
SPRINGONE2GXWASHINGTON, DC
Spark meets Spring
Ludwine Probst @nivdul
Ilayaperumal Gopinathan@ilayaperumalg

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Agenda • Introduction to Apache Spark • Spark ecosystem
• Spark streaming • Spark SQL & DataFrame • MLlib and others
• More on Spark Streaming • Spring XD integration
2

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Speakers
3
Ludwine Probst Data Engineer @nivdul
Ilayaperumal Gopinathan Software Engineer at Spring Team @ilayaperumalg

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
MOTIVATION
4
Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
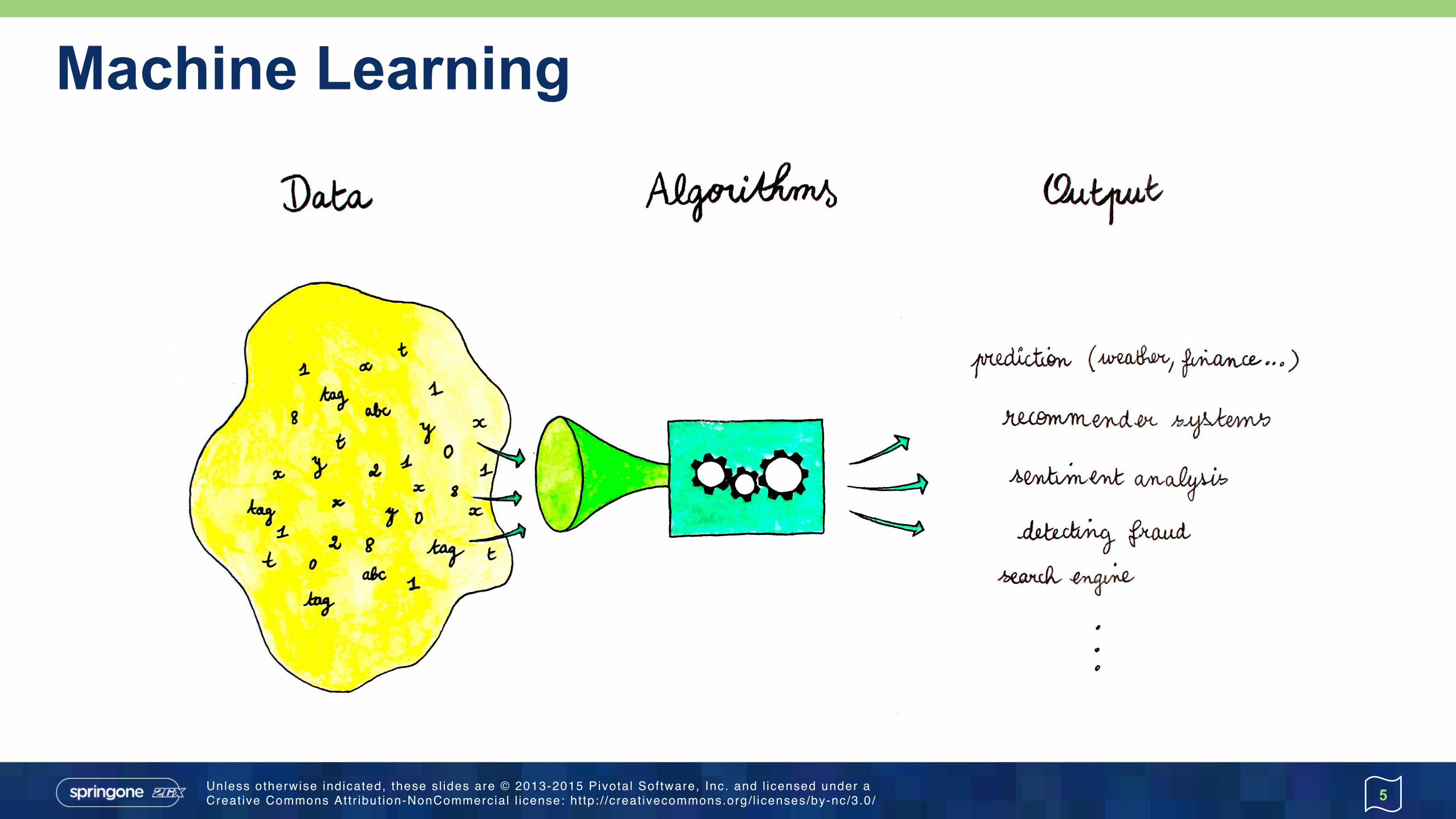
Machine Learning
5

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
I/O overhead
6
Map Reduce pattern

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
SPARK
7

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Apache Spark
• big data analytics in memory / disk • complements Hadoop • faster and more flexible • Resilient Distributed Datasets (RDDs)
8
Java 8 (lambda) interactive shell

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Resilient Distributed Datasets (RDDs) • process in parallel • controllable persistence (memory, disk…) • high-level operations (action & transformation) • rebuild automatically
9

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Access data
10
SequenceFiles
Hadoop Input format
text files

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Deploy
11
cluster managers: Standalone - Apache Mesos - Hadoop YARN

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Global view
12

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/ 13
An example: the word count
The goal is to count how much each word appears in a file. We use the MapReduce pattern.

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Entry point: the Spark context
14
// create the configuration for Spark and then the Spark context SparkConf conf = new SparkConf() .setAppName("Wordcount") .setMaster("local[*]"); // * means you will use as much as you have cores // it returns an RDD where each "element" is a word JavaRDD<String> words = sc.textFile("words.txt") // load the data .flatMap(line -> Arrays.asList(line.split(" ")));
code on my github account https://github.com/nivdul/spark-in-practice

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Count the words
15
// mapper step JavaPairRDD<String, Integer> couples = words.mapToPair(
word -> new Tuple2<String, Integer>(word, 1)); // reducer step JavaPairRDD<String, Integer> result = couples.reduceByKey((a, b) -> a + b); // persist the data in memory result.cache();

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Filter on words
16
// just keep the word which appear strictly more than 4 times! // here the variable couple represents (word, number) JavaPairRDD<String, Integer> filtered = wordcounts.filter(couple ->
couple._2() > 4);

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
SPARK ECOSYSTEM
17

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming
18

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
How to detect the language of a tweet?
19
1. Collect the data using Twitter streaming API & Spark Streaming 2. Use the DataFrames as abstraction and select the data you need 3. use the K-means algorithm provided by MLlib
code on my github account https://github.com/nivdul/tweet-language

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Twitter streaming connection
20
// connect to the Twitter streaming API (twitter4J) SparkConf conf = new public static OAuthAuthorization getAuth() { return new OAuthAuthorization( new ConfigurationBuilder().setOAuthConsumerKey(CONSUMER_KEY) .setOAuthConsumerSecret(CONSUMER_SECRET) .setOAuthAccessToken(ACCESS_TOKEN) .setOAuthAccessTokenSecret(ACCESS_TOKEN_SECRET) .build()); }

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Starting point: Spark streaming context
21
// create configuration for Spark and the Spark context // create a Java streaming context and define the window of the batch JavaStreamingContext jssc = new JavaStreamingContext(conf,
Durations.seconds(2)); … jssc.start(); // start the computation jssc.awaitTermination();
SparkConf conf = new SparkConf() .setAppName("Play with Spark Streaming") .setMaster("local[*]")

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Creating a DStream
22
ObjectMapper mapper = new ObjectMapper(); // create a DStream String[] filters = {"spring", "#s2gx", "java", "spark" , "#DC", "washington"}; JavaDStream<String> tweets = TwitterUtils.createStream(jssc, getAuth(), filters)
.map(tweetStatus -> mapper.writeValueAsString(tweetStatus));
// so you can see tweets in your console tweets.print();

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Save the data
23
// save the tweets in a file tweets.repartition(1).dstream().saveAsTextFiles(PATH, "stream");

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
DEMO
24
code on my github account https://github.com/nivdul/tweet-language

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark SQL & DataFrame
25

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
SQL context
26
// create configuration for Spark and the Spark context SparkConf conf = new SparkConf() .setAppName("Dataframes") .setMaster("local[*]"); JavaSparkContext sc = new JavaSparkContext(conf); // the SQL context wraps the SparkContext and is specific to Spark SQL/Dataframe SQLContext sqlContext = new SQLContext(sc); // you can also create a HiveContext

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Creating a DataFrame
27
// load the data (json file here) and register the data in a table DataFrame df = sqlContext.read().json("tweets.json"); // you can also read different type of files: Parquet, ORC, Web APIs… // display the content of the DataFrame to stdout df.show(5);

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
DataFrames operations
28
// select the languages df.select("lang").show(); // count tweets by language df.groupBy("lang").count().show(); // keep tweets in english and french. Remove all the Rows that are not correct or contains null or N/A values by using na().drop() DataFrame filtered = df.filter((df.col("lang").equalTo("en")) .or(df.col("lang").equalTo("fr"))) .na().drop();

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Running SQL queries
29
// register the DataFrame as SQL table on which we can query // now we have a table named « tweets » df.registerTempTable("tweets"); DataFrame df = sqlContext.sql("SELECT lang, name, text FROM tweets");

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
MLlib
30
original API Machine Learning Pipeline

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Main algorithms provided MLlib
31
Classification & Regression • linear models (SVMs, logistic regression, linear regression) • decision / ensembles of trees (Random Forests & Gradient-Boosted Trees) • naive Bayes…
Clustering • k-means, streaming k-means • Gaussian mixture • latent Dirichlet allocation (LDA)…
Collaborative filtering • alternating least squares (ALS)
Dimensionality reduction • singular value decomposition (SVD) • principal component analysis (PCA)

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
How to detect the language of a tweet?
32
It can be resolve using a clustering algorithms like the K-means algorithm. 1. Collect the data using Twitter streaming API & Spark Streaming 2. Use the DataFrames as abstraction and select the data you need 3. use the K-means algorithm provided by MLlib

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Clustering: K-means algorithm
33
Goal: • partition the n observations into different cluster k • minimize the within-cluster sum of squares (WCSS)

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Load the data using DataFrames
34
// create a sql context from the Spark context
SparkConf conf = new SparkConf().setAppName("K-means")
.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
// load the data :D from a local file
DataFrame df = sqlContext.jsonFile(pathToFile);
code on my github account https://github.com/nivdul/tweet-language

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Select only 3 languages
35
// create an RDD of Tweet objects and register it as a table df.registerTempTable("tweets"); // SQL statements DataFrame dfSelect = sqlContext.sql( "SELECT lang, text FROM tweets WHERE lang in ('en', 'es', ‘ja')" );

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Working on the tweet’s content
36
// extract the content of a tweet JavaPairRDD<String, String> pairs = dfSelect.javaRDD().mapToPair(
row -> new Tuple2(row.get(0).toString(), row.get(1).toString())); // RDD of tweet’s content JavaRDD<String> contents = pairs.map(e -> e._2());

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Features extraction and transformation
37
// clean the data JavaRDD<String> points = texts .map(e -> e.toLowerCase()) .map(e -> e.replaceAll("rt\\s+", "")) .map(e -> e.replaceAll("#\\w+", "")) .map(e -> e.replaceAll("(?:https?|http?)://[\\w/%.-]+", "")) .map(e -> e.replaceAll("(?:https?|http?)//[\\w/%.-]+", "")) … .filter(e -> e.length() > 80);
more about the topic on https://github.com/shuyo/language-detection

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
N-gram & HashingTF
38
// Create feature vectors by turning each tweet into bigrams of characters JavaRDD<Iterable<String>> lists = points.map(ele -> NGram.ngrams(2, ele)); HashingTF hash = new HashingTF(1000); // then we hash each element to a length-1000 feature vector // to finish the RDD of vector can be pass to MLlib RDD<Vector> vectors = lists.map(line -> hash.transform(line)).rdd().cache();

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
K-means algorithm
39
int clusterNumber = 3; // cluster number int iter = 20; // iterations number KMeansModel model = KMeans.train(vectors, clusterNumber, iter); // save and then load the model (Spark > 1.4) model.save(sc.sc(), "kmean-model"); KMeansModel modelLoaded = KMeansModel.load(sc.sc(), "kmean-model");
code on my github account https://github.com/nivdul/tweet-language

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
DEMO
40
code on my github account https://github.com/nivdul/tweet-language

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Other..
41
Feature extraction and transformation • TF-IDF (HashingTF and IDF) • Word2Vec • Tokenizer • n-gram…
Frequent pattern mining Basic Statistic Evaluation metrics Optimization
• stochastic gradient descent • BFGS

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Other interesting projects
42
R spark-cassandra connector

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Focus on Apache Spark’s 1.5 release
43
Spark’s performance • Project Tungsten "Explicit Management of memory with sun.misc.unsafe to reduce Garbage collection impact" Spark Streaming • backpressure support • Python API’s • Amazon Kinesis, Apache Flume, and the MQTT protocol Data science • new algorithms • add DataFrames & machine learning pipelines • R language support

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Why should I care about Spark?
44
• good performances • flexible API • compatible with Hadoop • active community • ecosystem

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming • Streaming Context – batch duration • Discretized Stream (DStream)
• Sequence of RDDs • An RDD for each batch interval
• Creation of DStream • InputDStream (at the Spark Driver) • ReceiverInputDStream
o Requires Receiver at the executor node as a long running task • DStream operations on existing DStream
45

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming • Receiver
• Long Running Task (Reliable/Un-reliable) on executor node • Uses a dedicated core allocated to spark streaming • Receives data from data source and creates block
• BlockGenerator • Generates a block at every block interval (rate limiter for the Receiver) • Pushes the block into BlockManager
• JobGenerator at batch interval • Generates a batch (of blocks) at every batch interval • Batch (of blocks) -> BlockRDD (replicated, partitioned) • Driver launches tasks on BlockRDD
46

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming
• A BlockRDD for every batch interval
• BlockRDD is partitioned based on block ID
• Tasks are mapped to each partition(block ID)
47

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming • Receiver reliability
• Acknowledging the data source after storing in Spark storage • Time process the BlockRDD (batch) < batch interval • Executes tasks closer to the data (RDD operations)
48

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming failure scenarios • Driver node failure
• Check-pointing (useful if the RDD lineage is long) • Executor node failure
• Receiver failure o Receiver restarted but un-reliable receiver has data loss
• Tasks failure o Tasks restarted and use replicated BlockRDDs
49

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spring XD • Platform for developing and deploying data driven applications • Data ingestion • Transformation(s) • Analytics • Stream
• Source • Processor(s) • Sink
• Batch job • Tap
50

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark integration in Spring XD • Spark Streaming Processor • Spark Streaming Sink • Spark job as a Tasklet (batch job)
51

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Advantages when using with Spring XD • Simplified Development experience
• Implement/extend a single interface/trait • Supports both Java and Scala • Boilerplate (setup/launch) is managed within Spring XD
• Orchestration of streaming components • Data ingestion in XD • Transformation (using parallelized computation) on Spark engine
• Multiple streaming pipelines using the same data source
52

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Advantages… • Reliable Receiver
• Message-Bus receiver (Rabbit /Kafka) • Scalability at the stream level (partitioned stream)
• A receiver (Message-Bus receiver) for each partitioned module • Lifecycle management • Error handling
• Driver failure o Spring XD admin restarts driver upon failure
• Receiver failure o No need of Write Ahead Log (if appropriate Storage Level is set)
53

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark integration in Spring XD
54

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spark streaming marker interface
55
• trait Processor[I, O] extends SparkStreamingSupport { def process(input: ReceiverInputDStream[I]): DStream[O] }
• public interface Processor<I extends JavaDStreamLike, O extends JavaDStreamLike> extends SparkStreamingSupport { O process(I input); }

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
DEMO
56

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Spring Cloud and Spark
• Run Spark streaming application as a boot app • Streaming module
• Run Spark application • Task (batch job)
57

Unless otherwise indicated, these sl ides are © 2013-2015 Pivotal Software, Inc. and l icensed under a Creat ive Commons Attr ibut ion-NonCommercial l icense: ht tp: / /creat ivecommons.org/ l icenses/by-nc/3.0/
Resources
58
https://github.com/nivdul/tweet-language https://github.com/nivdul/spark-in-practice https://github.com/shuyo/language-detection
https://spark.apache.org/docs/latest/
https://databricks.com/blog
https://github.com/spring-projects/spring-xd
https://github.com/spring-projects/spring-xd-samples


















