
Apache Spark Crash Course
84
Robert Hryniewicz Developer Advocate @RobertH8z Apache Spark Crash Course - DataWorks Summit - Munich 2017
-
Upload
dataworks-summithadoop-summit -
Category
Technology
-
view
18 -
download
0
Transcript of Apache Spark Crash Course

RobertHryniewiczDeveloperAdvocate
@RobertH8z
ApacheSparkCrashCourse- DataWorks Summit- Munich2017

2 ©HortonworksInc.2011– 2016.AllRightsReserved
“BigData”à InternetofAnything(IoT)
– WindTurbines,OilRigs– Beacons,Wearables– SmartCars
à UserGeneratedContent(Social,Web&Mobile)– Twitter,Facebook,Snapchat– Clickstream– Paypal,Venmo
44ZBin2020

3 ©HortonworksInc.2011– 2016.AllRightsReserved
Visualizing44ZB
100pixels=1MTB
100px ->1MTBassumes5Mpixelresolutionscreen

4 ©HortonworksInc.2011– 2016.AllRightsReserved

5 ©HortonworksInc.2011– 2016.AllRightsReserved
The“BigData”Problem
à Asinglemachinecannotprocessorevenstoreallthedata!Problem
Solutionà Distributedataoverlargeclusters
Difficultyà Howtosplitworkacrossmachines?
à Movingdataovernetworkisexpensive
à Mustconsiderdata&networklocality
à Howtodealwithfailures?
à Howtodealwithslownodes?

6 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkBackground

7 ©HortonworksInc.2011– 2016.AllRightsReserved
WhatIsApacheSpark?
à ApacheopensourceprojectoriginallydevelopedatAMPLab(UniversityofCaliforniaBerkeley)
à Unifieddataprocessingenginethatoperatesacrossvarieddataworkloadsandplatforms

8 ©HortonworksInc.2011– 2016.AllRightsReserved
WhyApacheSpark?
à ElegantDeveloperAPIs– Singleenvironmentfordatamunging,datawrangling,andMachineLearning(ML)
à In-memorycomputationmodel– Fast!– EffectiveforiterativecomputationsandML
à MachineLearning– ImplementationofdistributedMLalgorithms– PipelineAPI(SparkML)

9 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis

10 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkBasics

11 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSession
à MainentrypointforSparkfunctionality
à AllowsprogrammingwithDataFrame andDatasetAPIs– FewerconceptsandconstructsadeveloperhastojugglewhileinteractingwithSpark
à Representedassparkandauto-initializedinZeppelinenv.
Whatisit?

12 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis

13 ©HortonworksInc.2011– 2016.AllRightsReserved
MoreFlexible BetterStorageandPerformance///

14 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLOverview
à Sparkmoduleforstructureddataprocessing(e.g.DBtables,JSONfiles,CSV)
à Threewaystomanipulatedata:– DataFrames API– SQLqueries– DatasetsAPI

15 ©HortonworksInc.2011– 2016.AllRightsReserved
DataFrames
à Distributed collection ofdata organized intonamedcolumns
à ConceptuallyequivalenttoatableinrelationalDBoradataframeinR/Python
à APIavailableinScala,Java,Python,andR
Col1 Col2 … … ColN
DataFrame
Column
Row
DataisdescribedasaDataFramewithrows,columns,andaschema

16 ©HortonworksInc.2011– 2016.AllRightsReserved
Sources
CSVAvro
HIVE
SparkSQL
Col1 Col2 … … ColN
DataFrame
Column
Row
JSON

17 ©HortonworksInc.2011– 2016.AllRightsReserved
CreateaDataFrame
val path = "examples/flights.json"
val flights = spark.read.json(path)
Example

18 ©HortonworksInc.2011– 2016.AllRightsReserved
RegisteraTemporaryView(SQLAPI)
Example
flights.createOrReplaceTempView("flightsView")

19 ©HortonworksInc.2011– 2016.AllRightsReserved
TwoAPIExamples:DataFrame andSQLAPIs
flights.select("Origin", "Dest", "DepDelay”)
.filter($"DepDelay" > 15).show(5)
Results+------+----+--------+|Origin|Dest|DepDelay|+------+----+--------+| IAD| TPA| 19|| IND| BWI| 34|| IND| JAX| 25|| IND| LAS| 67|| IND| MCO| 94|+------+----+--------+
SELECT Origin, Dest, DepDelayFROM flightsViewWHERE DepDelay > 15 LIMIT 5
SQLAPI
DataFrame API
20 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis

21 ©HortonworksInc.2011– 2016.AllRightsReserved
WhatisStreamProcessing?
BatchProcessing• Abilitytoprocessandanalyzedataat-rest(storeddata)• Request-based,bulkevaluationandshort-livedprocessing• EnablerforRetrospective,ReactiveandOn-demandAnalytics
StreamProcessing• Abilitytoingest,processandanalyzedatain-motioninreal- ornear-real-time• Eventormicro-batchdriven,continuousevaluationandlong-livedprocessing• Enablerforreal-timeProspective,ProactiveandPredictiveAnalytics forNextBest
Action
StreamProcessing +BatchProcessing =AllDataAnalyticsreal-time (now) historical (past)

22 ©HortonworksInc.2011– 2016.AllRightsReserved
Next Generation AnalyticsIterative & ExploratoryData is the structure
Traditional AnalyticsStructured & Repeatable
Structure built to store data
22
ModernDataApplicationsapproachtoInsights
Start with hypothesisTest against selected data
Data leads the way Explore all data, identify correlations
Analyze after landing… Analyze in motion…

23 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkStreaming
à ExtensionofSparkCoreAPI
à Streamprocessingoflivedatastreams– Scalable– High-throughput– Fault-tolerant
Overview
ZeroMQ
MQTT
Nolongersupported
inSpark2.x

24 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkStreaming

25 ©HortonworksInc.2011– 2016.AllRightsReserved
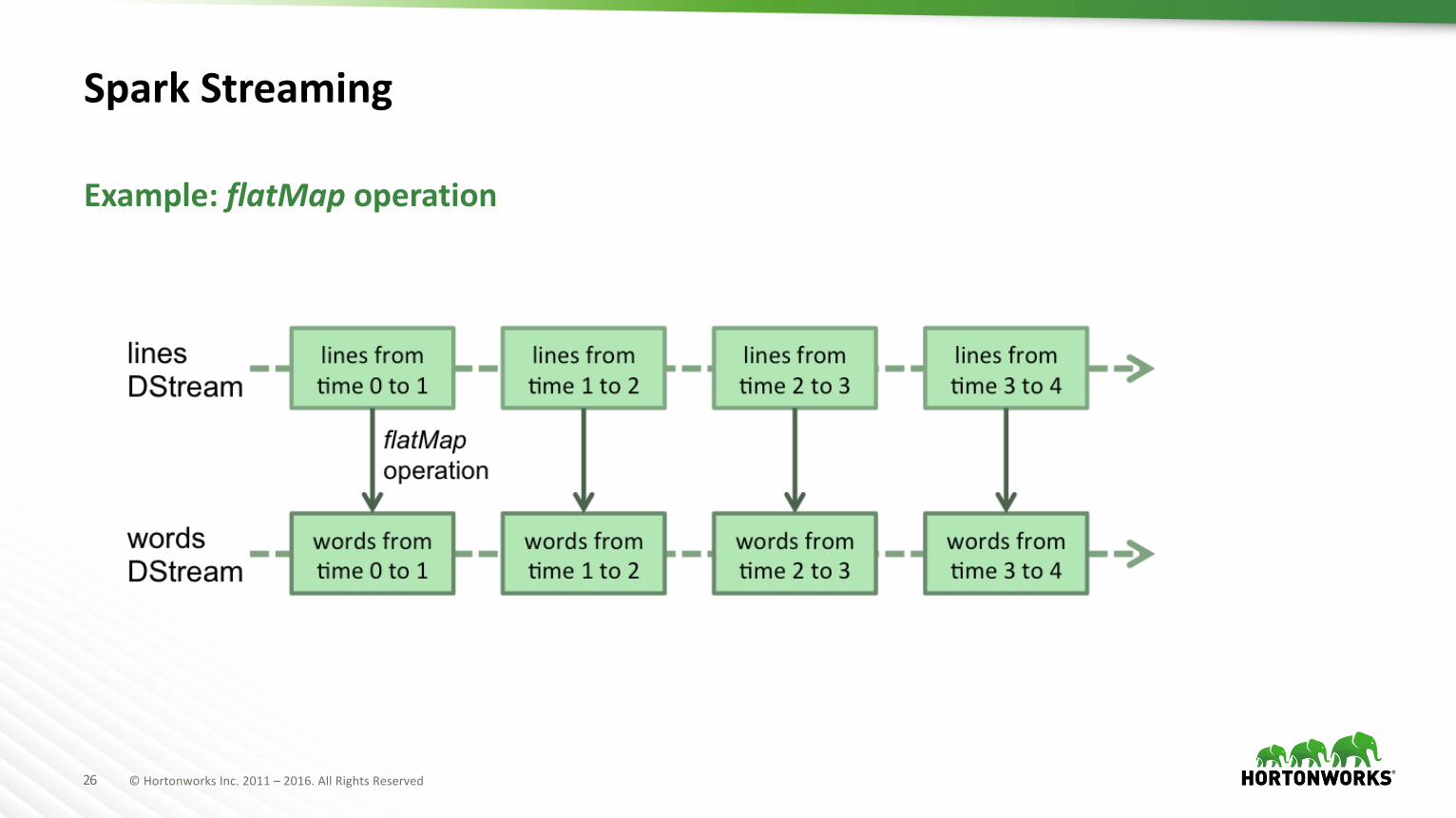
SparkStreaming
DiscretizedStreams(DStreams)Ã High-levelabstractionrepresentingcontinuousstreamofdata
à InternallyrepresentedasasequenceofRDDs
à OperationappliedonaDStream translatestooperationsontheunderlyingRDDs
26 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkStreaming
Example:flatMap operation
27 ©HortonworksInc.2011– 2016.AllRightsReserved
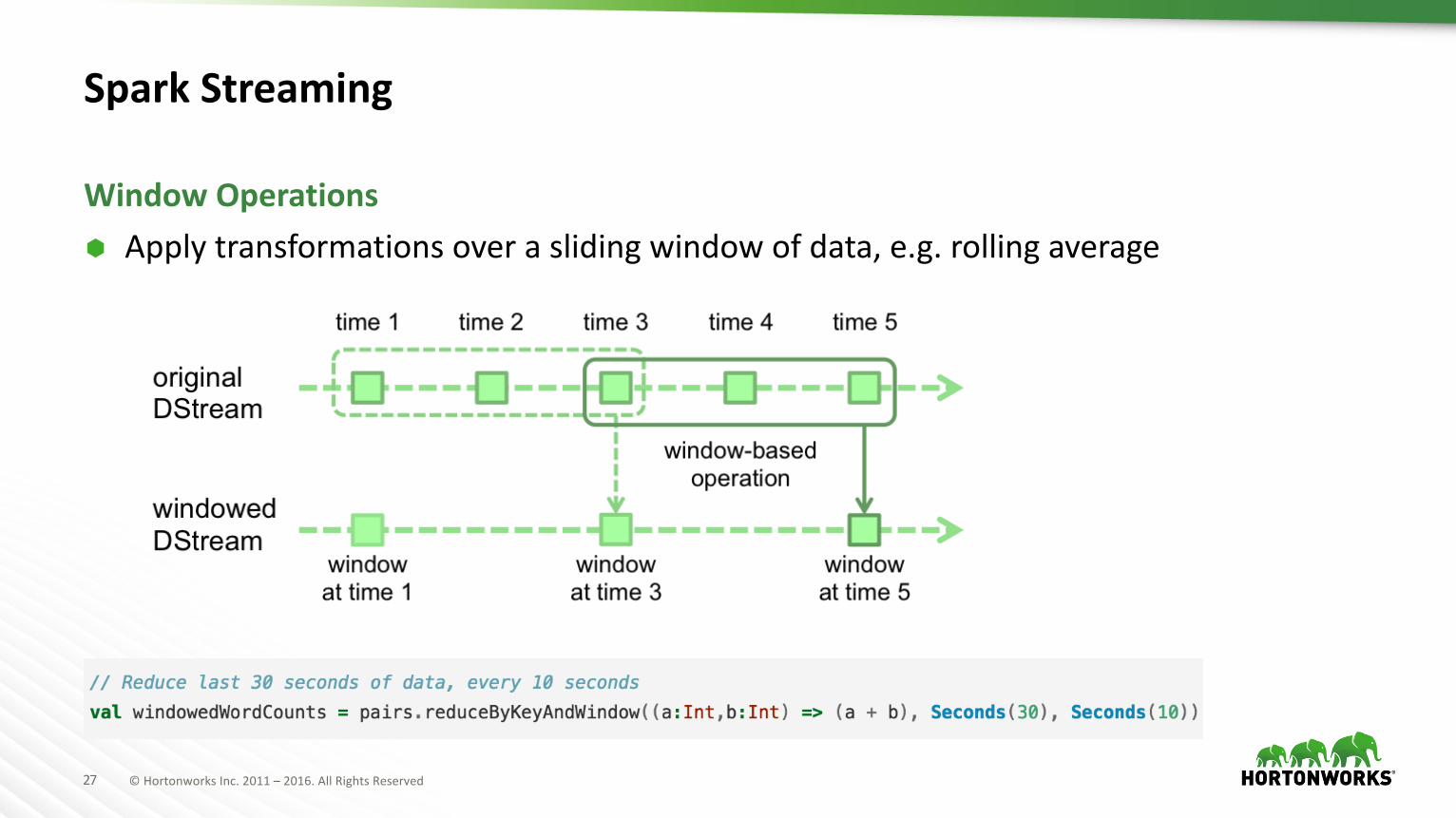
SparkStreaming
à Applytransformationsoveraslidingwindowofdata,e.g.rollingaverageWindowOperations

28 ©HortonworksInc.2011– 2016.AllRightsReserved
ChallengesinStreamingData
à Consistency
à Faulttolerance
à Out-of-orderdata

29 ©HortonworksInc.2011– 2016.AllRightsReserved
StructuredStreaming:Basics

30 ©HortonworksInc.2011– 2016.AllRightsReserved
StructuredStreaming:Model

31 ©HortonworksInc.2011– 2016.AllRightsReserved
Handlinglatearrivingdata
32 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis

33 ©HortonworksInc.2011– 2016.AllRightsReserved
AIinMedia&PopCulture
34 ©HortonworksInc.2011– 2016.AllRightsReserved
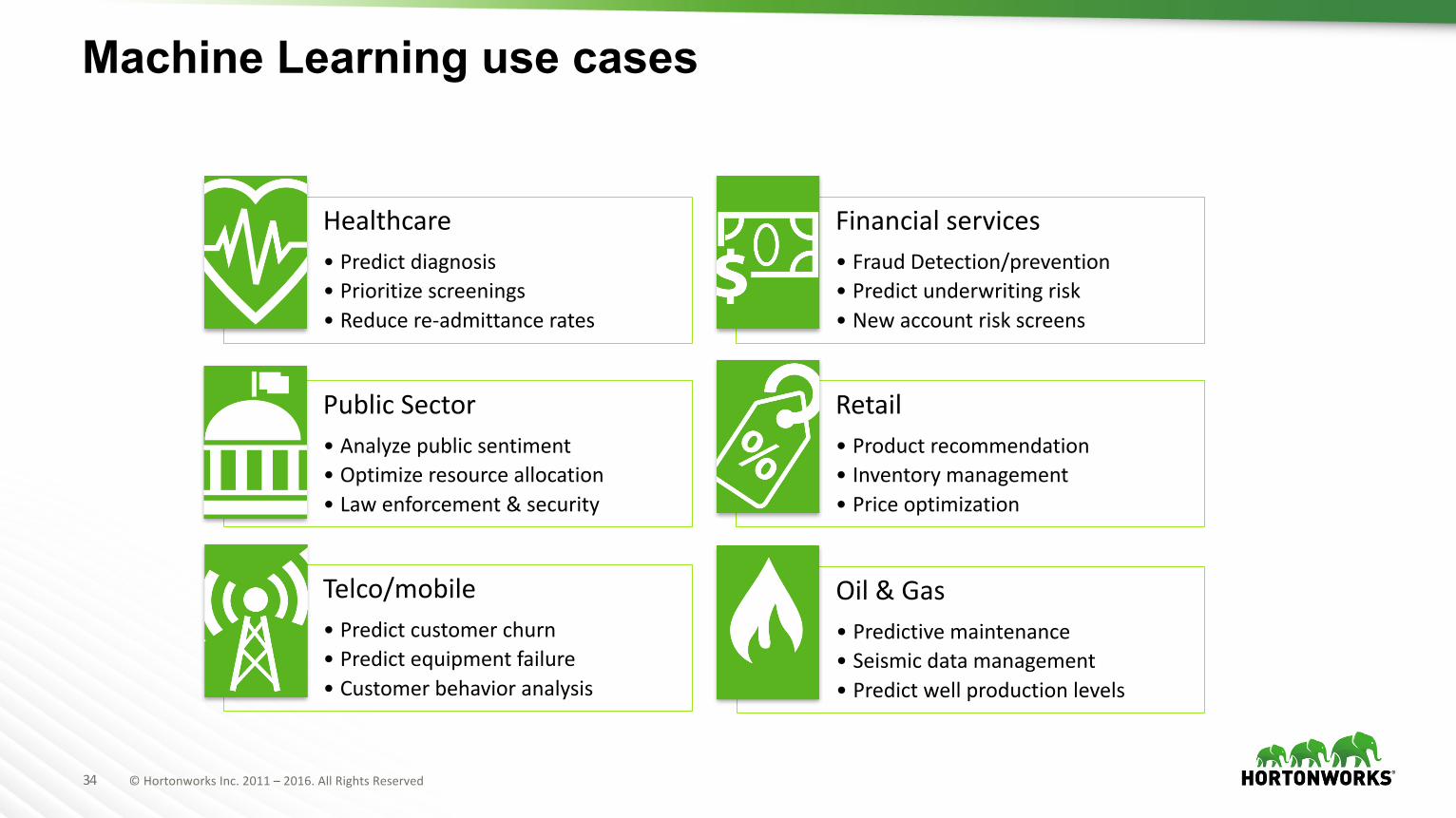
Machine Learning use cases
Healthcare• Predictdiagnosis• Prioritizescreenings• Reducere-admittancerates
Financialservices• FraudDetection/prevention• Predictunderwritingrisk• Newaccountriskscreens
PublicSector• Analyzepublicsentiment• Optimizeresourceallocation• Lawenforcement&security
Retail• Productrecommendation• Inventorymanagement• Priceoptimization
Telco/mobile• Predictcustomerchurn• Predictequipmentfailure• Customerbehavioranalysis
Oil&Gas• Predictivemaintenance• Seismicdatamanagement• Predictwellproductionlevels

35 ©HortonworksInc.2011– 2016.AllRightsReserved
Scatter 2D Data Visualized
scatterData ç DataFrame
+-----+--------+
|label|features|
+-----+--------+
|-12.0| [-4.9]|
| -6.0| [-4.5]|
| -7.2| [-4.1]|
| -5.0| [-3.2]|
| -2.0| [-3.0]|
| -3.1| [-2.1]|
| -4.0| [-1.5]|
| -2.2| [-1.2]|
| -2.0| [-0.7]|
| 1.0| [-0.5]|
| -0.7| [-0.2]|.........

36 ©HortonworksInc.2011– 2016.AllRightsReserved
Linear Regression Model Training (one feature)
Coefficients:2.81Intercept:3.05
y=2.81x+3.05
TrainingResult

37 ©HortonworksInc.2011– 2016.AllRightsReserved
Linear Regression (two features)
Coefficients: [0.464, 0.464] Intercept: 0.0563

38 ©HortonworksInc.2011– 2016.AllRightsReserved
Spark API for building ML pipelines
Featuretransform
1
Featuretransform
2
Combinefeatures
LinearRegression
InputDataFrame
InputDataFrame
OutputDataFrame
Pipeline
PipelineModel
Train
Predict
ExportModel

39 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis

40 ©HortonworksInc.2011– 2016.AllRightsReserved

41 ©HortonworksInc.2011– 2016.AllRightsReserved
à PageRank
à TopicModeling(LDA)
à CommunityDetection
Source:ampcamp.berkeley.edu

42 ©HortonworksInc.2011– 2016.AllRightsReserved
Zeppelin&HDP

43 ©HortonworksInc.2011– 2016.AllRightsReserved
What’s Apache Zeppelin?
Web-based notebook that enables interactive
data analytics.
You can make beautiful data-driven, interactive
and collaborative documents with SQL,
Python, Scala and more

44 ©HortonworksInc.2011– 2016.AllRightsReserved
Simplelinechart
45 ©HortonworksInc.2011– 2016.AllRightsReserved
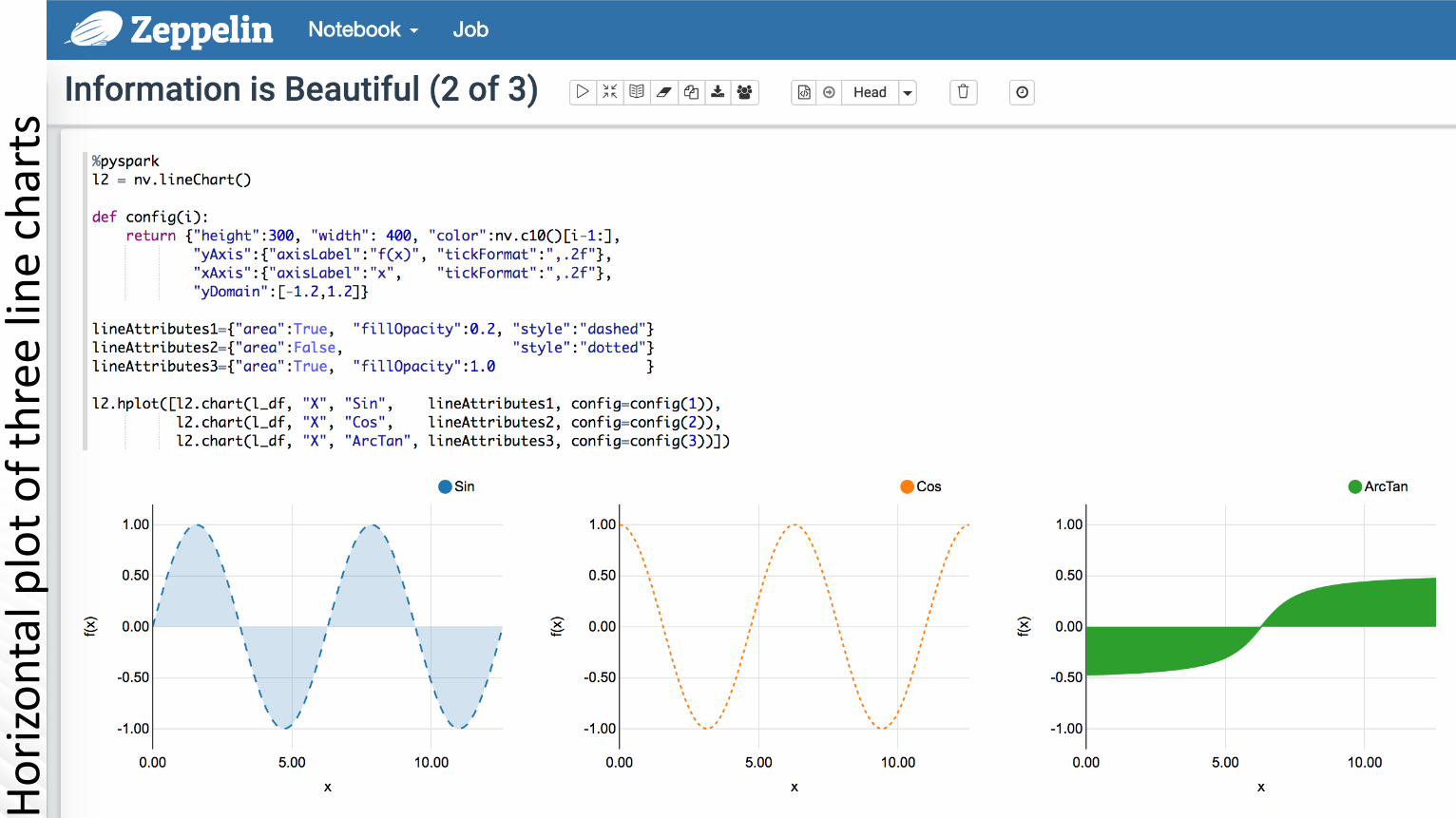
Horizon
talploto
fthreeline
charts

46 ©HortonworksInc.2011– 2016.AllRightsReserved
Stream
ingdataintoaline
chart
47 ©HortonworksInc.2011– 2016.AllRightsReserved
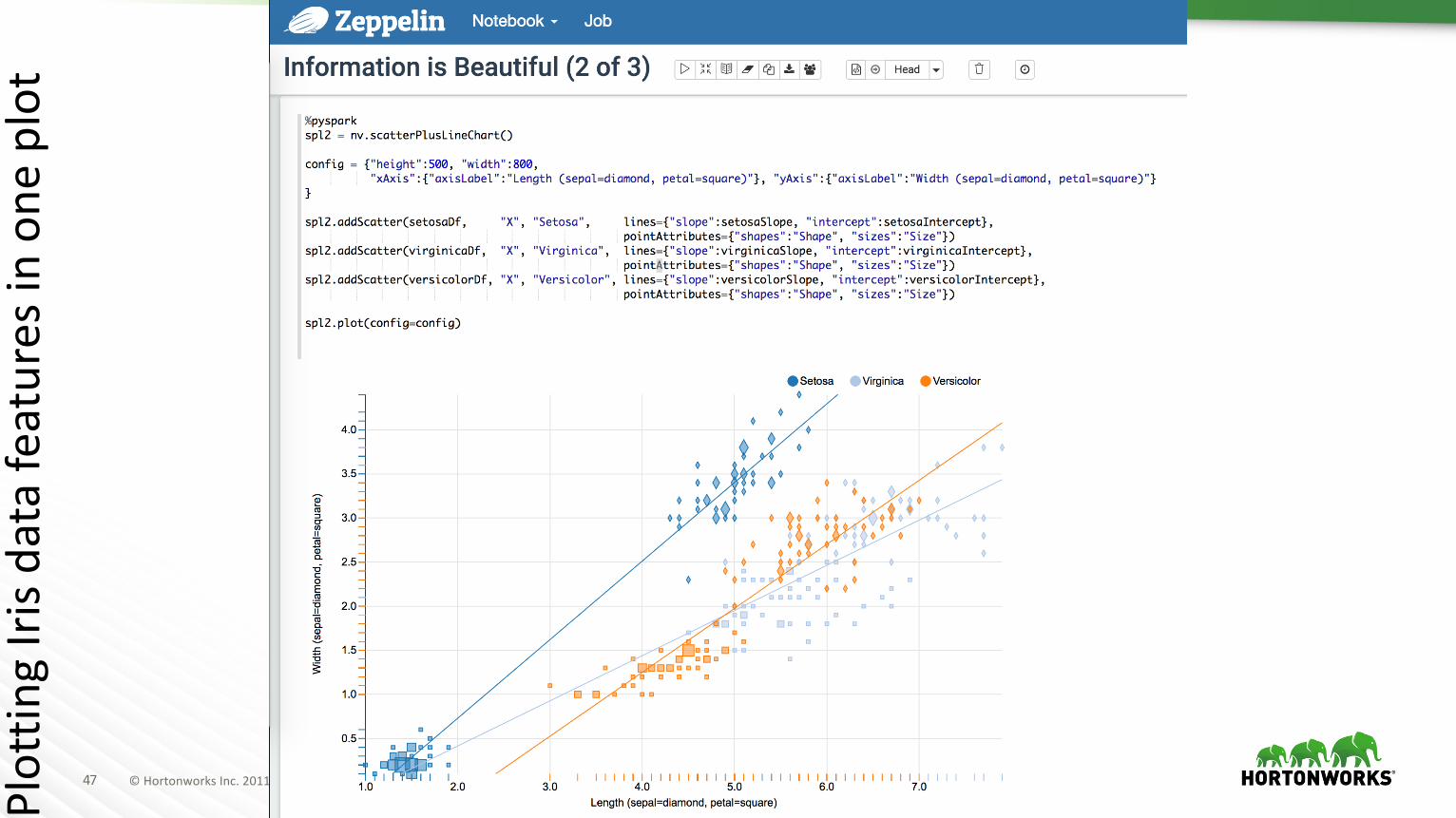
Plottin
gIrisd
atafeaturesinone
plot

48 ©HortonworksInc.2011– 2016.AllRightsReserved
Comparin
gIrisd
atadistrib
utions

49 ©HortonworksInc.2011– 2016.AllRightsReserved
What is a Note/Notebook?
• AwebbasedGUIforsmallcodesnippets
• Writecodesnippetsinbrowser
• Zeppelinsendscodetobackendforexecution
• Zeppelingetsdatabackfrombackend
• Zeppelinvisualizesdata
• ZeppelinNote=Setof(Paragraphs/Cells)
• OtherFeatures- Sharing/Collaboration/Reports/Import/Export
50 ©HortonworksInc.2011– 2016.AllRightsReserved
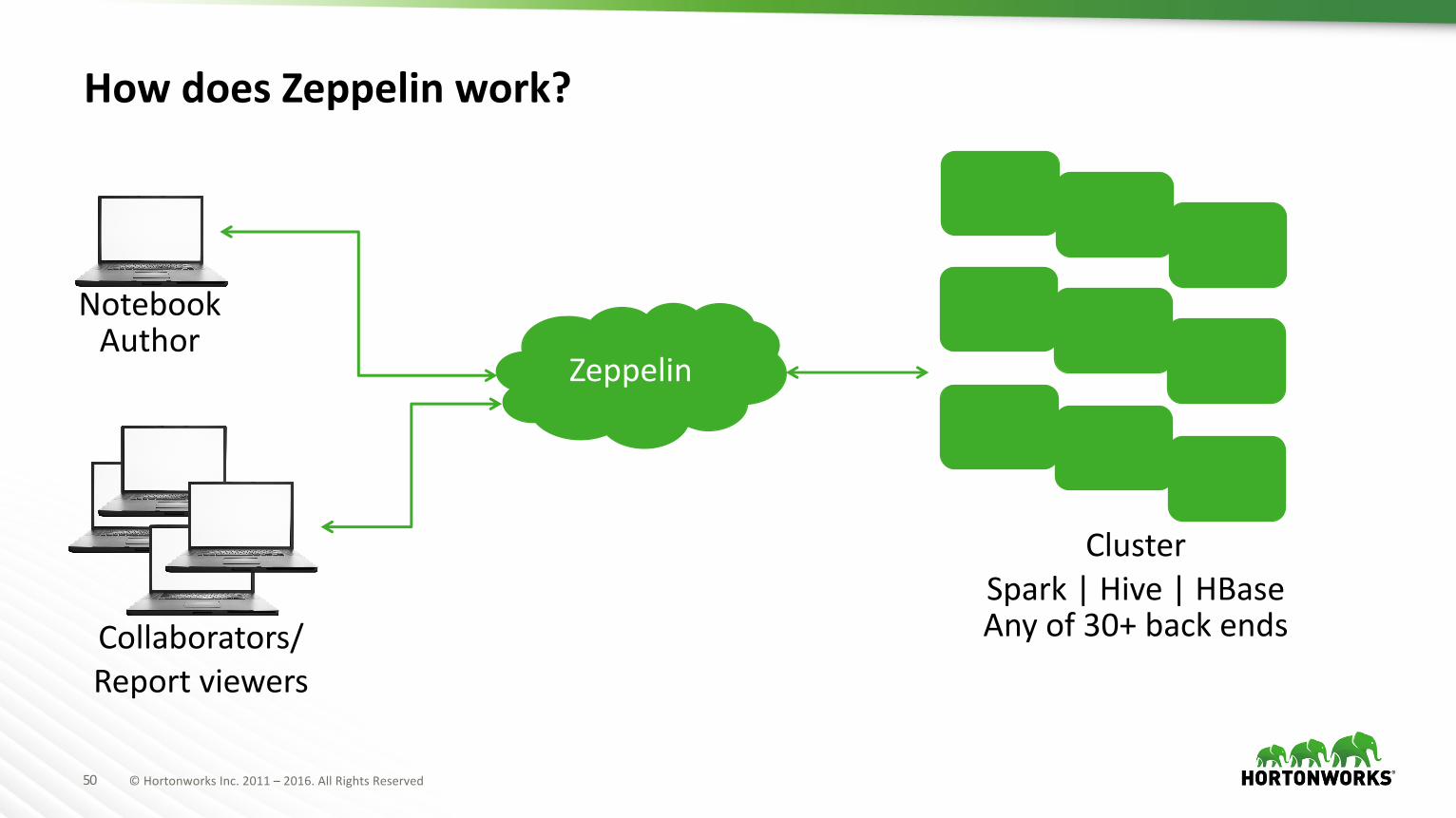
HowdoesZeppelinwork?
NotebookAuthor
Collaborators/Reportviewers
Zeppelin
ClusterSpark|Hive|HBaseAnyof30+backends

51 ©HortonworksInc.2011– 2016.AllRightsReserved
BigDataLifecycle
Collect ETL/Process Analysis
Report
DataProduct
BusinessuserCustomer
DataScientistDataEngineer
AllinZeppelin!

52 ©HortonworksInc.2011– 2016.AllRightsReserved
à Zeppelinè Interactivenotebook
à Spark
à YARNè ResourceManagement
à HDFSè DistributedStorageLayerYARN
ScalaJava
PythonR
APIs
Spark Core Engine
Spark SQL
Spark StreamingMLlib GraphX
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° ° °
°
NHDFS
53 ©HortonworksInc.2011– 2016.AllRightsReserved
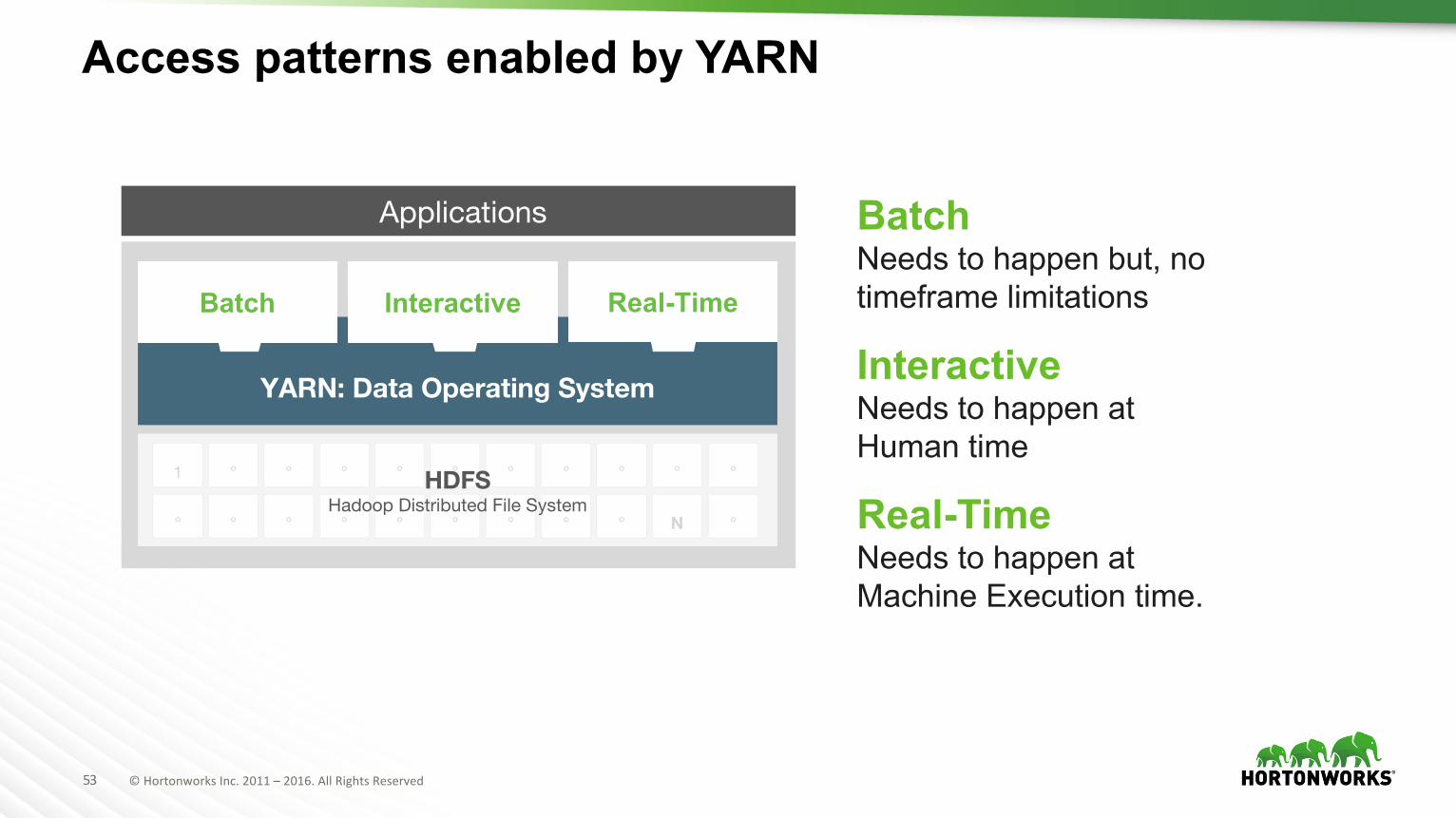
Access patterns enabled by YARN
YARN: Data Operating System
1 ° ° ° ° ° ° ° ° °
° ° ° ° ° ° ° ° °
°
°N
HDFS Hadoop Distributed File System
Interactive Real-TimeBatch
Applications BatchNeeds to happen but, no timeframe limitations
InteractiveNeeds to happen at Human time
Real-Time Needs to happen at Machine Execution time.
54 ©HortonworksInc.2011– 2016.AllRightsReserved
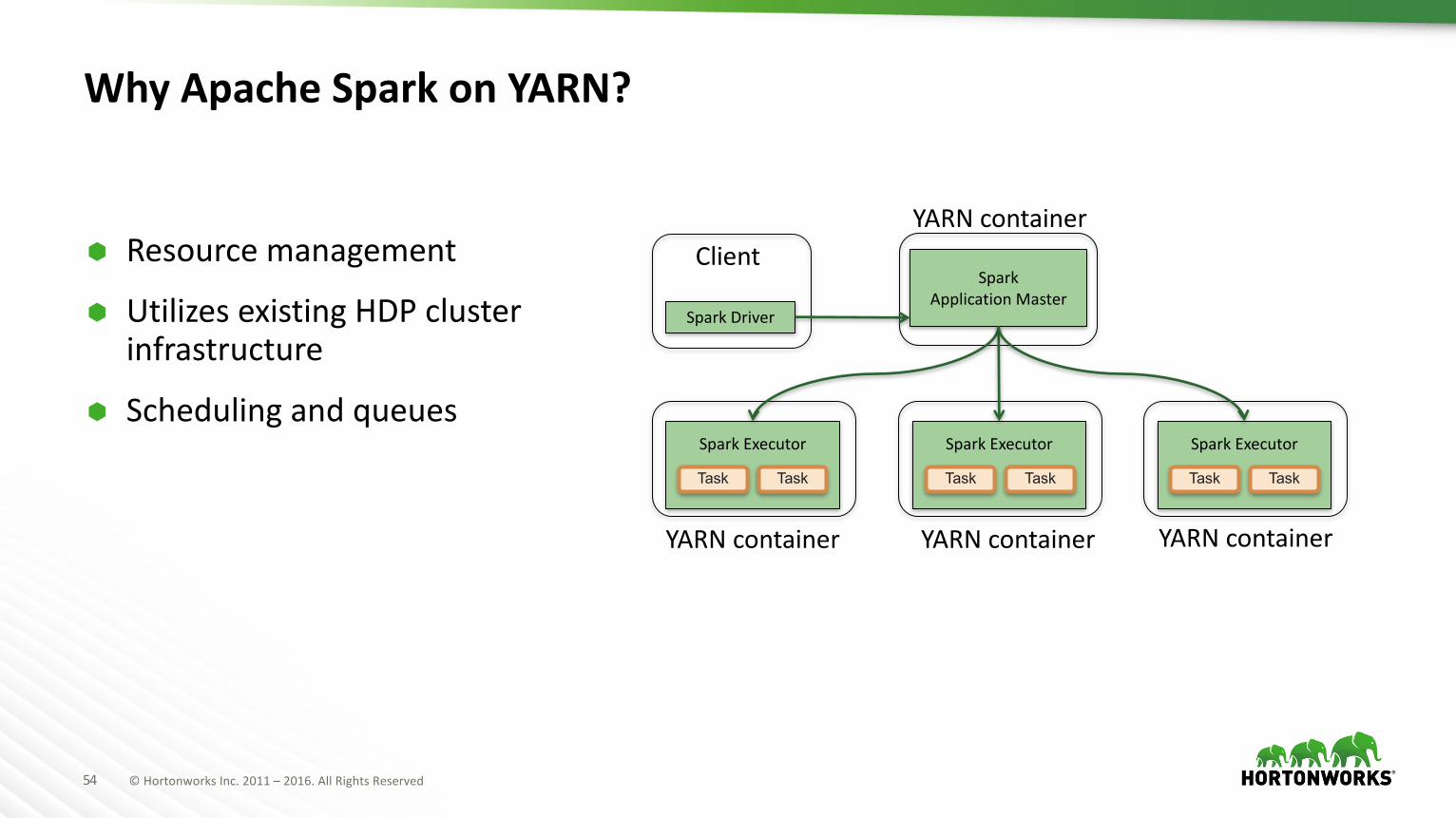
WhyApacheSparkonYARN?
à Resourcemanagement
à UtilizesexistingHDPclusterinfrastructure
à Schedulingandqueues
SparkDriver
ClientSpark
ApplicationMaster
YARNcontainer
SparkExecutor
YARNcontainer
Task Task
SparkExecutor
YARNcontainer
Task Task
SparkExecutor
YARNcontainer
Task Task

55 ©HortonworksInc.2011– 2016.AllRightsReserved
Why HDFS?Fault Tolerant Distributed Storage• Dividefilesintobigblocksanddistribute3copiesrandomly acrossthecluster• ProcessingDataLocality
• NotJuststoragebutcomputation
10110100101001001110011111100101001110100101001011001001010100110001010010111010111010111101101101010110100101010010101010101110010011010111010
0
Logical File
1
2
3
4
Blocks
1
Cluster
1
1
2
22
3
3
34
44

56 ©HortonworksInc.2011– 2016.AllRightsReserved
Spark and HDP

57 ©HortonworksInc.2011– 2016.AllRightsReserved
HDCloud

58 ©HortonworksInc.2011– 2016.AllRightsReserved
HortonworksCloudSolutions
Microsoft AWS Google
Managed AzureHDInsight
Non-Managed/Marketplace
HortonworksDataCloudforAWS
CloudIaaS HortonworksDataPlatform(viaAmbariandviaCloudbreak)
59 ©HortonworksInc.2011– 2016.AllRightsReserved
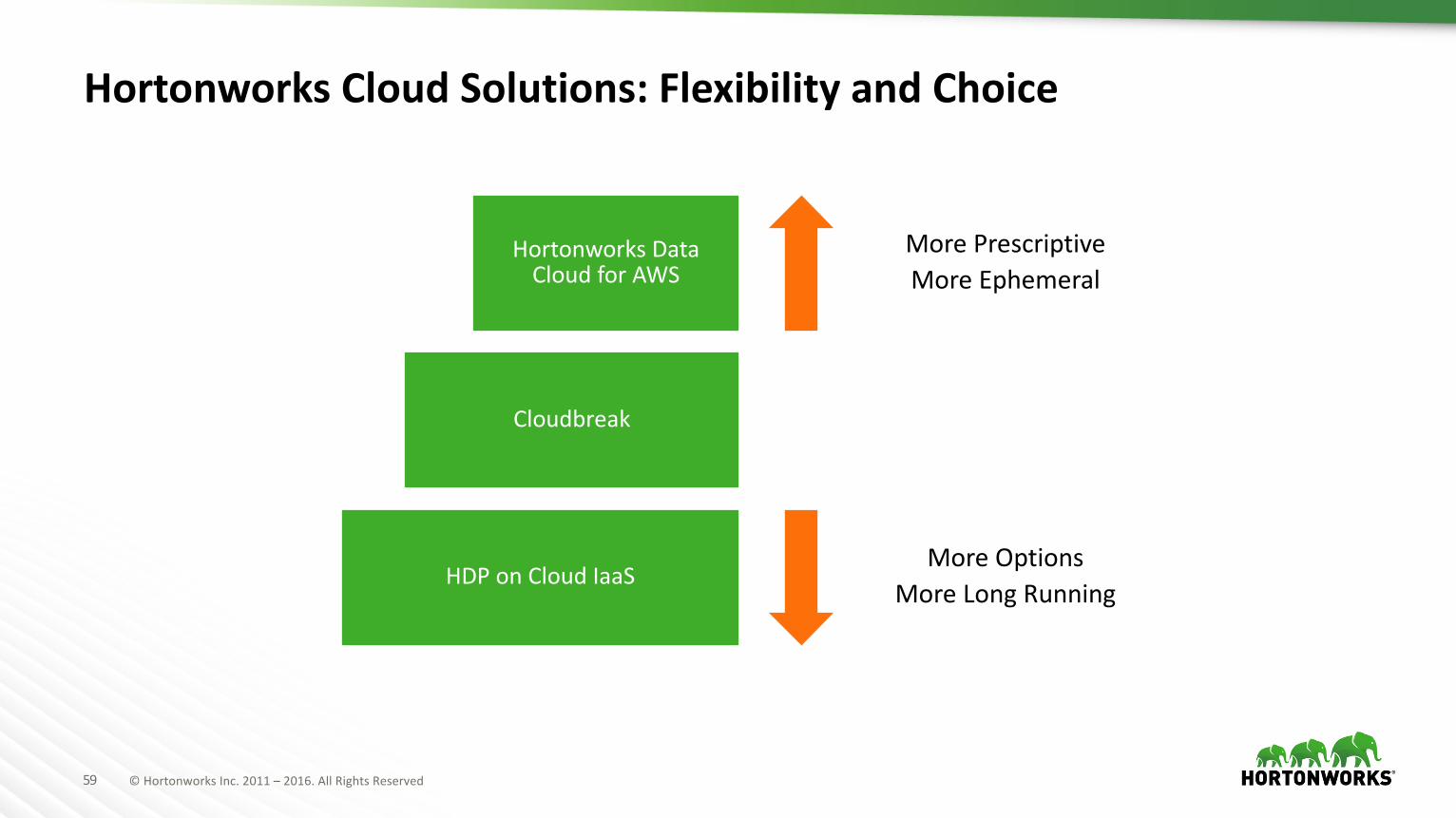
HortonworksCloudSolutions:FlexibilityandChoice
HortonworksDataCloudforAWS
Cloudbreak
HDPonCloudIaaS
MorePrescriptiveMoreEphemeral
MoreOptionsMoreLongRunning
60 ©HortonworksInc.2011– 2016.AllRightsReserved
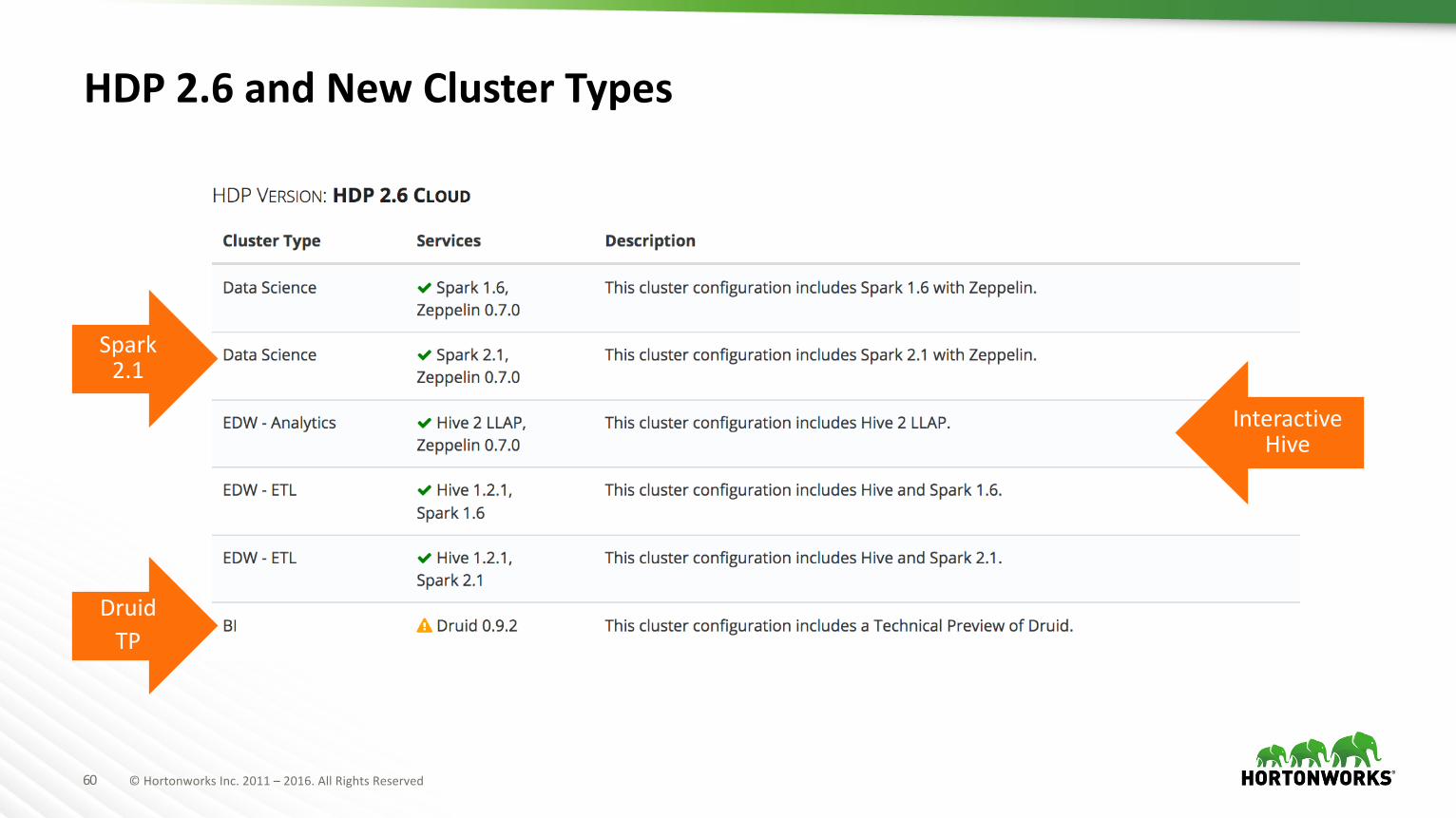
HDP2.6andNewClusterTypes
Spark2.1
DruidTP
InteractiveHive

61 ©HortonworksInc.2011– 2016.AllRightsReserved

62 ©HortonworksInc.2011– 2016.AllRightsReserved

63 ©HortonworksInc.2011– 2016.AllRightsReserved
MultitenancywithZeppelin

64 ©HortonworksInc.2011– 2016.AllRightsReserved
Livy
à LivyistheopensourceRESTinterfaceforinteractingwithApacheSparkfromanywhere
à InstalledasSparkAmbari Service
Livy Client
HTTP HTTP(RPC)
SparkInteractiveSessionSparkContext
SparkBatchSessionSparkContext
Livy Server

65 ©HortonworksInc.2011– 2016.AllRightsReserved
SecurityAcrossZeppelin-Livy-Spark
Shiro
IsparkGroupInterpreter
SPNego:Kerberos Kerberos
LivyAPIs
SparkonYARN
Zeppelin
Driver
LDAP
Livy Server

66 ©HortonworksInc.2011– 2016.AllRightsReserved
ReasonstoIntegratewithLivy
à BringSessionstoApacheZeppelin– Isolation– Sessionsharing
à Enableefficientclusterresourceutilization– DefaultSparkinterpreterkeepsYARN/Sparkjobrunningforever– Livyinterpreterrecycledafter60minutesofinactivity
(controlledbylivy.server.session.timeout )
à ToIdentityPropagation– SenduseridentityfromZeppelin>Livy>SparkonYARN
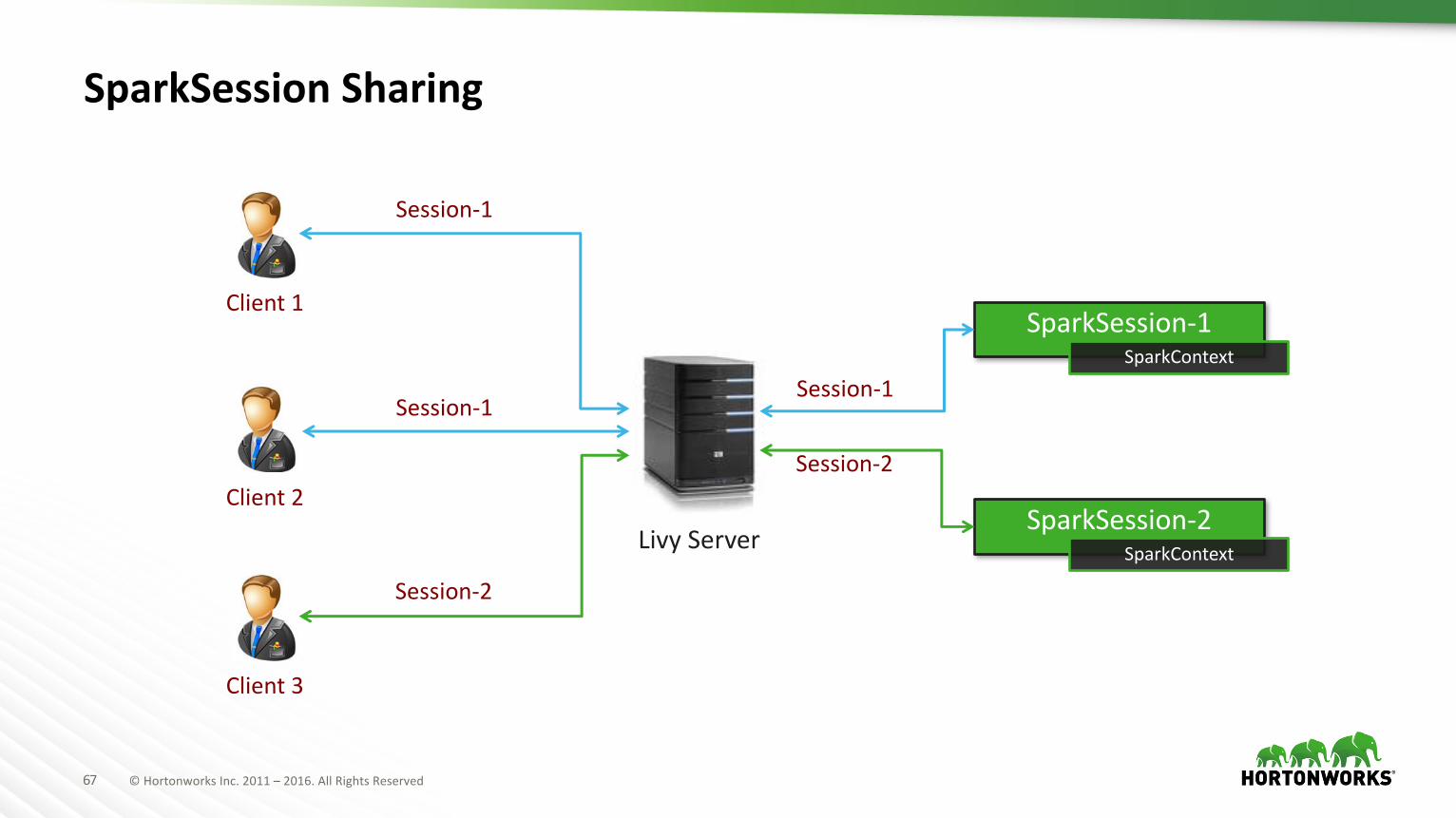
67 ©HortonworksInc.2011– 2016.AllRightsReserved
Livy Server
SparkSession Sharing
Session-2
Session-1
SparkSession-1SparkContext
SparkSession-2SparkContext
Client1
Client2
Client3
Session-1
Session-1
Session-2

68 ©HortonworksInc.2011– 2016.AllRightsReserved
ApacheZeppelinSecurity:Authentication+SSL
TommyCallahan
Zeppelin SparkonYARN
LDAP
SSL
Firewall
1
2
3
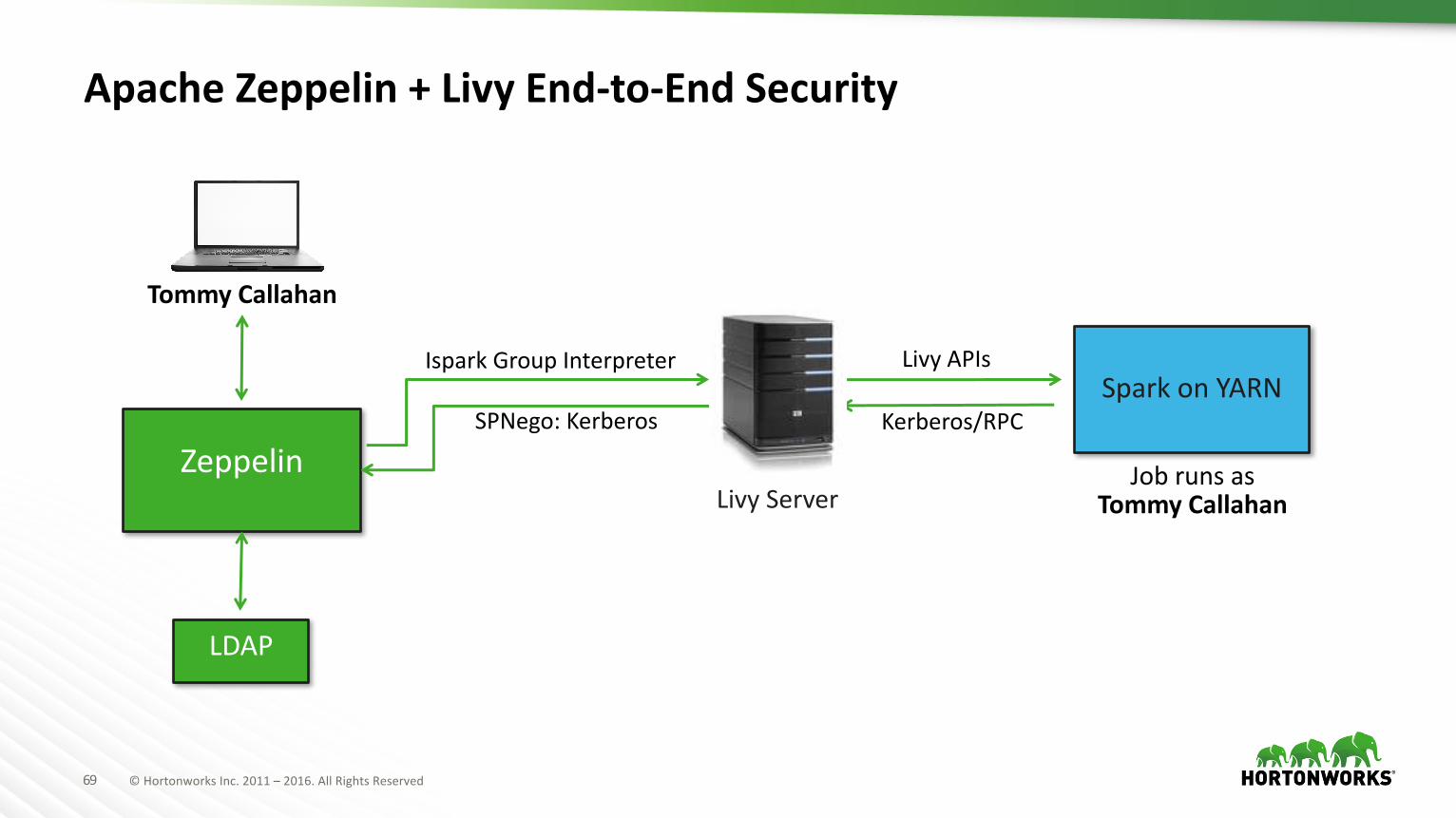
69 ©HortonworksInc.2011– 2016.AllRightsReserved
ApacheZeppelin+LivyEnd-to-EndSecurity
IsparkGroupInterpreter
SPNego:Kerberos Kerberos/RPC
LivyAPIsSparkonYARN
Zeppelin
LDAP
Livy ServerJobrunsas
TommyCallahan
TommyCallahan

70 ©HortonworksInc.2011– 2016.AllRightsReserved
SampleArchitecture

71 ©HortonworksInc.2011– 2016.AllRightsReserved
ModernDataApps
à HDP2.6– BatchProcessing
à HDF2.1– StreamingApps
DATAATREST
DATAINMOTION
ACTIONABLEINTELLIGENCE
ModernDataApplications
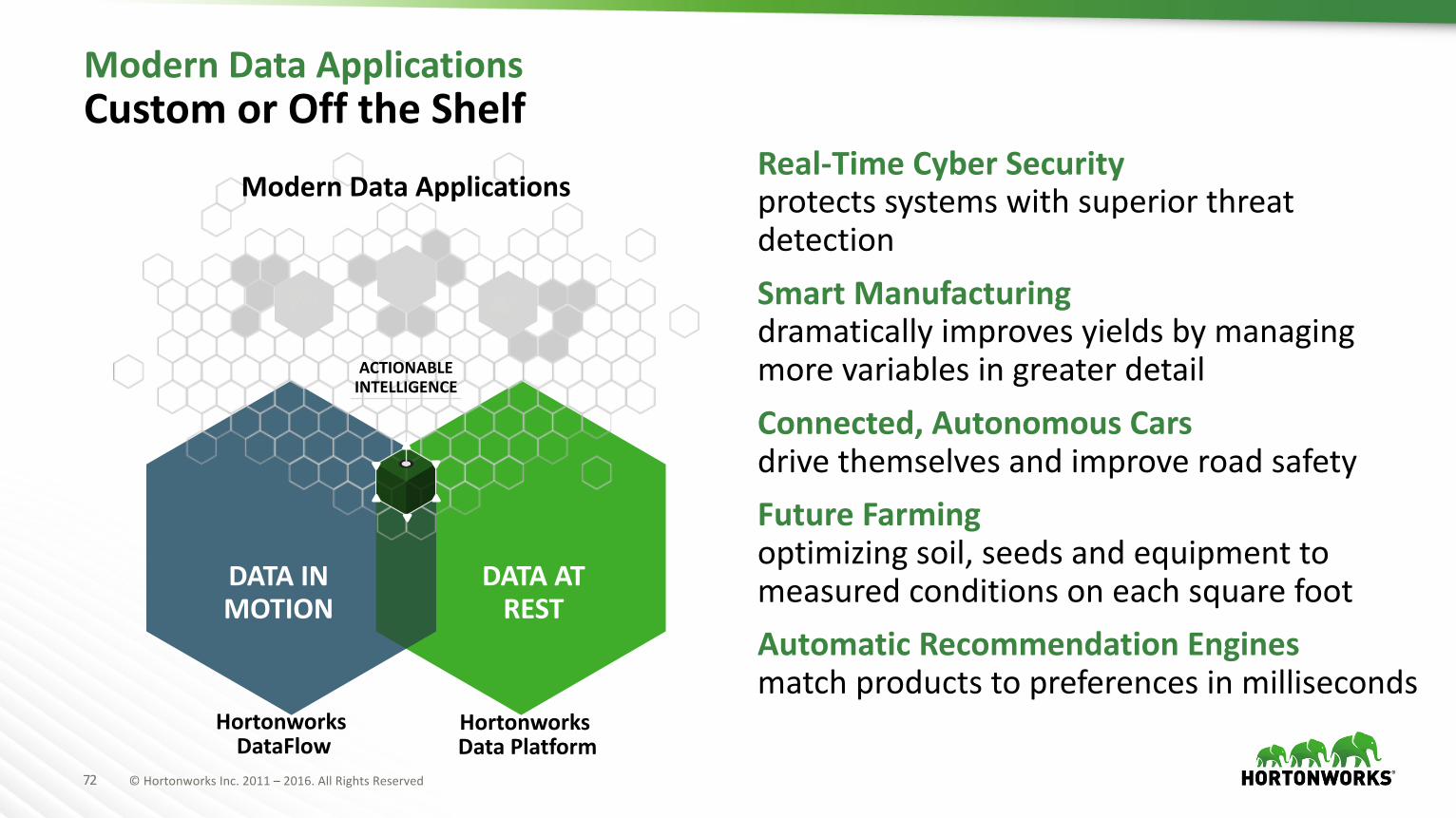
72 ©HortonworksInc.2011– 2016.AllRightsReserved
ModernDataApplicationsCustomorOfftheShelf
Real-TimeCyberSecurityprotectssystemswithsuperiorthreatdetectionSmartManufacturingdramaticallyimprovesyieldsbymanagingmorevariablesingreaterdetailConnected,AutonomousCarsdrivethemselvesandimproveroadsafetyFutureFarmingoptimizingsoil,seedsandequipmenttomeasuredconditionsoneachsquarefootAutomaticRecommendationEnginesmatchproductstopreferencesinmilliseconds
DATAATREST
DATAINMOTION
ACTIONABLEINTELLIGENCE
ModernDataApplications
HortonworksDataFlow
HortonworksDataPlatform

73 ©HortonworksInc.2011– 2016.AllRightsReserved
ManagedDataflowSOURCES REGIONAL
INFRASTRUCTURECORE
INFRASTRUCTURE

74 ©HortonworksInc.2011– 2016.AllRightsReserved

75 ©HortonworksInc.2011– 2016.AllRightsReserved
High-LevelOverview
IoT Edge(singlenode)
IoT Edge(singlenode)
IoT Devices
IoT Devices
NiFi Hub DataBroker
ColumnDB
DataStore
LiveDashboard
DataCenter(onprem/cloud)
HDFS/S3 HBase/Cassandra

76 ©HortonworksInc.2011– 2016.AllRightsReserved
Labs/Tutorials

77 ©HortonworksInc.2011– 2016.AllRightsReserved
FutureTutorials
à DeployingModelswithSparkStructuredStreaming
à PredictingAirlineDelayswithSparkR
à SentimentAnalysiswithApacheSpark(GradientBoosting)
à AutoTextClassification(NaïveBayes)
78 ©HortonworksInc.2011– 2016.AllRightsReserved
HortonworksCommunityConnection
Read access for everyone, join to participate and be recognized
• FullQ&APlatform(likeStackOverflow)
• KnowledgeBaseArticles
• CodeSamplesandRepositories

79 ©HortonworksInc.2011– 2016.AllRightsReserved
CommunityEngagement
Participate now at: community.hortonworks.com©HortonworksInc.2011– 2015.AllRightsReserved
12,000+RegisteredUsers
35,000+Answers
55,000+TechnicalAssets
One Website!

80 ©HortonworksInc.2011– 2016.AllRightsReserved
www.futureofdata.io
FutureofDataMeetups

81 ©HortonworksInc.2011– 2016.AllRightsReserved
FBSort
à Sparkjobthatreads60TBofcompresseddataandperformsa90TBshuffleandsort.
à Largestreal-worldSparkjobtodate!– Databricks’PetaByte sortwasonsyntheticdata.
à Multiplereliabilityfixes.
à Sparkjobthatreads60TBofcompresseddataandperformsa90TBshuffleandsort.
à Largestreal-worldSparkjobtodate!– Databricks’PetaByte sortwasonsyntheticdata.
à Multiplereliabilityfixes.
“Sparkcouldreliablyshuffleandsort90TB+intermediatedataandrun250,000tasksinasinglejob[...]andithasbeenrunninginproductionforseveralmonths.”

82 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkSQLStructuredData
SparkStreamingNearReal-time
SparkMLlibMachineLearning
GraphXGraphAnalysis
RobertHryniewicz@robertH8z

83 ©HortonworksInc.2011– 2016.AllRightsReserved
What’snewinHDP2.6– Spark&Zeppelin
à Spark1.6.3GA
à Spark2.1GA
à RESTAPI(Livy)GA
à SparkThriftServerdoAS GA
à SparkSQL – Row/ColumnSecurity(GA)
à SparkStreaming+KafkaoverSSL
à MultiClusterHBase supportforSHC
à PackagesupportinPySpark &SparkR
Sparkà Spark2.xsupport
à ImprovedLivyintegration
à Nopasswordinclear
à JDBCinterpreterimprovements
à SmartSenseintegration
à KnoxproxyZeppelinUI
Zeppelin0.7.x

RobertHryniewicz@RobertH8z
Thanks!


















