
Apache Spark 1.6 with Zeppelin - Transformations and Actions on RDDs
32
Learning Apache Spark – Part 2 – Transformations and Actions on RDDs
-
Upload
timothy-spann -
Category
Data & Analytics
-
view
1.321 -
download
1
Transcript of Apache Spark 1.6 with Zeppelin - Transformations and Actions on RDDs

LearningApacheSpark–Part2– TransformationsandActionsonRDDs

PresenterIntroductionTimSpann,SeniorSolutionsArchitect,airis.DATA
• ex-PivotalSeniorFieldEngineer• DZONEMVBandZoneLeader• ex-StartupSeniorEngineer/TeamLead
http://www.slideshare.net/bunkertorhttp://sparkdeveloper.com/http://www.twitter.com/PaasDev

airis.DATAairis.DATA isanextgenerationsystemintegratorthatspecializesinrapidlydeployablemachinelearningandgraphsolutions.
Ourcorecompetenciesinvolveprovidingmodular,scalableBigDataproductsthatcanbetailoredtofitusecasesacrossindustryverticals.
WeofferpredictivemodelingandmachinelearningsolutionsatPetabytescaleutilizingthemostadvanced,best-in-classtechnologiesandframeworksincludingSpark,H20,andFlink.
Ourdatapipeliningsolutionscanbedeployedinbatch,real-timeornear-real-timesettingstofityourspecificbusinessuse-case.

Agenda
• Hands-On:QuickInstallZeppelin
• RDDTransformations
• RDDActions
• Hands-On:• RDDtransformationsandactionsinScalaonSparkStandalonelocal

InstallingZeppelinandSpark1.6• JavaJDK8,Scala2.10,SBT0.13,Maven3.,Spark1.6.0• http://www.oracle.com/technetwork/java/javase/downloads/index.html• http://www.scala-lang.org/download/2.10.6.html• http://www.scala-lang.org/download/install.html• http://www.scala-sbt.org/download.html• http://apache.claz.org/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.zip• http://spark.apache.org/downloads.html• http://d3kbcqa49mib13.cloudfront.net/spark-1.6.0-bin-hadoop2.6.tgz• http://www.apache.org/dyn/closer.cgi/incubator/zeppelin/0.5.6-incubating/zeppelin-0.5.6-incubating-bin-all.tgz• ForMac(brewinstallsbt)

InstallingZeppelinandSpark1.6no.2export SPARK_MASTER_IP=127.0.0.1export SPARK_LOCAL_IP=127.0.0.1export SCALA_HOME={YOURDIR}/scala-2.10.6export PATH=$PATH:$SCALA_HOME/bin
For Windows, use SET instead of EXPORT and ; and not :.

RunningZeppelinandSpark1.6https://zeppelin.incubator.apache.org/docs/0.5.6-incubating/install/install.htmlhttps://github.com/hortonworks-gallery/zeppelin-notebooks
DownloadtheApacheZeppelinbinary(MacandLinux)zeppelin-0.5.6-incubating-bin-allUnzipRuncdzeppelin-0.5.6-incubating-bin-all./bin/zeppelin-daemon.shstarthttp://localhost:8080/

ResilientDistributedDatasets(RDDs)haveACTIONS thatreturnvalues(output)
val textfile =sc.textFile(”mydata.txt”)textfile.count()
TRANSFORMATIONSwhichreturnpointerstonewRDDs.
val lines =textFile.filter(line=>line.contains(“Spark”))

Transformation Meaningmap(func) Returnanewdistributeddatasetformedbypassingeachelementofthesourcethrougha
function func.
filter(func) Returnanewdatasetformedbyselectingthoseelementsofthesourceonwhich funcreturnstrue.flatMap(func) Similartomap,buteachinputitemcanbemappedto0ormoreoutput items(so funcshouldreturna
Seqratherthanasingleitem).
mapPartitions(func) Similartomap,butrunsseparatelyoneachpartition(block)oftheRDD,so funcmustbeoftypeIterator<T>=>Iterator<U>whenrunningonanRDDoftypeT.
mapPartitionsWithIndex(func) SimilartomapPartitions,butalsoprovides funcwithanintegervaluerepresentingthe indexofthepartition,so funcmustbeoftype(Int,Iterator<T>)=>Iterator<U>whenrunningonanRDDoftypeT.
sample(withReplacement, fraction, seed)
Sampleafraction fraction ofthedata,withorwithout replacement,usingagivenrandomnumbergeneratorseed.
union(otherDataset) Returnanewdatasetthatcontainstheunionoftheelementsinthesourcedatasetandtheargument.intersection(otherDataset) ReturnanewRDDthatcontainstheintersectionofelementsinthesourcedatasetandtheargument.distinct([numTasks])) Returnanewdatasetthatcontainsthedistinctelementsofthesourcedataset.groupByKey([numTasks]) Whencalledonadatasetof(K,V)pairs,returnsadatasetof(K,Iterable<V>)pairs.
Note: Ifyouaregroupinginordertoperformanaggregation(suchasasumoraverage)overeachkey,using reduceByKey or aggregateByKeywillyieldmuchbetterperformance.Note:Bydefault,the levelofparallelismintheoutput dependsonthenumberofpartitionsoftheparentRDD.Youcanpassanoptional numTasks argumenttosetadifferentnumberoftasks.
Transformations

Transformation Meaning
reduceByKey(func,[numTasks])
Whencalledonadatasetof(K,V)pairs,returnsadatasetof(K,V)pairswherethevaluesforeachkeyareaggregatedusingthegivenreducefunction func,whichmustbeoftype(V,V)=>V.Likein groupByKey,thenumberofreducetasksisconfigurablethroughanoptionalsecondargument.
aggregateByKey(zeroValue)(seqOp, combOp,[numTasks])
Whencalledonadatasetof(K,V)pairs,returnsadatasetof(K,U)pairswherethevaluesforeachkeyareaggregatedusingthegivencombinefunctionsandaneutral"zero"value.Allowsanaggregatedvaluetypethat isdifferentthantheinputvaluetype,whileavoidingunnecessaryallocations.Likein groupByKey,thenumberofreducetasksisconfigurablethroughanoptionalsecondargument.
sortByKey([ascending],[numTasks])
Whencalledonadatasetof(K,V)pairswhereKimplementsOrdered,returnsadatasetof(K,V)pairssortedbykeysinascendingordescendingorder,asspecifiedinthebooleanascending argument.
join(otherDataset,[numTasks])
Whencalledondatasetsoftype(K,V)and(K,W),returnsadatasetof(K,(V,W))pairswithallpairsofelementsforeachkey.Outerjoinsaresupportedthrough leftOuterJoin,rightOuterJoin,and fullOuterJoin.
cogroup(otherDataset,[numTasks])
Whencalledondatasetsoftype(K,V)and(K,W),returnsadatasetof(K,(Iterable<V>,Iterable<W>))tuples.Thisoperationisalsocalled groupWith.
Transformations

Transformation Meaning
cartesian(otherDataset) WhencalledondatasetsoftypesTandU,returnsadatasetof(T,U)pairs(allpairsofelements).
pipe(command, [envVars]) PipeeachpartitionoftheRDDthroughashellcommand,e.g.aPerlorbashscript.RDDelementsarewrittentotheprocess'sstdinandlinesoutput toitsstdoutarereturnedasanRDDof strings.
coalesce(numPartitions) DecreasethenumberofpartitionsintheRDDtonumPartitions.Usefulforrunningoperationsmoreefficientlyafterfilteringdownalargedataset.
repartition(numPartitions) Reshuffle thedataintheRDDrandomly tocreateeithermoreorfewerpartitionsandbalanceitacrossthem.Thisalwaysshufflesalldataoverthenetwork.
repartitionAndSortWithinPartitions(partitioner)
RepartitiontheRDDaccordingtothegivenpartitionerand,withineachresultingpartition, sortrecordsbytheirkeys.Thisismoreefficientthancalling repartition andthensortingwithineachpartitionbecauseitcanpush thesortingdown intotheshufflemachinery.
Transformations

MAPlogFile.map(parseLogLine)
WhereparseLogLineisaScalafunctionthattakesonelineoftheApachelogasaStringandparsesitintoaLogRecordcaseclass.ForeachlineinthefileRDD,wecalltheMapfunctiononit,thefinalresultisanewRDD.
FILTERfilter(!_.clientIp.equals("Empty"))
Wherewefilterout”Empty”linesfromourresultingRDD.ThisfilterisoperatingonanRDDofLogRecords
MAP FILTERTransformations

FLATMAPvalflatRDD=originalRDD.flatMap(_.split(""))
Mapsto0ormoreitemsreturningaScalaSeq(uence).
MAPPARTITIONSWITHINDEXvalmapped=originalRDD.mapPartitionsWithIndex{
(index,iterator)=>{println("Index->"+index)valmyList=iterator.toListmyList.map(x=>x+"->"+index).iterator}
}
Runamaponeachpartitionandgetanindex.OtherwisesameasMapPartitions.
FLATMAP MAPPARTITIONS+Transformations

valrddSpark =sc.parallelize(List("SQL","Streaming","GraphX","MLLib","Bagel","SparkR","Python","Scala","Java","Alluxio","Tungsten","Zeppelin"))valrddHadoop =sc.parallelize(List("HDFS","YARN","TEZ","Hive","HBase","Pig","Atlas","Storm","Accumulo","Ranger","Phoenix","MapReduce","Slider","Flume","Kafka","Oozie","Sqoop","Falcon","Knox","Ambari","Zookeeper","Cloudbreak","SQL","Java","Scala","Python"))
UNIONrddHadoop.union(rddSpark).collect()
DoasetUNIONonsourcedatasetandargument
INTERSECTIONrddHadoop.intersection(rddSpark).collect()
Doasetintersectiononsourcedatasetandargument
UNION INTERSECTIONTransformations

DISTINCTbigDataRDD.distinct().collect()
Getdistinctelementsfromthesourcedataset
SAMPLEbigDataRDD.sample(true,0.25).collect()res89:Array[String]=Array(HDFS,TEZ,Pig,Knox,Python,Python)
Sampleafraction(0.25)ofthedatawithreplacement(true).
SamplingwithoutreplacementrequiresoneadditionalpassovertheRDDtoguaranteesamplesize,whereassamplingwithreplacementrequirestwoadditionalpasses.Withreplacementisslower.
DISTINCT SAMPLETransformations

GROUPBYKEYvalgroupByRDD=keyValueRDD.groupByKey()
ForDatasets(K,V)pairs,notoftenused.reduceByKeyispreferred.
REDUCEBYKEYvalkvRDD=sc.parallelize(Seq((1,"Bacon"),(1,"Hamburger"),(1,"Cheeseburger")))valreducedByRDD=kvRDD.reduceByKey((a,b)=>a.concat(b))reducedByRDD:org.apache.spark.rdd.RDD[(Int,String)]=ShuffledRDD[66]atreduceByKeyat<console>:31res136:Array[(Int,String)]=Array((1,BaconHamburgerCheeseburger))
Reducebyfunction(concat)onthekey.
GROUPBYKEY REDUCEBYKEYTransformations

AGGREGATEBYKEYvalnamesRDD=sc.parallelize(List((1,25),(1,27),(3,25),(3,27)))valgroupByRDD=namesRDD.aggregateByKey(0)((k,v)=>v.toInt+k,(v,k)=>k+v).collect()groupByRDD:Array[(Int,Int)]=Array((1,52),(3,52))
ForDatasets(K,V)pairs,returnspairswherevaluesforeachkeyareaggregatedwithafunctionand“zero”value.
SORTBYKEYvalsortByRDD=namesRDD.sortByKey(true).collect()sortByRDD:Array[(Int,Int)]=Array((1,25),(1,27),(3,25),(3,27))
Returnsadatasetofpairssortedbykeysinascendingordescendingorder
AGGREGATEBYKEY SORTBYKEYTransformations

JOINvalotherKeyValueRDD=sc.parallelize(Seq(("Bacon", "Amazing"), ("Steak", "Fine"), ("Lettuce","Sad")))
keyValueRDD.join(otherKeyValueRDD).collect()res166:Array[(String, (String, String))]=Array((Bacon,(Awesome,Amazing)))
Returnsadatasetwithpairsforeachkey.
LEFTOUTERJOINkeyValueRDD.leftOuterJoin(otherKeyValueRDD).collect()res170:Array[(String,(String,Option[String]))]=Array((PorkRoll,(Great,None)),(Tofu,(Bogus,None)),(Bacon,(Awesome,Some(Amazing))))
ReturnsadatasetfollowingSQLstyleouterjoins.
JOIN LEFTOUTERJOIN RIGHTOUTERJOIN FULLOUTERJOIN

COGROUPkeyValueRDD.cogroup(otherKeyValueRDD).collect()res178:Array[(String,(Iterable[String],Iterable[String]))]=Array((PorkRoll,(CompactBuffer(Great),CompactBuffer())),(Steak,(CompactBuffer(),CompactBuffer(Fine))),(Tofu,(CompactBuffer(Bogus),CompactBuffer())), (Lettuce,(CompactBuffer(),CompactBuffer(Sad))),(Bacon,(CompactBuffer(Awesome),CompactBuffer(Amazing))))
Alsoknownas”groupWith”.
CARTESIANkeyValueRDD.cartesian(otherKeyValueRDD).collect()res182:Array[((String,String),(String,String))]=Array(((Bacon,Awesome),(Bacon,Amazing)),((Bacon,Awesome),(Steak,Fine)),((Bacon,Awesome),(Lettuce,Sad)),((PorkRoll,Great),(Bacon,Amazing)),((PorkRoll,Great),(Steak,Fine)),((PorkRoll,Great),(Lettuce,Sad)),((Tofu,Bogus),(Bacon,Amazing)),((Tofu,Bogus),(Steak,Fine)),((Tofu,Bogus),(Lettuce,Sad)))Returnsdatasetofallpairsofelements. CartesianProduct.
COGROUP CARTESIANTransformations

PIPEkeyValueRDD.pipe("cut-c2-4").collect()res213:Array[String]=Array(Bac,Por,Tof)
Callacommandlinefunction.
COALESCEkeyValueRDD.coalesce(1).collect()
Decreasethenumberofpartitions.
PIPE COALESCETransformations

REPARTITIONkeyValueRDD.repartition(2).collect()res241:Array[(String,String)]=Array((Bacon,Awesome), (PorkRoll,Great), (Tofu,Bogus))
ReshufflethedataintheRDDrandomlytocreateeithermoreorlesspartitionsandbalanceacrossthem.Goodafterfilteringdownalargedataset.
REPARTITIONANDSORTWITHINPARTITIONSkeyValueRDD.repartitionAndSortWithinPartitions(YourPartioner).collect()
Repartitionusingacustomerpartitioner,sortrecordsbytheirkeys.Secondarysorting.
See:http://codingjunkie.net/spark-secondary-sort/
REPARTITION REPARTITIONANDSORTWITHINPARTITIONS

Action Meaning
reduce(func) Aggregatetheelementsofthedatasetusingafunction func (which takestwoargumentsandreturnsone).Thefunctionshouldbecommutativeandassociativesothatitcanbecomputedcorrectlyinparallel.
collect() Returnalltheelementsofthedatasetasanarrayatthedriverprogram.Thisisusuallyusefulafterafilterorotheroperation thatreturnsasufficiently smallsubsetofthedata.
count() Returnthenumber ofelementsinthedataset.
first() Returnthefirstelementofthedataset(similartotake(1)).
take(n) Returnanarraywiththefirst n elementsof thedataset.
takeSample(withReplacement,num, [seed])
Returnanarraywitharandomsampleof num elementsofthedataset,withorwithoutreplacement,optionallypre-specifying arandomnumbergeneratorseed.
takeOrdered(n, [ordering]) Returnthefirst n elementsoftheRDDusingeithertheirnaturalorderoracustomcomparator.
Actions

Action MeaningsaveAsTextFile(path) Writetheelementsof thedatasetasatextfile(or setoftextfiles) inagivendirectory inthe
localfilesystem,HDFSoranyotherHadoop-supported filesystem.SparkwillcalltoStringoneachelementtoconvertittoalineoftextinthefile.
saveAsSequenceFile(path)(JavaandScala)
Writetheelementsof thedatasetasaHadoopSequenceFile inagivenpathinthelocalfilesystem,HDFSoranyotherHadoop-supported filesystem.ThisisavailableonRDDsofkey-valuepairsthatimplementHadoop'sWritableinterface.InScala,itisalsoavailableontypesthatareimplicitlyconvertibletoWritable(SparkincludesconversionsforbasictypeslikeInt,Double, String,etc).
saveAsObjectFile(path)
(JavaandScala)
Writetheelementsof thedatasetinasimpleformatusing Javaserialization,whichcanthenbeloadedusingSparkContext.objectFile().
countByKey() OnlyavailableonRDDsof type(K,V).Returnsahashmapof(K, Int)pairswiththecountofeachkey.
foreach(func) Runafunction func oneachelementofthedataset.Thisisusuallydone forsideeffectssuchasupdatinganAccumulator orinteractingwithexternalstoragesystems.Note:modifying variablesother thanAccumulatorsoutsideofthe foreach() mayresultinundefined behavior.See Understandingclosures formoredetails.
Actions

ACTIONSoriginalRDD.collect()originalRDD.collect().foreach(println)originalRDD.count()originalRDD.first()originalRDD.take(2)originalRDD.takeSample(true,5,7634184)originalRDD.takeOrdered(5)
TakeSampletakesthe#ofsamples,ifyouwantreplacementsanarandomnumbergeneratorseed.
COLLECT COUNT FIRST TAKE TAKESAMPLE TAKEORDERED
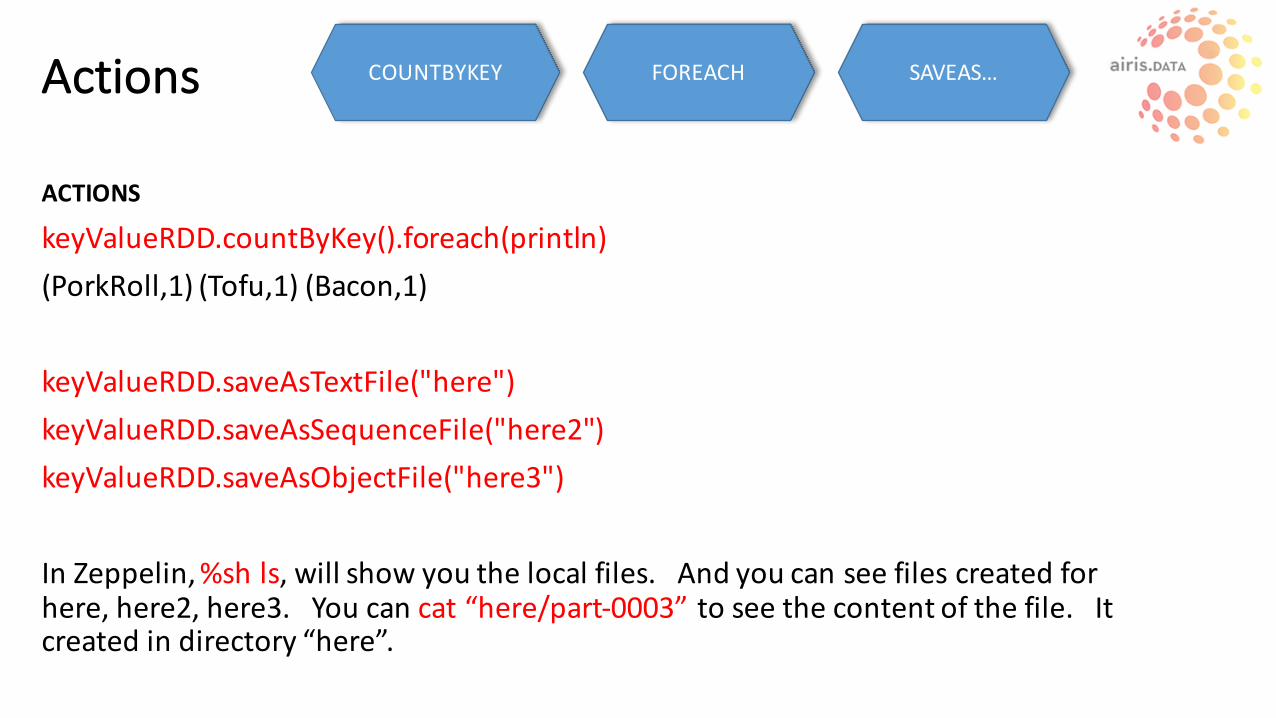
ACTIONS
keyValueRDD.countByKey().foreach(println)(PorkRoll,1)(Tofu,1)(Bacon,1)
keyValueRDD.saveAsTextFile("here")keyValueRDD.saveAsSequenceFile("here2")keyValueRDD.saveAsObjectFile("here3")
InZeppelin,%shls,willshowyouthelocalfiles.Andyoucanseefilescreatedforhere,here2,here3.Youcancat“here/part-0003”toseethecontentofthefile.Itcreatedindirectory“here”.
COUNTBYKEY FOREACH SAVEAS…Actions

ACTIONS
bigDataRDD.reduce((a,b)=>a.concat(b))res154:String=AmbariZookeeperCloudbreakSQLJavaScalaPythonFlumeKafkaOozieSqoopFalconKnoxAtlasStormAccumuloRangerPhoenixMapReduceSliderHDFSYARNTEZHiveHBasePigSQLStreamingGraphXMLLibBagelSparkRPythonScalaJavaAlluxioTungstenZeppelin
Aggregatestheelementsofthedatasetusingafunction.Forthisone,weconcatenatealltheBigDataStringsintoonelongStringappropriateforresumes.
REDUCEActions

ApacheZeppelin
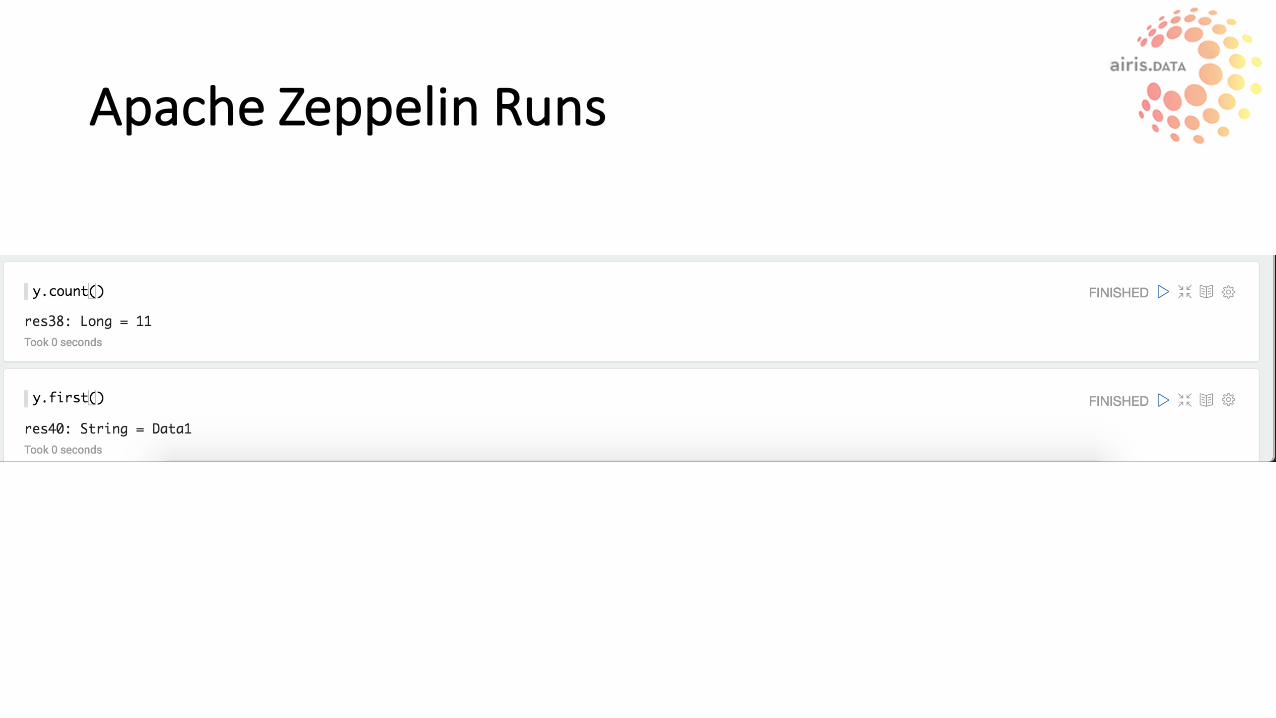
ApacheZeppelinRuns
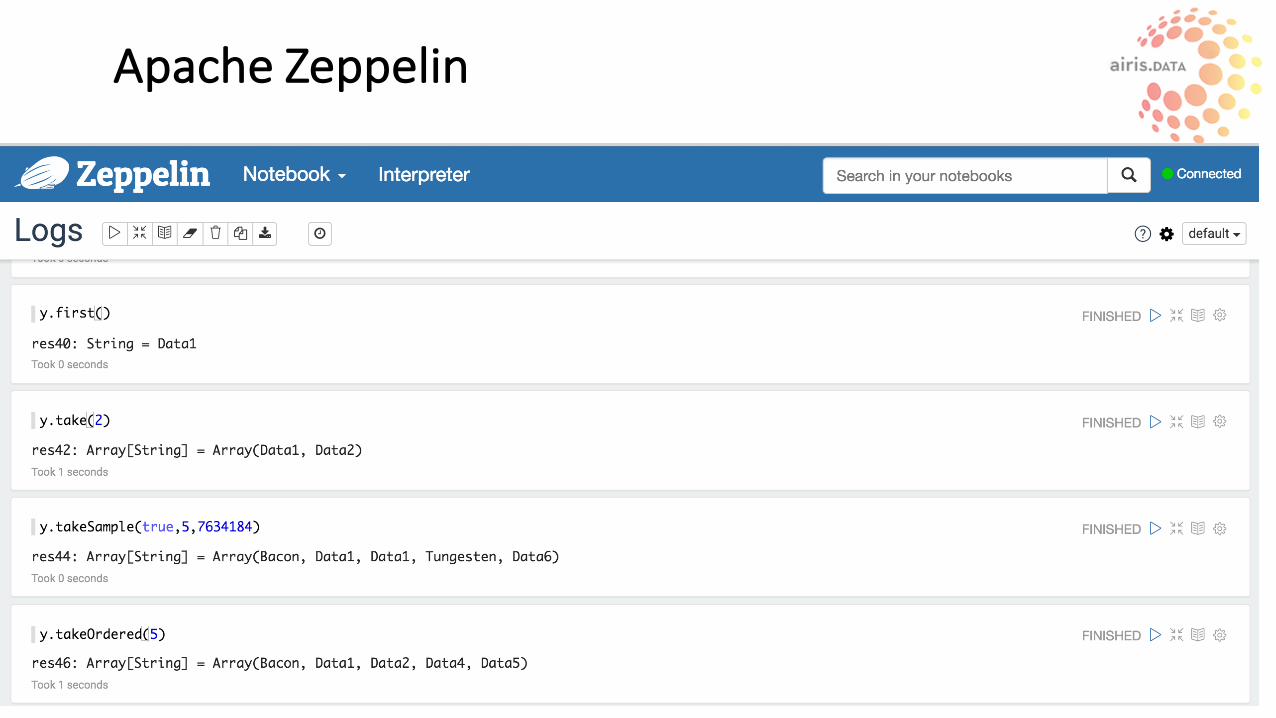
ApacheZeppelin
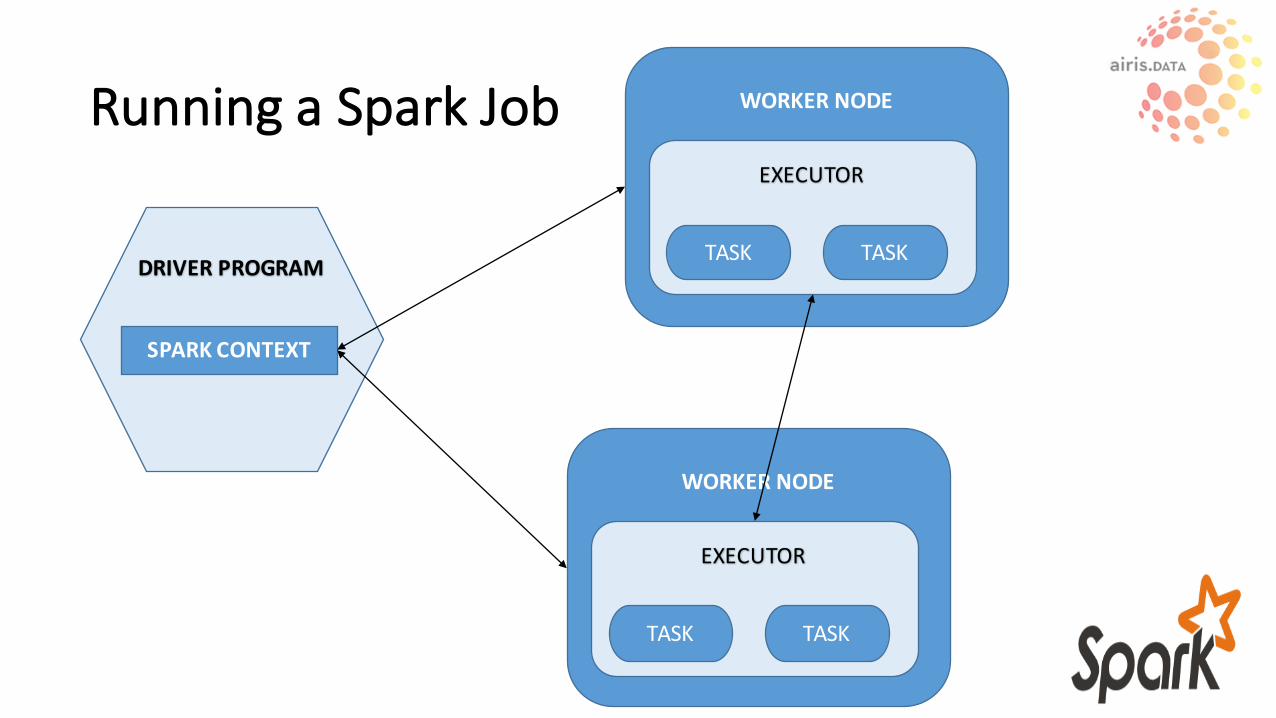
RunningaSparkJob
DRIVERPROGRAM
SPARKCONTEXT
WORKERNODE
EXECUTOR
TASKTASK
WORKERNODE
EXECUTOR
TASKTASK
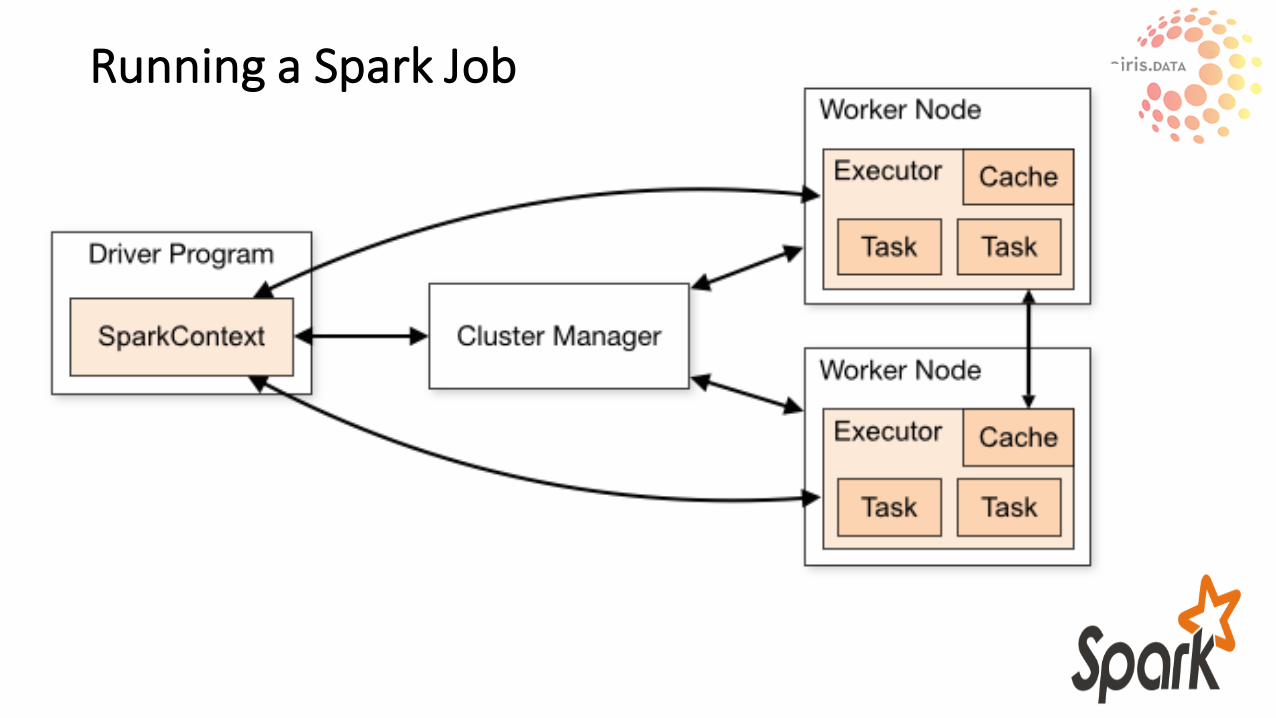
RunningaSparkJob

SparkResources
http://www.slideshare.net/airisdata/parquet-and-avrohttp://airisdata.com/scala-spark-resources-setup-learning/https://dzone.com/articles/anatomy-of-a-scala-spark-programhttps://dzone.com/articles/proper-sbt-setup-for-scala-210-and-spark-streaminghttps://github.com/airisdata/sparkworkshophttps://github.com/airisdata/SparkTransformationshttps://github.com/airisdata/avroparquethttp://www.slideshare.net/airisdata/apache-spark-overview-59903397https://plugins.jetbrains.com/plugin/?id=1347http://mund-consulting.com/Products/Sparklet.aspx

















![Rectal drug delivery system [RDDS]](https://static.fdocuments.net/doc/165x107/587aa8501a28abed218b4e75/rectal-drug-delivery-system-rdds.jpg)
