
Apache Kylin 云原生架构 思考及规划Kylin云原生架构思考及规划...Apache Kylin...
28
Apache Kylin 云原生架构 思考及规划 演讲人 史少锋 Kyligence 首席架构师 Apache Kylin PMC & Committer
Transcript of Apache Kylin 云原生架构 思考及规划Kylin云原生架构思考及规划...Apache Kylin...

Effective Cloud User Group www.ecug.org
Apache Kylin 云原生架构
思考及规划
演讲人史少锋
Kyligence首席架构师Apache Kylin PMC & Committer

Effective Cloud User Group www.ecug.org
关于 Apache Kylin
Extreme OLAP Engine for Big Data
Apache Kylin™是一个开源的分布式分析引擎,为 Hadoop等大型分布式数据平台之上的超大规模数据集通过标准 SQL查询及多维分析(OLAP)功能,提供亚秒级的交互式分析能力。
官方网站: https://kylin.apache.org
Effective Cloud User Group www.ecug.org
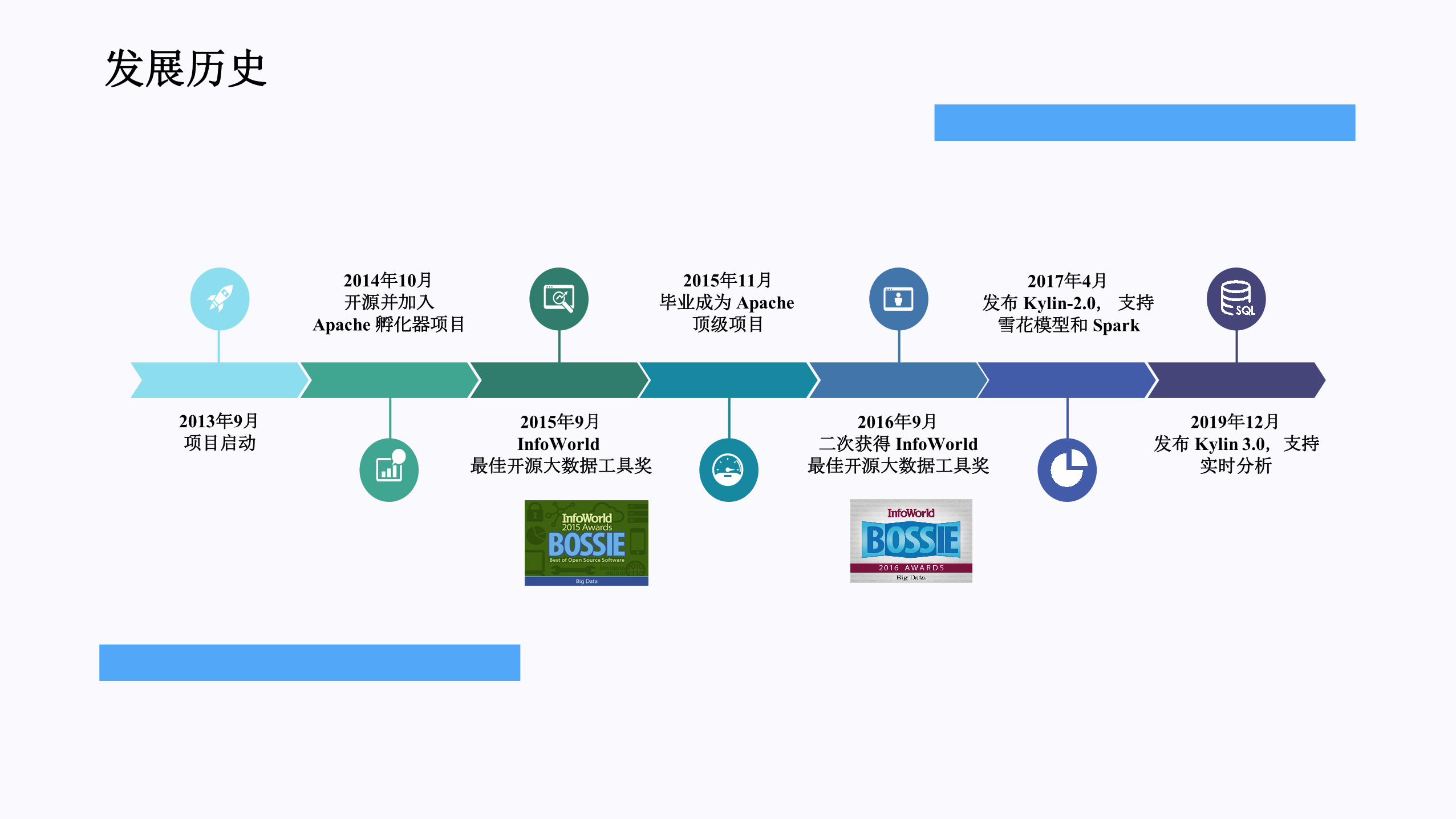
发展历史
2014年10月开源并加入
Apache孵化器项目
2013年9月项目启动
2015年11月毕业成为 Apache顶级项目
2015年9月InfoWorld
最佳开源大数据工具奖
2016年9月二次获得 InfoWorld最佳开源大数据工具奖
2017年4月发布 Kylin-2.0,支持雪花模型和 Spark
2019年12月发布 Kylin 3.0,支持
实时分析

Effective Cloud User Group www.ecug.org
Apache Kylin 基础架构
Data analytics
Hive / Kafka / RDBMS
Apache Kylin
MR/Spark HBase / Parquet
Interactive Reporting Dashboard
OLAP / Data mart
Hadoop
- Build OLAP cube on Hadoop
- Support TB to PB level data
- Sub-second query latency
- ANSI-SQL
- JDBC / ODBC / REST API
- BI integration
- Web GUI
- LDAP/SSO
Effective Cloud User Group www.ecug.org
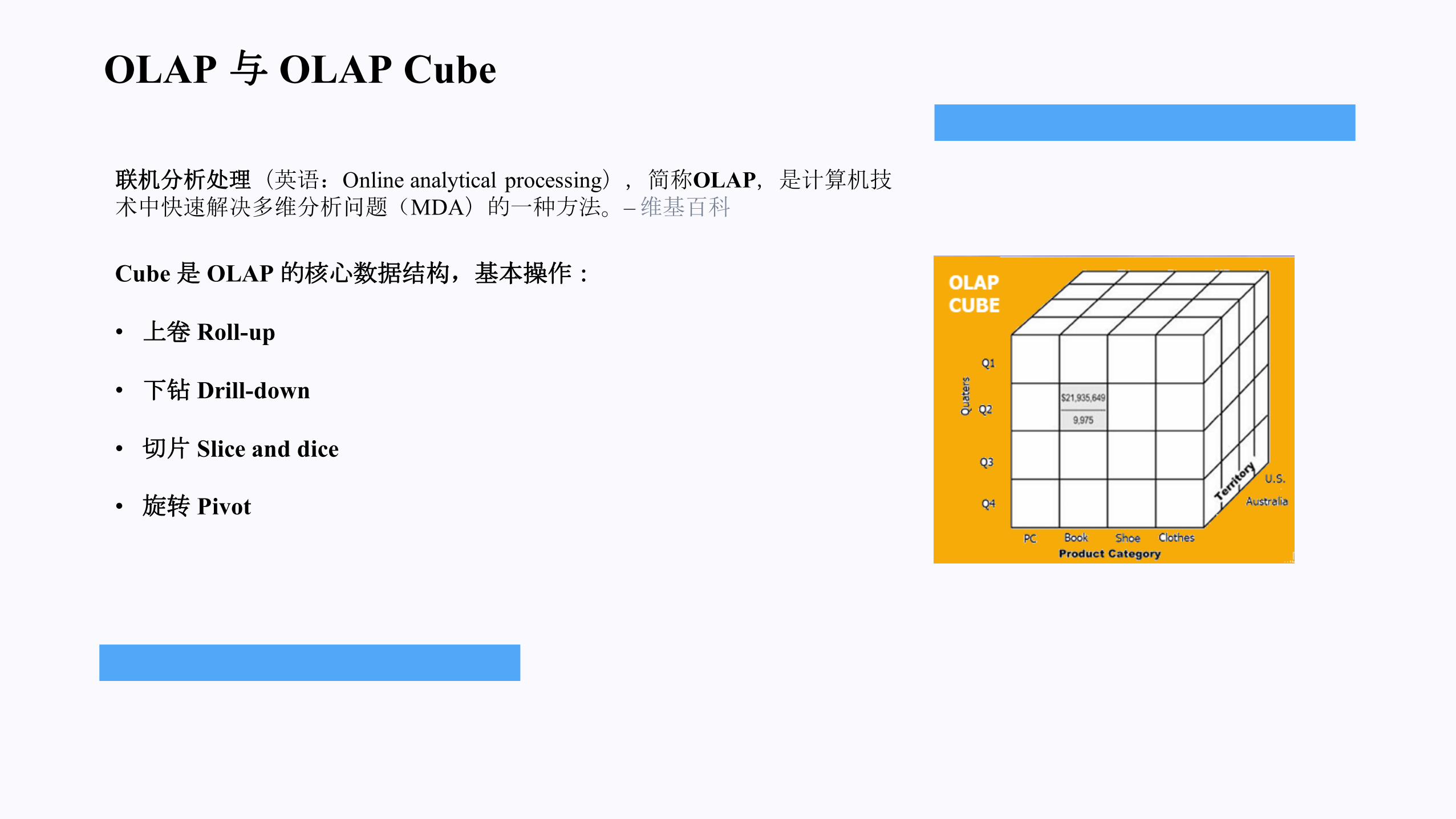
OLAP 与 OLAP Cube
联机分析处理(英语:Online analytical processing),简称OLAP,是计算机技术中快速解决多维分析问题(MDA)的一种方法。–维基百科
Cube 是 OLAP 的核心数据结构,基本操作:
• 上卷 Roll-up
• 下钻 Drill-down
• 切片 Slice and dice
• 旋转 Pivot
Effective Cloud User Group www.ecug.org
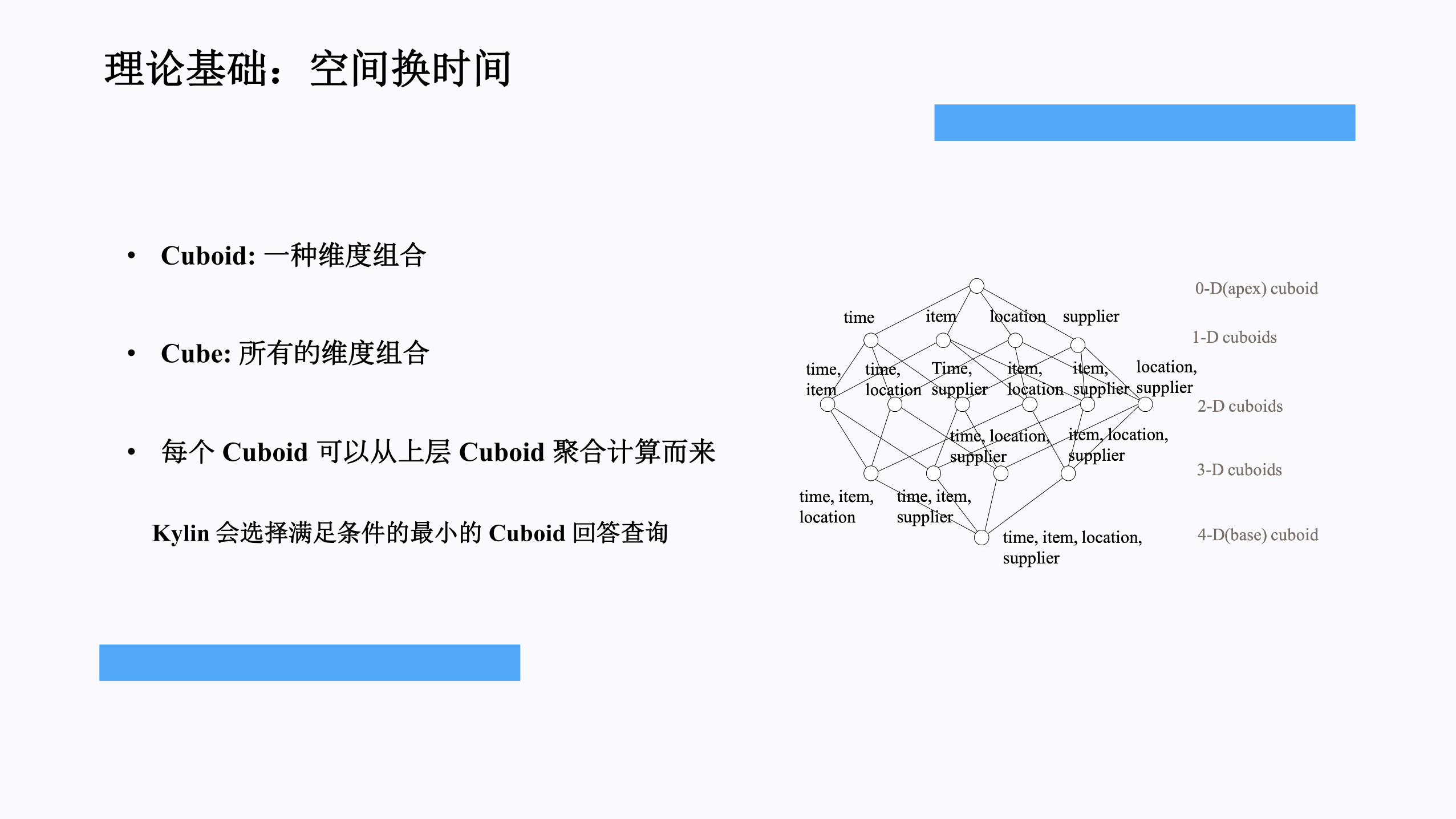
理论基础:空间换时间
• Cuboid:一种维度组合
• Cube:所有的维度组合
• 每个 Cuboid可以从上层 Cuboid 聚合计算而来
Kylin 会选择满足条件的 小的 Cuboid 回答查询
Effective Cloud User Group www.ecug.org
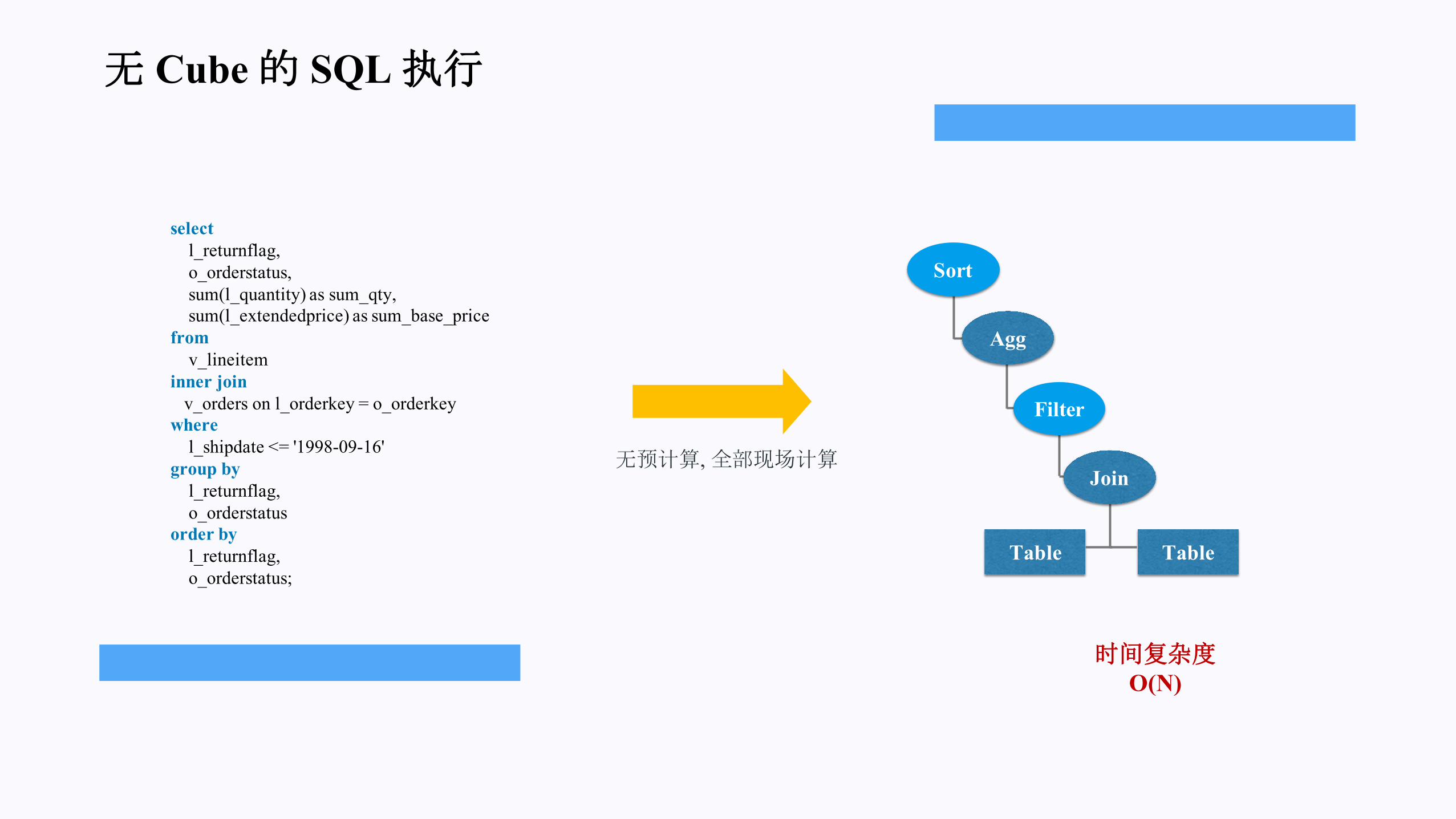
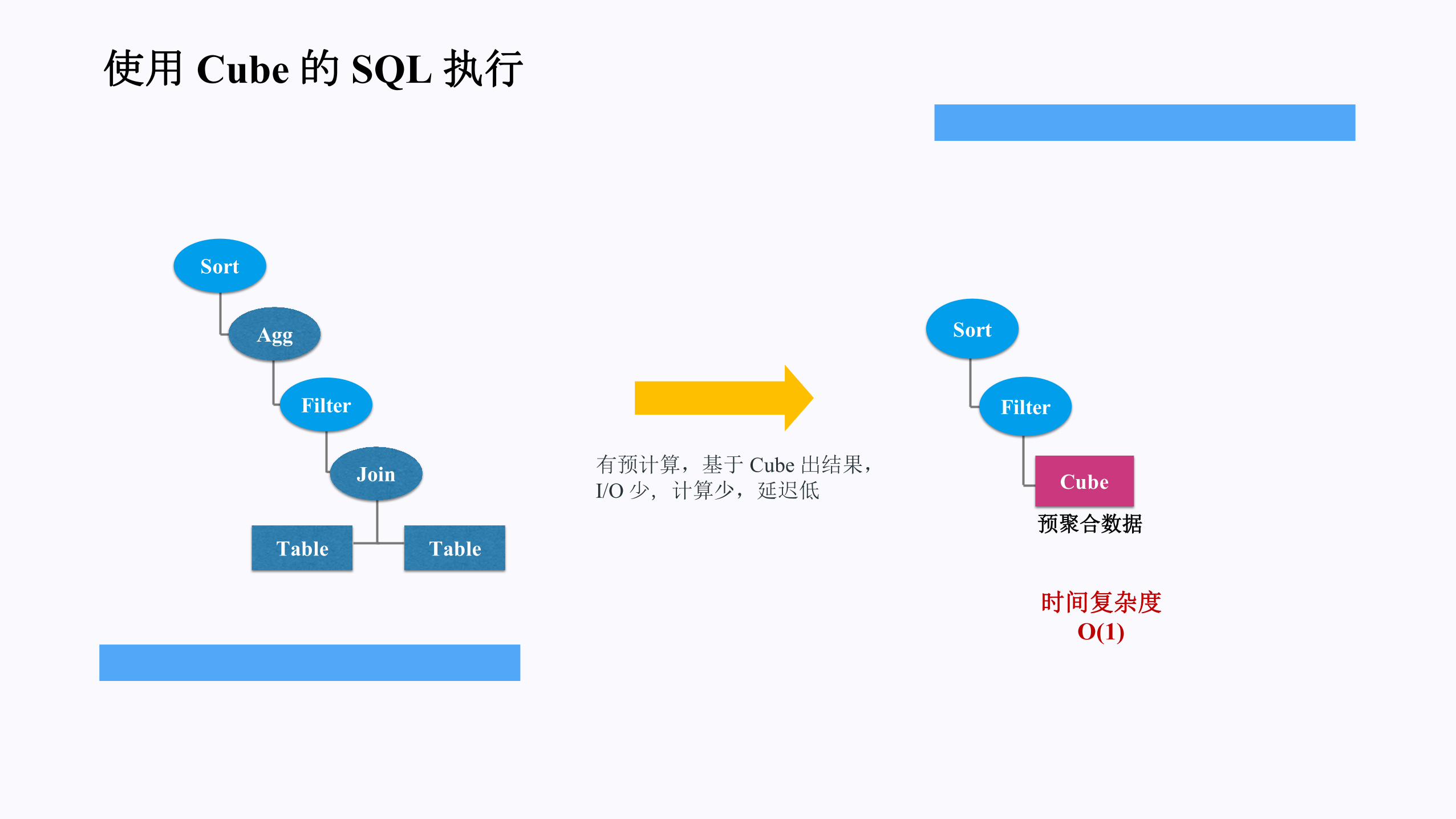
无 Cube的 SQL执行
selectl_returnflag,o_orderstatus,sum(l_quantity) as sum_qty,sum(l_extendedprice) as sum_base_price
fromv_lineitem
inner join v_orders on l_orderkey = o_orderkey
wherel_shipdate <= '1998-09-16'
group byl_returnflag,o_orderstatus
order byl_returnflag,o_orderstatus;
时间复杂度O(N)
无预计算,全部现场计算
Sort
Agg
Filter
Table
Join
Table
Effective Cloud User Group www.ecug.org
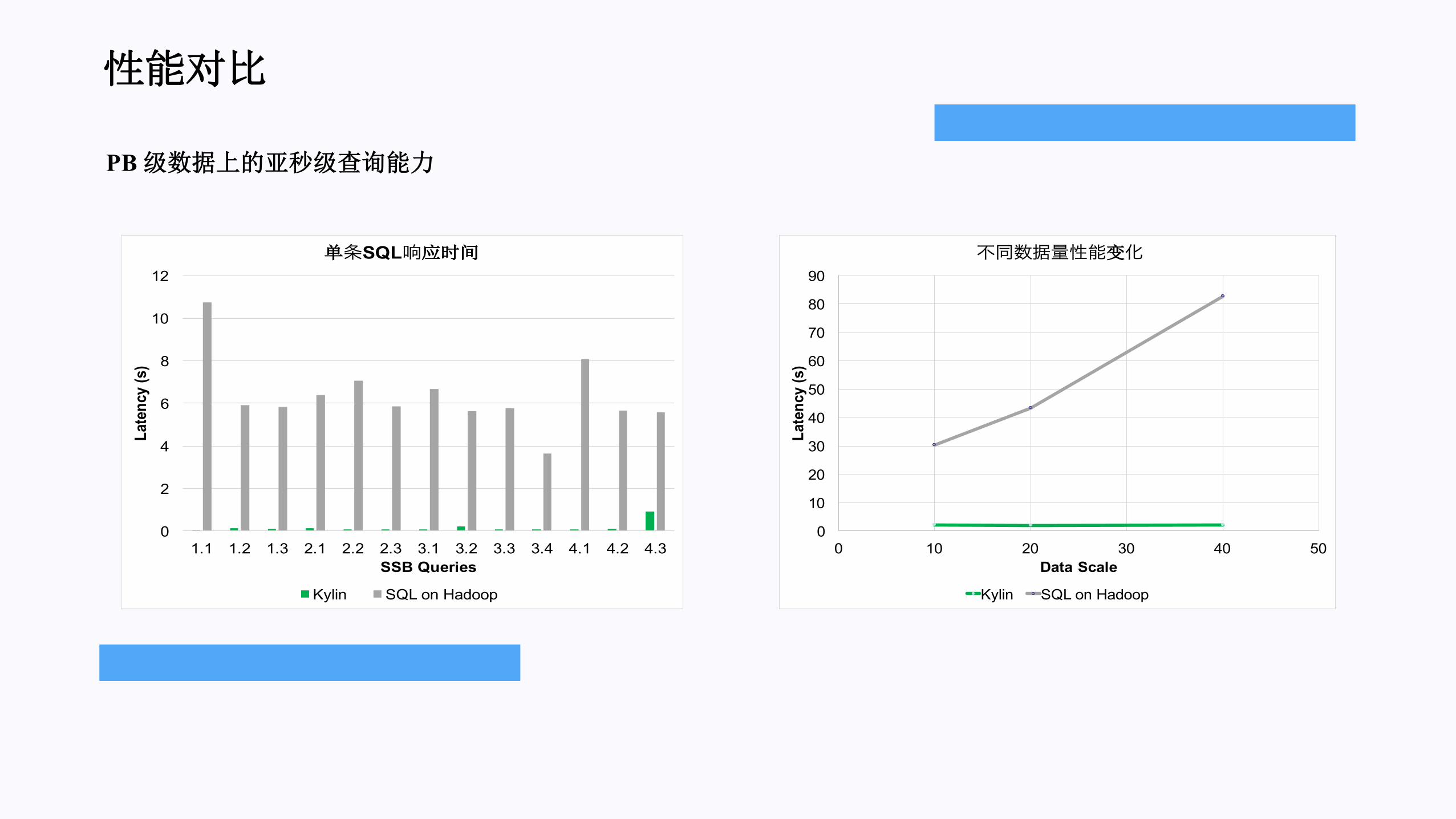
使用 Cube的 SQL 执行
Sort
Cube
Filter
预聚合数据
有预计算,基于 Cube 出结果,I/O少,计算少,延迟低
Sort
Agg
Filter
Table
Join
Table
时间复杂度O(1)
Effective Cloud User Group www.ecug.org
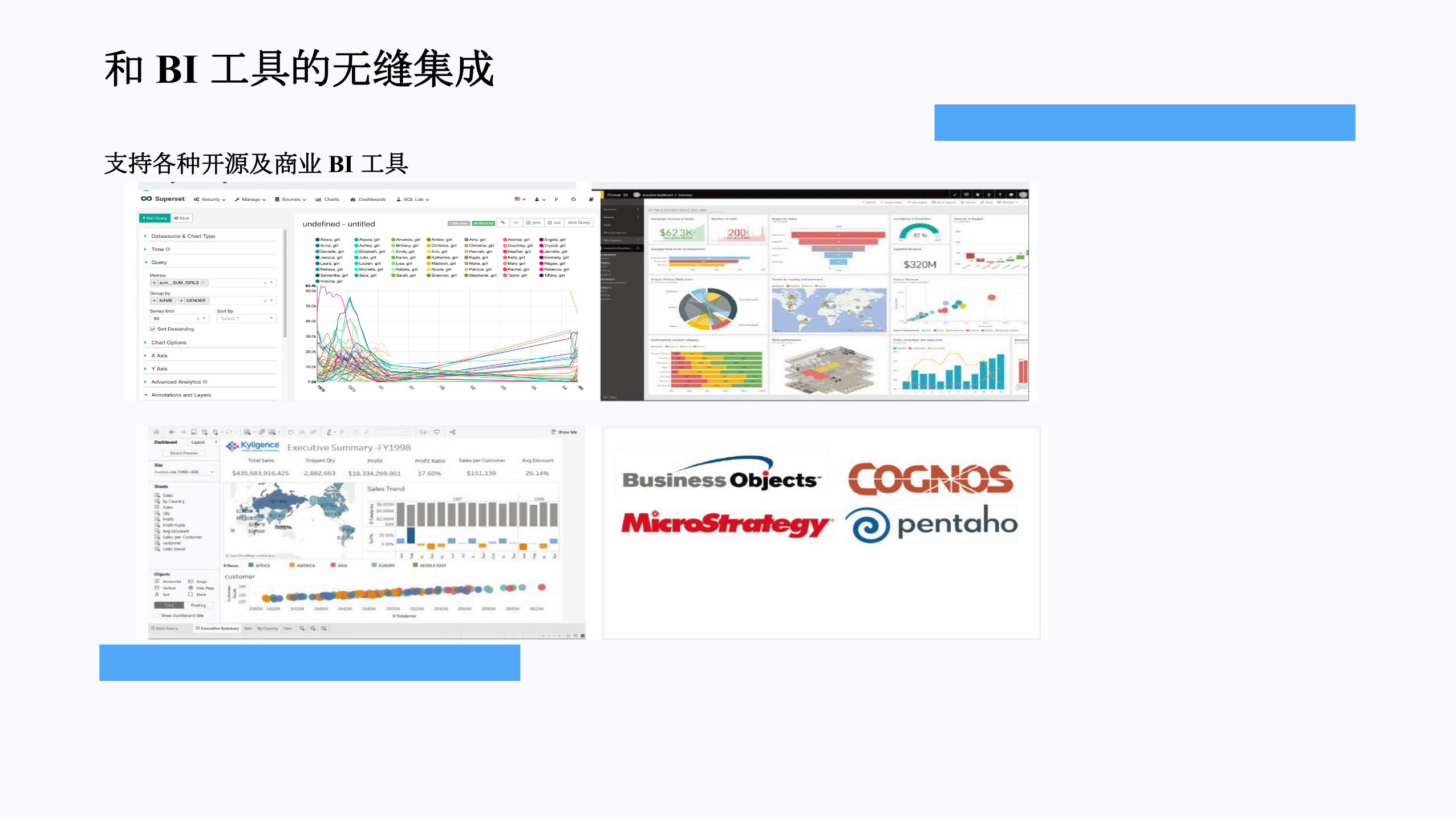
性能对比
0
2
4
6
8
10
12
1.1 1.2 1.3 2.1 2.2 2.3 3.1 3.2 3.3 3.4 4.1 4.2 4.3
Latency(s)
SSB Queries
�条SQL响���
Kylin SQL on Hadoop
0
10
20
30
40
50
60
70
80
90
0 10 20 30 40 50
Latency(s)
Data Scale
不同数据量性能�化
Kylin SQL on Hadoop
PB级数据上的亚秒级查询能力
Effective Cloud User Group www.ecug.org
和 BI工具的无缝集成
支持各种开源及商业 BI工具

Effective Cloud User Group www.ecug.org
全球用户认可
全球 1000+用户

Effective Cloud User Group www.ecug.org
Kylin 基于 Hadoop /HBase 架构的局限
Hadoop 运维困难
• 计算与存储紧耦合,扩容/缩容难
• 组件多,架构复杂,学习成本高
• 问题排查难,故障恢复慢
• 整体拥有成本高
HBase 不适合 OLAP 场景
• 为写多读少场景而设计,适合小量的写和读,不适合大范围读
• 索引简单,不适合复杂检索
• 非真正列存,I/O 消耗大
• MPP 架构,难以下压复杂计算,存在单点
• 故障恢复、升级等困难

Effective Cloud User Group www.ecug.org
云计算正在吞噬整个世界,包括 Hadoop
用对象存储代替 HDFS 本地磁盘存储
• 近乎无限的容量
• 更高的可靠性和持久性
• 按实际使用量付费
云上大数据处理的基础:存储与计算分离
• 更加灵活地 scale,无需担心数据的持久
用容器代替 YARN 管理资源
• 更好的应用隔离
• 更高的资源利用率
• 全方位的运营监控
Effective Cloud User Group www.ecug.org
云原生架构正在成为主流
敏捷开发持续集成/持续交付
容器编排
Effective Cloud User Group www.ecug.org
Apache Kylin 如何适应这一趋势?
Effective Cloud User Group www.ecug.org
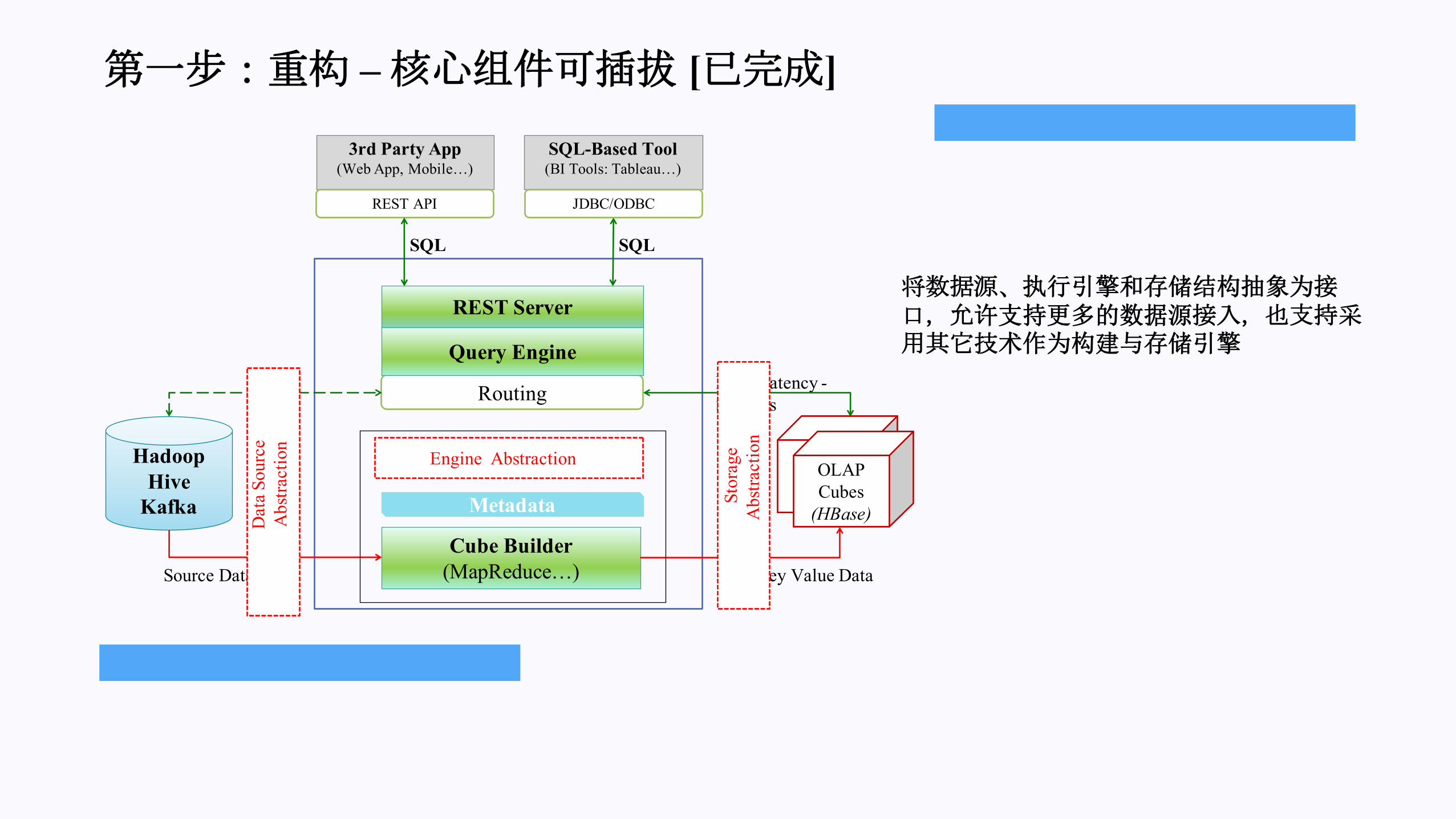
第一步:重构 –核心组件可插拔 [已完成]
Cube Builder (MapReduce…)
SQL
Low Latency -SecondsRouting
3rd Party App(Web App, Mobile…)
Metadata
SQL-Based Tool(BI Tools: Tableau…)
Query Engine
HadoopHive
Kafka
REST API JDBC/ODBC
Source Data Key Value Data
Data Cube
OLAPCubes(HBase)
SQL
REST Server
Dat
a So
urce
A
bstra
ctio
n
Engine Abstraction
Stor
age
Abs
tract
ion
将数据源、执行引擎和存储结构抽象为接口,允许支持更多的数据源接入,也支持采用其它技术作为构建与存储引擎
Effective Cloud User Group www.ecug.org
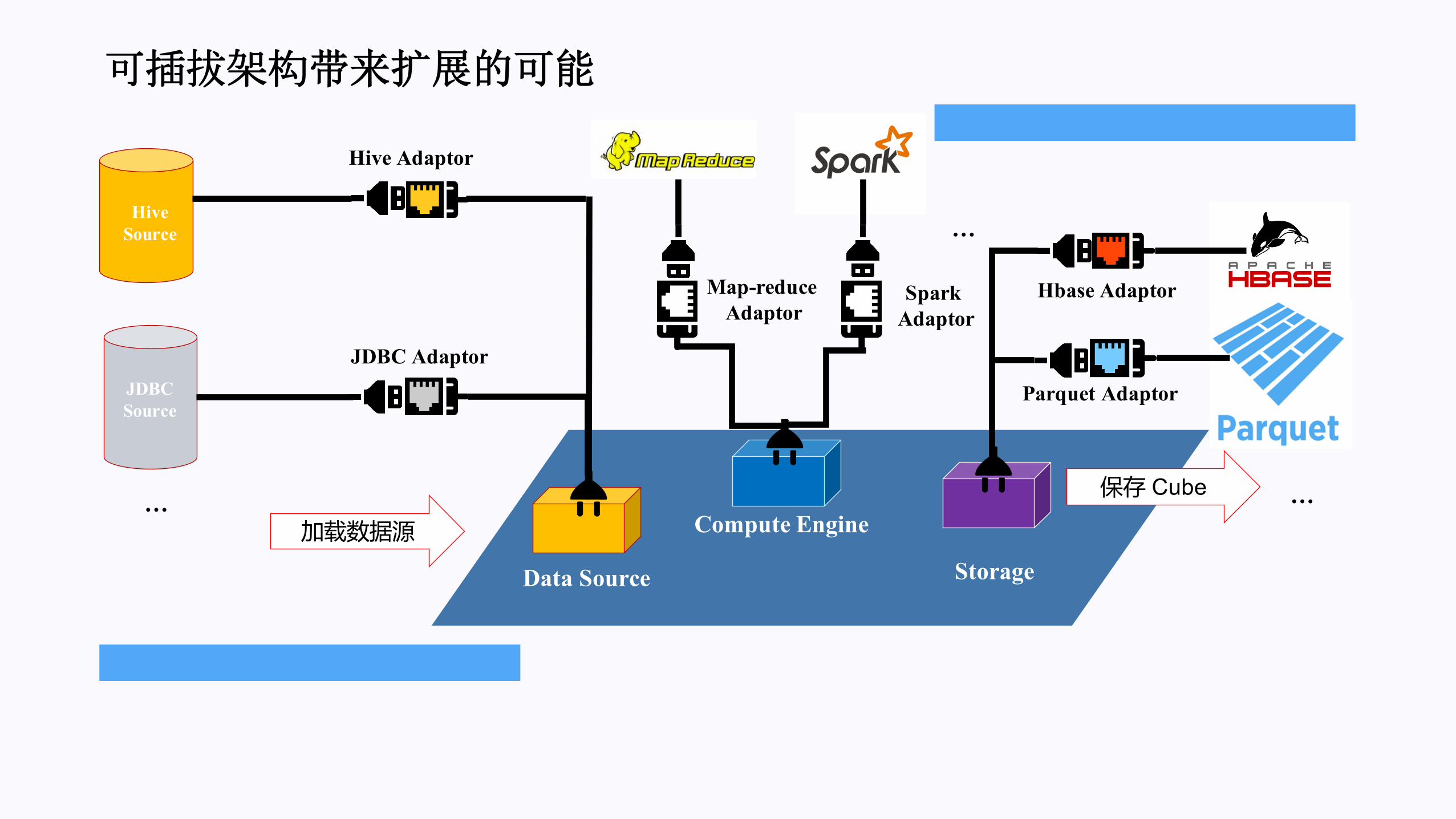
可插拔架构带来扩展的可能
HiveSource
Data Source Storage
Compute Engine
Hive Adaptor
…
JDBCSource
JDBC Adaptor
加载数据源
Map-reduceAdaptor
SparkAdaptor
…
Hbase Adaptor
Parquet Adaptor
保存 Cube …
Effective Cloud User Group www.ecug.org
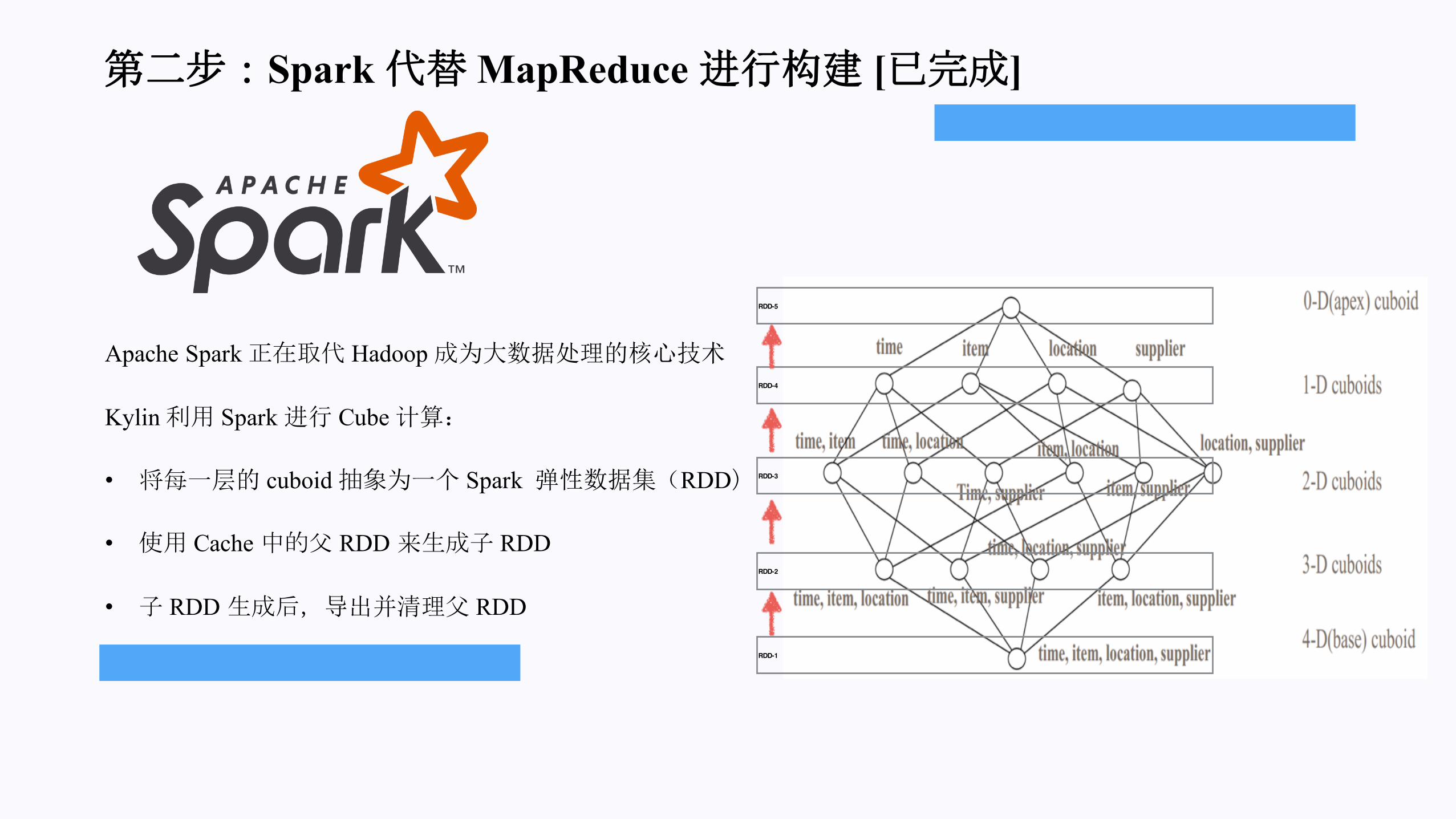
第二步:Spark 代替MapReduce进行构建 [已完成]
RDD-1
RDD-2
RDD-3
RDD-4
RDD-5
Apache Spark 正在取代 Hadoop 成为大数据处理的核心技术
Kylin 利用 Spark 进行 Cube计算:
• 将每一层的 cuboid抽象为一个 Spark 弹性数据集(RDD)
• 使用 Cache中的父 RDD来生成子 RDD
• 子 RDD生成后,导出并清理父 RDD
Effective Cloud User Group www.ecug.org
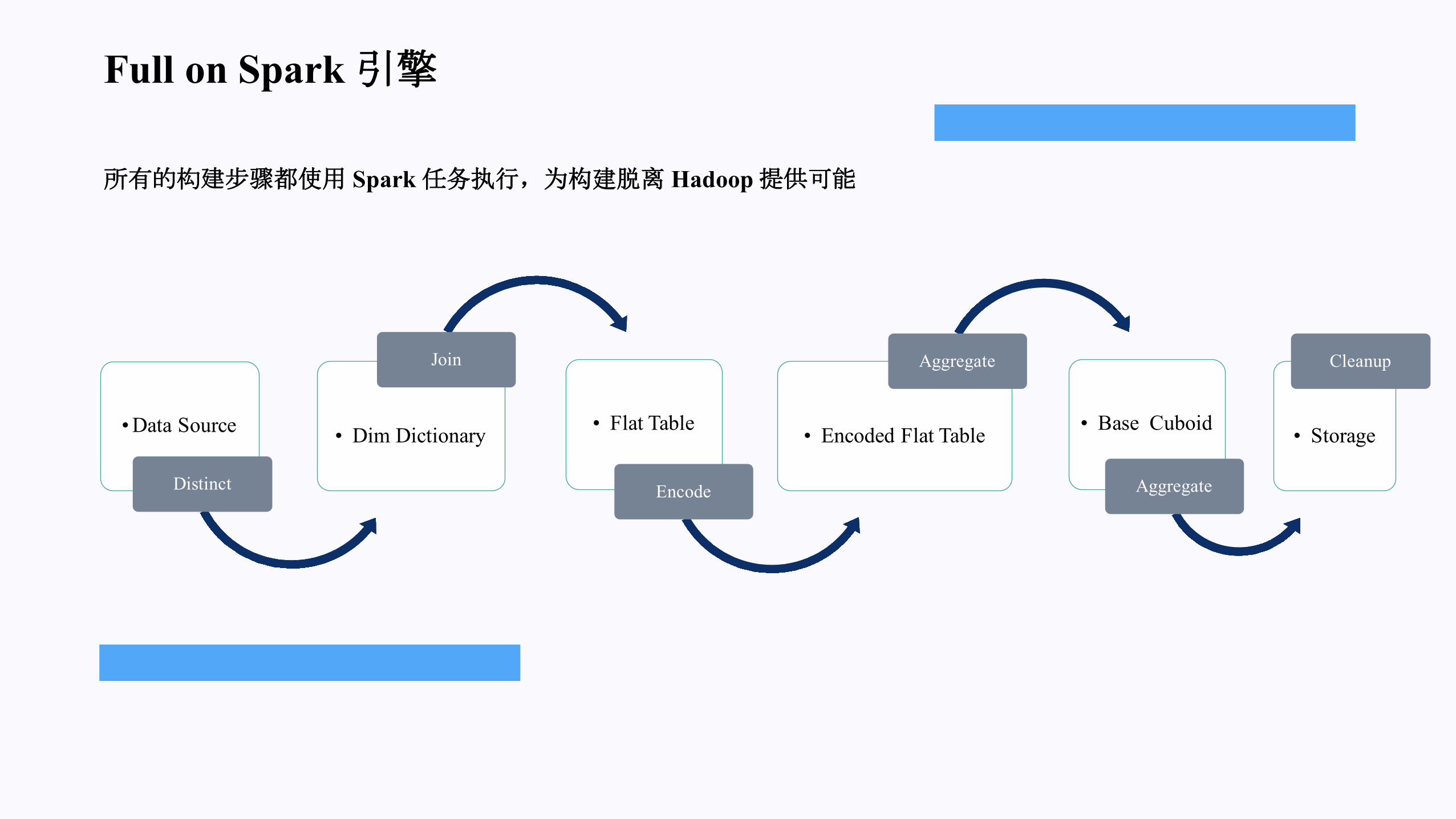
Full on Spark 引擎
• Data Source
Distinct
• Dim Dictionary
Join
• Flat Table
Encode
• Encoded Flat Table
Aggregate
• Base Cuboid
Aggregate
• Storage
Cleanup
所有的构建步骤都使用 Spark任务执行,为构建脱离 Hadoop 提供可能
Effective Cloud User Group www.ecug.org
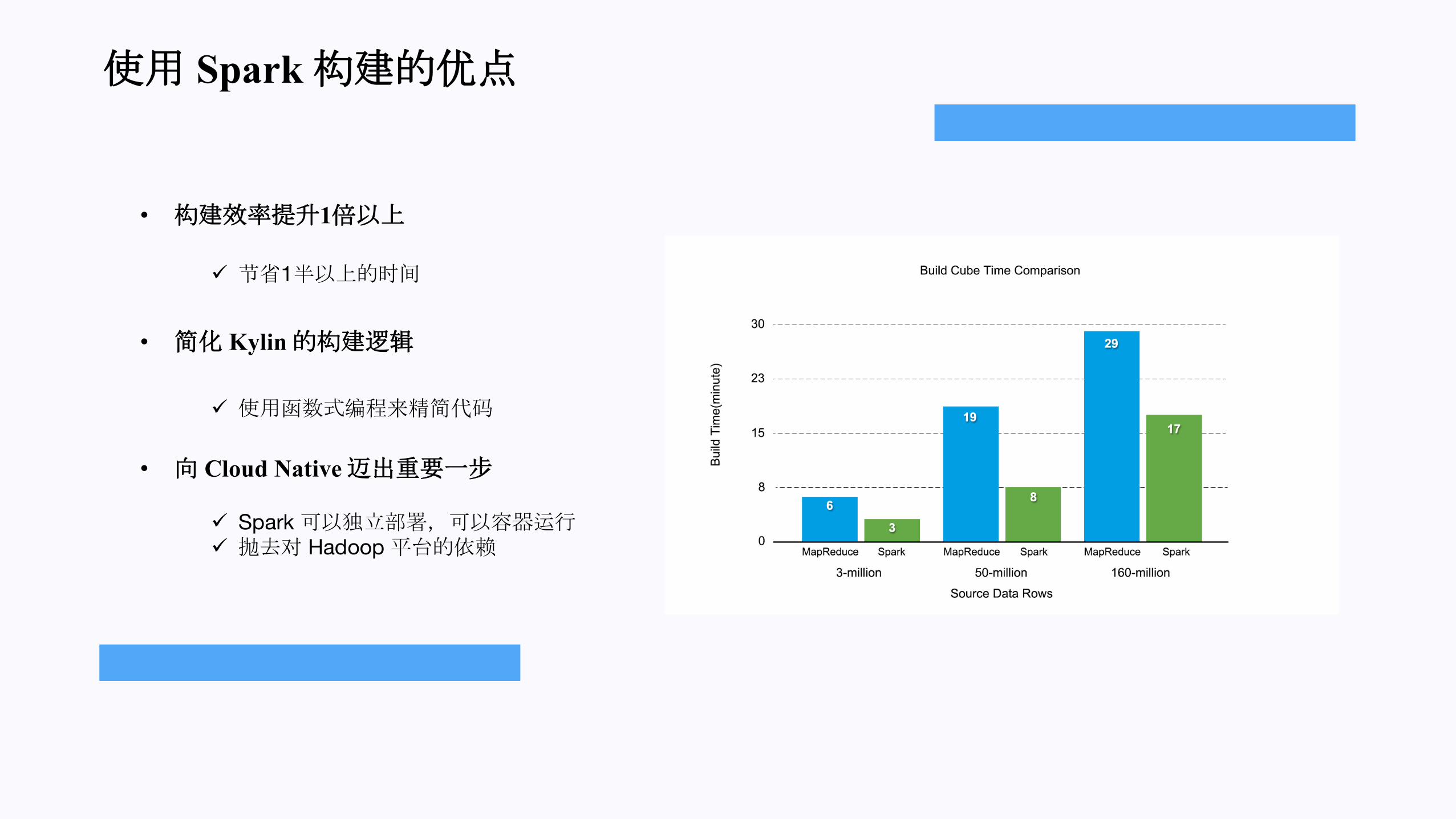
使用 Spark构建的优点
• 构建效率提升1倍以上
• 简化 Kylin的构建逻辑
• 向 Cloud Native迈出重要一步
ü 节省1半以上的时间
ü 使用函数式编程来精简代码
ü Spark 可以独立部署,可以容器运行ü 抛去对 Hadoop平台的依赖

Effective Cloud User Group www.ecug.org
第三步: Docker 运行 Kylin [已完成]
Kylin 查询服务本身无状态,天然适合 docker化;
通过 Zookeeper 注册和协调多个节点角色分配
Effective Cloud User Group www.ecug.org
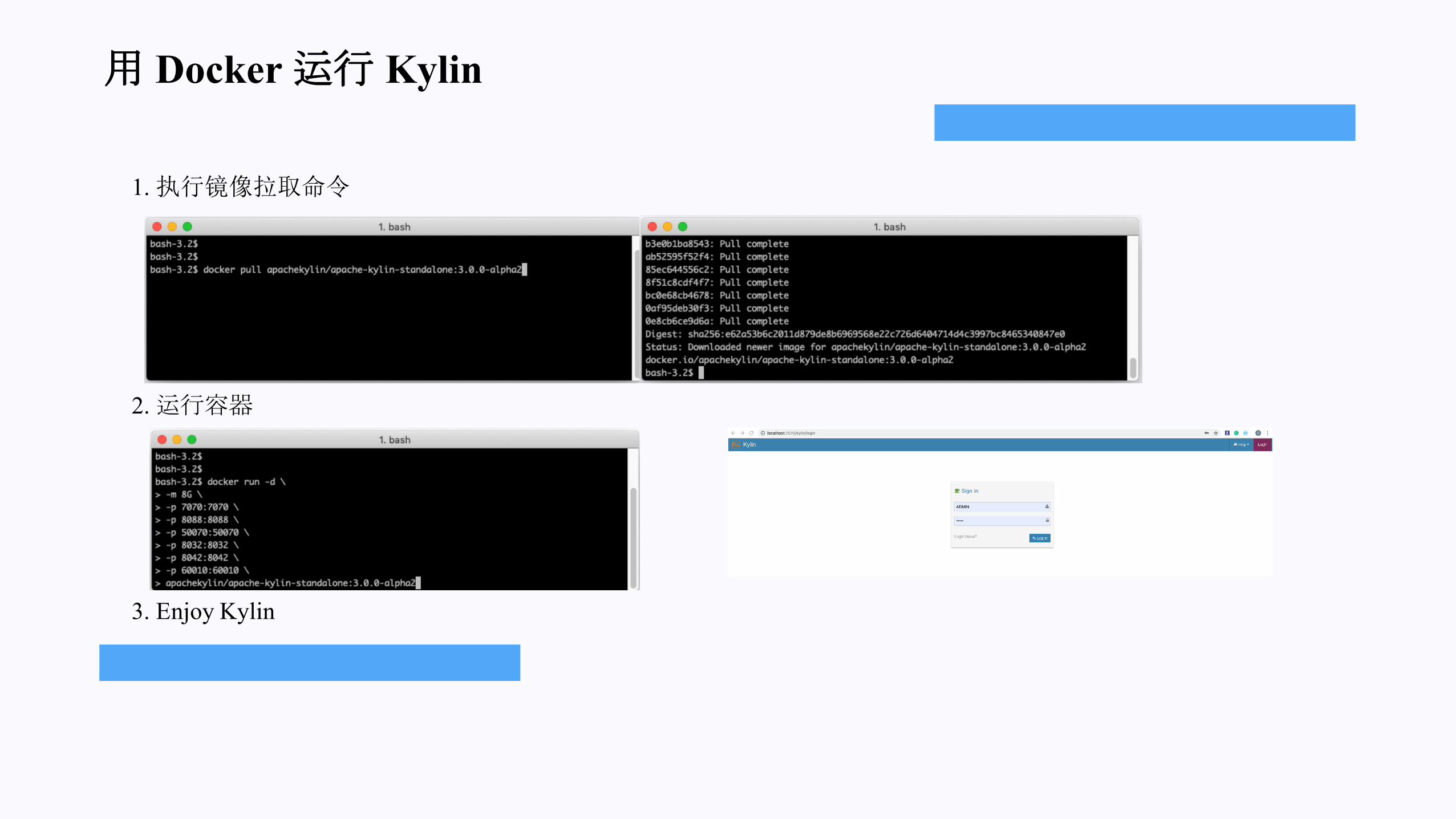
用 Docker 运行 Kylin
1.执行镜像拉取命令
2.运行容器
3. Enjoy Kylin
Effective Cloud User Group www.ecug.org
第四步: Kubernetes部署 Kylin [开发中]
Job Query Query Query

Effective Cloud User Group www.ecug.org
使用 Kubernetes部署 Kylin集群1.创建 ConfigMap以配置 Kubernetes资源对象
2.创建 Service 和 StatefulSet
3. Enjoy Kylin cluster

Effective Cloud User Group www.ecug.org
第五步:Parquet 代替 HBase(开发中)
Parquet 存储的优点
• 以原生 Apache Parquet格式作为 Cube存储,自带 schema和
编码,更易于与大数据生态整合
• 真正列存,I/O 效率高,压缩率高
• 与 Spark有很好的结合,利用 Spark 并行化、向量化技术提
速
• 可存储在对象存储上,实现服务无状态化
Effective Cloud User Group www.ecug.org
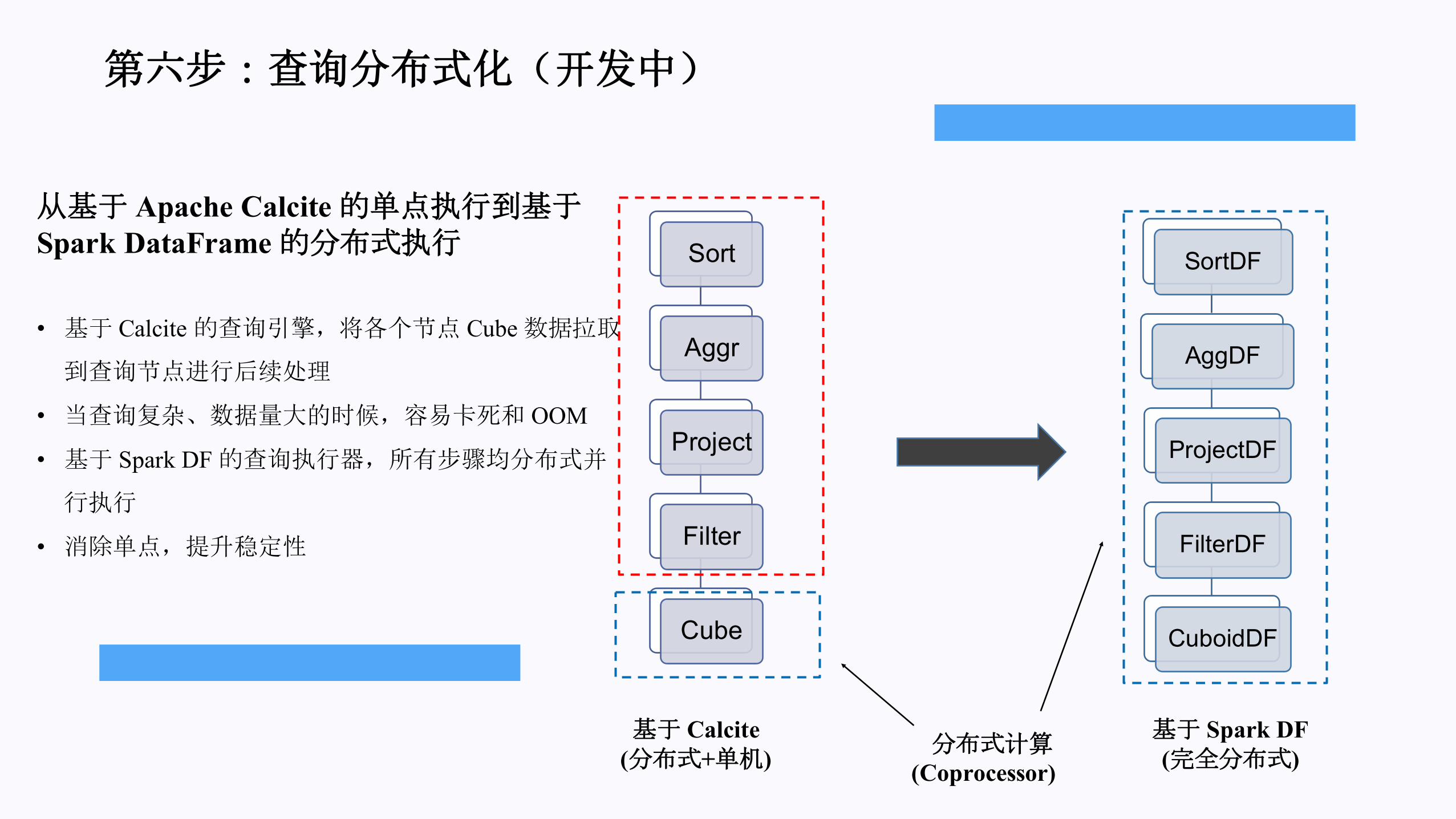
第六步:查询分布式化(开发中)
从基于 Apache Calcite 的单点执行到基于Spark DataFrame 的分布式执行
• 基于 Calcite 的查询引擎,将各个节点 Cube 数据拉取
到查询节点进行后续处理
• 当查询复杂、数据量大的时候,容易卡死和 OOM
• 基于 Spark DF 的查询执行器,所有步骤均分布式并
行执行
• 消除单点,提升稳定性
Sort
Aggr
Project
Filter
Cube
基于 Calcite(分布式+单机) 分布式计算
(Coprocessor)
基于 Spark DF(完全分布式)
SortDF
AggDF
ProjectDF
FilterDF
CuboidDF

Effective Cloud User Group www.ecug.org
Apache Kylin NG目标:云原生的大数据 OLAP 引擎
Data analytics
Apache Kylin
Container Service (K8S, Docker)
Interactive Reporting Dashboard
OLAP / Data mart
Resource Orchestration
Data Lake Source file, Streams, Parquet on Object Storage (S3, ADSL)
Metadata
Security

Effective Cloud User Group www.ecug.org
Thanks


















