Interactive Data Analysis with Apache Flink @ Flink Meetup in Berlin
Upload
apache-flink-taiwan-user-groupCategory
view
103download
2
Apache Flink OverviewGordon Tai @ Flink.tw Meetup
*Note: Many content and illustrations of this slide is referenced from data-artisans.com

00 Flink.tw 部落格、臉書社團、Meetup
● Facebook 社團:
https://www.facebook.com/groups/flink.tw/
● Blog:http://blog.flink.tw
● Meetup.com:
http://www.meetup.com/flink-tw/
1

01 Me & Flink
● 戴資力(Gordon)● Data Engineer @ VMFive● Java, Scala● Love working on distributed computing systems● Love Flink & Spark● Using Flink on VMFive’s Ads data pipeline● Currently trying to contribute to Flink:
Flink Kinesis Streaming Connector(FLINK-3211, FLINK-3229)
2

3
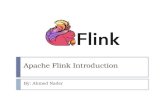
4

02 今天的內容,會針對 …
● 對 Flink 或者 Spark 完全沒接觸過的人
● 先前使用 Spark,對 Flink 抱著存疑的人
5
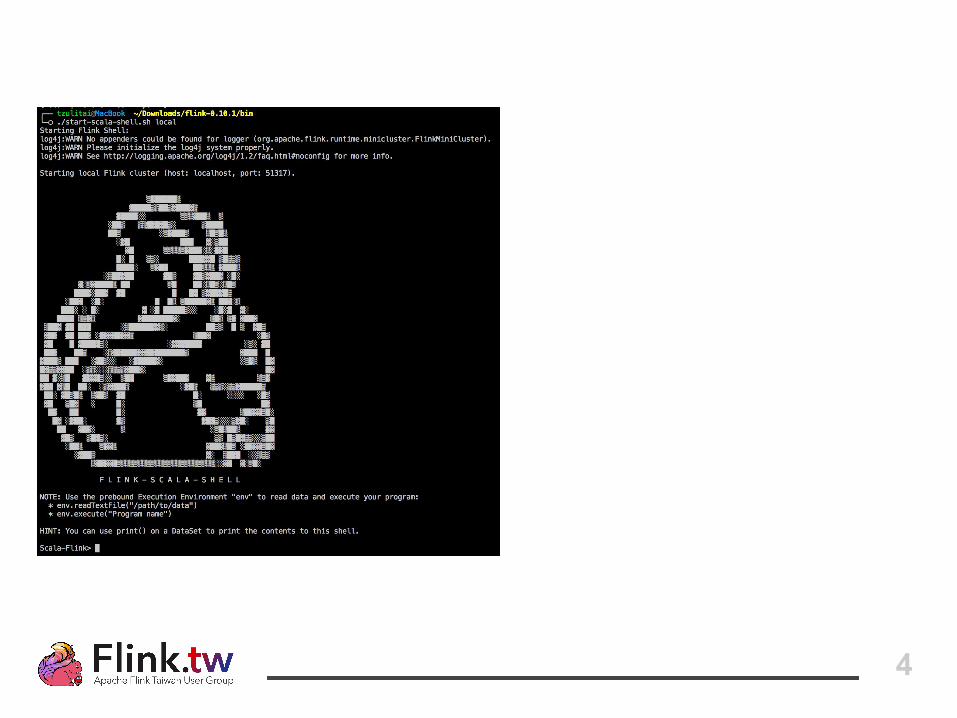
03 Trend #1: “Dataflow” model
● Immutable collections API mimic● Express data computation as a DAG flow
IN OUT
6

04 Trend #2: Platform v.s. Frameworks
● Single core engine for all workloads● Easier to build focused data engineering teams
centered around few technologies
Core Computational Engine
StreamingComputation
BatchComputation Graph Machine
Learning...
Local Filesystem
Distributed Filesystem
MessageBuffers
...
DataAccess
DataStorage
7

05 Apache Flink
“Distributed streaming dataflow engine for streaming processing and batch processing workloads”
● Streaming first:以資料串流(data stream)為核心,採用 True-streaming所有運算皆為 Pipelined Execution
● Batch over streaming:批次為串流運算之特例,屬於有限串流(bounded streams)
● APIs & Libraries:DataStream, DataSet, Gelly, FlinkML, etc.
8
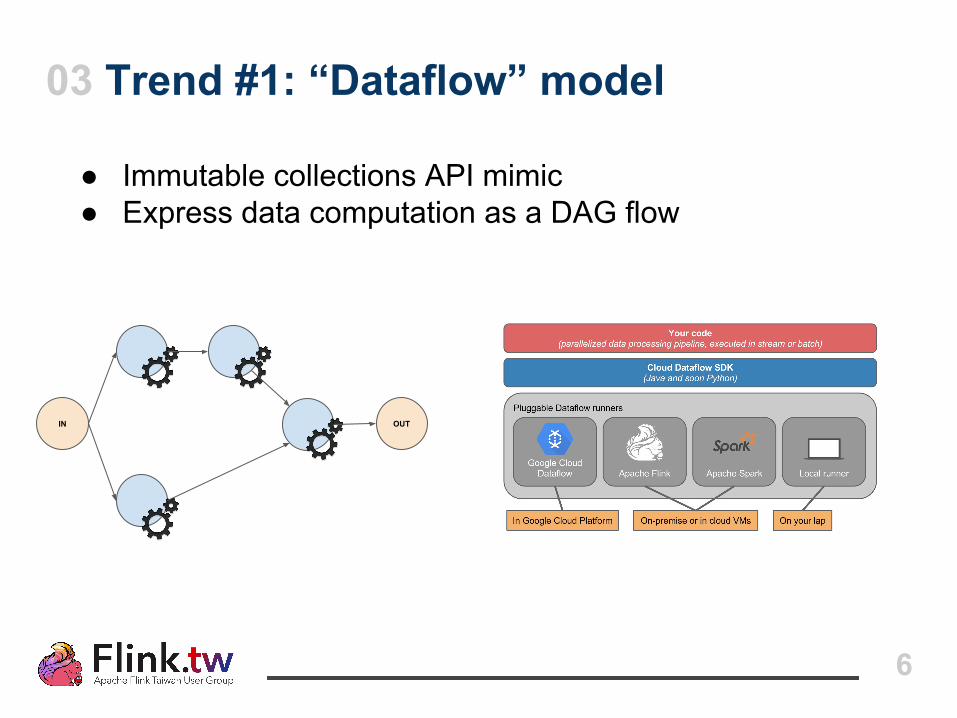
06 Apache Flink 發展史
2010
Stratosphere 研發專案起源於 TU Berlin,
Database Systems andInformation Management
Group
April 2014
Flink StreamingDataflow Runtime
Stratosphere 進入 Apache Incubator, 並且改名為 Flink
DataSet API (Java/Scala)
Flink Optimizer
Jan 2015
Local Remote YARN
Flink 成為 Apache Top-Level Project (Flink 0.9)
9
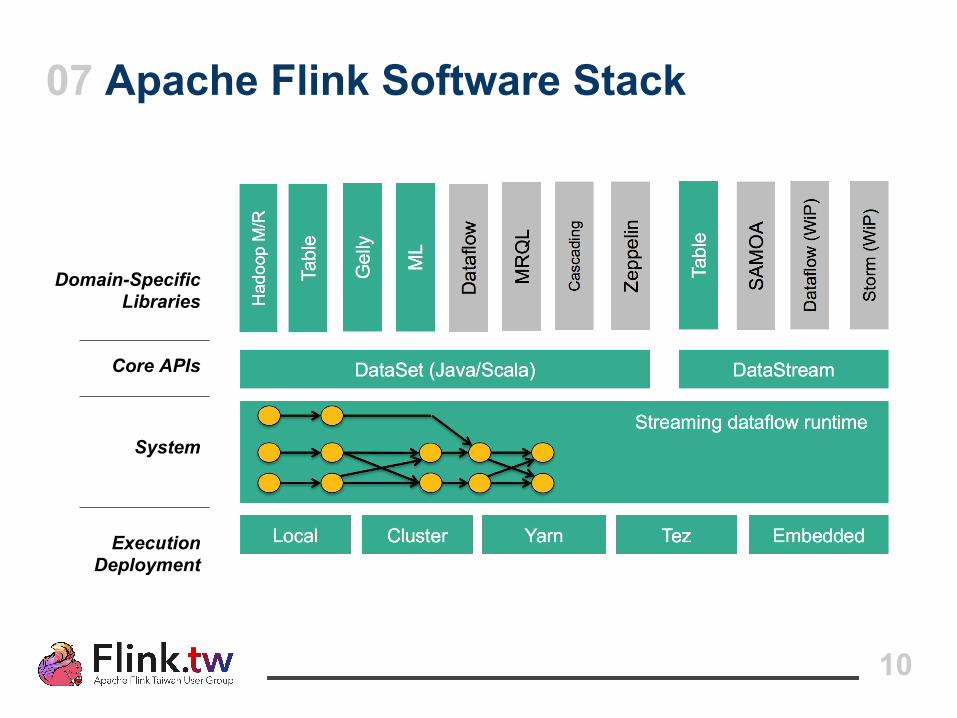
07 Apache Flink Software Stack
System
Domain-SpecificLibraries
ExecutionDeployment
Core APIs
10
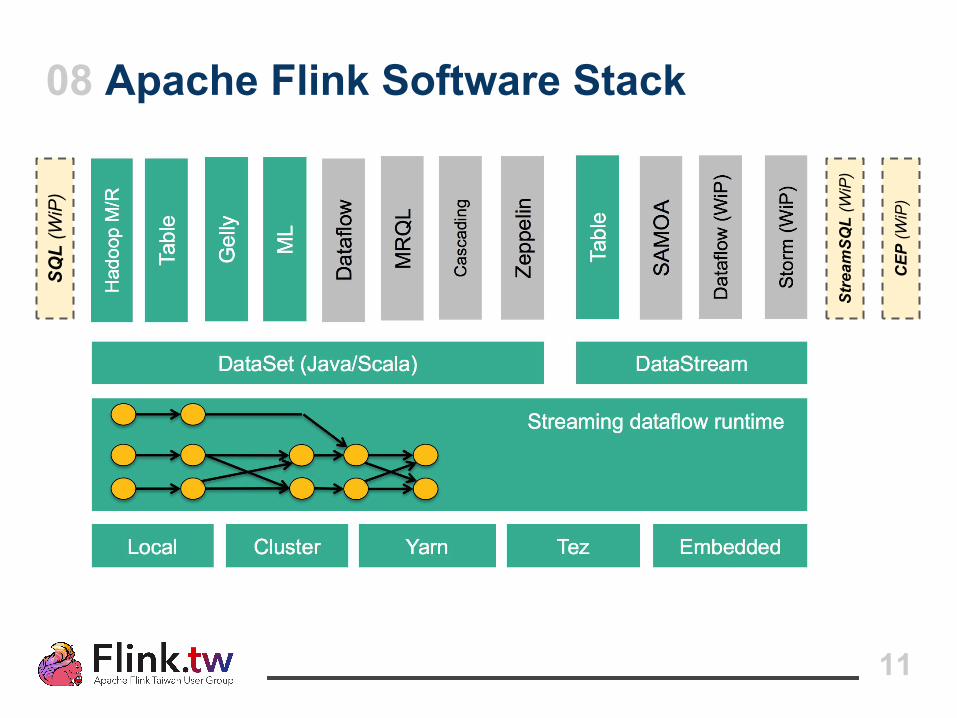
08 Apache Flink Software StackSQ
L (W
iP)
Stre
amSQ
L (W
iP)
CEP
(WiP
)
11
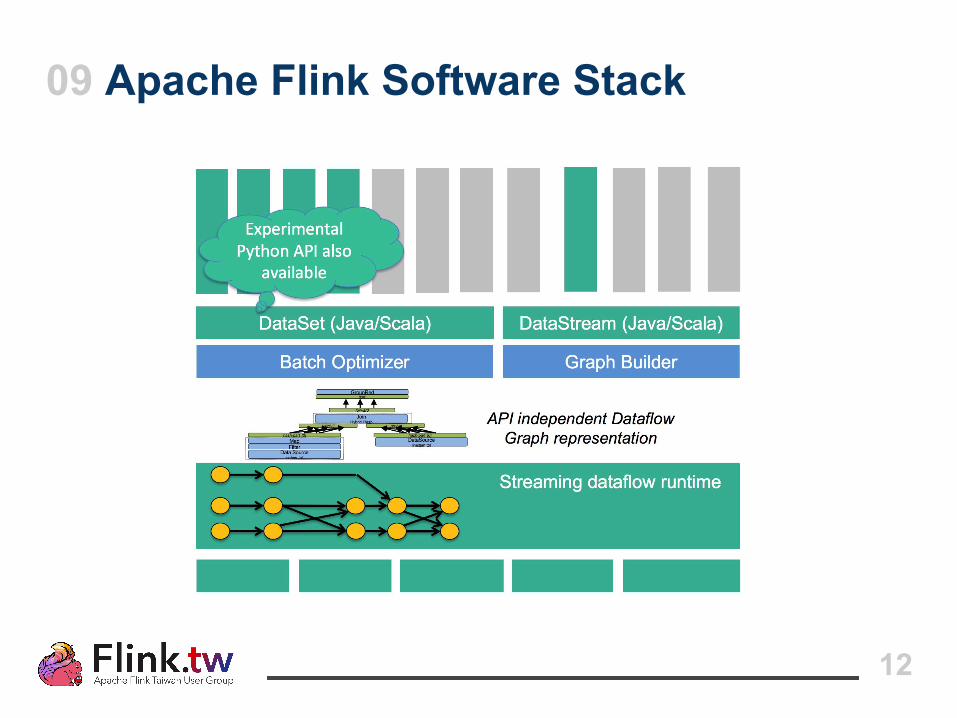
09 Apache Flink Software Stack
12

10 Apache Flink Core APIs
13
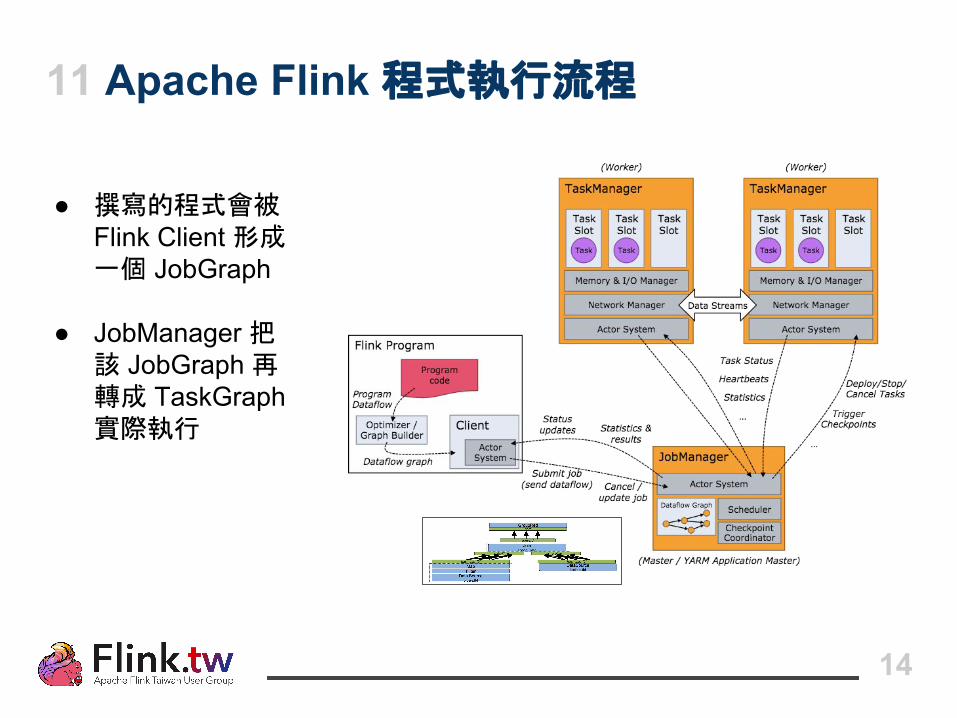
11 Apache Flink 程式執行流程
● 撰寫的程式會被 Flink Client 形成一個 JobGraph
● JobManager 把該 JobGraph 再轉成 TaskGraph 實際執行
14
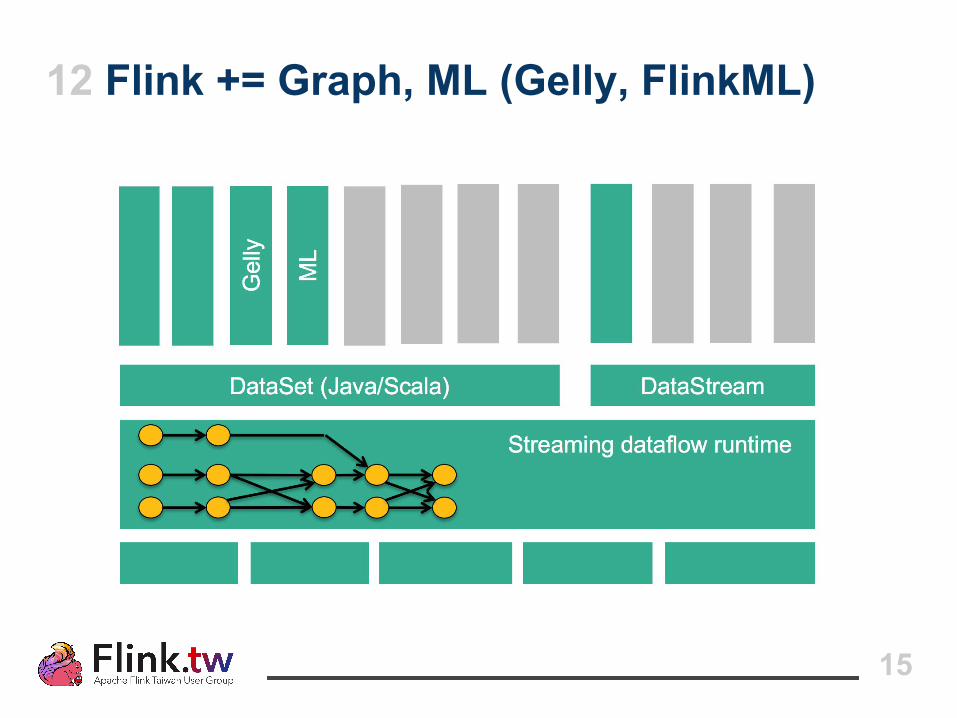
12 Flink += Graph, ML (Gelly, FlinkML)
15

13 FlinkML
● Flink 機器學習套件● 目前支援:SVM, Linear Regression, ALS, …● Runthrough:http://data-artisans.com/data-analysis-with-flink-a-case-study-and-tutorial/
16

14 Gelly
● Flink 圖運算套件● 目前支援:PageRank, Community Detection,
Connected Components, etc.
17
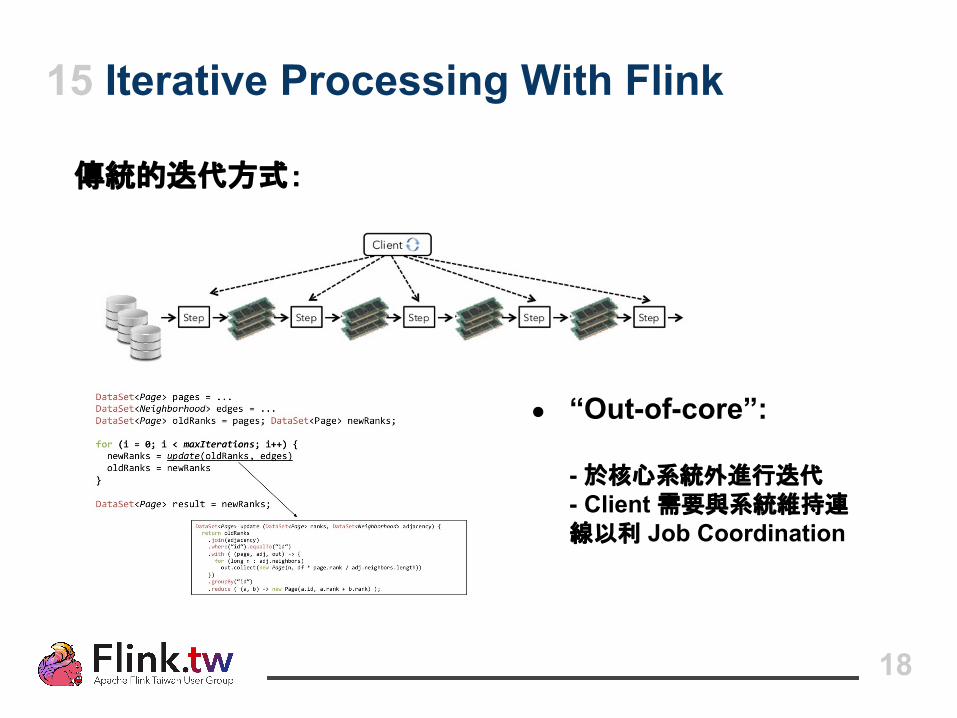
15 Iterative Processing With Flink
● “Out-of-core”:
- 於核心系統外進行迭代- Client 需要與系統維持連線以利 Job Coordination
傳統的迭代方式:
18
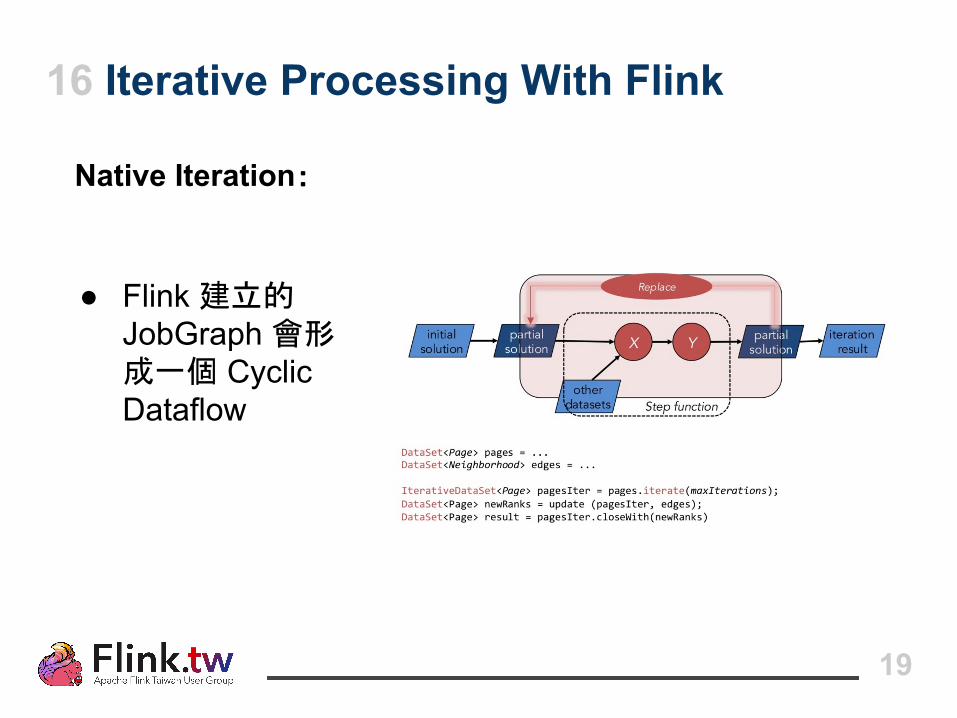
16 Iterative Processing With Flink
Native Iteration:
● Flink 建立的 JobGraph 會形成一個 Cyclic Dataflow
19
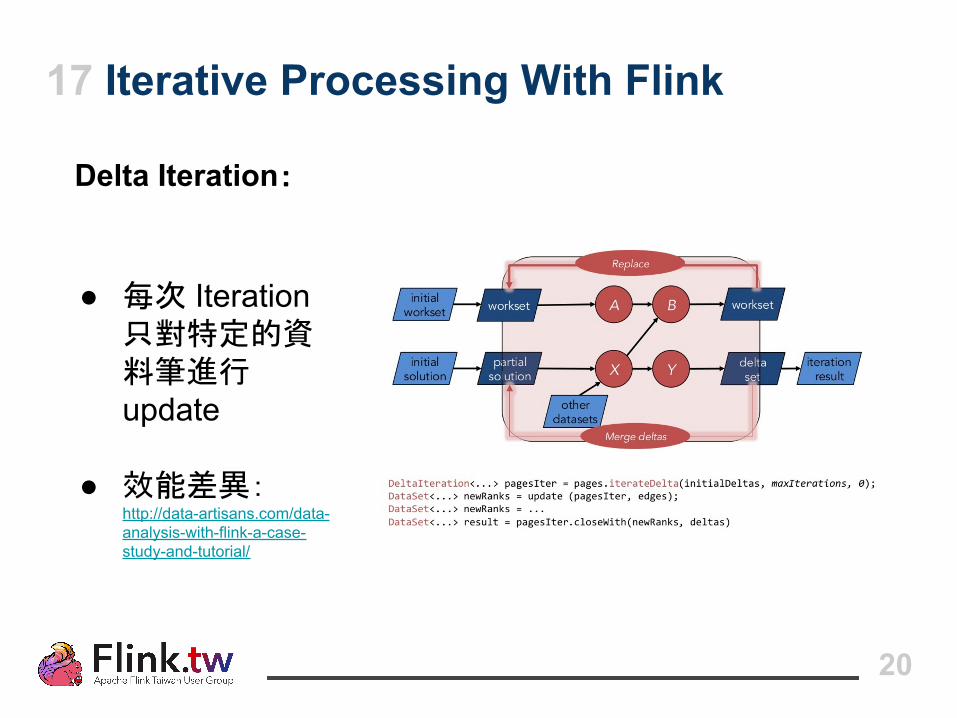
17 Iterative Processing With Flink
Delta Iteration:
● 每次 Iteration 只對特定的資料筆進行 update
● 效能差異:http://data-artisans.com/data-analysis-with-flink-a-case-study-and-tutorial/
20

18 Stateful Stream Processing
● 只有最基本的串流運算應用不具有狀態性
○ 即時算得每天造訪網站的獨立人數,則需維護至目前為止看到的獨立 UID
○ 廣告領域中,即時偵測看到某擋廣告後,在有效時間內進行點擊轉換
● Flink 中的每一個運算子(Operator)皆可以具有狀態,且能有效容錯並且提供 exactly-once guarantee
21
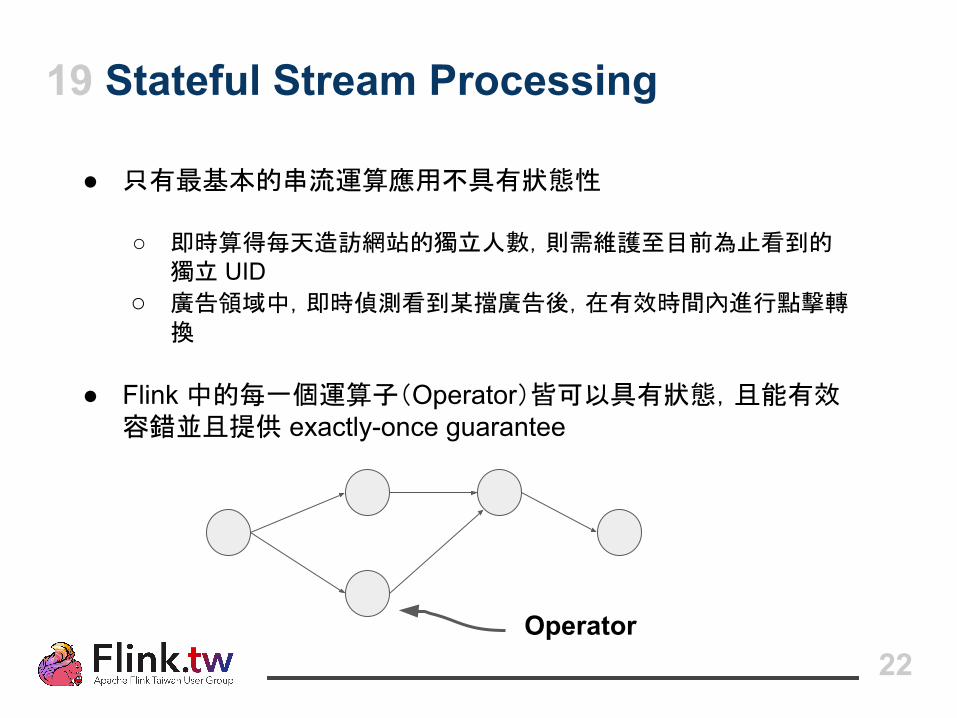
19 Stateful Stream Processing
● 只有最基本的串流運算應用不具有狀態性
○ 即時算得每天造訪網站的獨立人數,則需維護至目前為止看到的獨立 UID
○ 廣告領域中,即時偵測看到某擋廣告後,在有效時間內進行點擊轉換
● Flink 中的每一個運算子(Operator)皆可以具有狀態,且能有效容錯並且提供 exactly-once guarantee
Operator22
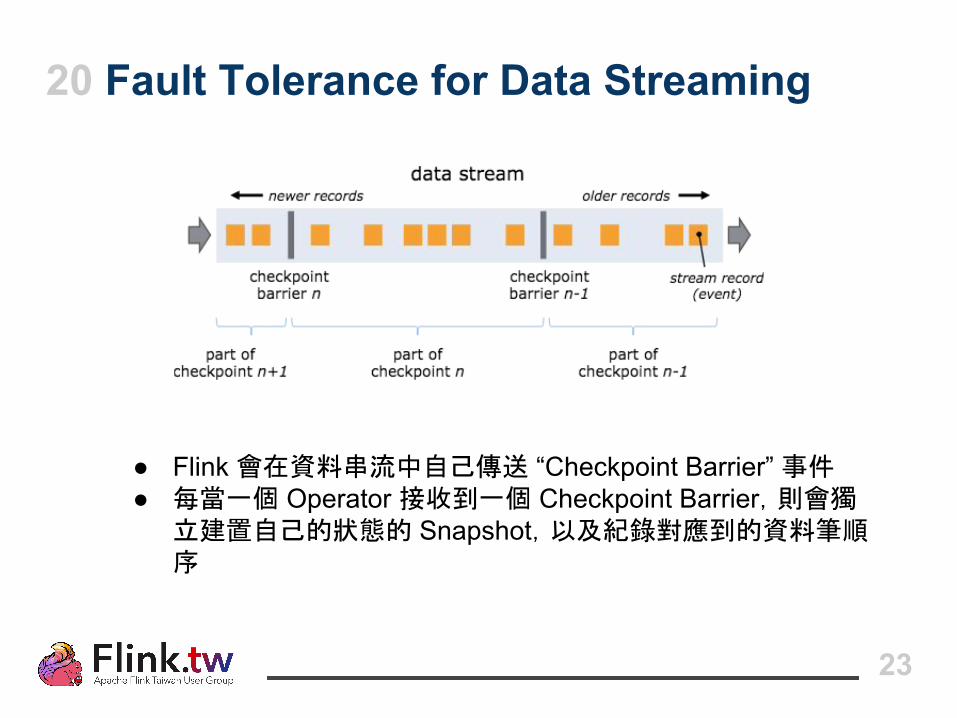
20 Fault Tolerance for Data Streaming
● Flink 會在資料串流中自己傳送 “Checkpoint Barrier” 事件● 每當一個 Operator 接收到一個 Checkpoint Barrier,則會獨
立建置自己的狀態的 Snapshot,以及紀錄對應到的資料筆順序
23
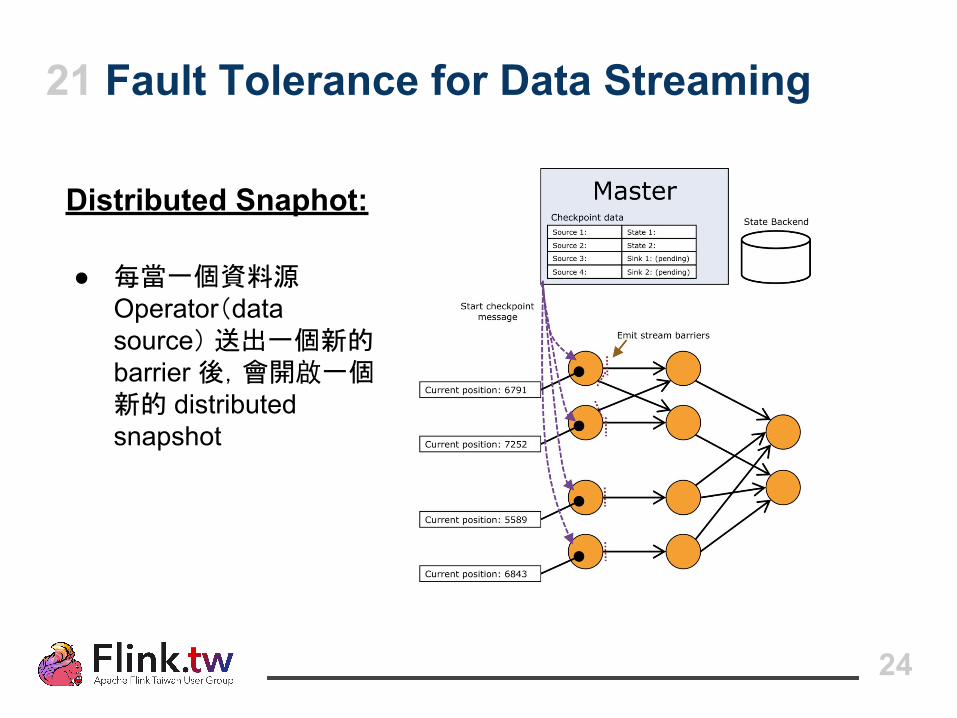
21 Fault Tolerance for Data Streaming
Distributed Snaphot:
● 每當一個資料源 Operator(data source) 送出一個新的 barrier 後,會開啟一個新的 distributed snapshot
24
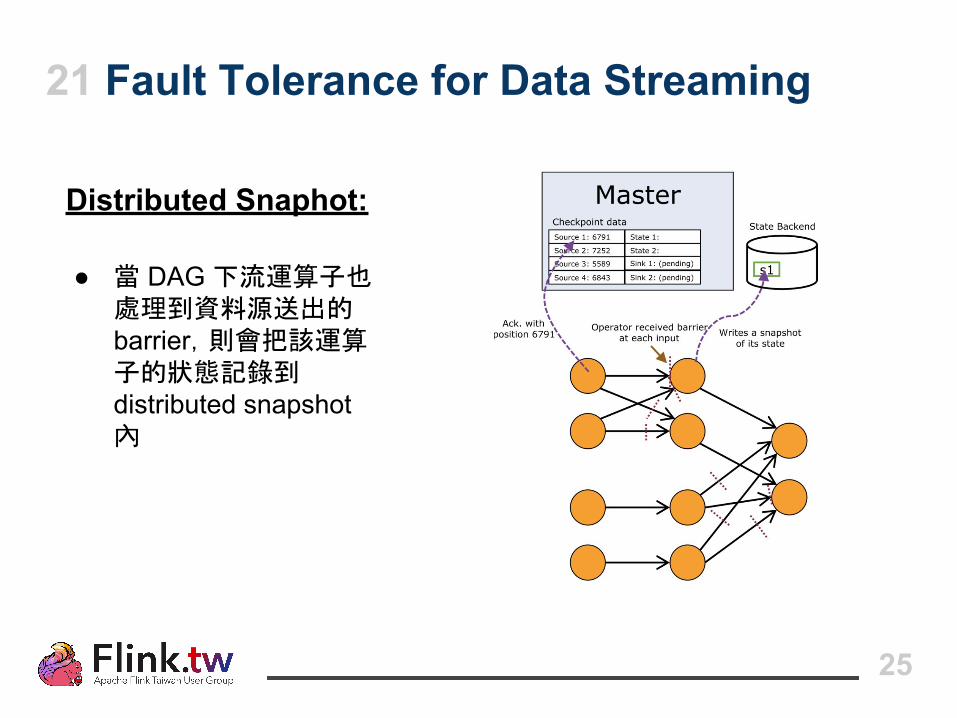
21 Fault Tolerance for Data Streaming
Distributed Snaphot:
● 當 DAG 下流運算子也處理到資料源送出的 barrier,則會把該運算子的狀態記錄到 distributed snapshot 內
25
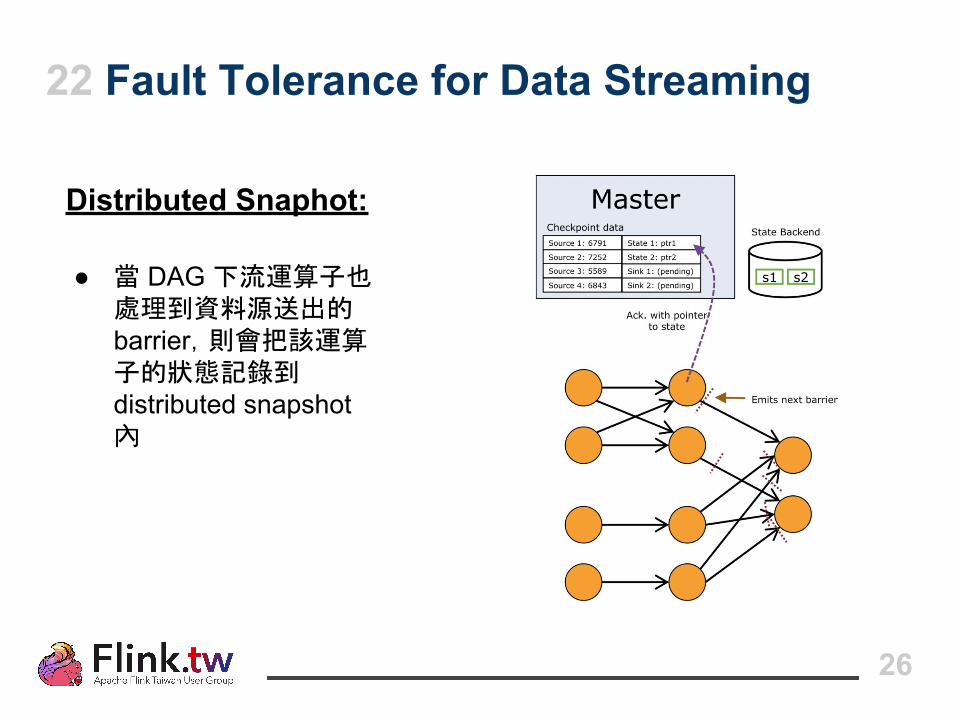
22 Fault Tolerance for Data Streaming
Distributed Snaphot:
● 當 DAG 下流運算子也處理到資料源送出的 barrier,則會把該運算子的狀態記錄到 distributed snapshot 內
26
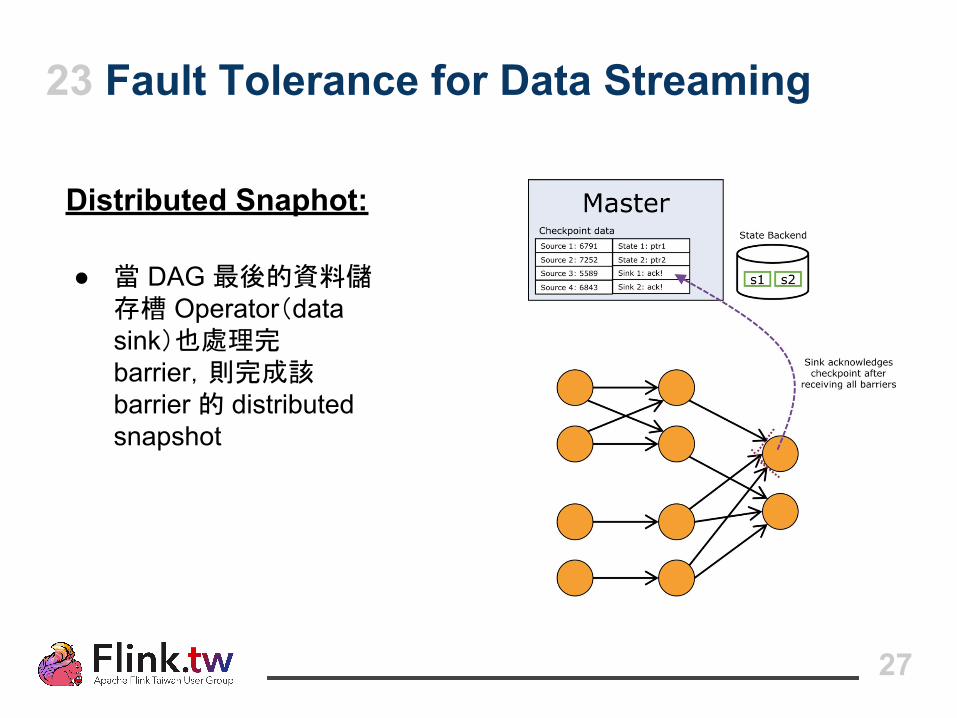
23 Fault Tolerance for Data Streaming
Distributed Snaphot:
● 當 DAG 最後的資料儲存槽 Operator(data sink)也處理完 barrier,則完成該 barrier 的 distributed snapshot
27