
Analysis and Digital Implementation of the Talk Box Effect Yuan Chen Advisor: Professor Paul Cuff.
14
Analysis and Digital Implementation of the Talk Box Effect Yuan Chen Advisor: Professor Paul Cuff
-
Upload
amira-izard -
Category
Documents
-
view
226 -
download
2
Transcript of Analysis and Digital Implementation of the Talk Box Effect Yuan Chen Advisor: Professor Paul Cuff.

Analysis and Digital Implementation of the Talk Box Effect
Yuan Chen
Advisor: Professor Paul Cuff

Introduction What is a talk box?
Allows a musician to add diction and intelligibility to an instrument’s sound
Motivation? Popular as an analog
device Application of signal
processing Goals?
Analyze output Digital
implementationFigure 1 – Talk Box

Background – Speech and Intelligibility Human speech production of convolution
between source and filter (1)
Not really time invariant Only valid for voiced speech
Frequencies of formant peaks account for intelligibility of speech (Lingard, McLoughlin) Most important are F2, F3 formants which occur in
frequency band 800 Hz – 3 kHz
)()()( nnens

Complex Cepstrum Formant peaks arise from , need a way to
“deconvolve”
Intuitively source excitation varies quickly in frequency, vocal tract response varies slowly in frequency (Deller)
Complex Cepstrum (eq. 2) (Deller):
Apply a low quefrency lifter to separate source and filter
deSn njs )(log
2
1)(

Analysis Results – Vowel Sounds Talk box most successfully impresses F2, F3
peaks Relative Error in peak frequency: F1 – 19.6%, F2 –
9.33%, F3 – 6.22% Error due to inability to replicate sound
For voice, ~90% of energy in 0 Hz – 1000 Hz For talk box, ~10% of energy in 0 Hz – 1000
Hz

Design Overview Problem definition:
Implement in MATLAB

Vocal Tract Impulse Response Extraction
Calculate cepstrum (eq. 3):
Lifter: Eliminate all quefrency above cutoff nc (eq. 4)
From liftered cepstrum, invert to calculate impulse/frequency response (eq. 5):

Impulse Response Preprocessing Calculated impulse response has too high low
frequency (0 – 1000 Hz) magnitude
Different frames of speech have different energy levels Speech input should not directly determine output
amplitude
Normalize, preprocess in frequency domain (eq. 6):

Synthesis 50% overlap between successive frames
Define system response to be linear interpolation of vocal tract impulse responses in overlapping region (eq. 7):
α: relative index (eq. 8)
p: frame index (eq. 9)

Synthesis From causality, output at time n0 depends only
on input occurring no later than n0
From finite-length impulse response, output at time n0 depends only on input occurring no earlier than n0 – M + 1
Closed Form expression for y(n) (eq.11):
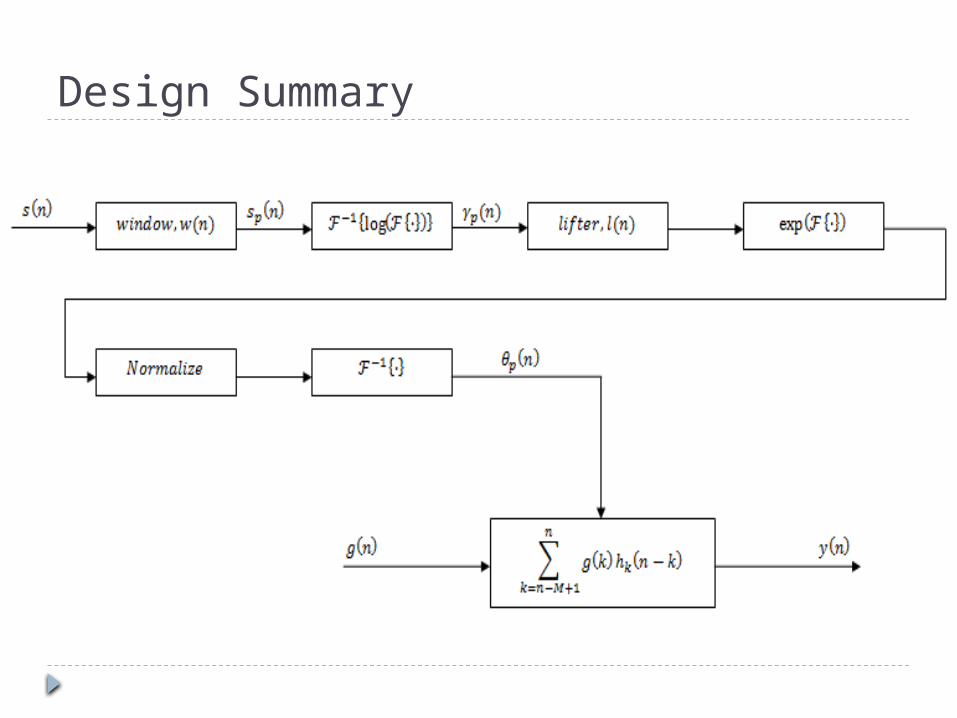
Design Summary

Performance F2, F3 peaks on vowel speech inputs:
Static implementation relative error: 3.0% F2, 3.5% F3
Dynamic implementation relative error: 3.7% F2, 3.2% F3
Qualitatively, output has similar intelligibility to analog talk box
Dynamic implementation can produce voiced non-vowel phonemes and whole words Not always consistent, depends on alignment in
time

Performance Issues Even with linearly-interpolated system
impulse response, noticeable transitions between frames
Computationally expensive: 2 FFTs, 2 IFFTs per frame In MATLAB, computation time takes longer than
duration of the frame
Performance dependent on alignment of input signals

Conclusions and Further Considerations Dynamic implementation closely models
performance of analog talk box: Can produce vowels and voiced phonemes Real-time setup
Demonstrate possibility of fully digital implementation of talk box using speech input
Further considerations: Improve transitions between frames Decrease calculation time Physical implementation


















