
An Unsupervised Framework for Extracting and Normalizing Product Attributes from Multiple Web Sites...
22
An Unsupervised Framework for An Unsupervised Framework for Extracting and Normalizing Product Extracting and Normalizing Product Attributes from Multiple Web Sites Attributes from Multiple Web Sites Center for E-Business Technology Seoul National University Seoul, Korea Nam, Kwang-hyun Intelligent Database Systems Lab School of Computer Science & Engineering Seoul National University, Seoul, Korea Tak-Lam Wong, Wai Lam, Tik-Shun Wong The Chinese University of Hong Kong SIGIR 2008
-
Upload
morgan-chase -
Category
Documents
-
view
217 -
download
0
Transcript of An Unsupervised Framework for Extracting and Normalizing Product Attributes from Multiple Web Sites...

An Unsupervised Framework for An Unsupervised Framework for Extracting and Normalizing Product Extracting and Normalizing Product Attributes from Multiple Web SitesAttributes from Multiple Web Sites
Center for E-Business TechnologySeoul National University
Seoul, Korea
Nam, Kwang-hyun
Intelligent Database Systems LabSchool of Computer Science & EngineeringSeoul National University, Seoul, Korea
Tak-Lam Wong, Wai Lam, Tik-Shun Wong
The Chinese University of Hong Kong
SIGIR 2008

Copyright 2009 by CEBT
ContentsContents
Introduction
Problem Definition
Model
Inference Method
Experimental Results
Conclusions
Discussion
IDS Lab Seminar - 2
Copyright 2009 by CEBT
IntroductionIntroduction
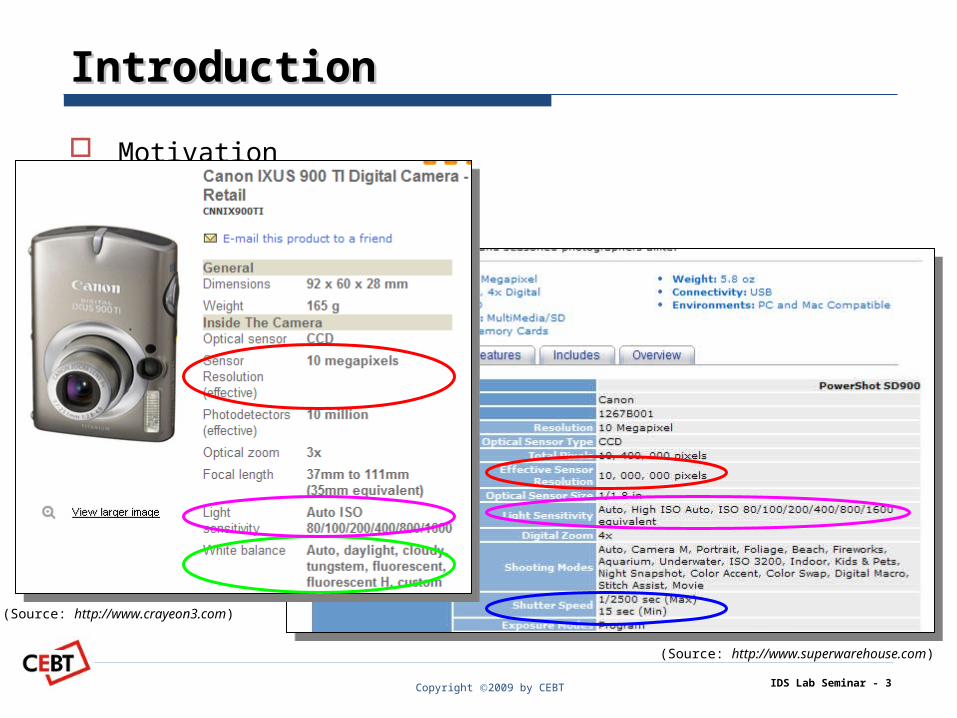
Motivation
IDS Lab Seminar - 3
(Source: http://www.superwarehouse.com)
(Source: http://www.crayeon3.com)

Copyright 2009 by CEBT
IntroductionIntroduction
Information Extraction
Prior knowledge about content
– Sensor resolution
Previously unseen attributes
– Layout format
White balance, shutter speed
– Mutual influence
Light sensitivity
IDS Lab Seminar - 4

Copyright 2009 by CEBT
IntroductionIntroduction
Attribute Normalization Samples of extracted text fragments from a page:
– Cloudy, daylight, etc…
– What do they refer to?
A text fragment extracted from another page:– white balance auto, daylight,
cloudy, etc…
Attribute normalization– To cluster text fragments into the same group
– Better indexing for product search
– Easier understanding and interpretation
IDS Lab Seminar - 5

Copyright 2009 by CEBT
IntroductionIntroduction
Existing Works
Supervised wrapper induction
– They need training examples.
– The wrapper learned from a Web site cannot be applied to other sites.
Template-independent extraction (Zhu et al., 2007)
– They cannot handle previously unseen attributes.
Unsupervised wrapper learning (Crescenzi et al, 2001)
– Extracted data are not normalized.
IDS Lab Seminar - 6

Copyright 2009 by CEBT
IntroductionIntroduction
Contributions
Unsupervised learning framework for jointly extracting and normalizing product attributes from multiple Web sites.
Can extract unlimited number of product attributes (Dirichlet process)
Can visualize the semantic meaning of each product attribute
IDS Lab Seminar - 7

Copyright 2009 by CEBT
Problem Definition (1)Problem Definition (1)
A product domain,
E.g., Digital camera domain
A set of reference attributes,
E.g., “resolution”, “white balance”, etc.
A special element, , representing “not-an-attribute”
A collection of Web pages from any Web sites, , each of which contains a single product
Let be any text fragment from a Web page
IDS Lab Seminar - 8

Copyright 2009 by CEBT
Problem Definition (2)Problem Definition (2)
IDS Lab Seminar - 9
<TR> <TD> <P> <SPAN> White balance </SPAN> </P> </TD> <TD> <P> <SPAN> Auto, daylight, cloudy, tungstem, fluorescent, fluorescent H, custom </SPAN> </P> </TD></TR><TR>
<TR> <TD> <P> <SPAN> White balance </SPAN> </P> </TD> <TD> <P> <SPAN> Auto, daylight, cloudy, tungstem, fluorescent, fluorescent H, custom </SPAN> </P> </TD></TR><TR>
Line separator
Line separator

Copyright 2009 by CEBT
Problem Definition (3)Problem Definition (3)
IDS Lab Seminar - 10
Information extraction:
Attribute normalization:
Joint attribute extraction and normalization:
Attribute information
Target informationLayout information
Content information
e.g., x =(resolution 10,000,000 pixels, black and in small font size, 1, resolution)

Copyright 2009 by CEBT
Problem Definition (4)Problem Definition (4)
White balance Auto, daylight, cloudy, tungstem, fluorescent, fluorescent H, custom T=1 A=“white balance”
“Cloudy, daylight” T=1 A=“white balance”
View larger image T=0 A=“not-an-attribute”
IDS Lab Seminar - 11

Copyright 2009 by CEBT
ModelModel
IDS Lab Seminar - 12
Dirichlet Process Prior(Infinite Mixture Model) N Text Fragments S Different Web Pages
k-th component proportion
Content info. generation
Target info. generation
A set of layout distribution

Copyright 2009 by CEBT
Generation ProcessGeneration Process
IDS Lab Seminar - 13

Copyright 2009 by CEBT
Generation ProcessGeneration Process
The joint probability for generating a particular text fragment given the parameters, , , , and,
Inference
Intractable (means very difficult to deal with)
IDS Lab Seminar - 14

Copyright 2009 by CEBT
Variational MethodVariational Method
Finding is intractable
Goal
Design a tractable distribution such that
should be as close to as possible.
Kullback-Leibler(KL) divergence
Since D(Q||P) ≥ 0,
IDS Lab Seminar - 15

Copyright 2009 by CEBT
ExperimentsExperiments
We have conducted experiments on four different domains:
Digital camera: 85 Web pages from 41 different sites
MP3 player: 96 Web pages from 62 different sites
Camcorder: 111 Web pages from 61 different sites
Restaurant: 29 Web pages from LA-Weekly Restaurant Guide
In each domain, we conducted 10 runs of experiments.
In each run, we randomly selected a Web page and use the attributes inside as prior knowledge.
IDS Lab Seminar - 16

Copyright 2009 by CEBT
Evaluation on Attribute Evaluation on Attribute NormalizationNormalization
Baseline approach
Agglomerative clustering
– Only consider the text content of text fragments
Evaluation metrics
Recall (R)
Precision (P)
F1-measure (F)
IDS Lab Seminar - 17

Copyright 2009 by CEBT
Results of Attribute Results of Attribute NormalizationNormalization
IDS Lab Seminar - 18

Copyright 2009 by CEBT
Visualize the Normalized Visualize the Normalized AttributesAttributes
The top five weighted terms in the ten largest normalized attributes in the digital camera domain
IDS Lab Seminar - 19

Copyright 2009 by CEBT
Evaluation on Attribute Evaluation on Attribute ExtractionExtraction
Surprisingly, in the restaurant domain, our framework achieves
A performance (0.95 F1-measure) which is comparable to the supervised method (Muslea et al. 2001)
IDS Lab Seminar - 20

Copyright 2009 by CEBT
ConclusionsConclusions
Developed an unsupervised framework aiming at simultaneously extracting and normalizing product attributes from Web pages collected from different sites.
Developed a graphical model to model the generation of text fragments in Web pages.
Showed that content and layout information can collaborate and improve both extraction and normalization performance under our model.
IDS Lab Seminar - 21

Copyright 2009 by CEBT
DiscussionDiscussion
Pros
Good motivation and proposed solution
Performance is good enough for real situation.
Cons
Lack explanation of equations
Some words used wrongly
IDS Lab Seminar - 22








![Graph Normalizing Flows · 2.2 Normalizing Flows Normalizing flows (NFs) [22, 3, 4] are a class of generative models that use invertible mappings to transform an observed vector](https://static.fdocuments.net/doc/165x107/5f37164f015bfa67bd3ee458/graph-normalizing-flows-22-normalizing-flows-normalizing-iows-nfs-22-3-4.jpg)









