
An Introduct to Spark - Atlanta Spark Meetup
85
Apache Spark, an Introduction Jonathan Lacefield – Solution Architect DataStax
-
Upload
jlacefie -
Category
Technology
-
view
536 -
download
1
Transcript of An Introduct to Spark - Atlanta Spark Meetup

Apache Spark, an Introduction
Jonathan Lacefield – Solution Architect
DataStax

Disclaimer
The contents of this presentation represent my personal views and do not reflect or represent any views of my employer.
This is my take on Spark.
This is not DataStax’s take on Spark.

Notes
• Meetup Sponsor: – Data Exchange Platform – Core Software Engineering – Equifax
• Announcement: – Data Exchange Platform is currently hiring to build the
next generation data platform. We are looking for people with experience in one or more of the following skills: Spark, Storm, Kafka, samza, Hadoop, Cassandra
– How to apply? – Email [email protected]

Introduction
• Jonathan Lacefield
– Solutions Architect, DataStax
– Former Dev, DBA, Architect, reformed PM
– Email: [email protected]
– Twitter: @jlacefie
– LinkedIn: www.linkedin.com/in/jlacefield
This deck represents my own views and not the views of my employer

DataStax IntroductionDataStax delivers Apache Cassandra in a database platform
purpose built for the performance and availability demands of IOT, web, and mobile applications, giving enterprises a secure always-on database that remains operationally simple when scaled in a single datacenter or across multiple datacenters
and clouds.
Includes1. Apache Cassandra2. Apache Spark3. Apache SOLR4. Apache Hadoop5. Graph Coming Soon

DataStax, What we Do (Use Cases)
• Fraud Detection• Personalization• Internet of Things• Messaging• Lists of Things (Products, Playlists, etc)• Smaller set of other things too!
We are all about working with temporal data sets at large volumes with high transaction counts (velocity).

Agenda
• Set Baseline (Pre Distributed Days and Hadoop)
• Spark Conceptual Introduction
• Spark Key Concepts (Core)
• Spark Look at Each Module– Spark SQL
– MLIB
– Spark Streaming
– GraphX

In the Beginning….
OLTP
Web Application Tier
OLAP
Statistical/Analytical Applications
ETL

Data Requirements Broke
the Architecture

Along Came Hadoop with ….
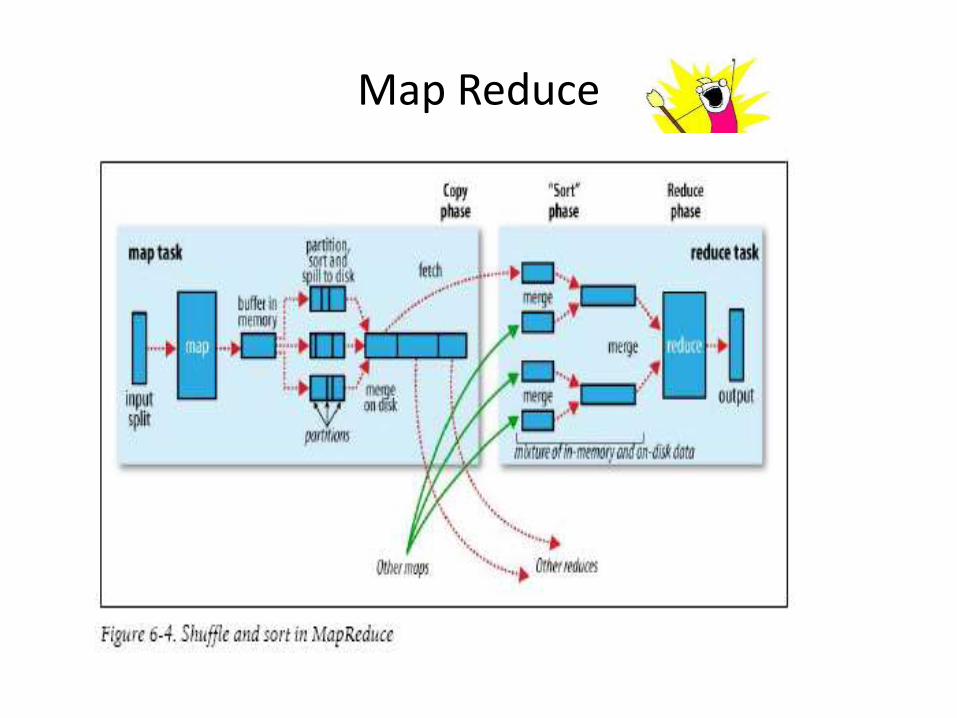
Map Reduce

Lifecycle of a MapReduce Job

But….

• Started in 2009 in Berkley’s AMP Lab• Open Sources in 2010• Commercial Provider is Databricks – http://databricks.com• Solve 2 Big Hadoop Pain Points
Speed - In Memory and Fault Tolerant
Ease of Use – API of operations and datasets

Use Cases for Apache Spark
• Data ETL
• Interactive dashboard creation for customers
• Streaming (e.g., fraud detection, real-time video optimization)
• “Complex analytics” (e.g., anomaly detection, trend analysis)

Key Concepts - Core• Resilient Distributed Datasets (RDDs) – Spark’s datasets
• Spark Context – Provides information on the Spark environment and the application
• Transformations - Transforms data
• Actions - Triggers actual processing
• Directed Acyclic Graph (DAG) – Spark’s execution algorithm
• Broadcast Variables – Read only variables on Workers
• Accumulators – Variables that can be added to with an associated function on Workers
• Driver - “Main” application container for Spark Execution
• Executors – Execute tasks on data
• Resource Manager – Manages task assignment and status
• Worker – Execute and Cache

Resilient Distributed Datasets (RDDs)
• Fault tolerant collection of elements that enable parallel processing
• Spark’s Main Abstraction
• Transformation and Actions are executed against RDDs
• Can persist in Memory, on Disk, or both
• Can be partitioned to control parallel processing
• Can be reused
– HUGE Efficiencies with processing

RDDs - Resilient
Source – databricks.com
HDFS File Filtered RDD Mapped RDDfilter
(func = someFilter(…))map
(func = someAction(...))
RDDs track lineage information that can be used to efficiently recompute lost data

RDDs - Distributed
Image Source - http://1.bp.blogspot.com/-jjuVIANEf9Y/Ur3vtjcIdgI/AAAAAAAABC0/-Ou9nANPeTs/s1600/p1.pn

RDDs – From the API
val someRdd = sc.textFile(someURL)• Create an RDD from a text file
val lines = sc.parallelize(List("pandas", "i like pandas")) • Create an RDD from a list of elements
• Can create RDDs from many different sources• RDDs can, and should, be persisted in most cases
– lines.persist() or lines.cache()
• See here for more info– http://spark.apache.org/docs/1.2.0/programming-guide.html

Transformations• Create one RDD and transform the contents into another RDD
• Examples
– Map
– Filter
– Union
– Distinct
– Join
• Complete list -http://spark.apache.org/docs/1.2.0/programming-guide.html
• Lazy execution– Transformations aren’t applied to an RDD until an Action is executed
inputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda x: "error" in x)

Actions
• Cause data to be returned to driver or saved to output
• Cause data retrieval and execution of all Transformations on RDDs
• Common Actions– Reduce
– Collect
– Take
– SaveAs….
• Complete list - http://spark.apache.org/docs/1.2.0/programming-guide.html
• errorsRDD.take(1)

Example App
import sysfrom pyspark import SparkContext
if __name__ == "__main__":sc = SparkContext( “local”, “WordCount”,
sys.argv[0], None)
lines = sc.textFile(sys.argv[1])
counts = lines.flatMap(lambda s: s.split(“ ”)) \.map(lambda word: (word, 1)) \.reduceByKey(lambda x, y: x + y)
counts.saveAsTextFile(sys.argv[2])
Based on source from – databricks.com
1
2
3

Conceptual Representation
RDDRDD
RDDRDD
Transformations
Action Value
counts = lines.flatMap(lambda s: s.split(“ ”)) \.map(lambda word: (word, 1)) \.reduceByKey(lambda x, y: x + y)
counts.saveAsTextFile(sys.argv[2])
lines = sc.textFile(sys.argv[1])
Based on source from – databricks.com
1
2
3

Spark Execution
Image Source – Learning Spark http://shop.oreilly.com/product/0636920028512.do

Demo
Via the REPL

Spark SQL
Abstraction of Spark API to support SQL like interaction
Pars
e
An
alyz
e
Logi
cal P
lan
Op
tim
ize
Spark SQL
HiveQL
Ph
ysic
al P
lan
Exec
ute
Catalyst SQL Core
• Programming Guide - https://spark.apache.org/docs/1.2.0/sql-programming-guide.html• Used for code source in examples
• Catalyst - http://spark-summit.org/talk/armbrust-catalyst-a-query-optimization-framework-for-spark-and-shark/

SQLContext and SchemaRDD
val sc: SparkContext // An existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// createSchemaRDD is used to implicitly convert an RDD to a SchemaRDD.
import sqlContext.createSchemaRDD
SchemaRDD can be created
1) Using reflection to infer schema Structure from an existing RDD
2) Programmable interface to create Schema and apply to an RDD

SchemaRDD Creation - Reflection// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)// createSchemaRDD is used to implicitly convert an RDD to a SchemaRDD.import sqlContext.createSchemaRDD
// Define the schema using a case class.// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,// you can use custom classes that implement the Product interface.case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt))people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are SchemaRDDs and support all the normal RDD operations.// The columns of a row in the result can be accessed by ordinal.teenagers.map(t => "Name: " + t(0)).collect().foreach(println)

SchemaRDD Creation - Explicit// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDDval people = sc.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a stringval schemaString = "name age"
// Import Spark SQL data types and Row.import org.apache.spark.sql._
// Generate the schema based on the string of schemaval schema =
StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
// Convert records of the RDD (people) to Rows.val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// Apply the schema to the RDD.val peopleSchemaRDD = sqlContext.applySchema(rowRDD, schema)
// Register the SchemaRDD as a table.peopleSchemaRDD.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.val results = sqlContext.sql("SELECT name FROM people")
// The results of SQL queries are SchemaRDDs and support all the normal RDD operations.// The columns of a row in the result can be accessed by ordinal.results.map(t => "Name: " + t(0)).collect().foreach(println)

Data Frames
• Data Frames will replace SchemaRDD
• https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html

Demo
• SparkSQL via the REPL

Once Schema Exists on and RDD
It’s either Spark SQL or HiveQL
Can use Thrift ODBC/JDBC for Remote Execution

MLib
• Scalable, distributed, Machine Learning library• Base Statistics - summary statistics, correlations, stratified sampling, hypothesis
testing, random data generation• Classification and Regression - linear models (SVMs, logistic regression, linear
regression), naive Bayes, decision trees, ensembles of trees (Random Forests and Gradient-Boosted Trees)
• Clustering – k-means• Collaborative Filtering - alternating least squares (ALS)• Dimensionality Reduction - singular value decomposition (SVD), principal
component analysis (PCA)• Optimization Primitives - stochastic gradient descent, limited-memory BFGS (L-
BFGS)
• In 1.2, Spark.ml has been introduced in Alpha form– Provides more uniformity across API
• Programming guide - https://spark.apache.org/docs/1.2.0/mllib-guide.html

Dependencies
• Linear Algebra package – Breeze
• For Python integration you must use NumPy

Spark Streaming
From a DataStax Presentation by Rustam Aliyev
https://academy.datastax.com
@rstml

https://github.com/rstml/datastax-spark-streaming-demo

1. Main Concepts

Message… 9 8 7 6 5 4 3 12
Block 5 Block 4 Block 3Block 6 Block 2 Block 1
… 9 8 7 6 5 4 3 12Block
200ms200ms
µBatch 2 µBatch 1
µBatchBlock 5 Block 4 Block 3Block 6 Block 2 Block 1
… 9 8 7 6 5 4 3 12
1s

µBatch 1
µBatch
Message7 6 5 4 3 12
Block 2 Block 1
7 6 5 4 3 12
Block 2 Block 1
7 6 5 4 3 12
Block
200ms
1s
• Partitioning of data
• Impacts parallelism
• Default 200ms
• Min recommended 50ms
• Essentially RDD
• Sequence forms Discretized Stream – DStream
• Operation on DStream translates to RDDs

µBatch 1
7 6 5 4 3 12
Block 2 Block 1
7 6 5 4 3 12
Block 2 Block 1
7 6 5 4 3 12
200ms
1s
sparkConf.set("spark.streaming.blockInterval", "200")
new StreamingContext(sparkCtx, Seconds(1))µBatch
Message
Block

Initializing Streaming Context
import org.apache.spark._import org.apache.spark.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))

2. Stream Sources

7 6 5 4 3 12
µBatch 1
Block 2 Block 1
7 6 5 4 3 12
DStream
Message Source
Receiver
Receiver

Stream Sources (Receivers)
1. Basic Sources• fileStream / textFileStream
• actorStream (AKKA)
• queueStream (Queue[RDD])
• rawSocketStream
• socketStream / socketTextStream
2. Advanced Sources
• Kafka
• ZeroMQ
• MQTT
• Flume
• AWS Kinesis
3. Custom

Initializing Socket Stream
import org.apache.spark._import org.apache.spark.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val text = ssc.socketTextStream("localhost", "9191")

Initializing Twitter Stream
import org.apache.spark._import org.apache.spark.streaming._import org.apache.spark.streaming.twitter._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val tweets = TwitterUtils.createStream(ssc, auth)

Custom Receiver (WebSocket)
import org.apache.spark._import org.apache.spark.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val rsvp = ssc.receiverStream(new WebSocketReceiver("ws://stream.meetup.com/2/rsvps"))
import org.apache.spark.streaming.receiver.Receiver
class WebSocketReceiver(url: String)extends Receiver[String](storageLevel)
{// ...
}

3. Transformations

DStream Transformations
Single Stream
map
flatMap
filter
repartition
count
countByValue
reduce
reduceByKey
transform
updateStateByKey
Multiple Streams
union
join
leftOuterJoin
rightOuterJoin
Cogroup
transformWith

Single Stream Transformation
3 2 1
9 8 7 6 5 4 3 12count
1s1s 1s
3
2
2
4
1
3
1s 1s 1s
* Digits.count()
Digits

Multiple Streams Transformation
2 1
5 4 3 12
union
1s 1s
* Chars.union(Digits)
2 1
E D C AB
2
E 5 D 4
1s
1
C 3 B 2
1s
A 1
Digits
Chars

Word Count
import org.apache.spark._import org.apache.spark.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val text = ssc.socketTextStream("localhost", "9191")
val words = text.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1))
.reduceByKey(_ + _)

4. Window Operations

Window Operations• Transformations over a sliding window of data
1. Window Length – duration of the window
2. Sliding Interval – interval at which operation performed
Window Length = 60 sec
2 1
5s5s
4 3
5s5s
6 5
5s5s
12
5s
...

Window Operations• Transformations over a sliding window of data
1. Window Length – duration of the window
2. Sliding Interval – interval at which operation performed
Window Length = 60s
2 1
5s5s
4 3
5s5s
6 5
5s5s
12
5s
14 13
5s5s
Sliding Interval =
10s
...

Window Length = 60s
Window Operations• Transformations over a sliding window of data
1. Window Length – duration of the window
2. Sliding Interval – interval at which operation performed
2 1
5s5s
4 3
5s5s
6 5
5s5s
12
5s
14 13
5s5s
16 15
5s5s
Sliding Interval =
10s
...

Window Operations
Window based transformations:
window
countByWindow
countByValueAndWindow
reduceByWindow
reduceByKeyAndWindow
groupByKeyAndWindow

Word Count by Window
import org.apache.spark._import org.apache.spark.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val text = ssc.socketTextStream("localhost", "9191")
val words = text.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1))
.reduceByKeyAndWindow((a:Int,b:Int) => a+b, Seconds(60), Seconds(10))

Large Window Considerations
• Large windows:
1. Take longer to process
2. Require larger batch interval for stable processing
• Hour-scale windows are not recommended
• For multi-hour aggregations use real data stores (e.g Cassandra)
• Spark Streaming is NOT design to be a persistent data store
• Set spark.cleaner.ttl and spark.streaming.unpersist (be careful)

5. Output Operations

DStream Output Operations
Standard
saveAsTextFiles
saveAsObjectFiles
saveAsHadoopFiles
saveAsCassandra*
foreachRDD
persist

Saving to Cassandra
import org.apache.spark._import org.apache.spark.streaming._import com.datastax.spark.connector.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val text = ssc.socketTextStream("localhost", "9191")
val words = text.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.saveToCassandra("keyspace", "table", SomeColumns("word", "total"))

Start Processing
import org.apache.spark._import org.apache.spark.streaming._import com.datastax.spark.connector.streaming._
// Spark connection optionsval conf = new SparkConf().setAppName(appName).setMaster(master)
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
val text = ssc.socketTextStream("localhost", "9191")
val words = text.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.saveToCassandra("keyspace", "table", SomeColumns("word", "total"))
scc.start()scc.awaitTermination()

6. Scalability

Scaling Streaming
• How to scale stream processing?
Kafka
Producer
Spark
Receiver
Spark
ProcessorOutput

Parallelism – Partitioning• Partition input stream (e.g. by topics)• Each receiver can be run on separate worker
Kafka
Topic 2
Spark
Receiver 2
Spark
ProcessorOutput
Kafka
Topic 3
Spark
Receiver 3
Spark
ProcessorOutput
Kafka
Topic 1
Spark
Receiver 1
Spark
ProcessorOutput
Kafka
Topic N
Spark
Receiver N
Spark
ProcessorOutput

Parallelism – Partitioning
• Partition stream (e.g. by topics)
• Use union() to create single DStream
• Transformations applied on the unified stream
val numStreams = 5val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }val unifiedStream = streamingContext.union(kafkaStreams)unifiedStream.print()

Parallelism – RePartitioning• Explicitly repartition input stream• Distribute received batches across specified number of machines
Producer
Spark
Receiver
Spark
ProcessorOutput
Spark
ProcessorOutput
Spark
ProcessorOutput
Spark
ProcessorOutput

Parallelism – RePartitioning
• Explicitly repartition input stream
• Distribute received batches across specified number of machines
• Use inputstream.repartition(N)
val numWorkers = 5val twitterStream = TwitterUtils.createStream(...)twitterStream.repartition(numWorkers)

Parallelism – Tasks
• Each block processed by separate task
• To increase parallel tasks, increase number of blocks in a batch
• Tasks per Receiver per Batch ≈ Batch Interval / Block Interval
• Example: 2s batch / 200ms block = 10 tasks
• CPU cores will not be utilized if number of tasks is too low
• Consider tuning default number of parallel tasks
spark.default.parallelism

7. Fault Tolerance

Fault Tolerance
To recover streaming operation, Spark needs:
1. RDD data
2. DAG/metadata of DStream

Fault Tolerance – RDD
• Recomputing RDD may be unavailable for stream source
• Protect data by replicating RDD
• RDD replication controlled by org.apache.spark.storage.StorageLevel
• Use storage level with _2 suffix (2 replicas):– DISK_ONLY_2
– MEMORY_ONLY_2
– MEMORY_ONLY_SER_2
– MEMORY_AND_DISK_2
– MEMORY_AND_DISK_SER_2 Default for most receivers

Fault Tolerance – Checkpointing
• Periodically writes:
1. DAG/metadata of DStream(s)
2. RDD data for some stateful transformations (updateStateByKey &
reduceByKeyAndWindow*)
• Uses fault-tolerant distributed file system for persistence.
• After failure, StreamingContext recreated from checkpoint data
on restart.
• Choose interval carefully as storage will impact processing times.

Fault Tolerance – Checkpointingimport org.apache.spark._import org.apache.spark.streaming._
val checkpointDirectory = "words.cp" // Directory name for checkpoint data
def createContext(): StreamingContext = {// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))val text = ssc.socketTextStream("localhost", "9191")ssc.checkpoint(checkpointDirectory) // set checkpoint directory
val words = text.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)wordCounts.saveToCassandra("keyspace", "table", SomeColumns("word", "total"))
ssc}
val conf = new SparkConf().setAppName(appName).setMaster(master)
// Get StreamingContext from checkpoint data or create a new oneval scc = StreamingContext.getOrCreate(checkpointDirectory, createContext _)
scc.start()scc.awaitTermination()

Fault Tolerance – Checkpointing
$ dse hadoop fs -ls words.cp
Found 11 itemsdrwxrwxrwx - rustam staff 0 2014-12-21 13:24 /user/rustam/words.cp/b8e8e262-2f8d-4e2f-ae28-f5cfbadb29bf-rwxrwxrwx 1 rustam staff 3363 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168345000-rwxrwxrwx 1 rustam staff 3368 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168345000.bk-rwxrwxrwx 1 rustam staff 3393 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168350000-rwxrwxrwx 1 rustam staff 3398 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168350000.bk-rwxrwxrwx 1 rustam staff 3422 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168355000-rwxrwxrwx 1 rustam staff 3427 2014-12-21 13:25 /user/rustam/words.cp/checkpoint-1419168355000.bk-rwxrwxrwx 1 rustam staff 3447 2014-12-21 13:26 /user/rustam/words.cp/checkpoint-1419168360000-rwxrwxrwx 1 rustam staff 3452 2014-12-21 13:26 /user/rustam/words.cp/checkpoint-1419168360000.bk-rwxrwxrwx 1 rustam staff 3499 2014-12-21 13:26 /user/rustam/words.cp/checkpoint-1419168365000-rwxrwxrwx 1 rustam staff 3504 2014-12-21 13:26 /user/rustam/words.cp/checkpoint-1419168365000.bk
• Verifying checkpoint data on CFS:
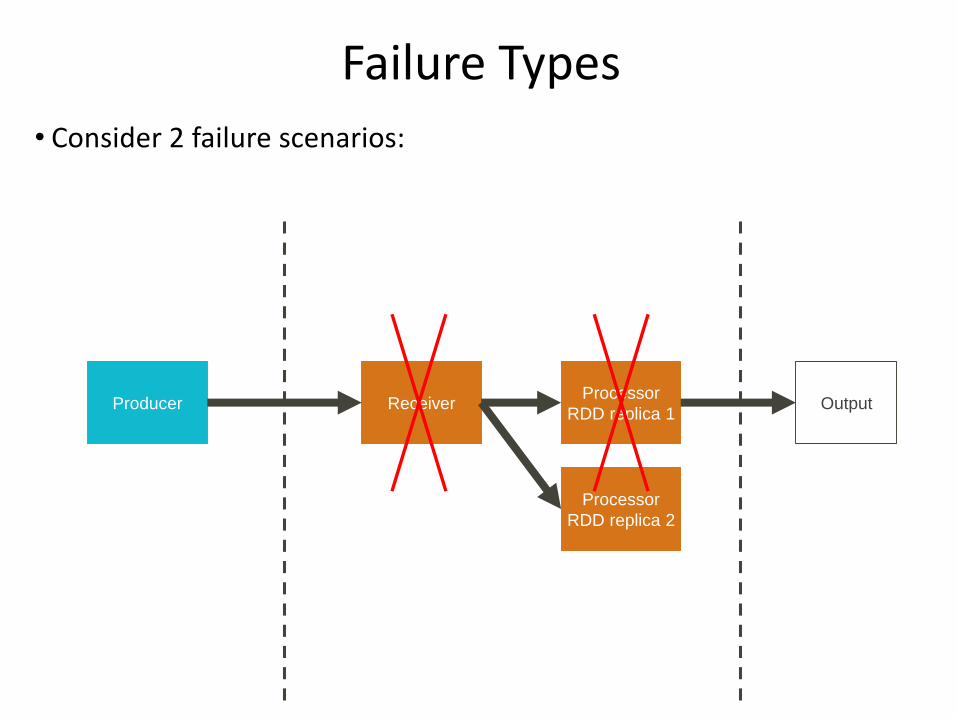
Failure Types
• Consider 2 failure scenarios:
Producer ReceiverProcessor
RDD replica 1Output
Processor
RDD replica 2

State of Data
1. Data received and replicated
• Will survive failure of 1 replica
2. Data received but only buffered for replication
• Not replicated yet
• Needs recomputation if lost

Receiver Reliability Types
1. Reliable Receivers
• Receiver acknowledges source only after ensuring that data replicated.
• Source needs to support message ack. E.g. Kafka, Flume.
2. Unreliable Receivers
• Data can be lost in case of failure.
• Source doesn’t support message ack. E.g. Twitter.

Fault Tolerance
• Spark 1.2 adds Write Ahead Log (WAL) support for Streaming
• Protection for Unreliable Receivers
• See SPARK-3129 for architecture details
State / Receiver
Type
Received,
Replicated
Received, Only
Buffered
Reliable Receiver Safe Safe
Unreliable
ReceiverSafe Data Loss

GraphX
• Alpha release
• Provides Graph computation capabilities on top of RDDs
• Resilient Distributed Property Graph: a directed multigraph with properties attached to each vertex and edge.
• The goal of the GraphX project is to unify graph-parallel and data-parallel computation in one system with a single composable API.

I am not a Graph-guy yet.
Who here is working with Graph today?

Handy Tools
• Ooyala Spark Job Server -https://github.com/ooyala/spark-jobserver
• Monitoring with Graphite and Grafana –http://www.hammerlab.org/2015/02/27/monitoring-spark-with-graphite-and-grafana/



















