
An Innovative Massively Parallelized Molecular Dynamic Software
22
Renewable energies | Eco-friendly production | Innovative transport | Eco-efficient processes | Sustainable resources © 2011 - IFP Energies nouvelles ICE Consortium The CADENCED Project DTIMA – VASP¨on GPU – GTC 2012 15/05/2012 An Innovative Massively Parallelized Molecular Dynamic Software Mohamed Hacene, Ani Anciaux, Xavier Rozanska, Paul Fleurat Lessard, Thomas Guignon
Transcript of An Innovative Massively Parallelized Molecular Dynamic Software

Renewable energies | Eco-friendly production | Innovative transport | Eco-efficient processes | Sustainable resources ©
2011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
The
CADENCED
Project
DTIMA – VASP¨on GPU – GTC 2012 15/05/2012
An Innovative Massively Parallelized Molecular Dynamic Software
Mohamed Hacene, Ani Anciaux,
Xavier Rozanska, Paul Fleurat Lessard,
Thomas Guignon

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
CADENCED Project SP3 CADENCED Project
Join project with KAUST, CNRS, ENS Lyon and IFPEN
Goal: design new catalyst with focus on hydrogen production
Sub project 3: improve simulation tools to help new catalyst
design
Explore GPU computing for MD simulation
Develop tools for MD code coupling (Vasp + TurboMole)
DTIMA – VASP on GPU – GTC 2012 15/05/2012 2

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
VASP
developed by the University of Vienna
package for performing ab-initio quantum-mechanical molecular
dynamics (MD) using pseudo potentials and a plane wave basis
set.
VASP implementation approach
based on a finite-temperature local-density approximation (with the
free energy as variation quantity) and an exact evaluation of the
instantaneous electronic ground state at each optimization step
Target high performance VASP 5.2 version
hybrid (CPU+GPU) version
DTIMA – VASP on GPU – GTC 2012 15/05/2012 3

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
GPU methodology (1)
Formal view of VASP:
“Don’t care” about physic models
Care about numeric algorithm (linear algebra, FFT…) work flow and
data flow
profile VASP to identify the most time consuming functions
Move the most expensive functions to GPU
Analyze transfers between the CPU and the GPU
DTIMA – VASP on GPU – GTC 2012 15/05/2012 4

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
GPU methodology (2)
VASP profile shows that majority of time is spent in:
FFT
BLAS
Time consuming functions:
EDDAV for the Blocked Davidson method (IALGO=38)
EDDIAG, RMM-DIIS, ORTHCH for the RMMDIIS method
(IALGO=48)
POTLOK and CHARGE functions for both methods
DTIMA – VASP on GPU – GTC 2012 15/05/2012
5

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
GPU methodology (3) Step by Step approach:
Inside a function identify computation
parts that can move on GPU:
Rewrite them for GPU (or use library):
FFT CUFFT, BLAS BLAS, Specific
computation loops hand coded kernels
Introduce them with data transfer
before/after each kernel call.
Easy validity check with CPU version
Analyze data flow to
Remove unnecessary copy.
Find asynchronous transfer opportunity.
DTIMA – VASP on GPU – GTC 2012 15/05/2012 6
BLAS FFT
t
CPU
CPU
CUBLAS CUFFT GPU
CPU
CUBLAS CUFFT GPU
FFT
Check GPU vs CPU results
CPU
CUBLAS CUFFT GPU

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
CPU/GPU Automatic choice
CPU computation between 2
GPU calls (HAMILTMU PROJALL)
Algorithm not GPU friendly
Too small data set (low
parallelism)
DTIMA – VASP on GPU – GTC 2012 15/05/2012 7
GPU kernel 1 GPU
CPU
GPU kernel 2
t
GPU CPU GPU data transfers reduce GPU gains.
Move CPU comp. To GPU implies no data transfers.
No performance model: Do we reduce computation time?

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
CPU/GPU Automatic choice
First iteration: take CPU time
DTIMA – VASP on GPU – GTC 2012 15/05/2012 8
GPU kernel 1 GPU
CPU t
GPU kernel 2
Tcpu
Second iteration: take GPU time GPU kernel 1 GPU
CPU t
GPU kernel 2
Tgpu
Following iterations: take the fastest one
GPU computation can be longer but we avoid copy.

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Results: Test systems Initially developed on a 2xE5420 with S1070 GPU system
Tests systems:
1 workstation: 4c Core2 @ 2.66 Ghz (Q9450) + C2070;
1 bullx system (9 nodes): 2x 4c Nehalem @ 2.5 Ghz (E5540) + 2x M1060
DTIMA – VASP on GPU – GTC 2012 15/05/2012 9
M1
06
0
M1
06
0
Bullx node:
Each GPU has it’s own PCI Express bus.
Care of CPU/GPU affinity.

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Acceleration, 1 core/1 GPU
test cases (algo=Fast)
SILICA, 240 atoms
SLAB, 328 atoms
Acceleration:
3.8 to 5.0 vs 1core Nehalem
2.5 Ghz
C2070: no significant gain
over M1060
Slow host processor
Slow PCI express
DTIMA – VASP on GPU – GTC 2012 15/05/2012
10
Total time comparison between Xeon E5540,
E5540+M1060 and Q9450+C2070, CUDA 3.2 Acceleration factors are given in brackets

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Acceleration: iteration details
SLAB 1 iteration (ialgo=48)
acc vs E5540:
EDDIAG:
M1060: 6.49 - C2070: 12.1
ORTHCH:
M1060: 5.46 - C2070: 14.2
RMMDIIS:
M1060: 2,3 - C2070: 2,54
Overall acc. is limited by
RMMDIIS function
DTIMA – VASP on GPU – GTC 2012 15/05/2012 11
279
30
142
285
43
6
26
124
23
4 10
112
0
50
100
150
200
250
300
EDDIAG CHARGE ORTHCH RMMDIIS
Xeon E5540 Tesla M1060 Tesla C2070

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
GPU / core balance
Compare 1 GPU vs 1 core is not really fair:
Typical balance is 4 cores for one GPU
Consider linear acceleration for cpu version:
One GPU does not improve performance compared to 4 cores
More dense GPU system (4c 4GPU) ? Problems
PCI Express scalability
Power supply, Thermal dissipation
Multiple core VASP with MPI
DTIMA – VASP on GPU – GTC 2012 15/05/2012 12
© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
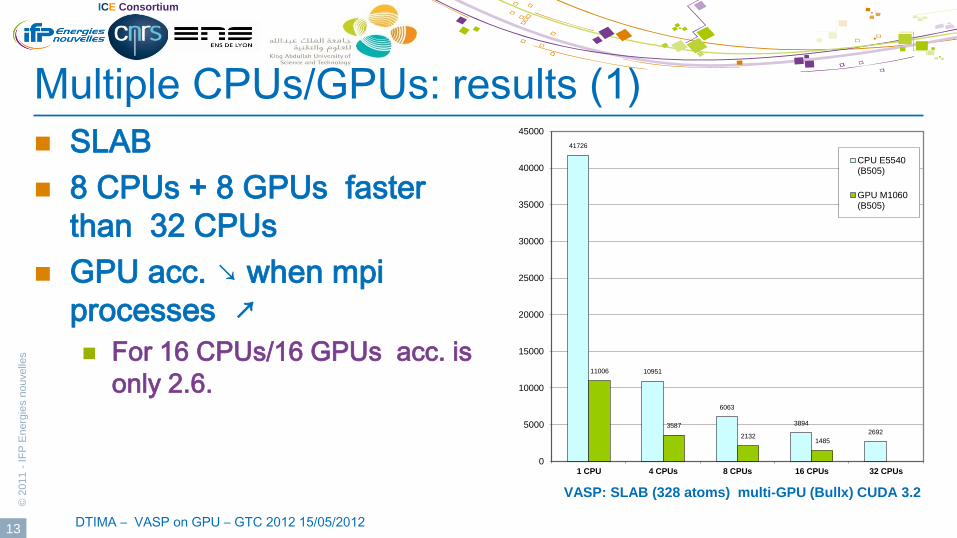
Multiple CPUs/GPUs: results (1)
SLAB
8 CPUs + 8 GPUs faster
than 32 CPUs
GPU acc. ↘ when mpi
processes ↗
For 16 CPUs/16 GPUs acc. is
only 2.6.
DTIMA – VASP on GPU – GTC 2012 15/05/2012 13
41726
10951
6063
3894
2692
11006
3587
2132 1485
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
1 CPU 4 CPUs 8 CPUs 16 CPUs 32 CPUs
CPU E5540(B505)
GPU M1060(B505)
VASP: SLAB (328 atoms) multi-GPU (Bullx) CUDA 3.2

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Multiple CPUs/GPUs: results (2)
WGPS3 1138 atoms,
Algo=Fast (SP1 test case)
8CPUs + 8 GPUs faster than
32 cpus
For 16 CPUs/16 GPUs acc.
is only 2.6.
DTIMA – VASP on GPU – GTC 2012 15/05/2012 14
74454
40972
31285
18455
24901
15759
11825
0
10000
20000
30000
40000
50000
60000
70000
80000
4 CPUs 8 CPUs 16 CPUs 32 CPUs
CPU E5540(B505)
GPU M1060(B505)
WGPS3 (1138 atoms) test on VASP multi-GPU Bullx, CUDA 3.2

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Beyond initial results
Updated system:
Nehalem @ 2.8 Ghz (WS3530) + C2070
SLAB test case (NSW=1)
CPU time 1 core : 17623 s.
GPU time : 4064 s.
Acc. is only 4.33, previous was: 5 !
The hard point is still RMMDIIS function
DTIMA – VASP on GPU – GTC 2012 15/05/2012 15

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Closer look to RMMDIIS
RMMDIIS function : 92.4 s. , 74% of iteration time
DTIMA – VASP on GPU – GTC 2012 15/05/2012 16
time (s.) % PROJALL 2,30E+01 24,8
Init 4,40E+00 4,8 Hamil 2,93E+01 31,8
ECCP 5,35E+00 5,8 FFTWAV 1,07E+01 11,6
BLAS 1,19E+01 12,9 LAPACK 7,48E-02 0,1
Transfer 7,66E+00 8,3
Only on CPU (see slide 9)

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Performance problem (PROJALL)
low parallelism:
Number of grid points per ions (∼1000 for SLAB)
A solution: use parallelism over ions with cuda stream for
PROJALL (RPROMU)
RMMDIIS time goes down to 62.8 s. (92.4 s.)
Overall simulation time: 3126 s. (4064s)
Acceleration is now 5.64
DTIMA – VASP on GPU – GTC 2012 15/05/2012 17

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Performance problem (HAMIL)
Similar to PROJALL but:
Update real space grid for each ions:
no simple parallelism when overlap.
Possible solutions:
Atomic operations: does not work with
double precision, may be inefficient .
Finding independent sets of ions:
All ions in one set do not overlap.
DTIMA – VASP on GPU – GTC 2012 15/05/2012 18

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Conclusions and Future work (1)
Best effort approach for VASP GPU:
>10 acceleration factor on some functions
RMMDIIS need more improvement.
Best effort approach for multicore VASP ? (OpenMP,
Pthreads) ?
Can GPU compete with multicore
Possible solution: multicore with GPU
In a node, balance work between all cores and all gpu
DTIMA – VASP on GPU – GTC 2012 15/05/2012 19

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Conclusions and Future work (2)
Benefit from cuda 4.0:
Direct data transfer from GPU memory to infiniband network
Mixed precision ?
For some parts, may be single precision is enough.
New GPUs cards:
M2090 30% faster than M2070
Don’t use ECC memory…
DTIMA – VASP on GPU – GTC 2012 15/05/2012 20

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
Question ?
DTIMA – VASP on GPU – GTC 2012 15/05/2012 21

© 2
011 -
IF
P E
nerg
ies n
ouvelle
s
ICE Consortium
www.ifpenergiesnouvelles.com


















