An Ecosystem for Linked Humanities Data
72
An Ecosystem for Linked Humanities Data Rinke Hoekstra Vrije Universiteit Amsterdam/University of Amsterdam [email protected] Albert Meroño-Peñuela, Kathrin Dentler, Auke Rijpma, Richard Zijdeman and Ivo Zandhuis legend data legend data
-
Upload
rinke-hoekstra -
Category
Science
-
view
78 -
download
0
Transcript of An Ecosystem for Linked Humanities Data

An Ecosystem for Linked Humanities Data
Rinke HoekstraVrije Universiteit Amsterdam/University of [email protected] Meroño-Peñuela, Kathrin Dentler, Auke Rijpma, Richard Zijdeman and Ivo Zandhuis
legenddata legend data

The Promise of Digital Humanities

The Promise of Digital Humanities


The Problem of Digital Humanities
Pacific Barreleye, http://imgur.com/gallery/Mzyb5 (can rotate its eyes forwards or upwards to look through the transparent head to prey above)

http://www.asergeev.com/pictures/archives/compress/2012/1034/24.htm


The Cost of Data Preparation
Common Motifs in Scientific Workflows:An Empirical Analysis
Daniel Garijo⇤, Pinar Alper †, Khalid Belhajjame†, Oscar Corcho⇤, Yolanda Gil‡, Carole Goble†⇤Ontology Engineering Group, Universidad Politecnica de Madrid. {dgarijo, ocorcho}@fi.upm.es
†School of Computer Science, University of Manchester. {alperp, khalidb, carole.goble}@cs.manchester.ac.uk‡Information Sciences Institute, Department of Computer Science, University of Southern California. [email protected]
Abstract—While workflow technology has gained momentumin the last decade as a means for specifying and enacting compu-tational experiments in modern science, reusing and repurposingexisting workflows to build new scientific experiments is still adaunting task. This is partly due to the difficulty that scientistsexperience when attempting to understand existing workflows,which contain several data preparation and adaptation steps inaddition to the scientifically significant analysis steps. One wayto tackle the understandability problem is through providingabstractions that give a high-level view of activities undertakenwithin workflows. As a first step towards abstractions, we reportin this paper on the results of a manual analysis performed overa set of real-world scientific workflows from Taverna and Wingssystems. Our analysis has resulted in a set of scientific workflow
motifs that outline i) the kinds of data intensive activities that areobserved in workflows (data oriented motifs), and ii) the differentmanners in which activities are implemented within workflows(workflow oriented motifs). These motifs can be useful to informworkflow designers on the good and bad practices for workflowdevelopment, to inform the design of automated tools for thegeneration of workflow abstractions, etc.
I. INTRODUCTION
Scientific workflows have been increasingly used in the lastdecade as an instrument for data intensive scientific analysis.In these settings, workflows serve a dual function: first asdetailed documentation of the method (i. e. the input sourcesand processing steps taken for the derivation of a certaindata item) and second as re-usable, executable artifacts fordata-intensive analysis. Workflows stitch together a varietyof data manipulation activities such as data movement, datatransformation or data visualization to serve the goals of thescientific study. The stitching is realized by the constructsmade available by the workflow system used and is largelyshaped by the environment in which the system operates andthe function undertaken by the workflow.
A variety of workflow systems are in use [10] [3] [7] [2]serving several scientific disciplines. A workflow is a softwareartifact, and as such once developed and tested, it can beshared and exchanged between scientists. Other scientists canthen reuse existing workflows in their experiments, e.g., assub-workflows [17]. Workflow reuse presents several advan-tages [4]. For example, it enables proper data citation andimproves quality through shared workflow development byleveraging the expertise of previous users. Users can alsore-purpose existing workflows to adapt them to their needs[4]. Emerging workflow repositories such as myExperiment
[14] and CrowdLabs [8] have made publishing and findingworkflows easier, but scientists still face the challenges of re-use, which amounts to fully understanding and exploiting theavailable workflows/fragments. One difficulty in understandingworkflows is their complex nature. A workflow may containseveral scientifically-significant analysis steps, combined withvarious other data preparation activities, and in differentimplementation styles depending on the environment andcontext in which the workflow is executed. The difficulty inunderstanding causes workflow developers to revert to startingfrom scratch rather than re-using existing fragments.
Through an analysis of the current practices in scientificworkflow development, we could gain insights on the creationof understandable and more effectively re-usable workflows.Specifically, we propose an analysis with the following objec-tives:
1) To reverse-engineer the set of current practices in work-flow development through an analysis of empirical evi-dence.
2) To identify workflow abstractions that would facilitateunderstandability and therefore effective re-use.
3) To detect potential information sources and heuristicsthat can be used to inform the development of tools forcreating workflow abstractions.
In this paper we present the result of an empirical analysisperformed over 177 workflow descriptions from Taverna [10]and Wings [3]. Based on this analysis, we propose a catalogueof scientific workflow motifs. Motifs are provided through i)a characterization of the kinds of data-oriented activities thatare carried out within workflows, which we refer to as data-oriented motifs, and ii) a characterization of the different man-ners in which those activity motifs are realized/implementedwithin workflows, which we refer to as workflow-orientedmotifs. It is worth mentioning that, although important, motifsthat have to do with scheduling and mapping of workflowsonto distributed resources [12] are out the scope of this paper.
The paper is structured as follows. We begin by providingrelated work in Section II, which is followed in Section III bybrief background information on Scientific Workflows, and thetwo systems that were subject to our analysis. Afterwards wedescribe the dataset and the general approach of our analysis.We present the detected scientific workflow motifs in SectionIV and we highlight the main features of their distribution
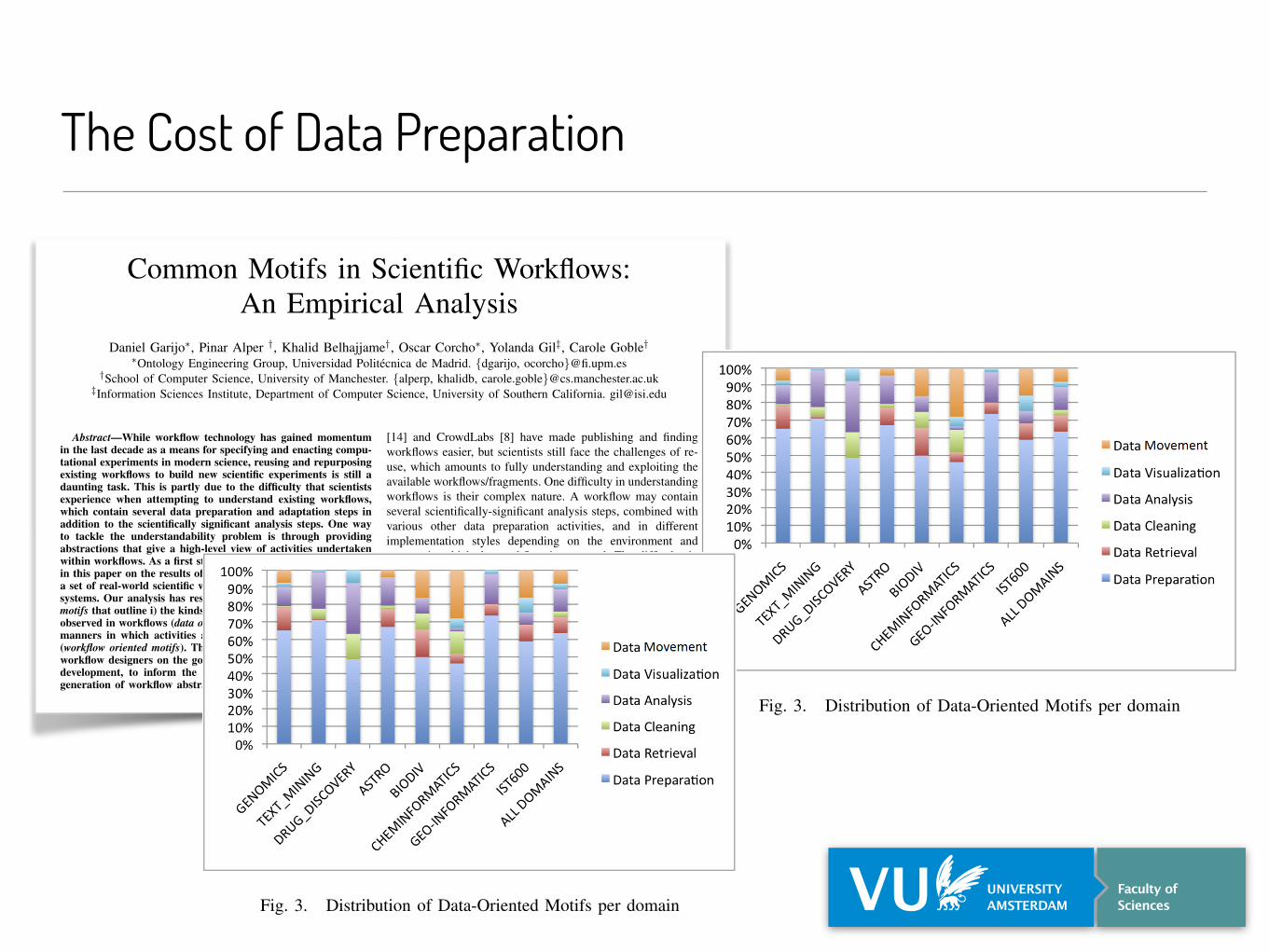
Fig. 3. Distribution of Data-Oriented Motifs per domain
Fig. 4. Distribution of Data Preparation motifs per domain
databases and shipping data to necessary locations for analysis.The impact of the environmental difference of Wings and
Taverna on the workflows is also observed in the workflow-oriented motifs (Figure 7). Stateful invocations motifs are notpresent in Wings workflows, as all steps are handled by adedicated workflow scheduling framework and the details arehidden from the workflow developers. In Taverna, the work-flow developer is responsible for catering for various differentinvocation requirements of 3rd party services, which mayinclude stateful invocations requiring execution of multipleconsecutive steps in order to undertake a single function.
Regarding workflow-oriented motifs, Figure 8 shows thatHuman-interaction steps are increasingly used in scientificworkflows, especially in the Biodiversity and Cheminformat-ics domains. Human interactions in Taverna workflows arehandled either through external tools (e.g., Google Refine),facilitated via a human-interaction plug-in, or through simplelocal scripts (e.g., selection of configuration values frommulti-choice lists). We have observed that non-trivial humaninteractions involving external tooling require a large numberof workflow steps dedicated to deploying or configuring theexternal tools, resulting in very large and complex workflows.Wings workflows do not support human interaction steps.
Finally, the large proportion of the combination of Compos-ite Workflows and Atomic Workflows motif in Figure 8 shows
Fig. 5. Data Preparation Motifs in the Genomics Workflows
Fig. 6. Data-Oriented Motifs in the Genomics Workflows
that the use of sub-workflows is an established best practicefor modularizing functionality.
VI. DISCUSSION
Our analysis shows that the nature of the environment inwhich a workflow system operates can bring-about obstaclesagainst the re-usability of workflows.
A. Obfuscation of Scientific WorkflowsData-intensive scientific analysis could be large and com-
plex with several processing steps corresponding to differentphases of data analysis performed over various kinds of data.This complexity is exacerbated when the workflow operates inan open environment, like Taverna’s, and composes multiplethird party services supporting different data formats andprotocols. In such cases the workflow contains additional stepsfor coping with different format and protocol requirements.This obfuscation of the workflow burdens the documentationfunction and creates difficulty for the workflow re-user sci-entists, who seeks to have a complete understanding of thefunction and the details of the workflow that they are re-usingin order to be able make scientific claims with their workflowbased studies.
Obfuscation is caused by the abundance of data preparationsteps, data movement operations and multi-step stateful invo-cations. One way to overcome obfuscation is to encapsulate
Fig. 3. Distribution of Data-Oriented Motifs per domain
Fig. 4. Distribution of Data Preparation motifs per domain
databases and shipping data to necessary locations for analysis.The impact of the environmental difference of Wings and
Taverna on the workflows is also observed in the workflow-oriented motifs (Figure 7). Stateful invocations motifs are notpresent in Wings workflows, as all steps are handled by adedicated workflow scheduling framework and the details arehidden from the workflow developers. In Taverna, the work-flow developer is responsible for catering for various differentinvocation requirements of 3rd party services, which mayinclude stateful invocations requiring execution of multipleconsecutive steps in order to undertake a single function.
Regarding workflow-oriented motifs, Figure 8 shows thatHuman-interaction steps are increasingly used in scientificworkflows, especially in the Biodiversity and Cheminformat-ics domains. Human interactions in Taverna workflows arehandled either through external tools (e.g., Google Refine),facilitated via a human-interaction plug-in, or through simplelocal scripts (e.g., selection of configuration values frommulti-choice lists). We have observed that non-trivial humaninteractions involving external tooling require a large numberof workflow steps dedicated to deploying or configuring theexternal tools, resulting in very large and complex workflows.Wings workflows do not support human interaction steps.
Finally, the large proportion of the combination of Compos-ite Workflows and Atomic Workflows motif in Figure 8 shows
Fig. 5. Data Preparation Motifs in the Genomics Workflows
Fig. 6. Data-Oriented Motifs in the Genomics Workflows
that the use of sub-workflows is an established best practicefor modularizing functionality.
VI. DISCUSSION
Our analysis shows that the nature of the environment inwhich a workflow system operates can bring-about obstaclesagainst the re-usability of workflows.
A. Obfuscation of Scientific WorkflowsData-intensive scientific analysis could be large and com-
plex with several processing steps corresponding to differentphases of data analysis performed over various kinds of data.This complexity is exacerbated when the workflow operates inan open environment, like Taverna’s, and composes multiplethird party services supporting different data formats andprotocols. In such cases the workflow contains additional stepsfor coping with different format and protocol requirements.This obfuscation of the workflow burdens the documentationfunction and creates difficulty for the workflow re-user sci-entists, who seeks to have a complete understanding of thefunction and the details of the workflow that they are re-usingin order to be able make scientific claims with their workflowbased studies.
Obfuscation is caused by the abundance of data preparationsteps, data movement operations and multi-step stateful invo-cations. One way to overcome obfuscation is to encapsulate

We do this repeatedly for the same datasets

Top Down: Big Micro Data(sets)
• North Atlantic Population Project (NAPP)
• Integrated Public Use Microdata Series (IPUMS)
• Mosaic

Top Down: Big Micro Data(sets)
• North Atlantic Population Project (NAPP)
• Integrated Public Use Microdata Series (IPUMS)
• Mosaic
• Only data slices can be downloaded
• Standardisation leads to loss of detail
• Results are not mutually compatible
• Large scale efforts are very expensive

Top Down: Big Micro Data(sets)
• North Atlantic Population Project (NAPP)
• Integrated Public Use Microdata Series (IPUMS)
• Mosaic
• Only data slices can be downloaded
• Standardisation leads to loss of detail
• Results are not mutually compatible
• Large scale efforts are very expensive
… and they do not solve the problem!

… the current workflow

… the current workflow

… the current workflow
Do adverse conditions (Great Depression) around birth or early in life affect socioeconomic and health outcomes?

… the current workflow
Do adverse conditions (Great Depression) around birth or early in life affect socioeconomic and health outcomes?
Does GDP per capita at birth year negatively affect occupational status in later life?

… the current workflow
Do adverse conditions (Great Depression) around birth or early in life affect socioeconomic and health outcomes?
Dutch “Hunger-winter” studies (cf Lindeboom)
Does GDP per capita at birth year negatively affect occupational status in later life?

… the current workflow
Do adverse conditions (Great Depression) around birth or early in life affect socioeconomic and health outcomes?
Thomasson and Fishback. 2014. “Hard Times in the Land of Plenty: The Effect on Income and Disability Later in Life for People Born during the Great Depression.” Expl in Eco Hist 54: 64–78.
Dutch “Hunger-winter” studies (cf Lindeboom)
Does GDP per capita at birth year negatively affect occupational status in later life?
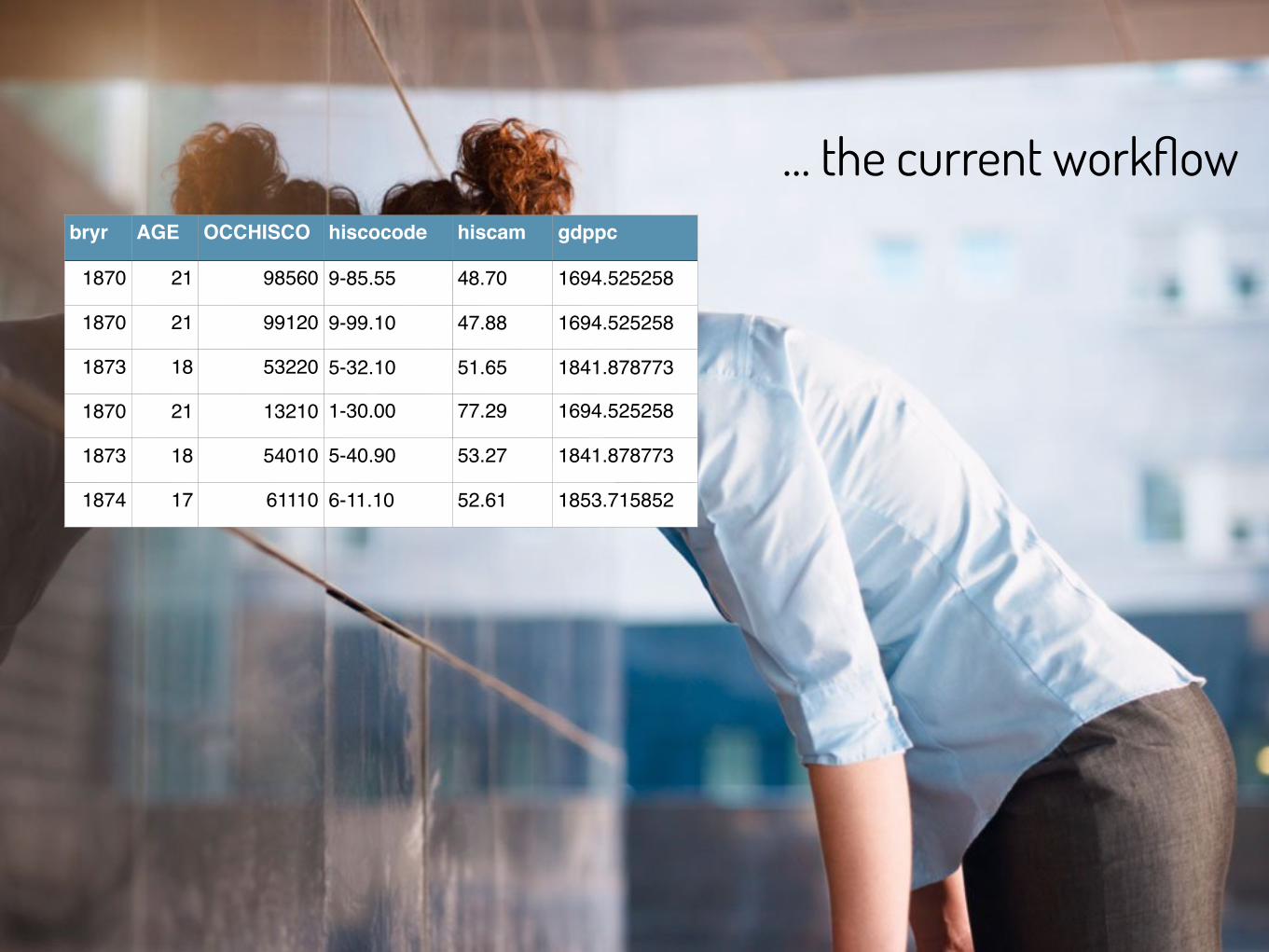
… the current workflowbryr AGE OCCHISCO hiscocode hiscam gdppc
1870 21 98560 9-85.55 48.70 1694.525258
1870 21 99120 9-99.10 47.88 1694.525258
1873 18 53220 5-32.10 51.65 1841.878773
1870 21 13210 1-30.00 77.29 1694.525258
1873 18 54010 5-40.90 53.27 1841.878773
1874 17 61110 6-11.10 52.61 1853.715852

… the current workflowbryr AGE OCCHISCO hiscocode hiscam gdppc
1870 21 98560 9-85.55 48.70 1694.525258
1870 21 99120 9-99.10 47.88 1694.525258
1873 18 53220 5-32.10 51.65 1841.878773
1870 21 13210 1-30.00 77.29 1694.525258
1873 18 54010 5-40.90 53.27 1841.878773
1874 17 61110 6-11.10 52.61 1853.715852
1. Gather and enter own data
2. Find data on multiple repositories
3. Download
4. Clean and reshape
5. Merge
6. Clean and reshape…
7. Analyse
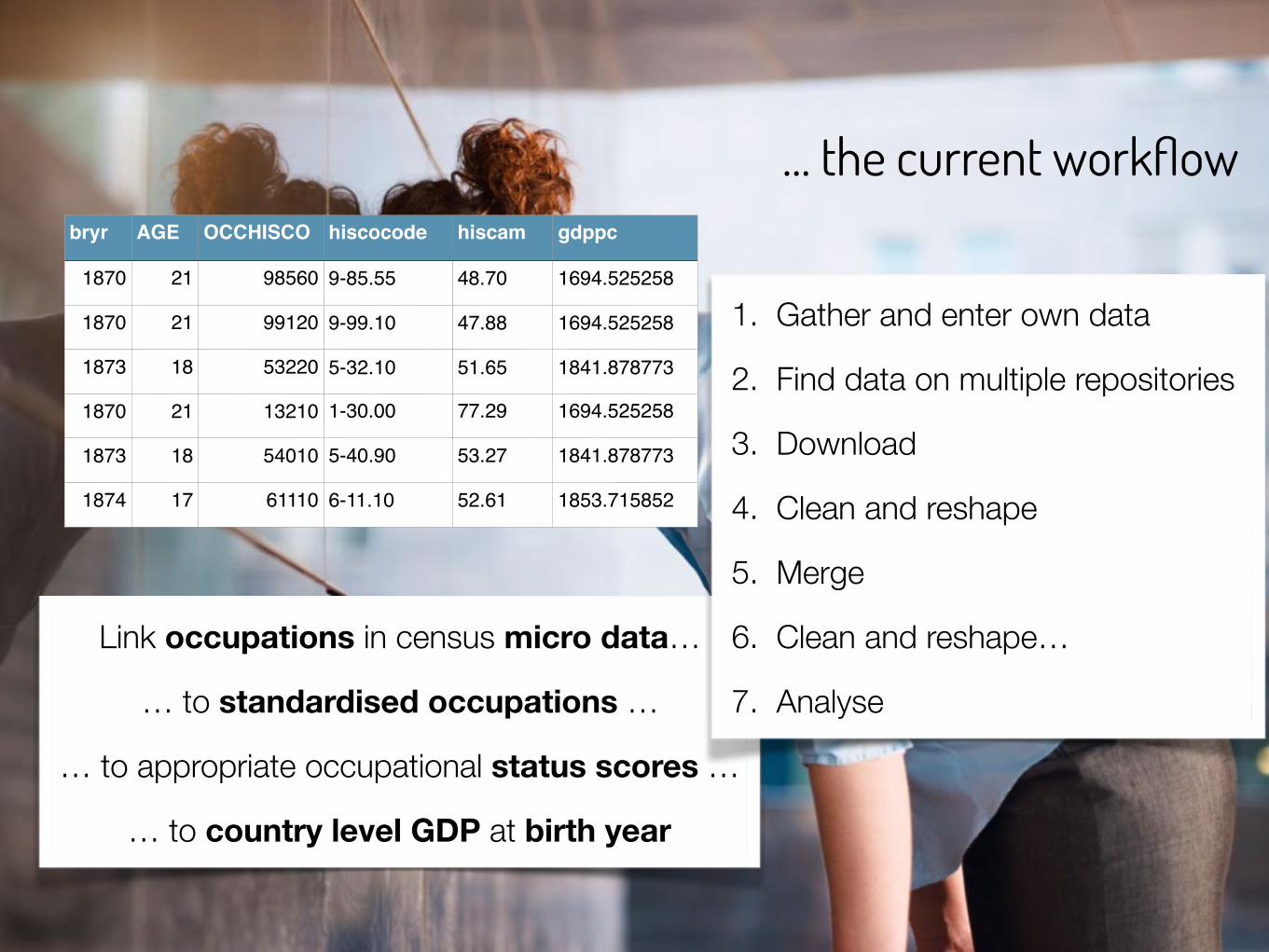
… the current workflowbryr AGE OCCHISCO hiscocode hiscam gdppc
1870 21 98560 9-85.55 48.70 1694.525258
1870 21 99120 9-99.10 47.88 1694.525258
1873 18 53220 5-32.10 51.65 1841.878773
1870 21 13210 1-30.00 77.29 1694.525258
1873 18 54010 5-40.90 53.27 1841.878773
1874 17 61110 6-11.10 52.61 1853.715852
Link occupations in census micro data…
… to standardised occupations …
… to appropriate occupational status scores …
… to country level GDP at birth year
1. Gather and enter own data
2. Find data on multiple repositories
3. Download
4. Clean and reshape
5. Merge
6. Clean and reshape…
7. Analyse
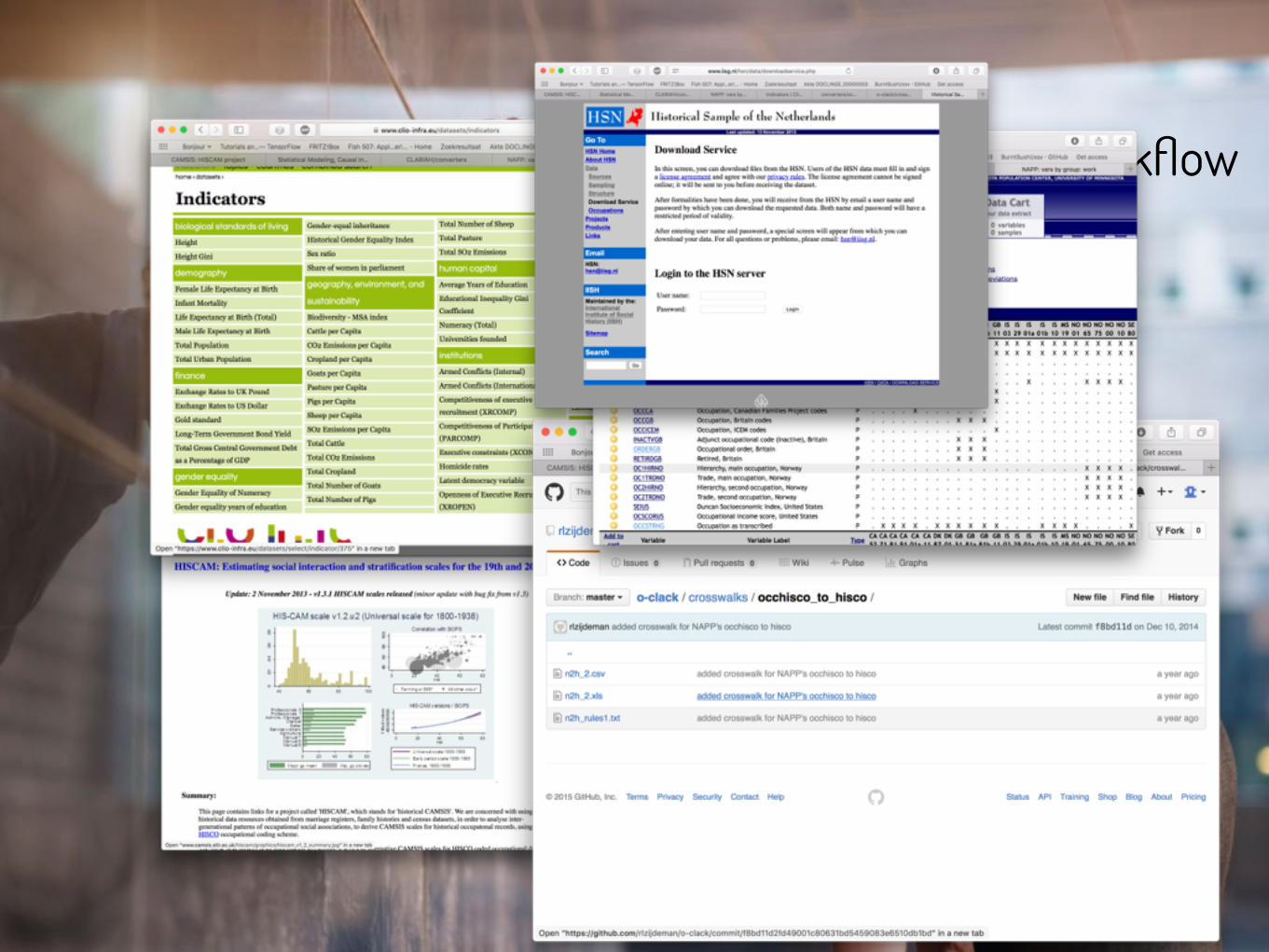
… the current workflow
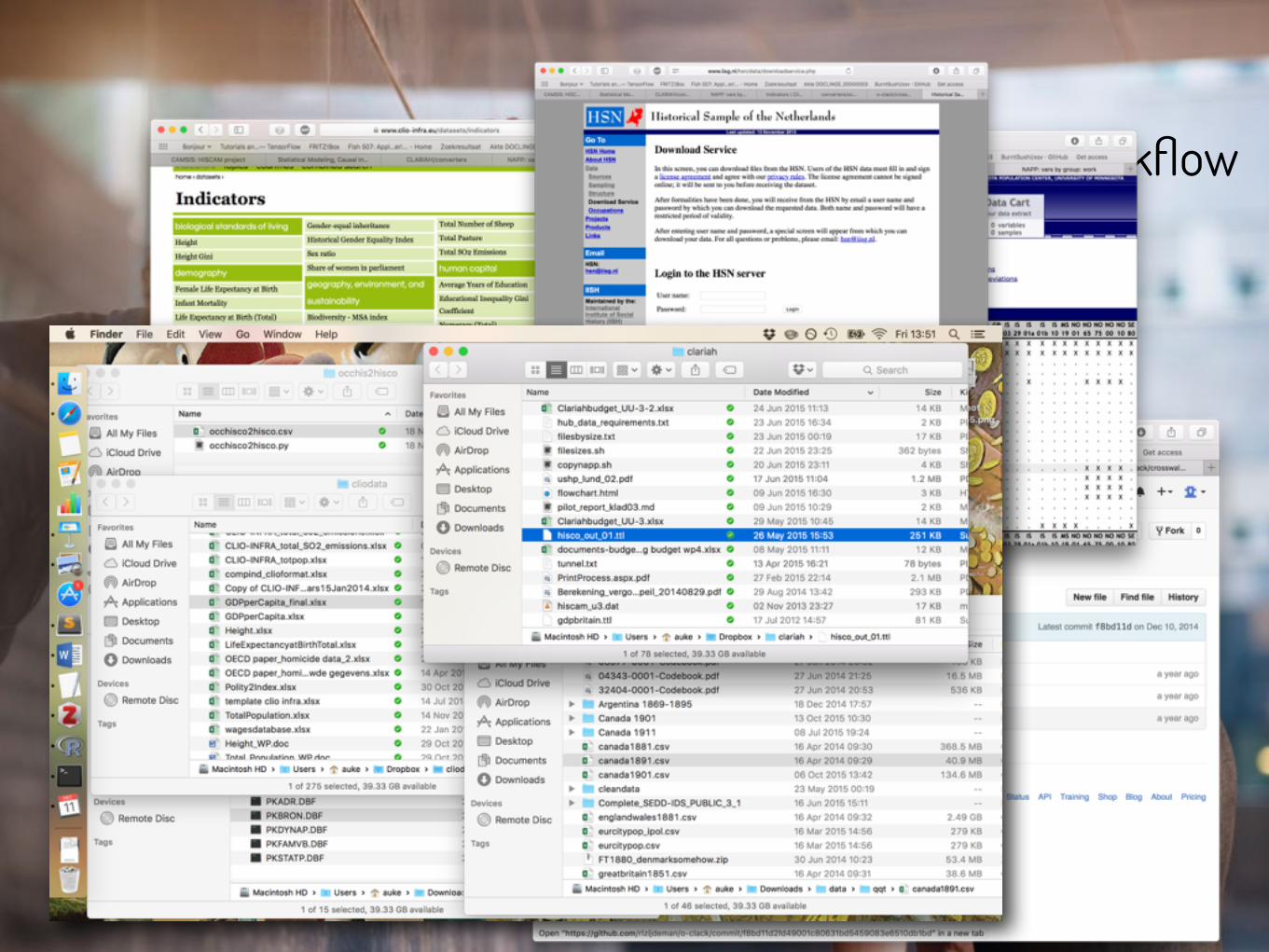
… the current workflow
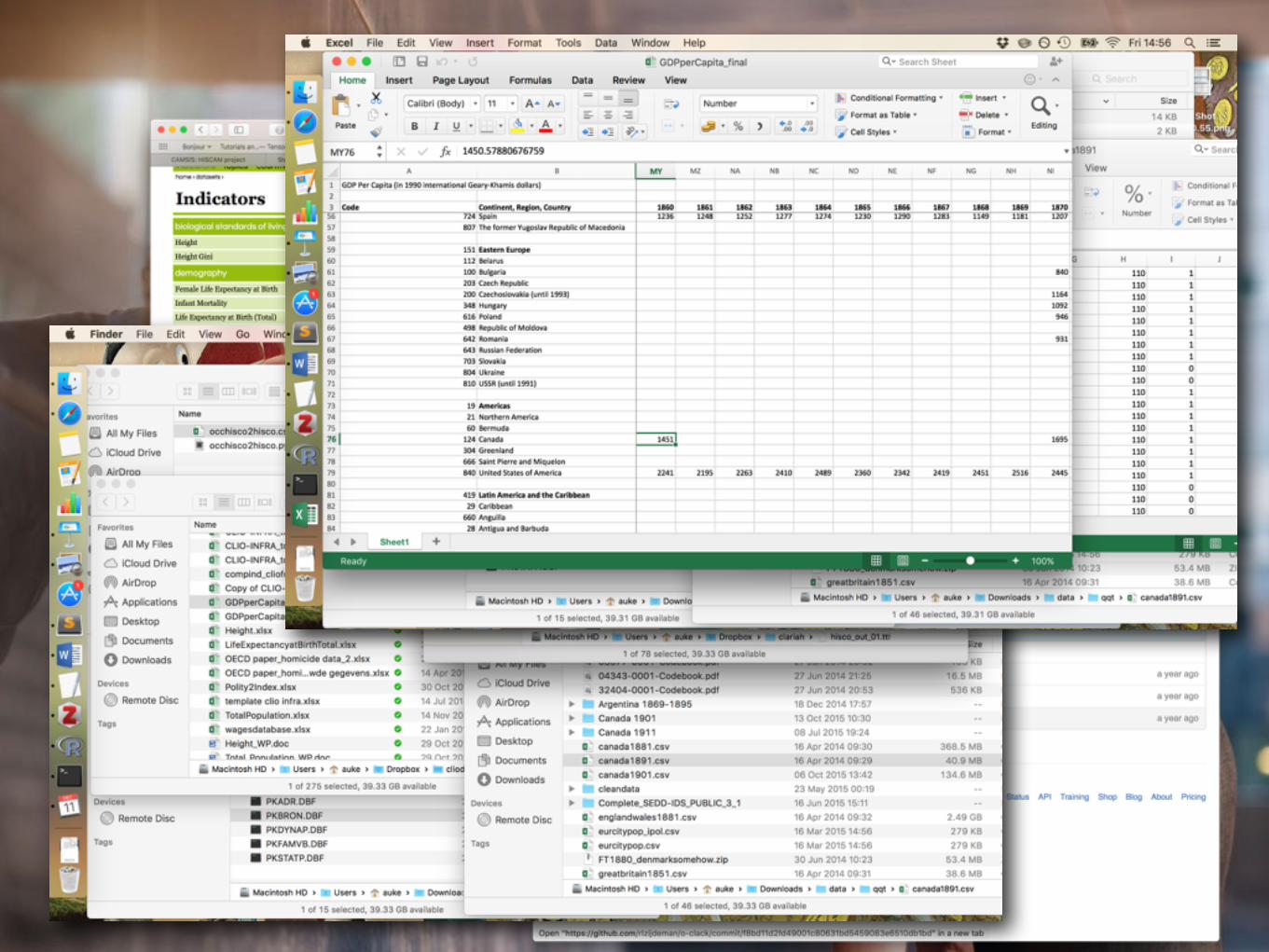
… the current workflow
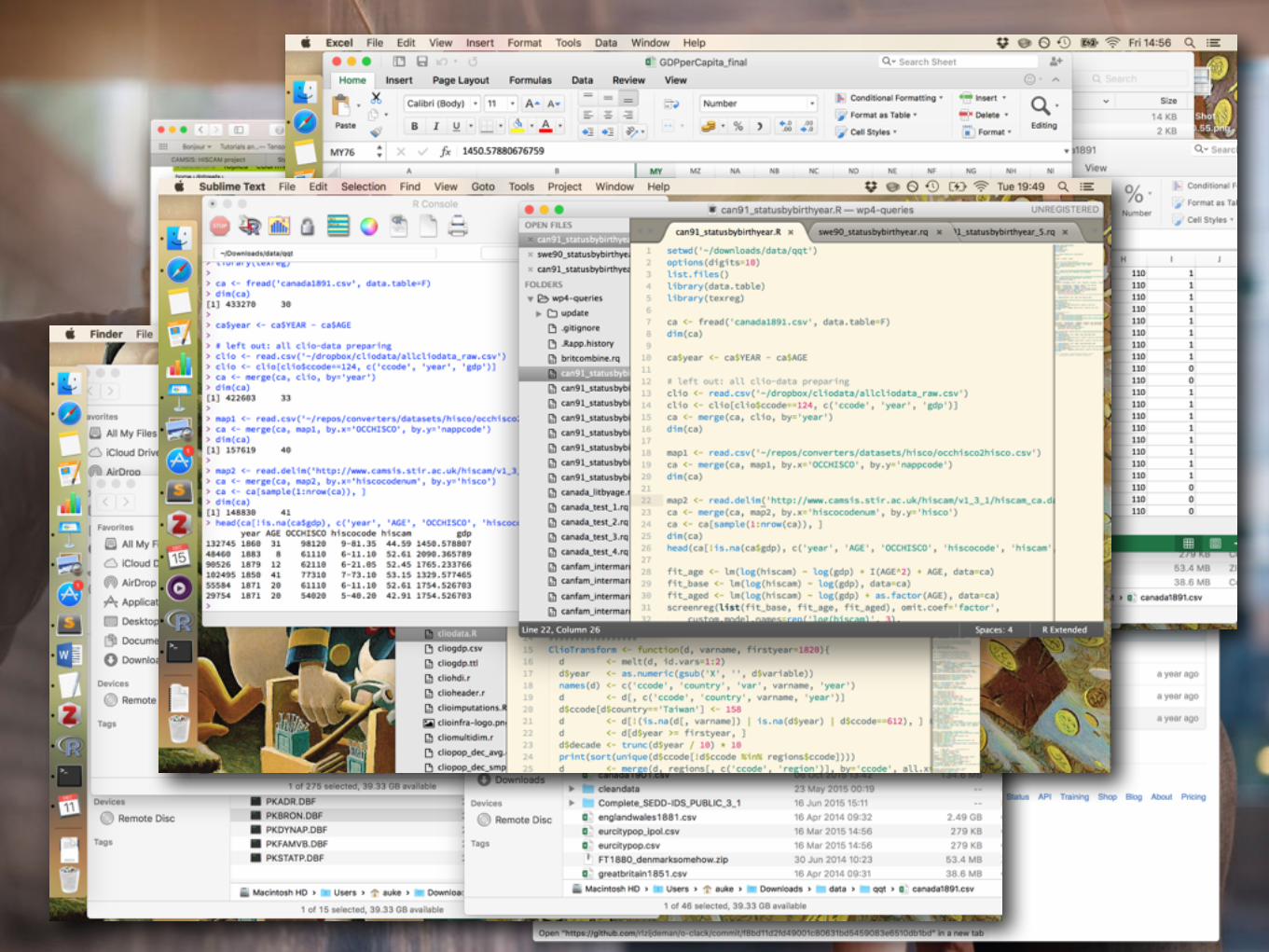
… the current workflow
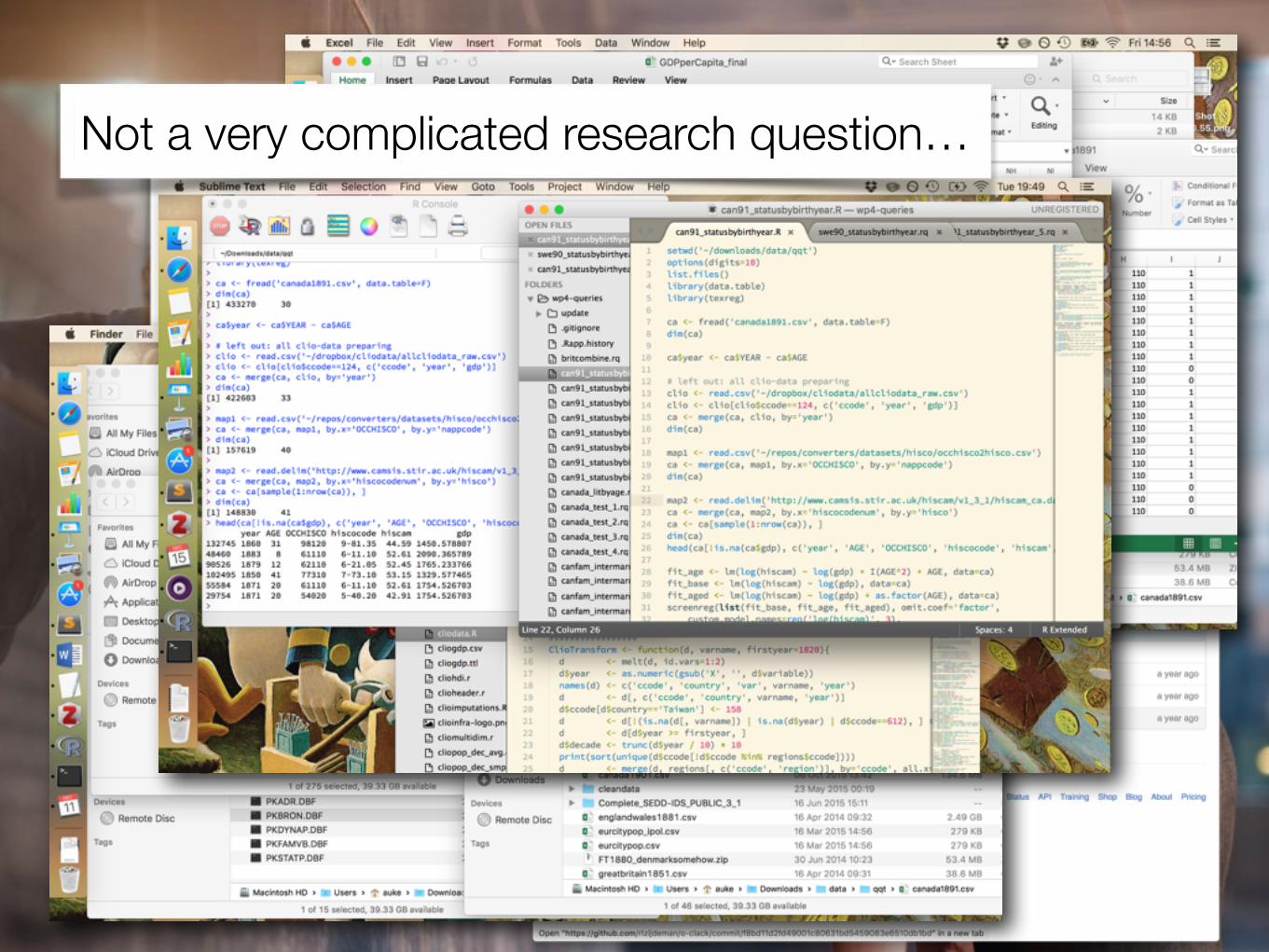
… the current workflowNot a very complicated research question…
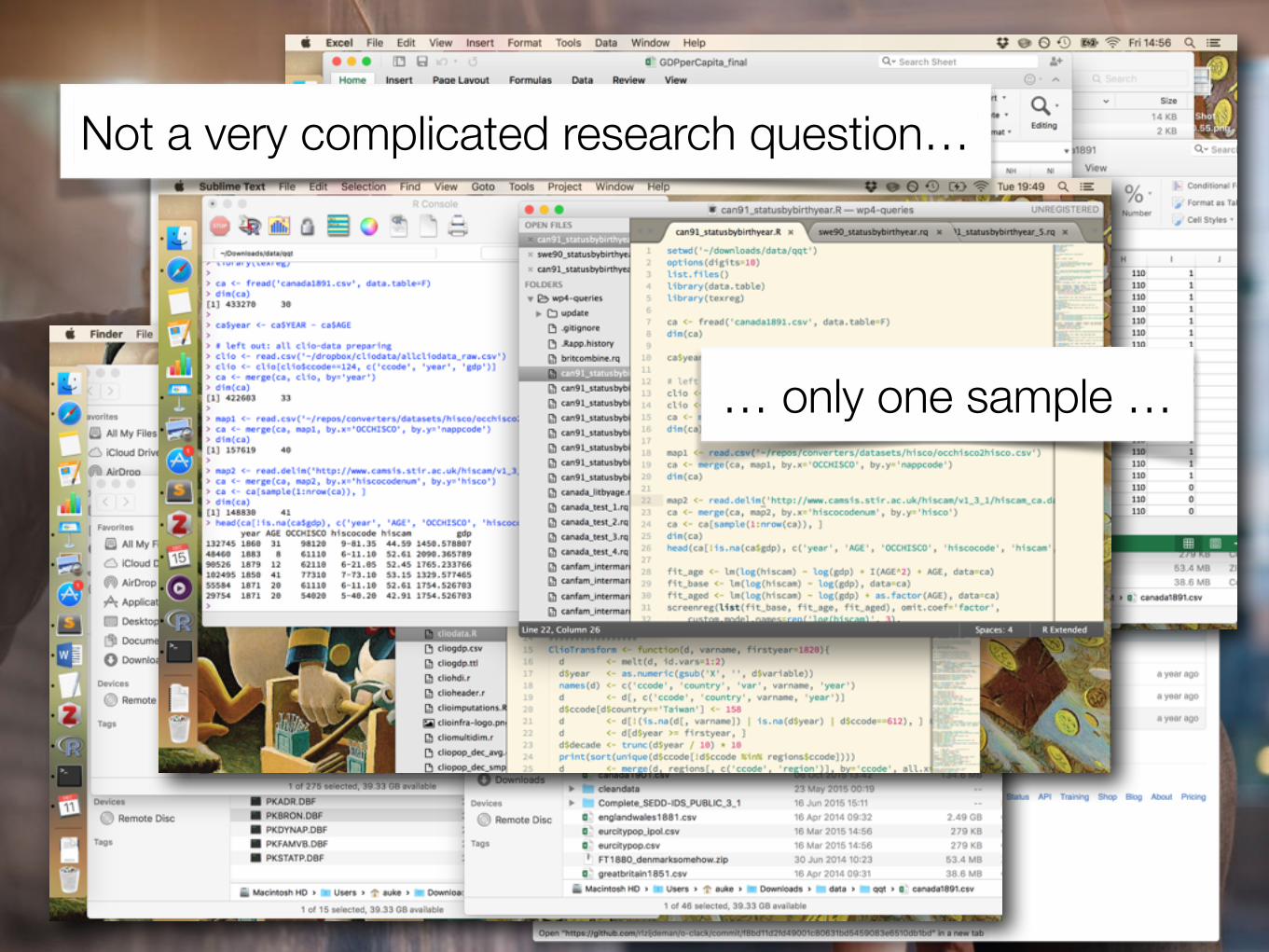
… the current workflowNot a very complicated research question…
… only one sample …
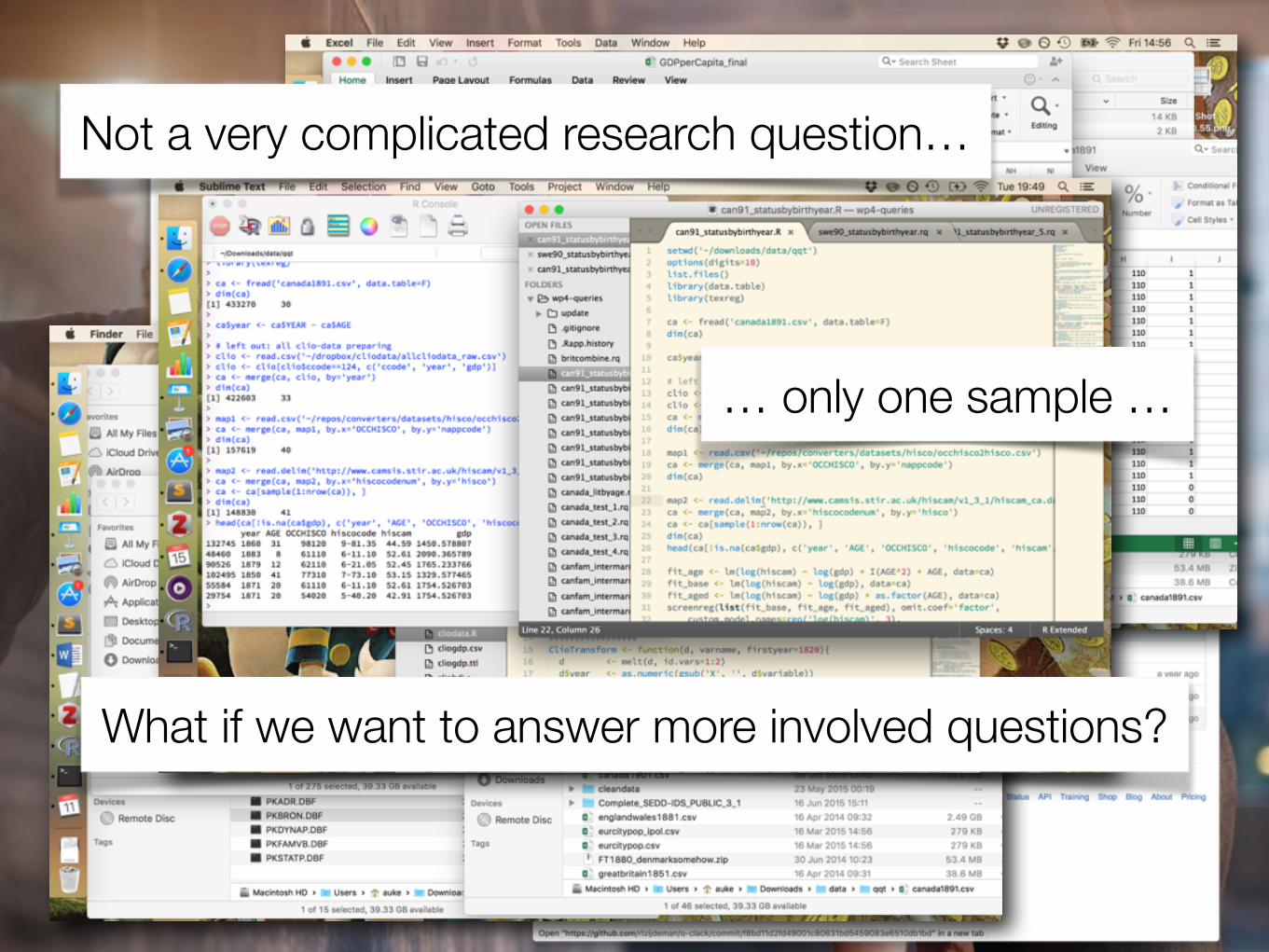
… the current workflowNot a very complicated research question…
… only one sample …
What if we want to answer more involved questions?
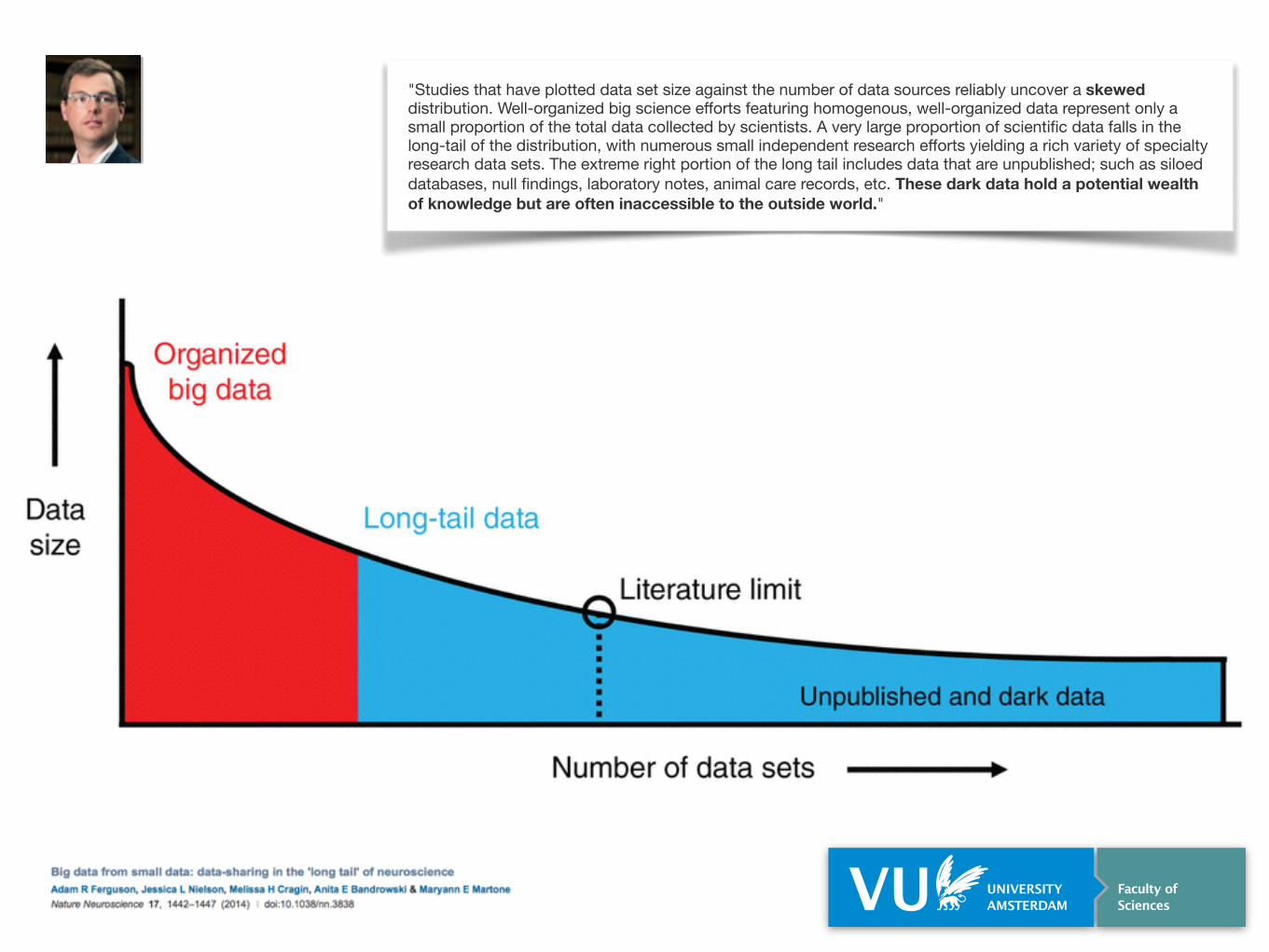
"Studies that have plotted data set size against the number of data sources reliably uncover a skewed distribution. Well-organized big science efforts featuring homogenous, well-organized data represent only a small proportion of the total data collected by scientists. A very large proportion of scientific data falls in the long-tail of the distribution, with numerous small independent research efforts yielding a rich variety of specialty research data sets. The extreme right portion of the long tail includes data that are unpublished; such as siloed databases, null findings, laboratory notes, animal care records, etc. These dark data hold a potential wealth of knowledge but are often inaccessible to the outside world."

In the fast moving data analysis industry, real-time traceability could help identify supply chain, brand and repetitional risks

Our Goals
• Empower individual researchers to
• Code and harmonize individual datasets according to best practices of the community (e.g. HISCO, SDMX, World Bank, etc.) or against their colleagues
• Share their own code lists with fellow researchers
• Align code lists across datasets
• Publish their standards-compliant datasets
• Perform analyses across multiple datasets at the same time
• While tracking provenance of both data and analyses

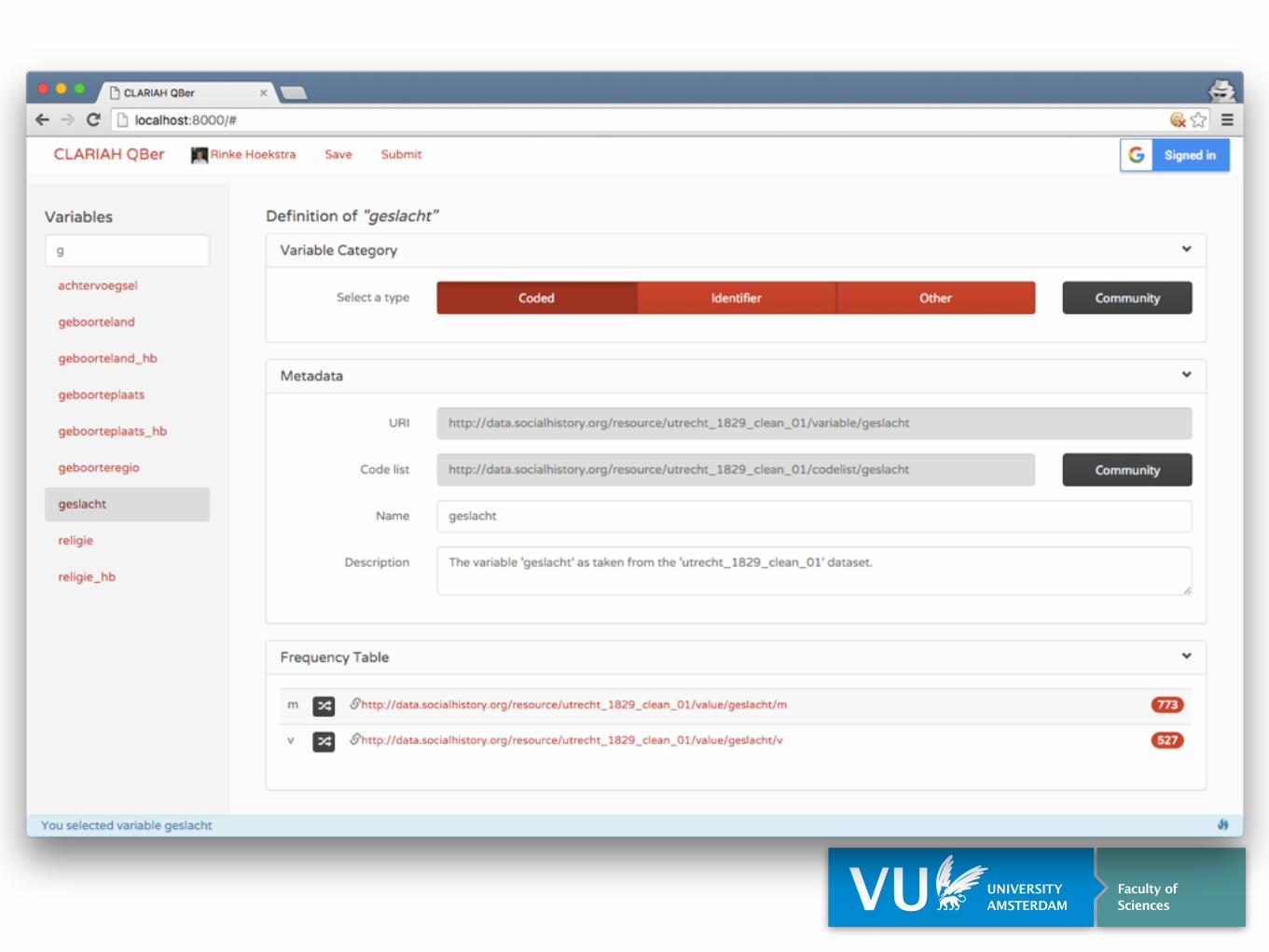
A Linked Data Handbook for Historians? Nah…
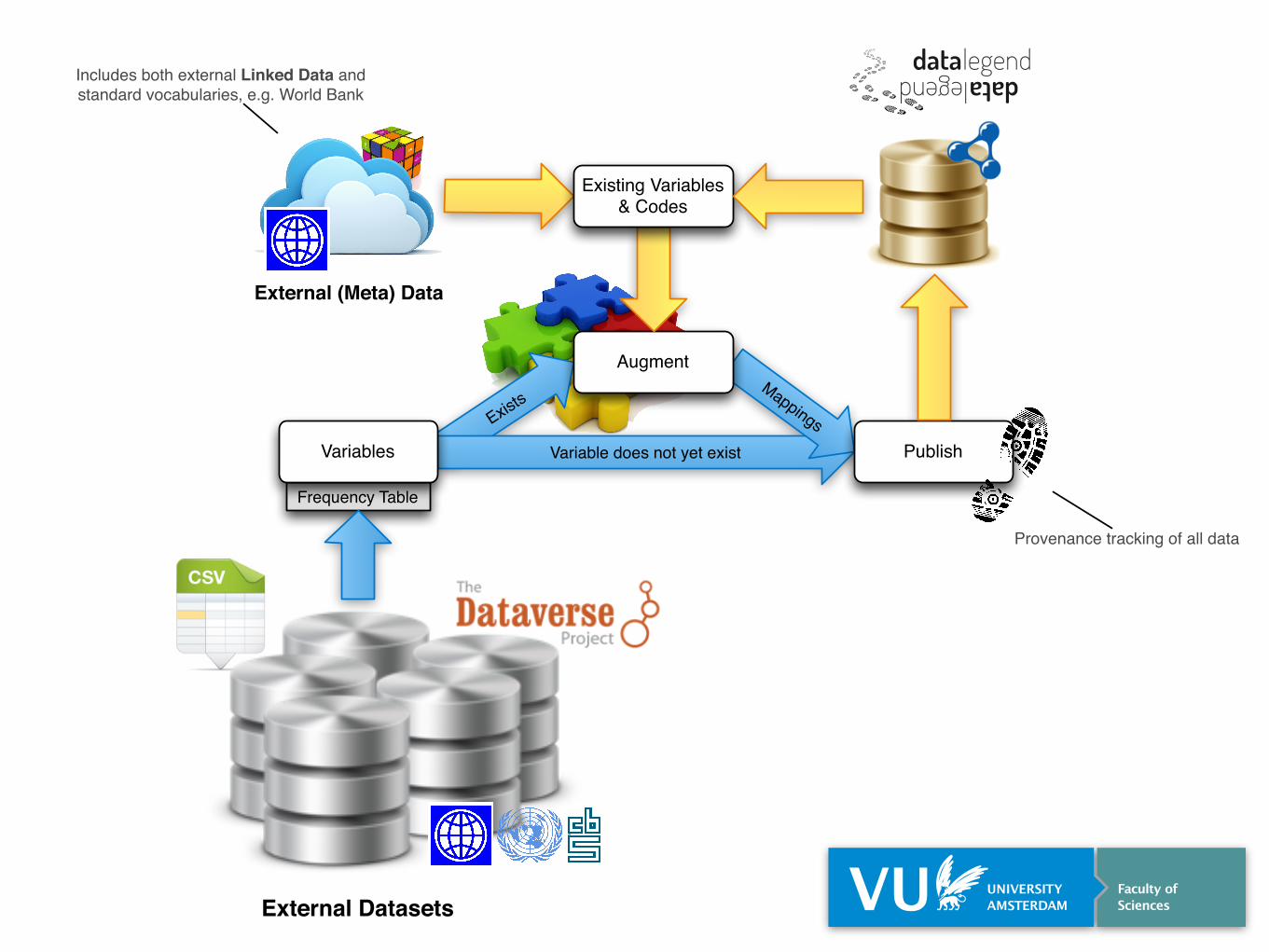
Exists
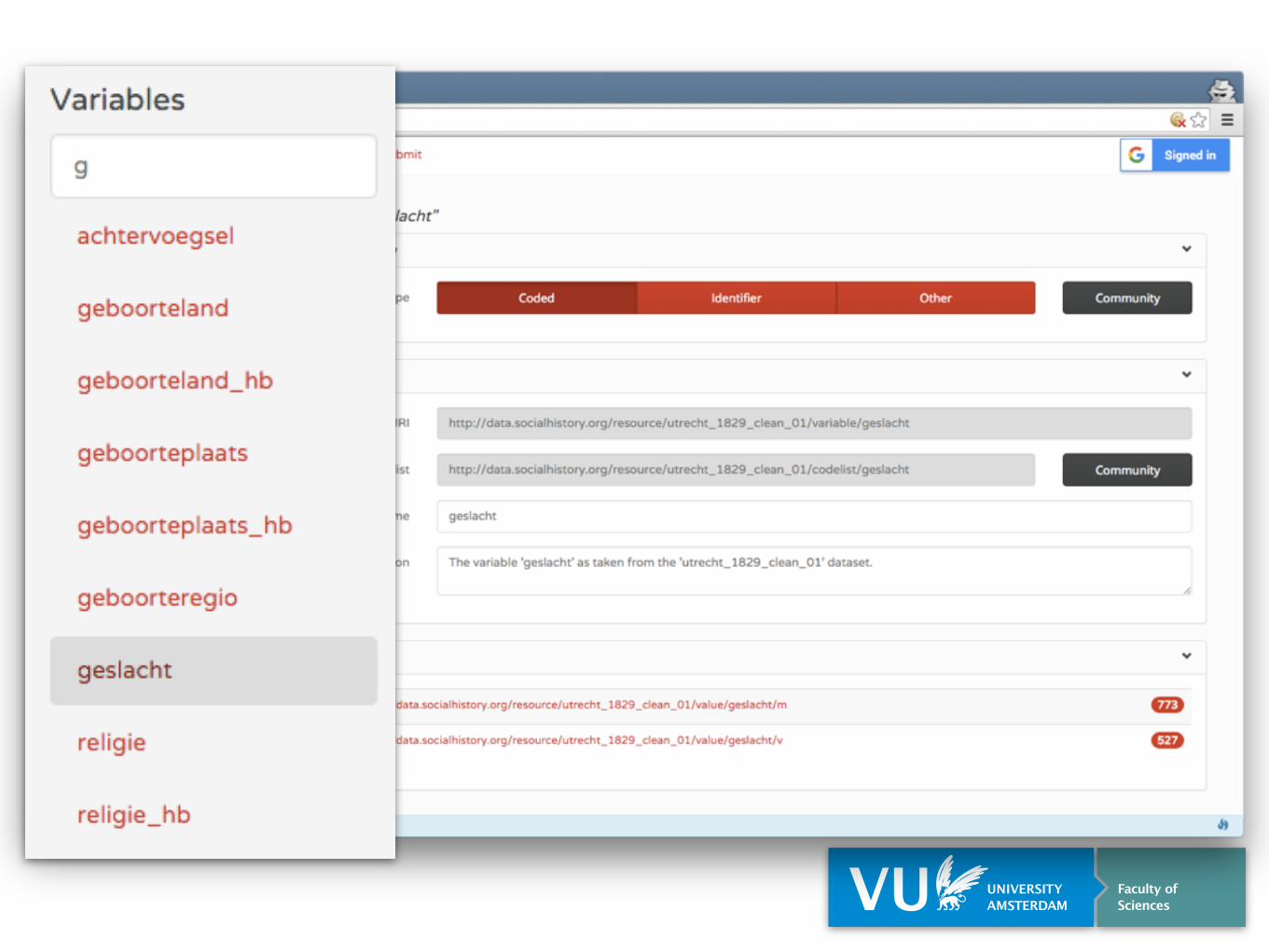
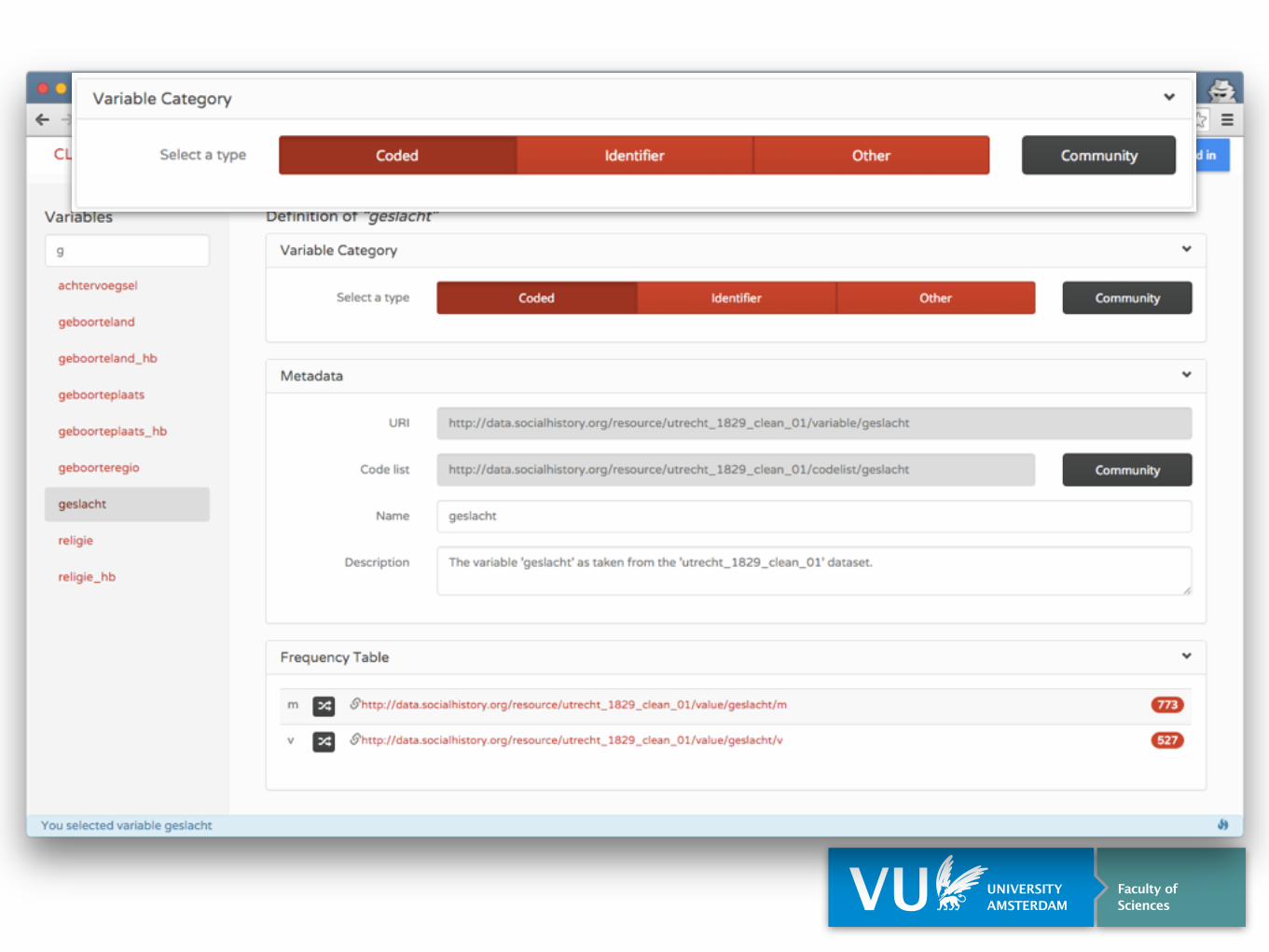
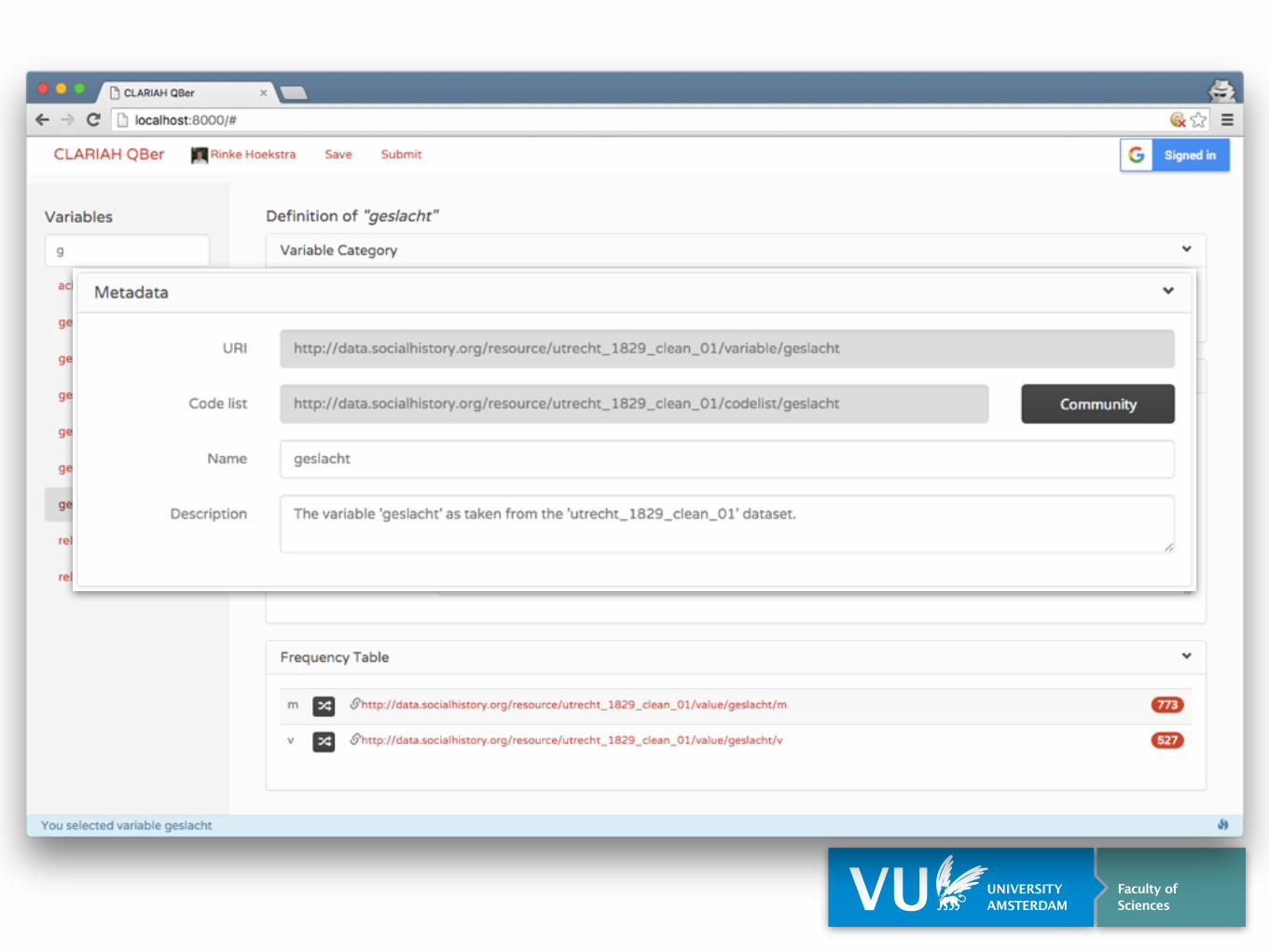
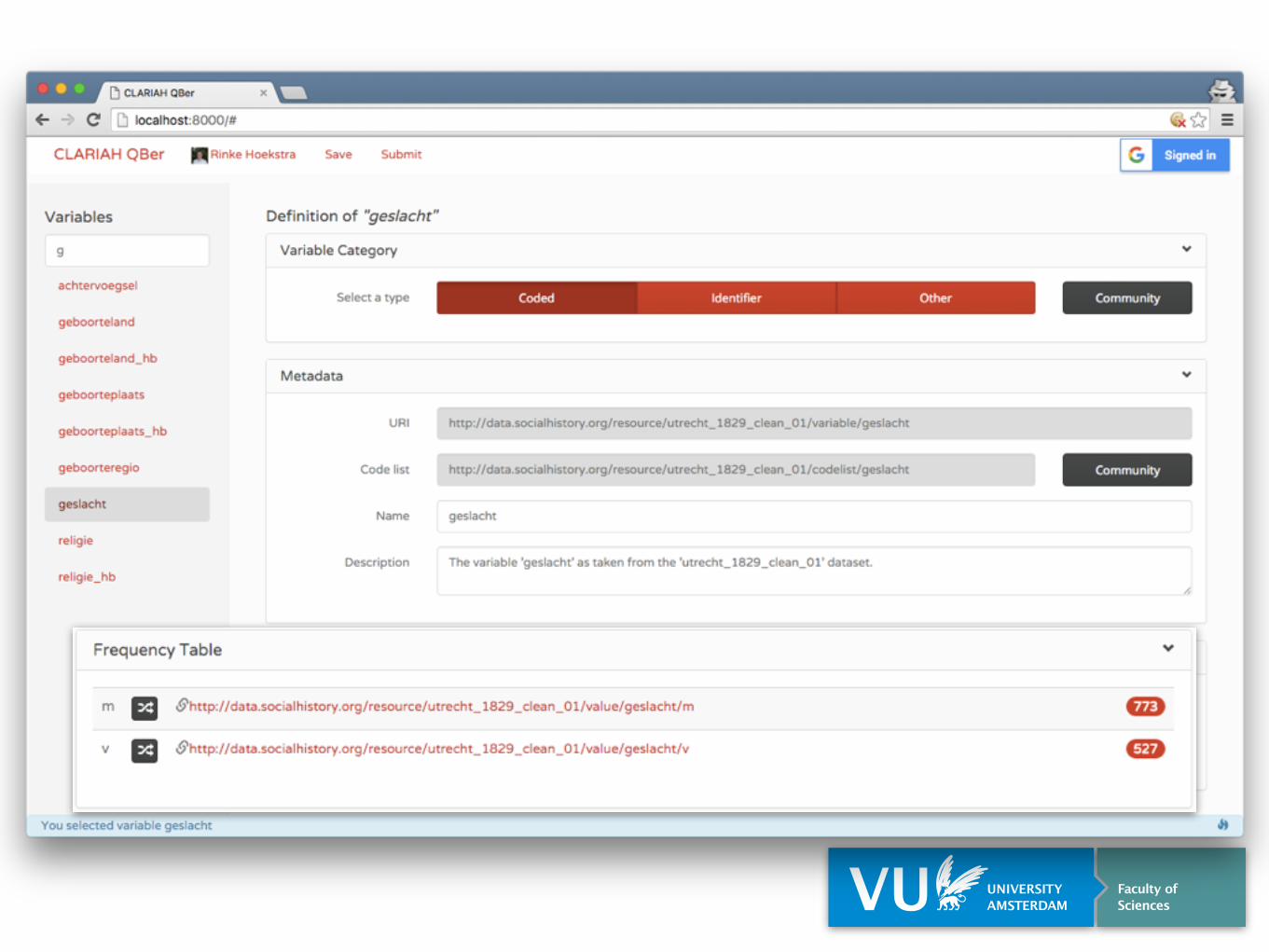
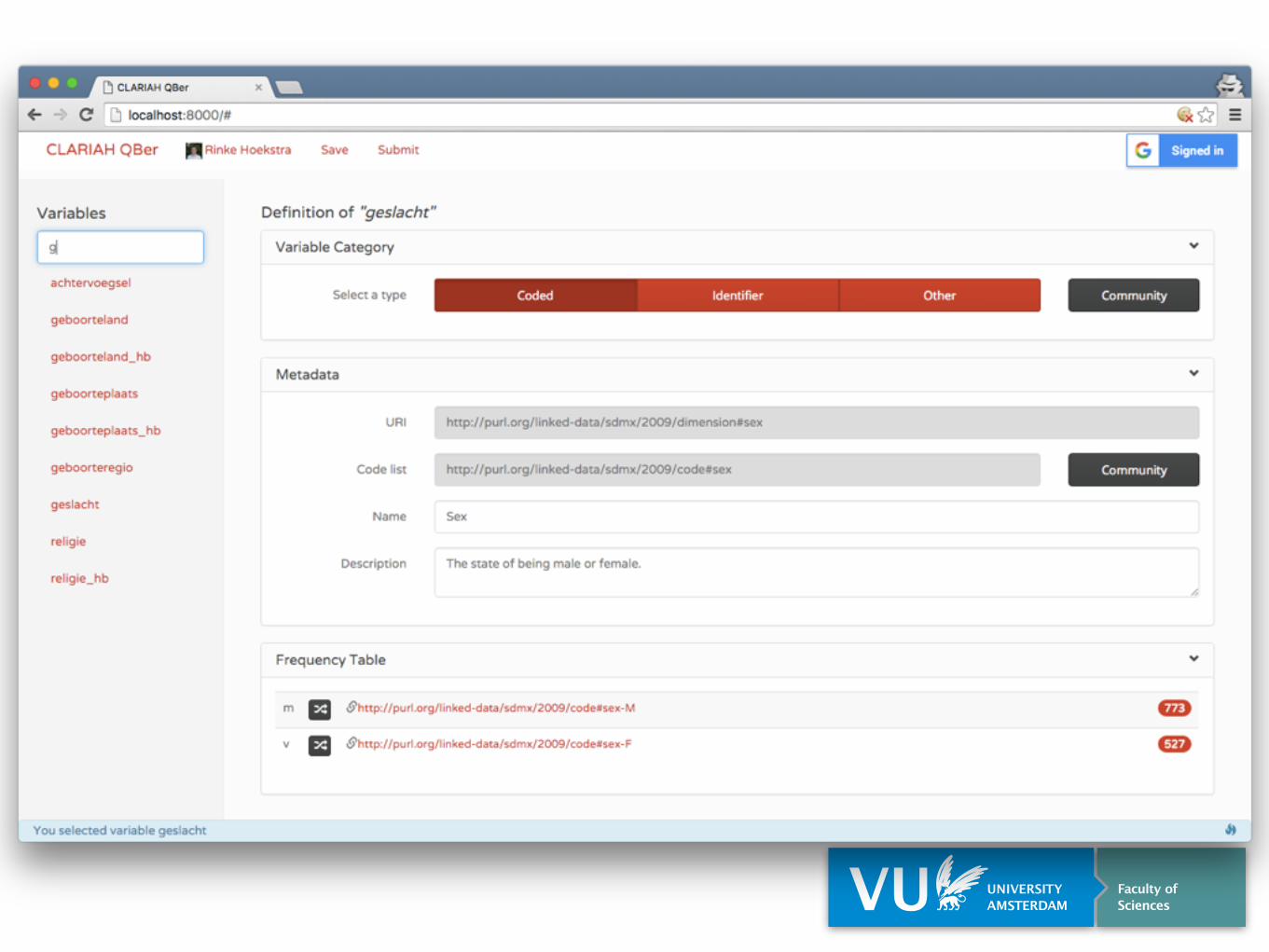
Frequency Table
Variable does not yet existVariables
Mappings
Publish
Augment
Includes both external Linked Data and standard vocabularies, e.g. World Bank
External (Meta) Data
Existing Variables & Codes
Provenance tracking of all data
External Datasets
Structured Data Hub
legenddata legend data
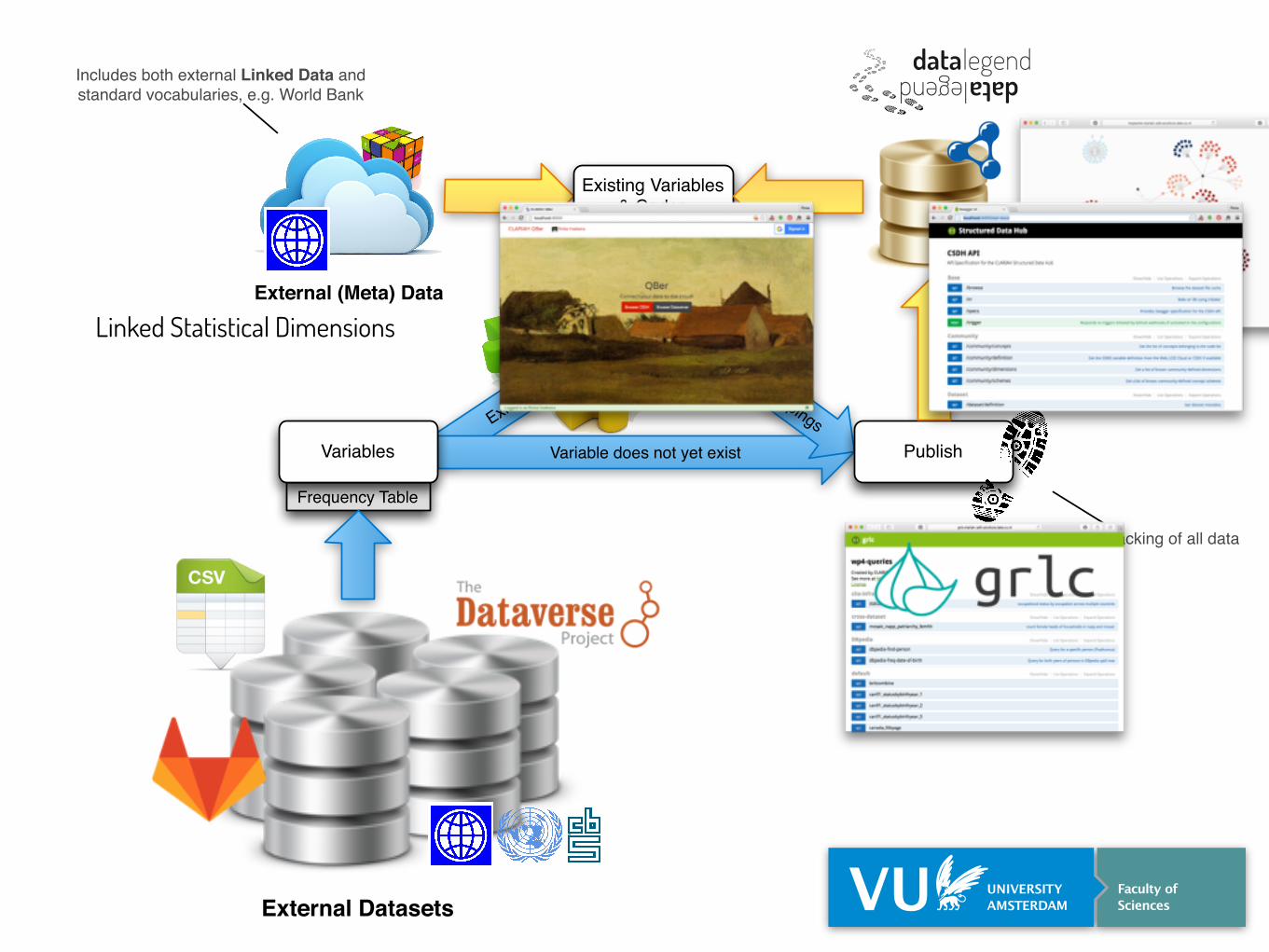
Exists
Frequency Table
Variable does not yet existVariables
Mappings
Publish
Augment
Includes both external Linked Data and standard vocabularies, e.g. World Bank
External (Meta) Data
Existing Variables & Codes
Provenance tracking of all data
External Datasets
Structured Data Hub
legenddata legend data
Linked Statistical Dimensions
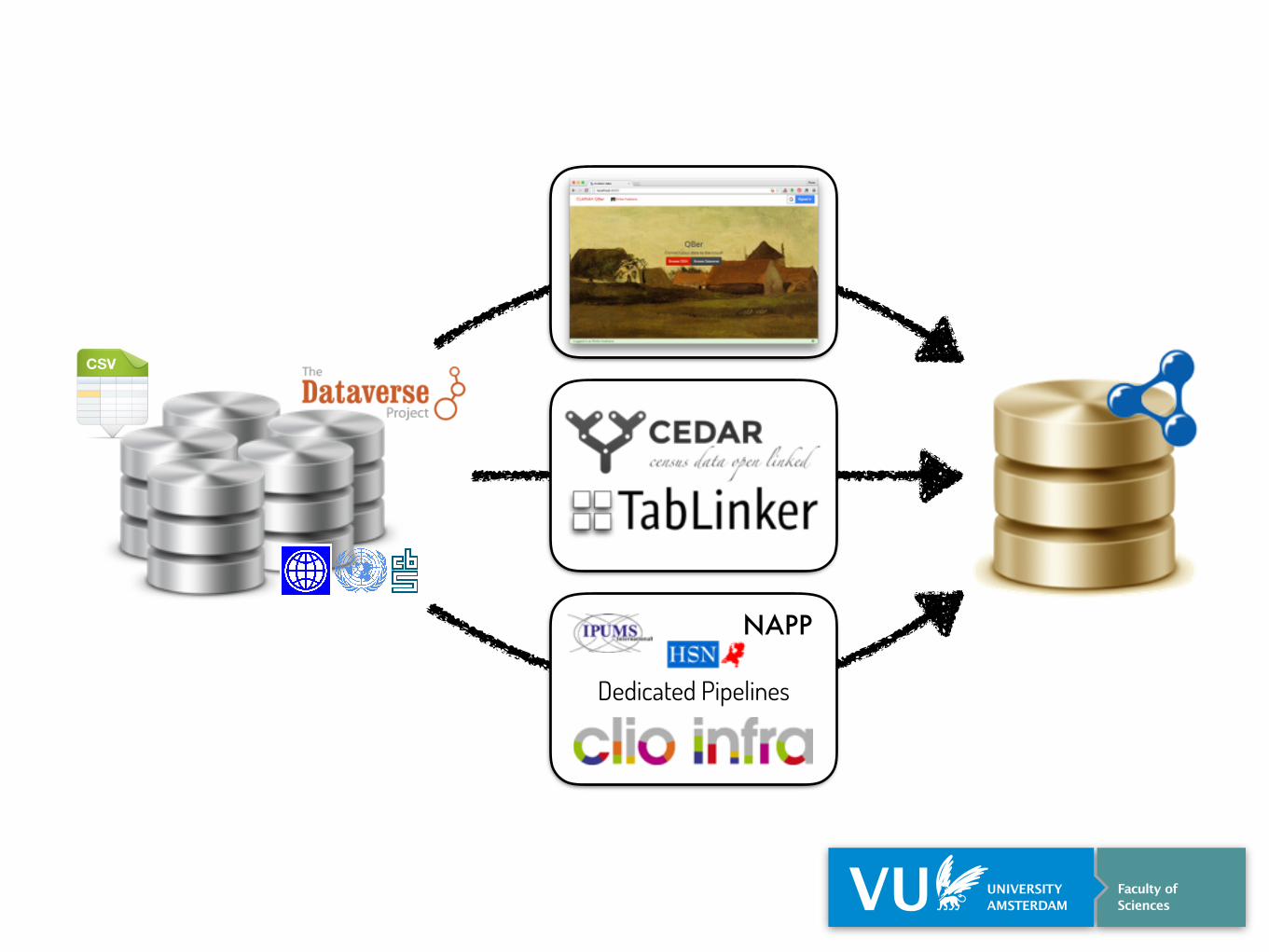
Dedicated Pipelines
NAPP

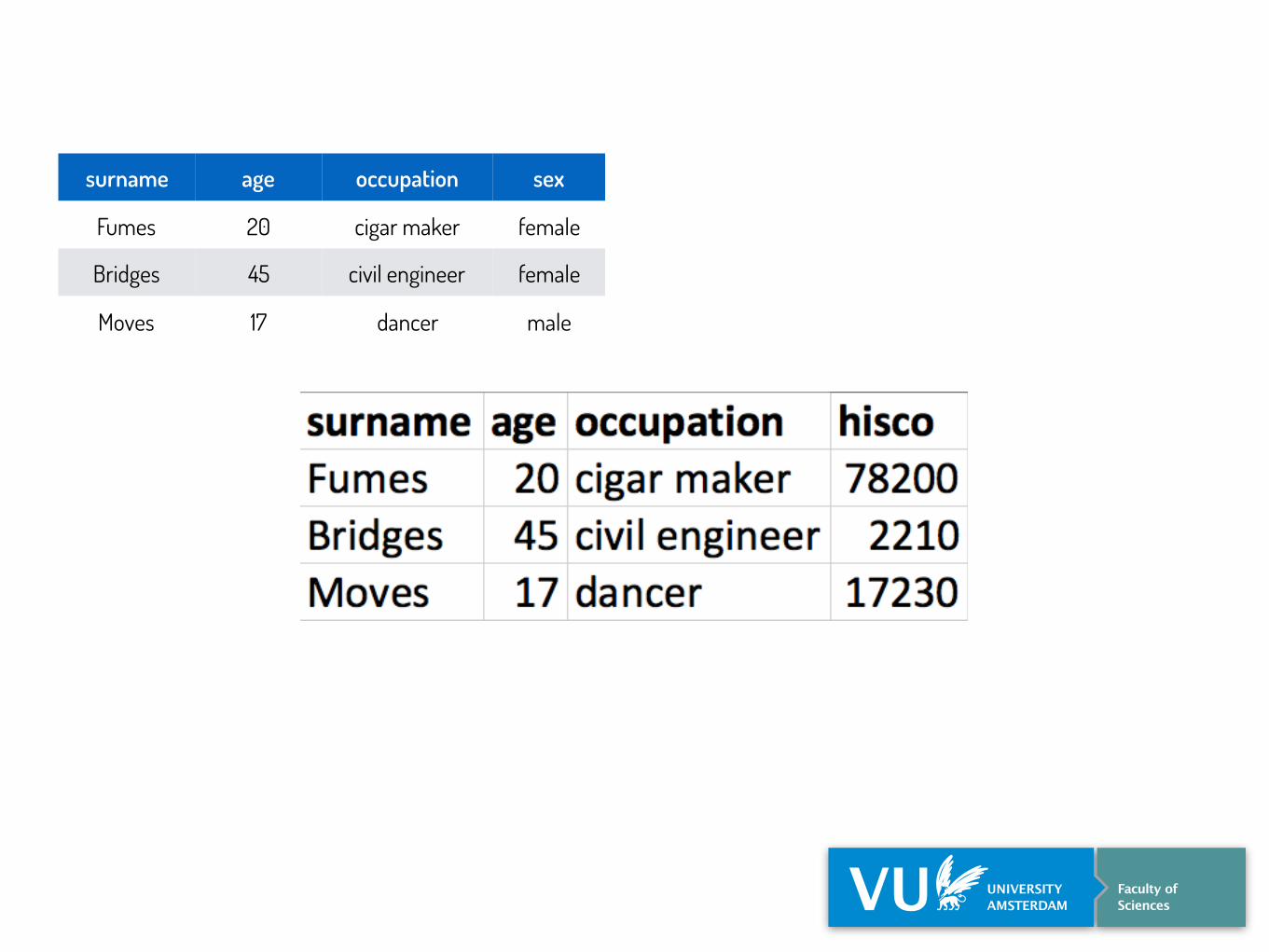
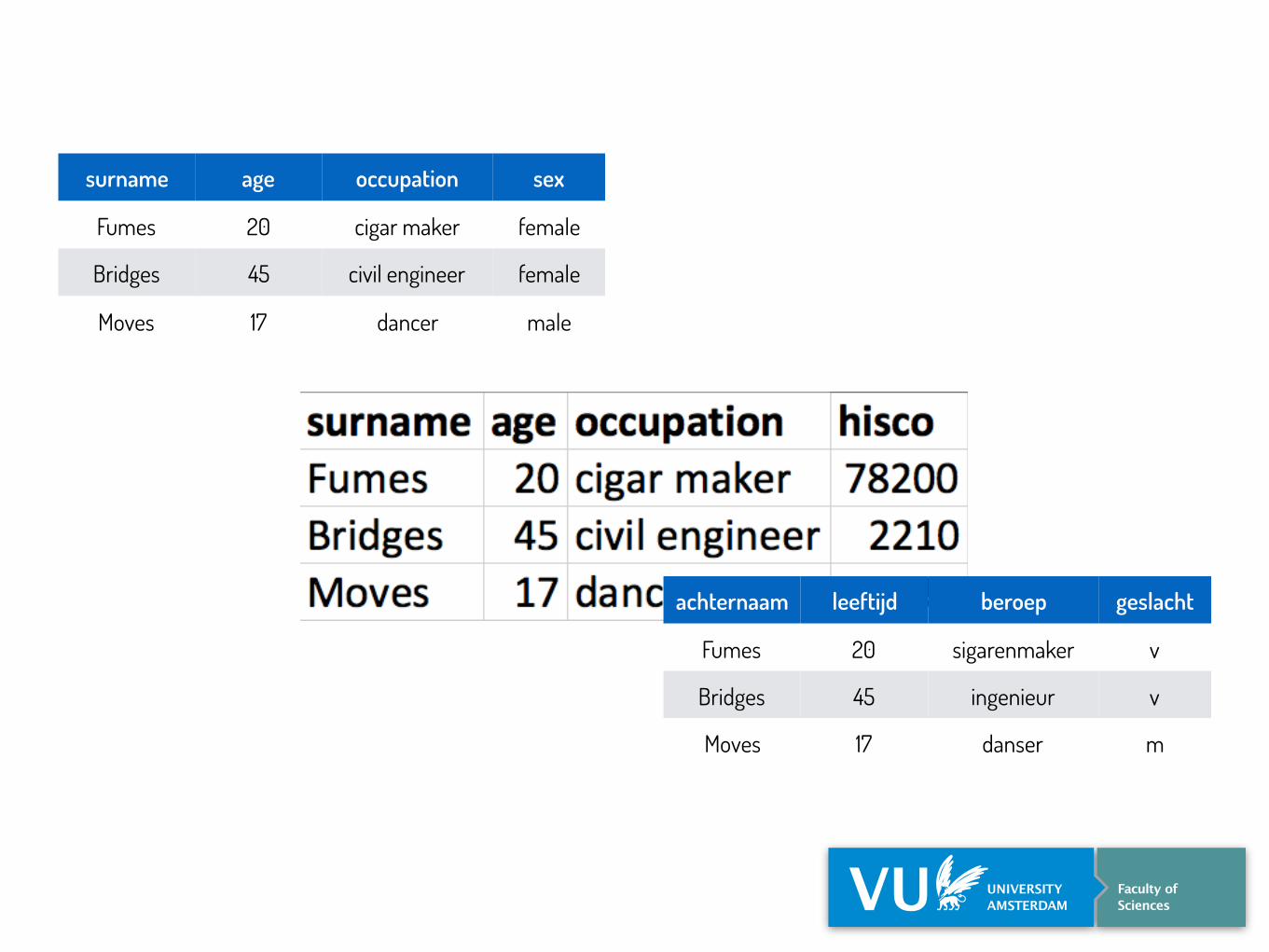
surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
achternaam leeftijd beroep geslacht
Fumes 20 sigarenmaker v
Bridges 45 ingenieur v
Moves 17 danser m
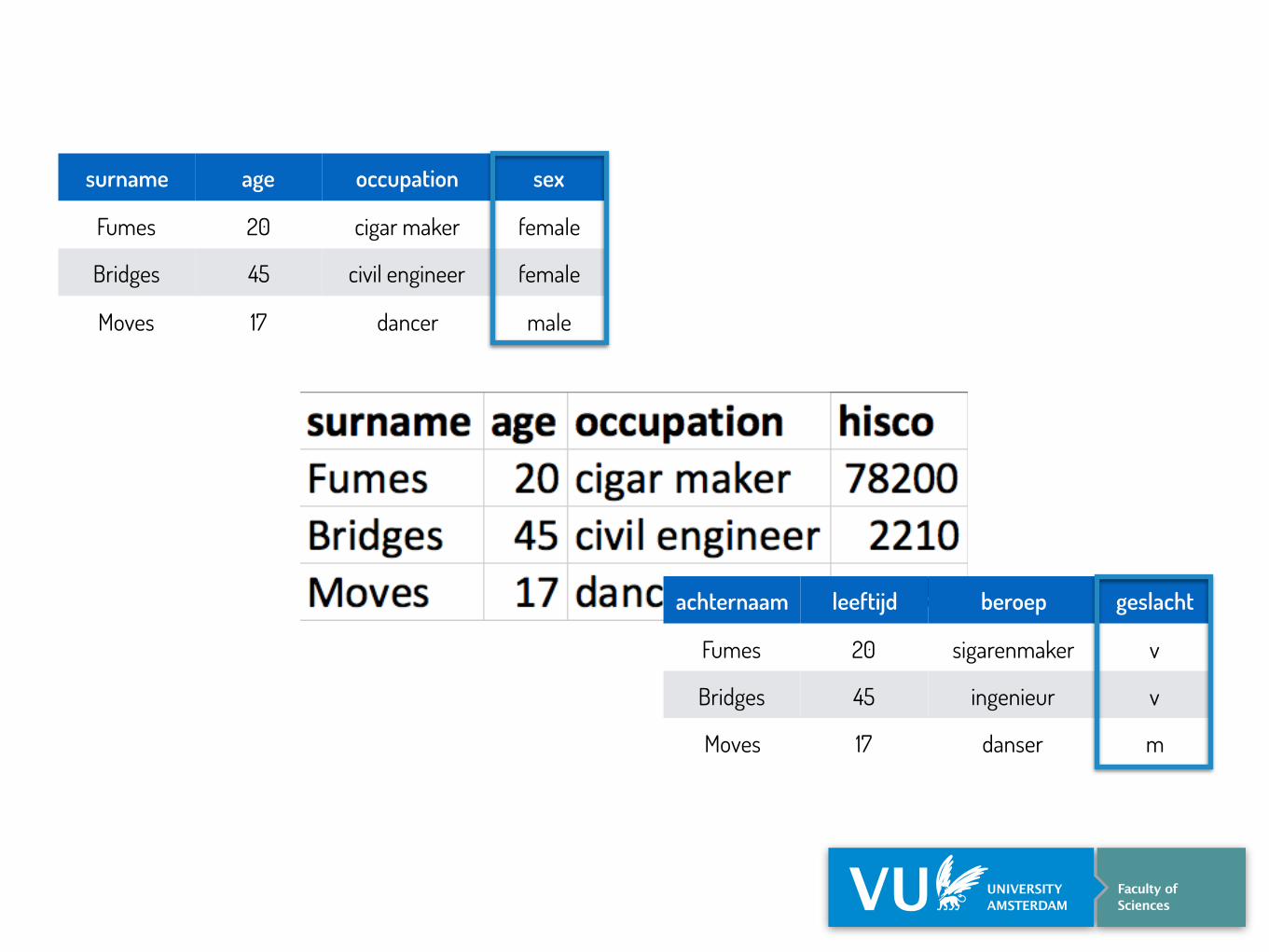
surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
achternaam leeftijd beroep geslacht
Fumes 20 sigarenmaker v
Bridges 45 ingenieur v
Moves 17 danser m

surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
achternaam leeftijd beroep geslacht
Fumes 20 sigarenmaker v
Bridges 45 ingenieur v
Moves 17 danser m

surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
achternaam leeftijd beroep geslacht
Fumes 20 sigarenmaker v
Bridges 45 ingenieur v
Moves 17 danser m
achternaam leeftijd beroep sdmx:Sex
Fumes 20 sigarenmaker sdmx:F
Bridges 45 ingenieur sdmx:F
Moves 17 danser sdmx:M
surname age occupation sdmx:Sex
Fumes 20 cigar maker sdmx:F
Bridges 45 civil engineer sdmx:F
Moves 17 dancer sdmx:M

surname age occupation sex
Fumes 20 cigar maker female
Bridges 45 civil engineer female
Moves 17 dancer male
achternaam leeftijd beroep geslacht
Fumes 20 sigarenmaker v
Bridges 45 ingenieur v
Moves 17 danser m
achternaam leeftijd beroep sdmx:Sex
Fumes 20 sigarenmaker sdmx:F
Bridges 45 ingenieur sdmx:F
Moves 17 danser sdmx:M
surname age occupation sdmx:Sex
Fumes 20 cigar maker sdmx:F
Bridges 45 civil engineer sdmx:F
Moves 17 dancer sdmx:M
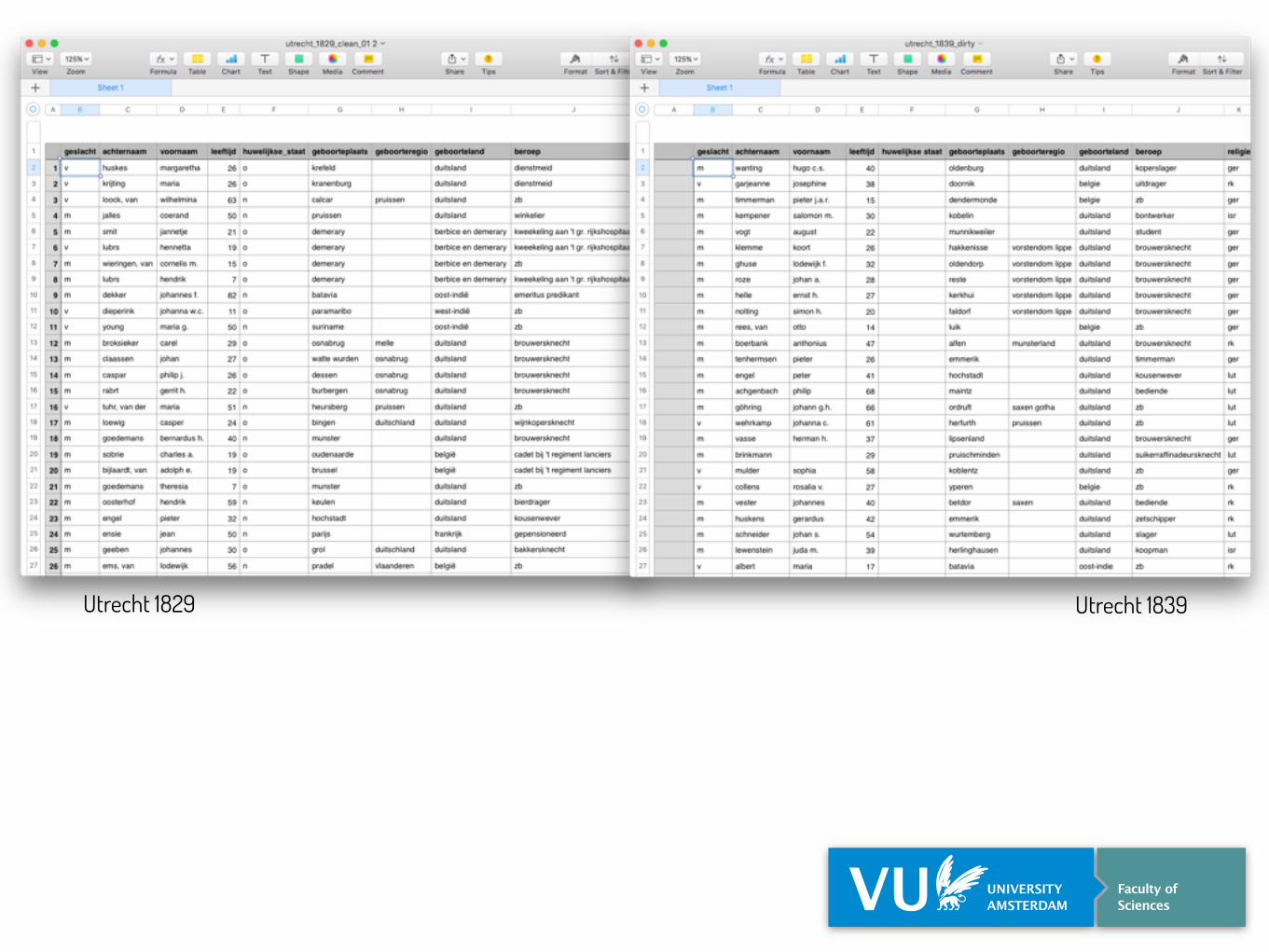
Utrecht 1829 Utrecht 1839

Utrecht 1829 Utrecht 1839

An ecosystem is a community of living organisms in conjunction with the nonliving components of their environment (things like air, water and mineral soil), interacting as a system.
- Wikipedia
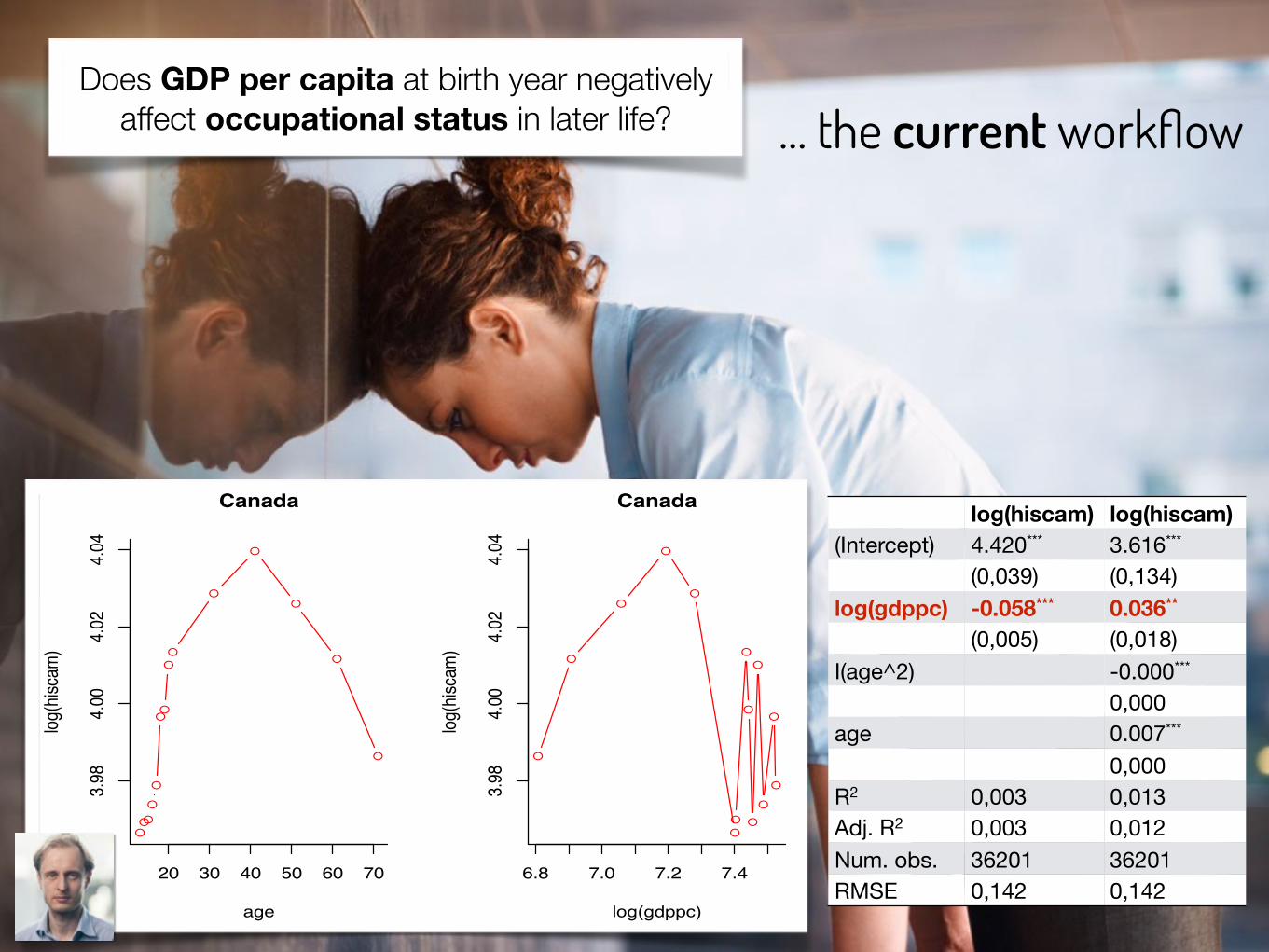
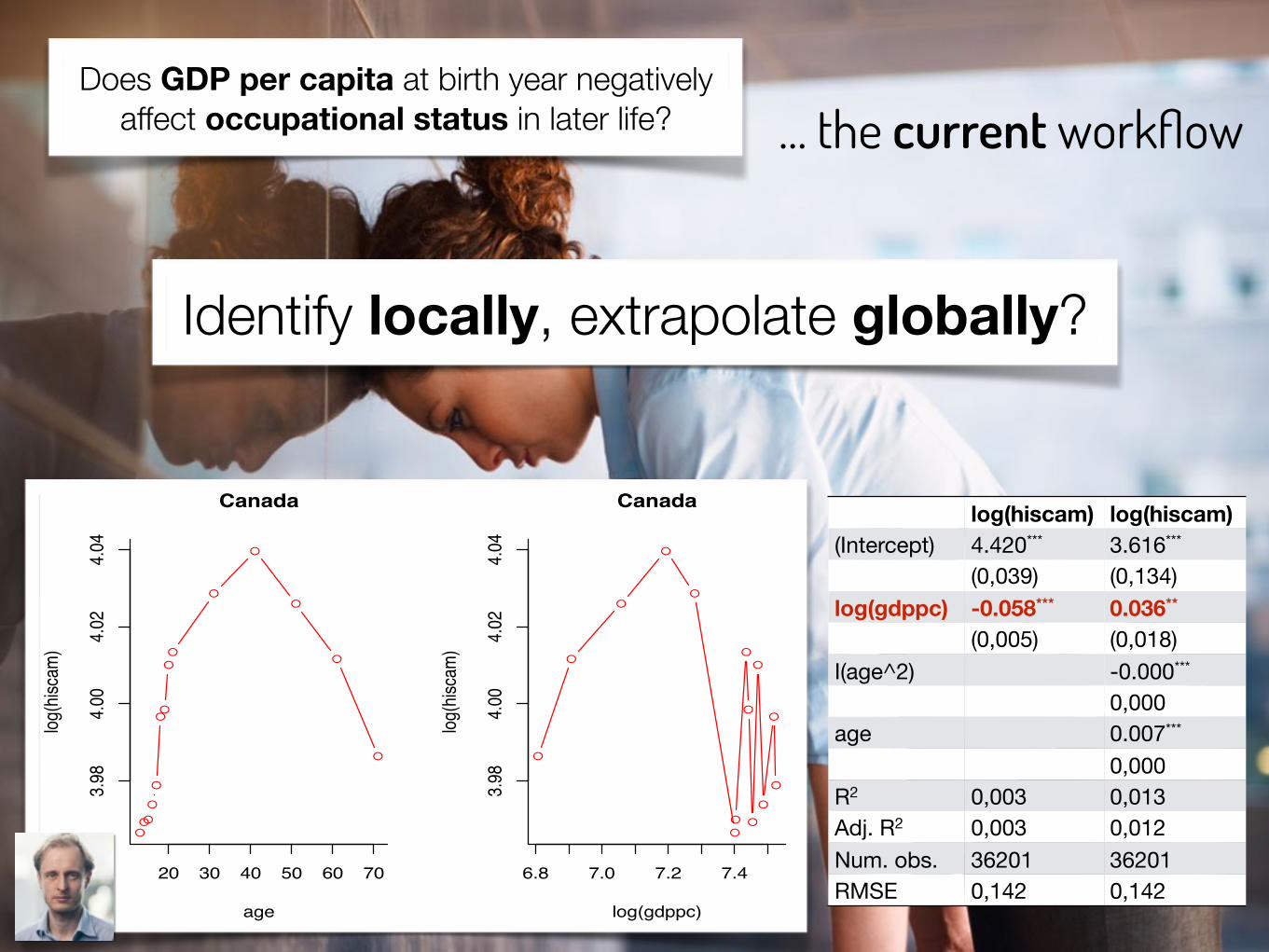
… the current workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
●
●
●
●
●
●
●
●●
●
●
●●●
20 30 40 50 60 70
3.98
4.00
4.02
4.04
Canada
age
log(hiscam
)
●
●
●
●
●
●
●
●
●
●
●
●
●
●
6.8 7.0 7.2 7.4
3.98
4.00
4.02
4.04
Canada
log(gdppc)
log(hiscam
)
log(hiscam) log(hiscam)(Intercept) 4.420*** 3.616***
(0,039) (0,134)log(gdppc) -0.058*** 0.036**
(0,005) (0,018)I(age^2) -0.000***
0,000age 0.007***
0,000R2 0,003 0,013Adj. R2 0,003 0,012Num. obs. 36201 36201RMSE 0,142 0,142
… the current workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
●
●
●
●
●
●
●
●●
●
●
●●●
20 30 40 50 60 70
3.98
4.00
4.02
4.04
Canada
age
log(hiscam
)
●
●
●
●
●
●
●
●
●
●
●
●
●
●
6.8 7.0 7.2 7.4
3.98
4.00
4.02
4.04
Canada
log(gdppc)
log(hiscam
)
log(hiscam) log(hiscam)(Intercept) 4.420*** 3.616***
(0,039) (0,134)log(gdppc) -0.058*** 0.036**
(0,005) (0,018)I(age^2) -0.000***
0,000age 0.007***
0,000R2 0,003 0,013Adj. R2 0,003 0,012Num. obs. 36201 36201RMSE 0,142 0,142
Identify locally, extrapolate globally?

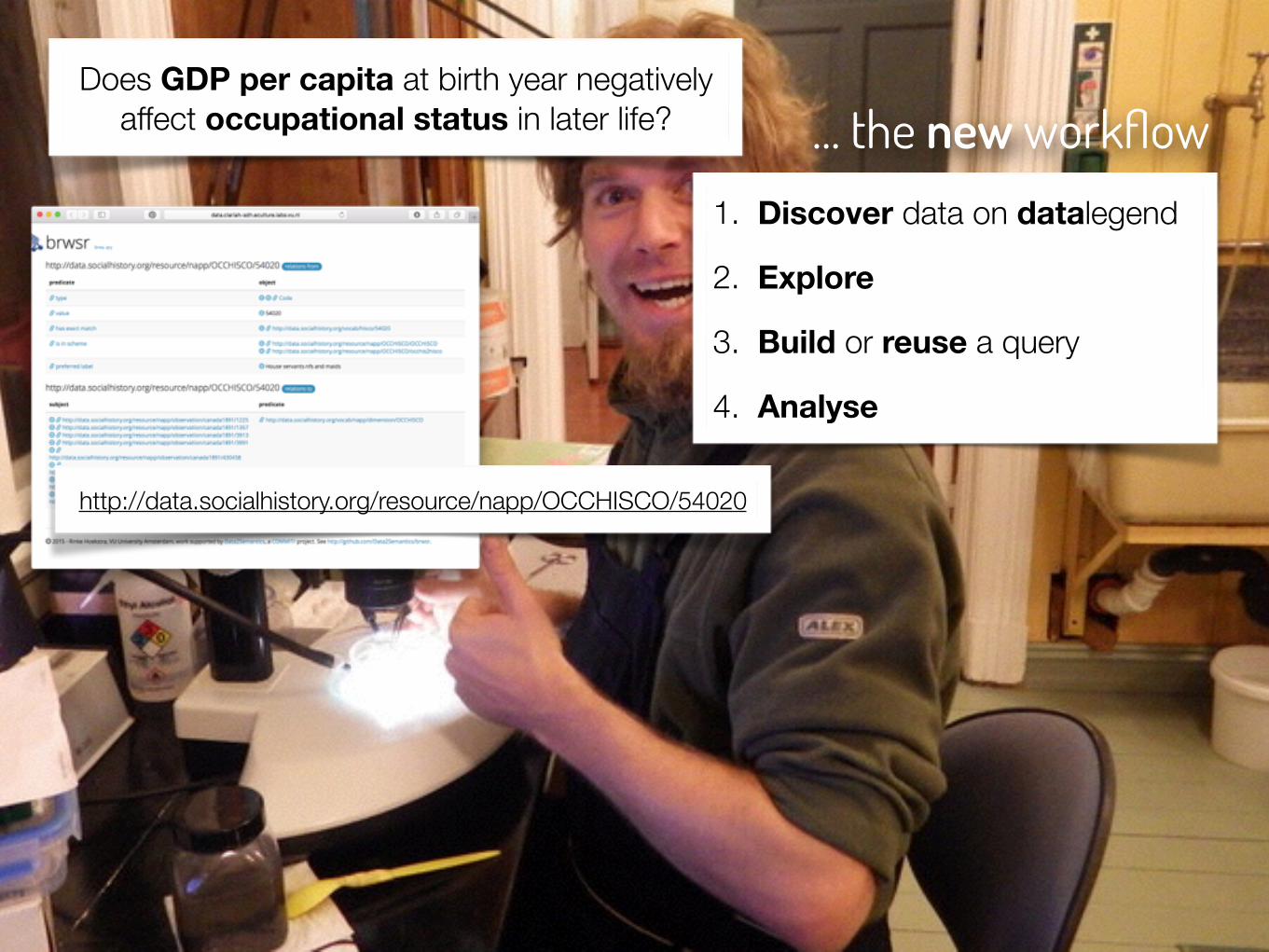
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?

… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
1. Discover data on datalegend
2. Explore
3. Build or reuse a query
4. Analyse
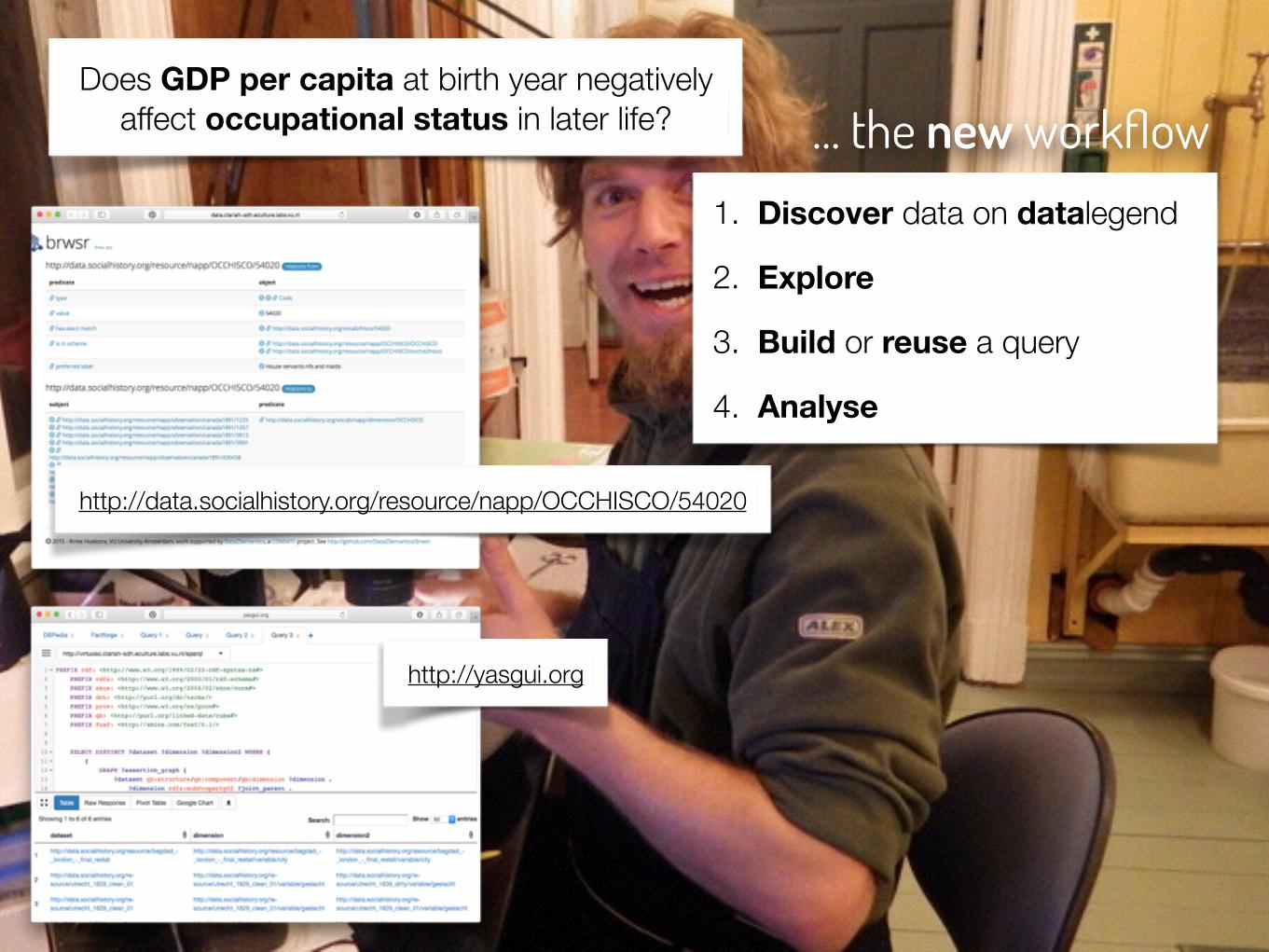
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
1. Discover data on datalegend
2. Explore
3. Build or reuse a query
4. Analyse
http://data.socialhistory.org/resource/napp/OCCHISCO/54020
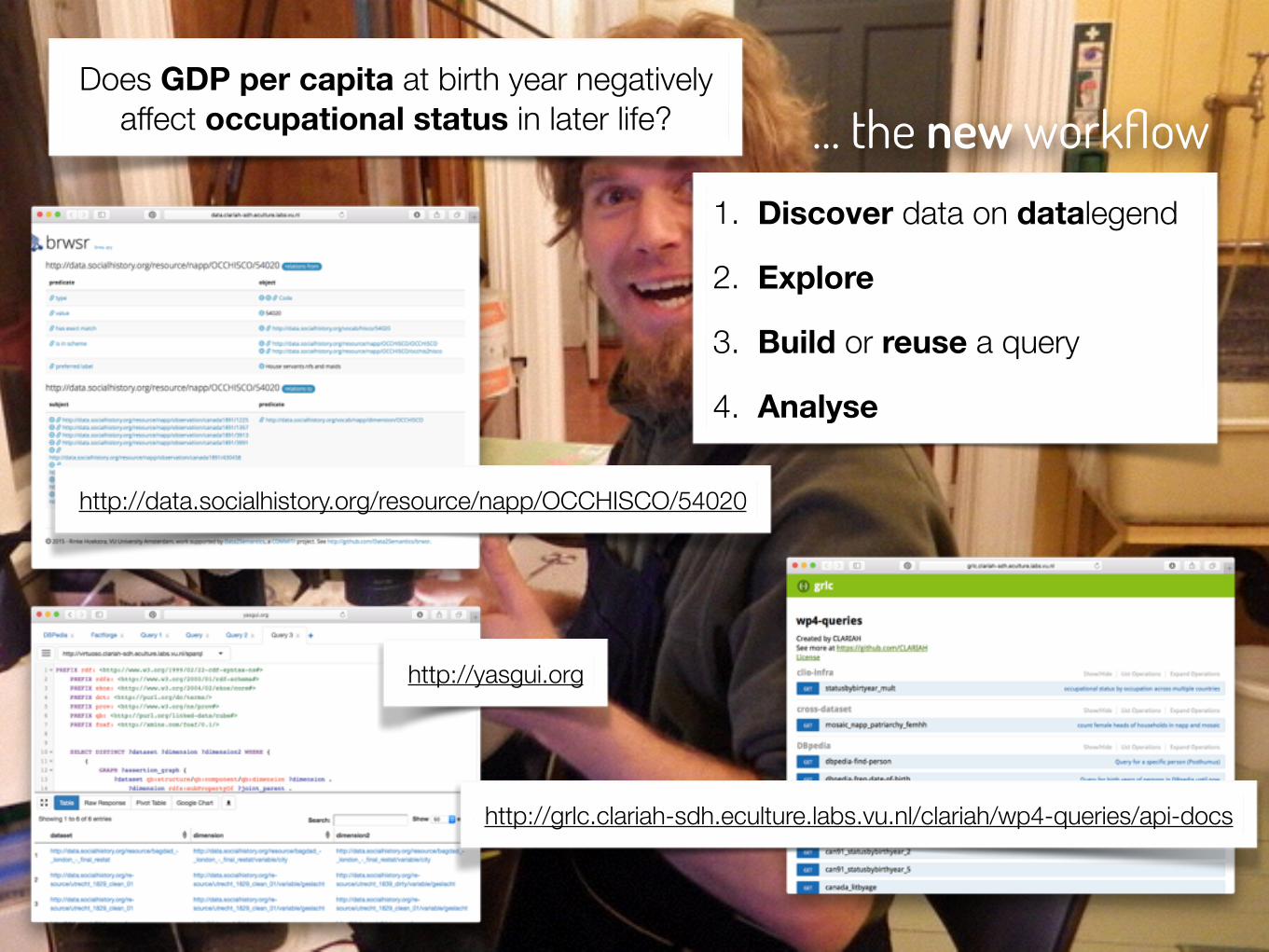
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
1. Discover data on datalegend
2. Explore
3. Build or reuse a query
4. Analyse
http://data.socialhistory.org/resource/napp/OCCHISCO/54020
http://yasgui.org
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
1. Discover data on datalegend
2. Explore
3. Build or reuse a query
4. Analyse
http://data.socialhistory.org/resource/napp/OCCHISCO/54020
http://yasgui.org
http://grlc.clariah-sdh.eculture.labs.vu.nl/clariah/wp4-queries/api-docs

… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?

… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
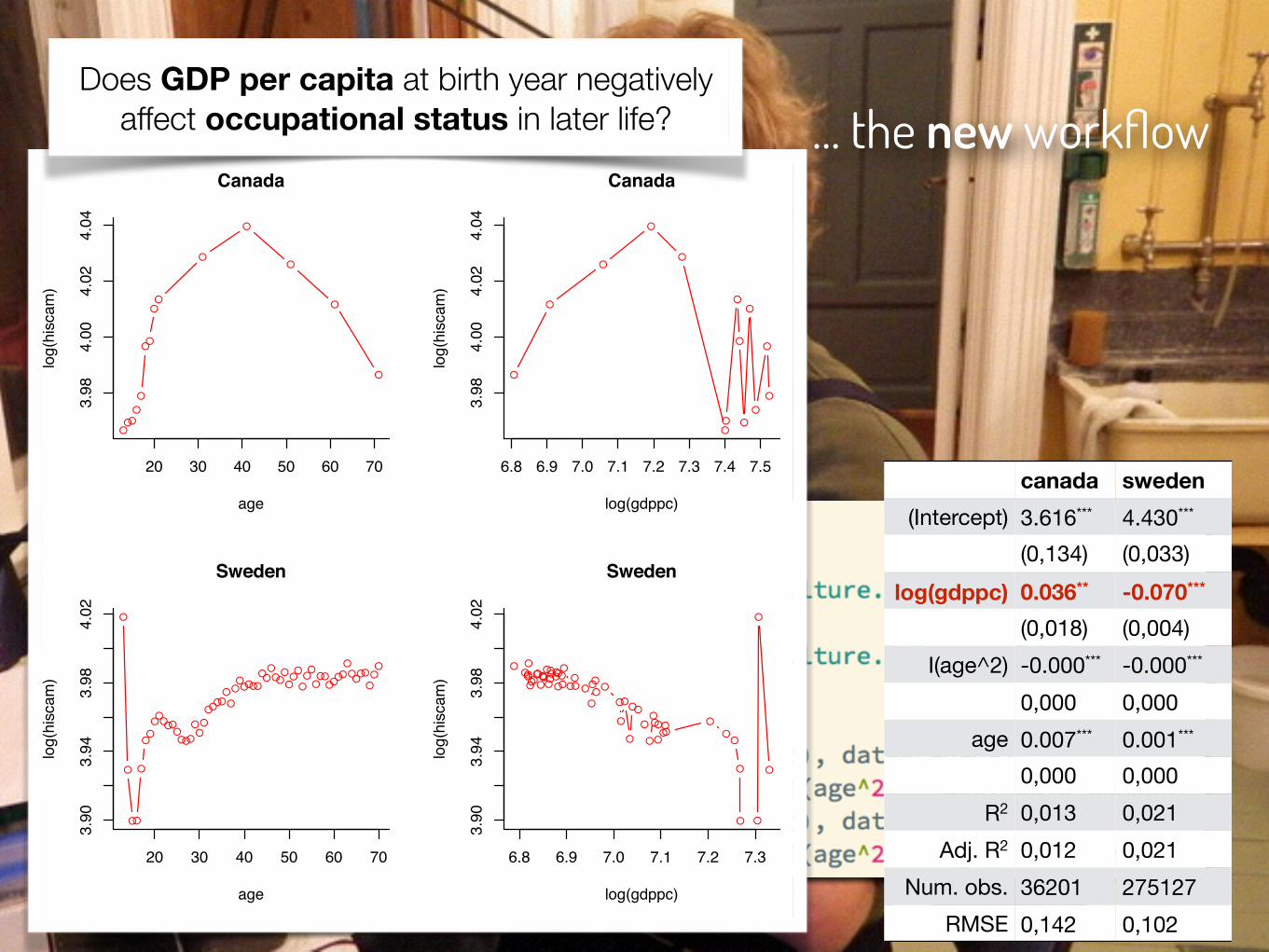
… the new workflow
canada sweden(Intercept) 3.616*** 4.430***
(0,134) (0,033)log(gdppc) 0.036** -0.070***
(0,018) (0,004)I(age^2) -0.000*** -0.000***
0,000 0,000age 0.007*** 0.001***
0,000 0,000R2 0,013 0,021
Adj. R2 0,012 0,021Num. obs. 36201 275127
RMSE 0,142 0,102
●
●
●
●
●
●●
●●
●
●●●
●
20 30 40 50 60 70
3.98
4.00
4.02
4.04
Canada
age
log(hiscam
)
●
●
●
●
●
●●
●
●
●
●
●
●
●
6.8 6.9 7.0 7.1 7.2 7.3 7.4 7.53.98
4.00
4.02
4.04
Canada
log(gdppc)
log(hiscam
)
●●●
●●●●●●●
●●●●
●
●●●
●●●
●●●
●●●
●●●●●●
●●●●●●
●●●
●●●●●●●
●●
●●
●
●●
●
●
20 30 40 50 60 70
3.90
3.94
3.98
4.02
Sweden
age
log(hiscam
)
●●●●●
●●●●●●●●●●
●●●●●●
●
●●●
●
●●●●
●
●●●●
●
●
●
●
●●
●
●
●●
●
●●●●
●
●●
●
● ●
●
●
6.8 6.9 7.0 7.1 7.2 7.3
3.90
3.94
3.98
4.02
Sweden
log(gdppc)
log(hiscam
)
Does GDP per capita at birth year negatively affect occupational status in later life?

… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?
… the new workflowDoes GDP per capita at birth year negatively
affect occupational status in later life?

Discussion
• Data-driven research in the humanities is too expensive and confined to single datasets.
• Linked Data can be a solution, but historians cannot be expected to change their current workflow, or craft RDF by hand.
• QBer allows historians to upload their data, connect it to earlier work by peers, while preserving provenance of their steps.
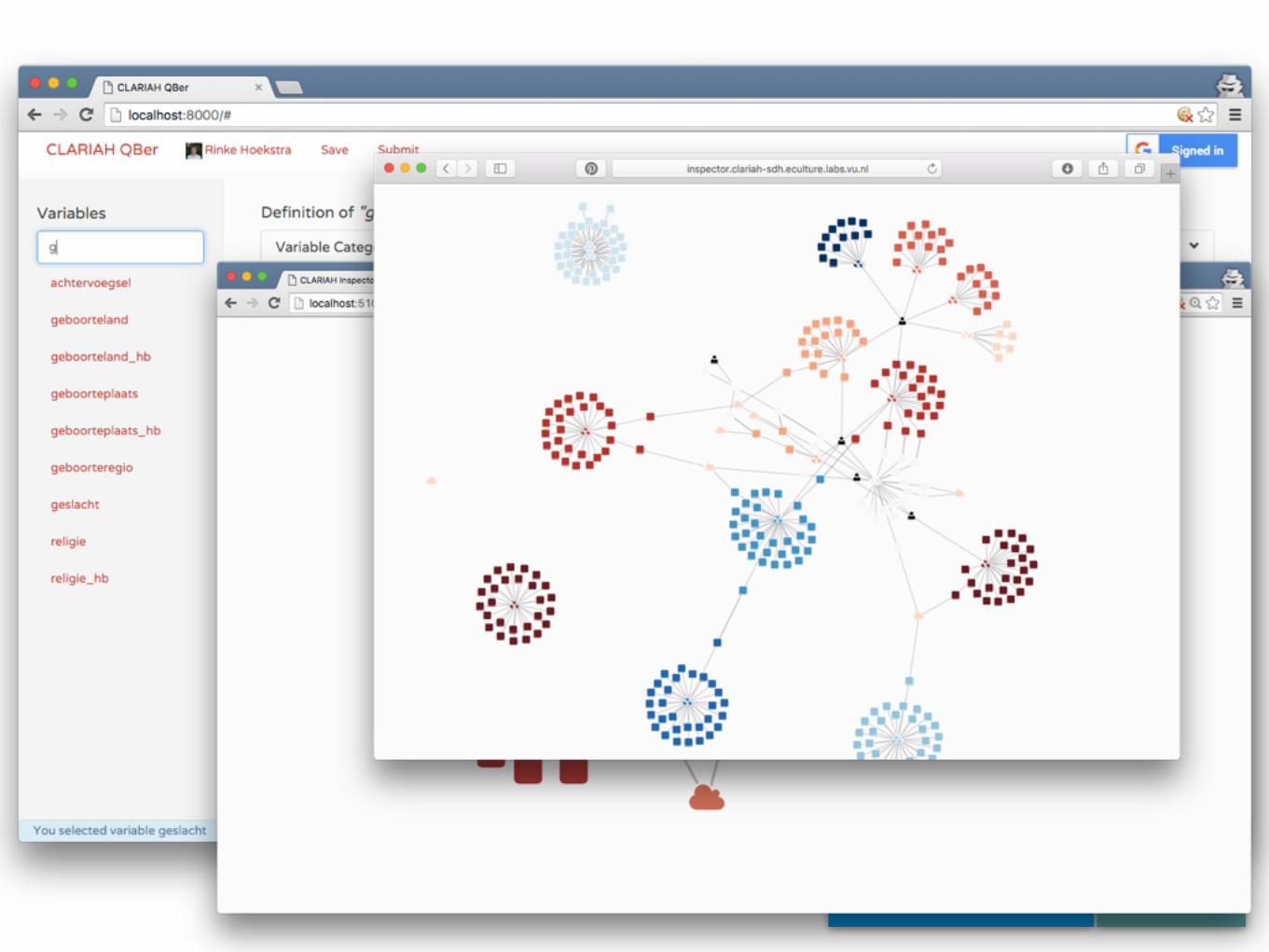
• The inspector view gives instant feedback of the impact on the network
• Standard SPARQL queries are converted to APIs through grlc.
• Research questions can thus be shared, replicated and applied to new data.
• This gives rise to different roles of researchers in our ecosystem
legenddata legend data

Discussion
• Data-driven research in the humanities is too expensive and confined to single datasets.
• Linked Data can be a solution, but historians cannot be expected to change their current workflow, or craft RDF by hand.
• QBer allows historians to upload their data, connect it to earlier work by peers, while preserving provenance of their steps.
• The inspector view gives instant feedback of the impact on the network
• Standard SPARQL queries are converted to APIs through grlc.
• Research questions can thus be shared, replicated and applied to new data.
• This gives rise to different roles of researchers in our ecosystem
legenddata legend data