

[email protected] and Confidential NOTICE: Proprietary and Confidential This material is...
50
[email protected] Proprietary and Confidential NOTICE: Proprietary and Confidential This material is proprietary to A. Teredesai and GCCIS, RIT. Slide 1 Decision Trees AMT
-
Upload
joel-wright -
Category
Documents
-
view
219 -
download
1
Transcript of [email protected] and Confidential NOTICE: Proprietary and Confidential This material is...

[email protected] Proprietary and Confidential
NOTICE: Proprietary and Confidential
This material is proprietary to A. Teredesai and GCCIS, RIT.
Slide 1
Decision Trees
AMT

[email protected] Dr. Ankur M. Teredesai P2
OverviewDecision trees
Appropriate problems for decision trees
Entropy and Information Gain
The ID3 algorithm
Avoiding Overfitting via Pruning
Handling Continuous-Valued Attributes
Handling Missing Attribute Values
Alternative Measures for Selecting Attributes

[email protected] Dr. Ankur M. Teredesai P3
Decision TreesDecision Trees
Definition: A decision tree is a tree s.t.:
• Each internal node tests an attribute
• Each branch corresponds to attribute value
• Each leaf node assigns a classification
Outlook
sunny overcast rainy
Humidity Windy
high normal
no
false true
yes
yes yes no

[email protected] Dr. Ankur M. Teredesai P4
Data Set for Playing TennisData Set for Playing Tennis
Outlook Temp. Humidity Windy Play
Sunny Hot High False No
Sunny Hot High True No
Overcast Hot High False Yes
Rainy Mild High False Yes
Rainy Cool Normal False Yes
Rainy Cool Normal True No
Overcast Cool Normal True Yes
Outlook Temp. Humidity Windy play
Sunny Mild High False No
Sunny Cool Normal False Yes
Rainy Mild Normal False Yes
Sunny Mild Normal True Yes
Overcast Mild High True Yes
Overcast Hot Normal False Yes
Rainy Mild High True No

[email protected] Dr. Ankur M. Teredesai P5
Decision Tree For Playing TennisDecision Tree For Playing Tennis
Outlook
sunny overcast rainy
Humidity Windy
high normal
no
false true
yes
yes yes no

[email protected] Dr. Ankur M. Teredesai P6
When to Consider Decision TreesWhen to Consider Decision TreesEach instance consists of an attribute with discrete values (e.g. outlook/sunny, etc..)
The classification is over discrete values (e.g. yes/no )
It is okay to have disjunctive descriptions – each path in the tree represents a disjunction of attribute combinations. Any Boolean function can be represented!It is okay for the training data to contain errors – decision trees are robust to classification errors in the training data.It is okay for the training data to contain missing values – decision trees can be used even if instances have missing attributes.

[email protected] Dr. Ankur M. Teredesai P7
Decision Tree InductionDecision Tree Induction
Basic Algorithm:
1. A the “best" decision attribute for a node N.
2. Assign A as decision attribute for the node N.
3. For each value of A, create new descendant of the node N.
4. Sort training examples to leaf nodes.
5. IF training examples perfectly classified, THEN STOP.
ELSE iterate over new leaf nodes

[email protected] Dr. Ankur M. Teredesai P8
Decision Tree InductionDecision Tree Induction
_____________________________________Outlook Temp Hum Wind Play ---------------------------------------------------------Rain Mild High Weak YesRain Cool Normal Weak YesRain Cool Normal Strong NoRain Mild Normal Weak YesRain Mild High Strong No
Outlook
____________________________________Outlook Temp Hum Wind Play -------------------------------------------------------Sunny Hot High Weak NoSunny Hot High Strong NoSunny Mild High Weak NoSunny Cool Normal Weak YesSunny Mild Normal Strong Yes
_____________________________________Outlook Temp Hum Wind Play ---------------------------------------------------------Overcast Hot High Weak YesOvercast Cool Normal Strong Yes
SunnyOvercast
Rain

[email protected] Dr. Ankur M. Teredesai P9
EntropyEntropy
Let S be a sample of training examples, and
p+ is the proportion of positive examples in S and
p- is the proportion of negative examples in S.
Then: entropy measures the impurity of S:
E( S) = - p+ log2 p+ – p- log2 p
-
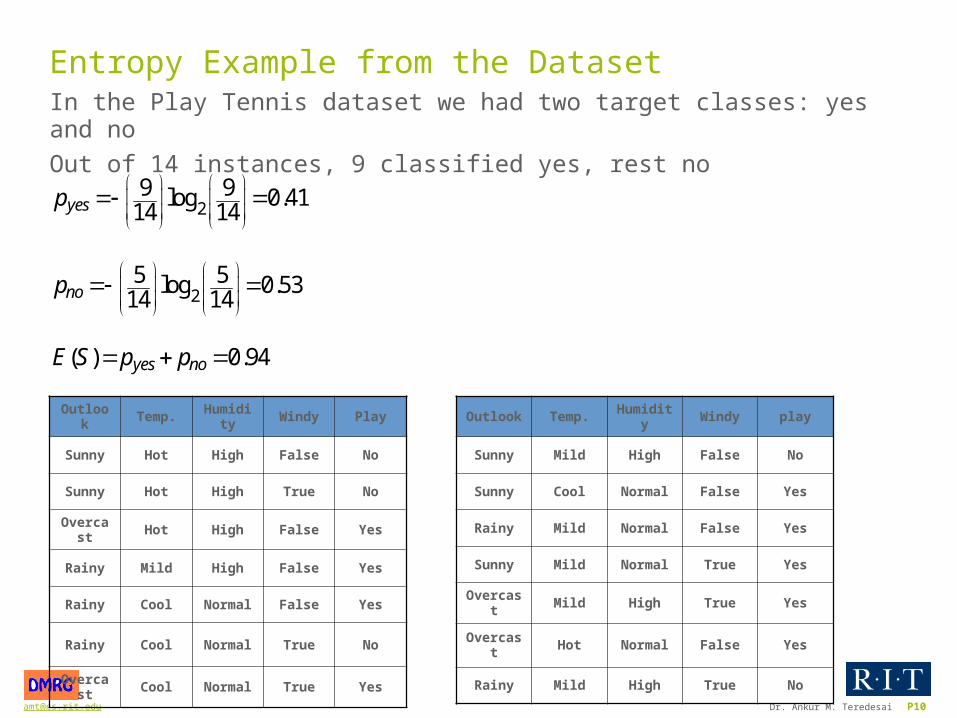
[email protected] Dr. Ankur M. Teredesai P10
Entropy Example from the DatasetIn the Play Tennis dataset we had two target classes: yes and no
Out of 14 instances, 9 classified yes, rest no
2
2
9 9log 0.4114 14
5 5log 0.5314 14
( ) 0.94
yes
no
yes no
p
p
E S p p
Outlook Temp. Humidity Windy Play
Sunny Hot High False No
Sunny Hot High True No
Overcast Hot High False Yes
Rainy Mild High False Yes
Rainy Cool Normal False Yes
Rainy Cool Normal True No
Overcast Cool Normal True Yes
Outlook Temp. Humidity Windy play
Sunny Mild High False No
Sunny Cool Normal False Yes
Rainy Mild Normal False Yes
Sunny Mild Normal True Yes
Overcast Mild High True Yes
Overcast Hot Normal False Yes
Rainy Mild High True No

[email protected] Dr. Ankur M. Teredesai P11
Information GainInformation Gain Information Gain is the expected reduction in entropy caused by partitioning the instances according to a given attribute.
Gain(S, A) = E(S) -
where SV = { s S | A(s) = V}
)(||||
)(v
AValuesv
v SESS

[email protected] Dr. Ankur M. Teredesai P12
ExampleExample
_____________________________________Outlook Temp Hum Wind Play ---------------------------------------------------------Rain Mild High Weak YesRain Cool Normal Weak YesRain Cool Normal Strong NoRain Mild Normal Weak YesRain Mild High Strong No
Outlook
____________________________________Outlook Temp Hum Wind Play -------------------------------------------------------Sunny Hot High Weak NoSunny Hot High Strong NoSunny Mild High Weak NoSunny Cool Normal Weak YesSunny Mild Normal Strong Yes
_____________________________________Outlook Temp Hum Wind Play ---------------------------------------------------------Overcast Hot High Weak YesOvercast Cool Normal Strong Yes
SunnyOvercast
Rain
Which attribute should be tested here?
Gain (Ssunny , Humidity) = = .970 - (3/5) 0.0 - (2/5) 0.0 = .970
Gain (Ssunny , Temperature) = .970 - (2/5) 0.0 - (2/5) 1.0 - (1/5) 0.0 = .570
Gain (Ssunny , Wind) = .970 - (2/5) 1.0 - (3/5) .918 = .019

[email protected] Dr. Ankur M. Teredesai P13
ID3 AlgorithmInformally:
• Determine the attribute with the highest information gain on the training set.
• Use this attribute as the root, create a branch for each of the values the attribute can have.
• For each branch, repeat the process with subset of the training set that is classified by that branch.

[email protected] Dr. Ankur M. Teredesai P14
Hypothesis Space Search in ID3Hypothesis Space Search in ID3
The hypothesis space is the set of all decision trees defined over the given set of attributes.
ID3’s hypothesis space is a compete space; i.e., the target description is there!
ID3 performs a simple-to-complex, hill climbing search through this space.
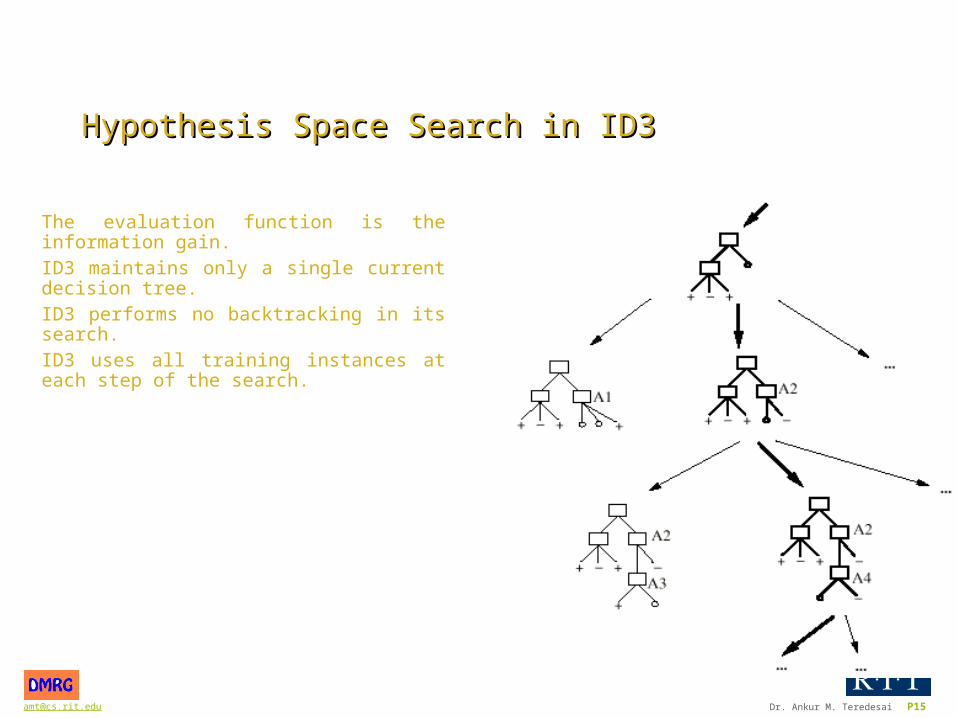
[email protected] Dr. Ankur M. Teredesai P15
Hypothesis Space Search in ID3Hypothesis Space Search in ID3
The evaluation function is the information gain.ID3 maintains only a single current decision tree.ID3 performs no backtracking in its search.ID3 uses all training instances at each step of the search.

[email protected] Dr. Ankur M. Teredesai P16
Inductive Bias in ID3Inductive Bias in ID3
Preference for short trees
Preference for trees with high information gain attributes near the root.
Bias is a preference to some hypotheses, not a restriction on the hypothesis space

[email protected] Dr. Ankur M. Teredesai P17

[email protected] Dr. Ankur M. Teredesai P18
OverfittingOverfitting
Definition: Given a hypothesis space H, a hypothesis h H is said to overfit the training data if there exists some hypothesis h’ H, such that h has smaller error than h’ over the training instances, but h’ has a smaller error than h over the entire distribution of instances.

[email protected] Dr. Ankur M. Teredesai P19
Reasons for OverfittingReasons for Overfitting
• Noisy training instances. Consider an noisy training example: Outlook = Sunny;Temperature = Hot; Humidity = Normal; Wind = Strong; PlayTennis = No
Outlook
sunny overcast rainy
Humidity Windy
high normal
no
false true
yes
yes yes no
add new test

[email protected] Dr. Ankur M. Teredesai P20
area with probablywrong predictions
+
++
++ +
+
-
-
- -
-
---
---
-
-
- +
---
-
-
Reasons for OverfittingReasons for Overfitting
• Small number of instances are associated with leaf nodes. In this case it is possible that for coincidental regularities to occur that are unrelated to the actual target concept.

[email protected] Dr. Ankur M. Teredesai P21
Approaches to Avoiding OverfittingApproaches to Avoiding OverfittingPre-pruning: stop growing the tree earlier, before it reaches the point where it perfectly classifies the training data
Post-pruning: Allow the tree to overfit the data, and then post-prune the tree.

[email protected] Dr. Ankur M. Teredesai P22
Criteria for PruningCriteria for Pruning
Use a separate set of instances, distinct from the training instances, to evaluate the utility of nodes in the tree. This requires the data to be split into a training set and a validation set which is then used for pruning. The reason is that the validation set is unlikely to suffer from same errors or fluctuations as the training set.
Use all the available data for training, but apply a statistical test to estimate whether expanding/pruning a particular node is likely to produce improvement beyond the training set.
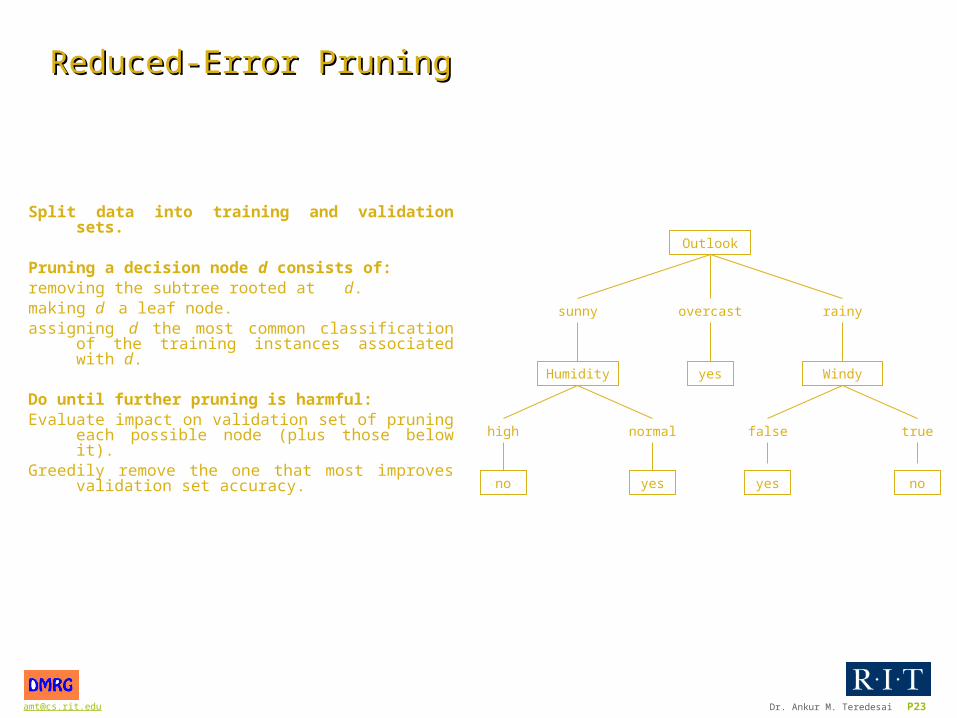
[email protected] Dr. Ankur M. Teredesai P23
Reduced-ErrorReduced-Error PruningPruning
Split data into training and validation sets.
Pruning a decision node d consists of:removing the subtree rooted at d.making d a leaf node. assigning d the most common classification of the training
instances associated with d.
Do until further pruning is harmful:Evaluate impact on validation set of pruning each possible
node (plus those below it).Greedily remove the one that most improves validation set
accuracy.
Outlook
sunny overcast rainy
Humidity Windy
high normal
no
false true
yes
yes yes no

[email protected] Dr. Ankur M. Teredesai P24
Reduced Error Pruning ExampleReduced Error Pruning Example

[email protected] Dr. Ankur M. Teredesai P25
Rule Post-PruningRule Post-Pruning
IF (Outlook = Sunny) & (Humidity = High)THEN PlayTennis = NoIF (Outlook = Sunny) & (Humidity = Normal)THEN PlayTennis = Yes……….
1. Convert tree to equivalent set of rules.2. Prune each rule independently of others.3. Sort final rules by their estimated accuracy, and consider them
in this sequence when classifying subsequent instances.
Outlook
sunny overcast rainy
Humidity Windy
normal
no
false true
yes
yes yes no

[email protected] Dr. Ankur M. Teredesai P26
Continuous Valued AttributesContinuous Valued Attributes
Create a set of discrete attributes to test continuous.
Apply Information Gain in order to choose the best attribute.
Temperature: 40 48 60 72 80 90
PlayTennis: No No Yes Yes Yes No
Temp>54 Tem>85

[email protected] Dr. Ankur M. Teredesai P27
An Alternative Measure for Attribute SelectionAn Alternative Measure for Attribute Selection
),(),(
),(ASmationSplitInfor
ASGainASGainRatio
||||
log||||
),(1
2 SS
SS
ASmatioSplitInfro ic
i
i
where:

[email protected] Dr. Ankur M. Teredesai P28
Missing Attribute ValuesMissing Attribute Values
Strategies:
1. Assign most common value of A among other examples belonging to the same concept.
2. If node n tests the attribute A, assign most common value of A among other examples sorted to node n.
3. If node n tests the attribute A, assign a probability to each of possible values of A. These probabilities are estimated based on the observed frequencies of the values of A. These probabilities are used in the information gain measure.

[email protected] Dr. Ankur M. Teredesai P29
Summary PointsSummary Points
1. Decision tree learning provides a practical method for concept learning.
2. ID3-like algorithms search complete hypothesis space.3. The inductive bias of decision trees is preference (search)
bias.4. Overfitting the training data is an important issue in
decision tree learning.5. A large number of extensions of the ID3 algorithm have
been proposed for overfitting avoidance, handling missing attributes, handling numerical attributes, etc.

[email protected] Dr. Ankur M. Teredesai P30
ReferencesReferencesMitchell, Tom. M. 1997. Machine Learning. New York: McGraw-Hill
Quinlan, J. R. 1986. Induction of decision trees. Machine Learning
Stuart Russell, Peter Norvig, 1995. Artificial Intelligence: A Modern Approach. New Jersey: Prantice Hall

[email protected] Proprietary and Confidential
NOTICE: Proprietary and Confidential
This material is proprietary to A. Teredesai and GCCIS, RIT.
Slide 31
RainForestRainForest - A Framework for Fast Decision Tree Construction of Large Datasets
J. Gehrke, R. Ramakrishnan, V. GantiDept. of Computer Sciences University of Wisconsin-Madison

[email protected] Dr. Ankur M. Teredesai P32
Introduction to ClassificationAn important Data Mining ProblemInput: a database of training records
– Class label attributes– Predictor Attributes
Goal
• to build a concise model of the distribution of class label in terms of predictor attributes
Applications
• scientific experiments,medical diagnosis, fraud detection, etc.

[email protected] Dr. Ankur M. Teredesai P33
It is one of the most attractive classification models
There are a large number of algorithms to construct decision trees
• E.g.: SLIQ, CART, C4.5 SPRINT
• Most are main memory algorithms
• Tradeoff between supporting large databases, performance and constructing more accurate decision trees
Decision Tree:A Classification Model

[email protected] Dr. Ankur M. Teredesai P34
Motivation of RainForest
Developing a unifying framework that can be applied to most decision tree algorithms, and results in a scalable version of this algorithm without modifying the results.
Separating the scalability aspects of these algorithms from the central features that determine the quality of the decision trees

[email protected] Dr. Ankur M. Teredesai P35
Decision Tree Terms
Root,Leaf, Internal Nodes
Each leaf is labeled with one class label
Each internal node is labeled with one predictor attribute called the splitting attribute
Each edge e from node n has a predicate q associated with it, q only involves splitting attributes.
P : set of predicates on all outgoing edges of an internal node; Non-overlapping, Exhaustive
Crit(n): splitting criteria of n; combination of splitting attributes and predicates

[email protected] Dr. Ankur M. Teredesai P36
Decision Tree Terms(Cont’d)
F(n) :Family of database(D) tuples of a node nDefinition: let E={e1,e2,…,ek}, Q={q1,q2,…,qk} be the edge set and predicate set for
a node n; p be the parent node of n If n=root, F(n) = DIf n≠root, let q(p→n) be the predicate on e(p→n), F(n) = {t: t€F(n),t €F(p), and q(p→ n= True}

[email protected] Dr. Ankur M. Teredesai P37
Decision Tree Terms (Cont’d)P { q1, q2, … , qk }
n
ek { qk}e2 {
q2 }
e1 { q1 }

[email protected] Dr. Ankur M. Teredesai P38
RainForest Framework:Top-down Tree Induction Schema
Input: node n, partition D, classification algorithm CL Output: decision tree for D rooted at n Top Down Decision Tree Induction Schema: BuildTree(Node n, datapartition D, algorithm CL) (1) Apply CL to D to find crit(n) (2) let k be the number of children of n (3) if (k > 0) (4) Create k children c1 ; ... ; ck of n (5) Use best split to partition D into D1 ; . . . ; Dk (6) for (i = 1; i <= k; i++) (7) BuildTree(ci , Di ) (8) endfor (9) endif RainForest Refinement: (1a) for each predictor attribute p (1b) Call CL.find_best_partitioning(AVC set of p) (1c) endfor
(2a) k = CL:decide_splitting_criterion();

[email protected] Dr. Ankur M. Teredesai P39
RainForest:Tree Induction Schema (Cont’d)
AVC stands for Attribute Value, ClasslabelAVC-set: AVC-set of a predictor attribute a to be the projection of F(n) onto a and the class label whereby counts of the individual class labels are aggregated AVC-group: the AVC group of a node n to be the set of all AVC sets at node n. Size of the AVC set of a predictor attribute a at node n
• depends only on the number of distinct attribute values of a and the number of class labels in F(n).
AVC-group(r) is not equal to F( r ) : contains aggregated information that is sufficient for decision tree construction

[email protected] Dr. Ankur M. Teredesai P40
AVC-groups and Main Memory
The memory size determines the implementation of RainForest Schema.Case 1: AVC-group of the root node fits in the M.M.
• RF-Write; RF-Read; RF-HybridCase 2: each individual AVC-set of the root node fits into M.M., but the AVC-group does not.
• RF-VerticalCase 3: Other than Case 1&2

[email protected] Dr. Ankur M. Teredesai P41
Steps for Algorithms in RainForest Family1. AVC group Construction
2. Choose Splitting Attribute and Predicate
• This step uses the decision tree algorithm CL that is being scaled using the RainForest framework
3. Partition D Across the Children Nodes
• We must read the entire dataset and write out all records, partitioning them into child ``buckets'' according to the splitting criterion chosen in the previous step.

[email protected] Dr. Ankur M. Teredesai P42
Algorithms: RF-Write/RF-ReadPrerequisite:AVC-group fits into M.M.RF-Write:
• For each level of the tree,it reads the entire database twice and writes the entire database once
RF-Read
• Makes an increasing number of scans of entire database
• Marks one end of the design spectrum in the RainForest framework

[email protected] Dr. Ankur M. Teredesai P43
Algorithm:RF-HybridCombination of RF-Write and RF-Read
Performance can be improved by concurrent construction of AVC-sets

[email protected] Dr. Ankur M. Teredesai P44
Algorithm:RF-VerticalPrerequisite: individual AVC-set can fit into M.M.
For very large sets, a temporary file is generated for each node, the large sets are constructed from this temporary file.
For small sets, construct them in M.M.

[email protected] Dr. Ankur M. Teredesai P46
Experiment Results: (1)When the overall maximum number of entries in the AVC-group of the root node is about 2.1 million, requiring a maximum memory size of 17MB.
[email protected] Dr. Ankur M. Teredesai P47
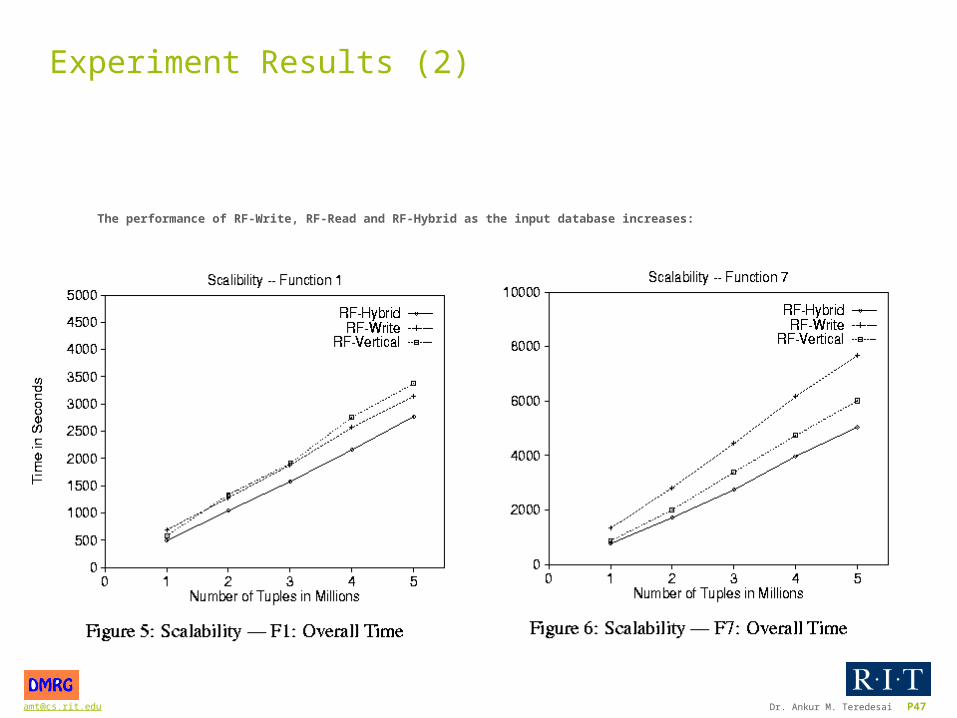
Experiment Results (2)
The performance of RF-Write, RF-Read and RF-Hybrid as the input database increases:
[email protected] Dr. Ankur M. Teredesai P48
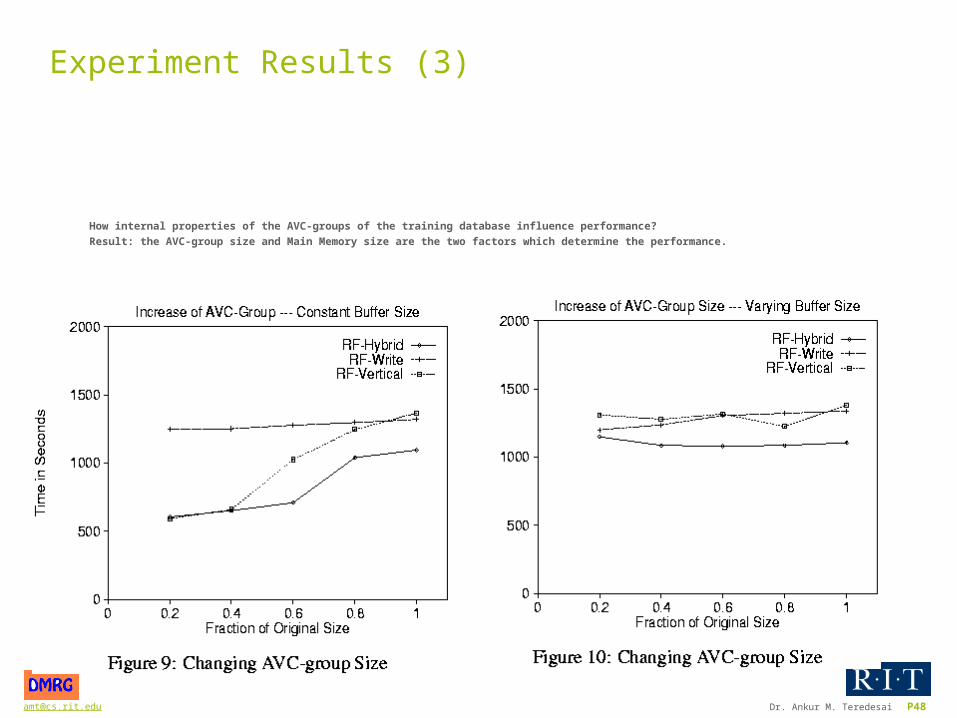
Experiment Results (3)
How internal properties of the AVC-groups of the training database influence performance?
Result: the AVC-group size and Main Memory size are the two factors which determine the performance.

[email protected] Dr. Ankur M. Teredesai P49
Experiment Results (4)
How performance is affected as the number of attributes is increasing?
Result: a roughly linear scaleup with the number of attributes.

[email protected] Dr. Ankur M. Teredesai P50
ConclusionA scaling decision tree algorithm that is applicable to all decision tree algorithms at that time.AVC-group is the key idea.
Database scan at each level of the decision treeToo much dependence over the size of available main memory


















