
Amazon Athena - Guia do usuárioAmazon Athena Guia do usuário Amazon's trademarks and trade dress...
363
Amazon Athena Guia do usuário Amazon Athena: Guia do usuário Copyright © 2020 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Transcript of Amazon Athena - Guia do usuárioAmazon Athena Guia do usuário Amazon's trademarks and trade dress...

Amazon AthenaGuia do usuário
Amazon Athena: Guia do usuárioCopyright © 2020 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.

Amazon Athena Guia do usuário
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's,in any manner that is likely to cause confusion among customers, or in any manner that disparages or discreditsAmazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may notbe affiliated with, connected to, or sponsored by Amazon.

Amazon Athena Guia do usuário
Table of ContentsO que é o Amazon Athena? ................................................................................................................ 1
Quando devo usar o Athena? ...................................................................................................... 1Acesso ao Athena ...................................................................................................................... 1Noções básicas de tabelas, bancos de dados e o Data Catalog ......................................................... 2Integrações de serviços da AWS com o Athena .............................................................................. 3
Configuração ...................................................................................................................................... 6Cadastre-se na AWS .................................................................................................................. 6
Para criar uma conta da AWS .............................................................................................. 6Criar um usuário do IAM ............................................................................................................. 6
Para criar um grupo de administradores ................................................................................ 6Para criar um usuário do IAM para você mesmo, adicione o usuário ao grupo de administradorese crie uma senha para o usuário. ......................................................................................... 7
Anexar políticas gerenciadas para usar o Athena ............................................................................ 7Conceitos básicos ............................................................................................................................... 8
Pré-requisitos ............................................................................................................................. 8Etapa 1: Criar um banco de dados ............................................................................................... 8Etapa 2: Criar uma tabela ............................................................................................................ 9Etapa 3: consultar dados ........................................................................................................... 10
Acesso ao Amazon Athena ................................................................................................................ 12Utilização do console ................................................................................................................ 12Uso da API .............................................................................................................................. 12Uso da CLI .............................................................................................................................. 13
Criar tabelas e bancos de dados ........................................................................................................ 14Processo de criação de tabelas e bancos de dados no Athena ........................................................ 14
Requisitos para tabelas no Athena e dados no Amazon S3 ..................................................... 15Funções compatíveis ......................................................................................................... 15Transformações de dados transacionais não são compatíveis .................................................. 16Operações que alteram estados de tabela são ACID .............................................................. 16Todas as tabelas são EXTERNAL ....................................................................................... 16Para criar uma tabela usando o AWS Glue Data Catalog ........................................................ 16Para criar uma tabela usando o assistente ........................................................................... 17Para criar um banco de dados usando a DDL do Hive ........................................................... 17Para criar uma tabela usando a DDL do Hive ....................................................................... 18
Nomes para tabelas, bancos de dados e colunas .......................................................................... 18Os nomes de tabelas e de colunas de tabela no Athena devem estar em minúsculas ................... 19Os nomes de tabelas, visualizações, bancos de dados e colunas do Athena permitem somentecaracteres especiais sublinhados ........................................................................................ 19Nomes que começam com um sublinhado ............................................................................ 19Nomes de tabelas ou visualizações que incluem números ....................................................... 19
Palavras-chave reservadas ......................................................................................................... 19Lista de palavras-chave reservadas em instruções DDL .......................................................... 20Lista de palavras-chave reservadas em instruções SELECT do SQL ......................................... 20Exemplos de consultas com palavras reservadas .................................................................. 20
Local da tabela no Amazon S3 ................................................................................................... 21Local e partições de tabela ................................................................................................ 22
Particionar dados ...................................................................................................................... 23Cenário 1: os dados já estão particionados e armazenados no S3 no formato hive ...................... 23Cenário 2: os dados não estão particionados ........................................................................ 25
Formatos de armazenamento colunar .......................................................................................... 26Converter em formatos colunares ................................................................................................ 27
Visão geral ...................................................................................................................... 27Antes de começar .............................................................................................................. 8Exemplo: converter dados em Parquet usando um cluster do EMR ........................................... 29
Conectar a fontes de dados ............................................................................................................... 32
iii

Amazon Athena Guia do usuário
Integração com o AWS Glue ...................................................................................................... 32Usar o AWS Glue para se conectar a fontes de dados no Amazon S3 ...................................... 33Melhores práticas ao usar o Athena com o AWS Glue ............................................................ 35Atualizar para o AWS Glue Data Catalog passo a passo ........................................................ 43Perguntas frequentes: atualização para o Catálogo de dados do AWS Glue ............................... 45
Usar um metastore do Hive ........................................................................................................ 47Condições e limitações ...................................................................................................... 48Conectar o Athena a um metastore do Apache Hive .............................................................. 48
O uso do ................................................................................................................................. 49Condições e limitações ...................................................................................................... 50Implantar um conector e conectar-se a uma fonte de dados .................................................... 50Usar o AWS Serverless Application Repository ..................................................................... 51Conectores de fontes de dados do Athena ........................................................................... 52Gravar consultas federadas ................................................................................................ 54Gravar um conector de fonte de dados ................................................................................ 58Gerenciar fontes de dados ................................................................................................. 58
Conexão ao Amazon Athena com drivers ODBC e JDBC ................................................................ 59Uso do Athena com o driver JDBC ...................................................................................... 59Conexão ao Amazon Athena com o ODBC ........................................................................... 61
Executar consultas ............................................................................................................................ 65Resultados de consulta e histórico de consultas ............................................................................ 65
Obter um ID de consulta .................................................................................................... 66Identificar arquivos de saída da consulta .............................................................................. 66Fazer download de arquivos de resultados da consulta usando o console do Athena ................... 68Especificar um local de resultados da consulta ...................................................................... 69Ver histórico de consultas .................................................................................................. 71
Como trabalhar com exibições .................................................................................................... 72Quando usar as visualizações? ........................................................................................... 72Ações com suporte para visualizações no Athena .................................................................. 73Considerações para exibições ............................................................................................ 73Limitações de visualizações ............................................................................................... 74Trabalho com exibições no console ..................................................................................... 74Criação de exibições ......................................................................................................... 75Exemplos de exibições ...................................................................................................... 76Atualização de exibições .................................................................................................... 77Exclusão de exibições ....................................................................................................... 77
Criar uma tabela a partir de resultados da consulta (CTAS) ............................................................. 77Considerações e Limitações de Consultas CTAS ................................................................... 77Executar consultas CTAS no console .................................................................................. 79Armazenar em bucket vs particionar .................................................................................... 82Exemplos de consultas CTAS ............................................................................................. 83Usar CTAS e INSERT INTO para ETL ................................................................................. 86Criar uma tabela com mais de 100 partições ........................................................................ 92
Tratamento de atualizações de esquema ...................................................................................... 95Resumo: atualizações e formatos de dados no Athena ........................................................... 96Acesso ao índice em ORC e Parquet .................................................................................. 97Tipos de atualizações ........................................................................................................ 98Atualizações em tabelas com partições .............................................................................. 103
Consultar matrizes .................................................................................................................. 105Criar matrizes ................................................................................................................. 105Concatenar matrizes ........................................................................................................ 107Converter tipos de dados da matriz ................................................................................... 107Encontrar tamanhos ........................................................................................................ 108Acessar elementos de matriz ............................................................................................ 108Nivelar matrizes aninhadas ............................................................................................... 109Criar conjuntos com base em subconsultas ......................................................................... 111Filtrar matrizes ................................................................................................................ 112
iv

Amazon Athena Guia do usuário
Classificar matrizes ......................................................................................................... 113Usar funções de agregação com matrizes .......................................................................... 113Converter matrizes em strings ........................................................................................... 114Usar matrizes para criar mapas ........................................................................................ 114Como consultar matrizes com tipos complexos e estruturas aninhadas .................................... 115
Consultar JSON ...................................................................................................................... 121Melhores práticas de leitura de dados JSON ....................................................................... 121Extrair dados do JSON .................................................................................................... 122Pesquisando valores em matrizes JSON ............................................................................ 125Obter comprimento e tamanho de matrizes JSON ................................................................ 126
Consultar dados geoespaciais ................................................................................................... 127O que é uma consulta geoespacial? .................................................................................. 127Formatos de dados de entrada e tipos de dados de geometria ............................................... 128Lista de funções geoespaciais compatíveis ......................................................................... 128Exemplos: consultas geoespaciais ..................................................................................... 137
O uso do ............................................................................................................................... 139Condições e limitações .................................................................................................... 139Sintaxe do ...................................................................................................................... 139
Consultas com UDFs ............................................................................................................... 140Condições e limitações .................................................................................................... 141Sintaxe de consulta da UDF ............................................................................................. 141Criar e implantar uma UDF usando o Lambda ..................................................................... 143
Consultar logs de serviço da AWS ............................................................................................ 148Consultar logs do Application Load Balancer ....................................................................... 149Consultar logs do Classic Load Balancer ............................................................................ 150Consulta de logs do Amazon CloudFront ............................................................................ 152Consulta de logs do AWS CloudTrail ................................................................................. 153Consulta de logs do Amazon EMR .................................................................................... 157Consultar a logs de fluxo do AWS Global Accelerator ........................................................... 161Consulta de logs do Load balancer de rede ........................................................................ 162Consulta a logs de fluxo da Amazon VPC .......................................................................... 164Consulta de logs do AWS WAF ........................................................................................ 166
Consulta no Catálogo de dados do AWS Glue ............................................................................ 168Listagem de bancos de dados e pesquisa em um banco de dados especificado ........................ 168Listagem de tabelas em um banco de dados especificado e pesquisa de uma tabela por nome .... 169Listagem de partições de uma tabela específica .................................................................. 170Listagem ou pesquisa de colunas de uma tabela ou exibição especificada ............................... 170
Segurança ...................................................................................................................................... 173Proteção de dados .................................................................................................................. 173
Criptografia em repouso ................................................................................................... 174Criptografia em trânsito .................................................................................................... 179Gerenciamento de chaves ................................................................................................ 179Privacidade do tráfego entre redes .................................................................................... 180
Identity and Access Management .............................................................................................. 180Políticas gerenciadas para o acesso de usuários ................................................................. 181Acesso por meio de conexões JDBC e ODBC ..................................................................... 185Acesso ao Amazon S3 .................................................................................................... 185Acesso granular a bancos de dados e tabelas ..................................................................... 185Acesso a metadados criptografados no Data Catalog ........................................................... 192Acesso entre contas ........................................................................................................ 192Acesso a grupos de trabalho e tags ................................................................................... 195Permitir acesso a um ....................................................................................................... 196Permitir acesso ao .......................................................................................................... 198Permitir acesso ao .......................................................................................................... 200Permitir acesso para o ..................................................................................................... 202Permitir acesso federado à API do Athena .......................................................................... 202
Registro e monitoramento ........................................................................................................ 205
v

Amazon Athena Guia do usuário
Validação de conformidade ....................................................................................................... 206Resiliência .............................................................................................................................. 207Segurança da infraestrutura ...................................................................................................... 207
Conectar-se ao Amazon Athena usando um VPC endpoint de interface ................................... 208Análise de configuração e vulnerabilidade ................................................................................... 209Usar o Athena com o Lake Formation ........................................................................................ 209
Como funciona o acesso a dados do Lake Formation ........................................................... 210Condições e limitações .................................................................................................... 211Gerenciamento de permissões de usuário ........................................................................... 213Aplicação de permissões do Lake Formation a bancos de dados e tabelas existentes ................. 216
Usar grupos de trabalho para controlar o acesso à consulta e os custos .................................................. 217Usar grupos de trabalho para executar consultas ......................................................................... 217
Benefícios do uso de grupos de trabalho ............................................................................ 218Como funcionam os grupos de trabalho ............................................................................. 218Definir grupos de trabalho ................................................................................................ 219Políticas do IAM para acessar grupos de trabalho ............................................................... 221Exemplo de políticas de grupo .......................................................................................... 222Configurações do grupo de trabalho .................................................................................. 226Gerenciar grupos de trabalho ............................................................................................ 227APIs do grupo de trabalho do Athena ............................................................................... 233Resolver problemas nos grupos de trabalho ........................................................................ 233
Controlar custos e monitorar consultas com métricas do CloudWatch .............................................. 235Habilitar métricas de consulta do CloudWatch ..................................................................... 236Monitorar consultas de Athena com métricas de CloudWatch ................................................. 236Definir limites de controle de uso de dados ......................................................................... 238
Marcar com tags os grupos de trabalho ............................................................................................. 242Conceitos básicos de tags ........................................................................................................ 242Restrições de tag .................................................................................................................... 243Trabalho com tags usando o console ......................................................................................... 243
Exibir tags para grupos de trabalho individuais .................................................................... 243Adicionar e excluir tags em um grupo de trabalho individual ................................................... 244
Trabalhar com tags usando as ações da API .............................................................................. 245Políticas de controle de acesso do IAM baseadas em tags ............................................................ 246
Exemplos da política de tags ............................................................................................ 246Monitorar logs e solucionar problemas ............................................................................................... 249
Registro em log de chamadas à API do Amazon Athena com o AWS CloudTrail ............................... 249Informações sobre o Athena no CloudTrail .......................................................................... 249Noções básicas das entradas dos arquivos de log do Athena ................................................. 250
Solução de problemas ............................................................................................................. 252Referência de SerDe ....................................................................................................................... 253
Usar um SerDe ....................................................................................................................... 253Para usar um SerDe em consultas .................................................................................... 253
SerDes e formatos de dados compatíveis ................................................................................... 254Avro SerDe .................................................................................................................... 255RegexSerDe para processar logs do Apache Web Server ..................................................... 258CloudTrail SerDe ............................................................................................................. 258OpenCSVSerDe para processar CSV ................................................................................. 260Grok SerDe .................................................................................................................... 263Bibliotecas SerDe JSON .................................................................................................. 266LazySimpleSerDe para arquivos CSV, TSV e delimitados personalizados ................................. 269ORC SerDe .................................................................................................................... 274Parquet SerDe ................................................................................................................ 277
Formatos de compactação ....................................................................................................... 279Referência SQL .............................................................................................................................. 281
Tipos de dados compatíveis ..................................................................................................... 281Consultas, funções e operadores em DML .................................................................................. 282
SELECT ........................................................................................................................ 282
vi

Amazon Athena Guia do usuário
INSERT INTO ................................................................................................................. 286Funções do Presto .......................................................................................................... 288
Instruções DDL ....................................................................................................................... 289DDL incompatível ............................................................................................................ 290ALTER DATABASE SET DBPROPERTIES ......................................................................... 291ALTER TABLE ADD PARTITION ....................................................................................... 292ALTER TABLE DROP PARTITION .................................................................................... 293ALTER TABLE RENAME PARTITION ................................................................................ 293ALTER TABLE SET LOCATION ........................................................................................ 294ALTER TABLE SET TBLPROPERTIES .............................................................................. 294CREATE DATABASE ...................................................................................................... 295CREATE TABLE ............................................................................................................. 295CREATE TABLE AS ........................................................................................................ 299CREATE VIEW ............................................................................................................... 301DESCRIBE TABLE .......................................................................................................... 301DESCRIBE VIEW ............................................................................................................ 302DROP DATABASE .......................................................................................................... 302DROP TABLE ................................................................................................................. 303DROP VIEW .................................................................................................................. 303MSCK REPAIR TABLE .................................................................................................... 304SHOW COLUMNS .......................................................................................................... 304SHOW CREATE TABLE .................................................................................................. 304SHOW CREATE VIEW .................................................................................................... 305SHOW DATABASES ....................................................................................................... 305SHOW PARTITIONS ....................................................................................................... 305SHOW TABLES .............................................................................................................. 306SHOW TBLPROPERTIES ................................................................................................ 306SHOW VIEWS ................................................................................................................ 307
Condições e limitações ............................................................................................................ 307Exemplos de código, cotas de serviço e driver JDBC anterior ................................................................ 309
Exemplos de código ................................................................................................................ 309Constantes ..................................................................................................................... 309Criar um cliente para acessar o Athena .............................................................................. 310Iniciar execução da consulta ............................................................................................. 310Interromper execução da consulta ..................................................................................... 313Listar execuções de consulta ............................................................................................ 314Criar uma consulta nomeada ............................................................................................ 315Excluir uma consulta nomeada .......................................................................................... 315Listar consultas nomeadas ............................................................................................... 316
Drivers JDBC da versão anterior ............................................................................................... 317Instruções para o driver JDBC versão 1.1.0 ........................................................................ 318
Cotas de serviço ..................................................................................................................... 322Consultas ....................................................................................................................... 322Grupos de trabalho ......................................................................................................... 323AWS Glue ...................................................................................................................... 323Buckets do Amazon S3 .................................................................................................... 323Cotas de chamada de APIs por conta ................................................................................ 323
Notas de release ............................................................................................................................ 32526 de novembro de 2019 ......................................................................................................... 326
Consultas SQL federadas ................................................................................................. 326Chamar modelos de machine learning em consultas SQL ..................................................... 327Funções definidas pelo usuário (UDFs) (visualização) ........................................................... 327Usar o Apache Hive Metastore como um metacatalog com o Amazon Athena (visualização) ........ 328Novas métricas relacionadas à consulta ............................................................................. 328
12 de novembro de 2019 ......................................................................................................... 3298 de novembro de 2019 ........................................................................................................... 3298 de outubro de 2019 .............................................................................................................. 329
vii

Amazon Athena Guia do usuário
19 de setembro de 2019 .......................................................................................................... 32912 de setembro de 2019 .......................................................................................................... 33016 de agosto de 2019 ............................................................................................................. 3309 de agosto de 2019 ............................................................................................................... 33026 de junho de 2019 ............................................................................................................... 33124 de maio de 2019 ................................................................................................................ 33105 de março de 2019 .............................................................................................................. 33122 de fevereiro de 2019 ........................................................................................................... 33218 de fevereiro de 2019 ........................................................................................................... 33220 de novembro de 2018 ......................................................................................................... 33315 de outubro de 2018 ............................................................................................................ 33410 de outubro de 2018 ............................................................................................................ 3346 de setembro de 2018 ............................................................................................................ 33523 de agosto de 2018 ............................................................................................................. 33516 de agosto de 2018 ............................................................................................................. 3367 de agosto de 2018 ............................................................................................................... 3365 de junho de 2018 ................................................................................................................. 336
Suporte para exibições .................................................................................................... 337Melhorias e atualizações em mensagens de erro ................................................................. 337Correções de bugs .......................................................................................................... 337
17 de maio de 2018 ................................................................................................................ 33719 de abril de 2018 ................................................................................................................. 3386 de abril de 2018 .................................................................................................................. 33815 de março de 2018 .............................................................................................................. 3382 de fevereiro de 2018 ............................................................................................................ 33819 de janeiro de 2018 ............................................................................................................. 33913 de novembro de 2017 ......................................................................................................... 3391 de novembro de 2017 ........................................................................................................... 34019 de outubro de 2017 ............................................................................................................ 3403 de outubro de 2017 .............................................................................................................. 34025 de setembro de 2017 .......................................................................................................... 34014 de agosto de 2017 ............................................................................................................. 3404 de agosto de 2017 ............................................................................................................... 34022 de junho de 2017 ............................................................................................................... 3418 de junho de 2017 ................................................................................................................. 34119 de maio de 2017 ................................................................................................................ 341
Melhorias ....................................................................................................................... 342Correções de bugs .......................................................................................................... 342
4 de abril de 2017 .................................................................................................................. 342Recursos ....................................................................................................................... 342Melhorias ....................................................................................................................... 342Correções de bugs .......................................................................................................... 343
24 de março de 2017 .............................................................................................................. 343Recursos ....................................................................................................................... 343Melhorias ....................................................................................................................... 343Correções de bugs .......................................................................................................... 343
20 de fevereiro de 2017 ........................................................................................................... 344Recursos ....................................................................................................................... 344Melhorias ....................................................................................................................... 345
Histórico do documento .................................................................................................................... 346AWS Glossary ................................................................................................................................ 355
viii

Amazon Athena Guia do usuárioQuando devo usar o Athena?
O que é o Amazon Athena?O Amazon Athena é um serviço de consulta interativo que facilita a análise de dados diretamente noAmazon Simple Storage Service (Amazon S3) usando SQL padrão. Com algumas ações no Consolede Gerenciamento da AWS, você pode apontar o Athena para os dados armazenados no Amazon S3 ecomeçar a usar o SQL padrão para executar consultas ad-hoc e receber resultados em segundos.
O Athena não possui servidor, portanto, não há infraestrutura para configurar nem gerenciar, e você pagaapenas pelas consultas executadas. O Athena escala automaticamente — executando consultas emparalelo — portanto, os resultados são rápidos, mesmo com grandes conjuntos de dados e consultascomplexas.
Tópicos• Quando devo usar o Athena? (p. 1)• Acesso ao Athena (p. 1)• Noções básicas de tabelas, bancos de dados e o Data Catalog (p. 2)• Integrações de serviços da AWS com o Athena (p. 3)
Quando devo usar o Athena?O Athena ajuda a analisar dados desestruturados, semiestruturados e estruturados armazenados noAmazon S3. Entre os exemplos estão formatos de dados CSV, JSON ou colunares, como ApacheParquet e Apache ORC. Você pode usar o Athena para executar consultas ad-hoc com o SQL ANSI, semnecessidade de agregar ou carregar os dados no Athena.
O Athena se integra ao Amazon QuickSight para oferecer fácil visualização de dados. Você pode usar oAthena para gerar relatórios ou explorar dados com ferramentas de business intelligence ou clientes SQLconectados com um driver JDBC ou ODBC. Para obter mais informações, consulte O que é o AmazonQuickSight no Guia do usuário do Amazon QuickSight e Conectar-se ao Amazon Athena com driversODBC e JDBC (p. 59).
O Athena se integra ao Catálogo de dados do AWS Glue, que oferece um armazenamento de metadadospersistente para os dados no Amazon S3. Isso permite criar tabelas e consultar dados no Athena combase em um armazenamento de metadados central disponível em toda a conta da AWS e integradocom o ETL e os recursos de descoberta de dados do AWS Glue. Para obter mais informações, consulteIntegração com o AWS Glue (p. 32) e O que é o AWS Glue no Guia do desenvolvedor do AWS Glue.
Para obter uma lista de serviços da AWS que o Athena utiliza ou se integra, consulte the section called“Integrações de serviços da AWS com o Athena” (p. 3).
Acesso ao AthenaVocê pode acessar o Athena usando o Console de gerenciamento da AWS, por meio de uma conexãoJDBC ou ODBC, usando a API do Athena ou a CLI do Athena.
• Para começar a usar o console, consulte Conceitos básicos (p. 8).• Para saber como usar drivers JDBC ou ODBC, consulte Conectar-se ao Amazon Athena com
JDBC (p. 59) e Conectar-se ao Amazon Athena com ODBC (p. 61).• Para usar a API do Athena, consulte o Referência de API do Amazon Athena.• Para usar a CLI, instale a CLI da AWS e digite aws athena help na linha de comando para ver
comandos disponíveis. Para obter mais informações sobre comandos disponíveis, consulte a Referênciade linha de comando do AWS Athena.
1

Amazon Athena Guia do usuárioNoções básicas de tabelas,
bancos de dados e o Data Catalog
Noções básicas de tabelas, bancos de dados e oData Catalog
No Athena, tabelas e bancos de dados são contêineres para as definições de metadados que definem umesquema para dados de origem subjacentes. Para cada conjunto de dados, deve existir uma tabela noAthena. Os metadados na tabela informam ao Athena onde os dados estão localizados no Amazon S3 eespecificam a estrutura dos dados, por exemplo, nomes de coluna, tipos de dados e o nome da tabela.Os bancos de dados são um agrupamento lógico de tabelas e também mantêm somente metadados einformações do esquema de um conjunto de dados.
Para cada conjunto de dados que você deseja consultar, o Athena deve ter uma tabela subjacente queusará para obter e retornar os resultados da consulta. Por isso, antes de consultar dados, uma tabela deveser registrada no Athena. O registro ocorre quando você cria tabelas automática ou manualmente.
Independentemente de como as tabelas são criadas, o processo de criação de tabelas registra o conjuntode dados no Athena. Esse registro ocorre no AWS Glue Data Catalog e permite que o Athena executeconsultas nos dados.
• Para criar uma tabela automaticamente, use um crawler do AWS Glue de dentro do Athena. Para obtermais informações sobre o AWS Glue e os crawlers, consulte Integração com o AWS Glue (p. 32).Quando o AWS Glue cria uma tabela, ela é registrada em seu próprio Data Catalog do AWS Glue. OAthena usa o Data Catalog do AWS Glue para armazenar e recuperar esses metadados ao executarconsultas para analisar o conjunto de dados subjacente.
O Data Catalog do AWS Glue é acessível em toda a sua conta da AWS. Outros serviços da AWS podemcompartilhar o Data Catalog do AWS Glue, para que você veja bancos de dados e tabelas criados em todaa organização usando o Athena e vice-versa. Além disso, o AWS Glue permite descobrir automaticamenteo esquema de dados e extrair, transformar e carregar dados (ETL – extração, transformação e carga).
Note
Você pode usar o catálogo de dados internos do Athena nas regiões em que o AWS Glue nãoestá disponível e onde o Data Catalog do AWS Glue não possa ser usado.
• Para criar uma tabela manualmente:• Use o console do Athena para executar o Create Table Wizard (Assistente de Criação de tabela).• Use o console do Athena para escrever instruções DDL do Hive no Query Editor (Editor de consultas).• Use a API ou a ILC do Athena para executar uma string de consulta SQL com instruções DDL.• Use o driver JDBC ou ODBC do Athena:
Quando você cria tabelas e bancos de dados manualmente, o Athena usa instruções de Data DefinitionLanguage (DDL) do HiveQL, como CREATE TABLE, CREATE DATABASE e DROP TABLE, nos bastidorespara criar tabelas e bancos de dados no AWS Glue Data Catalog ou em seu catálogo de dados internonessas regiões onde o AWS Glue não está disponível.
Note
Se você tiver tabelas no Athena criadas antes de 14 de agosto de 2017, elas terão sido criadasem um catálogo de dados gerenciado pelo Athena que existe lado a lado com o AWS Glue DataCatalog até você optar por atualizar. Para obter mais informações, consulte Atualizar para o AWSGlue Data Catalog passo a passo (p. 43).
Quando você consulta uma tabela existente, nos bastidores, o Amazon Athena usa o Presto, ummecanismo SQL distribuído. Temos exemplos com dados de exemplo no Athena para mostrar comocriar uma tabela e, em seguida, enviar uma consulta para ela usando o Athena. O Athena também
2

Amazon Athena Guia do usuárioIntegrações de serviços da AWS com o Athena
tem um tutorial no console que ajuda você a começar a criar uma tabela com base nos dados que sãoarmazenados no Amazon S3.
• Para obter um tutorial passo a passo sobre como criar uma tabela e escrever consultas no editor deconsultas do Athena, consulte Conceitos básicos (p. 8).
• Execute o tutorial do Athena no console. Ele será iniciado automaticamente quando você fizer loginpela primeira vez no https://console.aws.amazon.com/athena/. Você também pode escolher Tutorial noconsole para iniciá-lo.
Integrações de serviços da AWS com o AthenaVocê pode consultar dados de outros serviços da AWS no Athena. O Athena utiliza vários desses serviços.Para obter mais informações, consulte a tabela a seguir.
Note
Para ver a lista de regiões com suporte para cada serviço, consulte Regiões e endpoints noReferência geral do Amazon Web Services.
AWS Serviço Tópico Descrição
AWS CloudTrail Consulta de logs do AWSCloudTrail (p. 153)
O uso de Athena com logsCloudTrail é uma maneiraavançada de melhorar a suaanálise das atividades do serviçoAWS. Por exemplo, é possívelusar consultas para identificartendências e isolar ainda maisa atividade por atributos, comoendereço IP de origem ouusuário.
Você pode criar tabelas para logsde consulta de forma automática,diretamente no console doCloudTrail e usar essas tabelaspara executar as consultasem Athena. Para obter maisinformações, consulte Criar umatabela de logs do CloudTrail noConsole do CloudTrail (p. 155)
Amazon CloudFront Consulta de logs do AmazonCloudFront (p. 152)
Use o Athena para consultar oAmazon CloudFront.
Elastic Load Balancing • Consultar logs do ApplicationLoad Balancer (p. 149)
• Consultar logs do Classic LoadBalancer (p. 150)
Consultar logs do ApplicationLoad Balancer permite consultara origem do tráfego, a latênciae os bytes transferidos de epara instâncias do Elastic LoadBalancing e aplicativos de back-end. Consulte Criar tabela paralogs do ALB (p. 149)
Consulte os logs do ClassicLoad Balancer para analisar
3

Amazon Athena Guia do usuárioIntegrações de serviços da AWS com o Athena
AWS Serviço Tópico Descriçãoe compreender padrões detráfego de e para instânciasdo Elastic Load Balancing eaplicativos de back-end. Vocêpode ver a origem do tráfego, dalatência e dos bytes transferidos.Consulte Criar tabela para logsdo ELB (p. 151).
Amazon Virtual Private Cloud Consultar a logs de fluxo daAmazon VPC (p. 164)
Os logs de fluxo da AmazonVirtual Private Cloud capturaminformações sobre o tráfego IPde entrada e saída de interfacesde rede em sua VPC. Consulteos logs no Athena para investigarpadrões de tráfego de rede eidentificar ameaças e riscos emtoda a rede da Amazon VPC.
AWS CloudFormation AWS:: Athena:: NamedQueryno Guia do usuário do AWSCloudFormation.
Crie consultas nomeadascom o AWS CloudFormatione as execute no Athena. Asconsultas nomeadas permitemmapear um nome de consultapara uma consulta e chamar aconsulta várias vezes fazendoreferência a ela pelo nome.Para obter mais informações,consulte CreateNamedQueryna Referência de APIdo Amazon Athena eAWS::Athena::NamedQueryno Guia do usuário do AWSCloudFormation.
Catálogo de dados do AWS Glue Integração com o AWSGlue (p. 32)
O Athena se integra ao Catálogode dados do AWS Glue, queoferece um armazenamentode metadados persistente paraos dados no Amazon S3. Issopermite criar tabelas e consultardados no Athena com baseem um armazenamento demetadados central disponívelem toda a conta da AWS eintegrado com o ETL e osrecursos de descoberta de dadosdo AWS Glue. Para obter maisinformações, consulte Integraçãocom o AWS Glue (p. 32) eO que é AWS Glue no Guia dodesenvolvedor do AWS Glue.
4

Amazon Athena Guia do usuárioIntegrações de serviços da AWS com o Athena
AWS Serviço Tópico Descrição
Amazon QuickSight Conectar-se ao AmazonAthena com drivers ODBC eJDBC (p. 59)
O Athena se integra ao AmazonQuickSight para oferecer fácilvisualização de dados. Vocêpode usar o Athena para gerarrelatórios ou explorar dadoscom ferramentas de businessintelligence ou clientes SQLconectados com um driverJDBC ou ODBC. Para obtermais informações, consulte Oque é o Amazon QuickSight noGuia do usuário do AmazonQuickSight e Conectar-se aoAmazon Athena com driversODBC e JDBC (p. 59).
IAM Ações do Amazon Athena Você pode usar as ações deAPI do Athena em políticas depermissão do IAM. ConsulteAções para o Amazon Athena eGerenciamento de identidade eacesso no Athena (p. 180).
5

Amazon Athena Guia do usuárioCadastre-se na AWS
ConfiguraçãoSe já tiver se cadastrado na Amazon Web Services (AWS), você poderá começar a usar o AmazonAthena imediatamente. Se você ainda não tiver se cadastrado na AWS, ou se precisar de assistência paraconsultar dados usando o Athena, primeiro conclua as tarefas abaixo:
Cadastre-se na AWSAo se cadastrar na AWS, sua conta é automaticamente cadastrada em todos os serviços da AWS,incluindo o Athena. Você será cobrado apenas pelos serviços que usar. Ao usar o Athena, você usa oAmazon S3 para armazenar dados. O Athena não tem definição de preço de nível gratuito da AWS.
Caso você já tenha uma conta da AWS, passe para a próxima tarefa. Se você ainda não possui uma contada AWS, use o procedimento a seguir para criar uma.
Para criar uma conta da AWS1. Abra http://aws.amazon.com/ e escolha Create an AWS Account (Criar uma conta da AWS).2. Siga as instruções online. Parte do procedimento de cadastro envolve uma chamada telefônica e a
digitação de um PIN usando o teclado do telefone.
Observe o número da conta da AWS, porque você precisará dele na próxima tarefa.
Criar um usuário do IAMUm usuário do AWS Identity and Access Management (IAM) é uma conta criada por você para acessarserviços. Ele é um usuário diferente da conta da AWS principal. Como melhor prática de segurança,recomendamos que você use as credenciais do usuário do IAM para acessar os serviços da AWS. Crieum usuário do IAM e adicione o usuário a um grupo do IAM com permissões administrativas ou concedapermissões administrativas a esse usuário. Depois disso, você poderá acessar o AWS usando um URLespecial e as credenciais do usuário do IAM.
Se tiver se cadastrado na AWS, mas não tiver criado um usuário do IAM para si mesmo, você poderácriar um usando o console do IAM. Caso você não esteja familiarizado com o uso do console, consulteTrabalhar com o Console de Gerenciamento da AWS.
Para criar um grupo de administradores1. Faça login no console do IAM em https://console.aws.amazon.com/iam/.2. No painel de navegação, escolha Grupos, Criar novo grupo.3. Em Group Name, digite um nome para o grupo, como Administrators, e escolha Next Step.4. Na lista de políticas, marque a caixa de seleção ao lado da política AdministratorAccess. Você pode
usar o menu Filter e o campo Search para filtrar a lista de políticas.5. Escolha Next Step, Create Group. O grupo novo é listado em Group Name.
6

Amazon Athena Guia do usuárioPara criar um usuário do IAM para vocêmesmo, adicione o usuário ao grupo de
administradores e crie uma senha para o usuário.
Para criar um usuário do IAM para você mesmo,adicione o usuário ao grupo de administradores e crieuma senha para o usuário.1. No painel de navegação, escolha Users e Create New Users.2. Em 1, digite um nome do usuário.3. Desmarque a caixa de seleção ao lado de Generate an access key for each user e Create.4. Na lista de usuários, selecione o nome (e não a caixa de seleção) do usuário que você acabou de criar.
Você pode usar o campo Search para procurar o nome do usuário.5. Escolha Groups, Add User to Groups.6. Marque a caixa de seleção ao lado dos administradores e escolha Add to Groups.7. Selecione a guia Security Credentials (Credenciais de segurança). Em Credenciais de login, escolha
Gerenciar senha.8. Escolha Assign a custom password. Digite uma senha nos campos Password e Confirm Password. Ao
concluir, selecione Apply.9. Para fazer login como esse novo usuário do IAM, faça logout do Console AWS e use o seguinte URL,
onde your_aws_account_id é o número da conta da AWS sem os hifens (por exemplo, se o númeroda conta da AWS for 1234-5678-9012, o ID da conta da AWS será 123456789012):
https://*your_account_alias*.signin.aws.amazon.com/console/
Também é possível que o link de login usará o nome da conta em vez do número. Para verificar o link decadastro para usuários do IAM para a conta, abra o console do IAM e marque IAM users sign-in link nopainel.
Anexar políticas gerenciadas para usar o AthenaAnexe políticas gerenciadas do Athena à conta do IAM que você usa para acessar o Athena. Existem duaspolíticas gerenciadas para o Athena: AmazonAthenaFullAccess e AWSQuicksightAthenaAccess.Essas políticas concedem permissões ao Athena para consultar o Amazon S3, bem como para gravar osresultados das consultas em um bucket separado em seu nome. Para obter mais informações e instruçõespasso a passo, consulte Adicionar permissões de identidade do IAM (console) no Guia do usuário do AWSIdentity and Access Management. Para obter mais informações sobre o conteúdo, consulte Políticas doIAM para acesso do usuário (p. 181).
Note
Você pode precisar de permissões adicionais para acessar o conjunto de dados subjacente noAmazon S3. Se você não for o proprietário da conta ou tiver o acesso restringido de alguma formaa um bucket, entre em contato com o proprietário do bucket para conceder acesso usando umapolítica de bucket com base em recursos, ou entre em contato com o administrador da conta paraconceder acesso usando uma política baseada em identidade. Para obter mais informações,consulte Permissões do Amazon S3 (p. 185). Se o conjunto de dados ou os resultados daconsulta do Athena estiverem criptografados, poderão ser necessárias permissões adicionais.Para obter mais informações, consulte Configurar opções de criptografia avançadas (p. 174).
7

Amazon Athena Guia do usuárioPré-requisitos
Conceitos básicosEste tutorial orienta você a usar o Amazon Athena para consultar dados. Você criará uma tabela com baseem dados de exemplo armazenados no Amazon Simple Storage Service, consultará a tabela e verificaráos resultados da consulta.
O tutorial está usando recursos dinâmicos. Dessa maneira, você é cobrado pelas consultas executadas.Você não é cobrado pelos conjuntos de dados de exemplo usados, mas, se fizer upload de seus própriosarquivos de dados no Amazon S3, cobranças serão aplicadas.
Pré-requisitosSe você ainda não tiver feito isso, cadastre-se em uma conta em Configurar (p. 6).
Etapa 1: Criar um banco de dadosVocê primeiro precisa criar um banco de dados no Athena.
Para criar um banco de dados
1. Abra o console do Athena.2. Se essa for a primeira vez que você visita o console do Athena, vá para a página Getting Started
(Conceitos básicos). Escolha Get Started para abrir o Query Editor. Se esta não for a primeira vez, oQuery Editor (Editor de consultas) do Athena será aberto.
3. No Query Editor (Editor de consultas) do Athena, você vê um painel de consulta com uma consulta deexemplo. Comece digitando a consulta em qualquer lugar do painel de consulta.
4. Para criar um banco de dados chamado mydatabase, digite a seguinte instrução CREATEDATABASE e escolha Run Query:
CREATE DATABASE mydatabase
5. Confirme se a exibição do catálogo é atualizada e se mydatabase é exibido na lista DATABASE dopainel Catalog no lado esquerdo.
8

Amazon Athena Guia do usuárioEtapa 2: Criar uma tabela
Etapa 2: Criar uma tabelaAgora que já tem um banco de dados, você está pronto para criar uma tabela com base no arquivo dedados de exemplo. Você define colunas que são mapeadas para os dados, especifica como os dados sãodelimitados e fornece o local do arquivo no Amazon S3.
Para criar uma tabela
1. Verifique se mydatabase está selecionado para DATABASE e escolha New Query.2. No painel de consulta, digite a seguinte instrução CREATE TABLE e escolha Run Query:
Note
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, alémdas cobranças padrão do Athena. Para reduzir as cobranças de transferência de dados,substitua myregion em s3://athena-examples-myregion/path/to/data/ peloidentificador da região onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( `Date` DATE, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, os STRING, Browser STRING, BrowserVersion STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$" ) LOCATION 's3://athena-examples-myregion/cloudfront/plaintext/';
O table cloudfront_logs é criado e exibido no painel Catalog do banco de dados.
9

Amazon Athena Guia do usuárioEtapa 3: consultar dados
Etapa 3: consultar dadosAgora que você criou a tabela cloudfront_logs no Athena com base nos dados do Amazon S3, vocêpode executar consultas na tabela e ver os resultados no Athena.
Para executar uma consulta
1. Escolha New Query, digite a seguinte instrução em qualquer lugar no painel de consulta e escolhaRun Query:
SELECT os, COUNT(*) countFROM cloudfront_logsWHERE date BETWEEN date '2014-07-05' AND date '2014-08-05'GROUP BY os;
Os resultados são retornados com a seguinte aparência:
10

Amazon Athena Guia do usuárioEtapa 3: consultar dados
2. Você também pode salvar os resultados de uma consulta em CSV escolhendo o ícone de arquivo nopainel Results.
Você também pode ver os resultados de consultas anteriores ou consultas que possam levar algum tempopara serem concluídas. Escolha History e procure a consulta ou escolha View ou Download para ver oufazer download dos resultados de consultas concluídas anteriormente. Isso também exibe o status deconsultas em execução no momento. O histórico de consultas é mantido por 45 dias. Para obter maisinformações, consulte Ver histórico de consultas (p. 71).
Os resultados da pesquisa também são armazenados no Amazon S3 em um bucket chamado aws-athena-query-results-ACCOUNTID-REGION. Você pode alterar o local padrão no console e as opçõesde criptografia escolhendo Settings no painel superior direito. Para obter mais informações, consulteResultados da consulta (p. 65).
11

Amazon Athena Guia do usuárioUtilização do console
Acesso ao Amazon AthenaVocê pode acessar o Amazon Athena usando o console do Console de gerenciamento da AWS, a API doAmazon Athena ou a ILC da AWS.
Utilização do consoleVocê pode usar o Console de gerenciamento da AWS para o Amazon Athena fazer o seguinte:
• Criar ou selecionar um banco de dados.• Criar, visualizar e excluir tabelas.• Filtrar tabelas começando a digitar os nomes delas.• Visualizar tabelas e gerar CREATE TABLE DDL para elas.• Mostrar as propriedades da tabela.• Executar consultas em tabelas, salvar e formatar consultas e visualizar o histórico de consultas.• Criar até dez consultas usando diferentes guias de consulta no editor de consultas. Para abrir uma nova
aba, clique no sinal de adição.• Exibir, salvar e exportar os resultados da consulta.• Acessar o Catálogo de dados do AWS Glue.• Visualizar e alterar as configurações, como visualizar o local do resultado da consulta, configurar o
preenchimento automático e criptografar os resultados da consulta.
No painel direito, o Query Editor exibe uma tela de introdução que solicita a criação de sua primeira tabela.Você pode visualizar suas tabelas em Tables no painel esquerdo.
Veja a visão geral de alto nível das ações disponíveis para cada tabela:
• Preview tables (Visualizar tabelas) – visualizar a sintaxe de consulta no Editor de consulta à direita.• Show properties (Mostrar propriedades) – mostrar o nome de uma tabela, sua localização no Amazon
S3, os formatos de entrada e saída, a biblioteca de serialização (SerDe) utilizada e se a tabela temdados criptografados.
• Delete table (Excluir tabela) – excluir tabela.• Generate CREATE TABLE DDL (Gerar CREATE TABLE DDL) – gerar a consulta por trás de uma tabela
e visualizá-la no editor de consultas.
Uso da APIO Amazon Athena habilita a programação de aplicativos para Athena. Para obter mais informações,consulte o Referência de API do Amazon Athena. Os SDKs da AWS mais recentes incluem suporte para aAPI do Athena.
Para obter exemplos de como usar o AWS SDK for Java com Athena, consulte Exemplos decódigo (p. 309).
Para obter mais informações sobre a documentação e os downloads do AWS SDK for Java, consulte aseção SDKs em Ferramentas para o Amazon Web Services.
12

Amazon Athena Guia do usuárioUso da CLI
Uso da CLIVocê pode acessar o Amazon Athena usando a ILC da AWS. Para obter mais informações, consulte aReferência da CLI da AWS para o Athena.
13

Amazon Athena Guia do usuárioProcesso de criação de tabelase bancos de dados no Athena
Criar tabelas e bancos de dadosO Amazon Athena oferece suporte a um subconjunto de instruções de linguagem de definição de dados(DDL) e a funções e operadores SQL ANSI para definir e consultar tabelas externas em que os dadosresidem no Amazon Simple Storage Service.
Ao criar um banco de dados e uma tabela no Athena, você descreve o esquema e o local dos dados,deixando os dados da tabela prontos para consulta em tempo real.
Para melhorar o desempenho das consultas e reduzir os custos, recomendamos particionar seus dadose usar formatos colunares de código-fonte aberto para o armazenamento no Amazon S3, como ApacheParquet ou ORC.
Tópicos• Processo de criação de tabelas e bancos de dados no Athena (p. 14)• Nomes para tabelas, bancos de dados e colunas (p. 18)• Palavras-chave reservadas (p. 19)• Local da tabela no Amazon S3 (p. 21)• Particionar dados (p. 23)• Formatos de armazenamento colunar (p. 26)• Converter em formatos colunares (p. 27)
Processo de criação de tabelas e bancos de dadosno Athena
É possível executar instruções DDL no console do Athena usando um driver JDBC ou ODBC ou usando oassistente Create Table (Criar tabela) do Athena.
Quando você cria um novo esquema de tabela no Athena, o Athena armazena o esquema em um catálogode dados e usa-o ao executar consultas.
O Athena usa uma abordagem conhecida como schema-on-read, o que significa que um esquema éprojetado nos dados no momento em que você executa uma consulta. Isso elimina a necessidade decarregamento ou transformação de dados.
O Athena não modifica os dados no Amazon S3.
O Athena usa o Apache Hive para definir tabelas e criar bancos de dados, que, essencialmente, são umnamespace lógico de tabelas.
Ao criar um banco de dados e uma tabela no Athena, você está simplesmente descrevendo o esquema eo local onde os dados da tabela estão localizados no Amazon S3 para consulta em tempo de leitura. Porisso, o banco de dados e a tabela têm um significado um pouco diferente do que o de sistemas de bancosde dados relacionais tradicionais porque os dados não são armazenados com a definição de esquemapara o banco de dados e a tabela.
14

Amazon Athena Guia do usuárioRequisitos para tabelas no Athena e dados no Amazon S3
Ao consultar, você consulta a tabela usando SQL padrão e os dados são lidos neste momento. Você podeencontrar orientações sobre como criar bancos de dados e tabelas usando a Documentação do ApacheHive, mas as orientações a seguir são especificamente para o Athena.
O tamanho máximo da string de consulta é 256 KB.
O Hive oferece suporte a vários formatos de dados por meio do uso de bibliotecas Serializer-Deserializer(SerDe – Serializador-desserializador). Você também pode definir esquemas complexos usandoexpressões regulares. Para obter uma lista de bibliotecas SerDe compatíveis, consulte Formatos de dadoscompatíveis, SerDes e formatos de compactação (p. 254).
Requisitos para tabelas no Athena e dados noAmazon S3Ao criar uma tabela, você especifica o local de um bucket do Amazon S3 para os dados subjacentesusando a cláusula LOCATION. Considere o seguinte:
• O Athena pode consultar somente a versão mais recente dos dados em um bucket versionado doAmazon S3 e não pode consultar versões anteriores dos dados.
• Você deve ter as permissões apropriadas para trabalhar com dados no local do Amazon S3. Para obtermais informações, consulte Acesso ao Amazon S3 (p. 185).
• Se os dados não estiverem criptografados no Amazon S3, eles poderão ser armazenados em umaregião diferente da primária onde você executa o Athena. Taxas de transferência de dados padrão entreregiões do Amazon S3 se aplicam, além das cobranças padrão do Athena.
• Se estiverem criptografados no Amazon S3, os dados deverão ser armazenados na mesma região eo usuário ou a entidade principal que cria a tabela no Athena deverá ter as permissões apropriadaspara descriptografar os dados. Para obter mais informações, consulte Configurar opções de criptografiaavançadas (p. 174).
• O Athena oferece suporte para consulta de objetos armazenados com várias classes de armazenamentono mesmo bucket especificado pela cláusula LOCATION. Por exemplo, é possível consultar dados emobjetos armazenados em diferentes classes de armazenamento (Standard, Standard-IA e Intelligent-Tiering) no Amazon S3.
• O Athena oferece suporte a Buckets de pagamento pelo solicitante. Para obter informações sobre comohabilitar Pagamentos pelo solicitante para buckets com dados de origem que você pretende consultar noAthena, consulte Criar um grupo de trabalho (p. 228).
• O Athena não oferece suporte para consulta dos dados na classe de armazenamento do GLACIER. Eleignora objetos que fazem a transição para a classe de armazenamento do GLACIER com base em umapolítica de ciclo de vida do Amazon S3.
Para obter mais informações, consulte Classes de armazenamento, Alterar a classe de armazenamentode um objeto no Amazon S3, Transição para a classe de armazenamento GLACIER (arquivamento deobjeto) e Buckets de pagamento pelo solicitante no Guia do desenvolvedor do Amazon Simple StorageService.
• Se você emitir consultas em buckets do Amazon S3 com um grande número de objetos, e os dadosnão estiverem particionados, essas consultas poderão afetar os limites da taxa de solicitações GET noAmazon S3 e resultar em exceções do Amazon S3. Para evitar erros, particione seus dados. Além disso,considere ajustar suas taxas de solicitações do Amazon S3. Para obter mais informações, consulte Taxade solicitações e considerações sobre desempenho.
Funções compatíveisAs funções compatíveis em consultas do Athena são as encontradas dentro do Presto. Para obter maisinformações, consulte Funções e operadores do Presto 0.172 na documentação do Presto.
15

Amazon Athena Guia do usuárioTransformações de dados
transacionais não são compatíveis
Transformações de dados transacionais não sãocompatíveisO Athena não oferece suporte a operações baseadas em transações (como as encontradas no Hive ou noPresto) na tabela de dados. Para obter uma lista completa de palavras-chave não compatíveis, consulteDDL incompatível (p. 290).
Operações que alteram estados de tabela são ACIDQuando você cria, atualiza ou exclui tabelas, essas operações têm compatibilidade com ACID garantida.Por exemplo, se vários usuários ou clientes tentarem criar ou alterar uma tabela existente ao mesmotempo, somente um será bem-sucedido.
Todas as tabelas são EXTERNALSe você usar CREATE TABLE sem a palavra-chave EXTERNAL, o Athena emitirá um erro, somente tabelascom a palavra-chave EXTERNAL poderão ser criadas. Recomendamos sempre usar a palavra-chaveEXTERNAL. Quando você ignora uma tabela no Athena, somente os metadados da tabela são removidos.Os dados permanecem no Amazon S3.
Para criar uma tabela usando o AWS Glue DataCatalog1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha AWS GlueData Catalog (Catálogo de dados do AWS Glue). Agora você pode criar uma
tabela com o crawler do AWS Glue. Para obter mais informações, consulte Usar crawlers do AWSGlue (p. 36).
16
Amazon Athena Guia do usuárioPara criar uma tabela usando o assistente
Para criar uma tabela usando o assistente1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Na exibição do banco de dados, no editor Query Editor, escolha Add table, que exibe um assistente.3. Siga as etapas para criar a tabela.
Para criar um banco de dados usando a DDL do HiveUm banco de dados no Athena é um agrupamento lógico para tabelas que você cria nele.
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Query Editor.3. Digite CREATE DATABASE myDataBase e escolha Run Query.
4. Selecione o banco de dados no menu. É provável que ele seja um banco de dados vazio.
17

Amazon Athena Guia do usuárioPara criar uma tabela usando a DDL do Hive
Para criar uma tabela usando a DDL do HiveO editor de consulta do Athena exibe o banco de dados atual. Se você criar uma tabela e não especificarum banco de dados, a tabela será criada no banco de dados escolhido na seção Databases da guiaCatalog.
1. No banco de dados criado por você, crie uma tabela digitando a seguinte instrução e escolhendo RunQuery:
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( `Date` Date, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, OS String, Browser String, BrowserVersion String) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ("input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$") LOCATION 's3://athena-examples-MyRegion/cloudfront/plaintext/';
2. Se a tabela tiver sido criada com êxito, você poderá executar consultas nos dados.
Nomes para tabelas, bancos de dados e colunasUse estas dicas para denominar itens no Athena
18

Amazon Athena Guia do usuárioOs nomes de tabelas e de colunas de tabela
no Athena devem estar em minúsculas
Os nomes de tabelas e de colunas de tabela noAthena devem estar em minúsculasSe você estiver interagindo com o Apache Spark, os nomes de tabelas e de colunas de tabela devem estarem minúsculas. O Athena não diferencia maiúsculas de minúsculas e transforma nomes de tabelas e decolunas em letras minúsculas, mas o Spark exige nomes de tabelas e de colunas em minúsculas.
As consultas com nomes de coluna mixedCase, como profileURI, ou nomes de coluna em maiúsculasnão funcionam.
Os nomes de tabelas, visualizações, bancos de dadose colunas do Athena permitem somente caracteresespeciais sublinhadosOs nomes de tabelas, visualizações, bancos de dados e colunas do Athena não podem conter caracteresespeciais, exceto sublinhado (_).
Nomes que começam com um sublinhadoColoque entre acentos graves os nomes de tabelas, visualizações ou colunas que começam com umsublinhado. Por exemplo:
CREATE TABLE `_myunderscoretable` (`_id` string,`_index`string,...
Nomes de tabelas ou visualizações que incluemnúmerosColoque nomes de tabela que incluam números entre aspas. Por exemplo:
CREATE TABLE "table123"`_id` string,`_index` string,...
Palavras-chave reservadasQuando você executa consultas no Athena que incluem palavras-chave reservadas, você deve efetuarescape delas com caracteres especiais. Use as listas deste tópico para verificar quais palavras-chave sãoreservadas no Athena.
Para inserir um caractere de escape em palavras-chave reservadas em instruções DDL, coloque-as entreacentos graves (`). Para inserir um caractere de escape em palavras-chave reservadas em instruções SQLSELECT e em consultas em Como trabalhar com exibições (p. 72), coloque-a entre aspas duplas (").
• Lista de palavras-chave reservadas em instruções DDL (p. 20)• Lista de palavras-chave reservadas em instruções SELECT do SQL (p. 20)
19

Amazon Athena Guia do usuárioLista de palavras-chave reservadas em instruções DDL
• Exemplos de consultas com palavras-chave reservadas (p. 20)
Lista de palavras-chave reservadas em instruçõesDDLO Athena usa a lista de palavras-chave reservadas a seguir em suas instruções DDL. Se você usá-las semefetuar escape, o Athena emitirá um erro. Para inserir um caractere de escape nelas, coloque-as entreacentos graves (`).
Você não pode usar palavras-chave reservadas do DDL como nomes de identificadores em instruçõesDDL sem colocá-las entre acentos graves (`).
ALL, ALTER, AND, ARRAY, AS, AUTHORIZATION, BETWEEN, BIGINT, BINARY, BOOLEAN, BOTH, BY, CASE, CASHE, CAST, CHAR, COLUMN, CONF, CONSTRAINT, COMMIT, CREATE, CROSS, CUBE, CURRENT, CURRENT_DATE, CURRENT_TIMESTAMP, CURSOR, DATABASE, DATE, DAYOFWEEK, DECIMAL, DELETE, DESCRIBE, DISTINCT, DOUBLE, DROP, ELSE, END, EXCHANGE, EXISTS, EXTENDED, EXTERNAL, EXTRACT, FALSE, FETCH, FLOAT, FLOOR, FOLLOWING, FOR, FOREIGN, FROM, FULL, FUNCTION, GRANT, GROUP, GROUPING, HAVING, IF, IMPORT, IN, INNER, INSERT, INT, INTEGER,INTERSECT, INTERVAL, INTO, IS, JOIN, LATERAL, LEFT, LESS, LIKE, LOCAL, MACRO, MAP, MORE, NONE, NOT, NULL, NUMERIC, OF, ON, ONLY, OR, ORDER, OUT, OUTER, OVER, PARTIALSCAN, PARTITION, PERCENT, PRECEDING, PRECISION, PRESERVE, PRIMARY, PROCEDURE, RANGE, READS, REDUCE, REGEXP,REFERENCES, REVOKE, RIGHT, RLIKE, ROLLBACK, ROLLUP, ROW, ROWS, SELECT, SET, SMALLINT, START,TABLE, TABLESAMPLE, THEN, TIME, TIMESTAMP, TO, TRANSFORM, TRIGGER, TRUE, TRUNCATE, UNBOUNDED,UNION, UNIQUEJOIN, UPDATE, USER, USING, UTC_TIMESTAMP, VALUES, VARCHAR, VIEWS, WHEN, WHERE, WINDOW, WITH
Lista de palavras-chave reservadas em instruçõesSELECT do SQLO Athena usa a lista de palavras-chave reservadas a seguir em instruções SQL SELECT e em consultasem visualizações.
Se você usar essas palavras-chave como identificadores, deverá colocá-las entre aspas duplas (") emsuas instruções de consulta.
ALTER, AND, AS, BETWEEN, BY, CASE, CAST,CONSTRAINT, CREATE, CROSS, CUBE, CURRENT_DATE, CURRENT_PATH, CURRENT_TIME, CURRENT_TIMESTAMP, CURRENT_USER, DEALLOCATE, DELETE, DESCRIBE, DISTINCT, DROP, ELSE, END, ESCAPE, EXCEPT, EXECUTE, EXISTS, EXTRACT, FALSE, FIRST, FOR, FROM, FULL, GROUP, GROUPING, HAVING, IN, INNER, INSERT, INTERSECT, INTO, IS, JOIN, LAST, LEFT, LIKE, LOCALTIME, LOCALTIMESTAMP, NATURAL, NORMALIZE, NOT, NULL, ON, OR, ORDER, OUTER, PREPARE, RECURSIVE, RIGHT, ROLLUP, SELECT, TABLE, THEN, TRUE, UNESCAPE, UNION, UNNEST, USING, VALUES, WHEN, WHERE, WITH
Exemplos de consultas com palavras reservadasA consulta no exemplo a seguir usa acentos graves (`) para efetuar escape das palavras-chave reservadaspartition e date relacionadas à DDL que são usadas para um nome de tabela e um dos nomes de coluna:
CREATE EXTERNAL TABLE `partition` (
20

Amazon Athena Guia do usuárioLocal da tabela no Amazon S3
`date` INT, col2 STRING)PARTITIONED BY (year STRING)STORED AS TEXTFILELOCATION 's3://test_bucket/test_examples/';
As consultas de exemplo a seguir incluem um nome de coluna que contém as palavras-chave reservadasrelacionadas ao DDL em instruções ALTER TABLE ADD PARTITION e ALTER TABLE DROPPARTITION. As palavras-chave reservadas do DDL são circunscritas com acentos graves (`):
ALTER TABLE test_table ADD PARTITION (`date` = '2018-05-14')
ALTER TABLE test_table DROP PARTITION (`partition` = 'test_partition_value')
A consulta de exemplo a seguir inclui uma palavra-chave reservada (end) como um identificador em umainstrução SELECT. O escape da palavra-chave é efetuado com aspas duplas:
SELECT * FROM TestTableWHERE "end" != nil;
A consulta de exemplo a seguir inclui uma palavra-chave reservada (first) em uma instrução SELECT. Oescape da palavra-chave é efetuado com aspas duplas:
SELECT "itemId"."first" FROM testTable LIMIT 10;
Local da tabela no Amazon S3Ao executar uma consulta CREATE TABLE no Athena, você registra a tabela no Data Catalog do AWSGlue. Se você estiver usando o próprio catálogo do Athena, é altamente recomendável atualizar (p. 43)para o Data Catalog do AWS Glue. Você especifica o caminho para os dados na propriedade LOCATION,como é mostrado no seguinte exemplo abreviado:
CREATE EXTERNAL TABLE `test_table`(...)ROW FORMAT ...STORED AS INPUTFORMAT ...OUTPUTFORMAT ...LOCATION s3://bucketname/prefix/
Esse local no Amazon S3 compreende todos os arquivos que representam a sua tabela. Para obter maisinformações, consulte Usar pastas no Guia do usuário do console do Amazon Simple Storage Service.
Important
O Athena lê todos os dados armazenados em 's3://bucketname/prefix/'. Se vocêtiver dados que não quer que o Athena leia, não armazene esses dados no mesmo prefixodo Amazon S3 que os dados que você quer que o Athena leia. Se você estiver utilizando o
21

Amazon Athena Guia do usuárioLocal e partições de tabela
particionamento de dados, para garantir que o Athena verifique dados dentro de uma partição,seu filtro WHERE deverá incluir a partição. Para obter mais informações, consulte Local e partiçõesde tabela (p. 22).
Use estes exemplos e dicas ao especificar o local do Amazon S3 dos seus dados na instrução CREATETABLE do Athena:
• Na cláusula LOCATION, use uma barra no final.
Use:
s3://bucketname/prefix/
• Não use nenhum dos itens a seguir para especificar a localização dos seus dados.• Não use nomes de arquivo, sublinhado, curingas ou padrões glob para especificar locais de arquivos.• Não adicione a notação HTTP completa, como s3.amazon.com para o caminho do bucket do
Amazon S3.• Não use prefixos vazio (com o / extra) no caminho, da seguinte forma: S3://bucketname/prefix//prefix/. Embora esse seja um caminho válido do Amazon S3, o Athena não o permite e oaltera para s3://bucketname/prefix/prefix/, removendo a barra (/) extra.
Não use:
s3://path_to_buckets3://path_to_bucket/*s3://path_to_bucket/mySpecialFile.dats3://bucketname/prefix/filename.csvs3://test-bucket.s3.amazon.comS3://bucket/prefix//prefix/arn:aws:s3:::bucketname/prefix
Local e partições de tabelaSeus dados de origem podem ser agrupados em prefixos do Amazon S3, também conhecido comopartições, com base em um conjunto de colunas. Por exemplo, essas colunas podem representar o ano, omês e o dia em que o registro em particular foi criado.
Ao criar uma tabela, você pode optar por torná-la particionada. Quando o Athena executa uma consultaSQL em uma tabela não particionada, ele usa a propriedade LOCATION da definição da tabela comoo caminho base para listar e, depois, verificar todos os arquivos disponíveis. Para que uma tabelaparticionada possa ser consultada, você deve primeiro atualizar o Data Catalog do AWS Glue cominformações sobre partição. Essas informações representam o esquema de arquivos na partição específicae a LOCATION de arquivos no Amazon S3 da partição. Para saber como o crawler do AWS Glue adicionapartições, consulte Como um crawler determina quando criar partições? no Guia do desenvolvedor doAWS Glue. Para saber como configurar o crawler para que ele crie tabelas para dados em partiçõesexistentes, consulte Como usar várias fontes de dados com crawlers (p. 36). Você também podecriar partições em uma tabela diretamente no Athena. Para obter mais informações, consulte Particionardados (p. 23).
Quando o Athena executa uma consulta em uma tabela particionada, ele primeiro verifica se quaisquercolunas particionadas foram usadas na cláusula WHERE da consulta. Se as colunas particionadas tiveremsido usadas, o Athena solicitará o Data Catalog do AWS Glue para retornar a especificação de partiçãocorrespondente às colunas da partição especificada. A especificação de partição inclui a propriedadeLOCATION, que indica ao Athena qual prefixo do Amazon S3 usar ao ler dados. Nesse caso, somente osdados armazenados nesse prefixo são verificados. Se você não usar colunas particionadas na cláusulaWHERE, o Athena verifica todos os arquivos que pertencem às partições da tabela.
22

Amazon Athena Guia do usuárioParticionar dados
Para ver exemplos de como usar o particionamento com o Athena para melhorar o desempenho e reduziros custos de consultas, consulte Dicas para ajustar desempenho máximo do Amazon Athena.
Particionar dadosParticionando os dados, você pode restringir o volume de dados examinados em cada consulta, o quemelhora a performance e reduz o custo. O Athena utiliza o Hive para particionamento de dados. Vocêpode dividir seus dados em partições usando qualquer chave. Uma prática comum é particionar os dadoscom base no tempo, normalmente acarretando um esquema de particionamento em vários níveis. Porexemplo, um cliente que tenha dados vindos a cada hora pode optar por particionar por ano, mês, data ehora. Outro cliente, que tem dados vindos de muitas origens diferentes, mas carregados uma vez por dia,pode particionar por um identificador de fonte de dados e data.
Se você emitir consultas em buckets do Amazon S3 com um grande número de objetos, e os dados nãoestiverem particionados, essas consultas poderão afetar os limites da taxa de solicitações GET no AmazonS3 e resultar em exceções do Amazon S3. Para evitar erros, particione seus dados. Além disso, considereajustar suas taxas de solicitações do Amazon S3. Para obter mais informações, consulte Melhores práticase padrões de design: otimização do desempenho do Amazon S3.
Note
Se você consultar uma tabela particionada e especificar a partição na cláusula WHERE, o Athenaverificará somente os dados dessa partição. Para obter mais informações, consulte Local epartições de tabela (p. 22).
Para criar uma tabela com partições, você deve defini-la durante a instrução CREATE TABLE. UsePARTITIONED BY para definir as chaves segundo as quais particionar os dados. Há dois cenáriosdiscutidos nas seguintes seções:
1. Os dados já estão particionados, armazenados no Amazon S3, e você precisa acessar os dados noAthena.
2. Os dados não são particionados.
Cenário 1: os dados já estão particionados earmazenados no S3 no formato hiveArmazenar dados particionadosAs partições são armazenadas em pastas separadas no Amazon S3. Por exemplo, aqui está a listagemparcial para impressões de anúncio de exemplo:
aws s3 ls s3://elasticmapreduce/samples/hive-ads/tables/impressions/
PRE dt=2009-04-12-13-00/ PRE dt=2009-04-12-13-05/ PRE dt=2009-04-12-13-10/ PRE dt=2009-04-12-13-15/ PRE dt=2009-04-12-13-20/ PRE dt=2009-04-12-14-00/ PRE dt=2009-04-12-14-05/ PRE dt=2009-04-12-14-10/ PRE dt=2009-04-12-14-15/ PRE dt=2009-04-12-14-20/ PRE dt=2009-04-12-15-00/
23

Amazon Athena Guia do usuárioCenário 1: os dados já estão particionados
e armazenados no S3 no formato hive
PRE dt=2009-04-12-15-05/
Aqui, os logs são armazenados com o nome da coluna (dt) definido igual a incrementos de data, hora eminuto. Quando fornece uma DDL com o local da pasta pai, o esquema e o nome da coluna particionada,o Athena pode consultar dados nessas subpastas.
Criação de uma tabelaPara criar uma tabela a partir desses dados, crie uma partição com 'dt', como na seguinte instrução DDLdo Athena:
CREATE EXTERNAL TABLE impressions ( requestBeginTime string, adId string, impressionId string, referrer string, userAgent string, userCookie string, ip string, number string, processId string, browserCookie string, requestEndTime string, timers struct<modelLookup:string, requestTime:string>, threadId string, hostname string, sessionId string)PARTITIONED BY (dt string)ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe' with serdeproperties ( 'paths'='requestBeginTime, adId, impressionId, referrer, userAgent, userCookie, ip' )LOCATION 's3://elasticmapreduce/samples/hive-ads/tables/impressions/' ;
Esta tabela usa o serializador-desserializador JSON nativo do Hive para ler dados JSON armazenadosno Amazon S3. Para obter mais informações sobre os formatos compatíveis, consulte Formatos de dadoscompatíveis, SerDes e formatos de compactação (p. 254).
Depois de executar essa instrução no Athena, escolha New Query (Nova consulta) e execute:
MSCK REPAIR TABLE impressions
O Athena carrega os dados nas partições.
Consultar os dadosAgora consulte os dados da tabela de impressões usando a coluna de partição. Veja um exemplo abaixo:
SELECT dt,impressionid FROM impressions WHERE dt<'2009-04-12-14-00' and dt>='2009-04-12-13-00' ORDER BY dt DESC LIMIT 100
Esta consulta deve mostrar dados semelhantes aos seguintes:
2009-04-12-13-20 ap3HcVKAWfXtgIPu6WpuUfAfL0DQEc2009-04-12-13-20 17uchtodoS9kdeQP1x0XThKl5IuRsV2009-04-12-13-20 JOUf1SCtRwviGw8sVcghqE5h0nkgtp2009-04-12-13-20 NQ2XP0J0dvVbCXJ0pb4XvqJ5A4QxxH2009-04-12-13-20 fFAItiBMsgqro9kRdIwbeX60SROaxr2009-04-12-13-20 V4og4R9W6G3QjHHwF7gI1cSqig5D1G2009-04-12-13-20 hPEPtBwk45msmwWTxPVVo1kVu4v11b
24

Amazon Athena Guia do usuárioCenário 2: os dados não estão particionados
2009-04-12-13-20 v0SkfxegheD90gp31UCr6FplnKpx6i2009-04-12-13-20 1iD9odVgOIi4QWkwHMcOhmwTkWDKfj2009-04-12-13-20 b31tJiIA25CK8eDHQrHnbcknfSndUk
Cenário 2: os dados não estão particionadosPorém, um layout como o seguinte não funciona para adicionar automaticamente dados de partição comMSCK REPAIR TABLE:
aws s3 ls s3://athena-examples-myregion/elb/plaintext/ --recursive
2016-11-23 17:54:46 11789573 elb/plaintext/2015/01/01/part-r-00000-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:46 8776899 elb/plaintext/2015/01/01/part-r-00001-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:46 9309800 elb/plaintext/2015/01/01/part-r-00002-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:47 9412570 elb/plaintext/2015/01/01/part-r-00003-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:47 10725938 elb/plaintext/2015/01/01/part-r-00004-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:46 9439710 elb/plaintext/2015/01/01/part-r-00005-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:47 0 elb/plaintext/2015/01/01_$folder$2016-11-23 17:54:47 9012723 elb/plaintext/2015/01/02/part-r-00006-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:47 7571816 elb/plaintext/2015/01/02/part-r-00007-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:47 9673393 elb/plaintext/2015/01/02/part-r-00008-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 11979218 elb/plaintext/2015/01/02/part-r-00009-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 9546833 elb/plaintext/2015/01/02/part-r-00010-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 10960865 elb/plaintext/2015/01/02/part-r-00011-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 0 elb/plaintext/2015/01/02_$folder$2016-11-23 17:54:48 11360522 elb/plaintext/2015/01/03/part-r-00012-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 11211291 elb/plaintext/2015/01/03/part-r-00013-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:48 8633768 elb/plaintext/2015/01/03/part-r-00014-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:49 11891626 elb/plaintext/2015/01/03/part-r-00015-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:49 9173813 elb/plaintext/2015/01/03/part-r-00016-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:49 11899582 elb/plaintext/2015/01/03/part-r-00017-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:49 0 elb/plaintext/2015/01/03_$folder$2016-11-23 17:54:50 8612843 elb/plaintext/2015/01/04/part-r-00018-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:50 10731284 elb/plaintext/2015/01/04/part-r-00019-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:50 9984735 elb/plaintext/2015/01/04/part-r-00020-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:50 9290089 elb/plaintext/2015/01/04/part-r-00021-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:50 7896339 elb/plaintext/2015/01/04/part-r-00022-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 8321364 elb/plaintext/2015/01/04/part-r-00023-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 0 elb/plaintext/2015/01/04_$folder$
25

Amazon Athena Guia do usuárioFormatos de armazenamento colunar
2016-11-23 17:54:51 7641062 elb/plaintext/2015/01/05/part-r-00024-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 10253377 elb/plaintext/2015/01/05/part-r-00025-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 8502765 elb/plaintext/2015/01/05/part-r-00026-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 11518464 elb/plaintext/2015/01/05/part-r-00027-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 7945189 elb/plaintext/2015/01/05/part-r-00028-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 7864475 elb/plaintext/2015/01/05/part-r-00029-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 0 elb/plaintext/2015/01/05_$folder$2016-11-23 17:54:51 11342140 elb/plaintext/2015/01/06/part-r-00030-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:51 8063755 elb/plaintext/2015/01/06/part-r-00031-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 9387508 elb/plaintext/2015/01/06/part-r-00032-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 9732343 elb/plaintext/2015/01/06/part-r-00033-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 11510326 elb/plaintext/2015/01/06/part-r-00034-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 9148117 elb/plaintext/2015/01/06/part-r-00035-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 0 elb/plaintext/2015/01/06_$folder$2016-11-23 17:54:52 8402024 elb/plaintext/2015/01/07/part-r-00036-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 8282860 elb/plaintext/2015/01/07/part-r-00037-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:52 11575283 elb/plaintext/2015/01/07/part-r-00038-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:53 8149059 elb/plaintext/2015/01/07/part-r-00039-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:53 10037269 elb/plaintext/2015/01/07/part-r-00040-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:53 10019678 elb/plaintext/2015/01/07/part-r-00041-ce65fca5-d6c6-40e6-b1f9-190cc4f93814.txt2016-11-23 17:54:53 0 elb/plaintext/2015/01/07_$folder$2016-11-23 17:54:53 0 elb/plaintext/2015/01_$folder$2016-11-23 17:54:53 0 elb/plaintext/2015_$folder$
Neste caso, você precisaria usar ALTER TABLE ADD PARTITION para adicionar cada partiçãomanualmente.
Por exemplo, para carregar os dados em s3://athena-examples-myregion/elb/plaintext/2015/01/01/, épossível executar o seguinte:
ALTER TABLE elb_logs_raw_native_part ADD PARTITION (year='2015',month='01',day='01') location 's3://athena-examples-us-west-1/elb/plaintext/2015/01/01/'
Você também pode automatizar a adição de partições usando o driver JDBC (p. 59).
Formatos de armazenamento colunarApache Parquet e ORC são formatos de armazenamento colunar otimizados para recuperação rápida dedados e usados em aplicativos de análises da AWS.
Os formatos de armazenamento colunar têm as seguintes características que os tornam adequados para ouso com o Athena:
26

Amazon Athena Guia do usuárioConverter em formatos colunares
• Compactação por coluna, com algoritmo de compactação selecionado para o tipo de dados da colunapara economizar espaço de armazenamento no Amazon S3 e reduzir o E/S e espaço de disco e duranteo processamento de consultas.
• A aplicação de predicados em Parquet e ORC permite que as consultas do Athena obtenham somenteos blocos de que precisa, melhorando o desempenho das consultas. Quando uma consulta do Athenaobtém valores de coluna específicos de seus dados, ela usa estatísticas de predicados de bloco dedados, como valores máximos e mínimos, para determinar se deseja ler ou ignorar o bloco.
• A divisão de dados em Parquet e ORC permite que o Athena divida a leitura de dados entre váriosleitores e aumente o paralelismo durante o processamento da consulta.
Para converter seus dados brutos existentes de outros formatos de armazenamento para Parquet ou ORC,é possível executar consultas CREATE TABLE AS SELECT (CTAS) (p. 77) no Athena e especificar umformato de armazenamento físico de dados como Parquet ou ORC, ou usar o crawler do AWS Glue.
Converter em formatos colunaresA performance de consultas do Amazon Athena será melhor se você converter os dados em formatoscolunares de código-fonte aberto, como o Apache Parquet ou o ORC.
Note
Use as consultas CREATE TABLE AS (CTAS) (p. 84) para executar a conversão em formatoscolunares, como Parquet e ORC, em uma única etapa.
Você pode fazer isso para fontes de dados existentes do Amazon S3 criando um cluster no Amazon EMRe convertendo-o usando o Hive. O exemplo a seguir usando a ILC da AWS mostra como fazer isso comum script e dados armazenados no Amazon S3.
Visão geralO processo para converter em formatos colunares usando um cluster do EMR é o seguinte:
1. Crie um cluster do EMR com o Hive instalado.2. Na seção da etapa da instrução de criação do cluster, especifique um script armazenado no Amazon
S3, que aponte para os dados de entrada e crie os dados de saída no formato colunar em um local doAmazon S3. Neste exemplo, o cluster é encerrado automaticamente.
Note
O script é baseado na versão 4.7 do Amazon EMR e precisa ser atualizado para a versão atual.Para obter mais informações sobre as versões, consulte Guia de release do Amazon EMR.
O script completo está localizado no Amazon S3 em:
s3://athena-examples-myregion/conversion/write-parquet-to-s3.q
Aqui está um script de exemplo começando com o trecho CREATE TABLE:
ADD JAR /usr/lib/hive-hcatalog/share/hcatalog/hive-hcatalog-core-1.0.0-amzn-5.jar;CREATE EXTERNAL TABLE impressions ( requestBeginTime string, adId string, impressionId string, referrer string, userAgent string, userCookie string,
27

Amazon Athena Guia do usuárioVisão geral
ip string, number string, processId string, browserCookie string, requestEndTime string, timers struct<modelLookup:string, requestTime:string>, threadId string, hostname string, sessionId string)PARTITIONED BY (dt string)ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe'with serdeproperties ( 'paths'='requestBeginTime, adId, impressionId, referrer, userAgent, userCookie, ip' )LOCATION 's3://MyRegion.elasticmapreduce/samples/hive-ads/tables/impressions/' ;
Note
Substitua MyRegion na cláusula LOCATION pela região onde você está executando consultas.Por exemplo, se o console estiver em us-west-1, s3://us-west-1.elasticmapreduce/samples/hive-ads/tables/.
Isso cria a tabela no Hive no cluster que usa exemplos localizados no bucket de exemplos do AmazonEMR.
3. No Amazon EMR versão 4.7.0, inclua a linha ADD JAR para encontrar o JsonSerDe apropriado. Osdados de exemplo têm a seguinte aparência:
{ "number": "977680", "referrer": "fastcompany.com", "processId": "1823", "adId": "TRktxshQXAHWo261jAHubijAoNlAqA", "browserCookie": "mvlrdwrmef", "userCookie": "emFlrLGrm5fA2xLFT5npwbPuG7kf6X", "requestEndTime": "1239714001000", "impressionId": "1I5G20RmOuG2rt7fFGFgsaWk9Xpkfb", "userAgent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506; InfoPa", "timers": { "modelLookup": "0.3292", "requestTime": "0.6398" }, "threadId": "99", "ip": "67.189.155.225", "modelId": "bxxiuxduad", "hostname": "ec2-0-51-75-39.amazon.com", "sessionId": "J9NOccA3dDMFlixCuSOtl9QBbjs6aS", "requestBeginTime": "1239714000000"}
4. No Hive, carregue os dados das partições, de maneira que o script execute o seguinte:
MSCK REPAIR TABLE impressions;
Em seguida, o script cria uma tabela que armazena os dados em um arquivo formatado em Parquet noAmazon S3:
CREATE EXTERNAL TABLE parquet_hive ( requestBeginTime string, adId string, impressionId string, referrer string,
28

Amazon Athena Guia do usuárioAntes de começar
userAgent string, userCookie string, ip string) STORED AS PARQUETLOCATION 's3://myBucket/myParquet/';
Os dados são inseridos na tabela impressions em parquet_hive:
INSERT OVERWRITE TABLE parquet_hiveSELECTrequestbegintime,adid,impressionid,referrer,useragent,usercookie,ip FROM impressions WHERE dt='2009-04-14-04-05';
O script armazena as colunas da tabela impressions acima da data, 2009-04-14-04-05, em s3://myBucket/myParquet/ em um arquivo formatado em Parquet.
5. Depois que o cluster do EMR for encerrado, crie a tabela no Athena, que usa os dados no formatoproduzido pelo cluster.
Antes de começar• Você precisa criar clusters do EMR. Para obter mais informações sobre o Amazon EMR, consulte o Guia
de gerenciamento do Amazon EMR.• Siga as instruções encontradas em Configurar (p. 6).
Exemplo: converter dados em Parquet usando umcluster do EMR1. Use a AWS CLI para criar um cluster. Se você precisar instalar o AWS CLI, consulte Instalação do AWS
Command Line Interface no Guia do usuário do AWS Command Line Interface.2. Você precisa de funções para usar o Amazon EMR, portanto, se você ainda não tiver usado o Amazon
EMR, crie as funções padrão usando o seguinte comando:
aws emr create-default-roles
3. Crie um cluster do Amazon EMR usando a versão emr-4.7.0 para converter os dados usando ocomando emr create-cluster da AWS CLI.
export REGION=us-west-1export SAMPLEURI=s3://${REGION}.elasticmapreduce/samples/hive-ads/tables/impressions/export S3BUCKET=myBucketName
aws emr create-cluster --applications Name=Hadoop Name=Hive Name=HCatalog \--ec2-attributes KeyName=myKey,InstanceProfile=EMR_EC2_DefaultRole,SubnetId=subnet-mySubnetId \--service-role EMR_DefaultRole --release-label emr-4.7.0 --instance-type \m4.large --instance-count 1
29

Amazon Athena Guia do usuárioExemplo: converter dados em
Parquet usando um cluster do EMR
--steps Type=HIVE,Name="Convert to Parquet",\ActionOnFailure=CONTINUE,ActionOnFailure=TERMINATE_CLUSTER,Args=[-f,\s3://athena-examples/conversion/write-parquet-to-s3.q,-hiveconf,INPUT=${SAMPLEURI},-hiveconf,OUTPUT=s3://${S3BUCKET}/myParquet,-hiveconf,REGION=${REGION}] \--region ${REGION} --auto-terminate
Para obter mais informações, consulte Criar e usar funções do IAM para o Amazon EMR no Guia degerenciamento do Amazon EMR.
Uma solicitação bem-sucedida fornece um ID de cluster.4. Monitore o andamento do cluster usando o Console de Gerenciamento da AWS ou o ID do cluster com
o subcomando list-steps na AWS CLI:
aws emr list-steps --cluster-id myClusterID
Procure o status de etapa do script. Se ele for COMPLETED, a conversão estará pronta e você jápoderá consultar os dados.
5. Crie a mesma tabela criada por você no cluster do EMR.
Você pode usar a mesma instrução acima. Faça login no Athena e digite a instrução na janela QueryEditor (Editor de consultas):
CREATE EXTERNAL TABLE parquet_hive ( requestBeginTime string, adId string, impressionId string, referrer string, userAgent string, userCookie string, ip string) STORED AS PARQUETLOCATION 's3://myBucket/myParquet/';
Escolha Run Query.6. Execute a seguinte consulta para mostrar que você pode consultar esses dados:
SELECT * FROM parquet_hive LIMIT 10;
Você também pode selecionar o ícone de exibição (olho) ao lado do nome da tabela em Catalog:
Os resultados devem mostrar uma saída semelhante a esta:
30

Amazon Athena Guia do usuárioExemplo: converter dados em
Parquet usando um cluster do EMR
31

Amazon Athena Guia do usuárioIntegração com o AWS Glue
Conectar a fontes de dadosÉ possível usar o Amazon Athena para consultar dados armazenados em diferentes locais e formatosem um conjunto de dados. Esse conjunto de dados pode estar em CSV, JSON, Avro, Parquet ou outroformato.
As tabelas e bancos de dados com os quais você trabalha no Athena para executar consultas sãobaseados em metadados. Metadados são dados sobre os dados subjacentes em seu conjunto de dados.A forma como esses metadados descrevem seu conjunto de dados é chamada de esquema. Por exemplo,um nome de tabela, os nomes de coluna na tabela e o tipo de dados de cada coluna são esquemas,salvos como metadados, que descrevem um conjunto de dados subjacente. No Athena, chamamos umsistema para organizar metadados de um catálogo de dados ou um metastore. A combinação de umconjunto de dados e o catálogo de dados que o descreve é chamada de fonte de dados.
A relação dos metadados com um conjunto de dados subjacente depende do tipo de fonte de dados coma qual você trabalha. Fontes de dados relacionais como MySQL, PostgreSQL e SQL Server integramtotalmente os metadados ao conjunto de dados. Nesses sistemas, os metadados são gravados com maiorfrequência quando os dados são gravados. Outras fontes de dados, como aquelas criadas usando o Hive,permitem definir metadados em tempo real ao ler o conjunto de dados. O conjunto de dados pode estar emuma grande variedade de formatos. Por exemplo, CSV, JSON, Parquet ou Avro.
O Athena oferece suporte nativamente ao Catálogo de dados do AWS Glue. O Catálogo de dados do AWSGlue é um catálogo de dados criado com base em outros conjuntos de dados e fontes de dados, como oAmazon S3, o Amazon Redshift e o Amazon DynamoDB. Também é possível conectar o Athena a outrasfontes de dados usando uma grande variedade de conectores.
Tópicos• Integração com o AWS Glue (p. 32)• O uso do (p. 47)• O uso do (p. 49)• Conexão ao Amazon Athena com drivers ODBC e JDBC (p. 59)
Integração com o AWS GlueO AWS Glue é um serviço de ETL (extração, transformação e carga) totalmente gerenciado que podecategorizar os dados, limpá-los, enriquecê-los e movê-los de forma confiável entre vários armazenamentosde dados. Os crawlers do AWS Glue inferem automaticamente o banco de dados e o esquema da tabelado conjunto de dados, armazenando os metadados associados no Catálogo de dados do AWS Glue.
O Athena oferece suporte nativo à consulta de conjuntos de dados e fontes de dados que são registradoscom o Catálogo de dados do AWS Glue. Ao executar consultas em DML (Data Manipulation Language– Linguagem de manipulação de dados) no Athena com o Data Catalog como origem, você está usandoo esquema do Data Catalog para derivar informações do conjunto de dados subjacente. Ao executarconsultas DDL (Data Definition Language), o esquema que você define é definido no Catálogo de dadosdo AWS Glue. No Athena, também é possível executar um crawler do AWS Glue em uma fonte de dadospara criar um esquema no Catálogo de dados do AWS Glue.
32

Amazon Athena Guia do usuárioUsar o AWS Glue para se conectara fontes de dados no Amazon S3
Em regiões onde o AWS Glue tem suporte, o Athena usa o AWS Glue Data Catalog como um local centralpara armazenar e recuperar metadados da tabela em uma conta da AWS. O mecanismo de execução doAthena exige os metadados da tabela que o instruem para ler dados, como lê-los e outras informaçõesnecessárias para processar os dados. O AWS Glue Data Catalog fornece um repositório de metadadosunificado em uma grande variedade de fontes e formatos de dados, integrando-se não apenas ao Athena,mas ao Amazon S3, ao Amazon RDS, ao Amazon Redshift, ao Amazon Redshift Spectrum, ao AmazonEMR e a qualquer aplicativo compatível com a metastore do Apache Hive.
Para obter mais informações sobre o AWS Glue Data Catalog, consulte Preencher o AWS Glue DataCatalog no Guia de desenvolvedor do AWS Glue. Para obter uma lista de regiões onde o AWS Glue estejadisponível, consulte Regiões e endpoints na Referência geral da AWS.
Cobranças à parte se aplicam ao AWS Glue. Para obter mais informações, consulte Definição de preço doAWS Glue e Existem cobranças à parte para o AWS Glue? (p. 46) Para obter mais informações sobreos benefícios de como usar o AWS Glue com o Athena, consulte Por que devo atualizar para o AWS GlueData Catalog? (p. 45)
Tópicos• Usar o AWS Glue para se conectar a fontes de dados no Amazon S3 (p. 33)• Melhores práticas ao usar o Athena com o AWS Glue (p. 35)• Atualizar para o AWS Glue Data Catalog passo a passo (p. 43)• Perguntas frequentes: atualização para o Catálogo de dados do AWS Glue (p. 45)
Usar o AWS Glue para se conectar a fontes de dadosno Amazon S3O Athena pode se conectar aos dados armazenados no Amazon S3 usando o Catálogo de dados do AWSGlue para armazenar metadados, como nomes de tabela e coluna. Depois que a conexão for feita, osbancos de dados, tabelas e exibições serão exibidos no editor de consultas do Athena.
Para definir informações de esquemas para o AWS Glue usar, é possível configurar um crawler do AWSGlue para recuperar as informações ou adicionar manualmente uma tabela e inserir as informações doesquema.
33

Amazon Athena Guia do usuárioUsar o AWS Glue para se conectara fontes de dados no Amazon S3
Configurar um crawlerVocê configura um crawler ao começar no console do Athena e usar o console do AWS Glue de formaintegrada. Ao criar um crawler, é possível escolher armazenamentos de dados para rastrear ou apontar ocrawler para tabelas de catálogo existentes.
Como configurar um crawler no AWS Glue para recuperar informações de esquemaautomaticamente
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Connect data source (Conectar fonte de dados).3. Na página Connect data source (Conectar fonte de dados), escolha AWS Glue Data Catalog.4. Clique em Next (Próximo).5. Na página Connection details (Detalhes da conexão), escolha Set up crawler in AWS Glue to retrieve
schema information automatically (Configurar crawler no AWS Glue para recuperar informações doesquema automaticamente).
6. Clique em Connect to AWS AWS Glue (Conectar ao AWS AWS Glue).7. No console do AWS Glue, na página Add crawler (Adicionar crawler), siga as etapas para criar um
crawler. Para obter mais informações, consulte Preencher o Catálogo de dados do AWS Glue.
Adicionar uma tabela de esquema manualmenteO procedimento a seguir mostra como usar o console do Athena para adicionar uma tabela manualmente.
Como adicionar uma tabela e inserir informações de esquema manualmente
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Connect data source (Conectar fonte de dados).3. Na página Connect data source (Conectar fonte de dados), escolha AWS Glue Data Catalog.4. Clique em Next (Próximo).5. Na página Connection details (Detalhes da conexão), escolha Add a table and enter schema
information manually (Adicionar uma tabela e insira as informações do esquema manualmente).6. Clique em Continue to add table (Continuar a adicionar tabela).7. Na página Add table (Adicionar tabela) do console do Athena, em Database (Banco de dados),
escolha um banco de dados existente ou crie um novo.8. Insira ou escolha um nome de tabela.9. Em Location of Input Data Set (Local do conjunto de dados de entrada), especifique o caminho no
Amazon S3 para a pasta que contém o conjunto de dados que você deseja processar.10. Clique em Next (Próximo).11. Em Data Format (Formato de dados), escolha um formato de dados (Apache Web Logs, CSV, TSV,
Text File with Custom Delimiters (Arquivo de texto com delimitadores personalizados), JSON, Parquetou ORC).
• Na opção Apache Web Logs também é necessário inserir uma expressão regex na caixa Regex.• Na opção Text File with Custom Delimiters (Arquivo de texto com delimitadores personalizados),
especifique um Field terminator (Terminador de campo) (ou seja, um delimitador de coluna).Opcionalmente, é possível especificar um Collection terminator (Terminador de coleta) para tipos dematriz ou um Map key terminator (Terminador de chave do mapa).
12. Em Columns (Colunas), especifique um nome de coluna e o tipo de dados da coluna.
• Para adicionar mais colunas uma de cada vez, escolha Add a column (Adicionar uma coluna).
34

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
• Para adicionar rapidamente mais colunas, escolha Bulk add columns (Adicionar colunas em massa).Na caixa de texto, insira uma lista separada por vírgulas de colunas no formato column_namedata_type, column_name data_type[, …] e escolha Add (Adicionar).
13. Escolha Next (Próximo).14. (Opcional) Em Partitions (Partições), clique em Add a partition (Adicionar uma partição) para adicionar
nomes de coluna e tipos de dados.15. Escolha Create table. O DDL para a tabela que você especificou é exibido no Query Editor (Editor de
consultas). O exemplo a seguir mostra o DDL gerado para uma tabela de duas colunas no formatoCSV:
CREATE EXTERNAL TABLE IF NOT EXISTS MyManualDB.MyManualTable ( `cola` string, `colb` string )ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'WITH SERDEPROPERTIES ( 'serialization.format' = ',', 'field.delim' = ',') LOCATION 's3://bucket_name/'TBLPROPERTIES ('has_encrypted_data'='false');
16. Escolha Run query (Executar consulta) para criar a tabela.
Melhores práticas ao usar o Athena com o AWS GlueAo usar o Athena com o AWS Glue Data Catalog, você pode usar o AWS Glue para criar bancos de dadose tabelas (esquema) a serem consultados no Athena ou pode usar o Athena para criar o esquema e,em seguida, usá-lo no AWS Glue e em serviços relacionados. Este tópico apresenta considerações emelhores práticas durante o uso de um dos métodos.
Nos bastidores, o Athena usa o Presto para executar instruções DML, e o Hive para executar instruçõesDDL que criam e modificam o esquema. Com essas tecnologias, existem algumas convenções a seremseguidas para que o Athena e o AWS Glue funcionem bem em conjunto.
Neste tópico
• Nomes de bancos de dados, tabelas e colunas (p. 36)• Uso de crawlers do AWS Glue (p. 36)
• Programar um crawler para manter o AWS Glue Data Catalog e o Amazon S3sincronizados (p. 36)
• Usar várias fontes de dados com crawlers (p. 36)• Sincronizar o esquema da partição para evitar
"HIVE_PARTITION_SCHEMA_MISMATCH" (p. 38)• Atualizar metadados de tabela (p. 39)
• Trabalhar com arquivos CSV (p. 39)• Dados CSV entre aspas (p. 39)• Arquivos CSV com cabeçalhos (p. 41)
• Trabalhar com dados geoespaciais (p. 41)• Uso de trabalhos do AWS Glue para a ETL com o Athena (p. 41)
• Criar tabelas usando o Athena para trabalhos ETL do AWS Glue (p. 41)• Usar trabalhos ETL para otimizar o desempenho da consulta (p. 42)• Converter tipos de dados SMALLINT e TINYINT em INT durante a conversão em ORC (p. 43)• Automatizar o AWS Glue para a ETL (p. 43)
35

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
Nomes de bancos de dados, tabelas e colunasAo criar um esquema no AWS Glue para consulta no Athena, considere o seguinte:
• Um nome do banco de dados não pode ter mais que 252 caracteres.• Um nome da tabela não pode ter mais que 255 caracteres.• Um nome da coluna não pode ter mais que 128 caracteres.• Os únicos caracteres aceitáveis para nomes de banco de dados, nomes de tabela e nomes de coluna
são letras minúsculas, números e o caractere sublinhado.
Você pode usar o AWS Glue Catalog Manager para renomear colunas, mas, no momento, os nomes detabela e os nomes de bancos de dados não podem ser alterados usando o console do AWS Glue. Paracorrigir nomes de banco de dados, você precisa criar um novo banco de dados e copiar tabelas paraele (em outras palavras, copie os metadados para uma nova entidade). Você pode seguir um processosemelhante para tabelas. Você pode usar o SDK do AWS Glue ou a ILC da AWS para fazer isso.
Uso de crawlers do AWS GlueOs crawlers do AWS Glue ajudam a descobrir e registrar o esquema para conjuntos de dados no AWSGlue Data Catalog. Os crawlers passam pelos dados e inspecionam partes deles para determinar oesquema. Além disso, o crawler pode detectar e registrar partições. Para obter mais informações, consulteCatalogar dados com um crawler no Guia do desenvolvedor do AWS Glue.
Programação de um crawler para manter o AWS Glue Data Catalog e o AmazonS3 sincronizados
Os crawlers do AWS Glue podem ser configurados para serem executados em uma programação ou sobdemanda. Para obter mais informações, consulte Programações baseadas em tempo para trabalhos ecrawlers no Guia do desenvolvedor do AWS Glue.
Se você tiver dados que chegam a uma tabela particionada em um horário fixo, poderá configurar umcrawler do AWS Glue para ser executado na programação para detectar e atualizar partições da tabela.Isso pode eliminar a necessidade de executar um comando MSCK REPAIR potencialmente longo e caroou executar manualmente um comando ALTER TABLE ADD PARTITION. Para obter mais informações,consulte Partições de tabela no Guia do desenvolvedor do AWS Glue.
Como usar várias fontes de dados com crawlers
Quando um crawler do AWS Glue examina o Amazon S3 e detecta vários diretórios, ele usa umaheurística para determinar onde a raiz de uma tabela está na estrutura do diretório e quais diretórios
36

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
são partições da tabela. Em alguns casos, quando o esquema detectado em dois ou mais diretórios ésemelhante, o crawler pode tratá-lo como partições, em vez de tabelas à parte. Uma maneira de ajudar ocrawler a descobrir tabelas individuais é adicionar o diretório raiz de cada tabela como um armazenamentode dados para o crawler.
As seguintes partições no Amazon S3 são um exemplo:
s3://bucket01/folder1/table1/partition1/file.txts3://bucket01/folder1/table1/partition2/file.txts3://bucket01/folder1/table1/partition3/file.txts3://bucket01/folder1/table2/partition4/file.txts3://bucket01/folder1/table2/partition5/file.txt
Se o esquema de table1 e table2 forem semelhantes e uma única fonte de dados for definida comos3://bucket01/folder1/ no AWS Glue, o crawler poderá criar uma única tabela com duas colunas departição: uma coluna de partição que contém table1 e table2 e uma segunda coluna de partição quecontém partition1 até partition5.
Para fazer com que o crawler do AWS Glue crie duas tabelas separadas, defina o crawler para terduas fontes de dados, s3://bucket01/folder1/table1/ e s3://bucket01/folder1/table2,conforme mostrado no procedimento a seguir.
Para adicionar outro armazenamento de dados a um crawler existente no AWSGlue
1. Faça login no Console de gerenciamento da AWS e abra o console do AWS Glue em https://console.aws.amazon.com/glue/.
2. Escolha Crawlers, selecione o crawler e escolha Action (Ação), Edit crawler (Editar crawler).
37

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
3. Em Add information about your crawler, escolha configurações adicionais conforme apropriado e Next.4. Em Add a data store, altere Include path para o diretório no nível da tabela. Por exemplo, considerando
o exemplo acima, você deve alterá-lo no s3://bucket01/folder1 to s3://bucket01/folder1/table1/. Escolha Next.
5. Em Add another data store, escolha Yes, Next.6. Em Include path (Incluir caminho), insira o outro diretório no nível da tabela (por exemplo, s3://
bucket01/folder1/table2/) e escolha Next (Avançar).a. Repita as etapas de 3 a 5 para todos os diretórios no nível da tabela e conclua a configuração do
crawler.
Os novos valores de Include locations (Incluir locais) são exibidos em armazenamentos de dados daseguinte forma:
Sincronizar o esquema da partição para evitar"HIVE_PARTITION_SCHEMA_MISMATCH"
Para cada tabela no AWS Glue Data Catalog que tenha colunas de partição, o esquema é armazenadono nível de tabela e para cada partição individual dentro da tabela. O esquema de partições é preenchido
38

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
por um crawler do AWS Glue com base no exemplo de dados lido dentro da partição. Para obter maisinformações, consulte Usar várias fontes de dados com crawlers (p. 36).
Ao executar uma consulta, o Athena valida o esquema da tabela e o esquema de todas as partiçõesnecessárias para a consulta. A validação compara os tipos de dados da coluna em ordem e verifica seeles correspondem às colunas que se sobrepõem. Isso evita operações inesperadas, como adicionarou remover colunas no meio de uma tabela. Se o Athena detectar que o esquema de uma partiçãoé diferente do esquema da tabela, o Athena talvez não possa processar a consulta e falhe comHIVE_PARTITION_SCHEMA_MISMATCH.
Existem algumas maneiras de corrigir esse problema. Primeiro, se os dados tiverem sido adicionadosacidentalmente, você poderá remover os arquivos de dados que causam a diferença no esquema,ignorar a partição e rastrear novamente os dados. Segundo, você pode ignorar a partição individual eexecutar MSCK REPAIR dentro do Athena para recriar a partição usando o esquema da tabela. Essasegunda opção só funcionará se você tiver certeza de que o esquema aplicado continuará lendo os dadoscorretamente.
Atualização de metadados de tabelasDepois de um rastreamento, o crawler do AWS Glue atribui automaticamente determinados metadadospara ajudar a torná-los compatíveis com outras tecnologias externas, como Apache Hive, Presto e Spark.Às vezes, o crawler pode atribuir incorretamente propriedades de metadados. Corrija manualmente aspropriedades no AWS Glue antes de consultar a tabela usando o Athena. Para obter mais informações,consulte Visualização e edição dos detalhes da tabela no Guia do desenvolvedor do AWS Glue.
O AWS Glue pode atribuir indevidamente metadados quando um arquivo CSV tem aspas em torno decada campo de dados, processando a propriedade serializationLib incorretamente. Para obter maisinformações, consulte Dados CSV entre aspas (p. 39).
Trabalhar com arquivos CSVÀs vezes, os arquivos CSV têm aspas em valores de dados destinados a cada coluna e talvez haja valoresde cabeçalho incluídos em arquivos CSV, que não fazem parte dos dados a serem analisados. Ao usar oAWS Glue para criar um esquema com base nesses arquivos, siga as orientações desta seção.
Dados CSV entre aspasSe você executar uma consulta no Athena em uma tabela criada com base em um arquivo CSV comvalores de dados entre aspas, atualize a definição da tabela no AWS Glue para que ela especifique oSerDe correto e as propriedades de SerDe. Isso permite que a definição da tabela use o OpenCSVSerDe.Para obter mais informações sobre o OpenCSV SerDe, consulte OpenCSVSerDe para processarCSV (p. 260).
Nesse caso, faças as seguintes alterações:
• Altere a propriedade serializationLib no campo em SerDeInfo na tabela paraorg.apache.hadoop.hive.serde2.OpenCSVSerde.
• Insira os valores apropriados para separatorChar, quoteChar e escapeChar. O valorseparatorChar é uma vírgula, o valor quoteChar são aspas duplas (``) e o valor escapeChar é abarra invertida (\).
Por exemplo, para um arquivo CSV com registros, como o seguinte:
"John","Doe","123-555-1231","John said \"hello\"""Jane","Doe","123-555-9876","Jane said \"hello\""
Você pode usar o console do AWS Glue para editar os detalhes da tabela, conforme mostrado nesteexemplo:
39

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
Como alternativa, você pode atualizar a definição da tabela no AWS Glue para ter um bloco SerDeInfocomo o seguinte:
"SerDeInfo": {
40

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
"name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "," "quoteChar": """ "escapeChar": "\\" }},
Para obter mais informações, consulte Visualização e edição dos detalhes da tabela no Guia dodesenvolvedor do AWS Glue.
Arquivos CSV com cabeçalhosSe estiver gravando arquivos CSV do AWS Glue para consulta usando o Athena, remova os cabeçalhosCSV para que as informações do cabeçalho não sejam incluídas nos resultados da consulta do Athena.Uma maneira de fazer isso é usar os trabalhos do AWS Glue, que excutam o trabalho de Extract,Transform, and Load (ETL - Extração, transformação e carga). Você pode escrever scripts no AWS Glueusando uma linguagem que é uma extensão do dialeto PySpark Python. Para obter mais informações,consulte Criação de trabalhos no Glue no Guia do desenvolvedor do AWS Glue.
O exemplo a seguir mostra uma função em um script do AWS Glue que escreve um quadro dinâmicousando from_options e define a opção de formato writeHeader como falsa, o que remove asinformações do cabeçalho:
glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://MYBUCKET/MYTABLEDATA/"}, format = "csv", format_options = {"writeHeader": False}, transformation_ctx = "datasink2")
Trabalhar com dados geoespaciaisO AWS Glue não oferece suporte nativo a Well-known Text (WKT – Texto bem conhecido), Well-KnownBinary (WKB – Binário bem conhecido) ou outros tipos de dados PostGIS. O classificador do AWS Glueanalisa dados geoespaciais e os classifica usando tipos de dados compatíveis para o formato, comovarchar para CSV. Assim como ocorre com outras tabelas do AWS Glue, pode ser necessário atualizaras propriedades das tabelas criadas a partir de dados geoespaciais para permitir que o Athena analiseesses tipos de dados no estado em que se encontram. Para obter mais informações, consulte Uso decrawlers do AWS Glue (p. 36) e Trabalhar com arquivos CSV (p. 39). O Athena pode não ser capazde analisar alguns tipos de dados geoespaciais em tabelas do AWS Glue no estado em que se encontram.Para obter mais informações sobre como trabalhar com dados geoespaciais no Athena, consulte Consultardados geoespaciais (p. 127).
Uso de trabalhos do AWS Glue para ETL com o AthenaOs trabalhos do AWS Glue realizam operações de ETL. Um trabalho do AWS Glue executa um scriptque extrai dados de fontes, transforma os dados e os carrega em destinos. Para obter mais informações,consulte Criação de trabalhos no Glue no Guia do desenvolvedor do AWS Glue.
Criação de tabelas usando o Athena para trabalhos de ETL do AWS GlueAs tabelas que você cria no Athena devem ter uma propriedade de tabela adicionada, chamadaclassification, que identifica o formato dos dados. Isso permite que o AWS Glue use as tabelas paratrabalhos de ETL. Os valores de classificação podem ser csv, parquet, orc, avro ou json. A seguinte éuma instrução CREATE TABLE de exemplo no Athena:
CREATE EXTERNAL TABLE sampleTable ( column1 INT, column2 INT
41

Amazon Athena Guia do usuárioMelhores práticas ao usar o Athena com o AWS Glue
) STORED AS PARQUET TBLPROPERTIES ( 'classification'='parquet')
Se a propriedade da tabela não tiver sido adicionada quando a tabela foi criada, a propriedade poderá seradicionada com o console do AWS Glue.
Para alterar a propriedade de classificação usando o console
1. Escolha Edit Table.
2. Em Classification, selecione o tipo de arquivo e escolha Apply.
Para obter mais informações, consulte Trabalhar com tabelas no Guia do desenvolvedor do AWS Glue.
Com usar trabalhos de ETL para otimizar a performance da consultaOs trabalhos do AWS Glue podem ajudar a transformar dados em um formato que otimiza a performanceda consulta no Athena. Os formatos de dados têm um grande impacto sobre a performance e os custos daconsulta no Athena.
42

Amazon Athena Guia do usuárioAtualizar para o AWS Glue Data Catalog passo a passo
É recomendável usar os formatos de dados Parquet e ORC. O AWS Glue oferece suporte à gravaçãonesses dois formatos de dados, o que pode facilitar e agilizar a transformação de dados em um formatoideal para Athena. Para obter mais informações sobre esses formatos e outras maneiras de melhorar aperformance, consulte Dicas para ajustar a performance do Amazon Athena ao máximo.
Conversão de tipos de dados SMALLINT e TINYINT em INT ao converter emORC
Para reduzir a probabilidade do Athena não poder ler os tipos de dados SMALLINT e TINYINT produzidospor um trabalho de ETL do AWS Glue, converta o SMALLINT e o TINYINT em INT ao usar o assistente ouao escrever um script para um trabalho de ETL.
Automatização do AWS Glue para a ETL
Você pode configurar trabalhos de ETL do AWS Glue para serem executados automaticamente com baseem gatilhos. Esse recurso é ideal quando dados externos à AWS estão sendo enviados para um bucketdo Amazon S3 em um formato não ideal para consultas no Athena. Para obter mais informações, consulteDisparo de trabalhos do AWS Glue no Guia do desenvolvedor do AWS Glue.
Atualizar para o AWS Glue Data Catalog passo apassoAtualmente, todas as regiões que oferecem suporte ao Athena também oferecem suporte ao Catálogo dedados do AWS Glue. Bancos de dados e tabelas estão disponíveis para o Athena usando o AWS GlueData Catalog e vice-versa.
Se você criou bancos de dados e tabelas usando o Athena ou o Amazon Redshift Spectrum antes queuma região tenha oferecido suporte ao AWS Glue, é possível atualizar o Athena para usar o AWS GlueData Catalog.
Se você estiver usando o catálogo de dados gerenciado pelo Athena mais antigo, verá a opção paraatualizar na parte superior do console. Os metadados no catálogo gerenciado pelo Athena não estãodisponíveis no AWS Glue Data Catalog ou vice-versa. Embora os catálogos existam lado a lado, ocorreuma falha na criação de tabelas ou bancos de dados com os mesmos nomes no AWS Glue ou no Athena.Isso evita colisões de nome quando você faz a atualização. Para obter mais informações sobre osbenefícios de como usar o AWS Glue Data Catalog, consulte Perguntas frequentes: atualizar para o AWSGlue Data Catalog (p. 45).
Um assistente no console do Athena pode orientá-lo durante a atualização para o console do AWS Glue.A atualização leva apenas alguns minutos, e você pode recomeçar de onde parou. Para obter informaçõessobre cada etapa da atualização, consulte os tópicos nesta seção.
Para obter mais informações sobre como trabalhar com dados e tabelas no Catálogo de dados do AWSGlue, consulte as diretrizes em Melhores práticas durante o uso do Athena com o AWS Glue (p. 35).
Etapa 1 – Permitir que um usuário realize a atualizaçãoPor padrão, a ação que possibilita que um usuário realize a atualização não é permitida em qualquerpolítica, inclusive todas as políticas gerenciadas. Como o AWS Glue Data Catalog é compartilhado emuma conta, essa segurança extra evita que alguém migre acidentalmente o catálogo.
Para realizar a atualização, você precisa anexar uma política do IAM gerenciada pelo cliente com umainstrução de política que permita a ação de atualização ao usuário que realiza a migração.
Esta é uma instrução de política de exemplo.
43

Amazon Athena Guia do usuárioAtualizar para o AWS Glue Data Catalog passo a passo
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:ImportCatalogToGlue " ], "Resource": [ "*" ] } ] }
Etapa 2 – Atualizar políticas gerenciadas pelo cliente/em linhaassociadas aos usuários do AthenaSe você tiver políticas gerenciadas pelo cliente ou políticas em linha do IAM associadas a usuários doAthena, será necessário atualizar as políticas para permitir as ações exigidas pelo AWS Glue. Se vocêusar a política gerenciada pelo Athena, nenhuma ação será necessária. As ações de política do AWSGlue a serem permitidas estão listadas na política de exemplo abaixo. Para obter a instrução de políticacompleta, consulte Políticas do IAM para acesso do usuário (p. 181).
{ "Effect":"Allow", "Action":[ "glue:CreateDatabase", "glue:DeleteDatabase", "glue:GetDatabase", "glue:GetDatabases", "glue:UpdateDatabase", "glue:CreateTable", "glue:DeleteTable", "glue:BatchDeleteTable", "glue:UpdateTable", "glue:GetTable", "glue:GetTables", "glue:BatchCreatePartition", "glue:CreatePartition", "glue:DeletePartition", "glue:BatchDeletePartition", "glue:UpdatePartition", "glue:GetPartition", "glue:GetPartitions", "glue:BatchGetPartition" ], "Resource":[ "*" ]}
Etapa 3 – Escolher a atualização no console do AthenaDepois de fazer as alterações necessárias na política do IAM, escolha Upgrade (Atualizar) no console doAthena. O Athena transfere seus metadados para o Catálogo de dados do AWS Glue. A atualização levasomente alguns minutos. Depois de atualizar, o console do Athena terá um link para abrir o AWS GlueCatalog Manager no Athena.
44

Amazon Athena Guia do usuárioPerguntas frequentes: atualização para
o Catálogo de dados do AWS Glue
Ao criar uma tabela usando o console, você já tem a opção de criar uma tabela usando um crawler doAWS Glue. Para obter mais informações, consulte Usar crawlers do AWS Glue (p. 36).
Perguntas frequentes: atualização para o Catálogo dedados do AWS GlueSe você criou bancos de dados e tabelas usando o Athena em uma região antes do AWS Glue estardisponível nessa região, os metadados serão armazenados em um catálogo de dados gerenciado peloAthena, que pode ser acessado somente pelo Athena e pelo Amazon Redshift Spectrum. Para usar o AWSGlue com o Athena e o Redshift Spectrum, é necessário atualizar para o Catálogo de dados do AWS Glue.
Por que devo atualizar para o Catálogo de dados do AWS Glue?O AWS Glue é um serviço de extração, transformação e carga (ETL) totalmente gerenciado. Ele tem trêscomponentes principais:
• Um crawler do AWS Glue pode examinar automaticamente as fontes de dados, identificar os formatosde dados e inferir os esquemas.
• Um serviço ETL totalmente gerenciado permite transformar e mover dados para diversos destinos.• O Catálogo de dados do AWS Glue armazena informações de metadados sobre bancos de dados e
tabelas e aponta para um armazenamento de dados no Amazon S3 ou um armazenamento de dadoscompatível com JDBC.
45

Amazon Athena Guia do usuárioPerguntas frequentes: atualização para
o Catálogo de dados do AWS Glue
Para obter mais informações, consulte Conceitos do AWS Glue.
A atualização para o Catálogo de dados do AWS Glue apresenta os seguintes benefícios.
Repositório de metadados unificadoO Catálogo de dados do AWS Glue fornece um repositório de metadados unificado em uma grandevariedade de fontes de dados e formatos de dados. Ele fornece integração pronta para uso com o AmazonSimple Storage Service (Amazon S3), o Amazon Relational Database Service (Amazon RDS), o AmazonRedshift, o Amazon Redshift Spectrum, o Athena, o Amazon EMR e qualquer aplicativo compatível como metastore do Apache Hive. Você pode criar as definições de tabela uma vez e consultar dados emmecanismos.
Para obter mais informações, consulte Preencher o Catálogo de dados do AWS Glue.
Reconhecimento automático de esquema e partiçãoOs crawlers do AWS Glue rastreiam automaticamente as fontes de dados, identificam os formatos dedados e sugerem os esquemas e as transformações. Os crawlers podem ajudar a automatizar a criaçãode tabelas e o carregamento automático de partições que podem ser consultadas usando o Athena, oAmazon EMR e o Redshift Spectrum. Também é possível criar tabelas e partições diretamente usando aAPI do AWS Glue, os SDKs e a CLI da AWS.
Para obter mais informações, consulte Catalogar tabelas com um crawler.
Pipelines fáceis de criarO mecanismo ETL do AWS Glue gera um código Python totalmente personalizável, reutilizável e portátil.Você pode editar o código usando o IDE favorito ou um notebook e compartilhá-lo com outras pessoasusando o GitHub. Depois que seu trabalho ETL estiver pronto, é possível programá-lo para ser executadona infraestrutura Spark de dimensionamento totalmente gerenciada do AWS Glue. O AWS Glue lida como provisionamento, a configuração e o dimensionamento dos recursos necessários para executar seustrabalhos ETL, permitindo integrar totalmente o ETL ao seu fluxo de trabalho.
Para obter mais informações, Criar trabalhos do AWS Glue no Guia do desenvolvedor do AWS Glue.
Existem cobranças à parte para o AWS Glue?Sim. Com o AWS Glue, você paga uma taxa mensal para armazenar e acessar os metadadosarmazenados no Catálogo de dados do AWS Glue, uma taxa por hora cobrada por segundo para trabalhosETL do AWS Glue e tempo de execução do crawler, além de uma taxa por hora cobrada por segundo paracada endpoint de desenvolvimento provisionado. O Catálogo de dados do AWS Glue permite armazenaraté um milhão de objetos gratuitamente. Se você armazenar mais de um milhão de objetos, será cobradouma taxa de USD$1 por cada 100.000 objetos em mais de um milhão. Um objeto no Catálogo de dadosdo AWS Glue é uma tabela, uma partição ou um banco de dados. Para obter mais informações, consulteDefinição de preço do AWS Glue.
Perguntas frequentes sobre o processo de atualização• Quem pode realizar a atualização? (p. 47)• Meus usuários usam uma política gerenciada com o Athena e o Redshift Spectrum. Quais etapas
preciso seguir para atualizar? (p. 47)• O que acontecerá se eu não atualizar? (p. 47)• Por que é necessário adicionar políticas do AWS Glue aos usuários do Athena? (p. 47)• O que acontecerá se eu não permitir as políticas do AWS Glue para usuários do Athena? (p. 47)• Existe risco de perda de dados durante a atualização? (p. 47)• Os dados também são movidos durante essa atualização? (p. 47)
46

Amazon Athena Guia do usuárioUsar um metastore do Hive
Quem pode realizar a atualização?Você precisa anexar uma política do IAM gerenciada pelo cliente com uma instrução de política quepermita a ação de atualização para o usuário que realizará a migração. Essa verificação extra evita quealguém migre acidentalmente o catálogo de toda a conta. Para obter mais informações, consulte Etapa 1 –Permitir que um usuário realize a atualização (p. 43).
Meus usuários usam uma política gerenciada com o Athena e o RedshiftSpectrum. Quais etapas preciso seguir para atualizar?A política gerenciada do Athena foi atualizada automaticamente com novas ações de política que permitemque os usuários do Athena acessem o AWS Glue. No entanto, você ainda deverá permitir explicitamente aação de atualização para o usuário que realiza a atualização. Para evitar a atualização acidental, a políticagerenciada não permite essa ação.
O que acontecerá se eu não atualizar?Se você não atualizar, não será possível usar os recursos do AWS Glue com as tabelas e os bancos dedados criados no Athena ou vice-versa. Você pode usar esses serviços de maneira independente. Duranteesse período, o Athena e o AWS Glue impedem que você crie bancos de dados ou tabelas que tenham osmesmos nomes no outro catálogo de dados. Isso evita colisões de nome quando você faz a atualização.
Por que é necessário adicionar políticas do AWS Glue aos usuários do Athena?Antes de você atualizar, o Athena gerencia o catálogo de dados, de maneira que as ações do Athenaprecisem ser permitidas para os usuários executarem consultas. Depois de atualizar para o Catálogo dedados do AWS Glue, as ações do AWS Glue devem ser permitidas para seus usuários. Lembre-se de quea política gerenciada para o Athena já foi atualizada para permitir as ações do AWS Glue necessárias.Portanto, nenhuma ação será necessária se você usar a política gerenciada.
O que acontecerá se eu não permitir as políticas do AWS Glue para os usuáriosdo Athena?Se você atualizar para o Catálogo de dados do AWS Glue e não atualizar as políticas gerenciadas pelocliente ou as políticas em linha do IAM de um usuário, as consultas do Athena falharão porque o usuárionão terá permissão para executar ações no AWS Glue. Para ver as ações específicas a serem permitidas,consulte Etapa 2 – Atualizar políticas gerenciadas pelo cliente/em linha associadas aos usuários doAthena (p. 44).
Existe risco de perda de dados durante a atualização?Não.
Os dados também são movidos durante essa atualização?Não. A migração afeta apenas os metadados.
O uso doÉ possível usar o para consultar conjuntos de dados no Amazon S3 que usam um metastore do ApacheHive. Não é necessária nenhuma migração de metadados para o Catálogo de dados do AWS Glue.No console de gerenciamento do Athena, configure uma função do Lambda para se comunicar como metastore do Hive em sua VPC privada e conecte-a. Para o código da função do Lambda, use aimplementação padrão do Athena – o conector da fonte de dados do Athena para o metastore do Hiveexterno – ou forneça seu próprio.
47

Amazon Athena Guia do usuárioCondições e limitações
Condições e limitaçõesConectores de dados predefinidos e personalizados podem exigir acesso aos recursos a seguir parafuncionar corretamente. Verifique as informações do conector que você usa para garantir que tenhaconfigurado sua VPC corretamente. Para obter informações sobre as permissões do IAM necessáriaspara executar consultas e criar um conector de fonte de dados no Athena, consulte Permitir acesso a um (p. 196).
• Grupo de trabalho AmazonAthenaPreviewFunctionality –• Amazon S3 – além de gravar os resultados da consulta no local dos resultados de consultas do Athena
no Amazon S3, os conectores de dados também gravam em um bucket de vazamento no Amazon S3.Conectividade e permissões para esse local do Amazon S3 são necessárias.
• Athena – para verificar o status da consulta e evitar a verificação em excesso.• AWS Secrets Manager• AWS Glue se o conector usar o AWS Glue para metadados complementares ou primários.• AWS Key Management Service• Policies (Políticas) – metastore do Hive, federação de consulta do Athena e UDFs exigem políticas além
do Política gerenciada AmazonAthenaFullAccess (p. 181). Para obter mais informações, consulteGerenciamento de identidade e acesso no Athena (p. 180).
Conectar o Athena a um metastore do Apache HivePara conectar o Athena a um metastore do Apache Hive, você deverá criar e configurar uma funçãodo Lambda. Para uma implementação básica, execute todas as etapas necessárias no console degerenciamento do Athena.
Como conectar o Athena a uma metastore do Hive
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Connect data source (Conectar fonte de dados).3. Na página Connect data source (Conectar fonte de dados) em Choose a metadata catalog (Escolher
um catálogo de metadados), escolha Apache Hive metastore (Metastore do Apache Hive).4. Escolha Next (Próximo).5. Na página Connection details (Detalhes da conexão), em Lambda function (Função do Lambda),
clique em Create Lambda function (Criar função do Lambda).6. Na caixa de diálogo Create Lambda function (Criar função do Lambda), insira as informações a seguir
para a função do Lambda. Para usar a implementação padrão, aceite os padrões para o local docódigo da função no Amazon S3 e para o handler do Lambda.
• Lambda Function Name (Nome da função do Lambda) – forneça um nome para a função. Porexemplo, myHiveMetastore.
• Lambda execution role (Função de execução do Lambda) – escolha uma função do IAM ou cliqueem Create a new role (Criar uma nova função) para criar uma.
• Function code (Código da função) – o local no Amazon S3 para o arquivo JAR da função doLambda. Use o padrão ou insira o local de seu arquivo JAR personalizado.
• Lambda handler (Handler do Lambda) – o método no arquivo JAR que implementa o conector doHive. Use o padrão ou substitua-o pelo handler em seu código personalizado.
• Hive metastore (HMS) URI (URI do metastore do Hive (HMS)) – insira o nome do host do metastoredo Hive que usa o protocolo Thrift na porta 9083 com a sintaxe thrift://<host_name>:9083.
• Spill location in S3 (Local de vazamento no S3) – especifique um local no Amazon S3 nesta contapara manter os metadados que vazarem se o tamanho da resposta da função do Lambda exceder 4MB.
48

Amazon Athena Guia do usuárioO uso do
• Virtual Private Cloud (VPC) (Nuvem privada virtual (VPC)) – escolha a VPC que contém o metastoredo Hive.
• Subnets (Sub-redes) – escolha as sub-redes da VPC para o Lambda usar para definir aconfiguração da VPC.
• Security Groups (Grupos de segurança) – escolha os grupos de segurança da VPC para o Lambdausar para definir a configuração da VPC.
• Memory (Memória) – especifique um valor de 128 MB a 3008 MB. A função do Lambda alocaráciclos de CPU proporcionais à quantidade de memória que você configurar.
• Timeout (Tempo limite) – especifique um valor de 1 segundo a 15 minutos e 59 segundos. O padrãoé 3 segundos.
7. Clique em Criar. A página Connection details (Detalhes da conexão) informa que a função está sendocriada. Quando a operação for concluída, o nome de sua função estará disponível na caixa Choose afunction name (Escolher um nome de função) e o ARN da função do Lambda será exibido.
8. Em Catalog name (Nome do catálogo), insira um nome exclusivo a ser usado para a fonte de dadosnas consultas SQL. O nome pode ter até 127 caracteres e deve ser exclusivo na sua conta. Ele nãopoderá ser alterado após a criação. Os caracteres válidos são a-z, A-z, 0-9, _ (sublinhado), @ (ecomercial) e - (hífen).
9. Clique em Connect (Conectar) para conectar o Athena à fonte de dados.
A página Data sources (Fontes de dados) exibirá o conector na lista de nomes de catálogo. Agoravocê poderá usar o Catalog name (Nome do catálogo) especificado para fazer referência ao metastoredo Hive em suas consultas SQL. Use a sintaxe no exemplo a seguir, em que MyHiveMetastore é onome do catálogo especificado anteriormente.
SELECT * FROM MyHiveMetastore.CustomerData.customers;
O uso doSe tiver dados em fontes que não sejam o Amazon S3, você poderá usar o para consultar os dados nolocal ou criar pipelines que extraiam dados de várias fontes de dados e os armazene no Amazon S3. Opermite executar consultas SQL em dados armazenados em fontes de dados relacionais, não relacionais,personalizadas e de objetos.
O Athena usa conectores de fontes de dados executados no AWS Lambda para executar consultasfederadas. Um conector de fonte de dados é uma parte de código que pode traduzir entre sua fonte dedados de destino e o Athena. Pense em um conector como uma extensão do mecanismo de consultado Athena. Há conectores de fontes de dados predefinidos do Athena para fontes de dados, comoAmazon CloudWatch Logs Amazon DynamoDB, Amazon DocumentDB e Amazon RDS, e fontes de dadosrelacionais compatíveis com JDBC, como MySQL e PostgreSQL sob os termos da licença do Apache 2.0.Também é possível usar o para gravar conectores personalizados. Para escolher, configurar e implantarum conector de fonte de dados em sua conta, use os consoles do Athena e do Lambda ou o AWSServerless Application Repository. Depois que implantar conectores de fonte de dados, o conector seráassociado a um catálogo que pode ser especificado nas consultas SQL. É possível combinar instruçõesSQL de vários catálogos e abranger várias fontes de dados com uma única consulta.
Quando uma consulta é enviada em relação a uma fonte de dados, o Athena chama o conectorcorrespondente para identificar partes das tabelas que devem ser lidas, gerencia o paralelismo e enviaos predicados do filtro. Com base no usuário que envia a consulta, os conectores podem fornecer ourestringir o acesso a elementos de dados específicos. Os conectores usam o Apache Seta como o formatopara retornar dados solicitados em uma consulta, o que permite que os conectores sejam implementadosem linguagens como C, C++, Java, Python e Rust. Como os conectores são executados no Lambda,eles podem ser usados para acessar dados de qualquer fonte de dados na nuvem ou no local que sejaacessível do Lambda.
49

Amazon Athena Guia do usuárioCondições e limitações
Para gravar seu próprio conector de fonte de dados, use o para personalizar um dos conectorespredefinidos que o Amazon Athena fornece e mantém. Modifique uma cópia do código-fonte do repositóriodo GitHub e use a Ferramenta de publicação do conector para criar seu próprio pacote do AWS ServerlessApplication Repository.
Para obter uma lista de conectores de fonte de dados do Athena disponíveis, consulte Usar conectores defontes de dados do Athena (p. 52).
Para obter informações sobre como gravar seu próprio conector de fonte de dados, consulte Exemplo deconector do Athena no GitHub.
Condições e limitaçõesConectores de fonte de dados podem exigir acesso aos recursos a seguir para funcionar corretamente.Se você usar um conector predefinido, verifique as informações do conector para garantir que tenhaconfigurado sua VPC corretamente. Além disso, certifique-se de que os principais do IAM executandoconsultas e criando conectores tenham privilégios para as ações necessárias. Para obter maisinformações, consulte Exemplo de políticas de permissões do IAM para permitir o (p. 198).
• Para obter as informações mais atualizadas sobre problemas e limitações conhecidos, consulteLimitações e problemas no repositório GitHub aws-athena-query-federation.
• Grupo de trabalho AmazonAthenaPreviewFunctionality –• Amazon S3 – além de gravar os resultados da consulta no local dos resultados de consultas do Athena
no Amazon S3, os conectores de dados também gravam em um bucket de vazamento no Amazon S3.Conectividade e permissões para esse local do Amazon S3 são necessárias.
• Athena – as fontes de dados precisam de conectividade com o Athena e vice-versa para verificar ostatus da consulta e evitar a verificação em excesso.
• Catálogo de dados do AWS Glue – conectividade e permissões são necessárias se o conector usar oData Catalog para metadados complementares ou primários.
Implantar um conector e conectar-se a uma fonte dedadosPreparar-se para criar consultas federadas é um processo de duas partes: implantar um conector de fontede dados da função do Lambda e conectar a função do Lambda a uma fonte de dados. Na primeira parte,dê à função do Lambda um nome que poderá escolher posteriormente no console do Athena. Na segundaparte, dê ao conector um nome ao qual você poderá fazer referência em suas consultas SQL.
Parte 1: Implantar um conector de fonte de dadosPara escolher, nomear e implantar um conector de fonte de dados, use os consoles do Lambda e doAthena e em um processo integrado.
Note
Como implantar um conector de fonte de dados
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Connect data source (Conectar fonte de dados).3. Na página Connect data source (Conectar fonte de dados) escolha Query a data source (Consultar
uma fonte de dados).4. Em Choose a data source (Escolher uma fonte de dados), escolha a fonte de dados que deseja
consultar com o Athena, como o Amazon CloudWatch Logs.
50

Amazon Athena Guia do usuárioUsar o AWS Serverless Application Repository
5. Escolha Next (Próximo).6. Em Lambda function (Função do Lambda), escolha Configure new function (Configurar nova função).
A página de função do conector escolhido será aberta no console do Lambda. A página incluiinformações detalhadas sobre o conector.
7. Em Application settings (Configurações do aplicativo), insira as informações necessárias. No mínimo,isso inclui:
• AthenaCatalogName – um nome para a função do Lambda que indica a fonte de dados que elavisa, como cloudwatchlogs.
• SpillBucket – um bucket do Amazon S3 em sua conta para armazenar os dados que excederem oslimites de tamanho da resposta da função do Lambda.
8. Selecione I acknowledge that this app creates custom IAM roles (Eu reconheço que este aplicativo criafunções personalizadas do IAM). Para obter mais informações, escolha o link Info (Informações).
9. Escolha Deploy (Implantar). A seção Resources (Recursos) do console do Lambda mostra o status deimplantação do conector e informa quando a implantação for concluída.
Parte 2: Conectar-se a uma fonte de dadosDepois de implantar o conector da fonte de dados em sua conta, você poderá conectá-lo a uma fonte dedados.
Como conectar-se a uma fonte de dados usando um conector que você implantou em sua conta
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha Connect data source (Conectar fonte de dados).3. Escolha Query a data source (Consultar uma fonte de dados).4. Escolha a fonte de dados para o conector que você acabou de implantar, como o Amazon
CloudWatch Logs. Se usou o para criar seu próprio conector e o implantou em sua conta, escolha Allother data sources (Todas as outras fontes de dados).
5. Escolha Next (Próximo).6. Em Choose Lambda function (Escolher função do Lambda), escolha a função que você nomeou. O
ARN da função do Lambda será exibido.7. Em Catalog name (Nome do catálogo), insira um nome exclusivo a ser usado para a fonte de dados
em suas consultas SQL, como cloudwatchlogs. O nome pode ter até 127 caracteres e deve serexclusivo na sua conta. Ele não poderá ser alterado após a criação. Os caracteres válidos são a-z, A-z, 0-9, _ (sublinhado), @ (e comercial) e - (hífen).
8. Selecione Conectar. A página Data sources (Fontes de dados) agora exibirá o conector na lista denomes de catálogo. Agora é possível usar o conector em suas consultas.
Para obter informações sobre como gravar consultas com conectores de dados, consulte Gravarconsultas federadas (p. 54).
Usar o AWS Serverless Application Repository paraimplantar um conector de fonte de dadosTambém é possível usar o AWS Serverless Application Repository para implantar um conector de fontede dados do Athena. Encontre o conector que deseja usar, forneça os parâmetros que o conector exige eimplante o conector em sua conta.
Note
51

Amazon Athena Guia do usuárioConectores de fontes de dados do Athena
Como usar o AWS Serverless Application Repository para implantar um conector de fonte dedados em sua conta
1. Abra o console do Serverless App Repository (Repositório de aplicativos sem servidor).2. Selecione a opção Show apps that create custom IAM roles or resource policies (Mostrar aplicativos
que criam funções do IAM personalizadas ou políticas de recursos).3. Na caixa de pesquisa, digite o nome do conector ou procure aplicativos publicados com o nome do
autor Amazon Athena Federation (Federação do Amazon Athena). Esse nome de autor é reservadopara aplicativos que a equipe do Amazon Athena escreveu, testou e validou.
4. Escolha o nome do conector. Isso abrirá a página Application details (Detalhes do aplicativo) dafunção do Lambda no console do AWS Lambda.
5. No lado direito da página de detalhes, em SpillBucket, especifique um bucket do Amazon S3 parareceber dados de cargas de resposta grandes. Para obter informações sobre as opções configuráveisrestantes, consulte o tópico correspondente Conectores disponíveis no GitHub.
6. Na parte inferior direita da página Application details (Detalhes do aplicativo) escolha Deploy(Implantar).
Usar conectores de fontes de dados do AthenaEsta seção lista conectores de fontes de dados do Athena pré-criados que podem ser usados paraconsultar uma grande variedade de fontes de dados externas do Amazon S3. Para usar um conector emsuas consultas do Athena, configure-o e implante-o em sua conta.
Note
Consulte os tópicos a seguir para obter mais informações:
• Para obter informações sobre como implantar um conector de fonte de dados do Athena, consulteImplantar um conector e conectar-se a uma fonte de dados (p. 50).
• Para obter informações sobre como escrever consultas que usam conectores de fonte de dados doAthena, consulte Gravar consultas federadas (p. 54).
• Para obter informações completas sobre os conectores de fonte de dados do Athena, consulteConectores disponíveis no GitHub.
Tópicos• Conectores CMDB da AWS do Athena (p. 52)• Conector do CloudWatch do Amazon Athena (p. 53)• Conector de métricas do CloudWatch do Amazon Athena (p. 53)• Conector do DocumentDB do Amazon Athena (p. 53)• Conector do DynamoDB do Amazon Athena (p. 53)• Conector do HBase do Amazon Athena (p. 53)• O conector do Amazon Athena para fontes de dados compatíveis com JDBC (p. 53)• Conector Redis do Amazon Athena (p. 54)• Conector do TPC Benchmark DS (TPC-DS) do Amazon Athena (p. 54)
Conectores CMDB da AWS do AthenaO conector CMDB da AWS do Amazon Athena permite que o Amazon Athena se comunique com váriosserviços da AWS para que seja possível consultá-los com SQL.
52

Amazon Athena Guia do usuárioConectores de fontes de dados do Athena
Para obter informações sobre serviços, parâmetros, permissões, implantação, desempenho elicenciamento compatíveis, consulte Conector CMDB da AWS do Amazon Athena no GitHub.
Conector do CloudWatch do Amazon AthenaO conector do CloudWatch do Amazon Athena permite que o Amazon Athena se comunique com oCloudWatch para que seja possível consultar os dados de log com SQL.
O conector mapeia os LogGroups como esquemas e cada LogStream como uma tabela. O conectortambém mapeia uma exibição all_log_streams especial que contém todos os LogStreams noLogGroup. Essa exibição permite consultar todos os logs em um LogGroup de uma só vez, em vez depesquisar cada LogStream individualmente.
Para obter mais informações sobre opções de configuração, controle de limitação, esquemas demapeamento de tabelas, permissões, implantação, considerações de desempenho e licenciamento,consulte Conector do CloudWatch do Amazon Athena no GitHub.
Conector de métricas do CloudWatch do Amazon AthenaO conector de métricas do CloudWatch do Amazon Athena permite que o Amazon Athena se comuniquecom métricas do CloudWatch para que seja possível consultar os dados de métricas com SQL.
Para obter informações sobre opções de configuração, mapeamento de tabelas, permissões, implantação,considerações de desempenho e licenciamento, consulte Conector de métricas do Cloudwatch do AmazonAthena no GitHub.
Conector do DocumentDB do Amazon AthenaO conector do Amazon DocumentDB do Amazon Athena permite que o Amazon Athena se comuniquecom as instâncias do Amazon DocumentDB para que seja possível consultar os dados do AmazonDocumentDB com SQL. O conector também funciona com qualquer endpoint compatível com o MongoDB.
Para obter informações sobre como o conector gera esquemas, opções de configuração, permissões,implantação e considerações de desempenho, consulte Conector do DocumentDB do Amazon Athena noGitHub.
Conector do DynamoDB do Amazon AthenaO conector do DynamoDB do Amazon Athena permite que o Amazon Athena se comunique com oDynamoDB para que seja possível consultar as tabelas com SQL.
Para obter informações sobre opções de configuração, permissões, implantação e considerações dedesempenho, consulte Conector do DynamoDB do Amazon Athena no GitHub.
Conector do HBase do Amazon AthenaO conector do HBase do Amazon Athena permite que o Amazon Athena se comunique com as instânciasdo HBase para que seja possível consultar os dados do HBase com SQL.
Para obter informações sobre opções de configuração, tipos de dados, permissões, implantação,desempenho e licenciamento, consulte o Conector do HBase do Amazon Athena no GitHub.
O conector do Amazon Athena para fontes de dados compatíveiscom JDBCO conector JDBC do Lambda do Amazon Athena permite que o Amazon Athena acesse o banco de dadoscompatível com JDBC. No momento, os bancos de dados compatíveis incluem MySQL, PostgreSQL eAmazon Redshift.
53

Amazon Athena Guia do usuárioGravar consultas federadas
Para obter informações sobre bancos de dados compatíveis, parâmetros de configuração, tipos de dadoscompatíveis, versões de driver JDBC, limitações e outras informações, consulte Conector JDBC doLambda do Amazon Athena no GitHub.
Conector Redis do Amazon AthenaO conector do Redis do Amazon Athena permite que o Amazon Athena se comunique com as instânciasdo Redis para que seja possível consultar os dados do Redis com SQL. É possível usar o Catálogo dedados do AWS Glue para mapear os pares de chave-valor do Redis em tabelas virtuais.
Para obter informações sobre opções de configuração, configuração de bancos de dados e tabelas, tiposde dados, permissões, implantação, desempenho e licenciamento, consulte Conector do Redis do AmazonAthena no GitHub.
Conector do TPC Benchmark DS (TPC-DS) do Amazon AthenaO conector do TPC-DS do Amazon Athena permite que o Amazon Athena se comunique com uma fontede dados do TPC Benchmark DS gerada aleatoriamente para uso em benchmarking e testes funcionais.O conector do TPC-DS do Athena gera um banco de dados compatível com TPC-DS em um dos quatrofatores de escala.
Para obter informações sobre opções de configuração, bancos de dados e tabelas, permissões,implantação, desempenho e licenciamento, consulte Conector do TPC-DS do Amazon Athena no GitHub.
Gravar consultas federadasDepois de configurar um ou mais conectores de dados e implantá-los em sua conta, você poderá usá-losnas consultas do Athena.
Consultar uma única fonte de dadosOs exemplos nesta seção pressupõem que você tenha configurado e implantado o conector doCloudWatch do Athena em sua conta. Use a mesma abordagem para consultar quando usar outrosconectores.
Como criar uma consulta do Athena que usa o conector do CloudWatch
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. No Editor de consultas do Athena, crie uma consulta SQL que use a sintaxe a seguir na cláusula
FROM.
MyCloudwatchCatalog.database_name.table_name
Exemplos
O exemplo a seguir usa o conector do CloudWatch do Athena para se conectar à visualizaçãoall_log_streams no Grupo de logs de /var/ecommerce-engine/order-processor doCloudWatch Logs. A visualização all_log_streams é uma visualização de todos os fluxos de log nogrupo de logs. A consulta de exemplo limita o número de linhas retornadas a 100.
Example
SELECT * FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams limit 100;
54

Amazon Athena Guia do usuárioGravar consultas federadas
O exemplo a seguir analisa informações da mesma visualização que o exemplo anterior. O exemplo extraio ID da ordem e o nível de log e filtra qualquer mensagem que tenha o nível INFO.
Example
SELECT log_stream as ec2_instance, Regexp_extract(message '.*orderId=(\d+) .*', 1) AS orderId, message AS order_processor_log, Regexp_extract(message, '(.*):.*', 1) AS log_level FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams WHERE Regexp_extract(message, '(.*):.*', 1) != 'INFO'
A imagem a seguir mostra um exemplo de resultado.
Note
Este exemplo mostra uma consulta na qual a fonte de dados foi registrada como um catálogo noAthena. Também é possível fazer referência a uma função do Lambda do conector de fonte dedados usando o formato lambda:MyLambdaFunctionName.
Consultar várias fontes de dadosComo um exemplo mais complexo, imagine uma empresa de comércio eletrônico que tenha umainfraestrutura de aplicativos, como a mostrada no diagrama a seguir.
55

Amazon Athena Guia do usuárioGravar consultas federadas
As descrições a seguir explicam os itens numerados no diagrama.
1. Processamento de pagamento em uma VPC segura com registros de transação armazenados noHBase no Amazon EMR
2. Redis para armazenar ordens ativas para que o mecanismo de processamento possa acessá-losrapidamente
3. Amazon DocumentDB para dados da conta do cliente, como endereços de e-mail e endereços de envio4. Um catálogo de produtos no Amazon Aurora para um site de comércio eletrônico que usa escalabilidade
automática no Fargate5. CloudWatch Logs para alojar os eventos de log do processador de pedidos6. Um data warehouse de gravação única e várias leituras (WORM – write-once-read-many) no Amazon
RDS7. DynamoDB para armazenar dados de rastreamento de remessa
Imagine que um analista de dados para este aplicativo de comércio eletrônico descobre que o estado dealguns pedidos está sendo relatado incorretamente. Alguns pedidos são exibidos como pendentes, emboratenham sido entregues, enquanto outros são exibidos como entregues, mas não foram enviados.
O analista quer saber quantos pedidos estão com atraso e o que os pedidos afetados têm em comum emtoda a infraestrutura do comércio eletrônico. Em vez de investigar as fontes de informação separadamente,o analista federa as fontes de dados e recupera as informações necessárias em uma única consulta.Extrair os dados em um único local não é necessário.
A consulta do analista usa os seguintes conectores de dados do Athena:
• CloudWatch Logs – recupera logs do serviço de processamento de pedidos e usa correspondência eextração regex para filtrar pedidos com eventos WARN ou ERROR.
56

Amazon Athena Guia do usuárioGravar consultas federadas
• Redis – recupera os pedidos ativos da instância do Redis.• CMDB – recupera o ID e o estado da instância do Amazon EC2 que executou o serviço de
processamento de pedidos e registrou em log a mensagem ERROR ou WARN.• DocumentDB – recupera o e-mail e o endereço do cliente no Amazon DocumentDB para os pedidos
afetados.• DynamoDB – recupera o status da remessa e os detalhes de rastreamento da tabela de remessas para
identificar possíveis discrepâncias entre o status relatado e o status real.• HBase – recupera o status de pagamento dos pedidos afetados no serviço de processamento de
pagamento.
ExampleNote
Este exemplo mostra uma consulta na qual a fonte de dados foi registrada como um catálogo noAthena. Também é possível fazer referência a uma função do Lambda do conector de fonte dedados usando o formato lambda:MyLambdaFunctionName.
--Sample query using multiple Athena data connectors.WITH logs AS (SELECT log_stream, message AS order_processor_log, Regexp_extract(message, '.*orderId=(\d+) .*', 1) AS orderId, Regexp_extract(message, '(.*):.*', 1) AS log_level FROM "MyCloudwatchCatalog"."/var/ecommerce-engine/order-processor".all_log_streams WHERE Regexp_extract(message, '(.*):.*', 1) != 'INFO'), active_orders AS (SELECT * FROM redis.redis_db.redis_customer_orders), order_processors AS (SELECT instanceid, publicipaddress, state.NAME FROM awscmdb.ec2.ec2_instances), customer AS (SELECT id, email FROM docdb.customers.customer_info), addresses AS (SELECT id, is_residential, address.street AS street FROM docdb.customers.customer_addresses), shipments AS ( SELECT order_id, shipment_id, from_unixtime(cast(shipped_date as double)) as shipment_time, carrier FROM lambda_ddb.default.order_shipments), payments AS ( SELECT "summary:order_id", "summary:status", "summary:cc_id", "details:network" FROM "hbase".hbase_payments.transactions) SELECT _key_ AS redis_order_id, customer_id, customer.email AS cust_email, "summary:cc_id" AS credit_card,
57

Amazon Athena Guia do usuárioGravar um conector de fonte de dados
"details:network" AS CC_type, "summary:status" AS payment_status, status AS redis_status, addresses.street AS street_address, shipments.shipment_time as shipment_time, shipments.carrier as shipment_carrier, publicipaddress AS ec2_order_processor, NAME AS ec2_state, log_level, order_processor_log FROM active_orders LEFT JOIN logs ON logs.orderid = active_orders._key_ LEFT JOIN order_processors ON logs.log_stream = order_processors.instanceid LEFT JOIN customer ON customer.id = customer_id LEFT JOIN addresses ON addresses.id = address_id LEFT JOIN shipments ON shipments.order_id = active_orders._key_ LEFT JOIN payments ON payments."summary:order_id" = active_orders._key_
A imagem a seguir mostra o exemplo de resultados da consulta.
Gravar um conector de fonte de dados usando oPara gravar seus próprios conectores de fonte de dados (p. 49), é possível usar o https://github.com/awslabs/aws-athena-query-federation/tree/master/athena-federation-sdk. O define um conjunto deinterfaces e protocolos de conexão que pode ser usado para permitir que o Athena delegue partes de seuplano de execução de consultas para codificar a gravação e a implantação. O SDK inclui um conjunto deconectores e um conector de exemplo.
Também é possível personalizar os conectores predefinidos do Amazon Athena para seu próprio uso.Modifique uma cópia do código-fonte do GitHub e use a Ferramenta de publicação do conector para criarseu próprio pacote do AWS Serverless Application Repository. Depois que implantar o conector dessamaneira, você poderá usá-lo em suas consultas do Athena.
Note
Para obter informações sobre como fazer download do SDK e obter instruções detalhadas para gravar seupróprio conector, consulte Exemplo de conector do Athena no GitHub.
Gerenciar fontes de dadosÉ possível usar a página Data Sources (Fontes de dados) do console do Athena para exibir, editar ouexcluir as fontes de dados criadas, incluindo o conector de fonte de dados do Athena, o Catálogo de dadosdo AWS Glue e tipos de catálogo de metastore do Hive.
58

Amazon Athena Guia do usuárioConexão ao Amazon Athena com drivers ODBC e JDBC
Como exibir uma fonte de dados
• Escolha o nome do catálogo da fonte de dados ou selecione o botão ao lado dele e escolha Viewdetails (Exibir detalhes). A página de detalhes inclui opções para Edit (Editar) ou Delete (Excluir) afonte de dados.
Como editar uma fonte de dados
1. Escolha o nome do catálogo da fonte de dados ou selecione o botão ao lado do nome do catálogo.2. Selecione Edit (Editar).3. Na página Edit (Editar) do metastore, é possível escolher uma função do Lambda diferente para a
fonte de dados ou alterar a descrição da função existente. Ao editar um catálogo do AWS Glue, oconsole do AWS Glue abre o catálogo correspondente para edição.
4. Escolha Save (Salvar).
Como excluir uma fonte de dados
1. Selecione o botão ao lado da fonte de dados ou do nome da fonte de dados e escolha Delete (Excluir).Você é avisado que, ao excluir uma fonte de dados de metastore, seu catálogo de dados, tabelas eexibições correspondentes são removidos do editor de consultas. Consultas salvas que usavam ometastore não são mais executadas no Athena.
2. Escolha Delete.
Conexão ao Amazon Athena com drivers ODBC eJDBC
Para explorar e visualizar os dados com as ferramentas de business intelligence, fazer download, instalar econfigurar um driver Open Database Connectivity (ODBC) ou Java Database Connectivity (JDBC).
Tópicos• Uso do Athena com o driver JDBC (p. 59)• Conexão ao Amazon Athena com o ODBC (p. 61)
Uso do Athena com o driver JDBCÉ possível usar uma conexão JDBC para conectar o Athena a ferramentas de inteligência empresarial eoutros aplicativos, como o SQL Workbench. Para isso, faça download, instale e configure o driver JDBC doAthena usando os links a seguir no Amazon S3.
Links para download do driver JDBCO driver JDBC versão 2.0.9 está em conformidade com os padrões de dados da API JDBC 4.1 e 4.2. Antesde fazer download do driver, verifique qual versão do Java Runtime Environment (JRE) você usa. A versãodo JRE depende da versão da JDBC API que você está usando com o driver. Se você não tiver certeza,faça download da versão mais recente do driver.
Faça download do driver que corresponde à sua versão do JDK e aos padrões de dados JDBC:
• O AthenaJDBC41-2.0.9.jar é compatível com o JDBC 4.1 e requer o JDK 7.0 ou posterior.• O AthenaJDBC42-2.0.9.jar é compatível com o JDBC 4.2 e requer o JDK 8.0 ou posterior.
59

Amazon Athena Guia do usuárioUso do Athena com o driver JDBC
Notas de release do driver JDBC, Contrato de licença e notificações
Depois de fazer download da versão que você precisa, leia as notas de release e revise o Contrato delicença e as notificações.
• Notas de release• Contrato de licença• Avisos• Licenças de terceiros
Documentação do driver JDBC
Faça download da seguinte documentação do driver:
• Guia de instalação e configuração do driver JDBC. Use este guia para instalar e configurar o driver.• Guia de migração do driver JDBC. Use este guia para migrar de versões anteriores para a versão atual.
Links para download do driver JDBC para recursos devisualizaçãoEsses drivers oferecem suporte a recursos de visualização do Athena. Faça download do driver quecorresponde à sua versão do JDK e aos padrões de dados JDBC:
• O AthenaJDBC41_preview.jar é compatível com o JDBC 4.1 e requer o JDK 7.0 ou posterior.• O AthenaJDBC42_preview.jar é compatível com o JDBC 4.2 e requer o JDK 8.0 ou posterior.
Notas de release do driver JDBC, contrato de licença e avisos para o driver devisualização
Depois de fazer download da versão que você precisa, leia as notas de release e revise o Contrato delicença e as notificações.
• Notas de release• Contrato de licença• Avisos• Licenças de terceiros
Documentação do driver JDBC para o driver de visualização
Faça download da seguinte documentação do driver:
• Guia de instalação e configuração do driver JDBC. Use este guia para instalar e configurar o driver.• Guia de migração do driver JDBC. Use este guia para migrar de versões anteriores para a versão atual.
Migração da versão anterior do driver JDBCA versão atual do driver JDBC 2.0.9 é uma substituta da versão anterior do driver JDBC versão 2.0.8 e écompatível com versões anteriores do driver JDBC versão 2.0.8. Execute a etapa a seguir para garantir aexecução do driver.
60

Amazon Athena Guia do usuárioConexão ao Amazon Athena com o ODBC
Important
Para usar o driver JDBC versão 2.0.5 ou posterior, associe uma política de permissõesàs entidades principais do IAM usando o driver JDBC que permita a ação da politicaathena:GetQueryResultsStream. Essa ação de política não é exposta diretamente coma API. Ela só é usada com o driver JDBC como parte do suporte a resultados de streaming.Para obter uma política de exemplo, consulte Política gerenciada AWSQuicksightAthenaAccessManaged (p. 183). Além disso, verifique se a porta 444 está aberta para tráfego de saída. Paraobter mais informações sobre como fazer a atualização da versão 2.0.2 para a versão 2.0.5 ousuperior, consulte o Guia de migração do driver JDBC.
Para obter informações sobre as versões anteriores do driver JDBC, consulte Usar o Athena com a versãoanterior do driver JDBC (p. 317).
Se estiver migrando de um driver 1.x para um driver 2.x, você precisará migrar suas configuraçõesexistentes para a nova configuração. É altamente recomendável que você migre para o driver versão 2.x.Para obter informações, consulte o Guia de migração do driver JDBC.
Conexão ao Amazon Athena com o ODBCFaça download da documentação do ODBC, de drivers ODBC e do Contrato de licença do driver ODBC doAmazon Athena usando os links a seguir.
Contrato de licença do driver ODBC do Amazon AthenaContrato de licença
Links para download do driver ODBCWindows
Versão do driver Link para download
ODBC 1.0.5 para Windows 32 bits Driver ODBC 1.0.5 para Windows 32 bits
ODBC 1.0.5 para Windows 64 bits Driver 1.0.5 para Windows 64 bits
Linux
Versão do driver Link para download
ODBC 1.0.5 para Linux 32 bits Driver ODBC 1.0.5 para Linux 32 bits
ODBC 1.0.5 para Linux 64 bits Driver 1.0.5 para Linux 64 bits
OSX
Versão do driver Link para download
ODBC 1.0.5 para OSX Driver OSX ODBC 1.0.5
61

Amazon Athena Guia do usuárioConexão ao Amazon Athena com o ODBC
Documentação
Versão do driver Link para download
Documentação para ODBC 1.0.5 Guia de instalação e configuração do driver ODBCversão 1.0.5
Notas de release do ODBC 1.0.5 Notas de release do driver ODBC versão 1.0.5
Links para download do driver ODBC de pré-visualizaçãoA versão de pré-visualização 1.1.0 do driver ODBC para Athena inclui suporte para catálogos dinâmicos.
Windows
Versão do driver Link para download
Pré-visualização 1.1.0 do ODBC para Windows 32bits
Driver ODBC 1.1.0 do Windows 32 bits
Pré-visualização 1.1.0 do ODBC para Windows 64bits
Driver ODBC 1.1.0 do Windows 64 bits
Linux
Versão do driver Link para download
Pré-visualização 1.1.0 do ODBC para Linux 32 bits Driver ODBC 1.1.0 do Linux 32 bits
Pré-visualização 1.1.0 do ODBC para Linux 64 bits Driver ODBC 1.1.0 do Linux 64 bits
OSX
Versão do driver Link para download
Pré-visualização 1.1.0 do ODBC para OSX Driver ODBC 1.1.0 do OSX
Documentação
Versão do driver Link para download
Documentação para a pré-visualização 1.1.0 doODBC
Guia de instalação e configuração do driver ODBCversão 1.1.0
Notas de release para a pré-visualização 1.1.0 doODBC
Notas de release da pré-visualização 1.1.0 dodriver ODBC
62

Amazon Athena Guia do usuárioConexão ao Amazon Athena com o ODBC
Migração da versão anterior do driver ODBCO driver ODBC atual versão 1.0.5 é um substituto pronto para a versão anterior do driver ODBC versão1.0.4. Ele também é compatível com a versão anterior do driver ODBC, 1.0.3, se você usar as seguintesetapas necessárias para se certificar de que o driver é executado.
Important
Para usar o driver ODBC versão 1.0.3 ou superior, siga estes requisitos:
• Mantenha a porta 444 aberta para tráfego de saída.• Adicione a ação de política athena:GetQueryResultsStream à lista de políticas para
Athena. Essa ação de política não é exposta diretamente com a operação da API e só éusada com os drivers ODBC e JDBC, como parte do suporte ao streaming de resultados. Paraobter uma política de exemplo, consulte Política gerenciada AWSQuicksightAthenaAccessManaged (p. 183).
Versões anteriores do driver ODBC
Versão 1.0.4 do driver Link para download
ODBC 1.0.4 para Windows 32 bits Driver ODBC 1.0.4 para Windows 32 bits
ODBC 1.0.4 para Windows 64 bits Driver ODBC 1.0.4 para Windows 64 bits
ODBC 1.0.4 para Linux 32 bits Driver ODBC 1.0.4 para Windows 64 bits
ODBC 1.0.4 para Linux 64 bits Driver ODBC 1.0.4 para Linux 64 bits
ODBC 1.0.4 para OSX Driver OSX ODBC 1.0.4
Documentação para ODBC 1.0.4 Guia de instalação e configuração do driver ODBCversão 1.0.4
Versão 1.0.3 do driver Link para download
ODBC 1.0.3 para Windows 32 bits Driver ODBC 1.0.3 para Windows 32 bits
ODBC 1.0.3 para Windows 64 bits Driver ODBC 1.0.3 para Windows 64 bits
ODBC 1.0.3 para Linux 32 bits Driver ODBC 1.0.3 para Linux 32 bits
ODBC 1.0.3 para Linux 64 bits Driver ODBC 1.0.3 para Linux 64 bits
ODBC 1.0.3 para OSX Driver ODBC OSX 1.0
Documentação para ODBC 1.0.3 Guia de instalação e configuração do driver ODBCversão 1.0.3
Versão 1.0.2 do driver Link para download
ODBC 1.0.2 para Windows 32 bits Driver ODBC 1.0.2 para Windows 32 bits
ODBC 1.0.2 para Windows 64 bits Driver ODBC 1.0.2 para Windows 64 bits
63

Amazon Athena Guia do usuárioConexão ao Amazon Athena com o ODBC
Versão 1.0.2 do driver Link para download
ODBC 1.0.2 para Linux 32 bits Driver ODBC 1.0.2 para Linux 32 bits
ODBC 1.0.2 para Linux 64 bits Driver ODBC 1.0.2 para Linux 64 bits
ODBC 1.0 para OSX Driver ODBC OSX 1.0
Documentação para ODBC 1.0.2 Guia de instalação e configuração do driver ODBCversão 1.0.2
64

Amazon Athena Guia do usuárioResultados de consulta e histórico de consultas
Executar consultas SQL usando oAmazon Athena
É possível executar consultas SQL usando fontes de dados do Amazon Athena que são registradas como Catálogo de dados do AWS Glue e as fontes de dados às quais você se conecta usando a federaçãode consulta (visualização) do Athena, como metastores do Hive e instâncias do Amazon DocumentDB.Para obter mais informações sobre como trabalhar com fontes de dados, consulte Conectar a fontes dedados (p. 32). Ao executar uma consulta de DDL (Data Definition Language) que modifica o esquema, oAthena grava os metadados no metastore associado à fonte de dados. Além disso, algumas consultas,como CREATE TABLE AS e INSERT INTO, podem gravar registros no conjunto de dados. Por exemplo,adicionar um registro CSV a um local do Amazon S3. Ao executar uma consulta, o Athena salva osresultados de uma consulta em um local de resultado de consulta especificado. Isso permite visualizar ohistórico de consultas e fazer download e exibir conjuntos de resultados de consulta.
Esta seção fornece orientações para executar consultas do Athena em fontes de dados comuns e tiposde dados usando uma variedade de instruções SQL. Orientações gerais são fornecidas para trabalharcom estruturas e operadores comuns. Por exemplo, trabalhar com matrizes, concatenação, filtragem,achatamento e classificação. Outros exemplos incluem consultas de dados em tabelas com mapas eestruturas aninhadas, tabelas baseadas em conjuntos de dados codificados em JSON e conjuntos dedados associados a serviços da AWS, como logs do AWS CloudTrail e do Amazon EMR.
Tópicos• Trabalhar com resultados de consulta, arquivos de saída e histórico de consultas (p. 65)• Como trabalhar com exibições (p. 72)• Criar uma tabela a partir de resultados da consulta (CTAS) (p. 77)• Tratamento de atualizações de esquema (p. 95)• Consultar matrizes (p. 105)• Consultar JSON (p. 121)• Consultar dados geoespaciais (p. 127)• O uso do (p. 139)• Consultas com funções definidas pelo usuário (visualização) (p. 140)• Consultar logs de serviço da AWS (p. 148)• Consulta no Catálogo de dados do AWS Glue (p. 168)
Trabalhar com resultados de consulta, arquivos desaída e histórico de consultas
O Amazon Athena armazena automaticamente os resultados da consulta e as informações de metadadospara cada consulta executada em um local de resultados da consulta que você pode especificar noAmazon S3. Se necessário, você pode acessar os arquivos nesse local para trabalhar com eles. Tambémé possível fazer download dos arquivos de resultados da consulta diretamente no console do Athena.
Os arquivos de saída são salvos automaticamente para cada consulta executada, independentementede a consulta em si ter sido salva ou não. Para acessar e visualizar arquivos de saída da consulta,as entidades principais do IAM (usuários e funções) precisam de permissão para a ação Amazon S3GetObject para o local de resultados da consulta, bem como permissão para a ação GetQueryResults
65

Amazon Athena Guia do usuárioObter um ID de consulta
do Athena. O local de resultados da consulta pode ser criptografado. Se o local estiver criptografado, osusuários deverão ter as permissões de chave apropriadas para criptografar e descriptografar o local deresultados da consulta.
Important
As entidades principais do IAM com permissão para a ação GetObject do Amazon S3 para olocal de resultados da consulta podem recuperar resultados da consulta do Amazon S3 mesmoque a permissão para a ação GetQueryResults do Athena seja negada.
Obter um ID de consultaCada consulta executada é conhecida como uma execução de consulta. A execução da consulta temum identificador exclusivo conhecido como ID da consulta ou ID de execução da consulta. Para trabalharcom arquivos de resultados da consulta e encontrar rapidamente arquivos de resultados da consulta, énecessário o ID da consulta. Nós nos referimos ao ID da consulta neste tópico como QueryID.
Como usar o console do Athena para obter o QueryID de uma consulta executada
1. Escolha History (Histórico) na barra de navegação.2. Na lista de consultas, escolha o status da consulta em State (Estado) — por exemplo, Failed (Com
falha).3. Escolha o ícone ao lado de Query ID (ID da consulta) a fim de copiar o ID para a área de
transferência.
Identificar arquivos de saída da consultaOs arquivos são salvos no local de resultados da consulta no Amazon S3 com base no nome, no ID daconsulta e na data em que ela foi executada. Os arquivos de cada consulta são denominados usandoQueryID, que é um identificador exclusivo que o Athena atribui a cada consulta quando ela é executada.
Os seguintes tipos de arquivo são salvos:
Tipo de arquivo Padrão de nomenclatura dearquivos
Descrição
Arquivos de resultados daconsulta
QueryID.csv Os arquivos de resultadosda consulta são salvos noformato CSV (valores separadospor vírgulas). Eles contêmo resultado tabular de cadaconsulta. Você pode fazerdownload desses arquivosno console do painel Results(Resultados) ao usar o consoleou no History (Histórico) daconsulta. Para obter maisinformações, consulte Fazerdownload de arquivos deresultados da consulta usando oconsole do Athena (p. 68).
Arquivos de metadados daconsulta
QueryID.csv.metadata Os arquivos de metadadosda consulta são salvos emformato binário e não são
66

Amazon Athena Guia do usuárioIdentificar arquivos de saída da consulta
Tipo de arquivo Padrão de nomenclatura dearquivos
Descrição
legíveis. O Athena usa osmetadados ao ler os resultadosda consulta usando a açãoGetQueryResults. Emboraesses arquivos possam serexcluídos, não recomendamosporque informações importantessobre a consulta são perdidas.
Arquivos manifesto de dados QueryID-manifest.csv Os arquivos manifesto de dadossão gerados para rastreararquivos que o Athena criaem locais de fonte de dadosdo Amazon S3 quando umaconsulta INSERT INTO (p. 286)é executada. Se uma consultafalhar, o manifesto tambémrastreará os arquivos que aconsulta pretendia gravar. Omanifesto é útil para identificararquivos órfãos resultantes deuma consulta com falha.
Os arquivos de saída da consulta são armazenados em subpastas de acordo com o padrão a seguir.
QueryResultsLocationInS3/[QueryName|Unsaved/yyyy/mm/dd/]
• QueryResultsLocationInS3 é o local de resultados da consulta especificado pelas configurações dogrupo de trabalho ou pelo lado do cliente. Consulte the section called “Especificar um local de resultadosda consulta” (p. 69) abaixo.
• As seguintes subpastas são criadas apenas para consultas executadas no console. Asconsultas executadas na AWS CLI ou usando a API do Athena são salvas diretamente noQueryResultsLocationInS3.• Queryname é o nome da consulta para a qual os resultados são salvos. Se a consulta foi executada,
mas não salva, Unsaved será usado.• aaaa/mm/dd é a data em que a consulta foi executada.
Os arquivos associados a uma consulta CREATE TABLE AS SELECT são armazenados em uma subpastatables do padrão acima.
Como identificar o local de saída da consulta e os arquivos de resultado da consulta usando aAWS CLI
• Use o comando aws athena get-query-execution conforme mostrado no exemplo a seguir.Substitua abc1234d-5efg-67hi-jklm-89n0op12qr34 pelo ID da consulta.
aws athena get-query-execution --query-execution-id abc1234d-5efg-67hi-jklm-89n0op12qr34
Esse comando retorna uma saída semelhante à seguinte. Para obter descrições de cada parâmetrode saída, consulte get-query-execution no AWS CLI Command Reference.
67

Amazon Athena Guia do usuárioFazer download de arquivos de resultadosda consulta usando o console do Athena
{ "QueryExecution": { "Status": { "SubmissionDateTime": 1565649050.175, "State": "SUCCEEDED", "CompletionDateTime": 1565649056.6229999 }, "Statistics": { "DataScannedInBytes": 5944497, "DataManifestLocation": "s3://aws-athena-query-results-123456789012-us-west-1/MyInsertQuery/2019/08/12/abc1234d-5efg-67hi-jklm-89n0op12qr34-manifest.csv", "EngineExecutionTimeInMillis": 5209 }, "ResultConfiguration": { "EncryptionConfiguration": { "EncryptionOption": "SSE_S3" }, "OutputLocation": "s3://aws-athena-query-results-123456789012-us-west-1/MyInsertQuery/2019/08/12/abc1234d-5efg-67hi-jklm-89n0op12qr34" }, "QueryExecutionId": "abc1234d-5efg-67hi-jklm-89n0op12qr34", "QueryExecutionContext": {}, "Query": "INSERT INTO mydb.elb_log_backup SELECT * FROM mydb.elb_logs LIMIT 100", "StatementType": "DML", "WorkGroup": "primary" }}
Fazer download de arquivos de resultados da consultausando o console do AthenaÉ possível fazer download do arquivo CSV dos resultados da consulta no painel logo depois de executaruma consulta ou usando o History (Histórico)da consulta.
Como fazer download do arquivo de resultados da consulta mais recente
1. Insira sua consulta no editor de consultas e escolha Run query (Executar consulta).
Quando a execução da consulta terminar, o painel Results (Resultados) mostrará os resultados daconsulta.
2. Para fazer download do arquivo de resultados da consulta, escolha o ícone de arquivo no painelde resultados da consulta. Dependendo da configuração do navegador e do navegador, pode sernecessário confirmar o download.
68

Amazon Athena Guia do usuárioEspecificar um local de resultados da consulta
Como fazer download de um arquivo de resultados de uma consulta anterior
1. Escolha History (Histórico).2. Percorra a lista de consultas até encontrar a consulta e escolha Download results (Fazer download de
resultados) em Action for the query (Ação para essa consulta).
Especificar um local de resultados da consultaO local de resultados da consulta usado pelo Athena é determinado por uma combinação de configuraçõesdo grupo de trabalho e configurações do lado do cliente. As configurações do lado do cliente são baseadasna forma como você executa a consulta.
• Se você executar a consulta usando o console do Athena, o Query result location (Local de resultadosda consulta) inserido em Settings (Configurações) na barra de navegação determinará a configuração dolado do cliente.
• Se você executar a consulta usando a API do Athena, o parâmetro OutputLocation da açãoStartQueryExecution determinará a configuração no lado do cliente.
• Se você usar os drivers ODBC ou JDBC para executar consultas, a propriedade S3OutputLocationespecificada no URL de conexão determinará a configuração no lado do cliente.
Important
Quando você executa uma consulta usando a API ou usando o driver ODBC ou JDBC, aconfiguração do console não se aplica.
Cada configuração de grupo de trabalho tem uma opção Override client-side settings (Substituirconfigurações no lado do cliente) que pode ser habilitada. Quando essa opção está habilitada, asconfigurações do grupo de trabalho têm precedência sobre as configurações aplicáveis do lado do clientequando uma entidade principal do IAM associada a esse grupo de trabalho executa a consulta.
Especificar um local de resultados da consulta usando o consoledo AthenaAntes de executar uma consulta, um local de bucket de resultados da consulta do Amazon S3 precisaser especificado, ou você deve usar um grupo de trabalho que especificou um bucket e cuja configuraçãosubstitui os ajustes do cliente. Se nenhum local de resultados da consulta for especificado, a consultaapresentará erro.
Anteriormente, se você executasse uma consulta sem especificar um valor para o Query result location(Local de resultados da consulta) e a configuração do local dos resultados da consulta não fossesubstituída por um grupo de trabalho, o Athena criava um local padrão para você. O local padrão era aws-athena-query-results-MyAcctID-MyRegion, em que MyAcctID era o ID da conta da AWS doprincipal do IAM que executava a consulta, e MyRegion era a região em que a consulta era executada(por exemplo, us-west-1.)
Agora, antes de executar uma consulta do Athena em uma região na qual sua conta não tenha usadoo Athena anteriormente, você deve especificar um local de resultado da consulta ou usar um grupo detrabalho que substitua a configuração do local de resultados da consulta. Embora o Athena não criemais um local padrão de resultados da consulta para você, os locais padrão aws-athena-query-results-MyAcctID-MyRegion criados anteriormente permanecem válidos e você pode continuar a usá-los.
Como especificar um local de resultados da consulta usando o console do Athena
1. Na barra de navegação, escolha Settings (Configurações).
69
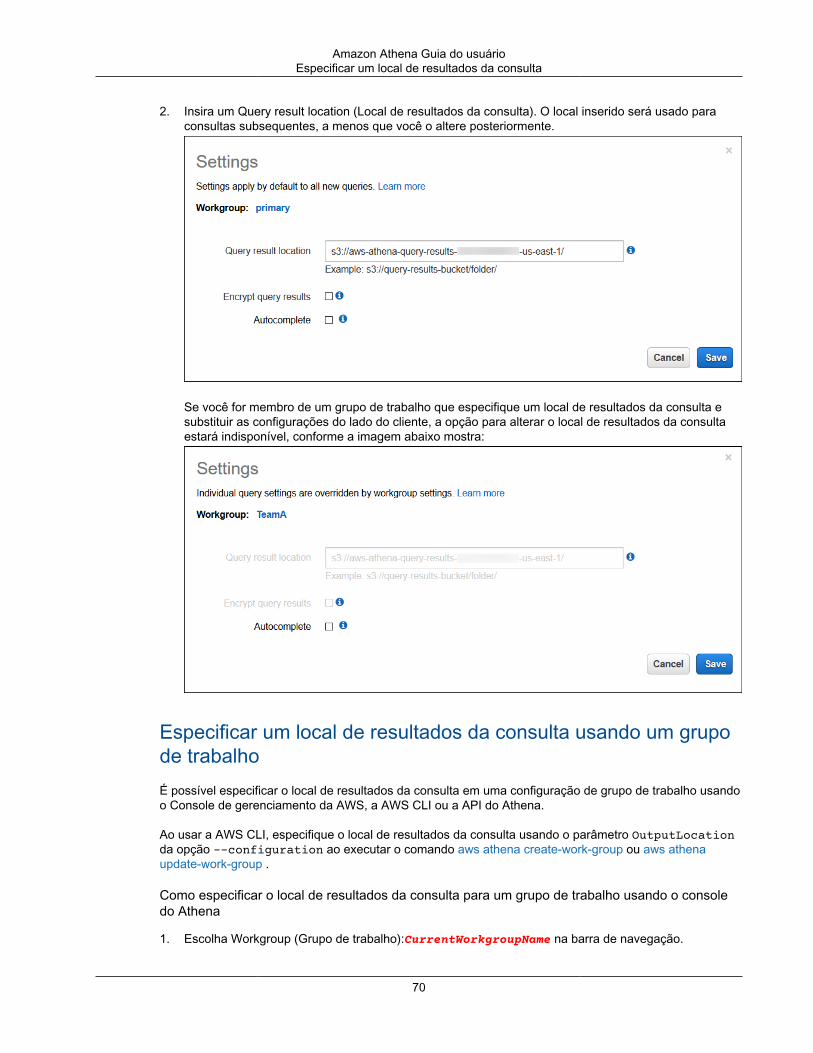
Amazon Athena Guia do usuárioEspecificar um local de resultados da consulta
2. Insira um Query result location (Local de resultados da consulta). O local inserido será usado paraconsultas subsequentes, a menos que você o altere posteriormente.
Se você for membro de um grupo de trabalho que especifique um local de resultados da consulta esubstituir as configurações do lado do cliente, a opção para alterar o local de resultados da consultaestará indisponível, conforme a imagem abaixo mostra:
Especificar um local de resultados da consulta usando um grupode trabalhoÉ possível especificar o local de resultados da consulta em uma configuração de grupo de trabalho usandoo Console de gerenciamento da AWS, a AWS CLI ou a API do Athena.
Ao usar a AWS CLI, especifique o local de resultados da consulta usando o parâmetro OutputLocationda opção --configuration ao executar o comando aws athena create-work-group ou aws athenaupdate-work-group .
Como especificar o local de resultados da consulta para um grupo de trabalho usando o consoledo Athena
1. Escolha Workgroup (Grupo de trabalho):CurrentWorkgroupName na barra de navegação.
70

Amazon Athena Guia do usuárioVer histórico de consultas
2. Execute um destes procedimentos:
• Se estiver editando um grupo de trabalho existente, selecione-o na lista, escolha View details(Visualizar detalhes), e, depois, escolha Edit Workgroup (Editar grupo de trabalho).
• Se estiver criando um novo grupo de trabalho, escolha Create workgroup (Criar grupo de trabalho).3. Em Query result location (Local de resultados da consulta), escolha a pasta Select (Selecionar).4. Na lista de locais do S3, escolha a seta azul sucessivamente até que o bucket e a pasta que você
deseja usar apareçam na linha superior. Escolha Select (Selecionar).5. Em Settings (Configurações), siga um destes procedimentos:
• Selecione Override client-side settings (Substituir configurações do lado do cliente) para salvararquivos de consulta no local especificado acima para todas as consultas executadas pelosmembros desse grupo de trabalho.
• Desmarque Override client-side settings (Substituir configurações no lado do cliente) para salvararquivos de consulta no local especificado acima somente quando os membros do grupo detrabalho executarem consultas usando a API do Athena, o driver ODBC ou o driver JDBC semespecificar um local de saída no Amazon S3.
6. Se estiver editando um grupo de trabalho, escolha Save (Salvar). Se estiver criando um grupo detrabalho, escolha Create workgroup (Criar grupo de trabalho).
Ver histórico de consultasO Athena mantém o histórico de consultas por 45 dias. Para manter o histórico de consultas por maistempo, é possível recuperar o histórico de consultas e salvá-lo em um armazenamento de dados, comoum Amazon S3 usando as seguintes ações de API do Athena. É possível automatizar esse processoprogramando ou criando scripts das operações, ou executá-las sob demanda usando a AWS CLI. Épossível usar o histórico de consultas no console do Athena para exibir erros de consultas que falharam oupara fazer download de arquivos de resultado de consulta para consultas bem-sucedidas.
1. Recupere os IDs de consulta com ListQueryExecutions.2. Recupere informações sobre cada consulta com base no ID com GetQueryExecution.3. Salve as informações obtidas em um armazenamento de dados, como o Amazon S3 usando o comando
put-object na API do Amazon S3.
Ver histórico de consultas1. Para usar o console do Athena para exibir o histórico de consultas, escolha History (Histórico) e
selecione uma consulta. Você também pode ver quais consultas foram bem-sucedidas e quais falharam,fazer download dos resultados e ver IDs de consulta clicando no valor de status.
71

Amazon Athena Guia do usuárioComo trabalhar com exibições
Como trabalhar com exibiçõesUma visualização no Amazon Athena é uma tabela lógica, não física. A consulta que define uma exibição éexecutada sempre que a exibição é referenciada em uma consulta.
Você pode criar uma exibição a partir de uma consulta SELECT e, em seguida, fazer referência a essaexibição em futuras consultas. Para obter mais informações, consulte CREATE VIEW (p. 301).
Tópicos• Quando usar as visualizações? (p. 72)• Ações com suporte para visualizações no Athena (p. 73)• Considerações para exibições (p. 73)• Limitações de visualizações (p. 74)• Trabalho com exibições no console (p. 74)• Criação de exibições (p. 75)• Exemplos de exibições (p. 76)• Atualização de exibições (p. 77)• Exclusão de exibições (p. 77)
Quando usar as visualizações?Talvez você queira criar visualizações para:
• Consultar um subconjunto de dados. Por exemplo, você pode criar uma tabela com um subconjunto decolunas a partir da tabela original para simplificar a consulta de dados.
• Combinar várias tabelas em uma consulta. Se você tem várias tabelas e deseja combiná-las com UNIONALL, é possível criar uma visualização com essa expressão para simplificar consultas em tabelascombinadas.
• Ocultar a complexidade de consultas básicas existentes e simplificar as consultas executadas pelosusuários. As consultas básicas geralmente incluem junções entre tabelas, expressões na lista decolunas e outra sintaxe de SQL que dificultam o entendimento e a depuração delas. Você pode criaruma exibição que oculta a complexidade e simplifica consultas.
• Experimente com técnicas de otimização e crie consultas otimizadas. Por exemplo, se você encontraruma combinação de condições WHERE, ordem JOIN ou outras expressões que demonstram o melhor
72

Amazon Athena Guia do usuárioAções com suporte para visualizações no Athena
desempenho, você poderá criar uma exibição com essas cláusulas e expressões. Os aplicativos podemrealizar consultas relativamente simples contra essa exibição. Posteriormente, se você encontrar umamelhor maneira de otimizar a consulta original, quando você recriar a exibição, todos os aplicativosaproveitam imediatamente a consulta básica otimizada.
• Oculte a tabela subjacente e os nomes de coluna e minimize os problemas de manutenção se essesnomes forem alterados. Nesse caso, recrie a exibição usando os novos nomes. Todas as consultas queusam a exibição ao invés de tabelas subjacentes continuarão em execução sem alterações.
Ações com suporte para visualizações no AthenaO Athena oferece suporte às seguintes ações para visualizações. Você pode executar esses comandos noEditor de consultas.
Declaração Descrição
CREATE VIEW (p. 301) Cria uma nova exibição a partir de uma consulta SELECT especificada. Paraobter mais informações, consulte Criação de exibições (p. 75).
A cláusula OR REPLACE opcional permite atualizar a exibição existentesubstituindo-a
DESCRIBEVIEW (p. 302)
Mostra a lista de colunas para a exibição nomeada. Isso permite examinaros atributos de uma exibição complexa.
DROP VIEW (p. 303) Exclui uma exibição existente. A cláusula IF EXISTS opcional suprimeo erro se a exibição não existir. Para obter mais informações, consulteExclusão de exibições (p. 77).
SHOW CREATEVIEW (p. 305)
Mostra a instrução SQL que cria a exibição específica.
SHOW VIEWS (p. 307) Lista as exibições no banco de dados especificado ou no banco de dadosatual se você omitir o nome do banco de dados. Use a cláusula LIKEopcional com uma expressão regular para restringir a lista de nomes deexibições. Você também pode ver a lista de exibições no painel esquerdono console.
SHOWCOLUMNS (p. 304)
Liste as colunas no esquema para obter uma visualização.
Considerações para exibiçõesAs seguintes considerações se aplicam a criação e uso de visualizações no Athena:
• No Athena, você pode visualizar e trabalhar com visualizações criadas no Console do Athena, noCatálogo de dados do AWS Glue, se tiver migrado para usá-lo ou com o Presto em execução no clusterdo Amazon EMR conectado ao mesmo catálogo. Você não pode visualizar nem adicionar ao Athenavisualizações que foram criadas de outras formas.
• Se você estiver criando visualizações por meio do Data Catalog do AWS Glue, deverá incluiro parâmetro PartitionKeys e definir seu valor como uma lista vazia, da seguinte forma:"PartitionKeys":[]. Caso contrário, sua consulta de visualização falhará no Athena. O exemplo aseguir mostra uma exibição criada no Data Catalog com "PartitionKeys":[]:
aws glue create-table
73

Amazon Athena Guia do usuárioLimitações de visualizações
--database-name mydb --table-input '{"Name":"test", "TableType": "EXTERNAL_TABLE", "Owner": "hadoop", "StorageDescriptor":{ "Columns":[{ "Name":"a","Type":"string"},{"Name":"b","Type":"string"}], "Location":"s3://xxxxx/Oct2018/25Oct2018/", "InputFormat":"org.apache.hadoop.mapred.TextInputFormat", "OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "SerdeInfo":{"SerializationLibrary":"org.apache.hadoop.hive.serde2.OpenCSVSerde", "Parameters":{"separatorChar": "|", "serialization.format": "1"}}},"PartitionKeys":[]}'
• Se você tiver criado visualizações do Athena no Data Catalog, o Data Catalog tratará as visualizaçõescomo tabelas. Você pode usar o controle de acesso granular no nível da tabela no Data Catalog pararestringir o acesso (p. 185) a essas visualizações.
• O Athena impede que você execute visualizações recursivas e exibe uma mensagem de erro nessescasos. Uma exibição recursiva é uma consulta de exibição que faz referência a si mesmo.
• O Athena detecta visualizações obsoletas e exibe uma mensagem de erro nesses casos. A exibiçãoobsoleta é uma consulta de exibição que faz referência a tabelas ou bancos de dados que não existem.
• Você pode criar e executar exibições aninhadas, desde que a consulta por trás da exibição aninhadaseja válida e as tabelas e os bancos de dados existirem.
Limitações de visualizações• Os nomes de visualização do Athena não podem conter caracteres especiais, exceto sublinhado (_).
Para obter mais informações, consulte Nomes para tabelas, bancos de dados e colunas (p. 18).• Evite usar palavras-chave reservadas para nomear visualizações. Se você usar palavras-chave
reservadas, use aspas duplas para delimitar as palavras-chave reservadas em suas consultas emvisualizações. Consulte Palavras-chave reservadas (p. 19).
• Não é possível usar visualizações com funções geoespaciais.• Não é possível usar visualizações para gerenciar o controle de acesso a dados no Amazon S3. Para
consultar uma visualização, é necessário ter permissões para acessar os dados armazenados noAmazon S3. Para obter mais informações, consulte Acesso ao Amazon S3 (p. 185).
Trabalho com exibições no consoleNo console do Athena, é possível:
• Localizar todas as visualizações no painel esquerdo, onde as tabelas são listadas. O Athena executauma operação SHOW VIEWS (p. 307) para apresentar essa lista.
• Filtre as exibições.• Visualize uma exibição, mostre suas propriedades, edite-a ou exclua-a.
Para listar as ações de exibição no console
Uma exibição é mostrada no console somente se você já a criou.
1. No console do Athena, escolha Views (Visualizações), escolha uma visualização e expanda-a.
A exibição é mostrada, com as colunas que ela contém, como mostrado no exemplo a seguir:
74

Amazon Athena Guia do usuárioCriação de exibições
2. Na lista de exibições, escolha uma exibição e abra o menu de contexto (clique com o botão direitodo mouse). O ícone do menu de ações (⋮) é realçado para a exibição que você escolheu, e a lista deações é aberta, conforme mostrado no exemplo a seguir:
3. Escolha uma opção. Por exemplo, Show properties (Mostrar propriedades) mostra o nome, o nome dobanco de dados em que a tabela da visualização é criada no Athena, e o time stamp de quando ela foicriada:
Criação de exibiçõesVocê pode criar uma exibição de qualquer consulta SELECT.
Para criar uma exibição no console
Antes de criar uma exibição, escolha um banco de dados e, em seguida, escolha uma tabela. Execute umaconsulta SELECT em uma tabela e, em seguida, crie uma exibição a partir dela.
1. No console do Athena, escolha Create view (Criar visualização).
No Editor de consultas, é exibida uma amostra de consulta de exibição.2. Edite o exemplo de consulta de exibição. Especifique o nome da tabela e adicione outra sintaxe. Para
obter mais informações, consulte CREATE VIEW (p. 301) e Exemplos de exibições (p. 76).
75

Amazon Athena Guia do usuárioExemplos de exibições
Os nomes de visualização não podem conter caracteres especiais, exceto sublinhado (_). ConsulteNomes para tabelas, bancos de dados e colunas (p. 18). Evite usar Palavras-chave reservadas (p. 19)para nomear visualizações.
3. Execute a consulta de exibição, depure-a e, se necessário, e salve-a.
Opcionalmente, crie uma consulta no Editor de consultas e, em seguida, use Criar exibição a partir deconsulta.
Se você executar uma visualização que não é válida, o Athena exibirá uma mensagem de erro.
Se excluir uma tabela a partir da qual a visualização foi criada, quando você tentar executar a visualização,o Athena exibirá uma mensagem de erro.
Você pode criar uma visualização aninhada, que é uma visualização sobre uma exibição existente. OAthena evita que você execute uma visualização recursiva que faz referência a si mesma.
Exemplos de exibiçõesPara mostrar a sintaxe da consulta de exibição, use SHOW CREATE VIEW (p. 305).
Example Exemplo 1
Considere as duas tabelas a seguir: uma tabela employees com duas colunas, id e name e uma tabelasalariescom duas colunas, id e salary.
Neste exemplo, criamos uma exibição chamada name_salary como uma consulta SELECT que obtémuma lista de IDs mapeados para salários a partir das tabelas employees e salaries:
CREATE VIEW name_salary ASSELECT employees.name, salaries.salary FROM employees, salaries WHERE employees.id = salaries.id
Example Exemplo 2
No exemplo a seguir, criamos uma exibição chamada view1 que permite que você oculte a sintaxe deconsulta mais complexa.
Essa exibição é executada sobre duas tabelas, table1 e table2, em que cada tabela é uma consultaSELECT diferente. A exibição seleciona todas as colunas a partir de table1 e une os resultados comtable2. A junção é baseada na coluna a presente em ambas as tabelas.
CREATE VIEW view1 ASWITH table1 AS ( SELECT a, MAX(b) AS b FROM x GROUP BY a
76

Amazon Athena Guia do usuárioAtualização de exibições
), table2 AS ( SELECT a, AVG(d) AS d FROM y GROUP BY a)SELECT table1.*, table2.*FROM table1JOIN table2 ON table1.a = table2.a;
Atualização de exibiçõesDepois de criar uma exibição, ela aparece na lista de Exibições no painel esquerdo.
Para editar a exibição, escolha-a, escolha o menu de contexto (clique com o botão direito do mouse) e, emseguida, selecione Exibir/editar consulta. Você também pode editar a exibição no Editor de consultas. Paraobter mais informações, consulte CREATE VIEW (p. 301).
Exclusão de exibiçõesPara excluir uma exibição, escolha-a, escolha o menu de contexto (clique com o botão direito do mouse) e,em seguida, selecione Excluir consulta. Para obter mais informações, consulte DROP VIEW (p. 303).
Criar uma tabela a partir de resultados da consulta(CTAS)
Uma consulta CREATE TABLE AS SELECT (CTAS) cria uma tabela Athena a partir dos resultados de umainstrução SELECT de outra consulta. O Athena armazena arquivos de dados criados pela instrução CTASem um local especificado no Amazon S3. Para ver a sintaxe, consulte CREATE TABLE AS (p. 299).
Use consultas CTAS consultas:
• Criar tabelas a partir dos resultados da consulta em uma etapa, sem consultar conjuntos de dadosbrutos repetidamente. Isso facilita o trabalho com conjuntos de dados brutos.
• Transforme os resultados da consulta em outros formatos de armazenamento, como Parquet e ORC.Isso melhora o desempenho da consulta e reduz seus custos no Athena. Para obter mais informações,consulte Formatos de armazenamento colunar (p. 26).
• Crie cópias de tabelas existentes que contêm somente os dados necessários.
Tópicos• Considerações e Limitações de Consultas CTAS (p. 77)• Executar consultas CTAS no console (p. 79)• Armazenar em bucket vs particionar (p. 82)• Exemplos de consultas CTAS (p. 83)• Usar CTAS e INSERT INTO para ETL e análise de dados (p. 86)• Usar CTAS e INSERT INTO para criar uma tabela com mais de 100 partições (p. 92)
Considerações e Limitações de Consultas CTASA tabela a seguir descreve o que você precisa saber sobre consultas CTAS no Athena:
77

Amazon Athena Guia do usuárioConsiderações e Limitações de Consultas CTAS
Item O que você precisa saber
Sintaxe daconsulta CTAS
A sintaxe de consulta CTAS é diferente da sintaxe de CREATE [EXTERNAL] TABLEusada para criar tabelas. Consulte CREATE TABLE AS (p. 299).
Note
Os nomes de colunas, bancos de dados ou tabelas para consultas CTAS nãodevem conter aspas nem acentos graves. Para garantir isso, verifique se atabela, o banco de dados ou os nomes de coluna não representam palavrasreservadas (p. 19) e não contêm caracteres especiais (que exigem que fiquementre aspas ou com acentos graves). Para obter mais informações, consulteNomes de tabelas, bancos de dados e colunas (p. 18).
Visualizaçõesvs. consultasCTAS
Consultas CTAS gravam novos dados em um local especificado no Amazon S3,enquanto as visualizações não gravam nenhum dado.
Local dosresultados daconsulta CTAS
O local para armazenar os resultados da consulta CTAS no Amazon S3 deve estarvazio. Uma consulta CTAS verifica se o local do caminho (prefixo) no bucket estávazio e nunca substitui os dados se o local já tiver dados. Para usar o mesmo localnovamente, exclua os dados no local do prefixo de chaves no bucket. Caso contrário,sua consulta CTAS falhará.
É possível especificar o local para armazenar os resultados da consulta CTAS. Sefor omitido e se o seu grupo de trabalho não substituir as configurações no lado docliente (p. 226), o Athena usará esse local por padrão: s3://aws-athena-query-results-<account>-<region>/<Unsaved-or-query-name>/<year>/<month/<date>/tables/<query-id>/.
Se o seu grupo de trabalho substituir as configurações no lado do cliente, isso significaque o local do resultado da consulta do grupo de trabalho é usado para suas consultasde CTAS. Se você especificar um local diferente para os resultados diferentes, suaconsulta falhará. Para obter o local dos resultados especificados para o grupo detrabalho, visualize os detalhes do grupo de trabalho (p. 230).
Se o grupo de trabalho em que uma consulta será executada estiver configuradocom um local imposto de resultados da consulta (p. 226), não especifique umexternal_location para a consulta CTAS. O Athena emitirá um erro e reprovaráuma consulta que especifica um external_location neste caso. Por exemplo,ocorrerá uma falha nesta consulta se você substituir as configurações do lado docliente para o local dos resultados da consulta, forçando o grupo de trabalho a usaro próprio local: CREATE TABLE <DB>.<TABLE1> WITH (format='Parquet',external_location='s3://my_test/test/') AS SELECT * FROM<DB>.<TABLE2> LIMIT 10;
Formatos paraarmazenarresultados daconsulta
Os resultados de consultas CTAS serão armazenados em Parquet por padrão, senão for especificado um formato de armazenamento de dados. É possível armazenarresultados de CTAS em PARQUET, ORC, AVRO, JSON e TEXTFILE. As consultas CTASnão exigem a especificação de um SerDe para interpretar transformações de formato.Consulte Exemplo: gravar resultados da consulta em um formato diferente (p. 84).
Formatos decompactação
A compactação em GZIP é usada para resultados de consulta CTAS por padrão.Para Parquet e ORC, também é possível especificar SNAPPY. Consulte Exemplo:especificar formatos de armazenamento e compactação de dados (p. 84).
Limites parapartições ebuckets
Você pode particionar e armazenar em buckets os dados resultantes de umaconsulta CTAS. Para obter mais informações, consulte Armazenar em bucket vsparticionar (p. 82). O Athena é compatível com a gravação de até 100 combinações
78

Amazon Athena Guia do usuárioExecutar consultas CTAS no console
Item O que você precisa saberúnicas de partições e buckets. Por exemplo, se não há buckets definidos na tabela dedestino, você pode especificar um máximo de 100 partições. Se você especificar cincobuckets, serão permitidas 20 partições (cada uma com cinco buckets). Se você excederessa contagem, ocorrerá um erro.
Inclua predicados de particionamento e bucketing no final da cláusula WITH queespecifica propriedades da tabela de destino. Para obter mais informações, consulteExemplo: criar tabelas em bucket e particionadas (p. 86) e Armazenar em bucket vsparticionar (p. 82).
Para obter informações sobre como contornar a limitação de 100 partições,consulte Usar CTAS e INSERT INTO para criar uma tabela com mais de 100partições (p. 92).
Criptografia É possível criptografar os resultados da consulta CTAS no Amazon S3, semelhante àforma como você criptografa outros resultados de consulta no Athena. Para obter maisinformações, consulte Configurar opções de criptografia avançadas (p. 174).
Tipos dedados
Os tipos de dados da coluna para uma consulta CTAS são os mesmos que os tiposespecificados para a consulta original.
Executar consultas CTAS no consoleNo console do Athena, é possível:
• Criar uma consulta CTAS a partir de outra consulta (p. 79)• Criar uma consulta CTAS do zero (p. 79)
Para criar uma consulta CTAS a partir de outra consulta
1. Execute a consulta, selecione Create (Criar) e, então, selecione Create table from query (Criar tabelaa partir da consulta).
2. No formulário Create a new table on the results of a query (Criar uma tabela com os resultados deuma consulta), preencha os campos da seguinte forma:
a. Em Database (Banco de dados), selecione o banco de dados no qual a consulta foi executada.b. Em Table name (Nome da tabela), especifique o nome para sua nova tabela. Use apenas letras
minúsculas e sublinhados, como my_select_query_parquet.c. Em Description (Descrição) você pode adicionar um comentário para descrever a consulta.d. Em Output location (Local de saída), você pode especificar o local no Amazon S3, como s3://
my_athena_results/mybucket/. Se você não especificar um local e o seu grupo de trabalhonão Substituir configurações no lado do cliente (p. 226), o seguinte local predefinido seráusado: s3://aws-athena-query-results-<account>-<region>/<query-name-or-unsaved>/year/month/date/<query-id>/.
79

Amazon Athena Guia do usuárioExecutar consultas CTAS no console
e. Em Output data format (Formato dos dados de saída), faça uma seleção na lista de formatoscompatíveis. Se não for especificado um formato, será usado Parquet. Consulte Formatos dearmazenamento colunar (p. 26).
f. Selecione Next (Próximo) para analisar sua consulta e revisá-la, conforme necessário. Para vera sintaxe de consulta, acesse CREATE TABLE AS (p. 299). A janela de visualização é aberta,conforme mostrado no exemplo a seguir:
80

Amazon Athena Guia do usuárioExecutar consultas CTAS no console
g. Escolha Criar.3. Selecione Run query (Executar consulta).
Para criar uma consulta CTAS do zero
Use o modelo CREATE TABLE AS SELECT para criar uma consulta CTAS do zero.
1. No console do Athena, selecione Create table (Criar tabela) e selecione CREATE TABLE AS SELECT.
2. No Editor de consultas, edite a consulta conforme necessário. Para ver a sintaxe de consulta, acesseCREATE TABLE AS (p. 299).
3. Selecione Run query (Executar consulta).4. Se preferir, selecione Save as (Salvar como) para salvar a consulta.
81

Amazon Athena Guia do usuárioArmazenar em bucket vs particionar
Consulte também Exemplos de consultas CTAS (p. 83).
Armazenar em bucket vs particionarÉ possível especificar o particionamento e o armazenamento em bucket para armazenar dados dosresultados de consultas CTAS no Amazon S3. Para obter informações sobre consultas CTAS, acesseCREATE TABLE AS (CTAS) (p. 77).
Esta seção discute o particionamento e o armazenamento em bucket, como eles se aplicam somente aconsultas CTAS. Para obter diretrizes gerais sobre como usar o particionamento em consultas CREATETABLE (CRIAR TABELA), acesse Dicas para ajustar desempenho máximo do Amazon Athena.
Use as seguintes dicas para decidir se prefere particionar e/ou configurar o armazenamento em bucket, epara selecionar colunas nas consultas CTAS para fazer isso:
• O particionamento dos resultados da consulta CTAS funciona bem quando o número de partições vocêpretende ter é limitado. Quando uma consulta CTAS é executada, o Athena grava os resultados em umlocal especificado no Amazon S3. Se são especificadas partições, ele as cria e armazena cada partiçãoem uma pasta de partição separada no mesmo local. O número máximo de partições que podemser configuradas com resultados de consulta CTAS em uma consulta é 100. No entanto, é possívelcontornar essa limitação. Para obter mais informações, consulte Usar CTAS e INSERT INTO para criaruma tabela com mais de 100 partições (p. 92).
Ter partições no Amazon S3 melhora o desempenho da consulta do Athena, pois isso ajuda a executarconsultas direcionadas somente para partições específicas. Em seguida, o Athena verifica somenteessas partições, economizando tempo e custos da consulta. Para obter informações sobre sintaxe departicionamento, procure partition_by em CREATE TABLE AS (p. 299).
Particione os dados por essas colunas com características semelhantes, como registros do mesmodepartamento, e que podem ter um número limitado de valores possíveis, como um número limitadode departamentos distintos em uma organização. Essa característica é conhecida como cardinalidadede dados. Por exemplo, se você particionar pela coluna department, e essa coluna tiver um númerolimitado de valores distintos, o particionamento por department funcionará bem e diminuirá a latênciada consulta.
• O armazenamento em bucket dos resultados da consulta CTAS funciona bem quando você armazenadados em bucket dados pela coluna que tem alta cardinalidade e valores uniformemente distribuídos.
Por exemplo, colunas que armazenam dados de timestamp possivelmente teriam um número muitogrande de valores distintos, e seus dados estariam distribuídos uniformemente em todo o conjunto dedados. Isso significa que uma coluna que armazena dados do tipo timestamp seria mais propensa ater valores e não ter nulos. Isso também significa que os dados de uma coluna desse tipo podem sercolocados em muitos buckets, e que cada bucket terá aproximadamente a mesma quantidade de dadosarmazenados no Amazon S3.
Para escolher a coluna pela qual armazenar os resultados da consulta CTAS em bucket, use acoluna com um alto número de valores (alta cardinalidade) e cujos dados possam ser divididos paraarmazenamento em vários buckets que terão aproximadamente a mesma quantidade de dados. Ascolunas que são preenchidas com poucos valores não são boas candidatas para o armazenamentoem bucket. Isso porque você obterá buckets com poucos dados e outros com muitos dados. Porcomparação, colunas que prevemos quase sempre ter valores, como valores do tipo timestamp, sãoboas candidatas para o armazenamento em bucket. Isso porque os dados dessas colunas têm altacardinalidade e podem ser armazenados em blocos aproximadamente iguais.
Para obter mais informações sobre sintaxe de armazenamento em bucket, procure bucketed_by emCREATE TABLE AS (p. 299).
82

Amazon Athena Guia do usuárioExemplos de consultas CTAS
Para concluir, é possível particionar e usar buckets para armazenar os resultados da mesma consultaCTAS. Essas técnicas de gravação de dados não se excluem mutuamente. Normalmente, as colunasusadas para o armazenamento em bucket são diferentes das usadas para o particionamento.
Por exemplo, se o seu conjunto de dados tiver as colunas department, sales_quarter e ts (paraarmazenar dados do tipo timestamp ), você poderá particionar os resultados da consulta CTAS pordepartment e sales_quarter. Essas colunas têm cardinalidade relativamente baixa de valores: umnúmero limitado de departamentos e trimestres de vendas. Além disso, para partições, não importa sealguns registros no conjunto de dados têm valores nulos ou nenhum valor atribuído para essas colunas.O que importa é que os dados com as mesmas características, como dados do mesmo departamento,estejam em uma partição que possa ser consultada no Athena.
Ao mesmo tempo, como todos os seus dados têm valores do tipo timestamp armazenados em umacoluna ts, é possível configurar o armazenamento em bucket para os mesmos resultados da consultapela coluna ts. Esta coluna tem alta cardinalidade. É possível armazenar os dados dela em mais de umbucket no Amazon S3. Considere um cenário oposto: se você não criasse buckets de dados do tipo timestamp e executasse uma consulta para determinados valores de data ou hora, seria necessário analisaruma grande quantidade de dados armazenados em um único local no Amazon S3. Em vez disso, se vocêconfigurar buckets para armazenar os resultados relacionados a data e hora, só será possível verificar econsultar buckets com seu valor e evitar consultas de execução prolongada, que verificam uma grandequantidade de dados.
Exemplos de consultas CTASUse os exemplos a seguir para criar consultas CTAS. Para obter informações sobre a sintaxe de CTAS,consulte CREATE TABLE AS (p. 299).
Nesta seção:
• Exemplo: duplicar tabela selecionando todas as colunas (p. 83)• Exemplo: selecionar colunas específicas de uma ou mais tabelas (p. 84)• Exemplo: criar uma cópia vazia de uma tabela existente (p. 84)• Exemplo: especificar formatos de armazenamento e compactação de dados (p. 84)• Exemplo: gravar resultados da consulta em um formato diferente (p. 84)• Exemplo: criar tabelas não particionadas (p. 85)• Exemplo: criar tabelas particionadas (p. 85)• Exemplo: criar tabelas em bucket e particionadas (p. 86)
Example Exemplo: duplicar tabela selecionando todas as colunas
O exemplo a seguir cria uma tabela copiando todas as colunas de uma tabela:
CREATE TABLE new_table AS SELECT * FROM old_table;
Na seguinte variação do mesmo exemplo, a instrução SELECT também inclui uma cláusula WHERE. Nessecaso, a consulta seleciona somente as linhas da tabela que satisfazem a cláusula WHERE:
CREATE TABLE new_table AS SELECT * FROM old_table WHERE condition;
83

Amazon Athena Guia do usuárioExemplos de consultas CTAS
Example Exemplo: selecionar colunas específicas de uma ou mais tabelas
O exemplo a seguir cria uma consulta que é executada em um conjunto de colunas de outra tabela:
CREATE TABLE new_table AS SELECT column_1, column_2, ... column_n FROM old_table;
Essa variação do mesmo exemplo cria uma tabela a partir de colunas específicas de várias tabelas:
CREATE TABLE new_table ASSELECT column_1, column_2, ... column_n FROM old_table_1, old_table_2, ... old_table_n;
Example Exemplo: criar uma cópia vazia de uma tabela existente
O exemplo a seguir usa WITH NO DATA para criar uma tabela vazia e que tenha o mesmo esquema databela original:
CREATE TABLE new_table AS SELECT * FROM old_tableWITH NO DATA;
Example Exemplo: especificar formatos de armazenamento e compactação de dados
O exemplo a seguir usa a consulta CTAS para criar uma nova tabela com dados em formato Parquetde uma tabela de origem em um formato diferente. É possível especificar PARQUET, ORC, AVRO, JSON eTEXTFILE de maneira semelhante.
Esse exemplo também especifica a compactação como SNAPPY. Se for omitido, será usado GZIP.GZIP e SNAPPY são os formatos de compactação compatíveis com os resultados das consultas CTASarmazenados em Parquet e ORC.
CREATE TABLE new_tableWITH ( format = 'Parquet', parquet_compression = 'SNAPPY')AS SELECT *FROM old_table;
O exemplo a seguir é semelhante, mas armazena os resultados da consulta CTAS em ORC, e usa oparâmetro orc_compression para especificar o formato de compactação. Se o formato de compactaçãofor omitido, o Athena usará GZIP por padrão.
CREATE TABLE new_tableWITH (format = 'ORC', orc_compression = 'SNAPPY')AS SELECT *FROM old_table ;
Example Exemplo: gravar resultados da consulta em um formato diferente
A consulta CTAS a seguir seleciona todos os registros de old_table, que poderiam ser armazenadosem CSV ou em outro formato, e cria uma nova tabela com dados subjacentes salvos no Amazon S3 noformato ORC:
CREATE TABLE my_orc_ctas_table
84

Amazon Athena Guia do usuárioExemplos de consultas CTAS
WITH ( external_location = 's3://my_athena_results/my_orc_stas_table/', format = 'ORC')AS SELECT * FROM old_table;
Example Exemplo: criar tabelas não particionadas
Os exemplos a seguir criam tabelas que não são particionadas. Os dados da tabela são armazenados emformatos diferentes. Alguns desses exemplos especificam o local externo.
O exemplo a seguir cria uma consulta CTAS que armazena os resultados como um arquivo de texto:
CREATE TABLE ctas_csv_unpartitioned WITH ( format = 'TEXTFILE', external_location = 's3://my_athena_results/ctas_csv_unpartitioned/') AS SELECT key1, name1, address1, comment1FROM table1;
No exemplo a seguir, os resultados são armazenados em Parquet, e os local padrão dos resultados éusado:
CREATE TABLE ctas_parquet_unpartitioned WITH (format = 'PARQUET') AS SELECT key1, name1, comment1FROM table1;
No a consulta a seguir, a tabela é armazenada em JSON, e colunas específicas são selecionadas entre osresultados da tabela original:
CREATE TABLE ctas_json_unpartitioned WITH ( format = 'JSON', external_location = 's3://my_athena_results/ctas_json_unpartitioned/') AS SELECT key1, name1, address1, comment1FROM table1;
No exemplo a seguir, o formato é ORC:
CREATE TABLE ctas_orc_unpartitioned WITH ( format = 'ORC') AS SELECT key1, name1, comment1 FROM table1;
No exemplo a seguir, o formato é Avro:
CREATE TABLE ctas_avro_unpartitioned WITH ( format = 'AVRO', external_location = 's3://my_athena_results/ctas_avro_unpartitioned/') AS SELECT key1, name1, comment1FROM table1;
Example Exemplo: criar tabelas particionadas
Os exemplos a seguir mostram consultas CREATE TABLE AS SELECT para tabelas particionadasem diferentes formatos de armazenamento, usando partitioned_by e outras propriedades na
85

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
cláusula WITH. Para ver a sintaxe, consulte Propriedades da tabela CTAS. (p. 299). Para obter maisinformações sobre como escolher as colunas para particionamento, consulte Armazenar em bucket vsparticionar (p. 82).
Note
Liste as colunas da partição no final da lista de colunas na instrução SELECT. Você podeparticionar por mais de uma coluna e ter até 100 combinações únicas de partições e buckets. Porexemplo, você pode ter 100 partições se nenhum bucket for especificado.
CREATE TABLE ctas_csv_partitioned WITH ( format = 'TEXTFILE', external_location = 's3://my_athena_results/ctas_csv_partitioned/', partitioned_by = ARRAY['key1']) AS SELECT name1, address1, comment1, key1FROM tables1;
CREATE TABLE ctas_json_partitioned WITH ( format = 'JSON', external_location = 's3://my_athena_results/ctas_json_partitioned/', partitioned_by = ARRAY['key1']) AS select name1, address1, comment1, key1 FROM table1;
Example Exemplo: criar tabelas em bucket e particionadas
O exemplo a seguir mostra uma consulta CREATE TABLE AS SELECT que usa tanto o particionamento,como o armazenamento em bucket para armazenar os resultados da consulta no Amazon S3. Osresultados da tabela são particionados e colocados em buckets por colunas diferentes. O Athena comportaum máximo de 100 combinações únicas de buckets e partições. Por exemplo, se você criar uma tabelacom cinco buckets, é possível ter 20 partições com cinco buckets cada. Para ver a sintaxe, consultePropriedades da tabela CTAS. (p. 299).
Para obter mais informações sobre como escolher as colunas para armazenamento em bucket, consulteArmazenar em bucket vs particionar (p. 82).
CREATE TABLE ctas_avro_bucketed WITH ( format = 'AVRO', external_location = 's3://my_athena_results/ctas_avro_bucketed/', partitioned_by = ARRAY['nationkey'], bucketed_by = ARRAY['mktsegment'], bucket_count = 3) AS SELECT key1, name1, address1, phone1, acctbal, mktsegment, comment1, nationkey FROM table1;
Usar CTAS e INSERT INTO para ETL e análise dedadosÉ possível usar as instruções Create Table as Select (CTAS (p. 77)) e INSERT INTO (p. 286) noAthena para extração, transformação e carregamento (ETL) de dados no Amazon S3 para processamentode dados. Este tópico mostra como usar essas instruções para particionar e converter um conjunto dedados em um formato de dados colunar para otimizá-lo para análise de dados.
As instruções CTAS usam consultas SELECT (p. 282) padrão para criar novas tabelas. É possívelusar uma instrução CTAS para criar um subconjunto de dados para análise. Em uma instrução CTAS,
86

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
é possível particionar os dados, especificar compactação e converter os dados em um formato colunar,como Apache Parquet ou Apache ORC. Ao executar a consulta CTAS, as tabelas e as partições criadassão adicionadas automaticamente ao Catálogo de dados do AWS Glue. Isso torna as novas tabelas epartições criadas imediatamente disponíveis para consultas subsequentes.
Instruções INSERT INTO inserem novas linhas em uma tabela de destino com base em uma instrução deconsulta SELECT que é executada em uma tabela de origem. É possível usar instruções INSERT INTOpara transformar e carregar dados da tabela de origem no formato CSV em dados da tabela de destinousando todas as transformações com suporte do CTAS.
Visão geralNo Athena, use uma instrução CTAS para executar uma conversão inicial em lote dos dados. Depoisdisso, use várias instruções INSERT INTO para fazer atualizações incrementais para a tabela criada pelainstrução CTAS.
Etapas
• Etapa 1: Criar uma tabela com base no conjunto de dados original (p. 87)• Etapa 2: Usar CTAS para particionar, converter e compactar os dados (p. 88)• Etapa 3: Usar INSERT INTO para adicionar dados (p. 89)• Etapa 4: Avaliar diferenças de custo e desempenho (p. 91)
Etapa 1: Criar uma tabela com base no conjunto de dadosoriginalO exemplo neste tópico usa um subconjunto legível no Amazon S3 do conjunto de dados NOAA GlobalHistorical Climatology Network Daily (GHCN-D) disponível publicamente. Os dados no Amazon S3 têm asseguintes características.
Location: s3://aws-bigdata-blog/artifacts/athena-ctas-insert-into-blog/Total objects: 41727Size of CSV dataset: 11.3 GBRegion: us-east-1
Os dados originais são armazenados no Amazon S3 sem partições. Os dados estão no formato CSV emarquivos, conforme mostrado a seguir.
2019-10-31 13:06:57 413.1 KiB artifacts/athena-ctas-insert-into-blog/2010.csv00002019-10-31 13:06:57 412.0 KiB artifacts/athena-ctas-insert-into-blog/2010.csv00012019-10-31 13:06:57 34.4 KiB artifacts/athena-ctas-insert-into-blog/2010.csv00022019-10-31 13:06:57 412.2 KiB artifacts/athena-ctas-insert-into-blog/2010.csv01002019-10-31 13:06:57 412.7 KiB artifacts/athena-ctas-insert-into-blog/2010.csv0101
Os tamanhos de arquivo neste exemplo são relativamente pequenos. Ao mesclá-los em arquivos maiores,é possível reduzir o número total de arquivos, permitindo uma execução de consultas mais rápida. Épossível usar instruções CTAS e INSERT INTO para melhorar o desempenho de consulta.
Como criar um banco de dados e uma tabela com base no conjunto de dados de exemplo
1. No editor de consulta do Athena, execute o comando CREATE DATABASE (p. 295) para criarum banco de dados. Para evitar cobranças de transferência de dados entre regiões do Amazon S3,execute essa e as outras consultas deste tópico na região us-east-1.
CREATE DATABASE blogdb
87

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
2. Execute a seguinte instrução para criar uma tabela (p. 295).
CREATE EXTERNAL TABLE `blogdb`.`original_csv` ( `id` string, `date` string, `element` string, `datavalue` bigint, `mflag` string, `qflag` string, `sflag` string, `obstime` bigint)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://aws-bigdata-blog/artifacts/athena-ctas-insert-into-blog/'
Etapa 2: Usar CTAS para particionar, converter e compactar osdadosDepois de criar uma tabela, é possível usar uma única instrução CTAS (p. 77) para converter os dadospara o formato Parquet com compactação Snappy e para particionar os dados por ano.
A tabela criada na Etapa 1 tem um campo date com a data formatada como YYYYMMDD (por exemplo,20100104). Como a nova tabela será particionada em year, a instrução de exemplo no procedimento aseguir usa a função Presto substr("date",1,4) para extrair o valor year do campo date.
Como converter os dados para o formato Parquet com compactação Snappy, particionando porano
• Execute a seguinte instrução CTAS, substituindo your-bucket pelo local do bucket do Amazon S3.
CREATE table new_parquetWITH (format='PARQUET',parquet_compression='SNAPPY',partitioned_by=array['year'],external_location = 's3://your-bucket/optimized-data/')ASSELECT id, date, element, datavalue, mflag, qflag, sflag, obstime, substr("date",1,4) AS yearFROM original_csvWHERE cast(substr("date",1,4) AS bigint) >= 2015 AND cast(substr("date",1,4) AS bigint) <= 2019
Note
Neste exemplo, a tabela criada inclui apenas os dados de 2015 a 2019. Na Etapa 3, adicionenovos dados a essa tabela usando o comando INSERT INTO.
88

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
Quando a consulta for concluída, use o procedimento a seguir para verificar a saída no local do AmazonS3 especificado na instrução CTAS.
Como ver as partições e os arquivos Parquet criados pela instrução CTAS
1. Para mostrar as partições criadas, execute o seguinte comando da AWS CLI. Certifique-se de incluir abarra final (/).
aws s3 ls s3://your-bucket/optimized-data/
A saída mostra as partições.
PRE year=2015/ PRE year=2016/ PRE year=2017/ PRE year=2018/ PRE year=2019/
2. Para ver os arquivos Parquet, execute o seguinte comando. Observe que a opção | head -5, querestringe a saída aos primeiros cinco resultados, não está disponível no Windows.
aws s3 ls s3://your-bucket/optimized-data/ --recursive --human-readable | head -5
A saída será semelhante à seguinte.
2019-10-31 14:51:05 7.3 MiB optimized-data/year=2015/20191031_215021_00001_3f42d_1be48df2-3154-438b-b61d-8fb23809679d2019-10-31 14:51:05 7.0 MiB optimized-data/year=2015/20191031_215021_00001_3f42d_2a57f4e2-ffa0-4be3-9c3f-28b16d86ed5a2019-10-31 14:51:05 9.9 MiB optimized-data/year=2015/20191031_215021_00001_3f42d_34381db1-00ca-4092-bd65-ab04e06dc7992019-10-31 14:51:05 7.5 MiB optimized-data/year=2015/20191031_215021_00001_3f42d_354a2bc1-345f-4996-9073-096cb863308d2019-10-31 14:51:05 6.9 MiB optimized-data/year=2015/20191031_215021_00001_3f42d_42da4cfd-6e21-40a1-8152-0b902da385a1
Etapa 3: Usar INSERT INTO para adicionar dadosNa Etapa 2, você usou o CTAS para criar uma tabela com partições para os anos de 2015 a 2019.No entanto, o conjunto de dados original também contém dados para os anos de 2010 a 2014. Agora,adicione esses dados usando uma instrução INSERT INTO (p. 286).
Como adicionar dados à tabela usando uma ou mais instruções INSERT INTO
1. Execute o seguinte comando INSERT INTO, especificando os anos antes de 2015 na cláusulaWHERE.
INSERT INTO new_parquetSELECT id, date, element, datavalue, mflag, qflag, sflag, obstime, substr("date",1,4) AS year
89

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
FROM original_csvWHERE cast(substr("date",1,4) AS bigint) < 2015
2. Execute o comando aws s3 ls novamente, usando a seguinte sintaxe.
aws s3 ls s3://your-bucket/optimized-data/
A saída mostra as novas partições.
PRE year=2010/ PRE year=2011/ PRE year=2012/ PRE year=2013/ PRE year=2014/ PRE year=2015/ PRE year=2016/ PRE year=2017/ PRE year=2018/ PRE year=2019/
3. Para ver a redução no tamanho do conjunto de dados obtido por meio do uso da compactação e doarmazenamento colunar no formato Parquet, execute o seguinte comando.
aws s3 ls s3://your-bucket/optimized-data/ --recursive --human-readable --summarize
Os resultados a seguir mostram que o tamanho do conjunto de dados após o Parquet comcompactação Snappy é 1.2 GB.
...2020-01-22 18:12:02 2.8 MiB optimized-data/year=2019/20200122_181132_00003_nja5r_f0182e6c-38f4-4245-afa2-9f5bfa8d6d8f2020-01-22 18:11:59 3.7 MiB optimized-data/year=2019/20200122_181132_00003_nja5r_fd9906b7-06cf-4055-a05b-f050e139946eTotal Objects: 300 Total Size: 1.2 GiB
4. Se mais dados CSV forem adicionados à tabela original, você pode adicionar esses dados à tabelaParquet usando instruções INSERT INTO. Por exemplo, se você tiver novos dados para o ano de2020, poderá executar a instrução INSERT INTO a seguir. A instrução adiciona os dados e a partiçãorelevante à tabela new_parquet.
INSERT INTO new_parquetSELECT id, date, element, datavalue, mflag, qflag, sflag, obstime, substr("date",1,4) AS yearFROM original_csvWHERE cast(substr("date",1,4) AS bigint) = 2020
Note
A instrução INSERT INTO oferece suporte à gravação de, no máximo, 100 partições natabela de destino. No entanto, para adicionar mais de 100 partições, você pode executar
90

Amazon Athena Guia do usuárioUsar CTAS e INSERT INTO para ETL
várias instruções INSERT INTO. Para obter mais informações, consulte Usar CTAS eINSERT INTO para criar uma tabela com mais de 100 partições (p. 92).
Etapa 4: Avaliar diferenças de custo e desempenhoDepois de transformar os dados, é possível avaliar os ganhos de desempenho e a economia de custosexecutando as mesmas consultas nas tabelas novas e antigas e comparando os resultados.
Note
Para obter informações de custo por consulta do Athena, consulte Definição de preço do AmazonAthena.
Como avaliar diferenças de custo e ganhos de desempenho
1. Execute a seguinte consulta na tabela original. A consulta localiza o número de IDs distintos para cadavalor do ano.
SELECT substr("date",1,4) as year, COUNT(DISTINCT id)FROM original_csvGROUP BY 1 ORDER BY 1 DESC
2. Observe o tempo em que a consulta foi executada e a quantidade de dados verificados.3. Execute a mesma consulta na nova tabela, observando o tempo de execução da consulta e a
quantidade de dados verificados.
SELECT year, COUNT(DISTINCT id)FROM new_parquetGROUP BY 1 ORDER BY 1 DESC
4. Compare os resultados e calcule a diferença de desempenho e custo. Os seguintes resultados deexemplo mostram que a consulta de teste na nova tabela foi mais rápida e mais econômica do que aconsulta na tabela antiga.
Tabela Tempo de execução Dados examinados
Original 16,88 segundos 11,35 GB
Novo 3,79 segundos 428,05 MB
5. Execute a seguinte consulta de exemplo na tabela original. A consulta calcula a temperatura máximamédia (Celsius), a temperatura mínima média (Celsius) e a precipitação média (mm) da Terra em2018.
SELECT element, round(avg(CAST(datavalue AS real)/10),2) AS valueFROM original_csvWHERE element IN ('TMIN', 'TMAX', 'PRCP') AND substr("date",1,4) = '2018'GROUP BY 1
6. Observe o tempo em que a consulta foi executada e a quantidade de dados verificados.7. Execute a mesma consulta na nova tabela, observando o tempo de execução da consulta e a
quantidade de dados verificados.
SELECT element, round(avg(CAST(datavalue AS real)/10),2) AS valueFROM new_parquetWHERE element IN ('TMIN', 'TMAX', 'PRCP') and year = '2018'
91

Amazon Athena Guia do usuárioCriar uma tabela com mais de 100 partições
GROUP BY 1
8. Compare os resultados e calcule a diferença de desempenho e custo. Os seguintes resultados deexemplo mostram que a consulta de teste na nova tabela foi mais rápida e mais econômica do que aconsulta na tabela antiga.
Tabela Tempo de execução Dados examinados
Original 18,65 segundos 11,35 GB
Novo 1,92 segundos 68 MB
ResumoEste tópico mostrou como executar operações ETL usando instruções CTAS e INSERT INTO no Athena.Você executou o primeiro conjunto de transformações usando uma instrução CTAS que converteu dadospara o formato Parquet com compactação Snappy. A instrução CTAS também converteu o conjunto dedados de não particionado em particionado. Isso reduziu seu tamanho e reduziu os custos de execuçãodas consultas. Quando novos dados são disponibilizados, é possível usar uma instrução INSERT INTOpara transformar e carregar os dados na tabela criada com a instrução CTAS.
Usar CTAS e INSERT INTO para criar uma tabelacom mais de 100 partiçõesÉ possível criar até 100 partições por consulta com uma consulta CREATE TABLE AS SELECT(CTAS (p. 77)). Da mesma forma, é possível adicionar, no máximo, 100 partições a uma tabela dedestino com uma instrução INSERT INTO. Para contornar essas limitações, é possível usar uma instruçãoCTAS e uma série de instruções INSERT INTO que criam ou inserem até 100 partições cada.
O exemplo neste tópico usa um banco de dados chamado tpch100 cujos dados residem no local dobucket do Amazon S3 s3://<my-tpch-bucket>/.
Como usar CTAS e INSERT INTO para criar uma tabela com mais de 100 partições
1. Use uma instrução CREATE EXTERNAL TABLE para criar uma tabela particionada no campodesejado.
A instrução de exemplo a seguir particiona os dados de acordo com a coluna l_shipdate. A tabelatem 2.525 partições.
CREATE EXTERNAL TABLE `tpch100.lineitem_parq_partitioned`( `l_orderkey` int, `l_partkey` int, `l_suppkey` int, `l_linenumber` int, `l_quantity` double, `l_extendedprice` double, `l_discount` double, `l_tax` double, `l_returnflag` string, `l_linestatus` string, `l_commitdate` string, `l_receiptdate` string, `l_shipinstruct` string, `l_comment` string)PARTITIONED BY ( `l_shipdate` string)
92

Amazon Athena Guia do usuárioCriar uma tabela com mais de 100 partições
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://<my-tpch-bucket>/lineitem/'
2. Execute um comando SHOW PARTITIONS <table_name> conforme o seguinte para listar aspartições.
SHOW PARTITIONS lineitem_parq_partitioned
Veja a seguir os resultados parciais de exemplo.
/*l_shipdate=1992-01-02l_shipdate=1992-01-03l_shipdate=1992-01-04l_shipdate=1992-01-05l_shipdate=1992-01-06
...
l_shipdate=1998-11-24l_shipdate=1998-11-25l_shipdate=1998-11-26l_shipdate=1998-11-27l_shipdate=1998-11-28l_shipdate=1998-11-29l_shipdate=1998-11-30l_shipdate=1998-12-01*/
3. Execute uma consulta CTAS para criar uma tabela particionada.
O exemplo a seguir cria uma tabela chamada my_lineitem_parq_partitioned e usa a cláusulaWHERE para restringir DATE a um valor anterior a 1992-02-01. Como o conjunto de dados deexemplo começa com janeiro de 1992, somente partições para janeiro de 1992 são criadas.
CREATE table my_lineitem_parq_partitionedWITH (partitioned_by = ARRAY['l_shipdate']) ASSELECT l_orderkey, l_partkey, l_suppkey, l_linenumber, l_quantity, l_extendedprice, l_discount, l_tax, l_returnflag, l_linestatus, l_commitdate, l_receiptdate, l_shipinstruct, l_comment, l_shipdateFROM tpch100.lineitem_parq_partitionedWHERE cast(l_shipdate as timestamp) < DATE ('1992-02-01');
4. Execute o comando SHOW PARTITIONS para verificar se a tabela contém as partições desejadas.
SHOW PARTITIONS my_lineitem_parq_partitioned;
93

Amazon Athena Guia do usuárioCriar uma tabela com mais de 100 partições
As partições no exemplo são de janeiro de 1992.
/*l_shipdate=1992-01-02l_shipdate=1992-01-03l_shipdate=1992-01-04l_shipdate=1992-01-05l_shipdate=1992-01-06l_shipdate=1992-01-07l_shipdate=1992-01-08l_shipdate=1992-01-09l_shipdate=1992-01-10l_shipdate=1992-01-11l_shipdate=1992-01-12l_shipdate=1992-01-13l_shipdate=1992-01-14l_shipdate=1992-01-15l_shipdate=1992-01-16l_shipdate=1992-01-17l_shipdate=1992-01-18l_shipdate=1992-01-19l_shipdate=1992-01-20l_shipdate=1992-01-21l_shipdate=1992-01-22l_shipdate=1992-01-23l_shipdate=1992-01-24l_shipdate=1992-01-25l_shipdate=1992-01-26l_shipdate=1992-01-27l_shipdate=1992-01-28l_shipdate=1992-01-29l_shipdate=1992-01-30l_shipdate=1992-01-31*/
5. Use uma instrução INSERT INTO para adicionar partições à tabela.
O exemplo a seguir adiciona partições para as datas do mês de fevereiro de 1992.
INSERT INTO my_lineitem_parq_partitionedSELECT l_orderkey, l_partkey, l_suppkey, l_linenumber, l_quantity, l_extendedprice, l_discount, l_tax, l_returnflag, l_linestatus, l_commitdate, l_receiptdate, l_shipinstruct, l_comment, l_shipdateFROM tpch100.lineitem_parq_partitionedWHERE cast(l_shipdate as timestamp) >= DATE ('1992-02-01')AND cast(l_shipdate as timestamp) < DATE ('1992-03-01');
6. Execute SHOW PARTITIONS novamente.
SHOW PARTITIONS my_lineitem_parq_partitioned;
94

Amazon Athena Guia do usuárioTratamento de atualizações de esquema
A tabela de exemplo agora tem partições de janeiro e fevereiro de 1992.
/*l_shipdate=1992-01-02l_shipdate=1992-01-03l_shipdate=1992-01-04l_shipdate=1992-01-05l_shipdate=1992-01-06
...
l_shipdate=1992-02-20l_shipdate=1992-02-21l_shipdate=1992-02-22l_shipdate=1992-02-23l_shipdate=1992-02-24l_shipdate=1992-02-25l_shipdate=1992-02-26l_shipdate=1992-02-27l_shipdate=1992-02-28l_shipdate=1992-02-29*/
7. Continue a usar instruções INSERT INTO que adicionam até 100 partições cada. Continue até atingiro número de partições necessárias.
Important
Ao definir a condição WHERE, certifique-se de que as consultas não se sobreponham. Casocontrário, algumas partições podem ter dados duplicados.
Tratamento de atualizações de esquemaEsta seção fornece orientações sobre como tratar atualizações de esquema de vários formatos de dados.O Athena é um mecanismo de consulta schema-on-read. Isso significa que, quando você cria uma tabelano Athena, ela aplica esquemas ao ler os dados. Ela não altera nem reescrever os dados subjacentes.
Se você antecipar alterações nos esquemas de tabela, considere criá-los em um formato de dadosadequado para suas necessidades. Seu objetivo é reutilizar as consultas existentes do Athena contraesquemas em evolução e evitar erros de incompatibilidade de esquemas ao consultar tabelas compartições.
Important
As atualizações de esquema descritas nesta seção não funcionam em tabelas com tipos de dadoscomplexos ou aninhados, como arrays e estruturas.
Para atingir essas metas, escolha um formato de dados da tabela com base na tabela no seguinte tópico.
Tópicos• Resumo: atualizações e formatos de dados no Athena (p. 96)• Acesso ao índice em ORC e Parquet (p. 97)• Tipos de atualizações (p. 98)• Atualizações em tabelas com partições (p. 103)
95

Amazon Athena Guia do usuárioResumo: atualizações e formatos de dados no Athena
Resumo: atualizações e formatos de dados no AthenaA tabela a seguir resume os formatos de armazenamento físico de dados e os manuseios do esquemacom suporte. Use essa tabela para ajudar a escolher o formato que permitirá que você continue usando asconsultas do Athena mesmo que seus esquemas sejam alterados ao longo do tempo.
Nessa tabela, observe que o Parquet e ORC são formatos de coluna com diferentes métodos de acessopadrão à coluna. Por padrão, o Parquet acessa colunas por nome e o ORC por índice (valor ordinal).Portanto, o Athena fornece uma propriedade SerDe, definida ao criar uma tabela, para alternar o métodode acesso padrão a colunas para permitir maior flexibilidade com evolução de esquema.
Para o Parquet, a propriedade parquet.column.index.access pode ser definida como TRUE, quedefine que o método de acesso à coluna usará o número ordinal da coluna. Definir essa propriedade comoFALSE fará com que o método de acesso à coluna use o nome da coluna. Da mesma forma, para ORC,use a propriedade orc.column.index.access para controlar o método de acesso à coluna. Para obtermais informações, consulte Acesso ao índice em ORC e Parquet (p. 97).
Os formatos CSV e TSV permitem que você faça todos os manuseios do esquema, exceto areorganização de colunas ou a adição de colunas ao início da tabela. Por exemplo, se a evolução do seuesquema requer apenas a renomeação de colunas, mas não a remoção delas, você pode optar por criarsuas tabelas nos formatos CSV ou TSV. Se você precisar remover colunas, não use os formatos CSVou TSV. Em vez disso, use qualquer um dos outros formatos compatíveis, de preferência um formato decoluna, como Parquet ou ORC.
Atualizações de esquema e formatos de dados no Athena
Tipoesperado deatualizaçãode esquema
Resumo CSV(come semcabeçalhos)e TSV
JSONAVROPARQUET:leiturapornome(padrão)
PARQUET:leituraporíndice
ORC:leiturapor índice(padrão)
ORC:leiturapor nome
Renomearcolunas (p. 101)
Armazene seusdados em CSV eTSV, ou em ORC eParquet se eles sãolidos por índice.
Y N N N Y Y N
Adicionarcolunas noinício ouno meio databela (p. 99)
Armazene seusdados em JSONe AVRO, ou emParquet e ORC seeles são lidos pornome. Não use CSVe TSV.
N Y Y Y N N Y
Adicionarcolunasno final databela (p. 100)
Armazene seusdados em CSV ouTSV, JSON, AVRO,ORC ou Parquet.
Y Y Y Y Y Y Y
Removercolunas (p. 100)
Armazene seusdados em JSONe AVRO, ou emParquet e ORC seeles são lidos pornome. Não use CSVe TSV.
N Y Y Y N N Y
96

Amazon Athena Guia do usuárioAcesso ao índice em ORC e Parquet
Tipoesperado deatualizaçãode esquema
Resumo CSV(come semcabeçalhos)e TSV
JSONAVROPARQUET:leiturapornome(padrão)
PARQUET:leituraporíndice
ORC:leiturapor índice(padrão)
ORC:leiturapor nome
Reclassificarcolunas (p. 102)
Armazene seusdados em AVRO,JSON ou emParquet e ORC seeles são lidos pornome.
N Y Y Y N N Y
Alterar o tipode dadosde umacoluna (p. 102)
Armazene seusdados em qualquerformato, mas teste aconsulta no Athenapara garantir queos tipos de dadossejam compatíveis.No Parquet e noORC, a alteraçãode um tipo dedados funcionaapenas para tabelasparticionadas.
Y Y Y Y Y Y Y
Acesso ao índice em ORC e ParquetPARQUET e ORC são formatos de coluna para armazenamento físico de dados que podem ser lidos poríndice ou por nome. O armazenamento dos dados em qualquer um desses formatos permite que vocêexecute todas as operações em esquemas e execute consultas do Athena sem erros de incompatibilidadede esquema.
• O Athena lê o ORC por índice, por padrão, conforme definido em SERDEPROPERTIES( 'orc.column.index.access'='true'). Para obter mais informações, consulte ORC: leitura poríndice (p. 98).
• O Athena lê Parquet por nome, por padrão, conforme definido em SERDEPROPERTIES( 'parquet.column.index.access'='false'). Para obter mais informações, consultePARQUET: leitura por nome (p. 98).
Uma vez que essas leituras são padrão, a especificação das propriedades SerDe em suas consultasCREATE TABLE é opcional; elas são usadas implicitamente. Quando são usadas, elas permitem quevocê execute algumas operações de atualização de esquema enquanto impedem outras operaçõessemelhantes. Para habilitar essas operações, execute outra consulta CREATE TABLE e altere asconfigurações SerDe.
Note
As propriedades SerDe não são propagadas automaticamente para cada partição. Use instruçõesALTER TABLE ADD PARTITION para definir as propriedades SerDe para cada partição. Paraautomatizar esse processo, escreva um script que execute instruções ALTER TABLE ADDPARTITION.
As seções a seguir descrevem esses casos em detalhes.
97

Amazon Athena Guia do usuárioTipos de atualizações
ORC: leitura por índiceUma tabela no formato ORC é lida por índice, por padrão. Isso é definido pela seguinte sintaxe:
WITH SERDEPROPERTIES ( 'orc.column.index.access'='true')
A leitura por índice permite renomear colunas. No entanto, não será mais possível remover colunas nemas adicionar no meio da tabela.
Para fazer com que o ORC seja lido por nome, o que permitirá que você adicione colunas no meio databela ou remova as colunas em ORC, defina a propriedade orc.column.index.access do SerDecomo FALSE na instrução CREATE TABLE. Com essa configuração, não será mais possível renomearcolunas.
O exemplo a seguir ilustra como alterar o ORC para que ele seja lido por nome:
CREATE EXTERNAL TABLE orders_orc_read_by_name ( `o_comment` string, `o_orderkey` int, `o_custkey` int, `o_orderpriority` string, `o_orderstatus` string, `o_clerk` string, `o_shippriority` int, `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' WITH SERDEPROPERTIES ( 'orc.column.index.access'='false') STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION 's3://schema_updates/orders_orc/';
Parquet: leitura por nomeUma tabela no formato Parquet é lida por nome, por padrão. Isso é definido pela seguinte sintaxe:
WITH SERDEPROPERTIES ( 'parquet.column.index.access'='false')
A leitura por nome permite que você remova colunas ou as adicione no meio da tabela. No entanto, nãoserá mais possível renomeá-las.
Para fazer com que o Parquet seja lido por índice, o que permitirá que você renomeie colunas, énecessário criar uma tabela com a propriedade parquet.column.index.access do SerDe e defini-lacomo TRUE.
Tipos de atualizaçõesVeja os tipos de atualizações que o esquema de uma tabela pode ter. Analisamos cada tipo de atualizaçãode esquema e especificamos quais formatos de dados permitem que você os tenha no Athena.
Important
As atualizações de esquema descritas nesta seção não funcionam em tabelas com tipos de dadoscomplexos ou aninhados, como arrays e estruturas.
98

Amazon Athena Guia do usuárioTipos de atualizações
• Adicionar colunas no início ou no meio da tabela (p. 99)• Adicionar colunas no final da tabela (p. 100)• Remoção de colunas (p. 100)• Renomeação de colunas (p. 101)• Reclassificação de colunas (p. 102)• Alteração de um tipo de dados de coluna (p. 102)
Dependendo de como você espera que seus esquemas evoluam, para continuar usando as consultas doAthena, escolha um formato de dados compatível.
Vamos considerar um aplicativo que lê informações sobre pedidos de uma tabela de orders que existeem dois formatos: CSV e Parquet.
O exemplo a seguir cria uma tabela em Parquet:
CREATE EXTERNAL TABLE orders_parquet ( `orderkey` int, `orderstatus` string, `totalprice` double, `orderdate` string, `orderpriority` string, `clerk` string, `shippriority` int) STORED AS PARQUETLOCATION 's3://schema_updates/orders_ parquet/';
O exemplo a seguir cria a mesma tabela em CSV:
CREATE EXTERNAL TABLE orders_csv ( `orderkey` int, `orderstatus` string, `totalprice` double, `orderdate` string, `orderpriority` string, `clerk` string, `shippriority` int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION 's3://schema_updates/orders_csv/';
Nas seções a seguir, analise como as atualizações nessas tabelas afetam as consultas do Athena.
Adicionar colunas no início ou no meio da tabelaA adição de colunas é uma das alterações do esquema mais frequentes. Por exemplo, você podeadicionar uma nova coluna para enriquecer a tabela com novos dados. Ou você poderá adicionar umanova coluna se a origem para uma coluna existente for alterada e manter a versão anterior deste colunapara ajustar os aplicativos que dependem delas.
Para adicionar colunas no início ou no meio da tabela e continuar executando consultas em tabelasexistentes, use os formatos AVRO e JSON, bem como Parquet e ORC, se a propriedade do SerDeestiver definida para leitura por nome. Para obter mais informações, consulte Acesso ao índice em ORC eParquet (p. 97).
Não adicione colunas no início ou no meio da tabela em CSV e TSV, pois esses formatos dependem daclassificação. Se uma coluna for adicionada em um desses casos, ocorrerá um erro de incompatibilidadede esquema quando o esquema de partições for alterado.
O exemplo a seguir mostra como adicionar uma coluna no meio de uma tabela JSON:
99

Amazon Athena Guia do usuárioTipos de atualizações
CREATE EXTERNAL TABLE orders_json_column_addition ( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_comment` string, `o_totalprice` double, `o_orderdate` string, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'LOCATION 's3://schema_updates/orders_json/';
Adição de colunas no final da tabelaAo criar tabelas em qualquer um dos formatos ao qual o Athena oferece suporte, como Parquet, ORC,AVRO, JSON, CSV e TSV, você pode adicionar novas colunas no final da tabela. Para tabelas emParquet e ORC, você pode adicionar colunas no final da tabela, independentemente do tipo de acesso aoíndice (p. 97) que elas usam.
No exemplo a seguir, solte uma tabela existente no Parquet e adicione uma nova tabela Parquet com umanova coluna `comment` no final da tabela:
DROP TABLE orders_parquet;CREATE EXTERNAL TABLE orders_parquet ( `orderkey` int, `orderstatus` string, `totalprice` double, `orderdate` string, `orderpriority` string, `clerk` string, `shippriority` int `comment` string) STORED AS PARQUETLOCATION 's3://schema_updates/orders_parquet/';
No exemplo a seguir, solte uma tabela existente no CSV e adicione uma nova tabela CSV com uma novacoluna `comment` no final da tabela:
DROP TABLE orders_csv;CREATE EXTERNAL TABLE orders_csv ( `orderkey` int, `orderstatus` string, `totalprice` double, `orderdate` string, `orderpriority` string, `clerk` string, `shippriority` int `comment` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION 's3://schema_updates/orders_csv/';
Remoção de colunasTalvez você precise remover colunas de tabelas se elas não contiverem dados ou restringir o acesso aosdados contidos nelas.
100

Amazon Athena Guia do usuárioTipos de atualizações
• Você pode remover colunas de tabelas em JSON, Avro e em ORC e Parquet se elas forem lidas pornome. Para obter mais informações, consulte Acesso ao índice em ORC e Parquet (p. 97).
• Não é recomendável remover colunas de tabelas em CSV e TSV ao manter as tabelas criadas noAthena. A remoção de uma coluna rompe o esquema e requer que você recrie a tabela sem a colunaremovida.
Neste exemplo, remova uma coluna `totalprice` de uma tabela em Parquet e execute umaconsulta. No Athena, o Parquet é lido por nome, por padrão. É por isso que omitimos a configuraçãoSERDEPROPERTIES que especifica a leitura por nome. Observe que a consulta a seguir é bem-sucedida,mesmo que você altere o esquema:
CREATE EXTERNAL TABLE orders_parquet_column_removed ( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_orderdate` string, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) STORED AS PARQUETLOCATION 's3://schema_updates/orders_parquet/';
Renomeação de colunasTalvez você queira renomear colunas em suas tabelas para corrigir ortografia, tornar os nomes dascolunas mais descritivos ou reutilizar uma coluna existente para evitar a reclassificação dela.
Você pode renomear colunas se armazenar seus dados em CSV e TSV, ou em Parquet e ORC, que sãoconfigurados para leitura por índice. Para obter mais informações, consulte Acesso ao índice em ORC eParquet (p. 97).
O Athena lê dados em CSV e TSV na ordem das colunas no esquema e retorna-os na mesma ordem. Elenão usa nomes de coluna para mapear dados para uma coluna, e é por isso que você pode renomearcolunas em CSV ou TSV sem quebrar consultas do Athena.
Neste exemplo, renomeie a coluna `o_totalprice` para `o_total_price` na tabela Parquet e, emseguida, execute uma consulta no Athena:
CREATE EXTERNAL TABLE orders_parquet_column_renamed ( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_total_price` double, `o_orderdate` string, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) STORED AS PARQUETLOCATION 's3://TBD/schema_updates/orders_parquet/';
No caso da tabela do Parquet, a consulta a seguir é executada. No entanto, a coluna renomeada não exibedados, porque ela estava sendo acessada por nome (um padrão no Parquet) em vez de por índice:
SELECT *
101

Amazon Athena Guia do usuárioTipos de atualizações
FROM orders_parquet_column_renamed;
Uma consulta com uma tabela em CSV tem aparência semelhante:
CREATE EXTERNAL TABLE orders_csv_column_renamed ( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_total_price` double, `o_orderdate` string, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION 's3://schema_updates/orders_csv/';
No caso da tabela CSV, a consulta a seguir é executada, e os dados são exibidos em todas as colunas,incluindo aquela que foi renomeada:
SELECT * FROM orders_csv_column_renamed;
Reclassificação de colunasVocê pode reordenar colunas apenas em tabelas com dados em formatos de leitura por nome,como JSON ou ORC, que leem por nome, por padrão. Você também pode fazer com que o Parquetleia por nome, se necessário. Para obter mais informações, consulte Acesso ao índice em ORC eParquet (p. 97).
O exemplo a seguir ilustra como reclassificar colunas:
CREATE EXTERNAL TABLE orders_parquet_columns_reordered ( `o_comment` string, `o_orderkey` int, `o_custkey` int, `o_orderpriority` string, `o_orderstatus` string, `o_clerk` string, `o_shippriority` int, `o_orderdate` string) STORED AS PARQUETLOCATION 's3://schema_updates/orders_parquet/';
Alteração de um tipo de dados de colunaVocê altera os tipos de coluna porque um tipo de dados da coluna não pode mais reter a quantidade deinformações, por exemplo, quando uma coluna de ID excede o tamanho de um tipo de dados INT e temque mudar para um tipo de dados BIGINT.
A alteração do tipo de dados de uma coluna tem estas limitações:
• Somente determinados tipos de dados podem ser convertidos em outros tipos de dados. Consulte atabela desta seção para obter os tipos de dados que podem ser alterados.
• Para dados em Parquet e ORC, você não pode alterar o tipo de dados de uma coluna se a tabela não forparticionada.
102

Amazon Athena Guia do usuárioAtualizações em tabelas com partições
Para tabelas particionadas no Parquet e no ORC, o tipo de coluna de uma partição pode ser diferentedo tipo de coluna de outra partição, e o Athena efetuará CAST para o tipo desejado, se possível. Paraobter informações, consulte Como evitar erros de incompatibilidade de esquema para tabelas compartições (p. 104)
Important
É altamente recomendável testar e verificar suas consultas antes de executar as conversões detipo de dados. Se o Athena não puder converter o tipo de dados original para o tipo de dados dedestino, a consulta CREATE TABLE poderá falhar.
A tabela a seguir lista os tipos de dados que você pode alterar:
Tipos de dados compatíveis
Tipo de dados originais Tipos de dados de destino disponíveis
STRING BYTE, TINYINT, SMALLINT, INT, BIGINT
BYTE TINYINT, SMALLINT, INT, BIGINT
TINYINT SMALLINT, INT, BIGINT
SMALLINT INT, BIGINT
INT BIGINT
FLOAT DOUBLE
No exemplo a seguir da tabela orders_json, altere o tipo de dados da coluna `o_shippriority` paraBIGINT:
CREATE EXTERNAL TABLE orders_json ( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderdate` string, `o_orderpriority` string, `o_clerk` string, `o_shippriority` BIGINT) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'LOCATION 's3://schema_updates/orders_json';
A seguinte consulta é executada com êxito, semelhante à consulta SELECT original, antes que o tipo dedados seja alterado:
Select * from orders_json LIMIT 10;
Atualizações em tabelas com partiçõesNo Athena, uma tabela e suas partições devem usar os mesmos formatos de dados, mas os esquemaspodem ser diferentes. Quando você cria uma nova partição, essa partição geralmente herda o esquema
103

Amazon Athena Guia do usuárioAtualizações em tabelas com partições
da tabela. Com o passar do tempo, os esquemas podem começar a ser diferentes. Os motivos para issoincluem:
• Se o esquema da tabela é alterado, os esquemas para as partições não são atualizados parapermanecer em sincronia com o esquema da tabela.
• O Crawler do AWS Glue permite que você descubra dados em partições com esquemas diferentes.Isso significa que, se você criar uma tabela no Athena com o AWS Glue, depois que o crawler concluir oprocessamento, os esquemas da tabela e suas partições poderão ser diferentes.
• Se você adicionar partições diretamente usando uma API da AWS.
O Athena processará tabelas com partições com êxito se elas estiverem de acordo comas restrições a seguir. Se essas restrições não forem atendidas, o Athena emitirá um erroHIVE_PARTITION_SCHEMA_MISMATCH.
• Cada esquema de partição é compatível com o esquema da tabela.• O formato de dados da tabela permite o tipo de atualização que você deseja executar: adicionar, excluir,
reclassificar colunas ou alterar um tipo de dados da coluna.
Por exemplo, para os formatos CSV e TSV, você pode renomear colunas, adicionar novas colunas nofinal da tabela e alterar o tipo de dados de uma coluna se os tipos forem compatíveis, mas você nãopode remover colunas. Para outros formatos, você pode adicionar ou remover colunas ou alterar o tipode dados de uma coluna para outro se os tipos forem compatíveis. Para obter informações, consulteResumo: atualizações e formatos de dados no Athena (p. 96).
Important
As atualizações de esquema descritas nesta seção não funcionam em tabelas com tipos de dadoscomplexos ou aninhados, como arrays e estruturas.
Como evitar erros de incompatibilidade do esquema para tabelascom partiçõesNo início da execução da consulta, o Athena verifica o esquema da tabela verificando se cada tipo dedados da coluna é compatível entre a tabela e partição.
• Para os tipos de armazenamento físico de dados ORC e do Parquet, o Athena depende dos nomesdas colunas e os utiliza para a verificação do esquema com base em nome de coluna. Isso eliminaerros HIVE_PARTITION_SCHEMA_MISMATCH nas tabelas com partições nos tipos Parquet e ORC.(Isso será verdadeiro para ORC se a propriedade SerDe for definida para acessar o índice por nome:orc.column.index.access=FALSE. O tipo Parquet lê o índice por nome, por padrão.
• Para CSV, JSON e AVRO, o Athena usa uma verificação de esquema com base em índice. Isso significaque, ao encontrar um erro de incompatibilidade de esquema, você deverá eliminar a partição que estácausando uma incompatibilidade de esquema e recriá-la, de modo que o Athena possa consultá-la semfalhas.
O Athena compara o esquema da tabela com os esquemas de partição. Se você criar uma tabelanos formatos CSV, JSON e AVRO no Athena com o AWS Glue, depois que o crawler concluir oprocessamento, os esquemas da tabela e suas partições poderão ser diferentes. Se houver umaincompatibilidade entre os esquemas da tabela e de partição, haverá falha nas consultas no Athena.Isso ocorre devido a um erro de verificação de esquema semelhante a este: 'crawler_test.click_avro' édeclarado como tipo 'string', mas a partição 'partition_0=2017-01-17' declarou a coluna 'col68' como tipo'dupla'."
Uma solução comum para esses erros é eliminar a partição que está causando o erro e recriá-la.
104

Amazon Athena Guia do usuárioConsultar matrizes
Consultar matrizesO Amazon Athena permite criar matrizes, concatená-las, convertê-las em tipos de dados diferentes e, emseguida, filtrar, nivelar e classificá-las.
Tópicos• Criar matrizes (p. 105)• Concatenar matrizes (p. 107)• Converter tipos de dados da matriz (p. 107)• Encontrar tamanhos (p. 108)• Acessar elementos de matriz (p. 108)• Nivelar matrizes aninhadas (p. 109)• Criar conjuntos com base em subconsultas (p. 111)• Filtrar matrizes (p. 112)• Classificar matrizes (p. 113)• Usar funções de agregação com matrizes (p. 113)• Converter matrizes em strings (p. 114)• Usar matrizes para criar mapas (p. 114)• Como consultar matrizes com tipos complexos e estruturas aninhadas (p. 115)
Criar matrizesPara criar um literal de matriz no Athena, use a palavra-chave ARRAY, seguida por colchetes [ ] e incluaos elementos da matriz separados por vírgulas.
ExemplosEssa consulta cria uma matriz com quatro elementos.
SELECT ARRAY [1,2,3,4] AS items
Ela retorna:
+-----------+| items |+-----------+| [1,2,3,4] |+-----------+
Essa consulta cria duas matrizes.
SELECT ARRAY[ ARRAY[1,2], ARRAY[3,4] ] AS items
Ela retorna:
+--------------------+| items |
105

Amazon Athena Guia do usuárioCriar matrizes
+--------------------+| [[1, 2], [3, 4]] |+--------------------+
Para criar uma matriz com base em colunas selecionadas de tipos compatíveis, use uma consulta, comoneste exemplo:
WITHdataset AS ( SELECT 1 AS x, 2 AS y, 3 AS z)SELECT ARRAY [x,y,z] AS items FROM dataset
Essa consulta retorna:
+-----------+| items |+-----------+| [1,2,3] |+-----------+
No exemplo a seguir, duas matrizes são selecionadas e retornadas como uma mensagem de boas-vindas.
WITHdataset AS ( SELECT ARRAY ['hello', 'amazon', 'athena'] AS words, ARRAY ['hi', 'alexa'] AS alexa)SELECT ARRAY[words, alexa] AS welcome_msgFROM dataset
Essa consulta retorna:
+----------------------------------------+| welcome_msg |+----------------------------------------+| [[hello, amazon, athena], [hi, alexa]] |+----------------------------------------+
Para criar uma matriz de pares chave/valor, use o operador MAP que utiliza uma matriz de chaves seguidade uma matriz de valores, como neste exemplo:
SELECT ARRAY[ MAP(ARRAY['first', 'last', 'age'],ARRAY['Bob', 'Smith', '40']), MAP(ARRAY['first', 'last', 'age'],ARRAY['Jane', 'Doe', '30']), MAP(ARRAY['first', 'last', 'age'],ARRAY['Billy', 'Smith', '8'])] AS people
Essa consulta retorna:
+-----------------------------------------------------------------------------------------------------+| people |+-----------------------------------------------------------------------------------------------------+
106
Amazon Athena Guia do usuárioConcatenar matrizes
| [{last=Smith, first=Bob, age=40}, {last=Doe, first=Jane, age=30}, {last=Smith, first=Billy, age=8}] |+-----------------------------------------------------------------------------------------------------+
Concatenar matrizesPara concatenar várias matrizes, use o operador || de barra dupla entre elas.
SELECT ARRAY [4,5] || ARRAY[ ARRAY[1,2], ARRAY[3,4] ] AS items
Essa consulta retorna:
+--------------------------+| items |+--------------------------+| [[4, 5], [1, 2], [3, 4]] |+--------------------------+
Para combinar várias matrizes em uma única, use a função concat.
WITHdataset AS ( SELECT ARRAY ['hello', 'amazon', 'athena'] AS words, ARRAY ['hi', 'alexa'] AS alexa)SELECT concat(words, alexa) AS welcome_msgFROM dataset
Essa consulta retorna:
+------------------------------------+| welcome_msg |+------------------------------------+| [hello, amazon, athena, hi, alexa] |+------------------------------------+
Converter tipos de dados da matrizPara converter dados em matrizes para tipos de dados com suporte, use o operador CAST, comoCAST(value AS type). O Athena oferece suporte a todos os tipos de dados nativos do Presto.
SELECT ARRAY [CAST(4 AS VARCHAR), CAST(5 AS VARCHAR)]AS items
Essa consulta retorna:
+-------+| items |+-------+| [4,5] |+-------+
107

Amazon Athena Guia do usuárioEncontrar tamanhos
Crie duas matrizes com elementos de par chave/valor, converta-as em JSON e concatene, como nesteexemplo:
SELECT ARRAY[CAST(MAP(ARRAY['a1', 'a2', 'a3'], ARRAY[1, 2, 3]) AS JSON)] || ARRAY[CAST(MAP(ARRAY['b1', 'b2', 'b3'], ARRAY[4, 5, 6]) AS JSON)]AS items
Essa consulta retorna:
+--------------------------------------------------+| items |+--------------------------------------------------+| [{"a1":1,"a2":2,"a3":3}, {"b1":4,"b2":5,"b3":6}] |+--------------------------------------------------+
Encontrar tamanhosA função cardinality retorna o tamanho de uma matriz, como neste exemplo:
SELECT cardinality(ARRAY[1,2,3,4]) AS item_count
Essa consulta retorna:
+------------+| item_count |+------------+| 4 |+------------+
Acessar elementos de matrizPara acessar elementos de matriz, use o operador [], com 1 especificando o primeiro elemento, 2especificando o segundo elemento e assim por diante, como neste exemplo:
WITH dataset AS (SELECT ARRAY[CAST(MAP(ARRAY['a1', 'a2', 'a3'], ARRAY[1, 2, 3]) AS JSON)] || ARRAY[CAST(MAP(ARRAY['b1', 'b2', 'b3'], ARRAY[4, 5, 6]) AS JSON)]AS items )SELECT items[1] AS item FROM dataset
Essa consulta retorna:
+------------------------+| item |+------------------------+| {"a1":1,"a2":2,"a3":3} |+------------------------+
Para acessar os elementos de uma matriz em uma determinada posição (conhecida como a posição deíndice), use a função element_at() e especifique o nome da matriz e a posição de índice:
• Se o índice for maior que 0, element_at() retornará o elemento especificado por você, contando doinício ao fim da matriz. Ele se comporta como o operador [].
108

Amazon Athena Guia do usuárioNivelar matrizes aninhadas
• Se o índice for menor que 0, element_at() retornará o elemento, contando do fim ao início da matriz.
A consulta a seguir cria uma matriz wordse seleciona o primeiro elemento hello dela como ofirst_word, o segundo elemento amazon (contagem a partir do final da matriz) como o middle_word eo terceiro elemento athena como o last_word.
WITH dataset AS ( SELECT ARRAY ['hello', 'amazon', 'athena'] AS words)SELECT element_at(words, 1) AS first_word, element_at(words, -2) AS middle_word, element_at(words, cardinality(words)) AS last_wordFROM dataset
Essa consulta retorna:
+----------------------------------------+| first_word | middle_word | last_word |+----------------------------------------+| hello | amazon | athena |+----------------------------------------+
Nivelar matrizes aninhadasAo trabalhar com matrizes aninhadas, você normalmente precisa expandir elementos de matriz aninhadospara uma única matriz ou expandir a matriz para várias linhas.
ExemplosPara nivelar elementos de uma matriz aninhada em uma única matriz de valores, use a função flatten.Essa consulta retorna uma linha para cada elemento na matriz.
SELECT flatten(ARRAY[ ARRAY[1,2], ARRAY[3,4] ]) AS items
Essa consulta retorna:
+-----------+| items |+-----------+| [1,2,3,4] |+-----------+
Para nivelar uma matriz em várias linhas, use CROSS JOIN com o operador UNNEST, como nesteexemplo:
WITH dataset AS ( SELECT 'engineering' as department, ARRAY['Sharon', 'John', 'Bob', 'Sally'] as users)SELECT department, names FROM datasetCROSS JOIN UNNEST(users) as t(names)
Essa consulta retorna:
109

Amazon Athena Guia do usuárioNivelar matrizes aninhadas
+----------------------+| department | names |+----------------------+| engineering | Sharon |+----------------------|| engineering | John |+----------------------|| engineering | Bob |+----------------------|| engineering | Sally |+----------------------+
Para nivelar uma matriz de pares chave/valor, transpor chaves selecionadas para colunas, como nesteexemplo:
WITHdataset AS ( SELECT 'engineering' as department, ARRAY[ MAP(ARRAY['first', 'last', 'age'],ARRAY['Bob', 'Smith', '40']), MAP(ARRAY['first', 'last', 'age'],ARRAY['Jane', 'Doe', '30']), MAP(ARRAY['first', 'last', 'age'],ARRAY['Billy', 'Smith', '8']) ] AS people )SELECT names['first'] AS first_name, names['last'] AS last_name, department FROM datasetCROSS JOIN UNNEST(people) AS t(names)
Essa consulta retorna:
+--------------------------------------+| first_name | last_name | department |+--------------------------------------+| Bob | Smith | engineering || Jane | Doe | engineering || Billy | Smith | engineering |+--------------------------------------+
Em uma lista de funcionários, selecione o funcionário com a maior pontuação combinada. UNNEST podeser usado na cláusula FROM sem um CROSS JOIN anterior pois ele é o operador de junção padrão e,portanto, implícito.
WITHdataset AS ( SELECT ARRAY[ CAST(ROW('Sally', 'engineering', ARRAY[1,2,3,4]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))), CAST(ROW('John', 'finance', ARRAY[7,8,9]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))), CAST(ROW('Amy', 'devops', ARRAY[12,13,14,15]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))) ] AS users),users AS ( SELECT person, score FROM dataset, UNNEST(dataset.users) AS t(person),
110

Amazon Athena Guia do usuárioCriar conjuntos com base em subconsultas
UNNEST(person.scores) AS t(score))SELECT person.name, person.department, SUM(score) AS total_score FROM usersGROUP BY (person.name, person.department)ORDER BY (total_score) DESCLIMIT 1
Essa consulta retorna:
+---------------------------------+| name | department | total_score |+---------------------------------+| Amy | devops | 54 |+---------------------------------+
Em uma lista de funcionários, selecione o funcionário com a pontuação individual mais alta.
WITHdataset AS ( SELECT ARRAY[ CAST(ROW('Sally', 'engineering', ARRAY[1,2,3,4]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))), CAST(ROW('John', 'finance', ARRAY[7,8,9]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))), CAST(ROW('Amy', 'devops', ARRAY[12,13,14,15]) AS ROW(name VARCHAR, department VARCHAR, scores ARRAY(INTEGER))) ] AS users),users AS ( SELECT person, score FROM dataset, UNNEST(dataset.users) AS t(person), UNNEST(person.scores) AS t(score))SELECT person.name, score FROM usersORDER BY (score) DESCLIMIT 1
Essa consulta retorna:
+--------------+| name | score |+--------------+| Amy | 15 |+--------------+
Criar conjuntos com base em subconsultasCrie uma matriz com base em uma coleção de filas.
WITHdataset AS ( SELECT ARRAY[1,2,3,4,5] AS items)SELECT array_agg(i) AS array_itemsFROM datasetCROSS JOIN UNNEST(items) AS t(i)
111

Amazon Athena Guia do usuárioFiltrar matrizes
Essa consulta retorna:
+-----------------+| array_items |+-----------------+| [1, 2, 3, 4, 5] |+-----------------+
Para criar um conjunto de valores exclusivos com base em um conjunto de linhas, use a palavra-chavedistinct.
WITHdataset AS ( SELECT ARRAY [1,2,2,3,3,4,5] AS items)SELECT array_agg(distinct i) AS array_itemsFROM datasetCROSS JOIN UNNEST(items) AS t(i)
Essa consulta retorna o resultado a seguir. Observe que a ordem não é garantida.
+-----------------+| array_items |+-----------------+| [1, 2, 3, 4, 5] |+-----------------+
Filtrar matrizesCrie uma matriz com base em uma coleção de filas caso elas correspondam aos critérios de filtro.
WITHdataset AS ( SELECT ARRAY[1,2,3,4,5] AS items)SELECT array_agg(i) AS array_itemsFROM datasetCROSS JOIN UNNEST(items) AS t(i)WHERE i > 3
Essa consulta retorna:
+-------------+| array_items |+-------------+| [4, 5] |+-------------+
Filtrar uma matriz com base em se um dos elementos contêm um valor específico, como 2, como nesteexemplo:
WITHdataset AS ( SELECT ARRAY [ ARRAY[1,2,3,4],
112

Amazon Athena Guia do usuárioClassificar matrizes
ARRAY[5,6,7,8], ARRAY[9,0] ] AS items)SELECT i AS array_items FROM datasetCROSS JOIN UNNEST(items) AS t(i)WHERE contains(i, 2)
Essa consulta retorna:
+--------------+| array_items |+--------------+| [1, 2, 3, 4] |+--------------+
Classificar matrizesCrie uma matriz classificada de valores exclusivos com base em um conjunto de filas.
WITHdataset AS ( SELECT ARRAY[3,1,2,5,2,3,6,3,4,5] AS items)SELECT array_sort(array_agg(distinct i)) AS array_itemsFROM datasetCROSS JOIN UNNEST(items) AS t(i)
Essa consulta retorna:
+--------------------+| array_items |+--------------------+| [1, 2, 3, 4, 5, 6] |+--------------------+
Usar funções de agregação com matrizes• Para adicionar valores dentro de uma matriz, use SUM, como no exemplo a seguir.• Para agregar várias linhas dentro de uma matriz, use array_agg. Para obter mais informações,
consulte Criar matrizes de subconsultas (p. 111).
Note
ORDER BY não é compatível com funções de agregação, por exemplo, você não pode usá-lo emarray_agg(x).
WITHdataset AS ( SELECT ARRAY [ ARRAY[1,2,3,4], ARRAY[5,6,7,8], ARRAY[9,0] ] AS items
113

Amazon Athena Guia do usuárioConverter matrizes em strings
),item AS ( SELECT i AS array_items FROM dataset, UNNEST(items) AS t(i))SELECT array_items, sum(val) AS totalFROM item, UNNEST(array_items) AS t(val)GROUP BY array_items;
Esta consulta retorna os resultados a seguir. A ordem de resultados obtidos não é garantida.
+----------------------+| array_items | total |+----------------------+| [1, 2, 3, 4] | 10 || [5, 6, 7, 8] | 26 || [9, 0] | 9 |+----------------------+
Converter matrizes em stringsPara converter uma matriz em uma string única, use a função array_join.
WITHdataset AS ( SELECT ARRAY ['hello', 'amazon', 'athena'] AS words)SELECT array_join(words, ' ') AS welcome_msgFROM dataset
Essa consulta retorna:
+---------------------+| welcome_msg |+---------------------+| hello amazon athena |+---------------------+
Usar matrizes para criar mapasOs mapas são pares de chave-valor que consistem em tipos de dados disponíveis no Athena. Para criarmapas, use o operador MAP e passe duas matrizes: a primeira é de nomes de coluna (chave) e a segundaé de valores. Todos os valores nas matrizes devem ser do mesmo tipo. Se qualquer um dos elementos dematriz de valor de mapa precisar ser de tipos diferentes, você poderá convertê-los depois.
ExemplosEste exemplo seleciona um usuário em um conjunto de dados. Ele usa o operador MAP e passa duasmatrizes. A primeira matriz inclui valores para nomes de coluna, como "primeiro", "último" e "idade". Asegunda matriz consiste em valores para cada uma dessas colunas, como "Bob", "Smith", "35".
WITH dataset AS ( SELECT MAP( ARRAY['first', 'last', 'age'], ARRAY['Bob', 'Smith', '35'] ) AS user
114
Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
)SELECT user FROM dataset
Essa consulta retorna:
+---------------------------------+| user |+---------------------------------+| {last=Smith, first=Bob, age=35} |+---------------------------------+
Você pode recuperar valores Map selecionando o nome do campo seguido de [key_name], como nesteexemplo:
WITH dataset AS ( SELECT MAP( ARRAY['first', 'last', 'age'], ARRAY['Bob', 'Smith', '35'] ) AS user)SELECT user['first'] AS first_name FROM dataset
Essa consulta retorna:
+------------+| first_name |+------------+| Bob |+------------+
Como consultar matrizes com tipos complexos eestruturas aninhadasOs dados de origem normalmente contêm matrizes com tipos de dados complexos e estruturas aninhadas.Os exemplos nesta seção mostram como alterar o tipo de dados de elementos, localizar elementos emmatrizes e encontrar palavras-chave usando consultas do Athena.
• Criação de uma ROW (p. 115)• Alterar nomes de campo em matrizes usando CAST (p. 116)• Filtrar matrizes usando a notação . (p. 116)• Filtrar matrizes com valores aninhados (p. 117)• Filtrar matrizes usando UNNEST (p. 118)• Localização de palavras-chave em matrizes usando regexp_like (p. 118)
Criar um ROWNote
Os exemplos neste seção usam ROW como um meio para criar dados de exemplo com os quaistrabalhar. Ao consultar tabelas no Athena, você não precisa criar tipos de dados ROW, porqueeles já foram criados a partir de sua fonte de dados. Quando você usa CREATE_TABLE, o Athenadefine um STRUCT nele, preenche-o com dados e cria o tipo de dados ROW para você, para cada
115
Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
linha do conjunto de dados. O tipo de dados ROW subjacente consiste em campos nomeados detodos os tipos de dados SQL compatíveis.
WITH dataset AS ( SELECT ROW('Bob', 38) AS users )SELECT * FROM dataset
Essa consulta retorna:
+-------------------------+| users |+-------------------------+| {field0=Bob, field1=38} |+-------------------------+
Alterar nomes de campo em matrizes usando CASTPara alterar o nome de campo em uma matriz que contenha valores ROW, você pode CAST a declaraçãoROW:
WITH dataset AS ( SELECT CAST( ROW('Bob', 38) AS ROW(name VARCHAR, age INTEGER) ) AS users)SELECT * FROM dataset
Essa consulta retorna:
+--------------------+| users |+--------------------+| {NAME=Bob, AGE=38} |+--------------------+
Note
No exemplo acima, você declara name como um VARCHAR , porque esse é o tipo no Presto. Sevocê declarar esse STRUCT dentro de uma instrução CREATE TABLE, use o tipo String porqueo Hive define esse tipo de dados como String.
Filtrar matrizes usando a notação .No exemplo a seguir, selecione o campo accountId na coluna userIdentity de uma tabela de logsdo AWS CloudTrail usando a notação .. Para obter mais informações, consulte Consultar logs do AWSCloudTrail (p. 153).
SELECT CAST(useridentity.accountid AS bigint) as newidFROM cloudtrail_logsLIMIT 2;
Essa consulta retorna:
116

Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
+--------------+| newid |+--------------+| 112233445566 |+--------------+| 998877665544 |+--------------+
Para consultar um conjunto de valores, execute esta consulta:
WITH dataset AS ( SELECT ARRAY[ CAST(ROW('Bob', 38) AS ROW(name VARCHAR, age INTEGER)), CAST(ROW('Alice', 35) AS ROW(name VARCHAR, age INTEGER)), CAST(ROW('Jane', 27) AS ROW(name VARCHAR, age INTEGER)) ] AS users)SELECT * FROM dataset
Ela retorna este resultado:
+-----------------------------------------------------------------+| users |+-----------------------------------------------------------------+| [{NAME=Bob, AGE=38}, {NAME=Alice, AGE=35}, {NAME=Jane, AGE=27}] |+-----------------------------------------------------------------+
Filtrar matrizes com valores aninhadosMatrizes grandes normalmente contêm estruturas aninhadas, e você precisa ser capaz de filtrar oupesquisar valores dentro delas.
Para definir um conjunto de dados para uma matriz de valores que inclui um valor BOOLEAN aninhado,execute esta consulta:
WITH dataset AS ( SELECT CAST( ROW('aws.amazon.com', ROW(true)) AS ROW(hostname VARCHAR, flaggedActivity ROW(isNew BOOLEAN)) ) AS sites)SELECT * FROM dataset
Ela retorna este resultado:
+----------------------------------------------------------+| sites |+----------------------------------------------------------+| {HOSTNAME=aws.amazon.com, FLAGGEDACTIVITY={ISNEW=true}} |+----------------------------------------------------------+
Em seguida, para filtrar e acessar o valor BOOLEAN desse elemento, continue usando a notação .
WITH dataset AS ( SELECT CAST(
117
Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
ROW('aws.amazon.com', ROW(true)) AS ROW(hostname VARCHAR, flaggedActivity ROW(isNew BOOLEAN)) ) AS sites)SELECT sites.hostname, sites.flaggedactivity.isnewFROM dataset
Essa consulta seleciona os campos aninhados e retorna este resultado:
+------------------------+| hostname | isnew |+------------------------+| aws.amazon.com | true |+------------------------+
Filtrar matrizes usando UNNESTPara filtrar uma matriz que inclua uma estrutura aninhada por um dos elementos filho, emita uma consultacom um operador UNNEST. Para obter mais informações sobre UNNEST, consulte Nivelar matrizesaninhadas (p. 109).
Por exemplo, esta consulta encontra nomes de host de sites no conjunto de dados.
WITH dataset AS ( SELECT ARRAY[ CAST( ROW('aws.amazon.com', ROW(true)) AS ROW(hostname VARCHAR, flaggedActivity ROW(isNew BOOLEAN)) ), CAST( ROW('news.cnn.com', ROW(false)) AS ROW(hostname VARCHAR, flaggedActivity ROW(isNew BOOLEAN)) ), CAST( ROW('netflix.com', ROW(false)) AS ROW(hostname VARCHAR, flaggedActivity ROW(isNew BOOLEAN)) ) ] as items)SELECT sites.hostname, sites.flaggedActivity.isNewFROM dataset, UNNEST(items) t(sites)WHERE sites.flaggedActivity.isNew = true
Ela retorna:
+------------------------+| hostname | isnew |+------------------------+| aws.amazon.com | true |+------------------------+
Localização de palavras-chave em matrizes usandoregexp_like
Os exemplos a seguir ilustram como pesquisar uma palavra-chave em um conjunto de dados em umelemento dentro de uma matriz usando a função regexp_like. Ele usa como entrada um padrão deexpressão regular para avaliar ou uma lista de termos separados por uma barra vertical (|), avalia o padrãoe determina se a string especificada a contém.
118

Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
O padrão da expressão regular precisa estar contido na string e não precisa corresponder a ela. Paracorresponder à string inteira, coloque o padrão com ^ no início e $ no final, como '^pattern$'.
Considere uma matriz de sites contendo o nome de host, e um elemento flaggedActivity. Esseelemento inclui um ARRAY, contendo vários elementos MAP, cada um listando palavras-chave conhecidasdiferentes e a contagem de popularidade. Suponhamos que você encontre uma palavra-chave dentro deum MAP nesta matriz.
Para pesquisar esse conjunto de dados para sites com uma palavra-chave específica, usamosregexp_like em vez do operador SQL LIKE semelhante, porque a pesquisa de um grande número depalavras-chave é mais eficiente com regexp_like.
Example Exemplo 1: uso do regexp_like
A consulta neste exemplo usa a função regexp_like para pesquisar os termos 'politics|bigdata'encontrados em valores em matrizes:
WITH dataset AS ( SELECT ARRAY[ CAST( ROW('aws.amazon.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['bigdata', '10']), MAP(ARRAY['term', 'count'], ARRAY['serverless', '50']), MAP(ARRAY['term', 'count'], ARRAY['analytics', '82']), MAP(ARRAY['term', 'count'], ARRAY['iot', '74']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ), CAST( ROW('news.cnn.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['politics', '241']), MAP(ARRAY['term', 'count'], ARRAY['technology', '211']), MAP(ARRAY['term', 'count'], ARRAY['serverless', '25']), MAP(ARRAY['term', 'count'], ARRAY['iot', '170']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ), CAST( ROW('netflix.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['cartoons', '1020']), MAP(ARRAY['term', 'count'], ARRAY['house of cards', '112042']), MAP(ARRAY['term', 'count'], ARRAY['orange is the new black', '342']), MAP(ARRAY['term', 'count'], ARRAY['iot', '4']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ) ] AS items),sites AS ( SELECT sites.hostname, sites.flaggedactivity FROM dataset, UNNEST(items) t(sites))SELECT hostnameFROM sites, UNNEST(sites.flaggedActivity.flags) t(flags)WHERE regexp_like(flags['term'], 'politics|bigdata')GROUP BY (hostname)
Essa consulta retorna dois sites:
+----------------+| hostname |+----------------+
119

Amazon Athena Guia do usuárioComo consultar matrizes com tiposcomplexos e estruturas aninhadas
| aws.amazon.com |+----------------+| news.cnn.com |+----------------+
Example Exemplo 2: uso do regexp_like
A consulta no exemplo a seguir agrega ao total de pontuações de popularidade dos sites correspondentesaos termos de pesquisa com a função regexp_like e, em seguida, ordena da mais alta para a maisbaixa.
WITH dataset AS ( SELECT ARRAY[ CAST( ROW('aws.amazon.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['bigdata', '10']), MAP(ARRAY['term', 'count'], ARRAY['serverless', '50']), MAP(ARRAY['term', 'count'], ARRAY['analytics', '82']), MAP(ARRAY['term', 'count'], ARRAY['iot', '74']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ), CAST( ROW('news.cnn.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['politics', '241']), MAP(ARRAY['term', 'count'], ARRAY['technology', '211']), MAP(ARRAY['term', 'count'], ARRAY['serverless', '25']), MAP(ARRAY['term', 'count'], ARRAY['iot', '170']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ), CAST( ROW('netflix.com', ROW(ARRAY[ MAP(ARRAY['term', 'count'], ARRAY['cartoons', '1020']), MAP(ARRAY['term', 'count'], ARRAY['house of cards', '112042']), MAP(ARRAY['term', 'count'], ARRAY['orange is the new black', '342']), MAP(ARRAY['term', 'count'], ARRAY['iot', '4']) ]) ) AS ROW(hostname VARCHAR, flaggedActivity ROW(flags ARRAY(MAP(VARCHAR, VARCHAR)) )) ) ] AS items),sites AS ( SELECT sites.hostname, sites.flaggedactivity FROM dataset, UNNEST(items) t(sites))SELECT hostname, array_agg(flags['term']) AS terms, SUM(CAST(flags['count'] AS INTEGER)) AS totalFROM sites, UNNEST(sites.flaggedActivity.flags) t(flags)WHERE regexp_like(flags['term'], 'politics|bigdata')GROUP BY (hostname)ORDER BY total DESC
Essa consulta retorna dois sites:
+------------------------------------+| hostname | terms | total |+----------------+-------------------+| news.cnn.com | politics | 241 |+----------------+-------------------+| aws.amazon.com | big data | 10 |+----------------+-------------------+
120

Amazon Athena Guia do usuárioConsultar JSON
Consultar JSONO Amazon Athena permite analisar valores codificados em JSON, extrair dados do JSON, pesquisarvalores e localizar o comprimento e o tamanho de matrizes JSON.
Tópicos• Melhores práticas de leitura de dados JSON (p. 121)• Extrair dados do JSON (p. 122)• Pesquisando valores em matrizes JSON (p. 125)• Obter comprimento e tamanho de matrizes JSON (p. 126)
Melhores práticas de leitura de dados JSONJavaScript Object Notation (JSON) é um método comum para codificar estruturas de dados como texto.Muitos aplicativos e ferramentas produzem dados codificados em JSON.
No Amazon Athena, você pode criar tabelas a partir de dados externos e incluir dados codificadosem JSON nelas. Para esses tipos de dados de origem, use o Athena junto com as Bibliotecas JSONSerDe (p. 266).
Use as seguintes dicas para ler dados codificados por JSON:
• Escolha o SerDe certo: um JSON SerDe nativo, org.apache.hive.hcatalog.data.JsonSerDe; ouum OpenX SerDe, org.openx.data.jsonserde.JsonSerDe. Para obter mais informações, consulteBibliotecas SerDe JSON (p. 266).
• Certifique-se de que cada registro codificado por JSON esteja representado em uma linha separada.• Gere seus dados codificados por JSON em colunas sem distinção entre letras maiúsculas e minúsculas.• Forneça uma opção para ignorar registros malformadas, como neste exemplo.
CREATE EXTERNAL TABLE json_table ( column_a string column_b int ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' WITH SERDEPROPERTIES ('ignore.malformed.json' = 'true') LOCATION 's3://bucket/path/';
• Converta campos nos dados de origem que tenham um esquema indeterminado para strings codificadasem JSON no Athena.
Ao criar tabelas com suporte de dados JSON, o Athena analisa os dados com base no esquema existentee predefinido. No entanto, nem todos os dados podem ter um esquema predefinido. Para simplificar ogerenciamento de esquemas nesses casos, costuma ser útil converter campos em dados de origem quetenham um esquema indeterminado em strings JSON no Athena e, em seguida, usar Bibliotecas JSONSerDe (p. 266).
Por exemplo, considere um aplicativo IoT que publique eventos com campos comuns de sensoresdiferentes. Um desses campos deve armazenar uma carga útil personalizada que seja exclusiva dosensor que envia o evento. Nesse caso, como você não sabe o esquema, recomendamos armazenar asinformações como uma string codificada em JSON. Para isso, converta dados na tabela do Athena emJSON, como no exemplo a seguir. Você também pode converter dados codificados em JSON em tipos dedados do Athena.
• Converter tipos de dados do Athena em JSON (p. 122)
121

Amazon Athena Guia do usuárioExtrair dados do JSON
• Converter JSON em tipos de dados do Athena (p. 122)
Conversão de tipos de dados do Athena em JSONPara converter tipos de dados do Athena em JSON, use CAST.
WITH dataset AS ( SELECT CAST('HELLO ATHENA' AS JSON) AS hello_msg, CAST(12345 AS JSON) AS some_int, CAST(MAP(ARRAY['a', 'b'], ARRAY[1,2]) AS JSON) AS some_map)SELECT * FROM dataset
Essa consulta retorna:
+-------------------------------------------+| hello_msg | some_int | some_map |+-------------------------------------------+| "HELLO ATHENA" | 12345 | {"a":1,"b":2} |+-------------------------------------------+
Conversão de JSON em tipos de dados do AthenaPara converter dados JSON em tipos de dados do Athena, use CAST.
Note
Neste exemplo, para denotar strings como codificadas em JSON, comece com a palavra-chaveJSON e use aspas simples, como JSON '12345'
WITH dataset AS ( SELECT CAST(JSON '"HELLO ATHENA"' AS VARCHAR) AS hello_msg, CAST(JSON '12345' AS INTEGER) AS some_int, CAST(JSON '{"a":1,"b":2}' AS MAP(VARCHAR, INTEGER)) AS some_map)SELECT * FROM dataset
Essa consulta retorna:
+-------------------------------------+| hello_msg | some_int | some_map |+-------------------------------------+| HELLO ATHENA | 12345 | {a:1,b:2} |+-------------------------------------+
Extrair dados do JSONVocê pode ter dados de origem com strings codificadas pelo JSON que você não necessariamente desejadesserializar em uma tabela no Athena. Neste caso, você ainda pode executar operações SQL nessesdados usando as funções JSON disponíveis no Presto.
Considere essa string JSON como um conjunto de dados de exemplo.
122

Amazon Athena Guia do usuárioExtrair dados do JSON
{"name": "Susan Smith","org": "engineering","projects": [ {"name":"project1", "completed":false}, {"name":"project2", "completed":true} ]}
Exemplos: extrair propriedadesPara extrair as propriedades name e projects da string JSON, use a função json_extract comono exemplo a seguir. A função json_extract utiliza a coluna que contém a string JSON e a pesquisausando uma expressão como JSONPath com a notação .
Note
JSONPath realiza um transversal de árvore simples. Ele usa o sinal $ para denotar a raiz dodocumento JSON, seguido de um ponto final e um elemento aninhado diretamente na raiz, como$.name.
WITH dataset AS ( SELECT '{"name": "Susan Smith", "org": "engineering", "projects": [{"name":"project1", "completed":false}, {"name":"project2", "completed":true}]}' AS blob)SELECT json_extract(blob, '$.name') AS name, json_extract(blob, '$.projects') AS projectsFROM dataset
O valor retornado é uma string codificada por JSON, e não um tipo de dados nativo do Athena.
+-----------------------------------------------------------------------------------------------+| name | projects |+-----------------------------------------------------------------------------------------------+| "Susan Smith" | [{"name":"project1","completed":false},{"name":"project2","completed":true}] |+-----------------------------------------------------------------------------------------------+
Para extrair o valor escalar da string JSON, use a função json_extract_scalar. Ele é semelhante ajson_extract, mas retorna somente valores escalares (Booliano, número ou string).
Note
Não use a função json_extract_scalar em matrizes, mapas ou structs.
WITH dataset AS ( SELECT '{"name": "Susan Smith", "org": "engineering", "projects": [{"name":"project1", "completed":false},{"name":"project2", "completed":true}]}'
123

Amazon Athena Guia do usuárioExtrair dados do JSON
AS blob)SELECT json_extract_scalar(blob, '$.name') AS name, json_extract_scalar(blob, '$.projects') AS projectsFROM dataset
Essa consulta retorna:
+---------------------------+| name | projects |+---------------------------+| Susan Smith | |+---------------------------+
Para obter o primeiro elemento da propriedade projects na matriz de exemplo, use a funçãojson_array_get e especifique a posição de índice.
WITH dataset AS ( SELECT '{"name": "Bob Smith", "org": "engineering", "projects": [{"name":"project1", "completed":false},{"name":"project2", "completed":true}]}' AS blob)SELECT json_array_get(json_extract(blob, '$.projects'), 0) AS itemFROM dataset
Ele retorna o valor na posição de índice especificada na matriz codificada em JSON.
+---------------------------------------+| item |+---------------------------------------+| {"name":"project1","completed":false} |+---------------------------------------+
Para retornar um tipo de string do Athena, use o operador [] em uma expressão JSONPath e, emseguida, use a função json_extract_scalar. Para obter mais informações sobre [], consulte Acessarelementos de matriz (p. 108).
WITH dataset AS ( SELECT '{"name": "Bob Smith", "org": "engineering", "projects": [{"name":"project1", "completed":false},{"name":"project2", "completed":true}]}' AS blob)SELECT json_extract_scalar(blob, '$.projects[0].name') AS project_nameFROM dataset
Ela retorna este resultado:
+--------------+| project_name |+--------------+| project1 |+--------------+
124

Amazon Athena Guia do usuárioPesquisando valores em matrizes JSON
Pesquisando valores em matrizes JSONPara determinar se um valor específico existe dentro de uma matriz codificada em JSON, use a funçãojson_array_contains.
A consulta a seguir lista os nomes dos usuários que estão participando de "project2".
WITH dataset AS ( SELECT * FROM (VALUES (JSON '{"name": "Bob Smith", "org": "legal", "projects": ["project1"]}'), (JSON '{"name": "Susan Smith", "org": "engineering", "projects": ["project1", "project2", "project3"]}'), (JSON '{"name": "Jane Smith", "org": "finance", "projects": ["project1", "project2"]}') ) AS t (users))SELECT json_extract_scalar(users, '$.name') AS userFROM datasetWHERE json_array_contains(json_extract(users, '$.projects'), 'project2')
Essa consulta retorna uma lista de usuários.
+-------------+| user |+-------------+| Susan Smith |+-------------+| Jane Smith |+-------------+
O exemplo de consulta a seguir lista os nomes de usuários que concluíram projetos com o número total deprojetos realizados. Ele realiza estas ações:
• Usa instruções SELECT aninhadas para fins de clareza.• Extrai a matriz de projetos.• Converte a matriz em uma matriz nativa de pares de chave/valor usando CAST.• Extrai cada elemento de matriz individual usando o operador UNNEST.• Filtra valores obtidos por projetos concluídos e os conta.
Note
Ao usar CAST em MAP, você pode especificar o elemento de chave como VARCHAR (String nativano Presto), mas deixar o valor como JSON, porque os valores no MAP são de tipos diferentes:string para o primeiro par de chave/valor e Booliano para o segundo.
WITH dataset AS ( SELECT * FROM (VALUES (JSON '{"name": "Bob Smith", "org": "legal", "projects": [{"name":"project1", "completed":false}]}'), (JSON '{"name": "Susan Smith", "org": "engineering", "projects": [{"name":"project2", "completed":true}, {"name":"project3", "completed":true}]}'), (JSON '{"name": "Jane Smith", "org": "finance", "projects": [{"name":"project2", "completed":true}]}') ) AS t (users)),
125

Amazon Athena Guia do usuárioObter comprimento e tamanho de matrizes JSON
employees AS ( SELECT users, CAST(json_extract(users, '$.projects') AS ARRAY(MAP(VARCHAR, JSON))) AS projects_array FROM dataset),names AS ( SELECT json_extract_scalar(users, '$.name') AS name, projects FROM employees, UNNEST (projects_array) AS t(projects))SELECT name, count(projects) AS completed_projects FROM namesWHERE cast(element_at(projects, 'completed') AS BOOLEAN) = trueGROUP BY name
Esta consulta retorna o seguinte resultado:
+----------------------------------+| name | completed_projects |+----------------------------------+| Susan Smith | 2 |+----------------------------------+| Jane Smith | 1 |+----------------------------------+
Obter comprimento e tamanho de matrizes JSONExemplo: json_array_lengthPara obter o tamanho de uma matriz codificada em JSON, use a função json_array_length.
WITH dataset AS ( SELECT * FROM (VALUES (JSON '{"name": "Bob Smith", "org": "legal", "projects": [{"name":"project1", "completed":false}]}'), (JSON '{"name": "Susan Smith", "org": "engineering", "projects": [{"name":"project2", "completed":true}, {"name":"project3", "completed":true}]}'), (JSON '{"name": "Jane Smith", "org": "finance", "projects": [{"name":"project2", "completed":true}]}') ) AS t (users))SELECT json_extract_scalar(users, '$.name') as name, json_array_length(json_extract(users, '$.projects')) as countFROM datasetORDER BY count DESC
Essa consulta retorna este resultado:
+---------------------+| name | count |+---------------------+| Susan Smith | 2 |+---------------------+| Bob Smith | 1 |+---------------------+| Jane Smith | 1 |
126

Amazon Athena Guia do usuárioConsultar dados geoespaciais
+---------------------+
Exemplo: json_sizePara obter o tamanho de uma matriz ou de um objeto codificado em JSON, use a função json_size eespecifique a coluna que contém a string JSON e a expressão JSONPath para a matriz ou o objeto.
WITH dataset AS ( SELECT * FROM (VALUES (JSON '{"name": "Bob Smith", "org": "legal", "projects": [{"name":"project1", "completed":false}]}'), (JSON '{"name": "Susan Smith", "org": "engineering", "projects": [{"name":"project2", "completed":true},{"name":"project3", "completed":true}]}'), (JSON '{"name": "Jane Smith", "org": "finance", "projects": [{"name":"project2", "completed":true}]}') ) AS t (users))SELECT json_extract_scalar(users, '$.name') as name, json_size(users, '$.projects') as countFROM datasetORDER BY count DESC
Essa consulta retorna este resultado:
+---------------------+| name | count |+---------------------+| Susan Smith | 2 |+---------------------+| Bob Smith | 1 |+---------------------+| Jane Smith | 1 |+---------------------+
Consultar dados geoespaciaisOs dados geoespaciais contêm identificadores que especificam uma posição geográfica para um objeto.Entre os exemplos desse tipo de dados estão previsões do tempo, rotas em mapa, tweets com posiçõesgeográficas, locais de lojas e rotas aéreas. Os dados geoespaciais têm uma função importante na análisecomercial, na geração de relatórios e na previsão.
Os identificadores geoespaciais, como latitude e longitude, permitem converter qualquer endereço postalem um conjunto de coordenadas geográficas.
Tópicos• O que é uma consulta geoespacial? (p. 127)• Formatos de dados de entrada e tipos de dados de geometria (p. 128)• Lista de funções geoespaciais compatíveis (p. 128)• Exemplos: consultas geoespaciais (p. 137)
O que é uma consulta geoespacial?Consultas geoespaciais são tipos especializados de consultas SQL com suporte no Athena. Elas diferemde consultas SQL não espaciais das seguintes maneiras:
127

Amazon Athena Guia do usuárioFormatos de dados de entradae tipos de dados de geometria
• Usando os seguintes tipos de dados de geometria especializados: point, line, multiline,polygone multipolygon.
• Expressando relacionamentos entre tipos de dados, como geometria distance, equals, crosses,touches, overlaps, disjoint e outros.
Usando consultas geoespaciais no Athena, você pode executar estas e outras operações semelhantes:
• Encontre a distância entre dois pontos.• Verifique se uma área (polígono) contém outra.• Verifique se uma linha cruza ou toca outra linha ou polígono.
Por exemplo, para obter um tipo de dado de geometria de point a partir de um par de valores doublepara as coordenadas geográficas do Mount Rainier no Athena, use a função geoespacial ST_POINT(double, double) (longitude, latitude), especificando primeiro longitude depois a latitude:
ST_POINT(-121.7602, 46.8527) (longitude, latitude)
Formatos de dados de entrada e tipos de dados degeometriaPara usar funções geoespaciais no Athena, insira os dados no formato WKT ou use o SerDe do HiveJSON. Você também pode usar os tipos de dados de geometria com suporte no Athena.
Formatos de dados de entradaPara processar consultas geoespaciais, o Athena oferece suporte a dados de entrada nestes formatos dedados:
• Well-Known Text (WKT – Texto bem conhecido). No Athena, o WKT é representado como um tipo dedados varchar.
• Dados geoespaciais codificados por JSON. Para analisar arquivos JSON com dados geoespaciais ecriar tabelas para eles, o Athena usa o SerDe do Hive JSON. Para obter mais informações sobre comousar esse SerDe no Athena, consulte Bibliotecas SerDe JSON (p. 266).
Tipos de dados de geometriaPara processar consultas geoespaciais, o Athena oferece suporte a estes tipos de dados de geometriaespecializados:
• point
• line
• polygon
• multiline
• multipolygon
Lista de funções geoespaciais compatíveisAs funções geoespaciais no Athena têm estas características:
128

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
• As funções seguem os princípios gerais de Consulta espacial.• As funções são implementadas como um plug-in do Presto que usa a biblioteca de geometrias Java do
ESRI. Esta biblioteca tem uma licença do Apache 2.• As funções contam com a API do ESRI Geometry.• Nem todas as funções com suporte do ESRI estão disponíveis no Athena. Este tópico lista somente as
funções geoespaciais do ESRI com suporte no Athena.• Não é possível usar visualizações com funções geoespaciais.
O Athena oferece suporte a quatro tipos de funções geoespaciais:
• Funções de construtor (p. 130)• Funções de relacionamento geoespaciais (p. 131)• Funções de operação (p. 133)• Funções do acessor (p. 134)
Antes de começarCrie duas tabelas, earthquakes e counties, da seguinte maneira:
CREATE external TABLE earthquakes( earthquake_date STRING, latitude DOUBLE, longitude DOUBLE, depth DOUBLE, magnitude DOUBLE, magtype string, mbstations string, gap string, distance string, rms string, source string, eventid string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS TEXTFILE LOCATION 's3://my-query-log/csv'
CREATE external TABLE IF NOT EXISTS counties ( Name string, BoundaryShape binary )ROW FORMAT SERDE 'com.esri.hadoop.hive.serde.JsonSerde'STORED AS INPUTFORMAT 'com.esri.json.hadoop.EnclosedJsonInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://my-query-log/json'
Alguns dos exemplos subsequentes se baseiam nessas tabelas e dependem de dois arquivos de exemploarmazenados no local do Amazon S3. Esses arquivos não são incluídos com o Athena e são usadosapenas para fins de ilustração:
• Um arquivo earthquakes.csv, que lista terremotos ocorridos na Califórnia. Este arquivo tem camposque correspondem aos campos na tabela earthquakes.
• Um arquivo california-counties.json, que lista dados do condado codificados por JSON emformato compatível com ESRI e inclui vários campos, como AREA, PERIMETER, STATE, COUNTY
129

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
e NAME. A tabela counties se baseia nesse arquivo e tem somente dois campos: Name (string) eBoundaryShape (binário).
Funções de construtorUse funções do construtor para obter representações binárias dos tipos de dados de geometria point,line ou polygon. Você também pode usar essas funções para converter dados binários em texto eobter valores binários para dados de geometria expressos como Well-Known Text (WKT – Texto bemconhecido).
ST_POINT(double, double)
Retorna uma representação binária de um tipo de dados de geometria point.
Para obter o tipo de dados de geometria point, use a função ST_POINT em Athena. Para os valores dedados de entrada para essa função, use valores geométricos, como valores do sistema de coordenadascartesianas da Universal Transversa de Mercator (UTM) ou unidades de mapas geográficos (latitudee longitude) em graus decimais. Os valores de latitude e longitude usam o sistema geodésico mundial,também conhecido como WGS 1984 ou EPSG:4326. WGS 1984 é o sistema de coordenadas usado pelosistema GPS.
Por exemplo, na seguinte notação, as coordenadas do mapa são especificadas em latitude e longitude,e o valor .072284, que é a distância de folga, é especificada em unidades anguladas na forma de grausdecimais:
ST_BUFFER(ST_POINT(-74.006801, 40.705220), .072284)
Sintaxe:
SELECT ST_POINT(longitude, latitude) FROM earthquakes LIMIT 1;
Na sintaxe alternativa, você também pode especificar as coordenadas como um tipo de dados point comdois valores:
SELECT ST_POINT('point (-74.006801 40.705220)');
Exemplo. Este exemplo usa coordenadas de longitude e latitude específicas de earthquakes.csv:
SELECT ST_POINT(61.56, -158.54)FROM earthquakesLIMIT 1;
Ele retorna essa representação binária de um tipo de dados de geometria point:
00 00 00 00 01 01 00 00 00 48 e1 7a 14 ae c7 4e 40 e1 7a 14 ae 47 d1 63 c0
O próximo exemplo usa coordenadas de longitude e latitude específicas:
SELECT ST_POINT(-74.006801, 40.705220);
Ele retorna essa representação binária de um tipo de dados de geometria point:
00 00 00 00 01 01 00 00 00 20 25 76 6d 6f 80 52 c0 18 3e 22 a6 44 5a 44 40
130

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
No exemplo a seguir, usamos a função ST_GEOMETRY_TO_TEXT para obter os valores binários deWKT:
SELECT ST_GEOMETRY_TO_TEXT(ST_POINT(-74.006801, 40.705220)) AS WKT;
Esta consulta retorna uma representação de WKT do tipo de geometria point: 1 POINT (-74.00680140.70522).
ST_LINE(varchar)
Retorna um valor no tipo de dados line, que é uma representação binária do tipo de dados degeometria (p. 128) line. Exemplo:
SELECT ST_Line('linestring(1 1, 2 2, 3 3)')
ST_POLYGON(varchar)
Retorna um valor no tipo de dados polygon, que é uma representação binária do tipo de dados degeometria (p. 128) polygon. Exemplo:
SELECT ST_POLYGON('polygon ((1 1, 1 4, 4 4, 4 1))')
ST_GEOMETRY_TO_TEXT (varbinary)
Converte cada um dos tipos de dados de geometria (p. 128) especificados em texto. Retorna um valorem um tipo de dados de geometria, que é uma representação WKT do tipo de dados de geometria.Exemplo:
SELECT ST_GEOMETRY_TO_TEXT(ST_POINT(61.56, -158.54))
ST_GEOMETRY_FROM_TEXT (varchar)
Converte texto em um tipo de dados de geometria. Retorna um valor em um tipo de dados de geometria,que é uma representação binária do tipo de dados de geometria. Exemplo:
SELECT ST_GEOMETRY_FROM_TEXT(ST_GEOMETRY_TO_TEXT(ST_Point(1, 2)))
Funções de relacionamento geoespaciaisAs funções a seguir expressam relacionamentos entre duas geometrias diferentes especificadas porvocê como entrada. Elas retornam resultados do tipo boolean. A ordem na qual você especifica o par degeometrias importa: o primeiro valor de geometria é chamado de geometria à esquerda, o segundo valorde geometria é chamado de geometria à direita.
Essas funções retornam:
• TRUE se e somente se o relacionamento descrito pela função é atendido.• FALSE se e somente se o relacionamento descrito pela função não é atendido.
ST_CONTAINS (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda contiver a geometria à direita. Exemplos:
131

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
SELECT ST_CONTAINS('POLYGON((0 2,1 1,0 -1,0 2))', 'POLYGON((-1 3,2 1,0 -3,-1 3))')
SELECT ST_CONTAINS('POLYGON((0 2,1 1,0 -1,0 2))', ST_Point(0, 0));
SELECT ST_CONTAINS(ST_GEOMETRY_FROM_TEXT('POLYGON((0 2,1 1,0 -1,0 2))'), ST_GEOMETRY_FROM_TEXT('POLYGON((-1 3,2 1,0 -3,-1 3))'))
ST_CROSSES (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda cruzar a geometria à direita. Exemplo:
SELECT ST_CROSSES(ST_LINE('linestring(1 1, 2 2 )'), ST_LINE('linestring(0 1, 2 2)'))
ST_DISJOINT (geometry, geometry)
Retornará TRUE se e somente se a interseção da geometria à esquerda e da geometria à direita estivervazia. Exemplo:
SELECT ST_DISJOINT(ST_LINE('linestring(0 0, 0 1)'), ST_LINE('linestring(1 1, 1 0)'))
ST_EQUALS (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda for igual à geometria à direita. Exemplo:
SELECT ST_EQUALS(ST_LINE('linestring( 0 0, 1 1)'), ST_LINE('linestring(1 3, 2 2)'))
ST_INTERSECTS (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda apresentar intersecção com a geometria àdireita. Exemplo:
SELECT ST_INTERSECTS(ST_LINE('linestring(8 7, 7 8)'), ST_POLYGON('polygon((1 1, 4 1, 4 4, 1 4))'))
ST_OVERLAPS (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda sobrepuser a geometria à direita. Exemplo:
SELECT ST_OVERLAPS(ST_POLYGON('polygon((2 0, 2 1, 3 1))'), ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
ST_RELATE (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda tiver o relacionamento Dimensionally Extendednine-Intersection Model (DE-9IM – Modelo de nove intersecções estendido dimensionalmente) com ageometria à direita. Para obter mais informações, consulte o tópico na Wikipédia DE-9IM. Exemplo:
SELECT ST_RELATE(ST_LINE('linestring(0 0, 3 3)'), ST_LINE('linestring(1 1, 4 4)'), 'T********')
132

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
ST_TOUCHES (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda tocar a geometria à direita.
Exemplo:
SELECT ST_TOUCHES(ST_POINT(8, 8), ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
ST_WITHIN (geometry, geometry)
Retornará TRUE se e somente se a geometria à esquerda estiver dentro da geometria à direita.
Exemplo:
SELECT ST_WITHIN(ST_POINT(8, 8), ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
Funções de operaçãoUse funções de operação para realizar operações nos valores do tipo de dados de geometria. Porexemplo, você pode obter os limites de um único tipo de dados de geometria, interseções entre dois tiposde dados de geometria, diferença entre geometrias à esquerda e à direita, em que cada um é do mesmotipo de dados de geometria ou um buffer externo ou um anel em torno de um tipo de dados de geometriaespecífico.
Todas as funções de operação utilizam como entrada um dos tipos de dados de geometria e retornam asrepresentações binárias.
ST_BOUNDARY (geometry)
Utiliza como entrada um dos tipos de dados de geometria e retorna uma representação binária do tipo dedados de geometria boundary.
Exemplos:
SELECT ST_BOUNDARY(ST_LINE('linestring(0 1, 1 0)')))
SELECT ST_BOUNDARY(ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
ST_BUFFER (geometry, double)
Usa como entrada um dos tipos de dados de geometria, como ponto, linha, polígono, multilinha oumultipolígono e uma distância como tipo double). Retorna uma representação binária do tipo de dados degeometria armazenado em buffer pela distância especificada (ou o raio). Exemplo:
SELECT ST_BUFFER(ST_Point(1, 2), 2.0)
No seguinte exemplo, as coordenadas do mapa são especificadas em latitude e longitude, e o valor.072284, que é a distância de folga, é especificado em unidades anguladas na forma de graus decimais:
ST_BUFFER(ST_POINT(-74.006801, 40.705220), .072284)
ST_DIFFERENCE (geometry, geometry)
Retorna uma representação binária de uma diferença entre a geometria à esquerda e a geometria à direita.Exemplo:
133

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
SELECT ST_GEOMETRY_TO_TEXT(ST_DIFFERENCE(ST_POLYGON('polygon((0 0, 0 10, 10 10, 10 0))'), ST_POLYGON('polygon((0 0, 0 5, 5 5, 5 0))')))
ST_ENVELOPE (geometry)
Recebe como entrada os tipos de dados de geometria line, polygon, multiline e multipolygon.Não oferece suporte ao tipo de dados de geometria point. Retorna uma representação binária de umenvelope, na qual o envelope é um retângulo em torno do tipo de dados da geometria especificada.Exemplos:
SELECT ST_ENVELOPE(ST_LINE('linestring(0 1, 1 0)'))
SELECT ST_ENVELOPE(ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
ST_EXTERIOR_RING (geometry)
Retorna uma representação binária do anel externo do tipo de entrada polygon. Exemplos:
SELECT ST_EXTERIOR_RING(ST_POLYGON(1,1, 1,4, 4,1))
SELECT ST_EXTERIOR_RING(ST_POLYGON('polygon ((0 0, 8 0, 0 8, 0 0), (1 1, 1 5, 5 1, 1 1))'))
ST_INTERSECTION (geometry, geometry)
Retorna uma representação binária da intersecção da geometria à esquerda e da geometria à direita.Exemplos:
SELECT ST_INTERSECTION(ST_POINT(1,1), ST_POINT(1,1))
SELECT ST_INTERSECTION(ST_LINE('linestring(0 1, 1 0)'), ST_POLYGON('polygon((1 1, 1 4, 4 4, 4 1))'))
SELECT ST_GEOMETRY_TO_TEXT(ST_INTERSECTION(ST_POLYGON('polygon((2 0, 2 3, 3 0))'), ST_POLYGON('polygon((1 1, 4 1, 4 4, 1 4))')))
ST_SYMMETRIC_DIFFERENCE (geometry, geometry)
Retorna uma representação binária da diferença geometricamente simétrica entre a geometria à esquerdae a geometria à direita. Exemplo:
SELECT ST_GEOMETRY_TO_TEXT(ST_SYMMETRIC_DIFFERENCE(ST_LINE('linestring(0 2, 2 2)'), ST_LINE('linestring(1 2, 3 2)')))
Funções do acessorAs funções do acessor são úteis para obter valores em tipos varchar, bigint ou double de tipos dedados geometry diferentes, em que geometry é qualquer um dos tipos de dados de geometria comsuporte no Athena: point, line, polygon, multiline e multipolygon. Por exemplo, você pode obteruma área de um tipo de dados de geometria polygon, valores X e Y máximos e mínimos para um tipo de
134

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
dados de geometria especificado, obter o comprimento de um line ou receber o número de pontos emum tipo de dados de geometria especificado.
ST_AREA (geometry)
Utiliza como entrada um tipo de dados de geometria polygon e retorna uma área no tipo double.Exemplo:
SELECT ST_AREA(ST_POLYGON('polygon((1 1, 4 1, 4 4, 1 4))'))
ST_CENTROID (geometry)
Utiliza como entrada um tipo de dados de geometria (p. 128) polygon e retorna um point que é ocentro do envelope do polígono no tipo varchar. Exemplos:
SELECT ST_CENTROID(ST_GEOMETRY_FROM_TEXT('polygon ((0 0, 3 6, 6 0, 0 0))'))
SELECT ST_GEOMETRY_TO_TEXT(ST_CENTROID(ST_ENVELOPE(ST_GEOMETRY_FROM_TEXT('POINT (53 27)'))))
ST_COORDINATE_DIMENSION (geometry)
Utiliza como entrada um dos tipos de geometria (p. 128) compatíveis e retorna a contagem decomponentes de coordenadas no tipo bigint. Exemplo:
SELECT ST_COORDINATE_DIMENSION(ST_POINT(1.5,2.5))
ST_DIMENSION (geometry)
Utiliza como entrada um dos tipos de dados de geometria (p. 128) compatíveis e retorna a dimensãoespacial de uma geometria no tipo bigint. Exemplo:
SELECT ST_DIMENSION(ST_POLYGON('polygon((1 1, 4 1, 4 4, 1 4))'))
ST_DISTANCE (geometry, geometry)
Retorna a distância no tipo double entre a geometria à esquerda e a geometria à direita. Exemplo:
SELECT ST_DISTANCE(ST_POINT(0.0,0.0), ST_POINT(3.0,4.0))
ST_IS_CLOSED (geometry)
Retornará TRUE (tipo boolean) se e somente se a linha for fechada. Exemplo:
SELECT ST_IS_CLOSED(ST_LINE('linestring(0 2, 2 2)'))
ST_IS_EMPTY (geometry)
Utiliza como entrada somente os tipos de dados de geometria (p. 128) line e multiline. RetornaráTRUE (tipo boolean) se e somente se a geometria especificada estiver vazia; em outras palavras, quandoos valores inicial e final de line coincidirem. Exemplo:
135

Amazon Athena Guia do usuárioLista de funções geoespaciais compatíveis
SELECT ST_IS_EMPTY(ST_POINT(1.5, 2.5))
ST_IS_RING (geometry)
Retornará TRUE (tipo boolean) se e somente se o tipo line for fechado e simples. Exemplo:
SELECT ST_IS_RING(ST_LINE('linestring(0 2, 2 2)'))
ST_LENGTH (geometry)
Retorna o comprimento de line no tipo double. Exemplo:
SELECT ST_LENGTH(ST_LINE('linestring(0 2, 2 2)'))
ST_MAX_X (geometry)
Retorna a coordenada X máxima de uma geometria no tipo double. Exemplo:
SELECT ST_MAX_X(ST_LINE('linestring(0 2, 2 2)'))
ST_MAX_Y (geometry)
Retorna a coordenada Y máxima de uma geometria no tipo double. Exemplo:
SELECT ST_MAX_Y(ST_LINE('linestring(0 2, 2 2)'))
ST_MIN_X (geometry)
Retorna a coordenada X mínima de uma geometria no tipo double. Exemplo:
SELECT ST_MIN_X(ST_LINE('linestring(0 2, 2 2)'))
ST_MIN_Y (geometry)
Retorna a coordenada Y mínima de uma geometria no tipo double. Exemplo:
SELECT ST_MAX_Y(ST_LINE('linestring(0 2, 2 2)'))
ST_START_POINT (geometry)
Retorna o primeiro ponto de um tipo de dados de geometria line no tipo point. Exemplo:
SELECT ST_START_POINT(ST_LINE('linestring(0 2, 2 2)'))
ST_END_POINT (geometry)
Retorna o último ponto de um tipo de dados de geometria line no tipo point. Exemplo:
SELECT ST_END_POINT(ST_LINE('linestring(0 2, 2 2)'))
136

Amazon Athena Guia do usuárioExemplos: consultas geoespaciais
ST_X (point)
Retorna a coordenada X de um ponto no tipo double. Exemplo:
SELECT ST_X(ST_POINT(1.5, 2.5))
ST_Y (point)
Retorna a coordenada Y de um ponto no tipo double. Exemplo:
SELECT ST_Y(ST_POINT(1.5, 2.5))
ST_POINT_NUMBER (geometry)
Retorna o número de pontos na geometria no tipo bigint. Exemplo:
SELECT ST_POINT_NUMBER(ST_POINT(1.5, 2.5))
ST_INTERIOR_RING_NUMBER (geometry)
Retorna o número de anéis internos na geometria polygon no tipo bigint. Exemplo:
SELECT ST_INTERIOR_RING_NUMBER(ST_POLYGON('polygon ((0 0, 8 0, 0 8, 0 0), (1 1, 1 5, 5 1, 1 1))'))
Exemplos: consultas geoespaciaisOs exemplos a seguir criam duas tabelas e emitem uma consulta em relação a elas.
Note
Esses arquivos não estão incluídos com o produto e são usados na documentação somente parafins ilustrativos. Eles contêm dados de exemplo e não têm precisão garantida.
Esses exemplos contam com dois arquivos:
• Um arquivo de exemplo earthquakes.csv, que lista terremotos ocorridos na Califórnia. Este arquivotem campos que correspondem aos campos na tabela earthquakes no exemplo a seguir.
• Um arquivo california-counties.json, que lista dados do condado codificados por JSON emformato compatível com ESRI e inclui vários campos, como AREA, PERIMETER, STATE, COUNTY eNAME. O exemplo a seguir mostra a tabela counties desse arquivo com somente dois campos: Name(string) e BoundaryShape (binário).
Para ver outros exemplos de consultas geoespaciais, consulte essas postagens de blog:
• Consultar OpenStreetMap com Amazon Athena• Visualizar mais de 200 anos de dados de clima global usando Amazon Athena e Amazon QuickSight.
O exemplo de código a seguir cria uma tabela chamada earthquakes:
CREATE external TABLE earthquakes( earthquake_date string,
137

Amazon Athena Guia do usuárioExemplos: consultas geoespaciais
latitude double, longitude double, depth double, magnitude double, magtype string, mbstations string, gap string, distance string, rms string, source string, eventid string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS TEXTFILE LOCATION 's3://my-query-log/csv/';
O exemplo de código a seguir cria uma tabela chamada counties:
CREATE external TABLE IF NOT EXISTS counties ( Name string, BoundaryShape binary )ROW FORMAT SERDE 'com.esri.hadoop.hive.serde.JsonSerde'STORED AS INPUTFORMAT 'com.esri.json.hadoop.EnclosedJsonInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://my-query-log/json/';
O exemplo de código a seguir usa a função CROSS JOIN para as duas tabelas criadas anteriormente.Além disso, para ambas as tabelas, ele usa ST_CONTAINS e solicita condados cujos limites incluam umalocalização geográfica dos terremotos, especificada com ST_POINT. Em seguida, ele agrupa condadospor nome, ordena-os por contagem e os retorna em ordem decrescente.
SELECT counties.name, COUNT(*) cntFROM countiesCROSS JOIN earthquakesWHERE ST_CONTAINS (counties.boundaryshape, ST_POINT(earthquakes.longitude, earthquakes.latitude))GROUP BY counties.nameORDER BY cnt DESC
Essa consulta retorna:
+------------------------+| name | cnt |+------------------------+| Kern | 36 |+------------------------+| San Bernardino | 35 |+------------------------+| Imperial | 28 |+------------------------+| Inyo | 20 |+------------------------+| Los Angeles | 18 |+------------------------+| Riverside | 14 |+------------------------+| Monterey | 14 |+------------------------+| Santa Clara | 12 |+------------------------+
138

Amazon Athena Guia do usuárioO uso do
| San Benito | 11 |+------------------------+| Fresno | 11 |+------------------------+| San Diego | 7 |+------------------------+| Santa Cruz | 5 |+------------------------+| Ventura | 3 |+------------------------+| San Luis Obispo | 3 |+------------------------+| Orange | 2 |+------------------------+| San Mateo | 1 |+------------------------+
O uso doO permite que você use o Athena para gravar instruções SQL que executam inferências de MachineLearning (ML) usando o Amazon SageMaker. Esse recurso simplifica o acesso a modelos de ML paraanálise de dados, eliminando a necessidade de usar métodos de programação complexos para executarinferências.
Para usar o , você define uma função do com a cláusula USING FUNCTION. A função aponta para oendpoint do modelo do Amazon SageMaker que você deseja usar e especifica os nomes de variáveis etipos de dados para passar para o modelo. As cláusulas subsequentes na consulta fazem referência àfunção para passar os valores para o modelo. O modelo executa inferências com base nos valores quea consulta passa e retorna os resultados da inferência. Para obter mais informações sobre o AmazonSageMaker e como os endpoints do Amazon SageMaker funcionam, consulte Implantar um modelo nosserviços de hospedagem do Amazon SageMaker no Guia do desenvolvedor do Amazon SageMaker.
Condições e limitações• Grupo de trabalho AmazonAthenaPreviewFunctionality –• Endpoint do modelo do Amazon SageMaker deve aceitar e retornar text/csv – para obter mais
informações sobre formatos de dados, consulte Formatos de dados comuns para inferências no Guia dodesenvolvedor do Amazon SageMaker.
• Escalabilidade do endpoint do Amazon SageMaker – certifique-se de que o endpoint do modelo doAmazon SageMaker especificado seja suficientemente dimensionado para chamadas do Athena parao endpoint. Para obter mais informações, consulte Escalabilidade automática de modelos do AmazonSageMaker no Guia do desenvolvedor do Amazon SageMaker e CreateEndpointConfig na Referênciade API do Amazon SageMaker.
• Permissões do IAM – para executar uma consulta que especifica uma função do , o IAM principal queexecuta a consulta deve ter permissão para executar a ação sagemaker:InvokeEndpoint parao endpoint do modelo do Amazon SageMaker referenciado. Para obter mais informações, consultePermitir acesso para o (p. 202).
• As funções do não podem ser usadas diretamente nas cláusulas GROUP BY
Sintaxe doA cláusula USING FUNCTION especifica uma função do ou múltiplas funções que podem ser referenciadaspor uma instrução SELECT subsequente na consulta. Você define o nome da função, os nomes dasvariáveis e os tipos de dados das variáveis e dos valores de retorno.
139

Amazon Athena Guia do usuárioConsultas com UDFs
ResumoO exemplo a seguir mostra uma cláusula USING FUNCTION que especifica a função do .
USING FUNCTION ML_function_name(variable1 data_type[, variable2 data_type][,...]) RETURNS data_type TYPE SAGEMAKER_INVOKE_ENDPOINT WITH (sagemaker_endpoint= 'my_sagemaker_endpoint')[, FUNCTION...][, ...] SELECT [...] ML_function_name(expression) [...]
ParâmetrosUSING FUNCTION ML_function_name(variable1 data_type[, variable2 data_type][,...])
ML_function_name define o nome da função, que pode ser usada nas cláusulas de consultasubsequentes. Cada variable data_type especifica uma variável nomeada com o tipo de dadoscorrespondente que possa ser aceita como entrada pelo modelo do Amazon SageMaker. Especifiquedata_type como um dos tipos de dados compatível com o Athena que o modelo do AmazonSageMaker pode aceitar como entrada.
RETURNS data_type TYPE
O data_type especifica o tipo de dados SQL que o ML_function_name retorna para a consultacomo saída do modelo do Amazon SageMaker.
SAGEMAKER_INVOKE_ENDPOINT WITH (sagemaker_endpoint= 'my_sagemaker_endpoint')
O my_sagemaker_endpoint especifica o endpoint do modelo do Amazon SageMaker.SELECT [...] ML_function_name(expression) [...]
A consulta SELECT que passa valores para variáveis de função e o modelo do Amazon SageMakerque retorna um resultado. O ML_function_name especifica a função definida anteriormente naconsulta, seguida por uma expression que é avaliada para passar valores. Os valores que sãopassados e retornados devem coincidir com os tipos de dados correspondentes especificados para afunção na cláusula USING FUNCTION.
ExemplosO exemplo a seguir demonstra uma consulta usando o .
Example
USING FUNCTION predict_customer_registration(age INTEGER) RETURNS DOUBLE TYPE SAGEMAKER_INVOKE_ENDPOINT WITH (sagemaker_endpoint = 'xgboost-2019-09-20-04-49-29-303') SELECT predict_customer_registration(age) AS probability_of_enrolling, customer_id FROM "sampledb"."ml_test_dataset" WHERE predict_customer_registration(age) < 0.5;
Consultas com funções definidas pelo usuário(visualização)
As funções definidas pelo usuário (UDF) no Amazon Athena permitem criar funções personalizadas paraprocessar registros ou grupos de registros. Uma UDF aceita parâmetros, executa o trabalho e retorna umresultado.
140

Amazon Athena Guia do usuárioCondições e limitações
Para usar uma UDF no Athena, escreva uma cláusula USING FUNCTION antes de uma instrução SELECTem uma consulta SQL. A instrução SELECT faz referência à UDF e define as variáveis que são passadaspara a UDF quando a consulta é executada. A consulta SQL invoca uma função do Lambda usando oJava Runtime ao chamar a UDF. As UDFs são definidas dentro da função do Lambda como métodos emum pacote de implantação Java. É possível definir várias UDFs no mesmo pacote de implantação Javapara uma função do Lambda. Você também especifica o nome da função do Lambda na cláusula USINGFUNCTION.
Você tem duas opções para implantar uma função do Lambda para UDFs do Athena. É possível implantara função diretamente usando o Lambda ou o AWS Serverless Application Repository. Para encontrarfunções do Lambda existentes para UDFs, pesquise no AWS Serverless Application Repository públicoou em seu repositório privado e depois implante-as no Lambda. Você também pode criar ou modificar ocódigo-fonte Java, empacotá-lo em um arquivo JAR e implantá-lo usando o Lambda ou o AWS ServerlessApplication Repository. Nós fornecemos o código-fonte Java e os pacotes para você começar. Para obtermais informações sobre Lambda, consulte AWS Lambda Developer Guide. Para obter mais informaçõessobre o AWS Serverless Application Repository, consulte o Guia do desenvolvedor do AWS ServerlessApplication Repository.
Condições e limitações• Grupo de trabalho AmazonAthenaPreviewFunctionality –• Funções integradas do Athena – as funções integradas do Presto no Athena são desenvolvidas para
ter alto desempenho. Recomendamos usar as funções integradas em lugar das UDFs quando possível.Para obter mais informações sobre funções integradas, consulte Funções do Presto no AmazonAthena (p. 288).
• Somente UDFs escalares – o Athena é compatível somente com UDFs escalares, que processam umalinha por vez e retornam um único valor de coluna. O Athena passa um lote de linhas, potencialmenteem paralelo, para a UDF sempre que invoca o Lambda. Ao desenvolver UDFs e consultas, esteja cientedo possível impacto no tráfego de rede que esse design de processamento pode ter.
• Somente Java runtime – atualmente, UDFs do Athena são compatíveis somente com o Java 8 runtimepara Lambda.
• Permissões do IAM – para executar uma consulta no Athena que contenha uma instrução de consultaUDF e para criar instruções de UDF, o IAM principal que executa a consulta deve ter permissão paraexecutar ações além das funções do Athena. Para obter mais informações, consulte Exemplo depolíticas de permissões do IAM para permitir o (p. 200).
• Cotas do Lambda – as cotas do Lambda se aplicam a UDFs. Para obter mais informações, consulteCota do AWS Lambda no AWS Lambda Developer Guide.
• Problemas conhecidos – para obter a lista mais recente de problemas conhecidos, consulte Limitações eproblemas no
Sintaxe de consulta da UDFA cláusula USING FUNCTION especifica uma UDF ou várias UDFs que podem ser referenciadas por umainstrução SELECT subsequente na consulta. São necessários o nome do método da UDF e o nome dafunção do Lambda que hospeda a UDF.
Resumo
USING FUNCTION UDF_name(variable1 data_type[, variable2 data_type][,...]) RETURNS data_type TYPE LAMBDA_INVOKE WITH (lambda_name = 'my_lambda_function')[, FUNCTION][, ...] SELECT [...] UDF_name(expression) [...]
141

Amazon Athena Guia do usuárioSintaxe de consulta da UDF
ParâmetrosUSING FUNCTION UDF_name(variable1 data_type[, variable2 data_type][,...])
UDF_name especifica o nome da UDF, que deve corresponder a um método Java com a função doLambda referenciada. Cada variable data_type especifica uma variável nomeada com o tipode dados correspondente que possa ser aceita como entrada pela UDF. Especifique o data_typecomo um dos tipos de dados do Athena compatíveis listados na tabela a seguir. O tipo de dados devemapear para o tipo de dados Java correspondente.
Tipo de dados do Athena Tipo de dados Java
TIMESTAMP java.time.LocalDateTime (UTC)
DATE java.time.LocalDate (UTC)
TINYINT java.lang.Byte
SMALLINT java.lang.Short
REAL java.lang.Float
DOUBLE java.lang.Double
DECIMAL java.math.BigDecimal
BIGINT java.lang.Long
INTEGER java.lang.Int
VARCHAR java.lang.String
VARBINARY byte[]
BOOLEAN java.lang.Boolean
ARRAY java.util.List
ROW java.util.Map<String, Object>
RETURNS data_type TYPE
O data_type especifica o tipo de dados SQL que a UDF retorna como saída. Os tipos de dados doAthena listados na tabela acima são compatíveis.
LAMBDA_INVOKE WITH (lambda_name = 'my_lambda_function')
my_lambda_function especifica o nome da função do Lambda a ser invocada ao executar a UDF.SELECT [...] UDF_name(expression) [...]
A consulta SELECT que passa valores para a UDF e retorna um resultado. O UDF_name especificaa UDF a ser usada, seguida por uma expression que é avaliada para passar valores. Os valoresque são passados e retornados devem coincidir com os tipos de dados correspondentes especificadospara a UDF na cláusula USING FUNCTION.
ExemplosOs exemplos a seguir demonstram as consultas que usam UDFs. Os exemplos da consulta do Athena sãobaseados no código AthenaUDFHandler.java no GitHub.
142

Amazon Athena Guia do usuárioCriar e implantar uma UDF usando o Lambda
Example – Compactar e descompactar uma string
SQL do Athena
O exemplo a seguir demonstra o uso da UDF compress definida na função do Lambda chamadaMyAthenaUDFLambda.
USING FUNCTION compress(col1 VARCHAR) RETURNS VARCHAR TYPE LAMBDA_INVOKE WITH (lambda_name = 'MyAthenaUDFLambda') SELECT compress('StringToBeCompressed');
O resultado da consulta retorna ewLLinKzEsPyXdKdc7PLShKLS5OTQEAUrEH9w==.
O exemplo a seguir demonstra o uso da UDF decompress definida na mesma função do Lambda.
USING FUNCTION decompress(col1 VARCHAR) RETURNS VARCHAR TYPE LAMBDA_INVOKE WITH (lambda_name = 'MyAthenaUDFLambda') SELECT decompress('ewLLinKzEsPyXdKdc7PLShKLS5OTQEAUrEH9w==');
O resultado da consulta retorna StringToBeCompressed.
Criar e implantar uma UDF usando o LambdaPara criar uma UDF personalizada, crie uma nova classe Java ao estender a classeUserDefinedFunctionHandler. O código-fonte para UserDefinedFunctionHandler.java no SDKdisponível no GitHub no repositório awslabs/aws-athena-query-federation/athena-federation-sdk repository,junto com um exemplo de implementações de UDF que você pode analisar e modificar para criar uma UDFpersonalizada.
As etapas nessa seção demonstram a criação e compilação de um arquivo Jar da UDF usando ApacheMaven da linha de comando e uma implantação.
Etapas para criar uma UDF personalizada para Athena usando Maven• Clonar o SDK e preparar o ambiente de desenvolvimento (p. 143)• Criar o projeto Maven (p. 144)• Adicionar dependências e plugins ao projeto Maven (p. 144)• Escrever código Java para UDFs (p. 145)• Compilar o arquivo JAR (p. 146)• Implantar o JAR no AWS Lambda (p. 147)
Clonar o SDK e preparar o ambiente de desenvolvimentoAntes de começar, certifique-se de que o git esteja instalado no sistema usando sudo yum installgit -y.
Como instalar o Query Federation SDK da AWS
• Digite o seguinte na linha de comando para clonar o repositório do SDK. Este repositório inclui oSDK, exemplos e um conjunto de conectores de fonte de dados. Para obter mais informações sobreconectores de fonte de dados, consulte O uso do (p. 49).
git clone https://github.com/awslabs/aws-athena-query-federation.git
143

Amazon Athena Guia do usuárioCriar e implantar uma UDF usando o Lambda
Como instalar pré-requisitos para este procedimento
Se você estiver trabalhando em uma máquina de desenvolvimento que já tenha o Apache Maven, a AWSCLI e a ferramenta de compilação do Modelo de aplicativo sem servidor da AWS instalados, você podeignorar esta etapa.
1. Na raiz do diretório aws-athena-query-federation criado ao executar a clonagem, execute oscript prepare_dev_env.sh que prepara o ambiente de desenvolvimento.
2. Atualize o shell para fornecer novas variáveis criadas pelo processo de instalação ou reinicie a sessãodo terminal.
source ~/.profile
Important
Se você ignorar esta etapa, obterá erros posteriormente, pois a AWS CLI ou a ferramenta decompilação do AWS SAM não conseguirá publicar a função do Lambda.
Criar o projeto MavenExecute o seguinte comando para criar o projeto Maven. Substitua groupId pelo ID exclusivo daorganização e substitua my-athena-udf pelo nome do aplicativo. Para obter mais informações, consulteComo criar meu primeiro projeto Maven? na documentação Apache Maven.
mvn -B archetype:generate \-DarchetypeGroupId=org.apache.maven.archetypes \-DgroupId=groupId \-DartifactId=my-athena-udfs
Adicionar dependências e plugins ao projeto MavenAdicione as configurações a seguir ao arquivo pom.xml do projeto Maven. Para ver um exemplo, consulteo arquivo pom.xml no GitHub.
<properties> <aws-athena-federation-sdk.version>2019.48.1</aws-athena-federation-sdk.version></properties>
<dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-athena-federation-sdk</artifactId> <version>${aws-athena-federation-sdk.version}</version> </dependency></dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.1</version> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <filters> <filter> <artifact>*:*</artifact>
144

Amazon Athena Guia do usuárioCriar e implantar uma UDF usando o Lambda
<excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin> </plugins></build>
Escrever código Java para UDFsCrie uma nova classe ao estender UserDefinedFunctionHandler.java. Escreva as UDFs dentro da classe.
No exemplo a seguir, dois métodos Java para UDFs, compress() e decompress(), são criados dentroda classe MyUserDefinedFunctions.
*package *com.mycompany.athena.udfs;
public class MyUserDefinedFunctions extends UserDefinedFunctionHandler{ private static final String SOURCE_TYPE = "MyCompany";
public MyUserDefinedFunctions() { super(SOURCE_TYPE); }
/** * Compresses a valid UTF-8 String using the zlib compression library. * Encodes bytes with Base64 encoding scheme. * * @param input the String to be compressed * @return the compressed String */ public String compress(String input) { byte[] inputBytes = input.getBytes(StandardCharsets.UTF_8);
// create compressor Deflater compressor = new Deflater(); compressor.setInput(inputBytes); compressor.finish();
// compress bytes to output stream byte[] buffer = new byte[4096]; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(inputBytes.length); while (!compressor.finished()) { int bytes = compressor.deflate(buffer); byteArrayOutputStream.write(buffer, 0, bytes); }
145

Amazon Athena Guia do usuárioCriar e implantar uma UDF usando o Lambda
try { byteArrayOutputStream.close(); } catch (IOException e) { throw new RuntimeException("Failed to close ByteArrayOutputStream", e); }
// return encoded string byte[] compressedBytes = byteArrayOutputStream.toByteArray(); return Base64.getEncoder().encodeToString(compressedBytes); }
/** * Decompresses a valid String that has been compressed using the zlib compression library. * Decodes bytes with Base64 decoding scheme. * * @param input the String to be decompressed * @return the decompressed String */ public String decompress(String input) { byte[] inputBytes = Base64.getDecoder().decode((input));
// create decompressor Inflater decompressor = new Inflater(); decompressor.setInput(inputBytes, 0, inputBytes.length);
// decompress bytes to output stream byte[] buffer = new byte[4096]; ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(inputBytes.length); try { while (!decompressor.finished()) { int bytes = decompressor.inflate(buffer); if (bytes == 0 && decompressor.needsInput()) { throw new DataFormatException("Input is truncated"); } byteArrayOutputStream.write(buffer, 0, bytes); } } catch (DataFormatException e) { throw new RuntimeException("Failed to decompress string", e); }
try { byteArrayOutputStream.close(); } catch (IOException e) { throw new RuntimeException("Failed to close ByteArrayOutputStream", e); }
// return decoded string byte[] decompressedBytes = byteArrayOutputStream.toByteArray(); return new String(decompressedBytes, StandardCharsets.UTF_8); }}
Compilar o arquivo JARExecute mvn clean install para compilar o projeto. Após a compilação com êxito, um arquivo JAR écriado na pasta target do projeto nomeado como artifactId-version.jar, no qual artifactId éo nome fornecido por você no projeto Maven, por exemplo, my-athena-udfs.
146

Amazon Athena Guia do usuárioCriar e implantar uma UDF usando o Lambda
Implantar o JAR no AWS LambdaVocê tem duas opções para implantar o código no Lambda:
• Implantar usando AWS Serverless Application Repository (recomendado)• Criar uma função do Lambda no arquivo JAR
Opção 1: implantar no AWS Serverless Application Repository
Ao implantar o arquivo JAR no AWS Serverless Application Repository, você cria um arquivo YAML demodelo do AWS SAM que representa a arquitetura do aplicativo. Especifique esse arquivo YAML e umbucket do Amazon S3 no qual artefatos do aplicativo são carregados e disponibilizados no AWS ServerlessApplication Repository. O procedimento abaixo usa o script publish.sh localizado no diretório athena-query-federation/tools do Query Federation SDK do Athena clonado anteriormente.
Para obter mais informações e requisitos, consulte Publicar aplicativos no Guia do desenvolvedor doAWS Serverless Application Repository, Conceitos de modelo do AWS SAM no Guia do desenvolvedor doModelo de aplicativo sem servidor da AWS e Publicar aplicativos sem servidor usando a CLI do AWS SAM.
O exemplo a seguir demonstra parâmetros em um arquivo YAML. Adicione parâmetros similares aoarquivo YAML e salve-o no diretório de projetos. Consulte athena-udf.yaml no GitHub para ver o exemplocompleto.
Transform: 'AWS::Serverless-2016-10-31'Metadata: 'AWS::ServerlessRepo::Application': Name: MyApplicationName Description: 'The description I write for my application' Author: 'Author Name' Labels: - athena-federation SemanticVersion: 1.0.0Parameters: LambdaFunctionName: Description: 'The name of the Lambda function that will contain your UDFs.' Type: String LambdaTimeout: Description: 'Maximum Lambda invocation runtime in seconds. (min 1 - 900 max)' Default: 900 Type: Number LambdaMemory: Description: 'Lambda memory in MB (min 128 - 3008 max).' Default: 3008 Type: NumberResources: ConnectorConfig: Type: 'AWS::Serverless::Function' Properties: FunctionName: !Ref LambdaFunctionName Handler: "full.path.to.your.handler. For example, com.amazonaws.athena.connectors.udfs.MyUDFHandler" CodeUri: "Relative path to your JAR file. For example, ./target/athena-udfs-1.0.jar" Description: "My description of the UDFs that this Lambda function enables." Runtime: java8 Timeout: !Ref LambdaTimeout MemorySize: !Ref LambdaMemory
Copie o script publish.sh para o diretório de projetos no qual você salvou o arquivo YAML e execute ocomando:
147

Amazon Athena Guia do usuárioConsultar logs de serviço da AWS
./publish.sh MyS3Location MyYamlFile
Por exemplo, se o local do bucket for s3://mybucket/mysarapps/athenaudf e o arquivo YAML forsalvo como my-athena-udfs.yaml:
./publish.sh mybucket/mysarapps/athenaudf my-athena-udfs
Como criar uma função do Lambda
1. Abra o console do Lambda em https://console.aws.amazon.com/lambda/, escolha Create function(Criar função) e selecione Browse serverless app repository (Procurar repositório de aplicativos semservidor)
2. Selecione Private applications (Aplicativos privados), localize o aplicativo na lista ou procure usandopalavras-chave e selecione-o.
3. Verifique, forneça detalhes do aplicativo e selecione Deploy (Implantar).
Agora você pode usar os nomes dos métodos definidos no arquivo JAR da função do Lambda comoUDFs em Athena.
Opção 2: criar uma função do Lambda diretamenteVocê também pode criar uma função do Lambda diretamente usando o console ou a AWS CLI. O exemploa seguir demonstra o uso do comando create-function da CLI do Lambda.
aws lambda create-function \ --function-name MyLambdaFunctionName \ --runtime java8 \ --role arn:aws:iam::1234567890123:role/my_lambda_role \ --handler com.mycompany.athena.udfs.MyUserDefinedFunctions \ --timeout 900 \ --zip-file fileb://./target/my-athena-udfs-1.0-SNAPSHOT.jar
Consultar logs de serviço da AWSEsta seção inclui vários procedimentos para usar o Amazon Athena para consultar conjuntos de dadosconhecidos, como logs do AWS CloudTrail, logs do Amazon CloudFront, logs do Classic Load Balancer,logs do Application Load Balancer, logs de fluxo da Amazon VPC e logs do Load balancer de rede.
As tarefas desta seção usam o console do Athena, mas você também pode usar outras ferramentasque se conectam por meio de JDBC. Para obter mais informações, consulte Usar o Athena com o driverJDBC (p. 59), a CLI da AWS ou o Referência de API do Amazon Athena.
Os tópicos desta seção pressupõem que você tenha configurado um usuário do IAM com permissõesapropriadas para acessar o Athena e o bucket do Amazon S3 onde os dados a serem consultados devemresidir. Para obter mais informações, consulte Configurar (p. 6) e Conceitos básicos (p. 8).
Tópicos• Consultar logs do Application Load Balancer (p. 149)• Consultar logs do Classic Load Balancer (p. 150)• Consulta de logs do Amazon CloudFront (p. 152)• Consulta de logs do AWS CloudTrail (p. 153)• Consulta de logs do Amazon EMR (p. 157)
148

Amazon Athena Guia do usuárioConsultar logs do Application Load Balancer
• Consultar a logs de fluxo do AWS Global Accelerator (p. 161)• Consulta de logs do Load balancer de rede (p. 162)• Consulta a logs de fluxo da Amazon VPC (p. 164)• Consulta de logs do AWS WAF (p. 166)
Consultar logs do Application Load BalancerUm Application Load Balancer é uma opção de balanceamento de carga do Elastic Load Balancing quehabilita a distribuição de tráfego em uma implantação de microsserviços usando contêineres. Consultarlogs do Application Load Balancer permite consultar a origem do tráfego, a latência e os bytes transferidosde e para instâncias do Elastic Load Balancing e aplicativos de back-end.
Antes de começar, habilite o registro em log de acesso para que os logs do Application Load Balancersejam salvos no bucket do Amazon S3.
• Criação da tabela para logs do ALB (p. 149)• Consultas de exemplo para logs ALB (p. 150)
Criar a tabela para logs do ALB1. Copie e cole a instrução DDL a seguir no console do Athena e modifique os valores em LOCATION
's3://your-alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>/'.
Crie a tabela alb_logs da maneira a seguir.Note
Essa consulta inclui todos os campos presentes na lista de Entradas do log de acesso doApplication Load Balancer. Ela também inclui uma coluna de tabela new_field no final, casovocê requeira adições aos logs do ALB. Esse campo não interrompe a consulta. A expressãoregular nas propriedades SerDe ignorará esse campo se ele não existir em seus logs.
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs ( type string, time string, elb string, client_ip string, client_port int, target_ip string, target_port int, request_processing_time double, target_processing_time double, response_processing_time double, elb_status_code string, target_status_code string, received_bytes bigint, sent_bytes bigint, request_verb string, request_url string, request_proto string, user_agent string, ssl_cipher string, ssl_protocol string, target_group_arn string, trace_id string, domain_name string, chosen_cert_arn string,
149

Amazon Athena Guia do usuárioConsultar logs do Classic Load Balancer
matched_rule_priority string, request_creation_time string, actions_executed string, redirect_url string, lambda_error_reason string, new_field string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\"($| \"[^ ]*\")(.*)') LOCATION 's3://your-alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>/';
2. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela alb_logs, preparando os dados nela para você enviar consultas.
Consultas de exemplo para logs ALBA consulta a seguir conta o número de solicitações HTTP GET recebidas pelo load balancer agrupadaspelo endereço IP do cliente:
SELECT COUNT(request_verb) AS count, request_verb, client_ipFROM alb_logsGROUP BY request_verb, client_ipLIMIT 100;
Outra consulta mostra os URLs visitados por usuários do navegador Safari:
SELECT request_urlFROM alb_logsWHERE user_agent LIKE '%Safari%'LIMIT 10;
O exemplo a seguir mostra como analisar os registros por datetime:
SELECT client_ip, sum(received_bytes) FROM alb_logs_config_us WHERE parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') BETWEEN parse_datetime('2018-05-30-12:00:00','yyyy-MM-dd-HH:mm:ss') AND parse_datetime('2018-05-31-00:00:00','yyyy-MM-dd-HH:mm:ss') GROUP BY client_ip;
Consultar logs do Classic Load BalancerUse os logs do Classic Load Balancer para analisar e compreender padrões de tráfego de e parainstâncias e aplicativos de back-end do Elastic Load Balancing. Você pode ver a origem do tráfego, dalatência e dos bytes que foram transferidos.
Antes de analisar os logs do Elastic Load Balancing, configure-os para salvamento no bucket de destino doAmazon S3. Para obter mais informações, consulte Habilitar logs de acesso para o Classic Load Balancer.
150

Amazon Athena Guia do usuárioConsultar logs do Classic Load Balancer
• Criar a tabela para logs do Elastic Load Balancing (p. 151)• Consultas de exemplo do Elastic Load Balancing (p. 151)
Para criar a tabela para logs do Elastic Load Balancing1. Copie e cole a instrução DDL a seguir no console do Athena. Verifique a sintaxe dos registros em log
do Elastic Load Balancing. Pode ser necessário atualizar a consulta a seguir para incluir as colunas ea sintaxe Regex para a versão mais recente do registro.
CREATE EXTERNAL TABLE IF NOT EXISTS elb_logs ( timestamp string, elb_name string, request_ip string, request_port int, backend_ip string, backend_port int, request_processing_time double, backend_processing_time double, client_response_time double, elb_response_code string, backend_response_code string, received_bytes bigint, sent_bytes bigint, request_verb string, url string, protocol string, user_agent string, ssl_cipher string, ssl_protocol string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ( 'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \\\"([^ ]*) ([^ ]*) (- |[^ ]*)\\\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*)$' )LOCATION 's3://your_log_bucket/prefix/AWSLogs/AWS_account_ID/elasticloadbalancing/';
2. Modifique o bucket do Amazon S3 de LOCATION para especificar o destino dos logs do Elastic LoadBalancing.
3. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registraráa tabela elb_logs, preparando os dados da tabela para consultas. Para obter mais informações,consulte os Consultas de exemplo do Elastic Load Balancing (p. 151)
Consultas de exemplo do Elastic Load BalancingUse uma consulta semelhante à consulta do exemplo a seguir. Ele lista os servidores de aplicativos deback-end que retornaram um código de resposta de erro 4XX ou 5XX. Use o operador LIMIT para limitar onúmero de logs a serem consultados por vez.
SELECT timestamp, elb_name, backend_ip, backend_response_codeFROM elb_logsWHERE backend_response_code LIKE '4%' OR backend_response_code LIKE '5%'
151
Amazon Athena Guia do usuárioConsulta de logs do Amazon CloudFront
LIMIT 100;
Use uma consulta subsequente para somar o tempo de resposta de todas as transações agrupadas peloendereço IP de back-end e pelo nome da instância do Elastic Load Balancing.
SELECT sum(backend_processing_time) AS total_ms, elb_name, backend_ipFROM elb_logs WHERE backend_ip <> ''GROUP BY backend_ip, elb_nameLIMIT 100;
Para obter mais informações, consulte Analisar dados no S3 usando o Athena.
Consulta de logs do Amazon CloudFrontVocê pode configurar o CDN do Amazon CloudFront para exportar logs de acesso de distribuição da Webpara o Amazon Simple Storage Service. Use esses logs para explorar padrões de navegação dos usuáriosnas propriedades da web atendidas pelo CloudFront.
Antes de começar a consultar os logs, habilite o log de acesso de distribuições da Web na sua distribuiçãopreferida do CloudFront. Para obter informações, consulte Acessar logs no Guia do desenvolvedor doAmazon CloudFront.
Anote o bucket do Amazon S3 no qual salvar esses logs.
Note
Esse procedimento funciona para os logs de acesso de distribuição da web no CloudFront. Elenão se aplica a logs de streaming de distribuições RTMP.
• Criar a tabela para logs do CloudFront (p. 152)• Consulta de exemplo para logs do CloudFront (p. 153)
Criação da tabela para logs do CloudFrontPara criar a tabela do CloudFront
1. Copie e cole a instrução DDL a seguir no console do Athena. Modifique o LOCATION para o bucket doAmazon S3 que armazena os logs.
Essa consulta usa o LazySimpleSerDe (p. 269) por padrão e é omitida.
É efetuado o escape da coluna date usando acentos graves (`), pois trata-se de uma palavra reservadano Athena. Para obter mais informações, consulte Palavras-chave reservadas (p. 19).
CREATE EXTERNAL TABLE IF NOT EXISTS default.cloudfront_logs ( `date` DATE, time STRING, location STRING, bytes BIGINT, request_ip STRING, method STRING, host STRING, uri STRING,
152

Amazon Athena Guia do usuárioConsulta de logs do AWS CloudTrail
status INT, referrer STRING, user_agent STRING, query_string STRING, cookie STRING, result_type STRING, request_id STRING, host_header STRING, request_protocol STRING, request_bytes BIGINT, time_taken FLOAT, xforwarded_for STRING, ssl_protocol STRING, ssl_cipher STRING, response_result_type STRING, http_version STRING, fle_status STRING, fle_encrypted_fields INT, c_port INT, time_to_first_byte FLOAT, x_edge_detailed_result_type STRING, sc_content_type STRING, sc_content_len BIGINT, sc_range_start BIGINT, sc_range_end BIGINT)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'LOCATION 's3://CloudFront_bucket_name/CloudFront/'TBLPROPERTIES ( 'skip.header.line.count'='2' )
2. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela cloudfront_logs, preparando os dados nela para você enviar consultas.
Consulta de exemplo para logs do CloudFrontA consulta a seguir adiciona o número de bytes atendidos pelo CloudFront entre 9 de junho e 11 dejunho de 2018. Coloque o nome da coluna de data entre aspas duplas porque se trata de uma palavrareservada.
SELECT SUM(bytes) AS total_bytesFROM cloudfront_logsWHERE "date" BETWEEN DATE '2018-06-09' AND DATE '2018-06-11'LIMIT 100;
Em alguns casos, você precisa eliminar valores vazios dos resultados da consulta CREATE TABLE paraCloudFront. Para isso, execute:
SELECT DISTINCT * FROM cloudfront_logs LIMIT 10;
Para obter mais informações, consulte a postagem no blog AWS Big Data Construir uma arquitetura semservidor para analisar logs de acesso do Amazon CloudFront usando o AWS Lambda, o Amazon Athena eo Amazon Kinesis Analytics.
Consulta de logs do AWS CloudTrailO AWS CloudTrail é um serviço que registra chamadas à API da AWS e eventos para contas da AWS.
153

Amazon Athena Guia do usuárioConsulta de logs do AWS CloudTrail
Os logs do CloudTrail incluem detalhes sobre qualquer chamada à API feita para serviços da AWSincluindo o console. O CloudTrail gera arquivos de log criptografados e armazena-os no Amazon S3. Paraobter mais informações, consulte o Guia do usuário do AWS CloudTrail.
O uso do Athena com logs do CloudTrail é uma maneira avançada de melhorar a análise das atividades doserviço da AWS. Por exemplo, é possível usar consultas para identificar tendências e isolar ainda mais aatividade por atributos, como endereço IP de origem ou usuário.
Uma aplicação comum é usar logs do CloudTrail para analisar a segurança e a compatibilidade daatividade operacional. Para ver um exemplo detalhado, consulte a postagem no blog AWS Big Data,Analisar segurança, conformidade e atividade operacional usando o AWS CloudTrail e o Amazon Athena.
Você pode usar o Athena para consultar esses arquivos de log diretamente no Amazon S3 especificando oLOCATION dos arquivos de log. É possível fazer isso de duas formas:
• Criando tabelas para arquivos de log do CloudTrail diretamente no console do CloudTrail.• Criando manualmente tabelas para arquivos de log do CloudTrail no console do Athena.
Tópicos• Noções básicas de logs do CloudTrail e tabelas do Athena (p. 154)• Criação de uma tabela para logs do CloudTrail no console do CloudTrail (p. 155)• Criação manual da tabela para logs do CloudTrail no Athena (p. 155)• Consulta de exemplo para logs do CloudTrail (p. 156)• Dicas para consultar logs do CloudTrail (p. 157)
Noções básicas de logs do CloudTrail e tabelas do AthenaAntes de começar a criar tabelas, é preciso entender um pouco mais sobre o CloudTrail e como elearmazena dados. Isso pode ajudar a criar as tabelas necessárias, tanto pelo console do CloudTrail quantopelo Athena.
O CloudTrail salva logs como arquivos de texto JSON em formato gzip compactado (*.json.gzip). O localdos arquivos de log depende de como você configura as trilhas, da região da AWS ou das regiões nasquais está registrando, além de outros fatores.
Para obter mais informações sobre onde os logs são armazenados, a estrutura JSON e o conteúdo doarquivo de registro, consulte os seguintes tópicos no Guia do usuário do AWS CloudTrail:
• Encontrar os arquivos de log do CloudTrail• Exemplos de arquivos de log do CloudTrail• Conteúdo do registro do CloudTrail• Referência de evento do CloudTrail
Para coletar logs e salvá-los no Amazon S3, habilite o CloudTrail para o console. Para obter maisinformações, consulte Criar uma trilha no Guia do usuário do AWS CloudTrail.
Anote o bucket de destino do Amazon S3 no qual você salva os logs. Substitua a cláusula LOCATIONpelo caminho para o local do log do CloudTrail e pelo conjunto de objetos com os quais trabalhar. Oexemplo usa um valor LOCATION de logs para uma determinada conta, mas você pode usar o grau deespecificidade adequado ao aplicativo.
Por exemplo:
154

Amazon Athena Guia do usuárioConsulta de logs do AWS CloudTrail
• Para analisar dados de várias contas, você pode reverter o especificador LOCATION para indicar todosos AWSLogs usando LOCATION 's3://MyLogFiles/AWSLogs/.
• Para analisar dados de uma data, conta e região específica, use LOCATION `s3://MyLogFiles/123456789012/CloudTrail/us-east-1/2016/03/14/'.
Usar o nível mais alto na hierarquia do objeto fornece a maior flexibilidade ao consultar usando o Athena.
Criação de uma tabela para logs do CloudTrail no console doCloudTrailÉ possível criar tabelas para consultar logs do CloudTrail diretamente no console do CloudTrail. Esse é ummétodo simples de criar tabelas, mas só é possível criá-las dessa forma se o bucket do Amazon S3 quecontém os arquivos de log para a trilha estiver em uma região com suporte do Amazon Athena e se vocêestiver conectado com um usuário ou uma função do IAM com permissões suficientes para criar tabelas noAthena. Para obter mais informações, consulte Configuração (p. 6).
Para criar uma tabela para uma trilha do CloudTrail no console do CloudTrail
1. Abra o console do CloudTrail em https://console.aws.amazon.com/cloudtrail/.2. No painel de navegação, selecione Histórico de eventos.3. Em Event history (Histórico de eventos), escolha Run advanced queries no Amazon Athena (Executar
consultas avançadas no Amazon Athena).4. Em Storage location (Local de armazenamento), escolha o bucket do Amazon S3 no qual os arquivos
de log são armazenados para a trilha a ser consultada.
Note
É possível descobrir qual bucket está associado a uma trilha acessando Trails (Trilhas) eescolhendo a trilha. O nome do bucket é exibido em Storage location (Armazenamento local).
5. Escolha Create table. A tabela é criada com um nome padrão que inclui o nome do bucket do AmazonS3.
Criação manual da tabela para logs do CloudTrail no AthenaÉ possível criar manualmente tabelas para arquivos de log do CloudTrail no console do Athena e executarconsultas no Athena.
Para criar uma tabela para uma trilha do CloudTrail no console do CloudTrail
1. Copie e cole a instrução DDL a seguir no console do Athena.2. Modifique o s3://CloudTrail_bucket_name/AWSLogs/Account_ID/ a fim de apontar para o
bucket do Amazon S3 que contém os dados de logs.3. Verifique se os campos estão listados corretamente. Para obter mais informações sobre a lista
completa de campos em um registro do CloudTrail, consulte Conteúdo do registro do CloudTrail.
Neste exemplo, os campos requestparameters, responseelements e additionaleventdatasão listados como tipo STRING na consulta, mas são tipos de dados STRUCT usados em JSON.Portanto, para obter dados desses campos, use funções JSON_EXTRACT. Para obter maisinformações, consulte the section called “Extrair dados do JSON” (p. 122).
CREATE EXTERNAL TABLE cloudtrail_logs (eventversion STRING,useridentity STRUCT< type:STRING,
155

Amazon Athena Guia do usuárioConsulta de logs do AWS CloudTrail
principalid:STRING, arn:STRING, accountid:STRING, invokedby:STRING, accesskeyid:STRING, userName:STRING,sessioncontext:STRUCT<attributes:STRUCT< mfaauthenticated:STRING, creationdate:STRING>,sessionissuer:STRUCT< type:STRING, principalId:STRING, arn:STRING, accountId:STRING, userName:STRING>>>,eventtime STRING,eventsource STRING,eventname STRING,awsregion STRING,sourceipaddress STRING,useragent STRING,errorcode STRING,errormessage STRING,requestparameters STRING,responseelements STRING,additionaleventdata STRING,requestid STRING,eventid STRING,resources ARRAY<STRUCT< ARN:STRING, accountId:STRING, type:STRING>>,eventtype STRING,apiversion STRING,readonly STRING,recipientaccountid STRING,serviceeventdetails STRING,sharedeventid STRING,vpcendpointid STRING)ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://CloudTrail_bucket_name/AWSLogs/Account_ID/';
4. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrarácloudtrail_logs preparando os dados para você enviar consultas.
Consulta de exemplo para logs do CloudTrailO exemplo a seguir mostra uma parte de uma consulta que retorna todas as solicitações anônimas(não assinadas) da tabela criada na parte superior dos logs de eventos do CloudTrail. Essa consultaseleciona as solicitações em que useridentity.accountid são anônimos e useridentity.arn nãoé especificado:
SELECT *FROM cloudtrail_logsWHERE eventsource = 's3.amazonaws.com' AND eventname in ('GetObject') AND useridentity.accountid LIKE '%ANONYMOUS%' AND useridentity.arn IS NULL AND
156

Amazon Athena Guia do usuárioConsulta de logs do Amazon EMR
requestparameters LIKE '%[your bucket name ]%';
Para obter mais informações, consulte a postagem no blog AWS Big Data Analisar segurança,conformidade e atividade operacional usando o AWS CloudTrail e o Amazon Athena.
Dicas para consultar logs do CloudTrailPara explorar os dados de logs do CloudTrail, use estas dicas:
• Antes de consultar os logs, verifique se a tabela de logs tem a mesma aparência da tabela emthe section called “Criação manual da tabela para logs do CloudTrail no Athena” (p. 155). Senão for a primeira tabela, exclua a tabela existente usando o seguinte comando: DROP TABLEcloudtrail_logs;.
• Depois de ignorar a tabela existente, recrie-a. Para obter mais informações, consulte Criar a tabela paralogs do CloudTrail (p. 155).
Verifique se os campos na consulta do Athena estão listados corretamente. Para obter informaçõessobre a lista completa de campos em um registro do CloudTrail, consulte Conteúdo do registro doCloudTrail.
Se a consulta incluir campos em formatos JSON, como STRUCT, extraia dados de JSON. Para obtermais informações, consulte Extrair dados de JSON (p. 122).
Agora você está pronto para enviar consultas para a tabela do CloudTrail.• Comece observando quais usuários do IAM chamaram quais operações da API e de quais endereços IP
de origem.• Use a consulta SQL básica a seguir como o modelo. Cole a consulta no console do Athena e execute-a.
SELECT useridentity.arn, eventname, sourceipaddress, eventtimeFROM cloudtrail_logsLIMIT 100;
• Modifique a consulta anterior para explorar ainda mais seus dados.• Para melhorar o desempenho, inclua a cláusula LIMIT para retornar um subconjunto especificado de
linhas.
Consulta de logs do Amazon EMROs aplicativos do Amazon EMR e de big data que são executados no Amazon EMR geram arquivos delog. Os arquivos de log são gravados no nó principal e você também pode configurar o Amazon EMR pararealizar o arquivamento automático de arquivos de log no Amazon S3. Você pode usar o Amazon Athenapara consultar esses logs a fim de identificar eventos e tendências de aplicativos e clusters. Para obtermais informações sobre os tipos de arquivos de log no Amazon EMR e salvá-los no Amazon S3, consulteVisualizar arquivos de log no Guia de gerenciamento do Amazon EMR.
Criar e consultar uma tabela básica baseada nos arquivos de logdo Amazon EMRO exemplo a seguir cria uma tabela básica, myemrlogs, com base em arquivos de log salvos ems3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/
157

Amazon Athena Guia do usuárioConsulta de logs do Amazon EMR
elasticmapreduce/. O local do Amazon S3 usado nos exemplos abaixo reflete o padrão do localpredefinido do log de um cluster do EMR criado pela conta da AWS 123456789012 na região us-west-2. Se você usar um local personalizado, o padrão será s3://PathToEMRLogs/ClusterID.
Para obter informações sobre a criação de uma tabela particionada para potencialmente aprimorar odesempenho da consulta e reduzir a transferência de dados, consulte Criar e consultar uma tabelaparticionada baseada em logs do Amazon EMR (p. 159).
CREATE EXTERNAL TABLE `myemrlogs`( `data` string COMMENT 'from deserializer')ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'LINES TERMINATED BY '\n'STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6'
Os exemplos de consultas a seguir podem ser executados na tabela myemrlogs criada pelo exemploanterior.
Example – Consultar logs da etapa para ocorrências de ERROR, WARN, INFO, EXCEPTION,FATAL ou DEBUG
SELECT data, "$PATH"FROM "default"."myemrlogs"WHERE regexp_like("$PATH",'s-86URH188Z6B1') AND regexp_like(data, 'ERROR|WARN|INFO|EXCEPTION|FATAL|DEBUG') limit 100;
Example – Consultar um log de instância específico, i-00b3c0a839ece0a9c, para ERROR, WARN,INFO, EXCEPTION, FATAL ou DEBUG
SELECT "data", "$PATH" AS filepathFROM "default"."myemrlogs"WHERE regexp_like("$PATH",'i-00b3c0a839ece0a9c') AND regexp_like("$PATH",'state') AND regexp_like(data, 'ERROR|WARN|INFO|EXCEPTION|FATAL|DEBUG') limit 100;
Example – Consultar logs de aplicativo Presto para ERROR, WARN, INFO, EXCEPTION, FATALou DEBUG
SELECT "data", "$PATH" AS filepathFROM "default"."myemrlogs"WHERE regexp_like("$PATH",'presto') AND regexp_like(data, 'ERROR|WARN|INFO|EXCEPTION|FATAL|DEBUG') limit 100;
Example – Consultar logs de aplicativo Namenode para ERROR, WARN, INFO, EXCEPTION,FATAL ou DEBUG
SELECT "data", "$PATH" AS filepath
158

Amazon Athena Guia do usuárioConsulta de logs do Amazon EMR
FROM "default"."myemrlogs"WHERE regexp_like("$PATH",'namenode') AND regexp_like(data, 'ERROR|WARN|INFO|EXCEPTION|FATAL|DEBUG') limit 100;
Example – Consultar todos os logs por data e hora para ERROR, WARN, INFO, EXCEPTION,FATAL ou DEBUG
SELECT distinct("$PATH") AS filepathFROM "default"."myemrlogs"WHERE regexp_like("$PATH",'2019-07-23-10') AND regexp_like(data, 'ERROR|WARN|INFO|EXCEPTION|FATAL|DEBUG') limit 100;
Criar e consultar uma tabela particionada baseada em logs doAmazon EMREsses exemplos usam o mesmo local de log para criar uma tabela do Athena, mas a tabela é particionadae é criada uma partição para cada local de log. Para obter mais informações, consulte Particionardados (p. 23).
A consulta a seguir cria a tabela particionada denominada mypartitionedemrlogs:
CREATE EXTERNAL TABLE `mypartitionedemrlogs`( `data` string COMMENT 'from deserializer') partitioned by (logtype string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'LINES TERMINATED BY '\n'STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6'
Depois, as instruções de consulta a seguir criam partições de tabela com base em subdiretórios paradiferentes tipos de log que o Amazon EMR cria no Amazon S3:
ALTER TABLE mypartitionedemrlogs ADD PARTITION (logtype='containers') LOCATION s3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/containers/
ALTER TABLE mypartitionedemrlogs ADD PARTITION (logtype='hadoop-mapreduce') LOCATION s3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/hadoop-mapreduce/
ALTER TABLE mypartitionedemrlogs ADD PARTITION (logtype='hadoop-state-pusher') LOCATION s3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/hadoop-state-pusher/
ALTER TABLE mypartitionedemrlogs ADD
159

Amazon Athena Guia do usuárioConsulta de logs do Amazon EMR
PARTITION (logtype='node') LOCATION s3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/node/
ALTER TABLE mypartitionedemrlogs ADD PARTITION (logtype='steps') LOCATION s3://aws-logs-123456789012-us-west-2/elasticmapreduce/j-2ABCDE34F5GH6/steps/
Depois de criar as partições, você pode executar uma consulta SHOW PARTITIONS na tabela paraconfirmar:
SHOW PARTITIONS mypartitionedemrlogs;
Os exemplos a seguir demonstram que consultas para entradas de log específicas usam a tabela e aspartições criadas pelos exemplos acima.
Example – Consultar logs de aplicativos application_1561661818238_0002 na partição decontêineres para ERROR ou WARN
SELECT data, "$PATH"FROM "default"."mypartitionedemrlogs"WHERE logtype='containers' AND regexp_like("$PATH",'application_1561661818238_0002') AND regexp_like(data, 'ERROR|WARN') limit 100;
Example – Consultar a partição Hadoop-Mapreduce para a tarefa job_1561661818238_0004 efalhas em reduções
SELECT data, "$PATH"FROM "default"."mypartitionedemrlogs"WHERE logtype='hadoop-mapreduce' AND regexp_like(data,'job_1561661818238_0004|Failed Reduces') limit 100;
Example – Consultar logs de Hive na partição do nó para o ID de consulta056e0609-33e1-4611-956c-7a31b42d2663
SELECT data, "$PATH"FROM "default"."mypartitionedemrlogs"WHERE logtype='node' AND regexp_like("$PATH",'hive') AND regexp_like(data,'056e0609-33e1-4611-956c-7a31b42d2663') limit 100;
Example – Consultar logs do Resourcemanager na partição do nó para o aplicativo1567660019320_0001_01_000001
SELECT data, "$PATH"FROM "default"."mypartitionedemrlogs"WHERE logtype='node' AND regexp_like(data,'resourcemanager')
160

Amazon Athena Guia do usuárioConsultar a logs de fluxo do AWS Global Accelerator
AND regexp_like(data,'1567660019320_0001_01_000001') limit 100
Consultar a logs de fluxo do AWS Global AcceleratorÉ possível usar o AWS Global Accelerator para criar aceleradoras que direcionam o tráfego de rede paraendpoints ideais na rede global da AWS. Para obter mais informações sobre o Global Accelerator, consulteO que é o AWS Global Accelerator.
Os logs de fluxo do Global Accelerator capturam informações sobre o tráfego do endereço IP que percorreas interfaces de rede em suas aceleradoras. Os dados do log de fluxo são publicados no Amazon S3, ondeé possível recuperar e exibir seus dados. Para obter mais informações, consulte Logs de fluxo do AWSGlobal Accelerator.
É possível usar o Athena para consultar seus logs de fluxo do Global Accelerator criando uma tabela queespecifica seu local no Amazon S3.
Como criar a tabela para logs de fluxo do Global Accelerator
1. Copie e cole a instrução DDL a seguir no console do Athena. Esta consulta especifica ROW FORMATDELIMITED e omite a especificação de um SerDe (p. 253), o que significa que a consulta usaLazySimpleSerDe (p. 269). Nesta consulta, os campos terminam com um espaço.
CREATE EXTERNAL TABLE IF NOT EXISTS aga_flow_logs ( version string, account string, acceleratorid string, clientip string, clientport int, gip string, gipport int, endpointip string, endpointport int, protocol string, ipaddresstype string, numpackets bigint, numbytes int, starttime int, endtime int, action string, logstatus string, agasourceip string, agasourceport int, endpointregion string, agaregion string, direction string)PARTITIONED BY (dt string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ' 'LOCATION 's3://your_log_bucket/prefix/AWSLogs/account_id/globalaccelerator/region/'TBLPROPERTIES ("skip.header.line.count"="1");
2. Modifique o valor LOCATION a fim de apontar para o bucket do Amazon S3 que contém seus dadosde log.
's3://your_log_bucket/prefix/AWSLogs/account_id/globalaccelerator/region_code/'
3. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela aga_flow_logs, disponibilizando os dados dela para consultas.
4. Crie partições para ler os dados, conforme a consulta de exemplo a seguir. Esta consulta cria umaúnica partição para uma data especificada. Substitua os espaços reservados por data e local.
161

Amazon Athena Guia do usuárioConsulta de logs do Load balancer de rede
ALTER TABLE aga_flow_logsADD PARTITION (dt='YYYY-MM-dd')LOCATION 's3://your_log_bucket/prefix/AWSLogs/account_id/globalaccelerator/region_code/YYYY/MM/dd';
Consultas de exemplo para logs de fluxo do AWS GlobalAcceleratorExample – listar as solicitações que passam por um ponto de presença específico
A consulta de exemplo a seguir lista as solicitações que passaram pelo ponto de presença do LHR. Use ooperador LIMIT para limitar o número de logs a serem consultados por vez.
SELECT clientip, agaregion, protocol, action FROM aga_flow_logs WHERE agaregion LIKE 'LHR%' LIMIT 100;
Example – listar os endereços IP do endpoint que recebem a maioria das solicitações HTTPS
Para ver quais endereços IP do endpoint estão recebendo o maior número de solicitações HTTPS, use aseguinte consulta. Esta consulta conta o número de pacotes recebidos na porta HTTPS 443, agrupa-os porendereço IP de destino e retorna os 10 principais endereços IP.
SELECT SUM(numpackets) AS packetcount, endpointip FROM aga_flow_logs WHERE endpointport = 443 GROUP BY endpointip ORDER BY packetcount DESC LIMIT 10;
Consulta de logs do Load balancer de redeUse o Athena para analisar e processar logs do Load balancer de rede. Esses logs recebem informaçõesdetalhadas sobre as solicitações de Transport Layer Security (TLS) enviadas ao Load balancer de rede.Você pode usar esses logs de acesso para analisar padrões de tráfego e solucionar problemas.
Antes de analisar os logs de acesso do Load balancer de rede, habilite-os e configure-os para salvamentono bucket de destino do Amazon S3. Para obter mais informações, consulte Logs de acesso do Loadbalancer de rede.
• Criar a tabela para logs do Load balancer de rede (p. 163)
162

Amazon Athena Guia do usuárioConsulta de logs do Load balancer de rede
• Consultas de exemplo do Load balancer de rede (p. 163)
Para criar a tabela para logs do Load balancer de rede1. Copie e cole a instrução DDL a seguir no console do Athena. Verifique a sintaxe dos registros em log
do Load balancer de rede. Pode ser necessário atualizar a consulta a seguir para incluir as colunas ea sintaxe Regex para a versão mais recente do registro.
CREATE EXTERNAL TABLE IF NOT EXISTS nlb_tls_logs ( type string, version string, time string, elb string, listener_id string, client_ip string, client_port int, target_ip string, target_port int, tcp_connection_time_ms double, tls_handshake_time_ms double, received_bytes bigint, sent_bytes bigint, incoming_tls_alert int, cert_arn string, certificate_serial string, tls_cipher_suite string, tls_protocol_version string, tls_named_group string, domain_name string, new_field string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*):([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-0-9]*) ([-0-9]*) ([-0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*)($| [^ ]*)') LOCATION 's3://your_log_bucket/prefix/AWSLogs/AWS_account_ID/elasticloadbalancing/region';
2. Modifique o bucket do Amazon S3 de LOCATION para especificar o destino dos logs do Load balancerde rede.
3. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela nlb_tls_logs, preparando os dados da tabela para consultas.
Consultas de exemplo do Load balancer de redePara ver quantas vezes um certificado é usado, use uma consulta semelhante a este exemplo:
SELECT count(*) AS ct, cert_arnFROM "nlb_tls_logs"GROUP BY cert_arn;
A consulta a seguir mostra quantos usuários estão usando a versão mais antiga do TLS:
SELECT tls_protocol_version,
163

Amazon Athena Guia do usuárioConsulta a logs de fluxo da Amazon VPC
COUNT(tls_protocol_version) AS num_connections, client_ipFROM "nlb_tls_logs"WHERE tls_protocol_version < 'tlsv12'GROUP BY tls_protocol_version, client_ip;
Use a consulta a seguir para identificar conexões que levam muito tempo de handshake do TLS.
SELECT *FROM "nlb_tls_logs"ORDER BY tls_handshake_time_ms DESC LIMIT 10;
Consulta a logs de fluxo da Amazon VPCOs logs de fluxo da Amazon Virtual Private Cloud capturam informações sobre o tráfego IP de entradae saída de interfaces de rede em sua VPC. Use os logs para investigar padrões de tráfego de rede eidentificar ameaças e riscos em toda a rede da VPC.
Antes de começar a consultar os logs em Athena, habilite os logs de fluxo da VPC, e configure-os paraserem salvos em seu bucket do Amazon S3. Depois de criar os logs, deixe-os em execução por algunsminutos para coletar alguns dados. Os logs são criados em formato de compactação GZIP que o Athenapermite consultar diretamente.
Ao criar um log de fluxo da VPC, você pode usar o formato padrão ou especificar um formatopersonalizado. Um formato personalizado é onde você especifica quais campos devem ser retornados nolog de fluxo e a ordem em que eles devem aparecer. Para obter mais informações, consulte Registros delog de fluxo no Guia do usuário da Amazon VPC.
• Criar a tabela para logs de fluxo da VPC (p. 164)• Consultas de exemplo para logs de fluxo da Amazon VPC (p. 165)
Criar a tabela para logs de fluxo da VPCA seção a seguir cria uma tabela de Amazon VPC para logs de fluxo da VPC que usam o formato padrão.Se você criar um log de fluxo com um formato personalizado, deverá criar uma tabela com campos quecorrespondam aos especificados ao criar o log de fluxo, na mesma ordem em que os especificou.
Como criar a tabela de Amazon VPC
1. Copie e cole a instrução DDL a seguir no console do Athena. Essa consulta especifica ROW FORMATDELIMITED e omite a especificação de um SerDe. Isso significa que a consulta usa o LazySimpleSerDepara arquivos CSV, TSV e com delimitação personalizada (p. 269). Além disso, nesta consulta, oscampos são encerrados por um espaço. Para um log de fluxo da VPC com um formato personalizado,modifique os campos para que correspondam aos campos especificados ao criar o log de fluxo.
2. Modifique o LOCATION 's3://your_log_bucket/prefix/AWSLogs/{subscribe_account_id}/vpcflowlogs/{region_code}/' a fim de apontar para o bucket doAmazon S3 que contém seus dados de log.
CREATE EXTERNAL TABLE IF NOT EXISTS vpc_flow_logs ( version int, account string, interfaceid string, sourceaddress string, destinationaddress string,
164

Amazon Athena Guia do usuárioConsulta a logs de fluxo da Amazon VPC
sourceport int, destinationport int, protocol int, numpackets int, numbytes bigint, starttime int, endtime int, action string, logstatus string) PARTITIONED BY (dt string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ' 'LOCATION 's3://your_log_bucket/prefix/AWSLogs/{subscribe_account_id}/vpcflowlogs/{region_code}/'TBLPROPERTIES ("skip.header.line.count"="1");
3. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela vpc_flow_logs, preparando os dados nela para você enviar consultas.
4. Crie partições para poder ler os dados, conforme o exemplo de consulta a seguir. Esta consulta criauma única partição para uma data especificada. Substitua os espaços reservados por data e local,conforme necessário.
Note
Esta consulta cria apenas uma única partição, para uma data especificada por você. Paraautomatizar o processo, use um script que execute essa consulta e crie partições dessaforma para o year/month/day, ou use o Crawler do AWS Glue para criar partições para umdeterminado bucket do Amazon S3. Para obter informações, consulte Programação de umcrawler para manter o AWS Glue Data Catalog e o Amazon S3 sincronizados (p. 36).
ALTER TABLE vpc_flow_logsADD PARTITION (dt='YYYY-MM-dd')location 's3://your_log_bucket/prefix/AWSLogs/{account_id}/vpcflowlogs/{region_code}/YYYY/MM/dd';
Consultas de exemplo para logs de fluxo da Amazon VPCA consulta a seguir lista todas as conexões TCP rejeitadas e usa a coluna de partição de datas recém-criada, dt, para extrair o dia da semana em que ocorreram esses eventos.
Essa consulta usa Funções e operadores de data e hora Ele converte valores na coluna de String dt emtimestamp com a função de data from_iso8601_timestamp(string) e extrai o dia da semana detimestamp com day_of_week.
SELECT day_of_week(from_iso8601_timestamp(dt)) AS day, dt, interfaceid, sourceaddress, action, protocolFROM vpc_flow_logsWHERE action = 'REJECT' AND protocol = 6LIMIT 100;
Para ver qual dos servidores está recebendo o maior número de solicitações HTTPS, use essa consulta.Ela conta o número de pacotes recebidos na porta HTTPS 443, agrupa-os por endereço IP de destino eretorna os 10 principais.
165

Amazon Athena Guia do usuárioConsulta de logs do AWS WAF
SELECT SUM(numpackets) AS packetcount, destinationaddressFROM vpc_flow_logsWHERE destinationport = 443GROUP BY destinationaddressORDER BY packetcount DESCLIMIT 10;
Para obter mais informações, consulte a postagem no blog AWS Big Data Analisar logs de fluxo da VPCcom o Amazon Kinesis Firehose, o Athena e o Amazon QuickSight.
Consulta de logs do AWS WAFOs logs do AWS WAF incluem informações sobre o tráfego que é analisado pela sua ACL da web, como ahora em que o AWS WAF recebeu a solicitação do seu recurso da AWS, informações detalhadas sobre asolicitação e a ação para a regra a que cada solicitação correspondeu.
Você pode habilitar o registro em log de acesso para logs do AWS WAF, salvá-los no Amazon S3 econsultar os logs no Athena. Para obter mais informações sobre como habilitar logs do AWS WAF e sobrea estrutura de registro de log, consulte Registro em log das informações de tráfego da ACL da Web noGuia do desenvolvedor do AWS WAF.
Anote o bucket do Amazon S3 em que você salvar esses logs.
• Criação da tabela para logs do AWS WAF (p. 166)• Consultas de exemplo para logs do AWS WAF (p. 167)
Criação da tabela para logs do AWS WAFPara criar a tabela do AWS WAF
1. Copie e cole a instrução DDL a seguir no console do Athena. Modifique o LOCATION para o bucket doAmazon S3 que armazena os logs.
Essa consulta usa o Hive JSON SerDe (p. 266). O formato de tabela e o SerDe são sugeridos pelocrawler do AWS Glue quando ele analisa logs do AWS WAF.
CREATE EXTERNAL TABLE `waf_logs`( `timestamp` bigint, `formatversion` int, `webaclid` string, `terminatingruleid` string, `terminatingruletype` string, `action` string, `httpsourcename` string, `httpsourceid` string, `rulegrouplist` array<string>, `ratebasedrulelist` array< struct< ratebasedruleid:string, limitkey:string, maxrateallowed:int > >, `nonterminatingmatchingrules` array< struct< ruleid:string,
166

Amazon Athena Guia do usuárioConsulta de logs do AWS WAF
action:string > >, `httprequest` struct< clientip:string, country:string, headers:array< struct< name:string, value:string > >, uri:string, args:string, httpversion:string, httpmethod:string, requestid:string > )ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'WITH SERDEPROPERTIES ( 'paths'='action,formatVersion,httpRequest,httpSourceId,httpSourceName,nonTerminatingMatchingRules,rateBasedRuleList,ruleGroupList,terminatingRuleId,terminatingRuleType,timestamp,webaclId')STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://athenawaflogs/WebACL/'
2. Execute a consulta no console do Athena. Depois que a consulta for concluída, o Athena registrará atabela waf_logs, disponibilizando os dados dela para consultas.
Consultas de exemplo para logs do AWS WAFA consulta a seguir conta o número de vezes que um endereço IP foi bloqueado pela regra deencerramento RATE_BASED.
SELECT COUNT(httpRequest.clientIp) as count,httpRequest.clientIpFROM waf_logsWHERE terminatingruletype='RATE_BASED' AND action='BLOCK'GROUP BY httpRequest.clientIpORDER BY count LIMIT 100;
A consulta a seguir conta o número de vezes que a solicitação chegou de um endereço IP que pertence àIrlanda (IE) e foi bloqueada pela regra de de encerramento RATE_BASED.
SELECT COUNT(httpRequest.country) as count,httpRequest.countryFROM waf_logsWHERE terminatingruletype='RATE_BASED' AND httpRequest.country='IE'GROUP BY httpRequest.countryORDER BY countLIMIT 100;
A consulta a seguir conta o número de vezes que a solicitação foi bloqueada, com resultados agrupadospor WebACL, RuleId, ClientIP e HTTP Request URI.
SELECT COUNT(*) AScount,
167

Amazon Athena Guia do usuárioConsulta no Catálogo de dados do AWS Glue
webaclid,terminatingruleid,httprequest.clientip,httprequest.uriFROM waf_logsWHERE action='BLOCK'GROUP BY webaclid, terminatingruleid, httprequest.clientip, httprequest.uriORDER BY count DESCLIMIT 100;
A consulta a seguir conta o número de vezes que um ID de regra de encerramento específico foicorrespondido (WHERE terminatingruleid='e9dd190d-7a43-4c06-bcea-409613d9506e'). Aconsulta agrupa os resultados por WebACL, Action, ClientIP e HTTP Request URI.
SELECT COUNT(*) AScount,webaclid,action,httprequest.clientip,httprequest.uriFROM waf_logsWHERE terminatingruleid='e9dd190d-7a43-4c06-bcea-409613d9506e'GROUP BY webaclid, action, httprequest.clientip, httprequest.uriORDER BY count DESCLIMIT 100;
Consulta no Catálogo de dados do AWS GlueComo o Catálogo de dados do AWS Glue é usado por muitos serviços da AWS como repositório central demetadados, você pode querer consultar metadados do Data Catalog. Para fazer isso, use consultas SQLno Athena. Você pode usar o Athena para consultar metadados do catálogo do AWS Glue, como bancosde dados, tabelas, partições e colunas.
Note
Você também pode usar os comandos DDL (p. 289) do Hive individuais para extrair informaçõesde metadados para bancos de dados, tabelas, exibições, partições e colunas específicos doAthena, mas a saída estará em um formato não tabular.
Para obter metadados do catálogo do AWS Glue, consulte o banco de dados information_schema noback-end do Athena. As consultas de exemplo neste tópico mostram como usar o Athena para consultarmetadados do catálogo do AWS Glue em casos de uso comuns, mas não abrangem todos os cenários.
Tópicos• Listagem de bancos de dados e pesquisa em um banco de dados especificado (p. 168)• Listagem de tabelas em um banco de dados especificado e pesquisa de uma tabela por
nome (p. 169)• Listagem de partições de uma tabela específica (p. 170)• Listagem ou pesquisa de colunas de uma tabela ou exibição especificada (p. 170)
Listagem de bancos de dados e pesquisa em umbanco de dados especificadoOs exemplos nesta seção mostram como listar os bancos de dados em metadados por nome de esquema.
168

Amazon Athena Guia do usuárioListagem de tabelas em um banco de dados
especificado e pesquisa de uma tabela por nome
Example – Listar bancos de dados
A consulta de exemplo a seguir lista os bancos de dados da tabela information_schema.schemata.
SELECT schema_nameFROM information_schema.schemataLIMIT 10;
A tabela a seguir exibe os resultados do exemplo.
6 alb-databas1
7 alb_original_cust
8 alblogsdatabase
9 athena_db_test
10 athena_ddl_db
Example – Pesquisar um banco de dados especificado
Na consulta de exemplo a seguir, rdspostgresql é um banco de dados de exemplo.
SELECT schema_nameFROM information_schema.schemataWHERE schema_name = 'rdspostgresql'
A tabela a seguir exibe os resultados do exemplo.
schema_name
1 rdspostgresql
Listagem de tabelas em um banco de dadosespecificado e pesquisa de uma tabela por nomePara listar os metadados de tabelas, você pode consultar um esquema ou nome de tabela.
Example – Listar tabelas por esquema
A consulta a seguir lista tabelas que usam o esquema de tabela rdspostgresql.
SELECT table_schema, table_name, table_typeFROM information_schema.tablesWHERE table_schema = 'rdspostgresql'
A tabela a seguir mostra um exemplo de resultado.
table_schema table_name table_type
1 rdspostgresql rdspostgresqldb1_public_accountBASE TABLE
169

Amazon Athena Guia do usuárioListagem de partições de uma tabela específica
Example – Pesquisar uma tabela por nome
A consulta a seguir obtém informações de metadados para a tabela athena1.
SELECT table_schema, table_name, table_typeFROM information_schema.tablesWHERE table_name = 'athena1'
A tabela a seguir mostra um exemplo de resultado.
table_schema table_name table_type
1 default athena1 BASE TABLE
Listagem de partições de uma tabela específicaVocê pode usar uma consulta de metadados para listar os números e valores de partição de uma tabelaespecífica.
Example – Consultar as partições de uma tabela
A consulta de exemplo a seguir lista as partições da tabela CloudTrail_logs_test2.
SELECT *FROM information_schema.__internal_partitions__WHERE table_schema = 'default' AND table_name = 'cloudtrail_logs_test2'ORDER BY partition_number
Se a consulta não funcionar como esperado, use SHOW PARTITIONS table_name para extrair osdetalhes da partição de uma tabela especificada, como no exemplo a seguir.
SHOW PARTITIONS CloudTrail_logs_test2
A tabela a seguir exibe os resultados do exemplo.
table_catalog table_schema table_name partition_number partition_key partition_value
1 awsdatacatalogdefault CloudTrail_logs_test2 1 year 2018
2 awsdatacatalogdefault CloudTrail_logs_test2 1 mês 09
3 awsdatacatalogdefault CloudTrail_logs_test2 1 dia 30
Listagem ou pesquisa de colunas de uma tabela ouexibição especificadaVocê pode listar todas as colunas de uma tabela, todas as colunas de uma exibição ou pesquisar umacoluna por nome em um banco de dados e tabela especificados.
170

Amazon Athena Guia do usuárioListagem ou pesquisa de colunas deuma tabela ou exibição especificada
Example – Listar todas as colunas de uma tabela especificada
A consulta de exemplo a seguir lista todas as colunas da tabela rdspostgresqldb1_public_account.
SELECT *FROM information_schema.columnsWHERE table_schema = 'rdspostgresql' AND table_name = 'rdspostgresqldb1_public_account'
A tabela a seguir exibe os resultados do exemplo.
table_catalogtable_schematable_name column_nameordinal_positioncolumn_defaultis_nullabledata_typecomentárioextra_info
1 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accountpassword 1 SIM varchar
2 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accountuser_id 2 SIM inteiro
3 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accountcreated_on3 SIM timestamp
4 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accountlast_login 4 SIM timestamp
5 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accounte-mail 5 SIM varchar
6 awsdatacatalogrdspostgresqlrdspostgresqldb1_public_accountnomedeusuário
6 SIM varchar
Example – Listar as colunas de uma exibição especificada
A consulta de exemplo a seguir lista todas as colunas no banco de dados default para a exibiçãoarrayview.
SELECT *FROM information_schema.columnsWHERE table_schema = 'default' AND table_name = 'arrayview'
A tabela a seguir exibe os resultados do exemplo.
table_catalogtable_schematable_namecolumn_nameordinal_positioncolumn_defaultis_nullabledata_type comentárioextra_info
1 awsdatacatalogdefault arrayviewsearchdate 1 SIM varchar
2 awsdatacatalogdefault arrayviewsid 2 SIM varchar
3 awsdatacatalogdefault arrayviewbtid 3 SIM varchar
4 awsdatacatalogdefault arrayviewp 4 SIM varchar
5 awsdatacatalogdefault arrayviewinfantprice 5 SIM varchar
6 awsdatacatalogdefault arrayviewsump 6 SIM varchar
7 awsdatacatalogdefault arrayviewjourneymaparray7 SIM array(varchar)
171

Amazon Athena Guia do usuárioListagem ou pesquisa de colunas deuma tabela ou exibição especificada
Example – Pesquisar uma coluna por nome em um banco de dados e tabela especificados
A consulta de exemplo a seguir procura metadados para a coluna sid na exibição arrayview do bancode dados default.
SELECT *FROM information_schema.columnsWHERE table_schema = 'default' AND table_name = 'arrayview' AND column_name='sid'
A tabela a seguir mostra um exemplo de resultado.
table_catalogtable_schematable_namecolumn_nameordinal_positioncolumn_defaultis_nullabledata_typecomentárioextra_info
1 awsdatacatalogdefault arrayview sid 2 SIM varchar
172

Amazon Athena Guia do usuárioProteção de dados
Segurança do Amazon AthenaA segurança da nuvem na AWS é a nossa maior prioridade. Como cliente da AWS, você se beneficiaráde um datacenter e de uma arquitetura de rede criados para atender aos requisitos das empresas com asmaiores exigências de segurança.
A segurança é uma responsabilidade compartilhada entre a AWS e você. O modelo de responsabilidadecompartilhada descreve a segurança da nuvem e a segurança na nuvem:
• Segurança da nuvem – a AWS é responsável pela proteção da infraestrutura que executa serviçosda AWS na nuvem da AWS. A AWS também fornece serviços que você pode usar com segurança. Aeficácia de nossa segurança é regularmente testada e verificada por auditores terceirizados como partedos programas de conformidade da AWS. Para saber mais sobre os programas de conformidade que seaplicam ao Athena, consulte Serviços da AWS no escopo por programa de conformidade.
• Segurança na nuvem – Sua responsabilidade é determinada pelo serviço da AWS que você usa. Vocêtambém é responsável por outros fatores, incluindo a confidencialidade de seus dados, os requisitos dasua organização e as leis e regulamentos aplicáveis.
Esta documentação ajudará você a entender como aplicar o modelo de responsabilidade compartilhada aousar o Amazon Athena. Os tópicos a seguir mostram como configurar o Athena para cumprir os objetivosde segurança e de conformidade. Você também aprenderá como usar outros serviços da AWS que podemajudar a monitorar e proteger seus recursos do Athena.
Tópicos• Proteção de dados no Athena (p. 173)• Gerenciamento de identidade e acesso no Athena (p. 180)• Registro em log e monitoramento no Athena (p. 205)• Validação de conformidade do Amazon Athena (p. 206)• Resiliência no Athena (p. 207)• Segurança da infraestrutura no Athena (p. 207)• Análise de vulnerabilidade e configuração no Athena (p. 209)• Usar o Athena para consultar dados registrados com o AWS Lake Formation (p. 209)
Proteção de dados no AthenaVários tipos de dados estão envolvidos ao usar o Athena para criar bancos de dados e tabelas. Essestipos de dados incluem dados armazenados na origem no Amazon S3, metadados de bancos de dadose tabelas que você cria ao executar consultas ou o crawler do AWS Glue para descobrir dados, dadosde resultados de consultas e histórico de consultas. Esta seção discute cada tipo de dado e forneceorientação sobre a proteção.
• Dados na origem – Você armazena os dados de bancos de dados e tabelas no Amazon S3, e o Athenanão os modifica. Para obter mais informações, consulte Proteção de dados no Amazon S3 no Guia dodesenvolvedor do Amazon Simple Storage Service. Você controla o acesso aos seus dados de origem epode criptografá-los no Amazon S3. Você pode usar o Athena para criar tabelas com base em conjuntosde dados criptografados no Amazon S3 (p. 177).
• Metadados de tabelas e bancos de dados (esquema) – o Athena usa tecnologia schema-on-read, o quesignifica que as definições de tabela são aplicadas aos seus dados no Amazon S3 quando o Athena
173

Amazon Athena Guia do usuárioCriptografia em repouso
executa consultas. Todos os esquemas que você definir serão automaticamente salvos, a não ser quevocê os exclua explicitamente. No Athena, você pode modificar os metadados do Data Catalog usandoinstruções DDL. Você também pode excluir as definições de tabela e o esquema sem afetar os dadossubjacentes armazenados no Amazon S3.
Note
Os metadados para os bancos de dados e as tabelas que você usa no Athena sãoarmazenados no Catálogo de dados do AWS Glue. É altamente recomendável que você façauma atualização (p. 43) para usar o Catálogo de dados do AWS Glue com o Athena. Para obtermais informações sobre os benefícios de usar o Catálogo de dados do AWS Glue, consultePerguntas frequentes: atualizar para o AWS Glue Data Catalog (p. 45).
Você pode definir políticas de acesso granulares para bancos de dados e tabelas (p. 185) registradosno Catálogo de dados do AWS Glue usando o AWS Identity and Access Management (IAM). Você podecriptografar os metadados no AWS Glue Data Catalog. Você também pode criptografar metadados noCatálogo de dados do AWS Glue. Se você criptografar os metadados, use permissões para metadadoscriptografados (p. 179) para o acesso.
• Resultados de consultas e histórico de consultas, incluindo consultas salvas – os resultados dasconsultas são armazenados em um local no Amazon S3 que pode ser especificado globalmente oupara cada grupo de trabalho. Se não for especificado, o Athena usará o local padrão em cada caso.Você controla o acesso aos buckets do Amazon S3 em que armazena os resultados das consultas e asconsultas salvas. Além disso, você pode optar por criptografar os resultados da consulta armazenadosno Amazon S3. Seus usuários devem ter as permissões apropriadas para acessar os locais do AmazonS3 e descriptografar os arquivos. Para obter mais informações, consulte Criptografar resultados deconsultas armazenadas noAmazon S3 (p. 176) neste documento.
O Athena mantém o histórico de consultas por 45 dias. Você pode visualizar o histórico deconsulta (p. 71) usando as APIs do Athena, no console e com a AWS CLI. Para armazenar asconsultas para mais de 45 dias, salve-as. Para proteger o acesso a consultas salvas, use grupos detrabalho (p. 217) no Athena, restringindo o acesso a consultas salvas apenas para os usuários queestão autorizados a visualizá-las.
Tópicos• Criptografia em repouso (p. 174)• Criptografia em trânsito (p. 179)• Gerenciamento de chaves (p. 179)• Privacidade do tráfego entre redes (p. 180)
Criptografia em repousoVocê pode executar consultas no Amazon Athena para dados criptografados no Amazon S3, na mesmaregião. Você também pode criptografar os resultados da consulta no Amazon S3, e os dados no AWS GlueData Catalog.
Você pode criptografar os seguintes ativos no Athena:
• Os resultados de todas as consultas no Amazon S3, que o Athena armazena em um local conhecidocomo local dos resultados do Amazon S3. Você pode criptografar os resultados de consultasarmazenados no Amazon S3, independentemente do conjunto de dados subjacente estar ou nãocriptografado no Amazon S3. Para obter mais informações, consulte Permissões para resultados deconsultas criptografados armazenados no Amazon S3 (p. 176).
• Os dados no AWS Glue Data Catalog. Para obter informações, consulte Permissões para metadadoscriptografados no Catálogo de dados do AWS Glue (p. 179).
174

Amazon Athena Guia do usuárioCriptografia em repouso
Opções de criptografia suportadas no Amazon S3O Athena oferece suporte às seguintes opções de criptografia do Amazon S3 para conjuntos de dadoscriptografados no Amazon S3 na mesma região e para resultados de consulta criptografados:
• Criptografia do lado do servidor (SSE) com uma chave gerenciada pelo Amazon S3 (SSE-S3)• Criptografia do lado do servidor (SSE) com uma chave gerenciada pelo cliente do AWS Key
Management Service (SSE-KMS).• Criptografia do lado do cliente (CSE) com uma chave gerenciada pelo cliente do AWS KMS (CSE-KMS)
Note
Com o SSE-KMS, o Athena não exige que você indique que os dados são criptografados ao criaruma tabela.
Para obter mais informações sobre a criptografia do AWS KMS com o Amazon S3, consulte O que é AWSKey Management Service e Como o Amazon Simple Storage Service (Amazon S3) usa o AWS KMS noAWS Key Management Service Developer Guide.
O Athena não é compatível com SSE com chaves fornecidas pelo cliente (SSE-C), nem dá suporte àcriptografia do lado do cliente usando uma chave mestra do lado do cliente. O Athena não é compatívelcom chaves assimétricas. Para comparar opções de criptografia do Amazon S3, consulte Proteção dedados usando criptografia no Guia do desenvolvedor do Amazon Simple Storage Service.
O Athena não oferece suporte à execução de consultas de uma região em dados criptografadosarmazenados no Amazon S3 em outra região.
Important
A configuração para consultar um conjunto de dados criptografados no Amazon S3 e as opçõesno Athena para criptografar os resultados da consulta são independentes. Cada opção é ativadae configurada separadamente. Você pode usar métodos de criptografia diferentes ou chavespara cada uma. Isso significa que ler dados criptografados no Amazon S3 não criptografaautomaticamente os resultados de consultas do Athena no Amazon S3. O inverso também éverdadeiro. A criptografia dos resultados de consulta do Athena no Amazon S3 não criptografa oconjunto de dados subjacente no Amazon S3.
Independentemente de você usar opções para criptografar dados em repouso no Amazon S3 ou não,a Transport Layer Security (TLS) criptografa objetos em trânsito entre recursos do Athena e entre oAthena e o Amazon S3. Os resultados de consultas que transmitem para clientes JDBC ou ODBC sãocriptografados usando TLS.
Permissões para dados criptografados no Amazon S3Dependendo do tipo de criptografia que você usa no Amazon S3, pode ser necessário adicionarpermissões, também conhecidas como ações "Allow (Permitir)", a suas políticas usadas no Athena:
• SSE-S3 – Se você usar o SSE-S3 para criptografia, os usuários do Athena não exigirão permissõesadicionais em suas políticas. É suficiente ter as permissões do Amazon S3 apropriadas para o localdo Amazon S3 apropriado e para ações do Athena. Para obter mais informações sobre políticas quepossibilitam permissões do Athena e do Amazon S3 apropriadas, consulte Políticas do IAM para acessodo usuário (p. 181) e Permissões do Amazon S3 (p. 185).
• AWS KMS – se você usar o AWS KMS para criptografia, os usuários do Athena deverão ter permissãopara executar determinadas ações do AWS KMS além das permissões do Athena e do Amazon S3.Você permite essas ações editando a política de chaves das chaves gerenciadas pelo cliente (CMKs) doAWS KMS usadas para criptografar dados no Amazon S3. A maneira mais fácil de fazer isso é usando oconsole do IAM para adicionar usuários de chave às políticas de chaves do AWS KMS apropriadas. Para
175

Amazon Athena Guia do usuárioCriptografia em repouso
obter informações sobre como adicionar um usuário a uma política de chaves do AWS KMS, consulteComo modificar uma política de chaves no AWS Key Management Service Developer Guide.
Note
Os administradores de políticas de chaves avançadas podem ajustar as políticas de chaves.kms:Decrypt é a ação mínima permitida para que um usuário do Athena trabalhe com umconjunto de dados criptografados. Para trabalhar com resultados da consulta criptografados, asações permitidas mínimas são kms:GenerateDataKey e kms:Decrypt.
Ao usar o Athena para consultar conjuntos de dados no Amazon S3 com um grande número de objetoscriptografados com o AWS KMS, o AWS KMS pode controlar os resultados da consulta. Isso é maisprovável quando há um grande número de pequenos objetos. O Athena rejeita novas solicitações, masainda pode ocorrer um erro de controle de limitação. Nesse caso, você pode aumentar suas cotas deserviço do AWS KMS. Para obter mais informações, consulte Cotas no AWS Key Management ServiceDeveloper Guide.
Criptografia de resultados de consulta armazenados no AmazonS3Você pode configurar a criptografia de resultados de consulta usando o console do Athena. Grupos detrabalhos permitem que você reforce a criptografia dos resultados de consultas.
Se você se conectar usando o driver JDBC ou ODBC, configure as opções de driver para especificar otipo de criptografia a ser usado e o local do diretório de preparação do Amazon S3. Para configurar odriver JDBC ou ODBC para criptografar os resultados de consultas usando qualquer um dos protocolosde criptografia compatíveis com o Athena, consulte Conexão ao Amazon Athena com drivers ODBC eJDBC (p. 59).
Você pode fazer a configuração para criptografia dos resultados da consulta de duas formas:
• Configurações no lado do cliente – ao usar Settings (Configurações) no console ou as operações de APIpara indicar que deseja criptografar os resultados da consulta, isso é conhecido como configuraçõesno lado do cliente. As configurações no lado do cliente incluem o local dos resultados da consultae a criptografia. Se você especificá-los, elas serão usadas, a menos que sejam substituídas porconfigurações do grupo de trabalho.
• Configurações do grupo de trabalho – ao criar ou editar um grupo de trabalho (p. 228) e marcar ocampo Override client-side settings (Sobrepor configurações no lado do cliente), todas as consultasexecutadas nesse grupo de trabalho usarão as configurações de grupo de trabalho. Para obter maisinformações, consulte Configurações do grupo de trabalho sobrepõem as configurações do lado docliente (p. 226). As configurações do grupo de trabalho incluem o local dos resultados da consulta e acriptografia.
Para criptografar resultados de consulta armazenados no Amazon S3 usando o consoleImportant
Se o seu grupo de trabalho estiver com o campo Override client-side settings (Sobreporconfigurações no lado do cliente), as consultas usarão as configurações do grupo de trabalho.A configuração da criptografia e o local dos resultados da consulta listados em Settings(Configurações), as operações da API e os drivers não serão usados. Para obter maisinformações, consulte Configurações do grupo de trabalho sobrepõem as configurações do ladodo cliente (p. 226).
1. No console do Athena, escolha Settings (Configurações).
176

Amazon Athena Guia do usuárioCriptografia em repouso
2. Para Query result location, digite um valor personalizado ou deixe o padrão. Este é o diretório depreparação do Amazon S3 no qual os resultados de consulta são armazenados.
3. Escolha Encrypt query results.
4. Para Encryption type, escolha CSE-KMS, SSE-KMS ou SSE-S3.5. Se você escolher SSE-KMS ou CSE-KMS, especifique a Encryption key (Chave de criptografia).
• Se sua conta tiver acesso a uma chave gerenciada pelo cliente (CMK) do AWS KMS, escolha oalias ou escolha Enter a ARN key ARN (Inserir o ARN de uma chave do KMS) e insira um ARN.
• Se sua conta não tiver acesso a uma chave gerenciada pelo cliente (CMK) do AWS KMS, escolhaCreate KMS key (Criar chave do KMS) e, em seguida, abra o console do AWS KMS. No painelde navegação, selecione AWS managed keys (Chaves gerenciadas da AWS).Para obter maisinformações, consulte Como criar chaves no AWS Key Management Service Developer Guide.
Note
O Athena é compatível apenas com chaves simétricas para leitura e gravação de dados.6. Volte para o console do Athena para especificar a chave por alias ou ARN, conforme descrito na etapa
anterior.7. Escolha Salvar.
Criação de tabelas com base em conjuntos de dadoscriptografados no Amazon S3Ao criar uma tabela, você indica ao Athena que um conjunto de dados é criptografado no Amazon S3.Isso não é necessário ao usar o SSE-KMS. Para a criptografia do SSE-S3 e do AWS KMS, o Athenadetermina os materiais apropriados a serem usados para descriptografar o conjunto de dados e criar atabela, portanto, você não precisa fornecer informações de chaves.
Os usuários que executam consultas, inclusive o usuário que cria a tabela, devem ter as permissõesapropriadas, conforme descrito anteriormente neste tópico.
Important
Ao usar o Amazon EMR junto com o EMRFS para fazer upload de arquivosParquet criptografados, você deve desabilitar multipart uploads configurandofs.s3n.multipart.uploads.enabled como false. Se você não fizer isso, oAthena não poderá determinar o comprimento de um arquivo Parquet e ocorrerá um erroHIVE_CANNOT_OPEN_SPLIT. Para obter mais informações, consulte Configurar multipart uploadpara o Amazon S3 no Guia de gerenciamento do Amazon EMR.
177

Amazon Athena Guia do usuárioCriptografia em repouso
Indique que o conjunto de dados está criptografado no Amazon S3 de uma das maneiras a seguir. Essaetapa não será necessária, se o SSE-KMS for usado.
• Use a instrução CREATE TABLE (p. 295) com uma cláusula TBLPROPERTIES que especifica'has_encrypted_data'='true'.
• Use o driver JDBC (p. 59) e defina o valor de TBLPROPERTIES como mostrado no exemplo anterior, aoexecutar CREATE TABLE (p. 295) usando statement.executeQuery().
• Use o assistente Add table (Adicionar tabela) no console do Athena e escolha Encrypted data set(Conjunto de dados criptografados) ao especificar um valor para Location of input data set (Local doconjunto de dados de entrada).
As tabelas baseadas em dados criptografados no Amazon S3 são exibidas na lista Database (Banco dedados) com um ícone de criptografia.
178

Amazon Athena Guia do usuárioCriptografia em trânsito
Permissões para metadados criptografados no Catálogo dedados do AWS GlueSe você criptografar metadados no AWS Glue Data Catalog, deverá adicionar as ações"kms:GenerateDataKey", "kms:Decrypt" e "kms:Encrypt" às políticas que você usa para acessaro Athena. Para obter informações, consulte Acesso a metadados criptografados no Catálogo de dados doAWS Glue (p. 192).
Criptografia em trânsitoAlém de criptografar dados em repouso no Amazon S3, o Amazon Athena usa Transport Layer Security(TLS) para a criptografia de dados em trânsito entre o Athena e o Amazon S3, e entre o Athena eaplicativos do cliente que o acessam.
Você deve permitir que apenas conexões criptografadas por HTTPS (TLS) usandoaws:SecureTransport condition nas políticas do IAM no bucket do Amazon S3.
Os resultados de consultas que transmitem para clientes JDBC ou ODBC são criptografados usandoTLS. Para obter informações sobre as versões mais recentes dos drivers JDBC e ODBC e suasdocumentações, consulte Conexão com o driver JDBC (p. 59) e Conexão com o driver ODBC (p. 61).
Gerenciamento de chavesO Amazon Athena oferece suporte ao AWS Key Management Service (AWS KMS) para criptografarconjuntos de dados no Amazon S3 e resultados de consulta no Athena. O AWS KMS usa chaves mestrasde cliente (CMKs) para criptografar seus objetos do Amazon S3 e conta com a criptografia de envelope.
No AWS KMS, você pode realizar as seguintes ações:
• Criar chaves• Importar seu próprio material de chaves para novas CMKs
Note
O Athena é compatível apenas com chaves simétricas para leitura e gravação de dados.
179

Amazon Athena Guia do usuárioPrivacidade do tráfego entre redes
Para obter mais informações, consulte O que é o AWS Key Management Service no AWS KeyManagement Service Developer Guide e Como o Amazon Simple Storage Service usa o AWS KMS. Paraexibir as chaves em sua conta que AWS cria e gerencia para você, no painel de navegação, escolhachaves gerenciadas da AWS
Se você fizer upload ou acessar objetos criptografados por SSE-KMS, use o Signature versão 4 da AWSpara maior segurança. Para obter mais informações, consulte Especificar a versão do Signature naautenticação de solicitações no Guia do desenvolvedor do Amazon Simple Storage Service.
Privacidade do tráfego entre redesO tráfego é protegido entre o Athena e aplicativos locais, e entre o Athena e o Amazon S3. O tráfegoentre o Athena e outros serviços, como o AWS Glue e o AWS Key Management Service, usa HTTPS porpadrão.
• Para o tráfego entre o Athena e clientes e aplicativos locais, os resultados da consulta que sãotransmitidos para clientes JDBC ou ODBC são criptografados usando Transport Layer Security (TLS).
Você pode usar uma das opções de conectividade entre sua rede privada e a AWS:• Uma conexão AWS VPN VPN de local para local Para obter mais informações, consulte O que é VPN
de local para local AWS VPN? em Guia do usuário do AWS Site-to-Site VPN.• Uma conexão AWS Direct Connect. Para obter mais informações, consulte O que é AWS Direct
Connect? em Guia do usuário do AWS Direct Connect.• Para o tráfego entre o Athena e buckets do Amazon S3, o Transport Layer Security (TLS) criptografa
os objetos em trânsito entre o Athena e o Amazon S3, e entre o Athena e aplicativos de clientesque o acessam. Você deve permitir apenas conexões criptografadas por HTTPS (TLS) usando oaws:SecureTransport condition nas políticas do IAM de bucket do Amazon S3.
Gerenciamento de identidade e acesso no AthenaO Amazon Athena usa políticas do AWS Identity and Access Management (IAM) para restringir o acesso aoperações do Athena.
Para executar consultas no Athena, você deve ter as permissões apropriadas para fazer o seguinte:
• Ações de API do Athena, incluindo ações adicionais para grupos de trabalho (p. 217) do Athena.• Locais do Amazon S3 onde os dados subjacentes para consultar estão armazenados.• Os metadados e recursos armazenados no Catálogo de dados do AWS Glue, como bancos de dados e
tabelas, incluindo ações adicionais para metadados criptografados.
Se você for um administrador para outros usuários, verifique se eles têm permissões apropriadasassociadas aos perfis de usuário.
Tópicos• Políticas gerenciadas para o acesso de usuários (p. 181)• Acesso por meio de conexões JDBC e ODBC (p. 185)• Acesso ao Amazon S3 (p. 185)• Acesso granular a bancos de dados e tabelas no Catálogo de dados do AWS Glue (p. 185)• Acesso a metadados criptografados no Catálogo de dados do AWS Glue (p. 192)• Acesso entre contas (p. 192)• Acesso a grupos de trabalho e tags (p. 195)
180

Amazon Athena Guia do usuárioPolíticas gerenciadas para o acesso de usuários
• Permitir acesso a um (p. 196)• Exemplo de políticas de permissões do IAM para permitir o (p. 198)• Exemplo de políticas de permissões do IAM para permitir o (p. 200)• Permitir acesso para o (p. 202)• Permitir acesso federado à API do Athena (p. 202)
Políticas gerenciadas para o acesso de usuáriosPara permitir ou negar ações de serviço do Amazon Athena para si mesmo ou outros usuários usando oAWS Identity and Access Management (IAM), anexe as políticas baseadas em identidade às entidadesprincipais, como usuários ou grupos.
Cada política baseada em identidade consiste em instruções que definem as ações permitidas ounegadas. Para obter mais informações e instruções passo a passo para anexar uma política a um usuário,consulte Anexar políticas gerenciadas no Guia do usuário do AWS Identity and Access Management. Paraobter uma lista das ações, consulte Referência de API do Amazon Athena.
As políticas gerenciadas são fáceis de usar e são atualizadas automaticamente com as ações necessáriasà medida que o serviço evolui.
O Athena tem estas políticas gerenciadas:
• A política gerenciada do AmazonAthenaFullAccess concede acesso completo a Athena. Anexe-a ausuários e a outras entidades principais que precisam de acesso completo ao Athena. Consulte Políticagerenciada AmazonAthenaFullAccess (p. 181).
• A política gerenciada AWSQuicksightAthenaAccess concede acesso a ações de que oAmazon QuickSight precisa para integração com o Athena. Anexe essa política somente aentidades principais que usem o Amazon QuickSight com o Athena. Consulte Política gerenciadaAWSQuicksightAthenaAccess (p. 183).
Políticas baseadas em identidade gerenciadas pelo cliente e em linha permitem especificar ações doAthena mais detalhadas dentro de uma política para ajustar o acesso. Recomendamos usar a políticaAmazonAthenaFullAccess como um ponto de partida e permitir ou negar ações específicas listadasna Referência de API do Amazon Athena. Para obter mais informações sobre políticas em linha, consultePolíticas gerenciadas e em linha no Guia do usuário do AWS Identity and Access Management.
Se você também tiver entidades principais que se conectam usando JDBC, deverá fornecer as credenciaisdo driver JDBC para seu aplicativo. Para obter mais informações, consulte Ações de serviço paraconexões JDBC (p. 185).
Se você usar o AWS Glue com o Athena e tiver criptografado o AWS Glue Data Catalog, você deveespecificar ações adicionais nas políticas do IAM com base em identidade para o Athena. Para obter maisinformações, consulte Acesso a metadados criptografados no Catálogo de dados do AWS Glue (p. 192).
Important
Se você criar e usar grupos de trabalho, suas políticas devem incluir acesso adequado às açõesdo grupo de trabalho. Para obter informações detalhadas, consulte the section called “ Políticasdo IAM para acessar grupos de trabalho” (p. 221) e the section called “Exemplo de políticas degrupo” (p. 222).
Política gerenciada AmazonAthenaFullAccessA política gerenciada do AmazonAthenaFullAccess concede acesso completo a Athena.
181

Amazon Athena Guia do usuárioPolíticas gerenciadas para o acesso de usuários
Como o conteúdo da política gerenciada muda, a política mostrada aqui pode estar desatualizada.Verifique o console do IAM para obter a política mais atualizada.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "glue:CreateDatabase", "glue:DeleteDatabase", "glue:GetDatabase", "glue:GetDatabases", "glue:UpdateDatabase", "glue:CreateTable", "glue:DeleteTable", "glue:BatchDeleteTable", "glue:UpdateTable", "glue:GetTable", "glue:GetTables", "glue:BatchCreatePartition", "glue:CreatePartition", "glue:DeletePartition", "glue:BatchDeletePartition", "glue:UpdatePartition", "glue:GetPartition", "glue:GetPartitions", "glue:BatchGetPartition" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload", "s3:CreateBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::aws-athena-query-results-*" ] }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ],
182

Amazon Athena Guia do usuárioPolíticas gerenciadas para o acesso de usuários
"Resource": [ "arn:aws:s3:::athena-examples*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListAllMyBuckets" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "sns:ListTopics", "sns:GetTopicAttributes" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "cloudwatch:PutMetricAlarm", "cloudwatch:DescribeAlarms", "cloudwatch:DeleteAlarms" ], "Resource": [ "*" ] } ]}
Política gerenciada AWSQuicksightAthenaAccessA política gerenciada adicional, AWSQuicksightAthenaAccess, concede acesso a ações de que oAmazon QuickSight precisa para integração com o Athena. Essa política inclui algumas ações para oAthena que estão obsoletas e não estão incluídas na API pública atual ou que são usadas apenas comos drivers JDBC e ODBC. Anexe essa política somente às entidades principais que usam o AmazonQuickSight com o Athena.
Como o conteúdo da política gerenciada muda, a política mostrada aqui pode estar desatualizada.Verifique o console do IAM para obter a política mais atualizada.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:BatchGetQueryExecution", "athena:CancelQueryExecution", "athena:GetCatalogs", "athena:GetExecutionEngine", "athena:GetExecutionEngines", "athena:GetNamespace", "athena:GetNamespaces",
183

Amazon Athena Guia do usuárioPolíticas gerenciadas para o acesso de usuários
"athena:GetQueryExecution", "athena:GetQueryExecutions", "athena:GetQueryResults", "athena:GetQueryResultsStream", "athena:GetTable", "athena:GetTables", "athena:ListQueryExecutions", "athena:RunQuery", "athena:StartQueryExecution", "athena:StopQueryExecution" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "glue:CreateDatabase", "glue:DeleteDatabase", "glue:GetDatabase", "glue:GetDatabases", "glue:UpdateDatabase", "glue:CreateTable", "glue:DeleteTable", "glue:BatchDeleteTable", "glue:UpdateTable", "glue:GetTable", "glue:GetTables", "glue:BatchCreatePartition", "glue:CreatePartition", "glue:DeletePartition", "glue:BatchDeletePartition", "glue:UpdatePartition", "glue:GetPartition", "glue:GetPartitions", "glue:BatchGetPartition" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload", "s3:CreateBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::aws-athena-query-results-*" ] } ]}
184

Amazon Athena Guia do usuárioAcesso por meio de conexões JDBC e ODBC
Acesso por meio de conexões JDBC e ODBCPara obter acesso a serviços e recursos da AWS, como o Athena e os buckets do Amazon S3, forneça ascredenciais do driver JDBC ou ODBC para o aplicativo. Se você estiver usando o driver JDBC ou ODBC,verifique se as permissões da política de acesso do IAM incluem todas as ações listadas em Políticagerenciada AWSQuicksightAthenaAccess (p. 183).
Para obter informações sobre as versões mais recentes dos drivers JDBC e ODBC e suasdocumentações, consulte Conexão com o driver JDBC (p. 59) e Conexão com o driver ODBC (p. 61).
Acesso ao Amazon S3Se você ou seus usuários precisam criar tabelas e trabalhar com dados subjacentes, eles devem teracesso à localização dos dados no Amazon S3. Esse acesso é adicional às ações permitidas para oAthena, que você define nas políticas baseadas do IAM com base em identidade.
Você pode conceder acesso aos locais do Amazon S3 usando políticas baseadas em identidade, políticasde recursos de bucket ou os dois tipos. Para obter informações detalhadas e cenários sobre comoconceder acesso ao Amazon S3, consulte Demonstrações de exemplo: gerenciamento de acesso noGuia do desenvolvedor do Amazon Simple Storage Service. Para obter mais informações e um exemplode quais ações do Amazon S3 permitir, consulte o exemplo de política de bucket em Acesso entrecontas (p. 192).
Note
O Athena não oferece suporte à restrição ou permissão de acesso a recursos do Amazon S3 combase na chave de condição aws:SourceIp.
Acesso granular a bancos de dados e tabelas noCatálogo de dados do AWS GlueSe você usar o Catálogo de dados do AWS Glue com o Amazon Athena, você pode definir políticas nonível dos recursos para os seguintes objetos do Data Catalog que são usados nos bancos de dados etabelas do Athena.
Nas políticas baseadas em identidade do IAM, as permissões são definidas no nível de recurso.
Important
Esta seção aborda as permissões no nível do recurso em políticas baseadas em identidade doIAM. Elas são diferentes das políticas com base em recursos. Para obter mais informações sobreas diferenças, consulte Políticas baseadas em identidade e políticas baseadas em recurso noGuia do usuário do AWS Identity and Access Management.
Consulte os seguintes tópicos para essas tarefas:
Para executar essa tarefa Consulte o tópico a seguir
Criar uma política doIAM que define acessorefinado a recursos
Criação de políticas do IAM no Guia do usuário do AWS Identity andAccess Management.
Saiba mais sobre aspolíticas baseadas em
Políticas baseadas em identidade (políticas do IAM) no Guia dodesenvolvedor do AWS Glue.
185

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
Para executar essa tarefa Consulte o tópico a seguiridentidade do IAM usadasno AWS Glue
Nesta seção
• Limitações (p. 186)• Obrigatório: política de acesso ao catálogo e banco de dados padrão por região da AWS (p. 187)• Versões e partições de tabela no AWS Glue (p. 187)• Exemplos de políticas granulares (p. 188)
LimitaçõesConsidere as seguintes limitações ao usar um controle de acesso granular com o Catálogo de dados doAWS Glue e o Athena:
• Você pode limitar o acesso apenas a bancos de dados e tabelas. Controles de acesso granulares seaplicam no nível de tabela e não é possível limitar o acesso a partições individuais dentro de uma tabela.Para obter mais informações, consulte Versões e partições de tabela no AWS Glue (p. 187).
• O Athena não oferece suporte ao acesso entre contas para o Catálogo de dados do AWS Glue.• O Catálogo de dados do AWS Glue contém os seguintes recursos: CATALOG, DATABASE, TABLE eFUNCTION.
Note
Dessa lista, os recursos que são comuns entre o Athena e o Catálogo de dados do AWS Gluesão TABLE, DATABASE e CATALOG para cada conta. Function é específico do AWS Glue.Para excluir ações no Athena, você deve incluir permissões para ações do AWS Glue. ConsulteExemplos de políticas granulares (p. 188).
A hierarquia é a seguinte: CATALOG é um ancestral de todos os DATABASES em cada conta, e cadaDATABASE é um ancestral para todas as suas TABLES e FUNCTIONS. Por exemplo, para uma tabelachamada table_test que pertence a um banco de dados db no catálogo em sua conta, seusancestrais são db e catálogo na sua conta. Para o banco de dados db, seu ancestral é o catálogo emsua conta e seus descendentes são tabelas e funções. Para obter mais informações sobre a estruturahierárquica de recursos, consulte Lista de ARNs no catálogo de dados no Guia do desenvolvedor doAWS Glue.
• Para qualquer ação de não exclusão do Athena em um recurso, como CREATE DATABASE, CREATETABLE, SHOW DATABASE, SHOW TABLE ou ALTER TABLE, são necessárias permissões para chamaressa ação no recurso (tabela ou banco de dados) e todos os ancestrais do recurso no Data Catalog. Porexemplo, para uma tabela, seus ancestrais são o banco de dados ao qual ela pertence e o catálogo daconta. Para um banco de dados, seu ancestral é o catálogo da conta. Consulte Exemplos de políticasgranulares (p. 188).
• Para excluir uma ação no Athena, como DROP DATABASE ou DROP TABLE, você também precisa depermissões para chamar a ação de exclusão em todos os ancestrais e descendentes do recurso noData Catalog. Por exemplo, para excluir um banco de dados, você precisa de permissões no bancode dados, no catálogo, que é seu ancestral, e em todas as tabelas e funções definidas pelo usuário,que são seus descendentes. Uma tabela não tem descendentes. Para executar DROP TABLE, vocêprecisa de permissões para essa ação na tabela, no banco de dados ao qual ela pertence e no catálogo.Consulte Exemplos de políticas granulares (p. 188).
• Ao limitar o acesso a um banco de dados específico no Data Catalog, também é necessário especificara política de acesso ao catálogo e banco de dados default para cada região da AWS para as açõesGetDatabase e CreateDatabase. Se o Athena for usado em mais de uma região, adicione uma linha
186

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
separada à política para o ARN do recurso para cada catálogo e banco de dados default em cadaregião.
Por exemplo, para permitir a GetDatabase acesso a example_db na região us-east-1 (Norte daVirgínia), inclua também o catálogo e o banco de dados default na política para essa região para duasações: GetDatabase e CreateDatabase:
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default", "arn:aws:glue:us-east-1:123456789012:database/example_db" ]}
Obrigatório: política de acesso ao catálogo e banco de dadosDefault por região da AWSPara o Athena trabalhar com o Catálogo de dados do AWS Glue, a seguinte política de acesso ao bancode dados default e ao Catálogo de dados do AWS Glue por região da AWS para GetDatabase eCreateDatabase precisam estar presentes:
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]}
Versões e partições de tabela no AWS GlueNo AWS Glue, tabelas podem ter partições e versões. As versões e partições de tabelas não sãoconsideradas recursos independentes no AWS Glue. O acesso a versões e partições de tabela é garantidoconcedendo acesso na tabela e em recursos ancestrais da tabela.
Para fins de um controle de acesso detalhado, as seguintes permissões de acesso se aplicam:
• Controles de acesso granulares se aplicam no nível de tabela. Você pode limitar o acesso apenas abancos de dados e tabelas. Por exemplo, se você permitir acesso a uma tabela particionada, esseacesso se aplicará a todas as partições na tabela. Você não pode limitar o acesso a partições individuaisem uma tabela.
Important
Ter acesso a todas as partições em uma tabela não será suficiente se for necessárioexecutar ações em partições do AWS Glue. Para executar ações em partições, sãonecessárias permissões para essas ações. Por exemplo, para executar GetPartitions
187

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
na tabela myTable no banco de dados myDB, são necessárias permissões para a ação glue:GetPartitions no Data Catalog, no banco de dados myDB e em myTable.
• Controles de acesso granulares não se aplicam a versões da tabela. Assim como ocorre com aspartições, o acesso a versões anteriores de uma tabela é concedido por meio de acesso às APIs daversão da tabela do AWS Glue na tabela e aos ancestrais da tabela.
Para obter informações sobre permissões em ações do AWS Glue, consulte Permissões da API do AWSGlue: referência de ações e recursos no Guia do desenvolvedor do AWS Glue.
Exemplos de permissões granulares para tabelas e bancos dedadosA tabela a seguir lista exemplos de políticas baseadas em identidade do IAM que permitem acessoacurado a bancos de dados e tabelas no Athena. Recomendamos começar com esses exemplos e, deacordo com as suas necessidades, ajustá-los para permitir ou negar ações específicas a determinadosbancos de dados e tabelas.
Esses exemplos incluem a política de acesso ao catálogo e banco de dados default para as açõesGetDatabase e CreateDatabase. Essa política é necessária para que o Athena e o Catálogo de dadosdo AWS Glue funcionem em conjunto. Para várias regiões da AWS, inclua essa política para cada um doscatálogos e bancos de dados default, uma linha para cada região.
Além disso, substitua o banco de dados do example_db e os nomes de tabelas do test pelos nomes deseus bancos de dados e tabelas.
Declaração DDL Exemplo de uma política de acesso do IAM que concede acesso ao recurso
CREATE DATABASE Permite que você crie o banco de dados chamado example_db.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default", "arn:aws:glue:us-east-1:123456789012:database/example_db" ] }
ALTER DATABASE Permite que você modifique as propriedades do banco de dados doexample_db.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]},{ "Effect": "Allow",
188

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
Declaração DDL Exemplo de uma política de acesso do IAM que concede acesso ao recurso "Action": [ "glue:GetDatabase", "glue:UpdateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/example_db" ] }
DROP DATABASE Permite que você elimine o banco de dados do example_db incluindotodas as suas tabelas.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]},{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:DeleteDatabase", "glue:GetTables", "glue:GetTable", "glue:DeleteTable" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/example_db", "arn:aws:glue:us-east-1:123456789012:table/example_db/*", "arn:aws:glue:us-east-1:123456789012:userDefinedFunction/example_db/*" ] }
189

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
Declaração DDL Exemplo de uma política de acesso do IAM que concede acesso ao recurso
SHOW DATABASES Permite que você liste todos os bancos de dados no Catálogo de dados doAWS Glue.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase"
], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]}, { "Effect": "Allow", "Action": [ "glue:GetDatabases" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/*" ] }
CREATE TABLE Permite que você crie uma tabela chamada test no banco de dados doexample_db.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]}, { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetTable", "glue:CreateTable" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/example_db", "arn:aws:glue:us-east-1:123456789012:table/example_db/test" ] }
190

Amazon Athena Guia do usuárioAcesso granular a bancos de dados e tabelas
Declaração DDL Exemplo de uma política de acesso do IAM que concede acesso ao recurso
SHOW TABLES Permite que você liste todas as tabelas no banco de dados doexample_db.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]}, { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetTables" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/example_db", "arn:aws:glue:us-east-1:123456789012:table/example_db/*" ] }
DROP TABLE Permite que você elimine uma tabela particionada chamada test no bancode dados do example_db. Se a tabela não tiver partições, não incluaações de partição.
{ "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:CreateDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/default" ]}, { "Effect": "Allow", "Action": [ "glue:GetDatabase", "glue:GetTable", "glue:DeleteTable", "glue:GetPartitions", "glue:GetPartition", "glue:DeletePartition" ], "Resource": [ "arn:aws:glue:us-east-1:123456789012:catalog", "arn:aws:glue:us-east-1:123456789012:database/example_db", "arn:aws:glue:us-east-1:123456789012:table/example_db/test" ] }
191

Amazon Athena Guia do usuárioAcesso a metadados criptografados no Data Catalog
Acesso a metadados criptografados no Catálogo dedados do AWS GlueSe você usar o Catálogo de dados do AWS Glue com o Amazon Athena, poderá habilitar a criptografiano Catálogo de dados do AWS Glue usando o console do AWS Glue ou a API. Para obter informações,consulte Criptografia de seu catálogo de dados no Guia do desenvolvedor do AWS Glue.
Se o Catálogo de dados do AWS Glue for criptografado, você deve adicionar as seguintes ações paratodas as políticas que são usadas para acessar o Athena:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": [ "kms:GenerateDataKey", "kms:Decrypt", "kms:Encrypt" ], "Resource": "(arn of key being used to encrypt the catalog)" }}
Acesso entre contasUm cenário comum do Amazon Athena é conceder acesso a usuários em uma conta diferente doproprietário do bucket, de maneira que eles possam realizar consultas. Neste caso, use uma política debucket para conceder acesso.
A política de bucket de exemplo a seguir, criada e aplicada ao bucket s3://my-athena-data-bucketpelo proprietário do bucket, concede acesso a todos os usuários na conta 123456789123, que é umaconta diferente.
{ "Version": "2012-10-17", "Id": "MyPolicyID", "Statement": [ { "Sid": "MyStatementSid", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789123:root" }, "Action": [ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::my-athena-data-bucket", "arn:aws:s3:::my-athena-data-bucket/*" ] } ]
192

Amazon Athena Guia do usuárioAcesso entre contas
}
Para conceder acesso a um determinado usuário em uma conta, substitua a chave Principal poruma chave que especifique o usuário, em vez de root. Por exemplo, para o perfil do usuário Dave, usearn:aws:iam::123456789123:user/Dave.
Acesso entre contas a um bucket criptografado com uma chavepersonalizada do AWS KMSSe você tiver um bucket do Amazon S3 criptografado com uma chave AWS Key Management Service(AWS KMS) personalizada, talvez seja necessário conceder aos usuários acesso a ele de outra conta daAWS.
Conceder acesso a um bucket criptografado de AWS KMS na Conta A a um usuário na Conta B requer asseguintes permissões:
• A política de bucket na Conta A deve conceder acesso à Conta B.• A política de chave AWS KMS na Conta A deve conceder acesso ao usuário na Conta B.• A política de usuário do AWS Identity and Access Management (IAM) na Conta B deve conceder ao
usuário acesso ao bucket e à chave na Conta A.
Os procedimentos a seguir descrevem como conceder cada uma dessas permissões.
Como conceder acesso ao bucket na Conta A para o usuário na Conta B
• Na Conta A, revise a política de bucket do S3 e confirme se há uma instrução que permita o acesso apartir do ID da conta da Conta B.
Por exemplo, a política de bucket a seguir permite ao s3:GetObject acesso ao ID da conta111122223333:
{ "Id": "ExamplePolicy1", "Version": "2012-10-17", "Statement": [ { "Sid": "ExampleStmt1", "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": "arn:aws:s3:::awsexamplebucket/*", "Principal": { "AWS": [ "111122223333" ] } } ]}
Para conceder acesso ao usuário na Conta B a partir da política de chave de AWS KMS na ContaA
1. Na política de chave de AWS KMS para a Conta A, conceda ao usuário na Conta B permissões paraas seguintes ações:
193

Amazon Athena Guia do usuárioAcesso entre contas
• kms:Encrypt
• kms:Decrypt
• kms:ReEncrypt*
• kms:GenerateDataKey*
• kms:DescribeKey
O exemplo a seguir concede acesso de chave a apenas um usuário ou uma função do IAM.
{ "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::111122223333:role/role_name", ] }, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Resource": "*"
2. Na Conta A, revise a política de chave usando a visualização de políticas do Console deGerenciamento da AWS.
3. Na política de chave, verifique se a seguinte declaração lista a Conta B como principal.
"Sid": "Allow use of the key"
4. Se a instrução "Sid": "Allow use of the key" não estiver presente, execute as seguintesetapas:
a. Alterne para exibir a política de chave usando a exibição padrão do console.b. Adicione o ID da conta B como uma conta externa com acesso à chave.
Como conceder acesso ao bucket e à chave na Conta A a partir da política de usuário do IAM naConta B
1. Na Conta B, abra o console do IAM em https://console.aws.amazon.com/iam/.2. Abra o usuário ou a função do IAM associada ao usuário na Conta B.3. Revise a lista de políticas de permissão aplicadas ao usuário ou à função do IAM.4. Certifique-se de aplicar uma política que conceda acesso ao bucket.
A instrução de exemplo a seguir concede ao usuário do IAM acesso às operações s3:PutObject es3:GetObject no bucket awsexamplebucket:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ExampleStmt2", "Action": [ "s3:GetObject",
194

Amazon Athena Guia do usuárioAcesso a grupos de trabalho e tags
"s3:PutObject" ], "Effect": "Allow", "Resource": "arn:aws:s3:::awsexamplebucket/*" } ]}
5. Certifique-se de que seja aplicada uma política que conceda acesso à chave.Note
Se o usuário ou uma função do IAM na Conta B já tiver acesso de administrador, não seránecessário conceder acesso à chave a partir das políticas do usuário do IAM.
A instrução de exemplo a seguir concede ao usuário do IAM acesso para usar a chavearn:aws:kms:example-region-1:123456789098:key/111aa2bb-333c-4d44-5555-a111bb2c33dd.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ExampleStmt3", "Action": [ "kms:Decrypt", "kms:DescribeKey", "kms:Encrypt", "kms:GenerateDataKey", "kms:ReEncrypt*" ], "Effect": "Allow", "Resource": "arn:aws:kms:example-region-1:123456789098:key/111aa2bb-333c-4d44-5555-a111bb2c33dd" } ]}
Para obter instruções sobre como adicionar ou corrigir as permissões do usuário do IAM, consulte Alterarpermissões de um usuário do IAM.
Acesso entre contas a objetos de bucketOs objetos carregados por uma conta (Conta C) que não seja a conta proprietária do bucket (Conta A)podem exigir ACLs explícitas em nível de objeto que concedam acesso de leitura à conta de consulta(Conta B). Para evitar esse requisito, a Conta C deve assumir uma função na Conta A antes de colocarobjetos no bucket da Conta A. Para obter mais informações, consulte Como posso fornecer acesso entrecontas a objetos que estão em buckets do Amazon S3?.
Acesso a grupos de trabalho e tagsUm grupo de trabalho é um recurso gerenciado pelo Athena. Portanto, se sua política de grupo de trabalhousar ações que tomam workgroup como entrada, será necessário especificar o ARN do grupo detrabalho, onde workgroup-name é o nome do seu grupo de trabalho, da seguinte forma:
"Resource": [arn:aws:athena:region:AWSAcctID:workgroup/workgroup-name]
Por exemplo, para um grupo de trabalho chamado test_workgroup na região us-west-2 para a conta123456789012 da AWS, especifique o grupo de trabalho como um recurso, usando o seguinte ARN:
195

Amazon Athena Guia do usuárioPermitir acesso a um
"Resource":["arn:aws:athena:us-east-1:123456789012:workgroup/test_workgroup"]
• Para obter uma lista de políticas de grupo, consulte the section called “Exemplo de políticas degrupo” (p. 222).
• Para obter uma lista de políticas com base em tags para grupos de trabalho, consulte Políticas decontrole de acesso do IAM baseadas em tags (p. 246).
• Para obter mais informações sobre como criar políticas do IAM para grupos de trabalho, consultePolíticas do IAM no grupo de trabalho (p. 221).
• Para obter uma lista completa das ações do Amazon Athena, consulte os nomes de ação da API noReferência de API do Amazon Athena.
• Para obter mais informações sobre políticas do IAM, consulte Criar políticas com o editor visual no Guiado usuário do IAM.
Permitir acesso a umOs exemplos de política de permissão neste tópico demonstram as ações permitidas necessárias e osrecursos para os quais são permitidas. Examine essas políticas com atenção e modifique-as de acordocom seus requisitos antes de anexar políticas de permissões semelhantes às identidades do IAM.
• Exemplo de política para permitir que um principal do IAM consulte dados usando o (p. 196)• Exemplo de política para permitir que um principal do IAM crie um (p. 197)
Example – Permitir que um principal do IAM consulte dados usando o
A política a seguir é anexada aos principais do IAM, além do Política gerenciadaAmazonAthenaFullAccess (p. 181), que concede acesso total às ações do Athena.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "lambda:GetFunction", "lambda:GetLayerVersion", "lambda:InvokeFunction" ], "Resource": [ "arn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunction", "arn:aws:lambda:*:MyAWSAcctId:function:AnotherAthenaLambdaFunction", "arn:aws:lambda:*:MyAWSAcctId:layer:MyAthenaLambdaLayer:*" ] }, { "Sid": "VisualEditor2", "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:PutObject", "s3:ListMultipartUploadParts", "s3:AbortMultipartUpload" ], "Resource": "arn:aws:s3:::MyLambdaSpillBucket/MyLambdaSpillLocation"
196

Amazon Athena Guia do usuárioPermitir acesso a um
} ]}
Explicação de permissões
Ações permitidas Explicação
"s3:GetBucketLocation","s3:GetObject","s3:ListBucket","s3:PutObject","s3:ListMultipartUploadParts","s3:AbortMultipartUpload"
As ações do s3 permitem ler egravar no recurso especificado como"arn:aws:s3:::MyLambdaSpillBucket/MyLambdaSpillLocation", em queMyLambdaSpillLocation identifica obucket de derramamento especificado naconfiguração da função ou funções do Lambdaque estão sendo invocadas. O recursoarn:aws:lambda:*:MyAWSAcctId:layer:MyAthenaLambdaLayer:*só é necessário se você usar uma camada doLambda para criar dependências de tempo deexecução personalizadas para reduzir o tamanhodo artefato da função no momento da implantação.O * na última posição é um curinga para a versãoda camada.
"lambda:GetFunction","lambda:GetLayerVersion","lambda:InvokeFunction"
Permite que as consultas chamem asfunções do AWS Lambda especificadasno bloco Resource. Por exemplo,arn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunction,em que MyAthenaLambdaFunction especifica onome de uma função do Lambda a ser invocada.Várias funções podem ser especificadas conformemostrado no exemplo.
Example – Permitir que um principal do IAM crie um
A política a seguir é anexada aos principais do IAM, além do Política gerenciadaAmazonAthenaFullAccess (p. 181), que concede acesso total às ações do Athena.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "lambda:GetFunction", "lambda:ListFunctions", "lambda:GetLayerVersion", "lambda:InvokeFunction", "lambda:CreateFunction", "lambda:DeleteFunction", "lambda:PublishLayerVersion", "lambda:DeleteLayerVersion", "lambda:UpdateFunctionConfiguration", "lambda:PutFunctionConcurrency", "lambda:DeleteFunctionConcurrency" ], "Resource": "arn:aws:lambda:*:MyAWSAcctId: function: MyAthenaLambdaFunctionsPrefix*"
197

Amazon Athena Guia do usuárioPermitir acesso ao
} ]}
Explicação de permissões
Permite que as consultas chamem as funções do AWS Lambda para asfunções do AWS Lambda especificadas no bloco Resource. Por exemplo,arn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunction, em queMyAthenaLambdaFunction especifica o nome de uma função do Lambda a ser invocada. Váriasfunções podem ser especificadas conforme mostrado no exemplo.
Exemplo de políticas de permissões do IAM parapermitir oOs exemplos de política de permissão neste tópico demonstram as ações permitidas necessárias e osrecursos para os quais são permitidas. Examine essas políticas com atenção e modifique-as de acordocom suas necessidades antes de anexá-las às identidades do IAM.
• Exemplo de política para permitir que um principal do IAM execute e retorne resultados usando o (p. 198)
• Exemplo de política para permitir que um principal do IAM crie um conector de fonte de dados (p. 199)
Example – Permitir que um principal do IAM execute e retorne resultados usando o
A seguinte política de permissões baseadas em identidade permite ações que um usuário ou outroprincipal do IAM precisa para usar o . Os principais que têm permissão para realizar essas ações podemexecutar consultas que especificam catálogos do Athena associados a uma fonte de dados federada.
Explicação de permissões
Ações permitidas Explicação
"athena:StartQueryExecution", "athena:GetQueryResults", "athena:GetWorkGroup", "athena:CancelQueryExecution", "athena:StopQueryExecution", "athena:GetQueryExecution",
As permissões do Athena que são necessáriaspara executar consultas no grupo de trabalhoAmazonAthenaPreviewFunctionality.
"s3:PutObject","s3:GetObject","s3:AbortMultipartUpload"
s3:PutObject e s3:AbortMultipartUploadpermitem a gravação de resultados deconsulta em todas as subpastas do bucketde resultados de consulta conformeespecificado pelo identificador de recursoarn:aws:s3:::MyQueryResultsBucket/*,em que MyQueryResultsBucket é o bucket deresultados de consulta do Athena. Para obter maisinformações, consulte Trabalhar com resultadosde consulta, arquivos de saída e histórico deconsultas (p. 65).
s3:GetObject permite a leitura deresultados de consulta e histórico deconsultas para o recurso especificado como
198

Amazon Athena Guia do usuárioPermitir acesso ao
Ações permitidas Explicaçãoarn:aws:s3:::MyQueryResultsBucket, emque MyQueryResultsBucket é o bucket deresultados de consulta do Athena.
s3:GetObject também permite aleitura do recurso especificado como"arn:aws:s3:::MyLambdaSpillBucket/MyLambdaSpillPrefix*", em queMyLambdaSpillPrefix é especificado naconfiguração da função ou funções do Lambda queestão sendo invocadas.
"lambda:InvokeFunction"Permite que as consultas chamem as funções doAWS Lambda para as funções do AWS Lambdaespecificadas no bloco Resource. Por exemplo,arn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunction,em que MyAthenaLambdaFunction especifica onome de uma função do Lambda a ser invocada.Várias funções podem ser especificadas conformemostrado no exemplo.
Example – Permitir que um principal do IAM crie um conector de fonte de dados
Explicação de permissões
Ações permitidas Explicação
"lambda:CreateFunction","lambda:ListVersionsByFunction","lambda:GetFunctionConfiguration","lambda:PutFunctionConcurrency","lambda:ListTags","lambda:DeleteFunction","lambda:GetAlias","lambda:InvokeFunction","lambda:GetFunction","lambda:ListAliases","lambda:UpdateFunctionConfiguration","lambda:UpdateFunctionCode","lambda:AddPermission","lambda:DeleteFunctionConcurrency","lambda:RemovePermission","lambda:GetPolicy""lambda:GetAccountSettings","lambda:ListFunctions","lambda:ListEventSourceMappings",
Permite a criação e gerenciamentode funções do Lambda listadas comorecursos. No exemplo, um prefixo denome é usado no identificador de recursoarn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunctionsPrefix*,em que MyAthenaLambdaFunctionsPrefixé um prefixo compartilhado usado no nome deum grupo de funções do Lambda para que nãoprecisem ser especificadas individualmente comorecursos. É possível especificar um ou maisrecursos de função do Lambda.
"s3:GetObject"Permite a leitura de um bucket de que o AWSServerless Application Repository precisaconforme especificado pelo identificador derecurso arn:aws:s3:::awsserverlessrepo-changesets-1iiv3xa62ln3m/*. Esse bucketpode ser específico para sua conta.
"cloudformation:*"Permite a criação e o gerenciamento de pilhasespecificadas do AWS CloudFormation pelorecurso MyCFStackPrefix. Essas pilhas e
199

Amazon Athena Guia do usuárioPermitir acesso ao
Ações permitidas Explicaçãoconjuntos de pilhas são como o AWS ServerlessApplication Repository implanta conectores eUDFs.
"serverlessrepo:*"Permite pesquisar, exibir, publicare atualizar aplicativos no AWSServerless Application Repository,especificados pelo identificador de recursoarn:aws:serverlessrepo:*:*:applications/*.
Exemplo de políticas de permissões do IAM parapermitir oOs exemplos de política de permissão neste tópico demonstram as ações permitidas necessárias e osrecursos para os quais são permitidas. Examine essas políticas com atenção e modifique-as de acordocom seus requisitos antes de anexar políticas de permissões semelhantes às identidades do IAM.
• Exemplo de política para permitir que um principal IAM execute e retorne consultas que contêm umainstrução do (p. 200)
• Exemplo de política para permitir que um principal do IAM crie um (p. 201)
Example – Permitir que um principal do IAM execute e retorne consultas que contêm umainstrução do
A seguinte política de permissões baseada em identidade permite ações de que um usuário ou outroprincipal IAM precisa para executar consultas que usam instruções do .
Explicação de permissões
Ações permitidas Explicação
"athena:StartQueryExecution", "athena:GetQueryResults", "athena:GetWorkGroup", "athena:CancelQueryExecution", "athena:StopQueryExecution", "athena:GetQueryExecution",
As permissões do Athena que são necessáriaspara executar consultas no grupo de trabalhoAmazonAthenaPreviewFunctionality.
"s3:PutObject","s3:GetObject","s3:AbortMultipartUpload"
s3:PutObject e s3:AbortMultipartUploadpermitem a gravação de resultados deconsulta em todas as subpastas do bucketde resultados de consulta conformeespecificado pelo identificador de recursoarn:aws:s3:::MyQueryResultsBucket/*,em que MyQueryResultsBucket é o bucket deresultados de consulta do Athena. Para obter maisinformações, consulte Trabalhar com resultadosde consulta, arquivos de saída e histórico deconsultas (p. 65).
s3:GetObject permite a leitura deresultados de consulta e histórico de
200

Amazon Athena Guia do usuárioPermitir acesso ao
Ações permitidas Explicaçãoconsultas para o recurso especificado comoarn:aws:s3:::MyQueryResultsBucket, emque MyQueryResultsBucket é o bucket deresultados de consulta do Athena. Para obter maisinformações, consulte Trabalhar com resultadosde consulta, arquivos de saída e histórico deconsultas (p. 65).
s3:GetObject também permite aleitura do recurso especificado como"arn:aws:s3:::MyLambdaSpillBucket/MyLambdaSpillPrefix*", em queMyLambdaSpillPrefix é especificado naconfiguração da função ou funções do Lambda queestão sendo invocadas.
"lambda:InvokeFunction"Permite que as consultas chamem asfunções do AWS Lambda especificadasno bloco Resource. Por exemplo,arn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunction,em que MyAthenaLambdaFunction especifica onome de uma função do Lambda a ser invocada.Várias funções podem ser especificadas conformemostrado no exemplo.
Example – Permitir que um principal do IAM crie um
Explicação de permissões
Ações permitidas Explicação
"lambda:CreateFunction","lambda:ListVersionsByFunction","lambda:GetFunctionConfiguration","lambda:PutFunctionConcurrency","lambda:ListTags","lambda:DeleteFunction","lambda:GetAlias","lambda:InvokeFunction","lambda:GetFunction","lambda:ListAliases","lambda:UpdateFunctionConfiguration","lambda:UpdateFunctionCode","lambda:AddPermission","lambda:DeleteFunctionConcurrency","lambda:RemovePermission","lambda:GetPolicy""lambda:GetAccountSettings","lambda:ListFunctions","lambda:ListEventSourceMappings",
Permite a criação e gerenciamentode funções do Lambda listadas comorecursos. No exemplo, um prefixo denome é usado no identificador de recursoarn:aws:lambda:*:MyAWSAcctId:function:MyAthenaLambdaFunctionsPrefix*,em que MyAthenaLambdaFunctionsPrefixé um prefixo compartilhado usado no nome deum grupo de funções do Lambda para que nãoprecisem ser especificadas individualmente comorecursos. É possível especificar um ou maisrecursos de função do Lambda.
"s3:GetObject"Permite a leitura de um bucket de que o AWSServerless Application Repository precisaconforme especificado pelo identificador derecurso arn:aws:s3:::awsserverlessrepo-changesets-1iiv3xa62ln3m/*.
201

Amazon Athena Guia do usuárioPermitir acesso para o
Ações permitidas Explicação
"cloudformation:*"Permite a criação e o gerenciamento de pilhasespecificadas do AWS CloudFormation pelorecurso MyCFStackPrefix. Essas pilhas econjuntos de pilhas são como o AWS ServerlessApplication Repository implanta conectores eUDFs.
"serverlessrepo:*"Permite pesquisar, exibir, publicare atualizar aplicativos no AWSServerless Application Repository,especificados pelo identificador de recursoarn:aws:serverlessrepo:*:*:applications/*.
Permitir acesso para oOs principais do IAM que executam consultas de ML do Athena devem ter permissão para executar a açãosagemaker:invokeEndpoint para endpoints do Sagemaker que usam. Inclua uma instrução de políticasemelhante à seguinte em políticas de permissões baseadas em identidade anexadas a identidadesde usuário. Além disso, anexe o Política gerenciada AmazonAthenaFullAccess (p. 181), que concedeacesso total a ações do Athena ou uma política em linha modificada que permita um subconjunto deações.
Substitua arn:aws:sagemaker:region:AWSAcctID:ModelEndpoint no exemplo pelo ARN ou ARNsde endpoints do modelo a serem usados em consultas. Para obter mais informações, consulte Ações,recursos e chaves de condição do Amazon SageMaker no Guia do usuário do IAM.
{ "Effect": "Allow", "Action": [ "sagemaker:invokeEndpoint" ], "Resource": "arn:aws:sagemaker:us-west-2:123456789012:workteam/public-crowd/default"}
Permitir acesso federado à API do AthenaEsta seção fala sobre o acesso federado que permite que um usuário ou aplicativo cliente na suaorganização faça chamadas a operações da API do Amazon Athena. Neste caso, os usuários da suaorganização não têm acesso direto ao Athena. Em vez disso, você gerencia as credenciais do usuário forada AWS no Microsoft Active Directory. O Active Directory é compatível com SAML 2.0 (Security AssertionMarkup Language 2.0).
Para autenticar usuários nesse cenário, use o driver JDBC ou ODBC com suporte a SAML.2.0 paraacessar o Active Directory Federation Services (ADFS) 3.0 e permitir que um aplicativo cliente chameoperações de API do Athena.
Para obter mais informações sobre o suporte do SAML 2.0 na AWS, consulte Sobre a Federação SAML2.0 no Guia do usuário do IAM.
Note
O acesso federado à API do Athena tem suporte para um determinado tipo de provedor deidentidade (IdP), o Active Directory Federation Service (ADFS 3.0), que faz parte do Windows
202

Amazon Athena Guia do usuárioPermitir acesso federado à API do Athena
Server. O acesso é estabelecido por meio das versões dos drivers JDBC ou ODBC que oferecemsuporte ao SAML 2.0. Para obter informações, consulte Uso do Athena com o driver JDBC (p. 59)e Conexão ao Amazon Athena com o ODBC (p. 61).
Tópicos• Antes de começar (p. 203)• Diagrama de arquitetura (p. 203)• Procedimento: acesso federado baseado em SAML para a API do Athena (p. 204)
Antes de começarAntes de começar, conclua os pré-requisitos a seguir:
• Dentro da sua organização, instale e configure o ADFS 3.0 como seu IdP.• Instale e configure as versões mais recentes disponíveis dos drivers JDBC ou ODBC em clientes usados
para acessar o Athena. O driver deve incluir suporte para acesso federado compatível com o SAML2.0. Para obter informações, consulte Uso do Athena com o driver JDBC (p. 59) e Conexão ao AmazonAthena com o ODBC (p. 61).
Diagrama de arquiteturaO diagrama a seguir ilustra esse processo.
1. Um usuário na sua organização usa um aplicativo cliente com o driver JDBC ou ODBC para solicitar aautenticação do IdP da sua organização. O IdP é ADFS 3.0.
2. O IdP autentica o usuário no Active Directory, ou seja, o armazenamento de identidades da suaorganização.
3. O IdP cria uma declaração do SAML com informações sobre o usuário e a envia para o aplicativo clientepor meio do driver JDBC ou ODBC.
4. O driver JDBC ODBC chama a operação da API AWS Security Token Service AssumeRoleWithSAML epassa os seguintes parâmetros:
203

Amazon Athena Guia do usuárioPermitir acesso federado à API do Athena
• O ARN do provedor SAML• O ARN da função a ser assumida• A declaração do SAML do IdP
Para mais informações, consulte AssumeRoleWithSAML no AWS Security Token Service APIReference.
5. A resposta da API para o aplicativo cliente por meio do driver JDBC ou ODBC inclui credenciais desegurança temporárias.
6. O aplicativo cliente usa credenciais de segurança temporárias para chamar operações da API doAthena, permitindo que seus usuários acessem as operações da API do Athena.
Procedimento: acesso federado baseado em SAML para a APIdo AthenaEsse procedimento estabelece uma confiança entre seu IdP da organização e sua conta da AWS, a fim depermitir acesso federado baseado em SAML para a operação da API do Amazon Athena.
Como permitir acesso federado à API do Athena:
1. Em sua organização, registre a AWS como um provedor de serviços (SP) em seu IdP. Esseprocesso é conhecido como confiança da parte dependente. Para obter mais informações, consulteConfiguração do IdP do SAML 2.0 com Confiança da parte dependente no Guia do usuário do IAM.Como parte dessa tarefa, execute estas etapas:
a. Obtenha o documento de metadados do SAML de amostra deste URL: https://signin.aws.amazon.com/static/saml-metadata.xml.
b. No IdP da sua organização (ADFS), gere um arquivo XML de metadados equivalente quedescreva o seu IdP como um provedor de identidade para a AWS. O arquivo de metadados deveincluir o nome do emissor, uma data de criação, uma data de expiração e chaves que a AWS usapara validar as respostas de autenticação (declarações) da sua organização.
2. No console do IAM, crie uma entidade de provedor de identidade do SAML. Para obter maisinformações, consulte Criação de provedores de identidade SAML no Guia do usuário do IAM. Comoparte dessa etapa, realize as seguintes ações:
a. Abra o console do IAM em https://console.aws.amazon.com/iam/.b. Faça upload do documento de metadados SAML produzido pelo IdP (ADFS) na Etapa 1 deste
procedimento.3. No console do IAM, crie uma ou mais funções do IAM para o IdP. Para obter mais informações,
consulte Criação de uma função para um provedor de identidade de terceiros (federação) no Guia dousuário do IAM. Como parte dessa etapa, realize as seguintes ações:
• Na política de permissões da função, estabeleça o que os usuários da sua organização têmpermissão para fazer na AWS.
• Na política de confiança da função, defina como principal a entidade do provedor do SAML que vocêcriou na Etapa 2 deste procedimento.
Isso estabelece uma relação de confiança entre sua organização e a AWS.4. No IdP da sua organização (ADFS), defina declarações que mapeiam usuários ou grupos na sua
organização para as funções do IAM. O mapeamento de usuários e grupos para as funções do IAMtambém é conhecido como uma regra de declaração. Observe que usuários e grupos diferentes nasua organização podem ser mapeados para diferentes funções do IAM.
204

Amazon Athena Guia do usuárioRegistro e monitoramento
Para obter informações sobre como configurar o mapeamento no ADFS, consulte a postagem de blog:Como habilitar a federação com a AWS usando o Windows Active Directory, o ADFS e o SAML 2.0.
5. Instale e configure o driver JDBC ou ODBC com o suporte a SAML 2.0. Para obter informações,consulte Uso do Athena com o driver JDBC (p. 59) e Conexão ao Amazon Athena com oODBC (p. 61).
6. Especifique a string de conexão do seu aplicativo para o driver JDBC ou ODBC. Para obterinformações sobre a string de conexão que o aplicativo deve usar, consulte o tópico "Usar o provedorde credenciais do Active Directory Federation Services (ADFS)" no Guia de instalação e configuraçãodo driver JDBC, ou um tópico semelhante no Guia de instalação e configuração do driver ODBCdisponível como downloads de PDF dos tópicos Uso do Athena com o driver JDBC (p. 59) e Conexãoao Amazon Athena com o ODBC (p. 61).
A seguir, veja um resumo de alto nível de como configurar a string de conexão para os drivers:
1. Em AwsCredentialsProviderClass configuration, defina ocom.simba.athena.iamsupport.plugin.AdfsCredentialsProvider para indicar quevocê deseja usar a autenticação baseada em SAML 2.0 por meio do IdP do ADFS.
2. Em idp_host, forneça o nome de host do servidor do IdP do ADFS.3. Em idp_port, informe o número da porta que o IdP do ADFS identifica a solicitação de declaração
do SAML.4. Em UID e PWD, forneça as credenciais de usuário do domínio do AD. Ao usar o driver no Windows,
se UID e PWD não forem fornecidos, o driver tentará obter as credenciais de usuário do usuárioconectado no computador com Windows.
5. Opcionalmente, defina ssl_insecure para true. Nesse caso, o driver não verifica aautenticidade do certificado SSL para o servidor do IdP do ADFS. É necessário definir como truese o certificado SSL do IdP do ADFS não foi configurado como confiável pelo driver.
6. Para habilitar o mapeamento de um usuário ou grupo de domínio do Active Directory para uma oumais funções do IAM (como mencionado na etapa 4 deste procedimento), em preferred_role,na conexão do JDBC ou do ODBC, especifique a função do IAM (ARN) a ser assumida. Especificaro preferred_role é opcional. Ele é útil se a função não for a primeira a ser listada na regra dedeclaração.
As seguintes ações ocorrem como resultado desse procedimento:
1. O driver JDBC ou ODBC chama a API AWS STS AssumeRoleWithSAML e transmite asdeclarações, conforme mostrado na etapa 4 do diagrama de arquitetura (p. 203).
2. A AWS certifica-se de que a solicitação para assumir a função vem do IdP referenciado na entidadedo provedor do SAML.
3. Se a solicitação for bem-sucedida, a operação da API AWS STS AssumeRoleWithSAML retornaum conjunto de credenciais de segurança temporárias, que o aplicativo cliente usa para fazersolicitações assinadas à Athena.
Seu aplicativo agora tem informações sobre o usuário atual e pode acessar o Athena de formaprogramática.
Registro em log e monitoramento no AthenaPara detectar incidentes, receber alertas quando incidentes acontecerem e responder a eles, use essasopções com o Amazon Athena:
• Monitorar o Athena com o AWS CloudTrail – O AWS CloudTrail fornece um registro das açõesexecutadas por um usuário, uma função ou um serviço da AWS no Athena. Ele captura as chamadas
205

Amazon Athena Guia do usuárioValidação de conformidade
do console do Athena e chamadas de código para as operações de API do Athena como eventos. Issopermite determinar a solicitação que foi feita ao Athena, o endereço IP a partir do qual a solicitaçãofoi feita, quem fez a solicitação, quando foi feita e outros detalhes. Você também pode usar o Athenapara consultar os arquivos de log do CloudTrail para obter informações. Para obter mais informações,consulte Consulta de logs do AWS CloudTrail (p. 153) e CloudTrail SerDe (p. 258).
• Usar o Eventos do CloudWatch com o Athena – o Eventos do CloudWatch oferece uma transmissãoquase em tempo real dos eventos do sistema que descrevem as alterações nos recursos da AWS. OEventos do CloudWatch se torna ciente das alterações operacionais no momento em que elas ocorrem,responde a elas e executa a ação corretiva conforme necessário, enviando mensagens para responderao ambiente, ativando funções, fazendo alterações e capturando informações de estado. Para usar oEventos do CloudWatch com o Athena, crie uma regra que aciona uma chamada de API do Athenapor meio do CloudTrail. Para obter mais informações, consulte Criação de uma regra do Eventos doCloudWatch que é acionada em uma chamada de API da AWS usando o CloudTrail no Guia do usuáriodo Eventos do Amazon CloudWatch.
• Usar grupos de trabalho para separar usuários, equipes, aplicativos ou cargas de trabalho, bemcomo definir os limites de consulta e controlar os custos de consulta – você pode exibir métricasrelacionadas à consulta no Amazon CloudWatch, controlar custos de consulta ao configurar limitespara a quantidade de dados verificados, criar limites e acionar ações, como alarmes do AmazonSNS, quando esses limites forem violados. Para um procedimento de alto nível, consulte Configurargrupos de trabalho (p. 219). Use as permissões do IAM no nível do recurso para controlar oacesso a um determinado grupo de trabalho. Para obter mais informações, consulte Usar grupos detrabalho para executar consultas (p. 217) e Controlar custos e monitorar consultas com métricas doCloudWatch (p. 235).
Validação de conformidade do Amazon AthenaAuditores terceirizados avaliam a segurança e a conformidade do Amazon Athena como parte de váriosprogramas de conformidade da AWS. Isso inclui SOC, PCI, FedRAMP e outros.
Para obter uma lista de serviços da AWS no escopo de programas de conformidade específicos, consulteServiços da AWS no escopo pelo programa de conformidade. Para obter informações gerais, consulteProgramas de conformidade da AWS.
Você pode fazer download de relatórios de auditoria de terceiros usando o AWS Artifact. Para obter maisinformações, consulte Download de relatórios no AWS Artifact.
Sua responsabilidade de conformidade ao usar o Athena é determinada pela confidencialidade dos seusdados, pelos objetivos de conformidade da sua empresa e pelos regulamentos e leis aplicáveis. A AWSfornece os seguintes recursos para ajudar com a conformidade:
• Guias Quick Start de segurança e conformidade – esses guias de implantação abordam asconsiderações de arquitetura e fornecem etapas para implantação de ambientes de linha de basefocados em conformidade e segurança na AWS.
• Whitepaper Arquitetura para segurança e conformidade com HIPAA – esse whitepaper descreve comoas empresas podem usar a AWS para criar aplicativos em conformidade com a HIPAA.
• Recursos de conformidade da AWS – esta coleção de manuais e guias pode ser aplicada ao seu setor eao seu local.
• AWS Config – esse serviço da AWS avalia até que ponto suas configurações de recursos estão emconformidade com práticas internas e diretrizes e regulamentações do setor.
• AWS Security Hub – esse serviço da AWS fornece uma visão abrangente do estado da segurança naAWS que ajuda você a verificar sua conformidade com padrões e melhores práticas de segurança dosetor.
206

Amazon Athena Guia do usuárioResiliência
Resiliência no AthenaA infraestrutura global da AWS é criada com base em regiões e zonas de disponibilidade da AWS. Asregiões da AWS fornecem várias zonas de disponibilidade separadas e isoladas fisicamente, que sãoconectadas com baixa latência, altas taxas de transferência e redes altamente redundantes. Com as zonasde disponibilidade, você pode projetar e operar aplicativos e bancos de dados que executam o failoverautomaticamente entre as zonas de disponibilidade sem interrupção. As zonas de disponibilidade são maisaltamente disponíveis, tolerantes a falhas e escaláveis que uma ou várias infraestruturas de data centertradicionais.
Para obter mais informações sobre regiões e zonas de disponibilidade da AWS, consulte Infraestruturaglobal da AWS.
Além da infraestrutura global da AWS, o Athena oferece vários recursos para ajudar a oferecer suporte àssuas necessidades de resiliência de dados e backup.
O Athena não possui servidor, portanto, não há infraestrutura para configurar ou gerenciar. O Athenaé altamente disponível e executa consultas usando recursos de computação em várias zonas dedisponibilidade, fazendo consultas de roteamento de forma automática e adequada se uma zona dedisponibilidade específica estiver inacessível. O Athena usa o Amazon S3 como seu armazenamentode dados subjacente, tornando seus dados altamente disponíveis e duráveis. O Amazon S3 forneceuma infraestrutura durável para armazenar dados importantes e foi criado para oferecer durabilidade de99,999999999% dos objetos. Seus dados são armazenados com redundância em várias instalações ediversos dispositivos em cada instalação.
Segurança da infraestrutura no AthenaComo serviço gerenciado, o Amazon Athena é protegido pelos procedimentos de segurança da redeglobal da AWS que estão descritos no whitepaper Amazon Web Services: visão geral dos processos desegurança.
Você usa chamadas de API publicadas pela AWS para acessar o Athena por meio da rede. Os clientesdevem ter suporte ao TLS (Transport Layer Security) 1.0. Recomendamos o TLS 1.2 ou posterior. Osclientes também devem ter suporte a pacotes de criptografia com sigilo de encaminhamento perfeito (PFS)como Ephemeral Diffie-Hellman (DHE) ou Ephemeral Elliptic Curve Diffie-Hellman (ECDHE). A maioriados sistemas modernos como Java 7 e versões posteriores é compatível com esses modos. Além disso,as solicitações devem ser assinadas usando um ID da chave de acesso e uma chave de acesso secretaassociada a uma entidade principal do IAM. Ou você pode usar o AWS Security Token Service (AWS STS)para gerar credenciais de segurança temporárias para assinar solicitações.
Use as políticas do IAM para restringir o acesso a operações do Athena. As políticasgerenciadas (p. 181) do Athena são fáceis de usar e são automaticamente atualizadas com as açõesnecessárias conforme o serviço vai evoluindo. As políticas em linha e gerenciadas pelo cliente permitemajustar políticas especificando ações mais granulares do Athena dentro da política. Conceda acessoapropriado para a localização dos dados no Amazon S3. Para obter informações detalhadas e cenáriossobre como conceder acesso ao Amazon S3, consulte Demonstrações de exemplo: gerenciamento deacesso no Guia do desenvolvedor do Amazon Simple Storage Service. Para obter mais informações e umexemplo de quais ações do Amazon S3 permitir, consulte o exemplo de política de bucket em Acesso entrecontas (p. 192).
Tópicos• Conectar-se ao Amazon Athena usando um VPC endpoint de interface (p. 208)
207

Amazon Athena Guia do usuárioConectar-se ao Amazon Athena
usando um VPC endpoint de interface
Conectar-se ao Amazon Athena usando um VPCendpoint de interfaceVocê pode se conectar diretamente ao Athena usando um VPC endpoint de interface (AWS PrivateLink) nasua nuvem privada virtual (VPC), em vez de se conectar pela Internet. Quando você usa um VPC endpoint,a comunicação entre a VPC e o Athena é realizada inteiramente dentro da rede da AWS. Cada VPCendpoint é representado por uma ou mais interfaces de rede elástica (ENIs) com endereços IP privadosem sua sub-redes da VPC.
O VPC endpoint da interface conecta a VPC diretamente ao Athena sem um gateway da Internet,dispositivo NAT, conexão VPN ou conexão AWS Direct Connect. As instâncias na sua VPC não precisamde endereços IP públicos para a comunicação com a API do Athena.
Para usar o Athena por meio da VPC, você precisa se conectar de uma instância que esteja dentro daVPC ou conectar sua rede privada à sua VPC usando uma rede virtual privada (VPN) da Amazon ouAWS Direct Connect. Para obter informações sobre a Amazon VPN, consulte Conexões VPN, no Guia doUsuário da Amazon Virtual Private Cloud. Para obter informações sobre o AWS Direct Connect, consulteCriação de uma conexão, no Guia do Usuário do AWS Direct Connect.
Note
O AWS PrivateLink para Athena não tem suporte na região Europa (Estocolmo). O Athenaoferece suporte a VPC endpoints em todas as outras regiões da AWS onde a Amazon VPC e oAthena estão disponíveis.
É possível criar um VPC endpoint de interface para se conectar ao Athena usando o console da AWS ouos comandos da AWS Command Line Interface (AWS CLI). Para obter mais informações, consulte Criaçãode um endpoint de interface.
Depois de criar um VPC endpoint de interface, se você habilitar nomes de host DNS privados para oendpoint, o endpoint padrão do Athena (https://athena.Region.amazonaws.com) será resolvido para oVPC endpoint.
Se você não habilitar nomes de host DNS privados, a Amazon VPC fornecerá um nome de endpoint DNSque você pode usar no seguinte formato:
VPC_Endpoint_ID.athena.Region.vpce.amazonaws.com
Para obter mais informações, consulte VPC endpoints de interface (AWS PrivateLink) no Guia do usuárioda Amazon VPC.
O Athena oferece suporte a chamadas para todas as suas ações de API dentro da VPC.
Criar uma política de VPC endpoint para o AthenaÉ possível criar uma política para Amazon VPC endpoints para o Athena especificar o seguinte:
• O principal que pode executar ações.• As ações que podem ser executadas.• Os recursos sobre os quais as ações podem ser realizadas.
Para obter mais informações, consulte Controlar o acesso a serviços com VPC endpoints no Guia dousuário do Amazon VPC.
Example – Política de VPC Endpoint para ações do Athena
O endpoint ao qual essa política está associada concede acesso às ações athena listadas a todas asentidades principais no workgroupA.
208

Amazon Athena Guia do usuárioAnálise de configuração e vulnerabilidade
{ "Statement": [{ "Principal": "*", "Effect": "Allow", "Action": [ "athena:StartQueryExecution", "athena:RunQuery", "athena:GetQueryExecution", "athena:GetQueryResults", "athena:CancelQueryExecution", "athena:ListWorkGroups", "athena:GetWorkGroup", "athena:TagResource" ], "Resource": [ "arn:aws:athena:us-west-1:AWSAccountId:workgroup/workgroupA" ] }]}
Análise de vulnerabilidade e configuração noAthena
O Athena não possui servidor, portanto, não há infraestrutura para configurar ou gerenciar. A AWSlida com tarefas básicas de segurança, como aplicação de patches a bancos de dados e sistemasoperacionais (OS) convidados, configuração de firewalls e recuperação de desastres. Essesprocedimentos foram revisados e certificados por terceiros certificados. Para obter mais detalhes, consulteos recursos a seguir:
• Modelo de responsabilidade compartilhada• Amazon Web Services: visão geral do processo de segurança (whitepaper)
Usar o Athena para consultar dados registradoscom o AWS Lake Formation
O AWS Lake Formation permite definir e aplicar políticas de acesso em nível de banco de dados, tabelae coluna ao usar consultas do Athena para ler dados armazenados no Amazon S3. O Lake Formationfornece uma camada de autorização e governança nos dados armazenados no Amazon S3. É possívelusar uma hierarquia de permissões no Lake Formation para conceder ou revogar permissões de leiturade objetos do catálogo de dados, como bancos de dados, tabelas e colunas. O Lake Formation simplificao gerenciamento de permissões e permite implementar controle de acesso refinado (FGAC) para seusdados.
É possível usar o Athena para consultar dados registrados no Lake Formation e dados que não estãoregistrados no Lake Formation.
As permissões do Lake Formation se aplicam quando o Athena é usado para consultar dados de origemde locais do Amazon S3 registrados no Lake Formation. As permissões do Lake Formation também seaplicam ao criar bancos de dados e tabelas que apontam para locais de dados do Amazon S3 registrados.Para usar o Athena com dados registrados usando o Lake Formation, o Athena deve ser configurado parausar o Catálogo de dados do AWS Glue.
209

Amazon Athena Guia do usuárioComo funciona o acesso a dados do Lake Formation
As permissões do Lake Formation não se aplicam na gravação de objetos no Amazon S3 nem na consultade dados armazenados no Amazon S3 ou de metadados que não estão registrados no Lake Formation.Para dados de origem no Amazon S3 e metadados que não estão registrados no Lake Formation, oacesso é determinado por políticas de permissões do IAM para ações do Amazon S3 e do AWS Glue.Os locais dos resultados de consultas do Athena no Amazon S3 não podem ser registrados no LakeFormation, e políticas de permissões do IAM para controle de acesso do Amazon S3. Além disso, aspermissões do Lake Formation não se aplicam ao histórico de consultas do Athena. É possível usar gruposde trabalho do Athena para controlar o acesso ao histórico de consultas.
Para obter mais informações sobre o Lake Formation, consulte as Perguntas frequentes do LakeFormation e o Guia do desenvolvedor do AWS Lake Formation.
Tópicos• Como o Athena acessa dados registrados no Lake Formation (p. 210)• Considerações e limitações ao usar o Athena para consultar dados registrados no Lake
Formation (p. 211)• Gerenciamento de permissões de usuário do Lake Formation e do Athena (p. 213)• Aplicação de permissões do Lake Formation a bancos de dados e tabelas existentes (p. 216)
Como o Athena acessa dados registrados no LakeFormationO fluxo de trabalho de acesso descrito nesta seção se aplica somente à execução de consultas doAthena em locais e objetos de metadados do Amazon S3 registrados no Lake Formation. Para obtermais informações, consulte Como registrar um data lake no AWS Lake Formation Developer Guide.Além de registrar dados, o administrador do Lake Formation aplica permissões do Lake Formation queconcedem ou revogam o acesso aos metadados no Data Catalog e no local dos dados no Amazon S3.Para obter mais informações, consulte Controle de segurança e acesso a metadados e dados no AWSLake Formation Developer Guide.
Cada vez que uma entidade principal do Athena (usuário, grupo ou função) executa uma consulta emdados registrados usando o Lake Formation, o Lake Formation verifica se a entidade principal tem aspermissões apropriadas do Lake Formation para o banco de dados, a tabela e o local do Amazon S3,conforme apropriado para a consulta. Se a entidade principal tiver acesso, o Lake Formation venderácredenciais temporárias para o Athena e a consulta será executada.
O diagrama a seguir ilustra o fluxo descrito acima.
210

Amazon Athena Guia do usuárioCondições e limitações
O diagrama a seguir mostra como a venda de credenciais funciona no Athena com base em consultapara uma consulta SELECT hipotética em uma tabela com um local do Amazon S3 registrado no LakeFormation:
1. Uma entidade principal executa uma consulta SELECT no Athena.2. O Athena analisa a consulta e verifica as permissões do Lake Formation para ver se a entidade principal
recebeu acesso à tabela, às partições (se aplicável) e às colunas dela.3. Se a entidade principal tiver acesso, o Athena solicitará credenciais do Lake Formation. Se a entidade
principal não tiver acesso, o Athena emitirá um erro de acesso negado.4. O Lake Formation emite credenciais para o Athena usar ao ler dados do Amazon S3 e acessar
metadados do Data Catalog.5. O Lake Formation retorna os resultados da consulta para o Athena. Após a conclusão da consulta, o
Athena descarta as credenciais.
Considerações e limitações ao usar o Athena paraconsultar dados registrados no Lake FormationConsidere o seguinte ao usar o Athena para consultar dados registrados no Lake Formation. Para obterinformações adicionais, consulte Problemas conhecidos do AWS Lake Formation no AWS Lake FormationDeveloper Guide.
Condições e limitações• Metadados de coluna visíveis para usuários não autorizados em algumas circunstâncias com Avro e
SerDe personalizado (p. 212)• Trabalhar com permissões do Lake Formation para exibições (p. 212)• Local dos resultados de consultas do Athena no Amazon S3 não registrado no Lake
Formation (p. 212)• Usar grupos de trabalho do Athena para limitar o acesso ao histórico de consultas (p. 212)• Data Catalogs entre contas não compatíveis (p. 213)• Locais do Amazon S3 criptografados por SSE-KMS registrados no Lake Formation não podem ser
consultados no Athena (p. 213)
211

Amazon Athena Guia do usuárioCondições e limitações
• Locais de dados particionados registrados no Lake Formation devem estar em subdiretórios databela (p. 213)
• Consultas Create Table As Select (CTAS) exigem permissões de gravação do Amazon S3 (p. 213)
Metadados de coluna visíveis para usuários não autorizados emalgumas circunstâncias com Avro e SerDe personalizadoA autorização no nível da coluna do Lake Formation impede que os usuários acessem dados em colunaspara as quais o usuário não tem permissões do Lake Formation. No entanto, em determinadas situações,os usuários podem acessar metadados que descrevem todas as colunas na tabela, incluindo as colunaspara as quais eles não têm permissões para os dados.
Isso ocorre quando os metadados da coluna são armazenados nas propriedades das tabelas usandoo formato de armazenamento Avro ou um serializador/desserializador (SerDe) personalizado no qualo esquema da tabela é definido nas propriedades da tabela junto com a definição do SerDe. Ao usar oAthena com o Lake Formation, recomendamos revisar o conteúdo das propriedades da tabela registradano Lake Formation e, sempre que possível, limitar as informações armazenadas nas propriedades databela para impedir que metadados confidenciais fiquem visíveis para os usuários.
Trabalhar com permissões do Lake Formation para exibiçõesPara dados registrados no Lake Formation, um usuário do Athena poderá criar um VIEW somente se tiverpermissões do Lake Formation para as tabelas, colunas e locais de dados de origem do Amazon S3 nosquais a VIEW se baseia. Depois que uma VIEW é criada no Athena, as permissões do Lake Formationpodem ser aplicadas à VIEW. As permissões no nível da coluna não estão disponíveis para uma VIEW. Osusuários que têm permissões do Lake Formation para uma VIEW, mas não têm permissões para a tabelae as colunas em que a exibição foi baseada, não podem usar a VIEW para consultar dados. No entanto,os usuários com essa combinação de permissões podem usar instruções como DESCRIBE VIEW, SHOWCREATE VIEW e SHOW COLUMNS para ver metadados VIEW. Por esse motivo, alinhe as permissões doLake Formation a cada VIEW com permissões de tabela subjacentes.
Local dos resultados de consultas do Athena no Amazon S3 nãoregistrado no Lake FormationThe query results locations in Amazon S3 for Athena cannot be registered with Lake Formation. LakeFormation permissions do not limit access to these locations. Unless you limit access, Athena users canaccess query result files and metadata when they do not have Lake Formation permissions for the data.To avoid this, we recommend that you use workgroups to specify the location for query results and alignworkgroup membership with Lake Formation permissions. You can then use IAM permissions policiesto limit access to query results locations. For more information about query results, see Trabalhar comresultados de consulta, arquivos de saída e histórico de consultas (p. 65).
Usar grupos de trabalho do Athena para limitar o acesso aohistórico de consultasAthena query history exposes a list of saved queries and complete query strings. Unless you useworkgroups to separate access to query histories, Athena users who are not authorized to query datain Lake Formation are able to view query strings run on that data, including column names, selectioncriteria, and so on. We recommend that you use workgroups to separate query histories, and align Athenaworkgroup membership with Lake Formation permissions to limit access. For more information, see Usargrupos de trabalho para controlar o acesso à consulta e os custos (p. 217).
212

Amazon Athena Guia do usuárioGerenciamento de permissões de usuário
Data Catalogs entre contas não compatíveisAn Athena user from one account can not query databases and tables in the Data Catalog of a differentaccount, even when Lake Formation is used. To query an Amazon S3 data location in a different account,a resource-based IAM policy (bucket policy) must allow access to the location. For more information, seeAcesso entre contas (p. 192). You can use Lake Formation to register an accessible bucket location in anexternal account with the Data Catalog in the local account.
Locais do Amazon S3 criptografados por SSE-KMS registradosno Lake Formation não podem ser consultados no AthenaOs locais de dados do Amazon S3 registrados no Lake Formation e criptografados usando criptografia nolado do servidor com chaves gerenciadas por AWS KMS (SSE-KMS) não podem ser consultados com oAthena. Ainda é possível usar o Athena para consultar locais de dados do Amazon S3 criptografados porSSE-KMS que não estão registrados no Lake Formation e usar políticas do IAM para permitir ou negaracesso.
Locais de dados particionados registrados no Lake Formationdevem estar em subdiretórios da tabelaAs tabelas particionadas registradas no Lake Formation devem ter dados particionados em diretóriosque sejam subdiretórios da tabela no Amazon S3. Por exemplo, uma tabela com o local s3://mydata/mytable e as partições s3://mydata/mytable/dt=2019-07-11, s3://mydata/mytable/dt=2019-07-12 e assim por diante pode ser registrada no Lake Formation e consultada com o Athena.Por outro lado, uma tabela com o local s3://mydata/mytable e as partições localizadas em s3://mydata/dt=2019-07-11, s3://mydata/dt=2019-07-12 e assim por diante não pode ser registradano Lake Formation. É possível configurar o acesso a essas tabelas usando permissões do IAM forado Lake Formation para consultá-las no Athena. Para obter mais informações, consulte Particionardados (p. 23).
Consultas Create Table As Select (CTAS) exigem permissões degravação do Amazon S3Create Table As Statements (CTAS) require write access to the Amazon S3 location of tables. To runCTAS queries on data registered with Lake Formation, Athena users must have IAM permissions to write tothe table Amazon S3 locations in addition to the appropriate Lake Formation permissions to read the datalocations. For more information, see Criar uma tabela a partir de resultados da consulta (CTAS) (p. 77).
Gerenciamento de permissões de usuário do LakeFormation e do AthenaO Lake Formation vende credenciais para consultar armazenamentos de dados do Amazon S3 registradosno Lake Formation. Se você já usou políticas do IAM a fim de permitir ou negar permissões para ler locaisde dados no Amazon S3, pode usar permissões do Lake Formation. No entanto, outras permissões do IAMainda são necessárias.
As seções a seguir resumem as permissões necessárias para usar o Athena a fim de consultar dadosregistrados no Lake Formation. Para obter mais informações, consulte Segurança no AWS Lake Formationno AWS Lake Formation Developer Guide.
Resumo de permissões• Permissões baseadas em identidade para o Lake Formation e o Athena (p. 214)• Permissões do Amazon S3 para locais de resultados de consultas do Athena (p. 214)
213

Amazon Athena Guia do usuárioGerenciamento de permissões de usuário
• Associações de grupo de trabalho do Athena para consultar o histórico (p. 214)• Permissões do Lake Formation para dados (p. 215)• Permissões do IAM para gravar em locais do Amazon S3 (p. 215)• Permissões para dados criptografados, metadados e resultados de consultas do Athena (p. 215)• Permissões baseadas em recursos para buckets do Amazon S3 em contas externas
(opcional) (p. 215)
Permissões baseadas em identidade para o Lake Formation e oAthenaQualquer pessoa que use o Athena para consultar dados registrados no Lake Formation deve ter umapolítica de permissões do IAM que permita a ação lakeformation:GetDataAccess. O Políticagerenciada AmazonAthenaFullAccess (p. 181) permite essa ação. Se você usar políticas em linha,atualize as políticas de permissões para permitir essa ação.
No Lake Formation, um administrador de data lake tem permissões para criar objetos de metadados, comobancos de dados e tabelas, conceder permissões do Lake Formation a outros usuários e registrar novoslocais do Amazon S3. Para registrar novos locais, são necessárias permissões à função vinculada aoserviço para o Lake Formation. Para obter mais informações, consulte Criar um administrador de data lakee Permissões de função vinculada ao serviço para o Lake Formation no Guia do desenvolvedor do AWSLake Formation.
Um usuário do Lake Formation pode usar o Athena para consultar bancos de dados, tabelas, colunasde tabelas e armazenamentos de dados subjacentes do Amazon S3 com base em permissões do LakeFormation concedidas a eles por administradores de data lake. Os usuários não podem criar bancosde dados ou tabelas, nem registrar novos locais do Amazon S3 no Lake Formation. Para obter maisinformações, consulte Criar um usuário do data lake no Guia do desenvolvedor do AWS Lake Formation.
No Athena, as políticas de permissões baseadas em identidade, incluindo aquelas para grupos de trabalhodo Athena, ainda controlam o acesso a ações do Athena para usuários de contas da AWS. Além disso, oacesso federado pode ser fornecido por meio da autenticação baseada em SAML disponível em drivers doAthena. Para obter mais informações, consulte Usar grupos de trabalho para controlar o acesso à consultae os custos (p. 217), Políticas do IAM para acessar grupos de trabalho (p. 221) e Permitir acessofederado à API do Athena (p. 202).
Para obter mais informações, consulte Concessão de permissões do Lake Formation no AWS LakeFormation Developer Guide.
Permissões do Amazon S3 para locais de resultados deconsultas do AthenaThe query results locations in Amazon S3 for Athena cannot be registered with Lake Formation. LakeFormation permissions do not limit access to these locations. Unless you limit access, Athena users canaccess query result files and metadata when they do not have Lake Formation permissions for the data.To avoid this, we recommend that you use workgroups to specify the location for query results and alignworkgroup membership with Lake Formation permissions. You can then use IAM permissions policiesto limit access to query results locations. For more information about query results, see Trabalhar comresultados de consulta, arquivos de saída e histórico de consultas (p. 65).
Associações de grupo de trabalho do Athena para consultar ohistóricoAthena query history exposes a list of saved queries and complete query strings. Unless you useworkgroups to separate access to query histories, Athena users who are not authorized to query data
214

Amazon Athena Guia do usuárioGerenciamento de permissões de usuário
in Lake Formation are able to view query strings run on that data, including column names, selectioncriteria, and so on. We recommend that you use workgroups to separate query histories, and align Athenaworkgroup membership with Lake Formation permissions to limit access. For more information, see Usargrupos de trabalho para controlar o acesso à consulta e os custos (p. 217).
Permissões do Lake Formation para dadosAlém da permissão de linha de base para usar o Lake Formation, os usuários do Athena devem terpermissões do Lake Formation para acessar os recursos que eles consultam. Essas permissões sãoconcedidas e gerenciadas por um administrador do Lake Formation. Para obter mais informações,consulte Controle de segurança e acesso a metadados e dados no Guia do desenvolvedor do AWS LakeFormation.
Permissões do IAM para gravar em locais do Amazon S3As permissões do Lake Formation para o Amazon S3 não incluem a capacidade de gravar no AmazonS3. Create Table As Statements (CTAS) require write access to the Amazon S3 location of tables. To runCTAS queries on data registered with Lake Formation, Athena users must have IAM permissions to write tothe table Amazon S3 locations in addition to the appropriate Lake Formation permissions to read the datalocations. For more information, see Criar uma tabela a partir de resultados da consulta (CTAS) (p. 77).
Permissões para dados criptografados, metadados e resultadosde consultas do AthenaÉ possível criptografar dados de origem subjacentes no Amazon S3 e metadados no Data Catalogregistrados no Lake Formation. Não há alteração na maneira como o Athena lida com a criptografiade resultados da consulta ao usar o Athena para consultar dados registrados no Lake Formation. Paraobter mais informações, consulte Criptografia de resultados de consultas armazenados no AmazonS3 (p. 176).
• Criptografia de dados de origem – as criptografias SSE-S3 e CSE-KMS de dados de origem de locaisde dados do Amazon S3 são compatíveis. A criptografia SSE-KMS não é compatível. Os usuários doAthena que consultam locais criptografados do Amazon S3 registrados no Lake Formation precisam depermissões para criptografar e descriptografar dados. Para obter mais informações sobre os requisitos,consulte Permissões para dados criptografados no Amazon S3 (p. 175).
• Criptografia de metadados – a criptografia de metadados no Data Catalog é compatível. Paraentidades principais que usam o Athena, as políticas baseadas em identidade devem permitir asações "kms:GenerateDataKey", "kms:Decrypt" e "kms:Encrypt" para a chave usada paracriptografar metadados. Para obter mais informações, consulte Criptografia do Data Catalog no Guiado desenvolvedor do AWS Glue e Acesso a metadados criptografados no catálogo de dados do AWSGlue (p. 192).
Permissões baseadas em recursos para buckets do Amazon S3em contas externas (opcional)An Athena user from one account can not query databases and tables in the Data Catalog of a differentaccount, even when Lake Formation is used. To query an Amazon S3 data location in a different account,a resource-based IAM policy (bucket policy) must allow access to the location. For more information, seeAcesso entre contas (p. 192). You can use Lake Formation to register an accessible bucket location in anexternal account with the Data Catalog in the local account.
215

Amazon Athena Guia do usuárioAplicação de permissões do Lake Formation
a bancos de dados e tabelas existentes
Aplicação de permissões do Lake Formation a bancosde dados e tabelas existentesSe você for novo no Athena e usar o Lake Formation para configurar o acesso aos dados da consulta,não precisará configurar políticas do IAM para que os usuários possam ler dados do Amazon S3 e criarmetadados. É possível usar o Lake Formation para administrar permissões.
Registrar dados no Lake Formation e atualizar políticas de permissões do IAM não são requisitos. Se osdados não estiverem registrados no Lake Formation, os usuários do Athena com permissões apropriadasno Amazon S3 — e no AWS Glue, se aplicável — poderão continuar a consultar dados não registrados noLake Formation.
Se você tiver usuários existentes do Athena que consultam dados não registrados no Lake Formation,poderá atualizar permissões do IAM para o Amazon S3 — e o Catálogo de dados do AWS Glue, seaplicável — com o intuito de usar permissões do Lake Formation para gerenciar o acesso de usuárioscentralmente. A fim de obter permissão para ler locais de dados do Amazon S3, você pode atualizarpolíticas baseadas em recursos e em identidade para remover permissões do Amazon S3. Para obteracesso aos metadados, se você tiver configurado políticas em nível de recurso para controle de acessorefinado com o AWS Glue, poderá usar permissões do Lake Formation a fim de gerenciar o acesso.
Para obter mais informações, consulte Acesso granular a bancos de dados e tabelas no Catálogo dedados do AWS Glue (p. 185) e Como atualizar permissões de dados do AWS Glue para o modelo doAWS Lake Formation no Guia do desenvolvedor do AWS Lake Formation.
216

Amazon Athena Guia do usuárioUsar grupos de trabalho para executar consultas
Usar grupos de trabalho paracontrolar o acesso à consulta e oscustos
Use grupos de trabalho para separar usuários, equipes, aplicativos ou cargas de trabalho, para definirlimites de quantidade de dados que cada consulta ou todo o grupo de trabalho pode processar e paraacompanhar os custos. Como os grupos de trabalho atuam como recursos, você pode usar políticasbaseadas em identidade no nível de recurso para controlar o acesso a um grupo de trabalho específico.Você também pode visualizar métricas relacionadas a consultas no Amazon CloudWatch, controlar custosda consulta ao configurar limites para a quantidade de dados verificada, criar limites e acionar ações, comoAmazon SNS, quando esses limites forem violados.
Os grupos de trabalho se integram ao IAM, CloudWatch e Amazon Simple Notification Service da seguintemaneira:
• As políticas baseadas em identidade do IAM com permissões no nível de recurso controlam quem podeexecutar consultas em um grupo de trabalho.
• O Athena publicará as métricas da consulta do grupo de trabalho no CloudWatch, se você habilitar asmétricas de consulta.
• No Amazon SNS, você pode criar tópicos do Amazon SNS que emitem alarmes a usuários especificadosdo grupo de trabalho quando os controles de uso dos dados para consultas em um grupo de trabalhoexcederem os limites estabelecidos.
Tópicos• Usar grupos de trabalho para executar consultas (p. 217)• Controlar custos e monitorar consultas com métricas do CloudWatch (p. 235)
Usar grupos de trabalho para executar consultasRecomendamos usar grupos de trabalho para isolar consultas para equipes, aplicativos ou cargas detrabalho diferentes. Por exemplo, você pode criar grupos separados para duas equipes diferentes na suaorganização. Você também pode separar cargas de trabalho. Por exemplo, você pode criar dois grupos detrabalho independentes: um para aplicativos programados automatizados, como geração de relatórios, eoutro para uso ad-hoc por analistas. Você pode alternar entre os grupos de trabalho.
Tópicos• Benefícios do uso de grupos de trabalho (p. 218)• Como funcionam os grupos de trabalho (p. 218)• Definir grupos de trabalho (p. 219)• Políticas do IAM para acessar grupos de trabalho (p. 221)• Exemplo de políticas de grupo (p. 222)• Configurações do grupo de trabalho (p. 226)
217

Amazon Athena Guia do usuárioBenefícios do uso de grupos de trabalho
• Gerenciar grupos de trabalho (p. 227)• APIs do grupo de trabalho do Athena (p. 233)• Resolver problemas nos grupos de trabalho (p. 233)
Benefícios do uso de grupos de trabalhoOs grupos de trabalho permitem que você:
Isole usuários, equipes,aplicativos ou cargas detrabalho em grupos.
Cada grupo de trabalho tem seu próprio histórico de consulta distinto euma lista de consultas salvas. Para obter mais informações, consulteComo funcionam os grupos de trabalho (p. 218).
Para todas as consultas no grupo de trabalho, você pode optar porfazer as configurações dele. Elas incluem um local do Amazon S3para armazenar resultados da consulta e configuração de criptografia.Você também pode aplicar as configurações do grupo de trabalho.Para obter mais informações, consulte Configurações do grupo detrabalho (p. 226).
Imponha restrições decustos.
Você pode definir dois tipos de restrições de custo para as consultas deum grupo de trabalho:
• Per-query limit (Limite por consulta) é um limite para a quantidade dedados verificada para cada consulta. O Athena cancela as consultasquando elas excederem o limite especificado. O limite se aplica a cadaconsulta em execução dentro de um grupo de trabalho. Você podedefinir apenas um limite por consulta e atualizá-lo, se necessário.
• O Per-workgroup limit (Limite por grupo de trabalho) é um limite quevocê pode definir para cada grupo de trabalho para a quantidadede dados verificada por consultas no grupo de trabalho. Violar umlimite ativa um alarme do Amazon SNS que aciona uma ação de suaescolha, como enviar um e-mail para um usuário especificado. Vocêpode definir vários limites por grupo de trabalho para cada grupo detrabalho.
Para obter etapas detalhadas, consulte Configurar limites de controle deuso de dados (p. 238).
Acompanhe métricasrelacionadas a consultaspara todas as consultasno grupo de trabalho doCloudWatch.
Para cada consulta que for executada em um grupo de trabalho, sevocê configurar o grupo de trabalho para publicar métricas, o Athenavai publicá-las no CloudWatch. Você pode visualizar as métricas deconsulta (p. 236) para cada um de seus grupos de trabalho no consoledo Athena. No CloudWatch, você pode criar painéis personalizados edefinir limites e alarmes sobre essas métricas.
Como funcionam os grupos de trabalhoOs grupos de trabalho do Athena têm as seguintes características:
• Por padrão, cada conta tem um grupo de trabalho principal e as permissões padrão permitem que todosos usuários autenticados tenham acesso a esse grupo de trabalho. O grupo de trabalho principal nãopode ser excluído.
218

Amazon Athena Guia do usuárioDefinir grupos de trabalho
• Cada grupo de trabalho que você criar mostra as consultas salvas e o histórico de consultas somentepara consultas executadas, não para todas as consultas na conta. Isso separa suas consultas de outrasconsultas dentro de uma conta e as deixa mais eficientes, para você localizar suas próprias consultassalvas e consultas no histórico.
• Desativar um grupo de trabalho impede que as consultas sejam executadas nele até você ativá-lo. Asconsultas enviadas para um grupo de trabalho falham até você habilitá-lo novamente.
• Se tiver permissões, você poderá excluir um grupo de trabalho vazio e um grupo de trabalho quecontém consultas salvas. Nesse caso, antes de excluir um grupo de trabalho, o Athena avisa que asconsultas salvas serão excluídas. Antes de excluir um grupo de trabalho ao qual outros usuários têmacesso, verifique se eles têm acesso a outros grupos de trabalho nos quais podem continuar a executarconsultas.
• Você pode fazer as configurações em todo o grupo de trabalho e impor seu uso por todas as consultasexecutadas em um grupo de trabalho. As configurações incluem local dos resultados da consulta noAmazon S3 e configuração de criptografia.
Important
Quando você impuser configurações em todo o grupo de trabalho, todas as consultasexecutadas nesse grupo de trabalho usarão configurações de grupo de trabalho. Isso acontecemesmo que as configurações do lado do cliente forem diferentes do grupo de configurações.Para obter mais informações, consulte Configurações do grupo de trabalho sobrepõem asconfigurações do lado do cliente (p. 226).
Limitações de grupos de trabalho• Você pode criar até 1000 grupos de trabalho por região na sua conta.• O grupo de trabalho principal não pode ser excluído.• Você pode abrir até dez guias de consulta dentro de cada grupo de trabalho. Quando alternar entre
grupos de trabalho, suas guias de consulta permanecerão abertas para até três grupos de trabalho.
Definir grupos de trabalhoConfiguração de grupos de trabalho envolve a criação deles e a definição de permissões para seu uso.Primeiro, decida de quais grupos de trabalho sua organização precisa e crie-os. Configure as políticasde do grupo de trabalho do IAM que controlam o acesso do usuário e as ações em um recurso doworkgroup. Os usuários com acesso a esses grupos de trabalho agora podem executar consultas neles.
Note
Use essas tarefas para configurar grupos de trabalho quando você começar a usá-los pelaprimeira vez. Se sua conta no Athena já usar grupos de trabalho, o usuário de cada conta vaiexigir permissões para executar consultas em um ou mais grupos de trabalho na conta. Antes deexecutar consultas, verifique a política do IAM para ver quais grupos você pode acessar, ajuste apolítica, se necessário, e alterne (p. 232) para um grupo de trabalho que você pretende usar.
Por padrão, se você não tiver criado nenhum grupo de trabalho, todas as consultas na sua conta serãoexecutadas no grupo de trabalho principal:
Os grupos de trabalho são exibidos no console do Athena, na guia Workgroup: (Grupo detrabalho:)<workgroup_name>. O console lista o grupo de trabalho para o qual você mudou. Quando vocêexecutar consultas, elas serão executadas nesse grupo de trabalho. Você pode executar consultas nogrupo de trabalho no console ou usando as operações de API, a interface da linha de comando ou um
219

Amazon Athena Guia do usuárioDefinir grupos de trabalho
aplicativo cliente por meio do driver JDBC ou ODBC. Quando você tiver acesso a um grupo de trabalho,poderá visualizar as configurações de grupo de trabalho, as métricas e os limites de controle de uso dedados. Além disso, você pode ter permissões para editar as configurações e os limites de controle de usodos dados.
Para configurar grupos de trabalho
1. Decida quais grupos de trabalho deseja criar. Por exemplo, decida o seguinte:
• Quem pode executar consultas em cada grupo de trabalho e de quem é a configuração do grupo detrabalho. Isso determina as políticas do IAM que você criar. Para obter mais informações, consultePolíticas de acesso aos grupos de trabalho do IAM (p. 221).
• Quais locais no Amazon S3 usar para os resultados das consultas executadas em cada grupode trabalho. Deve existir um local no Amazon S3 antes de você especificá-lo nos resultados daconsulta do grupo de trabalho. Todos os usuários que usam um grupo de trabalho devem ter acessoa esse local. Para obter mais informações, consulte Configurações do grupo de trabalho (p. 226).
• Quais configurações de criptografia são necessárias e quais grupos de trabalho têm consultasque devem ser criptografadas. Recomendamos que você crie grupos de trabalho separados paraconsultas criptografadas e não criptografadas. Dessa forma, você pode impor a criptografia a umgrupo de trabalho que se aplica a todas as consultas executadas nele. Para obter mais informações,consulte Criptografar resultados de consultas armazenadas no Amazon S3 (p. 176).
2. Crie grupos de trabalho conforme o necessário e adicione tags a eles. Abra o console doAthena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name> e selecione Createworkgroup (Criar grupo de trabalho). Para obter etapas detalhadas, consulte Criar um grupo detrabalho (p. 228).
3. Crie políticas do IAM para seus usuários, grupos ou funções para habilitar o acesso deles aos gruposde trabalho. As políticas estabelecem a associação do grupo de trabalho e o acesso a ações em umrecurso workgroup. Para obter detalhes das etapas, consulte, Políticas do IAM para acessar gruposde trabalho (p. 221). Por exemplo, para políticas JSON, consulte Políticas de exemplo do grupo detrabalho (p. 195).
4. Definir as configurações do grupo de trabalho Especifique um local no Amazon S3 para osresultados da consulta e as configurações da criptografia, se necessário. Você pode impor asconfigurações do grupo de trabalho. Para obter mais informações, consulte configurações do grupo detrabalho (p. 226).
Important
Se você substituir configurações no lado do cliente (p. 226), o Athena usará asconfigurações do grupo de trabalho. Isso afeta as consultas que você executar no console,usando os drivers, a interface de linha de comando ou as operações da API.Embora as consultas continuem a ser executadas, a automação incorporada com basena disponibilidade de resultados em um determinado bucket do Amazon S3 poderá serinterrompida. Recomendamos que você informe seus usuários antes de fazer a substituição.Após definir as configurações do grupo de trabalho para que façam a substituição, vocêpoderá omitir a especificação das configurações no lado do cliente nos drivers ou na API.
5. Notifique os usuários sobre quais grupos de trabalho devem ser usados para executar consultas.Envie um e-mail para informar os usuários da sua conta sobre os nomes de grupo de trabalho queeles podem usar, as políticas do IAM necessárias e as configurações do grupo de trabalho.
6. Configure os limites de controle de custos, também conhecidos como limites de controle de uso dedados, para consultas e grupos de trabalho. Para notificar você quando o limite for violado, crie umtópico do Amazon SNS e configure assinaturas. Para obter etapas detalhadas, consulte Definir limitesde controle de uso de dados (p. 238) e Criar um tópico do Amazon SNS no Guia de conceitosbásicos do Amazon Simple Notification Service.
7. Alterne para o grupo de trabalho para que você possa executar consultas. Para executar consultas,alterne para o grupo de trabalho apropriado. Para obter detalhes das etapas, consulte, the sectioncalled “Especifique um grupo de trabalho no qual executar consultas” (p. 232).
220

Amazon Athena Guia do usuárioPolíticas do IAM para acessar grupos de trabalho
Políticas do IAM para acessar grupos de trabalhoPara controlar o acesso a grupos de trabalho, use permissões do IAM em nível de recurso ou políticas doIAM baseadas em identidade.
O procedimento a seguir é específico ao Athena.
Para obter informações específicas do IAM, consulte os links listados ao final desta seção. Para obter maisinformações sobre as políticas de grupo de trabalho JSON de exemplo, consulte Políticas de exemplo dogrupo de trabalho (p. 222).
Para usar o editor visual no console do IAM para criar uma política de grupo de trabalho
1. Faça login no Console de Gerenciamento da AWS e abra o console da IAM em https://console.aws.amazon.com/iam/.
2. No painel de navegação à esquerda, escolha Policies (Políticas) e Create policy (Criar política).3. Na guia Editor visual, selecione Escolher um serviço. Escolha Athena para adicionar à política.4. Escolha Select actions (Selecionar ações) e defina as ações para adicionar à política. O editor visual
mostra as ações disponíveis no Athena. Para obter mais informações, consulte Ações, recursos echaves de condição para o Amazon Athena, no Guia do usuário do IAM.
5. Escolha Add actions (Adicionar ações) para digitar uma ação específica ou use caracteres curinga (*)para especificar várias ações.
Por padrão, a política que você está criando permite as ações que você escolhe. Se você escolheruma ou mais ações que ofereçam suporte a permissões no nível de recursos ao recurso workgroupno Athena, o editor visual listará o recurso workgroup.
6. Escolha Resources (Recursos) para especificar os grupos de trabalho específicos para sua política.Por exemplo, para políticas do grupo de trabalho JSON, consulte Políticas de exemplo do grupo detrabalho (p. 222).
7. Especifique o recurso workgroup da seguinte forma:
arn:aws:athena:<region>:<user-account>:workgroup/<workgroup-name>
8. Selecione Review Policy (Revisar política), digite um Name (Nome) e uma Description (Descrição)(opcional) para a política que você está criando. Revise o resumo da política para ter certeza de quevocê concedeu as permissões que pretendia.
9. Escolha Create Policy (Criar política) para salvar sua nova política.10. Anexe essa política baseada em identidade a um usuário, um grupo ou uma função e especifique os
recursos do workgroup que eles podem acessar.
Para obter mais informações, consulte um dos tópicos a seguir no Guia do usuário do IAM.
• Ações, recursos e chaves de condição do Amazon Athena• Criar políticas com o editor visual• Adicionar e remover políticas do IAM• Controle de acesso aos recursos
Por exemplo, para políticas do grupo de trabalho JSON, consulte Políticas de exemplo do grupo detrabalho (p. 222).
Para obter uma lista completa das ações do Amazon Athena, consulte os nomes de ação da API noReferência de API do Amazon Athena.
221

Amazon Athena Guia do usuárioExemplo de políticas de grupo
Exemplo de políticas de grupoEsta seção inclui exemplos de políticas que você pode usar para habilitar várias ações nos grupos detrabalho.
Um grupo de trabalho é um recurso do IAM gerenciado pelo Athena. Portanto, se sua política de grupo detrabalho usar ações que tomam workgroup como entrada, especifique o ARN do grupo de trabalho daseguinte forma:
"Resource": [arn:aws:athena:<region>:<user-account>:workgroup/<workgroup-name>]
Onde <workgroup-name> é o nome do seu grupo de trabalho. Por exemplo, para o grupo de trabalhochamado test_workgroup, especifique-o como um recurso da seguinte forma:
"Resource": ["arn:aws:athena:us-east-1:123456789012:workgroup/test_workgroup"]
Para obter uma lista completa das ações do Amazon Athena, consulte os nomes de ação da API noReferência de API do Amazon Athena. Para obter mais informações sobre políticas do IAM, consulte Criarpolíticas com o editor visual no Guia do usuário do IAM. Para obter mais informações sobre como criarpolíticas do IAM para grupos de trabalho, consulte Políticas do IAM no grupo de trabalho (p. 221).
• Exemplo de política para acesso total a todos os grupos de trabalho (p. 222)• Exemplo de política para acesso total a um grupo de trabalho especificado (p. 223)• Exemplo de política para execução de consultas em um grupo de trabalho especificado (p. 223)• Exemplo de política para execução de consultas em um grupo de trabalho principal (p. 224)• Política de exemplo para operações de gerenciamento em um grupo de trabalho especificado (p. 225)• Exemplo de política para listar grupos de trabalho (p. 225)• Exemplo de política para execução e interrupção de consultas em um grupo de trabalho
específico (p. 225)• Política de exemplo para trabalhar com consultas nomeadas em um grupo de trabalho
específico (p. 225)
Example Exemplo de política para acesso total a todos os grupos de trabalho
A seguinte política permite acesso total a todos os recursos do grupo de trabalho que podem existir naconta. Recomendamos que você use essa política para os usuários da sua conta que devem administrar egerenciar grupos de trabalho para todos os outros usuários.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:*" ], "Resource": [ "*" ] } ]}
222

Amazon Athena Guia do usuárioExemplo de políticas de grupo
Example Exemplo de política para acesso total a um grupo de trabalho especificado
A seguinte política permite acesso total ao único recurso do grupo de trabalho específico, denominadoworkgroupA. Você pode usar essa política para os usuários com controle total sobre um determinadogrupo de trabalho.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:ListWorkGroups", "athena:GetExecutionEngine", "athena:GetExecutionEngines", "athena:GetNamespace", "athena:GetCatalogs", "athena:GetNamespaces", "athena:GetTables", "athena:GetTable" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "athena:StartQueryExecution", "athena:GetQueryResults", "athena:DeleteNamedQuery", "athena:GetNamedQuery", "athena:ListQueryExecutions", "athena:StopQueryExecution", "athena:GetQueryResultsStream", "athena:ListNamedQueries", "athena:CreateNamedQuery", "athena:GetQueryExecution", "athena:BatchGetNamedQuery", "athena:BatchGetQueryExecution" ], "Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA" ] }, { "Effect": "Allow", "Action": [ "athena:DeleteWorkGroup", "athena:UpdateWorkGroup", "athena:GetWorkGroup", "athena:CreateWorkGroup" ], "Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA" ] } ]}
Example Exemplo de política para execução de consultas em um grupo de trabalho especificado
Na política a seguir, um usuário tem permissão para executar consultas no workgroupA especificado evisualizá-las. O usuário não tem permissão de realizar tarefas de gerenciamento para o grupo de trabalhoem si, como atualizá-las ou excluí-las.
223

Amazon Athena Guia do usuárioExemplo de políticas de grupo
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:ListWorkGroups", "athena:GetExecutionEngine", "athena:GetExecutionEngines", "athena:GetNamespace", "athena:GetCatalogs", "athena:GetNamespaces", "athena:GetTables", "athena:GetTable" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "athena:StartQueryExecution", "athena:GetQueryResults", "athena:DeleteNamedQuery", "athena:GetNamedQuery", "athena:ListQueryExecutions", "athena:StopQueryExecution", "athena:GetQueryResultsStream", "athena:ListNamedQueries", "athena:CreateNamedQuery", "athena:GetQueryExecution", "athena:BatchGetNamedQuery", "athena:BatchGetQueryExecution", "athena:GetWorkGroup" ], "Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA" ] } ]}
Example Exemplo de política para execução de consultas em um grupo de trabalho principal
No exemplo a seguir, usamos a política que permite que um determinado usuário execute consultas nogrupo de trabalho principal.
Note
Recomendamos que você adicione essa política a todos os usuários configurados para executarconsultas em seus grupos de trabalho designados. Adicionar essa política às políticas do usuáriodo grupo de trabalho de usuário é útil caso o grupo de trabalho designado seja excluído ou estejadesabilitado. Neste caso, eles podem continuar executando consultas no grupo de trabalhoprincipal.
Para permitir que os usuários em sua conta executem consultas no grupo de trabalho principal, adicione aseguinte política a uma seção do recurso do Exemplo de política para execução de consultas em um grupode trabalho especificado (p. 223).
"arn:aws:athena:us-east-1:123456789012:workgroup/primary"
224

Amazon Athena Guia do usuárioExemplo de políticas de grupo
Example Política de exemplo para operações de gerenciamento em um grupo de trabalhoespecificado
Na política a seguir, o usuário tem permissão de criar, excluir, obter detalhes e atualizar um grupo detrabalho test_workgroup.
{ "Effect": "Allow", "Action": [ "athena:CreateWorkGroup", "athena:GetWorkGroup", "athena:DeleteWorkGroup", "athena:UpdateWorkGroup" ], "Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/test_workgroup" ]}
Example Exemplo de política para listar grupos de trabalho
A política a seguir permite que todos os usuários listem todos os grupos de trabalho:
{ "Effect": "Allow", "Action": [ "athena:ListWorkGroups" ], "Resource": "*"}
Example Exemplo de política para execução e interrupção de consultas em um grupo de trabalhoespecífico
Nesta política, o usuário tem a permissão de executar consultas no grupo de trabalho:
{ "Effect": "Allow", "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution" ], "Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/test_workgroup" ]}
Example Política de exemplo para trabalhar com consultas nomeadas em um grupo de trabalhoespecífico
Na política a seguir, o usuário tem permissões para criar, excluir e obter informações sobre consultasnomeadas no grupo de trabalho especificado:
{ "Effect": "Allow", "Action": [ "athena:CreateNamedQuery", "athena:GetNamedQuery", "athena:DeleteNamedQuery" ],
225

Amazon Athena Guia do usuárioConfigurações do grupo de trabalho
"Resource": [ "arn:aws:athena:us-east-1:123456789012:workgroup/test_workgroup" ]}
Configurações do grupo de trabalhoCada grupo de trabalho tem as seguintes configurações:
• Um nome exclusivo. Ele pode conter de 1 a 128 caracteres, incluindo caracteres alfanuméricos, traços esublinhados. Depois de criar um grupo de trabalho, não é possível alterar o nome dele. No entanto, vocêpode criar um novo grupo de trabalho com as mesmas configurações e um nome diferente.
• Configurações que se aplicam a todas as consultas em execução no grupo de trabalho. Incluindo:• Um local no Amazon S3 para armazenar resultados da consulta para todas as consultas executadas
neste grupo de trabalho. Esse local deve existir antes de você especificá-lo para o grupo de trabalhoao criá-lo.
• Uma configuração de criptografia, se você usar a criptografia para todas as consultas do grupo detrabalho. Você só pode criptografar todas as consultas em um grupo de trabalho, não apenas algumasdelas. É recomendável criar grupos separados para conter consultas que são criptografadas ou nãocriptografadas.
Além disso, você pode substituir as configurações no lado do cliente (p. 226). Antes do lançamentode grupos de trabalho, você podia especificar o local dos resultados e as opções de criptografia comoparâmetros no driver JDBC ou ODBC ou na guia Properties (Propriedades) no console do Athena.Essas configurações também podem ser especificadas diretamente por meio das operações da API.Essas configurações são conhecidas como "configurações do lado do cliente". Com grupos de trabalho,você pode fazer essas configurações no nível de grupo e impor controle sobre elas. Isso dispensa seususuários de configurá-las individualmente. Se você selecionar Override Client-Side Settings (Substituirconfigurações no lado do cliente), as consultas usarão as configurações do grupo de trabalho e ignorarãoas configurações no lado do cliente.
Se Override Client-Side Settings (Substituir configurações no lado do cliente) for selecionado, o usuárioserá notificado no console que suas configurações foram alteradas. Se as configurações do grupo detrabalho forem aplicadas dessa forma, os usuários poderão omitir as configurações correspondentes dolado do cliente. Neste caso, se você executar consultas no console, as configurações do grupo de trabalhoserão usadas para elas, mesmo se alguma consulta tiver configurações no lado do cliente. Além disso, sevocê executar consultas neste grupo de trabalho por meio da interface de linha de comando, operações deAPI ou drivers, as configurações que você especificou serão substituídas pelas configurações do grupo detrabalho. Isso afeta os resultados do local da consulta e a criptografia. Para conferir quais configuraçõessão usadas para o grupo de trabalho, veja os detalhes do grupo de trabalho (p. 230).
Você também pode definir limites de consulta (p. 235) para consultas nos grupos de trabalho.
Configurações do grupo de trabalho sobrepõem as configuraçõesdo lado do clienteAs caixas de diálogo Create workgroup (Criar grupo de trabalho) e Edit workgroup (Editar grupo detrabalho) têm um campo de nome Override client-side settings (Substituir configurações no lado do cliente).Esse campo não é selecionado por padrão. Dependendo de se você selecioná-lo ou não, o Athena faz oseguinte:
• Se a opção Override client-side settings (Substituir configurações no lado do cliente) não forselecionada, as configurações do grupo de trabalho não serão aplicadas. Nesse caso, para todas asconsultas executadas neste grupo de trabalho, o Athena usará as configurações do lado do cliente paralocalização e criptografia dos resultados da consulta. Cada usuário pode especificar as configurações
226
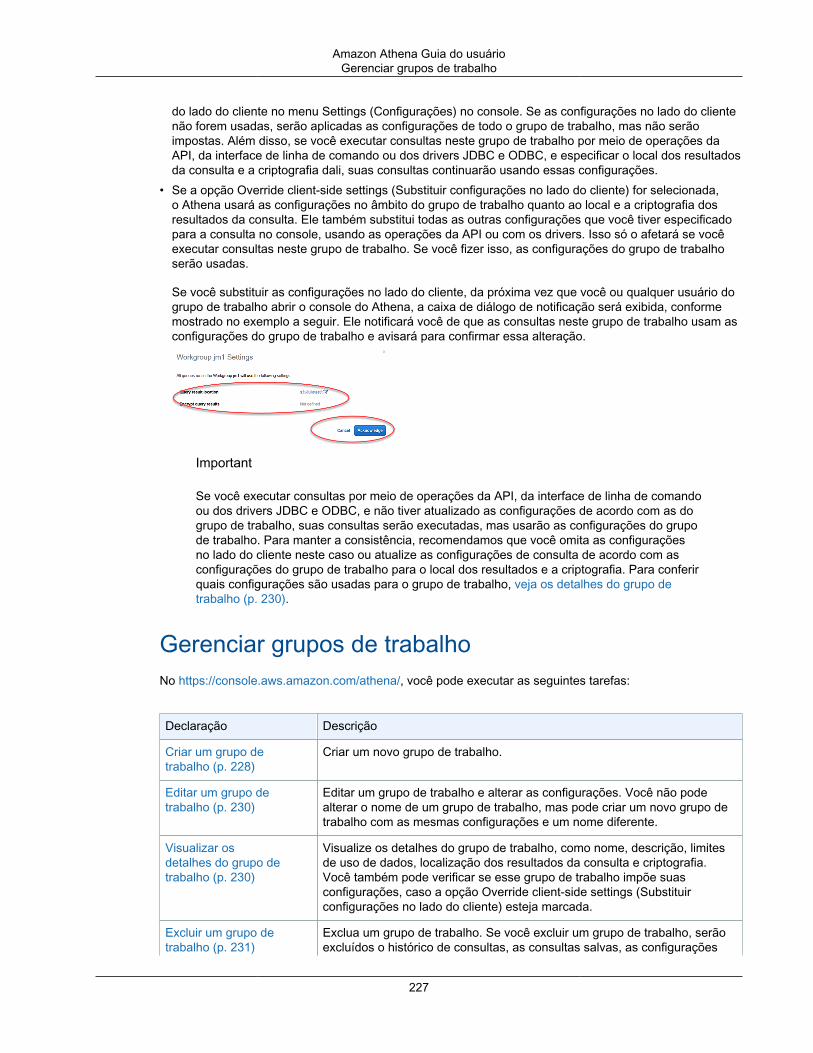
Amazon Athena Guia do usuárioGerenciar grupos de trabalho
do lado do cliente no menu Settings (Configurações) no console. Se as configurações no lado do clientenão forem usadas, serão aplicadas as configurações de todo o grupo de trabalho, mas não serãoimpostas. Além disso, se você executar consultas neste grupo de trabalho por meio de operações daAPI, da interface de linha de comando ou dos drivers JDBC e ODBC, e especificar o local dos resultadosda consulta e a criptografia dali, suas consultas continuarão usando essas configurações.
• Se a opção Override client-side settings (Substituir configurações no lado do cliente) for selecionada,o Athena usará as configurações no âmbito do grupo de trabalho quanto ao local e a criptografia dosresultados da consulta. Ele também substitui todas as outras configurações que você tiver especificadopara a consulta no console, usando as operações da API ou com os drivers. Isso só o afetará se vocêexecutar consultas neste grupo de trabalho. Se você fizer isso, as configurações do grupo de trabalhoserão usadas.
Se você substituir as configurações no lado do cliente, da próxima vez que você ou qualquer usuário dogrupo de trabalho abrir o console do Athena, a caixa de diálogo de notificação será exibida, conformemostrado no exemplo a seguir. Ele notificará você de que as consultas neste grupo de trabalho usam asconfigurações do grupo de trabalho e avisará para confirmar essa alteração.
Important
Se você executar consultas por meio de operações da API, da interface de linha de comandoou dos drivers JDBC e ODBC, e não tiver atualizado as configurações de acordo com as dogrupo de trabalho, suas consultas serão executadas, mas usarão as configurações do grupode trabalho. Para manter a consistência, recomendamos que você omita as configuraçõesno lado do cliente neste caso ou atualize as configurações de consulta de acordo com asconfigurações do grupo de trabalho para o local dos resultados e a criptografia. Para conferirquais configurações são usadas para o grupo de trabalho, veja os detalhes do grupo detrabalho (p. 230).
Gerenciar grupos de trabalhoNo https://console.aws.amazon.com/athena/, você pode executar as seguintes tarefas:
Declaração Descrição
Criar um grupo detrabalho (p. 228)
Criar um novo grupo de trabalho.
Editar um grupo detrabalho (p. 230)
Editar um grupo de trabalho e alterar as configurações. Você não podealterar o nome de um grupo de trabalho, mas pode criar um novo grupo detrabalho com as mesmas configurações e um nome diferente.
Visualizar osdetalhes do grupo detrabalho (p. 230)
Visualize os detalhes do grupo de trabalho, como nome, descrição, limitesde uso de dados, localização dos resultados da consulta e criptografia.Você também pode verificar se esse grupo de trabalho impõe suasconfigurações, caso a opção Override client-side settings (Substituirconfigurações no lado do cliente) esteja marcada.
Excluir um grupo detrabalho (p. 231)
Exclua um grupo de trabalho. Se você excluir um grupo de trabalho, serãoexcluídos o histórico de consultas, as consultas salvas, as configurações
227

Amazon Athena Guia do usuárioGerenciar grupos de trabalho
Declaração Descriçãodo grupo de trabalho e os controles do limite de dados por consulta. Oscontroles do limite de dados no âmbito do grupo de trabalho permanecemno CloudWatch, e você pode excluí-los um a um.
O grupo de trabalho principal não pode ser excluído.
Alternar entre grupos detrabalho (p. 232)
Alterne entre grupos de trabalho aos quais você tem acesso.
Habilitar e desabilitarum grupo detrabalho (p. 232)
Habilite ou desabilite um grupo de trabalho. Quando um grupo de trabalhoestiver desabilitado, os usuários não poderão executar consultas nemcriar novas consultas com nome. Se você tiver acesso a ele, aindapode visualizar métricas, os controles de limite de uso de dados, asconfigurações de grupo de trabalho, o histórico de consultas e as consultassalvas.
Especifique um grupo detrabalho no qual executarconsultas (p. 232)
Antes de executar as consultas, especifique ao Athena qual grupo detrabalho deve ser usado. Você deve ter permissões para o grupo detrabalho.
Criar um grupo de trabalhoCriar um grupo de trabalho requer permissões para ações da API CreateWorkgroup. Consulte Acessoaos grupos de trabalho do Athena (p. 195) e Políticas do IAM para acessar grupos de trabalho (p. 221).Se você adicionar tags, também precisará adicionar permissões para TagResource. Consulte the sectioncalled “Exemplos da política de tags” (p. 246).
Para criar um grupo de trabalho no console
1. No console do Athena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name>. O painelWorkgroups (Grupos de trabalho) é exibido.
2. No Workgroups (Grupos de trabalho), escolha Create workgroup (Criar grupo de trabalho).
3. Na caixa de diálogo Create workgroup (Criar grupo de trabalho), preencha os campos da seguinteforma:
Campo Descrição
Workgroup name (Nomedo grupo de trabalho)
Obrigatório. Digite um nome exclusivo para seu grupo de trabalho. Use 1a 128 caracteres. (A-Z,a-z,0-9,_,-,.). Esse nome não pode ser alterado.
Description (Descrição) Opcional. Insira uma descrição para seu grupo de trabalho. Ela podeconter até 1024 caracteres.
Query result location(Local dos resultados daconsulta)
Opcional. Insira um caminho para um prefixo ou bucket do Amazon S3.O bucket e o prefixo devem existir antes que você especificá-los.
228

Amazon Athena Guia do usuárioGerenciar grupos de trabalho
Campo Descrição
Note
Se você executar consultas no console, especificar o local dosresultados da consulta é opcional. Se você não especificá-lopara o grupo de trabalho nem em Settings (Configurações), aAthena usará o local do resultado da consulta padrão. Se vocêexecutar consultas com a API ou os drivers, deverá especificaro local dos resultados da consulta em pelo menos um de doislugares: para consultas individuais, com OutputLocation, oupara o grupo de trabalho, com WorkGroupConfiguration.
Encrypt query results(Criptografar resultadosda consulta)
Opcional. Criptografe resultados armazenados no Amazon S3. Seselecionada essa opção, todas as consultas do grupo de trabalho serãocriptografadas.
Se selecionada essa opção, você pode selecionar o Encryption type(Tipo de criptografia), a Encryption key (Chave de criptografia) e insira oKMS Key ARN (ARN da chave do KMS).
Se você não tiver a chave, abra o console do AWS KMS para criá-la.Para obter mais informações, consulte Como criar chaves no AWS KeyManagement Service Developer Guide.
Publish to CloudWatch(Publicar no &CW;)
Esse campo é selecionado por padrão. Publicar métricas deconsulta para Amazon CloudWatch. Consulte Exibir métricas deconsulta (p. 236).
Override client-sidesettings (Substituirconfigurações no lado docliente)
Esse campo não é selecionado por padrão. Se você selecionaressa opção, as configurações do grupo de trabalho se aplicarão atodas as consultas do grupo de trabalho e ficarão sobrepostas àsconfigurações no lado do cliente. Para obter mais informações, consulteConfigurações do grupo de trabalho sobrepõem as configurações dolado do cliente (p. 226).
Tags Opcional. Adicione uma ou mais tags a um grupo de trabalho. A tagé um rótulo atribuído a um recurso do grupo de trabalho do Athena.Ela é formada por uma chave e um valor. Use as melhores práticaspara estratégias de marcação com tags da AWS para criar um conjuntoconsistente de tags e categorizar os grupo de trabalho por finalidade,proprietário ou ambiente. Você também pode usar tags nas políticas doIAM e para controlar os custos de faturamento. Não use chaves de tagduplicadas no mesmo grupo de trabalho. Para obter mais informações,consulte Marcar com tags os grupos de trabalho (p. 242).
Buckets do S3 depagamento pelosolicitante
Optional. Escolha Enable queries on Requester Pays buckets in AmazonS3 (Habilitar consultas em buckets de pagamento pelo solicitante noAmazon S3) se os usuários do grupo de trabalho executarem consultasem dados armazenados em buckets do Amazon S3 configurados comoPagamentos pelo solicitante. A conta do usuário que executa a consultaé cobrada pelas taxas de acesso e transferência de dados aplicáveisassociadas à consulta. Para obter mais informações, consulte Bucketsde Pagamento pelo solicitante no Guia do desenvolvedor do AmazonSimple Storage Service.
4. Escolha Create workgroup (Criar grupo de trabalho). O grupo de trabalho aparece na lista no painelWorkgroups (Grupos de trabalho).
229

Amazon Athena Guia do usuárioGerenciar grupos de trabalho
Como alternativa, use as operações de API para criar um grupo de trabalho.Important
Depois de criar grupos de trabalho, crie Políticas do IAM para grupos de trabalho (p. 221) noIAM que permitem que você execute ações relacionadas ao grupo de trabalho.
Editar um grupo de trabalhoComo editar um grupo de trabalho requer permissões para operações da API UpdateWorkgroup.Consulte Acesso aos grupos de trabalho do Athena (p. 195) e Políticas do IAM para acessar gruposde trabalho (p. 221). Se você adicionar ou editar tags, também precisará ter permissões paraTagResource. Consulte the section called “Exemplos da política de tags” (p. 246).
Para editar um grupo de trabalho no console
1. No console do Athena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name>. O painelWorkgroups (Grupos de trabalho) é exibido, listando todos os grupos na conta.
2. No painel Workgroups (Grupos de trabalho), escolha o grupo de trabalho que você deseja editar. Opainel View details (Exibir detalhes) para o grupo de trabalho é exibido, com a guia Overview (Visãogeral) selecionada.
3. Escolha Edit workgroup (Editar grupo de trabalho).
4. Altere os campos conforme necessário. Para ver a lista de campos, consulte Criar grupo detrabalho (p. 228). Você pode alterar todos os campos, exceto pelo nome do grupo de trabalho.Se você precisar alterar o nome, crie outro grupo de trabalho com o novo nome e as mesmasconfigurações.
5. Escolha Salvar. O grupo de trabalho atualizado aparece na lista do painel Workgroups (Grupos detrabalho).
Visualizar os detalhes do grupo de trabalhoPara cada grupo de trabalho, você pode visualizar os detalhes. Os detalhes incluem o nome do grupode trabalho, a descrição, se ele está ativado ou desativado e as configurações usadas para consultasexecutadas no grupo de trabalho, que incluem a localização dos resultados da consulta e configuração decriptografia. Se um grupo de trabalho tiver limites de uso de dados, eles também serão exibidos.
230

Amazon Athena Guia do usuárioGerenciar grupos de trabalho
Para exibir os detalhes do grupo de trabalho
• No painel Workgroups (Grupos de trabalho), escolha o grupo de trabalho que você deseja editar. Opainel View details (Exibir detalhes) para o grupo de trabalho é exibido, com a guia Overview (Visãogeral) selecionada. São exibidos os detalhes do grupo de trabalho, como no exemplo a seguir:
Excluir um grupo de trabalhoVocê pode excluir um grupo de trabalho se tiver permissões para fazê-lo. O grupo de trabalho principal nãopode ser excluído.
Se tiver permissões, você poderá excluir um grupo de trabalho vazio a qualquer momento. Você tambémpode excluir um grupo de trabalho que contém as consultas salvas. Nesse caso, antes de prosseguir paraexcluir um grupo de trabalho, o Athena avisa que as consultas salvas são excluídas.
Se você excluir um grupo de trabalho enquanto estiver nele, o console vai alternar o foco para o grupo detrabalho principal. Se você tiver acesso a ele, pode executar consultas e exibir as configurações.
Se você excluir um grupo de trabalho, as configurações e os controles de limite de dados por consultaserão excluídos. O limite de dados no âmbito do grupo de trabalho permanece no CloudWatch, e vocêpode excluí-lo, se necessário.
Important
Antes de excluir um grupo de trabalho, verifique se os usuários também pertencem a outrosgrupos de trabalho onde podem continuar a executar consultas. Se as políticas do IAM dosusuários permitir que eles executem consultas somente neste grupo de trabalho e você excluí-las,eles não terão mais permissões para executar consultas. Para obter mais informações, consulteExemplo de política para execução de consultas em um grupo de trabalho principal (p. 224).
Para excluir um grupo de trabalho no console
1. No console do Athena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name>. O painelWorkgroups (Grupos de trabalho) é exibido.
231

Amazon Athena Guia do usuárioGerenciar grupos de trabalho
2. No painel Workgroups (Grupos de trabalho), escolha o grupo de trabalho que você deseja excluir. Opainel View details (Exibir detalhes) para o grupo de trabalho é exibido, com a guia Overview (Visãogeral) selecionada.
3. Escolha Delete workgroup (Excluir grupo de trabalho) e confirme a exclusão.
Para excluir um grupo de trabalho com a operação da API, use a ação DeleteWorkGroup.
Alternar entre grupos de trabalhoVocê pode alternar de um grupo de trabalho para outro caso você tenha permissões para ambos.
Você pode abrir até dez guias de consulta dentro de cada grupo de trabalho. Quando alternar entre gruposde trabalho, suas guias de consulta permanecerão abertas para até três grupos de trabalho.
Para alternar entre grupos de trabalho
1. No console do Athena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name>. O painelWorkgroups (Grupos de trabalho) é exibido.
2. No painel Workgroups (Grupos de trabalho), escolha o grupo de trabalho para o qual você desejaalternar e, depois, Switch workgroup (Alternar grupo de trabalho).
3. Escolha Switch (Alternar). O console mostra a guia Workgroup: (Grupo detrabalho:)<workgroup_name> com o nome do grupo de trabalho para o qual você mudou. Você jápode executar consultas nesse grupo de trabalho.
Habilitar e desabilitar um grupo de trabalhoSe você tiver permissões para fazê-lo, pode habilitar ou desabilitar grupos de trabalho no console usandoas operações de API ou com os drivers JDBC e ODBC.
Para habilitar ou desabilitar um grupo de trabalho
1. No console do Athena, escolha a guia Workgroup: (Grupo de trabalho:)<workgroup_name>. O painelWorkgroups (Grupos de trabalho) é exibido.
2. No painel Workgroups (Grupos de trabalho), escolha o grupo de trabalho e Enable workgroup(Habilitar grupo de trabalho) ou Disable workgroup (Desabilitar grupo de trabalho). Se você desativarum grupo de trabalho, os usuários não poderão executar consultas nem criar novas consultasnomeadas. Se você habilitar um grupo de trabalho, os usuários poderão usá-lo para executarconsultas.
Especifique um grupo de trabalho no qual executar consultasAntes de executar as consultas, especifique ao Athena qual grupo de trabalho deve ser usado. Vocêprecisa ter permissões para o grupo de trabalho.
232

Amazon Athena Guia do usuárioAPIs do grupo de trabalho do Athena
Para especificar um grupo de trabalho para o Athena
1. Suas permissões devem permitir que você execute consultas no grupo de trabalho que você pretendeusar. Para obter mais informações, consulte the section called “ Políticas do IAM para acessar gruposde trabalho” (p. 221).
2. Para especificar o grupo de trabalho para o Athena, use uma das seguintes opções:
• Se você estiver acessando o Athena por meio do console, defina o grupo de trabalho alternando osgrupos de trabalho (p. 232).
• Se você estiver usando as operações da API do Athena, especifique o nome do grupo detrabalho na ação da API. Por exemplo, você pode definir o nome do grupo de trabalho emStartQueryExecution, da seguinte forma:
StartQueryExecutionRequest startQueryExecutionRequest = new StartQueryExecutionRequest() .withQueryString(ExampleConstants.ATHENA_SAMPLE_QUERY) .withQueryExecutionContext(queryExecutionContext) .withWorkgroup(WorkgroupName)
• Se você estiver usando o driver JDBC ou ODBC, defina o nome do grupo de trabalho na string deconexão usando o parâmetro de configuração Workgroup. O driver passa o nome do grupo detrabalho para o Athena. Especifique o parâmetro do grupo de trabalho na string de conexão, comono exemplo a seguir:
jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>;PWD=<SECRETKEY>;S3OutputLocation=s3://<athena-output>-<AWSREGION>/;Workgroup=<WORKGROUPNAME>;
Para obter mais informações, pesquise "Workgroup" (grupo de trabalho) no link da documentaçãodo driver incluído em Documentação do driver JDBC (p. 60).
APIs do grupo de trabalho do AthenaA seguir estão algumas das operações da API REST usadas para os grupos de trabalho Athena. Em todasas operações a seguir, com exceção de ListWorkGroups, você deve especificar um grupo de trabalho.Em outras operações, como StartQueryExecution, o parâmetro do grupo de trabalho é opcional e asoperações não estão listadas aqui. Para obter a lista completa das operações, consulte Referência de APIdo Amazon Athena.
• CreateWorkGroup• DeleteWorkGroup• GetWorkGroup• ListWorkGroups• UpdateWorkGroup
Resolver problemas nos grupos de trabalhoUse as dicas a seguir para solucionar problemas com grupos de trabalho.
• Verifique as permissões para usuários individuais na sua conta. Eles devem ter acesso ao local para osresultados da consulta e ao grupo de trabalho no qual desejam executar consultas. Se eles quiseremalternar grupos de trabalho, vão precisar de permissões para ambos os grupos de trabalho. Para obterinformações, consulte Políticas de acesso aos grupos de trabalho do IAM (p. 221).
233

Amazon Athena Guia do usuárioResolver problemas nos grupos de trabalho
• Preste atenção ao contexto no console do Athena para ver em qual grupo de trabalho você vai executaras consultas. Se você usar o driver, defina o grupo de trabalho naquele de que você precisa. Paraobter mais informações, consulte the section called “Especifique um grupo de trabalho no qual executarconsultas” (p. 232).
• Se você usar a API ou os drivers para executar as consultas, será preciso especificar o local dosresultados da consulta usando uma das formas: seja para consultas individuais, usando OutputLocation(do lado do cliente), ou no grupo de trabalho, usando WorkGroupConfiguration. Se o local não estiverespecificado de nenhuma forma, o Athena emitirá um erro na execução da consulta.
• Se você substituir as configurações do lado do cliente pelas configurações do grupo de trabalho, poderáencontrar erros com o local de resultados da consulta. Por exemplo, o usuário de um grupo de trabalhopode não ter permissões para o local do grupo de trabalho no Amazon S3 para armazenar resultados daconsulta. Nesse caso, adicione as permissões necessárias.
• Os grupos de trabalho trazem mudanças no comportamento das operações da API. As chamadaspara as seguintes operações de API existentes exigem que os usuários em sua conta tenhampermissões baseadas em recursos no IAM para os grupos de trabalho em que o fazem. Senão houver permissões para o grupo de trabalho nem para ações do grupo de trabalho, aAPI a seguir emite AccessDeniedException: CreateNamedQuery, DeleteNamedQuery,GetNamedQuery, ListNamedQueries, StartQueryExecution, StopQueryExecution, ListQueryExecutions,GetQueryExecution, GetQueryResults e GetQueryResultsStream (esta ação da API só está disponívelpara uso com o driver, e não está exposta para uso público). Para obter mais informações, consulteAções, recursos e chaves de condição para o Amazon Athena, no Guia do usuário do IAM.
As chamadas para as operações da API BatchGetQueryExecution e BatchGetNamedQuery retornaminformações sobre execuções de consulta apenas para as consultas que forem executadas em gruposde trabalho aos quais os usuários têm acesso. Se o usuário não tiver acesso ao grupo de trabalho,essas operações da API retornarão os IDs de consulta não autorizados como parte da lista de IDs nãoprocessados. Para obter mais informações, consulte the section called “ APIs do grupo de trabalho doAthena” (p. 233).
• Se o grupo de trabalho em que uma consulta será executada estiver configurado com um local impostode resultados da consulta (p. 226), não especifique um external_location para a consulta CTAS.O Athena emitirá um erro e reprovará uma consulta que especifica um external_location nestecaso. Por exemplo, ocorrerá uma falha nesta consulta se você substituir as configurações do lado docliente para o local dos resultados da consulta, forçando o grupo de trabalho a usar o próprio local:CREATE TABLE <DB>.<TABLE1> WITH (format='Parquet', external_location='s3://my_test/test/') AS SELECT * FROM <DB>.<TABLE2> LIMIT 10;
Você pode ver os erros a seguir. Esta tabela fornece uma lista de alguns dos erros relacionados a gruposde trabalho e sugere soluções.
Erros do grupo de trabalho
Erro Ocorre quando...
query state CANCELED. Bytes scannedlimit was exceeded.
Uma consulta atinge um limite de dados porconsulta e é cancelada. Considere reescrever aconsulta para que leia menos dados ou entre emcontato com o administrador da conta.
User: arn:aws:iam::123456789012:user/abc is not authorized to perform:athena:StartQueryExecution onresource: arn:aws:athena:us-east-1:123456789012:workgroup/workgroupname
Um usuário executa uma consulta em um grupode trabalho, mas não tem acesso a ele. Atualize apolítica para ter acesso ao grupo de trabalho.
INVALID_INPUT. WorkGroup <name> isdisabled.
Um usuário executa uma consulta em um grupode trabalho, mas o grupo de trabalho está
234

Amazon Athena Guia do usuárioControlar custos e monitorar consultas
com métricas do CloudWatch
Erro Ocorre quando...desabilitado. Seu grupo de trabalho poderiaser desabilitado pelo administrador. É possíveltambém que você não tenha acesso a ele. Emambos os casos, entre em contato com umadministrador que tenha acesso para modificargrupos de trabalho.
INVALID_INPUT. WorkGroup <name> is notfound.
Um usuário executa uma consulta em um grupo detrabalho, mas o grupo de trabalho não existe. Issopode acontecer se o grupo de trabalho tiver sidoexcluído. Alterne para outro grupo de trabalho paraexecutar a consulta.
InvalidRequestException: when callingthe StartQueryExecution operation: Nooutput location provided. An outputlocation is required either throughthe Workgroup result configurationsetting or as an API input.
Um usuário executa uma consulta com a API semespecificar o local dos resultados da consulta.Você deve definir o local de saída para resultadosda consulta usando uma de duas formas: paraconsultas individuais, usando OutputLocation (nolado do cliente), ou, no grupo de trabalho, usandoWorkGroupConfiguration.
The Create Table As Select queryfailed because it was submitted withan 'external_location' property toan Athena Workgroup that enforcesa centralized output location forall queries. Please remove the'external_location' property andresubmit the query.
Se o grupo de trabalho em que uma consultafor executada estiver configurado com um localimposto para os resultados da consulta (p. 226)e você especificar um external_locationpara a consulta do CTAS. Neste caso, remova oexternal_location e execute a consulta.
Controlar custos e monitorar consultas commétricas do CloudWatch
Os grupos de trabalho permitem que você defina os limites de controle de uso de dados por consulta oupor workgroup, configure alarmes quando esses limites forem excedidos e publique métricas de consultano CloudWatch.
Em cada grupo de trabalho, você pode:
• Configurar os Data usage controls (Controles de uso de dados) por consulta e por grupo de trabalho eestabelecer ações que serão executadas se as consultas violarem os limites.
• Visualizar e analisar métricas de consulta e publicá-las no CloudWatch. Se você criar um grupo detrabalho no console, a configuração para a publicação de métricas no CloudWatch será selecionadapara você. Se você usar as operações de API, deve habilitar a publicação de métricas (p. 236).Quando são publicadas, as métricas são exibidas na guia Metrics (Métricas) do painel Workgroups(Grupos de trabalho). As métricas são desativadas por padrão para o grupo de trabalho principal.
Tópicos• Habilitar métricas de consulta do CloudWatch (p. 236)• Monitorar consultas de Athena com métricas de CloudWatch (p. 236)• Definir limites de controle de uso de dados (p. 238)
235

Amazon Athena Guia do usuárioHabilitar métricas de consulta do CloudWatch
Habilitar métricas de consulta do CloudWatchAo criar um grupo de trabalho no console, será selecionada por padrão a configuração para publicarmétricas de consulta no CloudWatch.
Se você usar operações de API, a interface de linha de comando ou o aplicativo cliente com o driverJDBC para criar grupos de trabalho, de forma a habilitar a publicação de métricas de consulta, definaPublishCloudWatchMetricsEnabled como true em WorkGroupConfiguration. O exemplo a seguirmostra apenas a configuração das métricas e omite outra configuração:
"WorkGroupConfiguration": { "PublishCloudWatchMetricsEnabled": "true" .... }
Monitorar consultas de Athena com métricas deCloudWatchO Athena publica métricas relacionadas à consulta no Amazon CloudWatch, quando a opção Publish toCloudWatch (Publicar no CloudWatch) estiver selecionada. Você pode criar painéis personalizados, definiralarmes e triggers nas métricas do CloudWatch ou usar painéis pré-preenchidos diretamente do consoleAthena.
Quando você habilitar as métricas de consulta para consultas nos grupos de trabalho, as métricas serãoexibidas na guia Metrics (Metrics) do painel Workgroups (Grupos de trabalho), para cada grupo de trabalhodo console Athena.
O Athena publica as seguintes métricas no console do CloudWatch:
• DataScannedInBytes – a quantidade total de dados verificados por consulta• EngineExecutionTime – em milissegundos• QueryPlanningTime – em milissegundos• QueryQueueTime – em milissegundos• QueryState – (com êxito, com falha ou canceladas)• QueryType – DDL ou DML• ServiceProcessingTime – em milissegundos• TotalExecutionTime – em milissegundos• WorkGroup – nome do grupo de trabalho.
Para obter mais informações, consulte Lista das métricas do CloudWatch para Athena (p. 237)posteriormente neste tópico.
Para visualizar as métricas de consulta para um grupo de trabalho no console
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha a guia Workgroup: (Grupo de trabalho)<name>.
Para visualizar uma métrica do grupo de trabalho, você não precisa alternar para ela, podendopermanecer em outro grupo. Você precisa selecionar o grupo de trabalho na lista. Você também deveter permissões para visualizar suas métricas.
236

Amazon Athena Guia do usuárioMonitorar consultas de Athena com métricas de CloudWatch
3. Selecione o grupo de trabalho na lista e escolha View details (Exibir detalhes). Se você tiverpermissões, os detalhes do grupo de trabalho são exibidos na guia Overview (Visão geral).
4. Escolha a guia Metrics.
Como resultado, as métricas são exibidas.5. Escolha o intervalo de métricas que o Athena deve usar para buscar as métricas de consulta do
CloudWatch, ou escolha o ícone de atualização para atualizar as métricas exibidas.
Para exibir métricas no console do Amazon CloudWatch
1. Abra o console do Amazon CloudWatch em https://console.aws.amazon.com/cloudwatch/.2. No painel de navegação, selecione Métricas.3. Selecione o namespace AWS/Athena.
Para exibir métricas com a CLI
• Abra um prompt de comando e use o seguinte comando:
aws cloudwatch list-metrics --namespace "AWS/Athena"
• Para listar todas as métricas disponíveis, use o comando a seguir:
aws cloudwatch list-metrics --namespace "AWS/Athena"
Lista das métricas do CloudWatch para AthenaSe tiver habilitado as métricas do CloudWatch no Athena, ele enviará as métricas a seguir ao CloudWatchpor grupo de trabalho. As métricas usam o namespace AWS/Athena.
Nome da métrica Descrição
DataScannedInBytes A quantidade total de dados, em megabytes que o Athena verificoupor consulta. Para consultas que foram canceladas (pelo usuários, ouautomaticamente, se atingiram o limite), isso inclui a quantidade dedados verificada antes da hora do cancelamento.
EngineExecutionTime O número de milissegundos que a consulta levou para ser executada.
237

Amazon Athena Guia do usuárioDefinir limites de controle de uso de dados
Nome da métrica Descrição
QueryPlanningTime O número de milissegundos que o Athena levou para planejar ofluxo de processamento da consulta. Isso inclui o tempo gastorecuperando partições de tabela da fonte de dados. Observeque, como o mecanismo de consulta executa o planejamento daconsulta, o tempo de planejamento de consulta é um subconjunto deEngineExecutionTime.
QueryQueueTime O número de milissegundos que a consulta estava na fila deconsultas aguardando recursos. Observe que, se ocorrerem errostemporários, a consulta poderá ser adicionada automaticamente devolta à fila.
QueryState O estado da consulta.
Estatísticas válidas: com êxito, com falha, canceladas
QueryType O tipo de consulta.
Estatísticas válidas: DDL ou DML.
ServiceProcessingTime Número de milissegundos que o Athena levou para processar osresultados da consulta depois que o mecanismo de consulta concluiusua execução.
TotalExecutionTime O número de milissegundos que o Athena levou para executar aconsulta.
WorkGroup O nome do grupo de trabalho.
Definir limites de controle de uso de dadosO Athena permite a definição de dois tipos de controles de custo: por limite de consulta e por limite degrupo de trabalho. Para cada grupo de trabalho, você só pode definir um limite por consulta e vários limitespor grupo de trabalho.
• O limite de controle por consulta especifica a quantidade total de dados analisados por consulta. Sequalquer consulta que for executada no grupo de trabalho exceder o limite, ela será cancelada. Vocêpode criar apenas um limite de controle por consulta em um grupo de trabalho e aplicá-lo a cadaconsulta que for executada nele. Edite o limite se precisar alterá-lo. Para obter etapas detalhadas,consulte Para criar um controle de uso de dados por consulta (p. 239).
• O limite de controle de uso de dados no âmbito do grupo de trabalho especifica a quantidade totalde dados verificados para todas as consultas que são executadas neste grupo de trabalho duranteo período especificado. Você pode criar vários limites por grupo de trabalho. O limite de consulta noâmbito do grupo de trabalho permite que você defina vários limites em agregados de hora e dia nosdados analisados por consultas em execução no grupo de trabalho.
Se a quantidade somada de dados verificados exceder o limite, você pode optar por executar uma dasseguintes ações:• Configure um alarme de Amazon SNS e uma ação no console do Athena para notificar um
administrador quando o limite for violado. Para obter etapas detalhadas, consulte Para criar umcontrole de uso de dados por grupo de trabalho (p. 240). Você também pode criar um alarme e umaação em qualquer métrica que o Athena publicar pelo console do CloudWatch. Por exemplo, vocêpode configurar um alerta para um determinado número de consultas com falha. Esse alerta podeacionar um e-mail para um administrador se o número ultrapassar um determinado limite. Se o limitefor excedido, uma ação enviará a notificação de alarme do Amazon SNS aos usuários especificados.
238

Amazon Athena Guia do usuárioDefinir limites de controle de uso de dados
• Invocar uma função do Lambda Para obter mais informações, consulte Invocar funções do Lambdausando notificações do Amazon SNS no Guia do desenvolvedor do Amazon Simple NotificationService.
• Desative o grupo de trabalho, impedindo que outras consultas sejam executadas.
Os limites por consulta e por grupo de trabalho são independentes um do outro. Uma ação especificadaserá executada sempre que o limite for excedido. Se dois ou mais usuários executarem consultas aomesmo tempo no mesmo grupo de trabalho, é possível que cada consulta não exceda nenhum dos limitesespecificados, mas a soma dos dados verificados exceda o limite de uso de dados por grupo de trabalho.Nesse caso, será enviado um alarme do Amazon SNS ao usuário.
Para criar um controle de uso de dados por consulta
O limite de controle por consulta especifica a quantidade total de dados analisados por consulta. Sequalquer consulta que for executada no grupo de trabalho exceder o limite, ela será cancelada. Asconsultas canceladas são cobrado de acordo com os preços de Amazon Athena.
Note
No caso de consultas canceladas ou com falha, o Athena pode já ter gravado resultados parciaisno Amazon S3. Nesses casos, o Athena não excluirá os resultados parciais do prefixo doAmazon S3 em que os resultados são armazenados. Você deve remover o prefixo do AmazonS3 com resultados parciais. O Athena usa multipart uploads do Amazon S3 para gravar dadosdo Amazon S3. Recomendamos que você defina a política do ciclo de vida do bucket para anularmultipart uploads nos casos em que as consultas falharem. Para obter mais informações, consulteCancelamento de multipart uploads incompletos usando uma política de ciclo de vida de bucket,no Guia do desenvolvedor do Amazon Simple Storage Service.
Você pode criar apenas um limite de controle por consulta em um grupo de trabalho e aplicá-lo a cadaconsulta que for executada nele. Edite o limite se precisar alterá-lo.
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha a guia Workgroup: (Grupo de trabalho)<name>.
Para criar um controle de uso de dados para uma consulta em um determinado grupo de trabalho,você não precisa alternar para ele, podendo permanecer em outro grupo. Você precisa selecionar ogrupo de trabalho na lista e ter permissões para editar o grupo de trabalho.
3. Selecione o grupo de trabalho na lista e escolha View details (Exibir detalhes). Se você tiverpermissões, os detalhes do grupo de trabalho são exibidos na guia Overview (Visão geral).
4. Escolha a guia Data usage controls (Controles de uso de dados). É exibida a caixa de diálogo PerQuery Data Usage Control (Controle de uso de dados por consulta).
239

Amazon Athena Guia do usuárioDefinir limites de controle de uso de dados
5. Especifique (ou atualize) os valores de campo, da seguinte forma:
• Para Data limit (Limite de dados), especifique um valor entre 10.000 KB (mínimo) e 7 EB (máximo).
Note
Esses são os limites impostos pelo console para controles de uso de dados dentro dosgrupos de trabalho. Eles não representam nenhum limite de consulta no Athena.
• Para unidades, selecione o valor da unidade na lista suspensa.• Analise a Action (Ação) padrão. A Action (Ação) padrão é cancelar a consulta se ela exceder o
limite. Isso não pode ser alterado.6. Escolha Create (Criar) se você estiver criando um novo limite, ou Update (Atualizar) se você estiver
editando um limite existente. Se você estiver editando um limite existente, atualize a guia Overview(Visão geral) para ver o limite atualizado.
Para criar um controle de uso de dados por grupo de trabalho
O limite de controle de uso de dados no âmbito do grupo de trabalho especifica a quantidade total dedados verificados para todas as consultas que são executadas neste grupo de trabalho durante o períodoespecificado. Você pode criar vários limites de controle por grupo de trabalho. Se o limite for excedido,você pode optar por realizar ações como enviar uma notificação de alarme do Amazon SNS a usuáriosespecificados.
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. Escolha a guia Workgroup: (Grupo de trabalho)<name>.
Para criar um controle de uso de dados para um determinado grupo de trabalho, você não precisaalternar para ele, podendo permanecer em outro grupo. Você precisa selecionar o grupo de trabalhona lista e ter permissões para editar o grupo de trabalho.
3. Selecione o grupo de trabalho na lista e escolha View details (Exibir detalhes). Se você tiverpermissões de edição, os detalhes do grupo de trabalho serão exibidos na guia Overview (Visãogeral).
4. Escolha a guia Data usage controls (Controles de uso de dados) e role para baixo. Escolha WorkgroupData Usage Control (Controle de uso de dados do grupo de trabalho) para criar um novo limite oueditar um limite existente. A caixa de diálogo Create workgroup data usage control (Criar controle deuso de dados do grupo de trabalho) é exibida.
5. Especifique os valores de campo da seguinte forma:
• Para Data limits (Limites de dados), especifique um valor entre 10.000 KB (mínimo) e 7 EB(máximo).
Note
Esses são os limites impostos pelo console para controles de uso de dados dentro dosgrupos de trabalho. Eles não representam nenhum limite de consulta no Athena.
• Para unidades, selecione o valor da unidade na lista suspensa.240

Amazon Athena Guia do usuárioDefinir limites de controle de uso de dados
• Com relação ao período, selecione um na lista suspensa.• Em Action (Ação), escolha o tópico Amazon SNS na lista suspensa, caso você já o tenha
configurado. Ou escolha Create an Amazon SNS topic (Criar um tópico do Amazon SNS) para irdiretamente ao console do Amazon SNS, crie o tópico do Amazon SNS e configure uma assinaturapara um dos usuários na sua conta do Athena. Para obter mais informações, consulte Criar umtópico do Amazon SNS no Guia de conceitos básicos do Amazon Simple Notification Service.
6. Escolha Create (Criar) se você estiver criando um novo limite, ou Save (Salvar) se você estivereditando um limite existente. Se você estiver editando um limite existente, atualize a guia Overview(Visão geral) do grupo de trabalho para ver o limite atualizado.
241

Amazon Athena Guia do usuárioConceitos básicos de tags
Marcar com tags os grupos detrabalho
Uma tag consiste em uma chave e um valor, ambos definidos por você. Quando você marca um grupo detrabalho, atribui metadados personalizados a ele. Você pode usar tags para categorizar seus recursos daAWS de diferentes formas – como por finalidade, por proprietário ou por ambiente. Para o Athena, o grupode trabalho é o recurso que você pode marcar. Por exemplo, você pode criar um conjunto de tags paragrupos de trabalho na sua conta que ajuda a rastrear os proprietários do grupo de trabalho ou identificargrupos de trabalho por finalidade. Recomendamos usar as melhores práticas de marcação com tags daAWS para criar um conjunto consistente de tags que atenda às necessidades da sua organização.
Você pode trabalhar com tags usando o console do Athena ou as operações de API.
Tópicos• Conceitos básicos de tags (p. 242)• Restrições de tag (p. 243)• Trabalho com tags usando o console (p. 243)• Trabalhar com tags usando as ações da API (p. 245)• Políticas de controle de acesso do IAM baseadas em tags (p. 246)
Conceitos básicos de tagsUma tag é um rótulo atribuído a um recurso do Athena. Cada tag consiste de uma chave e um valoropcional, ambos definidos por você.
As tags permitem categorizar seus recursos da AWS de maneiras diferentes. Por exemplo, você podedefinir um conjunto de tags para os grupos de trabalho da sua conta que ajudem a rastrear o proprietárioou a finalidade de cada grupo de trabalho.
Você pode adicionar tags ao criar um novo grupo de trabalho do Athena ou adicionar, editar ou removertags de um grupo de trabalho existente. Você pode editar uma tag no console. Se você usar as operaçõesde API, para editar uma tag, remova a tag antiga e adicione uma nova. Se você excluir um grupo detrabalho, todas as tags dele também serão excluídas. Outros grupos de trabalho da sua conta continuamusando as mesmas tags.
O Athena não atribui automaticamente tags aos seus recursos, como grupos de trabalho. Você pode editarchaves de tags e valores, e pode remover as tags de um grupo de trabalho a qualquer momento. Vocêpode definir o valor de uma tag a uma string vazia, mas não pode configurar o valor de um tag como nula.Não adicione chaves de tag duplicadas ao mesmo tempo ao mesmo grupo de trabalho. Se você fizer isso,o Athena emitirá uma mensagem de erro. Se você marcar um grupo de trabalho usando uma chave de tagexistente em uma ação separada de TagResource, o novo valor da tag será sobreposto ao valor antigo.
No IAM, é possível controlar quais usuários na sua conta da AWS têm permissão para criar, editar,remover ou listar tags. Para obter mais informações, consulte the section called “Exemplos da política detags” (p. 246).
Para obter uma lista completa de ações de tag do Amazon Athena, consulte os nomes de ação da API noReferência de API do Amazon Athena.
Você pode usar as mesmas tags para faturamento. Para obter mais informações, consulte Usar tags parafaturamento no Guia do usuário do AWS Billing and Cost Management;.
242

Amazon Athena Guia do usuárioRestrições de tag
Para obter mais informações, consulte Restrições de tag (p. 243).
Restrições de tagAs tags têm as seguintes restrições:
• No Athena, você pode marcar os grupos de trabalho com tags. Você não pode marcar consultas comtags.
• O número máximo de tags por grupo de trabalho é 50. Para permanecer no limite, revise e exclua tagsnão utilizadas.
• Para cada grupo de trabalho, cada chave de tag deve ser exclusiva e pode ter apenas um valor. Nãoadicione chaves de tag duplicadas ao mesmo tempo ao mesmo grupo de trabalho. Se você fizer isso, oAthena emitirá uma mensagem de erro. Se você marcar um grupo de trabalho usando uma chave de tagexistente em uma ação separada de TagResource, o novo valor da tag será sobreposto ao valor antigo.
• O comprimento da chave da tag é de 1-128 caracteres Unicode em UTF-8.• O comprimento do valor da tag é de 0-256 caracteres Unicode em UTF-8.
Marcar operações, como adicionar, editar, remover ou listar tags, exigem que você especifique um ARNpara o recurso do grupo de trabalho.
• O Athena permite usar letras, números e espaços representados em UTF-8, bem como os seguintescaracteres: + - = . _ : / @.
• As chaves e os valores de tags diferenciam maiúsculas de minúsculas.• Não use o prefixo "aws:" nas chaves de tags; ele é reservado para uso da AWS. Você não pode editar
nem excluir chaves de tag com esse prefixo. As tags com esse prefixo não contam contra o limite detags por recurso.
• As tags atribuídas estão disponíveis somente à sua conta da AWS.
Trabalho com tags usando o consoleUsando o console do Athena, você pode ver quais tags estão em uso por cada grupo de trabalho nasua conta. Você só pode visualizar as tags por grupo de trabalho. Você também pode usar o console doAthena para aplicar, editar ou remover as tags de um grupo de trabalho por vez.
Você pode pesquisar grupos de trabalho usando as tags criadas.
Tópicos• Exibir tags para grupos de trabalho individuais (p. 243)• Adicionar e excluir tags em um grupo de trabalho individual (p. 244)
Exibir tags para grupos de trabalho individuaisVocê pode exibir tags para um grupo de trabalho individual no console do Athena.
Para visualizar uma lista de tags para um grupo de trabalho, selecione o grupo de trabalho, escolha ViewDetails (Exibir detalhes) e escolha a guia Tags (Tags). É exibida a lista de tags para o grupo de trabalho.Você também pode visualizar tags em um grupo de trabalho se escolher Edit Workgroup (Editar grupo detrabalho).
Para pesquisar tags, escolha a guia Tags (Tags) e Manage Tags (Gerenciar tags). Insira um nome de tagna ferramenta de pesquisa.
243

Amazon Athena Guia do usuárioAdicionar e excluir tags em um grupo de trabalho individual
Adicionar e excluir tags em um grupo de trabalhoindividualVocê pode gerenciar as tags de um único grupo de trabalho diretamente pela guia Workgroups (Grupos detrabalho).
Para adicionar uma tag ao criar um novo grupo de trabalhoNote
Dê a um usuário as permissões do IAM para as ações CreateWorkGroup e TagResource sequiser permitir que ele adicione tags ao criar um grupo de trabalho no console ou passe tags emCreateWorkGroup.
1. Abra o console do Athena em https://console.aws.amazon.com/athena/.2. No menu de navegação, selecione a guia Workgroups (Grupos de trabalho).3. Escolha Create workgroup (Criar grupo de trabalho) e preencha os valores, conforme necessário. Para
obter detalhes das etapas, consulte, Criar um grupo de trabalho (p. 228).4. Adicione uma ou mais tags, especificando as chaves e os valores. Não adicione chaves de tag
duplicadas ao mesmo tempo ao mesmo grupo de trabalho. Se você fizer isso, o Athena emitirá umamensagem de erro. Para obter mais informações, consulte Restrições de tag (p. 243).
5. Quando concluir, escolha Create Workgroup (Criar grupo de trabalho).
Para adicionar ou editar uma tag a um grupo de trabalho existenteNote
Dê a um usuário as permissões do IAM para as ações CreateWorkGroup e TagResource sequiser permitir que ele adicione tags ao criar um grupo de trabalho no console ou passe tags emCreateWorkGroup.
1. Abra o console do Athena em https://console.aws.amazon.com/athena/, escolha a guia Workgroups(Grupos de trabalho) e selecione o grupo de trabalho.
2. Escolha View details (Exibir detalhes) ou Edit workgroup (Editar grupo de trabalho).3. Escolha a guia Tags.4. Na guia Tags (Tags), escolha Manage tags (Gerenciar tags) e especifique a chave e o valor de cada
tag. Para obter mais informações, consulte Restrições de tag (p. 243).
244

Amazon Athena Guia do usuárioTrabalhar com tags usando as ações da API
5. Quando concluir, selecione Save.
Para excluir uma tag de um grupo de trabalho individual
1. Abra o console do Athena e escolha a guia Workgroups (Grupos de trabalho).2. Na lista de grupos de trabalho, selecione View details (Exibir detalhes) e escolha a guia Tags (Tags).3. Na guia Tags (Tags), selecione Manage tags (Gerenciar tags).4. Na lista de tags, selecione o botão delete (excluir) (uma cross (cruz)) para a tag e escolha Save
(Salvar).
Trabalhar com tags usando as ações da APIVocê também pode usar a operação CreateWorkGroup da API com o parâmetro de tag opcionalque pode usar para passar uma ou mais tags para o grupo de trabalho. Para adicionar, removerou listar tags, use as seguintes operações da API da AWS: TagResource, UntagResource eListTagsForResource.
Tags das ações da API no Athena
Nome da API Descrição da ação
TagResource Adicione ou substitua uma ou mais tags no grupode trabalho com o ARN especificado.
UntagResource Exclua uma ou mais tags do grupo de trabalho como ARN especificado.
ListTagsForResource Liste uma ou mais tags para o recurso do grupo detrabalho com o ARN especificado.
Para obter mais informações, consulte o Referência de API do Amazon Athena.
Example TagResource
No exemplo a seguir, adicionamos duas tags ao workgroupA:
List<Tag> tags = new ArrayList<>();tags.add(new Tag().withKey("tagKey1").withValue("tagValue1"));tags.add(new Tag().withKey("tagKey2").withValue("tagValue2"));
TagResourceRequest request = new TagResourceRequest() .withResourceARN("arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA") .withTags(tags);
client.tagResource(request);
Note
Não adicione chaves de tag duplicadas ao mesmo tempo ao mesmo grupo de trabalho. Se vocêfizer isso, o Athena emitirá uma mensagem de erro. Se você marcar um grupo de trabalho usandouma chave de tag existente em uma ação separada de TagResource, o novo valor da tag serásobreposto ao valor antigo.
Example UntagResource
No exemplo a seguir, removemos a tagKey2 do workgroupA:
245

Amazon Athena Guia do usuárioPolíticas de controle de acesso do IAM baseadas em tags
List<String> tagKeys = new ArrayList<>();tagKeys.add("tagKey2");
UntagResourceRequest request = new UntagResourceRequest() .withResourceARN("arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA") .withTagKeys(tagKeys);
client.untagResource(request);
Example ListTagsForResource
No exemplo a seguir, listamos as tags para workgroupA:
ListTagsForResourceRequest request = new ListTagsForResourceRequest() .withResourceARN("arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA");
ListTagsForResourceResult result = client.listTagsForResource(request);
List<Tag> resultTags = result.getTags();
Políticas de controle de acesso do IAM baseadasem tags
A disponibilidade de tags permite gravar uma política do IAM que inclua um bloco condicional, de forma acontrolar o acesso a grupos de trabalho com base em suas tags.
Exemplos da política de tagsExample 1. Política básica de marcação com tags
A política do IAM a seguir permite que você execute consultas e interaja com tags para o grupo de trabalhode nome workgroupA:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "athena:ListWorkGroups", "athena:GetExecutionEngine", "athena:GetExecutionEngines", "athena:GetNamespace", "athena:GetCatalogs", "athena:GetNamespaces", "athena:GetTables", "athena:GetTable" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "athena:StartQueryExecution", "athena:GetQueryResults", "athena:DeleteNamedQuery",
246

Amazon Athena Guia do usuárioExemplos da política de tags
"athena:GetNamedQuery", "athena:ListQueryExecutions", "athena:StopQueryExecution", "athena:GetQueryResultsStream", "athena:GetQueryExecutions", "athena:ListNamedQueries", "athena:CreateNamedQuery", "athena:GetQueryExecution", "athena:BatchGetNamedQuery", "athena:BatchGetQueryExecution", "athena:GetWorkGroup", "athena:TagResource", "athena:UntagResource", "athena:ListTagsForResource" ], "Resource": "arn:aws:athena:us-east-1:123456789012:workgroup/workgroupA" } ]}
Example 2: Bloco de política que nega ações em um grupo de trabalho com base em uma chavede tag e um par de valores de tag
As tags associadas a um grupo de trabalho existente são chamadas de tags de recurso. Tags de recursospermitem que você escreva blocos de políticas como o seguinte, que nega as ações listadas em qualquergrupo de trabalho marcado com chave de tag e par de valores de tag, como stack, production.
{ "Effect": "Deny", "Action": [ "athena:StartQueryExecution", "athena:GetQueryResults", "athena:DeleteNamedQuery", "athena:UpdateWorkGroup", "athena:GetNamedQuery", "athena:ListQueryExecutions", "athena:GetWorkGroup", "athena:StopQueryExecution", "athena:GetQueryResultsStream", "athena:GetQueryExecutions", "athena:ListNamedQueries", "athena:CreateNamedQuery", "athena:GetQueryExecution", "athena:BatchGetNamedQuery", "athena:BatchGetQueryExecution", "athena:TagResource", "athena:UntagResource", "athena:ListTagsForResource" ], "Resource": "arn:aws:athena:us-east-1:123456789012:workgroup/*", "Condition": { "StringEquals": { "aws:ResourceTag/stack": "production" } }}
Example 3. Bloco de política que restringe solicitações de ação de mudança de tag a tagsespecíficas
Tags passadas como parâmetros para uma ação de API com mutação de tag, como CreateWorkGroupcom tags, TagResource e UntagResource, são conhecidas como tags de solicitação. Use essas tags,
247

Amazon Athena Guia do usuárioExemplos da política de tags
conforme mostrado no seguinte bloco de política de exemplo. Isso permite CreateWorkGroup somente seuma das tags incluídas ao criar um grupo de trabalho for uma tag com a chave costcenter com um dosvalores de tag permitidos: 1, 2 ou 3.
Observação: Conceda a um usuário permissões do IAM às operações da API TagResource eCreateWorkGroup, se você quiser permitir que elas passem tags em CreateWorkGroup.
{ "Effect": "Allow", "Action": [ "athena:CreateWorkGroup", "athena:TagResource" ], "Resource": "arn:aws:athena:us-east-1:123456789012:workgroup/*", "Condition": { "StringEquals": { "aws:RequestTag/costcenter": [ "1", "2", "3" ] } }}
248

Amazon Athena Guia do usuárioRegistro em log de chamadas à API doAmazon Athena com o AWS CloudTrail
Monitorar logs e solucionarproblemas
Examine as solicitações do Athena usando logs do CloudTrail e consultas para resolução de problemas.
Tópicos• Registro em log de chamadas à API do Amazon Athena com o AWS CloudTrail (p. 249)• Solução de problemas (p. 252)
Registro em log de chamadas à API do AmazonAthena com o AWS CloudTrail
O Athena é integrado com o AWS CloudTrail, um serviço que fornece um registro das ações realizadas porum usuário, uma função ou um serviço da AWS no Athena.
O CloudTrail captura todas as chamadas à API do Athena como eventos. As chamadas capturadasincluem as chamadas do console do Athena e as chamadas de código a operações da API do Athena.Se você criar uma trilha, poderá habilitar a entrega contínua de eventos do CloudTrail para um bucket doAmazon S3, incluindo eventos para o Athena. Se não configurar uma trilha, você ainda poderá visualizaros eventos mais recentes no console do CloudTrail em Event history.
Com as informações coletadas pelo CloudTrail, determine a solicitação feita para o Athena, o endereço IPdo qual a solicitação foi feita, quem fez a solicitação, quando ela foi feita e detalhes adicionais.
Para saber mais sobre CloudTrail, consulte o AWS CloudTrail User Guide.
Você também pode usar o Athena para consultar os arquivos de log do CloudTrail para obter informações.Para obter mais informações, consulte Consulta de logs do AWS CloudTrail (p. 153) e CloudTrailSerDe (p. 258).
Informações sobre o Athena no CloudTrailO CloudTrail está habilitado na sua conta da AWS ao criá-la. Quando ocorre uma atividade no Athena, elaé registrada em um evento do CloudTrail junto com outros eventos de serviços da AWS em Event history(Histórico de eventos). Você pode visualizar, pesquisar e fazer download de eventos recentes em suaconta da AWS. Para obter mais informações, consulte Visualizar eventos com o histórico de eventos doCloudTrail.
Para obter um registro contínuo de eventos em sua conta da AWS, incluindo eventos para o Athena,crie uma trilha. Uma trilha permite CloudTrail para fornecer arquivos de log a um bucket do Amazon S3.Por padrão, quando você cria uma trilha no console, ela é aplicada a todas as regiões da AWS. A trilharegistra eventos de todas as regiões na partição da AWS e fornece os arquivos de log para o bucket doAmazon S3 que você especificar. Além disso, é possível configurar outros serviços da AWS para analisarmais profundamente e agir sobre os dados de evento coletados nos logs do CloudTrail. Para obter maisinformações, consulte:
• Visão geral da criação de uma trilha
249

Amazon Athena Guia do usuárioNoções básicas das entradas dos arquivos de log do Athena
• CloudTrail Serviços compatíveis e integrações do• Configuração de notificações do Amazon SNS para o CloudTrail• Receber arquivos de log do CloudTrail de várias regiões e receber arquivos de log do CloudTrail de
várias contas
Todas as ações do Athena são registradas em log pelo CloudTrail e documentadas no Referência de APIdo Amazon Athena. Por exemplo, as chamadas às ações StartQueryExecution e GetQueryResults nosarquivos de log do CloudTrail.
Cada entrada de log ou evento contém informações sobre quem gerou a solicitação. As informações deidentidade ajudam a determinar:
• Se a solicitação foi feita com credenciais de usuário da raiz ou do AWS Identity and Access Management(IAM).
• Se a solicitação foi feita com credenciais de segurança temporárias de uma função ou de um usuáriofederado.
• Se a solicitação foi feita por outro serviço da AWS.
Para obter mais informações, consulte Elemento userIdentity do CloudTrail.
Noções básicas das entradas dos arquivos de log doAthenaUma trilha é uma configuração que permite a entrega de eventos como arquivos de log em um bucketdo Amazon S3 que você especificar. Os arquivos de log do CloudTrail contêm uma ou mais entradasde log. Um evento representa uma única solicitação de qualquer origem e inclui informações sobre aação solicitada, a data e hora da ação, parâmetros de solicitação, e assim por diante. arquivos de log doCloudTrail não são um rastreamento de pilha ordenada das chamadas da API pública. Assim, elas não sãoexibidas em nenhuma ordem específica.
Os seguintes exemplos demonstram entradas de log do CloudTrail para:
• StartQueryExecution (bem-sucedido) (p. 250)• StartQueryExecution (falha) (p. 251)• CreateNamedQuery (p. 251)
StartQueryExecution (bem-sucedido){ "eventVersion":"1.05", "userIdentity":{ "type":"IAMUser", "principalId":"EXAMPLE_PRINCIPAL_ID", "arn":"arn:aws:iam::123456789012:user/johndoe", "accountId":"123456789012", "accessKeyId":"EXAMPLE_KEY_ID", "userName":"johndoe" }, "eventTime":"2017-05-04T00:23:55Z", "eventSource":"athena.amazonaws.com", "eventName":"StartQueryExecution", "awsRegion":"us-east-1", "sourceIPAddress":"77.88.999.69", "userAgent":"aws-internal/3",
250

Amazon Athena Guia do usuárioNoções básicas das entradas dos arquivos de log do Athena
"requestParameters":{ "clientRequestToken":"16bc6e70-f972-4260-b18a-db1b623cb35c", "resultConfiguration":{ "outputLocation":"s3://athena-johndoe-test/test/" }, "query":"Select 10" }, "responseElements":{ "queryExecutionId":"b621c254-74e0-48e3-9630-78ed857782f9" }, "requestID":"f5039b01-305f-11e7-b146-c3fc56a7dc7a", "eventID":"c97cf8c8-6112-467a-8777-53bb38f83fd5", "eventType":"AwsApiCall", "recipientAccountId":"123456789012"}
StartQueryExecution (falha){ "eventVersion":"1.05", "userIdentity":{ "type":"IAMUser", "principalId":"EXAMPLE_PRINCIPAL_ID", "arn":"arn:aws:iam::123456789012:user/johndoe", "accountId":"123456789012", "accessKeyId":"EXAMPLE_KEY_ID", "userName":"johndoe" }, "eventTime":"2017-05-04T00:21:57Z", "eventSource":"athena.amazonaws.com", "eventName":"StartQueryExecution", "awsRegion":"us-east-1", "sourceIPAddress":"77.88.999.69", "userAgent":"aws-internal/3", "errorCode":"InvalidRequestException", "errorMessage":"Invalid result configuration. Should specify either output location or result configuration", "requestParameters":{ "clientRequestToken":"ca0e965f-d6d8-4277-8257-814a57f57446", "query":"Select 10" }, "responseElements":null, "requestID":"aefbc057-305f-11e7-9f39-bbc56d5d161e", "eventID":"6e1fc69b-d076-477e-8dec-024ee51488c4", "eventType":"AwsApiCall", "recipientAccountId":"123456789012"}
CreateNamedQuery{ "eventVersion":"1.05", "userIdentity":{ "type":"IAMUser", "principalId":"EXAMPLE_PRINCIPAL_ID", "arn":"arn:aws:iam::123456789012:user/johndoe", "accountId":"123456789012", "accessKeyId":"EXAMPLE_KEY_ID", "userName":"johndoe" }, "eventTime":"2017-05-16T22:00:58Z", "eventSource":"athena.amazonaws.com",
251

Amazon Athena Guia do usuárioSolução de problemas
"eventName":"CreateNamedQuery", "awsRegion":"us-west-2", "sourceIPAddress":"77.88.999.69", "userAgent":"aws-cli/1.11.85 Python/2.7.10 Darwin/16.6.0 botocore/1.5.48", "requestParameters":{ "name":"johndoetest", "queryString":"select 10", "database":"default", "clientRequestToken":"fc1ad880-69ee-4df0-bb0f-1770d9a539b1" }, "responseElements":{ "namedQueryId":"cdd0fe29-4787-4263-9188-a9c8db29f2d6" }, "requestID":"2487dd96-3a83-11e7-8f67-c9de5ac76512", "eventID":"15e3d3b5-6c3b-4c7c-bc0b-36a8dd95227b", "eventType":"AwsApiCall", "recipientAccountId":"123456789012"},
Solução de problemasUse esses tópicos de documentação para solucionar problemas com Amazon Athena.
• Cotas de serviço (p. 322)• Considerações e limitações de consultas SQL no Amazon Athena (p. 307)• DDL incompatível (p. 290)• Nomes para tabelas, bancos de dados e colunas (p. 18)• Tipos de dados compatíveis com o Amazon Athena (p. 281)• SerDes e formatos de dados compatíveis (p. 254)• Formatos de compactação (p. 279)• Palavras-chave reservadas (p. 19)• Resolver problemas nos grupos de trabalho (p. 233)
Além disso, use os seguintes recursos da AWS:
• Tópicos do Athena no Centro de conhecimento da AWS• Fórum de discussão do Athena• Posts do Athena no blog AWS Big Data
252

Amazon Athena Guia do usuárioUsar um SerDe
Referência de SerDeO Athena oferece suporte a várias bibliotecas SerDe para analisar dados de formatos diferentes, comoCSV, JSON, Parquet e ORC. O Athena não oferece suporte a SerDes personalizados.
Tópicos• Usar um SerDe (p. 253)• SerDes e formatos de dados compatíveis (p. 254)• Formatos de compactação (p. 279)
Usar um SerDeUm SerDe (Serializador/desserializador) é uma maneira na qual o Athena interage com dados em váriosformatos.
É o SerDe especificado por você, e não a DDL, que define o esquema de tabela. Em outras palavras, oSerDe pode substituir a configuração da DDL que você especifica no Athena ao criar a tabela.
Para usar um SerDe em consultasPara usar um SerDe ao criar uma tabela no Athena, use um dos seguintes métodos:
• Use instruções DDL para descrever como ler e gravar dados na tabela e não especifique um ROWFORMAT, como neste exemplo. Isso omite a listagem do tipo SerDe real, e o LazySimpleSerDe nativoé usado por padrão.
Em geral, o Athena usará o LazySimpleSerDe, se você não especificar um ROW FORMAT, ou seespecificar ROW FORMAT DELIMITED.
ROW FORMATDELIMITED FIELDS TERMINATED BY ','ESCAPED BY '\\'COLLECTION ITEMS TERMINATED BY '|'MAP KEYS TERMINATED BY ':'
• Especifique explicitamente o tipo de SerDe que o Athena deve usar ao ler e gravar dados na tabela.Além disso, especifique propriedades adicionais em SERDEPROPERTIES, como neste exemplo.
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'WITH SERDEPROPERTIES ('serialization.format' = ',','field.delim' = ',','collection.delim' = '|','mapkey.delim' = ':','escape.delim' = '\\')
253
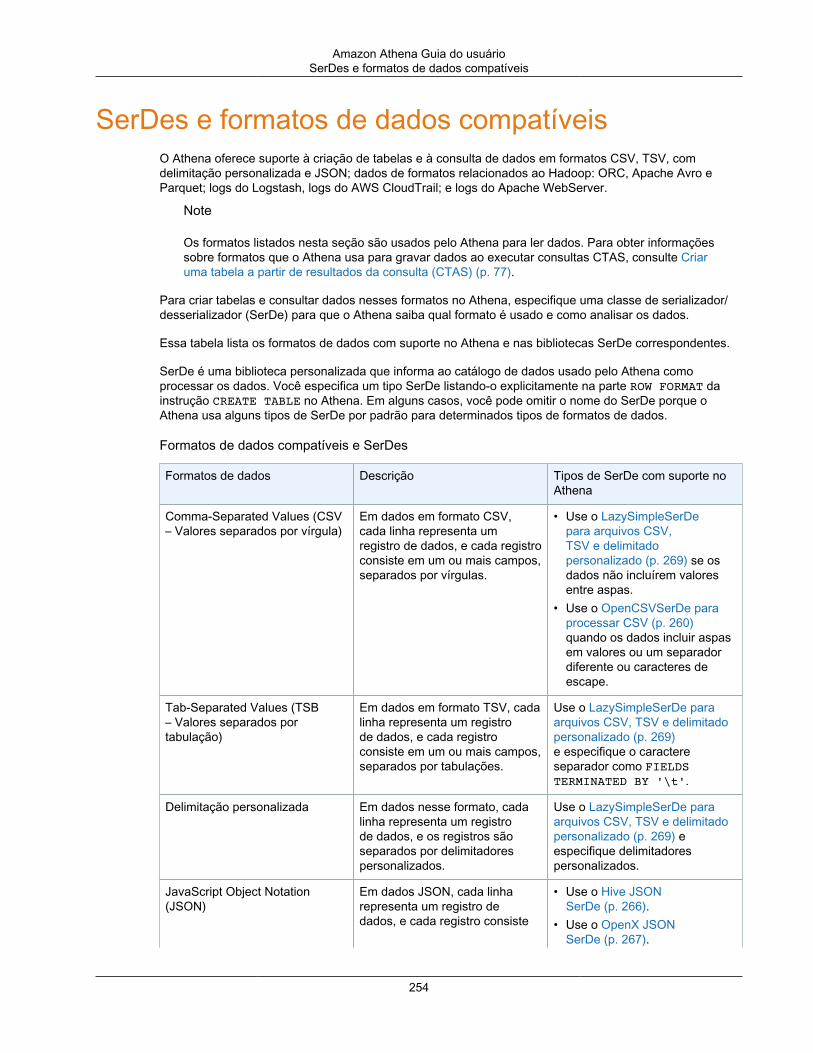
Amazon Athena Guia do usuárioSerDes e formatos de dados compatíveis
SerDes e formatos de dados compatíveisO Athena oferece suporte à criação de tabelas e à consulta de dados em formatos CSV, TSV, comdelimitação personalizada e JSON; dados de formatos relacionados ao Hadoop: ORC, Apache Avro eParquet; logs do Logstash, logs do AWS CloudTrail; e logs do Apache WebServer.
Note
Os formatos listados nesta seção são usados pelo Athena para ler dados. Para obter informaçõessobre formatos que o Athena usa para gravar dados ao executar consultas CTAS, consulte Criaruma tabela a partir de resultados da consulta (CTAS) (p. 77).
Para criar tabelas e consultar dados nesses formatos no Athena, especifique uma classe de serializador/desserializador (SerDe) para que o Athena saiba qual formato é usado e como analisar os dados.
Essa tabela lista os formatos de dados com suporte no Athena e nas bibliotecas SerDe correspondentes.
SerDe é uma biblioteca personalizada que informa ao catálogo de dados usado pelo Athena comoprocessar os dados. Você especifica um tipo SerDe listando-o explicitamente na parte ROW FORMAT dainstrução CREATE TABLE no Athena. Em alguns casos, você pode omitir o nome do SerDe porque oAthena usa alguns tipos de SerDe por padrão para determinados tipos de formatos de dados.
Formatos de dados compatíveis e SerDes
Formatos de dados Descrição Tipos de SerDe com suporte noAthena
Comma-Separated Values (CSV– Valores separados por vírgula)
Em dados em formato CSV,cada linha representa umregistro de dados, e cada registroconsiste em um ou mais campos,separados por vírgulas.
• Use o LazySimpleSerDepara arquivos CSV,TSV e delimitadopersonalizado (p. 269) se osdados não incluírem valoresentre aspas.
• Use o OpenCSVSerDe paraprocessar CSV (p. 260)quando os dados incluir aspasem valores ou um separadordiferente ou caracteres deescape.
Tab-Separated Values (TSB– Valores separados portabulação)
Em dados em formato TSV, cadalinha representa um registrode dados, e cada registroconsiste em um ou mais campos,separados por tabulações.
Use o LazySimpleSerDe paraarquivos CSV, TSV e delimitadopersonalizado (p. 269)e especifique o caractereseparador como FIELDSTERMINATED BY '\t'.
Delimitação personalizada Em dados nesse formato, cadalinha representa um registrode dados, e os registros sãoseparados por delimitadorespersonalizados.
Use o LazySimpleSerDe paraarquivos CSV, TSV e delimitadopersonalizado (p. 269) eespecifique delimitadorespersonalizados.
JavaScript Object Notation(JSON)
Em dados JSON, cada linharepresenta um registro dedados, e cada registro consiste
• Use o Hive JSONSerDe (p. 266).
• Use o OpenX JSONSerDe (p. 267).
254

Amazon Athena Guia do usuárioAvro SerDe
Formatos de dados Descrição Tipos de SerDe com suporte noAthena
em pares de atributo-valor ematrizes, separados por vírgulas.
Apache Avro Um formato para armazenardados no Hadoop que usaesquemas baseados em JSONpara valores de registro.
Use o Avro SerDe (p. 255).
Optimized Row Columnar (ORC– Colunar de linha otimizada)
Um formato paraarmazenamento colunarotimizado de dados do Hive.
Use o ORC SerDe (p. 274) e acompactação ZLIB.
Apache Parquet Um formato paraarmazenamento colunar dedados no Hadoop.
Use o Parquet SerDe (p. 277) ea compactação SNAPPY.
Logs do Logstash Um formato para armazenar logsno Logstash.
Use o Grok SerDe (p. 263).
Logs do Apache WebServer Um formato para armazenar logsno Apache WebServer.
Use o RegexSerDe paraprocessar logs do Apache WebServer (p. 258).
Logs do CloudTrail Um formato para armazenar logsno CloudTrail.
• Use o SerDe doCloudTrail (p. 258) paraconsultar o máximo de camposem logs do CloudTrail.
• Use o OpenX JSONSerDe (p. 267) em algunscampos nos quais o formatodependa do serviço. Para obtermais informações, consulteCloudTrail SerDe (p. 258).
Tópicos• Avro SerDe (p. 255)• RegexSerDe para processar logs do Apache Web Server (p. 258)• CloudTrail SerDe (p. 258)• OpenCSVSerDe para processar CSV (p. 260)• Grok SerDe (p. 263)• Bibliotecas SerDe JSON (p. 266)• LazySimpleSerDe para arquivos CSV, TSV e delimitados personalizados (p. 269)• ORC SerDe (p. 274)• Parquet SerDe (p. 277)
Avro SerDeNome do SerDeAvro SerDe
255

Amazon Athena Guia do usuárioAvro SerDe
Nome da bibliotecaorg.apache.hadoop.hive.serde2.avro.AvroSerDe
ExemplosO Athena não oferece suporte ao uso de avro.schema.url para especificar o esquema de tabela pormotivos de segurança. Use avro.schema.literal. Para extrair esquema de dados no formato Avro,você pode usar o Apache avro-tools-<version>.jar com o parâmetro getschema. Isso retorna umesquema que você pode usar na instrução WITH SERDEPROPERTIES. Por exemplo:
java -jar avro-tools-1.8.2.jar getschema my_data.avro
O arquivo avro-tools-<version>.jar está localizado no subdiretório java da versão do Avroinstalada. Para fazer download, consulte Versões do Apache Avro. Para fazer download do Apache AvroTools diretamente, consulte o Repositório do Apache Avro Tools Maven.
Depois de obter o esquema, use uma instrução CREATE TABLE para criar uma tabelado Athena com base em dados subjacentes do Avro armazenados no Amazon S3.No ROW FORMAT, especifique o Avro SerDe da seguinte forma: ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe'. Conforme demonstrado no exemploa seguir, é necessário especificar o esquema usando a cláusula WITH SERDEPROPERTIES, além deespecificar os nomes das colunas e os tipos de dados correspondentes para a tabela.
Note
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além dascobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
CREATE EXTERNAL TABLE flights_avro_example ( yr INT, flightdate STRING, uniquecarrier STRING, airlineid INT, carrier STRING, flightnum STRING, origin STRING, dest STRING, depdelay INT, carrierdelay INT, weatherdelay INT)PARTITIONED BY (year STRING)ROW FORMATSERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'WITH SERDEPROPERTIES ('avro.schema.literal'='{ "type" : "record", "name" : "flights_avro_subset", "namespace" : "default", "fields" : [ { "name" : "yr", "type" : [ "null", "int" ], "default" : null }, { "name" : "flightdate",
256

Amazon Athena Guia do usuárioAvro SerDe
"type" : [ "null", "string" ], "default" : null }, { "name" : "uniquecarrier", "type" : [ "null", "string" ], "default" : null }, { "name" : "airlineid", "type" : [ "null", "int" ], "default" : null }, { "name" : "carrier", "type" : [ "null", "string" ], "default" : null }, { "name" : "flightnum", "type" : [ "null", "string" ], "default" : null }, { "name" : "origin", "type" : [ "null", "string" ], "default" : null }, { "name" : "dest", "type" : [ "null", "string" ], "default" : null }, { "name" : "depdelay", "type" : [ "null", "int" ], "default" : null }, { "name" : "carrierdelay", "type" : [ "null", "int" ], "default" : null }, { "name" : "weatherdelay", "type" : [ "null", "int" ], "default" : null } ]}')STORED AS AVROLOCATION 's3://athena-examples-myregion/flight/avro/';
Execute a instrução MSCK REPAIR TABLE na tabela para atualizar metadados da partição.
MSCK REPAIR TABLE flights_avro_example;
Consulte as 10 principais cidades de partida pelo número total de partidas.
SELECT origin, count(*) AS total_departuresFROM flights_avro_exampleWHERE year >= '2000'GROUP BY originORDER BY total_departures DESCLIMIT 10;
Note
Dados de lista de voo provenientes de Flights (Voos) fornecidos pelo Departamento de Transportedos EUA, Bureau of Transportation Statistics. Dessaturado do original.
257

Amazon Athena Guia do usuárioRegexSerDe para processar logs do Apache Web Server
RegexSerDe para processar logs do Apache WebServerNome do SerDeRegexSerDe
Nome da bibliotecaRegexSerDe
ExemplosO exemplo a seguir cria uma tabela de logs do CloudFront usando o RegExSerDe do Tutorial de conceitosbásicos do Athena.
Note
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além dascobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( `Date` DATE, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, os STRING, Browser STRING, BrowserVersion STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$" ) LOCATION 's3://athena-examples-myregion/cloudfront/plaintext/';
CloudTrail SerDeO AWS CloudTrail é um serviço que registra chamadas à API da AWS e eventos para contas da AWS.O CloudTrail gera logs criptografados e armazena-os no Amazon S3. Você pode usar o Athena paraconsultar esses logs diretamente no Amazon S3 especificando o LOCATION de logs.
Para consultar logs do CloudTrail no Athena, crie a tabela a partir dos logs e use o SerDe do CloudTrailpara desserializar os dados dos logs.
Além de usar o SerDe do CloudTrail, existem instâncias nas quais você precisa usar um SerDe diferenteou extrair dados do JSON. Alguns campos em logs do CloudTrail são valores STRING que podemter um formato de dados variável, dependendo do serviço. Por isso, o SerDe do CloudTrail não podedesserializá-los de maneira previsível. Para consultar os seguintes campos, identifique o padrão de dados
258

Amazon Athena Guia do usuárioCloudTrail SerDe
e use um SerDe diferente, como o OpenX JSON SerDe (p. 267). Como alternativa, para obter dadosdesses campos, use funções JSON_EXTRACT. Para obter mais informações, consulte Extrair dados deJSON (p. 122).
• requestParameters
• responseElements
• additionalEventData
• serviceEventDetails
Nome do SerDeCloudTrail SerDe
Nome da bibliotecacom.amazon.emr.hive.serde.CloudTrailSerde
ExemplosO exemplo a seguir usa o SerDe do CloudTrail em um conjunto de logs fictício para criar uma tabela combase nesses logs.
Neste exemplo, os campos requestParameters, responseElements e additionalEventData sãoincluídos como parte do tipo de dados STRUCT usado em JSON. Para obter dados desses campos, usefunções JSON_EXTRACT. Para obter mais informações, consulte Extrair dados de JSON (p. 122).
CREATE EXTERNAL TABLE cloudtrail_logs (eventversion STRING,userIdentity STRUCT< type:STRING, principalid:STRING, arn:STRING, accountid:STRING, invokedby:STRING, accesskeyid:STRING, userName:STRING,sessioncontext:STRUCT<attributes:STRUCT< mfaauthenticated:STRING, creationdate:STRING>,sessionIssuer:STRUCT< type:STRING, principalId:STRING, arn:STRING, accountId:STRING, userName:STRING>>>,eventTime STRING,eventSource STRING,eventName STRING,awsRegion STRING,sourceIpAddress STRING,userAgent STRING,errorCode STRING,errorMessage STRING,requestParameters STRING,responseElements STRING,additionalEventData STRING,requestId STRING,eventId STRING,resources ARRAY<STRUCT<
259

Amazon Athena Guia do usuárioOpenCSVSerDe para processar CSV
ARN:STRING, accountId:STRING, type:STRING>>,eventType STRING,apiVersion STRING,readOnly STRING,recipientAccountId STRING,serviceEventDetails STRING,sharedEventID STRING,vpcEndpointId STRING)ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://cloudtrail_bucket_name/AWSLogs/Account_ID/';
A consulta a seguir retorna os logins ocorridos durante um período de 24 horas:
SELECT useridentity.username, sourceipaddress, eventtime, additionaleventdataFROM default.cloudtrail_logsWHERE eventname = 'ConsoleLogin' AND eventtime >= '2017-02-17T00:00:00Z' AND eventtime < '2017-02-18T00:00:00Z';
Para obter mais informações, consulte Consultar logs do AWS CloudTrail (p. 153).
OpenCSVSerDe para processar CSVAo criar uma tabela com base em dados CSV no Athena, determine os tipos de valores que ela contém:
• Se os dados contiverem valores entre aspas duplas ("), você pode usar o OpenCSV SerDe paradesserializar os valores no Athena. Nas seções a seguir, observe o comportamento deste SerDe comtipos da dados STRING.
• Se os dados não contêm valores entre aspas duplas ("), você pode omitir especificando qualquerSerDe. Neste caso, o Athena usa o LazySimpleSerDe padrão. Para obter mais informações, consulteLazySimpleSerDe para arquivos CSV, TSV e delimitados personalizados (p. 269).
CSV SerDe (OpenCSVSerDe)O OpenCSV SerDe se comporta da seguinte maneira:
• Converte todos os valores de tipo de coluna em STRING.• Para reconhecer tipos de dados diferentes de STRING, ele conta com o analisador do Presto e converte
os valores de STRING nesses tipos de dados caso ele consiga reconhecê-los.• Usa aspas duplas (") como o caractere de aspas padrão e permite que você especifique separadores,
aspas e caracteres de escape, como:
WITH SERDEPROPERTIES ("separatorChar" = ",", "quoteChar" = "`", "escapeChar" = "\\" )
• Não é possível inserir um caractere de escape em \t ou \n diretamente. Para inserir um caractere deescape neles, use "escapeChar" = "\\". Consulte o exemplo neste tópico.
• Não oferece suporte a quebras de linha incorporadas em arquivos CSV.• Não há suporte para campos vazios em colunas que sejam definidas como um tipo de dados numéricos.
260

Amazon Athena Guia do usuárioOpenCSVSerDe para processar CSV
Note
Quando você usa o Athena com OpenCSVSerDe, o SerDe converte todos os tipos de coluna emSTRING. Em seguida, o analisador no Athena analisa os valores de STRING em tipos reais combase no que localiza. Por exemplo, ele analisa os valores para tipos de dados BOOLEAN, BIGINT,INT e DOUBLE quando ele pode distingui-los. Se os valores estiverem em TIMESTAMP no formatoUNIX, o Athena os analisará como TIMESTAMP. Se os valores estiverem em TIMESTAMP noformato Hive, o Athena os analisará como INT. Os valores do tipo DATE também serão analisadoscomo INT.Para converter mais colunas para o tipo desejado em uma tabela, crie uma visualização (p. 72)sobre a tabela e use CAST para converter para o tipo desejado.
Para tipos de dados diferentes de STRING, quando o analisador no Athena puder reconhecê-los, esseSerDe se comporta da seguinte forma:
• Reconhece tipos de dados BOOLEAN, BIGINT, INT e DOUBLE e os analisa sem alterações.• Reconhece o tipo TIMESTAMP caso esteja especificado no formato numérico UNIX, como 1564610311.• Não oferece suporte a TIMESTAMP no formato java.sql.Timestamp compatível com JDBC,
como "YYYY-MM-DD HH:MM:SS.fffffffff" (precisão de 9 casas decimais). Caso você estejaprocessando dados CSV no Hive, use o formato numérico UNIX.
• Reconhece o tipo DATE caso esteja especificado no formato numérico UNIX, como 1562112000.• Não oferece suporte a DATE em outro formato. Caso você esteja processando dados CSV no Hive, use
o formato numérico UNIX.
Note
Para obter informações sobre como usar as colunas TIMESTAMP e DATE quando elas não estãoespecificadas no formato numérico UNIX, consulte o artigo Quando consulto uma tabela noAmazon Athena, o resultado TIMESTAMP é vazio no Centro de conhecimento da AWS.
Example Exemplo: usar o tipo TIMESTAMP e o tipo DATE especificados no formato numéricoUNIX.
Considere os seguintes dados de teste:
"unixvalue creationdate 18276 creationdatetime 1579146280000","18276","1579146280000"
A instrução a seguir cria uma tabela do Athena da localização do bucket do Amazon S3 especificada.
CREATE EXTERNAL TABLE IF NOT EXISTS testtimestamp1( `profile_id` string, `creationdate` date, `creationdatetime` timestamp ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' LOCATION 's3://<location>'
Em seguida, execute a consulta a seguir:
select * from testtimestamp1
A consulta retorna o seguinte resultado, exibindo os dados de data e hora:
profile_id creationdate creationdatetime1 unixvalue creationdate 18276 creationdatetime 1579146280000 2020-01-15 2020-01-16 03:44:40.000
261

Amazon Athena Guia do usuárioOpenCSVSerDe para processar CSV
Example Exemplo: como inserir caracteres de escape em \t ou \n
Considere os seguintes dados de teste:
" \\t\\t\\n 123 \\t\\t\\n ",abc" 456 ",xyz
A instrução a seguir cria uma tabela no Athena especificando que "escapeChar" = "\\".
CREATE EXTERNAL TABLE test1 (f1 string,s2 string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ("separatorChar" = ",", "escapeChar" = "\\") LOCATION 's3://user-test-region/dataset/test1/'
Em seguida, execute a consulta a seguir:
select * from test1;
Ele retorna esse resultado, inserindo corretamente caracteres de escape em \t ou \n:
f1 s2\t\t\n 123 \t\t\n abc456 xyz
Nome do SerDeCSV SerDe
Nome da bibliotecaPara usar esse SerDe, especifique o nome de classe totalmente qualificado em ROW FORMAT. Especifiquetambém os delimitadores dentro de SERDEPROPERTIES, da seguinte forma:
...ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "`", "escapeChar" = "\\")
ExemploEste exemplo pressupõe dados CSV salvos em s3://mybucket/mycsv/ com o seguinte conteúdo:
"a1","a2","a3","a4""1","2","abc","def""a","a1","abc3","ab4"
Use uma instrução CREATE TABLE para criar uma tabela do Athena com base nos dados e façareferência à classe OpenCSVSerDe no ROW FORMAT, especificando também as propriedades SerDe paraseparadores de caracteres, caracteres de aspas e caracteres de escape, da seguinte forma:
CREATE EXTERNAL TABLE myopencsvtable (
262

Amazon Athena Guia do usuárioGrok SerDe
col1 string, col2 string, col3 string, col4 string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ( 'separatorChar' = ',', 'quoteChar' = '"', 'escapeChar' = '\\' )STORED AS TEXTFILELOCATION 's3://location/of/csv/';
Consulte todos os valores na tabela:
SELECT * FROM myopencsvtable;
A consulta retorna os valores a seguir:
col1 col2 col3 col4-----------------------------a1 a2 a3 a41 2 abc defa a1 abc3 ab4
Note
Dados de lista de voo provenientes de Flights (Voos) fornecidos pelo Departamento de Transportedos EUA, Bureau of Transportation Statistics. Dessaturado do original.
Grok SerDeO Logstash Grok SerDe é uma biblioteca com um conjunto de padrões especializados paradesserialização de arquivos de texto desestruturados, normalmente logs. Cada padrão Grok é umaexpressão regular nomeada. Você pode identificar e reutilizar esses padrões de desserialização conformenecessário. Isso facilita o uso de Grok, em comparação com o uso de expressões regulares. O Grokoferece um conjunto de padrões predefinidos. Você também pode criar padrões personalizados.
Para especificar o Grok SerDe ao criar uma tabela no Athena, use a cláusula ROW FORMAT SERDE'com.amazonaws.glue.serde.GrokSerDe', seguida pela cláusula WITH SERDEPROPERTIES queespecifica os padrões para correspondência com os dados, em que:
• A expressão input.format define os padrões para que correspondam aos dados. É necessário.• A expressão input.grokCustomPatterns define um padrão personalizado nomeado, que você
poderá usar depois dentro da expressão input.format. Ela é opcional. Para incluir várias entradaspadrão na expressão input.grokCustomPatterns, use o caractere de escape de nova linha(\n) para separá-las, da seguinte forma: 'input.grokCustomPatterns'='INSIDE_QS ([^\"]*)\nINSIDE_BRACKETS ([^\\]]*)').
• As cláusulas STORED AS INPUTFORMAT e OUTPUTFORMAT são obrigatórias.• A cláusula LOCATION especifica um bucket do Amazon S3, que pode conter vários objetos de dados de
origem. Todos os objetos de dados no bucket são desserializados para criar a tabela.
ExemplosEsses exemplos dependem da lista de padrões Grok predefinidos. Consulte padrões predefinidos.
263

Amazon Athena Guia do usuárioGrok SerDe
Exemplo 1
Este exemplo usa os dados de origem das entradas de maillog do Postfix salvas em s3://mybucket/groksample/.
Feb 9 07:15:00 m4eastmail postfix/smtpd[19305]: B88C4120838: connect from unknown[192.168.55.4]Feb 9 07:15:00 m4eastmail postfix/smtpd[20444]: B58C4330038: client=unknown[192.168.55.4]Feb 9 07:15:03 m4eastmail postfix/cleanup[22835]: BDC22A77854: message-id=<[email protected]>
A instrução a seguir cria uma tabela no Athena chamada mygroktable com base nos dados de origemusando um padrão personalizado e os padrões predefinidos especificados:especificados:
CREATE EXTERNAL TABLE `mygroktable`( syslogbase string, queue_id string, syslog_message string )ROW FORMAT SERDE 'com.amazonaws.glue.serde.GrokSerDe'WITH SERDEPROPERTIES ( 'input.grokCustomPatterns' = 'POSTFIX_QUEUEID [0-9A-F]{7,12}', 'input.format'='%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}' )STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://mybucket/groksample/';
Comece com um padrão simples, como %{NOTSPACE:column}, para obter as colunas mapeadasprimeiro e, em seguida, especifique as colunas, se necessário.
Exemplo 2
No exemplo a seguir, você cria uma consulta para logs Log4j. Os logs de exemplo têm as entradas nesteformato:
2017-09-12 12:10:34,972 INFO - processType=AZ, processId=ABCDEFG614B6F5E49, status=RUN,threadId=123:amqListenerContainerPool23[P:AJ|ABCDE9614B6F5E49||2017-09-12T12:10:11.172-0700],executionTime=7290, tenantId=12456, userId=123123f8535f8d76015374e7a1d87c3c, shard=testapp1,jobId=12312345e5e7df0015e777fb2e03f3c, messageType=REAL_TIME_SYNC,action=receive, hostname=1.abc.def.com
Para consultar os dados desses logs:
• Adicione o padrão Grok ao input.format para cada coluna. Por exemplo, para timestamp, adicione%{TIMESTAMP_ISO8601:timestamp}. Para loglevel, adicione %{LOGLEVEL:loglevel}.
• Verifique se o padrão em input.format está de acordo com o formato exato do log mapeando ostraços (-) e as vírgulas que separam as entradas no formato do log.
CREATE EXTERNAL TABLE bltest ( timestamp STRING, loglevel STRING,
264

Amazon Athena Guia do usuárioGrok SerDe
processtype STRING, processid STRING, status STRING, threadid STRING, executiontime INT, tenantid INT, userid STRING, shard STRING, jobid STRING, messagetype STRING, action STRING, hostname STRING )ROW FORMAT SERDE 'com.amazonaws.glue.serde.GrokSerDe'WITH SERDEPROPERTIES ("input.grokCustomPatterns" = 'C_ACTION receive|send',"input.format" = "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} - processType=%{NOTSPACE:processtype}, processId=%{NOTSPACE:processid}, status=%{NOTSPACE:status}, threadId=%{NOTSPACE:threadid}, executionTime=%{POSINT:executiontime}, tenantId=%{POSINT:tenantid}, userId=%{NOTSPACE:userid}, shard=%{NOTSPACE:shard}, jobId=%{NOTSPACE:jobid}, messageType=%{NOTSPACE:messagetype}, action=%{C_ACTION:action}, hostname=%{HOST:hostname}") STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://mybucket/samples/';
Exemplo 3O exemplo de consulta de logs do Amazon S3 a seguir mostra a expressão'input.grokCustomPatterns' que contém duas entradas padrão, separadas pelo caracterede escape de nova linha (\n), conforme mostrado neste trecho de consulta do exemplo:'input.grokCustomPatterns'='INSIDE_QS ([^\"]*)\nINSIDE_BRACKETS ([^\\]]*)').
CREATE EXTERNAL TABLE `s3_access_auto_raw_02`( `bucket_owner` string COMMENT 'from deserializer', `bucket` string COMMENT 'from deserializer', `time` string COMMENT 'from deserializer', `remote_ip` string COMMENT 'from deserializer', `requester` string COMMENT 'from deserializer', `request_id` string COMMENT 'from deserializer', `operation` string COMMENT 'from deserializer', `key` string COMMENT 'from deserializer', `request_uri` string COMMENT 'from deserializer', `http_status` string COMMENT 'from deserializer', `error_code` string COMMENT 'from deserializer', `bytes_sent` string COMMENT 'from deserializer', `object_size` string COMMENT 'from deserializer', `total_time` string COMMENT 'from deserializer', `turnaround_time` string COMMENT 'from deserializer', `referrer` string COMMENT 'from deserializer', `user_agent` string COMMENT 'from deserializer', `version_id` string COMMENT 'from deserializer')ROW FORMAT SERDE 'com.amazonaws.glue.serde.GrokSerDe' WITH SERDEPROPERTIES ( 'input.format'='%{NOTSPACE:bucket_owner} %{NOTSPACE:bucket} \\[%{INSIDE_BRACKETS:time}\\] %{NOTSPACE:remote_ip} %{NOTSPACE:requester} %{NOTSPACE:request_id} %{NOTSPACE:operation} %{NOTSPACE:key} \"?%{INSIDE_QS:request_uri}\"? %{NOTSPACE:http_status} %{NOTSPACE:error_code} %{NOTSPACE:bytes_sent} %{NOTSPACE:object_size} %{NOTSPACE:total_time} %{NOTSPACE:turnaround_time} \"?%{INSIDE_QS:referrer}\"? \"?%{INSIDE_QS:user_agent}\"? %{NOTSPACE:version_id}', 'input.grokCustomPatterns'='INSIDE_QS ([^\"]*)\nINSIDE_BRACKETS ([^\\]]*)') STORED AS INPUTFORMAT
265

Amazon Athena Guia do usuárioBibliotecas SerDe JSON
'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION 's3://bucket-for-service-logs/s3_access/'
Bibliotecas SerDe JSONNo Athena, você pode usar duas bibliotecas SerDe para processar dados em JSON:
• A nativa Hive JSON SerDe (p. 266)• A OpenX JSON SerDe (p. 267)
Nomes do SerDeHive-JsonSerDe
Openx-JsonSerDe
Nomes de bibliotecaUse uma das seguintes opções:
org.apache.hive.hcatalog.data.JsonSerDe
org.openx.data.jsonserde.JsonSerDe
Hive JSON SerDeO Hive JSON SerDe é usado para processar dados JSON, eventos mais comuns. Esses eventos sãorepresentados como blocos de texto codificado em JSON separados por uma nova linha.
Também é possível usar o Hive JSON SerDe para analisar dados codificados em JSON mais complexoscom estruturas aninhadas. No entanto, isso exige uma DDL correspondente que represente os tipos dedados complexos. Consulte Exemplo: desserializar JSON aninhado (p. 268).
Com esse SerDe, não são permitidas chaves duplicadas em nomes de chave map (ou struct).
Note
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além dascobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
A seguinte instrução DDL usa o Hive JSON SerDe:
CREATE EXTERNAL TABLE impressions ( requestbegintime string, adid string, impressionid string, referrer string, useragent string, usercookie string,
266

Amazon Athena Guia do usuárioBibliotecas SerDe JSON
ip string, number string, processid string, browsercookie string, requestendtime string, timers struct < modellookup:string, requesttime:string >, threadid string, hostname string, sessionid string) PARTITIONED BY (dt string)ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe'with serdeproperties ( 'paths'='requestbegintime, adid, impressionid, referrer, useragent, usercookie, ip' )LOCATION 's3://myregion.elasticmapreduce/samples/hive-ads/tables/impressions';
OpenX JSON SerDeO OpenX SerDe é usado pelo Athena para desserializar dados, o que significa convertê-los do formatoJSON em preparação para serializá-los no formato Parquet ou ORC. Esse é um dos dois desserializadoresque você pode escolher, dependendo de qual oferece a funcionalidade de que você precisa. A outra opçãoé o Hive JsonSerDe.
Esse SerDe tem algumas propriedades úteis que você pode especificar ao criar tabelas no Athena, paraajudar a lidar com inconsistências nos dados:
ignore.malformed.json
Opcional. Quando definido como TRUE, permite ignorar a sintaxe JSON malformada. O padrão éFALSE.
dots.in.keys
Opcional. O padrão é FALSE. Quando definido como TRUE, permite que o SerDe substitua porsublinhados os pontos nos nomes-chave. Por exemplo, se o conjunto de dados JSON contiver umachave com o nome "a.b", você pode usar essa propriedade para definir o nome da coluna como"a_b" no Athena. Por padrão (sem esse SerDe), o Athena não permite pontos nos nomes da coluna.
case.insensitive
Opcional. Por padrão, o Athena exige que todas as chaves do seu dataset JSON usem caixa baixa. Opadrão é TRUE. Quando definido como TRUE, o SerDe converte todas as colunas em maiúsculas paraminúsculas. O uso de WITH SERDEPROPERTIES ("case.insensitive"= FALSE;) permite usarnomes de chaves com diferenciação de maiúsculas e minúsculas nos seus dados.
ColumnToJsonKeyMappings
Opcional. Mapeia os nomes das colunas para chaves JSON que não são idênticas aos nomes dacoluna. Isso é útil quando os dados de JSON contiverem chaves que sejam palavras-chave (p. 19).Por exemplo, se você tiver uma chave JSON chamada timestamp, defina esse parâmetro como{"ts": "timestamp"} a fim de mapear a chave para uma coluna denominada ts. Esse parâmetropega os valores do tipo string. Ele usa o seguinte padrão de chave: ^\S+$ e o seguinte padrão devalor: ^(?!\s*$).+
Com esse SerDe, não são permitidas chaves duplicadas em nomes de chave map (ou struct).
A seguinte instrução DDL usa o OpenX JSON SerDe:
267

Amazon Athena Guia do usuárioBibliotecas SerDe JSON
CREATE EXTERNAL TABLE impressions ( requestbegintime string, adid string, impressionId string, referrer string, useragent string, usercookie string, ip string, number string, processid string, browsercokie string, requestendtime string, timers struct< modellookup:string, requesttime:string>, threadid string, hostname string, sessionid string) PARTITIONED BY (dt string)ROW FORMAT serde 'org.openx.data.jsonserde.JsonSerDe'with serdeproperties ( 'paths'='requestbegintime, adid, impressionid, referrer, useragent, usercookie, ip' )LOCATION 's3://myregion.elasticmapreduce/samples/hive-ads/tables/impressions';
Exemplo: desserializar JSON aninhadoPode ser um desafio desserializar dados JSON ao criar uma tabela no Athena.
Durante o processamento de JSON aninhado complexo, existem problemas comuns que você podeencontrar. Para obter mais informações sobre esses problemas e práticas para solução de problemas,consulte o artigo do Centro de conhecimento da AWS Recebo erros ao tentar ler dados JSON no AmazonAthena.
Para obter mais informações sobre cenários comuns e dicas de consulta, consulte Criar tabelas noAmazon Athena com base em JSON aninhado e mapeamentos usando JSONSerDe.
O exemplo a seguir demonstra uma abordagem simples para criação de uma tabela do Athena a partir dedados com estruturas aninhadas no JSON. Para analisar dados codificados em JSON no Athena, cadadocumento JSON deve estar em sua própria linha, separado por uma nova linha.
Este exemplo pressupõe dados codificados em JSON com a seguinte estrutura:
{"DocId": "AWS","User": { "Id": 1234, "Username": "bob1234", "Name": "Bob","ShippingAddress": {"Address1": "123 Main St.","Address2": null,"City": "Seattle","State": "WA" },"Orders": [ { "ItemId": 6789, "OrderDate": "11/11/2017" }, { "ItemId": 4352,
268

Amazon Athena Guia do usuárioLazySimpleSerDe para arquivos CSV,
TSV e delimitados personalizados
"OrderDate": "12/12/2017" } ] }}
O comando CREATE TABLE a seguir usa o Openx-JsonSerDe com tipos de dados de coleção comostruct e array para estabelecer grupos de objetos. Cada documento JSON é listado em sua próprialinha, separado por uma nova linha. Para evitar erros, os dados que estão sendo consultados não incluemchaves duplicadas em nomes de chaves de mapa e struct. Não são permitidas chaves duplicadas emnomes de chaves de mapa (ou struct).
CREATE external TABLE complex_json ( docid string, `user` struct< id:INT, username:string, name:string, shippingaddress:struct< address1:string, address2:string, city:string, state:string >, orders:array< struct< itemid:INT, orderdate:string > > > )ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'LOCATION 's3://mybucket/myjsondata/';
LazySimpleSerDe para arquivos CSV, TSV edelimitados personalizadosEspecificar esse SerDe é opcional. Este é o SerDe para dados em formatos CSV, TSV e delimitadospersonalizados que o Athena por padrão. Este SerDe será usado se você não especificar qualquer SerDee especificar somente ROW FORMAT DELIMITED. Use esse SerDe caso os dados não tenham valoresentre aspas.
Nome da bibliotecaO nome da biblioteca de classes de LazySimpleSerDe éorg.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe. Para obter mais informações, consulteLazySimpleSerDe.
ExemplosOs exemplos a seguir mostram como criar tabelas no Athena a partir de CSV e TSV usando oLazySimpleSerDe. Para desserializar um arquivo delimitado personalizado usando esse SerDe,especifique os delimitadores semelhantes aos exemplos a seguir.
• Exemplo de CSV (p. 270)• Exemplo de TSV (p. 272)
269

Amazon Athena Guia do usuárioLazySimpleSerDe para arquivos CSV,
TSV e delimitados personalizados
Note
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além dascobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
Note
Dados de lista de voo provenientes de Flights (Voos) fornecidos pelo Departamento de Transportedos EUA, Bureau of Transportation Statistics. Dessaturado do original.
Exemplo do CSV
Use a instrução CREATE TABLE para criar uma tabela do Athena usando os dados subjacentes em CSVarmazenados no Amazon S3.
CREATE EXTERNAL TABLE flight_delays_csv ( yr INT, quarter INT, month INT, dayofmonth INT, dayofweek INT, flightdate STRING, uniquecarrier STRING, airlineid INT, carrier STRING, tailnum STRING, flightnum STRING, originairportid INT, originairportseqid INT, origincitymarketid INT, origin STRING, origincityname STRING, originstate STRING, originstatefips STRING, originstatename STRING, originwac INT, destairportid INT, destairportseqid INT, destcitymarketid INT, dest STRING, destcityname STRING, deststate STRING, deststatefips STRING, deststatename STRING, destwac INT, crsdeptime STRING, deptime STRING, depdelay INT, depdelayminutes INT, depdel15 INT, departuredelaygroups INT, deptimeblk STRING, taxiout INT, wheelsoff STRING, wheelson STRING, taxiin INT, crsarrtime INT, arrtime STRING, arrdelay INT,
270

Amazon Athena Guia do usuárioLazySimpleSerDe para arquivos CSV,
TSV e delimitados personalizados
arrdelayminutes INT, arrdel15 INT, arrivaldelaygroups INT, arrtimeblk STRING, cancelled INT, cancellationcode STRING, diverted INT, crselapsedtime INT, actualelapsedtime INT, airtime INT, flights INT, distance INT, distancegroup INT, carrierdelay INT, weatherdelay INT, nasdelay INT, securitydelay INT, lateaircraftdelay INT, firstdeptime STRING, totaladdgtime INT, longestaddgtime INT, divairportlandings INT, divreacheddest INT, divactualelapsedtime INT, divarrdelay INT, divdistance INT, div1airport STRING, div1airportid INT, div1airportseqid INT, div1wheelson STRING, div1totalgtime INT, div1longestgtime INT, div1wheelsoff STRING, div1tailnum STRING, div2airport STRING, div2airportid INT, div2airportseqid INT, div2wheelson STRING, div2totalgtime INT, div2longestgtime INT, div2wheelsoff STRING, div2tailnum STRING, div3airport STRING, div3airportid INT, div3airportseqid INT, div3wheelson STRING, div3totalgtime INT, div3longestgtime INT, div3wheelsoff STRING, div3tailnum STRING, div4airport STRING, div4airportid INT, div4airportseqid INT, div4wheelson STRING, div4totalgtime INT, div4longestgtime INT, div4wheelsoff STRING, div4tailnum STRING, div5airport STRING, div5airportid INT, div5airportseqid INT, div5wheelson STRING, div5totalgtime INT, div5longestgtime INT, div5wheelsoff STRING, div5tailnum STRING
271
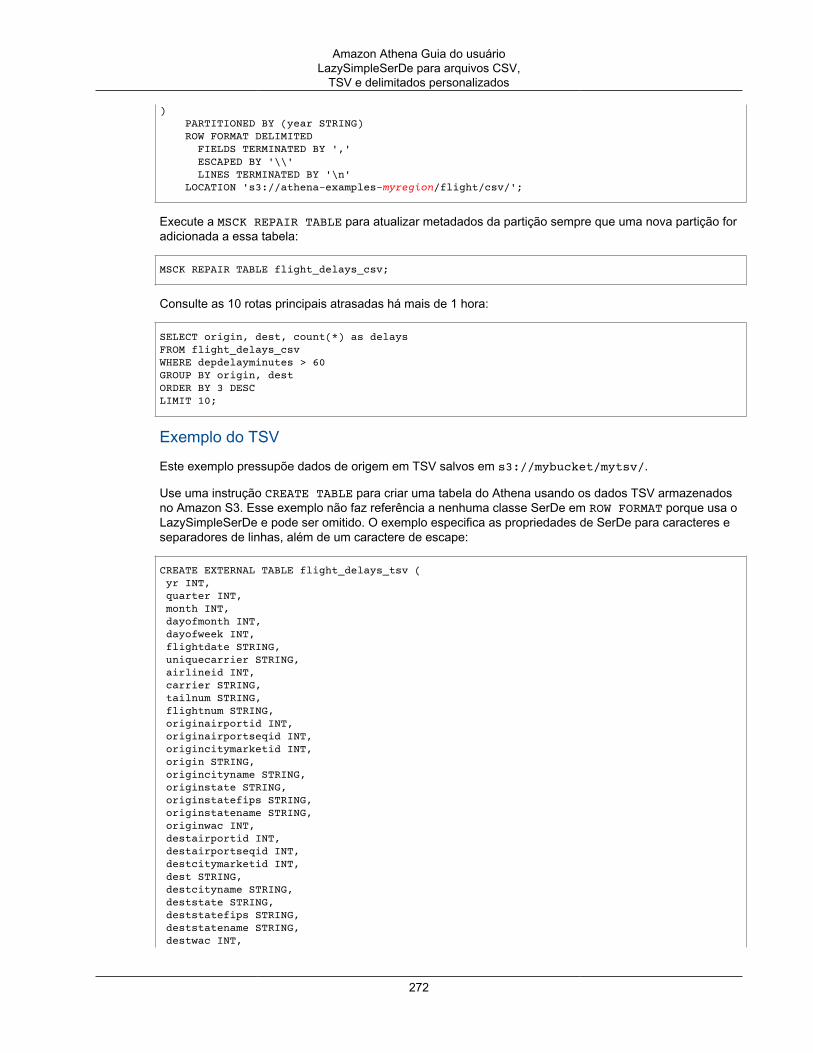
Amazon Athena Guia do usuárioLazySimpleSerDe para arquivos CSV,
TSV e delimitados personalizados
) PARTITIONED BY (year STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ESCAPED BY '\\' LINES TERMINATED BY '\n' LOCATION 's3://athena-examples-myregion/flight/csv/';
Execute a MSCK REPAIR TABLE para atualizar metadados da partição sempre que uma nova partição foradicionada a essa tabela:
MSCK REPAIR TABLE flight_delays_csv;
Consulte as 10 rotas principais atrasadas há mais de 1 hora:
SELECT origin, dest, count(*) as delaysFROM flight_delays_csvWHERE depdelayminutes > 60GROUP BY origin, destORDER BY 3 DESCLIMIT 10;
Exemplo do TSV
Este exemplo pressupõe dados de origem em TSV salvos em s3://mybucket/mytsv/.
Use uma instrução CREATE TABLE para criar uma tabela do Athena usando os dados TSV armazenadosno Amazon S3. Esse exemplo não faz referência a nenhuma classe SerDe em ROW FORMAT porque usa oLazySimpleSerDe e pode ser omitido. O exemplo especifica as propriedades de SerDe para caracteres eseparadores de linhas, além de um caractere de escape:
CREATE EXTERNAL TABLE flight_delays_tsv ( yr INT, quarter INT, month INT, dayofmonth INT, dayofweek INT, flightdate STRING, uniquecarrier STRING, airlineid INT, carrier STRING, tailnum STRING, flightnum STRING, originairportid INT, originairportseqid INT, origincitymarketid INT, origin STRING, origincityname STRING, originstate STRING, originstatefips STRING, originstatename STRING, originwac INT, destairportid INT, destairportseqid INT, destcitymarketid INT, dest STRING, destcityname STRING, deststate STRING, deststatefips STRING, deststatename STRING, destwac INT,
272

Amazon Athena Guia do usuárioLazySimpleSerDe para arquivos CSV,
TSV e delimitados personalizados
crsdeptime STRING, deptime STRING, depdelay INT, depdelayminutes INT, depdel15 INT, departuredelaygroups INT, deptimeblk STRING, taxiout INT, wheelsoff STRING, wheelson STRING, taxiin INT, crsarrtime INT, arrtime STRING, arrdelay INT, arrdelayminutes INT, arrdel15 INT, arrivaldelaygroups INT, arrtimeblk STRING, cancelled INT, cancellationcode STRING, diverted INT, crselapsedtime INT, actualelapsedtime INT, airtime INT, flights INT, distance INT, distancegroup INT, carrierdelay INT, weatherdelay INT, nasdelay INT, securitydelay INT, lateaircraftdelay INT, firstdeptime STRING, totaladdgtime INT, longestaddgtime INT, divairportlandings INT, divreacheddest INT, divactualelapsedtime INT, divarrdelay INT, divdistance INT, div1airport STRING, div1airportid INT, div1airportseqid INT, div1wheelson STRING, div1totalgtime INT, div1longestgtime INT, div1wheelsoff STRING, div1tailnum STRING, div2airport STRING, div2airportid INT, div2airportseqid INT, div2wheelson STRING, div2totalgtime INT, div2longestgtime INT, div2wheelsoff STRING, div2tailnum STRING, div3airport STRING, div3airportid INT, div3airportseqid INT, div3wheelson STRING, div3totalgtime INT, div3longestgtime INT, div3wheelsoff STRING, div3tailnum STRING, div4airport STRING, div4airportid INT,
273

Amazon Athena Guia do usuárioORC SerDe
div4airportseqid INT, div4wheelson STRING, div4totalgtime INT, div4longestgtime INT, div4wheelsoff STRING, div4tailnum STRING, div5airport STRING, div5airportid INT, div5airportseqid INT, div5wheelson STRING, div5totalgtime INT, div5longestgtime INT, div5wheelsoff STRING, div5tailnum STRING) PARTITIONED BY (year STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ESCAPED BY '\\' LINES TERMINATED BY '\n' LOCATION 's3://athena-examples-myregion/flight/tsv/';
Execute a MSCK REPAIR TABLE para atualizar metadados da partição sempre que uma nova partição foradicionada a essa tabela:
MSCK REPAIR TABLE flight_delays_tsv;
Consulte as 10 rotas principais atrasadas há mais de 1 hora:
SELECT origin, dest, count(*) as delaysFROM flight_delays_tsvWHERE depdelayminutes > 60GROUP BY origin, destORDER BY 3 DESCLIMIT 10;
Note
Dados de lista de voo provenientes de Flights (Voos) fornecidos pelo Departamento de Transportedos EUA, Bureau of Transportation Statistics. Dessaturado do original.
ORC SerDeNome do SerDeOrcSerDe
Nome da bibliotecaEsta é a classe SerDe para os dados no formato ORC. Ela passa o objeto do ORC para o leitor e do ORCpara o gravador: OrcSerDe
ExemplosNote
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além das
274

Amazon Athena Guia do usuárioORC SerDe
cobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
O exemplo a seguir cria uma tabela para dados de voos em atraso no ORC. A tabela inclui partições:
DROP TABLE flight_delays_orc;CREATE EXTERNAL TABLE flight_delays_orc ( yr INT, quarter INT, month INT, dayofmonth INT, dayofweek INT, flightdate STRING, uniquecarrier STRING, airlineid INT, carrier STRING, tailnum STRING, flightnum STRING, originairportid INT, originairportseqid INT, origincitymarketid INT, origin STRING, origincityname STRING, originstate STRING, originstatefips STRING, originstatename STRING, originwac INT, destairportid INT, destairportseqid INT, destcitymarketid INT, dest STRING, destcityname STRING, deststate STRING, deststatefips STRING, deststatename STRING, destwac INT, crsdeptime STRING, deptime STRING, depdelay INT, depdelayminutes INT, depdel15 INT, departuredelaygroups INT, deptimeblk STRING, taxiout INT, wheelsoff STRING, wheelson STRING, taxiin INT, crsarrtime INT, arrtime STRING, arrdelay INT, arrdelayminutes INT, arrdel15 INT, arrivaldelaygroups INT, arrtimeblk STRING, cancelled INT, cancellationcode STRING, diverted INT, crselapsedtime INT, actualelapsedtime INT, airtime INT, flights INT, distance INT, distancegroup INT,
275

Amazon Athena Guia do usuárioORC SerDe
carrierdelay INT, weatherdelay INT, nasdelay INT, securitydelay INT, lateaircraftdelay INT, firstdeptime STRING, totaladdgtime INT, longestaddgtime INT, divairportlandings INT, divreacheddest INT, divactualelapsedtime INT, divarrdelay INT, divdistance INT, div1airport STRING, div1airportid INT, div1airportseqid INT, div1wheelson STRING, div1totalgtime INT, div1longestgtime INT, div1wheelsoff STRING, div1tailnum STRING, div2airport STRING, div2airportid INT, div2airportseqid INT, div2wheelson STRING, div2totalgtime INT, div2longestgtime INT, div2wheelsoff STRING, div2tailnum STRING, div3airport STRING, div3airportid INT, div3airportseqid INT, div3wheelson STRING, div3totalgtime INT, div3longestgtime INT, div3wheelsoff STRING, div3tailnum STRING, div4airport STRING, div4airportid INT, div4airportseqid INT, div4wheelson STRING, div4totalgtime INT, div4longestgtime INT, div4wheelsoff STRING, div4tailnum STRING, div5airport STRING, div5airportid INT, div5airportseqid INT, div5wheelson STRING, div5totalgtime INT, div5longestgtime INT, div5wheelsoff STRING, div5tailnum STRING)PARTITIONED BY (year String)STORED AS ORCLOCATION 's3://athena-examples-myregion/flight/orc/'tblproperties ("orc.compress"="ZLIB");
Execute a instrução MSCK REPAIR TABLE na tabela para atualizar metadados da partição:
MSCK REPAIR TABLE flight_delays_orc;
Use esta consulta para obter as 10 rotas principais atrasadas há mais de 1 hora:
276

Amazon Athena Guia do usuárioParquet SerDe
SELECT origin, dest, count(*) as delaysFROM flight_delays_orcWHERE depdelayminutes > 60GROUP BY origin, destORDER BY 3 DESCLIMIT 10;
Parquet SerDeNome do SerDeParquetHiveSerDe é usado para dados armazenados no Formato Parquet.
Nome da bibliotecaO Athena usa essa classe quando precisa desserializar dados armazenados no Parquet:org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe.
Exemplo: consultar um arquivo armazenado no ParquetNote
Você pode consultar dados em regiões que não sejam aquelas onde o Athena é executado.Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, além dascobranças padrão do Athena. Para reduzir as cobranças de transferência de dados, substituamyregion em s3://athena-examples-myregion/path/to/data/ pelo identificador daregião onde o Athena é executado, por exemplo, s3://athena-examples-us-west-1/path/to/data/.
Use a instrução CREATE TABLE a seguir para criar uma tabela do Athena a partir dos dados subjacentesem CSV armazenados no Amazon S3 no Parquet:
CREATE EXTERNAL TABLE flight_delays_pq ( yr INT, quarter INT, month INT, dayofmonth INT, dayofweek INT, flightdate STRING, uniquecarrier STRING, airlineid INT, carrier STRING, tailnum STRING, flightnum STRING, originairportid INT, originairportseqid INT, origincitymarketid INT, origin STRING, origincityname STRING, originstate STRING, originstatefips STRING, originstatename STRING, originwac INT, destairportid INT, destairportseqid INT, destcitymarketid INT, dest STRING, destcityname STRING, deststate STRING,
277

Amazon Athena Guia do usuárioParquet SerDe
deststatefips STRING, deststatename STRING, destwac INT, crsdeptime STRING, deptime STRING, depdelay INT, depdelayminutes INT, depdel15 INT, departuredelaygroups INT, deptimeblk STRING, taxiout INT, wheelsoff STRING, wheelson STRING, taxiin INT, crsarrtime INT, arrtime STRING, arrdelay INT, arrdelayminutes INT, arrdel15 INT, arrivaldelaygroups INT, arrtimeblk STRING, cancelled INT, cancellationcode STRING, diverted INT, crselapsedtime INT, actualelapsedtime INT, airtime INT, flights INT, distance INT, distancegroup INT, carrierdelay INT, weatherdelay INT, nasdelay INT, securitydelay INT, lateaircraftdelay INT, firstdeptime STRING, totaladdgtime INT, longestaddgtime INT, divairportlandings INT, divreacheddest INT, divactualelapsedtime INT, divarrdelay INT, divdistance INT, div1airport STRING, div1airportid INT, div1airportseqid INT, div1wheelson STRING, div1totalgtime INT, div1longestgtime INT, div1wheelsoff STRING, div1tailnum STRING, div2airport STRING, div2airportid INT, div2airportseqid INT, div2wheelson STRING, div2totalgtime INT, div2longestgtime INT, div2wheelsoff STRING, div2tailnum STRING, div3airport STRING, div3airportid INT, div3airportseqid INT, div3wheelson STRING, div3totalgtime INT, div3longestgtime INT, div3wheelsoff STRING,
278

Amazon Athena Guia do usuárioFormatos de compactação
div3tailnum STRING, div4airport STRING, div4airportid INT, div4airportseqid INT, div4wheelson STRING, div4totalgtime INT, div4longestgtime INT, div4wheelsoff STRING, div4tailnum STRING, div5airport STRING, div5airportid INT, div5airportseqid INT, div5wheelson STRING, div5totalgtime INT, div5longestgtime INT, div5wheelsoff STRING, div5tailnum STRING)PARTITIONED BY (year STRING)STORED AS PARQUETLOCATION 's3://athena-examples-myregion/flight/parquet/'tblproperties ("parquet.compress"="SNAPPY");
Execute a instrução MSCK REPAIR TABLE na tabela para atualizar metadados da partição:
MSCK REPAIR TABLE flight_delays_pq;
Consulte as 10 rotas principais atrasadas há mais de 1 hora:
SELECT origin, dest, count(*) as delaysFROM flight_delays_pqWHERE depdelayminutes > 60GROUP BY origin, destORDER BY 3 DESCLIMIT 10;
Note
Dados de lista de voo provenientes de Flights (Voos) fornecidos pelo Departamento de Transportedos EUA, Bureau of Transportation Statistics. Dessaturado do original.
Formatos de compactaçãoO Athena oferece suporte aos seguintes formatos de compactação:
Note
Os formatos de compactação listados nesta seção são usados para consultas CREATETABLE (p. 295). Para consultas CTAS, o Athena oferece suporte a GZIP e SNAPPY (paradados armazenados em Parquet e ORC). Se você omitir um formato, GZIP é usado por padrão.Para obter mais informações, consulte CREATE TABLE AS (p. 299).
• SNAPPY. Esse é o formato de compactação padrão para arquivos no formato de armazenamento físicode dados Parquet.
• ZLIB. Esse é o formato de compactação padrão para arquivos no formato de armazenamento físico dedados ORC.
• LZO
279

Amazon Athena Guia do usuárioFormatos de compactação
• GZIP.
Para dados em CSV, TSV e JSON, o Athena determina o tipo de compactação a partir da extensãodo arquivo. Se ele não estiver presente, os dados não serão descompactados. Se os dados estiveremcompactados, certifique-se de que o nome do arquivo inclua a extensão de compactação, como gz.
Use a compactação GZIP no Athena para consultar logs do Amazon Kinesis Data Firehose. O Athenae o Amazon Kinesis Data Firehose suportam versões diferentes de SNAPPY. Portanto, GZIP é o únicoformato compatível.
280

Amazon Athena Guia do usuárioTipos de dados compatíveis
Referência SQL para o AmazonAthena
O Amazon Athena oferece suporte a um subconjunto de instruções, funções, operadores e tipos de dadosem Data Definition Language (DDL — Linguagem de definição de dados) e Data Manipulation Language(DML — Linguagem de manipulação de dados). Com algumas exceções, a DDL do Athena é baseada naDDL do HiveQL e a DML do Athena é baseada no Presto 0.172.
Tópicos• Tipos de dados compatíveis com o Amazon Athena (p. 281)• Consultas, funções e operadores em DML (p. 282)• Instruções DDL (p. 289)• Considerações e limitações de consultas SQL no Amazon Athena (p. 307)
Tipos de dados compatíveis com o Amazon AthenaAo executar CREATE TABLE (p. 295), especifique os nomes de coluna e o tipo de dados que cadacoluna pode conter. O Athena oferece suporte aos tipos de dados listados abaixo. Para obter informaçõessobre os mapeamentos de tipo de dados compatíveis com o driver JDBC entre o Athena, o JDBC e o Java,consulte Tipos de dados no Guia de instalação e configuração do driver JDBC. Para obter informaçõessobre os mapeamentos de tipo de dados compatíveis com o driver ODBC entre o Athena e o SQL,consulte Tipos de dados no Guia de instalação e configuração do driver ODBC.
Tipos de dados compatíveis
• BOOLIANO (p. 281)• Tipos inteiros (p. 281)• Tipos de ponto flutuante (p. 282)• Tipos de precisão fixa (p. 282)• Tipos de string (p. 282)• BINÁRIO (p. 282)• Tipos de data e hora (p. 282)• Tipos estruturais (p. 282)
• BOOLEAN. Os valores são true e false.• Tipos inteiros
• TINYINT. Um valor INTEGER assinado de 8 bits no formato complemento para dois, com um valormínimo de -2^7 e um valor máximo de 2^7-1.
• SMALLINT. Um valor INTEGER assinado de 16 bits no formato complemento para dois, com um valormínimo de -2^15 e um valor máximo de 2^15-1.
• INT. O Athena combina duas implementações diferentes do tipo de dados INTEGER. Nas consultasda Linguagem de Definição de Dados (DDL), o Athena usa o tipo de dados INT. Em todas as outrasconsultas, o Athena usa o tipo de dados INTEGER, em que INTEGER é representado por um valorassinado de 32 bits no formato complemento para dois, com um valor mínimo de -2^31 e um valormáximo de 2^31-1. No driver JDBC, INTEGER é retornado para garantir a compatibilidade com osaplicativos de análise de negócios.
281

Amazon Athena Guia do usuárioConsultas, funções e operadores em DML
• BIGINT. Um valor INTEGER assinado de 64 bits no formato complemento para dois, com um valormínimo de -2^63 e um valor máximo de 2^63-1.
• Tipos de ponto flutuante• DOUBLE
• REAL
• Tipo de precisão fixa• DECIMAL [ (precision, scale) ], onde precision é o número total de dígitos e scale
(opcional) é o número de dígitos na parte fracionada, o padrão é 0. Por exemplo, use estas definiçõesde tipo: DECIMAL(11,5), DECIMAL(15).
Para especificar valores decimais como literais, como ao selecionar filas com um valor decimalespecífico em uma expressão de consulta DDL, especifique a definição de tipo DECIMAL e liste o valordecimal como um literal (em aspas simples) na consulta, como neste exemplo: decimal_value =DECIMAL '0.12'.
• Tipos de string• CHAR. Os dados de caractere de comprimento fixo, com um tamanho especificado entre 1 e 255,
como char(10). Para obter mais informações, consulte Tipo de dados do Hive CHAR.• VARCHAR. Os dados de caractere de comprimento variável, com um tamanho especificado entre
1 e 65535, como varchar(10). Para obter mais informações, consulte Tipo de dados do HiveVARCHAR.
• BINARY (para dados em Parquet)• Tipos de data e hora
• DATE, no formato UNIX, como YYYY-MM-DD.• TIMESTAMP. Instantâneo em hora e data no formato UNiX, como yyyy-mm-dd hh:mm:ss[.f...].
Por exemplo, TIMESTAMP '2008-09-15 03:04:05.324'. Esse formato usa o fuso horário dasessão.
• Tipos estruturais• ARRAY < data_type >• MAP < primitive_type, data_type >• STRUCT < col_name : data_type [COMMENT col_comment] [, ...] >
Consultas, funções e operadores em DMLAs instruções de consulta em DML do Athena são baseadas no Presto 0.172. Para obter mais informaçõessobre essas funções, consulte Funções e operadores do Presto 0.172 na documentação do Presto decódigo aberto. Fornecemos links para subseções específicas dessa documentação no tópico Funções doPresto (p. 288).
O Athena não oferece suporte a todos os recursos do Presto e há algumas diferenças significativas. Paraobter mais informações, consulte os tópicos de referência para instruções específicas nesta seção e emCondições e limitações (p. 307).
Tópicos• SELECT (p. 282)• INSERT INTO (p. 286)• Funções do Presto no Amazon Athena (p. 288)
SELECTRecupera linhas de zero ou mais tabelas.
282

Amazon Athena Guia do usuárioSELECT
Resumo[ WITH with_query [, ...] ]SELECT [ ALL | DISTINCT ] select_expression [, ...][ FROM from_item [, ...] ][ WHERE condition ][ GROUP BY [ ALL | DISTINCT ] grouping_element [, ...] ][ HAVING condition ][ UNION [ ALL | DISTINCT ] union_query ][ ORDER BY expression [ ASC | DESC ] [ NULLS FIRST | NULLS LAST] [, ...] ][ LIMIT [ count | ALL ] ]
Parâmetros[ WITH with_query [, ....] ]
Você pode usar WITH para nivelar consultas aninhadas ou para simplificar subconsultas.
Usar a cláusula WITH para criar consultas recursivas não é compatível.
A cláusula WITH precede a lista SELECT em uma consulta e define uma ou mais subconsultas a seremusadas dentro da consulta SELECT.
Cada subconsulta define uma tabela temporária, semelhante a uma definição de exibição, que vocêpode referenciar na cláusula FROM. As tabelas são usadas apenas quando a consulta é executada.
A sintaxe with_query é:
subquery_table_name [ ( column_name [, ...] ) ] AS (subquery)
Onde:• subquery_table_name é um nome exclusivo para uma tabela temporária que define os
resultados da subconsulta de cláusula WITH. Cada subquery deve ter um nome de tabela quepossa ser referenciado na cláusula FROM.
• column_name [, ...] é uma lista opcional de nomes de coluna de saída. O número de nomesde coluna deve ser igual a ou menor que o número de colunas definido por subquery.
• subquery é uma instrução da consulta qualquer.[ ALL | DISTINCT ] select_expr
select_expr determina as linhas a serem selecionadas.
ALL é o padrão. Usar ALL será tratado da mesma maneira como se tivesse sido omitido. Todas aslinhas de todas as colunas são selecionadas, e as duplicações são mantidas.
Use DISTINCT para retornar somente valores distintos quando uma coluna contém valoresduplicados.
FROM from_item [, ...]
Indica a entrada para a consulta, em que from_item pode ser uma exibição, um construto de uniãoou uma subconsulta conforme descrito abaixo.
O from_item pode ser:• table_name [ [ AS ] alias [ (column_alias [, ...]) ] ]
Em que table_name é o nome da tabela de destino da qual selecionar linhas, alias é o nomepara indicar a saída da instrução SELECT e column_alias define as colunas para o aliasespecificado.
283

Amazon Athena Guia do usuárioSELECT
-OU-• join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]
Em que join_type é um dos:• [ INNER ] JOIN
• LEFT [ OUTER ] JOIN
• RIGHT [ OUTER ] JOIN
• FULL [ OUTER ] JOIN
• CROSS JOIN
• ON join_condition | USING (join_column [, ...]) Em que usar join_conditionpermite especificar nomes de coluna para chaves de união em várias tabelas e usarjoin_column exige que join_column exista em ambas as tabelas.
[ WHERE condição ]
Filtra resultados de acordo com o condition especificado por você.[ GROUP BY [ ALL | DISTINCT ] grouping_expressions [, ...] ]
Divide a saída da instrução SELECT em linhas com valores correspondentes.
ALL e DISTINCT determinam se conjuntos de agrupamentos duplicados produzem linhas de saídadistintas. Se omitido, ALL será pressuposto.
grouping_expressions permite realizar operações de agrupamento complexas.
O elemento grouping_expressions pode ser qualquer função, como SUM, AVG e COUNT, realizadaem colunas de entrada, ou ser um número ordinal que seleciona uma coluna de saída por posição, apartir de um.
As expressões GROUP BY podem agrupar a saída por nomes de coluna de entrada não exibidos nasaída da instrução SELECT.
Todas as expressões de saída devem ser funções agregadas ou colunas presentes na cláusulaGROUP BY.
Você pode usar uma única consulta para realizar uma análise que exija a agregação de váriosconjuntos de colunas.
Essas operações de agrupamento complexas não oferecem suporte a expressões que abranjamcolunas de entrada. Somente nomes de coluna ou ordinais são permitidos.
Você normalmente pode usar UNION ALL para obter os mesmos resultados dessas operações GROUPBY, mas consultas que usam GROUP BY têm a vantagem de ler os dados uma vez, e UNION ALL lêos dados subjacentes três vezes e podem produzir resultados inconsistentes quando a fonte de dadosestá sujeita a alterações.
GROUP BY CUBE gera todos os possíveis conjuntos de agrupamento para um determinado conjuntode colunas. GROUP BY ROLLUP gera todos os possíveis subtotais para um determinado conjunto decolunas.
[ HAVING condition ]
Usada com funções de agregação e a cláusula GROUP BY. Controla quais grupos são selecionados,eliminando grupos que não atendam a condition. A filtragem ocorrerá depois de grupos, e asagregações serão calculadas.
[ UNION [ ALL | DISTINCT ] union_query] ]
Combina os resultados de mais de uma instrução SELECT em uma única consulta. ALL ou DISTINCTcontrola quais linhas são incluídas no conjunto de resultados final.
ALL faz com que todas as linhas sejam incluídas, mesmo se elas forem idênticas.
284

Amazon Athena Guia do usuárioSELECT
DISTINCT faz com que apenas linhas exclusivas sejam incluídas no conjunto de resultadoscombinados. DISTINCT é o padrão.
Várias cláusulas UNION são processadas da esquerda para a direita, a menos que você useparênteses para definir explicitamente a ordem de processamento.
[ ORDER BY expression [ ASC | DESC ] [ NULLS FIRST | NULLS LAST] [, ...] ]
Classifica um conjunto de resultados por um ou mais expression de saída.
Quando a cláusula contém várias expressões, o conjunto de resultados é classificado de acordo como primeiro expression. Em seguida, o segundo expression é aplicado a linhas que tenham valorescorrespondentes da primeira expressão, e assim por diante.
Cada expression pode especificar colunas de saída de SELECT ou um número ordinal para umacoluna de saída por posição, a partir de um.
ORDER BY é avaliada como a última etapa após qualquer cláusula GROUP BY ou HAVING. ASC e DESCdeterminam se os resultados são classificados em ordem crescente ou decrescente.
A ordem nula padrão é NULLS LAST, independentemente da ordem de classificação crescente oudecrescente.
LIMIT [ count | ALL ]
Restringe o número de linhas no conjunto de resultados a count. LIMIT ALL é igual à omissão dacláusula LIMIT. Se a consulta não tiver a cláusula ORDER BY, os resultados serão arbitrários.
TABLESAMPLE BERNOULLI | SYSTEM (percentage)
Operador operacional para selecionar linhas de uma tabela com base em um método de amostragem.
BERNOULLI seleciona cada linha para estar no exemplo da tabela com uma probabilidade depercentage. Todos os blocos físicos da tabela são examinados, e determinadas linhas sãoignoradas com base em uma comparação entre o percentage de exemplo e um valor aleatóriocalculado no tempo de execução.
Com SYSTEM, a tabela é dividida em segmentos lógicos de dados, e a tabela mostra um exemplodessa granularidade.
Todas as linhas de um determinado segmento são selecionadas, ou o segmento é ignorado com baseem uma comparação entre o percentage de exemplo e um valor aleatório calculado em tempo deexecução. A amostragem de SYTSTEM depende do conector. Esse método não garante probabilidadesde amostragem independentes.
[ UNNEST (array_or_map) [WITH ORDINALITY] ]
Expande uma matriz ou um mapa para uma relação. As matrizes são expandidas para uma únicacoluna. Os mapas são expandidos para duas colunas (chave, valor).
Você pode usar UNNEST com vários argumentos, que são expandidos para várias colunas com omáximo de linhas do maior argumento de cardinalidade.
Outras colunas são preenchidas com nulos.
A cláusula WITH ORDINALITY adiciona uma coluna de ordinalidade ao final.
UNNEST costuma ser usado com um JOIN e pode fazer referência a colunas de relações no ladoesquerdo do JOIN.
ExemplosSELECT * FROM table;
285

Amazon Athena Guia do usuárioINSERT INTO
SELECT os, COUNT(*) count FROM cloudfront_logs WHERE date BETWEEN date '2014-07-05' AND date '2014-08-05' GROUP BY os;
Para obter mais exemplos, consulte Consulta de dados em tabelas do Amazon Athena (p. 65).
INSERT INTOInsere novas linhas em uma tabela de destino com base em uma instrução de consulta SELECT executadaem uma tabela de origem ou com base em um conjunto de VALUES fornecidos como parte da instrução.Quando a tabela de origem é baseada em dados subjacentes em um formato, como CSV ou JSON,e a tabela de destino é baseada em outro formato, como Parquet ou ORC, é possível usar consultasINSERT INTO para transformar dados selecionados no formato da tabela de destino. INSERT INTOdetecta automaticamente quando uma coluna em uma tabela de destino é particionada e grava os dadosno Amazon S3 de acordo. Nenhuma sintaxe especial de particionamento é necessária.
Note
• Para obter informações sobre como usar INSERT INTO para inserir dados não particionadosem uma tabela particionada, consulte Usar CTAS e INSERT INTO para ETL e análise dedados (p. 86).
• Para obter informações sobre como usar INSERT INTO para inserir dados particionados emuma tabela particionada, consulte Usar CTAS e INSERT INTO para criar uma tabela com maisde 100 partições (p. 92).
Condições e limitaçõesConsidere o seguinte ao usar consultas INSERT com o Athena.
Important
Ao executar uma consulta INSERT em uma tabela com dados subjacentes criptografados noAmazon S3, os arquivos de saída que a consulta INSERT grava não são criptografados porpadrão. Recomendamos que você criptografe os resultados da consulta INSERT se estiverinserindo em tabelas com dados criptografados.Para obter mais informações sobre como criptografar resultados da consulta usando oconsole, consulte Criptografia de resultados de consulta armazenados no Amazon S3 (p. 176).Para habilitar a criptografia usando a AWS CLI ou a API do Athena, use as propriedadesEncryptionConfiguration da ação StartQueryExecution para especificar as opções decriptografia do Amazon S3 de acordo com seus requisitos.
Formatos compatíveis e SerDes
É possível executar uma consulta INSERT em tabelas criadas de dados com os seguintes formatos eSerDes.
Formato dedados
SerDe
Avro org.apache.hadoop.hive.serde2.avro.AvroSerDe
JSON org.apache.hive.hcatalog.data.JsonSerDe
ORC org.apache.hadoop.hive.ql.io.orc.OrcSerde
Parquet org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
286

Amazon Athena Guia do usuárioINSERT INTO
Formato dedados
SerDe
Arquivo detexto
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Note
Arquivos CSV, TSV e delimitados personalizados são compatíveis.
Tabelas em bucket incompatíveisINSERT INTO não é compatível com tabelas em bucket. Para obter mais informações, consulteArmazenar em bucket vs particionar (p. 82).
Limites de partiçãoA instrução INSERT INTO comporta a gravação de no máximo 100 combinações de partições na tabelade destino. Se você executar a cláusula SELECT em uma tabela com mais de 100 partições, a consultafalhará a menos que a consulta SELECT seja limitada a 100 partições ou menos.
Para obter informações sobre como contornar essa limitação, consulte Usar CTAS e INSERT INTO paracriar uma tabela com mais de 100 partições (p. 92).
Arquivos gravados no Amazon S3O Athena grava arquivos em locais de dados de origem no Amazon S3 como resultado do comandoINSERT. Cada operação INSERT cria um novo arquivo, em vez de anexar a um arquivo existente. Oslocais de arquivos dependem da estrutura da tabela e da consulta SELECT, se presente. O Athena gera umarquivo manifesto de dados para cada consulta INSERT. O manifesto rastreia os arquivos que a consultagravou. Ele é salvo no local do resultado da consulta do Athena no Amazon S3. Se uma consulta falhar, omanifesto também rastreará os arquivos que a consulta pretendia gravar. O manifesto é útil para identificararquivos órfãos resultantes de uma consulta com falha. Para obter mais informações, consulte Trabalharcom resultados de consulta, arquivos de saída e histórico de consultas (p. 65).
INSERT INTO...SELECTEspecifica a consulta a ser executada em uma tabela, source_table, que determina as linhas a sereminseridas em uma segunda tabela, destination_table. Se a consulta SELECT especificar colunas nasource_table, as colunas deverão corresponder precisamente àquelas na destination_table.
Para obter mais informações sobre consultas SELECT, consulte SELECT (p. 282).
Resumo
INSERT INTO destination_table SELECT select_query FROM source_table_or_view
Exemplos
Selecione todas as linhas na tabela vancouver_pageviews e insira-as na tabela canada_pageviews:
INSERT INTO canada_pageviews SELECT * FROM vancouver_pageviews;
Selecione apenas as linhas na tabela vancouver_pageviews em que a coluna date tenha um valorentre 2019-07-01 e 2019-07-31, e insira-as em canada_july_pageviews:
287

Amazon Athena Guia do usuárioFunções do Presto
INSERT INTO canada_july_pageviewsSELECT *FROM vancouver_pageviewsWHERE date BETWEEN date '2019-07-01' AND '2019-07-31';
Selecione os valores nas colunas city e state na tabela cities_world somente dessas linhas comum valor usa na coluna country e insira-os nas colunas city e state na tabela cities_usa:
INSERT INTO cities_usa (city,state)SELECT city,stateFROM cities_world WHERE country='usa'
INSERT INTO...VALUESInsere linhas em uma tabela existente especificando colunas e valores. As colunas especificadas e os tiposde dados associados devem corresponder precisamente às colunas e aos tipos de dados na tabela dedestino.
Important
Não recomendamos inserir linhas usando VALUES porque o Athena gera arquivos para cadaoperação INSERT. Isso pode fazer com que muitos arquivos pequenos sejam criados e degrademo desempenho de consulta da tabela. Para identificar arquivos que uma consulta INSERT cria,examine o arquivo manifesto de dados. Para obter mais informações, consulte Trabalhar comresultados de consulta, arquivos de saída e histórico de consultas (p. 65).
Resumo
INSERT INTO destination_table [(col1,col2,...)] VALUES (col1value,col2value,...)[, (col1value,col2value,...)][, ...]
Exemplos
Nos exemplos a seguir, a tabela de cidades tem três colunas: id, city, state, state_motto. A colunaid é do tipo INT, e todas as outras colunas são do tipo VARCHAR.
Insira uma única linha na tabela cities, com todos os valores da coluna especificados:
INSERT INTO cities VALUES (1,'Lansing','MI','Si quaeris peninsulam amoenam circumspice')
Insira duas linhas na tabela cities:
INSERT INTO cities VALUES (1,'Lansing','MI','Si quaeris peninsulam amoenam circumspice'), (3,'Boise','ID','Esto perpetua')
Funções do Presto no Amazon AthenaO mecanismo de consulta do Athena se baseia no Presto 0.172. Para obter mais informações sobre essasfunções, consulte Funções e operadores do Presto 0.172 e as seções específicas da documentação doPresto referenciadas abaixo.
288

Amazon Athena Guia do usuárioInstruções DDL
O Athena não oferece suporte a todos os recursos do Presto. Para obter mais informações, consulteCondições e limitações (p. 307).
• Operadores lógicos• Funções e operadores comparativos• Expressões condicionais• Funções da conversão• Funções e operadores matemáticos• Funções bitwise• Funções e operadores decimais• Funções e operadores de string• Funções binárias• Funções e operadores de data e hora• Funções de expressão regulares• Funções e operadores JSON• Funções URL• Funções agregadas• Funções de janela• Funções de cor• Funções e operadores de matriz• Funções e operadores de mapa• Expressões e funções Lambda• Funções de teradados
Instruções DDLUse as instruções DDL a seguir diretamente no Athena.
O mecanismo de consulta do Athena se baseia na DDL do HiveQL.
O Athena não oferece suporte a todas as instruções DDL, e há algumas diferenças entre a DDL do HiveQLe a DDL do Athena. Para obter mais informações, consulte os tópicos de referência nesta seção e em DDLincompatível (p. 290).
Tópicos• DDL incompatível (p. 290)• ALTER DATABASE SET DBPROPERTIES (p. 291)• ALTER TABLE ADD PARTITION (p. 292)• ALTER TABLE DROP PARTITION (p. 293)• ALTER TABLE RENAME PARTITION (p. 293)• ALTER TABLE SET LOCATION (p. 294)• ALTER TABLE SET TBLPROPERTIES (p. 294)• CREATE DATABASE (p. 295)• CREATE TABLE (p. 295)• CREATE TABLE AS (p. 299)• CREATE VIEW (p. 301)• DESCRIBE TABLE (p. 301)
289

Amazon Athena Guia do usuárioDDL incompatível
• DESCRIBE VIEW (p. 302)• DROP DATABASE (p. 302)• DROP TABLE (p. 303)• DROP VIEW (p. 303)• MSCK REPAIR TABLE (p. 304)• SHOW COLUMNS (p. 304)• SHOW CREATE TABLE (p. 304)• SHOW CREATE VIEW (p. 305)• SHOW DATABASES (p. 305)• SHOW PARTITIONS (p. 305)• SHOW TABLES (p. 306)• SHOW TBLPROPERTIES (p. 306)• SHOW VIEWS (p. 307)
DDL incompatívelAs seguintes DDLs do Hive nativas não têm suporte do Athena:
• ALTER INDEX• ALTER TABLE table_name ARCHIVE PARTITION• ALTER TABLE table_name CLUSTERED BY• ALTER TABLE table_name EXCHANGE PARTITION• ALTER TABLE table_name NOT CLUSTERED• ALTER TABLE table_name NOT SKEWED• ALTER TABLE table_name NOT SORTED• ALTER TABLE table_name NOT STORED AS DIRECTORIES• ALTER TABLE table_name partitionSpec ADD COLUMNS• ALTER TABLE table_name partitionSpec CHANGE COLUMNS• ALTER TABLE table_name partitionSpec COMPACT• ALTER TABLE table_name partitionSpec CONCATENATE• ALTER TABLE table_name partitionSpec REPLACE COLUMNS• ALTER TABLE table_name partitionSpec SET FILEFORMAT• ALTER TABLE table_name RENAME TO• ALTER TABLE table_name SET SKEWED LOCATION• ALTER TABLE table_name SKEWED BY• ALTER TABLE table_name TOUCH• ALTER TABLE table_name UNARCHIVE PARTITION• COMMIT• CREATE INDEX• CREATE ROLE• CREATE TABLE table_name LIKE existing_table_name• CREATE TEMPORARY MACRO• DELETE FROM• DESCRIBE DATABASE• DFS
290

Amazon Athena Guia do usuárioALTER DATABASE SET DBPROPERTIES
• DROP INDEX• DROP ROLE• DROP TEMPORARY MACRO• EXPORT TABLE• GRANT ROLE• IMPORT TABLE• INSERT INTO• LOCK DATABASE• LOCK TABLE• REVOKE ROLE• ROLLBACK• SHOW COMPACTIONS• SHOW CURRENT ROLES• SHOW GRANT• SHOW INDEXES• SHOW LOCKS• SHOW PRINCIPALS• SHOW ROLE GRANT• SHOW ROLES• SHOW TRANSACTIONS• START TRANSACTION• UNLOCK DATABASE• UNLOCK TABLE
ALTER DATABASE SET DBPROPERTIESCria uma ou mais propriedades para um banco de dados. O uso de DATABASE e SCHEMA é intercambiável.Eles são iguais.
Resumo
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES ('property_name'='property_value' [, ...] )
ParâmetrosSET DBPROPERTIES ('property_name'='property_value' [, ...]
Especifica uma propriedade ou propriedades para o banco de dados chamado property_name eestabelece o valor para cada uma das propriedades, respectivamente como property_value. Seproperty_name já existir, o valor anterior será substituído por property_value.
Exemplos
ALTER DATABASE jd_datasets SET DBPROPERTIES ('creator'='John Doe', 'department'='applied mathematics');
291

Amazon Athena Guia do usuárioALTER TABLE ADD PARTITION
ALTER SCHEMA jd_datasets SET DBPROPERTIES ('creator'='Jane Doe');
ALTER TABLE ADD PARTITIONCria uma ou mais colunas de partição para a tabela. Cada partição consiste em uma ou mais combinaçõesde nome/valor de coluna distintas. Um diretório de dados à parte é criado para cada combinaçãoespecificada, o que pode melhorar o desempenho da consulta em algumas circunstâncias. As colunasparticionadas não existem dentro da própria tabela de dados. Dessa forma, se usar o nome de umacoluna com o mesmo nome de uma coluna na própria tabela, você receberá um erro. Para obter maisinformações, consulte Particionar dados (p. 23).
Resumo
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION (partition_col1_name = partition_col1_value [,partition_col2_name = partition_col2_value] [,...]) [LOCATION 'location1'] [PARTITION (partition_colA_name = partition_colA_value [,partition_colB_name = partition_colB_value [,...])] [LOCATION 'location2'] [,...]
Parâmetros[IF NOT EXISTS]
Suprimirá o erro se uma partição com a mesma definição já existir.PARTITION (partition_col_name = partition_col_value [,...])
Cria uma partição com as combinações de nome/valor de coluna especificadas por você. Coloquepartition_col_value entre caracteres de string somente se o tipo de dados da coluna for umastring.
[LOCATION 'location']
Especifica o diretório no qual armazenar as partições definidas pela instrução anterior.
Exemplos
ALTER TABLE orders ADD PARTITION (dt = '2016-05-14', country = 'IN');
ALTER TABLE orders ADD PARTITION (dt = '2016-05-14', country = 'IN') PARTITION (dt = '2016-05-15', country = 'IN');
ALTER TABLE orders ADD PARTITION (dt = '2016-05-14', country = 'IN') LOCATION 's3://mystorage/path/to/INDIA_14_May_2016/'
292

Amazon Athena Guia do usuárioALTER TABLE DROP PARTITION
PARTITION (dt = '2016-05-15', country = 'IN') LOCATION 's3://mystorage/path/to/INDIA_15_May_2016/';
ALTER TABLE DROP PARTITIONIgnora uma ou mais partições especificadas para a tabela nomeada.
ResumoALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition_spec) [, PARTITION (partition_spec)]
Parâmetros[IF EXISTS]
Suprimirá a mensagem de erro se a partição especificada não existir.PARTITION (partition_spec)
Cada partition_spec especifica uma combinação nome/valor na forma partition_col_name =partition_col_value [,...].
ExemplosALTER TABLE orders DROP PARTITION (dt = '2014-05-14', country = 'IN');
ALTER TABLE orders DROP PARTITION (dt = '2014-05-14', country = 'IN'), PARTITION (dt = '2014-05-15', country = 'IN');
ALTER TABLE RENAME PARTITIONRenomeia uma coluna de partição, partition_spec, da tabela chamada table_name, paranew_partition_spec.
ResumoALTER TABLE table_name PARTITION (partition_spec) RENAME TO PARTITION (new_partition_spec)
ParâmetrosPARTITION (partition_spec)
Cada partition_spec especifica uma combinação nome/valor na forma partition_col_name =partition_col_value [,...].
ExemplosALTER TABLE orders
293

Amazon Athena Guia do usuárioALTER TABLE SET LOCATION
PARTITION (dt = '2014-05-14', country = 'IN') RENAME TO PARTITION (dt = '2014-05-15', country = 'IN');
ALTER TABLE SET LOCATIONAltera o local da tabela chamada table_name e, como opção, uma partição com partition_spec.
ResumoALTER TABLE table_name [ PARTITION (partition_spec) ] SET LOCATION 'new location'
ParâmetrosPARTITION (partition_spec)
Especifica a partição com parâmetros partition_spec cujo local você deseja alterar. Opartition_spec especifica uma combinação nome/valor na forma partition_col_name =partition_col_value.
SET LOCATION 'new location'
Especifica o novo local, que deve ser um local do Amazon S3. Para obter informações sobre a sintaxe,consulte Local da tabela no Amazon S3 (p. 21).
ExemplosALTER TABLE customers PARTITION (zip='98040', state='WA') SET LOCATION 's3://mystorage/custdata/';
ALTER TABLE SET TBLPROPERTIESAdiciona propriedades de metadados personalizados a uma tabela e define os valores atribuídos.
Não há suporte para tabelas gerenciadas, portanto, a configuração 'EXTERNAL'='FALSE' não teráefeito.
ResumoALTER TABLE table_name SET TBLPROPERTIES ('property_name' = 'property_value' [ , ... ])
ParâmetrosSET TBLPROPERTIES ('property_name' = 'property_value' [ , ... ])
Especifica as propriedades de metadados a serem adicionadas como property_name e o valorpara cada uma como property value. Se property_name já existir, o valor será redefinido comoproperty_value.
ExemplosALTER TABLE orders
294

Amazon Athena Guia do usuárioCREATE DATABASE
SET TBLPROPERTIES ('notes'="Please don't drop this table.");
CREATE DATABASECria um banco de dados. O uso de DATABASE e SCHEMA é intercambiável. Eles significam a mesma coisa.
ResumoCREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT 'database_comment'] [LOCATION 'S3_loc'] [WITH DBPROPERTIES ('property_name' = 'property_value') [, ...]]
Parâmetros[IF NOT EXISTS]
Fará o erro ser suprimido se um banco de dados chamado database_name já existir.[COMMENT database_comment]
Estabelece o valor de metadados para a propriedade de metadados interna chamada comment e ovalor fornecido por você para database_comment.
[LOCATION S3_loc]
Especifica o local onde arquivos de banco de dados e metastore existirão como S3_loc. O local deveser um local do Amazon S3.
[WITH DBPROPERTIES ('property_name' = 'property_value') [, ...] ]
Permite especificar propriedades de metadados personalizados para a definição do banco de dados.
ExemplosCREATE DATABASE clickstreams;
CREATE DATABASE IF NOT EXISTS clickstreams COMMENT 'Site Foo clickstream data aggregates' LOCATION 's3://myS3location/clickstreams/' WITH DBPROPERTIES ('creator'='Jane D.', 'Dept.'='Marketing analytics');
CREATE TABLECria uma tabela com o nome e os parâmetros especificados por você.
ResumoCREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [COMMENT col_comment] [, ...] )] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [ROW FORMAT row_format] [STORED AS file_format] [WITH SERDEPROPERTIES (...)] ] [LOCATION 's3_loc']
295

Amazon Athena Guia do usuárioCREATE TABLE
[TBLPROPERTIES ( ['has_encrypted_data'='true | false',] ['classification'='aws_glue_classification',] property_name=property_value [, ...] ) ]
Parâmetros[EXTERNAL]
Especifica que a tabela se baseia em um arquivo de dados subjacente existente no Amazon S3, noLOCATION especificado por você. Quando você cria uma tabela externa, os dados referenciadosdevem estar em conformidade com o formato padrão ou o formato especificado por você com ascláusulas ROW FORMAT, STORED AS e WITH SERDEPROPERTIES.
[IF NOT EXISTS]
Fará a mensagem de erro ser suprimida se uma tabela chamada table_name já existir.[db_name.]table_name
Especifica um nome para a tabela a ser criada. O parâmetro db_name opcional especifica o bancode dados no qual a tabela existe. Se omitido, o banco de dados atual será assumido. Se o nome databela inclui números, coloque table_name entre aspas, por exemplo "table123". Se table_namecomeçar com um sublinhado, use acentos graves, por exemplo, `_mytable`. Os caracteresespeciais (que não sejam sublinhado) não são compatíveis.
Os nomes de tabela do Athena não diferenciam maiúsculas de minúsculas. Porém, se você trabalharcom o Apache Spark, o Spark exigirá nomes de tabela em minúsculas.
[ ( col_name data_type [COMMENT col_comment] [, ...] ) ]
Especifica o nome de cada coluna a ser criada, além do tipo de dados da coluna. Os nomes decoluna não permitem caracteres especiais além de sublinhado (_). Se col_name começar com umsublinhado, coloque o nome da coluna entre acentos graves, por exemplo `_mycolumn`.
O valor data_type pode ser qualquer um dos seguintes:• BOOLEAN. Os valores são true e false.• TINYINT. Um valor INTEGER assinado de 8 bits no formato complemento para dois, com um valor
mínimo de -2^7 e um valor máximo de 2^7-1.• SMALLINT. Um valor INTEGER assinado de 16 bits no formato complemento para dois, com um
valor mínimo de -2^15 e um valor máximo de 2^15-1.• INT. O Athena combina duas implementações diferentes do tipo de dados INTEGER. Nas consultas
da Linguagem de Definição de Dados (DDL), o Athena usa o tipo de dados INT. Em todas as outrasconsultas, o Athena usa o tipo de dados INTEGER, em que INTEGER é representado por um valorassinado de 32 bits no formato complemento para dois, com um valor mínimo de -2^31 e um valormáximo de 2^31-1. No driver JDBC, INTEGER é retornado para garantir a compatibilidade com osaplicativos de análise de negócios.
• BIGINT. Um valor INTEGER assinado de 64 bits no formato complemento para dois, com um valormínimo de -2^63 e um valor máximo de 2^63-1.
• DOUBLE
• FLOAT
• DECIMAL [ (precision, scale) ], onde precision é o número total de dígitos e scale(opcional) é o número de dígitos na parte fracionada, o padrão é 0. Por exemplo, use estasdefinições de tipo: DECIMAL(11,5), DECIMAL(15).
Para especificar valores decimais como literais, como ao selecionar filas com um valor decimalespecífico em uma expressão de consulta DDL, especifique a definição de tipo DECIMAL eliste o valor decimal como um literal (em aspas simples) na consulta, como neste exemplo:decimal_value = DECIMAL '0.12'.
296

Amazon Athena Guia do usuárioCREATE TABLE
• CHAR. Os dados de caractere de comprimento fixo, com um tamanho especificado entre 1 e 255,como char(10). Para obter mais informações, consulte Tipo de dados do Hive CHAR.
• VARCHAR. Os dados de caractere de comprimento variável, com um tamanho especificado entre1 e 65535, como varchar(10). Para obter mais informações, consulte Tipo de dados do HiveVARCHAR.
• BINARY (para dados em Parquet)• Tipos de data e hora• DATE, no formato UNIX, como YYYY-MM-DD.• TIMESTAMP. Instantâneo em hora e data no formato UNiX, como yyyy-mm-ddhh:mm:ss[.f...]. Por exemplo, TIMESTAMP '2008-09-15 03:04:05.324'. Esse formatousa o fuso horário da sessão.
• ARRAY < data_type >• MAP < primitive_type, data_type >• STRUCT < col_name : data_type [COMMENT col_comment] [, ...] >
[COMMENT table_comment]
Cria a propriedade da tabela comment e a preenche com o table_comment especificado por você.[PARTITIONED BY (col_name data_type [ COMMENT col_comment ], ... ) ]
Cria uma tabela particionada com uma ou mais colunas de partição que tenham col_name,data_type e col_comment especificados. A tabela pode ter uma ou mais partições, que consistemem uma combinação distinta de nome e valor de coluna. Um diretório de dados à parte é criadopara cada combinação especificada, o que pode melhorar o desempenho da consulta em algumascircunstâncias. As colunas particionadas não existem na própria tabela de dados. Se você usar umvalor para col_name que é o mesmo valor usado na coluna da tabela, obterá um erro. Para obtermais informações, consulte Particionar dados (p. 23).
Note
Depois de criar uma tabela com partições, execute uma consulta que consista na cláusulaMSCK REPAIR TABLE (p. 304) para atualizar metadados de partição, por exemplo, MSCKREPAIR TABLE cloudfront_logs;.
[ROW FORMAT row_format]
Especifica o formato de linha da tabela e os dados de origem subjacente, se aplicável. Pararow_format, você pode especificar um ou mais delimitadores com a cláusula DELIMITED ou, comoalternativa, usar a cláusula SERDE conforme descrito abaixo. Se ROW FORMAT for omitido ou ROWFORMAT DELIMITED for especificado, um SerDe nativo será usado.• [DELIMITED FIELDS TERMINATED BY char [ESCAPED BY char]]• [DELIMITED COLLECTION ITEMS TERMINATED BY char]• [MAP KEYS TERMINATED BY char]• [LINES TERMINATED BY char]• [NULL DEFINED AS char]
Disponível somente com o Hive 0.13 e quando o formato de arquivo em STORED AS(ARMAZENADO COMO) for TEXTFILE.
--OU--• SERDE 'serde_name' [WITH SERDEPROPERTIES ("property_name" = "property_value",
"property_name" = "property_value" [, ...] )]
O serde_name indica o SerDe a ser usado. A cláusula WITH SERDEPROPERTIES permite forneceruma ou mais propriedades personalizadas permitidas pelo SerDe.
297

Amazon Athena Guia do usuárioCREATE TABLE
[STORED AS formato do arquivo]
Especifica o formato de arquivo para dados da tabela. Se omitido, TEXTFILE será o padrão. Asopções de file_format são:• SEQUENCEFILE• TEXTFILE• RCFILE• ORC• PARQUET• AVRO• INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
[LOCATION 'S3_loc']
Especifica o local dos dados subjacentes no Amazon S3 a partir do qual a tabela é criada, porexemplo, 's3://mystorage/'. Para obter mais informações sobre considerações, como o formatode dados e as permissões, consulte Requisitos para tabelas no Athena e dados no Amazon S3 (p. 15).
Use uma barra à direita para a pasta ou o bucket. Não use nomes de arquivo ou caracteres glob.
Use: s3://mybucket/key/
Não use: s3://path_to_bucket s3://path_to_bucket/* s3://path_to-bucket/mydatafile.dat
[TBLPROPERTIES ( ['has_encrypted_data'='true | false',] ['classification'='aws_glue_classification',]property_name=property_value [, ...] ) ]
Especifica pares de chave/valor de metadados personalizados para a definição da tabela, além daspropriedades da tabela predefinidas, como "comment".
O Athena tem uma propriedade integrada, has_encrypted_data. Defina essa propriedade comotrue para indicar que o conjunto de dados subjacente especificado por LOCATION está criptografado.Se omitido e se as configurações do grupo de trabalho não substituírem as configurações do ladodo cliente, a pressuposição será false. Se omitido ou definido como false quando os dadossubjacentes estiverem criptografados, a consulta resultará em um erro. Para obter mais informações,consulte Configurar opções de criptografia avançadas (p. 174).
Para executar trabalhos ETL, o AWS Glue exige que você crie uma tabela com a propriedadeclassification para indicar o tipo de dados para o AWS Glue como csv, parquet, orc, avro oujson. Por exemplo, 'classification'='csv'. Os trabalhos ETL falharão se você não especificaressa propriedade. Você poderá especificá-la depois usando o console do AWS Glue, a API ou a CLI.Para obter mais informações, consulte Usar trabalhos do AWS Glue para ETL com Athena (p. 41) eCriar trabalhos no Glue no Guia do desenvolvedor do AWS Glue.
ExemplosCREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.cloudfront_logs ( Date DATE, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, os STRING,
298

Amazon Athena Guia do usuárioCREATE TABLE AS
Browser STRING, BrowserVersion STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$" ) LOCATION 's3://athena-examples-myregion/cloudfront/plaintext/';
CREATE TABLE ASCria uma tabela preenchida com os resultados de uma consulta SELECT (p. 282). Para criar uma tabelavazia, use CREATE TABLE (p. 295).
Tópicos• Resumo (p. 283)• Propriedades da tabela CTAS. (p. 299)• Exemplos (p. 301)
ResumoCREATE TABLE table_name[ WITH ( property_name = expression [, ...] ) ]AS query[ WITH [ NO ] DATA ]
Onde:
WITH ( property_name = expression [, ...] )
Uma lista de propriedades da tabela CTAS opcionais, algumas das quais são específicas do formatode armazenamento físico de dados. Consulte Propriedades da tabela CTAS. (p. 299).
query
Uma consulta SELECT (p. 282) que é usada para criar uma tabela.Important
Se você planeja criar uma consulta com partições, especifique os nomes das colunasparticionadas por último na lista de colunas na instrução SELECT.
[WITH [NO] DATA]
Se WITH NO DATA for usado, será criada uma tabela vazia com o mesmo esquema da tabela original.
Propriedades da tabela CTAS.Cada tabela CTAS no Athena tem uma lista de propriedades da tabela CTAS opcionais que sãoespecificadas usando WITH (property_name = expression [, ...] ). Para obter maisinformações sobre como usar esses parâmetros, consulte Exemplos de consultas CTAS (p. 83).
WITH (property_name = expression [, ...], )
external_location = [location]
O local onde o Athena salva a consulta CTAS no Amazon S3, por exemplo, WITH(external_location ='s3://my-bucket/tables/parquet_table/'). Essa
299

Amazon Athena Guia do usuárioCREATE TABLE AS
propriedade é opcional. Quando você não especificar nenhum local, e o seu grupo detrabalho não substituir as configurações no lado do cliente (p. 226), o Athena armazenará osresultados da consulta CTAS em external_location = 's3://aws-athena-query-results-<account>-<region>/<query-name-or-unsaved>/<year>/<month>/<date>/<query-id>/' e não usará o mesmo caminho novamente. Se o local for especificadomanualmente, certifique-se de que o local do Amazon S3 não tenha dados. O Athena nuncatenta excluir seus dados. Se você quiser usar o mesmo local novamente, exclua os dadosmanualmente. Caso contrário, sua consulta CTAS falhará.
Se o grupo de trabalho em que uma consulta será executada estiver configurado com umlocal imposto de resultados da consulta (p. 226), não especifique um external_locationpara a consulta CTAS. O Athena emitirá um erro e reprovará uma consulta que especificaum external_location neste caso. Por exemplo, esta consulta falhará se você aplicaro grupo de trabalho para usar o próprio local: CREATE TABLE <DB>.<TABLE1> WITH(format='Parquet', external_location='s3://my_test/test/') AS SELECT *FROM <DB>.<TABLE2> LIMIT 10;
Para obter o local dos resultados especificados para o grupo de trabalho, visualize os detalhes dogrupo de trabalho (p. 230).
format = [format]
O formato de dados dos resultados da consulta CTAS, como ORC, PARQUET, AVRO, JSON ouTEXTFILE. Por exemplo, WITH (format = 'PARQUET'). Se for omitido, PARQUET é usado porpadrão. O nome deste parâmetro, format, deve estar listado em minúsculas, ou sua consultaCTAS falhará.
partitioned_by = ARRAY( [col_name,…])
Opcional. Uma lista matriz de colunas pela qual a tabela CTAS será particionada. Verifique seos nomes das colunas particionadas estão listados por último na lista de colunas da instruçãoSELECT.
bucketed_by( [bucket_name,…])
Uma lista matriz de buckets para dados do bucket. Se for omitido, o Athena não armazenará seusdados em um bucket nessa consulta.
bucket_count = [int]
O número de buckets para armazenar seus dados em um bucket. Se for omitido, o Athena nãoarmazenará seus dados em um bucket.
orc_compression = [format]
O tipo de compactação a ser usado para dados ORC. Por exemplo, WITH (orc_compression= 'ZLIB'). Se for omitido, a compactação GZIP será usada por padrão para ORC e outrosformatos de armazenamento físico de dados compatíveis com CTAS.
parquet_compression = [format]
O tipo de compactação a ser usado para dados Parquet. Por exemplo, WITH(parquet_compression = 'SNAPPY'). Se for omitido, a compactação GZIP será usadapor padrão para Parquet e outros formatos de armazenamento físico de dados compatíveis comCTAS.
field_delimiter = [delimiter]
Opcionais e específicos para formatos de armazenamento físico de dados com base em texto.O delimitador do campo para arquivos em CSV, TSV e arquivos de texto. Por exemplo, WITH(field_delimiter = ','). Se você não especificar um delimitador do campo, \001 seráusado por padrão.
300

Amazon Athena Guia do usuárioCREATE VIEW
ExemplosConsulte Exemplos de consultas CTAS (p. 83).
CREATE VIEWCria uma nova exibição a partir de uma consulta SELECT especificada. A exibição é uma tabela lógica quepode ser referenciada por futuras consultas. As visualizações não contêm todos os dados e não gravamdados. Em vez disso, a consulta especificada pela exibição é executada sempre que você fizer referênciaà exibição por outra consulta.
A cláusula OR REPLACE opcional permite atualizar a exibição existente substituindo-a Para obter maisinformações, consulte Criação de exibições (p. 75).
ResumoCREATE [ OR REPLACE ] VIEW view_name AS query
ExemplosPara criar uma exibição test a partir da tabela orders, use uma consulta semelhante à seguinte:
CREATE VIEW test ASSELECT orderkey, orderstatus, totalprice / 2 AS halfFROM orders;
Para criar uma exibição orders_by_date a partir da tabela orders, use a seguinte consulta:
CREATE VIEW orders_by_date ASSELECT orderdate, sum(totalprice) AS priceFROM ordersGROUP BY orderdate;
Para atualizar uma exibição existente, use um exemplo semelhante ao seguinte:
CREATE OR REPLACE VIEW test ASSELECT orderkey, orderstatus, totalprice / 4 AS quarterFROM orders;
Consulte também SHOW COLUMNS (p. 304), SHOW CREATE VIEW (p. 305), DESCRIBEVIEW (p. 302) e DROP VIEW (p. 303).
DESCRIBE TABLEMostra a lista de colunas, inclusive de partição, da coluna nomeada. Isso permite examinar os atributos deuma coluna complexa.
ResumoDESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name [PARTITION partition_spec] [col_name ( [.field_name] | [.'$elem$'] | [.'$key$'] | [.'$value$'] )]
301

Amazon Athena Guia do usuárioDESCRIBE VIEW
Parâmetros[EXTENDED | FORMATTED]
Determina o formato da saída. Se você especificar EXTENDED, todos os metadados da tabela serãoproduzidos na forma serializada Thrift. Isso é útil principalmente para depuração, e não para uso geral.Use FORMATTED ou omita a cláusula para mostrar os metadados em formato tabular.
[PARTITION partition_spec]
Lista os metadados da partição com partition_spec, se incluídos.[col_name ( [.field_name] | [.'$elem$'] | [.'$key$'] | [.'$value$'] )* ]
Especifica a coluna e os atributos a serem examinados. Você pode especificar .field_name para umelemento de uma struct, '$elem$' para um elemento de matriz, '$key$' para uma chave de mapae '$value$' para um valor de mapa. Você pode especificar isso de maneira recursiva para explorarmais a coluna complexa.
Exemplos
DESCRIBE orders;
DESCRIBE VIEWMostra a lista de colunas para a exibição nomeada. Isso permite examinar os atributos de uma exibiçãocomplexa.
ResumoDESCRIBE [view_name]
ExemploDESCRIBE orders;
Consulte também SHOW COLUMNS (p. 304), SHOW CREATE VIEW (p. 305), SHOWVIEWS (p. 307) e DROP VIEW (p. 303).
DROP DATABASERemove o banco de dados nomeado do catálogo. Se o banco de dados contiver tabelas, você deveráignorar as tabelas antes de executar DROP DATABASE ou usar a cláusula CASCADE. O uso de DATABASE eSCHEMA é intercambiável. Eles significam a mesma coisa.
ResumoDROP {DATABASE | SCHEMA} [IF EXISTS] database_name [RESTRICT | CASCADE]
Parâmetros[IF EXISTS]
Fará o erro ser suprimido se database_name não existir.
302

Amazon Athena Guia do usuárioDROP TABLE
[RESTRICT|CASCADE]
Determina como tabelas dentro de database_name são consideradas durante a operação DROP.Se você especificar RESTRICT, o banco de dados não será ignorado se ele contiver tabelas. Esseé o comportamento padrão. Especificar CASCADE faz o banco de dados e todas as tabelas seremignorados.
ExemplosDROP DATABASE clickstreams;
DROP SCHEMA IF EXISTS clickstreams CASCADE;
DROP TABLERemove a definição da tabela de metadados da tabela nomeada table_name. Quando você eliminauma tabela externa, os dados subjacentes permanecem intactos porque todas as tabelas no Athena sãoEXTERNAL.
ResumoDROP TABLE [IF EXISTS] table_name
Parâmetros[ IF EXISTS ]
Fará o erro ser suprimido se table_name não existir.
ExemplosDROP TABLE fulfilled_orders;
DROP TABLE IF EXISTS fulfilled_orders;
DROP VIEWExclui uma exibição existente. A cláusula IF EXISTS opcional faz com que o erro seja suprimido se aexibição não existir.
Para obter mais informações, consulte Exclusão de exibições (p. 77).
ResumoDROP VIEW [ IF EXISTS ] view_name
ExemplosDROP VIEW orders_by_date
303

Amazon Athena Guia do usuárioMSCK REPAIR TABLE
DROP VIEW IF EXISTS orders_by_date
Consulte também CREATE VIEW (p. 301), SHOW COLUMNS (p. 304), SHOW CREATEVIEW (p. 305), SHOW VIEWS (p. 307) e DESCRIBE VIEW (p. 302).
MSCK REPAIR TABLERecupera partições e dados associados a partições. Use essa instrução ao adicionar partições aocatálogo. É possível que demore algum tempo para adicionar todas as partições. Se expirar, essaoperação estará em um estado incompleto, quando somente algumas partições são adicionadas aocatálogo. Você deverá executar a instrução na mesma tabela até todas as partições serem adicionadas.Para obter mais informações, consulte Particionar dados (p. 23).
ResumoMSCK REPAIR TABLE table_name
ExemplosMSCK REPAIR TABLE orders;
SHOW COLUMNSLista as colunas do esquema para uma tabela-base ou uma exibição.
ResumoSHOW COLUMNS IN table_name|view_name
ExemplosSHOW COLUMNS IN clicks;
SHOW CREATE TABLEAnalisa uma tabela existente chamada table_name para gerar a consulta que a criou.
ResumoSHOW CREATE TABLE [db_name.]table_name
ParâmetrosTABLE [db_name.]table_name
O parâmetro db_name é opcional. Se omitido, o contexto assumirá como padrão o banco de dadosatual.
Note
O nome da tabela é obrigatório.
304

Amazon Athena Guia do usuárioSHOW CREATE VIEW
Exemplos
SHOW CREATE TABLE orderclickstoday;
SHOW CREATE TABLE `salesdata.orderclickstoday`;
SHOW CREATE VIEWMostra a instrução SQL que cria a exibição específica.
Resumo
SHOW CREATE VIEW view_name
Exemplos
SHOW CREATE VIEW orders_by_date
Consulte também CREATE VIEW (p. 301) e DROP VIEW (p. 303).
SHOW DATABASESLista todos os bancos de dados definidos na metastore. Você pode usar DATABASES ou SCHEMAS. Elessignificam a mesma coisa.
Resumo
SHOW {DATABASES | SCHEMAS} [LIKE 'regular_expression']
Parâmetros[LIKE 'regular_expression']
Filtra a lista de bancos de dados às correspondentes ao regular_expression especificado porvocê. Curingas só podem ser *, e precisam ser precedidos por [a-z0-9], que indica qualquercaractere no intervalo de “a” a “z” e 0 a 9, ou |, que indica uma escolha entre caracteres.
Exemplos
SHOW SCHEMAS;
SHOW DATABASES LIKE '[a-z0-9]*analytics';
SHOW PARTITIONSLista todas as partições em uma tabela.
305

Amazon Athena Guia do usuárioSHOW TABLES
Resumo
SHOW PARTITIONS table_name
Exemplos
SHOW PARTITIONS clicks;
SHOW TABLESLista todas as tabelas base e exibe em um banco de dados.
Resumo
SHOW TABLES [IN database_name] ['regular_expression']
Parâmetros[IN database_name]
Especifica o database_name de quais tabelas serão listadas. Se omitido, o banco de dados docontexto atual é assumido.
['regular_expression']
Filtra a lista de tabelas às correspondentes ao regular_expression especificado por você.Somente o curinga *, o que indica qualquer caractere, ou |, o que indica uma escolha entrecaracteres, podem ser usados.
Exemplos
SHOW TABLES;
SHOW TABLES IN marketing_analytics 'orders*';
SHOW TBLPROPERTIESLista propriedades da tabela nomeada.
Resumo
SHOW TBLPROPERTIES table_name [('property_name')]
Parâmetros[('property_name')]
Se incluído, somente o valor da propriedade chamada property_name será listado.
306

Amazon Athena Guia do usuárioSHOW VIEWS
ExemplosSHOW TBLPROPERTIES orders;
SHOW TBLPROPERTIES orders('comment');
SHOW VIEWSLista as exibições no banco de dados especificado ou no banco de dados atual se você omitir o nome dobanco de dados. Use a cláusula LIKE opcional com uma expressão regular para restringir a lista de nomesde exibições.
O Athena retorna uma lista de valores do tipo STRING em que cada valor é um nome de visualização.
ResumoSHOW VIEWS [IN database_name] LIKE ['regular_expression']
Parâmetros
[IN database_name]
Especifica o database_name do qual as exibições serão listadas. Se omitido, o banco de dados docontexto atual é assumido.
[LIKE 'regular_expression']
Filtra a lista de exibições às correspondentes ao regular_expression especificado por você.Somente o curinga *, o que indica qualquer caractere, ou |, o que indica uma escolha entrecaracteres, podem ser usados.
ExemplosSHOW VIEWS;
SHOW VIEWS IN marketing_analytics LIKE 'orders*';
Consulte também SHOW COLUMNS (p. 304), SHOW CREATE VIEW (p. 305), DESCRIBEVIEW (p. 302) e DROP VIEW (p. 303).
Considerações e limitações de consultas SQL noAmazon Athena
• Os procedimentos armazenados não são compatíveis.• O número máximo de partições que podem ser criadas com instruções CREATE TABLE AS SELECT
(CTAS) é de 100. Para obter informações, consulte CREATE TABLE AS (p. 299).• As instruções PREPARED não são compatíveis. Você não pode executar EXECUTE com USING.• CREATE TABLE LIKE não é compatível.
307

Amazon Athena Guia do usuárioCondições e limitações
• DESCRIBE INPUT e DESCRIBE OUTPUT não são compatíveis.• As instruções EXPLAIN não são compatíveis.• Os conectores federados do Presto não são compatíveis. Use o para conectar fontes de dados. Para
obter mais informações, consulte O uso do (p. 49).• Ao consultar colunas com tipos de dados complexos (array, map, struct) e usar Parquet para
armazenar dados, o Athena atualmente lê a linha de dados inteira em vez de somente as colunasespecificadas. Esse é um problema conhecido.
308

Amazon Athena Guia do usuárioExemplos de código
Exemplos de código, cotas de serviçoe driver JDBC anterior
Use exemplos de código para criar aplicativos do Athena baseados no AWS SDK para Java.
Use os links desta seção para utilizar versões anteriores do driver JDBC.
Saiba mais sobre as cotas de serviço.
Tópicos• Exemplos de código (p. 309)• Usar drivers JDBC da versão anterior (p. 317)• Cotas de serviço (p. 322)
Exemplos de códigoUse os exemplos deste tópico como um ponto de partida para escrever aplicativos do Athena usando oSDK para Java 2.x.
• Exemplos de código Java• Constantes (p. 309)• Criar um cliente para acessar o Athena (p. 310)• Trabalhar com execuções de consulta
• Iniciar execução da consulta (p. 310)• Interromper execução da consulta (p. 313)• Listar execuções de consulta (p. 314)
• Trabalhar com consultas nomeadas• Criar uma consulta nomeada (p. 315)• Excluir uma consulta nomeada (p. 315)• Listar execuções de consulta (p. 314)
Note
Estes exemplos usam constantes (por exemplo, ATHENA_SAMPLE_QUERY) para strings, definidasem uma declaração da classe ExampleConstants.java. Substitua essas constantes pelaspróprias strings ou constantes definidas.
ConstantesA classe ExampleConstants.java demonstra como consultar uma tabela criada pelo tutorial deConceitos básicos (p. 8) no Athena.
309

Amazon Athena Guia do usuárioCriar um cliente para acessar o Athena
package aws.example.athena;
public class ExampleConstants {
public static final int CLIENT_EXECUTION_TIMEOUT = 100000; public static final String ATHENA_OUTPUT_BUCKET = "s3://my-athena-bucket"; // This example demonstrates how to query a table created by the "Getting Started" tutorial in Athena public static final String ATHENA_SAMPLE_QUERY = "SELECT elb_name, " + " count(1)" + " FROM elb_logs" + " Where elb_response_code = '200'" + " GROUP BY elb_name" + " ORDER BY 2 DESC limit 10;"; public static final long SLEEP_AMOUNT_IN_MS = 1000; public static final String ATHENA_DEFAULT_DATABASE = "default";
}
Criar um cliente para acessar o AthenaA classe AthenaClientFactory.java mostra como criar e configurar um cliente do Amazon Athena.
package aws.example.athena;
import software.amazon.awssdk.auth.credentials.InstanceProfileCredentialsProvider;import software.amazon.awssdk.regions.Region;import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.AthenaClientBuilder;
/** * AthenaClientFactory * ------------------------------------- * This code shows how to create and configure an Amazon Athena client. */public class AthenaClientFactory { /** * AthenaClientClientBuilder to build Athena with the following properties: * - Set the region of the client * - Use the instance profile from the EC2 instance as the credentials provider * - Configure the client to increase the execution timeout. */ private final AthenaClientBuilder builder = AthenaClient.builder() .region(Region.US_WEST_2) .credentialsProvider(InstanceProfileCredentialsProvider.create());
public AthenaClient createClient() { return builder.build(); }}
Iniciar execução da consultaO StartQueryExample mostra como enviar uma consulta ao Athena para execução, aguardar até queos resultados estejam disponíveis e processá-los.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.*;
310

Amazon Athena Guia do usuárioIniciar execução da consulta
import software.amazon.awssdk.services.athena.paginators.GetQueryResultsIterable;
import java.util.List;
/** * StartQueryExample * ------------------------------------- * This code shows how to submit a query to Athena for execution, wait till results * are available, and then process the results. */public class StartQueryExample { public static void main(String[] args) throws InterruptedException { // Build an AthenaClient client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
String queryExecutionId = submitAthenaQuery(athenaClient);
waitForQueryToComplete(athenaClient, queryExecutionId);
processResultRows(athenaClient, queryExecutionId); }
/** * Submits a sample query to Athena and returns the execution ID of the query. */ private static String submitAthenaQuery(AthenaClient athenaClient) { // The QueryExecutionContext allows us to set the Database. QueryExecutionContext queryExecutionContext = QueryExecutionContext.builder() .database(ExampleConstants.ATHENA_DEFAULT_DATABASE).build();
// The result configuration specifies where the results of the query should go in S3 and encryption options ResultConfiguration resultConfiguration = ResultConfiguration.builder() // You can provide encryption options for the output that is written. // .withEncryptionConfiguration(encryptionConfiguration) .outputLocation(ExampleConstants.ATHENA_OUTPUT_BUCKET).build();
// Create the StartQueryExecutionRequest to send to Athena which will start the query. StartQueryExecutionRequest startQueryExecutionRequest = StartQueryExecutionRequest.builder() .queryString(ExampleConstants.ATHENA_SAMPLE_QUERY) .queryExecutionContext(queryExecutionContext) .resultConfiguration(resultConfiguration).build();
StartQueryExecutionResponse startQueryExecutionResponse = athenaClient.startQueryExecution(startQueryExecutionRequest); return startQueryExecutionResponse.queryExecutionId(); }
/** * Wait for an Athena query to complete, fail or to be cancelled. This is done by polling Athena over an * interval of time. If a query fails or is cancelled, then it will throw an exception. */
private static void waitForQueryToComplete(AthenaClient athenaClient, String queryExecutionId) throws InterruptedException { GetQueryExecutionRequest getQueryExecutionRequest = GetQueryExecutionRequest.builder() .queryExecutionId(queryExecutionId).build();
GetQueryExecutionResponse getQueryExecutionResponse; boolean isQueryStillRunning = true; while (isQueryStillRunning) {
311

Amazon Athena Guia do usuárioIniciar execução da consulta
getQueryExecutionResponse = athenaClient.getQueryExecution(getQueryExecutionRequest); String queryState = getQueryExecutionResponse.queryExecution().status().state().toString(); if (queryState.equals(QueryExecutionState.FAILED.toString())) { throw new RuntimeException("Query Failed to run with Error Message: " + getQueryExecutionResponse .queryExecution().status().stateChangeReason()); } else if (queryState.equals(QueryExecutionState.CANCELLED.toString())) { throw new RuntimeException("Query was cancelled."); } else if (queryState.equals(QueryExecutionState.SUCCEEDED.toString())) { isQueryStillRunning = false; } else { // Sleep an amount of time before retrying again. Thread.sleep(ExampleConstants.SLEEP_AMOUNT_IN_MS); } System.out.println("Current Status is: " + queryState); } }
/** * This code calls Athena and retrieves the results of a query. * The query must be in a completed state before the results can be retrieved and * paginated. The first row of results are the column headers. */ private static void processResultRows(AthenaClient athenaClient, String queryExecutionId) { GetQueryResultsRequest getQueryResultsRequest = GetQueryResultsRequest.builder() // Max Results can be set but if its not set, // it will choose the maximum page size // As of the writing of this code, the maximum value is 1000 // .withMaxResults(1000) .queryExecutionId(queryExecutionId).build();
GetQueryResultsIterable getQueryResultsResults = athenaClient.getQueryResultsPaginator(getQueryResultsRequest);
for (GetQueryResultsResponse Resultresult : getQueryResultsResults) { List<ColumnInfo> columnInfoList = Resultresult.resultSet().resultSetMetadata().columnInfo(); List<Row> results = Resultresult.resultSet().rows(); processRow(results, columnInfoList); } }
private static void processRow(List<Row> row, List<ColumnInfo> columnInfoList) { for (ColumnInfo columnInfo : columnInfoList) { switch (columnInfo.type()) { case "varchar": // Convert and Process as String break; case "tinyint": // Convert and Process as tinyint break; case "smallint": // Convert and Process as smallint break; case "integer": // Convert and Process as integer break; case "bigint": // Convert and Process as bigint break; case "double": // Convert and Process as double break;
312

Amazon Athena Guia do usuárioInterromper execução da consulta
case "boolean": // Convert and Process as boolean break; case "date": // Convert and Process as date break; case "timestamp": // Convert and Process as timestamp break; default: throw new RuntimeException("Unexpected Type is not expected" + columnInfo.type()); } } }}
Interromper execução da consultaO StopQueryExecutionExample executa um exemplo de consulta, imediatamente interrompe aconsulta e verifica o status dela para garantir que foi cancelada.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.*;
/** * StopQueryExecutionExample * ------------------------------------- * This code runs an example query, immediately stops the query, and checks the status of the query to * ensure that it was cancelled. */public class StopQueryExecutionExample { public static void main(String[] args) throws Exception { // Build an Athena client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
String sampleQueryExecutionId = submitAthenaQuery(athenaClient);
// Submit the stop query Request StopQueryExecutionRequest stopQueryExecutionRequest = StopQueryExecutionRequest.builder() .queryExecutionId(sampleQueryExecutionId).build();
StopQueryExecutionResponse stopQueryExecutionResponse = athenaClient.stopQueryExecution(stopQueryExecutionRequest);
// Ensure that the query was stopped GetQueryExecutionRequest getQueryExecutionRequest = GetQueryExecutionRequest.builder() .queryExecutionId(sampleQueryExecutionId).build();
GetQueryExecutionResponse getQueryExecutionResponse = athenaClient.getQueryExecution(getQueryExecutionRequest); if (getQueryExecutionResponse.queryExecution() .status() .state() .equals(QueryExecutionState.CANCELLED)) { // Query was cancelled. System.out.println("Query has been cancelled");
313

Amazon Athena Guia do usuárioListar execuções de consulta
} }
/** * Submits an example query and returns a query execution ID of a running query to stop. */ public static String submitAthenaQuery(AthenaClient athenaClient) { QueryExecutionContext queryExecutionContext = QueryExecutionContext.builder() .database(ExampleConstants.ATHENA_DEFAULT_DATABASE).build();
ResultConfiguration resultConfiguration = ResultConfiguration.builder() .outputLocation(ExampleConstants.ATHENA_OUTPUT_BUCKET).build();
StartQueryExecutionRequest startQueryExecutionRequest = StartQueryExecutionRequest.builder() .queryExecutionContext(queryExecutionContext) .queryString(ExampleConstants.ATHENA_SAMPLE_QUERY) .resultConfiguration(resultConfiguration).build();
StartQueryExecutionResponse startQueryExecutionResponse = athenaClient.startQueryExecution(startQueryExecutionRequest);
return startQueryExecutionResponse.queryExecutionId();
}}
Listar execuções de consultaO ListQueryExecutionsExample mostra como obter uma lista de IDs de execução de consulta.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.ListQueryExecutionsRequest;import software.amazon.awssdk.services.athena.model.ListQueryExecutionsResponse;import software.amazon.awssdk.services.athena.paginators.ListQueryExecutionsIterable;
import java.util.List;
/** * ListQueryExecutionsExample * ------------------------------------- * This code shows how to obtain a list of query execution IDs. */public class ListQueryExecutionsExample { public static void main(String[] args) throws Exception { // Build an Athena client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
// Build the request ListQueryExecutionsRequest listQueryExecutionsRequest = ListQueryExecutionsRequest.builder().build();
// Get the list results. ListQueryExecutionsIterable listQueryExecutionResponses = athenaClient.listQueryExecutionsPaginator(listQueryExecutionsRequest);
for (ListQueryExecutionsResponse listQueryExecutionResponse : listQueryExecutionResponses) {
314

Amazon Athena Guia do usuárioCriar uma consulta nomeada
List<String> queryExecutionIds = listQueryExecutionResponse.queryExecutionIds(); // process queryExecutionIds.
System.out.println(queryExecutionIds); }
}}
Criar uma consulta nomeadaO CreateNamedQueryExample mostra como criar uma consulta nomeada.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.CreateNamedQueryRequest;import software.amazon.awssdk.services.athena.model.CreateNamedQueryResponse;
/** * CreateNamedQueryExample * ------------------------------------- * This code shows how to create a named query. */public class CreateNamedQueryExample { public static void main(String[] args) throws Exception { // Build an Athena client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
// Create the named query request. CreateNamedQueryRequest createNamedQueryRequest = CreateNamedQueryRequest.builder() .database(ExampleConstants.ATHENA_DEFAULT_DATABASE) .queryString(ExampleConstants.ATHENA_SAMPLE_QUERY) .description("Sample Description") .name("SampleQuery2").build();
// Call Athena to create the named query. If it fails, an exception is thrown. CreateNamedQueryResponse createNamedQueryResult = athenaClient.createNamedQuery(createNamedQueryRequest); }}
Excluir uma consulta nomeadaO DeleteNamedQueryExample mostra como excluir uma consulta nomeada usando o ID da consultanomeada.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.CreateNamedQueryRequest;import software.amazon.awssdk.services.athena.model.CreateNamedQueryResponse;import software.amazon.awssdk.services.athena.model.DeleteNamedQueryRequest;import software.amazon.awssdk.services.athena.model.DeleteNamedQueryResponse;
/** * DeleteNamedQueryExample * -------------------------------------
315

Amazon Athena Guia do usuárioListar consultas nomeadas
* This code shows how to delete a named query by using the named query ID. */public class DeleteNamedQueryExample { private static String getNamedQueryId(AthenaClient athenaClient) { // Create the NameQuery Request. CreateNamedQueryRequest createNamedQueryRequest = CreateNamedQueryRequest.builder() .database(ExampleConstants.ATHENA_DEFAULT_DATABASE) .queryString(ExampleConstants.ATHENA_SAMPLE_QUERY) .name("SampleQueryName") .description("Sample Description").build();
// Create the named query. If it fails, an exception is thrown. CreateNamedQueryResponse createNamedQueryResponse = athenaClient.createNamedQuery(createNamedQueryRequest); return createNamedQueryResponse.namedQueryId(); }
public static void main(String[] args) throws Exception { // Build an Athena client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
String sampleNamedQueryId = getNamedQueryId(athenaClient);
// Create the delete named query request DeleteNamedQueryRequest deleteNamedQueryRequest = DeleteNamedQueryRequest.builder() .namedQueryId(sampleNamedQueryId).build();
// Delete the named query DeleteNamedQueryResponse deleteNamedQueryResponse = athenaClient.deleteNamedQuery(deleteNamedQueryRequest); }}
Listar consultas nomeadasO ListNamedQueryExample mostra como obter uma lista de IDs de consultas nomeadas.
package aws.example.athena;
import software.amazon.awssdk.services.athena.AthenaClient;import software.amazon.awssdk.services.athena.model.ListNamedQueriesRequest;import software.amazon.awssdk.services.athena.model.ListNamedQueriesResponse;import software.amazon.awssdk.services.athena.paginators.ListNamedQueriesIterable;
import java.util.List;
/** * ListNamedQueryExample * ------------------------------------- * This code shows how to obtain a list of named query IDs. */public class ListNamedQueryExample { public static void main(String[] args) throws Exception { // Build an Athena client AthenaClientFactory factory = new AthenaClientFactory(); AthenaClient athenaClient = factory.createClient();
// Build the request ListNamedQueriesRequest listNamedQueriesRequest = ListNamedQueriesRequest.builder().build();
316

Amazon Athena Guia do usuárioDrivers JDBC da versão anterior
// Get the list results. ListNamedQueriesIterable listNamedQueriesResponses = athenaClient.listNamedQueriesPaginator(listNamedQueriesRequest);
// Process the results. for (ListNamedQueriesResponse listNamedQueriesResponse : listNamedQueriesResponses) { List<String> namedQueryIds = listNamedQueriesResponse.namedQueryIds(); // process named query IDs
System.out.println(namedQueryIds); }
}}
Usar drivers JDBC da versão anteriorRecomendamos que você use a versão mais recente do driver JDBC. Para obter informações, consulteUsar o Athena com o driver JDBC (p. 59). Links para drivers da versão 2.x anteriores e materiais desuporte estão abaixo, se necessário, para seu aplicativo.
Drivers JDBC da versão anterior
Versão dodriver JDBC
Downloads
Compatívelcom JDBC4.2 eJDK 8.0 –AthenaJDBC42-2.0.8.jar
2.0.8Compatívelcom JDBC4.1 eJDK 7.0 –AthenaJDBC41-2.0.8.jar
Notas derelease
Contrato delicença Avisos
Guia deinstalação econfiguração(PDF)
Guia demigração(PDF)
Compatívelcom JDBC4.2 eJDK 8.0 –AthenaJDBC42-2.0.7.jar
2.0.7Compatívelcom JDBC4.1 eJDK 7.0 –AthenaJDBC41-2.0.7.jar
Notas derelease
Contrato delicença Avisos
Guia deinstalação econfiguração(PDF)
Guia demigração(PDF)
2.0.6
Compatívelcom JDBC4.2 eJDK 8.0 –AthenaJDBC42-2.0.6.jar
Notas derelease
Contrato delicença Avisos
Guia deinstalação econfiguração(PDF)
Guia demigração(PDF)
317

Amazon Athena Guia do usuárioInstruções para o driver JDBC versão 1.1.0
Versão dodriver JDBC
Downloads
Compatívelcom JDBC4.1 eJDK 7.0 –AthenaJDBC41-2.0.6.jar
Compatívelcom JDBC4.2 eJDK 8.0 –AthenaJDBC42-2.0.5.jar
2.0.5Compatívelcom JDBC4.1 eJDK 7.0 –AthenaJDBC41-2.0.5.jar
Notas derelease
Contrato delicença Avisos
Guia deinstalação econfiguração(PDF)
Guia demigração(PDF)
Compatívelcom JDBC4.2 eJDK 8.0 –AthenaJDBC42-2.0.2.jar
2.0.2Compatívelcom JDBC4.1 eJDK 7.0 –AthenaJDBC41-2.0.2.jar
Notas derelease
Contrato delicença Avisos
Guia deinstalação econfiguração(PDF)
Guia demigração(PDF)
Instruções para o driver JDBC versão 1.1.0Esta seção inclui um link para fazer download da versão 1.1.0 do driver JDBC. É altamente recomendávelmigrar para a versão atual do driver. Para obter informações, consulte o Guia de migração do driver JDBC.
O driver JDBC versão 1.0.1 e as versões anteriores estão obsoletas.
O driver JDBC versão 1.1.0 é compatível com o JDBC 4.1 e o JDK 7.0. Use o link a seguir parafazer download do driver: AthenaJDBC41-1.1.0.jar. Além disso, faça download da licença do drivere das licenças de terceiros para o driver. Use a ILC da AWS com o seguinte comando: aws s3 cps3://path_to_the_driver [local_directory] e, em seguida, use as instruções restantes destaseção.
Note
As instruções a seguir são específicas ao JDBC versão 1.1.0 e anterior.
Driver JDBC versão 1.1.0: especifique a string de conexãoPara especificar o URL de conexão do driver JDBC no aplicativo personalizado, use a string neste formato:
jdbc:awsathena://athena.{REGION}.amazonaws.com:443
318

Amazon Athena Guia do usuárioInstruções para o driver JDBC versão 1.1.0
em que {REGION} é um identificador de região, como us-west-2. Para obter informações sobre asregiões do Athena, consulte Regiões.
Driver JDBC versão 1.1.0: especifique o nome da classe dodriver JDBCPara usar o driver em aplicativos personalizados, configure o caminho da classe Java para o local doarquivo JAR obtido por download do Amazon S3https://s3.amazonaws.com/athena-downloads/drivers/JDBC/AthenaJDBC_1.1.0/AthenaJDBC41-1.1.0.jar. Isso disponibiliza as classes dentro do JAR disponíveispara uso. A classe do driver JDBC principal é com.amazonaws.athena.jdbc.AthenaDriver.
Driver JDBC versão 1.1.0: forneça as credenciais do driver JDBCPara obter acesso aos serviços e recursos da AWS, como o Athena e os buckets do Amazon S3, forneçaas credenciais do driver JDBC ao aplicativo.
Para fornecer credenciais no código Java para o aplicativo:
1. Use uma classe que implemente o AWSCredentialsProvider.2. Defina a propriedade JDBC, aws_credentials_provider_class, igual ao nome da classe, e a
inclua no caminho da classe.3. Para incluir parâmetros de construtor, defina a propriedade JDBC
aws_credentials_provider_arguments conforme especificado na seção a seguir sobre opçõesde configuração.
Outro método para fornecer credenciais a ferramentas de BI, como SQL Workbench, é fornecer ascredenciais usadas para o JDBC como a chave de acesso da AWS e a chave secreta da AWS para aspropriedades JDBC de usuário e senha, respectivamente.
Os usuários que se conectam por meio do driver JDBC e têm políticas de acesso personalizadas anexadasaos perfis precisam de permissões para ações de políticas além das constantes no Referência de API doAmazon Athena.
Políticas para o Driver JDBC versão 1.1.0Você deve permitir que os usuários JDBC realizem um conjunto de ações específicas de política. Se asseguintes ações não forem permitidas, os usuários não poderão ver bancos de dados e tabelas:
• athena:GetCatalogs
• athena:GetExecutionEngine
• athena:GetExecutionEngines
• athena:GetNamespace
• athena:GetNamespaces
• athena:GetTable
• athena:GetTables
Driver JDBC versão 1.1.0: configure as opções do driver JDBCVocê pode configurar as seguintes opções para o driver JDBC versão 1.1.0. Com essaversão do driver, você também pode passar parâmetros usando a sintaxe do URL JDBCpadrão. Por exemplo: jdbc:awsathena://athena.us-west-1.amazonaws.com:443?max_error_retries=20&connection_timeout=20000.
319

Amazon Athena Guia do usuárioInstruções para o driver JDBC versão 1.1.0
Opções para o Driver JDBC versão 1.0.1
Nome da propriedade Descrição Valorpadrão
Éobrigatório
s3_staging_dir O local do S3 no qual a saída da consulta égravada, por exemplo s3://query-results-bucket/folder/, que é estabelecida em Settings(Configurações) no console do Athena, https://console.aws.amazon.com/athena/. Em seguida,o driver JDBC solicita ao Athena para ler osresultados e fornecer as linhas de dados de voltapara o usuário.
N/D Sim
query_results_encryption_optionO método de criptografia a ser usado no diretórioespecificado por s3_staging_dir. Se não forespecificado, o local não será criptografado. Osvalores válidos são SSE_S3, SSE_KMS e CSE_KMS.
N/D Não
query_results_aws_kms_keyO ID da Customer Master Key (CMK – Chavemestra do KMS) da AWS a ser usado sequery_results_encryption_optionespecificar SSE-KMS ou CSE-KMS. Por exemplo,123abcde-4e56-56f7-g890-1234h5678i9j.
N/D Não
aws_credentials_provider_classO nome da classe do provedor decredenciais, que implementa a interfaceAWSCredentialsProvider.
N/D Não
aws_credentials_provider_argumentsArgumentos do construtor do provedor decredenciais como valores separados por vírgulas.
N/D Não
max_error_retries O número máximo de novas tentativas desolicitação que o cliente JDBC faz para o Athena.
10 Não
connection_timeout O tempo máximo, em milissegundos, paraestabelecer uma conexão bem-sucedida com oAthena antes de uma tentativa ser encerrada.
10.000 Não
socket_timeout O tempo máximo, em milissegundos, para aguardarpor um soquete para enviar dados ao Athena.
10.000 Não
retry_base_delay Valor de atraso mínimo, em milissegundos, entretentativas de se reconectar ao Athena.
100 Não
retry_max_backoff_timeValor de atraso máximo, em milissegundos, entretentativas de se conectar ao Athena.
1000 Não
log_path Caminho local dos logs do driver JDBC do Athena.Se nenhum caminho de log for fornecido, nenhumarquivo de log será criado.
N/D Não
log_level Nível de log do driver JDBC do Athena. Valoresválidos: INFO, DEBUG, WARN, ERROR, ALL, OFF,FATAL, TRACE.
N/D Não
320

Amazon Athena Guia do usuárioInstruções para o driver JDBC versão 1.1.0
Exemplos: como usar a versão anterior do driver JDBC versão1.1.0 com o JDKOs exemplos de código a seguir demonstram como usar o driver JDBC versão 1.1.0 em um aplicativoJava. Estes exemplos supõem que o AWS JAVA SDK está incluído em seu classpath, especificamenteo módulo aws-java-sdk-core, que inclui os pacotes de autorização (com.amazonaws.auth.*)referenciados nos exemplos.
Example Exemplo: Criação de um driver versão 1.0.1
Properties info = new Properties(); info.put("user", "AWSAccessKey"); info.put("password", "AWSSecretAccessKey"); info.put("s3_staging_dir", "s3://S3 Bucket Location/"); info.put("aws_credentials_provider_class","com.amazonaws.auth.DefaultAWSCredentialsProviderChain"); Class.forName("com.amazonaws.athena.jdbc.AthenaDriver"); Connection connection = DriverManager.getConnection("jdbc:awsathena://athena.us-east-1.amazonaws.com:443/", info);
Os exemplos a seguir demonstram diferentes maneiras de usar um provedor de credenciais queimplementa a interface AWSCredentialsProvider com a versão anterior do driver JDBC.
Example Exemplo: Uso de um provedor de credenciais para o driver JDBC 1.0.1
Properties myProps = new Properties(); myProps.put("aws_credentials_provider_class","com.amazonaws.auth.PropertiesFileCredentialsProvider"); myProps.put("aws_credentials_provider_arguments","/Users/myUser/.athenaCredentials");
Nesse caso, o arquivo /Users/myUser/.athenaCredentials deve conter o seguinte:
accessKey = ACCESSKEYsecretKey = SECRETKEY
Substitua a parte direita das atribuições pelas chaves secretas e de acesso da AWS de sua conta.
Example Exemplo: como usar um provedor de credenciais com várias argumentos
Este exemplo mostra um provedor de credenciais de exemplo,CustomSessionsCredentialsProvider, que usa uma chave de acesso e uma chave secreta, alémde um token de sessão. O CustomSessionsCredentialsProvider é mostrado por exemplo apenas enão está incluído no driver. A assinatura da classe tem a seguinte aparência:
public CustomSessionsCredentialsProvider(String accessId, String secretKey, String token) { //... }
Em seguida, você define as propriedades da seguinte maneira:
Properties myProps = new Properties();
321

Amazon Athena Guia do usuárioCotas de serviço
myProps.put("aws_credentials_provider_class","com.amazonaws.athena.jdbc.CustomSessionsCredentialsProvider"); String providerArgs = "My_Access_Key," + "My_Secret_Key," + "My_Token"; myProps.put("aws_credentials_provider_arguments",providerArgs);
Note
Se você usar o InstanceProfileCredentialsProvider, não precisará fornecer nenhumargumento de provedor e credenciais porque eles são fornecidos usando o perfil de instância doAmazon EC2 para a instância em que você está executando o aplicativo. Você ainda pode definira propriedade aws_credentials_provider_class para esse nome de classe, no entanto.
Políticas para o Driver JDBC anteriores à versão 1.1.0Use essas ações obsoletas em políticas apenas com drivers JDBC anteriores à versão 1.1.0. Se estiveratualizando o driver JDBC, substitua as declarações de política que permitem ou negam ações obsoletaspelas ações da API apropriada conforme listadas ou ocorrerão erros.
Ação específica da política obsoleta Ação da API do Athena correspondente
athena:RunQuery athena:StartQueryExecution
athena:CancelQueryExecution athena:StopQueryExecution
athena:GetQueryExecutions athena:ListQueryExecutions
Cotas de serviçoNote
O console de Cotas de serviço fornece informações sobre as cotas do Amazon Athena. Além deexibir as cotas padrão, você pode usar o console de Cotas de serviço para solicitar aumentos decotas para aquelas que são ajustáveis.
ConsultasSua conta tem as seguintes cotas relacionadas à consulta padrão para o Amazon Athena:
• DDL query quota (Cota de consultas DDL) – 20 consultas DDL ativas. As consultas DDL incluemconsultas CREATE TABLE e CREATE TABLE ADD PARTITION.
• DDL query timeout (Tempo limite de consulta DDL) – o tempo limite de consulta DDL é de 600 minutos.• DML query quota (Cota de consultas DML) – 20 consultas DML ativas. As consultas DML incluem
consultas SELECT e CREATE TABLE AS (CTAS).• DML query timeout (Tempo limite de consulta DML) – o tempo limite de consulta DML é de 30 minutos.
Essas são cotas flexíveis. Você pode usar o console do Cotas de serviço do Athena para solicitar umaumento.
O Athena processa consultas atribuindo recursos com base na carga geral do serviço e no número desolicitações recebidas.
322
Amazon Athena Guia do usuárioGrupos de trabalho
Comprimento da string de consultaO comprimento máximo permitido da string da consulta é de 262.144 bytes, pois as strings são codificadasem UTF-8. Esta não é uma cota ajustável. Use estas dicas (p. 18) para nomear colunas, tabelas e bancosde dados do Athena.
Note
Se você precisar de um tamanho maior para a string de consulta, envie um feedback para [email protected] com os detalhes do seu caso de uso ou entre em contato com o AWSSupport.
Grupos de trabalhoAo trabalhar com grupos de trabalho do Athena, lembre-se dos seguintes pontos:
• As cotas de serviço do Athena são compartilhadas entre todos os grupos de trabalho em uma conta.• O número máximo de grupos de trabalho que podem ser criados por região em uma conta é 1000.• O número máximo de tags por grupo de trabalho é 50. Para obter mais informações, consulte Restrições
de tag (p. 243).
AWS Glue• Se você estiver usando o Catálogo de dados do AWS Glue com o Athena, consulte Endpoints e cotas do
AWS Glue para ver as cotas de serviço em tabelas, bancos de dados e partições.• Se você não estiver usando o Catálogo de dados do AWS Glue, o número de partições por tabela é
20.000. É possível solicitar um aumento da cota.
Note
Se você ainda não migrou para o Catálogo de dados do AWS Glue, consulte Atualizar para oAWS Glue Data Catalog passo a passo (p. 43) para obter instruções de migração.
Buckets do Amazon S3Ao trabalhar com buckets do Amazon S3, lembre-se dos seguintes pontos:
• O Amazon S3 tem uma cota de serviço padrão de 100 buckets por conta.• O Athena precisa de um bucket à parte para registrar resultados.• Você pode solicitar um aumento da cota para até 1.000 buckets do Amazon S3 por conta da AWS.
Cotas de chamada de APIs por contaAs APIs do Athena têm as seguintes cotas padrão para o número de chamadas para a API por conta (nãopor consulta):
Nome da API Número padrãode chamadas porsegundo
Capacidade deintermitência
BatchGetNamedQuery, ListNamedQueries,ListQueryExecutions
5 até 10
323

Amazon Athena Guia do usuárioCotas de chamada de APIs por conta
Nome da API Número padrãode chamadas porsegundo
Capacidade deintermitência
CreateNamedQuery, DeleteNamedQuery,GetNamedQuery
5 até 20
BatchGetQueryExecution 20 até 40
StartQueryExecution, StopQueryExecution 20 até 80
GetQueryExecution, GetQueryResults 100 até 200
Por exemplo, para StartQueryExecution, é possível fazer até 20 chamadas por segundo. Além disso,se essa API não for chamada por 4 segundos, sua conta acumulará uma capacidade de intermitênciade até 80 chamadas. Nesse caso, o aplicativo pode fazer até 80 chamadas para essa API no modo deintermitência.
Se você usar qualquer uma dessas APIs e exceder a cota padrão do número de chamadas por segundoou a capacidade de intermitência da conta, a API do Athena emitirá um erro semelhante ao seguinte:"ClientError: Ocorreu um erro (ThrottlingException) ao chamar a <API_name> operação: taxa excedida."Reduza o número de chamadas por segundo ou a capacidade de intermitência da API para essa conta.Para solicitar um aumento na cota, entre em contato com o AWS Support. Abra a página do AWS SupportCenter, faça login se necessário e selecione Create case (Criar caso). Selecione Service limit increase(Aumento de limite do serviço). Preencha e envie o formulário.
Note
Não é possível alterar essa cota no console de cotas de serviço do Athena.
324

Amazon Athena Guia do usuário
Notas de releaseDescreve recursos, melhorias e correções de bugs do Amazon Athena por data de lançamento.
Data de lançamento• 26 de novembro de 2019 (p. 326)• 12 de novembro de 2019 (p. 329)• 8 de novembro de 2019 (p. 329)• 8 de outubro de 2019 (p. 329)• 19 de setembro de 2019 (p. 329)• 12 de setembro de 2019 (p. 330)• 16 de agosto de 2019 (p. 330)• 9 de agosto de 2019 (p. 330)• 26 de junho de 2019 (p. 331)• 24 de maio de 2019 (p. 331)• 05 de março de 2019 (p. 331)• 22 de fevereiro de 2019 (p. 332)• 18 de fevereiro de 2019 (p. 332)• 20 de novembro de 2018 (p. 333)• 15 de outubro de 2018 (p. 334)• 10 de outubro de 2018 (p. 334)• 6 de setembro de 2018 (p. 335)• 23 de agosto de 2018 (p. 335)• 16 de agosto de 2018 (p. 336)• 7 de agosto de 2018 (p. 336)• 5 de junho de 2018 (p. 336)• 17 de maio de 2018 (p. 337)• 19 de abril de 2018 (p. 338)• 6 de abril de 2018 (p. 338)• 15 de março de 2018 (p. 338)• 2 de fevereiro de 2018 (p. 338)• 19 de janeiro de 2018 (p. 339)• 13 de novembro de 2017 (p. 339)• 1 de novembro de 2017 (p. 340)• 19 de outubro de 2017 (p. 340)• 3 de outubro de 2017 (p. 340)• 25 de setembro de 2017 (p. 340)• 14 de agosto de 2017 (p. 340)• 4 de agosto de 2017 (p. 340)• 22 de junho de 2017 (p. 341)• 8 de junho de 2017 (p. 341)
325

Amazon Athena Guia do usuário26 de novembro de 2019
• 19 de maio de 2017 (p. 341)• 4 de abril de 2017 (p. 342)• 24 de março de 2017 (p. 343)• 20 de fevereiro de 2017 (p. 344)
26 de novembro de 2019Publicado em 17-12-2019
O Amazon Athena adiciona suporte para executar consultas SQL em fontes de dados relacionais, nãorelacionais, de objeto e personalizadas, invocar modelos de machine learning em consultas SQL, funçõesdefinidas pelo usuário (UDFs) (demonstração), usar o Apache Hive Metastore como um catálogo demetadados com o Amazon Athena (demonstração) e quatro métricas relacionadas a consulta adicionais.
Consultas SQL federadasUse consultas SQL federadas para executar consultas SQL em fontes de dados relacionais, nãorelacionais, de objeto e personalizadas.
Agora é possível usar a consulta federada do Athena para verificar dados armazenados em fontes dedados relacionais, não relacionais, de objeto e personalizadas. Graças às consultas federadas, é possívelenviar uma única consulta SQL que verifica dados de várias fontes em execução no local ou hospedadasna nuvem.
A execução de análises em dados distribuídos entre aplicativos pode ser complexa e demorada pelosseguintes motivos:
• Os dados necessários para realizar análises costumam estar distribuídos em armazenamentos dedados relacionais, documentais, gráficos, na memória, de busca, de objetos, com séries temporais, comvalores-chave e livros contábeis.
• Para analisar dados de todas essas fontes, são criados pipelines complexos para extrair, transformar ecarregar dados em um data warehouse, para que eles possam ser consultados.
• Para acessar dados de várias fontes, é necessário aprender novas linguagens de programação econstruções de acesso de dados.
As consultas SQL federadas do Athena eliminam essa complexidade e permitem que os usuáriosconsultem dados de qualquer lugar. Os analistas podem usar construções SQL familiares para executarJOIN em dados de várias fontes para análises rápidas e armazenar os resultados no Amazon S3 para usosubsequente.
Conectores de fontes de dadosO Athena executa consultas federadas usando conectores de fonte de dados do Athena executadosem AWS Lambda. Use esses conectores de fonte de dados de código aberto para executar consultasSQL federadas no Athena entre o Amazon DynamoDB, o Apache HBase, o Amazon Document DB, oAmazon Redshift, o Amazon CloudWatch, Métricas do Amazon CloudWatch e bancos de dados relacionaiscompatíveis com JDBC, como MySQL e PostgreSQL com a licença do Apache 2.0.
Conectores de fontes de dados personalizados
Com o uso do Athena Query Federation SDK, os desenvolvedores podem criar conectores para qualquerfonte de dados e permitir que o Athena execute consultas SQL nessa fonte de dados. O Athena QueryFederation Connector amplia os benefícios de consultas federadas para além dos conectores fornecidos
326
Amazon Athena Guia do usuárioChamar modelos de machine learning em consultas SQL
pela AWS. Como os conectores são executados no AWS Lambda, não é necessário gerenciar ainfraestrutura nem planejar o dimensionamento para atender às demandas máximas.
Disponibilidade de visualizaçãoA consulta federada do Athena está disponível na visualização no Leste dos EUA (Norte da Virgínia)Região.
Próximas etapas• Para iniciar sua visualização, siga as instruções nas Perguntas frequentes sobre recursos de
visualização do Athena.• Para saber mais sobre o recurso de consulta federada, consulte Usar consulta federada do Amazon
Athena (visualização).• Para começar a usar um conector existente, consulte Implantar um conector e conectar a uma fonte de
dados.• Para saber como criar seu próprio conector de fonte de dados usando o Athena Query Federation SDK,
consulte Exemplo de conector do Athena no GitHub.
Chamar modelos de machine learning em consultasSQLAgora é possível invocar modelos de machine learning para inferência diretamente de suas consultasdo Athena. A capacidade de usar modelos de machine learning em consultas SQL simplifica tarefascomplexas como detecção de anomalias, análise de coorte de clientes e previsões de vendas, para quesejam tão simples quanto invocar uma função em uma consulta SQL.
Modelos de MLÉ possível usar mais de uma dúzia de algoritmos de machine learning incorporados disponibilizadospelo Amazon SageMaker, treinar seus próprios modelos ou encontrar e assinar pacotes de modelosno AWS Marketplace e implantá-los no Amazon SageMaker Hosting Services. Não há necessidade deconfigurações adicionais. É possível invocar esses modelos de ML em suas consultas SQL do console doAthena, de APIs do Athena e por meio do driver JDBC de demonstração do Athena.
Disponibilidade de visualizaçãoA funcionalidade de ML do Athena está disponível hoje na visualização no Leste dos EUA (Norte daVirgínia) Região.
Próximas etapas• Para iniciar sua visualização, siga as instruções nas Perguntas frequentes sobre recursos de
visualização do Athena.• Para saber mais sobre o recurso de machine learning, consulte Usar o machine learning (ML) com
Amazon Athena (visualização).
Funções definidas pelo usuário (UDFs) (visualização)Escreva funções escalares personalizadas e use-as em consultas do Athena. É possível gravar seusUDFs em Java usando o Athena Query Federation SDK. Quando um UDF é usado em uma consulta
327

Amazon Athena Guia do usuárioUsar o Apache Hive Metastore como um
metacatalog com o Amazon Athena (visualização)
SQL enviada para o Athena, ele é chamado e executado no AWS Lambda. UDFs podem ser usados emcláusulas SELECT e FILTER de uma consulta SQL. E possível chamar vários UDFs na mesma consulta.
Disponibilidade de visualizaçãoA funcionalidade de UDF do Athena está disponível no modo de visualização no Leste dos EUA (Norte daVirgínia) Região.
Próximas etapas• Para iniciar sua visualização, siga as instruções nas Perguntas frequentes sobre recursos de
visualização do Athena.• Para saber mais, consulte Consultar com funções definidas pelo usuário (visualização).• Para obter exemplos de implementação de UDF, consulte Amazon Athena UDF Connector no GitHub.• Para saber como gravar suas próprias funções usando o Athena Query Federation SDK, consulte Criar e
implantar um UDF usando o Lambda.
Usar o Apache Hive Metastore como um metacatalogcom o Amazon Athena (visualização)Agora é possível conectar o Athena a um ou mais Apache Hive Metastores, além do Catálogo de dados doAWS Glue com o Athena.
Conector de metastorePara se conectar a um Hive Metastore auto-hospedado, você precisa de um conector do Athena HiveMetastore. O Athena fornece um conector de implementação de referência que você pode usar. Oconector é executado na sua conta como uma função do AWS Lambda. Para obter mais informações,consulte Usar o Athena Data Connector para Hive Metastore externo (visualização).
Disponibilidade de visualizaçãoO recurso Hive Metastore está disponível no modo de visualização no Leste dos EUA (Norte da Virgínia)Região.
Próximas etapas• Para iniciar sua visualização, siga as instruções nas Perguntas frequentes sobre recursos de
visualização do Athena.• Para saber mais sobre esse recurso, acesse Usar o Athena Data Connector para Hive Metastore externo
(visualização).
Novas métricas relacionadas à consultaO Athena agora publica métricas de consulta adicionais que podem ajudar você a entender o desempenhodo Amazon Athena. O Athena publica métricas relacionadas a consulta no Amazon CloudWatch. Nestaversão, o Athena publica as seguintes métricas de consulta adicionais:
• Query Planning Time (Tempo de planejamento da consulta) – o tempo necessário para planejar aconsulta. Isso inclui o tempo gasto recuperando partições de tabela da fonte de dados.
328

Amazon Athena Guia do usuário12 de novembro de 2019
• Query Queuing Time (Tempo de fila da consulta) – o tempo que a consulta ficou na fila aguardandorecursos.
• Service Processing Time (Tempo de processamento do serviço) – o tempo que levou para gravar osresultados após o mecanismo de consulta ser executado.
• Total Execution Time (Tempo de execução total) – o tempo necessário para o Athena executar aconsulta.
Para consumir essas novas métricas de consulta, é possível criar painéis personalizados, definir alarmes etriggers baseados em métricas no CloudWatch ou usar painéis pré-preenchidos diretamente do console doAthena.
Próximas etapasPara obter mais informações, consulte Monitorar consultas do Athena com métricas do CloudWatch.
12 de novembro de 2019Publicado em 17-12-2019
O Amazon Athena agora está disponível no Região do Oriente Médio (Bahrein).
8 de novembro de 2019Publicado em 17-12-2019
O Amazon Athena já está disponível nas regiões Região do Oeste dos EUA (Norte da Califórnia) e RegiãoEuropa (Paris).
8 de outubro de 2019Publicado em 17-12-2019
O Amazon Athena agora permite que você se conecte diretamente ao Athena por um VPC endpoint deinterface na sua Virtual Private Cloud (VPC). Com esse recurso, é possível enviar suas consultas aoAthena com segurança, sem a necessidade de um gateway da Internet na VPC.
Para criar um VPC endpoint de interface para se conectar ao Athena, é possível usar o console da AWSou a AWS Command Line Interface (AWS CLI). Para obter informações sobre como criar um endpoint deinterface, consulte Criar um endpoint de interface.
Ao usar um VPC endpoint de interface, a comunicação entre a VPC e as APIs do Athena é segura epermanece na rede da AWS. Não há custos adicionais do Athena por usar esse recurso. São aplicáveistaxas de VPC endpoint de interface.
Para saber mais sobre esse recurso, consulte Conectar-se ao Amazon Athena usando um VPC endpointde interface.
19 de setembro de 2019Publicado em 17-12-2019
329

Amazon Athena Guia do usuário12 de setembro de 2019
O Amazon Athena adiciona suporte para inserir novos dados em uma tabela existente usando a instruçãoINSERT INTO. É possível inserir linhas em uma tabela de destino com base em uma instrução deconsulta SELECT executada em uma tabela de origem ou em um conjunto de valores informados comoparte da instrução de consulta. Os formatos de dados compatíveis incluem arquivos Avro, JSON, ORC,Parquet e de texto.
As instruções INSERT INTO também podem ajudar a simplificar processos de ETL. Por exemplo, épossível usar INSERT INTO em uma única consulta para selecionar dados de uma tabela de origem noformato JSON e gravá-los em uma tabela de destino no formato Parquet.
Instruções INSERT INTO são cobradas com base no número de bytes que são verificados na faseSELECT, semelhante à forma como o Athena cobra por consultas SELECT. Para obter mais informações,consulte Definição de preço do Amazon Athena.
Para obter mais informações sobre como usar INSERT INTO, incluindo formatos compatíveis, SerDes eexemplos, consulte INSERT INTO no Guia do usuário do Athena.
12 de setembro de 2019Publicado em 17-12-2019
O Amazon Athena agora está disponível no Região Ásia-Pacífico (Hong Kong).
16 de agosto de 2019Publicado em 17-12-2019
O Amazon Athena adiciona suporte para consulta de dados em buckets de pagamento pelo solicitante doAmazon S3.
Quando um bucket do Amazon S3 é configurado como Pagamento pelo solicitante, o solicitante, nãoo proprietário do bucket, paga pelos custos de solicitação e transferência de dados do Amazon S3. NoAthena, os administradores do grupo de trabalho agora podem definir configurações de grupo de trabalhopara permitir que os membros do grupo de trabalho consultem buckets de Pagamento pelo solicitante doS3.
Para obter informações sobre como definir a configuração Pagamento pelo solicitante para o seu grupode trabalho, consulte Criar um grupo de trabalho no Guia do usuário do Amazon Athena. Para obter maisinformações sobre buckets de Pagamento pelo solicitante, consulte Buckets de Pagamento pelo solicitanteno Guia do desenvolvedor do Amazon Simple Storage Service.
9 de agosto de 2019Publicado em 17-12-2019
O Amazon Athena agora oferece suporte à aplicação de políticas do AWS Lake Formation para controle deacesso refinado a bancos de dados, tabelas e colunas novos ou existentes definidos no Catálogo de dadosdo AWS Glue para dados armazenados no Amazon S3.
É possível usar esse recurso nas seguintes regiões da AWS: Leste dos EUA (Ohio), Leste dos EUA(Norte da Virgínia), Oeste dos EUA (Oregon), Ásia-Pacífico (Tóquio) e Europa (Irlanda). Não há cobrançasadicionais por esse recurso.
330

Amazon Athena Guia do usuário26 de junho de 2019
Para obter mais informações sobre como usar esse recurso, consulte Usar o Athena para consultar dadosregistrados no AWS Lake Formation. Para obter mais informações sobre o AWS Lake Formation, consulteAWS Lake Formation.
26 de junho de 2019Agora, o Amazon Athena está disponível na região Europa (Estocolmo). Para obter uma lista de regiõescompatíveis, consulte Regiões e endpoints da AWS.
24 de maio de 2019Publicado em 24-05-2019
Agora o Amazon Athena está disponível nas regiões AWS GovCloud (Leste dos EUA) e AWS GovCloud(US-West). Para obter uma lista de regiões compatíveis, consulte Regiões e endpoints da AWS.
05 de março de 2019Publicado em 05/03/2019
Agora, o Amazon Athena está disponível na região Canadá (Central). Para obter uma lista de regiõescompatíveis, consulte Regiões e endpoints da AWS. Lançada a nova versão do driver ODBC com suportepara grupos de trabalho do Athena. Para obter mais informações, consulte as Notas de release do driverODBC.
Para fazer download do driver ODBC versão 1.0.5 e da respectiva documentação, consulte Conexão aoAmazon Athena com o ODBC (p. 61). Para obter mais informações sobre essa versão, consulte as Notasde release do driver ODBC.
Para usar grupos de trabalho com o driver ODBC, defina a nova propriedade de conexão, Workgroup, nastring de conexão, conforme mostrado no exemplo a seguir:
Driver=Simba Athena ODBC Driver;AwsRegion=[Region];S3OutputLocation=[S3Path];AuthenticationType=IAM Credentials;UID=[YourAccessKey];PWD=[YourSecretKey];Workgroup=[WorkgroupName]
Para obter mais informações, procure "grupo de trabalho" no Guia de instalação e configuração do driverODBC versão 1.0.5. Não há alterações para a string de conexão do driver ODBC ao usar tags nos gruposde trabalho. Para usar tags, atualize para a versão mais recente do driver ODBC, que é a versão atual.
Esta versão do driver permite que você use as ações do grupo de trabalho da API Athena (p. 233) paracriar e gerenciar grupos de trabalho e ações da tag da API Athena (p. 245) para adicionar, listar ouremover tags nos grupos de trabalho. Antes de começar, verifique se você tem permissões no nível dorecurso no IAM para ações em grupos de trabalho e tags.
Para obter mais informações, consulte:
• Usar grupos de trabalho para executar consultas (p. 217) e Exemplo de políticas de grupo (p. 222).• Marcar com tags os grupos de trabalho (p. 242) e Políticas de controle de acesso do IAM baseadas em
tags (p. 246).
331

Amazon Athena Guia do usuário22 de fevereiro de 2019
Se você usar o driver JDBC ou o SDK da AWS, atualize para a versão mais recente do driver e do SDK,ambos incluindo suporte para grupos de trabalho e tags no Athena. Para obter mais informações, consulteUso do Athena com o driver JDBC (p. 59).
22 de fevereiro de 2019Publicado em 22/02/2019
Adição de suporte a tags para grupos de trabalho no Amazon Athena. Uma tag consiste em uma chavee um valor, ambos definidos por você. Quando você marca um grupo de trabalho, atribui metadadospersonalizados a ele. É possível adicionar tags a grupos de trabalho para ajudar a categorizá-los, usandoas melhores práticas de marcação com tags da AWS. Você pode usar tags para restringir o acesso agrupos de trabalho e rastrear custos. Por exemplo, crie um grupo de trabalho para cada centro de custo.Ao adicionar tags a esses grupos de trabalho, você pode rastrear os gastos com o Athena para cadacentro de custo. Para obter mais informações, consulte Usar tags para faturamento no Guia do usuário doAWS Billing and Cost Management;.
Você pode trabalhar com tags usando o console do Athena ou as operações da API. Para obter maisinformações, consulte Marcar com tags os grupos de trabalho (p. 242).
No console do Athena, você pode adicionar uma ou mais tags para cada um dos grupos de trabalhoe pesquisar por tags. Os grupos de trabalho são um recurso controlado pelo IAM no Athena. No IAM,você pode restringir quem pode adicionar, remover ou listar tags nos grupos de trabalho que você cria.Você também pode usar a operação de API CreateWorkGroup que tenha o parâmetro de tag opcionalpara adicionar uma ou mais tags ao grupo de trabalho. Para adicionar, remover ou listar tags, useTagResource, UntagResource e ListTagsForResource. Para obter mais informações, consulteTrabalhar com tags usando as ações da API (p. 242).
Para permitir que os usuários adicionem tags ao criar grupos de trabalho, você deve conceder a cadausuário permissões do IAM para as ações da API TagResource e CreateWorkGroup. Para obter maisinformações e exemplos, consulte Políticas de controle de acesso do IAM baseadas em tags (p. 246).
Não há alterações para o driver JDBC ao usar tags nos grupos de trabalho. Se você criar novos grupos detrabalho e usar o driver JDBC ou o SDK da AWS, faça upgrade para a versão mais recente do driver e doSDK. Para obter mais informações, consulte Uso do Athena com o driver JDBC (p. 59).
18 de fevereiro de 2019Publicado em 18/02/2019
Adição da capacidade de controlar os custos de consulta ao executar consultas nos grupos de trabalho.Para obter mais informações, consulte Usar grupos de trabalho para controlar o acesso a consultas ecustos (p. 217). Melhora do JSON OpenX SerDe usado em Athena, corrigido um problema em que Athenanão ignorou objetos que fizeram a transição para a classe de armazenamento do GLACIER e adicionadosexemplos para consultar logs do Load balancer de rede.
Foram feitas as seguintes alterações:
• Adição de suporte a grupos de trabalho. Uso de grupos de trabalho para separar usuários, equipes,aplicativos ou cargas de trabalho e para definir limites de quantidade de dados que cada consulta outodo o grupo de trabalho pode processar. Como os grupos de trabalho atuam como recursos do IAM,você pode usar permissões no nível do recurso para controlar o acesso a um determinado grupo detrabalho. Você também pode visualizar métricas relacionadas à consulta no Amazon CloudWatch,controlar custos da consulta ao configurar limites para a quantidade de dados verificada, criar os limites
332

Amazon Athena Guia do usuário20 de novembro de 2018
e acionar ações, como alarmes do Amazon SNS, quando esses limites forem violados. Para obter maisinformações, consulte Usar grupos de trabalho para executar consultas (p. 217) e Controlar custos emonitorar consultas com métricas do CloudWatch (p. 235).
Os grupos de trabalho são um recurso do IAM. Para obter uma lista completa de recursos, condições eações relacionadas ao grupo de trabalho no IAM, consulte ações, recursos e chaves de condição para oAmazon Athena no Guia do usuário do IAM. Antes de criar novos grupos de trabalho, use as políticas degrupo de trabalho do IAM (p. 221) e a Política gerenciada do AmazonAthenaFullAccess (p. 181).
Você pode começar a usar grupos de trabalho no console com as operações da API do grupo detrabalho (p. 233) ou com o driver JDBC. Para um procedimento de alto nível, consulte Configurar gruposde trabalho (p. 219). Para baixar o driver JDBC com suporte ao grupo de trabalho, consulte Uso doAthena com o driver JDBC (p. 59).
Se você usar grupos de trabalho com o driver JDBC, defina o nome do grupo de trabalho na string deconexão usando o parâmetro de configuração Workgroup, como no exemplo a seguir:
jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>;PWD=<SECRETKEY>;S3OutputLocation=s3://<athena-output>-<AWSREGION>/;Workgroup=<WORKGROUPNAME>;
Não há alterações na forma como você executa instruções SQL ou faz chamadas de API JDBC para odriver. O driver passa o nome do grupo de trabalho para o Athena.
Para obter mais informações sobre diferenças introduzidas com os grupos de trabalho, consulte APIs dogrupo de trabalho do Athena (p. 233) e Grupos de trabalho de solução de problemas (p. 233).
• Melhorado o JSON OpenX SerDe usado no Athena. As melhorias incluem, entre outros:• Suporte à propriedade ConvertDotsInJsonKeysToUnderscores. Quando definido como TRUE,
permite que o SerDe substitua por sublinhados os pontos nos nomes de chaves. Por exemplo, se oconjunto de dados JSON contiver uma chave com o nome "a.b", você pode usar essa propriedadepara definir o nome da coluna como "a_b" no Athena. O padrão é FALSE. Por padrão, o Athena nãopermite pontos nos nomes de coluna.
• Suporte à propriedade case.insensitive. Por padrão, o Athena exige que todas as chaves do seudataset JSON usem caixa baixa. O uso de WITH SERDE PROPERTIES ("case.insensitive"=FALSE;) permite usar nomes de chaves com diferenciação de maiúsculas e minúsculas nos seusdados. O padrão é TRUE. Quando definido como TRUE, o SerDe converte todas as colunas emmaiúsculas para minúsculas.
Para obter mais informações, consulte the section called “OpenX JSON SerDe” (p. 267).• Corrigido um problema em que o Athena retornava mensagens de erro "access denied" quando
processava objetos do Amazon S3 arquivados no Glacier por políticas de ciclo de vida do Amazon S3.Como resultado da correção desse problema, o Athena ignora os objetos que fizeram a transição paraa classe de armazenamento do GLACIER. O Athena não oferece suporte à consulta de dados da classede armazenamento GLACIER.
Para obter mais informações, consulte the section called “Requisitos para tabelas no Athena e dados noAmazon S3” (p. 15) e Transição para a classe de armazenamento GLACIER (arquivamento de objeto)no Guia do desenvolvedor do Amazon Simple Storage Service.
• Adição de exemplos para consultar logs de acesso ao Load balancer de rede que recebem informaçõessobre as solicitações de Transport Layer Security (TLS). Para obter mais informações, consulte thesection called “Consulta de logs do Load balancer de rede” (p. 162).
20 de novembro de 2018Publicado em 20/11/2018
333

Amazon Athena Guia do usuário15 de outubro de 2018
As novas versões dos drivers JDBC e ODBC foram lançada com suporte para acesso federado à API doAthena com o AD FS e o SAML 2.0 (Security Assertion Markup Language 2.0). Para obter mais detalhes,consulte as Notas de release do driver JDBC e Notas de release do driver ODBC.
Com esta versão, o acesso federado ao Athena tem suporte do Active Directory Federation Service (ADFS 3.0). O acesso é estabelecido por meio das versões dos drivers JDBC ou ODBC que oferecem suporteao SAML 2.0. Para obter mais informações sobre como configurar o acesso federado à API do Athena,consulte the section called “Permitir acesso federado à API do Athena” (p. 202).
Para fazer download do driver JDBC versão 2.0.6 e da respectiva documentação, consulte Uso do Athenacom o driver JDBC (p. 59). Para obter mais informações sobre essa versão, consulte as Notas de releasedo driver JDBC.
Para fazer download do driver ODBC versão 1.0.4 e da respectiva documentação, consulte Conexão aoAmazon Athena com o ODBC (p. 61). Para obter mais informações sobre essa versão, consulte as Notasde release do driver ODBC.
Para obter mais informações sobre o suporte do SAML 2.0 na AWS, consulte Sobre a Federação SAML2.0 no Guia do usuário do IAM.
15 de outubro de 2018Publicado em 15/10/2018
Se você tiver atualizado para o Catálogo de dados do AWS Glue, haverá dois novos recursos quefornecem suporte para:
• Criptografia de metadados do Data Catalog. Se escolher criptografar os metadados no Data Catalog,você deverá adicionar políticas específicas ao Athena. Para obter mais informações, consulte Acesso ametadados criptografados no Catálogo de dados do AWS Glue (p. 192).
• Permissões refinadas para acessar recursos no Catálogo de dados do AWS Glue. Agora, você podedefinir políticas baseadas em identidades (IAM) que restringem ou permitem o acesso a bancos dedados e tabelas específicas do Data Catalog usadas no Athena. Para obter mais informações, consulteAcesso refinado a bancos de dados e tabelas no Catálogo de dados do AWS Glue (p. 185).
Note
Os dados residem em buckets do Amazon S3, e o acesso é governado pelas Permissões doAmazon S3 (p. 185). Para acessar dados em bancos de dados e tabelas, continue a usar aspolíticas de controle de acesso aos buckets do Amazon S3 que armazenam os dados.
10 de outubro de 2018Publicado em 10/10/2018
O Athena oferece suporte a CREATE TABLE AS SELECT, que cria uma tabela a partir do resultado deuma instrução de consulta SELECT. Para obter detalhes, consulte Criar uma tabela a partir de resultadosda consulta (CTAS).
Antes de criar consultas CTAS, é importante saber mais sobre seu comportamento na documentaçãodo Athena. Ela contém informações sobre o local para salvar os resultados da consulta no Amazon S3,a lista de formatos compatíveis para armazenar resultados da consulta CTAS, o número de partiçõesque é possível criar e formatos de compactação compatíveis. Para obter mais informações, consulteConsiderações e limitações para consultas CTAS (p. 77).
Use consultas CTAS consultas:
334

Amazon Athena Guia do usuário6 de setembro de 2018
• Crie uma tabela a partir de resultados da consulta (p. 77) em uma etapa.• Crie consultas CTAS no console do Athena (p. 79), usando Exemplos (p. 83). Para obter informações
sobre a sintaxe, consulte CREATE TABLE AS (p. 299).• Transforme resultados da consulta em outros formatos de armazenamento, como PARQUET, ORC,
AVRO, JSON e TEXTFILE. Para obter mais informações, consulte Considerações e limitações paraconsultas CTAS (p. 77) e Formatos de armazenamento colunar (p. 26).
6 de setembro de 2018Publicado em 06/09/2018
Lançada a nova versão do driver ODBC (versão 1.0.3). A nova versão do driver ODBC transmiteresultados por padrão, em vez de paginação por meio deles, permitindo que as ferramentas de businessintelligence recuperem grandes conjuntos de dados com mais rapidez. Essa versão também incluimelhorias, correções de erros e uma documentação atualizada para "Usar SSL com um servidor de proxy".Para obter detalhes, consulte as Notas de release do driver.
Para fazer download do driver ODBC versão 1.0.3 e da respectiva documentação, consulte Conexão aoAmazon Athena com o ODBC (p. 61).
O recurso de streaming de resultados está disponível com essa nova versão do driver ODBC. Tambémestá disponível com o driver JDBC. Para obter informações sobre o streaming de resultados, consulte o Guia de instalação e configuração do driver ODBC e pesquise por UseResultsetStreaming.
O driver ODBC versão 1.0.3 é um substituto pronto para a versão anterior do driver. Recomendamos quevocê migre para o driver atual.
Important
Para usar o driver ODBC versão 1.0.3, siga estes requisitos:
• Mantenha a porta 444 aberta para tráfego de saída.• Adicione a ação de política athena:GetQueryResultsStream à lista de políticas para
Athena. Essa ação de política não é exposta diretamente com a API e só é usada comos drivers ODBC e JDBC, como parte do suporte ao streaming de resultados. Para obteruma política de exemplo, consulte Política gerenciada AWSQuicksightAthenaAccessManaged (p. 183).
23 de agosto de 2018Publicado em 23/08/2018
Adicionado suporte para estes recursos relacionados à DDL e corrigidos vários erros, como a seguir:
• Adicionado suporte para os tipos de dados BINARY e DATE para dados no Parquet, e para os tipos dedados DATE e TIMESTAMP para dados no Avro.
• Adicionamos suporte para INT e DOUBLE em consultas DDL. INTEGER é um alias para INT, e DOUBLEPRECISION é um alias para DOUBLE.
• Melhor performance de consultas DROP TABLE e DROP DATABASE.• Removida a criação de objeto _$folder$ no Amazon S3 quando um bucket de dados está vazio.• Corrigido um problema em que ALTER TABLE ADD PARTITION gerou um erro quando nenhum valor
de partição foi fornecido.• Corrigido um problema em que DROP TABLE ignorou o nome do banco de dados ao verificar partições
após o nome qualificado ter sido especificado na instrução.
335

Amazon Athena Guia do usuário16 de agosto de 2018
Para obter informações sobre os tipos de dados com suporte no Athena, consulte Tipos de dados (p. 281).
Para obter informações sobre mapeamentos de tipos de dados com suporte entre tipos no Athena, o driverJDBC e os tipos de dados do Java, consulte a seção Tipos de dados no Guia de instalação e configuraçãodo driver JDBC.
16 de agosto de 2018Publicado em 16/08/2018
Lançado o driver JDBC versão 2.0.5. A nova versão do driver JDBC transmite resultados por padrão,em vez de paginação por meio deles, permitindo que as ferramentas de business intelligence recuperemgrandes conjuntos de dados com mais rapidez. Em comparação com a versão anterior do driver JDBC,houve as seguintes melhorias de performance:
• Aproximadamente, o dobro da performance ao obter menos que 10.000 linhas.• Aproximadamente, cinco a seis vezes de aumento na performance ao obter mais que 10.000 linhas.
O recurso de streaming de resultados está disponível apenas com o driver JDBC. Não está disponívelcom o driver ODBC. Você não pode usá-lo com a API Athena. Para obter informações sobre ostreaming de resultados, consulte o Guia de instalação e configuração do driver JDBC e pesquise porUseResultsetStreaming.
Para fazer download do driver JDBC versão 2.0.5 e da respectiva documentação, consulte Uso do Athenacom o driver JDBC (p. 59).
O driver JDBC versão 2.0.5 é um substituto pronto para a versão anterior do driver (2.0.2).Para garantir que você possa usar o driver JDBC versão 2.0.5, adicione a ação da política doathena:GetQueryResultsStream à lista de políticas do Athena. Essa ação de política não é expostadiretamente com a API e só é usada com o driver JDBC, como parte do suporte ao streaming deresultados. Para obter uma política de exemplo, consulte Política gerenciada AWSQuicksightAthenaAccessManaged (p. 183). Para obter mais informações sobre como migrar da versão 2.0.2 para a versão 2.0.5 dodriver, consulte o Guia de migração do driver JDBC.
Se estiver migrando de um driver 1.x para um driver 2.x, você precisará migrar suas configuraçõesexistentes para a nova configuração. É altamente recomendável migrar para a versão atual do driver. Paraobter mais informações, consulte Usar a versão anterior do driver JDBC (p. 317) e o Guia de migração dodriver JDBC.
7 de agosto de 2018Publicado em 07/08/2018
Agora você pode armazenar logs de fluxo da Amazon Virtual Private Cloud diretamente no Amazon S3 emum formato GZIP, onde você pode consultá-los no Athena. Para obter informações, consulte Consulta alogs de fluxo da Amazon VPC (p. 164) e Logs de fluxo da Amazon VPC agora podem ser entregues parao S3.
5 de junho de 2018Publicado em 05/06/2018
336

Amazon Athena Guia do usuárioSuporte para exibições
Tópicos• Suporte para exibições (p. 337)• Melhorias e atualizações em mensagens de erro (p. 337)• Correções de bugs (p. 337)
Suporte para exibiçõesAdicionado suporte para exibições. Agora você pode usar CREATE VIEW (p. 301), DESCRIBEVIEW (p. 302), DROP VIEW (p. 303), SHOW CREATE VIEW (p. 305) e SHOW VIEWS (p. 307) no Athena.A consulta que define a exibição é executada sempre que você faz referência à exibição em uma consulta.Para obter mais informações, consulte Como trabalhar com exibições (p. 72).
Melhorias e atualizações em mensagens de erro• Foi incluída uma biblioteca GSON 2.8.0 no CloudTrail SerDe para resolver um problema com o
CloudTrail SerDe e habilitar a análise de strings JSON.• Validação aprimorada do esquema de partição no Athena para Parquet e, em alguns casos, para ORC,
permitindo a reclassificação de colunas. Isso permite que o Athena lide melhor com alterações naevolução do esquema ao longo do tempo e com as tabelas adicionadas pelo Crawler do AWS Glue.Para obter mais informações, consulte Tratamento de atualizações do esquema (p. 95).
• Foi adicionado suporte para análise de SHOW VIEWS.• Feitas as seguintes melhorias nas mensagens de erro mais comuns:
• Foi substituída uma mensagem de Internal Error (Erro interno) por uma mensagem descritiva doerro quando um SerDe não consegue analisar a coluna em uma consulta do Athena. Anteriormente,o Athena emitia um erro interno em caso de erros de análise. A nova mensagem de erro lê: "HIVE_BAD_DATA: Erro ao analisar o valor de campo para o campo 0: java.lang. A string não pode serconvertida para org.openx.data.jsonserde.json.JSONObject".
• Mensagens de erro aprimoradas sobre permissões insuficientes, adicionando mais detalhes.
Correções de bugsCorrigidos os seguintes bugs:
• Corrigido um problema que permite a conversão interna dos tipos de dados REAL em FLOAT. Issomelhora a integração com o Crawler do AWS Glue que retorna os tipos de dados FLOAT.
• Corrigido um problema em que o Athena não convertia DECIMAL do AVRO (um tipo lógico) em um tipoDECIMAL.
• Corrigido um problema em que o Athena não retornava resultados para consultas em dados do Parquetcom as cláusulas WHERE que faziam referência a valores no tipo de dados TIMESTAMP.
17 de maio de 2018Publicado em 17/05/2018
Cotas maiores de simultaneidade de consultas no Athena, de cinco para vinte. Isso significa que você podeenviar e executar até 20 consultas DDL e 20 consultas SELECT de cada vez. Observe que as cotas desimultaneidade são separadas para as consultas DDL e SELECT.
As cotas de simultaneidade no Athena são definidas como o número de consultas que podem ser enviadaspara o serviço simultaneamente. Você pode enviar até 20 consultas do mesmo tipo (DDL ou SELECT) por
337

Amazon Athena Guia do usuário19 de abril de 2018
vez. Se você enviar uma consulta que exceda a cota de consultas simultâneas, a API do Athena exibiráuma mensagem de erro.
Depois que você envia suas consultas para o Athena, ele processa as consultas, atribuindo recursos combase na carga de serviço geral e na quantidade de solicitações recebidas. Nós monitoramos e fazemosajustes continuamente no serviço para que suas consultas sejam processadas o mais rápido possível.
Para obter mais informações, consulte Cotas de serviço (p. 322). Esta é uma cota ajustável. Você podeusar o console de Cotas de serviço para solicitar um aumento de cotas para consultas simultâneas.
19 de abril de 2018Publicado em 19/04/2018
Lançada a nova versão do driver JDBC (versão 2.0.2) com suporte para retorno de dados de ResultSetcomo um tipo de dados Array, melhorias e correções de bugs. Para obter detalhes, consulte as Notas derelease do driver.
Para obter informações sobre como fazer download do novo driver JDBC versão 2.0.2 e respectivadocumentação, consulte Uso do Athena com o driver JDBC (p. 59).
A versão mais recente do driver JDBC é a 2.0.2. Se estiver migrando de um driver 1.x para um driver 2.x,você precisará migrar suas configurações existentes para a nova configuração. É altamente recomendávelque você migre para o driver atual.
Para obter informações sobre as alterações introduzidas na nova versão do driver, as diferenças de versãoe os exemplos, consulte o Guia de migração do driver JDBC.
Para obter informações sobre a versão anterior do driver JDBC, consulte Como usar o Athena com aversão anterior do driver JDBC (p. 317).
6 de abril de 2018Publicado em 06/04/2018
Use o preenchimento automático para digitar consultas no console do Athena.
15 de março de 2018Publicado em 15/03/2018
Incluída a capacidade de criar automaticamente tabelas do Athena para arquivos de log do CloudTraildiretamente no console do CloudTrail. Para obter mais informações, consulte Criação de uma tabela paralogs do CloudTrail no console do CloudTrail (p. 155).
2 de fevereiro de 2018Publicado em 12/02/2018
338

Amazon Athena Guia do usuário19 de janeiro de 2018
Adicionada a capacidade de descarregar com segurança dados intermediários no disco para consultascom uso intensivo de memória que empregam a cláusula GROUP BY. Isso melhora a confiabilidade dessasconsultas, evitando erros do tipo "Query resource exhausted" (Recurso de consulta esgotado).
19 de janeiro de 2018Publicado em 19/01/2018
O Athena usa o Presto, um mecanismo de consulta distribuído de código-fonte aberto, para executarconsultas.
Com o Athena, não há versões a serem gerenciadas. Atualizamos transparentemente o mecanismosubjacente no Athena para uma versão baseada no Presto versão 0.172. Não é necessária nenhuma açãode sua parte.
Com a atualização, você já pode usar as Funções e operadores do Presto 0.172 incluindo as Expressõesdo Lambda do Presto 0.172 no Athena.
Entre as principais atualizações desta versão, inclusive correções de contribuição da comunidade, estão:
• Suporte para ignorar cabeçalhos. Você pode usar a propriedade skip.header.line.count ao definirtabelas para permitir que o Athena ignore cabeçalhos. Atualmente, existe suporte para consultas queusam OpenCSV SerDe, e não para Grok ou SerDes Regex.
• Suporte para o tipo de dados CHAR(n) em funções STRING. O intervalo de CHAR(n) é [1.255], e ointervalo de VARCHAR(n) é [1,65535].
• Suporte para subconsultas correlacionadas.• Suporte para expressões e funções Lambda do Presto.• Desempenho aprimorado do tipo DECIMAL e dos operadores.• Suporte para agregações filtradas, como SELECT sum(col_name) FILTER, em que id > 0.• Predicados para os tipos de dados DECIMAL, TINYINT, SMALLINT e REAL.• Suporte para predicados de comparação quantificados: ALL, ANY e SOME.• Funções adicionadas: arrays_overlap(), array_except(), levenshtein_distance(),codepoint(), skewness(), kurtosis(), e typeof().
• Adicionada uma variante da função from_unixtime() que utiliza um argumento de fuso horário.• Adicionadas as funções de agregação bitwise_and_agg() e bitwise_or_agg().• Adicionadas as funções xxhash64() e to_big_endian_64().• Suporte adicional para aspas duplas ou barras invertidas de escape usando uma barra invertida com um
sublinhado de caminho JSON nas funções json_extract() e json_extract_scalar(). Isso alteraa semântica de qualquer invocação usando uma barra invertida, porque as barras invertidas já foramtratados como caracteres normais.
Para obter uma lista completa de funções e operadores, consulte Consultas, funções e operadoresSQL (p. 282) neste guia e Funções do Presto 0.172.
O Athena não oferece suporte a todos os recursos do Presto. Para obter mais informações, consulteLimitações (p. 307).
13 de novembro de 2017Publicado em 13/11/2017
339

Amazon Athena Guia do usuário1 de novembro de 2017
Suporte adicional para conectar o Athena ao driver ODBC. Para obter mais informações, consulte Conexãoao Amazon Athena com o ODBC (p. 61).
1 de novembro de 2017Publicado em 01/11/2017
Adicionado suporte para consultar dados geoespaciais e para regiões Ásia-Pacífico (Seul), Ásia-Pacífico(Mumbai) e UE (Londres). Para obter mais informações, consulte Consultar dados geoespaciais (p. 127) eRegiões e endpoints da AWS.
19 de outubro de 2017Publicado em 19/10/2017
Adicionado suporte para UE (Frankfurt). Para obter uma lista de regiões compatíveis, consulte Regiões eendpoints da AWS.
3 de outubro de 2017Publicado em 03/10/2017
Crie consultas do Athena nomeadas com o CloudFormation. Para obter mais informações, consulteAWS::Athena::NamedQuery no Guia do usuário do AWS CloudFormation.
25 de setembro de 2017Publicado em 25/09/2017
Adicionado o suporte para Ásia-Pacífico (Sydney). Para obter uma lista de regiões compatíveis, consulteRegiões e endpoints da AWS.
14 de agosto de 2017Publicado em 14/08/2017
Adicionada integração com o AWS Glue Data Catalog e um assistente de migração para atualizar docatálogo de dados gerenciados do Athena para o AWS Glue Data Catalog. Para obter mais informações,consulte Integração com o AWS Glue (p. 32).
4 de agosto de 2017Publicado em 04/08/2017
Adicionado suporte para Grok SerDe, que oferece um padrão de correspondência mais simples pararegistros em arquivos de texto desestruturados, como logs. Para obter mais informações, consulte Grok
340

Amazon Athena Guia do usuário22 de junho de 2017
SerDe (p. 263). Adicionados atalhos de teclado para percorrer o histórico de consultas usando o console(CTRL + ⇧/⇩ usando o Windows, CMD + ⇧/⇩ usando o Mac).
22 de junho de 2017Publicado em 22/06/2017
Adicionado suporte para Ásia-Pacífico (Tóquio) e Ásia-Pacífico (Cingapura). Para obter uma lista deregiões compatíveis, consulte Regiões e endpoints da AWS.
8 de junho de 2017Publicado em 08/06/2017
Adicionado o suporte para Europa (Irlanda). Para obter mais informações, consulte Regiões e endpoints daAWS.
19 de maio de 2017Publicado em 19/05/2017
Adicionado suporte a uma API do Amazon Athena e à CLI da AWS para o Athena; atualizado driver JDBCpara a versão 1.1.0; corrigidos diversos problemas.
• O Amazon Athena habilita a programação de aplicativos para Athena. Para obter mais informações,consulte o Referência de API do Amazon Athena. Os SDKs da AWS mais recentes incluem suporte paraa API do Athena. Para links da documentação e downloads, consulte a seção SDKs em Ferramentas daAmazon Web Services.
• A CLI da AWS inclui novos comandos para o Athena. Para obter mais informações, consulte oReferência de API do Amazon Athena.
• Um novo driver JDBC 1.1.0 está disponível, o que oferece suporte à nova API do Athena, bem como aosrecursos e às correções de bugs mais recentes. Faça download do driver em https://s3.amazonaws.com/athena-downloads/drivers/AthenaJDBC41-1.1.0.jar. Recomendamos atualizar para a versão maisrecente do driver JDBC do Athena. No entanto, você ainda pode usar a versão do driver anterior. Asversões anteriores do driver não oferecem suporte à API Athena. Para obter mais informações, consulteUso do Athena com o driver JDBC (p. 59).
• Ações específicas em declarações de política nas versões anteriores do Athena foram suspensas.Se atualizar o driver JDBC versão 1.1.0 e tiver políticas do IAM gerenciadas por clientes ou em linhaanexadas a usuários do JDBC, você deverá atualizar as políticas do IAM. Por outro lado, as versõesanteriores do driver JDBC não oferecem suporte à API Athena. Dessa maneira, você só pode especificarações suspensas em políticas anexadas a usuários do JDBC de uma versão anterior. Por esse motivo,você não precisa atualizar políticas do IAM gerenciadas pelo cliente ou em linha.
• Essas ações específicas da política foram usadas no Athena antes do lançamento da API Athena.Use essas ações obsoletas em políticas apenas com drivers JDBC anteriores a essa versão 1.1.0. Seestiver atualizando o driver JDBC, substitua as declarações de políticas que permitem ou negam açõesobsoletas por ações da API apropriada conforme listadas ou ocorrerão erros:
Ação específica da política obsoleta Ação da API do Athena correspondente
athena:RunQuery athena:StartQueryExecution
341

Amazon Athena Guia do usuárioMelhorias
Ação específica da política obsoleta Ação da API do Athena correspondente
athena:CancelQueryExecution athena:StopQueryExecution
athena:GetQueryExecutions athena:ListQueryExecutions
Melhorias• Aumentado o limite de tamanho da string de consulta para 256 KB.
Correções de bugs• Corrigido um problema que fazia os resultados da consulta terem aparência malformada durante a
rolagem pelos resultados no console.• Corrigido um problema em que uma string de caractere \u0000 nos arquivos de dados do Amazon S3
causaria erros.• Corrigido um problema que fazia as solicitações para cancelar uma consulta feita pelo driver JDBC
falharem.• Corrigido um problema que fazia com que o SerDe do AWS CloudTrail falhasse com dados do Amazon
S3 na Leste dos EUA (Ohio).• Corrigido um problema que fez com que DROP TABLE falhasse em uma tabela particionada.
4 de abril de 2017Publicado em 04/04/2017
Adicionado suporte à criptografia de dados do Amazon S3 e lançada uma atualização do driver JDBC(versão 1.0.1) com suporte à criptografia, melhorias e correções de erros.
Recursos• Adicionados os seguintes recursos de criptografia:
• Suporte para consultar dados criptografados no Amazon S3.• Suporte para criptografar resultados da consulta do Athena.
• Uma nova versão do driver oferece suporte a novos recursos de criptografia, adiciona melhorias ecorrige problemas.
• Adicionada a possibilidade de adicionar, substituir e alterar colunas usando ALTER TABLE. Para obtermais informações, consulte Alter Column na documentação do Hive.
• Adicionado suporte para consultar dados compactados por LZO.
Para obter mais informações, consulte Criptografia em repouso (p. 174).
Melhorias• Melhor desempenho da consulta JDBC com melhorias no tamanho da página, retornando 1.000 linhas,
em vez de 100.
342

Amazon Athena Guia do usuárioCorreções de bugs
• Adicionada capacidade para cancelar uma consulta usando a interface do driver JDBC.• Adicionada capacidade para especificar opções de JDBC no URL de conexão JDBC. Para obter mais
informações, consulte Como usar o Athena com a versão anterior do driver JDBC (p. 317) para a versãoanterior do driver, e Conectar com o JDBC (p. 59)para a versão mais recente.
• Adicionada configuração de PROXY no driver, que já pode ser definida usando-se ClientConfiguration noAWS SDK para Java.
Correções de bugsCorrigidos os seguintes bugs:
• Erros de controle de utilização ocorreriam quando várias consultas foram emitidas usando a interface dodriver JDBC.
• O driver JDBC anularia durante a projeção de um tipo de dados decimal.• O driver JDBC retornaria cada tipo de dados como uma string, independentemente de como o tipo de
dados foi definido na tabela. Por exemplo, selecionar uma coluna definida como um tipo de dados INTusando resultSet.GetObject() retornaria um tipo de dados STRING, em vez de INT.
• O driver JDBC verificaria credenciais no momento em que uma conexão foi estabelecida, e não nomomento em que uma consulta seria executada.
• As consultas feitas por meio do driver JDBC falhariam quando um esquema fosse especificado com oURL.
24 de março de 2017Publicado em 24/03/2017
Adicionado o AWS CloudTrail SerDe, melhorado o desempenho, corrigidos problemas de partição.
Recursos• Adicionado o SerDe do AWS CloudTrail. Para obter mais informações, consulte CloudTrail
SerDe (p. 258). Para obter exemplos de uso detalhados, consulte a publicação no blog AWS Big Data:Analisar segurança, conformidade e atividade operacional usando o AWS CloudTrail e o AmazonAthena.
Melhorias• Melhorado desempenho durante o exame de um grande número de partições.• Melhorado desempenho na operação MSCK Repair Table.• Adicionada a capacidade de consultar dados do Amazon S3 armazenados em regiões diferentes da
região principal. Taxas de transferência de dados padrão entre regiões do Amazon S3 se aplicam, alémdas cobranças padrão do Athena.
Correções de bugs• Corrigido um bug em que um erro "tabela não encontrada" poderá ocorrer se nenhuma partição for
carregada.
343

Amazon Athena Guia do usuário20 de fevereiro de 2017
• Corrigido um bug para evitar lançar uma exceção com consultas ALTER TABLE ADD PARTITION IFNOT EXISTS.
• Corrigido um bug em DROP PARTITIONS.
20 de fevereiro de 2017Publicado em 20/02/2017
Adicionado suporte para AvroSerDe e OpenCSVSerDe, região Leste dos EUA (Ohio), e colunas de ediçãoem massa no assistente do console. Melhorado desempenho em tabelas Parquet grandes.
Recursos• Introduzido suporte para novo SerDes:
• Avro SerDe (p. 255)• OpenCSVSerDe para processar CSV (p. 260)
• Lançamento na região Leste dos EUA (Ohio) (us-east-2). Você já pode executar consultas nessa região.• Você já pode usar o assistente Add Table para definir o esquema da tabela em massa. Escolha Catalog
Manager, Add table e Bulk add columns à medida que você avançar pelas etapas para definir a tabela.
Digite os pares de nome e valor na caixa de texto e escolha Add.
344

Amazon Athena Guia do usuárioMelhorias
Melhorias• Melhorado desempenho em tabelas Parquet grandes.
345

Amazon Athena Guia do usuário
Histórico do documentoLatest documentation update: February 6, 2020. (Última atualização da documentação: 6 de fevereiro de2020.)
Alteração Descrição Data delançamento
Adição de um tópicosobre a consultade logs de fluxodo AWS GlobalAccelerator com oAthena.
Para obter mais informações, consulte Consultar a logs defluxo do AWS Global Accelerator (p. 161).
6 de fevereiro de2020
• Adição dadocumentaçãosobre o usode CTAS comINSERT INTOpara adicionardados de umaorigem nãoparticionadaa um destinoparticionado.
• Adição de linkspara downloadda versão de pré-visualização 1.1.0do driver ODBCpara Athena.
• Correção dadescrição pararegex SHOWDATABASESLIKE.
• Correçãoda sintaxepartitioned_byno tópico de CTA.
• Outras pequenascorreções.
As atualizações da documentação incluem, entre outros, osseguintes tópicos:
• Usar CTAS e INSERT INTO para ETL e análise dedados (p. 86)
• Links para download do driver ODBC de pré-visualização (p. 62)
• SHOW DATABASES (p. 305)• CREATE TABLE AS (p. 299)
4 de fevereiro de2020
Adição dadocumentação sobrecomo usar CTAScom INSERT INTOpara adicionar dadosde uma origemparticionada a umdestino particionado.
Para obter mais informações, consulte Usar CTAS eINSERT INTO para criar uma tabela com mais de 100partições (p. 92).
22 de janeiro de2020
346

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Atualização deinformações de localdos resultados deconsulta.
O Athena não cria mais um local de resultados de consulta“padrão”. Para obter mais informações, consulte Especificarum local de resultados da consulta (p. 69).
20 de janeiro de2020
Adição de umtópico sobre comoconsultar o Catálogode dados do AWSGlue. Atualização deinformações sobrecotas de serviço(anteriormenteconhecidas como“limites de serviço”)no Athena.
Para obter mais informações, consulte os tópicos a seguir:
• Consulta no Catálogo de dados do AWS Glue (p. 168)• Cotas de serviço (p. 322)
17 de janeiro de2020
Correção dotópico sobreOpenCSVSerDepara destacarque o tipoTIMESTAMP deveser especificado noformato numéricoUNIX.
Para obter mais informações, consulte OpenCSVSerDe paraprocessar CSV (p. 260).
15 de janeiro de2020
Adição de um tópicode segurança sobrecriptografia paradestacar que oAthena não oferecesuporte a chavesassimétricas.
O Athena é compatível apenas com chaves simétricas paraleitura e gravação de dados.Para obter mais informações, consulte Opções decriptografia suportadas no Amazon S3 (p. 175).
8 de janeiro de2020
Adição deinformações sobreacesso entrecontas a bucketsdo Amazon S3criptografadoscom uma chavepersonalizada doAWS KMS.
Para obter mais informações, consulte Acesso entre contasa um bucket criptografado com uma chave personalizada doAWS KMS (p. 193).
13 de dezembrode 2019
347

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Adição dadocumentação paraconsultas federadas,metastores externosdo Hive, machinelearning e funçõesdefinidas pelousuário. Adição denovas métricas doCloudWatch.
Para obter mais informações, consulte os tópicos a seguir:
• O uso do (p. 49)• Usar conectores de fontes de dados do Athena (p. 52)• O uso do (p. 47)• O uso do (p. 139)• Consultas com funções definidas pelo usuário
(visualização) (p. 140)• Links para download do driver JDBC para recursos de
visualização (p. 60)• Lista das métricas do CloudWatch para Athena (p. 237)
26 de novembrode 2019
Adição da seçãopara o novocomando INSERTINTO e atualizaçãodas informaçõesde localização doresultado da consultapara oferecersuporte a arquivosmanifesto dos dados.
Para obter mais informações, consulte INSERTINTO (p. 286) e Trabalhar com resultados de consulta,arquivos de saída e histórico de consultas (p. 65).
18 de setembrode 2019
Adição da seçãode suporte aVPC endpointsde interface(PrivateLink).Atualização dosdrivers JDBC.Atualização dasinformações sobreos logs de fluxo daVPC aprimorados.
Para obter mais informações, consulte Conectar-se ao Amazon Athena usando um VPC endpoint deinterface (p. 208), Consulta a logs de fluxo da AmazonVPC (p. 164) e Uso do Athena com o driver JDBC (p. 59).
11 de setembrode 2019
Adição da seçãosobre integraçãoao AWS LakeFormation.
Para obter mais informações, consulte Usar o Athenapara consultar dados registrados com o AWS LakeFormation (p. 209).
26 de junho de2019
Atualização da seçãoSegurança paraconsistência comoutros serviços daAWS.
Para obter mais informações, consulte Segurança doAmazon Athena (p. 173).
26 de junho de2019
Adição da seçãosobre a consulta delogs do AWS WAF.
Para obter mais informações, consulte Consulta de logs doAWS WAF (p. 166).
31 de maio de2019
348

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Lançada a novaversão do driverODBC com suportepara grupos detrabalho do Athena.
Para fazer download do driver ODBC versão 1.0.5 e darespectiva documentação, consulte Conexão ao AmazonAthena com o ODBC (p. 61). Não há alterações para a stringde conexão do driver ODBC ao usar tags nos grupos detrabalho. Para usar tags, atualize para a versão mais recentedo driver ODBC, que é a versão atual.
Esta versão do driver permite que você use as açõesdo grupo de trabalho da API Athena (p. 233) para criare gerenciar grupos de trabalho e ações da tag da APIAthena (p. 245) para adicionar, listar ou remover tags nosgrupos de trabalho. Antes de começar, verifique se vocêtem permissões no nível do recurso no IAM para ações emgrupos de trabalho e tags.
5 de março de2019
Adição de suporte atags para grupos detrabalho no AmazonAthena.
Uma tag consiste em uma chave e um valor, ambosdefinidos por você. Quando você marca um grupo detrabalho, atribui metadados personalizados a ele. Porexemplo, crie um grupo de trabalho para cada centro decusto. Ao adicionar tags a esses grupos de trabalho, vocêpode rastrear os gastos com o Athena para cada centro decusto. Para obter mais informações, consulte Usar tags parafaturamento no Guia do usuário do AWS Billing and CostManagement;.
22 de fevereirode 2019
Melhorado o JSONOpenX SerDe usadono Athena.
As melhorias incluem, entre outros:
• Suporte à propriedadeConvertDotsInJsonKeysToUnderscores. Quandodefinido como TRUE, permite que o SerDe substituapor sublinhados os pontos nos nomes de chaves.Por exemplo, se o conjunto de dados JSON contiveruma chave com o nome "a.b", você pode usar essapropriedade para definir o nome da coluna como "a_b"no Athena. O padrão é FALSE. Por padrão, o Athena nãopermite pontos nos nomes de coluna.
• Suporte à propriedade case.insensitive. Por padrão,o Athena exige que todas as chaves do seu dataset JSONusem caixa baixa. O uso de WITH SERDE PROPERTIES("case.insensitive"= FALSE;) permite usar nomesde chaves com diferenciação de maiúsculas e minúsculasnos seus dados. O padrão é TRUE. Quando definido comoTRUE, o SerDe converte todas as colunas em maiúsculaspara minúsculas.
Para obter mais informações, consulte the section called“OpenX JSON SerDe” (p. 267).
18 de fevereirode 2019
349

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Adição de suporte agrupos de trabalho.
Uso de grupos de trabalho para separar usuários, equipes,aplicativos ou cargas de trabalho e para definir limites dequantidade de dados que cada consulta ou todo o grupode trabalho pode processar. Como os grupos de trabalhoatuam como recursos do IAM, você pode usar permissões nonível do recurso para controlar o acesso a um determinadogrupo de trabalho. Você também pode visualizar métricasrelacionadas à consulta no Amazon CloudWatch, controlarcustos da consulta ao configurar limites para a quantidadede dados verificada, criar os limites e acionar ações, comoalarmes do Amazon SNS, quando esses limites foremviolados. Para obter mais informações, consulte Usargrupos de trabalho para executar consultas (p. 217) eControlar custos e monitorar consultas com métricas doCloudWatch (p. 235).
18 de fevereirode 2019
Adicionado suportepara análise de logsdo Load balancer derede.
Adicionado exemplo de consultas do Athena para análisede logs do Load balancer de rede. Esses logs recebeminformações detalhadas sobre as solicitações de TransportLayer Security (TLS) enviadas ao Load balancer de rede.Você pode usar esses logs de acesso para analisarpadrões de tráfego e solucionar problemas. Para obter maisinformações, consulte the section called “Consulta de logs doLoad balancer de rede” (p. 162).
24 de janeiro de2019
As novas versõesdos drivers JDBC eODBC foram lançadacom suporte paraacesso federado àAPI do Athena com oAD FS e o SAML 2.0(Security AssertionMarkup Language2.0).
Com esta versão dos drivers, o acesso federado ao Athenatem suporte do Active Directory Federation Service (AD FS3.0). O acesso é estabelecido por meio das versões dosdrivers JDBC ou ODBC que oferecem suporte ao SAML2.0. Para obter mais informações sobre como configurar oacesso federado à API do Athena, consulte the section called“Permitir acesso federado à API do Athena” (p. 202).
10 de novembrode 2018
Adicionado suportepara controle deacesso granular abancos de dados etabelas no Athena.Além disso, foramadicionadas políticasno Athena quepermitem criptografaro banco de dadose os metadadosde tabelas no DataCatalog.
Adicionado suporte para a criação de políticas baseadasem identidades (IAM) que fornecem controle de acessorefinado a recursos no Catálogo de dados do AWS Glue,como bancos de dados e tabelas usadas em Athena.
Além disso, é possível criptografar o banco de dados e osmetadados de tabelas no Data Catalog, adicionando aspolíticas ao Athena.
Para obter mais detalhes, consulte Acesso granular abancos de dados e tabelas no Catálogo de dados do AWSGlue (p. 185).
15 de outubro de2018
350

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Adicionado suportepara instruçõesCREATE TABLE ASSELECT.
Outras melhoriasforam feitas nadocumentação.
Adicionado suporte para instruções CREATE TABLE ASSELECT. Consulte Criar uma tabela a partir de resultadosda consulta (p. 77), Considerações e Limitações (p. 77) eExemplos (p. 83).
10 de outubro de2018
Liberado o driverODBC versão1.0.3 com suportepara streaming deresultados em vez deobtê-los em páginas.
Outras melhoriasforam feitas nadocumentação.
O driver ODBC versão 1.0.3 oferece suporte ao streamingde resultados e também inclui melhorias, correções de errose uma documentação atualizada para "Usar o SSL com umservidor de proxy".
Para fazer download do driver ODBC versão 1.0.3 e darespectiva documentação, consulte Conexão ao AmazonAthena com o ODBC (p. 61).
6 de setembro de2018
Liberado o driverJDBC versão2.0.5 com suportepara padrão parastreaming deresultados em vezde buscá-los empáginas.
Outras melhoriasforam feitas nadocumentação.
Liberado o driver JDBC 2.0.5 com suporte para padrão parastreaming de resultados em vez de buscá-los em páginas.Para obter mais informações, consulte Uso do Athena com odriver JDBC (p. 59).
16 de agosto de2018
Atualizada adocumentação paraconsultar logs defluxo do AmazonVirtual PrivateCloud que podemser armazenadosdiretamente noAmazon S3 em umformato GZIP.
Atualizados osexemplos paraconsultar logs ALB.
Atualizada a documentação para consultar logs de fluxo doAmazon Virtual Private Cloud que podem ser armazenadosdiretamente no Amazon S3 em um formato GZIP. Para obtermais informações, consulte Consulta a logs de fluxo daAmazon VPC (p. 164).
Atualizados os exemplos para consultar logs ALB. Para obtermais informações, consulte Consultar logs do ApplicationLoad Balancer (p. 149).
7 de agosto de2018
351

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Adicionado suportepara exibições.Foram adicionadasorientações paramanuseios doesquema paravários formatos dearmazenamentofísico de dados.
Adicionado suporte para exibições. Para obter maisinformações, consulte Como trabalhar com exibições (p. 72).
Este guia foi atualizado com orientação sobre o manuseiode atualizações do esquema para vários formatosde armazenamento físico de dados. Para obter maisinformações, consulte Tratamento de atualizações deesquema (p. 95).
5 de junho de2018
Limites maiores desimultaneidade deconsultas padrão de5 para 20.
Você pode enviar e executar até 20 consultas DDL e20 consultas SELECT de cada vez. Para obter maisinformações, consulte Cotas de serviço (p. 322).
17 de maio de2018
Adicionadas asabas de consultae a capacidadede configurar opreenchimentoautomático no QueryEditor.
Adicionadas as abas de consulta e a capacidade deconfigurar o preenchimento automático no Query Editor.Para obter mais informações, consulte Utilização doconsole (p. 12).
8 de maio de2018
Lançado o driverJDBC versão 2.0.2.
Lançada a nova versão do driver JDBC (versão 2.0.2). Paraobter mais informações, consulte Uso do Athena com odriver JDBC (p. 59).
19 de abril de2018
Adicionado opreenchimentoautomático paradigitação deconsultas no consoledo Athena.
Adicionado o preenchimento automático para digitação deconsultas no console do Athena.
6 de abril de 2018
Incluída acapacidade de criartabelas do Athenapara arquivos delog do CloudTraildiretamenteno console doCloudTrail.
Incluída a capacidade de criar automaticamente tabelasdo Athena para arquivos de log do CloudTrail diretamenteno console do CloudTrail. Para obter mais informações,consulte Criação de uma tabela para logs do CloudTrail noconsole do CloudTrail (p. 155).
15 de março de2018
Inclusão de suportepara descargasegura de dadosintermediários emdisco para consultascom GROUP BY.
Adicionada a capacidade de descarregar com segurançadados intermediários no disco para consultas com usointensivo de memória que empregam a cláusula GROUP BY.Isso melhora a confiabilidade dessas consultas, evitandoerros do tipo "Query resource exhausted" (Recurso deconsulta esgotado). Para obter mais informações, consulte anota de release de 2 de fevereiro de 2018 (p. 338).
2 de fevereiro de2018
Inclusão de suporteao Presto versão0.172.
Atualizado o mecanismo subjacente no Amazon Athenapara uma versão baseada no Presto versão 0.172. Paraobter mais informações, consulte a nota de release de 19 dejaneiro de 2018 (p. 339).
19 de janeiro de2018
352

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Inclusão de suporteao Driver ODBC.
Adicionado suporte para conectar o Athena ao driver ODBC.Para obter informações, consulte Conectar-se ao AmazonAthena com ODBC.
13 de novembrode 2017
Adicionado suportepara as regiões Ásia-Pacífico (Seul), ÁsiaPacífico (Mumbai) eEuropa (Londres).Inclusão de suportepara consultar dadosgeoespaciais.
Adicionado suporte para consultar dados geoespaciais epara as regiões Ásia-Pacífico (Seul), Ásia Pacífico (Mumbai)e Europa (Londres). Para obter mais informações, consulteConsultar dados geoespaciais e Regiões e endpoints daAWS.
1 de novembrode 2017
Adicionado osuporte para Europa(Frankfurt).
Adicionado o suporte para Europa (Frankfurt). Para obteruma lista de regiões compatíveis, consulte Regiões eendpoints da AWS.
19 de outubro de2017
Adicionado suportepara consultasnomeadas doAthena com o AWSCloudFormation.
Adicionado suporte para a criação de consultas nomeadasdo Athena com o AWS CloudFormation. Para obter maisinformações, consulte AWS::Athena::NamedQuery no Guiado usuário do AWS CloudFormation.
3 de outubro de2017
Adicionado o suportepara Ásia-Pacífico(Sydney).
Adicionado o suporte para Ásia-Pacífico (Sydney). Paraobter uma lista de regiões compatíveis, consulte Regiões eendpoints da AWS.
25 de setembrode 2017
Inclusão de umaseção a este guiapara consulta de logse diferentes tiposde dados do serviçoda AWS, inclusivemapas, matrizes,dados aninhadose dados contendoJSON.
Adicionados exemplos para Consultar logs de serviço daAWS (p. 148) e para consultar diferentes tipos de dados noAthena. Para obter mais informações, consulte Executarconsultas SQL usando o Amazon Athena (p. 65).
5 de setembro de2017
Adicionado o suportepara Catálogo dedados do AWS Glue.
Adicionada integração com o Catálogo de dados do AWSGlue e um assistente de migração para atualizar o catálogode dados gerenciados do Athena para o Catálogo de dadosdo AWS Glue. Para obter mais informações, consulteIntegração com o AWS Glue e AWS Glue.
14 de agosto de2017
Inclusão de suporteao Grok SerDe.
Adicionado suporte para Grok SerDe, que oferece umpadrão de correspondência mais simples para registros emarquivos de texto desestruturados, como logs. Para obtermais informações, consulte Grok SerDe. Adicionados atalhosde teclado para percorrer o histórico de consultas usandoo console (CTRL + ⇧/⇩ usando o Windows, CMD + ⇧/⇩usando o Mac).
4 de agosto de2017
Adicionado o suportepara Ásia-Pacífico(Tóquio).
Adicionado suporte para Ásia-Pacífico (Tóquio) e Ásia-Pacífico (Cingapura). Para obter uma lista de regiõescompatíveis, consulte Regiões e endpoints da AWS.
22 de junho de2017
353

Amazon Athena Guia do usuário
Alteração Descrição Data delançamento
Adicionado osuporte para Europa(Irlanda).
Adicionado o suporte para Europa (Irlanda). Para obter maisinformações, consulte Regiões e endpoints da AWS.
8 de junho de2017
Adicionada uma APIdo Amazon Athenae suporte à ILC daAWS.
Adicionada uma API do Amazon Athena e suporte da ILC daAWS.para Athena. Atualização do driver JDBC para a versão1.1.0.
19 de maio de2017
Adicionado suporte àcriptografia de dadosdo Amazon S3.
Adicionado suporte à criptografia de dados do Amazon S3e lançada uma atualização do driver JDBC (versão 1.0.1)com suporte à criptografia, melhorias e correções de erros.Para obter mais informações, consulte Criptografia emrepouso (p. 174).
4 de abril de 2017
Adicionado o SerDedo AWS CloudTrail.
Adicionado o SerDe do AWS CloudTrail, melhorperformance, corrigidos problemas de partição. Para obtermais informações, consulte CloudTrail SerDe (p. 258).
• Melhorado desempenho durante o exame de um grandenúmero de partições.
• Melhorado desempenho na operação MSCK RepairTable.
• Adicionada a capacidade de consulta de dados doAmazon S3 armazenados em regiões diferentes da regiãoprincipal. Taxas de transferência de dados padrão entreregiões do Amazon S3 se aplicam, além das cobrançaspadrão do Athena.
24 de março de2017
Adicionado o suportepara Leste dos EUA(Ohio).
Adicionado suporte para Avro SerDe (p. 255) eOpenCSVSerDe para processar CSV (p. 260), Leste dosEUA (Ohio) e colunas de edição em massa no assistentedo console. Melhorado desempenho em tabelas Parquetgrandes.
20 de fevereirode 2017
A versão inicial do Guia do usuário do Amazon Athena. Novembro de2016
354

Amazon Athena Guia do usuário
AWS GlossaryFor the latest AWS terminology, see the AWS Glossary in the AWS General Reference.
355



![ATHENA - Coordinate System Document...[RD02] ATHENA Mission Requirements Document (MRD), ATHENA-ESA-URD-0010 [RD03] ATHENA Product Tree, ATHENA-ESA-PT-0001 [RD04] Ariane 5 User’s](https://static.fdocuments.net/doc/165x107/5ff23cd84225de2c7f4f21b6/athena-coordinate-system-document-rd02-athena-mission-requirements-document.jpg)














