
Integración Bigdata: punto de entrada al IoT - LibreCon 2016
Upload
igaliaCategory
view
146download
2
Almacenamiento de objetosen Ceph y su API S3
Javier M. Mellid @ Igalia

● ¿Quién soy?– Javier
– Igalia● Cloud & Virtualization team
– Ing. Informático● software developer, networking, distributed systems…
– Social media● twitter: @javimunhoz● LinkedIn: linkedin/in/javiermunhoz ● blog: javiermunhoz.com/blog

● La estructura de la charla– Ceph en 20 minutos
– La API S3 en 6 transparencias
– Dos casos de uso basados en Ceph y RGW/S3
– Instalando y probando Ceph fácilmente
– Algunos comandos habituales en Ceph
– Ceph RGW S3 con Apache Libcloud, Ansible y Minio
– Almacenamiento hyperescalable y diferenciación
– Q&A

Ceph en 20 minutos

● ¿Qué es Ceph?● Los bloques fundamentales● Principales abstracciones lógicas● Arquitectura● Extensiones

● ¿Qué es Ceph?– Una solución de almacenamiento Open Source
distribuído, escalable y tolerante a fallos
– La magia detrás de Ceph● Almacenamiento basado en objetos● CRUSH
– Sistema de ficheros, dispositivos de bloques y objetos de alto nivel (ej. API S3) son interfaces sobre objetos nativos

● ¿Qué es Ceph?– Cephalopd
– Sage Weil (Universidad de California, Santa Cruz)
– Red Hat compra Inktank en 2014
– En 2015 se forma el ‘Ceph Community Advisory Board’ (Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk y SUSE)
– ‘Releases’● Argonaut, Bobtail, Cuttlefish…● Jewel (v10.2.0), Kraken (v11.2.0) and Luminous (v12.2.0)

● ¿Qué desafíos estamos tratando de resolver?– El almacenamiento masivo de datos
– Un crecimiento en hyperescala
– Arquitecturas de almacenamiento tradicionales rígidas y poco flexibles
● ¿Quién tiene este problema?– Actores de nube
● Centros Científicos (ej. CERN)● Las llamadas ‘GAFA’ (Google, Apple, Facebook, Amazon)● Universidades (ej. OpenStack)● Proveedores Cloud independientes● ...

● ¿En qué magnitudes nos estamos moviendo?
https://www.eetimes.com/author.asp?section_id=36&doc_id=1330462
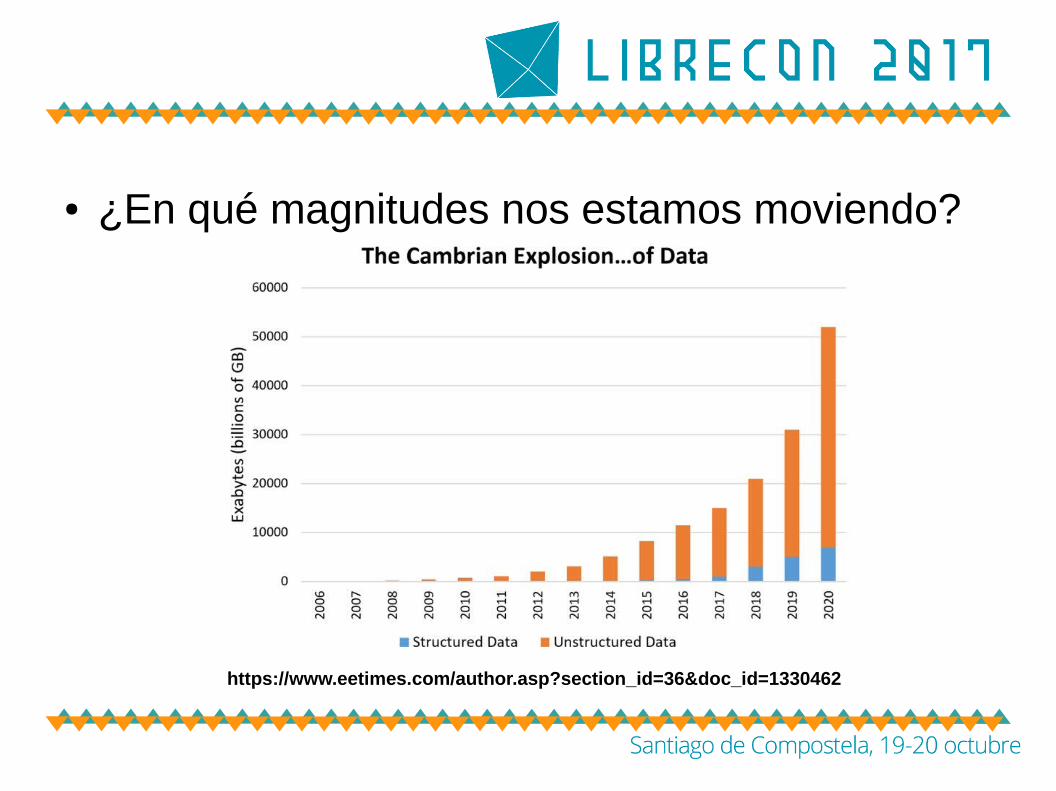
● ¿En qué magnitudes nos estamos moviendo?
https://www.eetimes.com/author.asp?section_id=36&doc_id=1330462

● ¿En qué magnitudes nos estamos moviendo?
https://www.eetimes.com/author.asp?section_id=36&doc_id=1330462

● ¿A qué desafíos técnicos nos enfrentamos?– Arquitecturas de almacenamiento tradicionales
● No gestionan de forma inteligente los metadatos● Usan y mantienen tablas de búsqueda para gestionar los
metadatos● Los metadatos son datos que permiten conocer donde
se almacenan los datos● Para sistemas de almacenamiento modestos puede no
apreciarse problemas de rendimiento pero esto limita la escalabilidad del sistema

● ¿Cómo trata de resolver estos desafíos Ceph?– A través de una arquitectura de almacenamiento de
datos basada en objetos
– Arquitectura diseñada para retener cantidades masivas de datos
– Objeto● datos, metadatos y un identificador global único

● ¿Cómo trata de resolver estos desafíos Ceph?– Ceph emplea la abstracción de objeto como un bloque de
construcción
– Cualquier tipo de dato (bloque, fichero, objeto, etc) se almacena en forma de objeto en el cluster
– Solución a las necesidades actuales y futuras de almacenamiento no estructurado
– Ceph replica estos objetos nativos para mejorar la disponibilidad y confiabilidad de los datos
– El almacenamiento de los objetos es flexible y no está predeterminado a nivel físico
– Este diseño permite escalar linealmente del petabyte al exabyte

● ¿Cómo trata de resolver estos desafíos Ceph?– Ceph no trata de buscar la localización de un objeto a
través de tablas y estructuras intermedias. Ceph computa esta localización a través de CRUSH
– CRUSH es un algoritmo y un conjunto de reglas que se aplican a un estado conocido del cluster
– Controlled Replication Under Scalable Hashing
– CRUSH es consciente de la geometría del cluster y gestiona las zonas de fallo a través de su mapa de forma autónoma

● Los bloques fundamentales– Los ‘MON’
● Monitores● Gestionan los mapa/s del cluster (CRUSH)● Un cluster suele tener más de un monitor. En este caso
llegan a consenso a través de Paxos● Mantienen un diálogo con todos los componentes que
necesiten conocer la geometría del cluster y sus actualizaciones

● Los bloques fundamentales– Los ‘OSD’
● ‘Object Storage Device’● Su responsabilidad principal es almacenar los bloques de
datos y los metadatos● Para garantizar la disponibilidad por replicación se necesitan
3 replicas● Mantienen un diálogo entre ellos para acordar su estado de
replicación, comprobar que sus datos no están corruptos, etc.● Mantienen un diálogo con los monitores para actualizar la
geometría del cluster

(fuente: http://javiermunhoz.com/blog/2016/04/30/scalable-placement-of-replicated-data-in-ceph.html)

● Principales abstracciones lógicas– El ‘pool’
● Particiona el almacenamiento global en ‘pools’● Un ‘pool’ es una división lógica● Sobre esta abstracción se aplican las políticas de
replicación, el control de acceso, etc● Ceph crea un ‘pool’ por defecto tras la instalación

● Principales abstracciones lógicas– El ‘placement group’ (PG)
● Grupo de colocación● Cada objeto es asignado a un PG durante su distribución● El sistema los genera automaticamente

● Principales abstracciones lógicas– Un ejemplo
●
http://javiermunhoz.com/blog/2016/04/30/scalable-placement-of-replicated-data-in-ceph.html

http://javiermunhoz.com/blog/2016/04/30/scalable-placement-of-replicated-data-in-ceph.html

● Reliable Autonomic Distributed Object Store (RADOS)
– Denominado también ‘Ceph storage cluster’
– Características● Disponibilidad● Confiabilidad● autogestionado● ‘self-healing’● ningún punto único de fallo

● Extensiones y Aplicaciones sobre RADOS– Librados
● Paradigma cliente-cluster
– Ceph FileSystem (CephFS)● Requiere un servidor de metadatos (MDS)
– Rados Block Device (RBD)● Dispositivos de bloque (Block Device)
– Object Gateway (RadosGW or RGW)● ‘Traduce’ los objetos nativos de Ceph a objetos S3/Swift

● La arquitectura

● OpenStack con Ceph como ‘backend’ de almacenamiento


La API S3 en 6 transparencias

● ¿Qué es Amazon S3?– Simple Storage Service (S3)
– Almacenamiento para Internet
– Web service interface (REST, SOAP)
– Permite almacenar objetos (1 byte a 5 GB)
– Los objetos contienen datos y metadatos
– Los objetos son almacenados y recuperados usando una clave (key)
– Los objetos son accesibles vía http, bittorrent, etc.

● ¿Qué es Amazon S3?– Todos los objetos son almacenados en ‘buckets’
– Un bucket es un contenedor para objetos● mybucket.s3.amazonaws.com
– Los buckets son útiles para particionar a nivel raíz
– Una ‘key’ (clave) es el identificador único para un objeto dentro de un ‘bucket’
– Ejemplo:● http://mybucket.s3.amazonaws.com/myhome.html

● ¿Qué es Amazon S3?– Ventajas
● Escalable● Alta disponibilidad● Almacenamiento “ilimitado”● Económico● Accesible desde cualquier localización● ...

● ¿Qué es Amazon S3?– Principales casos de uso
● Website estáticos● Media storage (videos, fotos, etc)● Backups● Almacenamiento intermedio (transcoding, etc)● ...

● ¿Qué es Amazon S3?– La API S3
● http://docs.aws.amazon.com/AmazonS3/latest/API/Welcome.html
● Algunas operaciones en ‘buckets’ y ‘objects’– CRUD– Casos de uso
● autenticación, ‘browser uploads’, analíticas, ciclos de vida, métricas, replicación, ‘tagging’, website support, logging, versionado, ‘multipart uploads’, ‘requestPayment’, ‘torrent support’, ‘copy-part support’...

● ¿Qué es Amazon S3?– Un ejemplo de llamada a la API S3 (GET Object)
● Obtiene los primeros 10 bytes de un objeto (test.txt) en el bucket ‘examplebucket’
GET /test.txt HTTP/1.1Host: examplebucket.s3.amazonaws.comx-amz-date:20130524T000000ZAuthorization: SignatureToBeCalculatedRange: bytes=0-9 x-amz-content-sha256:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855x-amz-date: 20130524T000000Z

Dos casos de uso de almacenamiento basado en Ceph / RadosGW / S3

https://www.slideshare.net/jenshadlich/ceph-object-storage-at-spreadshirt-49422450

Clientes
Nextcloud
RGW
Ceph cluster
HTTP/S
S3
librados
https://github.com/tigerlinux/tigerlinux-extra-recipes/tree/master/recipes/misc/ceph-owncloud-lab
● Sincronizando y compartiendo ficheros

Instalando y probando Ceph fácilmente

● La forma tradicional– http://docs.ceph.com/docs/master/start/
– Tres pasos● prevuelo (requisitos)● cluster de almacenamiento● los clientes (bloque, filesystem, etc)

● Archivos e imágenes de Docker para ejecutar Ceph en contenedores– https://github.com/ceph/ceph-dock
– https://hub.docker.com/r/ceph/demo/
– docker run -d –net=host -v /etc/ceph:/etc/ceph -e MON_IP=192.168.0.20 -e CEPH_PUBLIC_NETWORK=192.168.0.0/24 ceph/demo

● PetaSAN (www.petasan.org)

● PetaSAN (www.petasan.org)

Algunos comandos habituales en Ceph
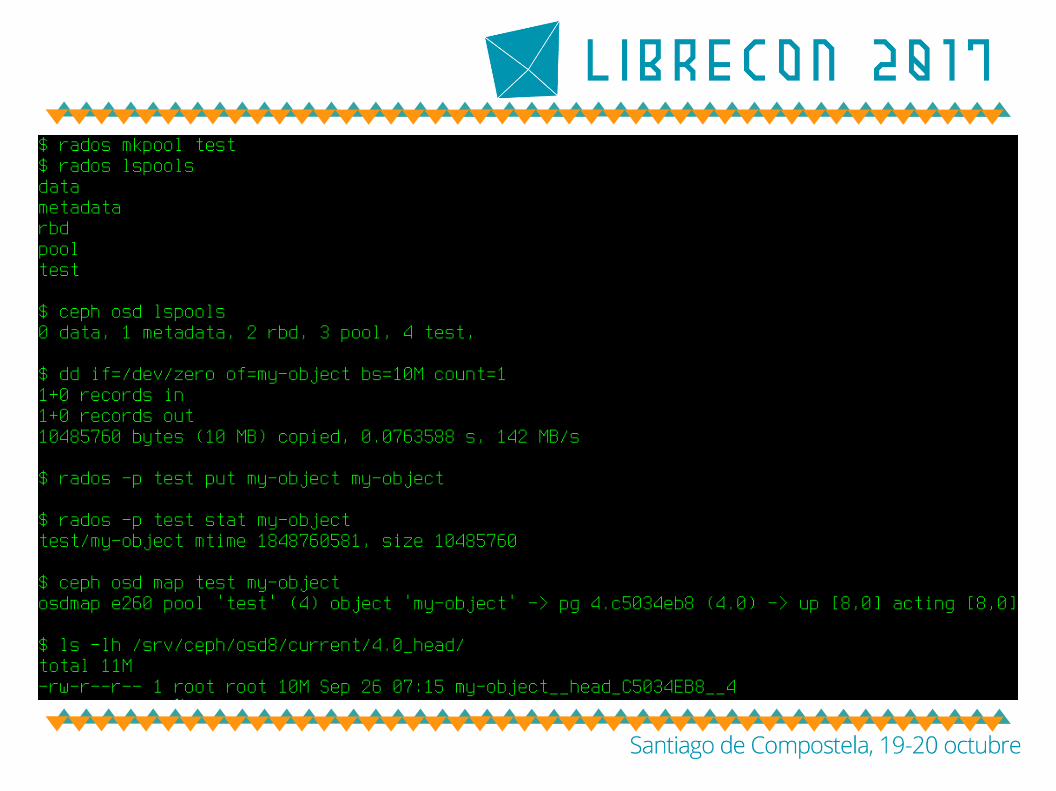

● pool quotas– ceph osd pool set-quota {pool-name} [max_objects
{obj-count}] [max_bytes {bytes}]
– $ ceph osd pool set-quota data max_objects 10000

● $ rados df

● Número de replicas– $ ceph osd pool set data size 3
– $ ceph osd pool set data min_size 2

● Estado del cluster

● RADOS Block Devices (RBD)– $ rbd create [image name] --size [size in MB]
– $ rbd --pool mypool create my-image --size 10
– $ rbd ls
– Map & Mount● $ sudo modprobe rbd● $ rbd map my-image –name client.admin -m node1● $ sudo mkfs.ext4 -m0 /dev/rbd/rbd/my-image● $ sudo mkdir /mnt/my-ceph-block-device● $ sudo mount /dev/rbd/rbd/my-image /mnt/my-ceph-block-device

Ceph RGW S3 con Apache Libcloud,Ansible y Minio

● Apache Libcloud– libcloud.apache.org
– Librería de Python para interactuar con proveedores de servicio de cloud
– API unificada
– ‘One interface to rule them all’

● Ceph RGW storage driver– upstream en Apache Libcloud 1.0.0
http://javiermunhoz.com/blog/2016/05/17/the-ceph-rgw-storage-driver-goes-upstream-in-libcloud.html

● Minio client– github.com/minio/mc
– cliente S3 ligero
– ls, cat, cp, diff, etc
http://javiermunhoz.com/blog/2016/12/16/ceph-rgw-aws4-presigned-urls-working-with-the-minio-cloud-client.html

● Ansible– www.ansible.com
– motor de automatización● aprovisionamiento● gestión de la configuración● despliegue de aplicaciones● orquestación● ...

● Ansible– Soporte para RGW upstream
– Parte del módulo core de Amazon S3
http://javiermunhoz.com/blog/2016/06/21/ansible-aws-s3-core-module-now-supports-ceph-rgw-s3.html

Comentarios en almacenamiento hyperescalable y diferenciación

● La capa de valor de almacenamiento– diferenciación, funcionalidades, etc. (RGW/S3)
● Estrategia de líder frente a perseguidor– innovación vs interoperabilidad
– cobertura de RGW/S3 vs AWS/S3
● Riesgos– obsolescencia/sustitución de funcionalides
● ej. AWS2/AWS4
● Innovación● ej. ‘Smart Buckets’

Ceph es comunidad!– ceph.com
– ceph.com/community
– ceph.com/get-involved
– @ceph (twitter.com/ceph)

Gracias!
Q&A


















