
AFID: An Automated Fault Identification Tool Alex Edwards Sean Tucker Sébastien Worms Rahul Vaidya...
32
AFID: An Automated Fault Identification Tool Alex Edwards Sean Tucker Sébastien Worms Rahul Vaidya Brian Demsky
-
date post
22-Dec-2015 -
Category
Documents
-
view
221 -
download
0
Transcript of AFID: An Automated Fault Identification Tool Alex Edwards Sean Tucker Sébastien Worms Rahul Vaidya...

AFID: An Automated Fault Identification Tool
Alex Edwards
Sean Tucker
Sébastien Worms
Rahul Vaidya
Brian Demsky

Motivation Much research focuses on software bugs Relatively little emphasis on empirical
methods as compared to other fields Remarkably few software fault data sets
are publically available that Are uniformly structured Contain faulty source code Contain fault correction Contain fault revealing test case
Lack of data sets affects how we approach research

Effects Guide research based on
General impressions of important bug classes Are these the important bug classes? What are we missing?
Often evaluate our research on Hand selected bugs Synthetic bugs
Difficult to study dynamic properties of software bugs

Manual Collection Colleagues tried to get students to manually
record their software faults Asked them to record:
Test case that revealed fault Copy of the source code with the fault Copy of the change that removed the fault
Limited success Tedious Often forgot

Goal Automatically record repositories of real
software bugs Minimize developer involvement Okay to miss software faults

Basic Approach Obtain fault revealing test cases Monitor source code for changes Use fault revealing test cases to detect fault
corrections When correction is detected, record
Fault revealing test case Faulty version Fault correcting source code change

Obtaining Fault Revealing Test Cases Wait for developer to execute program Record information about program interactions
with the operating system If it crashes, build test case from the recorded
information Record
Command line Files accessed Console interactions

Recording Interactions
Application
Operating System
System Calls
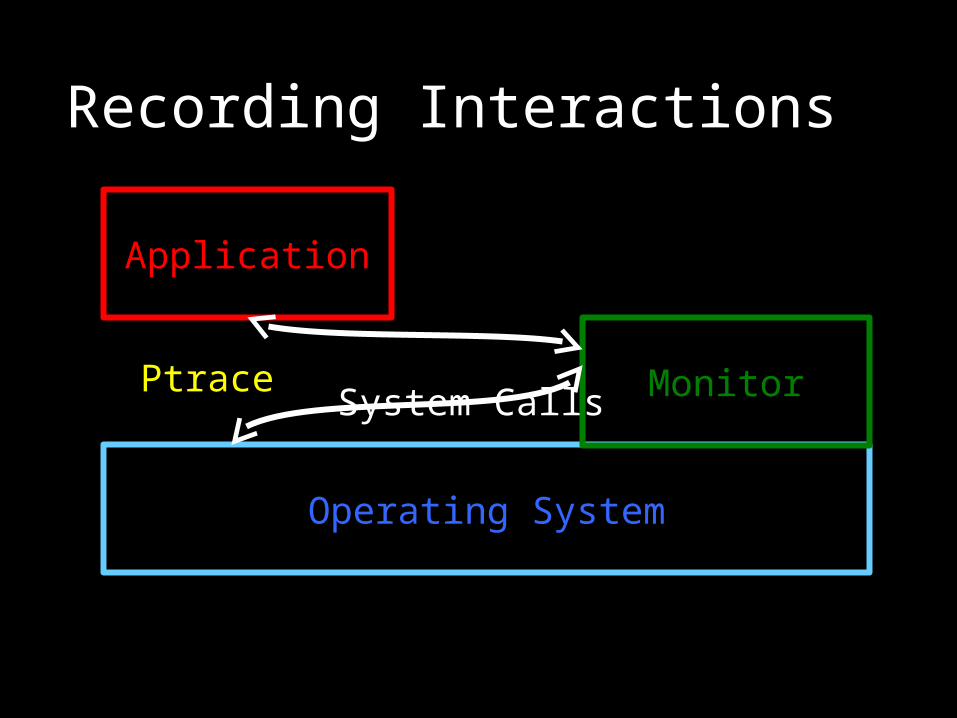
Recording Interactions
Application
Operating System
System Calls MonitorPtrace

Ptrace Monitoring
Open call for read access Record file name (and copy later if the program
crashes)
Open call for write access Record file name and copy file
Console input Record user input
Console output Record program prompting

Extraneous files Programs read many files that would not be
considered input Java programs read libraries, class files, JVM
components C programs read shared libraries
Such files are not interesting for the test case make the test case huge make the test case less portable

Remove Extraneous Files Can filter files Create a test program that does nothing
Record what files are read Exclude those files Use patterns to guess other files to exclude
Exclude class files Exclude library directories User can use regular expressions to
exclude other files (or include files)

Duplicate Test Cases Developers often rerun test cases Results in multiple copies of same test case Use hashing to avoid making multiple copies
of test cases Optimize for performance, ignore possibility
of hash collisions

Console Input Problem: Want to support user interactions Challenge: Would like to reuse test case in
the presence of small modification Approach:
Record transcript of user interactions Compute for each user response, the shortest
suffix of the output that uniquely identifies when the input occurred
Generate transcript using these suffixes and the user inputs
Provides flexibility to some prompt changes

Monitoring Source Code Changes Want to detect changes in source files Need to know which files comprise an
application Goals:
Want to avoid input from developer Should work with any tool chain

Approach Use same ptrace-based monitoring
infrastructure on the compiler Detect files when the compiler reads them Use wildcards to identify source files

Monitoring Source Changes Build internal SVN repository Add new files automatically as detected Check in updates at every compile

Detecting Fault Correcting Changes Test cases can be used to detect which
code changes correct which faults For each code change, we rerun
outstanding test cases to see if they still crash

Replaying Test Cases Could just copy test case files back to their
original locations Huge downsides
Developer may have written important data in new versions of these files
File system may have different directory structure Execution could overwrite important data
Need to sandbox execution

Sandboxing Make a copy of the test case Replay program in ptrace-based sandbox Use ptrace to intercept file open commands Use ptrace to replace open call’s file names
with our copies Intercept console I/O interactions to replay
user interactions Technical details in the paper

Looping Source code changes can cause formerly
crashing test cases to loop Solution:
Record elapsed time for every execution of application
Estimate upper bound on execution time Terminate replays once they exceed this bound Okay to be wrong - just miss recording a fault

Central Repository When fault correcting change is detected,
AFID uploads information to repository server
Information contains: Buggy source code SVN repository Fault correcting change Fault revealing test case

Overhead Measurements
Jasmin byte code assembler 11,450 lines of code I/O intensive benchmark
Inyo ray tracer 5,843 lines of code Longer running, compute bound benchmark
Measured on 2.2 GHz Core 2 Duo, 1GB RAM, Debian 2.6.23 HotSpot JVM version 1.5.0

Overheads
Jasmin Inyo
Normal compile 1.07 s 0.77 s
Monitored compile w/ svn 4.32 s 3.54 s
Monitored compile w/o svn 1.40 s 0.95 s
Normal execution 0.22 s 31.88 s
Monitored execution 0.47 s 32.64 s

Case Study Goal: To determine whether AFID
effectively records real software faults 8 participants Each participant
Solved a programming contest problem Used AFID while coding

Fault Breakdown
Fault Type Count
Parsing logic error 3
Null pointer dereference 3
Initialization error 2
Missing condition check 1
Loop bound error 1
Shadowed field 1
Incorrect comparison 1
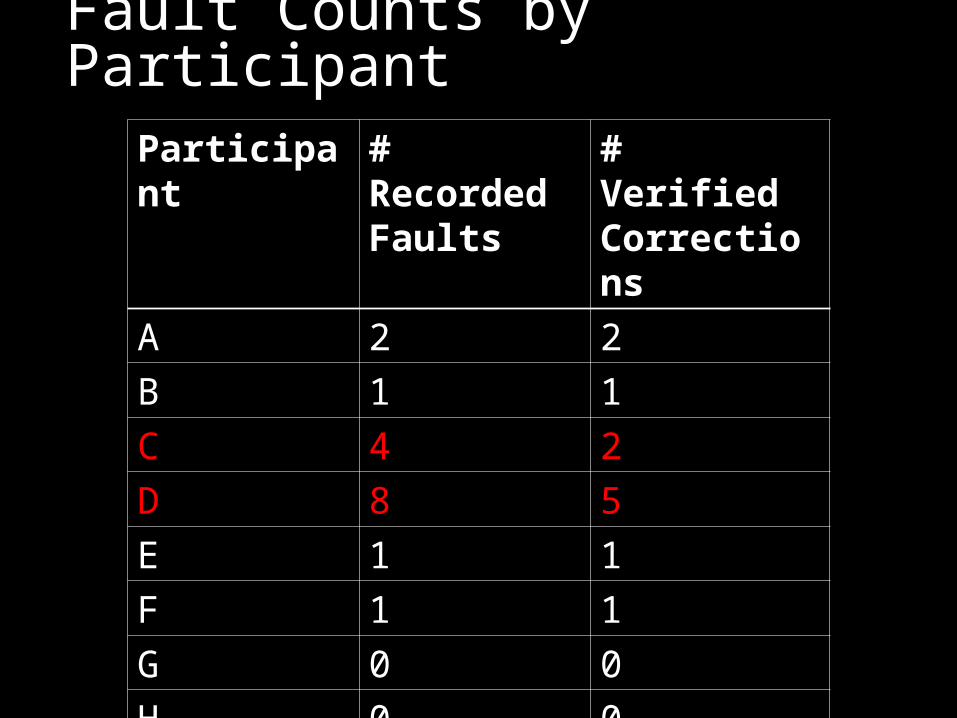
Fault Counts by ParticipantParticipant # Recorded
Faults# Verified Corrections
A 2 2
B 1 1
C 4 2
D 8 5
E 1 1
F 1 1
G 0 0
H 0 0

Lessons Some participants debugged by
commenting out code Cause AFID to detect the wrong fault correcting
change Modified AFID to ask when it detects a fault
correcting change
Source code changes can cause applications to loop instead of crash Execution time estimator

Participant feedback Found the user experience very good In general, tool was unnoticeable Noticed slight delay when compiling

Privacy Concerns AFID records all source code changes and
test inputs that crash the program Could easily record personal information Limit use of AFID to projects that are not
likely to process personal information Print out message to remind user that AFID
is running

Related Work Mining CVS Repositories Software-artifact Infrastructure Repository iBUGS Replay systems

Conclusion Next phase is data collection Plan to make data available to other
researchers We need participants Please go to
http://demsky.eecs.uci.edu/afid/


















