
Advanced Analytics and Recommendations with Apache Spark - Spark Maryland/DC Meetup Feb 22 2016
84
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Spark & Recommendations Spark, Streaming, Machine Learning, Graph Processing, Approximations, Probabilistic Data Structures, NLP Apache Spark Maryland Meetup Thanks to Tetra Concepts & Jailbreak Brewing Co!! Feb 22 nd , 2016 Chris Fregly Principal Data Solutions Engineer We’re Hiring! (Only Nice People) advancedspark.com
-
Upload
chris-fregly -
Category
Software
-
view
1.276 -
download
1
Transcript of Advanced Analytics and Recommendations with Apache Spark - Spark Maryland/DC Meetup Feb 22 2016

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Spark & Recommendations
Spark, Streaming, Machine Learning, Graph Processing, Approximations, Probabilistic Data Structures, NLP
Apache Spark Maryland Meetup Thanks to Tetra Concepts & Jailbreak Brewing Co!!
Feb 22nd, 2016
Chris Fregly Principal Data Solutions Engineer
We’re Hiring! (Only Nice People) advancedspark.com!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Who Am I?
2
Streaming Data Engineer Netflix OSS Committer
Data Solutions Engineer
Apache Contributor
Principal Data Solutions Engineer IBM Technology Center
Meetup Organizer Advanced Apache Meetup
Book Author Advanced .
Due 2016
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Recent World Tour: Freg-a-Palooza! London Spark Meetup (Oct 12th) Scotland Data Science Meetup (Oct 13th) Dublin Spark Meetup (Oct 15th)
Barcelona Spark Meetup (Oct 20th) Madrid Big Data Meetup (Oct 22nd)
Paris Spark Meetup (Oct 26th) Amsterdam Spark Summit (Oct 27th) Brussels Spark Meetup (Oct 30th)
Zurich Big Data Meetup (Nov 2nd) Geneva Spark Meetup (Nov 5th)
3
Oslo Big Data Hadoop Meetup (Nov 19th) Helsinki Spark Meetup (Nov 20th) Stockholm Spark Meetup (Nov 23rd)
Copenhagen Spark Meetup (Nov 25th) Istanbul Spark Meetup (Nov 26th)
Budapest Spark Meetup (Nov 28th) Singapore Spark Meetup (Dec 1st) Sydney Spark Meetup (Dec 8th)
Melbourne Spark Meetup (Dec 9th) Toronto Spark Meetup (Dec 14th)
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
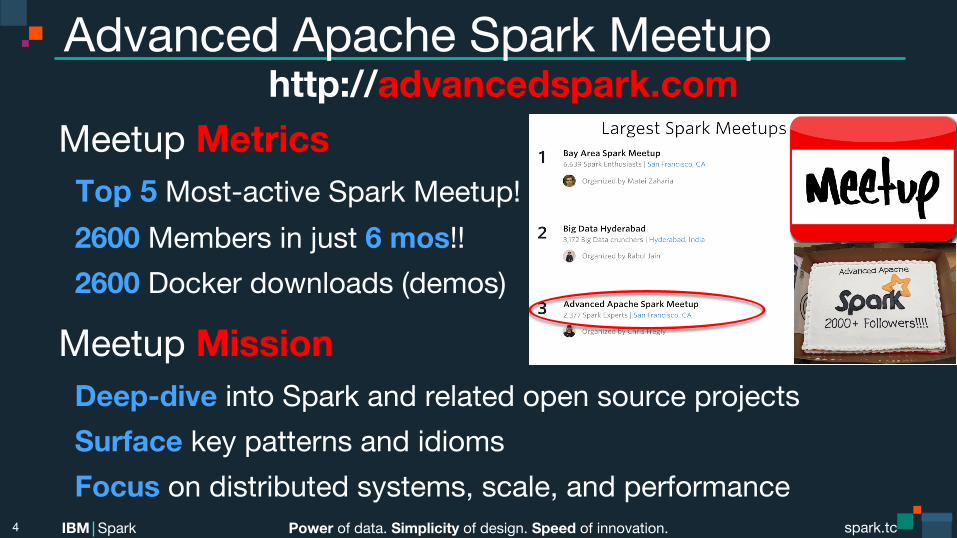
Advanced Apache Spark Meetup http://advancedspark.com
Meetup Metrics Top 5 Most-active Spark Meetup! 2600 Members in just 6 mos!! 2600 Docker downloads (demos)
Meetup Mission Deep-dive into Spark and related open source projects Surface key patterns and idioms Focus on distributed systems, scale, and performance
4

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Live, Interactive Demo!! Audience Participation Required
(cell phone or laptop)
5
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
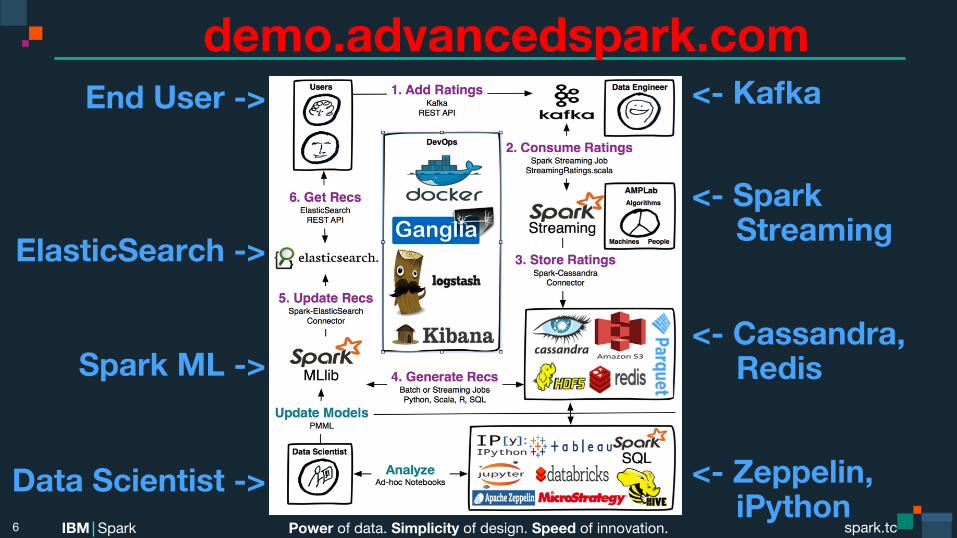
demo.advancedspark.com End User ->
ElasticSearch ->
Spark ML -> Data Scientist -> 6
<- Kafka <- Spark Streaming <- Cassandra, Redis <- Zeppelin, iPython

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 7
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
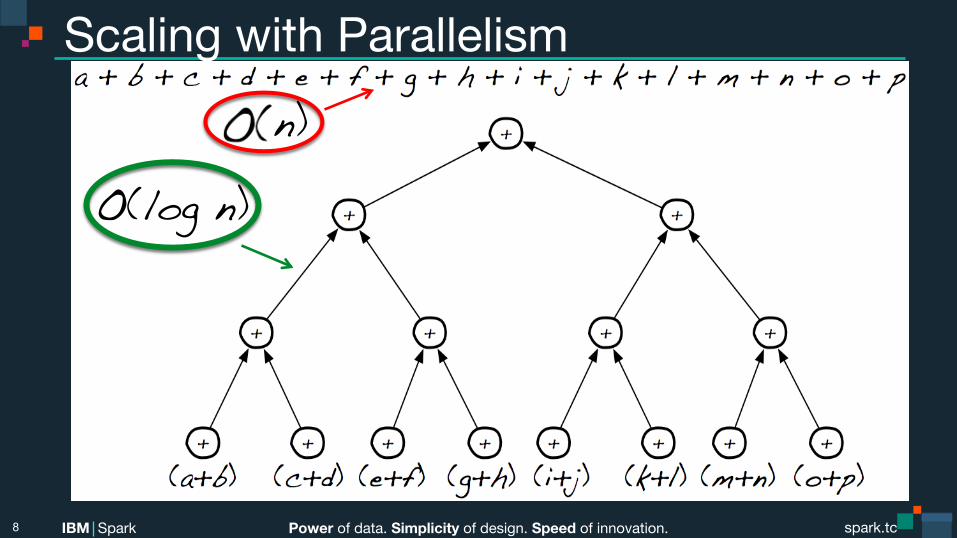
Scaling with Parallelism
8
Peter O(log n)
O(log n)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Scaling with Composability
Max (a max b max c max d) == (a max b) max (c max d)
Set Union (a U b U c U d) == (a U b) U (c U d)
Addition (a + b + c + d) == (a + b) + (c + d)
Multiply (a * b * c * d) == (a * b) * (c * d)
Division??
9

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
What about Division? Division (a / b / c / d) != (a / b) / (c / d) (3 / 4 / 7 / 8) != (3 / 4) / (7 / 8) (((3 / 4) / 7) / 8) != ((3 * 8) / (4 * 7)) 0.134 != 0.857
10
What were the Egyptians thinking?! Not Composable
“Divide like an Egyptian”

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
What about Average?
Overall AVG ( [3, 1] ((3 + 5) + (5 + 7)) 20 [5, 1] == ----------------------- == --- == 5 [5, 1] ((1 + 2) + 1) 4 [7, 1]
) 11
value
count
Pairwise AVG (3 + 5) (5 + 7) 8 12 20 ------- + ------- == --- + --- == --- == 10 != 5 2 2 2 2 2
Divide, Add, Divide? Not Composable
Single Divide at the End? Doesn’t need to be Composable!
AVG (3, 5, 5, 7) == 5
Add, Add, Add? Composable!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 12

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Similarity
13
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
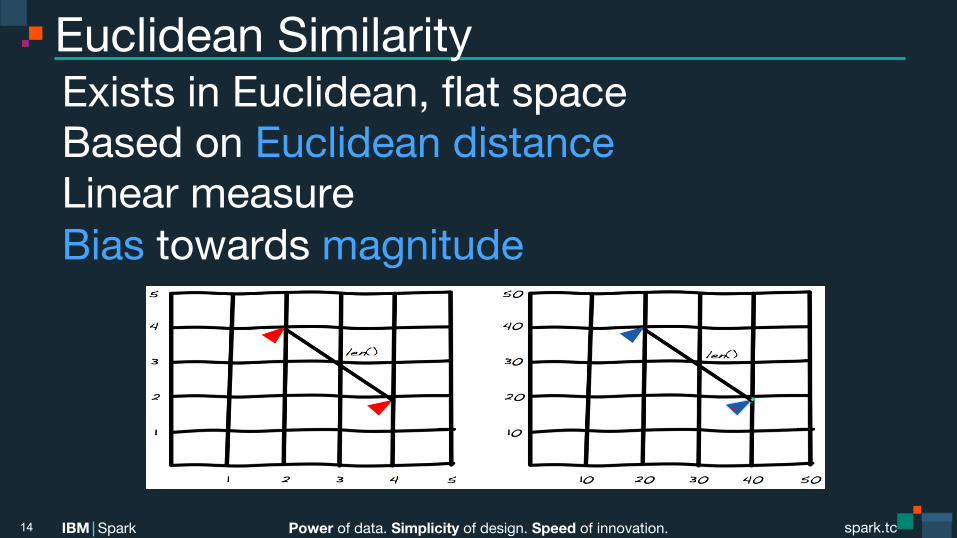
Euclidean Similarity Exists in Euclidean, flat space Based on Euclidean distance Linear measure Bias towards magnitude
14

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Cosine Similarity Angular measure Adjusts for Euclidean magnitude bias
15
Normalizes to unit vectors

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Jaccard Similarity Set similarity measurement Set intersection / set union -> Based on Jaccard distance Bias towards popularity
16

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Log Likelihood Similarity Adjusts for popularity bias Netflix “Shawshank” problem
17

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Word Similarity Based on edit distance Calculate char differences between words Deletes, transposes, replaces, inserts
18
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
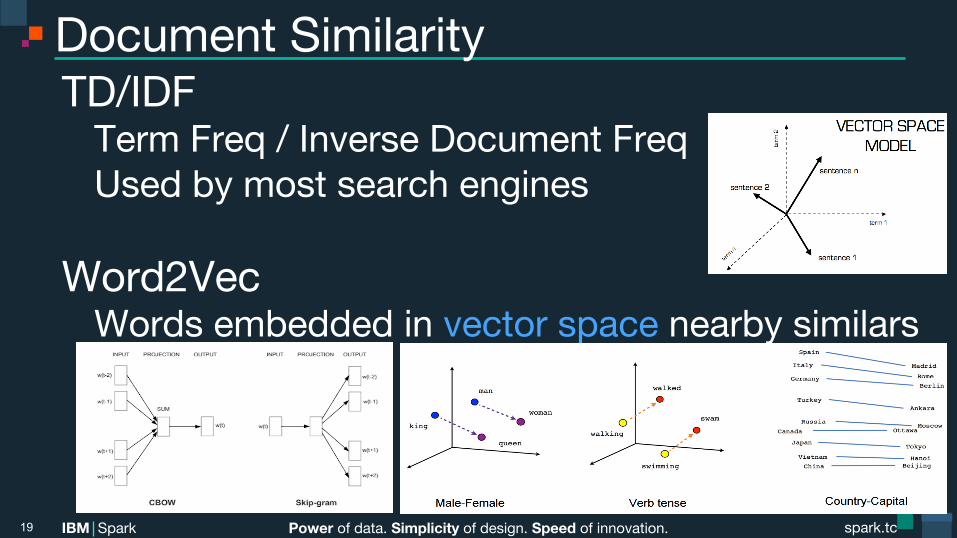
Document Similarity TD/IDF Term Freq / Inverse Document Freq Used by most search engines
Word2Vec Words embedded in vector space nearby similars
19

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Similarity Pathway ie. Closest recommendations between 2 people
20

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Calculating Similarity Exact Brute-Force “All-pairs similarity” aka “Pair-wise similarity”, “Similarity join” Cartesian O(n^2) shuffle and comparison
Approximate Sampling Bucketing (aka “Partitioning”, “Clustering”) Remove data with low probability of similarity
Reduce shuffle and comparisons 21

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Bonus: Document Summary Text Rank aka “Sentence Rank” TF/IDF + Similarity Graph + PageRank
Intuition Surface summary sentences (abstract) Most similar to all others (TF/IDF + Similarity Graph) Most influential sentences (PageRank)
22
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
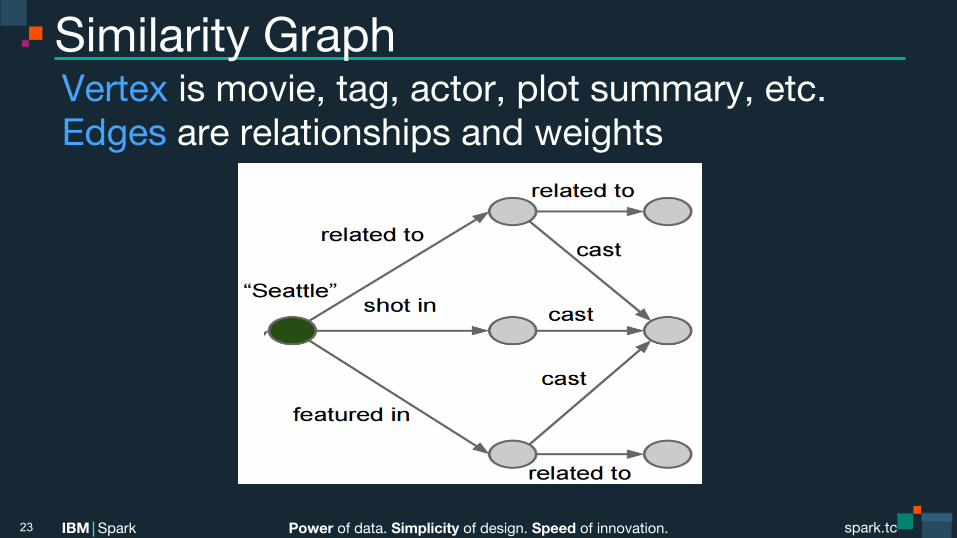
Similarity Graph Vertex is movie, tag, actor, plot summary, etc. Edges are relationships and weights
23

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Topic-Sensitive PageRank Graph diffusion algorithm Pre-process graph, add vector of probabilities to each vertex Probability of landing at this vertex from every other vertex
24

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Recommendations
25

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Basic Terminology User: User seeking recommendations Item: Item being recommended Explicit User Feedback: like, rating, movie view, profile read, search Implicit User Feedback: click, hover, scroll, navigation Instances: Rows of user feedback/input data Overfitting: Training a model too closely to the training data & hyperparameters Hold Out Split: Holding out some of the instances to avoid overfitting Features: Columns of instance rows (of feedback/input data) Cold Start Problem: Not enough data to personalize (new) Hyperparameter: Model-specific config knobs for tuning (tree depth, iterations) Model Evaluation: Compare predictions to actual values of hold out split Feature Engineering: Modify, reduce, combine features
26
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
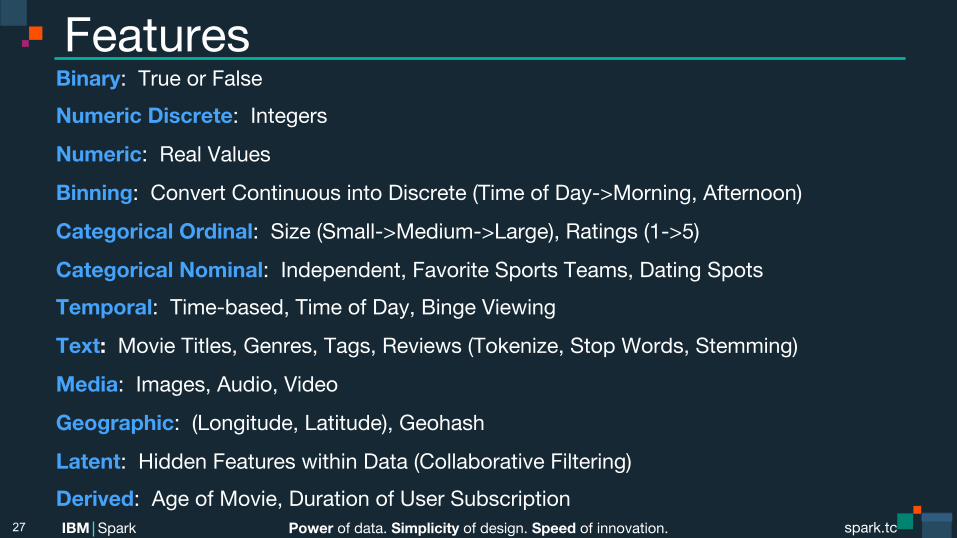
Features Binary: True or False Numeric Discrete: Integers
Numeric: Real Values
Binning: Convert Continuous into Discrete (Time of Day->Morning, Afternoon)
Categorical Ordinal: Size (Small->Medium->Large), Ratings (1->5)
Categorical Nominal: Independent, Favorite Sports Teams, Dating Spots Temporal: Time-based, Time of Day, Binge Viewing
Text: Movie Titles, Genres, Tags, Reviews (Tokenize, Stop Words, Stemming)
Media: Images, Audio, Video
Geographic: (Longitude, Latitude), Geohash
Latent: Hidden Features within Data (Collaborative Filtering) Derived: Age of Movie, Duration of User Subscription
27

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Feature Engineering Dimension Reduction Reduce number of features in feature space
Principle Component Analysis (PCA) Help find principle features that best describe variance in data Peel the dimensional layers back until you describe the data
One-Hot Encoding Convert nominal categorical feature values to 0’s, 1’s Remove numerical relationship between the categories Bears -> 1 Bears -> [1,0,0] 49’ers -> 2 --> 49’ers -> [0,1,0] Steelers-> 3 Steelers-> [0,0,1]
28
1 binary column per category

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Normalize and Standardize Features Goal Scale features to standard size Required by many ML algos
Normalize Features Calculate L1 (or L2, etc) norm Divide elements by norm org.apache.spark.ml.feature.Normalizer
Standardize Features Apply standard normal transformation Mean == 0 StdDev == 1 org.apache.spark.ml.feature.StandardScaler 29

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Non-Personalized Recommendations
30
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
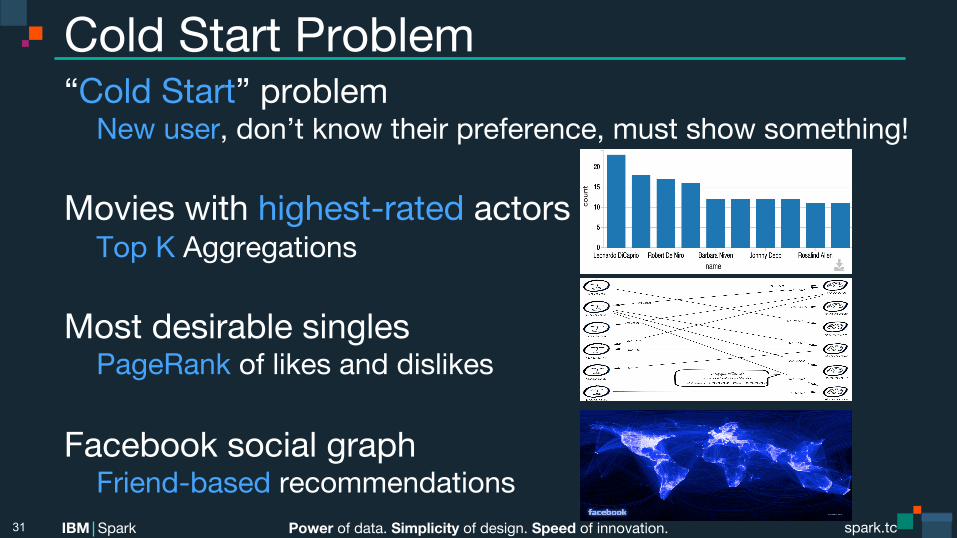
Cold Start Problem “Cold Start” problem New user, don’t know their preference, must show something!
Movies with highest-rated actors Top K Aggregations
Most desirable singles PageRank of likes and dislikes
Facebook social graph Friend-based recommendations
31

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Personalized Recommendations
32
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
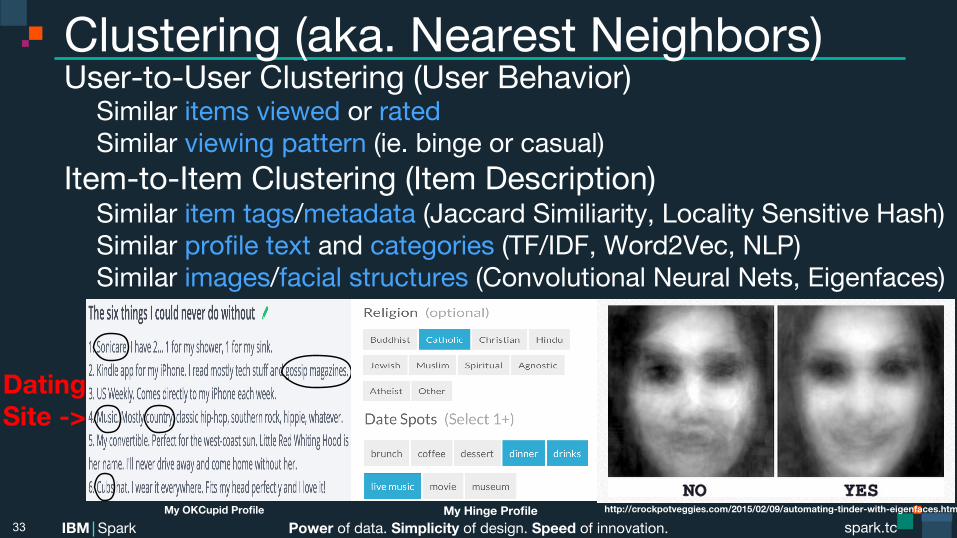
Clustering (aka. Nearest Neighbors) User-to-User Clustering (User Behavior) Similar items viewed or rated Similar viewing pattern (ie. binge or casual)
Item-to-Item Clustering (Item Description) Similar item tags/metadata (Jaccard Similiarity, Locality Sensitive Hash) Similar profile text and categories (TF/IDF, Word2Vec, NLP) Similar images/facial structures (Convolutional Neural Nets, Eigenfaces)
33 http://crockpotveggies.com/2015/02/09/automating-tinder-with-eigenfaces.html My OKCupid Profile My Hinge Profile
Dating Site ->

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Bonus: NLP Conversation Bot
34
“If your responses to my generic opening lines are positive, I may read your profile.” Spark ML and Stanford CoreNLP: TF/IDF, DecisionTrees, Sentiment
Analysis

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
User-to-Item Collaborative Filtering Matrix Factorization ① Factor the large matrix (left) into 2 smaller matrices (right) ② Smaller matrices, when multiplied, approximate original ③ Fill in the missing values with in the large matrix ④ Surface latent features from within user-item interaction
35

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Item-to-Item Collaborative Filtering Made famous by Amazon Paper ~2003 Problem As # of users grew, user-item collab filtering didn’t scale
Solution Offline/Batch Generate itemId -> List[userId] vectors
Online/Real-time For each item in cart, recommend similar items from vector space
36

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 37

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
When to Approximate? Memory or time constrained queries Relative vs. exact counts are OK (# errors between then and now)
Using machine learning or graph algos Inherently probabilistic and approximate Finding topics in documents (LDA) Finding similar pairs of users, items, words at scale (LSH) Finding top influencers (PageRank)
Streaming aggregations Inherently sloppy collection (exactly once?)
38
Approximate as much as you can get away with! Ask for forgiveness later !!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
When NOT to Approximate? If you’ve ever heard the term…
“Sarbanes-Oxley”
…at the office after 2002.
39

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 40

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
A Few Good Algorithms
41
You can’t handle the approximate!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Common to These Algos & Data Structs Low, fixed size in memory Known error bounds Store large amount of data Less memory than Java/Scala collections Tunable tradeoff between size and error Rely on multiple hash functions or operations Size of hash range defines error
42

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Bloom Filter Set.contains(key): Boolean
“Hash Multiple Times and Flip the Bits Wherever You Land”
43

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Bloom Filter Approximate set membership for key False positive: expect contains(), actual !contains() True negative: expect !contains(), actual !contains()
Elements are only added, never removed
44
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
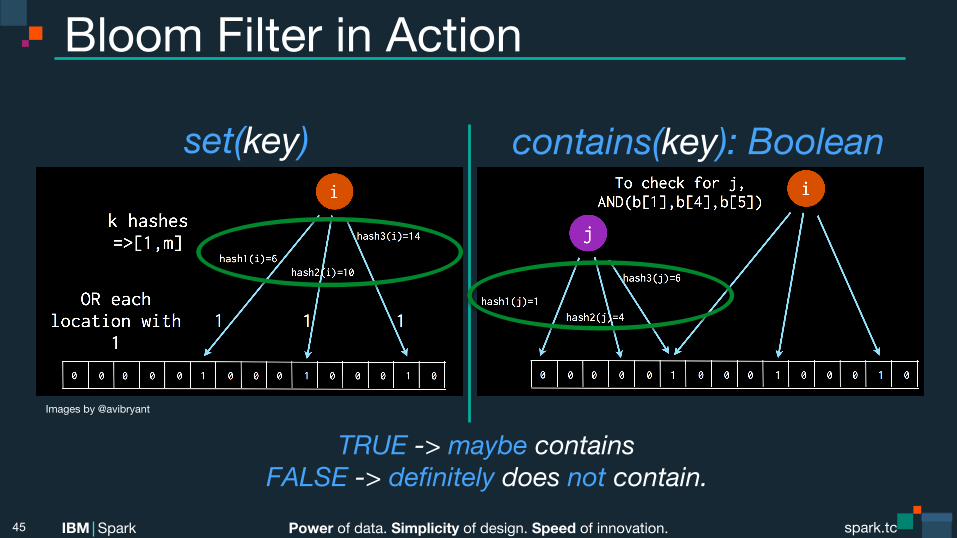
Bloom Filter in Action
45
set(key) contains(key): Boolean
Images by @avibryant
TRUE -> maybe contains FALSE -> definitely does not contain.

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
CountMin Sketch Frequency Count and TopK
“Hash Multiple Times and Add 1 Wherever You Land”
46

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
CountMin Sketch (CMS) Approximate frequency count and TopK for key ie. “Heavy Hitters” on Twitter
47
Matei Zaharia Martin Odersky Donald Trump
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
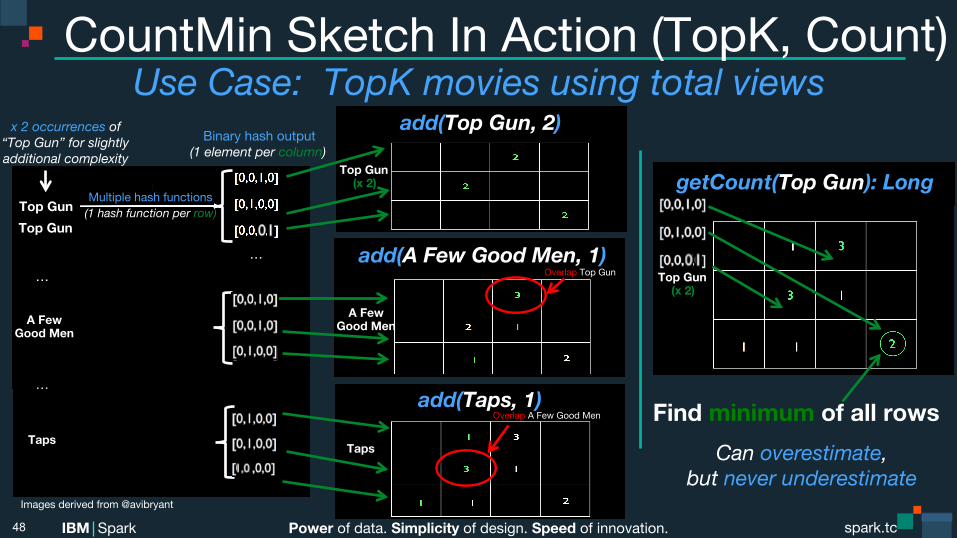
CountMin Sketch In Action (TopK, Count)
48
Images derived from @avibryant
Find minimum of all rows
… …
Can overestimate, but never underestimate
Multiple hash functions (1 hash function per row)
Binary hash output (1 element per column)
x 2 occurrences of “Top Gun” for slightly additional complexity
Top Gun Top Gun
Top Gun (x 2)
A FewGood Men
Taps
Top Gun (x 2)
add(Top Gun, 2)
getCount(Top Gun): Long
Use Case: TopK movies using total views
add(A Few Good Men, 1)
add(Taps, 1)
A FewGood Men
Taps
…
…
Overlap Top Gun
Overlap A Few Good Men

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
HyperLogLog Count Distinct
“Hash Multiple Times and Uniformly Distribute Where You Land”
49

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
HyperLogLog (HLL) Approximate count distinct Slight twist Special hash function creates uniform distribution
Error estimate 14 bits for size of range m = 2^14 = 16,384 hash slots error = 1.04/(sqrt(16,384)) = .81%
50
Not many of these
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
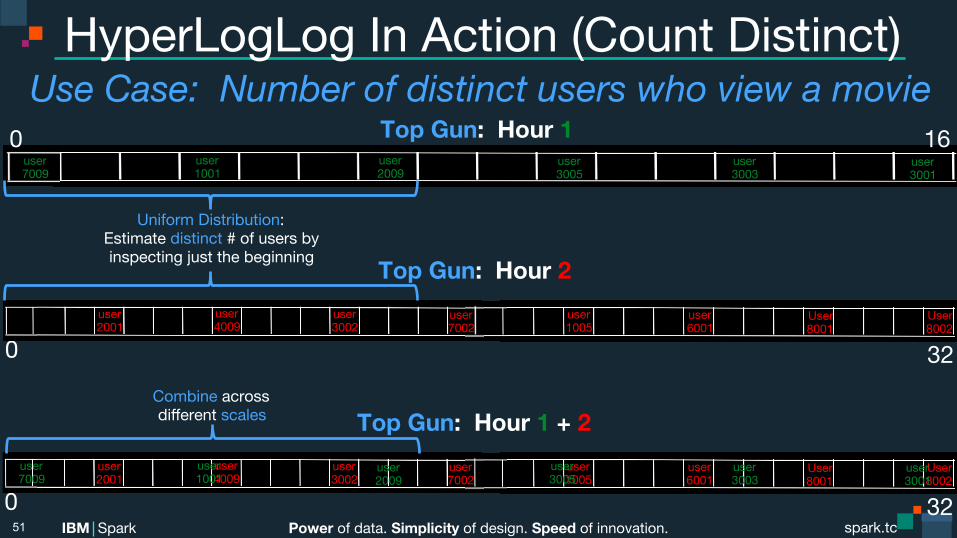
HyperLogLog In Action (Count Distinct) Use Case: Number of distinct users who view a movie
51
0 32
Top Gun: Hour 2 user2001
user 4009
user 3002
user 7002
user 1005
user 6001
User 8001
User 8002
user 1001
user 2009
user 3005
user 3003
Top Gun: Hour 1 user 3001
user 7009
0 16
Uniform Distribution: Estimate distinct # of users by inspecting just the beginning
0 32
Top Gun: Hour 1 + 2 user2001
user 4009
user 3002
user 7002
user 1005
user 6001
User 8001
User 8002
Combine across different scales
user 7009
user 1001
user 2009
user 3005
user 3003
user 3001

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Locality Sensitive Hashing Set Similarity
“Pre-process Items into Buckets, Compare Within Buckets”
52

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Locality Sensitive Hashing (LSH) Approximate set similarity Hash designed to cluster similar items Avoids cartesian all-pairs comparison Pre-process m rows into b buckets b << m
Hash items multiple times Similar items hash to overlapping buckets Compare just contents of buckets Much smaller cartesian … and parallel !!
53

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
DIMSUM Set Similarity
“Pre-process and ignore data that is unlikely to be similar.”
54
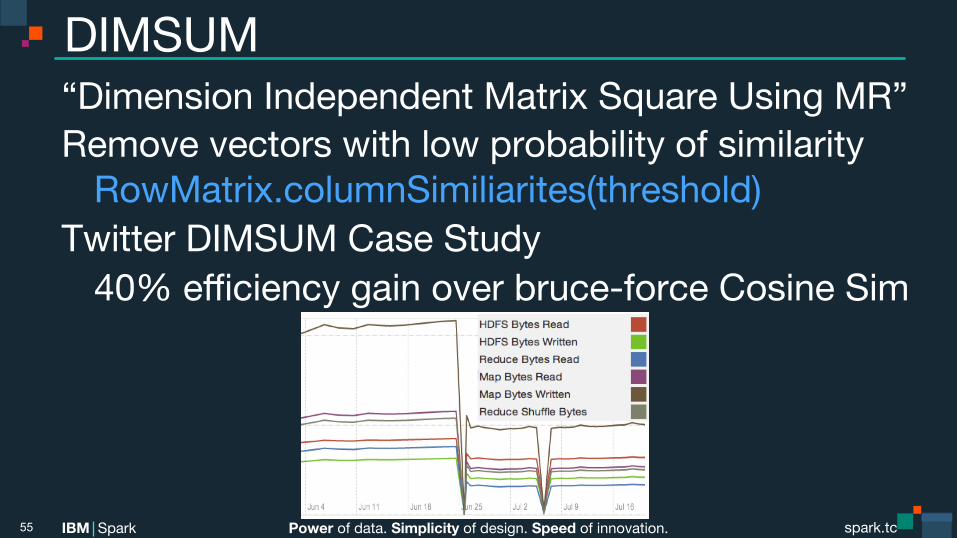
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
DIMSUM “Dimension Independent Matrix Square Using MR” Remove vectors with low probability of similarity RowMatrix.columnSimiliarites(threshold)
Twitter DIMSUM Case Study 40% efficiency gain over bruce-force Cosine Sim
55

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 56

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Common Tools to Approximate
Twitter Algebird
Redis
Apache Spark
57
Composable Library
Distributed Cache
Big Data Processing

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Twitter Algebird Rooted in Algebraic Fundamentals! Parallel Associative Composable Examples Min, Max, Avg BloomFilter (Set.contains(key)) HyperLogLog (Count Distinct) CountMin Sketch (TopK Count)
58

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Redis Implementation of HyperLogLog (Count Distinct) 12KB per item count 2^64 max # of items 0.81% error (Tunable) Add user views for given movie
PFADD TopGun_HLL user1001 user2009 user3005 PFADD TopGun_HLL user3003 user1001
Get distinct count (cardinality) of set
PFCOUNT TopGun_HLL Returns: 4 (distinct users viewed this movie)
59
ignore duplicates
Tunable
Union 2 HyperLogLog Data Structures PFMERGE TopGun_HLL Taps_HLL

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Spark Approximations Spark Core
RDD.count*Approx() Spark SQL
PartialResult approxCountDistinct(column), HyperLogLogPlus
Spark ML Stratified sampling PairRDD.sampleByKey(fractions: Double[ ]) DIMSUM sampling Probabilistic sampling reduces amount of comparison shuffle RowMatrix.columnSimilarities(threshold)
Spark Streaming A/B testing StreamingTest.setTestMethod(“welch”).registerStream(dstream)
60

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Demos!
61

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Counting Exact Count vs. Approx HyperLogLog, CountMin Sketch
62
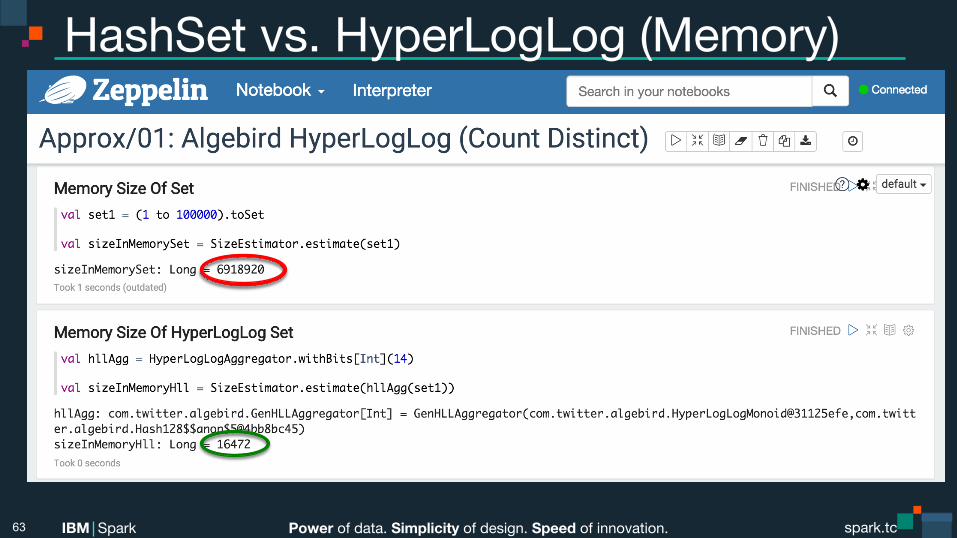
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
HashSet vs. HyperLogLog (Memory)
63
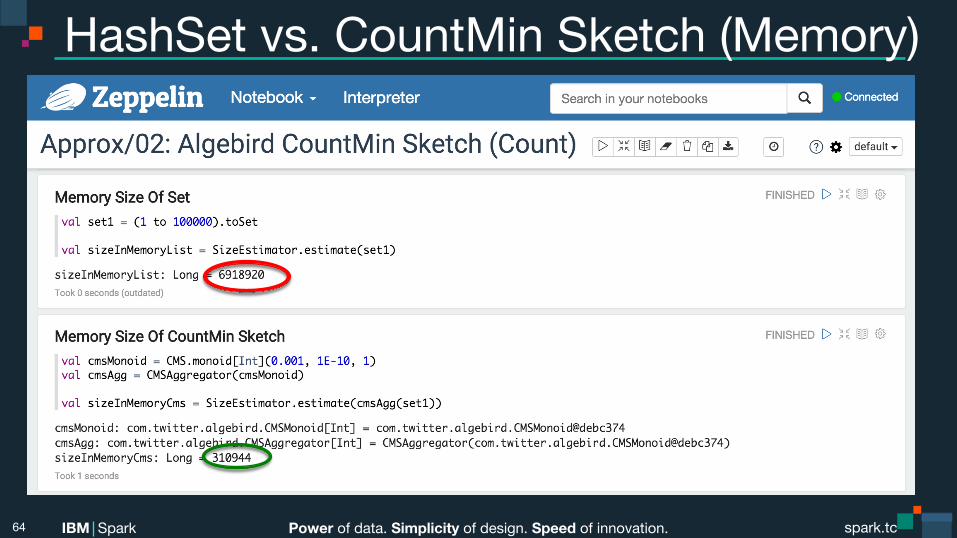
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
HashSet vs. CountMin Sketch (Memory)
64

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Set Similarity Bruce Force vs. Locality Sensitive Hashing Similarity
65

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Brute Force Cartesian All Pair Similarity
66
47 seconds

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Locality Sensitive Hash All Pair Similarity
67
6 seconds

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Many More Demos!
or Download Docker Clone Github
68
http://advancedspark.com

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Presentation Outline Scaling with Parallelism and Composability
Similarity and Recommendations
When to Approximate
Common Algorithms and Data Structures Common Libraries and Tools
Netflix Recommendations and Data Pipeline 69

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Netflix Recommendation & Data Pipeline From 5 Stars to Trending Now
70

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Has a Lot of Data Netflix has a lot of data about a lot of users and a lot of movies. Netflix can use this data to buy new movies. Netflix is global. Netflix can use this data to choose original programming. Netflix knows that a lot of people like politics and Kevin Spacey.
71
The UK doesn’t have White Castle. Renamed my favourite movie to:
“Harold and Kumar Get the Munchies”
My favorite movie: “Harold and Kumar Go to White Castle”
Summary: Buy NFLX Stock!
This broke my unit tests!

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
$1 Million Netflix Prize (2006-2009) Goal Improve movie predictions by 10% (RMSE)
Dataset (userId, movieId, rating, timestamp) Test data withheld to calculate RMSE upon submission
Winning algorithm 10.06% improvement (RMSE) Ensemble of 500+ ML combined with GBDT’s Computationally impractical
72

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Secrets to the Winning Algorithms Adjust for the following human bias… ① Alice Effect: rate lower than average user ② Inception Effect: rated higher than average movie
③ Overall mean rating of a movie
④ Number of people who have rated a movie
⑤ Mood, time of day, day of week, season, weather
⑥ Number of days since user’s first rating
⑦ Number of days since movie’s first rating 73
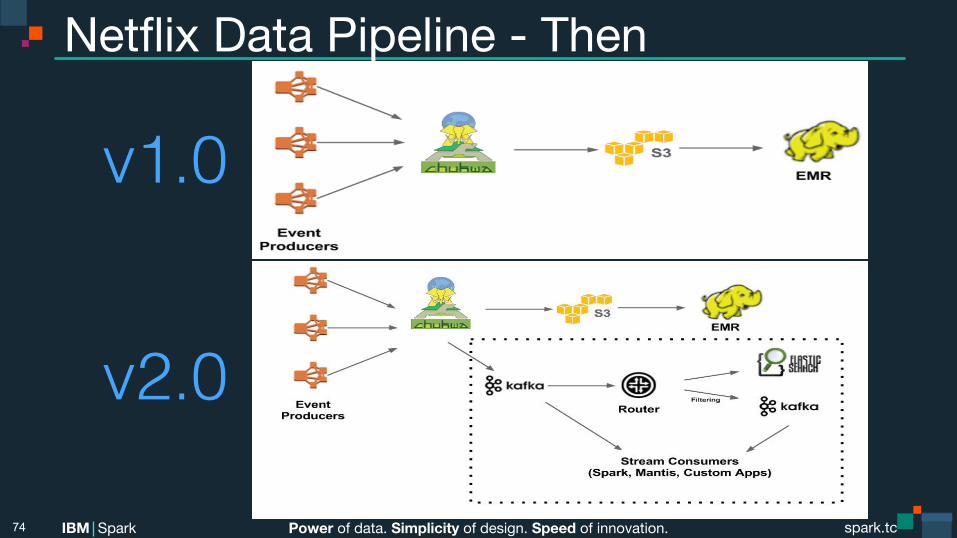
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Data Pipeline - Then
74
v1.0!
v2.0!
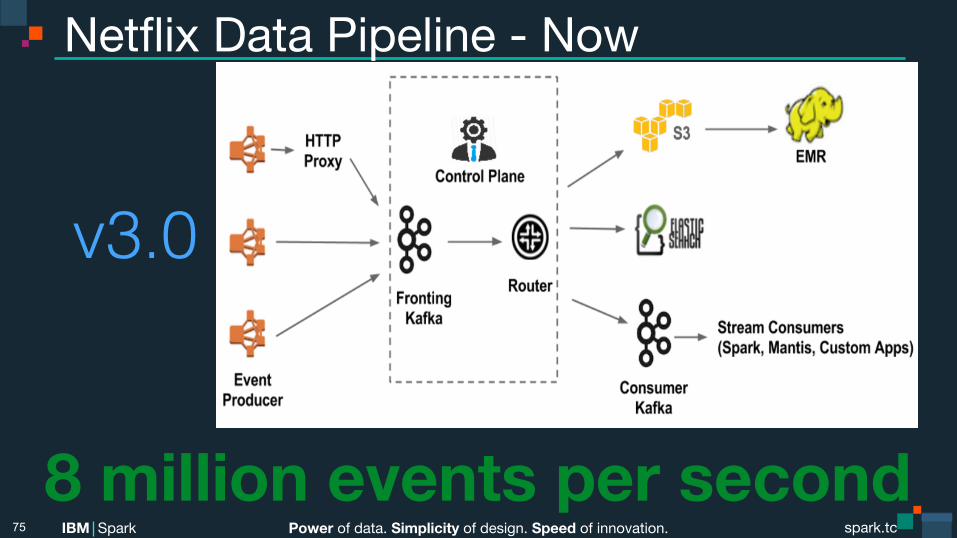
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Data Pipeline - Now
75
v3.0!
8 million events per second
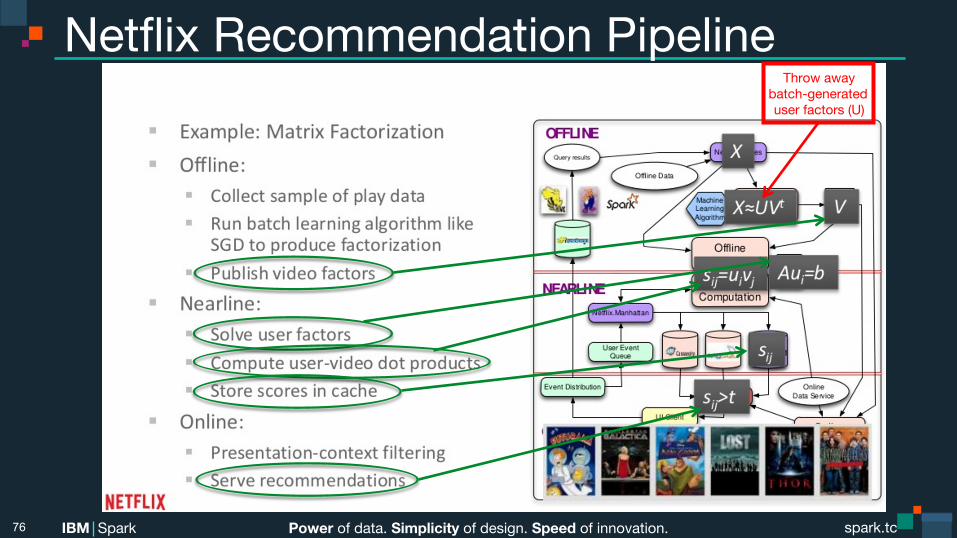
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Recommendation Pipeline
76
Throw away batch-generated user factors (U)

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Common ML Algorithms Logistic Regression Linear Regression Gradient Boosted Decision Trees Random Forest Matrix Factorization SVD Restricted Boltzmann Machines Deep Neural Nets Markov Models LDA Clustering
77
Ensembles
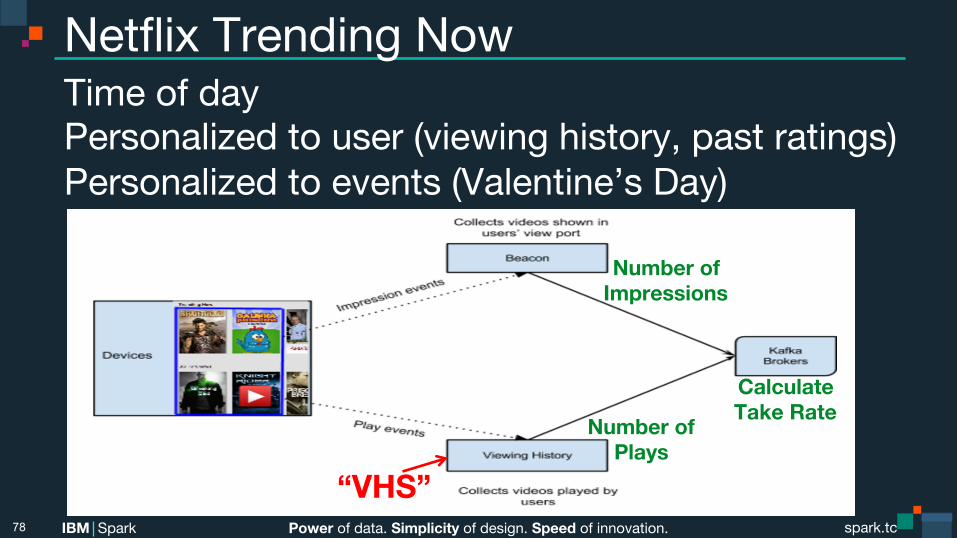
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Trending Now Time of day Personalized to user (viewing history, past ratings) Personalized to events (Valentine’s Day)
78
“VHS”
Number of Plays
Number of Impressions
Calculate Take Rate

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Bonus: Pandora Time of Day Recs Work Days Play familiar music User is less likely accept new music
Evenings and Weekends Play new music More like to accept new music
79

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Social Integration Post to Facebook after movie start (5 mins) Recommend without needing viewing history Helps with Cold Start problem
80

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Netflix Search No results? No problem… Show similar results!
Empty searches are good! Explicit feedback for future recommendations Content to buy and produce!
81

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Bonus: Netflix in 2004 Netflix noticed people started to rate movies higher!? Why?
Significant UI improvements made around that time Recommendation improvements (Cinematch)
82
Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc spark.tc Power of data. Simplicity of design. Speed of innovation. IBM Spark
Thank You!! Chris Fregly @cfregly IBM Spark Tech Center http://spark.tc San Francisco, California, USA
http://advancedspark.com Sign up for the Meetup and Book Contribute to Github Repo Run all Demos using Docker
Find me: LinkedIn, Twitter, Github, Email, Fax 83
Image derived from http://www.duchess-france.org/

Power of data. Simplicity of design. Speed of innovation. IBM Spark spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
advancedspark.com @cfregly









![[Spark meetup] Spark Streaming Overview](https://static.fdocuments.net/doc/165x107/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)








