
Adaptive Storage Management for Modern Data Centers Imranul Hoque 1.
42
Adaptive Storage Management for Modern Data Centers Imranul Hoque 1
-
Upload
isaac-wade -
Category
Documents
-
view
231 -
download
0
Transcript of Adaptive Storage Management for Modern Data Centers Imranul Hoque 1.

1
Adaptive Storage Management for Modern Data Centers
Imranul Hoque

2
Applications in Modern Data Centers
More than 20 PB of data (> 260 billion files) just in the photo app.
More than 500 million active users.
Over 2.5 million websites have integrated with Facebook.

3
Application Characteristics
• Type of data– Networked data (integration between content and
social sites)• Volume of data/scale of system– TB to PB (photos, videos, news articles, etc.)
• End-user performance requirement– Low latency (real time web)
Traditional storage systems have failed to satisfy these requirements.

4
New Classes of Storage SystemsApplication requirements
Why traditional storage systems have failed?
New storage system
Networked data Representation Join (e.g., friends of friends)
Graph databaseExample: Twitter uses FlockDB
Large data volume and massive scale of system
Consistency vs. (Performance and Availability)
(Small but frequent r/w and batch transactions with rare write) vs. Heavy read/write workload
Key-value storageExample: Digg uses Cassandra
Low latency and high throughput
Disk is bottleneck In-memory storageExample: Craigslist uses Redis
Absence of adaptive techniques for storage management cause these new storage systems to perform sub-optimally.
5
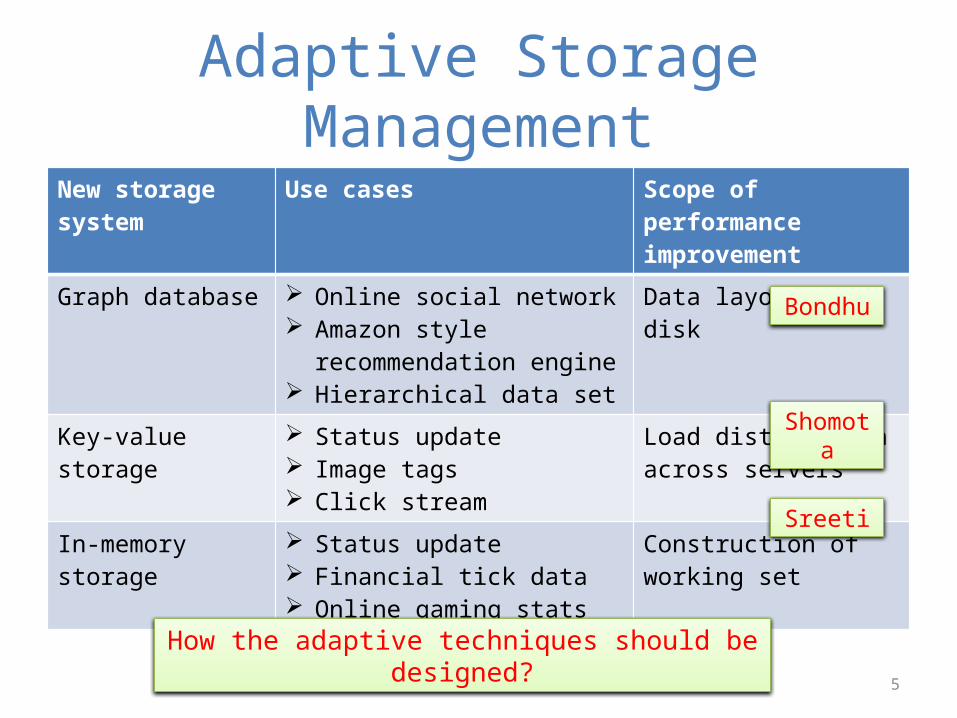
Adaptive Storage ManagementNew storage system Use cases Scope of performance
improvementGraph database Online social network
Amazon style recommendation engine
Hierarchical data set
Data layout on disk
Key-value storage Status update Image tags Click stream
Load distribution across servers
In-memory storage Status update Financial tick data Online gaming stats
Construction of working set
Bondhu
Shomota
Sreeti
How the adaptive techniques should be designed?

6
Hypothesis Statement
“Adaptive techniques which leverage the underlying heterogeneity of the system as a first class citizen, can improve the performance of these new classes of storage systems significantly.”
Leverage heterogeneity = exploit heterogeneity + mitigate heterogeneity.
7
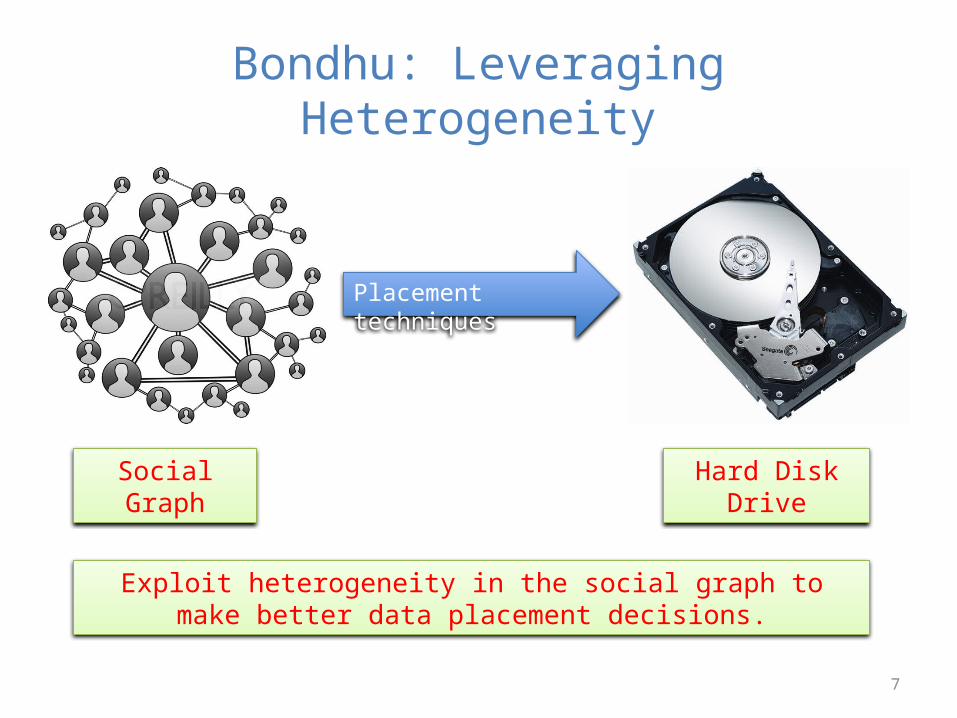
Bondhu: Leveraging Heterogeneity
Placement techniques
Social Graph Hard Disk Drive
Exploit heterogeneity in the social graph to make better data placement decisions.

8
Shomota: Leveraging Heterogeneity
Server 1 Server 2 Server 3 Server 4
SATTUE
SUNMON
WED THU
FRI
MON TUE WED THU FRI SAT SUN
Tablets Table
Mitigate load heterogeneity across servers to alleviate hot spot via adaptive load balancing techniques.
9
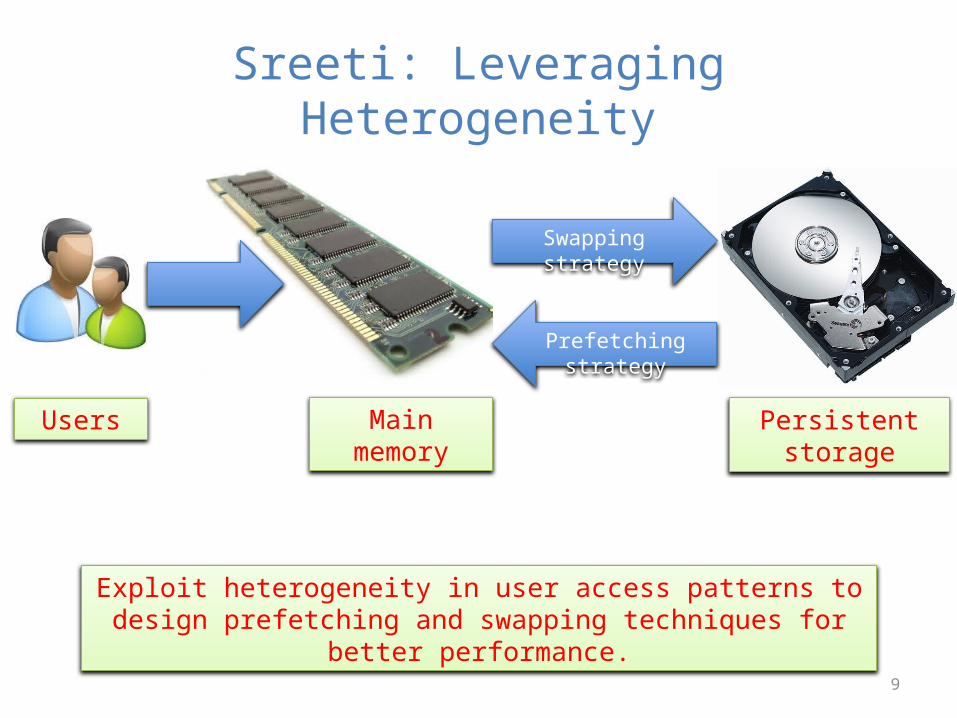
Sreeti: Leveraging Heterogeneity
Swapping strategy
Prefetching strategy
Exploit heterogeneity in user access patterns to design prefetching and swapping techniques for better performance.
Main memory Persistent storageUsers
10
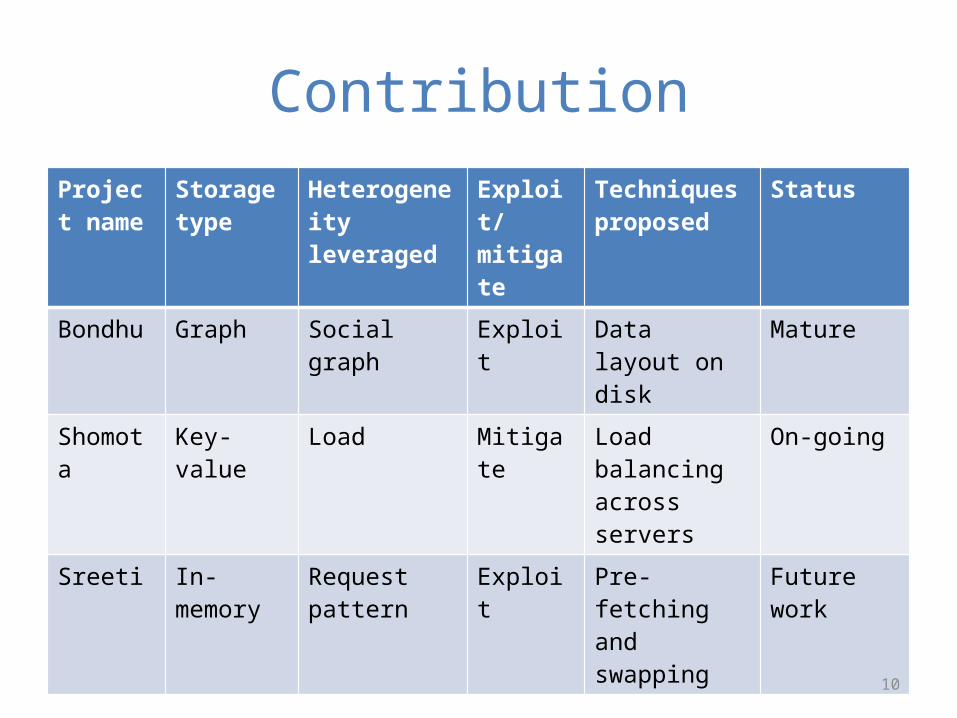
ContributionProject name
Storage type
Heterogeneity leveraged
Exploit/mitigate
Techniques proposed
Status
Bondhu Graph Social graph Exploit Data layout on disk
Mature
Shomota Key-value Load Mitigate Load balancing across servers
On-going
Sreeti In-memory Request pattern
Exploit Pre-fetching and swapping
Future work

11
Bondhu: A Social Network-Aware Disk Manager for Graph Databases
12
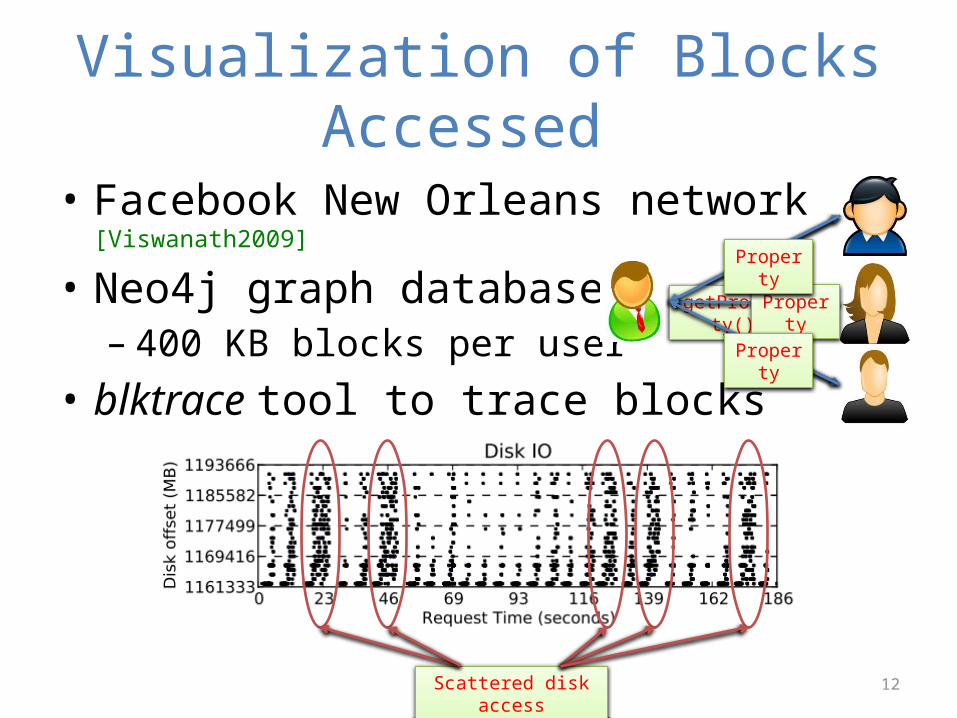
Visualization of Blocks Accessed
• Facebook New Orleans network [Viswanath2009]
• Neo4j graph database– 400 KB blocks per user
• blktrace tool to trace blocks
getProperty()Property
Property
Property
Scattered disk access

13
Sequential vs. Random Access
• How bad is random access?• fio benchmarking tool
Disk layout techniques might improve performance significantly.
70 vs. 0.7 MB/s
150 vs. 1 MB/s
98 vs. 0.8 MB/s

14
Social Network-Aware Disk Manager
• Approaches in other systems– Popularity-based approach: multimedia file system
[Wong1983]
– Tracking block access patterns [Li2004][Bhadkamkar2009]
• Properties of online social networks [Misolve2007]
– Strong community structure– Small world phenomenon
• Exploit heterogeneity in social graph– Keep related users’ data close by on disk– Reduce seek time, rotational latency, # of seeks

15
The Bondhu System
• Novel framework for disk layout algorithms– Based on community detection
• Integration into Neo4j, a widely-used open source graph database
• Experimentation using real social graph– Response time improvement by 48% compared to
the default Neo4j layout
16
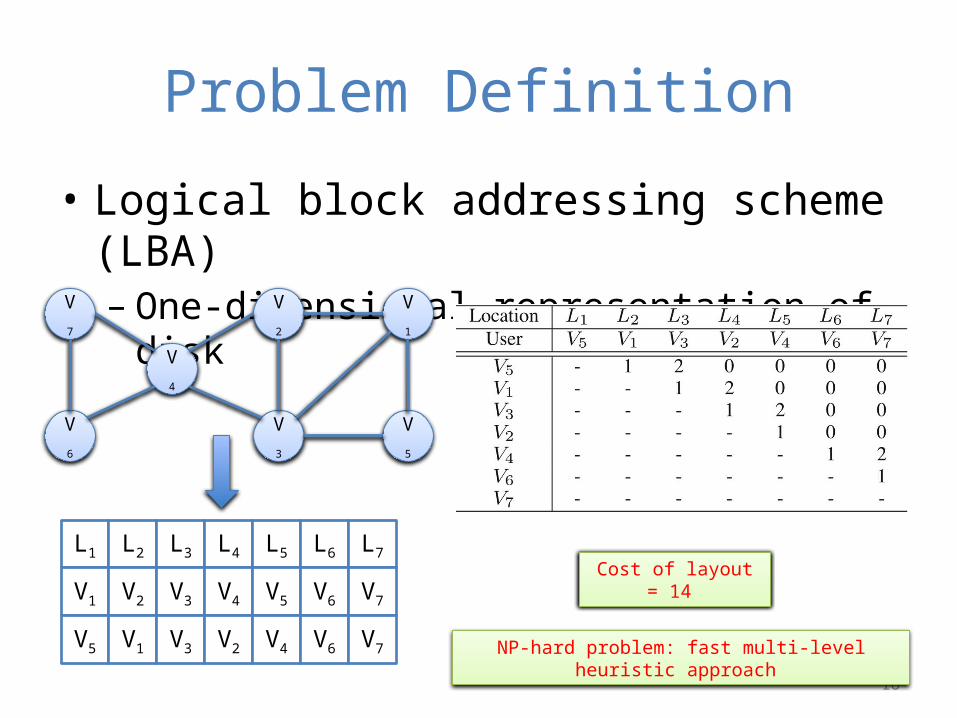
Problem Definition
• Logical block addressing scheme (LBA)– One-dimensional representation of disk
L1 L2 L3 L4 L5 L6 L7
V1 V2 V3 V4 V5 V6 V7
V5 V1 V3 V2 V4 V6 V7
Cost of layout = 18 Cost of layout = 14
NP-hard problem: fast multi-level heuristic approach
V1
V5
V2
V3
V4
V6
V7
17
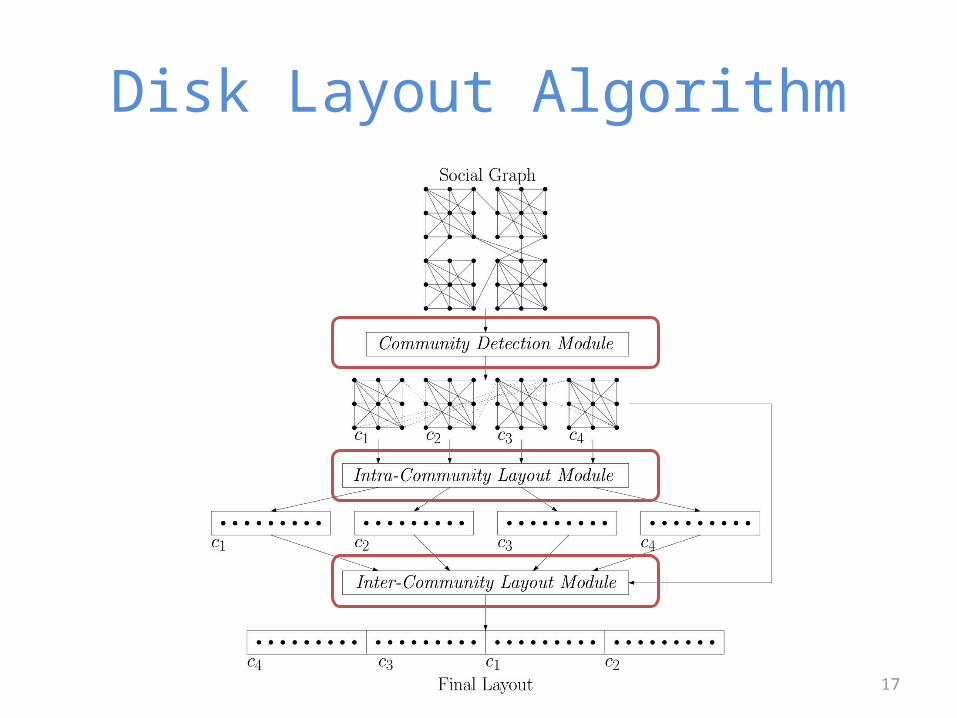
Disk Layout Algorithm

18
Community Detection Module
• Goal: organize the users of the social graph into clusters
• Based on community detection algorithms– Graph partition driven (ParCom) [Karypis1998]
– Modularity optimization driven (ModCom) [Blondel2008]
V1
V5
V2
V3
V4
V6
V7

19
Intra-community Layout Module
V1
V5
V2
V3
V4
V6
V7
1
1 1
1
1
1
1
1
V2 V1 V3 V5
V3
V1
2
2VC V5
V2
V7 V6 V4
• Goal: create a disk layout for each community

20
Inter-community Layout ModuleV1
V5
V2
V3
V4
V6
V7
VA VB
2
VA VB
V2 V1 V3 V5V7 V6 V4

21
Modeling OSN Dynamics
• Uniform Model– Assign equal weight
• Preferential Model– Weight of edge (Vi, Vj) edge degree of V∝ j
– We use [edge_degree(Vi) + edge_degree(Vj)]/2
• Overlap Model– Weight proportional to # of common friends– We use (c + 1), c = # of common friends
V1
V5
V2
V3
V4
V6
V7
degree = 4
degree= 3
3.52

22
Implementation and Evaluation
• Modified PropertyStore of Neo4j• Facebook New Orleans network [Viswanath2009]
– 63731 users– 817090 links– Assign weights according to uniform, preferential, and overlap models
• Workload: sample social network application– ‘List all friends’ operation– 1500 random users, 6 times/user
• Metrics– Cost (defined earlier)– Response time = time to fetch data blocks from all friends of a random
user
23
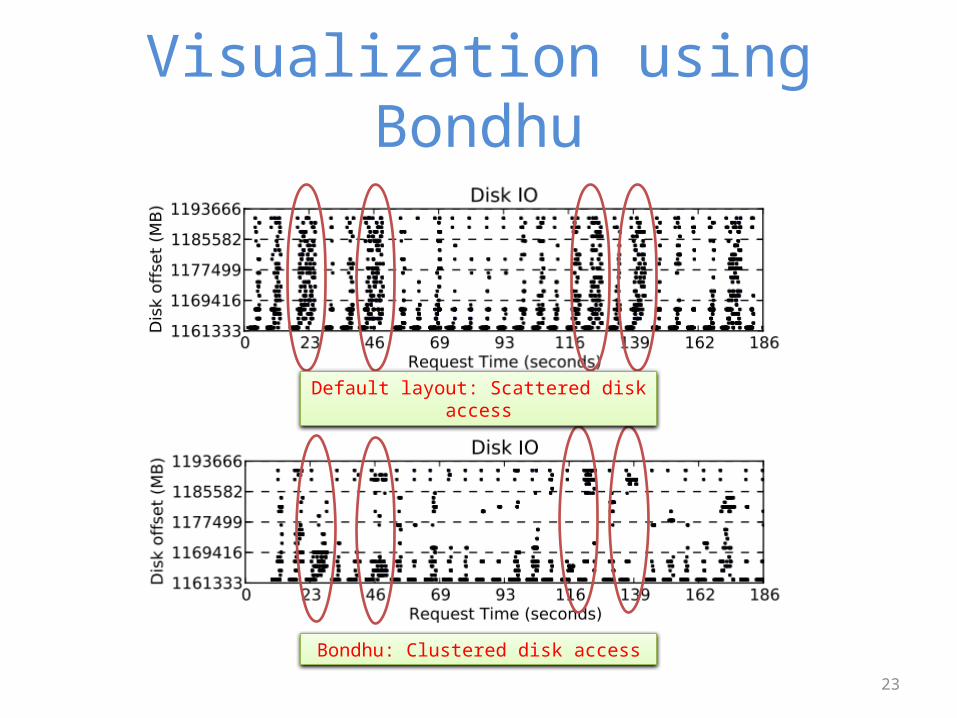
Visualization using Bondhu
Default layout: Scattered disk access
Bondhu: Clustered disk access

24
Effect of Block Size
Caching disabled Caching enabled
• File system reads data in chunks of 4KB– (4B, 40B, 400B) block = (1024, 102, 10) users data
• Default layout– 10x decrease in expected # of friends, when block size
increases from 4B to 40B to 400B • Bondhu layout
– 4B to 40B not much decrease in expected # of friends– 40B to 400B rapid decrease in expected # of friends
Cached in memory

25
Response Time Metric vs. Cost Metric
Improvement in response time is due to better placement decisions.
Block size: 40 B Block size: 400 KB
26
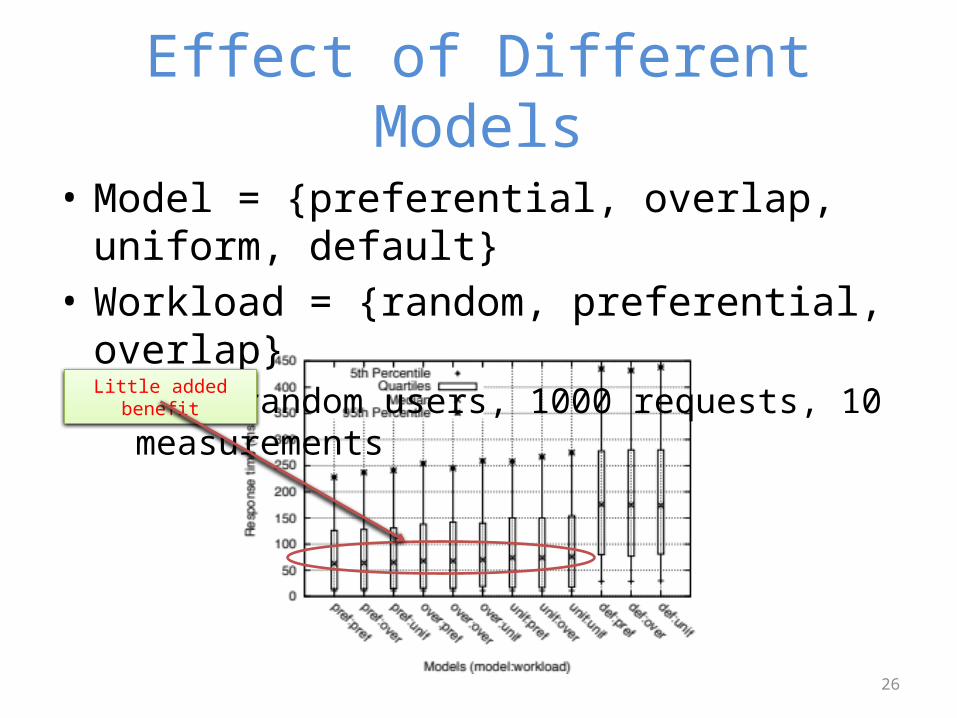
Effect of Different Models
• Model = {preferential, overlap, uniform, default}• Workload = {random, preferential, overlap}– 1000 random users, 1000 requests, 10 measurements
Little added benefit

27
Effect of OSN EvolutionStill better than the default layout by 72%
33% less nodes

28
Summary
• Adaptive disk layout techniques– Exploit heterogeneity of social graph (community
structure)• Implementation in Neo4j graph database• Extensive trace-driven experimentation• 48% improvement in median response time• Low additional benefit using complex models• Infrequent re-organization

29
Shomota: An Adaptive Load Balancer for Distributed Key-Value Storage Systems

30
31
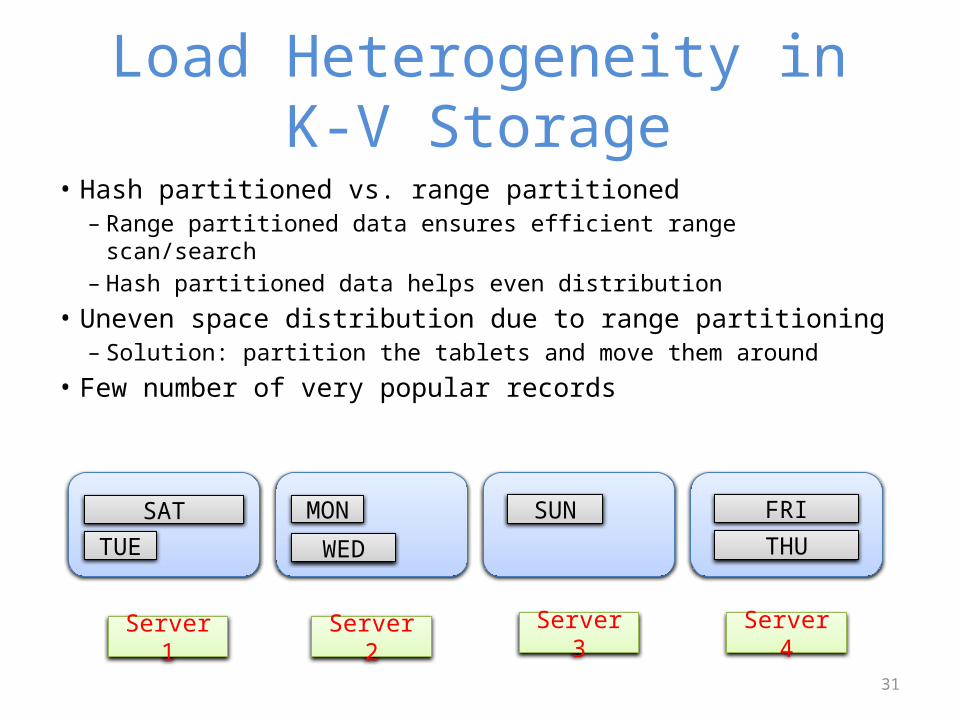
Load Heterogeneity in K-V Storage
• Hash partitioned vs. range partitioned– Range partitioned data ensures efficient range scan/search– Hash partitioned data helps even distribution
• Uneven space distribution due to range partitioning– Solution: partition the tablets and move them around
• Few number of very popular records
Server 1 Server 2 Server 3 Server 4
SATTUE
SUNMON
WED THU
FRI

32
The Shomota System
• Mitigate load heterogeneity• Algorithms for solving the load balancing problem– Load = space, bandwidth– Evenly distribute the spare capacity– Distributed algorithm, not a centralized one– Reduce the number of moves
• Previous solutions:– One dimensional/key-space redistribution/bulk loading
[Stoica2001, Byers2003, Karger2004, Rao2003, Godfrey2005, Silberstein2008]
33
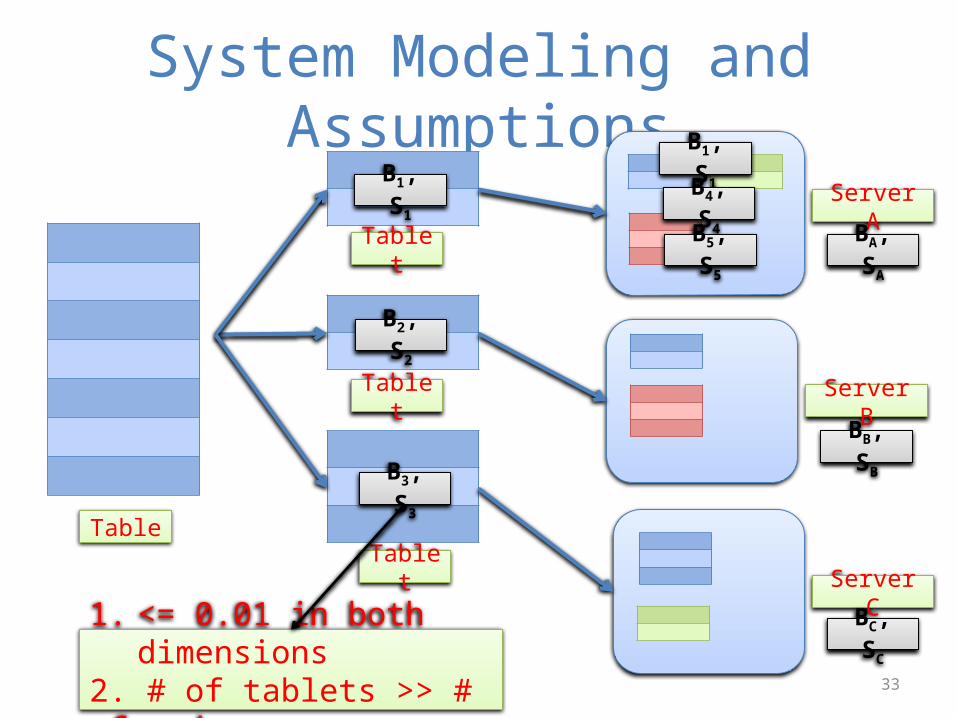
System Modeling and Assumptions
Table
Tablet
Tablet
Tablet
Server A
Server B
Server C
B1, S1
B2, S2
B3, S3
BA, SA
BB, SB
BC, SC1. <= 0.01 in both dimensions2. # of tablets >> # of nodes
B1, S1
B4, S4
B5, S5
34
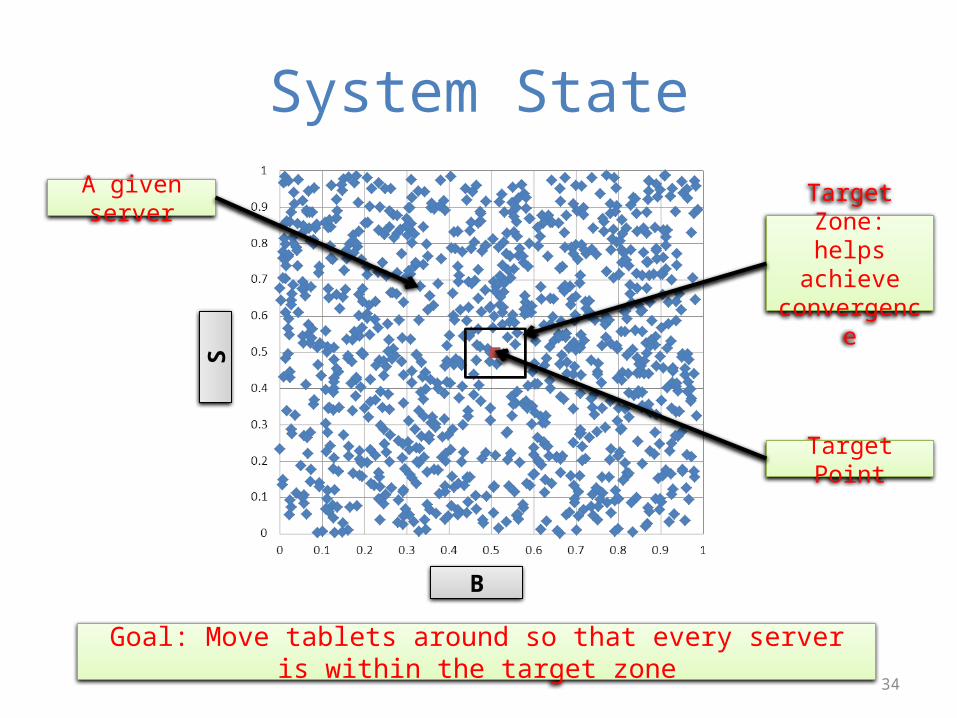
System State
B
STarget Zone:
helps achieve convergence
Target Point
Goal: Move tablets around so that every server is within the target zone
A given server
35
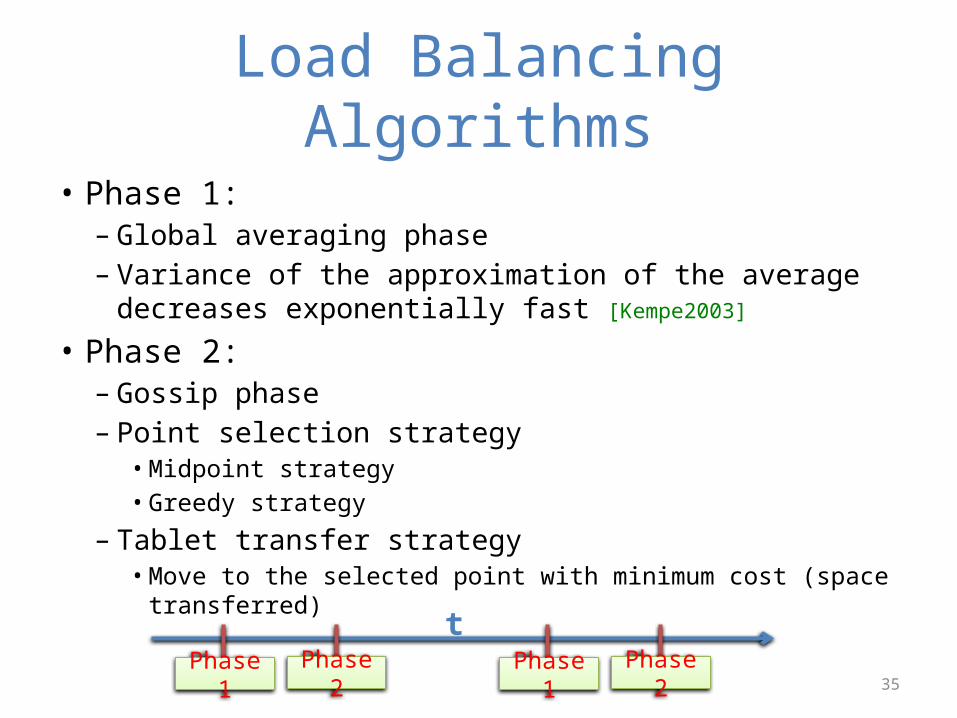
Load Balancing Algorithms
• Phase 1:– Global averaging phase– Variance of the approximation of the average decreases
exponentially fast [Kempe2003]
• Phase 2:– Gossip phase– Point selection strategy
• Midpoint strategy • Greedy strategy
– Tablet transfer strategy• Move to the selected point with minimum cost (space transferred)
Phase 1 Phase 2 Phase 1 Phase 2
t

36
Summary
• Distributed load balancing techniques for key-value storage system– Mitigates both space and throughput
heterogeneity across servers– PeerSim-based simulation– Integration in Voldemort (on-going)– Simulation results exhibit fast convergence while
keeping the data movements at a low level

37
Sreeti: Access Pattern-Aware Memory Management

38
In-memory Storage System
• Growth in Internet population– Search engine, social networking, blogging, e-commerce,
media sharing• User expectation– Fast response time + high availability
• Serving large number of users at real-time– Option 1: SSD– Option 2: memory
• Emerging trends– Memory caching system: Memcached– In-memory storage system: Redis, VoltDB, etc.

39
Motivation
• Assumption in existing in-memory storage systems– Enough RAM to fit all data in memory
• Counter example:– Values associated with keys are large
• Approach taken by existing systems:– Redis, Memcached: use LRU for swapping
Performance of in-memory storage systems can be improved further if heterogeneity in user request-pattern is leveraged.
40
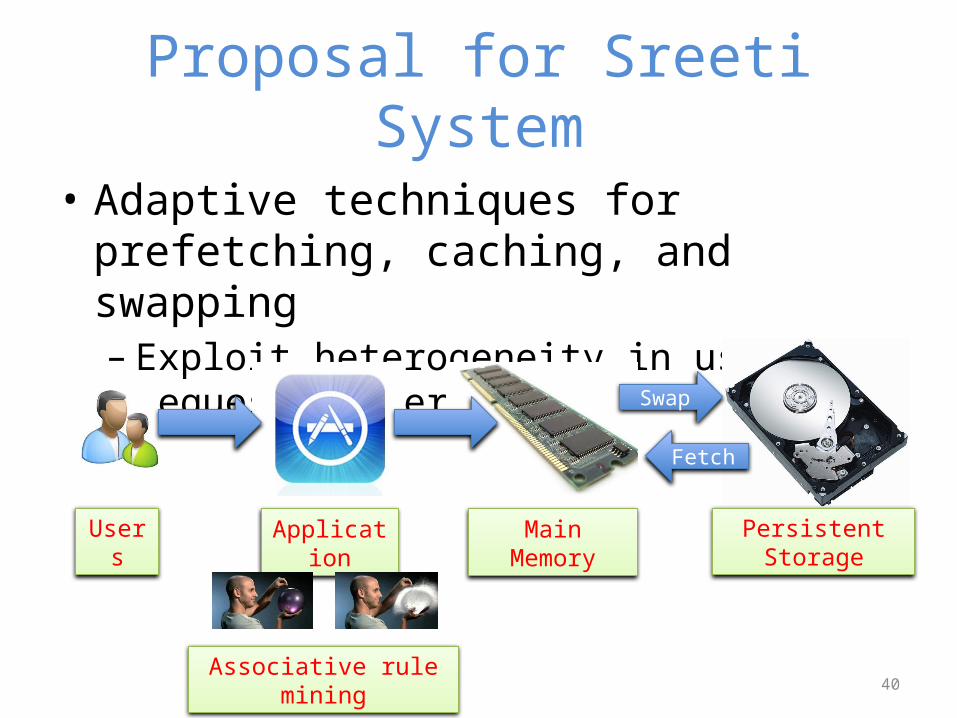
Proposal for Sreeti System
• Adaptive techniques for prefetching, caching, and swapping– Exploit heterogeneity in user request-patterns
Swap
Fetch
Users Application Main Memory Persistent Storage
Associative rule mining

41
Hypothesis Statement
• “Adaptive techniques which leverage the underlying heterogeneity of the system as a first class citizen, can improve the performance of these new classes of storage systems significantly.”
Disk layoutLoad balancing
Prefetching, caching, swapping
ExploitMitigate
Graph databaseKey-value storage
In-memory storage
42
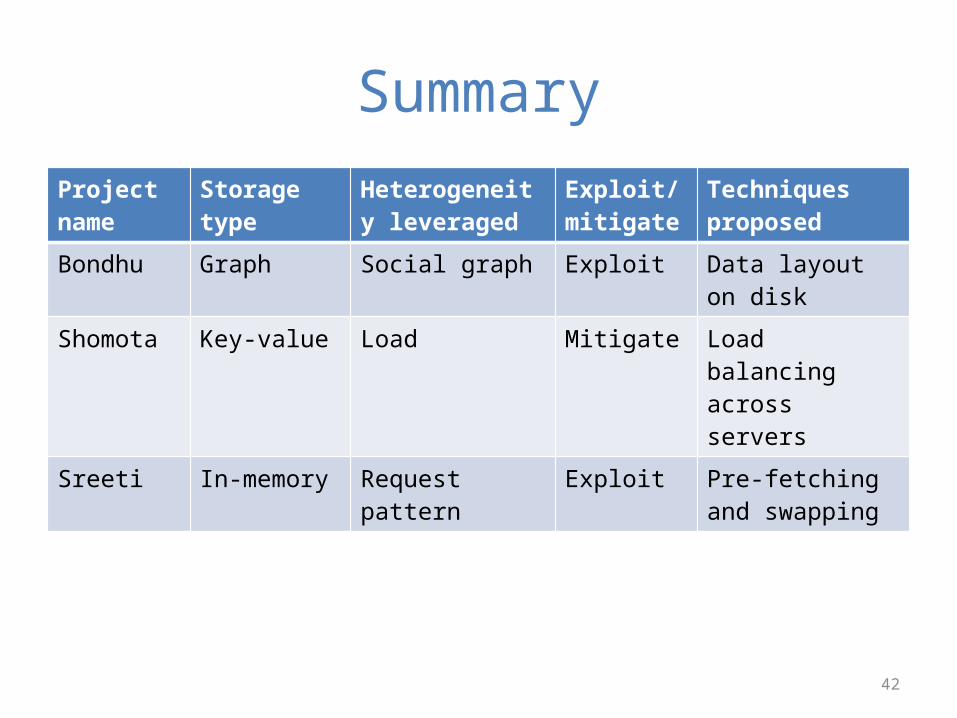
SummaryProject name
Storage type Heterogeneity leveraged
Exploit/mitigate
Techniques proposed
Bondhu Graph Social graph Exploit Data layout on disk
Shomota Key-value Load Mitigate Load balancing across servers
Sreeti In-memory Request pattern Exploit Pre-fetching and swapping


















