
Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors
Upload
marcus-allenCategory
view
228download
1
Adaptive proxies:handling widely-shared data
in shared-memory multiprocessors
Sarah A M TalbotOceanography Lab, T H Huxley School of the Environment
Paul H J KellySoftware Performance Optimisation Group, Dept of Computing
Imperial College, London

Large-scale shared-memory
• Future large-scale parallel computers must support shared memory
• Processors rely on cache for performance, so scalable cache coherency protocol needed - CC-NUMA
• Existing implementations have been plagued with performance anomalies

CC-NUMA performance anomalies
• This talk is about a simple scheme which– fixes various performance anomalies in CC-NUMA
machines – without compromising peak performance
• What performance anomalies?– Home placement: in which CPU’s main memory
should each object be allocated?– Contention for widely-shared data: what happens when
every CPU accesses the same object at the same time?

The challenge• Caching is a great way to enhance best-case
• Worst-case is terrible
• What powerful ideas do we have for dealing with worst-case contention?
– Combining– Randomisation
• How can we use caching most of the time, while using random data routing/placement and combining to avoid worst-case contention?

This talk• Introduce proxying concept
• Briefly review results presented in earlier papers
• Introduce adaptive proxying
• Present simulated benchmark results
• Show that adaptive, reactive proxying can improve performance of susceptible applications
• With no reduction in performance of other applications

Context: large CC-NUMA multicomputer
Network interfaceNetwork buffers
Node controller
SLC DRAM
First-level cache
CPU
Interconnection network
Full-crossbarinterconnection network
Stanford distributed-directoryprotocol with singly-linked
sharing chains

The home node for a memory address
Home for location x
Home is determined by high-order bits of physical address. All cache misses go first to home to locate a
CPU holding a validcopy

Widely-read data
Suppose many CPUshave read misses on
the same addressat the same time

CPUs in right half ofmachine send their
read request to pseudo-randomly
selected “proxy” node B
The basic idea: proxiesCPUs in left half ofmachine send their
read request to pseudo-randomly
selected “proxy” node A
A
B

Proxies - forwarding
The “proxy” nodesA and B forward
the read requests to the home
A
B

Reading the next location...
Suppose many CPUshave read misses on
the same addressat the same time...
and then they all access the next cache line
Locations on same page have same home node
So they all contend againfor the same home node

Reading the next location… randomisation
Suppose many CPUshave read misses on
the same addressat the same time...
and then they all access the next cache line
Proxy is selected pseudo-randomly based on low-
order address bits
So contention is spreadacross nodes, read isserviced in parallel

Combining - Pending Proxy Request Chain
As each read requestis received by theproxy, the client
as added to a chainof clients to be
informed when thereply arrives
1
1

Combining - Pending Proxy Request Chain
As each read requestis received by theproxy, the client
as added to a chainof clients to be
informed when thereply arrives
1
2
1
2

Combining - Pending Proxy Request Chain
As each read requestis received by theproxy, the client
as added to a chainof clients to be
informed when thereply arrives
1
2 1
2
3
3

Combining - Pending Proxy Request Chain
As each read requestis received by theproxy, the client
as added to a chainof clients to be
informed when thereply arrives
1
2 1
2
3
3
4
4

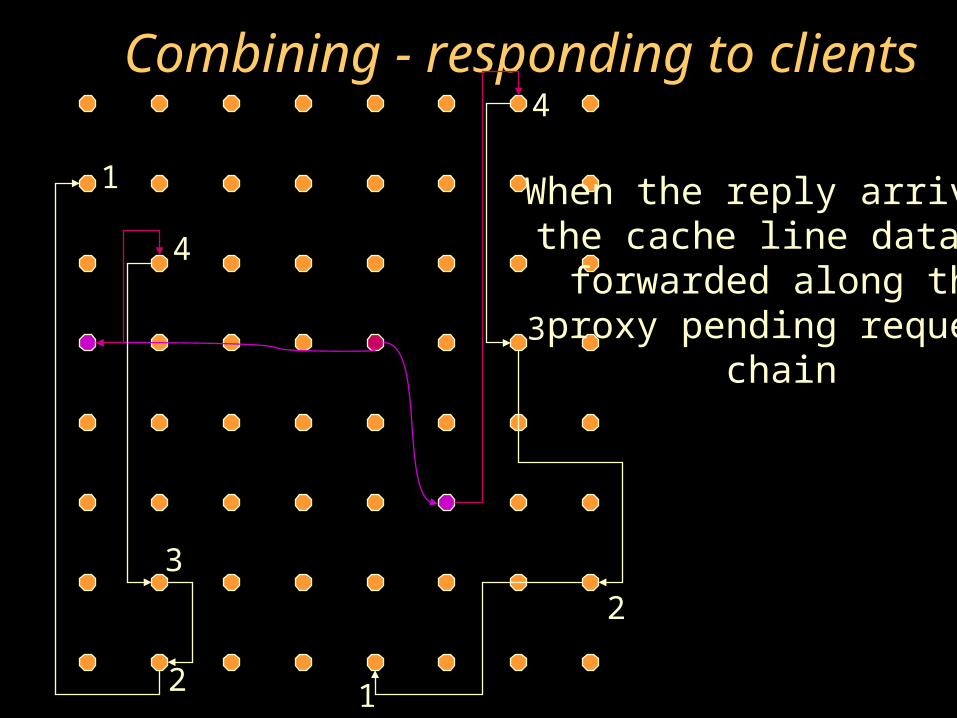
Combining - responding to clients
When the reply arrives,the cache line data isforwarded along the
proxy pending requestchain
1
2 1
2
3
3
4
4
Combining - responding to clients
1
2 1
2
3
3
4
4
When the reply arrives,the cache line data isforwarded along the
proxy pending requestchain

Combining - responding to clients
1
2 1
2
3
3
4
4
When the reply arrives,the cache line data isforwarded along the
proxy pending requestchain

Combining - responding to clients
1
2 1
2
3
3
4
4
When the reply arrives,the cache line data isforwarded along the
proxy pending requestchain

Combining - responding to clients
1
2 1
2
3
3
4
4
We chose a linked pending chain to minimise spaceoverhead and
make proxyingeasy to add to nodecontroller design

Previously-published results(Euro-Par’96) Proxying improves 512x512 Gauss
Elimination by >28% on 64 processors– But slows most other apps down, so has to be
controlled by programmer
(Euro-Par’98) Reactive proxies: send read request to proxy if request is NAKed due to buffer full– Reactive proxying doesn’t slow any apps– But performance improvement for GE only 21-23%– Some other apps show promising 3-10%
(HPCS’98) With reactive proxies, first-touch page placement is always better than round-robin (and at least as good as without proxying)

This paper• Adaptivity: if a “recent” request to node i was
NAKed, assume the buffer is still full and route a read request directly to a proxy
• Should proxy retain recently-proxied data? – Yes: space is allocated for proxied data in the proxy
node’s own SLC, which is kept coherent using the usual protocol
– No: a separate proxy buffer points to outstanding proxy pending request chains
– Yes: this separate proxy buffer retains proxied data, which is kept coherent using the usual protocol

This talk• Adaptivity: if a “recent” request to node i was
NAKed, assume the buffer is still full and route a read request directly to a proxy

This talk• Adaptivity: if a “recent” request to node i was
NAKed, assume the buffer is still full and route a read request directly to a proxy
• Each proxy x maintains two vectors:– LB[y]: time when last NAK received by x from y– PP[y]: current “proxy period” for reads to node y
• When a NAK arrives at x from y, PP[y] is– incremented if LB[y] is within given window– decremented otherwise
– (unless PPmin PP[y] PPmax)

Results - simulated benchmark executionG
E
GE
GE
CF
D
CF
D
CF
D
FF
T
FF
T
FF
T
Oce
an-c
ontig
Oce
an-C
ontig
Oce
an-c
ontig
Oce
an-N
on-C
ontig
Oce
an-N
on-C
ontig
Oce
an-N
on-C
ontig
Bar
nes
Bar
nes
Bar
nes
FM
M
FM
M
FM
M
Wat
er-N
sq
Wat
er-N
sq
Wat
er-N
sq
-15
-10
-5
0
5
10
15
20
25
30
35
Proxy caching:separate buffer
noneSLC
GE CFD FFT Oceancontig
Oceannon-
contig
Barnes FMM Waternsq

Gaussian elimination
12
34
56
78
SLC
none
buffer 29.5
30
30.5
31
31.5
32
SLC
none
buffer
Number of proxies

FFT
12
34
56
78
SLC
none
buffer 10.2
10.4
10.6
10.8
11
11.2
11.4
11.6
11.8
12
SLC
none
buffer
Number of proxies

Ocean, non-contiguous storage layout
12
34
56
78
SLC
none
buffer -12
-10
-8
-6
-4
-2
0
2
4
6
8
SLC
none
buffer
Number of proxies

Ocean, contiguous storage layout
12
34
56
78
SLC
none
buffer -7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
SLC
none
buffer
Number of proxies

CFD
12
34
56
78
SLC
none
buffer 0
2
4
6
8
10
12
14
Sp
ee
du
p r
ela
tiv
e t
o n
o-p
roxy
Number of proxies
CFD, 64x64
SLC
none
buffer
Number of proxies

Barnes-Hut, 16K particles
12
34
56
78
S1
S2
S3-0.5
0
0.5
1
1.5
2
2.5
3
3.5
4
Sp
ee
du
p r
ela
tiv
e t
o n
o-p
roxy
Number of proxies
Barnes, 16K particles, 64 procs
SLC
none
buffer
Number of proxies

FMM
12
34
56
78
SLC
none
buffer 0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
SLC
none
buffer
Number of proxies

Water-nsq
12
34
56
78
SLC
none
buffer 0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
SLC
none
buffer
Number of proxies

Conclusions• There is a lot of scope for further work -
– more applications, range of architectural parameters– clustered interconnection network– worst-case performance of writes?
• Proxying can solve serious performance anomalies– Using a separate proxy buffer is best– Proxying without allocating cache space for the proxied data works
remarkably well– The optimum number of proxies varies erratically – But a conservatively small number of proxies (1 or 2 for 64 procs) is a good
choice

Acknowledgements
• Colleagues Tony Field, Andrew Bennett (now with Micromuse), Ashley Saulsbury (now with Sun Labs)
• Funding: EPSRC PhD Studentship and Research Grant “CRAMP: Combining, Randomisation and Mixed-Policy Caching”


















