
Acoustically-Driven Talking Face Animations Using · PDF fileAcoustically-Driven Talking Face...
151
University of California Los Angeles Acoustically-Driven Talking Face Animations Using Dynamic Bayesian Networks A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Jianxia Xue 2008
Transcript of Acoustically-Driven Talking Face Animations Using · PDF fileAcoustically-Driven Talking Face...

University of California
Los Angeles
Acoustically-Driven Talking Face Animations
Using Dynamic Bayesian Networks
A dissertation submitted in partial satisfaction
of the requirements for the degree
Doctor of Philosophy in Electrical Engineering
by
Jianxia Xue
2008

c© Copyright by
Jianxia Xue
2008

The dissertation of Jianxia Xue is approved.
Lieven Vandenberghe
Ali H. Sayed
Patricia Keating
Abeer Alwan, Committee Chair
University of California, Los Angeles
2008
ii

dedicated to Chongsheng, Meilan, Fan, Ben, Zhixi, Weidong, and Yingjian
iii

Table of Contents
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Motivation and Overview of Talking Face Animations . . . . . . . 1
1.2 Overview of Acoustically-driven Talking Face Animations . . . . . 4
1.3 Feature extraction . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4 Acoustical to visual feature mapping . . . . . . . . . . . . . . . . 6
1.4.1 Regression methods . . . . . . . . . . . . . . . . . . . . . . 6
1.4.2 Statistical methods . . . . . . . . . . . . . . . . . . . . . . 7
1.4.3 Hidden Markov Models . . . . . . . . . . . . . . . . . . . . 9
1.4.4 Dynamic Bayesian Networks . . . . . . . . . . . . . . . . . 12
1.5 Animation rendering . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.6 Perceptual evaluation . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.7 Outline of this dissertation . . . . . . . . . . . . . . . . . . . . . . 17
2 Audio-Visual Database . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Efficient design of the audio-visual speech corpus . . . . . . . . . 19
2.2.1 Content influence on visual intelligibility . . . . . . . . . . 21
2.2.2 Training corpus requirement . . . . . . . . . . . . . . . . . 24
2.2.3 Final corpus . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3 Automatic Data Archiving . . . . . . . . . . . . . . . . . . . . . . 28
iv

2.3.1 Optical data preprocessing . . . . . . . . . . . . . . . . . . 30
2.3.2 Audio-visual speech end-point detection . . . . . . . . . . 41
2.3.3 Acoustic phoneme segmentation . . . . . . . . . . . . . . . 43
2.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3 Acoustic-to-optical Synthesis using Dynamic Bayesian Networks 46
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.2 System Architecture . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.2.1 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.2.2 Synthesis . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.2.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.3 Dynamic Bayesian Networks . . . . . . . . . . . . . . . . . . . . . 50
3.3.1 DBN models and configurations . . . . . . . . . . . . . . . 50
3.3.2 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.3.3 Inference of optical features from acoustic features . . . . . 55
3.4 Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.4.1 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.4.2 Feature extraction and inversion . . . . . . . . . . . . . . . 57
3.4.3 Acoustic-to-optical mapping models . . . . . . . . . . . . 58
3.4.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.4.5 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.4.6 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
v

4 Animation and Perceptual Evaluation . . . . . . . . . . . . . . . 67
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.2 From optical data to facial animation . . . . . . . . . . . . . . . . 69
4.2.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.2.2 The 3D head model . . . . . . . . . . . . . . . . . . . . . . 69
4.2.3 RBF-based deformation . . . . . . . . . . . . . . . . . . . 69
4.2.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4.2.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.3 Perceptual evaluation of facial animation . . . . . . . . . . . . . . 75
4.3.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.3.2 Lexicon distinction identification test . . . . . . . . . . . . 76
4.3.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.3.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5 Summary and Future Directions . . . . . . . . . . . . . . . . . . . 87
5.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5.1.1 Data acquisition . . . . . . . . . . . . . . . . . . . . . . . . 87
5.1.2 Acoustic-to-optical synthesis . . . . . . . . . . . . . . . . . 88
5.1.3 Optically-driven animation and perceptual evaluation . . . 89
5.2 Future research . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
A CorpusA: List of 320 IEEE sentences . . . . . . . . . . . . . . . . 93
vi

B CorpusB: List of pilot corpus . . . . . . . . . . . . . . . . . . . . . 101
C CorpusC: List of complementary corpus . . . . . . . . . . . . . . 105
C.1 Non-speech expressions . . . . . . . . . . . . . . . . . . . . . . . . 105
C.2 Mono-syllabic words . . . . . . . . . . . . . . . . . . . . . . . . . 105
C.3 Di-syllabic words . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
C.4 IEEE sentences . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
D Single letter representation of phonemes . . . . . . . . . . . . . . 116
E List of word pairs for visual lexicon distinction identification test118
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
vii

List of Figures
1.1 Gaussian Mixture Models (GMMs) applied to mapping continuous
speech to facial movements [13]. . . . . . . . . . . . . . . . . . . . 8
1.2 General structure of dynamic Bayesian networks for audio-visual
speech modeling . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1 Place of articulation for vowels [107] . . . . . . . . . . . . . . . . 25
2.2 Phoneme appearance distribution from 720 IEEE/Harvard sen-
tences. The meaning of the single-letter phoneme representations
listed in the figure can be found in Appendix D. . . . . . . . . . . 29
2.3 Marker settings in the new recording. Markers on the right side of
the speaker are labeled. . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4 Illustration of raw optical data problems from left to right: (a)
outlier, (b) collision, and (c) missing data. . . . . . . . . . . . . . 31
2.5 Raw marker data with multiple segments. . . . . . . . . . . . . . 32
2.6 Flowchart of optical data preprocessing. . . . . . . . . . . . . . . 33
2.7 Anchor points and vectors used in head motion compensation. . 34
2.8 Polynomial fitting of raw marker data on the x-z plane. . . . . . . 35
2.9 Primary judgment of 3D reconstruction outliers using a fitting er-
ror threshold. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.10 Secondary judgment of 3D reconstruction outliers using temporal
criteria. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.11 Example result after outlier deletion. . . . . . . . . . . . . . . . . 37
viii

2.12 Segment labellings using a neutral gesture marker template. . . . 38
2.13 Concatenated and labeled marker data. . . . . . . . . . . . . . . . 39
2.14 Example of interpolation for missing data. . . . . . . . . . . . . . 40
2.15 Acoustic silence detection. . . . . . . . . . . . . . . . . . . . . . . 42
2.16 Mouth shape parameters for audio-visual end-point detection. . . 42
2.17 Token alignment using optical features and acoustic silence seg-
mentations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1 Flowchart for the development of a talking face synthesis system. 47
3.2 Flowchart of the training module in the acoustic-to-optical synthe-
sis system. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3 Flowchart of the synthesis module in the acoustic-to-optical syn-
thesis system. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.4 Flow chart of the evaluation module in acoustic-to-optical synthe-
sis system. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5 State path diagrams for a DBN model with [Na, Nv] = [3, 3] and
MICSA = 1. Audio-visual synchronized (AVS) state transition
path is shown in (a). Audio containing video (ACV) transition
path is shown in (b). Video containing audio (VCA) transition
path is shown in (c). Audio preceding video (APV) transition
paths with modes 1 to 4 are shown in (d), (f), (h), and (j) respec-
tively. Video proceeding audio (VPA) transition paths with modes
1 to 4 are show in (e),(g),(i), and (k) respectively. . . . . . . . . 52
3.6 DBN training highlighted in the system training module . . . . . 53
ix

3.7 An example of a DBN with joint transition and observation param-
eters in HMM forms with maximum inter-chain state asynchrony
MICSA of 1, and [Na, Nv] of [3,3]. A refers to the state transi-
tion probability model, and B refers to the observation probability
model. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.8 DBN inference highlighted in system synthesis module . . . . . . 55
3.9 Feature extraction components highlighted in the acoustic-to-optical
synthesis system . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.10 Example of marker trajectory comparison between recorded data
in solid line and synthesized data in dash line. The background
is the spectrogram of the acoustical signal. The trajectory is the
summation of the mouth shape variations from width and height.
The sentence is “The baby puts his right foot in his mouth.” . . . 62
4.1 (a) Original markers, and (b) active facial mesh with white sphere-
shaped key points for a generic head model (mesh model from
http://www.digimation.com). . . . . . . . . . . . . . . . . . . . . 68
4.2 (a) A generic 3D head model in a neutral gesture based on Fig-
ure 4.1(b), and (b) the model’s rendered sub-facial regions used in
deformation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.3 Key-frames animated using the recorded marker data for the word
’brief’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4 Key-frames animated using the recorded marker data for the sen-
tence ’A big wet stain was on the round carpet.’ . . . . . . . . . 73
x

4.5 Key frames of animation using synthesized optical data for the
same word in Figure 4.3 . . . . . . . . . . . . . . . . . . . . . . . 79
4.6 Key frames of animation using synthesized optical data for the
same sentence in Figure 4.4 . . . . . . . . . . . . . . . . . . . . . 80
4.7 Notched-Box-and-Whisker Plot of the correct discrimination statis-
tics from all 16 subjects with (a) from recorded marker driven
animation and (b) from synthesized ones. . . . . . . . . . . . . . . 85
4.8 Average discrimination correct score comparison between recorded
and synthesized marker driven animations of 32 words . . . . . . 86
xi

List of Tables
1.1 Factors in audio-visual perceptual tests . . . . . . . . . . . . . . . 16
2.1 Average and maximum number of recordings for different utter-
ance types. n is the average number of utterances per take. . . . 21
2.2 Place and manner for consonants [107]. The meaning of the single-
letter phoneme representations can be found in Appendix D. . . 24
2.3 Speech materials of CorpusC . . . . . . . . . . . . . . . . . . . . . 26
2.4 Unit vocabularies in CorpusA and CorpusC . . . . . . . . . . . . 27
2.5 Unit average repetitions in CorpusA and CorpusC . . . . . . . . . 27
2.6 Unit vocabulary from key words in sentences . . . . . . . . . . . . 27
2.7 Unit average repetitions from key words in sentences . . . . . . . 28
2.8 Forced alignment calibration using manual segmentation of 5609
phonemes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.1 Comparison of MLR and the three DBN models with [Na, Nv] =
[3, 3] and MICSA = 1 in terms of motion trajectory reconstruc-
tion accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.2 Comparison of three DBN structures with [Na, Nv] = [3, 3] and
MICSA = 1 in terms of state path entropy and dominant state
path . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.3 Comparison of model selection parameters in three DBN structures
in terms of the correlations between synthesized and recorded op-
tical data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
xii

4.1 Human subject perceptual evaluation results of recorded marker
data. N refers to the number of valid subjects for each category.
The means and standard deviations were collected from the valid
subjects. Valid subjects are subjects with discrimination correct
scores significantly different(p < 0.05) from 50% chance level per
category. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.2 Human subject perceptual evaluation results of synthesized marker
data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
B.1 Diphone carrier words for the sentence Slide the tray across the
glass top. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
B.2 Diphone carrier words for the sentence ’Feel the heat of the weak
dying flame.’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
D.1 Phonemes in single letter symbols . . . . . . . . . . . . . . . . . . 116
D.1 Phonemes in single letter symbols . . . . . . . . . . . . . . . . . . 117
E.1 Animated words and their paired words from natural video in four
visual lexicon distinction levels . . . . . . . . . . . . . . . . . . . . 118
xiii

Acknowledgments
My sincere gratitude goes to my advisor, Dr. Abeer Alwan for her gracious
support, encouragement, and guidance. This dissertation will not be finished
without her patience and advice. I would also like to express my gratitude to
Dr. Patricia Keating for her insightful guidance and her generous encouragement
for this research. My thanks also go deeply to Dr. Ali H. Sayed and Dr. Lieven
Vandenberghe for their comments, encouragements, and especially their inspiring
graduate courses.
The collaborators in House Ear Institute had provided enormous support to
this study. I thank Dr. Jintao Jiang, Dr. Lynne E. Bernstein and Dr. Edward
Auer for their suggestions and comments on audio visual speech processing. My
thanks also go to Dr. Sumiko Takayanagi for her generous helps on statistical
analysis in behavioral studies and her long term encouragement and support.
My lab colleagues have also provided important helps. I especially thank Dr.
Xiaodong Cui, Dr. Panchapagisan, Dr. Markus Iseli, Hong, Yen, and Jonas for
countless technical discussions and for their friendships.
This dissertation would not have been possible without the love and support
of my family - my father Chongsheng, my mother Meilan, my husband Fan, my
son Ben, my father-in-law Zhixi, my mother-in-law Weidong, and my brother
Yingjian. This dissertation is dedicated to my family.
xiv

Vita
1976 Born, Wuhan, Hubei, China
1998-1999 Undergraduate Student Researcher
Electrical Engineering Dept, Tsinghua University,
1999 B.A. Electrical Engineering Dept. Tsinghua University, Beijing,
China
2001 M.S. Electrical Engineering
University of California, Los Angeles, (UCLA)
2001-2006 Graduate Student Researcher,
Teaching Assistant/Associate
Electrical Engineering Department,
University of California, Los Angeles (UCLA)
2006-2008 Software Engineer,
Sony Picture Imageworks Inc., Culver City
Publications
J. Xue, B. J. Borgstrom, J. Jiang, L. Bernstein, and A. Alwan, ”Acoustically-
driven Talking Face Synthesis Using Dynamic Bayesian Networks”, Proceedings
of IEEE ICME 2006, pp. 1165-1168, 2006.
J. Xue, J. Jiang, A. Alwan and L. Bernstein, ”Consonant confusion structure
based on machine classification of visual features in continuous speech,” Pro-
xv

cessings of Audio-Visual Speech Processing Workshop 2005, Vancouver Island,
Canada, pg. 103-108, 2005.
J. Xue, A. Alwan, J. Jiang, and L. E. Bernstein, ”Phoneme clustering based on
segmental lip configurations in naturally spoken sentences,” J. Acoust. Soc. Am.
117, 2573, 2005.
J. Xue, A. Alwan, E. T. Auer, Jr., and L. E. Bernstein, ”On audio-visual syn-
chronization for viseme-based speech synthesis,” J. Acoust. Soc. Am. 116, 2480,
2004
Z. AlBawab, I. Locher, J. Xue, and A. Alwan, ”Speech Recognition over Blue-
tooth Wireless Channels,” Proceedings of EUROSPEECH 2003, Switzerland, pp.
1233-1236, 2003.
xvi

Abstract of the Dissertation
Acoustically-Driven Talking Face Animations
Using Dynamic Bayesian Networks
by
Jianxia Xue
Doctor of Philosophy in Electrical Engineering
University of California, Los Angeles, 2008
Professor Abeer Alwan, Chair
Visual speech information on a speaker’s face is important for improving the
robustness and naturalness of both human and machine speech comprehension.
Natural and intelligible talking face animations can benefit a broad range of appli-
cations such as digital effects, computer animations, computer games, computer-
based tutoring, and scientific studies of human speech perception. In this study,
the focus is on developing an acoustically-driven talking face animation system.
Acoustical speech signals are found to be highly correlated with visual speech
signals, and thus can be used effectively to drive facial animations.
The acoustically-driven talking face animation system is developed using an
audio-visual speech database. The database used in this study includes a previous
recording (CorpusA), a pilot diphone-oriented recording (CorpusB), and a new
recording (CorpusC). The raw optical data from the new recording are processed
through an archiving pipeline. Acoustical and optical data are first segmented
into tokens, and then acoustical data are segmented into phonemes through HMM
forced-alignment.
xvii

Dynamic Bayesian networks (DBNs) are applied to the acoustic-to-optical
speech signal mapping in the acoustically-driven talking face animation system.
Different DBN structures and model selection parameters are studied. Exper-
imental results show that the state-dependent structures in the DBN models
yield high correlation between reconstructed and recorded facial motions. More
interestingly, the maximum inter-chain state asynchrony parameter of the DBN
configurations has a greater effect on synthesis accuracy than the number of hid-
den states in the audio and visual Markov chains. This study demonstrates the
potential of DBNs in acoustically-driven talking face synthesis.
An optical data-driven animation rendering tool is built based on radial basis
functions. Synthesized optical data and recorded optical data are both used to
generate animations for system evaluation. A lexicon distinction identification
test is conducted with 16 human subjects. Perceptual test results on original opti-
cal data-driven animations show that the radial basis function algorithm provides
highly natural rendering of talking faces. Perceptual test results on synthesized
optical data-driven animations show that for some words the synthesized results
yield similar lexicon distinction identification scores to the results using recorded
data-driven animations. The formal perceptual test provides quantitative evalu-
ation of the entire acoustically-driven talking face animation system, which can
be very useful for future system tuning and improvement.
xviii

CHAPTER 1
Introduction
1.1 Motivation and Overview of Talking Face
Animations
Visual speech information on a speaker’s face is important for improving the
robustness and naturalness of both human and machine speech comprehension.
Here, visual speech information refers to images of lower facial regions during
speech production. The lower facial region includes the cheeks, the lips, the
inner mouth organs, and the jaw. The teeth, velum, and tongue are inner mouth
organs that are usually partially perceived visually during speech production.
Deaf people use visual speech to lipread in speech communicatioin. In [2],
speech reading or lipreading as it is often called, was considered as a psychologi-
cal process not only in people with hearing loss and deafness, but also in normal
hearing people. The McGurk effect [31] demonstrated that, for normal hearing
people, visual information is integrated with speech information from the acous-
tical signals. For example, when an audio stimulus of /ba/ is presented with a
visual stimulus of /ga/, /da/ is perceived. Such perceptual results are repeat-
able among subjects across age, gender, and native language. Visual speech has
also been found to enhance speech comprehension in acoustically-noisy condi-
1

tions [97][98], and is a very important modality for infant language development
[1] and for non-native speakers [99].
Given the important role of visual speech, computer generated visual speech,
or automatic talking face animations, can provide better human-computer inter-
action. It can benefit a broad range of applications such as digital effects and
computer animations, computer games, computer-based tutoring, and scientific
studies of human speech perception.
Most automatic talking face animation systems involve three major modules
as follows:
• Finding key facial gestures;
• Aligning key gestures with the acoustical signal temporally;
• Interpolating key gestures temporally and/or spatially.
Systems such as Video Rewrite [10], MikeTalk [18], and Voice Puppetry [8], are
built on sequences of two-dimensional (2D) images. Smoothing and morphing are
applied between pre-stored image sequences in [10], or key frames in [6], [18], and
[8]. The selections of pre-stored image sequences or key frames are accomplished
manually [18] or automatically [10] [8].
A common method for selecting key frames focuses on the viseme [84] which
is a term abbreviated from visual phoneme. For example, the phonemes /p,
b, m/ share a common viseme. However, there is no complete agreement on the
viseme set in terms of corresponding phonemic clusters. For example, consonants
and vowels were categorized into 6 and 9 visemes respectively in [18], while 12
consonant visemes and 7 vowel visemes were used in [60].
2

Systems that directly manipulate three-dimensional (3D) facial models have
also been studied. Parameter-based 3D animations in [34], [35], and [14] used fa-
cial shape parameter sets to represent key facial gestures. The MPEG-4 standard
[3] specified the Facial Definition Parameters (FDPs) and the Facial Animation
Parameters (FAPs) to represent and animate any facial model. Physically-based
models in [43] and [36] simulated facial skin, tissue, and muscles, by multilayer
dense meshes. Facial gestures were represented through muscle contraction pa-
rameters. In [14], the Lofqvist gesture production model was adapted to simulate
speech coarticulation for better key gesture alignment and interpolation.
Modern 3D animation systems rely on Motion Capture (MoCap) systems
[112]. MoCap techniques have been widely used in military, entertainment,
sports, and medical applications. Markers glued on actors’ facial or body regions
are captured through an optical system with multiple cameras. The 3D positions
of the markers are directly recorded in synchrony with the acoustical signals.
These 3D marker data can be applied to deform dense 3D models. MoCap data
capture subtle human motions which lead to highly natural movements in ani-
mated characters. However, the data recording procedure is expensive and time
consuming. The raw data contains various artifacts that require semi-automatic
or manual corrections, labeling, interpolation, and smoothing.
With the development of computer-vision techniques, the so called two-and-
half-dimensional (2.5D), or performance-driven facial animation systems appeared
in [44], [111], etc. These systems used recordings of 2D talking face image se-
quences to drive a 3D facial model. Such approaches yield flexible rendering
results while preserving naturalness from video recordings. One important mod-
ule in many performance-driven animation systems is the Facial Action Coding
System (FACS) [16]. Performance of key facial expressions and Action Units
3

(AU) were captured and further applied to 3D facial animations. In [111], 3D
facial animations were highly natural given a video recording of the same speech.
Computational approaches were integrated in different modules in different
systems. One challenge is to integrate computational models into temporal align-
ment of key gestures and acoustical signals. Systems built with automatic acous-
tical signal alignment are limited. Furthermore, there are fewer systems that
can synthesize new speech content other than that in the training dataset with
automatic acoustical signal alignment.
The goal of this research is to develop a prototype 3D talking-face animation
system that is driven by the acoustical signals. Given a corpus of audio-visual
speech from motion capture data, the system can synthesize 3D talking face
animations in synchrony with an input acoustical signal that has no recorded
motion capture data. Such a system can be trained to automatically generate
new animations without capturing new motion data. Our system development
involves corpus collection and preprocessing, synthesis and animation system
development, and perceptual evaluations.
1.2 Overview of Acoustically-driven Talking Face
Animations
Many studies on the relationship between acoustical and visual signals led to the
development of acoustically-driven talking face animation systems. Regardless of
the form of the final production (e.g. 2D or 3D rendering), the main challenge
in such an approach is to generate facial key gestures that are aligned with the
input acoustical signals computationally.
4

An acoustically-driven talking face animation system is usually divided into
three main components:
1. Acoustical and visual feature extraction - the front end
2. Acoustical to visual feature mapping - the back end
3. Animation rendering driven by visual features - the rendering
In the front end, the speech signals in audio and visual modalities are pro-
cessed to obtain a sequence of audio and visual features. The back end contains
models of speech that are used to transform a sequence of acoustical features into
its corresponding sequence of optical features.
The visual features in the front end are also used in the rendering to drive the
animation. Thus, visual features not only need to be robust to represent a speech
unit, but also need to be detailed to drive the animation with subtle motions for
naturalness.
A back end mapping model is usually trained from aligned acoustical and
visual features for the speech unit that the model represents. Such a training
procedure can be applied to a set of back end models which correspond to a
speech unit set for a particular language. Then, given a sequence of acoustical
features, the trained mapping models can be temporally aligned, and can map
the corresponding acoustical features into visual feature sequences.
In this dissertation, most of the focus is on the acoustical to visual feature
mapping models.
5

1.3 Feature extraction
Linear Predictive Coding (LPC) is commonly used in audio signal processing
for representing the spectral envelope of a digital acoustic signal in compressed
form, using a linear predictive model. The model is an approximation of the
vocal tract transfer function. In [49], Line Spectral Pairs (LSPs) were used as
acoustical features for correlation analysis between acoustic and optical features.
The iFace system [21] used Mel Frequencey Cepstral Coefficients (MFCCs) as
acoustical features.
In [49], visual features were the results of the Principle Component Analysis
(PCA) of the 3D marker positions recorded from a human face while speaking.
PCA reduced 54 marker position data channels into 7 visual feature channels.
In [21], facial motions were represented in a set of motion units by video
tracking of dotted markers on a human talking face. Then, the facial motion
features were extracted into a set of Motion Unit Parameters (MUP) for each
motion unit.
1.4 Acoustical to visual feature mapping
Previous studies applied various techniques on acoustical to visual feature map-
ping from regression to other statistical methods.
1.4.1 Regression methods
In [25][49], linear regression techniques have been applied to speech acoustics and
optical data, and correlations between the estimated and recorded optical motion
6

tracks were about 75% for nonsense CV syllables.
In [48] [49] [21] [30], neural networks were used to map acoustical to visual
features. For one PCA component, a sub-network consists of 10 neurons and one
linear output layers. The network was trained on 3 to 4 repetitions and tested
on 1 for both English and Japanese sentences. The estimation resulted in an
average correlation with the original data of 0.85. In iFace [21], the mapping from
acoustical features to facial motion features MUPs were modeled using Multi-
layer Perceptrons (MLPs) and were trained using back-propagation algorithms.
The animation results showed reduced mouth motions and unnatural lip jitters.
In general, regression methods (linear or non-linear) have high demands on
training data. The training procedure is usually computationally expensive.
1.4.2 Statistical methods
In [13], Gaussian Mixture Models (GMMs) were used to model the audio-visual
joint features. Training of the model parameters was done by the Expectation
Maximization (EM) algorithm. Then for an input acoustical signal, the cepstrum
coefficients were used in the mixture component likelihood estimation. The width
and height of the lips were estimated by the weighted sum of the mixture models
for the visual modality. This work provided an interesting framework of a GMM
approach as shown in Figure 1.1. However, visual features that focused only on
the lips are not adequate for animation rendering.
In [45], lip movements were generated from acoustical signals using Hidden
Markov Models (HMMs). In the training stage, phoneme HMMs were trained
using acoustical features. Then these acoustical features were assigned to cor-
responding HMM state sequences using the forced Viterbi alignment. For each
7

Training Data
Visual Feature Extraction
Acoustic Feature Extraction
AV Joint Feature
VQ Clustering
New Audio
Acoustic Feature Extraction
Gaussian mixture components probabilities
GMM optimized by EM
Estimated Visual Parameter
Figure 1.1: Gaussian Mixture Models (GMMs) applied to mapping continuous
speech to facial movements [13].
HMM state, an average of the synchronous lip features was calculated from all
the associated frames as a viseme class. For synthesis, acoustical features were
aligned into a HMM state sequence using the Viterbi alignment, then the lip
features were retrieved from the associated viseme of each state and were con-
catenated together. Formal perception tests of the synthesized lip movements
showed that the method generates natural lip movements that are sensitive to
forward coarticulation. The precision of lip gesture alignment depends upon the
accuracy of the Viterbi algorithm. Incorrectly decoded frames of the HMM state
sequence yielded wrong lip shapes.
In our work, we consider statistical mapping methods with a focus on HMM-
based acoustical to visual feature mappings. Acoustical HMMs have been widely
applied in Automatic Speech Recognition (ASR) systems, and multi-model HMMs
have been applied in Audio-Visual Automatic Speech Recognition (AVASR) sys-
8

tems. The multi-model HMMs can be viewed as a special case of a general graph
model, the Dynamic Bayesian Networks (DBN). Although speech recognition is
not the interest of this study, the methodology of back end multi-model speech
processing in AVASR can be adapted and applied in developing a talking face
animation system. In the following sections, basic algorithms for HMMs and
DBNs are presented.
1.4.3 Hidden Markov Models
A HMM can be viewed as a special one-dimensional and directional graph; it
consists of a set of states. Each state is associated with a probability distribution
for the observation (or emission) of feature vectors from that state. Each state
can be connected with the following state or itself through a state transition
probability. There are also two non-emitting states: the initial state and the final
state. The reason for the word hidden in HMM, is that in practice, the state
sequence is hidden or unknown and what is known is the observation sequence.
For a HMM, let the states be numbered 1 ≤ i ≤ N , the transition probability
from state i to state j be aij , the observation vectors (speech features) be X =
{xt, 1 ≤ t ≤ T}, and the output probability density of feature vector x from
state j be bj(x).
The total likelihood of the observation sequence being produced by the model
with parameters Λ is easily shown to be [83]:
P (X|Λ) =∑
Θ
∏
t
ast,st+1bst
(xt) (1.4.1)
where the summation is over all possible state sequences Θ = {s1, s2, . . . , sT}.
The observation probability distribution is usually taken to be a Gaussian
9

mixture distribution
bj(x) =R
∑
r=1
cjr
(2π)d/2|Σjr|1/2exp
[
−1
2(x − µjr)
T Σ−1jr (x − µjr)
]
(1.4.2)
where R is the number of Gaussians in the mixture, cjr is the weight of mixture
component r for the hidden state j and∑R
r=1 cjr = 1, µjr is the mean of the
mixture component r for the hidden state j, and Σjr is the covariance matrix
of the mixture component r for the hidden state j. In practice, the covariance
matrices are usually taken to be diagonal for computational efficiency during
recognition.
During HMM training, the problem is to estimate HMM parameters given a
set of utterances along with transcriptions. Therefore, the observation sequences
along with the identities of the model sequences producing them are given, while
the state sequences of the HMMs are unknown.
The Expectation Maximization (EM) algorithm is an iterative algorithm to
obtain increasing-likelihood estimates of model parameters from incomplete data
([113]). Following [95], let the distribution p(X ,Y|Λ) of data (X ,Y) be known,
but whose parameters Λ need to be estimated given only X .
In the EM algorithm, given an initial estimate of the parameters Λ(i−1), we
form the auxiliary function
F(Λ, Λ(i−1)) = E[
log p(X ,Y|Λ)|X , Λ(i−1)]
(1.4.3)
A new estimate of the parameters is obtained as:
Λ(i) = arg maxΛ
F(Λ, Λ(i−1)) (1.4.4)
It can be proven that the likelihood of the observed data is non-decreasing:
p(X |Λ(i)) ≥ p(X |Λ(i−1)) (1.4.5)
10

If the EM algorithm converges, then the limit is a local maximum of the
likelihood function.
Given an initial estimate of the parameters of an HMM and given data that
was produced from the HMM, one can use the EM algorithm to derive a new
estimate of the parameters that is guaranteed to increase the likelihood. For
HMMs, the parameters are Λ = {∪g{cg, µg, Σg}, [aij]}, where g is a Gaussian
mixture distribution in the HMM. The missing information is the state sequence
Θ. The auxiliary function is therefore
F(Λ, Λ(i−1)) =∑
Θ
P (X, Θ|Λ(i−1)) · log P (X, Θ|Λ) (1.4.6)
Maximizing this auxiliary function with respect to the parameters results in the
Baum-Welch equations.
Let γjm(t) be the posterior probability of being in state j at time t and the
output being produced by mixture r. γjr(t) may be computed efficiently using
the forward-backward algorithm. Then the new Baum-Welch estimates of the
parameters are:
µjr =
∑Tt=1 γjr(t)xt
∑Tt=1 γjr(t)
(1.4.7)
Σjr =
∑Tt=1 γjr(t)(xt − µjr)(xt − µjr)
T
∑Tt=1 γjr(t)
(1.4.8)
cjr =
∑Tt=1 γjr(t)
∑Tt=1
∑Rl=1 γjl(t)
(1.4.9)
The re-estimation formulae for the transition probabilities aij may be found
in [83].
11

1.4.4 Dynamic Bayesian Networks
As mentioned earlier, HMMs are a special case of DBNs. A general dynamic
Bayesian network is a directional graph model that allows interactions between
multiple hidden Markov chains as shown in Figure 1.2. In this work, DBN mod-
els are used for back end audio-visual speech modeling. The physical concept
of multimodel speech processing can be more straight-forwardly represented by
DBNs through audio-visual joint state transition structures. DBNs provide flexi-
ble configurations of joint states given model selection parameters of the number
of states in each modality and the maximum state asynchrony between modal-
ities. Here, audio-visual asynchrony states refer to the off-diagonal joint state
elements in the 2D hidden state space. These asynchrony states provide struc-
tural potential to capture various audio-visual alignment patterns for a speech
unit. Given the joint state transition structure, different joint state transition
models can be applied to capture the interaction between two highly correlated
time series.
1.5 Animation rendering
Various 3D model deformation techniques have been studied since the first com-
puter generated talking face [34].
• Free-form face model Free-form face model approaches define a control
model to deform the face model. A control model consists of a set of control
points with their 3D coordinates. Vertices of the 3D facial model are deformed by
interpolation methods. Popular interpolation functions include affine functions,
B-spline functions, cardinal spline and springs, the combination of affine functions
12

11
12
13
21
22
23
31
32
33
Audio-visual joint states
A1 A2 A3 AcousticalStates
Acoustical Observations
V1
V2
V3
Op
tica
l O
bse
rvat
ion
s
Op
tica
lS
tate
s
Figure 1.2: General structure of dynamic Bayesian networks for audio-visual
speech modeling
13

and radial basis functions, rational functions, and Bezier volume models. Such
deformation mechanism fits well to motion capture data-driven animations.
• Parameterized face model Parameterized wire-frame models [34] [35]
[14] use a set of parameters to decide the shapes of the face models. For ex-
ample, vertices on the lips can be directly controlled through parameters such
as mouth opening width, mouth opening height, upper lip protrusion, and lower
lip protrusion. In Parke’s model [34], the initial coordinates of a set of anchor
vertices and the parameters are predefined. The remaining vertices in the face
model are calculated by a set of predefined interpolation functions whose vari-
ables are those parameters and the coordinates of the anchor vertices. Such an
approach has been integrated into various versions of facial animation editing
applications. Users can easily manipulate parameters to move facial models into
a desired gesture.
• Physics-based model Physics-based models [43] [36] simulate facial skin,
tissue, and muscles by multilayer dense meshes. Facial surface deformation is
triggered by the contractions of the synthetic facial muscles. The muscle forces
are propagated through the skin layer, and thereby deform the facial surface. The
simulation procedure solves a set of dynamics equations which is computationally
expensive. Such an approach can produce highly realistic rendering of facial
animation given detailed muscle contraction models.
1.6 Perceptual evaluation
One of the challenging problems to the technical development of a visual speech
synthesis system is to evaluate the final product, the animations. In our study, we
need to evaluate the animation results in terms of visual intelligibility. A formal
14

visual speech perceptual test needs to be designed and conducted to measure how
well the synthesized talking face animation can convey visual speech information.
In speech perception studies, human visual speech perceptual experiments
are usually conducted under laboratory conditions with controlled stimuli and
responses. Various perceptual tests exist with no standard experimental configu-
rations for intelligibility evaluations of talking face animations. The main factors
in the design of audio-visual perceptual tests are listed in Table 1.1.
In [54] [57] [62] [65] [67] [75] [70] and [81], animation systems were developed
with perceptual tests. Among the 8 studies, sentence stimuli were used in [54]
[62] [67] [70] with open-set identifications. With the exceptions of [54] and [70],
all studies used word or syllable stimuli. Three out of the six studies with word
or syllable stimuli used closed set identification tests. Short and isolated speech
stimuli were more common used than long and continuous stimuli.
Only one study [62] conducted the perceptual test with no audio stimuli. This
type of lipreading experiments yields low identification scores and very large
subject variation. In [54], clean acoustical signals were degraded by a three-
channel vocoder while the majority of similar studies used acoustical signals with
additive noise. For additive noise, different range of SNRs were tested in [57] [65]
[70] and in [81]. As we can see, audio treatments varied across studies significantly.
The shape of the noise and the SNRs are not standardized. However, audio-in-
noise experiment are more common than clean audio ones.
In all studies, the majority of the subjects were normal hearing and native
speakers of the language used in the stimuli. At least 16 subjects participated
in all studies except [81]. Identification correct scores are most common for
describing results from subjects’ reponses, again with the exception of [81] in
15

Table 1.1: Factors in audio-visual perceptual tests
Factors Options
Stimuli - Nonsense syllables
- McGurk words [75]
- Isolated words
- Isolated sentences
- Running speech, such as story telling
Task - Open set identification
- Close set identification
- Subjective judgments
Audio - Silent
- Vocoder degraded audio [54]
- Additive-noise degraded audio with different SNRs
and different noise types
Subjects - Normal hearing vs. hearing impaired
- Native speaker vs. non-native speakers
Scoring - Phoneme identification correct
- Clustered phoneme or viseme identification correct
- Syllable identification correct
- Word identification correct
- Keyword identification correct
which the subjects’ responses were from a 5-choice survey instead of identification
or discrimination tests.
16

In this study, a new perceptual test is designed and conducted for visual speech
intelligibility evaluation of both the synthesized and recorded optical data-driven
animations.
1.7 Outline of this dissertation
The rest of the dissertation is organized as follows.
Chapter 2 presents the database developed and used in this study. The record-
ing corpus design and final data set are presented. Raw optical recordings were
processed through an automatic data archiving pipeline. Preprocessings in the
data archiving pipeline are presented. Automatic segmentation of both acoustical
and optical signal are presented.
Chapter 3 presented the acoustically-driven visual speech synthesis system us-
ing DBNs. The DBN model training methods and the inference of visual states
given acoustical observation and DBN models are derived. Experiments on mul-
tiple DBN configurations and different DBN model parameters are presented and
discussed.
In Chapter 4, we describe the approach for animation rendering using optical
data and a generic three-dimensional head model. We also present a perceptual
evaluation method to evaluate the quality of the animation rendering algorithm
and the entire acoustically-driven talking face animation system.
Finally, Chapter 5 presents a summary of the dissertation and future research
directions.
17

CHAPTER 2
Audio-Visual Database
2.1 Introduction
In this study, the audio-visual database refers to a dataset of audio and opti-
cal signals which were simultaneously recorded from human subjects uttering a
corpus of speech materials in a quiet sound booth.
An audio-visual speech database is necessary in all three phases of developing
an intelligent acoustically-driven talking animation system, namely, multi-modal
speech analysis, automatic talking face animation, and audio-visual speech per-
ceptual evaluation. The multi-modal speech analysis in this study involves statis-
tical modeling of the relationship between acoustic and optical signals of audio-
visual speech. Hence, a large dataset is required for reliable statistical learning.
The automatic talking face animation requires the optical data to be anchored
on a 3-D generic head model, so that the motion of these anchor points can drive
the head model intelligibly. Perceptual evaluations require testing speech materi-
als to be representative for visual intelligibility measurement. In summary, each
phase dictates different aspects of database design, such as number of repetitions,
placement of markers, speech content, etc.
Given recording constraints such as recording time, recruitment of subjects,
18

available cameras, budget, etc., the data corpus was carefully designed to fulfill
the above requirements. The database was recorded and archived in collaboration
with researchers at the House Ear Institute (HEI). A data archiving pipeline was
developed.
The following sections present efficient corpus design and automatic data
archiving in detail.
2.2 Efficient design of the audio-visual speech corpus
Corpus efficiency is important for both robust system training and informative
visual speech intelligibility evaluation. One can maximize testing capacity for vi-
sual intelligibility evaluation, while minimizing training corpus size. This can be
approached through three directions: improving the synthesis system framework,
incorporating speech content influence on visual speech intelligibility, and opti-
mizing corpus selection techniques. Based on initial system development from an
existing audio-visual sentence corpus, a complementary corpus was designed for
statistical training and perceptual testing of the talking face synthesis system.
What speech content should be covered and how large should the corpus be
for the purpose of training and evaluating an acoustically-driven talking face
animation system?
Let c represent a subset from a speech material collection Ψ, nts(c) and ntr(c)
represents the number of testing and training utterances as a function of speech
material set c, respectively. We prefer to select c so that nts(c) + ntr(c) is small
while nts(c)/ntr(c) is large. The selection is under the following constraints:
• Recording time for all utterances T (c) must be less than a maximum dura-
19

tion of Tmax;
• nts(c) must be at least the minimum required number of testing utterances
Nts;
• ntr(c) must be at least the minimum required number of training utterances
Ntr.
A previously recorded sentence corpus (see Appendix A, referred to here as
CorpusA) and a pilot recording corpus (see Appendix B, referred to here as
CorpusB) are analyzed for the final design of the new recording corpus (see Ap-
pendix C, referred to here as CorpusC). CorpusA includes 320 IEEE sentences
from 8 subjects. CorpusB includes a set of 34 nonsense tri-syllables and one IEEE
sentence from one subject. The following results and analysis are all based on
the studies from CorpusA and CorpusB.
In designing CorpusC, a combination of material types such as sentences,
words, nonsenses syllables, etc. is needed. According to the recordings of Cor-
pusA and CorpusB, the average number of takes per recording day is 120. The
maximum number of recording days is 2. Let n be the average number of utter-
ance per take, and Nmax be the maximal number of utterance for a recording.
The following relationship applies for utterances from a type of material:
Nmax = 240 × n (2.2.1)
We are interested in the recording time constraints for material types such as
sentences, words, nonsense tri-syllables, etc. Thus, average recording times n are
collected from the recordings of CorpusA and CorpusB. Table 2.1 shows n and
corresponding Nmax for different materials.
20

Table 2.1: Average and maximum number of recordings for different utterance
types. n is the average number of utterances per take.
Utterances Sentence Words Nonsense Tri-syllable
n 4 10 6
Nmax 960 2400 1440
For a corpus with multiple types of materials, the maximal number of utter-
ance for the corpus, Nmax(c), can be estimated from Table 2.1. Hence, the first
constraint can be represented from recording time into number of utterances as
the following:
nts(c) + ntr(c) < Nmax(c) (2.2.2)
The minimum number of testing utterances Nts is determined from the perceptual
evaluation requirement. The effect of context on visual intelligibility had been
incorporated into the design of the testing corpus to reduce Nts. The minimum
number of training utterances Ntr is a function of the talking-face synthesis sys-
tem, and testing corpus requirement. In the following two subsections, methods
to reduce Nts and Ntr are discussed in detail based on the studies of CorpusA
and CorpusB. The third subsection describes the new recordings of CorpusC.
2.2.1 Content influence on visual intelligibility
Improving communicative functionality (intelligibility) of a synthetic talking face
is of primary concern during system development. Evaluating visual intelligibility
involved various factors such as noise condition of the audio signals, subject
21

hearing level, stimuli type, scoring method, etc. Among these factors, stimuli
types play an important role in corpus design. Thus, a brief review of content
influence on visual intelligibility is provided in this subsection. The testing corpus
is selected based on the following assumptions about content influence on visual
speech perception.
Previous studies [84][85][51] developed the concept of grouping phonemes that
are similar in terms of visual perception. These studies showed the existence of
visual perceptual confusion structures, and how clustering of visually-equivalent
phonemes varies across speakers. For each speaker, visually-equivalent phoneme
clusters can vary in the degree of easiness for lipreading. Moreover, word fre-
quency and lexicon-equivalent classes need to be taken into account during word
identification by lipreaders [51]. At the sentence level, the sentence duration can
also have an influence on visual intelligibility due to visual speech coarticulation.
We are interested in those materials that are strong in visual speech coartic-
ulation. For such test content, there is room to test how well our talking face
synthesis system can reproduce coarticulation effect. Secondly, testing content
should have the least semantic or syntactic cues. This ensures that the perceptual
test involves minimum top-down psycholinguistic processes [102]. The intelligi-
bility is then coming from bottom-up phonetic processing or lexicon processing
[102] and can be tested to the maximum extent in running speech. Finally, testing
speech materials are preferred to be highly intelligible. In such case, there is per-
ceptual room to evaluate synthetic talking faces in degraded conditions compared
to natural facial speech productions.
Given these constraints, it was first decided that the testing materials should
include both sentences and isolated words so both strong and weak coarticula-
22

tion cases can be tested. We then limited the testing sentences to be a subset of
the IEEE/Harvard sentences [106] which were designed to have minimal semantic
cues and were originally designed for the purpose of testing audio speech intelligi-
bility in various communication conditions (noise degraded). Then, a dictionary
with word frequency and lexicon equivalent class (LEC) sizes was used to obtain
the sentence/word frequency, LEC, and number of syllables information. A cost
function is formed from these factors. Sentences in the IEEE/Harvard corpus
were sorted using the cost function for visual speech perception. As for words,
the testing corpus was selected from the perceptual test corpus in [51].
However, there are no standard visual phoneme equivalent classes (PEC).
Viseme, made up of the words ‘visual’ and ‘phoneme’, is another name commonly
used for this concept. One can predict theoretical PEC given the manner and
place of articulations for each phoneme. Place and manner of articulation for
consonants are shown in Table 2.2. Place of articulation for vowels is shown in
Figure 2.1. Given the phoneme confusion structure, one can generate a dictionary
using phoneme equivalent class labels for visual phoneme transcription of each
word. Words that have the same visual PEC transcription form the visual lexicon
equivalent class.
Given the frequency and LEC size, one can have a scoring of potential visual
intelligibility of a given word. High frequency and low LEC words tend to be
easier for lipreading than low frequency and high LEC words. Study [51] showed
perceptual results that confirmed this hypothesis. Further, for each sentence, one
can calculate its potential visual intelligibility using LEC and frequency of the
key words.
23

Table 2.2: Place and manner for consonants [107]. The meaning of the single-let-
ter phoneme representations can be found in Appendix D.
Bila- Labio- Den- Alveo- Postal- Pala- Velar Glot-
bial dental tal lar veolar tal tal
Nasal m n G
Plosive p b t d k g
Fricative f v T D s z S Z h
Affricate C J
Approximant w l r j
2.2.2 Training corpus requirement
Training corpus requirements highly depend on the machine learning method of
the acoustic-to-optical mapping function. The speech unit potential in terms of
sentence generation and visual intelligibility need to be taken into account. Sim-
ilar to acoustical speech synthesis systems, visual speech synthesizers have used
data concatenation approaches, linear regression, HMMs, and different combina-
tions of these methods.
In data concatenation approaches, different units including visime [18], di-
phones [74], and triphones [10] have been used. The dynamics of facial gestures
during speech production are generated from recorded facial gestures or kinematic
data with various blending techniques.
Linear regression approaches have been experimented in [27][47][48]. Cor-
pusB includes 34 diphones which can be concatenated into one sentence. These
24

Figure 2.1: Place of articulation for vowels [107]
diphones were uttered in a fixed context condition with the /ta/ syllable before
and after it. The constraints of recording time resulted in 500 diphones which
can generate less than 45 sentences using a greedy algorithm [109] ).
Statistical approaches such as multi-stream HMM were studied in [70][91]. In
this study, dynamic Bayesian networks (DBN) were explored using CorpusA. Two
DBN structures, namely, product HMM (P-HMM) and coupled HMM (C-HMM)
generated talking face animations that are visually realistic. For phoneme-based
model training, 60 tokens per phoneme yield stable model training. The sentence
synthesis capacity is unlimited. Various testing contexts can be used for system
performance evaluation. Detailed results can be found in [100].
Given the pilot analysis of training data requirement, the new recording corpus
were selected based on HMM-based optical-to-acoustic mapping using phoneme
units. Each phoneme requires a minimum of 60 tokens for reliable model training.
25

2.2.3 Final corpus
Given the above analysis, CorpusC( see Appendix C ) was collected with the
speech content listed in Table 2.3. The non-speech expressions were produced
for 3D generic facial model calibration. All the 141 words and the 400 sentences
were uttered with a neutral facial expression. Words are used in perceptual
tests. Sentences are used for training only. The final corpus is the combination
of CorpusA and CorpusC. Sentences in CorpusA are partitioned into testing
and training set. Sentences in CorpusC and the training set from CorpusA are
combined together in one training corpus.
Table 2.3: Speech materials of CorpusC
Material Quantity Repetition Purpose
Non-speech expressions 12 2 facial motion calibration
Monosyllabic words 75 2 testing
Disyllabic words 66 2 testing
IEEE/Harvard Sentences 400 1 training
Table 2.4 shows the number of vocabularies in different speech unit for the
speech materials in CorpusA and CorpusC.
Table 2.5 shows the number of repetitions of averaged over all vocabularies
for each speech unit and material.
All sentences were constructed with 5 key words each [106]. The key words
supply the majority of the meaning in the sentences. Corresponding linguistic
information from key words for sentences in CorpusA, CorpusB, and both are
shown in Table 2.6 for vocabulary. From Table 2.7, the average number of repeti-
26

Table 2.4: Unit vocabularies in CorpusA and CorpusC
Material Words Phonemes Diphones Triphones
75 monosyllabic words 75 36 176 238
66 disyllabic words 66 38 187 271
720 sentences 1889 40 1042 6277
Table 2.5: Unit average repetitions in CorpusA and CorpusC
Material Words Phonemes Diphones Triphones
75 monosyllabic words - 7.5 2.0 1.1
66 disyllabic words - 9.7 2.3 1.4
720 sentences 3.0 343.6 18.2 2.9
tions for phonemes increases from 149.2 in CorpusA to 333.2 in the combination
of CorpusA and CorpusC.
Table 2.6: Unit vocabulary from key words in sentences
Material Words Phonemes Diphones Triphones
320 sentences 1040 40 883 3408
400 sentences 1214 39 948 3995
720 sentences 1810 40 1034 5625
Resources for robust training of diphone or triphone units are limited as shown
in Table 2.7. Thus phoneme-level modeling is most suitable for the visual speech
27

Table 2.7: Unit average repetitions from key words in sentences
Material Words Phonemes Diphones Triphones
320 sentences 1.5 149.2 7.7 1.8
400 sentences 1.6 188.8 8.9 1.8
720 sentences 2.0 333.2 14.7 2.4
synthesis system. Phonemes that are rich in the number of tokens can be further
divided into context-dependent subsets of tokens for improved modeling accuracy.
Figure 2.2 shows phoneme appearance distribution in the combined 720 sentences.
2.3 Automatic Data Archiving
The optical data were captured from sets of retro-reflective markers glued on
subjects’ faces. The audio and optical data modalities were synchronized during
recording [27]. Previous optical data were archived through manual labeling
and editing procedures in the Qualisys software. In the new data recording
sessions, the number of markers increased from 20 to 33 in order to capture more
facial motion detail that spanned over the jaw and cheek regions (as shown in
Figure 2.3).
With the increasing dimensions of marker data, 3D reconstruction problems
embedded in the Qualisys motion capture system increased to a scale that is
elaborate and prohibitive for human labelers. A highly automated data archiving
pipeline was developed. Raw optical were processed into a deformable format
for talking-face animation. Then optical and acoustic data were segmented per
utterance. Finally, acoustical data were automatically aligned with phoneme
28

ZODyJUTWCSGvughoaxA^bcRe@fmwEp i I z knd l r s t10
0
101
102
103
Num
ber
of S
ampl
es
Phoneme Distribution
Figure 2.2: Phoneme appearance distribution from 720 IEEE/Harvard sentences.
The meaning of the single-letter phoneme representations listed in the figure can
be found in Appendix D.
29

TopC
BroLBroR
NosC
NosLNosRCheLHCheRH
CheLMCheRMCheLLCheRL
MLFMLCULL
ULCULR
MRCMRF
LLLLLC
LLR JawLH
JawLMJawLL
ChiLChiC
ChiRJawRL
JawRM
JawRH
EarLEarR
Figure 2.3: Marker settings in the new recording. Markers on the right side of
the speaker are labeled.
transcriptions. This procedure greatly reduced the cost of data archiving.
Given raw optical and acoustical data with multiple speech utterances in each
take, the data archiving procedure produces deformable optical data, acoustic
data, transcription, and phoneme segmentation information for all valid utter-
ances. The main procedures for automatic data archiving includes:
• Optical data preprocessing
• Audio-visual speech end-point detection
• Acoustic phoneme segmentation
Detailed descriptions of each step are in the following three sub-sections.
2.3.1 Optical data preprocessing
Due to limited 3D space resolution of the infra-red light reflection system, markers
placed with an Euclidean distance less than 1 centimeter cannot be distinguished
30

Figure 2.4: Illustration of raw optical data problems from left to right: (a) outlier,
(b) collision, and (c) missing data.
in the 3D reconstruction procedure. Due to the limitation on the number of
infra-red emitting-receiving cameras, view angles for robust 3D reconstruction are
also limited. The main artifacts in raw optical takes include: 3D reconstruction
outliers, marker collisions, missing data, multiple segments for single marker, and
jitter noise. The first three problems can be detected in 3D space as shown in
Figure 2.4. The multi-segments problem is shown in Figure 2.5. For example, 3D
positions of the marker JawRL might lie in 5 groups of the trajectory channels
with 3 channels per group. Each group stores the 3D marker positions for one set
of continuous frames without overlapping frames among the groups. However,
which channels belong to these groups is not labelled in the raw data. The
jitter refers to trajectory noise. Jitter that is not strong in trajectory signals can
produce strong visual artifacts in 3D head animations. The goal of optical data
preprocessing is to resolve these problems in the raw data so that it can be used
to drive a 3D head model in the deformation component of the system.
31

200 400 600 800 1000 1200
77
73
69
65
61
57
53
49
45
41
37
33
29
25
21
17
13
9
5
1
Input Raw Data
Frame Index
Tra
ject
ory
Cha
nnel
Inde
x
Figure 2.5: Raw marker data with multiple segments.
A robust optical data preprocessing method was developed and applied to
the new recordings of 153 takes which includes 440 utterances of sentences, and
719 utterances of isolated speech (including words and nonsense syllables). The
flowchart of optical data preprocessing method is shown in Figure 2.6. The
resulting utterances were checked visually using the deformation software VSynth.
Step 1 (HMC) is for head motion compensation. Step 2 (Deletion) is for 3D
reconstruction outlier detection and removal. Step 3 (Concatenation) is for
temporal concatenation of multiple segments emitted from each marker. Step
4 (Interpolation) is for temporal interpolation of short duration missing data.
Step 5 (Registration) is for scaling and translations of the marker data to fit
into the 3D head models for deformation. The final step (Annealing) is a semi-
automatic procedure that involves manual inspection of marker-driven 3D face
32

HMC
Deletion
Concatenation
Interpolation
Registration
Annealing
Figure 2.6: Flowchart of optical data preprocessing.
model animation and case specific fixations of jitters, long duration missing data,
and smoothing. Without manual tuning, the methods had a success rate of
87.8%. With empirical tuning especially in the final annealing procedure, 98% of
the recorded utterances was retrieved for acceptable 3D head model animation.
In the following, each step is described in detail.
Step 1: Head motion compensation (HMC) is based on [27] by coordinate
transformation. The new coordinate in the 33 marker set is determined using
three anchor markers: TopC, BroL, and NosC (see Figure 2.3 for their facial
locations relative to the other markers). For each frame, the coordinates [~x, ~y, ~z]
is determined as follows:
~y = ~n1 (2.3.1)
~z = ~y × ~n2 (2.3.2)
33

TopC
NosC
BroLn1
n2
Head Motion Calibration
Figure 2.7: Anchor points and vectors used in head motion compensation.
~x = ~y × ~z (2.3.3)
where ~n1 is the norm of vector ~VTopC−NosC as shown in Figure 2.7, ~n2 is the norm
of vector ~VNosC−BroL as shown in Figure 2.7.
The three anchor markers were chosen by two assumptions: Their relative
distances are constant through speech articulations, and 3D reconstructions of
them are stable with fixed segment indices and no multiple segments. The left
brow marker, which has a smaller motion relative to the head motion, was selected
from the two brow markers. However jitter effects were introduced in this step
due to inevitable relative brow motions during speech production. Later steps in
the pipeline address this issue by smoothing, and by user corrections.
Step 2: Outliers are detected using a polynomial interpolation method. Out-
liers are defined as marker data that are unrealistically far from the facial surface.
Projections of valid markers (including jitters, collision markers) on to the x− z
plane form a stable curved region that represents realistic marker motion space
34

−100 −80 −60 −40 −20 0 20 40
−140
−120
−100
−80
−60
−40
−20
0
20
Top View
. Raw + Polynomial Fitted
Figure 2.8: Polynomial fitting of raw marker data on the x-z plane.
(shown in Figure 2.8). Outliers are assumed to appear with a small fraction of
the total data (less than 10%). Thus, polynomial coefficients W = [w0w1 . . . wp]T
were estimated using least mean-squared error estimation as the following:
W = (XTp Xp)
−1XTp z, (2.3.4)
where Xp = [1, x, x2, . . . xp], x = [x1 . . . xn]T , z = [z1 . . . zn]T , n is the total
number of dynamic marker data which is the product of total recording frames
and total number of marker (excluding missing marker-frames) in each take, and
p is the order of the polynomial function. The estimation error e = |z −XpW | is
compared to a cost threshold T that is determined using the mean and variance
of the errors as follows:
T = µe + α · σ1/2e , (2.3.5)
where µe and σe is the mean and variance of the polynomial fitting error respec-
tively, and α is a threshold control parameter. As shown in Figure 2.9, samples
35

1 2 3 4 5 6 7 8 9 10
x 104
10
20
30
40
50
60
70
80
90
100
Channel−Frame Index
Pol
ynom
ial F
ittin
g E
rror
Fitting Error Threshold
Outliers
Figure 2.9: Primary judgment of 3D reconstruction outliers using a fitting error
threshold.
with a cost higher than T are considered as potential outliers. Then a secondary
judgment is followed in each continuous potential outlier segments as shown in
Figure 2.10. Segments which satisfy the following conditions are judged to be
the final outlier data:
D1 + D2
2> ασ1/2
e (2.3.6)
L > τ (2.3.7)
Parameters [p, α, τ ] were chosen empirically for robust outlier detection; [4, 2, 50msec]
were used in this study. Figure 2.11 showed the top-view of the accumulated
marker data after outlier removal. Compared to Figure 2.8 with marker data be-
fore outlier removal, cleaner and more isolated marker clusters can be observed.
Step 3: The raw data had 80 segments in average. Some markers had up to
36

5320 5325 5330 5335 5340 5345 5350
5
10
15
20
25
30
35
Channel−Frame Index
Pol
ynom
ial F
ittin
g E
rror
Fitting Error Threshold
d 1
d 2
L
Figure 2.10: Secondary judgment of 3D reconstruction outliers using temporal
criteria.
−120 −100 −80 −60 −40 −20 0 20 40 60−160
−140
−120
−100
−80
−60
−40
−20
0
20
40
Top View
. Raw + Preserved
Figure 2.11: Example result after outlier deletion.
37

−120 −100 −80 −60 −40 −20 0 20 40 60−140
−120
−100
−80
−60
−40
−20
0
20
40
60Frame 1312, New Segment No. 78
Front View
JawRM
TemplateCurrent FrameNew Segment
Figure 2.12: Segment labellings using a neutral gesture marker template.
12 segments. Deformable marker data should have 33 segments with one segment
for each marker. Robust concatenation of multiple segments was achieved using a
marker template that was measured by a transducer system( developed by J. Jor-
dan at HEI). Head motion compensations for the template data were processed
using the same settings as in Step 1. For each frame with unknown segments, an
average translation from labeled segments to its template position was compen-
sated. Segment data at the first frame were assumed to be captured at neutral
facial gestures. Thus, the initial average translations in the three spatial axis
were zero. Then the template marker that had minimum Euclidean distance to
the new segment was selected as the marker label for that segment (as shown in
Figure 2.12). Segments sharing the same marker label were sequenced together
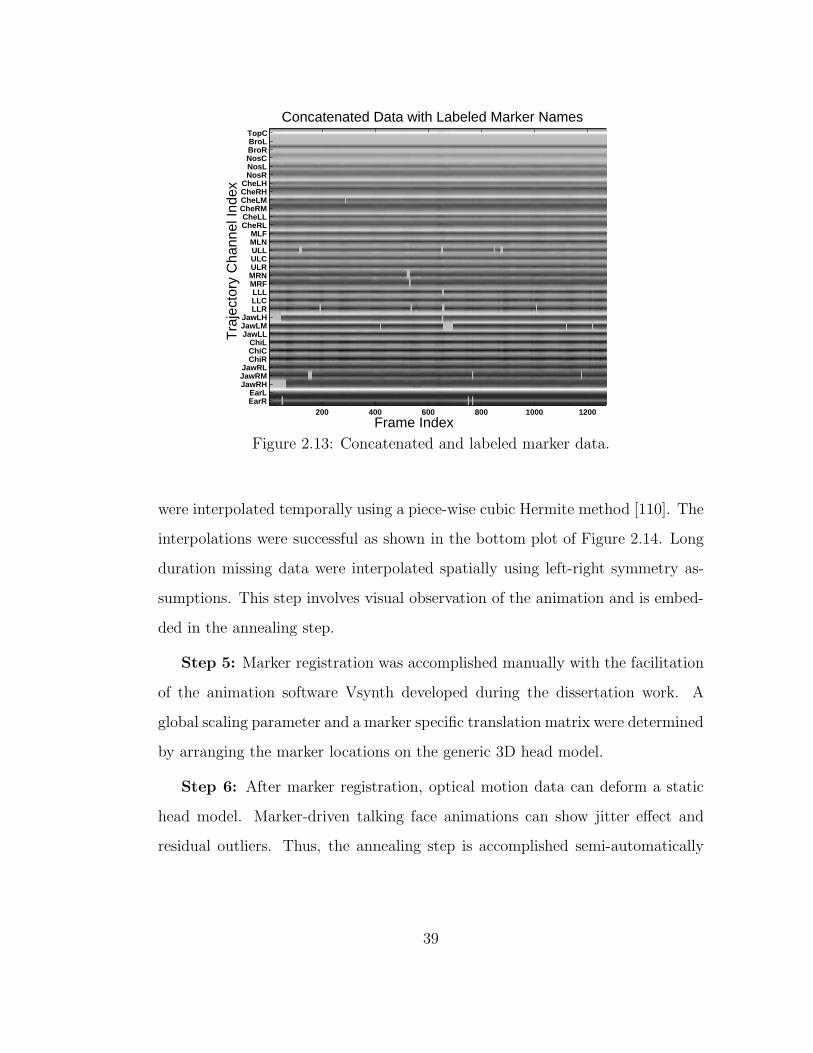
to represent single segment marker data (as shown in Figure 2.13).
Step 4: Short duration missing data as shown in the top plot of Figure 2.14
38
200 400 600 800 1000 1200
TopCBroLBroRNosCNosLNosR
CheLHCheRHCheLMCheRMCheLLCheRL
MLFMLNULLULCULRMRNMRFLLLLLCLLR
JawLHJawLMJawLL
ChiLChiCChiR
JawRLJawRMJawRH
EarLEarR
Concatenated Data with Labeled Marker Names
Frame Index
Tra
ject
ory
Cha
nnel
Inde
x
Figure 2.13: Concatenated and labeled marker data.
were interpolated temporally using a piece-wise cubic Hermite method [110]. The
interpolations were successful as shown in the bottom plot of Figure 2.14. Long
duration missing data were interpolated spatially using left-right symmetry as-
sumptions. This step involves visual observation of the animation and is embed-
ded in the annealing step.
Step 5: Marker registration was accomplished manually with the facilitation
of the animation software Vsynth developed during the dissertation work. A
global scaling parameter and a marker specific translation matrix were determined
by arranging the marker locations on the generic 3D head model.
Step 6: After marker registration, optical motion data can deform a static
head model. Marker-driven talking face animations can show jitter effect and
residual outliers. Thus, the annealing step is accomplished semi-automatically
39

Original
200 400 600 800 1000 1200
20
40
60
80
Interpolated
200 400 600 800 1000 1200
20
40
60
80
Frame Index
Cha
nnel
Inde
x C
hann
el In
dex
Figure 2.14: Example of interpolation for missing data.
40

by detecting the problems in animation visualization and fixing them in the
trajectory signal case by case.
The procedure reduced elaborate manual operations of raw data archiving
significantly. After the first four fully automatic steps, 87.8% of the utterances
were clean.
2.3.2 Audio-visual speech end-point detection
This step is to pick usable audio-visual recording segments temporally. Dura-
tion of speech events in the acoustic modality is assumed to lie in between the
boundaries of the visual modality. The in and out points from audio and visual
modality should follow the following relationship:
vin ≤ ain < aout ≤ vout, (2.3.8)
where vin and vout represent the starting and ending time of visual speech utter-
ances, and ain and aout represent the starting and ending times of an audio speech
utterance. This assumption is based on the speech motor control hypothesis that
facial muscles shift from released or equilibrium point in order to initiate speech
articulator motions [56].
Acoustic silence segment were determined using acoustic energy fa(t) as shown
in Figure 2.15.
fa(t) ≤ ǫa, ∀t ∈ [sin, sout] (2.3.9)
aout − ain ≥ τa (2.3.10)
where ǫa and τa are two heuristic parameters that varied according to average
utterance duration. Sentences have larger τa than words. Optical motion seg-
ment were determined using optical features fv(t) extracted from two lip shape
41

Fre
quen
cy
5 6 7 8
Acoustic Energy Silence Window Silence Segment
Time (seconds)
Figure 2.15: Acoustic silence detection.
D w D h
Figure 2.16: Mouth shape parameters for audio-visual end-point detection.
parameters Dw and Dh (see Figure 2.16) as follows:
fv(t) =√
D2w + D2
h, (2.3.11)
A motion segment [vin, vout] needs to satisfy the following conditions:
|f ′′v (t)| ≥ ǫv, ∀t ∈ [vin, vout] (2.3.12)
vout − vin ≥ τv (2.3.13)
The results have been evaluated by hearing and visualizing the chopped speech
segments as shown in Figure 2.17. The methods successfully generate robust
results on all takes with normal recording content. An acoustic silence
segment [sin, sout] needs to satisfy the following conditions:
42

4.5 5 5.5 6 6.5 7 7.5 8−0.5
0
0.5
1
Time (sec)
Mouth Opening Velocity
Mouth Opening Acceleration Motion Window
Acoustic Silence Segment Token Motion Segment
Figure 2.17: Token alignment using optical features and acoustic silence segmen-
tations.
2.3.3 Acoustic phoneme segmentation
Robust phoneme segmentation does not exist especially for American English due
to strong coarticulation. This has been experienced through manual segmentation
of phonemes. Context effect plays an important role in phoneme identification.
Thus for the purpose of machine learning of acoustic-to-optical speech mapping
functions, machine generated forced-alignment results of phoneme segmentation
is acceptable in terms of error rate. CorpusA has 320 sentences by 8 talkers, which
is not enough for robust HMM training. Thus, phoneme HMMs were trained on
TIMIT male training data. The TIMIT CDROM is a phonetically labeled speech
database and can be ordered from the Linguistic Data Consortium (LDC). TIMIT
contains a total of 6300 sentences, 10 sentences spoken by each of 630 speakers to
whom 438 are male. Each phoneme HMM model is composed of 3 hidden states
and 6 Gaussian mixtures each. Viterbi algorithm was used in forced alignment.
The procedures were built on HTK [87]. The results have been compared to
manual segmentation results (in Table 2.8)
43

Table 2.8: Forced alignment calibration using manual segmentation of 5609
phonemes
Error% Average Discrepancy%
Consonant 4.3 7.8
Vowel 1.4 7.3
All 3.1 7.6
For phoneme pi, machine segmentation discrepancy e(i) is calculated as fol-
lows:
e(i) = |sβ(i) − sα(i)
dα(i)| (2.3.14)
where sβ(i) is the middle temporal position of phoneme pi from forced alignment
result, sα(i) corresponds to the same parameter from manual segmentation result,
and dα(i) is phoneme duration determined manually. A forced alignment error
occurs with e(i) > 50%. The automatic phoneme segmentation methods can be
used for the training of acoustic-to-optical mapping.
2.4 Summary
The database used in this study includes a previous recording of CorpusA, a
pilot diphone-oriented recording of CorpusB, and a new recording of CorpusC.
CorpusA includes a set of 320 sentences spoken by 8 talkers. Among the 8
talkers, a subject with the highest visual intelligibility was chosen for CorpusC.
CorpusB includes 34 nonsense syllables and 1 sentence. CorpusC includes 141
words, a set of 400 sentences, and a set of non-speech expressions produced by
44

the selected subject. In all recording sessions, the talkers spoke with exaggerated
facial gestures as if interpreting to deaf people. CorpusA and CorpusB were used
for all pilot studies. CorpusC along with CorpusA from the same subject were
used in the final training and testing of the developed talking face animation
system.
The raw optical data from the new recording were processed through an
archiving pipeline. The optical data were processed through head motion com-
pensation, outlier removal, temporal concatenation and interpolation and 3D
model registration steps. The pipeline automatically converts raw marker data
into optical data that can drive a generic 3D facial model. Manual corrections
were made to opitical data that produce facial animation with artifacts. For
CorpusC, 87.8% of the utterances were processed automatically without manual
corrections for the optical data.
Acoustic and optical data were segmented into tokens first. Then acous-
tic data were segmented into phonemes through HMM forced-alignment reliably.
Since the acoustic and optical data are synchonized during recording, optical data
were segmented into phonemes following the acoustical segmentations. The devel-
oped automatic data archiving pipeline successfully processed the raw recording
data per take into synchronized, segmented, and deformable optical-acoustical
data files per utterance. The percentage of automation in the entire data archiv-
ing pipeline is significantly high.
45

CHAPTER 3
Acoustic-to-optical Synthesis
using Dynamic Bayesian
Networks
3.1 Introduction
In recent years, dynamic Bayesian networks (DBNs) have emerged as a powerful
and flexible theoretical framework for multi-modal stochastic processes [89]. Dif-
ferent DBN configurations have been applied to audio-visual speech recognition
[90] [92] [91] [38], and audio-visual speaker identification [93], etc. Here we use
DBNs for acoustic-to-optical feature mapping. Among the various configurations
of DBNs, three were chosen for this study: independent HMMs (I-HMMs), cou-
pled HMMs (C-HMMs), and product HMMs (P-HMMs). I-HMMs and P-HMMs
represent the two extreme cases of state transition integration: complete indepen-
dence and complete dependence, respectively. C-HMMs correlate the audio and
visual speech models using conditionally independent audio-visual hidden state
transitions. The three DBN configurations were implemented and evaluated in an
acoustically-driven talking face synthesis context. Basic model selection parame-
46

T r a i n i n g
S y n t h e s i s
E v a l u a t i o n
Figure 3.1: Flowchart for the development of a talking face synthesis system.
ters were studied under the synthesis framework using a quantitative evaluation
of the synthesized talking face.
In this chapter, an overview of the system architecture is presented first. Then
DBN training and synthesis are discussed in detail. Finally, the experimental
setup and results are reported.
3.2 System Architecture
In this study, the acoustic-to-optical synthesis system is composed of three mod-
ules: training, synthesis, and evaluation as shown in Figure 3.1.
3.2.1 Training
The training module is based on machine-learning techniques to define the DBN
models given a labeled database. It is composed of acoustical and optical feature
extraction, with DBN training based on the expectation maximization (EM) al-
gorithm shown in Figure 3.2. The input to the training module is the transcribed
47

Synchronized AV data
Training Acoustic
Training Optic
Acoustic FeatureExtraction
Optical FeatureExtraction
DBN EM
Training
(A, B)
Figure 3.2: Flowchart of the training module in the acoustic-to-optical synthesis
system.
Acoustic InputAcoustic Feature
ExtractionDBN Viterbi
Inference
DBN Models (A, B)
Inverse OpticalFeature Extraction
Synthetic
Optical Data
Figure 3.3: Flowchart of the synthesis module in the acoustic-to-optical synthesis
system.
acoustic data and the synchronized optical data. The output of the module is a
set of DBN models with observation parameters B and transition matrix A for
each phoneme. These DBN models are used in the synthesis module.
3.2.2 Synthesis
The synthesis module converts an acoustical signal into an optical signal given
the trained DBN models. It is composed of acoustic feature extraction, DBN
inference based on the Viterbi algorithm, and inverse optical feature extraction
as shown in Figure 3.3. For acoustical signals, the feature extraction is identical
to the one in the training module. For optical signals, the following constraint
applies:
O = gs(ft(O)) (3.2.1)
48

Testing Acoustic
Testing Optic
SynthesisQuantitative
Evaluation
Synthetic
Optical Synthesis
Quality
Figure 3.4: Flow chart of the evaluation module in acoustic-to-optical synthesis
system.
where O refers to an optical signal, ft(∗) refers to the optical feature extraction
transformation function in the training module, and gs(∗) refers to the inverse
optical feature extraction transformation function in the synthesis module.
The input to the synthesis module is transcribed acoustic data. The output
of the module is the synthesized optical data.
3.2.3 Evaluation
The evaluation module is an important module for system development and tun-
ing. In this chapter, quantitative evaluations based on synthesized and recorded
optical data are used as shown in Figure 3.4. Perceptual evaluation of the final
talking face animation will be discussed in the next chapter.
The input of the module is a set of recorded optical signal and their corre-
sponding synthesized optical signal. The output of the module is a set of scores
that describe the similarity (in statistical terms) between the synthesized and
recorded optical signals.
49

3.3 Dynamic Bayesian Networks
3.3.1 DBN models and configurations
A DBN model of a phoneme in the acoustic-to-optical synthesis system can be
described by the observation probability model B and the state transition proba-
bility model A. In this chapter, ’v’ is used to annotate optically-related variables
given that optical data constitute a sparse representation of the visual speech
information. Let a phoneme be represented by Na hidden Markov chain states
for the acoustical signals and Nv states for the optical signals. The observation
probability model at time t is defined as follows:
bt(I) =2
∏
s=1
bst (is) =
2∏
s=1
P (Ost |q
st = is), (3.3.1)
where I is the state vector with I = [i1, i2], i1 ∈ [1, Na] represents the acoustic
chain states, and i2 ∈ [1, Nv] represents the optical chain states. Hence bst (is) is
the observation probability of state is in chain s, Ost is the observation at time t
in chain s. Notice that in this study, chain s = 1 represents the acoustical signal,
and chain s = 2 represents the optical signal. The complete observation Ot can
be represented as the concatenation of the observation vectors in each chain as
follows:
Ot = [(O1t )
T , (O2t )
T ]T . (3.3.2)
In this study, we are interested in comparing the degree of dependency be-
tween audio and visual hidden Markov chains. The transition probability models
are defined according to three levels of inter-chain dependency: independent,
conditionally independent, and dependent, for I-HMM, P-HMM, and C-HMM,
50

respectively, as follows:
I − HMM : a(I|J) =2
∏
s=1
as(is|js) =2
∏
s=1
p(qst = is|q
st−1 = js), (3.3.3)
P − HMM : a(I|J) = p(qt = I|qt−1 = J), (3.3.4)
C − HMM : a(I|J) =
2∏
s=1
as(is|J) =
2∏
s=1
p(qst = is|qt−1 = J), (3.3.5)
where I is the current joint hidden states, J is the previous joint hidden states,
as(is|js) is the state transition from state js to state is in chain s in independent
HMMs, and as(is|J) is the state transition from joint state vector J to state is
in chain s in coupled HMMs, where chain index s in this study refers to either
the audio or visual hidden Markov chains. The joint state I are in the joint state
space defined as follows:
{I = [i1, i2]|i1 ∈ [1, Na], i2 ∈ [1, Nv], |i1 − i2| ≤ MICSA}, (3.3.6)
where [Na, Nv] is the number of hidden states in audio and visual modalities,
and MICSA is the maximum inter-chain state asynchrony. Figure 3.5 shows all
the possible state transition paths for a DBN model with [Na, Nv] = [3, 3] and
MICSA = 1. Under such combination, joint states I of [1, 3]T and [3, 1]T are
eliminated.
The effects of the two model selection parameters [Na, Nv] and MICSA were
studied in the three DBN structures.
3.3.2 Training
DBN training is an important step in the system training module as highlighted
in Figure 3.6.
All three prototypes can be represented in the traditional multi-stream single
51
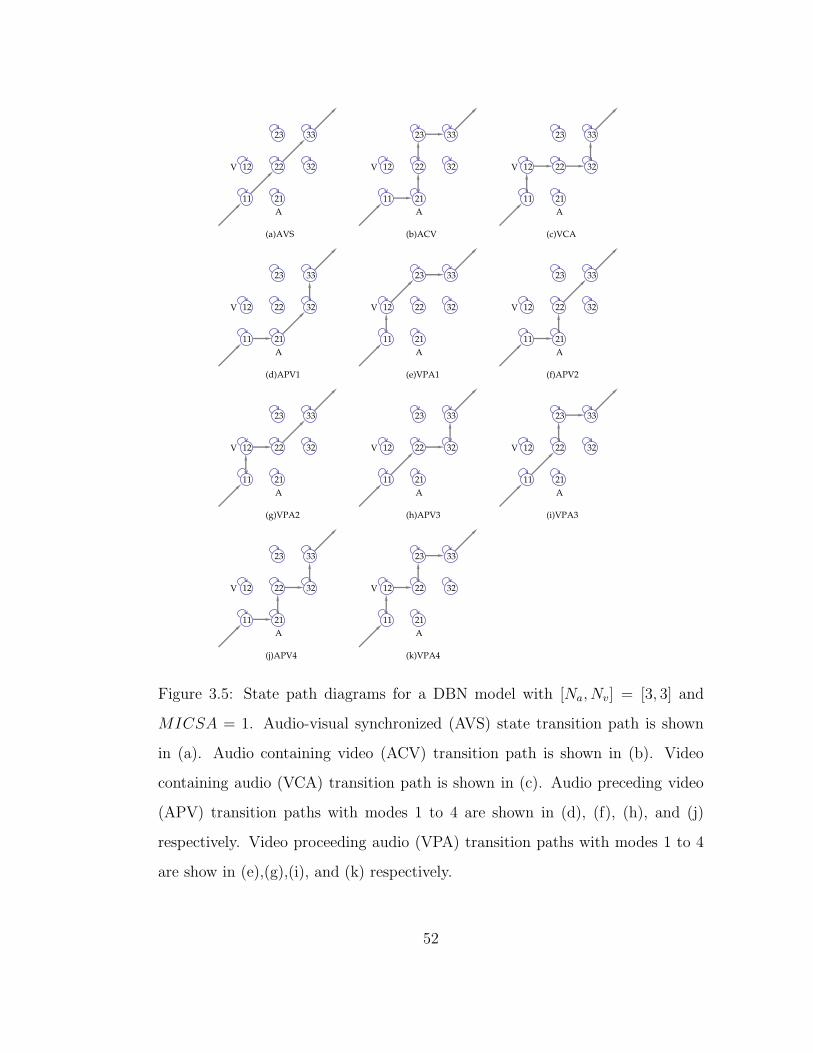
11
12
21
22
23
32
33
A
V
(a)AVS
11
12
21
22
23
32
33
A
V
(b)ACV
11
12
21
22
23
32
33
A
V
(c)VCA
11
12
21
22
23
32
33
A
V
(d)APV1
11
12
21
22
23
32
33
A
V
(e)VPA1
11
12
21
22
23
32
33
A
V
(f)APV2
11
12
21
22
23
32
33
A
V
(g)VPA2
11
12
21
22
23
32
33
A
V
(h)APV3
11
12
21
22
23
32
33
A
V
(i)VPA3
11
12
21
22
23
32
33
A
V
(j)APV4
11
12
21
22
23
32
33
A
V
(k)VPA4
Figure 3.5: State path diagrams for a DBN model with [Na, Nv] = [3, 3] and
MICSA = 1. Audio-visual synchronized (AVS) state transition path is shown
in (a). Audio containing video (ACV) transition path is shown in (b). Video
containing audio (VCA) transition path is shown in (c). Audio preceding video
(APV) transition paths with modes 1 to 4 are shown in (d), (f), (h), and (j)
respectively. Video proceeding audio (VPA) transition paths with modes 1 to 4
are show in (e),(g),(i), and (k) respectively.
52

Synchronized AV data
Training Acoustic
Training Optic
Acoustic FeatureExtraction
Optical FeatureExtraction
DBN EM
Training
(A, B)
Figure 3.6: DBN training highlighted in the system training module
21
32
12
23
11
22
33
21
32
21
32
12
23
12
23
11
22
33
11
22
33
11 12 21 22 23 32 33
12
21
22
23
32
33
11
E
E
b A 1 b A
1 b A 2 b A
2 b A 2 b A
3 b A 3
b V 1 b V
2 b V 1 b V
2 b V 3 b V
2 b V 3
b A 1 b A
1 b A 2 b A
2 b A 2 b A
3 b A 3
b V 1 b V
2 b V 1 b V
2 b V 3 b V
2 b V 3
A
B
Figure 3.7: An example of a DBN with joint transition and observation param-
eters in HMM forms with maximum inter-chain state asynchrony MICSA of 1,
and [Na, Nv] of [3,3]. A refers to the state transition probability model, and B
refers to the observation probability model.
chain HMM representations. Joint state transitions can be reformulated to single
state transition probability matrix representation. For the three structures, given
[Na, Nv] and MICSA, the joint state transition probability matrices follow the
same non-zero pattern (shown in Figure 3.7 as an example).
However, constraints on the non-zero elements are different across the three
DBN structures. The transition probability matrix of I-HMM has the following
relationship:
A = Aa ⊗ Av, (3.3.7)
53

where A is the I-HMM transition matrix, and Av along with Aa are the HMM
transition matrices independently trained from the visual and audio modality,
respectively. The symbol ⊗ represents the Kronecker product operation. The
transition probability matrix of C-HMM has the constraint:
a([ia, iv]|J) =Na∑
ka=1
a([ka, iv]|J) ·Nv∑
lv=1
a([ia, lv]|J) (3.3.8)
where ka represents an audio state given a visual state of iv, and lv represents
a visual state given an audio state of ia. P-HMMs, on the other hand, have no
constraint on the state transition probability matrix.
When the covariance matrices of the observation probabilities from both
modalities are diagonal, the observation means and variances can be directly
concatenated from different modalities to describe the joint observation proba-
bilities. Then, the EM algorithm from traditional HMM training can easily be
modified for P-HMM and C-HMM parameter training.
For P-HMM, the transition matrix can be updated without change to that
for single-chain HMMs. The means of the observation probability of joint state
I = [ia, iv] need to be updated with a modified EM algorithm as follows:
µaij =
∑Tt=1 (
∑
l γil(t))Oat
∑Tt=1 (
∑
l γil(t))(3.3.9)
µvij =
∑Tt=1 (
∑
k γkj(t)) Ovt
∑Tt=1 (
∑
k γkj(t))(3.3.10)
where µaij is the observation mean for the audio hidden state i, γil(t) is the
probability of frame t emitted from joint state [i, l] given all the observations
[O1, . . . , OT ], l refers to the visual state index that is feasible to form a joint state
with audio state i, and likewise, k refers to the audio state index that is feasible
with visual state j.
54

Acoustic InputAcoustic Feature
ExtractionDBN Viterbi
Inference
DBN Models (A, B)
Inverse OpticalFeature Extraction
Synthetic
Optical Data
Figure 3.8: DBN inference highlighted in system synthesis module
For C-HMMs, the observation probability follows the same algorithm as P-
HMMs. The transition matrix needs to be updated with the modified EM algo-
rithm by binding the joint state transition likelihood given all the observations
as in [92]. Given sufficient training data, P-HMMs should yield the best training
accuracy among the three joint state transition probability models. However,
when the database is limited, EM training of unconstrained transition structures
might yield suboptimal results compared to training using constrained transition
structures, such as C-HMMs.
3.3.3 Inference of optical features from acoustic features
The inference of optical features from acoustic features is a key step in acoustic-
to-optical synthesis module as highlighted in Figure 3.8.
An adapted Viterbi algorithm was used for the inference as follows:
q(t) = argmaxφi(t), (3.3.11)
where φi(t) is the partial forward probability of observation Ot and i is the per-
mutation index of the audio-visual joint state. Let φi(t) be the complete forward
probability of observation Ot at joint state i,
φi(t) =
[
Nav
∑
j=1
φj(t − 1)a(i|j)
]
p(Oat |q
at = ia) (3.3.12)
55

=φj(t)
p(Ovt |q
vt = iv)
+
Nav
∑
j=1
ǫj(t − 1)a(i|j)p(Oat |q
at = ia), (3.3.13)
where Nav is the total number of feasible audio-visual joint states, a(I|J) rep-
resents the transition probability from joint states J to joint state I, and ǫj(t)
represents the partial forward probability error φj(t) − φj(t). The incomplete
feature inference error e(t) = q(t) − q(t) cannot be represented by an analytical
function with regards to the transition matrix A. However, physical interpreta-
tion indicated that C-HMM has less dependency between the audio and visual
modalities, potentially providing less inference error compared to that using P-
HMM under the assumption that the two obtain equal training accuracy. So
the difference between C-HMM and P-HMM in this application is related to
the tradeoff between training accuracy and incomplete feature inference error.
When training data are limited, C-HMM should have the potential of reaching
the performance of P-HMM.
3.4 Experiments
3.4.1 Database
The database was CorpusA which includs 320 audio-visually recorded sentences
by a single talker. The sampling rates of the optical and the clean acoustic data
were 120 Hz and 44.1 KHz, respectively. Manual phoneme segmentations were
obtained using the acoustical signal.
56

Synchronized AV data
Training Acoustic
Training Optic
Acoustic FeatureExtraction
Optical FeatureExtraction
DBN EM
Training
(A, B)
Acoustic InputAcoustic Feature
ExtractionDBN Viterbi
Inference
DBN Models (A, B)
Inverse OpticalFeature Extraction
Synthetic
Optical Data
Figure 3.9: Feature extraction components highlighted in the acoustic-to-optical
synthesis system
3.4.2 Feature extraction and inversion
The feature extraction includes the acoustic feature extraction that is common in
both the system training and synthesis modules, and the optical feature extrac-
tion used in training and its inverse transform used in synthesis, as highlighted
in Figure 3.9.
Two representations of speech acoustics were used: Linear Predictive Cep-
stral Coefficients (LPCCs) LPCC for back end modeling and Line Spectral Pairs
(LSPs) LSP for optical feature transformation (see Eq. 3.4.1). A previous study
[27] showed that LSPs resulted in better linear estimation of optical features than
LPCCs. Our pilot studies confirmed that using LSP for optical feature transfor-
mation and LPCC for DBN training and inference was better than using either
in the synthesis framework. Optical feature extraction comprised three steps. Let
57

VDisp be the normalized displacement features relative to a neutral facial gesture
and obtained from the preprocessed optical data. Let WLMS be the matrix for
a global transformation from LSP to VDisp. Firstly, WLMS was estimated via
least-mean square (LMS) estimation. Then the residual optical signal VR was
obtained as follows:
VR = VDisp − LSP · WLMS. (3.4.1)
Finally, principal component analysis (PCA) was applied to VR for data dimension
reduction. Reduced optical features VRPC were used for back-end modeling, and
the corresponding inverse principle component transformation WIPCA was used
for visual feature inversion. In this operation, estimated residual optical feature
vectors VRPC were converted back to normalized optical displacement feature
vectors VDisp by the following equation:
VDisp = LSP · WLMS + VRPCWIPCA (3.4.2)
The position trajectories were recovered by de-normalization and through the
addition of neutral marker positions to the normalized displacement trajectories.
VDisp = ALSPWLMS + VRPCWIPCA (3.4.3)
The position trajectories were recovered by adding neutral marker positions to
the displacement trajectories.
In all experiments, the dimensions of acoustic and optical feature vectors are
17 and 57, respectively.
3.4.3 Acoustic-to-optical mapping models
The baseline for acoustic-to-optical mapping was obtained using a multilinear
regression method (MLR) [27].
58

The MLR model and the three DBN models, including I-HMM, C-HMM, and
P-HMM, were trained using the same features and the same training data set.
All methods had 41 phoneme models including a silence model. For the DBN
models, different configurations of the number of acoustic and optical states, and
the degree of asynchrony between the two chains, were tested.
3.4.4 Evaluation
3.4.4.1 Bootstrapping
Due to limited data, a resampling procedure was applied to minimize bias from
testing sentences. That is, one set was designated for testing while the remaining
sets were used for training; a rotation was then performed to guarantee that each
sentence was tested at least once. The results were averaged across the entire 320
sentences.
3.4.4.2 Quantized quality evaluation
Marker trajectories constitute a multi-variant time series with temporal and spa-
tial characteristics. Direct comparisons between synthesized and recorded marker
trajectories were carried out using similarity and dissimilarity measurements.
Pearson correlation (Corr) was used to measure the degree of similarity. The
three metrics for the degree of dissimilarity were normalized Manhattan (NM),
normalized Euclidean (NE), and Kullback-Leibler (KL) distances.
59

Table 3.1: Comparison of MLR and the three DBN models with [Na, Nv] = [3, 3]
and MICSA = 1 in terms of motion trajectory reconstruction accuracy
Baseline I-HMM C-HMM P-HMM
Corr .179 .427 .524 .558
NM .324 .280 .254 .251
NE .058 .049 .044 .044
KL .274 .231 .201 .193
3.4.5 Results
Results from four measurements were consistent in the relationship among dif-
ferent methods as shown in Table 3.1. In the remainder of the section, the
correlations between recorded and synthesized optical data, hereafter referred to
as the correlation results, are used for performance evaluation. Paired t-tests
(df = 319) with Bonferroni correction for multiple comparisons (p < 0.05) were
applied on the correlation vectors of all the methods or conditions. All the DBN
methods performed significantly better than the baseline (p < 0.05). C-HMMs
and P-HMMs performed similarly better than I-HMMs (p < 0.05). Context
independent modeling limited the overall performances.
C-HMMs generated the highest average state path entropy (see Table 3.2)
with [Na, Nv] = [3, 3], and MICSA = 1. The upper bound of the entropy is 3.459
bits. The table also showed the most frequent state transition path (DP ) in each
DBN configuration. Note that each DBN configuration can generate 11 possible
state transition paths as shown in Figure 3.5. In this table, DP only presents
60

Table 3.2: Comparison of three DBN structures with [Na, Nv] = [3, 3] and
MICSA = 1 in terms of state path entropy and dominant state path
I-HMM C-HMM P-HMM
Entropy(bits) 1.354 2.985 2.592
DP(appearance%) APV 3(70%) V CA(36%) APV 3(29%)
Table 3.3: Comparison of model selection parameters in three DBN structures in
terms of the correlations between synthesized and recorded optical data
[Na, Nv] [3, 3] [4, 4]
MICSA 1 2 1 2 3
JointState 7 9 10 14 16
I-HMM .427 .448 .464 .419 .422
C-HMM .524 .543 .534 .562 .561
P-HMM .548 .558 .536 .569 .563
one state transition path which had the maximum number of appearences. The
appearence number was collected from all the testing data. APV 3 refers to
acoustic events (state transitions) ahead of facial events in mode 3 (see Figure 3.5
(h)). V CA refers to facial events starting before and ending after acoustic events
(see Figure 3.5 (b)). The state path distribution resulting from C-HMMs showed a
higher percentage of paths corresponding to facial motion events beginning before
and ending after acoustic events than to paths where acoustic events preceded
61

Time (sec)
sil Dxb ebi p UtshI z r At f U t I nhI zm W T sil
0.417 0.833 1.250 1.667 2.083 2.500 2.917 3.333 3.750
Figure 3.10: Example of marker trajectory comparison between recorded data in
solid line and synthesized data in dash line. The background is the spectrogram
of the acoustical signal. The trajectory is the summation of the mouth shape
variations from width and height. The sentence is “The baby puts his right foot
in his mouth.”
facial ones (36% of V CA vs. 5% of APV 3).
Table 3.3 shows the correlations between synthesized and recorded optical
data from the three DBN approaches with different numbers of joint states, which
are a function of [Na, Nv] and MICSA. Changing the values of MICSA (1, 2 or
3) had a significant effect on the correlations between synthesized and recorded
optical data (p < 0.05). As the complexity of the model increased, results with
C-HMMs approached those with P-HMMs. As the joint states reached 16, the
results of C-HMMs and P-HMMs degraded due to insufficient training data. In
some resampling trials, P-HMMs failed in training for the same reason. These
observations confirmed the theoretical discussions on the two DBN configurations
in Sec. 3.3.3.
Figure 3.10 shows the motion trajectories of a synthesized sentence. Marker
trajectories during connected speech were better than during acoustical silence
62

period. For most phonemes, facial motion starts ahead of acoustic onset. The
facial motion various across different phonemes. For example /p,b,m/ share a lip
pressing motion before the acoustic onset. In the context of audio-visual joint
state modeling, acoustic-silence audio-visual models with context-dependencies
are expected to improve the quality.
3.4.6 Discussion
Four back-end models were evaluated in the context of acoustic-to-optical syn-
thesis including the multilinear regression (baseline), and three DBN models (I-
HMMs, C-HMMs, and P-HMMs). Paired t-tests (df = 319) with Bonferroni
correction for multiple comparisons were applied to the correlation vectors of
all methods and conditions. The DBN methods performed significantly better
than the baseline (p < 0.05) in terms of the correlations between synthesized
and recorded optical data. C-HMMs and P-HMMs performed similarly better
than I-HMMs (p < 0.05). However, the best correlation between synthesized
and recorded optical data is 0.559 from P-HMMs. In [27], a correlation result of
0.78 was obtained from multilinear regression on nonsense CV syllables where the
training and testing were from different repetitions of the same utterances. Here,
there is no overlap between training and testing sentences and the synthesizer is
capable of converting any acoustic sample from a speaker with no context con-
straint on the synthesis module. Given that, the DBNs with C-HMM or P-HMM
configurations generated promising results in terms of marker trajectoryrecon-
struction accuracies.
In Table 3.2, average state path entropies and dominant state path were com-
pared among the three DBN configurations. All the configurations used the same
63

model selection parameters [Na, Nv] of [3, 3], and MICSA of 1, under which 7
audio-visual joint states and 11 possible state paths exist. The upper bound of
the entropy is 3.459 bits. C-HMMs generated the highest state path entropy
with 0.393 bits increment from P-HMMs. I-HMMs generated the lowest state
path entropy with a degradation of 1.238 bits from P-HMMs. The state path
distribution resulting from C-HMMs showed a higher percentage of paths cor-
responding to facial motion events beginning before and ending after acoustic
events than to paths where acoustic events preceded facial ones. Higher state
path entropy corresponds to better capturing of audio-visual alignment patterns.
Thus, C-HMMs had the best performance in terms of reconstructing marker data
and hence, led to better audio-visual alignment. The constraint on the joint state
transition probabilities in C-HMMs yielded significantly different state transition
patterns compared to that in P-HMMs, though the trajectory accuracy results
between the two structures are similar.
Table 3.3 shows the correlation results of the three DBN approaches with dif-
ferent numbers of joint states, which are a function of [Na, Nv] and MICSA. As
the complexity of the model increased, results with C-HMMs approached those
with P-HMMs. The parameter MICSA, which determines the placements of
off-diagonal joint states, had a significant effect on the results (p < 0.05). The
traditional multi-stream HMM approach is equivalent to DBNs with MICSA of
0. The asynchronized audio-visual joint states played an important role in captur-
ing the audio-visual speech temporal alignment pattern. Results demonstrated
the advantage of DBN structures.
Given the above quantitative evaluations from physical measurements, Fig-
ure 3.10 shows recorded and C-HMM synthesized marker data in terms of motion
trajectories with a spectrogram in the background. The motion feature is the
64

summation of shape variations from mouth opening width and height. Synthe-
sized motion events align well with, but are less smooth than, recorded motion
events. The synthesized motion reduced mouth opening through the sentence ex-
cept for the second instance of phoneme /i/ in the word “baby”. Mouth shapes
for the two instances of the word “his” were distorted significantly. The tra-
jectory comparison shows that the relatively low correlation scores obtained in
Table 3.1 resulted mainly from reduced facial motions. However, major motion
events are well aligned temporally. This observation is consistent with the results
from Table 3.2 with C-HMMs capturing well audio-visual alignment.
3.5 Summary
This study applied dynamic Bayesian networks to the problem of acoustic-to-
optical speech mapping under the framework of an acoustically-driven talking face
animation system. Different DBN structures and model selection parameters were
studied through quantitative comparisons. The three tested DBN methods were
superior to the multilinear regression method in reconstructing facial motions
from acoustic signals. C-HMMs and P-HMMs generated similarly better results
than I-HMMs, suggesting the effectiveness of the state dependency structure in
the first two methods. C-HMMs generated higher state transition path entropy
and better captured audio-visual alignment than P-HMMs. Maximum inter-chain
state asynchrony had a greater effect on synthesis accuracy than the number of
hidden states in the two Markov chains. Evaluation results point out that the
DBN state transition models with integrated training algorithms capture audio-
visual speech alignment efficiently. This study demonstrated the potential of
DBNs in acoustically-driven talking face synthesis. In future work, improving
65

DBN observation models by combining DBN methods with visual feature re-
estimation and optimization methods with context-dependent modeling can be
pursued to improve system performance. This direction requires a larger training
dataset to provide enough amount of training samples for robust training of
context-dependent models.
66

CHAPTER 4
Animation and Perceptual
Evaluation
4.1 Introduction
The goal of this study is developing intelligible talking face animations based
on the acoustical speech signal. In Chapter 3, the acoustic-to-optical synthesis
system was introduced. Two questions need to be addressed: How does one
generate facial animations from optical data? And, how do we evaluate the
visual intelligibility of the talking face animation? This chapter focuses on optical
data visualization through 3D face animation and perceptual evaluation of the
animations.
Optical data are kinematic data of facial feature points. Feature points are
sparsely distributed on a complete facial mesh model. Visualization of optical
data can be viewed as an interpolation from feature points to entire facial meshes.
The interpolation method should smoothly deform the entire face model. A series
of marker data to mesh model calibration procedures is carried out first. Then,
the interpolation method, based on a radial-basis function, is applied frame by
frame. As a result of these procedures, an animation engine has been successfully
67

( a ) ( b )
Figure 4.1: (a) Original markers, and (b) active facial mesh with white
sphere-shaped key points for a generic head model (mesh model from
http://www.digimation.com).
developed.
Once animations are rendered, the full pipeline from acoustic data to talking
face animation is established. The next step is to formally evaluate its perfor-
mance. To this end, visual perceptual studies were conducted. Synthetic optically
driven animations are compared with recorded optically driven animation as well
as with video recordings of natural talking faces.
68

4.2 From optical data to facial animation
4.2.1 Background
The deformation process is to drive a 3D talking face animation using optical
data. Typical deformation methods include parameter-driven [34][35], physically-
driven [69][68] and free-form methods [22]. Here, we use a free-form method which
is computationally simple and is flexible to various marker settings. The main
challenge is to interpolate motions of surrounding vertices given the motions of a
set of key points while preserving the physiological structure among the key points
and the vertices on a human face. A key point corresponds to a registered marker,
and there are 20 key points registered from optical data. There are 623 active
vertices whose motions need to be interpolated from the key points. Figure 4.1
shows the original markers in (a), and deformable facial mesh with superimposed
key points in (b). The face in Figure 4.1(a) is of the subject recorded for Corpus
A. On average, motion from a key point spans 30 vertices.
4.2.2 The 3D head model
The original generic 3D face model in Figure 4.1(b) was edited. The model in-
cludes 1915 vertices and 1946 polygons with separate facial regions. These regions
were manually defined to benefit marker-driven model deformation. The smooth
rendering and regional rendering of the generic model are shown in Figure 4.2.
4.2.3 RBF-based deformation
Radial basis functions [94] were adapted to perform the deformation. In each
deformation region, positions of N vertices are interpolated from M key points
69

( a ) ( b )
Figure 4.2: (a) A generic 3D head model in a neutral gesture based on Fig-
ure 4.1(b), and (b) the model’s rendered sub-facial regions used in deformation.
as follows:
pki (t) = pk
i (0) +M
∑
m=1
wkm(t)φk
im(t), (4.2.1)
where pki (t) is the position of vertex i with i ∈ [1, N ], φk
im(t) is the basis function
of key point m at vertex i, and wkm(t) is the weight of the mth key point, all in
axes k at time t, the axis index k ∈ [1, 3] which corresponds to the three axes in
the Cartesian coordinate system.
The basis function is defined as follows:
φkim(t) = exp
(
−(pk
i (0) − vkm(0))2
2σ2m(t)
)
, (4.2.2)
where vkm(t) is the position of key point m at time t on axis k, t of 0 corresponds to
the neutral facial gesture. The Gaussian variance σm(t) of marker m is updated
every frame by solving the following equation:
exp
(
−minl=1,...,M,l 6=m ‖vl(t) − vm(t)‖2
2
2σ2m(t)
)
= τ, (4.2.3)
where τ is a threshold determined empirically. In this study, τ of 0.4 is used. All
the axes share the same variance in each frame for each marker. The Gaussian
70

weights W k(t) = [wk1(t) . . . wk
M(t)]T is updated by solving the following linear
equation:
Φk(t)W k(t) = Dk(t), (4.2.4)
with
Φk(t) =
φk11(t) . . . φk
1M(t)...
. . ....
φkM1(t) . . . φk
MM(t)
, (4.2.5)
and
Dk(t) =
vk1 (t) − vk
1(0)...
vkM(t) − vk
M(0)
. (4.2.6)
where Dk(t) represents the key verteces’ displacements at time t in axis k. The
Gaussian variances σ2m(t) and weights wk
m(t) embed the dynamic information.
The physiological structure among vertices and key points is preserved through
all time frames by two fixed factors: 1) For each vertex, the numerator in the
exponent is fixed to the static distance between the vertex and the key point for
the corresponding Gaussian basis; and 2) for each key point, the basis function
at the closest key point is fixed to τ . Perceptual tests of recorded marker driven
animations were conducted to evaluate the quality of the deformation algorithm.
4.2.4 Results
Figure 4.3 and Figure 4.4 show the key frames animated using the recorded
marker data in word and sentence, respectively. More animations are available
at http://spapl.ee.ucla.edu/talkingFaceDemo.html.
Observations of recorded marker driven animations showed that the front-
view and side-views reveal good quality in terms of naturalness. Facial motion
71

Figure 4.3: Key-frames animated using the recorded marker data for the word
’brief’
72

Figure 4.4: Key-frames animated using the recorded marker data for the sentence
’A big wet stain was on the round carpet.’
73

is in good synchonization with acoustical signals. The interpolation algorithm
provides decent animation results given the high ratio of the number of the de-
formable verteces to that of the key points.
Some artificial visual effects have also been observed. When rendering in the
50% transparent mode, teeth inside the mouth can be observed, and unnatural
teeth bending was perceived. For example, when the mouth was widely open,
the front teeth moved along with the lip opening nicely, while little motion could
be perceived for the back teeth. Second, even though the location of the teeth
had been adjusted to avoid unnatural teeth protrusion out of the lips, in one trial
of marker data for a sentence, unnatural teeth protrusion was observed. Third,
unnatural asymmetry was perceived for the recorded marker driven animation in
several trials of sentences with the lower face distorted to the right in the front
view. There was also jitter resulting from jitter in the optical data. The latter
two artifacts, which accounted for the majority of facial animation artifacts, were
both from optical data artifacts. Eye brow motion compensation was applied to
the raw recorded marker data as much as possible to eliminate such unnatural
facial asymmetry. For jitter, smoothing was applied to the marker data. Both
the motion compensation and smoothing process were discussed in Chapter ??.
4.2.5 Discussion
The RBF algorithm can directly manipulate the marker data and vertices of the
3D face model. The computational load is small, and the visual effects of the
rendering results are promising.
In the future, one can attempt to combine the current data-driven approach
with a parameter driven approach for more natural animation. For example, jaw
74

rotation can be better rendered using a parameter driven approach, and robust
estimation of jaw rotation from the marker data can be applied for more natural
jaw rotations.
Collision detections of inner mouth organs such as the teeth and tongue with
the inner mouth palate would be helpful to avoid teeth protrusion through the
lips during the deformation process.
Tongue motion is very important for improving visual intelligibility, yet tongue
motions were not captured in the optical corpus used here. Phoneme-based
tongue motion models can be built to improve the intelligibility of talking face
animations.
4.3 Perceptual evaluation of facial animation
4.3.1 Background
The talking face animation system in this study is developed as a first step to-
wards the goal of reconstructing intelligent visual speech information from speech
acoustical signals. In Chapter 3, physical measurements of the marker data re-
construction was introduced. However, physical measurement does not linearly
relate to visual intelligibility from face animations. Behavioral evaluation is nec-
essary to judge the performance of visual speech intelligibility. In the following
sections, perceptual evaluations of the synthesized talking face animation are
presented.
75

4.3.2 Lexicon distinction identification test
Subjective perceptual tests provide a direct evaluation of the visual quality of
the animation. Among various human perceptual tests, word identification of
audio-visual speech under different signal-to-noise (SNR) ratios is among the
most popular evaluation methods [71]. SNR and the shape of the noise can sig-
nificantly influence human perception. In this study, a binary lexicon distinction
identification test in noise was carried out to evaluate the intelligibility of the
animations.
4.3.2.1 Paticipants
Normal hearing subjects were screened for the following characteristics: (1) Be
between the age of 18 and 45 years, (2) vision 20/30 or better in each eye, as de-
termined with a standard Snellen chart, (3) better than half a standard deviation
below the mean on a lipreading screening test, as referenced to the appropriate
distribution of performance by deaf or hearing college-educated adults, and (4)
native English speaker. Most subjects were recruited through advertisements in
the local university newspaper. Participants were compensated for their time.
Sixteen subjects participated in this study.
4.3.2.2 Stimuli
The stimuli consisted of 32 high-frequency monosyllabic words chosen from the
35,000-word PhLex database. The words had varying degrees of lexicon equiv-
alent classes ranging from unique to high. All the words have 3 realizations a)
2D front-view video recording, b) 3D computer animation using recorded marker
76

data, and c) 3D computer animation using synthesized marker data from the
acoustical signals that are simultaneously recorded with the 2D video and marker
data. Two words are paired with varied visual differences: same, near, far, and
different.
A total of 128 word pairs were used. Each word was paired with 4 words
that lie in the 4 categories. For example, the word best, is paired with best for
no visual lexicon difference (same), with space for small visual differenc (near),
with floor for medium visual difference (far), and with growth for large visual
difference (different). Appendix E includes the list of word pairs and their lex-
icon distinction levels. Video and 3D marker data were recorded simultaneously.
Thus, for the video tokens, the speaker had the reflective motion capture dots on
his face. Subjects did not report perceptual problems due to the added dots.
4.3.2.3 Test procedure
All participants were tested individually at HEI in a quiet sound-proof booth
with minimal lighting. Optical stimuli were presented using a Pioneer DVD
player and were displayed on a 14 inch SONY Trinitron monitor at a distance
of about one meter from the participant. Subjects are shown the first token
either from marker-driven or acoustically-driven computer animation followed by
a token from the video.
The subjects’ task was to determine whether both tokens showed the same or
different English words. Subjects entered responses using a button box labeled
same or different. For each block, a total of 128 token pairs with 32 same word
pairs and 96 different word pairs with the other 3 levels of visual distinction
were displayed in randomized order.
77

A total of 4 blocks with the combination of same word pairs but alternated
marker-driven animation vs. video pair and acoustic-driven animation vs. video
pair. Each block took around 15 minutes to finish. Subjects were given breaks
between blocks to avoid fatigue.
The first 8 subjects received stimuli with block order of MAMA where M
represents marker-driven animation vs. video pairing, and A represents acoustic-
driven animation vs. video pairing. The second 8 subjects received stimuli with
block order of AMAM .
4.3.3 Results
Figure 4.5 and Figure 4.6 show key frames of animation using synthesized optical
data for the same content as shown in Figure 4.3 and Figure 4.4, respectively.
Figure 4.7(a) shows the correct discrimination scores from the four lexicon
distinction categories using recorded marker-driven animations. Each notched
box represents the distribution of the cross-word mean correct scores from all
16 subjects. Each mean correct score is averaged from all 32 animation words
per category per subject. Except for the lexicon distinction category “near”, the
remaining categories showed a concentration of average correct scores above 80%.
Since subjects gave a discrimination response, t-tests (df = 31) were applied to
each subject in each lexicon distinction category to determine if the mean correct
scores are valid in the sense that they are significantly different from the 50%
chance level.
Table 4.1 showed the statistics of valid correct scores in each category. From
the observation of the number of valid subjects N , we can see that in the lexicon
distinction category “near”, only 31.25% of the subjects yielded valid responses
78

Figure 4.5: Key frames of animation using synthesized optical data for the same
word in Figure 4.3
79

Figure 4.6: Key frames of animation using synthesized optical data for the same
sentence in Figure 4.4
80

different from 50% chance level. In the category “same”, 75% of the subjects
yielded valid responses, and resulted in 83.5% cross-subject mean correct.
Table 4.1: Human subject perceptual evaluation results of recorded marker data.
N refers to the number of valid subjects for each category. The means and
standard deviations were collected from the valid subjects. Valid subjects are
subjects with discrimination correct scores significantly different(p < 0.05) from
50% chance level per category.
same near med far
mean .835 .378 .839 .889
std .091 .194 .125 .103
N 12 5 16 15
Results showed that the recorded optical data and the deformation methods
can recover a significant amount of visual information compared to natural vi-
sual speech. Though no inner lip details are captured in the marker data, the
high discrimination correct percentage in the “same” category showed that the
recorded marker data and deformation methods reconstructed 3D facial anima-
tions effectively.
Perceptual results of synthesized marker driven animation are shown in Fig-
ure 4.7 (b) and Table 4.2. The overall correct discrimination means are high, but
the correct discrimination scores in the “same” category are close to chance. The
mean discrimination score from subjects with valid responses dropped to 20.9%
in the “same” category compared to the 83.5% correct for the recorded marker
driven animations. Significant differences exist between synthesized talking face
81

Table 4.2: Human subject perceptual evaluation results of synthesized marker
data
same near med far
mean .209 .724 .861 .824
std .082 .165 .081 .100
N 5 9 11 12
animations and natural front-view video recordings.
Other than the analysis per lexicon distinction categories, subject response
statistics per animated word were analyzed through the following procedures.
Each word pair had two trials from each subject. When the two trials are iden-
tical, the responses were considered as one valid discrimination response. Valid
responses of an animated word from all 4 lexicon pairing conditions and all 16 sub-
jects were collected to calculate the average correct discrimination score. Correct
responses from the “same” category were weighted by 3 to balance the pairing
bias (each animated word has one paired word in “same” while three in “differ-
ent”).
Figure 4.8 shows the order of the words sorted in descending order of the
differences of the average discrimination correct scores between recorded to syn-
thesized marker driven animations.
There are 10 out of 32 words with average discrimination correct scores higher
than 75%. The 10 words are:
son, food, hoarse, farm, far, stand, file, fall, charge, full
82

with increasing discrimination correct ranged from 75.0% to 86.6%. The vowel
/a/ appeared in 3 out of the 10 words, /u/ in 2 words, and the vowels /æ, o,
ai/ appeared once each. These vowels are distinct visually: /a, æ, ar, ai/ have a
large mouth opening while /u/ is produced with lip protrusion.
Paired t-tests with Bonferroni correction showed that 13 out of 32 words
have a significant degradation from the corresponding recorded marker driven
animations in terms of average discrimination correct scores (p < 0.05, df = 15).
Those words that have discrimination correct score reduction of 20% or higher are
needs, price, stage, strange, stock, smile, tried, case, shone. With the exceptions
of needs, stock, all remaining “difficult” words have diphthongs. Diphthongs
including /ei, ai, ou/ appeared in 7 out of 9 words. Significant differences were
found among different words. This agrees with our observation that diphthongs,
compared to monophones, are relatively difficult to synthesize intelligiblly. The
diphthong /ai/ was well perceived in file, but not in price, tried, smile. It is
possible that the 2 consonants proceeding them in the latter three words made
the diphthongs more challenging.
Word-wise average results showed that the synthesized marker data preserved
visual effects in some words but not all.
4.3.4 Discussion
The recorded marker data and deformation methods reconstructed 3D facial an-
imations effectively. The low accuracy of lexicon distinction discrimination using
synthesized marker driven animations are mainly coming from reduced facial
movements. The means in trained DBN models, which represent the statistical
mean gesture of a phoneme state, tend to lie in between neutral and natural
83

gestures. Other than the intrinsic reduction of facial motion in DBN training,
the difference between training on continuous speech versus testing on isolated
speech also contributed to the degraded visual intelligibility. Recall that the
training data were from sentences where one phoneme has various contexts in
the sample space. For those allophones that are stressed or visually empha-
sized, mouth openings might reach the configuration in isolated words. Informal
observations of recorded and synthesized marker driven sentences showed less
degradation than that from isolated words.
4.4 Summary
This chapter presented the algorithm that interpolates sparse optical data into
lower-face animation. The algorithm provided natural and well synchonized ani-
mation results using recorded optical data.
Perceptual evaluations were conducted to evaluate the synthesis system through
the lexicon distinction identification test. Synthesized marker driven animations
have reduced facial movements which leads to low accuracy of lexicon discrimi-
nation score.
84

same near medium far0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Cor
rect
Iden
tific
atio
n S
core
Word Pair Lexicon Difference
(a)
same near medium far
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Cor
rect
Iden
tific
atio
n S
core
Word Pair Lexicon Difference
(b)
Figure 4.7: Notched-Box-and-Whisker Plot of the correct discrimination statistics
from all 16 subjects with (a) from recorded marker driven animation and (b) from
synthesized ones.
85

1 2 3 4 5 6 7 8 9 10111213141516171819202122232425262728293031320.4
0.5
0.6
0.7
0.8
0.9
1
fall
foodforce
file
sonlive
stand
charge
far
growth
full
sent
site
farm
sound
hoarse
best
fare
meanhit
friend
soon
floor
shonecase
tried
smile
stock
strange
stage
price
needs
Ave
rage
Iden
tific
atio
n C
orre
ct
RecordedSynthesized
Figure 4.8: Average discrimination correct score comparison between recorded
and synthesized marker driven animations of 32 words
86

CHAPTER 5
Summary and Future Directions
5.1 Summary
In this dissertation, a complete acoustically-driven talking face animation sys-
tem is developed. This work establishes a promising foundation of a talking
face synthesis system which automatically synchronizes with acoustical speech
signals. The system includes a full path from database acquisition, front-end fea-
ture extraction, back-end acoustic-to-optical mapping, animation rendering, and
perception evaluation. This is the first effort that has been completely built upon
3D facial marker data for an acoustically-driven talking face animation system.
The system can be applied to audio-visual perception studies. The system
can also be extended to generate digital agents for multimodel human-computer
interactions. Furthermore, it can be expanded to language education oriented
software to facilitate learning with the visual modality of speech.
5.1.1 Data acquisition
The database used in this study includes 3 corpora. CorpusA includes a set of
320 sentences spoken by 8 talkers. CorpusB includes 34 nonsense syllables and
87

1 sentence for pilot study on diphone concatenated synthesis system. CorpusC
includes 141 words, a set of 400 sentences, and a set of non-speech expressions
produced by a subject with the highest visual intelligibility from CorpusA. Cor-
pusC, along with CorpusA from the same subject, were used in the final training
and testing of the developed talking face animation system.
An automatic archiving pipeline was developed and applied to CorpusC. The
optical data were processed through head motion compensation, outlier removal,
temporal concatenation and interpolation, and 3D model registration steps. The
pipeline converted raw marker data into optical data that could drive 3D facial
animation. Manual corrections were made to optical data that produced facial
animation with artifacts. For CorpusC, 87.8% of the utterances were processed
automatically without manual corrections for the optical data.
Acoustic and optical data were segmented automatically through two stages:
token and acoustic phoneme segmentations. Both the audio-visual token seg-
mentation and HMM-based acoustic phonemes forced-alignment generated highly
reliable segmentation results. The developed automatic data archiving pipeline
successfully processed the raw recording data per take into synchronized, seg-
mented, and deformable optical-acoustical data files per utterance. The percent-
age of automation in the entire data archiving pipeline is significantly high.
5.1.2 Acoustic-to-optical synthesis
Given the synchronized acoustic and optical signals, mapping models between the
audio and visual modalities for 40 phonemes were built using dynamic Bayesian
networks (DBN). The mapping models were further applied to an acoustically-
driven talking face animation.
88

Different DBN structures were studied through quantitative comparisons.
These structures included independent hidden Markov model (I-HMM), product
hidden Markov model (P-HMM), and coupled hidden Markov model (C-HMM).
The three tested DBN methods were superior to the multilinear regression method
in reconstructing facial motions from acoustical signals. C-HMMs and P-HMMs
generated similarly better results than I-HMMs, suggesting the effectiveness of
the state dependency structure in the first two methods. C-HMMs generated
higher state transition path entropy and better captured audio-visual alignment
than P-HMMs.
Multiple DBN model parameters were also studied through quantitative com-
parisons. The maximum inter-chain state asynchrony (MICSA) parameter corre-
sponded to the tolerance of audio-visual state offset in the model construct. The
number of audio and visual Markov states corresponds to the size of the audio-
visual joint state set. Maximum inter-chain state asynchrony had a greater effect
on synthesis accuracy than the number of hidden states in the audio and visual
Markov chains.
Evaluation results indicate that the DBN state transition models with in-
tegrated training algorithms capture audio-visual speech alignment efficiently.
This study demonstrated the potential for DBNs in acoustically-driven talking
face synthesis.
5.1.3 Optically-driven animation and perceptual evaluation
We developed a rendering tool for optically-driven animation. The deformation
algorithm implemented in the rendering tool interpolates the sparse optical data
for lower facial animations. Radial basis functions were applied to sub-regions
89

on the face using corresponding subsets of key points. The key point dynamics
were propagated jointly onto the vertices in the sub-region. The infra-structures
of the vertices were preserved during the animation. Informal evaluations of
results driven from recorded optical data showed that the deformation algorithm
provided natural and well synchronized talking face animations.
Animation results rendered from original and synthesized optical data were
both evaluated through formal perceptual tests. A lexicon distinction identifi-
cation test was conducted with 16 human subjects. Perceptual test results on
original optical data-driven animations showed that the radial basis function algo-
rithm provided highly natural rendering of talking faces. The formal perceptual
evaluations agree with the informal evaluation results regarding the deformation
algorithm. Perceptual test results on synthesized optical data-driven animations
generated reduced facial movements which led to lower accuracy of lexicon dis-
tinction identification score than that obtained from recorded marker data-driven
animations.
5.2 Future research
In the study, synthesized optical data-driven animations show limited facial mo-
tion. The system can be further improved in several directions using the existing
database.
The front end acoustic feature extraction is based on linear predictive anal-
ysis. Formant frequencies from the acoustical signals depend on the vocal tract
shape, which is highly related to the mouth opening parameters including the
width, height and lip protrusions. In [105], a robust vocal tract resonance (VTR)
tracking algorithm was proposed. The proposed VTR tracking algorithm can
90

provide formant information on both vowels and consonants and is a good source
to capture speech coarticulations.
The front end optical feature extractions are based on the principle compo-
nents of the residual optical displacement from multilinear regressions. Some
lip motions can only be captured with very small displacement on the markers
around the lips, yet the subtle displacements show important visual speech infor-
mation. For example, lip pressing can be observed in the consonants /p, b, m/,
especially when they are produced at the beginning of a utterance. The corre-
sponding acoustical signal, which is often silence, cannot predict such a motion
reliably. Both [104] and [74] produced highly natural and intelligible talking faces
based on effective 3D optical data concatenation. For some consonants that have
significant visual features but very limited or consistent acoustical features such
as the plosives, references from direct recordings of optical data are necessary.
The back end DBN models built on phonemes are not robust enough to cap-
ture variations of key gestures. In [80], an optimization algorithm was proposed
for audio-to-visual conversion. The approach took into account the variance of
the Gaussian mixtures of each hidden state, which is different from the standard
Baum-Welch algorithm. This is an interesting direction to improve the training
of the DBN models. In [105], adaptive Kalman filtering techniques were applied
for robust tracking of vocal tract information. The technique can be adapted into
the inference from acoustical-to-optical features given trained DBN models, so
the synthetic optical features can be smoother and more intelligible for animation
rendering.
Developing DBN models based on context-dependent speech units can im-
prove the accuracy of key gestures in continuous speech. However, this approach
91

requires more training data which in turn requires more data collection.
The rendering algorithm is based on RBF interpolation. However, given the
sparse distribution of the markers, facial motions such as jaw rotation can gen-
erate artifacts. Parameter driven approaches can be combined with the sparse
marker driven approach for more natural rendering of the lower facial region.
Collisions between teeth and lips need to be detected for natural rendering inner
mouth organisms.
92

APPENDIX A
CorpusA: List of 320 IEEE
sentences
001 a round mat will cover the dull spot 002 it matters not if he reads these words
or those 003 the curtain rose and the show was on 004 pour the stew from the
pot into the plate 005 the two met while playing on the sand 006 pile the coal
high in the shed corner 007 the urge to write short stories is rare 008 he picked
up the dice for a second roll 009 acid burns holes in wool cloth 010 lift the square
stone over the fence 011 press the pedal with your left foot 012 a big wet stain
was on the round carpet 013 he wrote his name boldly at the top of the sheet
014 the dusty bench stood by the stone wall 015 watch the log float in the wide
river 016 they could laugh although they were sad 017 he ran half way to the
hardware store 018 he takes the oath of office each March 019 a gray mare walked
before the colt 020 the brown house was on fire to the attic 021 the roof should
be tilted at a sharp slant 022 he sent the boy on a short errand 023 the stems
of the tall glasses cracked and broke 024 his wide grin earned many friends 025
split the log with a quick sharp blow 026 a sash of gold silk will trim her dress
027 the man went to the woods to gather sticks 028 the news struck doubt into
restless minds 029 the hostess taught the new maid to serve 030 the beauty of
93

the view stunned the young boy 031 take a chance and win a china doll 032 try
to trace the fine lines of the painting 033 slash the gold cloth into fine ribbons
034 a waxed floor makes us lose balance 035 grape juice and water mix well 036
a bowl of rice is free with chicken stew 037 to make pure ice you freeze water 038
the Navy attacked the big task force 039 dip the pail once and let it settle 040
hats are worn to tea and not to dinner 041 the tube was blown and the tire flat
and useless 042 he lent his coat to the tall gaunt stranger 043 the ramp led up
to the wide highway 044 we admire and love a good cook 045 take the winding
path to reach the lake 046 tack the strip of carpet to the worn floor 047 the odor
of spring makes young hearts jump 048 a siege will crack the strong defense 049
she has a smart way of wearing clothes 050 dig deep in the earth for pirate’s gold
051 the duke left the park in a silver coach 052 green moss grows on the northern
side 053 find the twin who stole the pearl necklace 054 the grass curled around
the fence post 055 code is used when secrets are sent 056 a shower of dirt fell
from the hot pipes 057 the lobes of her ears were pierced to hold rings 058 the
set of china hit the floor with a crash 059 two blue fish swam in the tank 060
hold the hammer near the end to drive the nail 061 cheap clothes are flashy but
don’t last 062 shut the hatch before the waves push it in 063 he wrote his last
novel there at the inn 064 let’s all join as we sing the last chorus 065 the stitch
will serve but needs to be shortened 066 weave the carpet on the right hand side
067 boards will warp unless kept dry 068 the little tales they tell are false 069
the rude laugh filled the empty room 070 this is a grand season for hikes on the
road 071 screw the round cap on as tight as needed 072 the key you designed
will fit the lock 073 the peace league met to discuss their plans 074 the bunch of
grapes was pressed into wine 075 we need grain to keep our mules healthy 076
the brass tube circled the high wall 077 slide the tray across the glass top 078 a
94

pod is what peas always grow in 079 bathe and relax in the cool green grass 080
fasten two pins on each side 081 pack the records in a neat thin case 082 the just
claim got the right verdict 083 they told wild tales to frighten him 084 the hilt of
the sword was carved with fine designs 085 cap the jar with a tight brass cover
086 the purple tie was ten years old 087 feel the heat of the weak dying flame
088 they took the axe and the saw to the forest 089 the knife was hung inside
its bright sheath 090 slide the box into that empty space 091 clothes and lodging
are free to new men 092 he knew the skill of the great young actress 093 we tried
to replace the coin but failed 094 a small creek cut across the field 095 beat the
dust from the rug onto the lawn 096 a man in a blue sweater sat at the desk 097
the wreck occurred by the bank on Main Street 098 torn scraps littered the stone
floor 099 the doorknob was made of bright clean brass 100 the pearl was worn
in a thin silver ring 101 brass rings are sold by these natives 102 the quick fox
jumped on the sleeping cat 103 a steep trail is painful for our feet 104 the dry
wax protects the deep scratch 105 he ordered peach pie with ice cream 106 the
bank pressed for payment of the debt 107 smoky fires lack flame and heat 108
a rag will soak up spilled water 109 fine soap saves tender skin 110 the nozzle
of the fire hose was bright brass 111 the thaw came early and freed the stream
112 the third act was dull and tired the players 113 fill the ink jar with sticky
glue 114 the store was jammed before the sale could start 115 shake hands with
this friendly child 116 a round hole was drilled through the thin board 117 ducks
fly north but lack a compass 118 the blind man counted his old coins 119 next
Sunday is the twelfth of the month 120 one step more and the board will collapse
121 the hitch between the horse and cart broke 122 the youth drove with zest
but little skill 123 the heart beat strongly and with firm strokes 124 the latch on
the back gate needed a nail 125 schools for ladies teach charm and grace 126 a
95

strong bid may scare your partner stiff 127 a thin stripe runs down the middle
128 they floated on the raft to sun their white backs 129 the long journey home
took a year 130 the child crawled into the dense grass 131 we find joy in the
simplest things 132 they sang the same tunes at each party 133 fairy tales should
be fun to write 134 the soft cushion broke the man’s fall 135 the ship was torn
apart on the sharp reef 136 the goose was brought straight from the old market
137 the houses are built of red clay bricks 138 these days a chicken leg is a rare
dish 139 the shaky barn fell with a loud crash 140 his shirt was clean but one
button was gone 141 he carved a head from the round block of marble 142 she
was waiting at my front lawn 143 the office paint was a dull sad tan 144 a severe
storm tore down the barn 145 the girl at the booth sold fifty bonds 146 they felt
gay when the ship arrived in port 147 a streak of color ran down the left edge
148 the copper bowl shone in the sun’s rays 149 serve the hot rum to the tired
heroes 150 the sand drifts over the sill of the old house 151 the horse trotted
around the field at a brisk pace 152 a pink shell was found on the sandy beach
153 soap can wash most dirt away 154 feed the white mouse some flower seeds
155 the plush chair leaned against the wall 156 nine rows of soldiers stood in
line 157 no hardship seemed to keep him sad 158 she saw a cat in the neighbor’s
house 159 the harder he tried the less he got done 160 the bark of the pine tree
was shiny and dark 161 these pills do less good than others 162 press the pants
and sew a button on the vest 163 the bills were mailed promptly on the tenth
of the month 164 a rich farm is rare in this sandy waste 165 put the chart on
the mantel and tack it down 166 breakfast buns are fine with a hot drink 167
dull stories make her laugh 168 the price is fair for a good antique clock 169 the
clock struck to mark the third period 170 every word and phrase he speaks is true
171 the idea is to sew both edges straight 172 the ripe taste of cheese improves
96

with age 173 read just what the meter says 174 the swan dive was far short of
perfect 175 our troops are set to strike heavy blows 176 the pipe ran almost the
length of the ditch 177 a white silk jacket goes with any shoes 178 slide the bill
between the two leaves 179 the desk was firm on the shaky floor 180 drive the
screw straight into the wood 181 a child’s wit saved the day for us 182 on the
islands the sea breeze is soft and mild 183 he offered proof in the form of a large
chart 184 ship maps are different from those for planes 185 the cloud moved in
a stately way and was gone 186 take the match and strike it against your shoe
187 the stray cat gave birth to kittens 188 the screen before the fire kept in the
sparks 189 the empty flask stood on the tin tray 190 the door was barred locked
and bolted as well 191 when you hear the bell come quickly 192 a vent near the
edge brought in fresh air 193 the gold ring fits only a pierced ear 194 high seats
are best for football fans 195 the lazy cow lay in the cool grass 196 raise the sail
and steer the ship northward 197 a break in the dam almost caused a flood 198
rice is often served in round bowls 199 the clothes dried on a thin wooden rack
200 light maple makes for a swell room 201 the young prince became heir to the
throne 202 the play seems dull and quite stupid 203 twist the valve and release
hot steam 204 the tree top waved in a graceful way 205 a stiff cord will do to
fasten your shoe 206 tear a thin sheet from the yellow pad 207 draw the chart
with heavy black lines 208 a fence cuts through the corner lot 209 the grass and
bushes were wet with dew 210 bail the boat to stop it from sinking 211 a flat pack
takes less luggage space 212 the fish twisted and turned on the bent hook 213
the cup cracked and spilled its contents 214 stop whistling and watch the boys
march 215 flax makes a fine brand of paper 216 the heap of fallen leaves was set
on fire 217 it takes a good trap to capture a bear 218 all sat frozen and watched
the screen 219 the sheep were led home by a dog 220 the tin box held priceless
97

stones 221 cod is the main business of the north shore 222 the wagon moved on
well oiled wheels 223 the friendly gang left the drug store 224 thick glasses helped
him read the print 225 the logs fell and tumbled into the clear stream 226 it is
late morning on the old wall clock 227 each penny shone like new 228 float the
soap on top of the bath water 229 it takes heat to bring out the odor 230 rake the
rubbish up and then burn it 231 pick a card and slip it under the pack 232 cut
the pie into large parts 233 the crooked maze failed to fool the mouse 234 a gold
vase is both rare and costly 235 trample the spark else the flames will spread 236
the wall phone rang loud and often 237 turn on the lantern which gives us light
238 the black trunk fell from the landing 239 the rush for funds reached its peak
Tuesday 240 the new girl was fired today at noon 241 the colt reared and threw
the tall rider 242 pink clouds floated with the breeze 243 he lay prone and hardly
moved a limb 244 the big red apple fell to the ground 245 the man wore a feather
in his felt hat 246 kick the ball straight and follow through 247 the zones merge
in the central part of town 248 the pennant waved when the wind blew 249 he
put his last cartridge into the gun and fired 250 dimes showered down from all
sides 251 we don’t like to admit our small faults 252 crack the walnut with your
sharp side teeth 253 the wrist was badly strained and hung limp 254 the loss of
the cruiser was a blow to the fleet 255 the dark pot hung in the front closet 256
the baby puts his right foot in his mouth 257 these coins will be needed to pay
his debt 258 the meal was cooked before the bell rang 259 always close the barn
door tight 260 a thin book fits in the side pocket 261 dots of light betrayed the
black cat 262 the beach is dry and shallow at low tide 263 the sink is the thing in
which we pile dishes 264 drop the ashes on the worn old rug 265 a list of names
is carved around the base 266 the first worm gets snapped early 267 the horn
of the car woke the sleeping cop 268 the leaf drifts along with a slow spin 269
98

the red tape bound the smuggled food 270 a yacht slid around the point into the
bay 271 pitch the straw through the door of the stable 272 roads are paved with
sticky tar 273 write a fond note to the friend you cherish 274 tin cans are absent
from store shelves 275 wood is best for making toys and blocks 276 he crawled
with care along the ledge 277 the lamp shone with a steady green flame 278 the
pirates seized the crew of the lost ship 279 some ads serve to cheat buyers 280 the
fur of cats goes by many names 281 take shelter in this tent but keep still 282 a
clean neck means a neat collar 283 read verse out loud for pleasure 284 the desk
and both chairs were painted tan 285 live wires should be kept covered 286 glue
the sheet to the dark blue background 287 jazz and swing fans like fast music
288 bottles hold four kinds of rum 289 port is a strong wine with a smoky taste
290 throw out the used paper cup and plate 291 the point of the steel pen was
bent and twisted 292 the doctor cured him with these pills 293 we now have a
new base for shipping 294 greet the new guests and leave quickly 295 the pencils
have all been used 296 wipe the grease off his dirty face 297 the ancient coin
was quite dull and worn 298 the coffee stand is too high for the couch 299 use a
pencil to write the first draft 300 the ink stain dried on the finished page 301 an
abrupt start does not win the prize 302 a rod is used to catch pink salmon 303
be sure to set that lamp firmly in the hole 304 smoke poured out of every crack
305 thieves who rob friends deserve jail 306 a pot of tea helps to pass the evening
307 bring your best compass to the third class 308 down that road is the way
to the grain farmer 309 a thing of small note can cause despair 310 you cannot
brew tea in a cold pot 311 smile when you say nasty words 312 the corner store
was robbed last night 313 a stuffed chair slipped from the moving van 314 the
young kid jumped the rusty gate 315 leave now and you will arrive on time 316
the theft of the pearl pin was kept secret 317 the bombs left most of the town in
99

ruins 318 dispense with a vest on a day like this 319 the salt breeze came across
from the sea 320 jump the fence and hurry up the bank
100

APPENDIX B
CorpusB: List of pilot corpus
Table B.1: Diphone carrier words for the sentence Slide
the tray across the glass top.
CarrierID Diphone Carrier Word Example Repetitions
0132 x g ( tagah ga ) the gold 6
0137 x t ( tatah ta ) the two 6
0221 e x ( tatA ahta ) tray across 6
0288 d D ( tad dhata ) and the 5
0403 s D ( tas dhata ) press the 5
0416 s t ( tas tata ) hostess taught 5
0781 x-’k ( takah-’ka ) across 6
0951 ’kr ( ta-’krata ) across 5
0970 @s ( tas@sa ) sand 4
0975 Ad ( tadIda ) dice 4
1067 ap ( tapapa ) spot 4
1068 ta ( tatata ) top 4
1078 cs ( tasawsa ) sword 4
Continued on next page
101
Table B.1 – continued from previous page
CarrierID Diphone Carrier Word Example Repetitions
1127 Dx ( tadhahdha ) the 4
1164 l@ ( tal@ta ) laugh 4
1169 lA ( talIta ) lines 4
1210 rc ( tarawta ) strong 4
1215 re ( tarAta ) gray 4
1344 gl ( ta-glata ) glass 5
1347 sl ( ta-slata ) slant 5
1357 tr ( ta-trata ) trim 5
1381 s ( sata ) split 2
1401 p ( tatap ) jump 5
Table B.2: Diphone carrier words for the sentence ’Feel
the heat of the weak dying flame.’
CarrierID Diphone Carrier Word Example Repetitions
0034 t ˆ ( tat uhtA ) picked up 4
0133 x h ( tahah ha ) the hot 5
0205 x w ( tawah wa ) the wide 5
0253 G f ( tang fata ) dying flame 4
0336 l D ( tal dhata ) pile the 4
0439 v D ( tav dhata ) of the 4
Continued on next page
102

Table B.2 – continued from previous page
CarrierID Diphone Carrier Word Example Repetitions
0567 k ’d ( tak ’data ) weak dying 4
0712 A-I ( tatI-ita ) dying 5
0820 ’dA ( ta’dIda ) dying 4
1098 fi ( tafeefa ) feel 4
1099 hi ( taheeha ) he 4
1100 ik ( takeeka ) key 5
1103 it ( tateeta ) dusty 5
1127 Dx ( tadhahdha ) the 4
1150 v ( tavuhva ) of 5
1212 le ( talAta ) plate 4
1221 wi ( taweeta ) we 4
1249 IG ( tatingta ) playing 5
1275 em ( tatAmta ) name 5
1277 il ( tateelta ) feel 5
1343 fl ( ta-flata ) float 5
1373 f ( fata ) find 2
1399 m ( tatam ) room 5
2001 G f ( ting fata ) dying flame 3
2002 flo ( ta-flOta ) float 5
2003 fle ( ta-flAta ) float 5
2008 em ( tatAmda ) name 5
2009 em ( tatAmba ) name 5
Continued on next page
103

Table B.2 – continued from previous page
CarrierID Diphone Carrier Word Example Repetitions
2010 em ( tatAmka ) name 5
2011 em ( tatAmra ) name 5
2012 em ( tadAmta ) name 5
2013 em ( tabAmta ) name 5
2014 em ( takAmta ) name 5
2015 em ( tarAmta ) name 5
104

APPENDIX C
CorpusC: List of complementary
corpus
C.1 Non-speech expressions
01 cheekPuff 02 chewing 03 fishFace 04 frownSmile 05 growl 06 gurn 07 kiss 08
noseWrinkling 09 raspberry 10 smirk 11 wink 12 yawn
C.2 Mono-syllabic words
001 both 002 brief 003 charge 004 far 005 fare 006 farm 007 file 008 film 009 floor
010 form 011 frame 012 friend 013 growth 014 hung 015 long 016 month 017 page
018 roof 019 school 020 smile 021 speech 022 spring 023 square 024 strange 025
strength 026 bill 027 brown 028 care 029 class 030 core 031 drive 032 fall 033
food 034 force 035 full 036 give 037 health 038 hoarse 039 late 040 line 041 live
042 march 043 point 044 price 045 serve 046 space 047 staff 048 stage 049 sure
050 voice 051 bad 052 best 053 case 054 dark 055 gone 056 gun 057 hit 058 keep
059 mean 060 meat 061 met 062 needs 063 news 064 note 065 peace 066 sent 067
shone 068 site 069 son 070 soon 071 sound 072 stand 073 stock 074 tax 075 tried
105

C.3 Di-syllabic words
076 central 077 children 078 college 079 congress 080 current 081 famous 082
foreign 083 function 084 knowledge 085 moment 086 normal 087 private 088
problem 089 process 090 product 091 question 092 science 093 social 094 southern
095 special 096 spirit 097 student 098 thousand 099 trouble 100 woman 101
certain 102 coming 103 common 104 district 105 final 106 human 107 husband
108 million 109 modern 110 morning 111 music 112 nation 113 person 114 present
115 purpose 116 reading 117 running 118 series 119 service 120 simple 121 single
122 surface 123 table 124 western 125 working 126 season 127 beaten 128 panic
129 gotten 130 market 131 model 132 pocket 133 battle 134 muscle 135 hidden
136 basis 137 subtle 138 basic 139 senate 140 dozen 141 saddle
C.4 IEEE sentences
321 The birch canoe slid on the smooth planks. 322 It’s easy to tell the depth
of a well. 323 The juice of lemons makes fine punch. 324 The box was thrown
beside the parked truck. 325 The hogs were fed chopped corn and garbage. 326
Four hours of steady work faced us. 327 A large size in stockings is hard to sell.
328 The boy was there when the sun rose. 329 The source of the huge river is
the clear spring. 330 Help the woman get back to her feet. 331 The small pup
gnawed a hole in the sock. 332 Her purse was full of useless trash. 333 It snowed,
rained, and hailed the same morning. 334 Hoist the load to your left shoulder.
335 Note closely the size of the gas tank. 336 Mend the coat before you go out.
337 The young girl gave no clear response. 338 What joy there is in living. 339
A king ruled the state in the early days. 340 Sickness kept him home the third
106

week. 341 The wide road shimmered in the hot sun. 342 The rope will bind
the seven books at once. 343 Hop over the fence and plunge in. 344 Mesh wire
keeps chicks inside. 345 The frosty air passed through the coat. 346 Adding fast
leads to wrong sums. 347 The show was a flop from the very start. 348 A saw
is a tool used for making boards. 349 March the soldiers past the next hill. 350
A cup of sugar makes sweet fudge. 351 Place a rosebush near the porch steps.
352 Both lost their lives in the raging storm. 353 We talked of the side show in
the circus. 354 Cars and busses stalled in snow drifts. 355 The dune rose from
the edge of the water. 356 Those words were the cue for the actor to leave. 357
The walled town was seized without a fight. 358 The lease ran out in sixteen
weeks. 359 A tame squirrel makes a nice pet. 360 The fruit peel was cut in thick
slices. 361 See the cat glaring at the scared mouse. 362 There are more than
two factors here. 363 The hat brim was wide and too droopy. 364 The lawyer
tried to lose his case. 365 Men strive but seldom get rich. 366 The slush lay deep
along the street. 367 A wisp of cloud hung in the blue air. 368 A pound of sugar
costs more than eggs. 369 The fin was sharp and cut the clear water. 370 The
term ended in late june that year. 371 A Tusk is used to make costly gifts. 372
Ten pins were set in order. 373 The bill was paid every third week. 374 Oak is
strong and also gives shade. 375 Cats and Dogs each hate the other. 376 The
pipe began to rust while new. 377 Open the crate but don’t break the glass. 378
Add the sum to the product of these three. 379 Act on these orders with great
speed. 380 The hog crawled under the high fence. 381 Move the vat over the
hot fire. 382 Leaves turn brown and yellow in the fall. 383 Burn peat after the
logs give out. 384 Hemp is a weed found in parts of the tropics. 385 A lame
back kept his score low. 386 Type out three lists of orders. 387 The boss ran the
show with a watchful eye. 388 Paste can cleanse the most dirty brass. 389 The
107

slang word for raw whiskey is booze. 390 It caught its hind paw in a rusty trap.
391 The wharf could be seen at the farther shore. 392 The tiny girl took off her
hat. 393 A cramp is no small danger on a swim. 394 He said the same phrase
thirty times. 395 Pluck the bright rose without leaves. 396 Two plus seven is
less than ten. 397 The glow deepened in the eyes of the sweet girl. 398 Bring
your problems to the wise chief. 399 We frown when events take a bad turn. 400
Guess the result from the first scores. 401 A salt pickle tastes fine with ham. 402
These thistles bend in a high wind. 403 Pure bred poodles have curls. 404 The
spot on the blotter was made by green ink. 405 Mud was spattered on the front
of his white shirt. 406 The cigar burned a hole in the desk top. 407 A speedy
man can beat this track mark. 408 He broke a new shoelace that day. 409 She
sewed the torn coat quite neatly. 410 The sofa cushion is red and of light weight.
411 The jacket hung on the back of the wide chair. 412 At that high level the
air is pure. 413 Drop the two when you add the figures. 414 A filing case is now
hard to buy. 415 Steam hissed from the broken valve. 416 The child almost hurt
the small dog. 417 There was a sound of dry leaves outside. 418 The sky that
morning was clear and bright blue. 419 Sunday is the best part of the week. 420
Add the store’s account to the last cent. 421 Eight miles of woodland burned
to waste. 422 A young child should not suffer fright. 423 Add the column and
put the sum here. 424 There the flood mark is ten inches. 425 The fruit of a
fig tree is apple shaped. 426 Corn cobs can be used to kindle a fire. 427 Where
were they when the noise started. 428 The paper box is full of thumb tacks. 429
Sell your gift to a buyer at a good gain. 430 The tongs lay beside the ice pail.
431 The petals fall with the next puff of wind. 432 Farmers came in to thresh
the oat crop. 433 The lure is used to catch trout and flounder. 434 A blue crane
is a tall wading bird. 435 A fresh start will work such wonders. 436 The club
108

rented the rink for the fifth night. 437 After the dance, they went straight home.
438 Even the worst will beat his low score. 439 The cement had dried when he
moved it. 440 The loss of the second ship was hard to take. 441 The fly made its
way along the wall. 442 Do that with a wooden stick. 443 The large house had
hot water taps. 444 It is hard to erase blue or red ink. 445 Write at once or you
may forget it. 446 A pencil with black lead writes best. 447 Coax a young calf
to drink from a bucket. 448 Try to have the court decide the case. 449 They are
pushed back each time they attack. 450 He broke his ties with groups of former
friends. 451 The map had an X that meant nothing. 452 Whitings are small fish
caught in nets. 453 Jerk the rope and the bell rings weakly. 454 Madam, this is
the best brand of corn. 455 The play began as soon as we sat down. 456 This
will lead the world to more sound and fury. 457 Add salt before you fry the egg.
458 The birch looked stark white and lonesome. 459 The box is held by a bright
red snapper. 460 Yell and clap as the curtain slides back. 461 They are men
who walk the middle of the road. 462 Both brothers wear the same size. 463 In
some form or other we need fun. 464 The prince ordered his head chopped off.
465 Fruit flavors are used in fizz drinks. 466 Canned pears lack full flavor. 467
Carry the pail to the wall and spill it there. 468 The train brought our hero to
the big town. 469 We are sure that one war is enough. 470 Gray paint stretched
for miles around. 471 Tea served from the brown jug is tasty. 472 A dash of
pepper spoils beef stew. 473 A zestful food is the hot-cross bun. 474 Cut the
cord that binds the box tightly. 475 Look in the corner to find the tan shirt. 476
The cold drizzle will halt the bond drive. 477 Nine men were hired to dig the
ruins. 478 The junk yard had a mouldy smell. 479 The flint sputtered and lit a
pine torch. 480 Soak the cloth and drown the sharp odor. 481 The shelves were
bare of both jam or crackers. 482 A joy to every child is the swan boat. 483 A
109

cloud of dust stung his tender eyes. 484 To reach the end he needs much courage.
485 Shape the clay gently into block form. 486 A ridge on a smooth surface is a
bump or flaw. 487 Hedge apples may stain your hands green. 488 Quench your
thirst, then eat the crackers. 489 Tight curls get limp on rainy days. 490 The
mute muffled the high tones of the horn. 491 The old pan was covered with hard
fudge. 492 The node on the stalk of wheat grew daily. 493 Write fast if you want
to finish early. 494 The barrel of beer was a brew of malt and hops. 495 The
plant grew large and green in the window. 496 The beam dropped down on the
workman’s head. 497 She danced like a swan, tall and graceful. 498 The last
switch cannot be turned off. 499 The fight will end in just six minutes. 500 The
store walls were lined with colored frocks. 501 The rise to fame of a person takes
luck. 502 Paper is scarce, so write with much care. 503 Time brings us many
changes. 504 Men think and plan and sometimes act. 505 He smoke a big pipe
with strong contents. 506 The crunch of feet in the snow was the only sound.
507 Glass will clink when struck by metal. 508 The kitten chased the dog down
the street. 509 Pages bound in cloth make a book. 510 Women form less than
half of the group. 511 A gem in the rough needs work to polish. 512 Most of the
news is easy for us to hear. 513 He used the lathe to make brass objects. 514
The vane on top of the pole revolved in the wind. 515 Mince pie is a dish served
to children. 516 The clan gathered on each dull night. 517 Let it burn, it gives
us warmth and comfort. 518 A castle built from sand fails to endure. 519 Next
Tuesday we must vote. 520 The dirt piles were lines along the road. 521 Just
hoist it up and take it away. 522 A ripe plum is fit for a king’s palate. 523 Our
plans right now are hazy. 524 He took the lead and kept it the whole distance.
525 Plead to the council to free the poor thief. 526 Better hash is made of rare
beef. 527 This plank was made for walking on. 528 The lake sparkled in the red
110

hot sun. 529 Tend the sheep while the dog wanders. 530 It takes a lot of help to
finish these. 531 Mark the spot with a sign painted red. 532 Take two shares as
a fair profit. 533 North winds bring colds and fevers. 534 He asks no person to
vouch for him. 535 Go now and come here later. 536 That move means the game
is over. 537 He wrote down a long list of items. 538 Fake stones shine but cost
little. 539 The drip of the rain made a pleasant sound. 540 Much of the story
makes good sense. 541 The sun came up to light the eastern sky. 542 Heave the
line over the port side. 543 A lathe cuts and trims any wood. 544 It’s a dense
crowd in two distinct ways. 545 His hip struck the knee of the next player. 546
The stale smell of old beer lingers. 547 Beef is scarcer than some lamb. 548 A
cone costs five cents on Mondays. 549 Jerk that dart from the cork target. 550
No cement will hold hard wood. 551 Three for a dime, the young peddler cried.
552 The sense of smell is better than that of touch. 553 Grace makes up for lack
of beauty. 554 Nudge gently but wake her now. 555 Once we stood beside the
shore. 556 A chink in the wall allowed a draft to blow. 557 A cold dip restores
health and zest. 558 There is a lag between thought and act. 559 Seed is needed
to plant the spring corn. 560 The boy owed his pal thirty cents. 561 The chap
slipped into the crowd and was lost. 562 Say it slowly but make it ring clear. 563
The straw nest housed five robins. 564 Screen the porch with woven straw mats.
565 This horse will nose his way to the finish. 566 The nag pulled the frail cart
along. 567 The vamp of the shoe had a gold buckle. 568 The smell of burned rags
itches my nose. 569 New pants lack cuffs and pockets. 570 The marsh will freeze
when cold enough. 571 They slice the sausage thin with a knife. 572 The bloom
of the rose lasts a few days. 573 He wheeled the bike past the winding road. 574
The couch cover and hall drapes were blue. 575 The cleat sank deeply into the
soft turf. 576 To have is better than to wait and hope. 577 The music played on
111

while they talked. 578 He sent the figs, but kept the ripe cherries. 579 The hinge
on the door creaked with old age. 580 Fly by night and you waste little time. 581
Birth and death mark the limits of life. 582 The chair looked strong but had no
bottom. 583 The kite flew wildly in the high wind. 584 A fur muff is stylish once
more. 585 We need an end of all such matter. 586 The case was puzzling to the
old and wise. 587 The bright lanterns were gay on the dark lawn. 588 We don’t
get much money but we have fun. 589 Five years he lived with a shaggy dog.
590 The way to save money is not to spend much. 591 Send the stuff in a thick
paper bag. 592 A quart of milk is water for the most part. 593 The three story
house was built of stone. 594 In the rear of the ground floor was a large passage.
595 Oats are a food eaten by horse and man. 596 Their eyelids droop for want
of sleep. 597 A sip of tea revives his tired friend. 598 There are many ways to do
these things. 599 Tuck the sheet under the edge of the mat. 600 A force equal
to that would move the earth. 601 We like to see clear weather. 602 The work of
the tailor is seen on each side. 603 Shake the dust from your shoes, stranger. 604
She was kind to sick old people. 605 The square wooden crate was packed to be
shipped. 606 We dress to suit the weather of most days. 607 The water in this
well is a source of good health. 608 That guy is the writer of a few banned books.
609 Ripe pears are fit for a queen’s table. 610 The kite dipped and swayed, but
stayed aloft. 611 The pleasant hours fly by much too soon. 612 The room was
crowded with a wild mob. 613 This strong arm shall shield your honor. 614 She
blushed when he gave her a white orchid. 615 The beetle droned in the hot June
sun. 616 Neat plans fail without luck. 617 The vast space stretched into the far
distance. 618 Hurdle the pit with the aid of a long pole. 619 Even a just cause
needs power to win. 620 Peep under the tent and see the clowns. 621 Flood the
mails with requests for this book. 622 A thick coat of black paint covered all.
112

623 The pencil was cut to be sharp at both ends. 624 Those last words were a
strong statement. 625 Dill pickles are sour but taste fine. 626 Either mud or dust
are found at all times. 627 The best method is to fix it in place with clips. 628
If you mumble your speech will be lost. 629 At night the alarm roused him from
a deep sleep. 630 Fill your pack with bright trinkets for the poor. 631 The small
red neon lamp went out. 632 Clams are small, round, soft, and tasty. 633 The
fan whirled its round blades softly. 634 The line where the edges join was clean.
635 Breathe deep and smell the piny air. 636 A brown leather bag hung from its
strap. 637 A toad and a frog are hard to tell apart. 638 Paint the sockets in the
wall dull green. 639 Bribes fail where honest men work. 640 Footprints showed
the path he took up the beach. 641 Prod the old mule with a crooked stick. 642
It is a band of steel three inches wide. 643 It was hidden from sight by a mass
of leaves and shrubs. 644 The weight of the package was seen on the high scale.
645 Wake and rise, and step into the green outdoors. 646 The green light in the
brown box flickered. 647 They took their kids from the public school. 648 Keep
the hatch tight and the watch constant. 649 Sever the twine with a quick snip of
the knife. 650 Paper will dry out when wet. 651 Slide the catch back and open
the desk. 652 Help the weak to preserve their strength. 653 A sullen smile gets
few friends. 654 Jerk the cord, and out tumbles the gold. 655 Set the piece here
and say nothing. 656 Get the trust fund to the bank early. 657 Choose between
the high road and the low. 658 A plea for funds seems to come again. 659 There
is a strong chance it will happen once more. 660 When the frost has come it
is time for turkey. 661 Sweet words work better than fierce. 662 A six comes
up more often than a ten. 663 Lush fern grow on the lofty rocks. 664 The ram
scared the school children off. 665 The team with the best timing looks good.
666 The farmer swapped his horse for a brown ox. 667 Sit on the perch and tell
113

the others what to do. 668 The early phase of life moves fast. 669 Tea in thin
china has a sweet taste. 670 A whiff of it will cure the most stubborn cold. 671
The facts don’t always show who is right. 672 She flaps her cape as she parades
the street. 673 Loop the braid to the left and then over. 674 Plead with the
lawyer to drop the lost cause. 675 Calves thrive on tender spring grass. 676 Post
no bills on this office wall. 677 A cruise in warm waters in a sleek yacht is fun.
678 It was done before the boy could see it. 679 Crouch before you jump or miss
the mark. 680 Pack the kits and don’t forget the salt. 681 The square peg will
settle in the round hole. 682 Poached eggs and tea must suffice. 683 Bad nerves
are jangled by a door slam. 684 The sky in the west is tinged with orange red.
685 The pods of peas ferment in bare fields. 686 The horse balked and threw the
tall rider. 687 The rarest spice comes from the far East. 688 A smatter of French
is worse than none. 689 The mule trod the treadmill day and night. 690 The
aim of the contest is to raise a great fund. 691 To send it now in large amounts
is bad. 692 There is a fine hard tang in salty air. 693 The slab was hewn from
heavy blocks of slate. 694 Dunk the stale biscuits into strong drink. 695 Hang
tinsel from both branches. 696 The poor boy missed the boat again. 697 The
first part of the plan needs changing. 698 A good book informs of what we ought
to know. 699 The mail comes in three batches per day. 700 The night shift men
rate extra pay. 701 The red paper brightened the dim stage. 702 See the player
scoot to third base. 703 Many hands help get the job done. 704 No doubt about
the way the wind blows. 705 The steady drip is worse than a drenching rain. 706
Green ice frosted the punch bowl. 707 The gloss on top made it unfit to read.
708 The hail pattered on the burnt brown grass. 709 Seven seals were stamped
on great sheets. 710 It was a bad error on the part of the new judge. 711 The
pot boiled but the contents failed to gel. 712 Stop and stare at the hard working
114

man. 713 The streets are narrow and full of sharp turns. 714 The pup jerked
the leash as he saw a feline shape. 715 Open your book to the first page. 716
Fish evade the net and swim off. 717 Will you please answer that phone. 718 A
gold ring will please most any girl. 719 Small children came to see him. 720 She
called his name many times.
115

APPENDIX D
Single letter representation of
phonemes
Table D.1: Phonemes in single letter symbols
Vowel Sample Consonant Sample
a to¯p b b
¯et
@ ba¯g C c
¯h¯eck
c bo¯u¯g¯h¯t D t
¯h¯is
x o¯f f f
¯act
E he¯a¯d g g
¯uess
i be¯a¯k h h
¯at
I bi¯t J j
¯et
R bi¯r¯d k k
¯ick
U bo¯o¯k l l
¯et
u bo¯o¯t m m
¯eet
W bo¯w¯
n n¯et
A bi¯ke G son
¯g¯
Continued on next page
116

Table D.1: Phonemes in single letter symbols
Vowel Sample Consonant Sample
e ba¯ke p p
¯et
o bo¯a¯t r r
¯ed
O bo¯y¯
s s¯ix
Consonant Sample S s¯h¯ip
t t¯ax T t
¯h¯at
v v¯est w w
¯est
y y¯atch z z
¯oo
Z treas¯ure silence
117

APPENDIX E
List of word pairs for visual
lexicon distinction identification
test
Table E.1: Animated words and their paired words from
natural video in four visual lexicon distinction levels
Animated Words from natural video
words same near med far
best best space floor growth
case case class form sure
charge charge march class frame
fall fall full growth roof
far far floor brown serve
fare fare farm stand roof
farm farm far live school
file file fall growth sure
Continued on next page
118

Table E.1 – continued from previous page
Animated Words from natural video
words same near med far
floor floor core health month
food food voice march core
force force voice keep growth
friend friend sent charge hoarse
full full soon price stand
growth growth note form point
hit hit needs form far
hoarse hoarse core frame brief
live live live2 brown spring
mean mean bill stand square
needs needs case shone brief
price price bad stand health
sent sent tax brief floor
shone shone sound speech frame
site site tried staff sure
smile smile son strength brief
son son stock best roof
soon soon sound march page
sound sound sent brief frame
stage stage strange month farm
stand stand sent brief spring
Continued on next page
119

Table E.1 – continued from previous page
Animated Words from natural video
words same near med far
stock stock stand march brief
strange strange strength brown form
tried tried drive film health
120

References
[1] P.K. Kuhl and A.N. Meltzoff The bimodal perception of speech in infancy.
Science, 218, 1138-1141, 1982.
[2] R. Campbell and B. Dodd Eds. Hearing by Eye: The Psychology of Lip-
Reading. London, United Kingdom: Lawrence Erlbaum Associates, 1987.
[3] ISO/IEC JTC1/WG11 N2202. Text for FCD 14496-2 System. Tokyo meet-
ing, March, 1998.
[4] http://www.opengl.org.
[5] L. B. Almeida Multilayer perceptrons. Handbook of Neural Computation,
IOP Publishing Ltd. and Oxford University Press, pp. C.1.2.1-C.1.2.30,
1997.
[6] C. Benoit, T. Lallouache, T. Mohamadi, and C. Abry. A set of French
visemes for visual speech synthesis. Talking machines: Theories, models
and designs, G. Bailly and C. Benoit Eds., Amsterdam, The Netherlands:
Elsevier Science BV, pp. 485-504, 1992
[7] A. W. Black. Perfect synthesis for all of the people all of the time. Proc.
IEEE TTS Workshop, Los Angeles, CA, 2002.
[8] M. Brand. Voice puppetry. in Proc. SIGGRAPH’99, ACM Press, New
York, pp. 21-28, 1999.
[9] M. Brand. Pattern discovery vis entropy minimization. in Proc. Artificial
Intelligence and Statistics, Mogan Kaufmann Publishers, Jan, 1999.
[10] C. Bregler, M. Covell, and M. Slaney. Video rewrite: Driving visual speech
with audio. in Proc. ACM SIGGRAPH’97, 1997.
[11] C. Bregler and Y. Konig. ’Eigenlips’ for robust speech recognition. in Proc.
ICASSP, pp.669-672, Australia, 1994.
121

[12] D. Chandramohan and P. L. Silsbee. A multiple deformable template ap-
proach for visual speech recognition. in Proc. ICSLP, Philadelphia, PA,
pp. 50-53, Oct. 1996.
[13] T. Chen and R. Rao. Audio-visual interaction in multimedia communi-
cation. in Proc. ICASSP’97, Munich, Germany, vol.1 pp. 179-182, Apr,
1997.
[14] M. Cohen and D. Massaro. Modeling coarticulation in synthetic visual
speech. Models and Techniques in Computer Animation, N. M. Thalmann
and D. Thalmann, eds. Tokyo: Springer-Verlg, p. 139-156, 1993.
[15] M. Covell and C. Bregler. Eigen-points. in Proc. IEEE Int. Conf. on Image
Processing, Lausanne, Switzerland, vol. 3, pp. 471-474, 1996.
[16] P. Ekman and W. Friesen. Manual for the facial action coding system.
Consulting Psychologist Press, Inc., Palo Alto, CA, 1978.
[17] O. Engwall. A 3D tongue model based on MRI data in Proc. ICSLP, vol.
3, pp. 901-904, Beijing, China, 2000.
[18] T. Ezzat and T. Poggio. Visual speech synthesis by morphing visemes.
International Journal of Computer Vision, 38(1), pp. 45-57, 2000.
[19] M. H. Gruber. Regression Estimators. Academic Press, Inc., San Dieogo,
CA, 1990.
[20] S. Gurbuz, Z. Tufekei, E. Patterson and J. N. Gowdy. Application of affine-
invariant Fourier descriptors to lipreadingfor audio-visual speech recogni-
tion. in Proc. ICASSP, pp. 177-180, Salt Lake City, UT, May 2001.
[21] P. Hong, Z. Wen and T. Huang. iFACE: a 3D synthetic talking face. In-
ternational Journal of Image and Graphics, vol. 1, no. 1, pp. 1-8, 2001.
122

[22] P. Hong, Z. Wen and T. Huang. Real-time speech-driven face animation
with expression using neural networks. IEEE Transaction On Neural Net-
works, vol. 13, no. 1, pp. 100-111, Jan, 2002.
[23] F. J. Huang and T. Chen. Real-time lip-synch face animation driven by hu-
man voice. IEEE Workshop on Multimedia Signal Processing, Los Angeles,
CA, Dec, 1998.
[24] A. J. Hunt and A. Black. Unit selection in a concatenative speech synthesis
system using a large speeech database. Proc. ICASSP’96, Atlanta, GA,
May, 1996.
[25] J. Jiang, A. Alwan, L. Bernstein, E. Auer, and P. Keating. Predicting face
movements from speech acoustics using spectral dynamics. in Proc. ICME
2002, Lausanne, Switzerland, pp. 181-184.
[26] J. Jiang, A. Alwan, P. Keating, E. Auer and L. Bernstein. On the relation-
ship between facial movements, tongue movements and speech acoustics.
in EURASIP Journal on Applied Signal Processing, vol. 11, pp. 1174-1185,
2002.
[27] J. Jiang. Relating Optical Speech to Speech Acostics and Visual Speech
Perception. UCLA Ph.D. Dissertation, 2003.
[28] P. Kalra, A. Mangili, N. Magnenat-Thalmann and D. Thalmann. Simula-
tion of facial muscle actions based on rational free form deformations. in
Proc. Eurographics’92, pp. 59-69, 1992.
[29] A. Lofqvist. Speech as audible gesures. Speech Production and Speech Mod-
eling, W. H. Hardcastle and A. Marchal Eds., Dordrecht: Kluwer Academic
Publishers, pp. 289-322, 1990.
[30] D. Massaro, J. Beskow, M. Cohen, C. L. Fry,, T. Rodriguez. Picture my
voice: audio to visual speech synthesis using artificial neural network. In
Proc. AVSP’99, Santa Cruz, CA, 1999.
123

[31] H. McGurk and J. MacDonald. Hearing lips and seeing voices. Nature,
264, pp. 746-748, 1976.
[32] M. Nahas, H. Huitric and M. Saintourens. Animation of a B-spline figure.
The Visual Computer, vol. 3, pp. 272-276, 1998.
[33] M. Nahas. Scatter Data Modeling. IEEE Computer Graphics and Appli-
cations, vol. 13, no. 1, pp. 60-70, 1993
[34] F. I. Parke. A parametric model for human faces. Tech. Report UTEC-
CSc-75-047, University of Utah, Salt Lake City, Utah, 1974.
[35] F. I. Parke. Parameterized models for facial animation. IEEE Computer
Graphics and Applications, vol. 2, no. 9, pp. 61-70, 1982.
[36] M. Pitermann and K. G. Munhall. An model inverse dynamics approach
to face animation. J. Acust. Soc. Am., 110(3), Pt. 1, pp. 1570-1580, Sep,
2001
[37] G. Potamianos, H. P. Graf and E. Cosatto. An image transform approach
for HMM based automatic lipreading. in Proc. Int. Conf. Image Processing,
vol. I, pp. 173-177, Chicago, Oct. 1998.
[38] G. Potamianos, C. Neti and S. Deligne. Joint audio-visual speech processing
for recognition and enhancement. AVSP’03, 2003.
[39] L. Rabiner. A tutorial on hidden Markov models and selected applications
in speech recognition. Proc. of the IEEE, vol. 77, no. 2, pp. 257-286, 1989.
[40] A. Q. Summerfield. Some preliminaries to a comprehensive account of
audio-visual speech perception. Hearing by Eye: The Psychology of Lip-
Reading, R. Campbell and B. Dodd, Eds. London, United Kingdom:
Lawrence Erlbaum Associates, pp. 3-51, 1987.
124

[41] H. Tao and T. S. Huang. Explanation-based facial motion tracking using a
piece-wise Bezier volume deformation model. Proc. IEEE Computer Vision
and Pattern Recognition, 1999.
[42] H. Timothy Bunnell, S. R. Hoskins and D. M. Yarrington. A bi-
phone constrained concatenation method for diphone synthesis. 3rd
ESCA/COSCOSDA Int. Workshop on Speech Synthesis, Australia, Nov.,
1998.
[43] K. Waters. A muscle model for animating three dimensional facial expres-
sions. Computer graphics, vol. 21, no. 4, pp. 17-24, Jul, 1987.
[44] L. Williams. Performance-driven facial animation. Computer Graphics,
vol. 2, no. 24, pp. 235-242, Aug, 1990.
[45] E. Yamamoto, S. Nakanura, and K. Shikano. Lip movement synthesis frm
speech based on Hidden Markov Models. Speech Communication, 26, pp.
105-115, 1998.
[46] D. Yarrington, H. Timonthy Bunnell, and Gene Ball. Robust automatic
extraction of diphones with variable boundaries. Proc. of Eurospeech’95,
1995.
[47] H. Yehia, P. Rubin, and E. Vatikiotis-Bateson. Quantitative association of
vocal-tract and facial behavior. Speech Communication, vol. 26, no. 1, pp.
23-43, 1998.
[48] H. Yehia, T. Kuratate, and E. Vatikiotis-Bateson. Using speech acoustics
to drive facial animation. In Proc. ICPhS 1999, San Francisco, CA.
[49] H. Yehia, T. Kuratate, and E. Vatikiotis-Bateson. Facial animation and
head motion driven by speech acoustics. In Proc. of 5th Seminar on Speech
Production: Models and Data, pp. 265-268, Germany, May, 2000.
[50] L.E. Bernstein, M.E. Demorest, and P.E. Tucker. Speech perception with-
out hearing Perception and Psychophysics, Vol. 62, No. 2, 233-252, 2000.
125

[51] S.L. Mattys, L.E. Bernstein, and E.T. Auer. Stimulus-based lexical dis-
tinctiveness as a general word-recognition mechanism Perception and Psy-
chophysics, Vol. 64, No. 4, 667-679, 2002.
[52] E.T. Auer and L.E. Bernstein. Speechreading and the structure of the lexi-
con: Computationally modeling the effects of reduced phonetic distinctive-
ness on lexical uniqueness J. Acoust. Soc. Am., Vol. 102, No. 6, 3704-3710,
Dec. 1997.
[53] L.E. Bernstein, J. Jiang, and A. Alwan. ITR-Collaborative research: Devel-
opment and evaluation of a hybrid concatenative/rule-based visual speech
synthesis system NSF Award #0312434 and #0312810 Proposal, 2003.
[54] J. Beskow. Taking Heads: Models and Applications for Multimodal Speech
Synthesis Ph.D. Dissertation, KTH, Stockholm, 2003.
[55] J. Beskow . Trainable articulatory control models for visual speech synthe-
sis. Int. J. of Speech Technology.
[56] P. Perrier, D.J. Ostry, and R. Laboissiere. The equilibrium point hypothesis
and its application to speech motor control. J. Speech Hearing Res. Vol.
39, No. 2, 365-378, Apr. 1996.
[57] M. Odisio, G. Bailly, and F. Elisei. Tracking talking faces with shape and
appearance models. Speech Communication, Vol. 44, 2004, 63-82.
[58] G. Bailly, M. Berar, F. Elisei, and M. Odisio. Audiovisual speech synthesis.
Int. J. Speech Technol. Vol. 6, 2003, 331-346.
[59] G.A. Kalberer and L. Van Gool. Realistic face animation for speech. Int.
J. of Visualization and Computer animation, Vol. 13, 2002, 97-106.
[60] G. A. Kalberer, P. Mueller and L. Van Gool Speech Animation using
Viseme Space Proc. Vision, Modeling, and Visualization VMV 2002, 2002
126

[61] G.A. Kalberer, P. Muller, and L. Van Gool. Animation pipeline: Realistic
speech based on observed 3D face dynamics. Proc. 1st European Conf. on
Visual Media Production (CVMP), 2004, 1-10.
[62] G. Geiger, T. Ezzat, and T. Poggio. Perceptual evaluation of video-realistic
speech. CBCL Paper #224/ AI Memo #2003-003, MIT, Cambridge, MA,
Feb, 2003.
[63] T. Ezzat, G. Geiger, and T. Poggio. Trainable videorealistic speech anima-
tion. Proc. ACM SIGGRAPH 2002, San Antonio, Texas, Jul, 2002.
[64] E. Cosatto, J. Ostermann, H.P. Graf, and J. Schroeter. Lifelike talking
faces for interactive services. Proc. IEEE. Vol. 91, No. 9, Sep. 2003, 1406-
1429.
[65] I. Pandzic, J. Ostermann, and D. Millen. User evaluation: Synthetic talking
faces for interactive services. Vis. Comput. Vol. 15, No. 7/8, Nov. 1999,
330-340.
[66] M.M. Cohen, D.W. Massaro, and R. Clark. Training a talking head. Proc.
IEEE 4th Int. Conf. on Multimodal Interface, Pittsburgh, PA, 2002, 499-
510.
[67] S. Ouni, M.M. Cohen, D.W. Massaro. Training Baldi to be multilingual:
A case study for an Arabic Badr. Speech Communication, Vol. 45, 2005,
115-137.
[68] S.A. King, and R.E. Parent. Creating speech-synchronized animation.
IEEE Trans. on Visualization and Computer Graphics, Vol. 11, No. 3,
May/June 2005, 341-352.
[69] S.A. King. A Facial Model and Animation Techniques for Animated
Speech. Ph.D. Dissertation, Ohio State University, 2001.
127

[70] J.J. Williams and A.K. Katsaggelos. An HMM-based speech-to-video syn-
thesizer. IEEE Trans. on Neural Networks, Vol. 13, No. 4, July 2002,
900-915.
[71] J.J. Williams. Speech-to-Video Conversion for Individuals with Imparied
Hearing. Ph.D. Dissertation, Northwestern University, Evanston, IL. 2000.
[72] R. Gutierrez-Osuna, P.K. Kakumanu, A. Esposito, O.N. Garcia, A. Bo-
jorquez, J.L. Castillow, and I. Rudomin. Speech-driven facial animation
with realistic dynamics. IEEE Trans. on Multimedia, Vol. 7, No. 1, Feb,
2005, 33-42.
[73] S. Fu, R. Gutierrez-Osuna, A. Esposito, P.K. Kakumanu, O.N. Garcia. Au-
dio/Visual mapping with cross-modal hidden Markov models IEEE Trans.
on Multimedia, Vol. 7, No. 2, Apr, 2005, 243-252.
[74] J. Ma, R.A. Cole, B. Pellom, W. Ward, and B. Wise. Accurate automatic
visible speech synthesis of arbitrary 3D models based on concatenation of
di-viseme motion capture data. J. of Computer Animation and Virtual
Worlds, Vol. 15, 2004, 485-500.
[75] D. Cosker, S. Paddock, D. Marshall, P.L. Rosin, and S. Rushton. Towards
perceptually realistic talking heads: Models, methods, and McGurk. Proc.
APGV, 2004, 151-158.
[76] D. Cosker, D. Marshall, P.L. Rosin, and Y. Hicks. Speech driven facial
animation using a hierarchical model. IEE Vision, Image and Signal Pro-
cessing, Vol. 151, No. 4, Aug, 2004, 314-321.
[77] T. Kuratate, T. and E. Vatikiotis-Bateson. Estimating 3D face expression
postures for animation from photographs using a 3D face database. Sym-
posium on Computer Animation (SCA2004), Grenoble-Grance, Aug, 2004,
22-23.
128

[78] T. Kuratate. Talking Head Animation System Driven by Facial Motion
Mapping and a 3D Face Database. Ph.D Dissertation, Dept. of Information
Processing, Nara Institute of Science and Technology, Nara, Japan, NAIST-
IS-DT0061204, June, 2004.
[79] Choi. K.H., Luo. Y. and Hwang. J.N. Hidden Markov model inversion for
audio-to-visual conversion in an MEPG-4 facial animation system. J. of
VLSI Signal Processing, Vol. 29, 2001, 51-61.
[80] K.H. Choi and J.N. Hwang. Constrained optimization for audio-to-visual
conversion. IEEE Transactions on Signal Processing, 52(6), June 2004,
1783-1790.
[81] K.H. Choi and J.N. Hwang. Automatic Creation of a Talking Head from A
Video Sequence. IEEE Trans. on Multimedia, 7(4), August 2005, 628-637.
[82] P. Saisan, A. Bissacco, and S. Soatto. Synthesis of facial motion driven by
speech ECCV, Prague, May, 2004.
[83] L. Rabiner and B. Juang. Fundamentals of Speech Recognition, Prentice
Hall, Englewood Cliffs, NJ, 1993.
[84] C. G. Fisher. Confusions among visually perceived consonants. Journal of
Speech and Hearing, 11, 1968, pp. 796-804.
[85] P. Kricos and S. Lesner Differences in visual intelligibility across talkers.
The Volta Review, Vol. 84, 1982, pp. 219-225.
[86] B. E. Walden, R. A. Prosek, A. A. Montgomery, C. K. Scherr, and C. J.
Jones. Effects of training on the visual recognition of consonants Journal
of Speech and Hearing Research, Vol. 20, 1977, 130-145.
[87] S.Young, et al. The HTK Book (version 3.1), Cambridge University, Engi-
neering Department, 2001.
129

[88] P.F. Seitz, L.E. Bernstein, E.T. Auer, and M. MacEachern. PhLex (Phono-
logically Transformable Lexicon): A 35,000- word pronouncing American
English lexicon on structural principles, with accompanying phonological
rules and word frequencies. Technical Report, House Ear Institute, 1998.
[89] V. Nefian, L. Liang, X. Pi, X. Liu, and K. Murphy Dynamic Bayesian net-
works for audio-visual speech recognition. EURASIP J. on Applied Signal
Process., vol. 11, 1-15, 2002.
[90] S. Nakamura. Statistical multimodal integration for audio-visual speech
processing. IEEE Trans. Neural Networks, vol. 13, no. 4, 854 - 866, 2002.
[91] P. S. Aleksic and A. K. Katsaggelos. Product HMMs for audio-visual con-
tinuous speech recognition using facial animation parameters. Proc. ICME,
vol. 2, 481-484, 2003.
[92] S. M. Chu and T. S. Huang An experimental study of coupled hidden
Markov models. Proc. ICASSP, vol. 4, 4100-4103, 2002.
[93] S. Lucey, T. Chen, S. Sridharan, and V. Chandran. Integration strate-
gies for audio-visual speech processing: Applied to text-dependent speaker
recognition. IEEE Trans. Multimedia, vol. 7, no. 3, 495-506, 2005.
[94] M.D. Buhmann. Radial Basis Functions: Theory and Implementation.
Cambridge University Press, 2003.
[95] J. A. Bilmes. A gentle tutorial on EM algorithms and its applications to
parameter estimation for Gaussian mixture and hidden Markov models.
ICSI-TR-97-021, 1997
[96] P. F. Seitz, L. E. Bernstein, and E. T. Auer. PhLex(Phonologically Trans-
formable Lexicon), A 35,000-word pronouncing American English lexicon
on structural principles, with accompanying phonological rules and word
frequencies. Gallaudet ResearchInstitute, Washington, DC, 1995.
130

[97] Girin et al. Audio-visual enhancement of speech in noise. J. Acoust. Soc.
Am., vol. 109, no. 6, 3007-3020, 2001.
[98] Sumby and Pollack. Visual contribution to speech intelligibility in noise.
J. Acoust. Soc. Am., vol. 26. 212-215, 1954.
[99] Debra M. Hardison Variability in bimodal spoken language processing by
native and nonnative speakers of English: A closer look at effects of speech
style. Speech Communication, vol. 46(1), 73-93, 2005.
[100] J. Xue, J. Borgstrom, J. Jiang, L.E. Bernstein, and A. Alwan. Acoustically-
driven Talking Face Synthesis Using Dynamic Bayesian Networks. Proc.
IEEE International Conference on Multimedia and Expo, Toronto, Canada,
pp. 1165-1168, 2006.
[101] J. Xue, J. Jiang, A. Alwan, L.E. Bernstein. Consonant confusion struc-
ture based on machine classification of visual features in continuous speech.
Proc. Auditory-Visual Speech Processing International Conference, British
Columbia, Canada. pp. 103-108, July 24-27, 2005.
[102] D.W. Massaro Speech Perception. N.M. Smelser and P.B. Baltes (Eds.)
and W. Kintsch (2nd Ed.). International Encyclopedia of Social and Be-
havioral Sciences, Amsterdam, The Netherlands:Elsevier, pp. 14870-14875,
2001.
[103] Y. Cao, W.C. Tien, P. Faloutsos, and F. Pighin Expressive speech-driven
facial animation. ACM Trans. Graph., vol. 24(4), 1283–1302, 2005.
[104] Y. Cao, P. Faloutsos, E. Kohler, and F. Pighin Real-time Speech Motion
Synthesis from Recorded Motions. Proc. of ACM SIGGRAPH / Euro-
graphics Symposium on Computer Animation, 347-355, 2004.
[105] Z. Deng and J. P. Lewis and U. Neumann Synthesizing Speech Animation
by Learning Compact Co-Articulation Models from Motion Capture Data.
131

Proc. of Computer Graphics International (CGI), long island, NY, 19-25,
2005.
[106] IEEE Subcommittee IEEE Recommended Practice for Speech Quality
Measurements. IEEE Trans. Audio and Electroacoustics, vol. AU-17(3),
225-246, 1969.
[107] IPA chart. http://www.phonetics.ucla.edu/course/chapter1/chapter1.html.
[108] J.S. Perkell, M. Zandipour, M.L. Matthies, and H. Lane. Economy of effort
in different speaking conditions. I. A preliminary study of intersubject.
differences and modeling issues. J. Acoust. Soc. Am. vol. 112(4), 1627-
1641, 2002.
[109] P.H. van Santen and A.L. Buchsbaum Methods for optimal text selection.
Proc. of Eurospeech, 553-556, 1997.
[110] Fritsch, F. N. and R. E. Carlson Monotone Piecewise Cubic Interpolation
SIAM J. Numerical Analysis, vol. 17, 238-246, 1980.
[111] http://www.image-metrics.com 2008.
[112] Motion Capture. http://en.wikipedia.org/wiki/Motion captures 2008.
[113] Dempster, A., Laird, N. and Rubin, D. Maximum Likelihood from incom-
plete data via the EM algorithm. Journal of the Royal Statistical Society
B, Vol.39(1), 1-38, 1977.
132


















