
Accelerated Data Management Systems Through Real-Time ...
28
Accelerated Data Management Systems Through Real-Time Specialization Anastasia Ailamaki for Periklis Chrysogelos, Aunn Raza, Panos Sioulas, and the DIAS team
Transcript of Accelerated Data Management Systems Through Real-Time ...

Accelerated Data Management Systems Through Real-Time Specialization
Anastasia Ailamakifor Periklis Chrysogelos, Aunn Raza, Panos Sioulas,
and the DIAS team

The game changers
2
Hardware Workloads
Heterogeneous and underutilized Complex and unpredictable

Agile data management engines
3Where’s the sweet spot?
HeterogeneityOblivious
HeterogeneityConscious
HardwareOblivious
HardwareConscious
Portability Performance
Portability Performance
+ALP +ALP

Analytics on heterogeneous hardware
4Device specialization carries portability debt
Perf
orm
ance
Portabilitydebt
XXX-consciousengine
HW-obliviousengine
YYY-consciousengine
Hardware Features & Diversity
HW-promisedperformance
Specializationbenefit

Analytics on heterogeneous hardware
5Device specialization carries portability debt
0
5
10
15
20
Join-heavy 50%-50% Mix Scan-heavy
Tota
l Exe
cutio
n Ti
me
(s) CPU-only Hybrid GPU-only
2x Intel(R) Xeon(R) Gold 5118 CPU2x Mellanox MT27800 100G IB NIC
2x NVIDIA Tesla V100S GPU13 Queries, CPU-resident data
96-144GB working set/queryJoin-heavy: SPJ{1-4}Aggr
Scan-heavy: Scan-Aggr4 servers

Lifetime of a Query
6
σ
⨝
Γ
filter
aggregate
scan
σ
T1
⨝σ
T2⨝
T3 ∏
T4
project
scan
scanscan
join
filter
join
join
SELECT SUM(T3.c * T4.d)FROM T1, T2, T3, T4, …WHERE T1.f < 50 AND T1.a = T2.t1_id AND …
Query Execution Plan
Query Execution
Result
Query
Query Parsing & Optimization
SUM
5
Random
Control-heavy
Sequential

Hardware-conscious Analytics?
Traditional CPU-optimized Relies on
radix-(join/group by) High cache-size-to-thread ratio
vector-at-a-time High cache-size-to-thread ratio
parallelism/inter-socket atomics Efficient inter-socket operations
7Won’t work on GPUs
⨝
T4
Random-access
Control-heavy
Sequential scan

A fast equi-join algorithmRadix-join
Partition both inputsSize partition fanout based on memory hierarchy (TLB+caches)Assuming sufficient cache-to-thread ratio
GPU memory hierarchyLow cache-to-thread ratioSoftware and hardware-managed cachesBut collaborative thread execution
8Think differently for GPUs!
[Boncz et al. VLDB1999]R SR hashtable
h
probe

GPU-aware radix-joinCollaboratively partition per GPU thread block
Amortize radix cluster maintenanceRely on big register files and thread overlappingAvoid random accesses to GPU memory
Stage partition output in scratchpadIrregular access patterns through scratchpadCoalesce writes through shared memoryMultiple threads “complete” a cache line
93.6x speedup
scratchpad
threads
input
Partitions
[ICDE2019]

Accelerator-conscious Analytics
Traditional CPU-optimized CPU-GPU
radix-(join/group by) Tune operators to memory hierarchy specifics
vector-at-a-time Code fusion & specializationfor fast composability
parallelism/inter-socket atomics Encapsulate heterogeneity and balance load
10
⨝
T4
Random-access
Control-heavy
Sequential scan

aggregate
router
segmenter
mem-move
cpu2gpu
unpack
filter
router
aggregate
gpu2cpu
9
8
4
3
2
1
7
10
11 5
6
devicecrossing
devicecrossing
pipeline id x
GPU pipelineCPU pipeline
JIT
instances
SQL à ALP-aware code
11JIT pipelines
filter
aggregate
scan
HetExchange
Logical plan
SELECT SUM(a)FROM TWHERE b > 42
[VLDB2019]

aggregate
router
segmenter
mem-move
cpu2gpu
unpack
filter
router
aggregate
gpu2cpu
9
8
4
3
2
1
7
10
11 5
6
devicecrossing
devicecrossing
JIT
12
JIT Code Generation for OLAP in GPUs[VLDB2019]

13
Device providers
Inject target-specific info
[VLDB2019]

aggregate
router
segmenter
mem-move
cpu2gpu
unpack
filter
router
aggregate
gpu2cpu
9
8
4
3
2
1
7
10
11 5
6
devicecrossing
devicecrossing
pipeline id x
GPU pipelineCPU pipeline
JIT
instances
From SQL to Pipeline Orchestration
14Multiple pipeline instances
Run
routing point
routing point
filter
aggregate
scan
HetExchange
Logical plan
SELECT SUM(a)FROM TWHERE b > 42
[VLDB2019]

JIT data flow inspectionDecouple data- from control-flowEncapsulate trait conversions into operatorsInspect flows to load-balance
15Distribute load to devices adaptively
filter
unpack
cpu2gpu
gpu2cpu
pack
mem-move
mem-move
aggregate
router
router
unpack
aggregate
Flow Scope Trait
ControlDelegation Heterogeneous Parallelism
Routing Homogeneous Parallelism
DataTransfer Data Locality
Granularity Execution Granularity
filter
aggregate
scan
[VLDB2019]

Abstractions for fast CPU-GPU analytics
16Selective obliviousness
intra-operator
inter-device
intra-device
Operator tuning is μ-architecture specific
Portability clashes with specialization Inject target-specific info using codegen
Limited device inter-operabilityEncapsulate heterogeneity and balance load
GPU⨝
CU⨝⨝σ
GPU⨝⨝σGPU⨝⨝σ
GPU⨝⨝σ
Tune operators to memory hierarchy specifics
[CIDR2019]
CPU
GPU

The game changers
17
Hardware Workloads
Heterogeneous and underutilized Complex and unpredictable
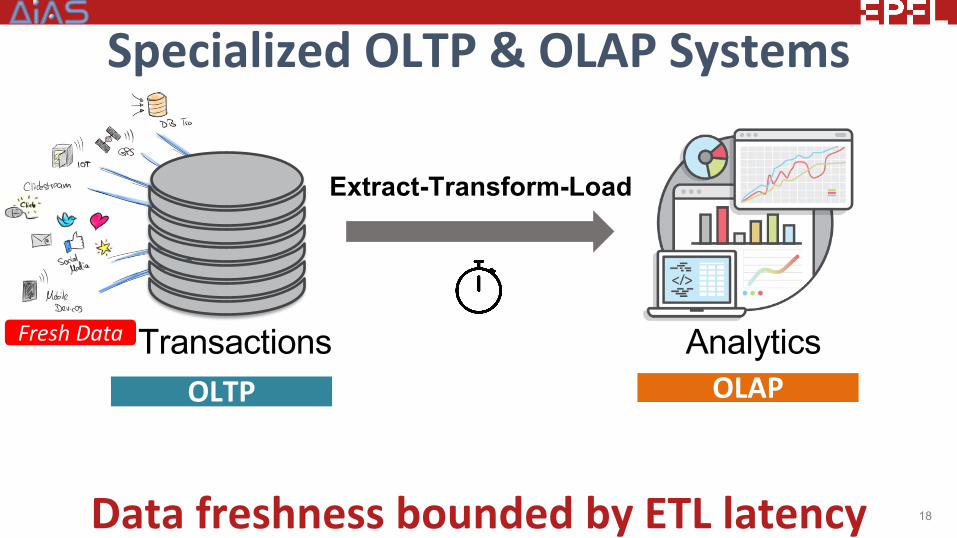
Specialized OLTP & OLAP Systems
18Data freshness bounded by ETL latency
AnalyticsTransactions
Extract-Transform-Load
OLTP OLAP
Fresh Data

Hybrid Transactional and Analytical Processing
OLTP: task-parallel– High rate of short-lived transactions– Mostly point accesses ( high data access locality)
OLAP: data-parallel– Few, but long-running queries– Scans large parts of database
19Align tasks & hardware to improve utilization

HTAP: Chasing ‘locality of freshness’Static OLAP-OLTP assignment
– Unnecessary tradeoff between interference and performance– Pre-determined resource assignment based on workload type– Wasteful data consolidation and synchronization
Real-time, Adaptive scheduling of HTAP workloads– Specialize to requirements and data/freshness-rates– Workload-based resource assignment– Pay-as-you-go snapshot updates
20Task placement based on resource usage
GPU
CPU
GPU
CPU
Colocatedexecution
Separated execution
PerformanceData freshness
GPU
CPU
GPU
CPU

Workload Isolation & Fresh Data Throughput
21no extreme is good
ETL
Isolated Elastic-ComputeHybrid-Access
Independent execution (isolation)Fresh Data Access Bandwidth
Fresh Data
OLAPOLTP Interference ßà performancePre-determined resource assignment
Colocated

Workload Isolation & Fresh Data
ETL
Isolated Elastic-ComputeHybrid-Access
Fresh Data
OLAPOLTP
Colocated
Task placement & consolidation based on resource usage
Real-time: Adaptive scheduling of HTAP workloads– Specialize to requirements and amount of unconsolidated data– Workload-based resource assignment– Pay-as-you-go snapshot updates
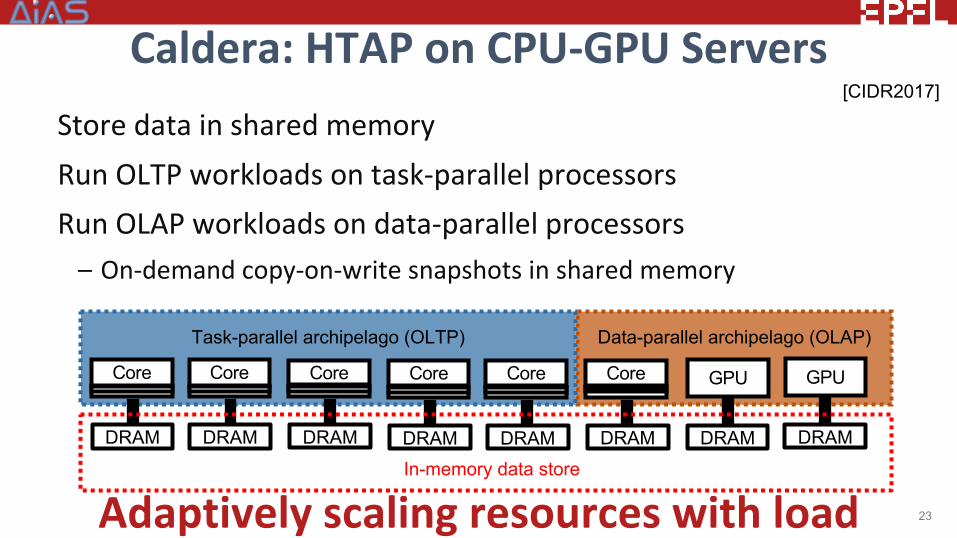
Caldera: HTAP on CPU-GPU ServersStore data in shared memoryRun OLTP workloads on task-parallel processorsRun OLAP workloads on data-parallel processors
– On-demand copy-on-write snapshots in shared memory
23Adaptively scaling resources with load
Data-parallel archipelago (OLAP)Task-parallel archipelago (OLTP)
Core GPUCore Core Core Core Core GPU
DRAMIn-memory data store
DRAMDRAM DRAM DRAM DRAM DRAM DRAM
[CIDR2017]

GPU Accesses Fresh Data from CPU MemoryOLTP generates fresh data
on CPU Memory
Data access protected byconcurrency control
OLAP needs to accessfresh data
24snapshot isolation for OLAP w/o CC overheads
Read / Write
Storage
Fetch Fresh Data
Main Memory
DRAM NVLink
PCIe
OLTP
OLAP
[CIDR2017, CIDR2020, SIGMOD2020]
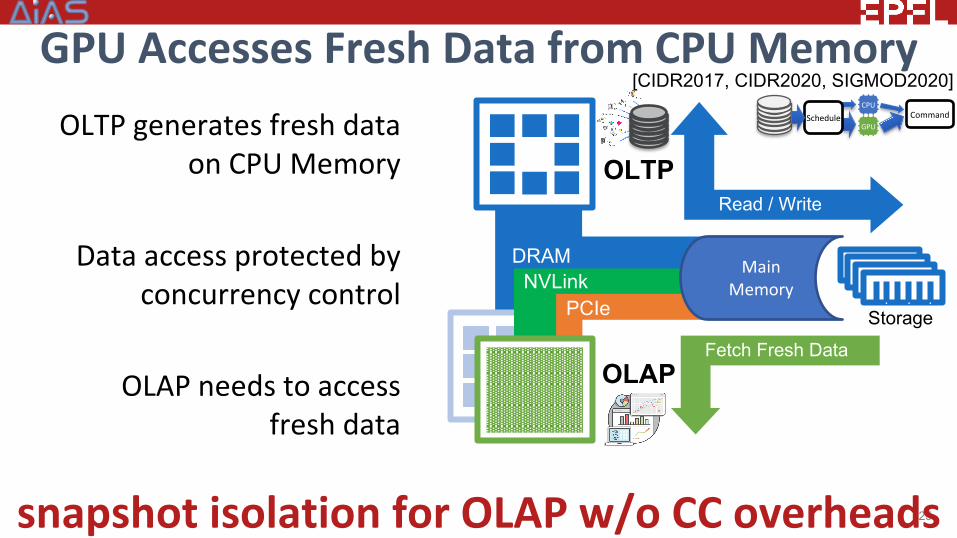
GPU Accesses Fresh Data from CPU MemoryOLTP generates fresh data
on CPU Memory
Data access protected byconcurrency control
OLAP needs to accessfresh data
25snapshot isolation for OLAP w/o CC overheads
Read / Write
Storage
Fetch Fresh Data
Main Memory
DRAM NVLink
PCIe
OLTP
OLAP
GPU
CPUCommandSchedule
[CIDR2017, CIDR2020, SIGMOD2020]

Increasing workload complexityDiverse modern data problems
– IOT, OCR, ML, NLP, Medical, Mathematics etc…
DBMS catch-up for popular functionality– Human effort and big delays– Oblivious to out-of-DBMS workflows
Vast resource of libraries– Authored by domain experts, used by everybody– Loose library-to-data-sources integration and optimization
26Need for systems that can “learn” new functionality

Network looks like a single machineSimilar intra-/inter-server interconnect bandwidthLocal memories and NUMA effects across devicesCPU-GPU: Capacity-Throughput
27Heterogeneous interconnected devices across the CPUs
IB
IB

A solution is only as efficient as its least adaptive component.
Intelligent Real-time Systems
Hardware Workloads

















