
ACADGILD Webinar - Big Data Analytics with 'Spark': The New Poster boy of Big Data
19
presents Spark Presented by: Sandy
-
Upload
acadgild -
Category
Technology
-
view
520 -
download
2
Transcript of ACADGILD Webinar - Big Data Analytics with 'Spark': The New Poster boy of Big Data

presents
Spark
Presented by: Sandy

© copyright ACADGILD
Introduction to ACADGILD
• You can also click on this link to view the video –
https://www.youtube.com/watch?v=7nipSdxv2Uo
Webinar on Spark 2

© copyright ACADGILD
Introduction of Mentor
• The Mentor for this Webinar is Mr. Sandy and below are his qualifications:
• 15 years of experience in IT focusing on Big Data, Data Science and IoT solutions and implementations.
• Expert in the Apache SPARK Ecosystem including Spark 1.6, Scala, Spark SQL, Spark Streaming, MLLIB , SparkR and GraphX.
• Extensive experience in Hadoop Framework solutions including YARN,/MesosHDFS, MapReduce, PigLatin , Hive, HBase/MongoDB/Cassandra, Mahout, Flume, Zookeeper, Oozie and Sqoop.
• Knowledge of Machine Learning for both Supervised and Unsupervised Learning Algorithms.
Webinar on Spark 3

© copyright ACADGILD
Agenda
4Webinar on Spark
Sl No. Agenda Title
1 What is Big data?
2 MapReduce Limitations
3 Introduction to Spark
4 Spark in Hadoop Ecosystem
5 Why In-memory Processing?
6 In-memory Caching
7 Resilient Distributed Dataset
8 Creating RDDs
9 Spark Unified Platform
10 Popular Use Cases
11 Apache Spark Case Studies
12 Get Your Feet Wet with Spark API's
4

© copyright ACADGILD5
What is Big data?
Webinar on Spark 5

© copyright ACADGILD
MapReduce Limitations
6
• MapReduce is based on disk based computing.
• It is more suitable for single pass computations.
• It is not at all suitable for iterative computations.
• Disk intensive.
Programming Model limitations:
• Developing efficient MapReduce applications requires advanced programming skills and deep understanding of the system architecture.
• Every problem has to be broken down in to Map and Reduce phases.
Webinar on Spark 6

© copyright ACADGILD
Introduction to Spark• Apache Spark is a fast and general-purpose cluster computing system.
• Spark is a framework for Scheduling, Monitoring and Distributing the applications.
• Spark is a General Unified Engine which can replace many specialized systems like Mahout, Tez, Graphlab, Storm, etc.
Webinar on Spark 7

© copyright ACADGILD
SQL
GraphX
MLlib
Streaming
RDBMS
Distributions:
DatabasesFile systems
Streaming
sources
Resource Managers
Libraries
APIs
Spark in Hadoop Ecosystem
8Webinar on Spark
- CDH- HDP- Map R- DSE

© copyright ACADGILD
Earlier Now
RAM was very costly. Comparatively, disk was cheap, so disk was primary source of data.
Cost of RAM has been sharply reduced with increase in performance. So, RAM is primary source of data and we use disk for fallback.
Network was costly so data locality Network is faster.
Single core machines were dominant Multi core machines are commonplace
Why In-memory processing?
• Drastic change in hardware
9Webinar on Spark

© copyright ACADGILD
In-memory Caching
10Webinar on Spark

© copyright ACADGILD
Resilient Distributed Dataset
• Resilient distributed dataset (RDD), represents an immutable collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
• It’s a distributed memory abstraction.
Features:
• Cache an RDD in memory across machines.
• Reuse in multiple MapReduce like parallel operations.
• Fault tolerant through lineage.
11Webinar on Spark
© copyright ACADGILD
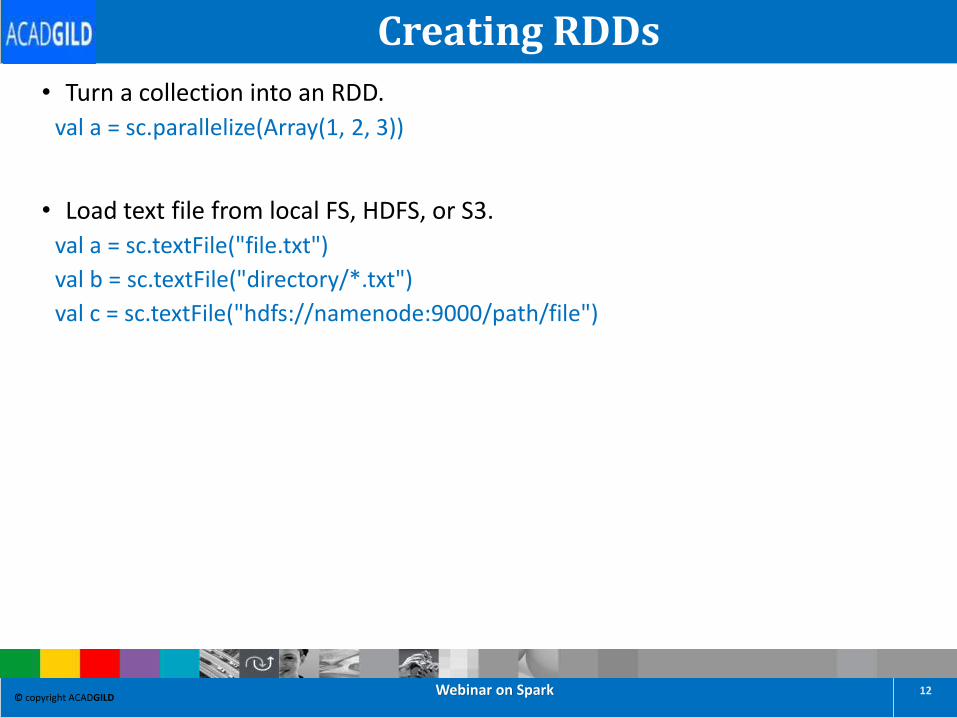
Creating RDDs
• Turn a collection into an RDD.
val a = sc.parallelize(Array(1, 2, 3))
• Load text file from local FS, HDFS, or S3.
val a = sc.textFile("file.txt")
val b = sc.textFile("directory/*.txt")
val c = sc.textFile("hdfs://namenode:9000/path/file")
12Webinar on Spark
© copyright ACADGILD
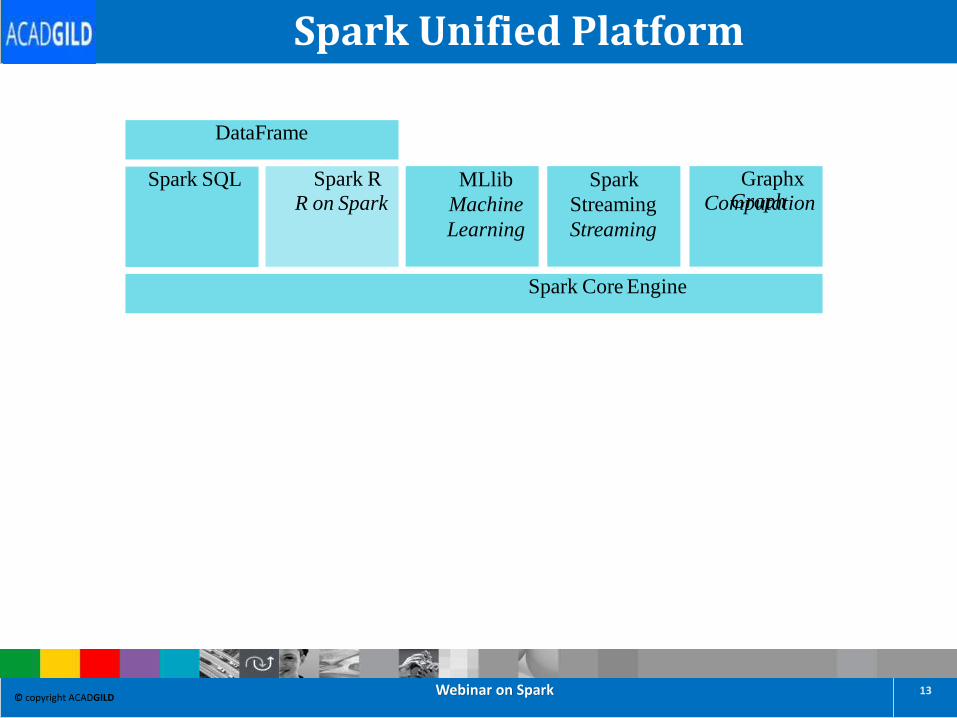
Graph
Spark Core Engine
MLlib
Machine
Learning
Spark
Streaming
Streaming
Graphx
ComputationSpark R
R on SparkSpark SQL
DataFrame
Spark Unified Platform
13Webinar on Spark

© copyright ACADGILD
29%
36%
40%
44%
52%
68%
Popular Use Cases
14
Business Intelligence
Data Warehousing
Recommendation
Log Processing
User-Facing Services
Fraud Detection/ Security
Webinar on Spark

© copyright ACADGILD
Apache Spark Case Studies
Credit Card Fraud Detection
Network Security
Genomic Sequencing
Real-Time Ad Processing
15Webinar on Spark

© copyright ACADGILD
Get Your Feet Wet with Spark API's
Quick tour of Scala, Python, Java API's
16Webinar on Spark

© copyright ACADGILD
Any Questions?
Webinar on Spark 17

Contact Info:
oWebsite : http://www.acadgild.com
oLinkedIn : https://www.linkedin.com/company/acadgild
oFacebook : https://www.facebook.com/acadgild
oSupport: [email protected]
© copyright ACADGILD
Get in Touch with Us
18Webinar on Spark 18

© copyright ACADGILD
Thank You
Webinar on Spark 19


















