
A survey of RDB to RDF translation approaches and tools A survey of RDB to RDF translation...
24
LABORATOIRE INFORMATIQUE, SIGNAUX ET SYSTÈMES DE SOPHIA ANTIPOLIS UMR7271 A survey of RDB to RDF translation approaches and tools Franck Michel, Johan Montagnat, Catherine Faron-Zucker Equipes Modalis/Wimmics Rapport de Recherche ISRN I3S/RR 2013-04-FR Version 2 May 2014 - 23 pages Laboratoire d'Informatique, Signaux et Systèmes de Sophia-Antipolis (I3S) - UMR7271 - UNS CNRS 2000, route des Lucioles - Les Algorithmes - bât. Euclide B 06900 Sophia Antipolis - France http://www.i3s.unice.fr
Transcript of A survey of RDB to RDF translation approaches and tools A survey of RDB to RDF translation...

LABORATOIRE
INFORMATIQUE, SIGNAUX ET SYSTÈMES DE SOPHIA ANTIPOLIS
UMR7271
A survey of RDB to RDF translation approaches and tools
Franck Michel, Johan Montagnat, Catherine Faron-Zucker
Equipes Modalis/Wimmics
Rapport de Recherche ISRN I3S/RR 2013-04-FR
Version 2
May 2014 - 23 pages
Laboratoire d'Informatique, Signaux et Systèmes de Sophia-Antipolis (I3S) - UMR7271 - UNS CNRS 2000, route des Lucioles - Les Algorithmes - bât. Euclide B 06900 Sophia Antipolis - France
http://www.i3s.unice.fr

A survey of RDB to RDF translationapproaches and toolsFranck Michel a, Johan Montagnat a and Catherine Faron-Zucker aa Univ. Nice Sophia Antipolis, CNRS, I3S, UMR 7271, 06900 Sophia Antipolis, FranceE-mail: [email protected], [email protected], [email protected]
Abstract. Relational databases scattered over the web are generally opaque to regular web crawling tools. To address thisconcern, many RDB-to-RDF approaches have been proposed over the last years. In this paper, we propose a detailed reviewof seventeen RDB-to-RDF initiatives, considering end-to-end projects that delivered operational tools. The different tools areclassified along three major axes: mapping description language, mapping implementation and data retrieval method. We analysethe motivations, commonalities and differences between existing approaches. The expressiveness of existing mapping languagesis not always sufficient to produce semantically rich data and make it usable, interoperable and linkable. We therefore brieflypresent various strategies investigated in the literature to produce additional knowledge. Finally, we show that R2RML, the W3Crecommendation for describing RDB to RDF mappings, may not apply to all needs in the wide scope of RDB to RDF translationapplications, leaving space for future extensions.
Keywords: Semantic Web, Database semantics, Database integration, RDB-to-RDF Mapping
1. Introduction
Making data hosted in relational databases (RDB)accessible to the semantic web has been an active fieldof research during the last decade. Converting rela-tional data into RDF or exposing relational data sothat it can be queried through the SPARQL1 querylanguage for RDF, is often referred to as the "RDB-to-RDF" process. In September 2012, the publicationby the W3C of the R2RML recommendation [20], astandard language to describe mappings between a re-lational database and an equivalent RDF dataset, hasmarked a new step towards the actualization of the webof data. R2RML encourages RDB-to-RDF tool devel-opers to comply with a standard mapping language.Data providers should benefit from the adoption of thiscommon language, allowing them to decouple rela-tional data integration problems from specific tools orapproaches, and ensuring sustainability.
Many RDB-to-RDF techniques and correspondingtools have been proposed over the last years. In spite ofthe observed convergence of several of them towards
1http://www.w3.org/TR/sparql11-overview/
R2RML, data providers willing to publish their datain a machine-readable format may find it difficult tomake a choice. Firstly, different techniques convey dif-ferent philosophical approaches (e.g. focus on ontol-ogy learning, mapping language design, query enginedesign...) which have implications on the way the rela-tional data is exposed. Secondly, choosing the R2RMLrecommendation does not answer all the questions:like any other language, R2RML has some limitationswith regards to the types of mappings that can be ex-pressed. Besides, as an implementation-independentmapping language, R2RML does not address somecommon questions that occur when translating rela-tional data into RDF, such as the implementation of thetranslation process, or the way the translated RDF datais accessed. Lastly, existing reviews of RDB-to-RDFapproaches often provide very brief descriptions ofthe tools developed, making them difficult to compare.Operational questions such as the choice between theconversion of relational data into RDF repositories andthe real-time use of the native relational databases, thechoice of access and querying means to the exposeddata, tools sustainability, etc., are hardly addressed.

1.1. Motivations for RDB-to-RDF Translation
In order to grasp the diversity of RDB-to-RDF ap-proaches, it is useful to understand the motivations ofthe RDB-to-RDF studies and projects, which led tothe emergence of R2RML. We identified three com-mon needs often targeted: accessing data from the deepweb, linking data, and integrating multiple heteroge-neous data sources. We describe them in the following.
The "deep web", as opposed to the "surface web", isa part of the web content that is hardly indexed by stan-dard search engines. It refers to the data hidden in un-structured documents (images, scans), semi-structureddocuments (CSV files, PDF files...), or structured datasources (relational databases, XML databases, NoSQLdatabases, LDAP directories...) that standard web toolscannot browse, but that are only accessible throughquery forms. As an illustration, in 2007, 70% of websites were backed up by RDBs, which contained 500times more data than directly available [34]. Mak-ing this huge amount of data available in a machine-readable format is expected to create opportunities fornovel applications and services. In this regard, RDFis a powerful pivot format. Yet, in order to ensurethe sustainability of the applications that were devel-oped along with the data they exploit, and to lever-age the properties engineered into RDB systems fordecades (scalability, ACID2 properties, security andperformance optimizations), the data should remainhosted and delivered by the legacy RDBs, hence theneed for RDB-to-RDF techniques that can access rela-tional data and convert it into RDF triples.
Linking open data to other related pieces of dataincreases its value. From this simple statement, theLinked Data principles, proposed by Tim Berners-Lee [9], recommend best practices for exposing, shar-ing, and connecting pieces of data, information, andknowledge on the Semantic Web using URIs andRDF. Driven by these recommendations, the Link-ing Open Data3 community project aims at extendingtoday’s web by publishing various open data sets inthe RDF model, and setting RDF links between datasources. In other words, it intends to solve the seman-tic web chicken-and-egg dilemma, stating that a crit-ical mass of machine-readable data must be availablefor novel mash-up applications to arise. Such applica-tions should create added-value by repurposing datasets, using the data in some new way, possibly beyond
2atomicity, consistency, isolation, durability3http://www.w3.org/wiki/SweoIG/TaskForces/CommunityProjects/LinkingOpenData
what data providers may have initially expected. In thisregard, the success of the Linking Open Data projectlargely depends on the accessibility of the deep webdata, and the availability of RDB-to-RDF tools to helppublish the existing relational data into RDF.
Integrating heterogeneous data has become a ma-jor challenge in several domains [46,14]. For instance,in neurosciences it is increasingly needed to con-nect, make sense of, and search across heterogeneousdata and knowledge describing different organizationscales (molecules, proteins, genes, cells, physiology,behaviours...) [1]. The first major step to integratingheterogeneous relational data sources is to make theirsemantics explicit. Relational schemas usually con-vey no or poor semantics. To some limited extent, im-plicit semantics can be figured out from integrity con-straints or usual database design patterns such as n-ary relations and inheritance. But additional seman-tics is frequently encoded in the application exploit-ing a relational database, for instance by means of do-main specific rules. Moreover, relational schemas areoften fine-tuned and customized for performance rea-sons. This results in mixing data semantics with tech-nical concerns, making it even more difficult to figureout the original data semantics. As a result, in order totackle the challenges of data integration in translationalscience, data integration techniques have to captureand expose its semantics in an explicit and machine-readable manner. Using RDF as a format for represent-ing relational data appears as a powerful and promis-ing method to achieve such data integration, in whichRDB-to-RDF methods will play a key role.
1.2. Previous Works
Facing the large variety of RDB-to-RDF mappinginitiatives, several studies have been conducted tocompare approaches and techniques.
In 2007 the W3C created the RDB2RDF Work-ing Group4 to standardize languages for mapping re-lational database schemas into RDF and OWL. Sahooet al. [47] conducted a wide scope review, addressingtheoretical articles, proofs of concept, domain-specificprojects as well as generic mapping tools. The goal ofthis survey was not to get into the details of each ap-proach, but to provide the RDB2RDF Working Groupwith a comprehensive overview of the different ap-proaches that had been investigated so far, in order toserve as a basis for the definition of R2RML.
4http://www.w3.org/2001/sw/rdb2rdf/

Hert et al. [36] proposed a feature-based compar-ison framework that they have applied to state ofthe art mapping languages. It is derived from theuse cases and requirements described by the W3CRDB2RDF Working Group [5]. The mapping lan-guages are sorted into four categories: direct map-ping, read-only general-purpose mapping, read-writegeneral-purpose mapping, special-purpose mapping.This paper focuses on the comparison of the mappinglanguage features and expressiveness, and it does notaddress the implementations proposed by their authorsor the way queries are rewritten.
In 2010, Spanos et al. [53] wrote a comprehen-sive review of RDB-to-RDF methods, with a particu-lar effort to classify them among disjoint categories:creation of database schema ontology, creation of adomain-specific ontology using either database modelreverse engineering or database expert knowledge, anddefinition or discovery of mappings between a rela-tional database and an existing ontology. Then, fea-tures are explored within each category, such as dataaccessibility or ontology language used. Nevertheless,the paper does not detail the specific features and ex-pressiveness of the mapping languages, and the au-thors put the stress specifically on the creation andalignment of ontologies.
Sequeda et al. [50] surveyed methods that apply Di-rect Mapping principles to automatically translate arelational database into RDF. They studied existingmethods to extract ontological knowledge as RDFSor OWL data from SQL DDL (Data Description Lan-guage) representations. This ranges from simple ap-proaches (table to class, column to property) to moreadvanced ones that try to discover relations such asmany-to-many, subsumption, meronymy, symmetricand transitive relations, and SQL features such as in-tegrity constraints, checks and triggers. Finally, the au-thors extend the work of Tirmizi et al. [55], that ex-ploits all the possible combinations of primary and for-eign keys in relational tables. One of their conclusionsis that the quality of an ontology resulting from a directmapping highly depends on the richness of the SQLschema with respect to its encoding of domain seman-tics.
Also to be mentioned, Sequeda proposed a shorthigh-level review5 of major RDB-to-RDF mappingproducts, along with a brief description of each ofthem. Unlike the two previous reviews that almost ex-
5http://semanticweb.com/relational-database-and-the-semantic-web_b16083
clusively focus on academic works, this blog article re-views products either from the academic world or fromthe industry. Hence, although very succinct, this workbroadens the scope towards the industrial approaches.
To our knowledge, no RDB-to-RDF study has beenconducted since R2RML was published in 2012. Asa result, none of the aforementioned articles reviewedR2RML compliant tools.
1.3. Goal of this work
In this paper, we propose a detailed review of stateof the art RDB-to-RDF tools, either academic or indus-trial. Especially, we take into account R2RML imple-mentations that recently emerged. We make a specificfocus on the specificities of each technique, and we de-scribe, as much as possible, the capabilities of the dif-ferent tools studied. Taking into account practical con-cerns, we specifically consider end-to-end projects thatdelivered operational tools to implement the RDB-to-RDF process, avoiding proofs of concepts and earlyprototypes. A classification is proposed to identify thedifferent approaches along three major axes that spanfrom mapping design to service deployment concerns:(i) mapping description (type of mapping, expressive-ness); (ii) mapping implementation (how and whenthe data is converted into RDF), and (iii) data re-trieval method (query-based, linked-data). These cate-gories are well identified in the literature. They avoidoverlaps, they can be identified non-ambiguously andthey cover the major concerns motivating RDB-to-RDF transformation. We also provide information onthe project maturity and sustainability when available.
2. Classification of RDB-To-RDF Approaches
2.1. Mapping Description
The mapping description refers to the way the map-ping between a relational database and an RDF rep-resentation of it is described. It is generally drivenby the fact that the resulting mapping should eithercome up with an ad-hoc ontology that reflects therelational schema (Direct Mapping), or comply withexisting well-defined domain-specific semantics, byreusing domain ontologies and possibly entailing morecomplex mappings (Domain Semantics-Driven Map-pings).
In the literature, Direct Mapping is frequently usedas a synonym of Automatic Mapping, and ManualMapping as a synonym of Domain Semantics-Driven

Mapping, although this happens to be misleading: adirect mapping is generally created automatically andlater customized manually. Yet, despite the manualedition, it can remain nothing more than a direct map-ping. Conversely, the domain semantics-driven map-ping is often called manual mapping, although an auto-matically generated direct mapping is frequently usedas a starting point to more complex domain-specificmappings. In addition, some approaches attempt toaugment direct mapping by automatically discover-ing domain semantics, we shall refer to this as theaugmented direct mapping. Consequently, hereafterwe shall sort the approaches along three distinct cat-egories: Direct Mapping, Augmented Direct Mappingand Domain Semantics-Driven Mapping. The termsmanual and automatic will be used for exactly whatthey mean: the manual edition of a mapping by a hu-man agent, vs. the automatic generation of a mappingby a program.
Direct MappingThe direct mapping approach intends to convert re-
lational data into RDF in a straightforward manner,by making explicit the semantics encoded in the re-lational schema. It involves the automatic creation ofURIs following simple rules, such as those defined byTim Berners-Lee [8]:
– table-to-class: a table is translated into an onto-logical class identified by a URI whose construc-tion follows the pattern "namespace/database/table";
– column-to-property: each column of a table istranslated into an ontological property whose URIfollows the pattern "namespace/database/table/-column";
– row-to-resource: each row of a table is trans-lated into a resource whose type is the class rep-resenting the table and whose URI is formedby using the table’s primary key: "namespace/-database/table/primaryKey" or "namespace/database/table#primaryKey";
– cell-to-literal-value: each cell with a literal valueis translated into the value of a data property;
– cell-to-resource-URI: each cell with a foreign keyconstraint is translated into a URI which is thevalue of an object property.
Applying this set of rules automatically creates an ad-hoc RDFS or OWL vocabulary reflecting the struc-ture of the relational schema. The ontology thus cre-ated by the direct mapping process is referred to asthe database schema ontology in [53], while ontologylearning approaches often use the term local ontology.
To avoid exposing unnecessary or sensitive data suchas passwords, most approaches automatically gener-ate a first mapping that can be manually customized tosome extent. Some specific cases such as multi-columnprimary keys and tables with no primary key are alsogenerally addressed.
The Direct Mapping method typically applies whenno ontology suitably describes the domain of the re-lational database, or when the goal is to rapidly makedata sources available in a web machine-readable for-mat, with little concern for semantic interoperability.Direct Mapping can also address versatile environ-ments in which databases may appear and disappearfrequently with no time for manual alignment [22].When semantic interoperability is required, ontologyalignment methods can be used later on to align thelocal ontology with existing domain ontologies.
The W3C recommendation "A Direct Mapping ofRelational Data to RDF" specifies direct mapping goodpractices [2]. It essentially proposes a formalization ofthe rules enounced by Tim Berners-Lee.
Augmented Direct MappingAugmented Direct Mapping targets to improve the
quality of a direct mapping by the automatic detec-tion of common database design patterns that can con-vey domain semantics. For instance, many-to-many re-lations are suggested by tables in which all non pri-mary key columns are foreign keys to other tables; nul-lable/not nullable columns can be converted into OWLcardinality constraints; implicit subclass relationshipsare often suggested by a primary key used as a for-eign key [18]. In the latter case though, the literatureargues that, in the context of databases not in the thirdnormal form, this pattern may reveal a vertical parti-tioning (splitting of a table into several smaller tablesfor performance concerns) rather than a subsumptionrelationship [55,50].
Some semi-automatic approaches propose an iter-ative process in which a domain expert validates ordismisses proposed mappings. Classes may be refinedbased on the detection of lexical clues in the columnnames or data redundancy suggesting categorizationpatterns [16]. Additionally, some research questionsremain open with regards to the possibility of translat-ing relational database triggers into additional knowl-edge in the form of semantic rules.
Domain Semantics-Driven MappingThe direct mapping approach is hardly sufficient
in real world applications, in which the data seman-tics lies outside the RDB schema, in domain-specific

rules encoded in the application that exploits thedatabase. This is outlined in a short but enlighteningfeedback from the Ordnance Survey of Great Britain:"databases are rarely good descriptions of a domain,being the result of both performance optimisation pro-cesses and contingent maintenance history. And, inany case, the schema itself will not support a full de-scription of the domain, other relevant relationshipsoften being buried in code or in the encoding of var-ious attributes" [26]. To overcome these limitations,the domain semantics-driven mapping approach ap-plies when the relational database must be translatedusing classes and properties of existing ontologies. Thedatabase and the ontology may have been designedseparately, and their similarity level may be low. Atypical use case is the alignment of a legacy databasewith an existing ontology describing or referring to thesame domain of interest.
Domain semantics-driven systems rely on mappingdescription languages to allow the description of ex-pressive mappings, able to bridge the conceptual gapbetween RDB and RDF. Mapping description lan-guages may support various features listed in Table 1.In any case, those languages generally implement twodifferent strategies:
(i) The mapping description essentially relies onSQL queries to present the data as RDF triples. Theexpressiveness of mappings is therefore constrained bythat of the SQL flavour used; in other words, complexcases that would require a richer expressiveness can-not be addressed, unless they are supported by exten-sions of a specific RDBMS. On the other hand, therewriting of a query on the target RDF data (generallya SPARQL query [33]) into SQL is almost straight-forward, and the query execution can benefit from thenative database optimizer. Besides, the great popular-ity of SQL facilitates the adoption of the mapping lan-guage by data providers who do not need to learn anew mapping language.
(ii) The mapping description uses a specific dedi-cated language. In this approach, the query rewritingprocess is more complex as it does not rely on SQLqueries written by the person who wrote the mapping.The mapping is not constrained by the expressivenessof SQL. As a result it can be extended in order to meetspecific complex needs such as keyword search, regu-lar expression matching, natural language processing,data mining, etc. Nevertheless, it must be underlinedthat most existing projects hardly reach the expressive-ness of SQL (for instance, aggregation and groupingare not always possible although they are natively sup-ported by SQL).
Some mapping languages such as R2RML andD2RQ use both strategies simultaneously: they areable to complement SQL snippets with specific map-ping descriptors.
2.2. Mapping Implementation
Given a mapping description, that is, the set of rulesthat map a relational model to a target ontology, themapping implementation refers to the way database tu-ples are translated into ontological instances (individ-uals). Two methods can be applied: data materialisa-tion, or on-demand mapping.
Data MaterialisationData materialisation is the static transformation of
the source database into an RDF representation, like inwarehouse approaches. Mapping rules are applied tothe whole content of the database to create an equiv-alent RDF graph. For this reason, it is also referred toas "graph dump", "graph extraction" or "RDF dump".When the materialisation process completes, the re-sulting RDF graph can be loaded into a triple store andaccessed through a SPARQL query engine. This wholeprocess is often referred to as the Extract-Transform-Load (ETL) approach that conveys the idea of data ma-terialisation and loading into a triple store.
With this approach, the number of data sources thatcan be integrated is only limited by the triple store andquery engine capacity. Besides, a major advantage ofthe materialisation is to facilitate further processing,analysis or reasoning on the RDF data, including itslinking to the Linked Open Data and the execution ofheavy inference rules on it. Indeed, as the RDF data ismade available at once, third party reasoning tools canbe used to apply complex entailments. Later on, com-plex queries can be answered without compromisingrun-time performances since the reasoning has beenperformed at an earlier stage.
Several limitations are to be noticed though. Thissolution hardly supports very large data sets, as thesize of the graph produced may exceed memory capac-ity. Another limitation concerns the way to deal withoutdated data: in the context of an application that up-dates the relational data frequently, the materializedRDF graph may be rapidly outdated. A solution is torun the extraction process periodically, which raisesthe question of compromising between the cost of ma-terializing and reloading the graph, and the toleranceof the application to outdated data.
On-Demand Mapping

Table 1Features of mapping languages
Feature description Feature description
generation of user defined unique Ids Ability to generate URIs of resources beyond the simple use of primary key values: reusingand combining column values, allowing for conversion tables, etc.
logical table Ability to read tuples not only from tables but also from SQL views or from the result of anSQL query.
column selection (also called projection) Ability to select only a subset of the columns of a table to translate. This is a very basic feature,almost a minimum pre-requisite of any RDB-to-RDF tool.
column renaming Ability to map a column to an RDF property with a different name. This is not always possiblein a direct mapping but quite obvious in a domain semantics-driven mapping.
select conditions Ability to translate only a subset of the tuples of a table using a select-where condition.
vocabulary reuse Ability to map relational entities to instances of existing vocabularies and ontologies. Thisis the main difference between domain semantics-driven mapping and direct mapping ap-proaches.
1 table to n classes Ability to use the values of a column as a categorization pattern: tuples of the table will betranslated into instances of different ontological classes based on the value of this attribute.This feature can be seen as an extension of the "select conditions" feature as it results in notonly filtering out rows, but the filter helps selecting rows to be converted into instance of oneclass or another.
many-to-many relation to simple triples Many-to-many relations are usually implemented in relational databases as a join table inwhich all columns are foreign keys to other tables (n-ary relations). This feature refers to theability to translate many-to-many join tables into simple triples, as opposed to a basic directmapping in which the join table will be translated into a distinct class.
blank nodes Ability to generate blank nodes and refer to them within the graph produced during the trans-lation process. Blank nodes can be used for instance to translate a table without a primarykey.
data types Ability to handle relational data types consistently with RDF data types per SQL-XSD map-ping.
data transformation Ability to apply transformation functions to the values before generating the RDF triples. Thiscan be used to perform complex type conversion, compute a value using several columns, andapplying methods such as string manipulation functions, decimals type conversions, etc.
named graphs Ability to create not only one default RDF graph but also multiple named graphs within asingle mapping definition.
user-defined namespaces Ability to declare and use namespace prefixes.
static metadata Ability to attach static metadata (such as licensing or provenance information) to the producedgraphs, and possibly to all RDF entities or instances of a certain class.
Conversely to the data materialisation method, theon-demand mapping approach is the run time eval-uation of queries against the relational data. In thismodel, the data remains located in the legacy database.Whatever the way the converted data is accessed,queries to the target RDF data must be rewritten intoSQL at query evaluation time.
The advantages and drawbacks of this approach arethe opposite of the materialisation approach. It is wellsuited in the context of very large data sets that wouldhardly support centralization due to resource limita-tions. It guarantees that the returned data is always upto date since no copy of the RDF data is made. Besides,it allows for the enforcement of access control policiesimplemented in the RDBMS.
On the other hand, query performance can beseverely penalised if entailment regimes must be im-plemented [47], or if many data sources are to be in-tegrated together. It has been suggested that in somecases, the expressiveness of SPARQL queries shouldbe limited, in order to be processed by on-demandmapping systems: in particular, a variable in the pred-icate position (resourceA ?r resourceB) ora variable in the object position representing a class(resourceA rdf:type ?c) can lead to "unionbomb" issues [28,27].
2.3. Data Retrieval
Independently of the way a mapping is imple-mented, the RDF data can be retrieved using two mainquery implementation methods: by sending a query

to a query processing engine or using the linked dataparadigm. The choice of the method largely dependson how the data should be exploited, as detailed below.
Query-based accessRDF data is retrieved by means of a query, generally
expressed in SPARQL, the standard query languagefor RDF. A SPARQL query engine may be accessedthrough an API6, or exposed through the SPARQL pro-tocol [29] resulting in a SPARQL endpoint.
In the data materialisation approach the SPARQLquery engine evaluates a query against the RDF repos-itory in which the materialised RDF data has beenloaded. In the case of the on-demand mapping, it eval-uates the query against a relational database. This in-volves rewriting the SPARQL query into SQL and,conversely, translating SQL results into equivalentSPARQL results according to the mapping.
Early approaches proposed query languages otherthan SPARQL. Nevertheless they were deprecated bythe standardization of SPARQL. Additionally, someRDBS providers have proposed alternative solutionsby integrating a SPARQL query evaluation enginewithin the native RDBS evaluation engine. This isthe case of SPASQL7 that allows for the execution ofSPARQL queries within SQL statements.
Linked DataDuring the RDB-to-RDF process, each logical rela-
tional entity translated into RDF is assigned a uniqueURI that identifies it in the data graph. According tothe principles of the Linked Data [9], it should be pos-sible to dereference any such URI by submitting anHTTP GET request with this URI, as if it was a URL.The HTTP response should provide a representation ofthe entity identified by the URI. The output format ofthe data description is generally agreed during a regu-lar HTTP content type negotiation procedure betweenthe client and the web server.
Two access methods are advised in [45], in relationto good practices for defining URIs:
(i) For an informational resource, a simple weblookup with HTTP content negotiation will return arepresentation of the entity (in XHTML, RDF/XML,N3, JSON, etc.).
(ii) If the URI refers to a non-informational re-source, i.e. an abstract concept or a physical object,it should not be dereferenced directly (dereferencingthe URI of a person cannot return this physical per-
6http://www.w3.org/wiki/SparqlImplementations7http://www.w3.org/wiki/SPASQL
son). An HTTP GET with such a URI should returnHTTP status 303 See other, providing the URI of aninformational resource that relates to or is a representa-tion of the non-informational resource, e.g. an HTMLdocument describing a person. This recommendationmay somehow be relaxed for technical concerns suchas the extra network traffic entailed by the additionalHTTP request, or time consuming definition of multi-ple URIs.
In the RDB-to-RDF context, the term Linked Datasometimes refers to the ability to dereference not onlya resource URI, but also a URI to a logical entity ofthe source database. For instance, dereferencing theURI of a database will return a human-readable listof classes corresponding to the tables, dereferencingthe URI of a class will return URIs of instances ofthis class. Closer to the spirit of the Linked Data,D2RQ dereferences a class URI by providing a fewtriples stating that it is a database or a class, includingrdfs:seeAlso statements when relevant. Such methodscan be exploited by crawlers of external search enginesto index the content of the database.
Graph Dump AccessOne could argue that a third data retrieval method
exists: graph dump over HTTP access. In this method,a client performs an HTTP GET request to the databaseURI and retrieves the entire RDF graph at once. The"SPARQL 1.1 Graph Store HTTP Protocol" [39] stan-dardizes this method within the wider scope of graphmanagement methods. Nevertheless, none of the toolsthat we have studied implements the graph dump overHTTP access method. This can be explained by thefact that the data materialisation process produces agraph serialization, generally in the form of an RDFfile. Hence, using the graph dump over HTTP accessmethod would be just another way of getting an al-ternative representation of the same graph from anHTTP endpoint. Moreover, in conjunction with the on-demand mapping implementation, the dump of largegraphs may induce significant performance issues.Therefore, in the following, we shall not consider theGraph Dump over HTTP access in the list of data re-trieval methods.
3. R2RML
R2RML [20] is a generic language to describe aset of mappings that translate data from a relationaldatabase into RDF. It is the result of preliminary worksheld by the W3C. Starting from an initial proposal in

2007 [24], the W3C RDB2RDF Incubator Group8 rana comprehensive survey of existing approaches [47]and described high level characteristics that a languageshould cover to map relational databases to RDF [3].Finally, the RDB2RDF Working Group standardizedthe R2RML mapping language in 2012. As a standard,R2RML has a particular importance as it steers the de-velopment of many RDB-to-RDF tools. Yet, it onlycovers the mapping description language, but does notrecommend any implementation. Compliant tools maytherefore adopt completely different strategies.
3.1. R2RML Features
The W3C RDB2RDF Working Group proposeda list of 11 mandatory or optional requirements forR2RML [5]. Table 1 provides a detailed description ofeach of these features.
Mandatory features state that R2RML must (i)support both the direct mapping and the domainsemantics-driven mapping (called transformative map-ping); (ii) provide sufficient information for a proces-sor to support both the on-demand mapping (rewriteSPARQL queries into SQL) and the data materiali-sation. Other mandatory features are: generation ofunique identifiers, support of data types conversions,column renaming, many-to-many relation to simpletriples, 1 table to n classes.
Optional features include data transformation, namedgraphs, namespace declaration, static metadata. Ad-ditionally, the "update logs" feature is also listed asa "nice-to-have feature": the mapping should provideextension points to support the creation of update logsof relational data. The final R2RML recommendationincludes all features listed above with the exceptionof the update logs and the data transformation that isleft to the capabilities of SQL in terms of string ornumber manipulations (no complex data transforma-tion method is specified).
Table 1 includes three additional features that werenot explicitly addressed in [5], but that are part ofR2RML: select conditions, column selection and blanknodes. The "select conditions" feature is implicit inR2RML as it is a pre-requisite of the "1 table to nclasses" feature. Similarly, the "column selection" fea-ture is implied by the more global support of the trans-formative mapping.
8http://www.w3.org/2005/Incubator/rdb2rdf/
3.2. R2RML Mapping Description
An R2RML mapping document is called an R2RMLmapping graph. It is written in RDF with the Tur-tle syntax9. In the following, we describe R2RMLmain components along with a running example. Leta database describe courses and participating students.Table COURSE has two columns: ID (primary key)and TITLE. Table PARTICIPATES has two columns:SID (a student identifier), and CID (foreign key tocolumn ID in table COURSE). The R2RML mappingin Listing 1 maps this database to RDF triples us-ing an existing ontology with classes co:Course,co:Student, a co:participatesIn object prop-erty and a co:title data property .
A mapping consists of several TriplesMaps, eachone specifying how to map rows of a logical table toRDF triples. The logical table may be a table, an SQLview, or the result of any valid SQL query. Our exam-ple defines two TriplesMaps, Course with logical ta-ble COURSE and Participates with logical tablePARTICIPATES.
A TriplesMap is composed of exactly one Sub-jectMap and any number of PredicateObjectMaps. Foreach row of the logical table, the SubjectMap generatesthe subject URI, for instance using the logical tableprimary key. The SubjectMap in TriplesMap Coursedefines a subject URI as the concatenation of names-pace http://univ.org/course/ with the valueof column ID. PredicateObjectMaps consist of Pred-icateMaps and ObjectMaps. Triples are produced bycombining the subject map with each predicate fromthe PredicateMap and each value from its associatedObjectMap. In TriplesMap Course, each subject URIwill have a predicate co:title with literal valueread from column TITLE.
@pref ix r r : < h t t p : / / www. w3 . org / ns / r 2 r m l # >.@pref ix co : < h t t p : / / c o u r s e s . o rg # >.@base < h t t p : / / example . com / base # >.
<Course >r r : l o g i c a l T a b l e [ r r : tableName "COURSE" ] ;r r : sub jec tMap [
r r : t e m p l a t e " h t t p : / / un iv . edu / c o u r s e / { ID } " ;r r : c l a s s co : Course ;
] ;r r : p r e d i c a t e O b j e c t M a p [
r r : p r e d i c a t e co : t i t l e ;r r : ob jec tMap [ r r : column " TITLE " ] ;
] .
9http://www.w3.org/TR/turtle/

< P a r t i c i p a t e s >r r : l o g i c a l T a b l e
[ r r : tab leName "PARTICIPATES" ] ;r r : sub jec tMap [
r r : t e m p l a t e" h t t p : / / un iv . edu / s t u d e n t / { SID } " ;
r r : c l a s s co : S t u d e n t ;] ;r r : p r e d i c a t e O b j e c t M a p [
r r : p r e d i c a t e co : p a r t i c i p a t e s I n ;r r : ob jec tMap [
r r : p a r e n t T r i p l e s M a p <Course > ;r r : j o i n C o n d i t i o n
[ r r : c h i l d "CID " ; r r : p a r e n t " ID " . ] ;] ;
] .
Listing 1: Example of an R2RML mapping
In TriplesMap Participates, object propertyrr:subjectMap defines URIs for students, whilerr:predicateObjectMap describes an SQL in-ner join between tables COURSE and PARTICI-PATES. This is denoted by the value of propertyrr:objectMap having two specific properties: prop-erty rr:parentTriplesMap refers to TriplesMapCourse as the parent in the join condition, and prop-erty rr:joinCondition defines the columns tojoin: PARTICIPATES.CID and COURSE.ID.
Assuming table COURSE contains one course withidentifier 1 and title "Semantic Web" and table PAR-TICIPATE contains one student with identifier 2 whoparticipates in course 1, the above R2RML mappingwill produce four RDF triples:
< h t t p : / / un iv . edu / c o u r s e /1 >a co : Course ;co : t i t l e " Semant i c Web " .
< h t t p : / / un iv . edu / s t u d e n t /2 >a co : S t u d e n t ;co : p a r t i c i p a t e s I n< h t t p : / / un iv . edu / c o u r s e / 1 > .
By default, all RDF triples are in the default graphof the output dataset. A TriplesMap can containGraphMaps that place some or all of the generatedtriples into named graphs.
The R2RML recommendation specifies that anR2RML processor may include an R2RML defaultmapping generator complying with the W3C directmapping rules [2].
3.3. Implementations
The first R2RML recommendation was issued Sept.27th 2012. Several candidate implementations havebeen evaluated against compliance tests described inthe R2RML and Direct Mapping Test Cases10, com-prising 24 Direct Mapping tests and 62 R2RML tests.Results are reported in the RDB2RDF ImplementationReport11.
4. RDB-to-RDF tools
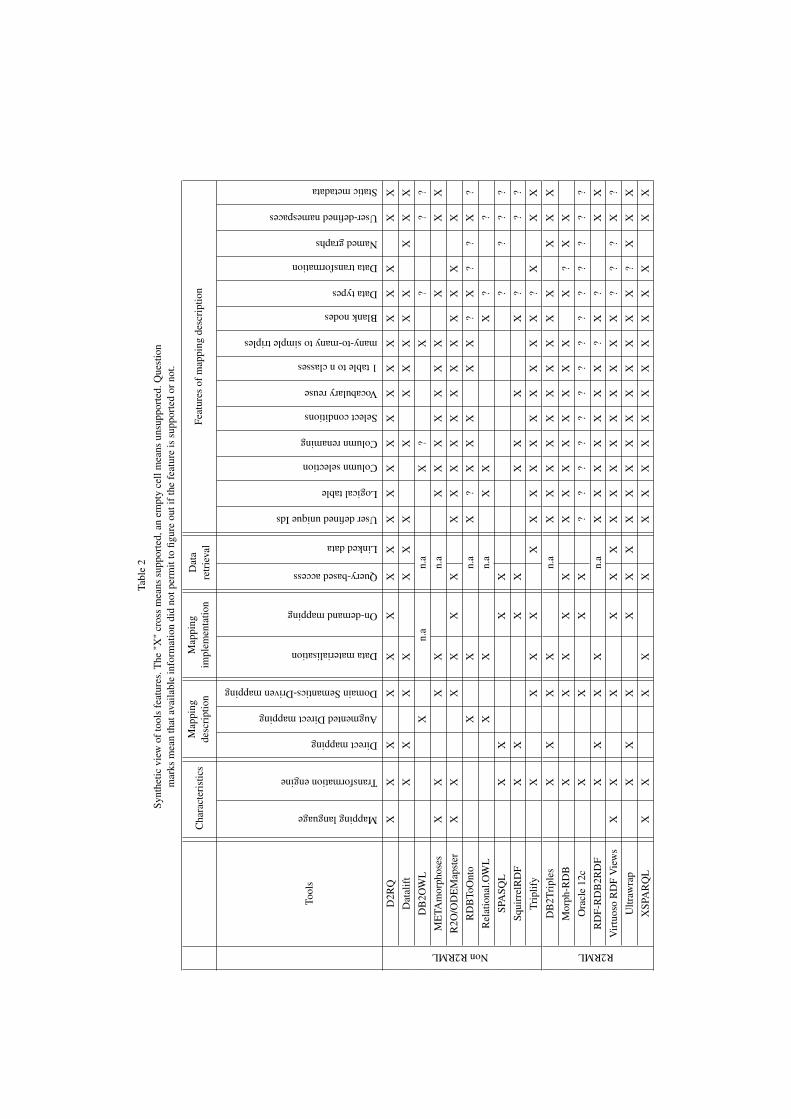
This section describes RDB-to-RDF tools classifiedalong the axis defined in section 2. Section 4.1 presentsthe tools that comply with R2RML, while section 4.2describes the tools that propose their own mapping lan-guage. In each section, tools are listed by alphabeticalorder. Table 2 (section 4.3) summarizes the informa-tion provided here after.
4.1. R2RML-Compliant Tools
Below we consider the R2RML candidate im-plementations and their results with regards to theR2RML test cases. Oracle Spatial and Graph 12c, re-leased in July 2013, supports R2RML. Yet, at the timeof writing, it has not been officially tested against theR2RML test cases and thus is not yet mentioned in theRDB2RDF Implementation Report.
4.1.1. DB2TriplesDB2Triples1213 is an implementation of R2RML
and the W3C Direct Mapping based on the Work-ing Draft of May 29th 201214. It is developed by theAntidot15 company as part of a larger software suite.DB2Triples is delivered as a Java library, available un-der the LGPL 2.1 open source licence, and validatedwith MySQL and PostgreSQL back-ends. It supportsthe data materialisation mapping implementation, butprovides no data retrieval method. The materializedgraph can be serialized in RDF/XML, N3, N-Triplesor Turtle. In the direct mapping mode, DB2Triples can
10http://www.w3.org/TR/2012/NOTE-rdb2rdf-test-cases-20120814/
11http://www.w3.org/TR/2012/NOTE-rdb2rdf-implementations-20120814/
12http://www.antidot.net/fr/Actualites/Produit/Antidot-fournit-db2triples-en-Open-Source
13https://github.com/antidot/db2triples14http://www.w3.org/TR/2012/WD-rdb-direct-mapping-2012052915http://www.antidot.net/

optionally apply queries from a SPARQL file in orderto transform the graph. This may be used to produceadditional triples using deduction rules in the form ofSPARQL INSERT clauses.
Compliance: DB2Triples failed on one of the 62R2RML test cases regarding the detection of a non-conforming mapping.
Sustainability: DB2triples version 0.9.9 was re-leased in 2012. No indication as to its support is pro-vided, one can expect Antidot to maintain it as part ofAntidot’s software suite.
4.1.2. Morph-RDBMorph-RDB16 is an implementation of R2RML, de-
veloped by the developers of R2O and ODEMapster. Itsupports the data materialisation (called data upgrademode) and the on-demand mapping using SPARQLqueries. In [43], authors describe the method they de-veloped to enable R2RML-based SPARQL to SQLquery translation.
Morph-RDB is developed in Scala and Java andis available under the Apache 2.0 open source li-cence. The development is ongoing. Authors arealso working on two other versions of Morph, thatrely on R2RML although they address non-relationaldatabases: Morph-streams deals with streamed datatypically produced by sensors, and Morph-GFT queriesGoogle Fusion Tables17 like relational tables.
Compliance: Morph-RDB failed on 8 of the 62R2RML test cases regarding the generation of a defaultmapping for tables without a primary key (2 tests),data type conversions (3 tests), different blank nodesgenerated for different rows when they should be thesame, detection of non-conforming mappings (2 tests).R2RML named graphs are not supported in the on-demand mapping but is supported in the data material-isation.
Sustainability: developers intend to continue thesupport and evolution of Morph-RDB, possibly ex-tending it beyond the official R2RML specification,e.g. by adding support for Google Fusion Tables. Littledocumentation is available, but extensive usage exam-ples are provided.
4.1.3. Oracle Database 12cOracle Spatial and Graph18 (formerly Oracle Se-
mantic Technologies) [41,40] is an option of Oracle
16https://github.com/fpriyatna/odemapster/wiki17http://www.google.com/drive/apps.html#fusiontables18http://www.oracle.com/technetwork/database-
options/spatialandgraph/overview/rdfsemantic-graph-1902016.html
Database Enterprise Edition (EE). Version 12c, re-leased in July 2013 comes with the RDF SemanticGraph data management and analysis features, thatsupport RDB-to-RDF conversion.
RDF Semantic Graph mainly focuses on the storage,simultaneous querying and reasoning on relational andRDF data. The RDF graph store can scale up to billionsof triples, supports graph versioning and the semanticindexing of documents. SPARQL graph patterns canbe included within an SQL query in order to join RDFand relational data. Extensive RDFS/OWL2 capabili-ties support the simultaneous reasoning on RDF andrelational data. The security model can enforce restric-tions at different levels, from graph to triple granular-ity.
RDB-to-RDF conversion is supported since version12c by providing RDF views on relational tables, SQLviews, and SQL query results. R2RML and the W3CDirect Mapping are supported. The RDF view can bequeried through SPARQL 1.1.
Oracle Spatial and Graph exploits several enter-prise features such as table compression (optimize diskspace and memory usage), partitioning (performance,scalability), and Real Applications Clusters (availabil-ity, scalability). As a result, using Oracle Spatial andGraph requires the acquisition of licenses for OracleDatabase EE and Partitioning option.
Compliance: no result is available as to the R2RMLcompliance tests, consequently, Table 2 shows ques-tion marks for all the features.
Sustainability: RDB-to-RDF is a newly added fea-ture in release 12c. No information is available on itssupport by Oracle in the future.
4.1.4. RDF-RDB2RDFPerl RDF is an open source software library de-
livered under the GPL license. It is a very completelibrary including the following features: RDF storein memory, support for relational databases (MySQL,PostgreSQL) and SQLite, SPARQL 1.1 query proces-sor and endpoint, Linked Data server, RDFa parser,WebID (FOAF+SSL) + ACLs, GRDDL, Microfor-mats, HTML5.
RDF-RDB2RDF19 is an additional library, devel-oped on top of Perl RDF, that implements R2RMLand the W3C Direct Mapping based on the WorkingDraft of May 29th 2012. RDF-RDB2RDF implementsthe data materialisation method. The materialized RDFdata can be loaded into the SPARQL endpoint pro-vided by Perl RDF, thus falling in the ETL approach.
19https://metacpan.org/release/RDF-RDB2RDF

Compliance: RDF-RDB2RDF failed on 12 of the 62R2RML test cases (either with PostgreSQL or SQLite)regarding data type conversions (5 tests), managementof joins and inverse expression (4 tests), named graphs,logical table named column, special chars and back-slashes.
Sustainability: the implementation of R2RML andthe direct mapping dates back to version 0.006 de-livered in June 2012. However Perl RDF is activelymaintained, version 0.008 was delivered in September2013.
4.1.5. UltrawrapInitially developed by the University of Texas in
Austin, Ultrawrap20 is now a commercial product ofthe Capsenta company, founded in 2011 as a spin-offof the University of Texas. It is based on SQL views topresent relational data as RDF triples.
A local ontology is defined through the direct map-ping. The RDF representation is implemented as athree-column SQL view (subject, predicate, object),defined as the union of all the queries that material-ize all the RDF triples as defined by the local ontol-ogy [52]. Consequently, a SPARQL query can be sim-ply rewritten into an SQL query on the SQL view.In [51], authors explain the need for two additionalcolumns in the SQL views: the primary keys of thesubject and the object. This change allows the nativequery optimizer to take advantage of existing indexes.Along with two other optimizations (the self-join elim-ination and the detection of unsatisfiable conditions),authors show that the query evaluation time is com-parable to that of SQL queries written directly for therelational representation. Ultrawrap also supports theLinked Data retrieval method (HTTP GET requests).
Recently, support for R2RML and D2RQ mappinglanguages has been added. There is no description,however, of the way the mapping description is de-rived into the SQL view. We make the hypothesisthat an R2RML/D2RQ document is compiled into anSQL view that reflects each triple map. The support ofR2RML named graphs does not seem easy using onlythe SQL triple view. A GUI that is part of the tool suitehelps align the local ontology with a domain ontology.
Compliance: Ultrawrap passed all R2RML testcases.
Sustainability: Ultrawrap was released to first betacustomers in May 2012. No information is given as tofuture releases. Prices are available on demand only.
20http://capsenta.com/ultrawrap
4.1.6. Virtuoso Universal Server & Virtuoso’s RDFViews
Virtuoso Universal Server21 is a commercial andopen-source comprehensive tool suite developed byOpenLink, designed to meet enterprise data manage-ment, access and integration needs. It comes withproduction-class features such as a relational database,clustering, data replication, RDF triple store, reason-ing capabilities (entailment regimes), multiple datasources integration (SQL, RDF, XML, free text, CMS,aggregation feeds...). The Virtuoso Open-Source Edi-tion22 is a sub-set of the Universal Server. Limitationsconcern production-class features such as the cluster-ing and data replication functions.
The RDF and SPARQL tool suite open sourceedition provides features such as: Object-RelationalDatabase for SQL, XML, RDF, and Free Text; RDFstore and SPARQL end-point; Web Application Server(see the full feature list23). In particular the RDF Viewsof SQL data functionality implements the RDB-to-RDF functionality. The open source edition only sup-ports the Virtuoso-based relational database whereasthe commercial edition supports most well known re-lational database systems.
The declarative Meta Schema Language24 (MSL) isan extension of the SPARQL query language, meshedwith Virtuoso’s SPASQL functionality (SPARQL-inside-SQL). The mapping does not only involve anMSL document, but it is itself a repository in whichmapping patterns can be grouped in named sets, andmanaged using operations such as create, drop, alter,etc. A rich web interface provides a wizard to auto-matically generate a direct mapping. R2RML supportis achieved by the inclusion of a simple adaptor whichbasically translates R2RML syntax to Virtuoso’s ownLinked Data Views syntax, which can then be executedto create the Linked Data Views themselves.
The on-demand mapping is provided through Vir-tuoso SPARQL 1.1 endpoint. The data materialisationmay be possible but this is not the goal of Virtuoso.The Linked Data retrieval method is also availableand exposes any Virtuoso-housed data (SQL and XMLdata sources) as dereferenceable URI. RDF data maybe retrieved as RDF/XML, JSON or N3 syntaxes.
Compliance: Virtuoso RDF Views did not pass 29of the 62 R2RML test cases; those are in status "can-
21http://www.w3.org/wiki/VirtuosoUniversalServer22http://virtuoso.openlinksw.com/dataspace/dav/wiki/Main/VOSIndex23http://virtuoso.openlinksw.com/features-comparison-matrix/24http://virtuoso.openlinksw.com/dataspace/dav/wiki/Main/
VOSSQL2RDF

notTell", meaning that the test could not be run. Noexplanation is provided.
Sustainability: Virtuoso is actively maintained bythe company OpenLink. Note that the DBpedia projectis operated using a Virtuoso triple store.
4.1.7. XSPARQLRDF/XML syntax provides a lot of variability
in the serialization of an RDF graph. As a result,XSLT+XPath processors are inappropriate to inte-grate XML and RDF/XML data. The XSPARQL25
query language was designed to address this diffi-culty, by combining XQuery and SPARQL for bidirec-tional transformations between RDF and XML: XS-PARQL merges SPARQL components into XQueryFLWOR expressions. XSPARQL is typically designedto extract RDF data out of existing Web pages, al-low an RDF-based client software to communicatewith XML-based Web services, or even enrich an RDFgraph with deduction rules described as RDF-to-RDFmappings.
Recently, Lopes et al. [38] have defined an RDB-to-RDF extension to XSPARQL, that provides theability to embed SQL snippets (select-from-where) inXQuery FLWOR expressions. Thus, the relational datacan be queried and transformed into XML or RDF. Ontop of this, an R2RML mapping document can be in-terpreted to produce appropriate XSPARQL constructexpressions that materialize the RDF data. The origi-nality of this approach is that it did not require the de-velopment of a specific module in the XSPARQL pro-cessing engine. Instead, the whole process is describedin XSPARQL: the R2RML mapping document is readas input RDF data, XQuery FLWOR expressions parseit, query the database accordingly, and ultimately gen-erate the RDF data using XSPARQL construct expres-sions.
XSPARQL comes with a prototype implementationdeveloped in Java and distributed under the Apache2 open source license. It implements the data mate-rialisation approach. Supporting the on-demand map-ping should be possible but is not straightforward: itwould require designing a query rewriter to convert aSPARQL query into an XSPARQL query that wouldin turn make the appropriate SQL queries.
Compliance: XSPARQL passed all R2RML testcases, although discussions with the developers re-vealed that named graphs are not supported, and logi-cal tables cannot refer to SQL queries (only relationaltables and views are supported).
25http://xsparql.deri.org/
Sustainability: Version 0.5 was released in Novem-ber 2012, supporting both Direct Mapping and R2RML.Several fixes were provided in early 2014.
4.2. Non-R2RML Tools
4.2.1. Asio Semantic Bridge for Relational Databasesand Automapper
Asio Tool Suite26 is a commercial product devel-oped by BBN Technologies. It provides several com-ponents: Asio Semantic Query Decomposition (SQD),Asio Semantic Bridge for Relational Databases27
(SBRD), Asio Semantic Bridge for Web Services, andtwo open source tools: Parliament and Snoggle.
Asio SBRD implements the RDB-to-RDF process.The BBN’s Automapper tool applies D2RQ-based di-rect mapping rules to create the local ontology thatdescribes the relational schema. The direct mappingis then augmented with OWL property restrictionsto model data types and nullable/not nullable prop-erties. Additional mapping rules between the domainontology and the local ontology are described as aset of SWRL28 rules. Asio SBRD implements the on-demand query mode: it rewrites SPARQL queries intoSQL queries and applies query planning and optimiza-tion techniques. The data materialisation mode is notavailable. The precise set of supported mapping fea-tures is not available, consequently we did not includeit in Table 2.
The Asio SQD module addresses the federation ofmultiple data sources: it breaks down SPARQL queriesexpressed using a domain ontology into sub-queriesusing the local ontology of each data source, and dis-tributes these optimized sub-queries to the applica-ble data sources: relational databases, web services ortriple stores.
4.2.2. D2R Server and the D2RQ languageThe D2R Server29 [12,13] is an open source aca-
demic project. It provides an integrated environmentwith multiple options to access relational data us-ing different methods such as the SPARQL endpoint,Linked Data (content negotiation, HTTP 303 deref-erencing), RDF dump. D2RQ supports both directand domain semantics-driven mappings. The DR2Qdeclarative mapping language [19] is formally definedby an RDFS schema. It is the successor to the XML-
26http://bbn.com/technology/knowledge/asio_tool_suite27http://bbn.com/technology/knowledge/asio_sbrd28http://www.w3.org/Submission/SWRL/29http://d2rq.org/

based D2R MAP language [11]. The mappings are ex-pressed in RDF, but also largely rely on SQL frag-ments to express SELECT statements or to use aggre-gate functions. The D2RQ direct mapping automati-cally creates a local ontology. This direct mapping canbe customized manually. Optionally, the direct map-ping generated can comply with the rules proposed inthe W3C Direct Mapping specification [2].
The Linked Data retrieval method is supported withHTTP content negotiation (RDF or XHTML), includ-ing HTTP status 303 See other.
The automatic addition of rdfs:seeAlso prop-erties and HTML hyperlinks leads to navigation pagescontaining lists of other resources of the same class,and to an overview page that lists all of these naviga-tion pages. This overview page provides an entry pointfor external Web search engines to index the content ofthe database.
The performance varies depending on the accessmethod and is reported to perform reasonably well forbasic triple patterns, but there are limitations for graphpatterns with filters and solution sequence modifiers.
Sustainability: D2R is a very active project. The lastversion released in June 2012 supports the W3C’s Di-rect Mapping specification. The first release of DBpe-dia in 2007 was done using D2R Server, which sincethen migrated to Virtuoso RDF Views.
4.2.3. DataliftDatalift30 is an experimental research project aimed
at helping users to publish and interlink their datasets on the web as Linked Data. It provides an inte-grated set of tools that ease the publication process ofraw structured data coming from various formats (re-lational databases, CSV, XML, ...). The tools cover thefollowing functions: selecting ontologies for publish-ing data, converting it to RDF by using the selected on-tology, publishing the produced RDF data, interlinkingit with other RDF datasets.
Datalift implements the ETL approach: the data isfirst materialised, loaded into the triple store, then it isretrieved through a SPARQL query engine or LinkedData navigation (URIs dereferencing based on contentnegotiation: RDF, CSV or XHTML).
The mapping description is done interactively througha web-based GUI: a user selects a data source that isautomatically translated following the direct mappingmethod. Then, a set of modules helps align the pro-duced RDF data on chosen ontologies: RDF-to-RDFtransformation (by means of SPARQL queries), re-
30http://datalift.org/en
naming of URIs (using regular expressions), conver-sion of strings into URIs, automatic discovery of linkswith other RDF datasets with the SILK31 tool. As a re-sult, although it starts with a Direct Mapping, the dif-ferent modules provide enough flexibility to performan a posteriori alignment with capabilities comparableto domain semantics-driven mapping approaches.
Sustainability: The project completed in March2014. The Datalift association has recently been founded,which should guarantee a maintenance task force.
4.2.4. DB2OWLDB2OWL is a proof of concept that was proposed
by Cullot et al. [18]. In the domain of ontology learn-ing, its goal is to automatically generate a direct map-ping describing a relational database, then refine thismapping by exploiting relational schema characteris-tics: detect many-to-many join tables (translated intoRDF triples) and concept subsumptions (when a pri-mary key is also a foreign key in another table). Theontology produced is expressed in OWL-DL, while themapping description is stored in an R2O document(see section 4.2.6).
DB2OWL is exclusively focused on the automaticcreation of ontologies (classes and properties) that re-flect the relational schema; it does not tackle the con-version of the relational data. It must be noticed thatmost direct mapping implementations are now able tohandle many-to-many relation (although it is not partof the W3C Direct Mapping), whereas this is hardlythe case of subsumption relations.
In [30], the authors of DB2OWL apply the on-demand mapping implementation to perform the inte-gration of several relational databases using two dif-ferent levels of ontologies: DB2OWL creates a localontology for each database and a wrapper convertsqueries to a local ontology into SQL queries. At thetop, user queries expressed on a domain ontology aremapped to queries on local ontologies.
Sustainability: DB2OWL is a prototype, with nomore development since 2007. The source code is notavailable.
4.2.5. METAmorphosesThe METAmorphoses processor32 transforms rela-
tional data into RDF using existing target ontologies.The mappings are specified in a declarative XML-based mapping language [54], and the RDF graphis produced at once (data materialisation) in an RD-
31http://silk.semwebcentral.org/32http://www.svihla.net/metamorphoses/METAmorphoses_pro-
cessor/#documentation

F/XML output document. METAmorphoses is pro-vided as a Java library under the LGPL open source li-cense. Although quite simple, METAmorphoses is aneffective tool. As other standalone applications, it doesnot require any complex deployment. Mappings can beimplemented and tested easily and quickly.
The mapping language is organised as a two-layerdata transformation model. The mapping layer de-scribes how to map database tuples, selected by em-bedded SQL snippets, to RDF individuals using exist-ing ontologies. The template layer describes how to se-rialize the mapped entities into RDF/XML.
METAmorphoses does not provide any data re-trieval method, but relies on the ETL approach to querythe materialized graph.
Sustainability: No update was provided since 2007.
4.2.6. R2O and ODEMapsterR2O is a declarative XML-based language [7] that
allows the description of complex domain semantics-driven mappings between existing ontologies and re-lational elements (relations and attributes). It was ini-tially designed to overcome weaknesses of D2R MAP[11], the predecessor of the D2RQ mapping language,for cases where the similarity between the relationaldatabase and the ontology is low. It addresses situa-tions such as: 1-table-to-n-classes or joined-tables-to-1-class, that are commonly addressed by other projectssuch as D2RQ or Virtuoso. R2O also provides datatransformation primitives such as string manipula-tions, arithmetic calculations, definition of order rela-tions, expression of restriction on range of values, etc.To our knowledge, other RDB-to-RDF tools do notaddress such transformations, but one can argue thatmajor RDB systems do cover such data manipulationsthrough specific SQL extensions.
R2O is an evolution of eD2R [6], which addressedthe mapping of lightly structured databases or databasesnot in first normal form. eD2R proposed complextransformations on field values based on techniquessuch as keyword search, regular expression matching,natural language processing and others.
The ODEMapster33 query engine uses an R2O map-ping document to either execute the transformation inresponse to a query expressed in the ODEMQL querylanguage, or to apply the data materialisation approach(called massive upgrade). SPARQL and the LinkedData retrieval methods are not supported, but the ETLapproach can be applied by loading the materialisedRDF data into a third party triple store.
33http://neon-toolkit.org/wiki/ODEMapster
Sustainability: ODEMapster has been integrated asa plug-in into the NeOn34 toolkit, an open source on-tology engineering environment (ODEMapster plug-in still maintained in last toolkit version Dec. 2011).The EU ADMIRE project reused the NeOn toolkit andprovided a distributed access to ODEMapster by us-ing OGSA-DAI [42]. It is likely that the R2O languagewill no longer be maintained as authors have rewrittenODEMapster into the Morph-RDB R2RML-compliantproduct (see section 4.1.2).
4.2.7. RDBToOntoThe RDBToOnto35 tool was designed in the context
of the TAO project36 (ended in early 2009) whose goalwas to allow a fast and effective transition of existinglegacy applications to ontologies.
RDBToOnto consists of a GUI-based extensible tooland a framework to ease the development and exper-imentation of "transitioning methods", i.e. ontologylearning from relational databases. RDBToOnto pro-poses a semi-automated method: first, a direct map-ping automatically creates a local ontology; then, theclasses of this ontology are refined based on the rela-tional data itself [16]: find lexical clues in the columnnames (matched against a predefined list of keywordse.g. "Type") or use data redundancy to discover cate-gorization patterns. Another step allows for databaseoptimization (removal of redundancies using the thirdparty tool LATINO). The whole process is interactive(user defined rules) and iterative. The process com-pletes with the production of the populated ontology:RDBToOnto implements the data materialisation ap-proach.
RDBToOnto can be extended by means of connec-tors and converters to implement new learning meth-ods. It does not specify any mapping language: con-straint rules are stored in application specific projectfiles and edited through the GUI only.
Sustainability: RDBToOnto has been used in a largereal-world case study in aircraft maintenance37, in-cluding mixing with existing ontologies, maintenancedocumentation annotation and WSDL annotation. Noindication of use and maintenance outside of this con-text is found.
34http://www.neon-project.org/nw/Welcome_to_the_NeOn_Project35http://www.tao-project.eu/researchanddevelopment/demosand-
downloads/RDBToOnto.html36http://www.tao-project.eu/index.html37http://videolectures.net/eswc08_cebrah_tla/

4.2.8. Relational.OWLPeer-to-peer databases are volatile distributed databases,
with frequently changing data and schema. Sharingdata between such databases requires an exchange for-mat that can be understood instantly, without requiringcontent negotiation or ontology alignment. The goalof Relational.OWL38 is to enable such data sharingby providing an application independent representa-tion technique expressed as an OWL ontology. Rela-tional.OWL helps represent relational schema compo-nents by means of a local ontology (e.g. complyingwith direct mapping rules), as well as the relationaldata itself. It defines classes for tables, columns, pri-mary and foreign keys, data types, and relations (prop-erties) between those classes. OWL-full is requiredin order to allow the creation of an ontology withclasses defined as instances of the Relational.OWL on-tology classes. The use of OWL-full may be consid-ered as a hurdle to the adoption of Relational.OWL,as it is non decidable. Nevertheless authors are "confi-dent of most OWL reasoning tools being able to han-dle data and schema representations created using Re-lational.OWL" [21].
The Relational.OWL application is a GUI that au-tomates the process of converting a database into itsequivalent OWL full expression. No data retrievalmethod is provided, but based on Relational.OWL, DeLaborda and Conrad [23] proposed a method to per-form domain-semantics mapping: in a nutshell, thesystem first implements the ETL approach, then alignsthe produced RDF data with the target ontology byprocessing SPARQL CONSTRUCT queries.
The advantage of expressing the schema of a re-lational database by building an ontology based onthe Relational.OWL ontology is interoperability. Thefact that two database schemas are described usingthe same base ontology helps compare classes withclasses and properties with properties. However it doesnot solve alignment issues: for instance, it cannothelp figure out that two columns from two databasesbear the same semantics. Another advantage of Rela-tional.OWL pointed out by De Laborda and Conrad[22] is that it keeps track of the relationship betweenthe produced RDF data and the original database. Ap-plications of this property could be the tracing of dataprovenance, the explanation of query results, or the as-sessment of confidence in query results.
Sustainability: Relational.OWL was not updatedsince 2006.
38http://sourceforge.net/projects/relational-owl/
4.2.9. SPASQLSPASQL39 is an open-source modified MySQL
server, able to parse both SQL and SPARQL queries.The goal of providing MySQL with native support forSPARQL is to allow the same performance as for well-tailored SQL queries, by avoiding a complex rewrit-ing phase [44]: SPARQL and SQL queries are com-piled into the same data structures, and are then equallyprocessed by the MySQL query processing engine.SPASQL is an extension of SQL allowing the exe-cution of SPARQL queries within SQL statements,typically by treating them as sub-queries or functionclauses. Variables in a SPARQL query are treated likeany variable in an SQL query, making the two lan-guages interchangeable to query the same database.
SPASQL applies an automatic direct mapping ap-proach, along with the on-demand query processing.No query rewriting process is needed, the SQL inter-preter is extended to support both SQL and SPARQL.The support of SPARQL is limited to SELECT clauseswith no variable in the predicate position of triple pat-terns. Results are returned like usual MySQL resultsets.
Sustainability: SPASQL was designed in the projectFeDeRate for Drug Research40 and remained in anearly prototype status . No update was reported since2008.
4.2.10. SquirrelRDFWith SquirrelRDF41, Seaborne et al. [48] propose a
tool to apply direct mapping rules to an input databaseor an LDAP directory, and to answer SPARQL queriesthrough an on-demand query rewriting process. Map-ping principles roughly follow [8]. The mapping de-scription file (in RDF/Turtle) can be generated auto-matically from the database. Note that we could notfind a definition of the mapping file vocabulary on theinternet nor in the downloaded archives. The mappingmay be customized in order to use an existing tar-get vocabulary, nevertheless the customization is ratherlimited, and the mapping essentially remains driven bydirect mapping rules. Jena rules may be used to pro-duce additional knowledge in the perspective of moredomain-driven mappings.
The data can be retrieved using SPARQL SELECT,ASK and CONSTRUCT query forms issued to theJena SPARQL API. A CLI tool is available to testwhether the configuration is properly set. A limited
39http://www.w3.org/wiki/SPASQL40http://www.w3.org/2004/10/04-pharmaFederate/41http://jena.sourceforge.net/SquirrelRDF/

demo SPARQL endpoint supports the SELECT queryform. Whatever the access method used, variables arenot allowed in the predicate position of triple pat-terns. An originality of SquirrelRDF is that it can querymultiple databases simultaneously (n tables from mdatabases).
Sustainability: SquirrelRDF has not been updatedsince 2006. It was delivered as part of the Jena frame-work distribution in 2006, however it is no longer partof it since Jena42 moved to the Apache foundation.
4.2.11. TriplifyThe goal of Triplify43 is to enable popular Web ap-
plications (like CMS or blog applications) to publishthe content of their relational database as RDF LinkedData or JSON. Given that many instances of such webapplications are deployed over the internet, helpingthem to quickly expose their database is expected toresult in a boost of the Semantic Web adoption [4].
Triplify is a simple but effective approach to be usedas a lightweight easy-to-learn plug-in for existing webapplications. It is based on the mapping of HTTP URIrequests onto queries to the relational database. Com-pared to the direct mapping approach, Triplify takesthe problem the other way round: it first focuses onthe relational data that actually matters and the queriesthat should be needed, instead of translating the wholerelational schema into an ad-hoc ontology. Mappingsare implemented as SQL statements embedded in PHPscripts, therefore any SQL construct or aggregationfunction of the back-end may be used. Transformationfunctions written in PHP may in turn be applied tothe data returned by the SQL queries. Authors arguethat "Triplify facilitates the creation of custom-tailoredsearch engines targeted at certain niches, e.g. searchingfor specific content in various blogs, wikis, or forums"[4].
Triplify provides the on-demand and data materi-alisation implementations. In the on-demand mode,data is retrieved as RDF Linked Data or JSON (boththrough HTTP GET), but no query rewriting process issupported.
Some Triplify modules specifically address theprovenance metadata generation (using the Prove-nance Vocabulary44), as well as the support of the LinkData Update Logs by interpreting URIs that containthe update keyword, and mapping them to appropriatequeries to update the database.
42http://jena.sourceforge.net/SquirrelRDF/43http://triplify.org/44http://sourceforge.net/apps/mediawiki/trdf/index.php?title=
Provenance_Vocabulary
Triplify is aimed at small to medium Web applica-tions (i.e. less than 100MB database content). How-ever, it supports the caching of the triplification re-sults and can hence be used with large Web applica-tions (160GB data for OpenStreetMap). It has beenadapted to several popular web applications (Word-Press, Joomla, osCommerce, etc.).
Sustainability: Triplify is provided under the LGPLv2 licence. The last version 0.8 was published inMarch 2010. However it seems to have a large and ac-tive user communities. Triplify is maintained by theAgile Knowledge Engineering and Semantic Web45.
4.3. Summary
Table 2 summarizes the characteristics of the toolsstudied in this section along the three axis defined insection 2 and the mapping features listed in Table 1.The two columns under the Characteristics categoryspecify whether each tool comes with a specific map-ping language and/or an implementation of a transfor-mation engine.
5. Synthesis
The previous section shows a large diversity of ap-proaches among the tools designed to translate rela-tional databases into RDF. Overall, although the var-ious approaches are driven by various motivations,three steps cannot be circumvented: the mapping de-scription (direct vs. domain semantics-driven), themapping implementation (data materialisation or on-demand) and the data retrieval (query-based access orlinked data). These steps have been described in sec-tions 2.1, 2.2 and 2.3. Figure 1 depicts their sequentialcomposition as well as the options applicable at eachstep. The figure reads from top to bottom, followingthe chronological order involved when setting up thetranslation process.
45http://aksw.org/About.html
Tabl
e2
Synt
hetic
view
ofto
ols
feat
ures
.The
"X"
cros
sm
eans
supp
orte
d,an
empt
yce
llm
eans
unsu
ppor
ted.
Que
stio
nm
arks
mea
nth
atav
aila
ble
info
rmat
ion
did
notp
erm
itto
figur
eou
tift
hefe
atur
eis
supp
orte
dor
not.
Tool
s
Cha
ract
eris
tics
Map
ping
desc
ript
ion
Map
ping
impl
emen
tatio
nD
ata
retr
ieva
lFe
atur
esof
map
ping
desc
ript
ion
Mappinglanguage
Transformationengine
Directmapping
AugmentedDirectmapping
DomainSemantics-Drivenmapping
Datamaterialisation
On-demandmapping
Query-basedaccess
Linkeddata
UserdefineduniqueIds
Logicaltable
Columnselection
Columnrenaming
Selectconditions
Vocabularyreuse
1tabletonclasses
many-to-manytosimpletriples
Blanknodes
Datatypes
Datatransformation
Namedgraphs
User-definednamespaces
Staticmetadata
NonR2RML
D2R
QX
XX
XX
XX
XX
XX
XX
XX
XX
XX
XX
Dat
alif
tX
XX
XX
XX
XX
XX
XX
XX
XD
B2O
WL
Xn.
an.
aX
?X
??
?M
ETA
mor
phos
esX
XX
Xn.
aX
XX
XX
XX
XX
XR
2O/O
DE
Map
ster
XX
XX
XX
XX
XX
XX
XX
XX
XX
RD
BTo
Ont
oX
Xn.
aX
?X
XX
XX
?X
??
X?
Rel
atio
nal.O
WL
XX
n.a
XX
X?
?SP
ASQ
LX
XX
X?
??
?Sq
uirr
elR
DF
XX
XX
XX
XX
??
?Tr
iplif
yX
XX
XX
XX
XX
XX
XX
X?
XX
X
R2RML
DB
2Tri
ples
XX
XX
n.a
XX
XX
XX
XX
XX
XX
XM
orph
-RD
BX
XX
XX
XX
XX
XX
XX
X?
XX
Ora
cle
12c
XX
XX
??
??
??
??
??
??
??
RD
F-R
DB
2RD
FX
XX
Xn.
aX
XX
XX
XX
?X
?X
XV
irtu
oso
RD
FV
iew
sX
XX
XX
XX
XX
XX
XX
XX
??
?X
?U
ltraw
rap
XX
XX
XX
XX
XX
XX
XX
XX
?X
XX
XSP
AR
QL
XX
XX
XX
XX
XX
XX
XX
XX
XX

Fig. 1. Steps of the RDB-to-RDF process. From top to bottom, thefigure depicts the steps needed to set up the translation process.Blue paths start with a direct mapping description, red pathsstart with a domain semantics-driven mapping description
The insight gained from this study suggests that themapping description method (top layer in Figure 1)splits existing approaches into two families with re-gards to the overall RDB-to-RDF process: the directmapping family is denoted by the blue arrows on Fig-ure 1, and the domain semantics-driven mapping fam-ily is denoted by the red arrows. In section 5.1 we high-light both families by examining the mapping steps or-chestration strategies, and we underline the relation-ship between the initial motivation and the way thetools were designed. Then, in section 5.2, we underlinethat the expressiveness of existing mapping languagesis not always sufficient to produce semantically richdata and make it usable, interoperable and linkable. Wetherefore briefly present various strategies investigatedin the literature to produce additional knowledge. Fi-nally, we discuss the applicability of R2RML to thewide scope of RDB to RDF translation needs.
5.1. Direct Mapping vs. Domain Semantics-DrivenMapping
5.1.1. Direct Mapping and Augmented DirectMapping
The direct mapping approach transforms the contentof a relational database into RDF by reflecting the re-lational schema in an ad-hoc ontology. Nevertheless,it is hardly a goal in itself and it is generally comple-mented by further steps depending on the work moti-
vation. The initial motivation of tools applying the Di-rect Mapping method is generally either to quickly ex-pose relational data on the web, or to learn ontologiesfrom a relational databases.
Direct Mapping and On-demand Implementa-tion
SquirrelRDF, SPASQL and Ultrawrap fall in the firstcategory (although Ultrawrap now supports domainsemantics-driven mapping with R2RML, but its pri-mary goal was the direct mapping implementation).Their point is to address the semantic web chicken-and-egg dilemma mentioned in the introduction: theyenable the publication of relational data as RDF, leav-ing the semantic interoperability concerns for a laterstep. All three provide an on-demand mapping im-plementation, thus focusing on the efficient imple-mentation of a query-rewriting process. Furthermore,SPASQL and Ultrawrap rely on the optimization en-gine of the relational backend to optimize rewrittenSQL queries.
Ontology Learning, Augmented Direct Mappingand Data Materialisation
Ontology learning approaches focus on the engi-neering of ontologies by extracting classes and proper-ties from relational schemas and data. The scope variesfrom the search for specific database design patternssuch as many-to-many relations or subsumption rela-tions, to data analysis techniques that help discoveror refine ontological classes and properties. Often thisis accompanied by semi-automatic methods that itera-tively extend the ontology with classes and propertieslearnt from the database, or suggest probable matcheswith existing ontologies. Various such strategies can befound in [50] and [53].
All the ontology learning tools studied in this paper(DB2OWL, RDBToOnto, Relational.OWL) apply theaugmented direct mapping description, that Spanos etal. [53] name creation of a domain-specific ontologywith database reverse engineering. This choice seemsnatural since their goal is not to align the database onexisting ontologies but to discover ontological knowl-edge. This is corroborated by Sequeda et al.’s sur-vey of direct mapping approaches [50]: all of theseven reviewed papers mainly address ontology learn-ing through the augmented direct mapping principles.
Most ontology learning approaches implement datamaterialisation. This is the case of RDBToOnto andRelational.OWL (DB2OWL does not provide any im-plementation) as well as the seven papers reviewed bySequeda et al. [50]. This choice does not seem obvious

though, as an on-demand implementation can applytoo, as illustrated by Ultrawrap. Two reasons mainlyexplain this choice. (i) As a pragmatic reason, ontol-ogy learning approaches need to demonstrate their fea-sibility, keeping the development effort as low as pos-sible. In this regard, implementing the data material-isation method is more straight-forward than the on-demand mapping. (ii) Some ontology learning meth-ods entail schema and data analysis possibly requiringmany requests to the RDF dataset, e.g. statistical anal-ysis of occurrences of values in a table, which may bevery inefficient in an on-demand implementation.
5.1.2. Domain Semantics-Driven MappingTools based on domain semantics-driven mapping
generally result from two motivations, the implemen-tation of an efficient transformation engine or the def-inition of a generic mapping language (or eventuallyboth).
Asio SBRD, D2R server, Triplify, Morph-RDB, Or-acle, Virtuoso and Ultrawrap target the developmentof production-class query engines able to handle alarge number of concurrent, potentially complex re-quests while ensuring acceptable performances. Thosetools apply the on-demand mapping implementation:they investigate methods to efficiently rewrite a queryon the target data model (either SPARQL or linkeddata HTTP dereferencing) into an SQL query, and ef-ficiently execute the translated query (query optimiza-tion and query planning).
Such tools may come with the definition of anexpressive generic mapping language (D2RQ, Virtu-oso), unless they rely on an existing language such asR2RML. The mapping language is even the prior focusof R2O/ODEMapster and METAmorphoses that bothimplement data materialisation. To some varying ex-tend, mapping languages rely on a mix of specific con-structors and embedded SQL snippets. Besides, Asio,Datalift and Virtuoso can be classified in a data inte-gration framework category: their focus is not only totranslate relational data into RDF, but also to querythis data along with other data sources. Datalift appliesdata materialisation to merge heterogeneous sources asmultiple graphs in a single RDF repository, while Asioand Virtuoso apply on-demand mapping.
5.1.3. Data Retrieval MethodsQuery-based retrieval is the most commonly im-
plemented method within the tools we have stud-ied, as evidenced by the "Query-based access" col-umn in Table 2. Five tools support the Linked Datamethod (D2RQ, Datalift, Triplify, Virtuoso, Ultra-
wrap). Triplify is the only one to support exclusivelythe Linked Data method.
5.1.4. Extract-Transform-Load (ETL)The Extract-Transform-Load (ETL) expression is
used in the literature to denote a 3-step approach: de-fine a mapping, materialise the RDF data based on thatmapping, and load the RDF data into a triple storeto query it, typically through a SPARQL endpoint.The green dotted line in Figure 1 denotes this wholeprocess. It shows that any of the direct or domainsemantics-driven mappings can apply. Strictly speak-ing, and as there is no formal definition of the ETL ap-proach, the Linked Data retrieval method could also beincluded. In practice though, ETL generally refers toquery-based retrieval, and more precisely the use of aSPARQL endpoint.
5.2. A posteriori Production of Semantically RichData
Producing RDF data with sufficient semantics, inorder to make it usable, interoperable and linkable, isa critical concern in most RDB-to-RDF tools. Exper-imentations that use direct mapping-based tools oftenunderline the weaknesses of this method: the reuse ofthe RDF data produced is not easy due to the lack offormal semantic reference. Hence, its interoperabilitywith other datasets requires to lift the data to a higherlevel of semantic formalisation. Furthermore, even inthe case of a domain semantics-driven mapping, theproduction of sufficiently semantically rich data can-not always be achieved by the expressiveness of exist-ing mapping languages. In other words, the alignmentof RDF data with existing ontologies has to be con-sidered carefully in any case. Consequently, variousstrategies are investigated in the literature to produceadditional semantics, a posteriori. Below we brieflypresent most common ones.
Aligning multiple levels of ontologiesSeveral RDB-to-RDF projects propose to enhance
the direct mapping by aligning the local ontologywith higher levels of abstraction formalized by domainand application ontologies. In this case, the domainsemantics-mapping is not performed beforehand as indomain semantics-driven mapping tools, but involvesthe later alignment of ontologies.
Asio SBRD, DataLift, as well as a DB2OWL-basedapproach [30], propose comparable methods using twodistinct levels of ontologies. In a first step, the directmapping method is applied to create a local ontology

that reflects the structure of the relational database. Ina second step, the local ontology is manually alignedwith an ontology that models some part of the domainwhich the relational database refers to. A query enginetranslates a query to the domain ontology into a queryto the local ontology. The query to the local ontologyis in turn translated into an SQL query to the relationaldatabase.
Alternatively, the alignment of the local ontologywith a domain ontology may be achieved by usingSPARQL CONSTRUCT or INSERT queries: given agraph pattern expressed with local ontology classesand properties, they produce new RDF data usingclasses and properties of the domain ontology. DeLaborda and Conrad [23] describe a use case in whichthey have applied this method with Relational.OWL.This turns out to be equivalent to the execution of rulesin a rule engine (see below). The difference, here, isthat the rules description language is SPARQL.
Hu and Qu [37] propose to apply data mining tech-niques to automatically disco ver simple mappings be-tween the relational entities (tables, columns, integrityconstraints) and the classes and properties of an ex-isting ontology. Relational and ontological entities arecompared using distance measures such as the TF-IDF(Term Frequency-Inverse Document Frequency), in ad-dition to the computation of the confidence in a map-ping and a validation phase. In this sense, it can be seenas an automatic, domain semantics-driven approach.However, for this method to perform efficiently, thesimilarity between the relational schema and the ontol-ogy should be high, unless human users provide initialreference mappings.
Besides the aforementioned generic methods, somedomain-specific projects propose alternative methods.For instance, Green et al. [32] describe a demonstra-tor that relies on existing tools to allow for the "spa-tial attribution" of RDF data sources, for the predic-tive modelling of diffuse water pollution. The feder-ation of different data sources lies on a 3-layer on-tology stack. The ontologies at the first level (calleddata ontologies) are used to map each data source toclasses of domain ontologies (at the second level) writ-ten by domain experts. At the top, the application on-tology links the domain ontologies together with theaddition of application-specific information. Much ofthe application ontology is created manually, as it re-quires domain knowledge of the scenario being mod-elled. D2RQ is used to map data sources to the dataontologies, and is extended to include spatial operatorsprovided by the Oracle Spatial database.
Fig. 2. Semantic enrichment. The green layer depicts strategies aimedat a posteriori production of additional semantic data
Using rules to infer additional knowledgeRule engines or reasoners are an alternative way to
enrich the semantics of RDF data. This option is de-picted by the green layer in Figure 2. Such techniquescan easily be used in conjunction with data materi-alisation in which case the whole graph is availableat once. The NeuroLOG project [31] illustrates thismethod: it uses METAmorphoses to create an RDFmaterialisation of federated neuro-imaging relationaldatabases. Some relational columns help infer whetherresources belong to specific classes of the applicationontology (1-table-to-n-classes property in table 1). Asthe METAmorphes mapping language is not capableof describing such categorization patterns, they are de-scribed as SWRL rules executed by the CORESE [17]semantic search engine. By raising the semantics of thedata, the process improves the possibilities of furtherapplication-specific reasoning.
Rule engines and reasoners can also apply on RDFdata translated on-demand, although the execution ofcomplex deduction rules, or the application of complexentailments, may generate a high volume of queries tothe database. In the worst case, the process may re-quire to translate the whole relational data to complete.Among the tools studied in this paper, several supportrules: SWRL rules for Asio, Silk module in DataLift,Jena Rules in SquirrelRDF, and proprietary RDF-to-RDF deduction rules in XSPARQL.

5.3. R2RML or not?
Today, R2RML seems to be inescapable when itcomes to transform relational data into RDF. It re-sults from the study of previous initiatives, it takes ad-vantage of their experience and encompasses most oftheir expressiveness. To our knowledge, one graphicaleditor currently proposes to help users write R2RMLmappings [49]. However, along with the wider adop-tion of the language, it is likely that other initiativeswill show up. Additionally, major actors born beforeR2RML now comply with it (D2R server, Virtuoso,Ultrawrap). Consequently, anyone looking for a ma-ture tool to perform RDB-to-RDF translation will mostlikely choose an R2RML compliant initiative.
Nevertheless, some situations suggest that R2RMLcannot be considered as a "catch-all" mapping lan-guage. Firstly, direct mapping based approaches do notnecessarily require a mapping language: direct map-ping rules can easily be encoded in a program with-out needing to interpret a mapping language. Sec-ondly, certain approaches (such as ontology learning)deal with complex patterns that cannot be expressed inR2RML. For instance, RDBToOnto [16] analyses dataredundancy to discover categorization patterns. Hu andQu [37] apply data mining techniques to automaticallydiscover mappings between the database and an ex-isting ontology. Lastly, R2RML does not provide datamanipulation functions but relies on the capabilities ofthe relational backend instead. To address those situa-tions, a further version of R2RML could, for instance,provide language extension points to enable the invo-cation of domain specific functions provided as a soft-ware plug-in.
6. Conclusion and Open Questions
Many techniques and tools have been proposed overthe last years to enable the publication of relationaldata on the web in RDF. RDB-to-RDF methods areone of the keys to populate the web of data by un-locking the huge amount of data stored in relationaldatabases. In this paper, we have described three axesto categorize such RDB-to-RDF approaches. We haveproposed a detailed review of seventeen RDB-to-RDFtools, either supporting the R2RML W3C recommen-dation or providing their own mapping language. Theproposed categorization helped us identify common-alities and differences between existing tools, under-line the relationship between the initial motivation andthe way the tools were designed, and discuss the or-
chestration of the solutions applicable at each step ofthe RDB-to-RDF translation process. Since producingRDF data with sufficiently rich semantics is often im-portant in order to make the data usable, interopera-ble and linkable, we have also briefly presented var-ious strategies investigated in the literature to enrichdata semantics. Finally, we have shown that, althoughR2RML is a promising language, it may not apply toall situations in the wide scope of RDB to RDF trans-lation needs, leaving space for future extensions.
Beyond RDB-to-RDF methods, a wide range ofother initiatives target the publication of non-RDFdata sources in RDF, such as academic tools (XS-PARQL supports XML sources, Datalift supports CSVand XML sources), ontology-based access to datastreamed from sensor webs [15], extension of R2RMLto support XML and JSON data sources [25], wrappersof popular web site APIs (e.g. flickrdf library) or mis-cellaneous format-specific converters and "RDFizers".Whatever the method though, the result is a read-onlyweb of data. And similarly to the tremendous changeof paradigm that lead to the Web 2.0 where the usercontribution plays a major role, the web of data willnecessarily have to shift to a write-enabled model. Inthe case of relational databases, although the expres-siveness of RDB-to-RDF mappings is a key to richsemantic alignment, it also often results in one-waytransformation mappings (one-way mappings cannotbe used to revert RDF data to the original relationaldata). Consequently, it will be necessarily to find acompromise between the expressiveness of RDB-to-RDF mapping languages and the need for updating re-lational data using protocols of the semantic web. TheR3M mapping language is an example of the searchfor such a compromise [35].
Berners-Lee et al. [10] investigate some of the is-sues and challenges related to a read-write web of data.They underline that creating, updating and deletingRDF data should only be made possible in a secure,reliable, trustworthy and scalable way. This questionsthe way to authenticate people and programs in theweb of data, to securely assign authorizations, to trackthe changes made, etc. As to the trustworthiness ques-tion, in a global data space made of heterogeneous datasources integrated together, it will become crucial toexplain query results, or to assess the confidence a usercan have in query results. To this end, applications ex-posing non-RDF data sources into RDF will have toensure the preservation of provenance information, al-lowing to track a piece of data back to its original datasource.

References
[1] H. Akil, M. E. Martone, and D. C. Van Essen. Challenges andopportunities in mining neuroscience data. Science, 331(6018):708–712, 2011. ISSN 0036-8075, 1095-9203.
[2] M. Arenas, A. Bertails, E. Prud’hommeaux, and J. Se-queda. A direct mapping of relational data to RDF,Sept. 2012. URL http://www.w3.org/TR/2012/REC-rdb-direct-mapping-20120927/.
[3] M. Ashok. W3C RDB2RDF incubator group report,2009. URL http://www.w3.org/2005/Incubator/rdb2rdf/XGR-rdb2rdf-20090126/.
[4] S. Auer, S. Dietzold, J. Lehmann, S. Hellmann, and D. Au-mueller. Triplify: light-weight linked data publication fromrelational databases. In Proceedings of the 18th Interna-tional conference on World Wide Web, pages 621–630, Madrid,Spain, 2009.
[5] S. Auer, L. Feigenbaum, D. Miranker, A. Fogarolli, and J. Se-queda. Use cases and requirements for mapping relationaldatabases to RDF, June 2010. URL http://www.w3.org/TR/2010/WD-rdb2rdf-ucr-20100608/.
[6] J. Barrasa, O. Corcho, and A. Gómez-Pérez. Fund finder: Acase study of database-to-ontology mapping. In Semantic In-tegration Workshop, in Proceedings of the 2nd InternationalSemantic Web Conference (ISWC 2003), 2003.
[7] J. Barrasa, O. Corcho, and A. Gómez-Pérez. R2O, an extensi-ble and semantically based database-to-ontology mapping lan-guage. In Proceedings of the 2nd Workshop on Semantic Weband Databases (SWDB 2004), volume 3372, Toronto, Canada,2004. Springer-Verlag. ISBN 978-3-540-24576-6.
[8] T. Berners-Lee. Relational databases and the semantic web, indesign issues of the WWW, 1998. URL http://www.w3.org/DesignIssues/RDB-RDF.html.
[9] T. Berners-Lee. Linked data, in design issues of the WWW,2006. URL http://www.w3.org/DesignIssues/LinkedData.html.
[10] T. Berners-Lee, R. Cyganiak, M. Hausenblas, J. Presbrey,O. Seneviratne, and O.-E. Ureche. Realising a read-write webof data, 2009. URL http://web.mit.edu/presbrey/Public/rw-wod.pdf.
[11] C. Bizer. D2R MAP - a database to RDF mapping language.In Proceedings of the 12th International World Wide Web Con-ference (WWW 2003), Budapest, Hungary, 2003.
[12] C. Bizer and R. Cyganiak. D2R server - publishing relationaldatabases on the semantic web. In Proceeding of the 5th Inter-national Semantic Web Conference (ISWC 2006), 2006.
[13] C. Bizer and A. Seaborne. D2RQ - treating non-RDF databasesas virtual RDF graphs. In Proceedings of the 3rd InternationalSemantic Web Conference (ISWC 2004), 2004.
[14] A. Burgun, O. Bodenreider, et al. Accessing and integratingdata and knowledge for biomedical research. Yearbook of Med-ical Informatics, 47 Suppl. 1:91–101, 2008.
[15] J.-P. Calbimonte, H. Jeung, O. Corcho, and K. Aberer. En-abling query technologies for the semantic sensor web. Inter-national Journal on Semantic Web and Information Systems, 8(1):43–63, 2012. ISSN 1552-6283, 1552-6291.
[16] F. Cerbah. Learning highly structured semantic repositoriesfrom relational databases: The RDBToOnto tool. In Proceed-ings of the 5th European Semantic Web Conference (ESWC2008), pages 777–781, Athens, GA, USA, 2008. ISBN 3-540-68233-3 978-3-540-68233-2.
[17] O. Corby, R. Dieng-Kuntz, and C. Faron-Zucker. Queryingthe semantic web with corese search engine. In Proceedingsof 16th European Conference on Artificial Intelligence, vol-ume 16, page 705, Valencia, Spain, 2004.
[18] N. Cullot, R. Ghawi, and K. Yetongnon. DB2OWL : A toolfor automatic database-to-ontology mapping. In Proceedingsof the 15th Italian Symposium on Advanced Database Systems,pages 491–494, Torre Canne, Fasano, BR, Italy, 2007.
[19] R. Cyganiak, C. Bizer, O. Maresch, and C. Becker. The D2RQmapping language v0.8, 2012. URL http://d2rq.org/d2rq-language.
[20] S. Das, S. Sundara, and R. Cyganiak. R2RML: RDB to RDFmapping language, Sept. 2012. URL http://www.w3.org/TR/2012/REC-r2rml-20120927/.
[21] C. P. De Laborda and S. Conrad. Querying relational databaseswith RDQL. In Proceeding of the Berliner XML Tage 2005,pages 161–172. Citeseer, 2005.
[22] C. P. De Laborda and S. Conrad. Relational.OWL: a data andschema representation format based on OWL. In Proceedingsof the 2nd Asia-Pacific conference on Conceptual modelling,volume 43, pages 89–96, Newcastle, Australia, 2005.
[23] C. P. De Laborda and S. Conrad. Database to semantic webmapping using RDF query languages. Conceptual Modeling-ER 2006, pages 241–254, 2006.
[24] M. Dean. Suggestions for semantic web interfaces torelational databases. In W3C Workshop on RDF Ac-cess to Relational Databases, Cambridge, MA, USA,2007. URL http://www.w3.org/2007/03/RdfRDB/papers/dean.html.
[25] A. Dimou, M. Vander Sande, P. Colpaert, R. Verborgh, E. Man-nens, and R. Van de Walle. RML: a generic language for inte-grated RDF mappings of heterogeneous data. In Proceedingsof the 7th Workshop on Linked Data on the Web (LDOW2014),Seoul, Korea, 2014.
[26] C. Dolbear and J. Goodwin. Position paper on expressing re-lational data as RDF. In W3C Workshop on RDF Access toRelational Databases, 2007. URL http://www.w3.org/2007/03/RdfRDB/papers/dolbear.pdf.
[27] O. Erling. Requirements for relational-to-RDF mapping, blogadditional, 2008. URL http://www.openlinksw.com/weblog/oerling/index.vspx?page=&id=1434.
[28] O. Erling. Requirements for relational to RDF mapping,2008. URL http://www.w3.org/wiki/Rdb2RdfXG/ReqForMappingByOErling.
[29] L. Feigenbaum, G. Todd Williams, K. Grant Clark,and E. Torres. SPARQL 1.1 protocol, Mar.2013. URL http://www.w3.org/TR/2013/REC-sparql11-protocol-20130321/.
[30] R. Ghawi and N. Cullot. Database-to-ontology mapping gen-eration for semantic interoperability. In Third InternationalWorkshop on Database Interoperability (InterDB 2007), inconjunction with VLDB 2007, Vienna, Austria, 2007.
[31] B. Gibaud, G. Kassel, M. Dojat, B. Batrancourt, F. Michel,A. Gaignard, and J. Montagnat. NeuroLOG: sharing neu-roimaging data using an ontology-based federated approach.In Proceedings of the AMIA Annual Symposium, volume 2011,page 472, Washington DC, USA, 2011.
[32] J. Green, C. Dolbear, G. Hart, J. Goodwin, and P. Engelbrecht.Creating a semantic integration system using spatial data. InProceedings of the 7th International Semantic Web Conference(ISWC 2008), pages 26–30, Karlshue, Germany, 2008.

[33] S. Harris and A. Seaborne. SPARQL 1.1 query language,Mar. 2013. URL http://www.w3.org/TR/2013/REC-sparql11-query-20130321/.
[34] B. He, M. Patel, Z. Zhang, and K. C.-C. Chang. Accessing thedeep web. Communications of the ACM, 50(5):94–101, 2007.ISSN 0001-0782. .
[35] M. Hert, G. Reif, and H. C. Gall. Updating relational data viaSPARQL/update. In Proceedings of the EDBT/ICDT Work-shops 2010, page 24, 2010.
[36] M. Hert, G. Reif, and H. C. Gall. A comparison of RDB-to-RDF mapping languages. In Proceedings of the 7th Interna-tional Conference on Semantic Systems, pages 25–32, Graz,Austria, 2011. ACM.
[37] W. Hu and Y. Qu. Discovering simple mappings between re-lational database schemas and ontologies. The Semantic Web,pages 225–238, 2007.
[38] N. Lopes, S. Bischof, S. Decker, and A. Polleres. On thesemantics of heterogeneous querying of relational, XML andRDF data with XSPARQL. In Proceedings of the 15th Por-tuguese Conference on Artificial Intelligence (EPIA 2011), Lis-bon, Portugal, 2011.
[39] C. Ogbuji. SPARQL 1.1 graph store HTTP protocol,Mar. 2013. URL http://www.w3.org/TR/2013/REC-sparql11-http-rdf-update-20130321/.
[40] Oracle. Semantic technologies in oracle database 11grelease 2: Capabilities, interfaces, performance, 2010.URL http://download.oracle.com/otndocs/tech/semantic_web/pdf/2010_ora_semtech_capintper.pdf.
[41] Oracle. Oracle spatial and graph 12c, RDF semanticgraph, 2013. URL http://download.oracle.com/otndocs/products/semantic_tech/pdf/12c/rdfsemanticgraph_12c_fo.pdf.
[42] F. Priyatna. RDF-based access to multiple relational datasources. PhD thesis, Universidad Politecnica de Madrid,Madrid, Spain, 2009.
[43] F. Priyatna, O. Corcho, and J. Sequeda. Formalisation and ex-periences of R2RML-based SPARQL to SQL query translationusing morph. In Proceeding of the World Wide Web Conference2014, Seoul, Corea, 2014.
[44] E. Prud’hommeaux. SPASQL: SPARQL support inMySQL, 2007. URL http://www.w3.org/2005/05/
22-SPARQL-MySQL/XTech.[45] L. Rhys. Dereferencing HTTP URIs - draft tag finding
31 august 2007, 2007. URL http://www.w3.org/2001/tag/doc/httpRange-14/2007-08-31/HttpRange-14.html.
[46] A. Ruttenberg, T. Clark, W. Bug, M. Samwald, O. Bodenreider,H. Chen, D. Doherty, K. Forsberg, Y. Gao, V. Kashyap, et al.Advancing translational research with the semantic web. BMCbioinformatics, 8(Suppl 3):S2, 2007.
[47] S. Sahoo, W. Halb, S. Hellman, K. Idehen, T. Thibodeau,S. Auer, J. Sequeda, and A. Ezzat. A survey of cur-rent approaches for mapping of relational databases to RDF,2009. URL http://www.w3.org/2005/Incubator/rdb2rdf/RDB2RDF_SurveyReport_01082009.pdf.
[48] A. Seaborne, D. Steer, and S. Williams. RDF-SQL (Squir-relRDF). In W3C Workshop on RDF Access to RelationalDatabases, 2007. URL http://www.w3.org/2007/03/RdfRDB/papers/seaborne.html.
[49] K. Sengupta, P. Haase, M. Schmidt, and P. Hitzler. EditingR2RML mappings made easy. In 12th International SemanticWeb Conference (posters and demos), Sydney, Australia, 2013.
[50] J. Sequeda, S. H. Tirmizi, O. Corcho, and D. P. Miranker. Sur-vey of directly mapping SQL databases to the semantic web.Knowledge Eng. Review, 26(4):445–486, 2011.
[51] J. F. Sequeda and D. P. Miranker. Ultrawrap: SPARQL execu-tion on relational data. Web Semantics: Science, Services andAgents on the World Wide Web, 22:19–39, Oct. 2013. ISSN15708268.
[52] J. F. Sequeda, R. Depena, and D. P. Miranker. Ultrawrap: Usingsql views for rdb2rdf. In Proceedings of the 8th InternationalSemantic Web Conference (ISWC 2009), Chantilly, VA, USA,2009.
[53] D.-E. Spanos, P. Stavrou, and N. Mitrou. Bringing relationaldatabases into the semantic web: A survey. Semantic Web Jour-nal, 3(2):169–209, 2012.
[54] M. Svihla and I. Jelinek. Two layer mapping from database toRDF. In Proceedings of Electronic Computers and Informatics(ECI), 2004.
[55] S. Tirmizi, J. Sequeda, and D. Miranker. Translating sql appli-cations to the semantic web. In Proceedings of the 19th inter-national conference on Database and Expert Systems Applica-tions (DEXA’08), pages 450–464, 2008.


















