
A Parallel Execution Approach for Efficient Regression ... · A Parallel Execution Approach for...
61
A Parallel Execution Approach for Efficient Regression Testing in the OutSystems Test Infrastructure Filipe Miguel Meireles Fonseca Dissertação para obtenção do Grau de Mestre em Engenharia Informática e de Computadores Júri Presidente: Doutor José Carlos Martins Delgado Orientador: Doutor Paulo Jorge Pires Ferreira Co-Orientador: Mestre João Pedro de Oliveira Portela Vogal: Doutor João Manuel Pinheiro Cachopo Novembro 2009
Transcript of A Parallel Execution Approach for Efficient Regression ... · A Parallel Execution Approach for...

A Parallel Execution Approachfor Efficient Regression Testing
in the OutSystems Test Infrastructure
Filipe Miguel Meireles Fonseca
Dissertação para obtenção do Grau de Mestre emEngenharia Informática e de Computadores
JúriPresidente: Doutor José Carlos Martins Delgado
Orientador: Doutor Paulo Jorge Pires Ferreira
Co-Orientador: Mestre João Pedro de Oliveira Portela
Vogal: Doutor João Manuel Pinheiro Cachopo
Novembro 2009

“Most software today is very much like an Egyptian pyramid with millions of bricks piled on
top of each other, with no structural integrity, but just done by brute force and thousands of
slaves.”
Alan Kay

Resumo
À medida que a complexidade do software aumenta o mesmo acontece com a dimensão
das suites e scripts de teste. Quando isso ocorre, problemas emergem para os programadores
sob a forma de maior esforço necessário para gerir o processo de teste e maior tempo de ex-
ecução das suites de teste. Este último é especialmente problemático uma vez que os custos
recorrentes de executar os mesmos testes regularmente (como os de regressão) durante o
tempo de vida dos produtos pode tornar-se incomportável. Sendo uma parte integral do de-
senvolvimento de software, o processo de teste precisa de evoluir e libertar-se dos métodos
convencionais.
Este projecto apresenta uma estratégia baseada na execução paralela das suites de teste,
alocando os casos de teste em multiplos processos em uma ou várias máquinas distribuidas,
de forma a alcançar uma solução escalável capaz de maior performance e fiabilidade.
Mas a distribuição de testes exige que se estabeleçam e mantenham recursos computa-
cionais replicados para cada configuração suportada pelos produtos. A administração manual
de tais operações é tipicamente bastante demorada e susceptivel a erros. Razão pela qual foi
também considerado um mecanismo de provisionamento automático para criar, configurar e
integrar novas máquinas de teste harmoniosamente nos sistemas com a mínima intervenção
humana, potenciando a repetibilidade e escalabilidade.
O trabalho está enquadrado na infra-estrutura de testes existente na OutSystems.
ii

Abstract
As software complexity grows so does the size of test suites and scripts. When that occurs,
problems emerge for developers in the form of increased effort to manage the test process and
longer execution time of test suites. The last is especially problematic as the recurring costs of
performing the same tests on a regular basis (like regression testing) throughout the products
lifetime may become unbearable. Being an integral part of software development, testing needs
to evolve and break free from the conventional methods.
This project presents a strategy which relies on parallel execution of test suites, allocat-
ing test cases across multiple processes on a single or on distributed machines to achieve a
scalable solution capable of higher performance and increased reliability.
But distributed testing urges to deploy and maintain replicated computing resources for every
system configuration supported by the products. Manual administration of such operations is
typically time-consuming and error-prone. For this reason it was also considered a mechanism
of automated systems provisioning to create, configure, and integrate new testing machines
seamlessly into the system with minimal human intervention, allowing for repeatability and scal-
ability.
The work is framed in the existing test infrastructure of OutSystems.
iii

Contents
Resumo ii
Abstract iii
List of Tables vi
List of Figures vii
1 Introduction 1
1.1 Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Document Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Related Work 6
2.1 Test Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Test Prioritization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Test Distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 On Local Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.2 On the Grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.3 Automated Systems Provisioning . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Solution Architecture 16
3.1 Hardware infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2 Former test infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Newly developed test infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3.1 Multiple Regressions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
iv

3.3.2 Multithreading . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3.3 Regression Factory application . . . . . . . . . . . . . . . . . . . . . . . . 26
4 Implementation 29
4.1 Multiple Regressions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2 Multithreading . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3 Regression Factory application . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.1 Virtualization Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.2 Provisioning Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3.2.1 Cloning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.3.2.2 Configuration Automation . . . . . . . . . . . . . . . . . . . . . . 36
4.3.2.3 Pooling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.3.2.4 Variable Hardware Settings . . . . . . . . . . . . . . . . . . . . . 37
4.3.2.5 Asynchrony . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5 Results and Evaluation 39
5.1 Trials Environment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.2 Quantitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.3 Qualitative Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6 Conclusion 46
6.1 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
A Figures Notation 48
Bibliography 49
v

List of Tables
1.1 Error removal costs grow over the development life cycle [10] . . . . . . . . . . . 3
3.1 Servers specifications and statistics . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Performance statistics for six main Instances running tests, all durations are given
in hh:mm format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
vi

List of Figures
2.1 The high-level architecture of Joshua . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 The high-level architecture of Metronome . . . . . . . . . . . . . . . . . . . . . . 12
2.3 A very basic Metronome specification file . . . . . . . . . . . . . . . . . . . . . . 13
3.1 The high-level hardware infrastructure . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Servers CPU usage during a twenty-four hour period . . . . . . . . . . . . . . . . 18
3.3 Servers Memory usage during a twenty-four hour period . . . . . . . . . . . . . . 19
3.4 The high-level test infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.5 The high-level test infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.6 Amdahl law with F=0.035 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.7 Run duration ÷ Amdahl speedup . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.8 Regression CPU usage during testing . . . . . . . . . . . . . . . . . . . . . . . . 25
3.9 Regression Memory usage during testing . . . . . . . . . . . . . . . . . . . . . . 25
3.10 Autonomous setup architecture on OutSystems platform . . . . . . . . . . . . . . 27
3.11 Farm setup architecture on OutSystems platform . . . . . . . . . . . . . . . . . . 27
4.1 Pseudocode for the PeekNextTest routine using database transactions . . . . . . 30
4.2 Manually editing the Regressions associated with an Instance . . . . . . . . . . . 31
4.3 Visualizing test results history, with Regression filtering possibility . . . . . . . . . 31
4.4 Installing a platform build on a particular Regression . . . . . . . . . . . . . . . . 32
4.5 Test queuing on a particular Regression . . . . . . . . . . . . . . . . . . . . . . . 32
4.6 Pseudocode for the Readers/Writers algorithm using database transactions . . . 34
4.7 User interface for monitoring the VM pool . . . . . . . . . . . . . . . . . . . . . . 37
4.8 User interface for provisioning a new Regression . . . . . . . . . . . . . . . . . . 38
4.9 User interface for monitoring provisioning requests . . . . . . . . . . . . . . . . . 38
5.1 Test time of multiple Regressions in a autonomous setup . . . . . . . . . . . . . . 40
vii

5.2 Failed test cases of multiple Regressions in a autonomous setup . . . . . . . . . 41
5.3 Test time of multiple Regressions in a farm setup . . . . . . . . . . . . . . . . . . 42
5.4 Failed test cases of multiple Regressions in a farm setup . . . . . . . . . . . . . . 42
5.5 Test time of multiple threads in a single Regression. . . . . . . . . . . . . . . . . 43
5.6 Failed test cases of multiple threads in a single Regression . . . . . . . . . . . . 44
5.7 Provisioning times of the Regression Factory . . . . . . . . . . . . . . . . . . . . 44
viii

Chapter 1
Introduction
To test means to compare an actual result to a standard [22]. Just as a mathematical statement
requires logical proof to demonstrate its trueness, so does a computer program requires testing
to determine its quality.
Nevertheless, in the case of mathematics, a counterexample can be used to completely dis-
credit the proof, but in software, an exception can only show there is some flaw in the logic used
to solve the problem. To really verify that no defects exist in a program it must be tested with
all possible input data—both valid and invalid. Ultimately this means that software testing which
isn’t fully exhaustive can only suggest the presence of defects and not prove their absence. But
because the complexity of software is generally intractable, complete testing is simply unfea-
sible: the domain of program input is too large, there are too many possible input paths, and
many of the design and specification issues are difficult to test [24].
A further difficulty has to do with the dynamic nature of programs. After a software module
experiences changes in the form of bug fixes or additional features, regression testing is rec-
ommended to ensure that functionalities previously working correctly still behave as expected.
This is usually performed by running some or all of the test cases created for previous versions.
While the positive influence on software quality is clear, the expenses of doing regression testing
are often prohibitive [45].
Regardless of all the inherent limitations, testing is an integral part in software development
and there are ways to apply techniques that enhance the process.
From all the breakthroughs in this field probably the most remarkable was the paradigm
shift from manual to automated testing about a decade ago [12, 32]. At first this brought great
1

value by releasing developers from labor-intensive and error-prone testing while simultaneously
increasing both the breadth and depth of test coverage. But today new challenges arise from
widespread usage of test automation techniques.
As software complexity grows so does the size of test suites and scripts. When that occurs,
problems reemerge for developers in the form of increased effort to manage the test process
and longer execution time of test suites. The last is especially problematic as the recurring costs
of performing the same tests (like regression testing) on a regular basis throughout the products
lifetime may become unbearable [26], particularly when:
• The commercial software industry is highly volatile. Entrepreneurial pressures are con-
stantly evolving product definitions and shrinking schedules. As part of their attempt to do
more with less, organizations want to test software appropriately and thoroughly but as
quickly as possible [10].
• In the popular agile methodologies, which preach for short development/test cycles and
where requirements are encouraged to evolve, each new release encompasses numer-
ous changes and additions. For this kind of environment, testing rapidly and constantly
becomes an important control mechanism to ensure the accuracy and stability of the
product [20].
• Early feedback on testing output is of the utmost importance, as the cost of fixing defects
is minimized if they are detected by the developer in the same context in which they were
introduced [26]. Cost is measured in terms of the amount of time and resources required
to correct the defect. A defect found at an early stage is relatively easy to fix, has no
operational impact and requires few resources. In contrast, a defect discovered at a later
stage is much harder to fix, slows the development effort considerably and can cause
operational downtime [10]. Table 1.1 shows that prevention is cheaper than cure.
For these and other reasons it’s clearly important to develop and refine techniques for effi-
cient testing.
1.1 Goal
OutSystems1 offers a fully integrated platform for the delivery and management of web business
applications, using agile methodologies. The development of such a revolutionary tool demands
1http://www.outsystems.com
2

Table 1.1: Error removal costs grow over the development life cycle [10]
Phase Cost
Definition $1
High-Level Design $2
Low-Level Design $5
Code $10
Unit Test $15
Integration Test $22
System Test $50
Post-Delivery $100+
an extremely efficient and high quality internal process which can only be achieved through a
fine tuned continuous software testing process.
There is already an implemented and well established test infrastructure at the company
which comprises about 20 independent (virtual) machines working independently, each associ-
ated with a particular system configuration and running its own test suite. Yet, it’s consensual
among R&D developers that the major drawback is related to the poor test execution perfor-
mance on each individual machine. The most expensive task is regression testing which is
performed on a daily basis when code is committed to promote confidence that changes are
correct and haven’t adversely affected other portions of the program [38]. Using the retest-all
approach for such tests leaves the average duration of a run on a single machine at eighteen
hours.
This value is clearly problematic as it doesn’t cope with the real needs of the established
agile development process. Programmers are unable to perform a full run for a target system
configuration during a working day and must rely solely on nightly tests. Still, sometimes not
even the whole night is enough owing to the fact that for a given system configuration there is
only one assigned machine and when a failure occurs the whole run stalls until someone manu-
ally fixes the problem. Such situation negatively influences crucial operations. For example, it’s
not uncommon for urgent fixes to be shipped to customers without full regression testing due to
time pressures.
The main target of this project is to propose and implement solutions to significantly de-
crease execution time of regression test suites. The work is framed in the existing test infras-
tructure of OutSystems.
3

1.2 Requirements
In order to solve the issues stated above and achieve the goal of this project, the solution(s)
must respect the following requirements:
1. Take into account the growth in the amount of tests . Over time, the increasing size
of test suites is unavoidable and therefore a scalable solution capable of maintaining the
performance under this condition is crucial.
2. Should be economic . Take advantage of the available resources by neither acquiring
extra hardware nor expensive commercial software;
3. Transparent to users . Any complexity added to the test process must be hidden from
the end-user whenever possible.
4. Extend the existing test infrastructure . It would be out of scope to fully redesign the
rooted infrastructure and related processes; for that reason, all work must augment and
enhance the current systems and not rebuild them.
5. Developed using OutSystems platform . The whole test infrastructure is already pow-
ered by OutSystems flagship product, and it’s utterly desirable to keep it that way.
1.3 Solution
Several methods exist to reduce the cost of regression testing. Test selection approaches at-
tempt to reduce the time required to retest a modified program by selecting a representative
subset of the existing test suite [38, 45]. Test prioritization techniques schedule test cases in an
order that increases their effectiveness at meeting a performance goal [39, 11, 45]. Both meth-
ods aim at revealing important defects in software earlier in the testing stage. Finally, distributed
testing attempts to speed up the test stage by simultaneously executing a test suite over a set
of machines [25, 9, 41].
Note that, like stated previously, a suitable test suite needs to incorporate a significant range
of data inputs to adequately cover the code under test. For that reason, effective testing is a
trade-off between the number of tests needed and the available budget. Running fewer tests
may be less expensive but has the potential of not being able to ensure that all inherited features
still behave as expected. Running all the tests provides a more complete program revalidation
at the expense of extra consumption of computational resources.
4

Noting that a considerable amount of computing resources were not used to their full advan-
tage at OutSystems, this project presents a strategy which relies on parallel execution of test
suites, allocating test cases across multiple processes on a single or on distributed machines to
achieve a scalable solution capable of higher performance and increased reliability.
But distributed testing urges to deploy and maintain replicated computing resources for every
system configuration supported by the products. Manual administration of such operations is
typically time-consuming and error-prone. For this reason it was also considered a mechanism
of automated systems provisioning to create, configure, and integrate new testing machines
seamlessly into the system with minimal human intervention, allowing for repeatability and scal-
ability.
1.4 Document Overview
Throughout this project, a detailed look at the design of a parallel execution approach for efficient
regression testing is given. Chapter 2 reviews the field in general and how others have tried to
solve this problem. Chapter 3 describes the central concept underlying the work, providing an
answer to the question posed in the introduction at a conceptual level. Chapter 4 specifies
the implementation highlights by presenting all relevant algorithms and diagrams. Chapter 5
contains the results of the performed work and corresponding evaluation. Finally, Chapter 6
concludes with an overall balance and possibilities for further research as well as topics of
improvement.
5

Chapter 2
Related Work
Despite the acknowledged importance of regression testing in maintaining the effectiveness
and quality guidelines of software, many development teams might choose to omit some or
all regression testing tasks because they can account for as much as one half of the cost of
software maintenance [29].
For that reason there has been a substantial amount of research in recent years regard-
ing different techniques that can be used to decrease the large overheads associated with
regression testing. This research includes test case selection, prioritization, and distribution
methodologies.
2.1 Test Selection
A basic regression testing strategy is the retest-all approach which reruns all available tests
created in previous software versions. Unfortunately, this strategy generally consumes exces-
sive time and resources. Regression test selection techniques, in contrast, attempt to reduce
the time required to retest a modified program by selecting some representative subset of the
existing test suite. Of course, this approach is imperfect as well since test selection can have
substantial computational costs and discard test cases that could reveal defects, hence reduc-
ing fault detection effectiveness. This trade-off between the time required to select and run test
cases and the fault detection ability of the test cases executed is central to regression test se-
lection. There are many ways with which to approach this trade-off. The primary solutions are
code-coverage, minimization techniques, and safe techniques [18].
Coverage techniques locate program components that have been modified or have been
6

affected by modifications and select tests in the suite that cover these components. Minimization
techniques work in the same manner as coverage analysis except that a minimal set of tests
needed are selected. If two test cases in the suite cover exactly the same code then only one of
the two will be kept in the new test suite. Both coverage and minimization methodologies have
the unfortunate possibility of failing to select a test case that would have revealed a fault in a
modified program. Safe techniques, on the other hand, make certain that no potential tests in
the suite that may expose one or more faults in the modified program are left out. The theory
behind safe test selection and the set of conditions required for safety have been detailed by
Rothermel and Harrold [38].
Some researchers have questioned the capabilities of regression test selection techniques.
In an empirical study completed by Graves et al. [18], minimization produced the smallest and
least effective test suites. Safe and code-coverage techniques had nearly equivalent average
behavior in terms of cost-effectiveness but code-coverage techniques required nearly double
the analysis of safe techniques. While safe techniques found all faults in the case study, for
several programs, it could not reduce the test suite size at all.
2.2 Test Prioritization
Test case prioritization techniques schedule test cases in an execution order according to some
criterion. The purpose of this prioritization is to increase the probability of the suite to detect
faults at earlier testing stages [39].
As in selection techniques, there are various procedures a tester could use in order to ar-
range the test sequence of a given test suite. One may choose to assign test case priority
based on the criticality of faults, placing test cases in such a sequence that test cases covering
the most crucial system components would run first. An alternative approach would be to ar-
range suites according to code coverage in such a way that the test cases that cover the most
code are executed first.
In practice, and depending upon the choice of objective, the test case prioritization problem
may be intractable and require the use of heuristics. It is also important to note that the increase
in the rate of fault detection is not necessarily significant. If all of the test cases within a test
suite can be executed in a short time, the fault detection gains achieved by prioritization may
not be worth the effort.
7

2.3 Test Distribution
To my knowledge, test distribution is the less researched strategy from the trio here analyzed,
most likely because until recently the costs of allocating dedicated computational resources for
testing were excessively high. However, the current proliferation of Virtualization [43], Grid [14]
and Cloud [44] technologies have drastically reduced the hardware maintenance expenditures
traditionally required. As a result, the choice of test distribution should be increasingly consid-
ered as it’s the only one that can scale along with test suites size without compromising the fault
detection rate.
There are currently a handful of frameworks and middleware systems to support distributed
computing like Condor [31], Globus [13] or Boinc [3], just to name a few. Any of these would be
a perfect foundation for the task of developing an effective test distribution system. Neverthe-
less, that possibility was not explored in this project as the use of such systems would require
rebuilding the existing OutSystems test infrastructure, therefore not complying with the require-
ments stated in Section 1.2. Instead, applications dedicated to test distribution are presented
next.
2.3.1 On Local Networks
Back in 2001, Kapfhammer first described the conceptual foundation, design and implementa-
tion of an approach to distribute the execution of regression test suites across multiple machines
[25]. Such strategy aims to reduce time costs by operating on the principle that large workloads
can be divided into smaller ones, which are then executed concurrently. Moreover, it can also
be used to complement regression test selection and prioritization approaches.
But the crucial contribution of Kapfhammer work is a compendium of considerations that
must be taken into account in order to ensure that the efficiency enhancement does not nega-
tively impact the reliability of the testing process:
1. Transparent and automatic distribution . The parties who are involved with regression
testing should be minimally responsible for test case distribution.
2. Test case contamination avoidance . A test case is classified as independent if its suc-
cess or failure does not depend upon the order in which the entire suite is executed.
3. Test load distribution . When test cases are distributed across a collection of machines,
it must be done in a manner that appropriately balances the load during execution.
8

4. Test suite integrity . The process of distributing test cases across a collection of ma-
chines should not affect the correctness of results or impede the proper execution.
5. Test execution control . It must be possible to control the execution and view the results
of each test from a centralized interface.
The tool built to put this logic into practice was Joshua [25], an extension of the widely
adopted JUnit testing framework that relies upon Jini network technology and JavaSpaces ob-
ject repository to perform test case distribution. JUnit provides a test description and automation
framework for Java software systems [1]. Jini allows for the creation of dynamic and self-healing
distributed systems [42]. JavaSpaces implement the concept of tuplespaces [5] enabling Java
programs to communicate through a shared, network-accessible “memory”. Together, these
technologies support Joshua architecture depicted in Figure 2.1.
TestExecutorTestController TestSpace
Figure 2.1: The high-level architecture of Joshua
Let’s examine Joshua workflow and how it handles the considerations previously enumer-
ated. When a tester starts Joshua, a central TestSpace is created automatically on an arbitrary
test machine to act as a pool for temporary storage of regression test cases and results. Both
the TestController and each of the TestExecutors use Jini’s discovery protocol to transparently
locate the TestSpace (Consideration 1).
Next, after the tester selects one or more test suites for execution, the TestController pre-
pares the test cases and successively writes them into the TestSpace. Here, Joshua relies upon
a priori knowledge of test contamination possibilities to appropriately schedule the execution or,
when impossible to do so, resort to the linear execution of the offending portion(s) on a single
machine (Consideration 2).
When a new test enters the TestSpace one of the available replicated TestExecutors ex-
tracts it, performs the appropriate computation, and writes back the final result. Even though
it isn’t perfect, this simple distribution mechanism certifies that each TestExecutor is always
9

busy (Consideration 3). It’s also worth mentioning that the transaction primitives provided by
Jini safeguard that the results are not lost, corrupted or discarded if a TestExecutor becomes
dysfunctional (Consideration 4).
Simultaneously, the TestController monitors the TestSpace, fetching the results and updat-
ing the interface (Consideration 5). The process continues until the supply of tests within the
TestSpace becomes exhausted and all the results have been reported.
While the substance of the previous implementation is indisputable, the absence of capa-
bility to handle/explore heterogeneous system configurations is definitely a downside. Although
software components may be exhaustively tested in a development configuration before going
to production, the ability to run tests in a variety of system configurations is not only useful but
also mandatory in several domains, as it allows finding platform-specific errors and software
defects that would otherwise be undetected if the software was tested within an homogeneous
configuration [9].
In view of this fact, recent approaches seek to bridge this gap by exploring the rich features
provided by general purpose Grid software libraries and middleware.
2.3.2 On the Grid
Grid technologies provide mechanisms for sharing and coordinating the use of diverse re-
sources and thus enable the creation, from geographically and organizationally distributed com-
ponents, of virtual computing systems that are sufficiently integrated to deliver nontrivial quali-
ties of service [14]. The high levels of parallelism provided by a Grid can be used to speed up
the test execution, increase productivity and make the testing process of very time consuming
test suites a less expensive task. Also, being a highly heterogeneous environment, the Grid can
be used to improve the reliability and coverage of the test suite [9].
Based on the previous observations, two projects have developed tools to explore the in-
trinsic characteristics of Grids for software testing. The first, Metronome (formerly the NMI
Build & Test System) [35], is a framework which powers the NMI Build & Test Laboratory at
the University of Wisconsin-Madison by providing automated software build and test services
for multi-platform systems based on proven Grid technologies. The second, GridUnit [9], was
developed on top of OurGrid solution [6] to distribute the execution of JUnit test suites and, de-
spite benefiting from the Grid computational power, the underlying features and principles are
basically those of Joshua which is the reason why it won’t be further detailed.
Metronome was developed to facilitate automatic build-and-test of software in a heteroge-
10

neous, multi-user, distributed computing environment. In this type of domain, facilities may be
comprised of a few computing resources in a single location or a large, heterogeneous collection
of machines in different geographical and administrative domains. To abstract the build-and-test
procedures from the underlying technology needed to execute them on multiple resources, the
framework was implemented as a lightweight software layer running on top of the Condor high-
throughput distributed batch computing system [31]. Leveraging a feature-rich batch system like
Condor provides Metronome with valuable elements:
• Harness non-dedicated resources . Unlike traditional batch systems which operate only
with dedicated machines, Condor is also designed to effectively utilize non-dedicated ma-
chines to run jobs. It identifies idle workstations (no keyboard activity, no load average,
no active telnet users, etc.) and schedules background jobs on them. This is important
because often times the amount of compute power represented by the aggregate total of
all the non-dedicated desktop workstations throughout the organization is far greater than
the compute power of a dedicated central resource.
• Job ordering . In addition to the usual scheduling policies, executing multiple jobs with
dependencies is easily accomplished by DAGMan, a meta-scheduler service. The set of
jobs is specified using a directed acyclic graph, where each node denotes an atomic job
and a directed edge indicates a dependency between two adjacent nodes. DAGMan then
submits jobs orderly to Condor following the dependencies given by the graph.
• Matchmaking with ClassAds . This mechanism provides an extremely flexible, expres-
sive scheme for matchmaking resource requests with resource offers. Both machines and
jobs advertise through ClassAds their attributes, requirements and preferences/constraints.
Condor plays the role of a matchmaker by continuously reading all the job ClassAds and
all the machine ClassAds, matching and ranking job ads with machine ads. Condor makes
certain that all requirements in both ClassAds are satisfied, warning users otherwise.
• Fault tolerance . The failure of a single component in a Condor pool only affects those
processes that deal directly with it. If a computing resource crashes while executing a
build-and-test routine, Condor can either migrate the job to another machine or restart
it when the resource returns. Condor uses a transient lease mechanism to ensure only
a single instance of a job exists in a pool at any one time. If a computing resource is
unable to communicate with the central negotiator when a job finishes execution, Condor
transfers back the retained results once network connectivity is restored.
11

• Grid resource access . Condor enables users to access computing resources in other
pools outside of their local domain. Condor can submit jobs to grid resource middleware
systems to allow builds and tests to execute on remote machines that may or may not be
running Condor [15].
Altogether, Metronome operates as presented in Figure 2.2. To start the execution users
submit a routine comprised of glue scripts and a specification file containing instructions about
how the application is built or tested. The glue scripts are nothing more than user-provided,
application-specific tasks that automate the build-and-test process. The specification file (see
Figure 2.3) conforms to a template provided by the framework and commands when to execute
the glue scripts, which platforms to execute them on, how to retrieve input data, and what
external dependencies exist.
Central
Repository
Web RSS
External
Input
Source
RepositoryNMI Results
Glue
Scripts
Condor
Input Data
Specification
File
MetronomeExecution
Workflow
Figure 2.2: The high-level architecture of Metronome
This routine is submitted to the framework and stored in the central repository together with
all the input data to ensure every build or test is reproducible. Metronome uses this information
to create a DAGMan execution workflow and transfer it to Condor, which then submits build-
and-test subtasks along with special framework software to one or more computing resources.
When the execution is complete, all output data produced by the routines jobs is sent back
to the central repository and made available at multiple user interfaces or for future builds and
tests.
12

project = tutorial
component = perlHelloWorld
component_version = 1.0.0
description = This is a simple example
run_type = build
inputs = perlHelloWorld.cvs
remote_task = helloWorld.pl
remote_task_args = "Remote_Task Task"
platforms = x86_fc_3, sun4u_sol_5.9
Figure 2.3: A very basic Metronome specification file
Several benefits arise from this design. The framework only needs to be installed on sub-
mission hosts, from where a subset of the framework is transferred to build-and-test resources
and automatically deployed at runtime. The abstraction afforded by working at batch level en-
sures that projects are not required to use a particular set of development or testing tools. To
build and test any application, users explicitly define the execution workflow of build-and-test
procedures, along with any external software dependencies and target platforms by using a
lightweight declarative syntax. Dynamic configuration automatically deploys prerequisite pack-
ages.
But not everything is perfect since, in the quest to build a comprehensive tool, some aspects
were sacrificed. Manually managing specification files and scripts is both unproductive, cum-
bersome and, besides requiring specific knowledge, routine actions like executing only a subset
of a test suite may prove too time-consuming. Storing all the execution input/output in plain
unstructured files is another nuisance since it’s impossible to easily extract information using
simple query languages. Lastly, several Condor features like checkpoints, migration and remote
system calls are only available where programs can be linked with Condor libraries.
2.3.3 Automated Systems Provisioning
Upon overcoming the challenge of parallel tests execution, it’s tempting to assume the job is
done. But all things considered, we must not forget that a distributed testing environment calls
for administration of replicated computing resources for every system configuration supported
by the products. For this reason it’s also worth introducing the topic of automated provisioning,
not as an instrument of direct tests speedup per se, but rather as a valuable aid to test distribu-
tion.
13

Systems provisioning is a standardized process of supplying new computational resources,
typically workstations or servers. Generically it boils down to three tasks [30]:
1. Loading the system software and applications initially;
2. Configuring the system, applications, and network parameters.
3. Updating the system software and applications;
It isn’t always easy to automate these processes as few are the cohesive solutions capable
of undertaking all facets of provisioning with ease.
Enterprise grade software like IBM Tivoli Framework [23], Microsoft System Center Suite [33]
or PlateSpin Orchestrate [34] support an extensive array of operations aided by user-friendly
interfaces, but their intricacy and pricing may be inadequate for anything but large-scale envi-
ronments.
More conventional is the combined use of free software tools like FAI [17] for OS loading,
OpenPKG [2] for software deployment, and Cfengine [4] for configuration management, just to
name the most popular in the Unix domain. Unfortunately, most of these tools are designed
monolithically [37], each one operates under a specific strategy, stores data in its own way, has
a fixed repertoire of actions, and often defines a unique declarative language for expressing the
procedures.
Finally, one could also use cloned hard disks to create new machines. Cloning hard disks
means setting up a golden host with the exact software configuration that is desired for all hosts
that are going to be deployed. The hard disk of this host is then cloned, or copied, to all new
machines as they are installed. Although the underlying rationale is sound, a single configura-
tion is hardly enough. Not much imagination is needed to envision ending up with many master
images, thus adding substantial expense and effort to the process [30].
In many cases, such inflexibility entails that to support the complete provisioning process
companies have to invent new tools from scratch [16] or build large layers of software on top of
various applications to make it manageable [21, 36].
14

2.4 Evaluation
None of the previously presented approaches is flawless. Test selection assumes that running
all test cases is wasteful and picks a representative subset of the whole test suite, while this
certainly reduces execution time, it does so at the cost of also reducing fault detection effec-
tiveness. Test prioritization schedules test cases in an order that increases the probability to
detect faults at earlier stages but, obviously, in the end the execution time will remain the same.
Finally, test distribution divides large workloads into smaller ones, which are then solved concur-
rently over a set of machines, but the cost of allocating and managing additional computational
resources is the biggest downside.
Not being mutually incompatible, the perfect solution would be to combine the three ap-
proaches to take advantage of each ones benefits. But because that would require an effort
beyond the available time for this project, the focus will be on test distribution as is the only that
alone conforms with all the requirements stated in Section 1.2.
15

Chapter 3
Solution Architecture
Before presenting the solution developed to tackle regression testing efficiency problems, this
chapter first overviews both hardware and test infrastructures in place at OutSystems prior to
the start of this project.
3.1 Hardware infrastructure
Like most companies, OutSystems owns and maintains a modest data center used for internal
and external operations. Despite currently having only three servers, virtualization [43] is the
key to run dozens of machines simultaneously. The infrastructure is depicted in Figure 3.1 and
comprises the following components:
• Servers , three dedicated high-performance host computers with ESX hypervisor installed.
• ESX, a “bare-metal” virtualization platform from VMware1 that allows multiple virtual ma-
chines to run on a host computer at the same time.
• Virtual Machines , a software computer that, like a physical computer, runs an operating
system and applications.
• Virtual Center , a central management service for configuring, provisioning and managing
virtual IT environments comprising multiple ESX hosts.
To understand to what extent the available servers would support additional load, the hard-
ware specifications and usage statistics are summarized in Table 3.1.
1http://www.vmware.com
16

Local
Network
VM VM... VM VM...VM VM...
Virtual Center
ESXESXESX
Figure 3.1: The high-level hardware infrastructure
17
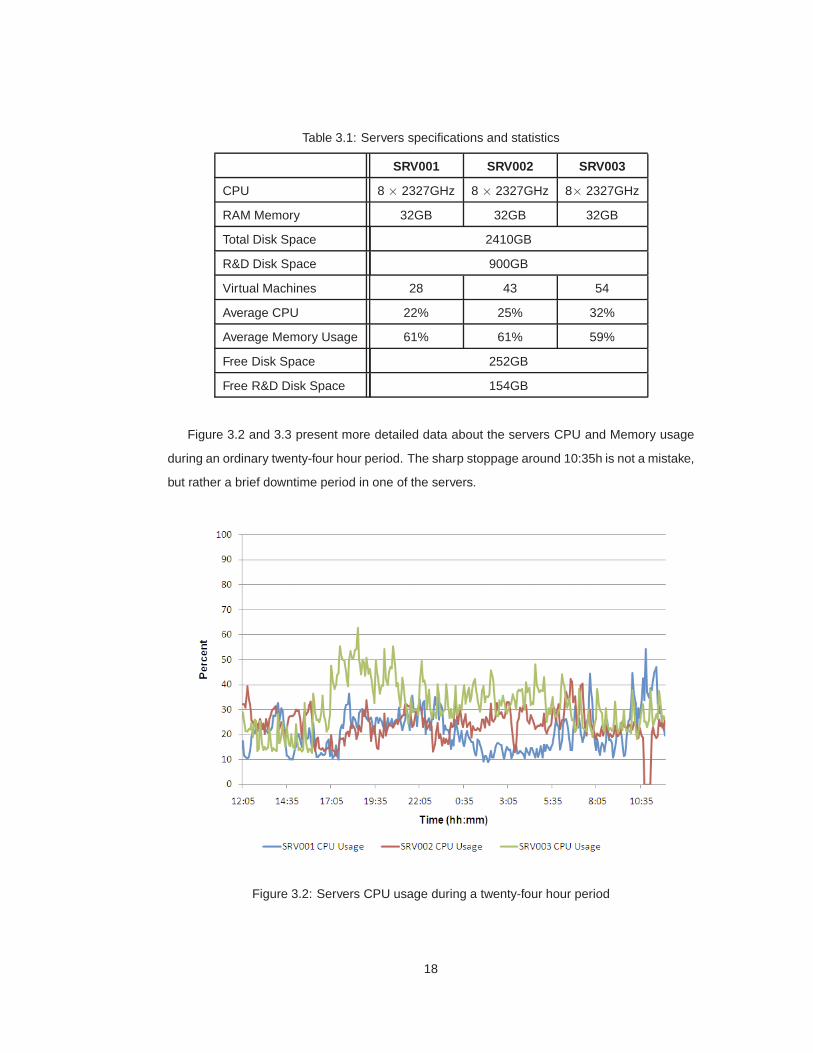
Table 3.1: Servers specifications and statistics
SRV001 SRV002 SRV003
CPU 8 × 2327GHz 8 × 2327GHz 8× 2327GHz
RAM Memory 32GB 32GB 32GB
Total Disk Space 2410GB
R&D Disk Space 900GB
Virtual Machines 28 43 54
Average CPU 22% 25% 32%
Average Memory Usage 61% 61% 59%
Free Disk Space 252GB
Free R&D Disk Space 154GB
Figure 3.2 and 3.3 present more detailed data about the servers CPU and Memory usage
during an ordinary twenty-four hour period. The sharp stoppage around 10:35h is not a mistake,
but rather a brief downtime period in one of the servers.
Figure 3.2: Servers CPU usage during a twenty-four hour period
18

Figure 3.3: Servers Memory usage during a twenty-four hour period
As is patent by these numbers there’s a surplus of hardware capacity which can be har-
vested to improve testing efficiency. Notwithstanding this evidence, overloading the servers may
lead to non-linear service degradation, meaning that smart resources management is desirable,
particularly for memory usage and disk space.
3.2 Former test infrastructure
To answer the specific testing challenges of its all-in-one agile development platform, the R&D
team at OutSystems built (some years ago) a custom solution powered by its own technology.
The never-ending improvements resulted in a complex system that works closely with several
other services to handle nearly all aspects of the testing process. The infrastructure is schema-
tized in Figure 3.4 and comprises the following major components:
• Dashboard , a central application for storage and management of tests, instances, and
test results.
• Instance , an abstract concept which represents a certain system configuration for testing
a certain product branch.
19

.. .Regression
Instance
Dashboard
Build Server SVN
Regression
Instance
Developers
Figure 3.4: The high-level test infrastructure
• Regression , an application installed on a dedicated (virtual) machine to fetch and execute
a set of general automated tests associated with an instance.
• Build Server , a dedicated machine to perform software builds from the platform source
code.
• SVN, a version control system where all source code resides.
For long this implementation fitted the R&D team requirements, but the continuous growth
of test suites size led to unbearable execution times. The statistics on the test infrastructure
performance are presented in Table 3.2 with one of the rows grayed to highlight the reference
instance, used as gauge throughout this project.
All the durations are extremely high and clearly don’t cope with the real needs of the estab-
lished agile development process.
20
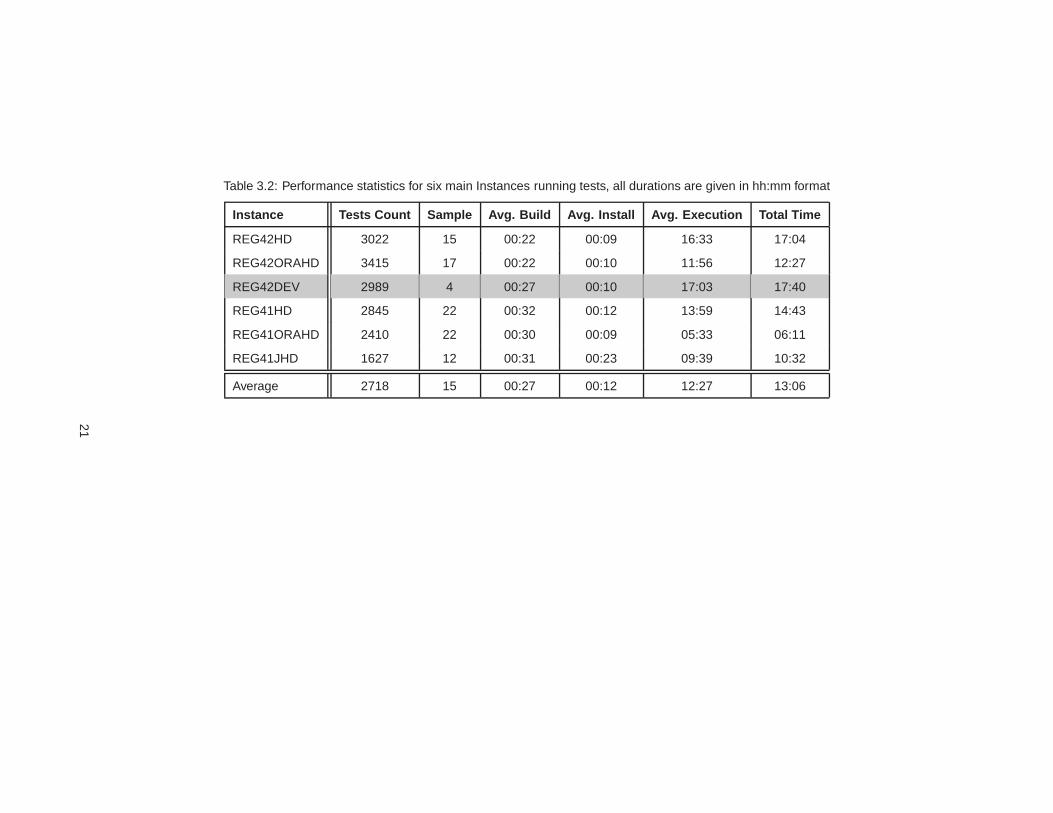
Table 3.2: Performance statistics for six main Instances running tests, all durations are given in hh:mm format
Instance Tests Count Sample Avg. Build Avg. Install Avg. Execution Total Time
REG42HD 3022 15 00:22 00:09 16:33 17:04
REG42ORAHD 3415 17 00:22 00:10 11:56 12:27
REG42DEV 2989 4 00:27 00:10 17:03 17:40
REG41HD 2845 22 00:32 00:12 13:59 14:43
REG41ORAHD 2410 22 00:30 00:09 05:33 06:11
REG41JHD 1627 12 00:31 00:23 09:39 10:32
Average 2718 15 00:27 00:12 12:27 13:06
21

3.3 Newly developed test infrastructure
Based on the observations and conclusions presented up to this point, a new architecture was
developed which relies on parallel execution of test suites, allocating test cases across multiple
processes on a single or on distributed machines, to achieve a scalable solution capable of
higher performance and increased reliability.
.. .Instance
Dashboard
Build Server SVN
Instance
Developers
Regression
Factory
Regressions (multithreaded)
Regressions(multithreaded)
Figure 3.5: The high-level test infrastructure
The implemented solution is depicted in Figure 3.5 and includes three significant enhance-
ments, described in detail next.
3.3.1 Multiple Regressions
The surplus hardware capacity together with the limitation of a single Regression per Instance
confirmed the necessity of refactoring the former infrastructure to enable multiple distributed
Regressions to process test cases simultaneously for a same Instance.
Ideally, the speedup from parallelization would be linear, but that is rarely the case in most
circumstances. In fact, the potential speedup of a parallel application is governed by Amdahl’s
22

Law [27], which states that if F is the fraction of the application that cannot be parallelized and
P processors are used then the maximum possible speedup is given by the Equation 3.1.
Speedup =1
F − 1−F
P
(3.1)
Considering the values from the reference instance (REG42DEV) on Table 3.2, the test
portion not parallelizable is the sum of build and installation times, therefore F is (27+10)/1060
or 0.035 and 1−F is 0.8865. Graphing the number of processors against the speedup shows
the effect of Amdahl’s law, as illustrated by Figure 3.6. The repercussion of speedup on the final
execution duration is illustrated by Figure 3.7. It’s clear that the speedup tails off as the number
of processes increases and that somewhere between 2 and 8 nodes is specially worth investing
in the parallelization of this particular instance. Remember these are theoretical values and
in practice the gains may be lower due to communication latencies and other miscellaneous
constraints.
Figure 3.6: Amdahl law with F=0.035
23

Figure 3.7: Run duration ÷ Amdahl speedup
3.3.2 Multithreading
Although the use of multiple Regressions undeniably represents a step forward to make the
most of the available infrastructure, it was found that each individual Regression could not avail
all computational power of its underlying machine. Figure 3.8 and Figure 3.9 present detailed
data about the CPU and Memory usage during an ordinary test run. This provided a leeway to
reduce testing duration using computational power that would otherwise be wasted.
The original Regression application had just a single thread of execution: sequentially run-
ning test cases until the test suite terminates. Since the testing process is predominantly I/O
bound, a thread spends most of its time waiting for network, file or database I/O and not actually
performing useful computation.
In view of this evidence, a second solution was implemented for Regressions to support
multiple testing threads. Within each thread, test cases are run sequentially, but the threads
themselves may be executed in parallel. Often (on single-core or single-CPU machines, for
instance), multiple threads are not actually executed in parallel, but parallelism is simulated by
quickly interleaving the execution of threads. Even so, owning to long idle periods, I/O-bound
programs can be usefully multithreaded even when there is only a single CPU available.
24

Figure 3.8: Regression CPU usage during testing
Figure 3.9: Regression Memory usage during testing
25

But while threads are a seemingly straightforward adaptation of the dominant sequential
model of computation to concurrent systems, it’s widely acknowledged that concurrent pro-
gramming is difficult and not without drawbacks. Edward Lee observes:
“Although threads seem to be a small step from sequential computation, in fact, theyrepresent a huge step. They discard the most essential and appealing properties ofsequential computation: understandability, predictability, and determinism.” [28]
Threads may represent a key concurrency model supported by modern computers, pro-
gramming languages, and operating systems. But as a rule programmers must still be careful
to avoid race conditions, deadlocks, and other non-intuitive behaviors.
For the Regression application, the effort on this matter focused on the need to run two
classes of tests under different conditions. The critical tests must have exclusive access to
the execution environment, but the non-critical tests may share the execution environment with
an unlimited number of other non-critical tests—a paradigm known as readers-writers problem
[7]. The solution is widely studied and relatively easy to implement using the widespread Dijk-
stra semaphore primitive [8]. However, the OutSystems platform does not provide that or any
other “classic” exclusion primitives built-in, fact that hampered the development, as evidenced
in Chapter 4.
3.3.3 Regression Factory application
The choice of enabling multiple distributed Regressions urges to deploy and maintain replicated
computing resources for every system configuration supported by the OutSystems product.
Manual administration of such operations is typically time-consuming and error-prone. For this
reason it was also considered a mechanism of automated systems provisioning to create, con-
figure, and integrate new testing machines seamlessly into the system with minimal human
intervention, allowing for repeatability and scalability.
Unluckily the feasibility of the idea ran into hurdles right upon the start. Turns out that the
bootstrap of a fresh, autonomous OutSystems-ready machine is bound to some manual con-
figuration steps, being the most problematic a license approval from the support team and a
database clone from the help-desk team, both puzzling to workaround due to technical and
political aspects. The practical alternative is to make use of the OutSystems farm setup fea-
ture in which additional machines (named Front-End’s) work subordinate to a master server
26

(named Controller ), sharing its license and database. The major downside is that the Front-
End’s depend on the Controller to perform some heavy CPU tasks, thus ceiling the achievable
performance gains. Figures 3.10 and 3.11 clarify the distinctions between the two setup possi-
bilities.
Database
Front-End
Server
Controller
Server
Database
Front-End
Server
Controller
Server
.. .
Figure 3.10: Autonomous setup architecture on OutSystems platform
Database
Front-End
Server
Front-End
Server.. . Controller
Server
Figure 3.11: Farm setup architecture on OutSystems platform
Accepted this shortcoming and bearing in mind the available options in this domain, de-
scribed in Chapter 2, it was considered more viable to build a new application from scratch,
doing so enabled: (1) tight integration with current infrastructure; (2) strike a balance in the
provisioning process by leveraging both configuration automation and cloning; (3) easy mainte-
nance and extensibility guaranteed.
27

Architecturally the application comprises two separate modules: one to encapsulate the
logic for interacting with the existing VMware virtualization platform to manage virtual machines;
another to define the complete provisioning workflow, based upon the operations made available
by the first.
28

Chapter 4
Implementation
Following the architectural plan outlined in Chapter 3, the implementation highlights are now
discussed by presenting all relevant algorithms and diagrams.
4.1 Multiple Regressions
For the purpose of allowing multiple distributed Regressions to process test cases simultane-
ously for a same Instance the work began with the challenge of making widespread adjustments
to the data model and subroutines logic of the Dashboard application (referred in Section 3.2)
in order to introduce the Regression concept, formerly masked by the Instance due to their one
to one mapping.
Among countless tweaks, the most noteworthy concerns the tests dispensation queue,
which serves as a shared repository where test cases are pushed before a test run begins.
From there the Regressions continually peek the top priority test case, perform the appropriate
computation and publish the test result, finally triggering its removal from the queue. Under the
former architecture each single Regression would be consuming its own test suite and peeking
a test case was nothing more than a plain database query, but with multiple consumers targeting
the same data new issues arouse.
On that account, a transient lease mechanism [19] was put in place to make sure that a test
case is only ran once while still on the queue and that crashing processes do not indefinitely
stall allocated test cases.
But the most challenging obstacle was to implement thread exclusion without resorting to
the usual system locking mechanisms. The solution found was via database abstractions, which
29

manage concurrency through such mechanisms as transactions. A transaction is a collection
of operations that form a single logical unit of work and have the following properties: atomic-
ity, consistency, isolation and durability (ACID). Taken as a whole, the transaction-management
component of a database system ensures the integrity of the data, concealing the issues of
concurrency and fault tolerance [40]. Additionally, this approach also guarantees synchroniza-
tion in a OutSystems farm setup (multiple machines sharing the same database). The algorithm
implemented to synchronize concurrent accesses to the tests dispensation queue is displayed
in Figure 4.1.
01. EntityIdentifier instance, regression, thread //Arguments
02. DataRow testcase
03.
04. loop
05. testcase = Database_QueryQueue(instance, regression, thread)
06. if testcase == empty then
07. return null
08. //Begin transaction
09. Database_LockRow(testcase)
10. if testcase.allocated == false then
11. break
12. else
13. Database_CommitTransaction()
14.
15. testcase.allocated = true
16. testcase.allocationDate = CurrentDateTime()
17. testcase.regression = regression
18. testcase.thread = thread
19.
20. Database_CommitTransaction()
21.
22. return testcase
Figure 4.1: Pseudocode for the PeekNextTest routine using database transactions
The solution central instruction is the database query (line number five) which retrieves a
unallocated test case. Special care is needed to make sure the same test case is not assigned
to different threads. The easiest approach would have been to enclose the query and following
update instructions (from line number fifteen to eighteen) in a common transaction, but doing so
would drive all requests to linear execution, an undesirable outcome being a highly concurrent
routine and rather complex query. Instead, a more optimistic approach was used: lock only the
database row of the retrieved test case (line number nine), in the event of a race condition amid
the query completion and the actual row locking the control instruction (line number ten) will fail,
causing the query to be made again.
30

Lastly, and not forgetting the opening requirement to keep all possible modifications trans-
parent to the user, it was imperative to polish a number of Dashboard application screens as
there are unavoidable aspects users must be aware of.
In Figure 4.2 is a snippet from an Instance administration screen, where authorized users
can manually edit the Regressions associated with that Instance.
Figure 4.2: Manually editing the Regressions associated with an Instance
In Figure 4.3 is a snippet from a test case details screen, where users can view the results
history and the Regression that executed it.
Figure 4.3: Visualizing test results history, with Regression filtering possibility
In Figure 4.4 is a snippet from a platform build details screen, where users can launch the
installation process on a particular Regression.
In Figure 4.5 is snippet from the test cases listing screen, where users can pick a set of test
cases and queue them on a particular Regression.
31
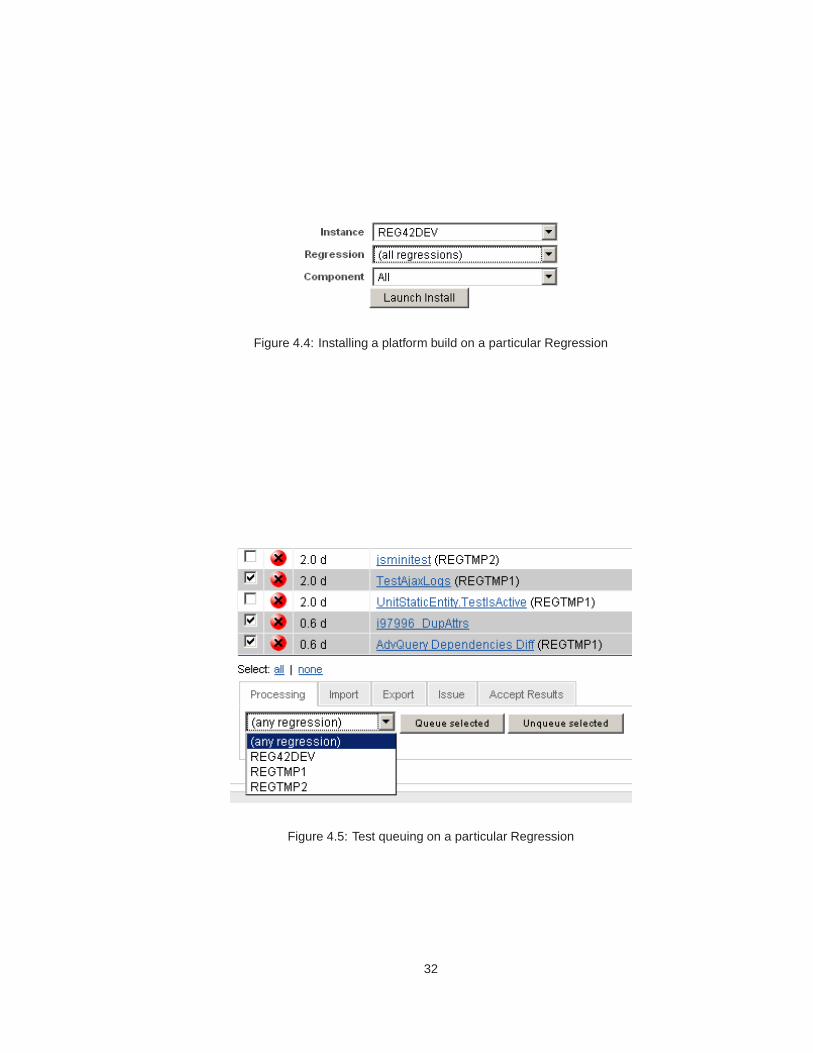
Figure 4.4: Installing a platform build on a particular Regression
Figure 4.5: Test queuing on a particular Regression
32

4.2 Multithreading
Luckily the support for multiple threads benefitted from a substantial portion of work previously
carried out, since the Dashboard application was already given the ability to serve multiple re-
quests for an Instance. It was not so easy, however, to build up the support for critical tests,
requiring exclusive access to the execution environment.
It was first necessary to catalogue all critical test cases, on the Dashboard application. Be-
cause reviewing every single one would be a herculean task, the choice was made to catalogue
instead the set of limited, reusable operations that constitute all test cases. Those made of at
least one critical operation are flagged as critical, information that is forwarded when a Regres-
sion peeks a test case.
On this point forward, the Regression application was adapted to receive the critical flag and
schedule the corresponding test case accordingly to the readers/writers paradigm. Remember
from Section 3.3.2 that the critical tests (writers) must have exclusive access to the execu-
tion environment, but the non-critical tests (readers) may share the execution environment with
an unlimited number of other non-critical tests. Having as starting point the original algorithm
described by Courtois et al. [7] an analogous routine was built using the same database ab-
straction just described in Section 4.1.
The initial plan was to appoint a fixed set of database rows to take the place of semaphore
variables and then use the LockRow and Commit operations to accurately replicate the original
readers/writers algorithm. However, there’s no possibility of executing selective commits nor the
ability to retain a row locked beyond the end of a routine, on the OutSystems platform. It was
thus pursued an alternative to more appropriately exploit the underlying relational paradigm.
Having as starting point a database table to keep track of all active threads and their complete
state, the concretized algorithm is displayed in Figure 4.6.
The solution is composed of two separate (but identical) procedures, executed accordingly
to the test case class. In both situations a thread starts by registering its arriving date (line
number six), which is used to guarantee a FIFO discipline. Next step is to acquire a global
lock and query the other threads state (from line number eleven to thirteen). If the control
instruction (line number fourteen) succeeds, then the thread continues to the reading/writing
region, otherwise it must wait a brief period and repeat the process afterwards (line number
seventeen and eighteen). After processing is done, the thread needs only to update its database
33

READER
01. DataRow thread, global
02. DataTable writers
03.
04. //Begin transaction
05. Database_LockRow(thread)
06. thread.arrivedate = CurrentDateTime()
07. Database_CommitTransaction()
08.
09. loop
10. //Begin transaction
11. Database_LockRow(global)
12. writers = Database_QueryThreads('w')
13.
14. if writers == 0 then
15. break
16. else
17. Database_CommitTransaction()
18. Sleep()
19.
20. thread.readlock = true
21. thread.readdate = CurrentDateTime()
22. thread.arrivedate = null
23.
24. Database_CommitTransaction()
...
reading is done
...
25. //Begin transaction
26. Database_LockRow(thread)
27. thread.readlock = false
28. Database_CommitTransaction()
WRITER
01. DataRow thread, global
02. DataTable writers, readers
03.
04. //Begin transaction
05. Database_LockRow(thread)
06. thread.arrivedate = CurrentDateTime()
07. Database_CommitTransaction()
08.
09. loop
10. //Begin transaction
11. Database_LockRow(global)
12. writers = Database_QueryThreads('w')
13. readers = Database_QueryThreads('r')
14. if readers == 0 and writers == 0 then
15. break
16. else
17. Database_CommitTransaction()
18. Sleep()
19.
20. thread.writelock = true
21. thread.writedate = CurrentDateTime()
22. thread.arrivedate = null
23.
24. Database_CommitTransaction()
...
writing is performed
...
25. //Begin transaction
26. Database_LockRow(thread)
27. thread.writelock = false
28. Database_CommitTransaction()
Figure 4.6: Pseudocode for the Readers/Writers algorithm using database transactions
34

row to release the lock held (line number twenty-seven).
All things considered, it’s obvious the distancing from the original algorithm, but the outcome
is equivalent. Moreover, additional benefits were attained with this design, like the ability to put
in place timeout and priority mechanisms, both originally inexistent.
4.3 Regression Factory application
Last but not least, the Regression Factory application is a central piece of this project and its
two core modules are detailed next.
4.3.1 Virtualization Module
This fully reusable module is what enables programatic interaction with a VMware server, pro-
viding several operations convenient to the provisioning process. It was implemented as an
OutSystems extension since the VMware API is only accessible by a limited number of pro-
gramming languages (Java, C#, Python). An extension is simply a bridge to link the OutSys-
tems platform and a foreign technology. The modular design allows for easy expansibility, but a
sizable number of operations is already available:
• GetSummary , lists basic information about a virtual machine, such as its power state.
• PowerOn , starts a virtual machine, as if pressed the power button.
• PowerOff , stops a virtual machine, as if pressed the power button.
• Reboot , issues a command to the guest operating system asking it to perform a reboot.
• Shutdown , issues a command to the guest operating system asking it to perform a clean
shutdown of all services.
• Move , moves a virtual machine into a folder or resource pool.
• Clone , creates a copy of the virtual machine and guest.
• Destroy , destroys a virtual machine, deleting its contents and removing it from its parent
folder (if any).
• CreateSnapshot , creates a snapshot of a virtual machine.
• GetSnapshots , lists all snapshots in a virtual machine.
35

• RevertToSnapshot , sets the virtual machine to its state at snapshot time.
• GetVirtualMachines , lists all virtual machines in a folder or resource pool.
• ReconfigureMemory , reconfigure memory size of a virtual machine.
• ReconfigureNetwork , reconfigure MAC address of a virtual machine.
• ReconfigureProcessor , reconfigure number of CPU’s of a virtual machine.
4.3.2 Provisioning Module
Sitting on top of the just described virtualization module is the actual provisioning application. In
essence, its functionality boils down to the provision and discard actions; the former manages
the process of automatically introducing new Regression machines and the latter reverts that
very same process. Working for opposite purposes doesn’t stop them, however, from sharing
the same operation guidelines.
4.3.2.1 Cloning
This key feature enables to strike a balance in the provisioning process by leveraging both
configuration automation and cloning. An existing standard virtual machine is first cloned to
establish a minimal OS install and, in a next step, all necessary applications and configurations
are layered on top.
4.3.2.2 Configuration Automation
Once a requested node is online, or just before going offline, it’s necessary to perform additional
system configurations to make it functional. This is accomplished by remotely executing a set
of dynamically generated commands according to a pre-defined workflow. Configurations now
performed include:
• Setting OS auto-login, required by some test cases;
• Switching SVN to correct branch, to synchronize auxiliary files with the product build to be
tested;
• Installing an SSL certificate, required by some test cases;
• Scheduling system tasks, for maintenance purposes;
36

• Cleaning temporary directories, for maintenance purposes;
• Launching the newest OutSystems platform build installation.
• Adjusting OutSystems platform parameters;
4.3.2.3 Pooling
Since cloning a virtual machine is a rather long operation (taking about 15 minutes to clone
the current standard template) the application takes advantage of a VM pool to shorten the
provisioning times (see Figure 4.7). A VM pool is a set of initialized virtual machines that are
kept ready to use, rather than allocated and destroyed on demand. When provisioning, the
application will request a virtual machine from the pool and configure it. When discarding a
virtual machine, it returns it to the pool, rather than being destroyed.
Figure 4.7: User interface for monitoring the VM pool
4.3.2.4 Variable Hardware Settings
The default hardware settings of the testing machines (1 CPU at 2.33GHz and 1024MB of
RAM) are generally adequate to handle the regular testing load. A fact called into question with
the new developments made, as the farm setup and multithreading substantially overload the
machines.
The ideal solution would be to upgrade the hardware settings of every testing machine but,
as mentioned in Section 3.1, smart resources management is desirable to avoid service degra-
dation. A simple mechanism was thereby implemented to automatically upgrade/downgrade the
37

hardware settings of Controller machines only. When the first additional machine is provisioned
the Controller CPU and RAM are doubled; subsequent additions do not make any changes; the
original settings are then restored when the last additional machine is discarded.
4.3.2.5 Asynchrony
When requests come through the user interface (see Figure 4.8) it isn’t possible to serve them
right away as both provision and discard processes are quite lengthy, requests are thereupon
registered and the actions carried asynchronously. The process status and detailed logs can be
constantly monitored through the application web interface (see Figure 4.9).
Figure 4.8: User interface for provisioning a new Regression
Figure 4.9: User interface for monitoring provisioning requests
38

Chapter 5
Results and Evaluation
The premise of this project stemmed from a realization that longer execution time of regression
test suites is a growing bottleneck in software development. The solutions implemented aimed to
fill such gap in the context of the existing OutSystems test infrastructure. This chapter presents
the results of the performed work and corresponding evaluation.
5.1 Trials Environment
The trial runs were conducted methodically, using a standard test suite (consisting of 2989 test
cases) executed in a semi-controlled environment.
Three Regression machines, were put aside specifically for this purpose and all software in-
stalled on them was frozen to safeguard new versions from influencing the performance. Version
4.2 of the OutSystems platform was used on every machine involved in the testing process. De-
spite these measures, the machines operate over an enterprise-wide virtualized environment,
with the underlying hardware infrastructure and global services subject to a heterogeneous load
throughout the trials, influencing the response times and possibly introducing a degree of en-
tropy in the results.
Notice that although these circumstances may have prevented from obtaining the best pos-
sible results, they also mirror more accurately the real gains achievable in the production envi-
ronment.
39

5.2 Quantitative Analysis
Figure 5.1 presents the results collected with multiple Regressions in a autonomous setup (re-
call from Section 3.3.3 that each machine has a different database and Controller ). The results
are encouraging and aligned with those predicted in the Amdahl analysis. The introduction of
two additional Regressions reduced the total test duration to 6:48h which represents a 62%
improvement. Don’t forget however this kind of setup is not automatically deployable by the
Regression Factory, it goes without saying that manual configuration is perfectly possible.
Figure 5.1: Test time of multiple Regressions in a autonomous setup
But it turns out that using multiple Regressions also led to an undesirable increase of failed
test cases, as patent in Figure 5.2. A test case fails when the output is different from expected
or when a unpredicted exception is raised. A brief inspection of the situation revealed it happens
mostly due to misconfiguration of test cases, presenting specific machine dependencies, that
eventually fail if not run on the original machine. The only solution is to gradually correct each
faulty test case over time.
40

Figure 5.2: Failed test cases of multiple Regressions in a autonomous setup
Figure 5.3 presents the results collected with multiple Regressions in a farm setup (recall
from Section 3.3.3 that all machines share the same database and Controller ). The results
are less satisfactory since the Controller is an inevitable constriction point. The introduction of
two additional Regressions reduced the total test duration to 11:14h which represents a 36%
improvement. Moreover, the minor gains achieved when introduced a third machine prefigures
that adding a forth won’t do any good, thus presenting a rather limited scalability.
An interesting fact is the lower number of failed test cases in comparison with the previous
setup, as patent in Figure 5.4. This happens because the Front-End’s delegate several tasks in
the Controller, thereby dodging some misconfiguration errors.
Figure 5.5 presents the results collected with multiple threads in a single Regression. As
expected, the improvements are behind of those achievable with multiple machines and there’s
a maximum threshold from which the performance starts to decline; in this particular scenario
the optimal value seems to be four threads. Even so, any speedup is welcome since the costs
are practically zero—using computational power that would otherwise be wasted.
Like the preceding strategies analyzed, multithreading is also afflicted by an increased num-
ber of failed test cases, as patent in Figure 5.6, yet the motive is quite distinct. The faults arise
41

Figure 5.3: Test time of multiple Regressions in a farm setup
Figure 5.4: Failed test cases of multiple Regressions in a farm setup
42

Figure 5.5: Test time of multiple threads in a single Regression.
from a group of heavyweight test cases that, when executed in parallel with others, usually end
up raising a timeout exception, after exceeding the time limits established by the OutSystems
platform. Two solutions exist to overcome this issue, the test cases can be split, making them
more lightweight, or tagged as critical, to have exclusive access to the execution environment.
Having seen the individual figures of each solution is fairly easy to foresee the outcome of
combining them. The overall top results recorded for each setup were:
• A duration of 4:51h with three autonomous Regressions running 4 threads each, which
represents a 73% improvement.
• A duration of 9:19h with two farm Regressions running 4 threads each, which represents
a 47% improvement.
On a different note, Figure 5.7 presents the results of the Regression Factory provisioning
process. The performance here may not seem a fundamental attribute at first, but the ability to
provision a Regression during the platform build period is definitely convenient to avoid spoiling
the total test duration. In that context the use of a pooling strategy proved worthwhile.
43

Figure 5.6: Failed test cases of multiple threads in a single Regression
Figure 5.7: Provisioning times of the Regression Factory
44

5.3 Qualitative Analysis
After demonstrating that the solutions implemented have the potential to bring significant time
improvements to regression testing, it’s still necessary to measure the absolute pros and cons.
Overall, when assessing the final project outcome up against each requirement listed in
Section 1.2, the balance is quite positive as all the items have been successfully accomplished.
The choice of parallelizing the execution of test suites was manifestly correct as the obtained
improvements would hardly be matched from test selection and/or prioritization methodologies.
As one would expect, there are also negative aspects. Together with the speedup, paral-
lelization strategies brought along the already reported increase of failed test cases, a nuisance
for testers who need to track and correct the problematic tests cases over time, fortunately only
accounting for 3.3% of the entire test suite. Regarding the Regression Factory application,
there are no actual setbacks, but the limitation to provisioning only Regressions in a farm setup
(explained in Section 3.3.3) is somewhat disconcerting as it stands in the way to achieve a truly
automatically scalable testing environment.
It remains only to mention that all the project developments have been deployed in the
production environment for a while now and no major issues were reported.
45

Chapter 6
Conclusion
Advances in technology and development tools have enabled the creation of complex software
but also hampered testing: long execution time of test suites top the recurrent problems. The
former OutSystems test infrastructure was patently afflicted by this situation since its native
design was not performance oriented.
Because testing is an integral part of software development, this project focused on solving
its efficiency problems, describing the conceptual foundation and architecture for a solution that
parallelizes the execution of regression test suites. Such strategy aims to reduce time costs by
operating on the principle that large workloads can be divided into smaller ones, which are then
solved concurrently.
The key feature of the proposed solution is the ability to create, configure and launch new
test machines on demand, over a virtualized infrastructure, responding dynamically to meet test
suites execution deadlines.
This approach is believed to have responded to OutSystems requirements, improving the
development process and therefore the product offered.
6.1 Future Work
Undoubtedly, any subsequent developments should first consider expanding the Regression
Factory functionality to support the provisioning of autonomous Regressions, which is far more
scalable than the farm setup now supported, as evidenced in Chapter 5.
A much bolder step would be to harness non-dedicated machines for testing; the essential
architectural foundations are now built but a number of challenges prevail.
46

Further performance optimizations may call for minor tuning actions: seek ways to reduce
database and web-services latencies; fetch the test cases and send the corresponding results
in bulk instead of individually; improve the product build and installation process now taking up
to one hour.
Not so urgent, but equally relevant, will be the creation of additional virtualization extensions
to interact with different platforms. A preliminary evaluation revealed that the Cloud services do
not present yet a good cost-value relationship (to deploy a dedicated testing environment), a
fact certainly bound to change as a consequence of the constant technological developments
and growing economies of scale attained from the service providers.
Finally, and probably the most complex development, would be the introduction of test se-
lection and prioritization techniques described in Chapter 2.
47

Appendix A
Figures Notation
- Repository Application, used primarily for data storage.
- General Application, used primarily for data processing.
.. .
- General Communications Network.
- Entity Multiplicity.
- Data Flow.
- Human Actor.
- Human Interaction.
- Aggregation Relationship.
- Computing Hardware.
- Computer File.
- Abstract Entity.
48

Bibliography
[1] Junit. http://www.junit.org.
[2] OpenPKG. http://www.openpkg.org/.
[3] D. P. Anderson. Boinc: A system for public-resource computing and storage. In GRID
’04: Proceedings of the 5th IEEE/ACM International Workshop on Grid Computing, pages
4–10, Washington, DC, USA, 2004. IEEE Computer Society.
[4] M. Burgess. Cfengine: a site configuration engine. USENIX Computing Systems, 8(3),
1995.
[5] N. Carriero and D. Gelernter. How to write parallel programs: a guide to the perplexed.
ACM Computing Surveys, 21(3):323–357, Sep 1989.
[6] W. Cirne, F. Brasileiro, N. Andrade, L. Costa, A. Andrade, R. Novaes, and M. Mowbray.
Labs of the world, unite!!! Journal of Grid Computing, 4(3):225–246, 2006.
[7] P. J. Courtois, F. Heymans, and D. L. Parnas. Concurrent control with “readers” and “writ-
ers”. Communications of the ACM, 14(10):667–668, 1971.
[8] E. W. Dijkstra. The structure of the “the”-multiprogramming system. In SOSP ’67: Pro-
ceedings of the first ACM symposium on Operating System Principles, New York, NY,
USA, 1967. ACM.
[9] A. Duarte, W. Cirne, F. Brasileiro, and P. Machado. Gridunit: software testing on the grid.
In ICSE ’06: Proceedings of the 28th International Conference on Software Engineering,
pages 779–782, New York, NY, USA, 2006. ACM Press.
[10] E. Dustin, J. Rashka, and J. Paul. Automated software testing. Addison-Wesley, 1999.
[11] S. Elbaum, A. G. Malishevsky, and G. Rothermel. Prioritizing test cases for regression
testing. SIGSOFT Softw. Eng. Notes, 25(5):102–112, Feb 2000.
49

[12] M. Fewster and D. Graham. Software testing automation. Addison-Wesley, 1999.
[13] I. Foster and C. Kesselman. Globus: A metacomputing infrastructure toolkit. International
Journal of Supercomputer Applications, 11:115–128, 1997.
[14] I. Foster and C. Kesselman. The Grid 2: blueprint for a new computing infrastructure.
Morgan Kaufmann, 2003.
[15] J. Frey, T. Tannenbaum, I. Foster, M. Livny, and S. Tuecke. Condor-g: a computation
management agent for multi-institutional grids. Cluster Computing, 5:237–246, 2002.
[16] R. Fulmer and A. Levine. Autoinstall for nt: complete nt installation over the network. In
LISA-NT’98: Proceedings of the 1998 Conference on Large Installation System Adminis-
tration of Windows NT, 1998.
[17] M. Gärtner, T. Lange, and J. Rühmkorf. The fully automatic installation of a linux cluster.
Technical report, Zentrum für Angewandte Informatik Köln, Lehrstuhl Jünger, 1999.
[18] T. L. Graves, M. J. Harrold, J.-M. Kim, A. Porter, and G. Rothermel. An empirical study
of regression test selection techniques. ACM Transactions on Software Engineering and
Methodology, 10(2):184–208, 2001.
[19] C. Gray and D. Cheriton. Leases: an efficient fault-tolerant mechanism for distributed file
cache consistency. In SOSP ’89: Proceedings of the twelfth ACM symposium on Operating
systems principles, pages 202–210, 1989.
[20] J. Grenning. Launching extreme programming at a process-intensive company. IEEE
Software, 18(6):27–33, Nov 2001.
[21] J. Heiss. Enterprise rollouts with jumpstart. In LISA ’99: Proceedings of the 13th USENIX
Conference on System administration, pages 267–274, 1999.
[22] M. Hutcheson. Software testing fundamentals. Wiley, 2003.
[23] IBM Corporation. Increase the speed of testing, reduce costs and shorten time to market
via automated provisioning. http://www-01.ibm.com/software/tivoli, 2007.
[24] C. Kaner, J. Falk, and H. Q. Nguyen. Testing computer software. Wiley, 1993.
[25] G. M. Kapfhammer. Automatically and transparently distributing the execution of regression
test suites. In Proceedings of the 18th International Conference on Testing Computer
Software, Washington, DC, USA, Jun 2001.
50

[26] E. Kit. Software testing in the real world. Addison-Wesley, 1995.
[27] S. Krishnaprasad. Uses and abuses of amdahl’s law. Journal of Computing Sciences in
Colleges, 17(2):288–293, Dec 2001.
[28] E. A. Lee. The problem with threads. IEEE Computer, 39(5):33–42, May 2006.
[29] H. K. N. Leung and L. White. Insights into regression testing. In Proceedings of the 11th
International Conference on Software Maintenance, pages 60–69. IEEE Computer Society,
Oct 1989.
[30] T. Limoncelli, C. Hogan, and S. Chalup. The practice of system and network administration.
Addison-Wesley, 2007.
[31] M. Litzkow, M. Livny, and M. Mutk. Condor - a hunter of idle workstations. In Proceedings
of the 8th International Conference of Distributed Computing Systems, Jun 1988.
[32] B. Marick. When should a test be automated. In Proceedings of The 11th International
Software/Internet Quality Week, 1998.
[33] Microsoft Corporation. Controlling costs and driving agility in the datacenter, Nov 2007.
[34] Novell. Platespin R© orchestrate: Simplify the management of all your virtual machines,
2009.
[35] A. Pavlo, P. Couvares, R. Gietzel, A. Karp, I. D. Alderman, M. Livny, and C. Bacon. The
nmi build & test laboratory: continuous integration framework for distributed computing
software. In LISA ’06: Proceedings of the 20th conference on Large Installation System
Administration, pages 263–273, Berkeley, CA, USA, Dec 2006. USENIX Association.
[36] D. Ressman and J. Valdés. Use of cfengine for automated, multi-platform software and
patch distribution. In LISA ’00: Proceedings of the 14th USENIX conference on System
administration, pages 207–218, 2000.
[37] M. D. Roth. Preventing wheel reinvention: The psgconf system configuration framework.
In LISA ’03: Proceedings of the 17th USENIX conference on System administration, pages
205–212, 2003.
[38] G. Rothermel and M. J. Harrold. Analyzing regression test selection techniques. IEEE
Transactions on Software Engineering, 22(8):529–551, Aug 1996.
51

[39] G. Rothermel, R. H. Untch, C. Chu, and M. J. Harrold. Test case prioritization: an empirical
study. In Proceedings of the International Conference on Software Maintenance, pages
179–188, 1999.
[40] A. Silberschatz, H. K. Korth, and S. Sudarshan. Database system concepts. McGraw-Hill,
2006.
[41] E. Starkloff. Designing a parallel, distributed test system. In AUTOTESTCON Proceedings,
2000 IEEE, pages 564–567, Washington, DC, USA, 2000. IEEE Computer Society.
[42] Sun Microsystems. Jini networking technology: An executive overview. Technical report,
Feb 2001.
[43] VMware. Understanding full virtualization, paravirtualization, and hardware assist, Nov
2007.
[44] A. Weiss. Computing in the clouds. netWorker, 11(4):16–25, Dec 2007.
[45] W. E. Wong, J. R. Horgan, S. London, and H. A. Bellcore. A study of effective regression
testing in practice. In ISSRE ’97: Proceedings of the Eighth International Symposium on
Software Reliability Engineering, pages 264–274, Washington, DC, USA, Nov 1997. IEEE
Computer Society.
52


















![1 arXiv:1005.3579v1 [stat.ML] 20 May 2010 › pdf › 1005.3579.pdf · arXiv:1005.3579v1 [stat.ML] 20 May 2010 Graph-Structured Multi-task Regression and an Efficient Optimization](https://static.fdocuments.net/doc/165x107/5f0f1dd67e708231d4429268/1-arxiv10053579v1-statml-20-may-2010-a-pdf-a-10053579pdf-arxiv10053579v1.jpg)