
A Batch Job Queuing System on Clouds with Hadoop and Hbase Presents By Niharika Potharam.
19
CLOUD BATCH A Batch Job Queuing System on Clouds with Hadoop and Hbase Presents By Niharika Potharam
-
date post
19-Dec-2015 -
Category
Documents
-
view
222 -
download
1
Transcript of A Batch Job Queuing System on Clouds with Hadoop and Hbase Presents By Niharika Potharam.

CLOUD BATCH
A Batch Job Queuing System on Clouds with Hadoop and Hbase
Presents ByNiharika Potharam

Introduction
“With CouldBATCH, a complete shift to Hadoop for managing an entire cluster to cater for hybrid computing needs becomes feasible.”
It is difficult to manage the Hadoop Clusters due to hadoop’s Lack of functionality ,user access control, accounting, finegrain performance monitoring, etc.
Hadoop is Incompatible with existing cluster batch job queuing systems and requires a dedicated cluster under its full control.

Existing Solutions
Hadoop Schedulers:FIFO Queue: But, It does not guarantee fair resource allocation.
Hadoop on Demand:Running deamons on each computer node creates an Hadoop on demand .But, Data locality of the external HDFS is not exploited.

Desired Properties for
A. Job Queue Management:Cluster nodes can be assigned to queues with a minimum and maximum quantity and capacity guarantee for optimized
resource utilization.
B. Job Scheduling and Resource Utilization: Jobs with higher priority must be scheduled first and may
require preemption based on priority.And reservation for pre-scheduled jobs can be supported by putting a Threshold on job submission allowance for each
user.
C. User Access Control & Accounting: Access control must be supported at least at queue level
(Stateful job execution).

CloudBATCH
Defintion: Uses a set of Hbase tables globally accessible, to maintain Meta-data for jobs and runs job through Hadoop MapReduce.

Cloud BATCH - Architecture
Hbase Tables Check Status
poll poll
Submit Wrapper Submit Wrapper
Execute Job Execute Job
wrapper wrapper
job X wn job Y
ClientJob
TableUser Table
Queue Table
Reservation Table
Map Reduce job Job
Broker j
Job Broker i
Reserved Job
Serial Job
Monitor
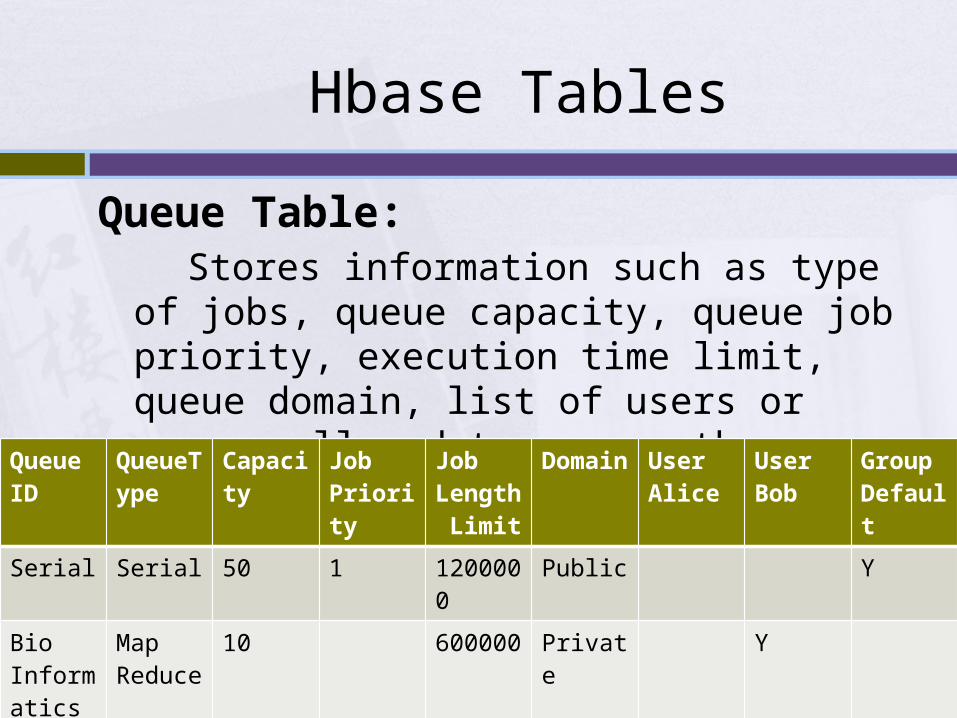
Hbase Tables
Queue Table: Stores information such as type of jobs, queue
capacity, queue job priority, execution time limit, queue domain, list of users or groups allowed to access the queue .
QueueID
QueueType
Capacity
Job Priority
Job Length Limit
Domain User Alice
User Bob
Group Default
Serial Serial 50 1 1200000
Public Y
Bio Informatics
Map Reduce
10 600000 Private Y

Job Table: Contains extensive information about jobs. Jobs are identified by unique IDs, submitted
to queues and associated with the submitting users.
Cloud-BATCH currently accepts 3 types of job.->serial->MapReduce->Scheduled Time

Job Table
JobID
Start Time
End Time
Submit Time
Queued Time
JobLengthLimit
Status:submitted
Status:queued
Status:running
Status:failed
Status:succeeded
23 T1 1200000
Y
24 T4 T2 t3 600000 Y
25 t5 1200000
Y
JobID
Queue ID: Serial
Queue ID:bioinformatics
JobType: serial
JobType: MapReduce
JobType:ScheduledTime
Priority: 1
Priority :5
23 Y Y Y
24 Y Y Y
25 Y Y Y Y

Scheduled Time Table: When Scheduled Time Table receives the information,
then it sets up the status of the job in Job Table as Status:Submitted.
The value of “scheduled time” in Scheduled Tabled is used to set the “Submit Time” in the Job Table.
When a Broker sees a Scheduled job, It will not process until its “Submit Time”
Scheduled TimeID
UserBob Group bio Job ID Scheduled Time
Request SubmitTime
2 Y Y 25 T5 T0

UserID Simultaneous JobNumLimit
Individual JobPriorityLimit
Group default
Group bio Group space
UserAlice
20 5 Y
UserBob 30 8 Y Y
USER TABLE:

CLIENT: Submits Job

Job Broker: Handles the Job Policies

Wrapper
Executes job through Hadoop Map Reduce frame work.
When a wrapper starts at some node, it grabs job information from Hbase table and stages it to local machine
Now, It performs job execution, and updates job status to “status:Running” .
After execution , sets Job status to “Status:successful” or “Status:failed”

Monitor: Detects and Handles wrapper failures
A threshold T is set , Monitor Polls the job the table for “queued” status for a time period longer than T.

Conclusion
“CloudBatch” enables Hadoop to function as a traditional batch queuing system with enhanced management functionalities for cluster resource management.

Future Enhancements
Future work will be explored in the directionof further testing the system under multi-queue, multi-user situations with heavy load and refining the prototype implementation of the system for trial production deployment in solving real-world use cases.
CloudBATCH may also be exploited to make dedicated Hadoop clusters useful for the load balancing of legacy batch job submissions.

Bibilography
[1] J. Dean and S. Ghemawat. Mapreduce: Simplified DataProcessing on Large Clusters. Commun. ACM, 51:107–113,2008.[2] Hadoop. http://hadoop.apache.org/.[3] HBase. http://hadoop.apache.org/hbase/.[4] T. Sandholm and K. Lai. Dynamic Proportional Share
Schedulingin Hadoop. In LNCS: Proceedings of the 15th Workshopon Job Scheduling Strategies for Parallel Processing, pages110–131, 2010.[5] M. Zaharia, D. Borthakur, J. Sen Sarma, K. Elmeleegy,S. Shenker, and I. Stoica. Delay Scheduling: A Simple

Technique for Achieving Locality and Fairness in ClusterScheduling. In Proceedings of the 5th European conferenceon Computer systems, EuroSys ’10, pages 265–278, 2010.
[6] C. Zhang and H. De Sterck. Supporting Multi-row DistributedTransactions with Global Snapshot Isolation Using Bare-bonesHBase. In Proceedings of the 11th International Conferenceon Grid Computing (Grid), 2010.
[7] C. Zhang, H. De Sterck, A. Aboulnaga, H. Djambazian, andR. Sladek. Case Study of Scientific Data Processing on a CloudUsing Hadoop. In LNCS: Proceedings of the 23rd InternationalSymposium of High Performance Computing Systems andApplications (HPCS), pages 400–415, 2009.


















