
最大熵模型
93
最大熵模型 最大熵模型 与 与 自然语言处理 自然语言处理 MaxEnt Model & NLP MaxEnt Model & NLP laputa laputa [email protected] [email protected] NLP Group, AI Lab, Tsinghua Univ. NLP Group, AI Lab, Tsinghua Univ.
-
Upload
jianingy -
Category
Technology
-
view
2.315 -
download
5
Transcript of 最大熵模型

最大熵模型最大熵模型与与
自然语言处理自然语言处理MaxEnt Model & NLPMaxEnt Model & NLP
[email protected]@mails.tsinghua.edu.cn
NLP Group, AI Lab, Tsinghua Univ.NLP Group, AI Lab, Tsinghua Univ.

Topics• NLP与随机过程的关系(背景)
• 最大熵模型的介绍(熵的定义、最大熵模型)
• 最大熵模型的解决(非线性规划、对偶问题、最大似然率)
• 特征选取问题
• 应用实例
• 总结与启发

NLP 与随机过程NLP: 已知一段文字: x1x2…xn ( n 个词)
标注词性 y1y2…yn
标注过程: 已知: x1x2…xn 求: y1
已知: x1x2…xn y1 求: y2
已知: x1x2…xn y1 y2 求: y3
已知: x1x2…xn y1 y2 y3 求: y4
…

NLP 与随机过程yi 可能有多种取值, yi 被标注为 a 的概率有多少
?随机过程:一个随机变量的序列。x1x2…xn p(y1=a|x1x2…xn)x1x2…xn y1 p(y2=a|x1x2…xn y1)x1x2…xn y1 y2 p(y3=a|x1x2…xn y1 y2)x1x2…xn y1 y2 y3 p(y4=a|x1x2…xn y1 y2 y3)…

NLP 与随机过程
x1x2…xn p(y1=a|x1x2…xn)x1x2…xn y1 p(y2=a|x1x2…xn y1)x1x2…xn y1 y2 p(y3=a|x1x2…xn y1 y2)x1x2…xn y1 y2 y3 p(y4=a|x1x2…xn y1 y2 y3)…
问题:• p(yi=a|x1x2…xn y1y2…yi-1) 怎么求 ?• yi 与 x1x2…xn y1y2…yi-1 的关系 ?

NLP 与随机过程问题:• p(yi=a|x1x2…xn y1y2…yi-1) 怎么求 ?• yi 与 x1x2…xn y1y2…yi-1 的关系 ?
)....(
)....,()....|(
11
1111
nn
nninni yyxxp
yyxxaypyyxxayp
一个直观的解决:
问题 again!• (x1x2…xn y1y2…yi-1) ?

What’s Entropy?An Example :
• 假设有 5 个硬币: 1,2,3,4,5 ,其中一个是假的,比其他的硬币轻。有一个天平,天平每次能比较两堆硬币,得出的结果可能是以下三种之一:
• 左边比右边轻
• 右边比左边轻
• 两边同样重
问:至少要使用天平多少次才能保证找到假硬币 ?(某年小学生数学竞赛题目 :P )
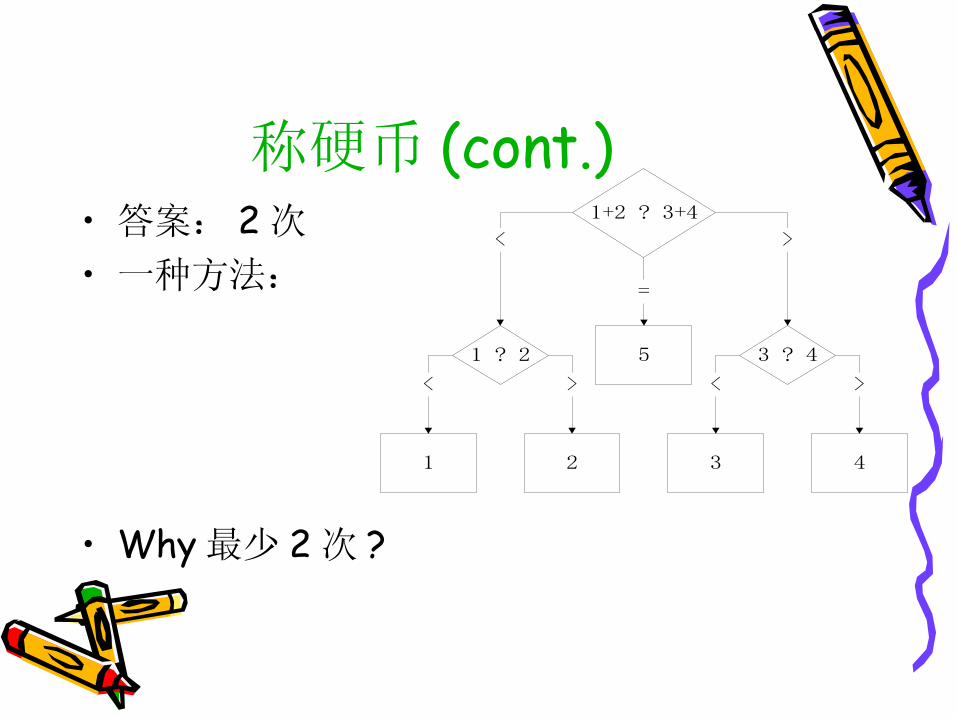
称硬币 (cont.)• 答案: 2 次
• 一种方法:
• Why 最少 2 次 ?
1+2 ? 3+4
1 ? 2 3 ? 45
1 4
>
=
><
<
2 3
<>

称硬币 (cont.)• Let: x 是假硬币的序号:
• Let: yi 是第 i 次使用天平所得到的结果:
• 用天平称 n 次,获得的结果是: y1 y2… yn
• y1 y2… yn 的所有可能组合数目是 3n
• 我们要通过 y1 y2… yn 找出 x 。所以:每个 y1 y2… yn 组合最多可能有一个对应的 x 取值。
• 因为 x 取 X 中任意一个值的时候,我们都要能够找出 x ,因此对于任意一个 x 的取值,至少要有一个 y1 y2… yn 与之对应。根据鸽笼原理……
5,4,3,2,1 Xx
表示;表示;表示其中 321:3..1Yyi
XYn

称硬币 (cont.)• Let: x 是假硬币的序号:
• Let: Yi 是第 i 次使用天平所得到的结果:
• 用 y1 y2… yn 表达 x 。即设计编码: x-> y1 y2… yn
• X 的“总不确定度”是:
• Y 的“表达能力”是:
• 至少要多少个 Y 才能准确表示 X ?
5,4,3,2,1 Xx
表示;表示;表示其中 321:3..1Yyi
5loglog XXH
3loglog YYH
46.1
3log
5log
)(
YH
XH

称硬币 (cont.)• Why???
• 为什么用 log?• “表达能力”与“不确定度”的关系?
5loglog XXH
3loglog YYH
46.1
3log
5log
)(
YH
XH

称硬币 (cont.)为什么用 log?• 假设一个 Y 的表达能力是 H(Y) 。显然,
H(Y) 与 Y 的具体内容无关,只与 |Y| 有关。
• 两个 Y( 就是: y1y2) 的表达能力是多少 ?
• y1 可以表达三种情况, y2 可以表达三种情况。两个并列,一共有: 3*3=9 种情况(乘法原理)。因此:
YYYY
YYHYHYHyHyH
注意:
)()()(21

称硬币 (cont.)“表达能力”与“不确定度”的关系?
• 都表达了一个变量所能变化的程度。在这个变量是用来表示别的变量的时候,这个程度是表达能力。在这个变量是被表示变量的时候,这个程度是不确定度。而这个可变化程度,就是一个变量的熵( Entropy )。
• 显然:熵与变量本身含义无关,仅与变量的可能取值范围有关。
46.1
3log
5log
)(
YH
XH

称硬币 -Version.2假设有 5 个硬币: 1,2,3,…5 ,其中一个是假的,比其他
的硬币轻。已知第一个硬币是假硬币的概率是三分之一;第二个硬币是假硬币的概率也是三分之一,其他硬币是假硬币的概率都是九分之一。
有一个天平,天平每次能比较两堆硬币,得出的结果可能是以下三种之一:
• 左边比右边轻• 右边比左边轻• 两边同样重假设使用天平 n 次找到假硬币。问 n 的期望值至少是多少
?(不再是小学生问题 :P )

称硬币 -Version.2因为第一个、第二个硬币是假硬币的概率是三分之一,比其他硬币的概率大,我们首先“怀疑”这两个。第一次可以把这两个做比较。成功的概率是三分之二。失败的概率是三分之一。如果失败了,第二次称剩下的三个。所以,期望值是:
3
4
3log
9log
9
13
3log
3log
3
1
3
1

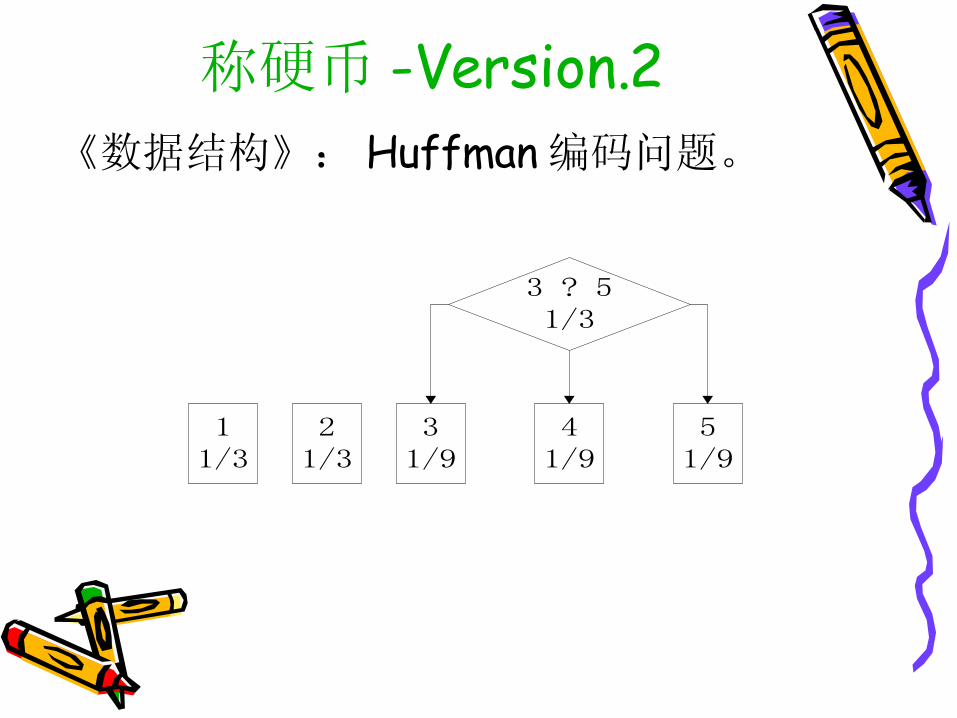
称硬币 -Version.2《数据结构》: Huffman 编码问题。
51/9
11/3
41/9
21/3
31/9
称硬币 -Version.2《数据结构》: Huffman 编码问题。
3 ? 51/3
51/9
11/3
41/9
21/3
31/9
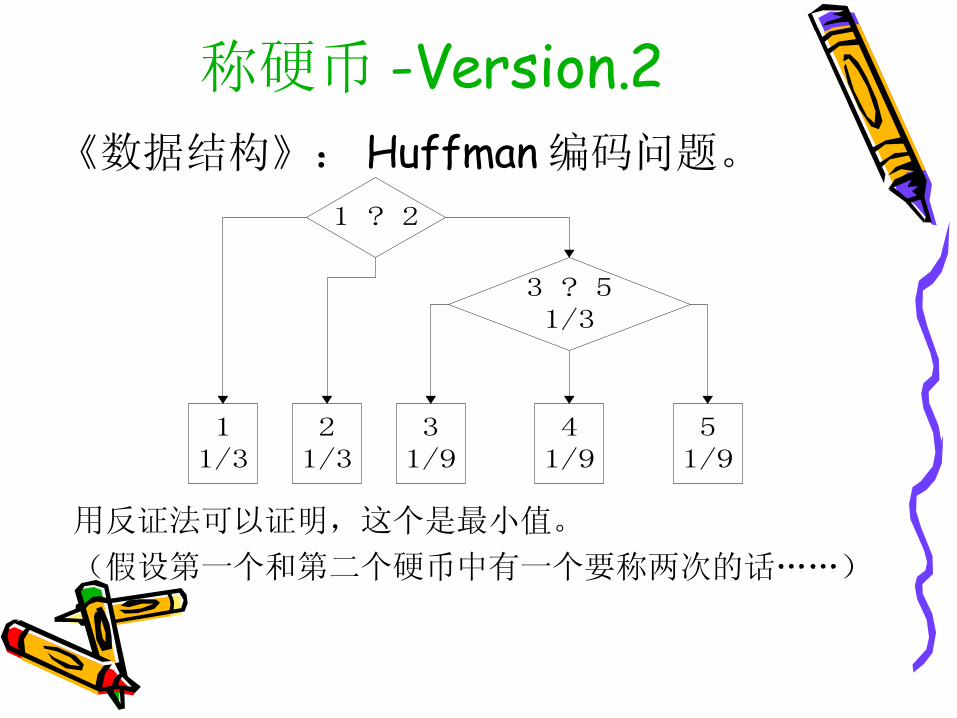
称硬币 -Version.2《数据结构》: Huffman 编码问题。
1 ? 2
3 ? 51/3
51/9
11/3
41/9
21/3
31/9
用反证法可以证明,这个是最小值。
(假设第一个和第二个硬币中有一个要称两次的话……)

称硬币 -Version.2《数据结构》: Huffman 编码问题。
1 ? 2
3 ? 51/3
51/9
11/3
41/9
21/3
31/9
1/9
1/9
1/9
1/9
1/9
1/9
3
4
3log
9log
9
13
3log
3log
3
1
3
1

称硬币 -Version.3,4,…∞更广泛地:如果一个随机变量 x 的可能取值为
X={x1, x2,…, xk} 。要用 n 位 y: y1y2…yn 表示(每
位 y 有 c 种取值) n 的期望值至少为:
k
i ii xxpxxpXH
1
1log
一般地,我们令 c 为 2 (二进制表示),于是,X 的信息量为:
c
xxpxxp
c
xxpxxp
k
i iik
i
ii log
1log
log
1log
1
1

What’s Entropy?• 定义 :
• X 的具体内容跟信息量无关,我们只关心概率分布,于是 H(X) 可以写成:
k
i ii xxpxxpXH
1
1log
Xx xpxpXH
1log

熵的性质
• 第一个等号在 X 为确定值的时候成立(没有变化的可能)
• 第二个等号在 X 均匀分布的时候成立。
XXH log0

熵的性质
• 证明:
)(0 XH
0
01
log
01
log
01
log11
01:
1log
XH
xpxp
xpxp
xpxp
xpx
xpxpXH
Xx
Xx
即

熵的性质
• 证明:
详细证明略。
求条件极值就可以证明了(求偏导数,条件是:所有的概率之和为 1 )
结论:均匀分布的时候,熵最大
XXH log)(

Conditional Entropy
• 有两个变量: x,y 。它们不是独立的。已知 y , x 的不确定度又是多少呢 ?
YXyx yxp
yxpYXH, |
1log,|
)()()|( YHXYHYXH
)()|( XHYXH

Conditional Entropy
• Condition Reduces Entropy (C.R.E.)• 知识( Y )减少不确定性( X )
• 证明(略)。用文氏图说明:
)()|( XHYXH
X Y(X&Y)
I: Complete KnowledgeSpace

已知与未知的关系
对待已知事物和未知事物的原则:
• 承认已知事物(知识);
• 对未知事物不做任何假设,没有任何偏见

已知与未知的关系—例子已知:
“学习”可能是动词,也可能是名词。可以被标为主语、谓语、宾语、定语……
令 x1 表示“学习”被标为名词, x2 表示“学习”被标为
动词。
令 y1 表示“学习”被标为主语, y2 表示被标为谓语, y3表示宾语, y4 表示定语。得到下面的表示:
5.0)()( 21 xpxp
如果仅仅知道这一点,根据无偏见原则,“学习”被标为名词的概率与它被标为动词的概率相等。
1)()( 21 xpxp 1)(4
1
i
iyp
25.0)()()()( 4321 ypypypyp

已知与未知的关系—例子
已知:“学习”可能是动词,也可能是名词。可以被标为主语、
谓语、宾语、定语……“学习”被标为定语的可能性很小,只有 0.05
5.0)()( 21 xpxp除此之外,仍然坚持无偏见原则:
05.0)( 4 yp我们引入这个新的知识:
1)()( 21 xpxp 1)(4
1
i
iyp
3
95.0)()()( 321 ypypyp

已知与未知的关系—例子
已知:
“学习”可能是动词,也可能是名词。可以被标为主语、谓语、宾语、定语……
“学习”被标为定语的可能性很小,只有 0.05当“学习”被标作动词的时候,它被标作谓语的概率为
0.95
除此之外,仍然坚持无偏见原则,我们尽量使概率分布平均。
但问题是:什么是尽量平均的分布?
05.0)( 4 yp
引入这个新的知识:
1)()( 21 xpxp 1)(4
1
i
iyp
95.0)|( 12 xyp

最大熵模型Maximum Entropy
• 概率平均分布〈 = 〉熵最大
• 我们要一个 x 和 y 的分布,满足:
• 同时使 H(Y|X) 达到最大值
1)()( 21 xpxp1)(
4
1
i
iyp 05.0)( 4 yp95.0)|( 12 xyp

最大熵模型Maximum Entropy
95.0)|(
05.0)(
1)()()()(
1)()(
)|(
1log),()|(max
12
4
4321
21
,,,,
4321
21
xyp
yp
ypypypyp
xpxp
xypyxpXYH
yyyyyxxx

最大熵模型Maximum Entropy
What is Constraints?-- 模型要与已知知识吻合
What is known?-- 训练数据集合
一般模型:
P={p|p 是 X 上满足条件的概率分布 }
yx
Pp xypyxpXYH
, )|(
1log),()|(max

特征 (Feature)特征: (x,y)y: 这个特征中需要确定的信息
x: 这个特征中的上下文信息
注意一个标注可能在一种情况下是需要确定的信息,在另一种情况下是上下文信息 :
x1x2…xn p(y1=a|x1x2…xn)x1x2…xn y1 p(y2=a|x1x2…xn y1)

样本 (Sample)关于某个特征 (x,y) 的样本 -- 特征所描述的语法现象在标准集合里的分布:
(xi,yi) pairs
yi 是 y 的一个实例
xi 是 yi 的上下文
(x1,y1) (x2,y2) (x3,y3)……

特征与样本
已知:
“学习”可能是动词,也可能是名词。可以被标为主语、谓语、宾语、定语……
“学习”被标为定语的可能性很小,只有 0.05特征:当“学习”被标作动词的时候,它被标作谓语的概率为 0.95
x 是什么 ? y 是什么 ?样本是什么 ?

特征与样本
已知:
“学习”可能是动词,也可能是名词。可以被标为主语、谓语、宾语、定语……
特征:“学习”被标为定语的可能性很小,只有0.05
当“学习”被标作动词的时候,它被标作谓语的概率为 0.95
x 是什么 ? y 是什么 ?样本是什么 ?

特征与样本
特征函数:对于一个特征 (x0,y0) ,定义特征函数:
特征函数期望值:
对于一个特征 (x0,y0) ,在样本中的期望值是:
:其他情况
而且:如果
0
xy1),( 00 xyyxf
ii yx
yxfyxpfp,
),(),()(
是 (x,y) 在样本中出现的概率),( yxp

条件( Constraints )
条件:
对每一个特征 (x,y) ,模型所建立的条件概率分布要与训练样本表现出来的分布相同。
出现的概率xxp )(
在样本中的期望值特征ffp )(
假设样本的分布是(已知):
出现的概率xyyxp ),(
特征 f 在模型中的期望值:
ii
ii
ii
yxiiiii
yxiiiii
yxiiii
yxfxpxyp
yxfxpxyp
yxfyxpfp
,
,
,
,|
,|
,,)(
)()( fpfp

最大熵模型Maximum Entropy
)|(* maxarg XYHpPp
NLP 模型:
P={p|p 是 y|x 的概率分布并且满足下面的条件 }
对训练样本,对任意给定的特征 fi :
)()( ii fpfp

最大熵模型Maximum Entropy
y
yxi
yxi
i
xypx
yxfyxp
yxfxpxyp
fxypP
1|:
),(,
),(|
:|
,
,
NLP 模型:
yxPp xyp
xpxypp, |
1log|* maxarg

最大熵模型的解决问题:已知若干条件,要求若干变量的值使到目标函数(熵)最大
数学本质:最优化问题( Optimization Problem )• 条件:线性、等式• 目标函数:非线性非线性规划(线性约束) (non-linear
programming with linear constraints)

非线性规划基本概念Nonlinear Programming
• 解决的思路:
非线性规划问题(带约束)
(拉格朗日法) -> 非线性规划问题(不带约束 Unconstrained Problem )
(求偏导数法) -> 解决不带约束求解问题
(解方程) -> 求出原问题的解法

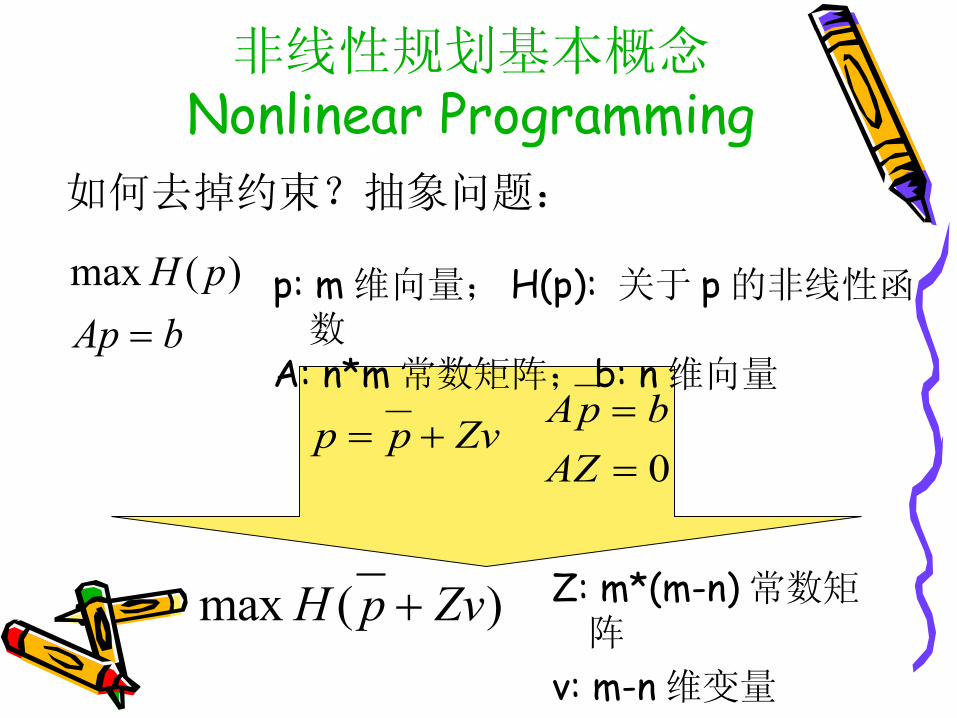
非线性规划基本概念Nonlinear Programming
p: m 维向量; H(p): 关于 p 的非线性函数
A: n*m 常数矩阵; b: n 维向量bAp
pH
)(max
如何去掉约束?抽象问题:
假设: A 的行向量线性无关。
bAp 确定了 m 维空间里面 n 个方向上(就是与 Ap=b 确定的 m-n 个方向“垂直”的 n 个方向)的取值。
p 只能在剩下的 r=m-n 个方向上面移动。

非线性规划基本概念Nonlinear ProgrammingbAp
假设 Z 是跟 Ap=b 垂直的方向量。• Z: m*(m-n) 常数矩阵 )
bpA
Zvpp
就是 p 能够自由活动的所有空间了。
• v: m-n 维变量
于是有:
0
0
:
AZ
ZvA
bZvpAv
非线性规划基本概念Nonlinear Programming
p: m 维向量; H(p): 关于 p 的非线性函数
A: n*m 常数矩阵; b: n 维向量bAp
pH
)(max
如何去掉约束?抽象问题:
0
AZ
bpAZvpp
)(max ZvpH Z: m*(m-n) 常数矩阵
v: m-n 维变量

极值条件
)(max ZvpH
Z: m*(m-n) 常数矩阵
v: m-n 维变量
是正定矩阵而且 0)(0)( *2* vHvH
0
AZ
bpAZvpp
极值条件:
ZpHZvHpHZvH TT )()();()( *2*2** 把 分解成 Z 方向向量和 A 方向向量:
)( *pH
TAZvpH ')( *

极值条件
Z: m*(m-n) 常数矩阵
v: m-n 维变量
0
AZ
bpAZvpp
0'0'0
0'
ZvZvZAZ
AZZvZ TTTT
0'0)()(
')(**
*
TTT
T
T
AZZvZpHZvH
AZvpH
TT
AxHZv
AZvpH
)(0'
')( **

极值条件
0)()( ** pLApH T
• p: m 维向量; H(p): 关于 p 的非线性函数
• A: n*m 常数矩阵; b: n 维向量bAp
pH
)(max
令:
假设: A 的行向量线性无关。
AppHpL )()(
*)()()( ** AppHApH T

拉格朗日算子Lagrange Multiplier
• 一般地,对于 k 个限制条件的Constrained Optimization 问题:
)(max pH ii bpCki :1
• 拉格朗日函数为:
k
iiii bpCpHpL
1
,
• 其中引入的拉格朗日算子: Tk ,...,1

拉格朗日算子Lagrange Multiplier
Tk ,...,1bAp
pH
)(max
k
iiiii bpCpHpL
1
,
0p
L

拉格朗日函数
1|
),()()|(),(
)|(
1log)()|(
0
),(
),(
y
i yxii
yx
xyp
yxpxpxypyxf
xypxpxypL
y
yxi
yxi
i
xypx
yxfyxp
yxfxpxyp
fxypP
1|:
),(,
),(|
:|
,
,
yxPp xyp
xpxypp, |
1log|* maxarg

可能的最优解( Exponential )
1|
),()()|(),(
)|(
1log)()|(
0
1 ),(
),(
y
k
i yxii
yx
xyp
yxpxpxypyxf
xypxpxypL
iii yxfxp
xypxp
xyp
L0),()()1
)|(
1)(log(
)|(
1)(
),( 0
)|(*
xpyxf
iii
exyp

最优解的存在性
0),()()1)|(
1)(log(
)|( 0
i
ii yxfxpxyp
xpxyp
L
1)(
),( 0
)|(*
xpyxf
iii
exyp
0)|(
)(
)|(2
2
xyp
xp
xyp
L一阶导数为零,
二阶导数小于零,
所得到的是最大值!

最优解形式( Exponential )
1)(
),( 0
)|(*
xpyxf
iii
exyp
i
ii yxf
cexyp),(
)|(*
y
yxfi
ii
e
c),(
1
y
yxfi
ii
ce 1),(

最优解( Exponential )
i
ii yxf
cexyp),(
)|(*
y
yxfi
ii
e
c),(
1
i
ii yxf
exZ
xyp),(
)(
1)|(*
y
yxfi
ii
exZ),(
)(
?i

最优解( Exponential )
• 能不能找到另一种逼近?比如……
等价成求某个函数 的最大 / 最小值?
?• 几乎不可能有解析解(包含指数函数)
• 近似解不代表接近驻点。
)(f

对偶问题Duality
对偶问题的引入。 Alice 和 Bob 的游戏:
有一个 2*2 的矩阵C。每次 Alice 挑一个数 x (x=1 或者 2) , Bob 也挑一个数 y (y=1 或者2) 。两人同时宣布所挑的数字。然后看 Cx,y 是多
少, Bob 要付 Alice Cx,y 块钱。(如果 Cx,y 是负
数, Alice 给 Bob 钱)。矩阵C如下:
34
21C

对偶问题 Alice vs Bob
假设: Alice 和 Bob 都是聪明而贪得无厌的人。而且他们都清楚对方也很聪明和很贪心。
Alice 的策略:
找一个 x ,无论 Bob 怎么挑 y , Cx,y 要尽量大。
Bob 的策略:
找一个 y ,无论 Alice 怎么挑 x , Cx,y 要尽量小。
yxCAliceBobyBob
xAliceC ,:
:
:
34
21
双方都很聪明:双方都对对方有“最坏打算”
yxxyC ,maxmin
yxyxC ,minmax

对偶问题 Alice vs BobyxCAliceBob
yBob
xAliceC ,:
:
:
34
21
yxxyCy ,maxminarg*
yxyxCx ,minmaxarg*
• Alice 的选择: x*=2• Bob 的选择: y*=2
3
1min ,yxyC
34max , yxxC
3: 2,2 CAliceBob

Alice vs Bob Version.2
yxCAliceBobyBob
xAliceC ,:
:
:
24
21
yxxyCy ,maxminarg*
yxyxCx ,minmaxarg*
• Alice 的选择: x*=1• Bob 的选择: y*=2
2
1min ,yxyC
24max , yxxC
2: 2,1 CAliceBob

对偶问题 Alice vs BobVersion 1: Alice 的估计 = 结果 =Bob 的估计
Version 2: Alice 的估计 < 结果 =Bob 的估计
一般情况 :Alice 的估计 <= 结果 <=Bob 的估计
yxxy
yxyx
CC ,, maxminminmax
定理:当存在马鞍点( Saddle Point )的时候,等号成立。并且结果 = 马鞍点的值。
马鞍点:yxyxyx CCCyx *,**,*,|*)*,(

非线性规划中的对偶问题
)(max pH ii bpCki :1
拉格朗日函数:
k
iiii bpCpHpL
1
,
于是:
,minmax pLp
ii
ii
bpCi
bpCipHpL
::
::,min
因此,为了尽量大, p 的选取必须保证
满足约束ppHpLp
|)(max,minmax
ii bpCki :1
考虑:

对偶问题与拉格朗日函数:
)(max pH ii bpCki :1
同时:
k
iiii
pbpCpHpL
1
,minmax
等价于:
,maxmin,minmax pLpLpp
而
*,,max pLpLp
i
ii yxf
exZ
xyp),(
)(
1)|(*

对偶问题与拉格朗日函数:
*,min
,maxmin
,minmaxmaxp
pL
pL
pLpH
p
p
满足约束
i
ii yxf
exZ
xyp),(
)(
1)|(*
?

梯度递减法
xyx
yx
yx
yx
k
i yxii
xZxpyxyxp
yxyxpxZxypxp
yxyxp
yxxZyxxypxp
yxyxpyxxypxypxp
yxpxypxpyxfpHpL
log,,
,,log|
,,
,log,|
,,,|log|
,|,*,
,
,
,
,
1 ,
把 p* 代入 L ,得到: 令:
k
iii yxfyx
1
,,

梯度递减法
求导,计算 -L 的梯度:
xyx
xZxpyxyxppL log,,*,,
k
iii yxfyx
1
,,
x yjip
x yj
yxf
yxi
x iyxi
xyx
k
jjj
ii
yxfxypxpfE
yxfexZ
xpyxfyxp
xZ
xZxpyxfyxp
xZxpyxfyxpL
k
jjj
,|*
,1
,,
1,,
log,,
1
,
,
,
, 1
y
yxfi
ii
exZ),(
)(

梯度递减法
递推公式:
yxjip
i
yxfxypxpfEL
,
,|*
yxjip
ni
ni yxfxypxpfEc
,
1 ,|*
收敛问题……

最大似然率 Maximum Likelihood
• 最大似然率:找出与样本的分布最接近的概率分布模型。
• 简单的例子。 10 次抛硬币的结果是:
画画字画画画字字画画
假设 p 是每次抛硬币结果为“画”的概率。则:
得到这样的实验结果的概率是: 37 1
111
pp
ppppppppppP

最大似然率 Maximum Likelihood
• 最大似然率:找出与样本的分布最接近的概率分布模型。 37 1 ppP
37
101maxmax ppP
p
• 最优解是: p=0.7• 似然率的一般定义:
x
xp
pxpL
是实验结果的分布
模型是估计的概率分布
xp
xp

最大似然率 Maximum Likelihood
• 似然率的一般定义: x
xp
pxpL
• 似然率的对数形式:
xx
xp
pxpxpxpL loglog
是实验结果的分布
模型是估计的概率分布
xp
xp

最大似然率 Maximum Likelihood
• 在 NLP 里面,要估计的是: 语法标注
上下文
:
:|y
xxyp
• 似然率是:
yxyx
yx
yxp
xpyxpxypyxp
xypxpyxp
yxpyxppL
,,
,
,
log,|log,
|log,
,log,
是常数,可以忽略 yx
xypxpyxp,
|log,

最大似然率 Maximum Likelihood
• 在 NLP 里面,要估计的是: 语法标注
上下文
:
:|y
xxyp
• 似然率可以定义为:
yx
pxypyxppL
,
|log,
• 通过求值可以发现,如果 p(y|x) 的形式是最大熵模型的形式的话,最大熵模型与最大似然率模型一致。

最大似然率
yx x
yx
yxyx
yxyx
p
xZxpyxyxp
xZeyxp
xZ
eyxp
xypyxppL
,
,
,,
,,
log,,
loglog,
log,
|log,
k
iii yxfyx
1
,, 为书写方便,令:
xZyx
exZ
xyp,
1|

最大似然率
xyx
yx
yx
yx
k
i yxii
xZxpyxyxp
yxyxpxZxypxp
yxyxp
yxxZyxxypxp
yxyxpyxxypxypxp
yxpxypxpyxfpHpL
log,,
,,log|
,,
,log,|
,,,|log|
,|,*,
,
,
,
,
1 ,

最大似然率 Maximum Likelihood
*,log,,,
pLxZxpyxyxppLxyx
p
*,min*,maxmax pLpLpLp
• 结论:最大熵的解(无偏见地对待不确定性)同时是最吻合样本数据分布的解。进一步证明了最大熵模型的合理性。

偶然?必然?
“It so happens that…”???熵:不确定度
似然率:与知识的吻合度
最大熵:对不确定度的无偏见分配
最大似然率:对知识的无偏见理解
知识=不确定度的补集
满足约束条件的模型集合P 指数模型集合Q(最大熵)
最大似然率方向(满足约束条件)
最大熵方向

特征选取问题问题:
• 所有知识可信吗?所有知识都有用吗?
• 太多知识怎么办?
在 NLP 里面:
• 上下文信息可以很多很多种,那些是有用呢?

特征选取问题Remind: “熵是描述不确定度的”
“知识是不确定度的补集”
--不确定度越小,模型越准确。
直观的过程:
• 什么特征都不限定:熵最大
• 加一个特征:熵少一点( C.R.E. )
• 加的特征越多,熵越少……

特征选取算法• 目标:选择最有用的K个特征(知识)
• “最”?--全局的最优解几乎不可能
• 可行的方法:逐步选择最有用的信息。
• 每一步用“贪心”原则:挑选“现在看来”最有用的那个特征。
• “有用?” 使到走这一步后熵减少最多

算法步骤
• 有效特征集合 E={} // 这个时候 p 均匀分布
• 计算最大熵 H(p*) 。显然:
• 对以下步骤循环 K 次:
对每个不在 E 里面的特征 fi ,把 E+{fi} 作为有效特征,计算最大熵 Hi(pi*) ;
假设 Hm(pm*) 最小,则: E=E+{fm} 。
pHpH *

敏感度分析与特征提取Sensitivity
• How to work on insufficient data set?最终结论应该是约束条件越确定( _p(x)越大), lambda 越大。

应用实例Adwait Ratnaparkhi’s “Learning to Parse
Natural Language with Maximum Entropy Models”
创新点:
用 MaxEnt 模型辅助 Shift-reduce Parsing

应用实例Parser 的特点:
三层 ParserK-BFS 搜索——每层只搜索最好的 K 个方案 (derivations)
“最好”:概率最大
概率:最大熵模型得到的概率分布
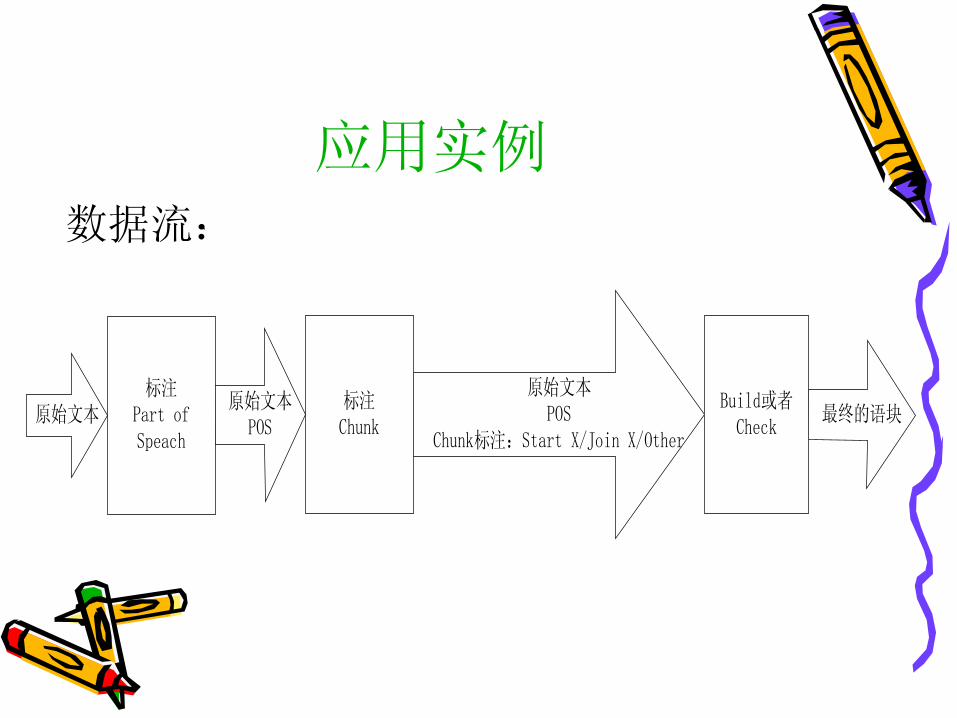
应用实例数据流:
标注Part ofSpeach
标注Chunk
Build或者Check
原始文本POS
原始文本POS
Chunk标注:Start X/Join X/Other原始文本 最终的语块

应用实例概率:最大熵模型得到的概率分布事先对每类 Parsing 都训练一个最大熵模型。得到概率分布: pX*(a|c) 。 a 是 action , c 是上下文。 X 可能是:
TAG, CHUNK, BUILD/CHECK最优解求法: GIS ( General Iterative
Scaling Algorithm “ 一般梯度算法”?)特征选取:只取出现次数大于等于 5 的所有特征(比较简单,但因此计算量也少多了)

应用实例• 实验结果:
Upenn 的 Corpus 作为训练集合
Wall Street Journal 上的句子作为测试对象
准确率: 90% 左右

应用实例分析:
三层 Parser 功不可没(上层 Parser 看到的是下层 Parser 的所有信息—包括处理点之前和之后的信息)
MaxEnt 模型提供了比较准确的评价模型(不然三层 Parser 会比单层 Parser 引起更大的误差累积,“失之毫厘谬以千里”)

相关项目• CMU: Adam Berger• U Penn: Adwait Ratnaparkhi• Source Forge: opennlp. MAXENT• ……

总结与启发
• MaxEnt 已经是比较成功的一个 NLP 模型,并获得广泛应用
• 从信息论获得启发( 1948- ):自然语言处理也是信息处理的一种。语法标注也可以看作一种编码的过程 ?
• 对偶问题: 从另一个角度看问题
• 可能从不同领域获得的启发。(概率论与随机过程、最优化问题、图形学……)
“All Models are wrong. Some are useful.”

参考文献1. A maximum entropy approach to natural
language processing (Adam Berger)2. A Brief MaxEnt Tutorial (Adam Berger)3. Learning to parse natural language with
maximum entropy models (Adwait Ratnaparkhi)
4. A simple Introduction to Maximum Entropy Models for Natural Language Processing (Adwait Ratnaparkhi)

参考文献 (Cont)• Elements of Information Theory (Cover &
Thomas) • Linear and Nonlinear Programming (Nash &
Sofer)• 《高等数学》
• 《运筹学》
• 《数据结构》

Q&AQ&A ??
Thank you!Thank you!


















