
5 Statistiche Inferenziali -...
99
Vittorio Maniezzo – Università di Bologna Statistiche Inferenziali introduzione (non per statistici!) 5
Transcript of 5 Statistiche Inferenziali -...

Vittorio Maniezzo – Università di Bologna
Statistiche Inferenziali
introduzione(non per statistici!)
5

Ringraziamenti
Questi lucidi derivano da adattamenti personali di materiale prodotto (fornitomi o reso scaricabile) da:
C. O’Dushlaine, S. Yule, I. Milošev, A. Valbonesi, F. Ronzon
… e da wikipedia.
Vittorio Maniezzo – Università di Bologna 2

Popolazione e campione
Popolazione: l’intero insieme dei dati, individui, oggetti o risultati di interesse.
• Spesso troppo grande per essere analizzato completamente
• Può essere reale o ipotetica (es. i risultati di un esperimento ripetuto infinite volte)
Campione: un sottinsieme della popolazione.
• Un campione può essere casuale (ogni membro ha la stessa probabilità di essere estratto dalla popolazione) o a scelta ragionata
(non probabilistica).
• La selezione casuale cerca di assicurare che il campione sia rappresentativo della popolazione.
3Vittorio Maniezzo – Università di Bologna

VariabiliLe variabili sono le quantità misurate in un campione. Possono essere:
• Quantitative (numeriche)
•Continue: Quantificate su scala continua (es. altezza delle persone nell’aula). Comunque si fissino due valori, tutti i valori intermedi potrebbero essere assunti.
•Discrete: quantificate con conteggi (es. numero di persone nell’aula). Per qualunque valore, esiste tutto un intervallo con il valore è il centro, in cui nessun altro valore può essere assunto.
• Categoriche
•Nominali: i valori identificano le categorie, ma le quantità non hanno senso (es. genere, nazionalità).
•Ordinali I valori permettono un ordinamento, ma gli intervalli fra valori possono essere variabili (es. livelli occupazionali, gerarchie al lavoro).
4Vittorio Maniezzo – Università di Bologna

Livelli di misuraScale nominali: i valori indentificano le categorie, le quantità non
hanno senso. Unica relazione: l’identità, unica operazione ammessa: il conteggio
Scale ordinali: i valori permettono un ordinamento, ma gli intervalli fra valori possono essere variabili. Relazione d’ordine asimmetrica e transitiva, non è possibile quantificare le differenze di intensità tra le osservazioni.
Scale a intervalli: le misure sono continue con intervalli uguali fra i punti; lo zero è arbitrario (es. tempo, temperatura Fahrenheit o Celsius). Lo zero non indica l’assenza totale della quantità che si sta misurando, non è possibile il rapporto tra coppie di valori (una temperatura di 80 gradi non è il doppio di una di 40 gradi)
Scale di rapporti: tutte le proprietà precedenti e anche uno zero naturale (es. altezza, distanza, velocità, età, peso, reddito, temperatura Kelvin).
Vittorio Maniezzo – Università di Bologna 5

Parametri e statistiche
Parametri: quantità che descrivono le caratteristiche di una popolazione. Di solito non sono note e vogliamo fare una inferenza statistica sui parametri.
Statistiche descrittive: quantità e tecniche usate per descrivere le caratteristiche di un insieme di dati, es. media, deviazione standard, box-plot, …
Statistica inferenziale: tecniche per analizzare i campioni e generalizzarli alla popolazione
Errore campionario: differenza fra le statistiche campionarie e i valori dei corrispondenti parametri della popolazione
6Vittorio Maniezzo – Università di Bologna

7Vittorio Maniezzo – Università di Bologna
Statistiche descrittive

Distribuzioni di frequenza
Una Distribuzione di Frequenza (empirica) o Istogramma per una variabile continua presenta un conteggio delle osservazioni, raggruppate in classi o gruppi predefiniti
Una Distribuzione di Frequenza Relativa presenta le corrispondenti proporzioni di osservazioni all’interno delle classi
Un grafico a barre (barchart) presenta le frequenze per una variabile categorica
8Vittorio Maniezzo – Università di Bologna

Esempio – Velocità autostradali
Rilevazioni autovelox di velocità di autoveicoli che percorrono un tratto autostradale, misurate in Km/h.
9
121 82 100 151 68 58
95 145 64 201 101 163
84 57 139 60 78 94
119 104 110 113 118 203
62 83 67 93 92 110
25 123 70 48 95 42
Vittorio Maniezzo – Università di Bologna

Tabella frequenze relative
Velocità (Km/h) Frequenza Frequenza Relativa
Frequenza rel. cumulata
20-39 1 0.028 0.028
40-59 4 0.111 0.139
60-79 7 0.194 0.333
80-99 8 0.222 0.555
100-119 8 0.222 0.777
120-139 3 0.083 0.860
140-159 2 0.056 0.916
160-179 1 0.028 0.944
180-199 0 0.000 0.944
200-219 2 0.056 1.000
Totale 36 1.000
Vittorio Maniezzo – Università di Bologna 10

Distribuzione di frequenza
11Vittorio Maniezzo – Università di Bologna

Misure di tendenza centrale
Le misure di tendenza centrale indicano in che zona dell’intervallo dei valori ammissibili si trovano i dati. Misure comuni sono:
1. La media aritmetica
2. La mediana
3. La moda
12Vittorio Maniezzo – Università di Bologna

La media
13
Siano x1,x2,x3,…,xn i valori misurati di una variabile casuale X, da un campione di cardinalità n.
La media aritmetica è definita come:
In Excel: MEDIA(dati)
In Octave: mean(X)
Vittorio Maniezzo – Università di Bologna

Esempio
14
Alcune delle velocità rilevate su un tratto autostradale sono:
151, 124, 132, 170, 146, 124, 113.
La media è
Vittorio Maniezzo – Università di Bologna

Mediana e Moda
• Si organizzano n dati campionari per valori crescenti, poi la mediana è
• Il valore di mezzo se n è dispari
• La media fra i due valori di mezzo se n è pari
• La moda è il valore rilevato più di frequente.
15
In Excel: MEDIANA(dati)
In Octave: median(X)
In Excel: MODA(dati)
In Octave: mode(X)
Vittorio Maniezzo – Università di Bologna

Esempio
N dispari
Le velocità viste prima, ordinate, sono:
113, 124, 124, 132, 146, 151, 170.
La mediana è il valore di mezzo: 132.
Due viaggiatori guidavano a 124 Km/h, quindi la moda è 124.
16
N pari
Volendo prenotare l’albergo per una settimana bianca in montagna si chiedono i preventivi a sei alberghi. I preventivi sono:366, 327, 274, 292, 274, 230.Riorganizzati per ordine crescente: 230, 274, 274, 292, 327, 366. La mediana è a metà fra i due valori centrali: (274+292) ÷ 2 = 283. Due alberghi hanno chiesto la stessa cifra, la moda è 274.
Vittorio Maniezzo – Università di Bologna

Media e mediana
Se il campione contiene dei valori molto alti o molto bassi, la media tende a venirne distorta.
La mediana non è influenzata da valori molto grandi (o molto piccoli), per cui è una misura migliore si centralità quando la distribuzione è distorta.
Se media=mediana=moda allora i dati sono detti simmetrici.
17Vittorio Maniezzo – Università di Bologna

Quartili e percentili
Utilizzando lo stesso principio dell’ordinamento crescente dei dati e della loro posizione, è possibile definire vari quantili (per esempio, dividendo in 4 intervalli si ottengono i quartili, e così via).
Se si divide in 100 intervalli, si ottengono i percentili.
Per esempio, il 75° percentile è il valore del dato che, nell’ordinamento crescente, ha un posizione tale che:
• il 75% dei dati ha un valore inferiore (cioè rimane a sinistra nell’ordinamento)
• il 25% dei dati ha un valore superiore (cioè rimane a destra nell’ordinamento)
Nota: la mediana è il 2° quartile e il 50° percentile
Vittorio Maniezzo – Università di Bologna18

Quartili e IQRLa mediana divide una distribuzione in due metà.
Il primo e terzo quartile (denotati Q1 e Q3) sono definiti come:
• 25% dei dati sono sotto Q1 (e 75% sopraQ1),
• 25% dei dati sono sopraQ3 (e75% sottoQ3)
L’inter-quartile range (IQR) è la differenza fra il primo e il terzo quartile: IQR = Q3- Q1
Esempio velocità ordinate:
113 124 124 132 146 151 170
Q1 Q3
Inter Quartile Range (IQR): 151-124 = 27
19Vittorio Maniezzo – Università di Bologna
In Excel: manuale (diff. Fra quartili)
In Octave: iqr(X)

Misure di dispersione
Le misure di dispersione caratterizzano quanto il campione è distribuito, quanto sono variabili i dati.
Misure di dispersione di uso comune sono:
1. Range
2. Varianza e deviazione standard
3. Coefficiente di variazione (o deviazione standard relativa)
4. Inter-quartile range (visto prima)
20Vittorio Maniezzo – Università di Bologna

Range (campo di variazione)
Il Range del campione è la differenza fra il valore più grande e il più piccolo nel campione.
Facile da calcolare:
• Esempio velocità: min=25, max=203, quindi range=178 Km/h
Utile per definire scenari, il migliore o il peggiore
Molto sensibile ai valori estremi.
21
In Excel: MAX(dati)-MIN(dati), RANGE (ingl) è un'altra cosa
In Octave: range(X)Vittorio Maniezzo – Università di Bologna

Varianza
22
La varianza, s2, è la media aritmetica del quadrato delle deviazioni rispetto alla media:
>
In Excel: VAR.P(dati), VAR.C(dati)
In Octave: var(x [,opt] )
Nota: un altro stimatore della varianza prevede di dividere per n-1 e non per n. La formula precedente è corretta se la media della popolazione è nota.
Vittorio Maniezzo – Università di Bologna

Deviazione standard
23
La deviazione standard (o scarto quadratico medio), s, è la radice quadrata della varianza
s ha il vantaggio di avere la stessa unità di misura della varibile originaria x
In Excel: DEV.ST.P(dati), DEV.ST.C(dati)In Octave: std(x [,opt] )
Vittorio Maniezzo – Università di Bologna

Esempio
Dati Deviazione Deviazione2
151 13.86 192.02
124 -13.14 172.73
132 -5.14 26.45
170 32.86 1079.59
146 8.86 78.45
124 -13.14 172.73
113 -24.14 582.88
Somma= 960.0 Somma= 0.00 Somma= 2304.86
24Vittorio Maniezzo – Università di Bologna

Il coefficiente di variazione (CV) o deviazione standard relativa (RSD) è la deviazione standard espressa come percentuale della media:
Il CV non è influenzato da variazioni moltiplicative dalla scala, quindi è utile quando si vogliono confrontare dispersioni di variabili misurate su scale diverse
Esempio:
Coefficiente di Variazione
25Vittorio Maniezzo – Università di Bologna

Box-plot
Un box-plot è una rappresentazione visiva di una distribuzione basata su:
• Minimo
• Q1
• Mediana
• Q3
• Massimo
Utile per confrontare grossi insiemi di dati
26
Valore max.
III quartile
Mediana
I quartile
Valore min.
Vittorio Maniezzo – Università di Bologna
In Octave: boxplot(data, notched, symbol, vertical, …)

Esempio
Velocità su strada extraurbana:
62, 64, 68, 70, 70, 74, 74, 76, 76, 78, 78, 80
Q1=(68+70)÷2 = 69,
Q3=(76+78)÷2 = 77
IQR = (77 – 69) = 8
27Vittorio Maniezzo – Università di Bologna

Esempio: confronto fra box-plot
28Vittorio Maniezzo – Università di Bologna

outlier
OutlierUn outlier (estremo, esterno) è una osservazione con valore molto diverso da quelli degli altri dati.
Un outlier può essere dovuto a un problema di misura o può essere indicativo di una sotto/popolazione con valori anormalmente alti o bassi.
Per rappresentarli in un box-plot, si ridefinisconoi limiti inferiori e superiori (delle linee) come:
Limite inferiore= Q1-1.5×IQR
Limite superiore= Q3+1.5×IQR
Le linee potrebbero non arrivare araggiungere questi valori!
Se ci sono dati < limite inf. o > limite sup., sono considerati outlier.
29Vittorio Maniezzo – Università di Bologna

Outlier
Gli outlier possono disturbare le descrizioni:
• Distorcendo la media.
• Aumentando la variabilità.
Eliminazione degli outlier:
• In un campione *normale* i valori campionari dovrebbero essere sempre entro 3 SD dalla media.
• Spesso i valori esterni a 1.5-2 SD sono scartati a priori.
Vittorio Maniezzo – Università di Bologna30

Scatter-plot
Rappresenta la relazione fra due variabili continue
Utile nelle prime fasi di un’indagine, per stabile se può esserci alta correlazione fra le due
Rende evidenti gli outlier
31Vittorio Maniezzo – Università di Bologna

32Vittorio Maniezzo – Università di Bologna
Statistiche inferenziali

Campionamento
Problema: come raccogliere solamente un numero limitato di dati, un campione, e attraverso la loro analisi pervenire a conclusioni generali, che possano essere estese a tutta la popolazione.
Per giungere a queste conclusioni si deve ricorrere all’inferenza: alla capacità di trarre conclusioni generali (sulla popolazione od universo) utilizzando solo un numero limitato di dati variabili (campione).
Vittorio Maniezzo – Università di Bologna 33

Popolazione
campione
Parametri
Statistiche
Politica di campionamento
stima
Stima statistica
Vittorio Maniezzo – Università di Bologna34

Stima statistica
Stima
Stima puntuale Stima a intervalli
media campionariaproporzioni (quantili)
intervallo di confidenza della mediaIntervallo di confidenza delle proporzioni
Le stime puntuali cadono sempre all’interno della stima degli intervalli corrispondenti
Vittorio Maniezzo – Università di Bologna35

Stimatore e stima
Esempio: Quale stipendio si può aspettare un neolaureato al primo impiego?
Si sceglie un campione casuale ad es. di n=5 neolaureati già assunti (a tempo indeterminato!) e si calcola il valore atteso della loro retribuzione. Sia ad esempio stipendio medio in busta paga = € 1100 / mese.
Questa è una stima del salario ipotetico, la media campionaria è uno stimatore del salario.
La stima è il valore assunto dallo stimatore per un campione, cioè in uno specifico punto dell’universo dei campioni
Vittorio Maniezzo – Università di Bologna 36

Distribuzione degli stimatori
Lo stimatore è una variabile casuale connessa all’estrazione casuale di un campione, la stima ottenuta da un campione può essere diversa da quella ottenuta con un altro campione
La stima tende differire dal parametro da stimare, ma se conosciamo la distribuzione campionaria dello stimatore possiamo quantificare probabilisticamente l’errore.
Conoscere la distribuzione serve per descrivere l’andamento dei risultati che si possono osservare replicando il piano di campionamento.
Degli stimatori (distribuzioni) interessa soprattutto valore atteso (media) e varianza.
Vittorio Maniezzo – Università di Bologna 37

Media del campione e media della popolazione
Se da una stessa popolazione si ripete 20 volte un'operazione di campionamento, ogni volta con un diverso campione casuale, si otterranno 20 medie diverse e 20 DS diverse.
Risultato fondamentale: l’insieme di queste medie dei campioni tende ad assumere una distribuzione particolare, detta normale, anche se la popolazione di origine non è distribuita normalmente.
Il processo di campionamento casuale è di per sé un fenomeno che si distribuisce normalmente.
Vittorio Maniezzo – Università di Bologna38

Teorema del limite centrale
Il teorema del limite centrale afferma che, data una certa
popolazione con media μ e DS σ, da cui si estrae un numero infinito di campioni casuali di numerosità n, man mano che n aumenta la
distribuzione delle medie dei campioni tende a una distribuzione
normale, con media μ uguale a quella della popolazione di origine) e DS = � �� .
Qualunque sia la forma della distribuzione della popolazione originale, la distribuzione delle medie dei campioni tende alla distribuzione normale.
Spesso la distribuzione normale viene raggiunta rapidamente, anche per valori non molto grandi di n.
Vittorio Maniezzo – Università di Bologna39

La distribuzione normale
Una distribuzione normale in una variabile X con media µ e varianza σ�è una distribuzione statistica con funzione di probabilità:
� � � 1
2� � ��� �/�����
definita sul dominio x ∈(∞, ∞). Statistici e matematici usano il termine “distribuzione normale”, i fisici talvolta la chiamano “distribuzione Gaussiana” e gli studiosi di scienze sociali si riferiscono ad essa come “curva a campana”.
Vittorio Maniezzo – Università di Bologna40

• L’ascissa rappresenta i valori. L’ordinata rappresenta la densità di
probabilità dei valori. L’area sotto la curva rappresenta l’insieme di tutti i casi possibili, cioè la probabilità totale.
• Le probabilità non sono mai riferite a un punto, ma a un intervallo, e rappresentano il rapporto fra tutti i casi che rientrano in quell’intervallo e il totale dei casi
Distribuzione normale (z)
Vittorio Maniezzo – Università di Bologna 41

In una distribuzione normale : 68.26% dei casi sono compresi fra -1 e +1 DS attorno alla media 95.46% dei casi sono compresi fra -2 e +2 DS attorno alla media 99.74% dei casi sono compresi fra -3 e +3 DS attorno alla media
Distribuzione normale (z)
Vittorio Maniezzo – Università di Bologna 42

Z score
Lo z-score (standard score, normal score) è un modo di trasformare un singolo valore di una distribuzione normale nel suo equivalente standardizzato, specificando di quante DS il valore dista dalla media della popolazione.
Vittorio Maniezzo – Università di Bologna43

Stima di intervalliIntervallo di confidenza (IC)
Fornisce un intervallo di valori al cui interno crediamo, conun certo livello di confidenza, che cada il valore vero
IC per medie di popolazione
Vittorio Maniezzo – Università di Bologna44

-3.0 -2.0 -1.0 0.0 1.0 2.0 3.0
34% 34%14% 14%
2% 2%z
-1.96 1.96-2.58 2.58
Stima di intervalliIntervallo di confidenza (CI)
Vittorio Maniezzo – Università di Bologna45

IpotesiDati per verifica delle ipotesi
Accetta ipotesi Rifiuta ipotesi
C A S O
L’errore casuale (il caso) può essere controllato gestendo la significatività statistica o gli intervalli di confidenza
Errore sistematico
Stima statistica: il ruolo del caso
Vittorio Maniezzo – Università di Bologna46

Test di verifica delle ipotesi
• Il test statistico della verifica delle ipotesi è un processo logico-matematico che porta alla conclusione di non
poter respingere oppure di poter respingere l'ipotesi
della casualità, mediante il calcolo di probabilità di commettere un errore con queste affermazioni.
• L’ipotesi che il risultato ottenuto con i dati sperimentali sia dovuto solo al caso è chiamata ipotesi nulla ed è indicata con H0. Di norma, con essa si afferma che le differenze tra due o più gruppi, quelle tra un gruppo e il valore atteso oppure le tendenze riscontrate siano imputabili essenzialmente al caso.
Vittorio Maniezzo – Università di Bologna 47

Test
Ci si pone il quesito:
Nell'ipotesi che le differenze fra gruppi di osservazioni empiriche siano dovute a fattori esclusivamente casuali, quale è la probabilità che fra tutte le alternative possibili si presenti proprio la situazione descritta dai dati raccolti (o una ancora più estrema)?
Se tale probabilità risulta (relativamente) alta, convenzionalmente uguale o superiore al 5%, si imputeranno le differenze a fattori puramente casuali (accettazione dell’ipotesi nulla).
Al contrario, se la probabilità risulta bassa, inferiore al valore prefissato, si accetta come verosimile che le differenze siano dovute a fattori non casuali (non accettazione dell’ipotesi nulla).
Vittorio Maniezzo – Università di Bologna 48

Esempio
Se gettiamo in aria una moneta per 10 volte consecutivamente abbiamo le seguenti probabilità che esca testa:
testa croce tot. lanci P (%) 10 0 10 0,10 9 1 10 0,98 Ipotesi nulla respinta 8 2 10 4,39 7 3 10 11,72 6 4 10 20,51 5 5 10 24,61 Ipotesi nulla accettata 4 6 10 20,51 3 7 10 11,72 2 8 10 4,39 1 9 10 0,98 Ipotesi nulla respinta 0 10 10 0,10
100
Vittorio Maniezzo – Università di Bologna 49

Errori di tipo 1 e di tipo 2
• Si commette un errore di tipo 1, quando si respinge un ipotesi nulla che in effetti è vera;
• si commette un errore di tipo 2, quando si accetta un ipotesi nulla che in effetti è falsa.
• La probabilità di commettere un errore di tipo 1 viene indicata con α e quindi la situazione complementare (ovvero di non sbagliare, accettando un ipotesi nulla che è vera) ha probabilità (1 - α).
• La probabilità di commettere un errore di tipo 2, viene invece indicata con β e quindi la situazione complementare (ovvero di non sbagliare, scartando un ipotesi nulla che è falsa) ha probabilità (1 - β).
Vittorio Maniezzo – Università di Bologna50

Errori di tipo 1 e di tipo 2
• Errore di tipo 1 è l’errore che si commette rifiutando l’ipotesi nulla quando è vera
È un risultato Falso positivo
La probabilità di commettere un tale errore è data dal livello di
significatività statistica α
• Errore di tipo 2 è l’errore che si commette accettando l’ipotesi nulla quando è falsa
È un risultato Falso negativo
La probabilità di commettere un tale errore è indicata con β.
La probabilità di prendere una decisione corretta rifiutando l’ipotesi nulla quando è falsa è 1- β e si chiama potenza del test
Vittorio Maniezzo – Università di Bologna51

Test di ipotesi: errori di tipo I e II
α: livello di significatività 1-β: potenza del test
Vittorio Maniezzo – Università di Bologna52

Test di ipotesi: errori di tipo I e II
La probabilità di commettere un errore di tipo I (α) può essere ridotta cambiando il livello di significatività.
α =0.05
Ci sono solo 5 possibilità su 100 che il risultato sia classificato come "significativo" per puro caso
sarà più difficile avere un risultato significativo
la potenza del test verrà ridottaIl rischio di un errore di tipo II crescerà
La probabilità di commettere un errore di tipo II (β) può essere ridotta aumentando il livello di significatività.
Aumenterà la probablità di un errore di tipo IVittorio Maniezzo – Università di Bologna 53

Errori
Vittorio Maniezzo – Università di Bologna54

Errori
• Se l’ipotesi nulla è falsa allora qualche altra ipotesi, H1, deve essere vera. Se non siamo in grado di specificare questa ipotesi alternativa, non è possibile determinare la probabilità di commettere un errore di tipo II.
• Spesso non è possibile individuare una unica ipotesi alternativa, per cui si considera solo il livello di significatività α, senza fissare β: si ritiene più opportuno cautelarsi nei confronti del tipo di errore più grave, quello di tipo I.
• Questo valutazione è motivata dal fatto che mentre il rifiuto di H0 implica che sia vera l’ipotesi alternativa, la sua accettazione implica che “non ci sono elementi sufficienti per rifiutarla”.
Vittorio Maniezzo – Università di Bologna 55

Conservatività
Nessun risultato è in assoluto impossibile nei confronti di H0 (ma solo più o meno probabile), quindi ogni volta che la si rifiuta si corre il rischio di fare un errore di tipo I con una probabilità α, livello di significatività di solito fissato al 5% (0,05) o al 1% (0,01), e per la stessa ragione ogni volta che si accetta si corre il rischio opposto (errore di tipo II).
I test di verifica dell’ipotesi ci consentono di prendere una decisione con una predeterminata probabilità di sbagliare (livello di significatività β, o di non sbagliare, livello di protezione 1 - β ).
Test con alto livello di protezione sono anche detti più conservativi.
Vittorio Maniezzo – Università di Bologna 56

Procedura per un test d’inferenzaI – IPOTESI
Ipotesi nulla, ipotesi alternativa
II - RACCOLTA DEI DATI
Tipo di scala; caratteristiche della distribuzione dei dati
III - SCELTA DEL TEST
Sulla base dell'ipotesi, del tipo di scala e delle caratteristiche dei dati
IV - RISULTATO DEL TEST- PROBABILITA'
Probabilità di ottenere quel risultato, nella condizione espressa dall'ipotesi nulla
V – DECISIONE - SCELTA TRA LE DUE IPOTESI
Probabilità α
VI – ANALISI DEL TEST E DEI DATI PER UN NUOVO ESPERIMENTO
Potenza a posteriori e a priori, probabilità βVittorio Maniezzo – Università di Bologna 57

Test: relazioni fra variabili
1) Relazioni fra variabili:
Esempi: correlazione, regressione.
2) Differenze fra variabili:
es. Test su differenza di efficacia di approcci risolutivi diversi
Esempi: t-test; Analysis of Variance (ANOVA), Wilcoxon, ...
Vittorio Maniezzo – Università di Bologna58

Test: tipi di testPrincipale distinzione fra test parametrici i non-parametrici
Test Parametrici sono basati su assunzioni sulla distribuzione dei parametri della popolazione. Di solito si assume una distribuzione normale (Gaussiana). I test parametrici sono i più potenti, ma possono essere fuorvianti se le ipotesi di base non sono soddisfatte.
Test non-parametrici non fanno assunzioni sulla distribuzione della popolazione (sono anche chiamati test liberi da distribuzione, distribution free tests). Di solito basati sui ranghi delle
osservazioni, cioè sul loro numero d'ordine invece che sulle osservazioni in se'.
Hanno minore potenza e sono meno flessibili dei test parametrici.
Vittorio Maniezzo – Università di Bologna59

Test: tipi di test
Test non parametrici sono giustificati quando:
1) le variabili hanno evidenti scostamenti dalla normalità (o sono fortemente asimmetriche o presentano più di un picco);
2) quando il campione è troppo piccolo per comprendere se esiste una distribuzione normale dei dati;
3) quando le osservazioni sono rappresentate da classifiche ordinali (es. gravità di una malattia da 1 a 4).
Vittorio Maniezzo – Università di Bologna60

Scelta di un test statistico
Griglia per la scelta:
1. Tipo di dati:
2. Se dati di frequenza, allora test della famiglia del Chi-quadro.
3. Altrimenti, interessano relazioni fra variabili o differenze fra gruppi?
4. Se relazioni fra variabili, allora test di correlazione.
5. Se differenze fra gruppi, allora ANOVA. t di Student, ….
6. In ogni famiglia, ci sono test equivalenti parametrici e non parametrici.
Vittorio Maniezzo – Università di Bologna61

Parametric: Non-param:Pearson's r Spearman's r
Point biserialPhi-coefficient
Vittorio Maniezzo – Università di Bologna
Differences ? Relationships ?
1 or 2 sample Chi-square
How many variables?
START
FrequencyData?
Same orDifferent
participants in each condition?
Two or more
Parametric: Unrelated t-testNon-param:Mann Whitney
Different
How many experimental conditions?
One
Factorial Within Subjects (Repeated Measures) ANOVA
Same
Factorial Mixed Design (Split-Plot)
ANOVA
Both True
Different
Factorial Between Groups ANOVA
3 or moreSame orDifferent
participants in each condition?
TwoSame orDifferent
participants in each condition?
Parametric: Non-param:Oneway FriedmanWithin Ss or(Repeated Page’s Lmeasures) Trend TestANOVA
Same
Different
Parametric: Non-param:Oneway Kruskal-Between Wallis orGroup JonckheereANOVA Trend Test
Same
Parametric: Non-Param:Related Wilcoxont-test
Flowchart
62

Test di ipotesi: il valore p
95%
2.5%
2.5%
La probabilità di avere un valore all’esterno dell’intervallo delle linee verdi se l’ipotesi nulla è vera è < 5%
Vittorio Maniezzo – Università di Bologna63

Test di ipotesi: il valore p
p = probabilità di osservare un valore più estremo di quello considerato, se l’ipotesi nulla è vera
Minore è il valore p, maggiore è la possibilità che l’ipotesi nulla sia una spiegazione dei dati
Nell’esempio:
• Risultati esterni alle linee verdi: p<0.05,
• Risultati interni alle linee verdi: p>0.05
Vittorio Maniezzo – Università di Bologna64

Il valore dell’ipotesi nullainterno all’intervallo 95%
Il valore dell’ipotesi nullaesterno all’intervallo 95%
p > 0.05
p < 0.05
Accettata l’ipotesi nulla
Rifiutata l’ipotesi nulla
Test di ipotesi: intervalli di confidenza e significatività
Vittorio Maniezzo – Università di Bologna65

Test di normalità: metodo 1 (rude)
1. Necessario un campione sufficientemente ampio, bene almeno 50 punti
2. Calcolare media (A), mediana (M), range (R), e deviazionestandard (σ) del campione.
3. A e M devono essere vicini, < 1% di R. (distrib. normale è simmetrica, A = M). Se molto diversi, distribuzione non normale.
4. Regola 68-95-99.7: in una distribuzione normale, 68% dei dati sono entro σ da A, il 95% entro 2σ, il 99.7% entro 3σ.
5. Se passi 3 e 4 soddisfatti, la distribuzione del campione potrebbe essere normale.
6. Bisognerebbe usare test più affidabili, come i test di Kolmogorov-Smirnov, Anderson-Darling, o Shapiro-Wilk.
Vittorio Maniezzo – Università di Bologna 66

Test di normalità: metodo 2 (rude)Altro modo immediato e rude: confronto dell'istogramma dei dati con la curva normale. Facile da fare in Excel.
Si ordinano i dati, li si raggruppa arbitrariamente (in "bins"). In Excel necessari i limiti inferiori di ogni bin.
In Excel bisogna attivare il componete aggiuntivo "Analisi dati", quindi scegliere istogramma. Inserire la serie dati in "intervallo di input" e la serie bins in "Intervallo della classe". Checkare "Grafico in output" e si ha una cosa del tipo:
Confrontare con una normale con la stessa media e DS:
Vittorio Maniezzo – Università di Bologna 67

Test di normalità: metodo 3 (rude)IDEA: i dati distribuiti normalmente hanno la stessa area compresa fra due dati successivi. Es., 7 punti, l'area sotto la curva fra due punti successivi è 1/7 dell'area totale.
In Excel, si può avere l'area sottesa fino a un punto x usando la Cumulative Distribution Function (CDF) :
CDF = DISTRIB.NORM.N(x, media, Standard Deviation, TRUE )
L’area nell'intervallo fra due punti successivi è la differenza delle relative CDF.
Esempio, dati -4 -3 0.8 1.8 3.9 6.2 6.5 (ordinati!)
Vittorio Maniezzo – Università di Bologna 68
Stessa area
sottesa

Test di normalità: metodo 3 (rude)
Vittorio Maniezzo – Università di Bologna 69
SI calcolano n (7), media (1.74), e DS (4.15) della colonna DATI.
• Si aggiunge una colonna CDFNORM con le CDF di n dati distribuiti normalmente. La CDF della media vale 0.5 (ovviamente). Le CDF degli altri dati sono centrate sulla media (0.5) e poi separate di 1/n
• Si aggiunge una colonna CDFNORMZ con le CDF dei dati in CDFNORM trasformate in z score tramite:
INV.NORM.S(CDFNORM)
• Si aggiunge una colonna DATINORM, con i dati normali adattatati ai parametri campionari:
INV.NORM.N(CDFNORM, media camp., dev.st. camp.)

Test di normalità: metodo 3 (rude)Il test si effettua plottando in un grafico (a dispersione) i valori dei dati reali (DATI) e quelli normali (DATINORM) verso gli z score (CDFNORMZ).
Nel grafico, i DATI dovrebbero approssimare la retta generata dai DATINORM.
Vittorio Maniezzo – Università di Bologna 70
Grafico: 1) inserisci grafico 2) mouse dx seleziona dati 3) voci aggiungi 4) modifica serie

Gradi di libertàil numero di punteggi, elementi o altre unità nei dati in ingresso, che sono liberi di variare,Spesso pari al numero di osservazioni meno 1.
Test su una o due codeI test su una coda sono usati per ipotesi già orientateI test su due code in tutti gli altri casi
Parametri caratterizzanti un test
Vittorio Maniezzo – Università di Bologna71

Distribuzione t di Student
Famiglia di distribuzioni al variare di k = gradi di libertà
Vittorio Maniezzo – Università di Bologna72

Distribuzione t di Student
Utilizzata se la varianza della popolazione non è nota (non lo
è quasi mai). La si stima con �∑ ���� �
���. Si passa da z a t.
La distribuzione t somiglia molto alla distribuzione Z, tranne che ha le code un po’ più pronunciate, a riflettere l’incertezza aggiunta dal processo di stima.
Maggiore è la dimensione del campione (quindi il numero di elementi usati per stimare σ), e maggiore è la somiglianza di t con Z.
Se n>50, t e Z sono molto simili.
Vittorio Maniezzo – Università di Bologna73

Distribuzione t di Student
t0
t (n = 5)
t (n = 13)Le distribuzioni t hanno forma a campana, ma con code maggiori di quelle della normale
Normale Standard
(t con n = ∞)
Nota: t → z se n cresce
Vittorio Maniezzo – Università di Bologna74

Distribuzione t di Student
La distribuzione t:
• Approssima la normale se n>100.
• Può essere utilizzata al posto della normale se la dimensione del campione è abbastanza ampia.
• Riflette l’incertezza introdotta dall’uso della deviazione standard del campione, invece che di quella della popolazione.
Vittorio Maniezzo – Università di Bologna75

T test
Il test t di Student si usa per verificare se c'è stato effetto da una operazione (dati accoppiati, misurando prima e dopo) o comunque per verificare se due gruppi (campioni) sono diversi.
Confronta due medie e dice se sono significativamente diverse. Si calcola un valore di t funzione della differenza di medie e varianze. Più è alto t più è probabile che le medie siano diverse.
In generale
t = (differenza fra medie) / (Variabilità dei gruppi)
La specifica formula dipende dal tipo di test, ce ne sono molti
Vittorio Maniezzo – Università di Bologna 76

t-test a una o due code
Nel test ad una coda, la zona di rifiuto è solamente da una parte della distribuzione (a sinistra quando il segno è negativo, a destra quando è positivo)
Nel test a due code, la zona di rifiuto è distribuita dalle due parti
Il test a due code è più conservativo (vi si ricorre quando non si ha alcuna idea sui possibili risultati) mentre il test ad una coda è più potente
Vittorio Maniezzo – Università di Bologna77
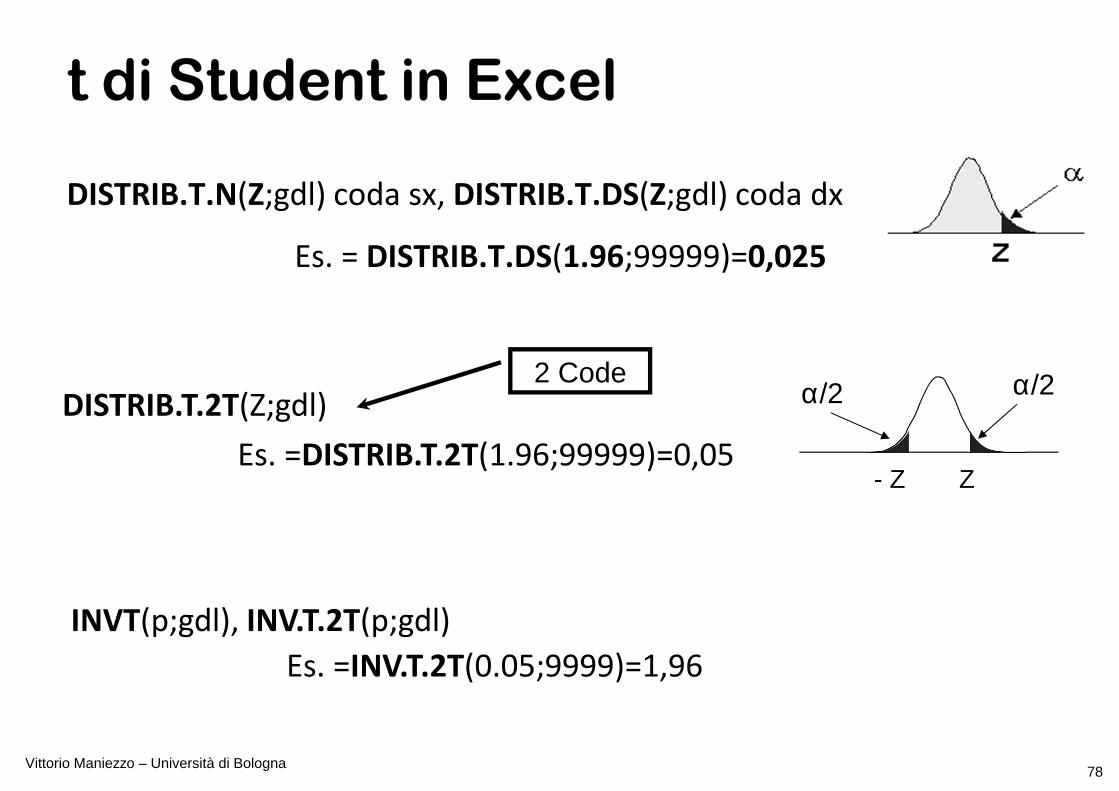
t di Student in Excel
DISTRIB.T.N(Z;gdl) coda sx, DISTRIB.T.DS(Z;gdl) coda dx
Es. = DISTRIB.T.DS(1.96;99999)=0,025
INVT(p;gdl), INV.T.2T(p;gdl)
Es. =INV.T.2T(0.05;9999)=1,96
DISTRIB.T.2T(Z;gdl)
Es. =DISTRIB.T.2T(1.96;99999)=0,05- Z Z
α/2α/22 Code
Vittorio Maniezzo – Università di Bologna78

Esempi valori critici di t
Coda di destra
gdl .25 .10 .05
1 1.000 3.078 6.314
2 0.817 1.886 2.920
3 0.765 1.638 2.353
t0 2.920
Le celle contengonovalori di t, non
probabilità
Dati: n = 3 gdl = n - 1 = 2 α = 0.10α/2 = 0.05
α/2 = .05
Vittorio Maniezzo – Università di Bologna79

Confronto fra una media campionaria e la media dellapopolazione completamente nota.
Es., è noto che il peso di un maschio adulto ha una media di 70.0 kg e una deviazione standard di 4.0 kg (media della popolazione µ= 70.0 e deviazione standard della popolazione σ= 4.0).
Dati di un campione di 28 ragazzi presi a caso in spiaggia : peso medio 67.0 kg e deviazione standard 4.2 kg.
Domanda: in spiaggia ci vanno i più magri?
Formula (gdl = n-1) t = �̅ � ��
���
Test parametrici: t-test fra ungruppo e popolazione nota
Vittorio Maniezzo – Università di Bologna80

Media della popolazione, µ= 70.0 Dev. standard popolazione, σ= 4.0
Dimensione campione n= 28
Media campionaria, �̅ = 67.0
Dev. standard campione, s= 4.2
Ipotesi nulla, H0 = non c’è differenza fra media campionaria e
media della popolazione.
Dalla formula ( � � ��̅ − ��/(� ⁄ ) ), t = -3.77964, lo si
confronta con il valore critico INVT(0.05,27) = -1.703288446 (una
coda perché testo solo se più magri, entrambi negativi non
importa tanto distribuzione simmetrica)
L’ipotesi nulla è rifiutata con un livello di confidenza del 5%
t-test su un gruppo, in Excel
Vittorio Maniezzo – Università di Bologna81

t test fra due gruppi
Formula della distribuzione
t = "#$%& $%''#(#�)# '(& *+,,%#
�-./01./�22030�40 50/�0�
= �̅6 � �̅�
�6�
�67
���
��
(con � = � se appaiati)
Il valore di t è il valore della funzione di distribuzione calcolato in corrispondenza dell'x di interesse.
Il test può essere a due code (più stringente, incertezza suddivisa) o a una coda (meno stringente, incertezza tutta da una parte).
Vittorio Maniezzo – Università di Bologna 82

t test fra due gruppi
• Nel t-test per campioni indipendenti (unpaired) si confrontano due campioni che si riferiscono a due gruppi di soggetti diversi (per esempio risultati ottenuti su uno stesso problema da algoritmo A o algoritmo B): between-subject design.
• Nel t-test per campioni appaiati (paired) i due campioni si riferiscono a due diverse misurazioni dello stesso parametro nello stesso gruppo di soggetti (per esempio una soluzione prima e dopo la ricerca locale). In questo caso ci saranno due misurazioni per ogni soggetto, e quindi la numerosità dei due campioni è necessariamente uguale:within-subject design.
Vittorio Maniezzo – Università di Bologna83

Esempio: t test su due gruppi
Nel 1980, una ricerca ha riportato che “i maschi hanno maggiori competenze matematiche delle femmine” come risulta dai dati SAT (Scholastic Aptitude Test, v. http://www.erikthered.com/tutor/sat-act-history.html) del 1979, dove un campione 30 ragazzi ha avuto un punteggio (media ± dev.st.) di 436±77, mentre 30 ragazze ha avuto 416±81.
Conclusioni corrette?
Metodologia:• Tipo di variabile? Continua• Distribuita (abbastanza) normalmente? Si• Osservazioni correlate? No• Numero di campioni da confrontare? due� t test su due campioni
Vittorio Maniezzo – Università di Bologna84

t testIpotesi: H0: ♂-♀ SAT = 0, H1: ♂-♀ SAT ≠ 0 [due code]
Dalla formula: t = 0.980188051
t critico (gdl = 58, 60-2) = INV.T.2T(0.05,58) = 2.001717484
t < t critico, H0 accettata
Vittorio Maniezzo – Università di Bologna85

t test appaiati: esempio 1 in excel
SI considera una ricerca locale su un problema di max. Prima della ricerca (10, 3, 5, 6, 3, 5) dopo (12, 15, 9, 7, 9, 6)
Poi componente aggiuntivo -> strumenti di analisi -> test t, due campioni accoppiati per medie
Media ipotizzata: 0 (ipotesi nulla, 0), alfa 0.05 (o 0.01).
Si ottiene
Vittorio Maniezzo – Università di Bologna 86

t test: esempio in excel
Risultati: il valore di t è 2.511.
Test a una coda
Il t è maggiore del t critico a una coda (2.015). Quindi con il 95% di certezza la differenza è significativa.
Stessa conclusione via p-value, che per una coda è 0.027 (< 0.05).
Test a due code
Qui ciascuna delle code ha una regione critica pari al 2.5% dell'area totale. Il t non è abbastanza grande per essere posizionato nel 2.5% più esterno: t = 2.511 < 2.571 (valore critico a due code).
Analogamente, p-value = 0.054 > 0.05 (alpha del test).
Vittorio Maniezzo – Università di Bologna 87

t test appaiati: esempio 2 in excel
88
Ancora confronto fra due algoritmi, qui uno provato su set di istanze diverse (congruenti).
Alg. A Alg. B Test t: due campioni assumendo varianze diverse1 639 650
2 646 633 Alg. A Alg. B
3 650 631 Media 643.8 637
4 641 637 Varianza 54.4 39.6
5 641 642 Osservazioni 10 11
6 637 638 Differenza ipotizzata per le medie 0
7 659 640 gdl 19
8 650 634 Stat t 2.261646
9 640 626 P(T<=t) una coda 0.018167
10 635 636 t critico una coda 1.734064
11- 640 P(T<=t) due code 0.036334
Medie 643.8 635.7 t critico due code 2.100922
Vittorio Maniezzo – Università di Bologna

t di Student in Excel
t = 2.261646.
• Confrontando t con il t critico per 19 gradi di libertà (gdl = num. dati – num. gruppi; 21-2=19) il valore è superiore a quello della colonna p=5%. Si rifiuta l'ipotesi zero, la differenza è significativa per p<0.05. Ciò significa che c'è una probabilità inferiore al 5% che la differenza sia dovuta al caso.
• Inoltre p=0.036334 (due code). Ciò significa che c'è una probabilità inferiore a 3.64% che la differenza sia dovuta al caso. Si può affermare che la differenza sia significativa per p=0.0344, quindi è significativa allo 0.05, ma non (ad. es.) allo 0.01.
Vittorio Maniezzo – Università di Bologna 89

Test non parametrici: dati ordinali
Gruppi correlati
• Wilcoxon matched-pairs signed rank test: confronto fra due gruppi
• Friedman matched samples: confronto fra due o più gruppi
Gruppi indipendenti
• Mann-Whitney U : confronto fra due gruppi
• Kruskal-Wallis H: confronto fra due o più gruppi
Vittorio Maniezzo – Università di Bologna90

Test non parametrici: Wilcoxon signed rank test
Domanda: c'è differenza di qualità fra i risultati prodotti da un algoritmo A e quelli di un algoritmo B?
Tipo di variabile da confrontare? Continua
Distribuita normalmente? No (e n piccola)
Quanti gruppi sono coinvolti? due
� Wilcoxon sum-rank test
Due variabili correlate, nessuna assunzione sulle loro distribuzioni.
Ipotesi nulla: le due variabili hanno la stessa distribuzione
Il test è basato sulla grandezza delle differenze fra coppie, e dà più peso alle coppie che hanno una differenza grande.
Considera i ranghi dei valori assoluti delle differenze fra due variabili
Vittorio Maniezzo – Università di Bologna91
Se normalet di Student

Test di WilcoxsonTest molto semplice: si ordinano i dati dei gruppi e si sommano le posizioni (rank) di ciascuno quando è migliore.
Idea: si sommano a turno i rank degli ordinamenti in cui uno dei due gruppi supera l'altro. Più le somme sono diverse, più i gruppi saranno diversi. Se gruppi simili, le posizioni alte e basse nell’ordinamento saranno equamente suddivise, se diversi uno tutte differenze basse e uno tutte alte.
La statistica del test di Wilcoxon W è la più piccola delle due somme. Più W è bassa meno è probabile che la differenza sia dovuta al caso. Se bassa uno va sempre meglio.
Una tabella di valori critici indica la probabilità di ottenere ogni particolare valore di W solo per caso. (Nota: Wilcoxon è atipico. Di solito, maggiore è la statistica, minore è la prob. di averla avuta per caso. Qui l’inverso).
Vittorio Maniezzo – Università di Bologna 92

1. Calcola le differenze (col segno) dei valori in ogni coppia di dati corrispondenti.
2. Ordina le differenze, ignorando il segno (val. assoluto). Ignora le differenze pari a 0. Minimo = 1. Differenze uguali hanno rank uguale alla media delle posizioni corrispondenti. Somma i rank positivi (nell’es. = 22, A meglio di B) e somma i rank negativi (es.= 6, B meglio di A).
3. W è la somma minima; es. W = 6. N è il numero di differenze, senza considerare quelle nulle. Es. N = 8 - 1 = 7.
4. Usa la tabella per trovare il valore critico di W, dato N. Il valore di W deve essere uguale o minore al valore critico per essere statisticamente significativo.
Wicoxson
Vittorio Maniezzo – Università di Bologna93

Tabella
Vittorio Maniezzo – Università di Bologna94
Se il campione più alto contiene più di venti elementi, la distribuzione di W si approssima alla normale con questi parametri:

Stessi dati, ricopiabili
Vittorio Maniezzo – Università di Bologna 95
Wilcoxon Signed-Ranks TableCritical Vaues for 2-tail significance levels
nalpha
0.10 0.05 0.02 0.01
5 06 2 07 3 2 08 5 3 1 09 8 5 3 1
10 10 8 5 311 13 10 7 512 17 13 9 713 21 17 12 914 25 21 15 1215 30 25 19 1516 35 29 23 1917 41 34 27 2318 47 40 32 2719 53 46 37 3220 60 52 43 3721 67 58 49 4222 75 65 56 4823 83 73 62 5424 91 81 69 6125 100 89 77 68

Due algoritmi che individuano quanti camion servono per trasportare un insieme dato di bancali (soggetti a vincoli operativi). 8 istanze diverse
Esempio, test di Wilcoxon
Istanza Alg. A Alg. B Differenza Rank
1 15 10 5 4.5
2 12 14 -2 2.5
3 11 11 0 Ignora
4 16 11 5 4.5
5 14 4 10 6
6 13 1 12 7
7 11 12 -1 1
8 8 10 -2 2.5
Media: 12.5, DS: 2.56
Mediana: 12.5 Mediana: 10.5Vittorio Maniezzo – Università di Bologna
96

Il valore critico di W per N = 7 è 2. Il valore calcolato W = 6 è maggiore di quello critico.I due gruppi non sono quindi significativamente diversi.
Conclusione: i due algoritmi hanno una efficacia equivalente.
Esempio, test di Wilcoxon
Vittorio Maniezzo – Università di Bologna97

Esempio 2
Il valore di W è sufficiente per ritenere che vi sia un effetto significativo della ricerca?
Confronto fra risultati ottenuti su 5 istanze da un algoritmo che implementa una ricerca locale di raffinamento
Vittorio Maniezzo – Università di Bologna98

Test di significatività parametrici e non parametrici
Vittorio Maniezzo – Università di Bologna99



![Octave - isi-personale.csr.unibo.itisi-personale.csr.unibo.it/vittorio.maniezzo/didattica/IntArt/... · Indicizzazione elementi octave> x = [1, 2, 3; 4, 5, 6; 7, 8, 9] octave> x(2)](https://static.fdocuments.net/doc/165x107/5c6a2dfa09d3f27a7e8c49a9/octave-isi-indicizzazione-elementi-octave-x-1-2-3-4-5-6-7-8-9.jpg)














