
4 Lexical Analysis
60
1 Programming Language Translators Unit 1 - Part2 : Lexical Analysis
-
Upload
vivek-shah -
Category
Documents
-
view
263 -
download
0
Transcript of 4 Lexical Analysis

1
Programming Language Translators
Unit 1 - Part2 : Lexical Analysis

2
Contents
• The role of the lexical analyzer
• Specification of tokens – Regular Expression
• Recognition of tokens – Finite State Machines
• From a Regular Expressions to an NFA – Thomson Construciton
• Convert NFA to DFA – Subset Construction
• Minimizing DFA
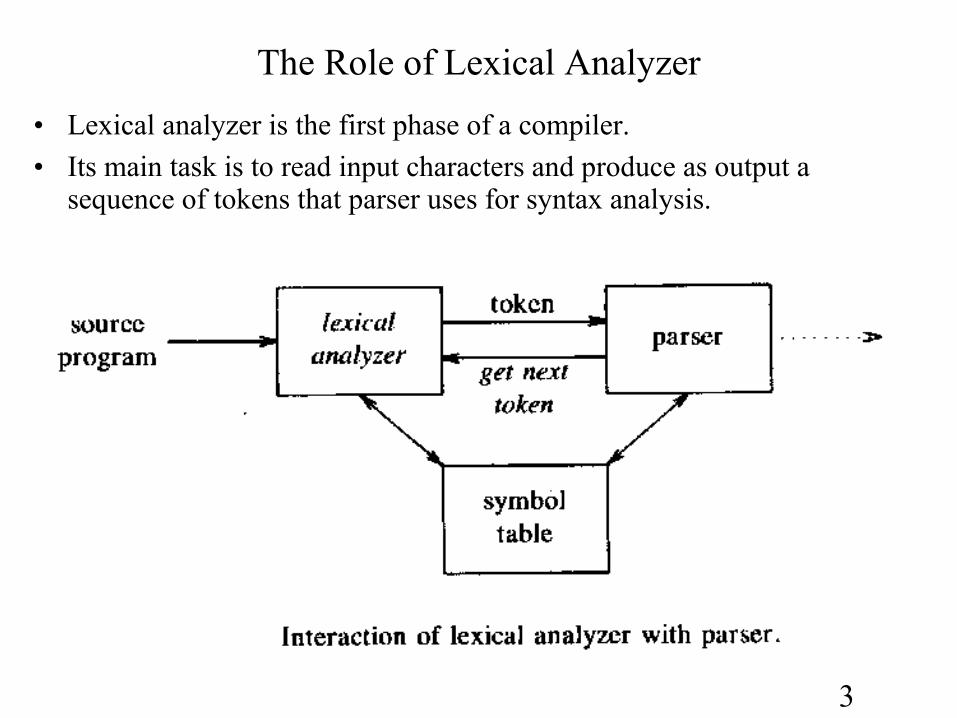
3
The Role of Lexical Analyzer
• Lexical analyzer is the first phase of a compiler.
• Its main task is to read input characters and produce as output a sequence of tokens that parser uses for syntax analysis.

Functions of Lexical Analyzer
Scans the source program character by character Produce the stream of tokens after recognizing them Identifies the lexical errors Eliminates the white space and comments It generates the symbol table It keeps track of line number It reports error encountered while generating the tokens

5
Issues in Lexical Analysis
• There are several reasons for separating the analysis phase of compiling into lexical analysis and parsing:
– Simpler design
– Compiler efficiency
– Compiler portability
Simpler design
Lexical and Syntax analysis are separated for simplifying the work of the parsing phase
Ex: Comments and white spaces are eliminated in lexical analysis

6
Issues in Lexical Analysis
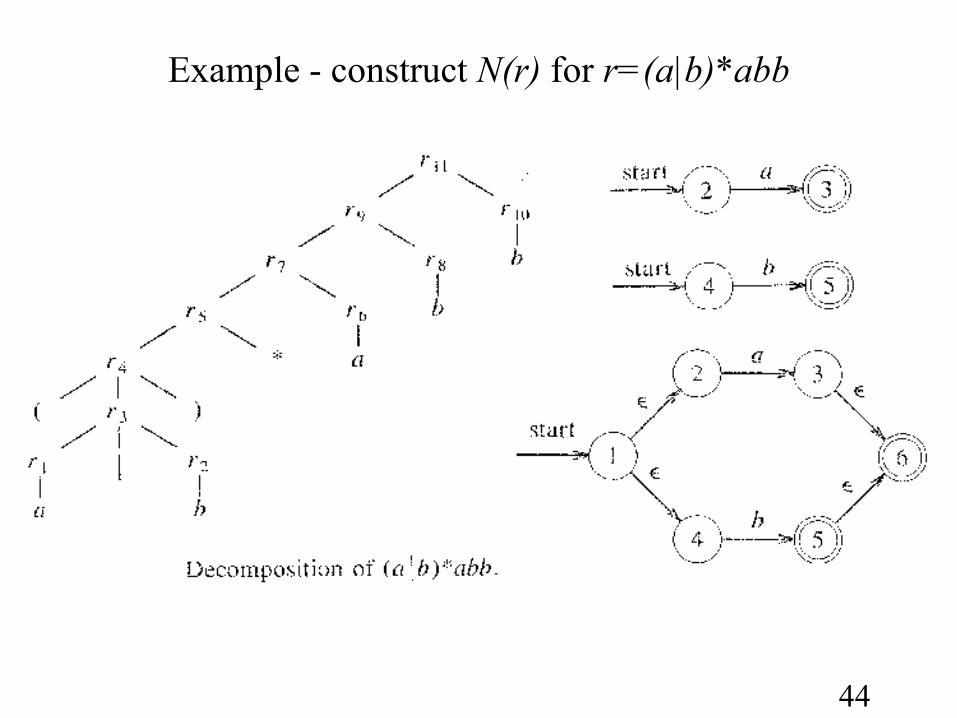
Improve the efficiencyLarge amount of time is spent on reading the source file and it could
be inefficient if each phase has to read the source file
Increase the efficiency ,lexical analyzer use the INPUT
BUFFERING technique
Enhanced portability
Input alphabet peculiarities and other device specific anomalies can be restricted to the lexical analyzer
The Representation of special or non standard symbol can be isolated in the lexical analyzer
Ex: ‘↑’ in Pascal can be isolated

7
Tokens, Patterns, Lexemes
• A lexeme is a sequence of characters in the source program that is matched by the pattern for a token.
• A lexeme is a basic lexical unit of a language comprising one or several words, the elements of which do not separately convey the meaning of the whole.
• The lexemes of a programming language include its identifier, literals, operators, and special words.
• A token of a language is a category of its lexemes.
• A pattern is a rule describing the set of lexemes that can represent as particular token in source program.

8
Examples of Tokens

9
Example 1
• If ( a < b )
Token Lexeme Pattern
Keyword if If, int, float,for,while…….
Spl. Symbol ( Any punctuation or special symbols
identifier a Letter followed by letter or digit
Re_op < =,<,<=,>,>=,!=
identifier b Letter followed by letter or digit
Spl. Symbol ) Any punctuation or special symbols
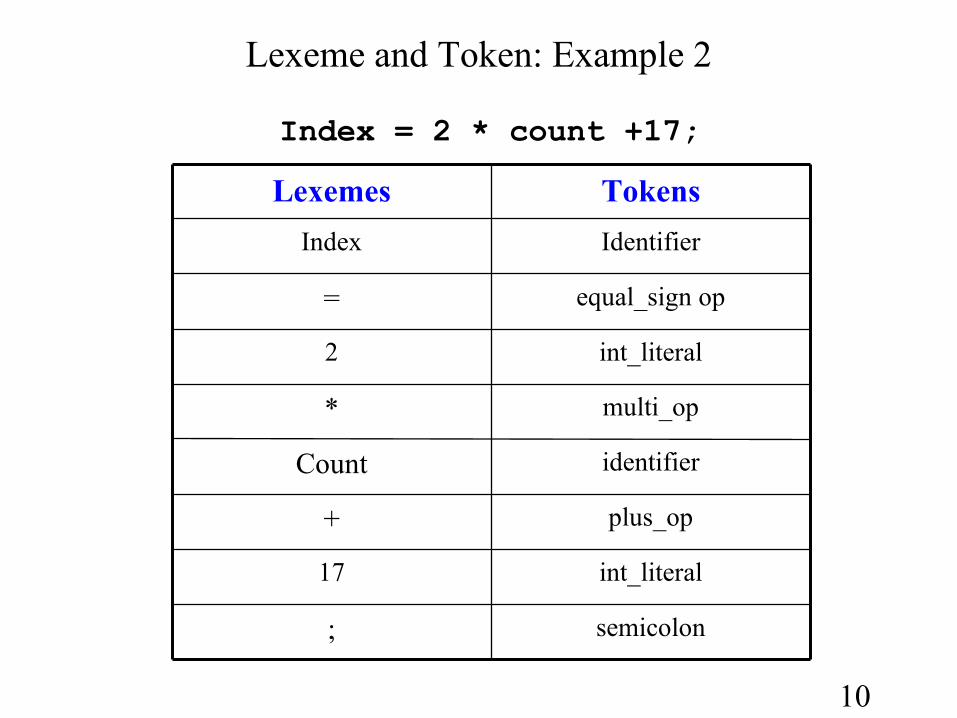
10
Lexeme and Token: Example 2
semicolon;
int_literal17
plus_op+
identifierCount
multi_op*
int_literal2
equal_sign op=
IdentifierIndex
TokensLexemes
Index = 2 * count +17;

11
Token attributes
When more than one pattern matches a lexeme, a lexical analyzer must provide additional information about particular lexeme that match to the subsequent phase of the compiler.
Example:
E = M * C ** 2• <id, pointer to symbol table entry for E>
• <assign-op>
• <id, pointer to symbol table entry for M>
• <mult-op>
• <id, pointer to symbol table entry for C>
• <exp-op>
• <number, integer value 2>

12
Lexical Errors
• Few errors are discernible at the lexical level alone, because a lexical analyzer has a very localized view of a source program.
• Let some other phase of compiler handle any error.
• Panic mode
• Error recovery

13
Lexical Errors
Some errors are identified and rectified at lexical level alone
Ex: c=*ab + 10; this type of error is identified and rectified at lexical level with help of “panic mode” technique(delete successive characters from the remaining input until the lexical analyzer can find a well-formed token)
Lexical analysis can’t identify some appearances
Ex: fi(x==10) : here fi is consider as a valid token
Other error recovery actions Deleting an extraneous characters Inserting a missing character Replacing an incorrect character by a correct character Transposing two adjacent characters

There are three general approaches to the implementation of a lexical analyzer.
1. Use a lexical analyzer generator
2. Write the lexical analyzer in a conventional programming language
3. Write the lexical analyzer in assembly language.
In one buffer technique, the last lexeme under process will be over-written when we reload the buffer.
Two-buffer scheme handling large look ahead safely
• We use a buffer divided into two N-characters halves.
Input Buffering

Two buffers of the same size, say 4096, are alternately reloaded.Two pointers to the input are maintained:
Pointer lexeme_Begin marks the beginning of the current lexeme.
Pointer forward scans ahead until a pattern match is found.
Buffer Pairs

If forward at end of first half then begin
reload second half;
forward:=forward + 1;
End
Else
if forward at end of second half then begin
reload first half;
move forward to beginning of first half
End
Else forward:=forward + 1;
Code to advance forward pointer

Sentinels
E = M * eof C * * 2 eof eof
If we use the input buffer scheme, we must check each time we move the forward pointer that we have noot moved off one half of the buffer.If we do then we must reload the other half.We can reduce the two tests to one if we extend each buffer half to hold a sentinel character at the end.The sentinal is a special character that can not be part of the source programA natural choice is eof.

forward:=forward+1;
If forward ^ = EOF then begin
If forward at end of first half then begin
reload second half;
forward:=forward + 1;
End
Else if forward at end of second half then begin
reload first half;
move forward to beginning of first half
End
Else terminate lexical analysis;
Lookahead code with sentinels

19
Specification of Tokens
• Tokens are specified by Regular Expression.
• Regular expressions are an important notation for specifying patterns.
• We have to discuss the following:– Operation on languages
– Regular expressions
– Regular definitions
– Notational shorthands

20
LanguagesAlphabet : a finite set of symbols
String : • Finite sequence of symbols on an alphabet• Sentence and word are also used in terms of string• ε is the empty string• |s| is the length of string s.
Language: Sets of strings over some fixed alphabet ∅ the empty set is a language. {ε} the set containing empty string is a language The set of well-formed C programs is a language The set of all possible identifiers is a language.

21
Operations on Languages

22
Regular Expressions
• Regular expression is a compact notation for describing string.
• In Pascal, an identifier is a letter followed by zero or more letter or digits
letter(letter |digit)*
• |: or
• *: zero or more instance

23
Rules
• ε is a regular expression that denotes {ε}, the set containing empty string.• If a is a symbol in Σ, then a is a regular expression that denotes {a}, the set
containing the string a.• Suppose R and S are regular expressions denoting the language L(R) and L(S),
then
– (R) |(S) is a regular expression denoting L(R)∪L(S).
– (R).(S) is regular expression denoting L (R).L(S).
– (R)* is a regular expression denoting (L(R))*.
– (R) is a regular expression denoting L(R).

24
Precedence Conventions
• The unary operator * has the highest precedence and is left associative.
• Concatenation has the second highest precedence and is left associative.
• | has the lowest precedence and is left associative.
• (a)|(b)*(c)→a|b*c

25
Example of Regular Expressions

26
Properties of Regular Expression

27
Regular Definitions
• To write regular expression for some languages can be difficult, because their regular expressions can be quite complex. In those cases, we may use regular definitions.
• If Σ is an alphabet of basic symbols, then a regular definition is a sequence of definitions of the form:
d1→r1
d2→r2
...
dn→rn
• where each di is a distinct name, and each ri is a regular expression over the symbols in Σ∪{d1,d2,…,di-1}, i.e., the basic symbols and the previously defined names.

28
Examples of Regular Definitions
Example: Unsigned numbers

29
Notational Shorthands
The following shorthands are often used:
r+ = r r*
r? = r ε[a-z] = a b c … z
Examples:
digit → [0-9]num → digit+ (. digit+)? ( (E | e) (+-)? digit+ )?
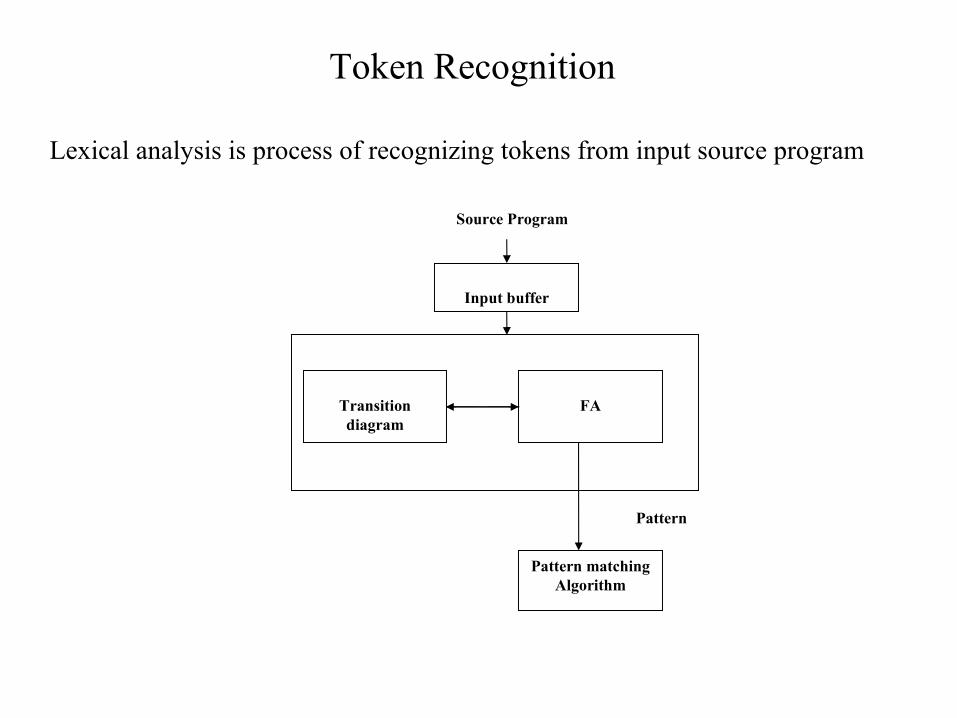
Token Recognition
Lexical analysis is process of recognizing tokens from input source program
Pattern
Transition diagram
FA
Input buffer
Pattern matching Algorithm
Source Program
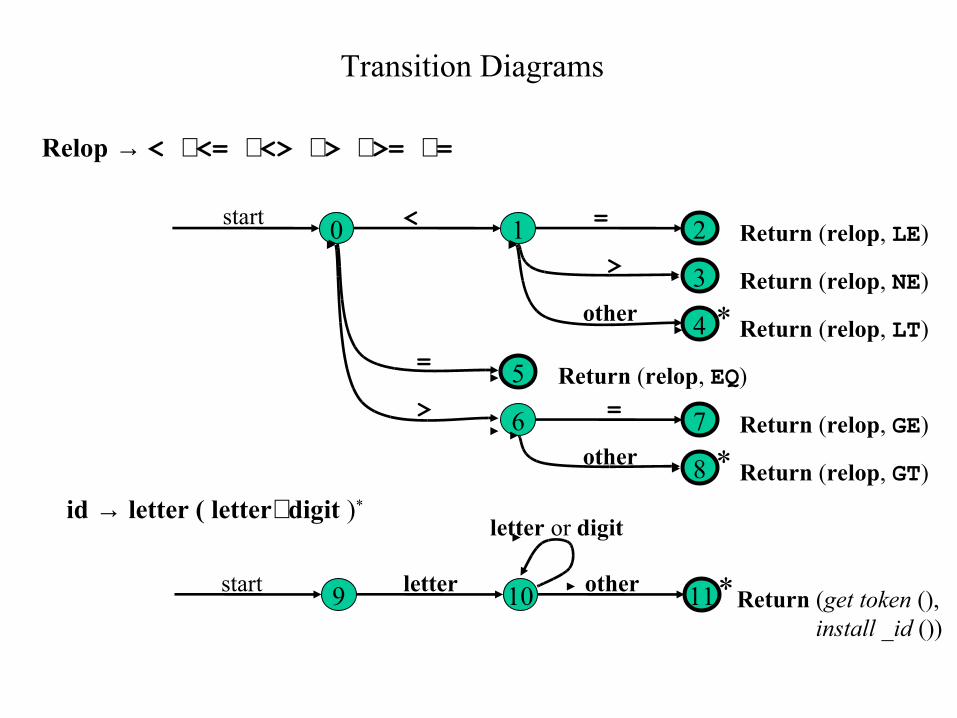
Transition Diagrams
0 21
6
3
4
5
7
8
Return (relop, LE)
Return (relop, NE)
Return (relop, LT)
Return (relop, EQ)
Return (relop, GE)
Return (relop, GT)
start <
=
>
=
>
=
other
other
*
*
9start letter 10 11*other
letter or digit
Return (get token (), install _id ())
Relop → < <= <> > >= =
id → letter ( letterdigit )*

Implementationtoken nexttoken(){ while (1) { switch (state) { case 0: c = nextchar(); if (c==blank || c==tab || c==newline) { state = 0; lexeme_beginning++; } else if (c==‘<’) state = 1; else if (c==‘=’) state = 5; else if (c==‘>’) state = 6; else state = fail(); break; case 1: … case 9: c = nextchar(); if (isletter(c)) state = 10; else state = fail(); break; case 10: c = nextchar(); if (isletter(c)) state = 10; else if (isdigit(c)) state = 10; else state = 11; break; …
int fail(){ forward = token_beginning; swith (start) { case 0: start = 9; break; case 9: start = 12; break; case 12: start = 20; break; case 20: start = 25; break; case 25: recover(); break; default: /* error */ } return start;}
Decides thenext start state
to check

33
Finite Automata• A recognizer for a language is a program that takes as input a string x and
answer “yes” if x is a sentence of the language and “no” otherwise.
• We compile a regular expression into a recognizer by constructing a generalized transition diagram called a finite automaton.
• A finite automaton can be deterministic or nondeterministic, where nondeterministic means that more than one transition out of a state may be possible on the same input symbol.
Deterministic – faster recognizer, but it may take more space Non-deterministic – slower, but it may take less space Deterministic automatons are widely used lexical analyzers.

34
Nondeterministic Finite Automata (NFA)
A non-deterministic finite automaton (NFA) is a mathematical model that consists of:• A set of states S• A set of input symbols Σ• A transition function move that maps state-symbol pairs to sets of states• A state s0 that is distinguished as the start (initial) state
• A set of states F distinguished as accepting (final) states.
ε- transitions are allowed in NFAs. In other words, we can move from one state to another one without consuming any symbol.
A NFA accepts a string x, if and only if there is a path from the starting state to one of accepting states such that edge labels along this path spell out x.

35
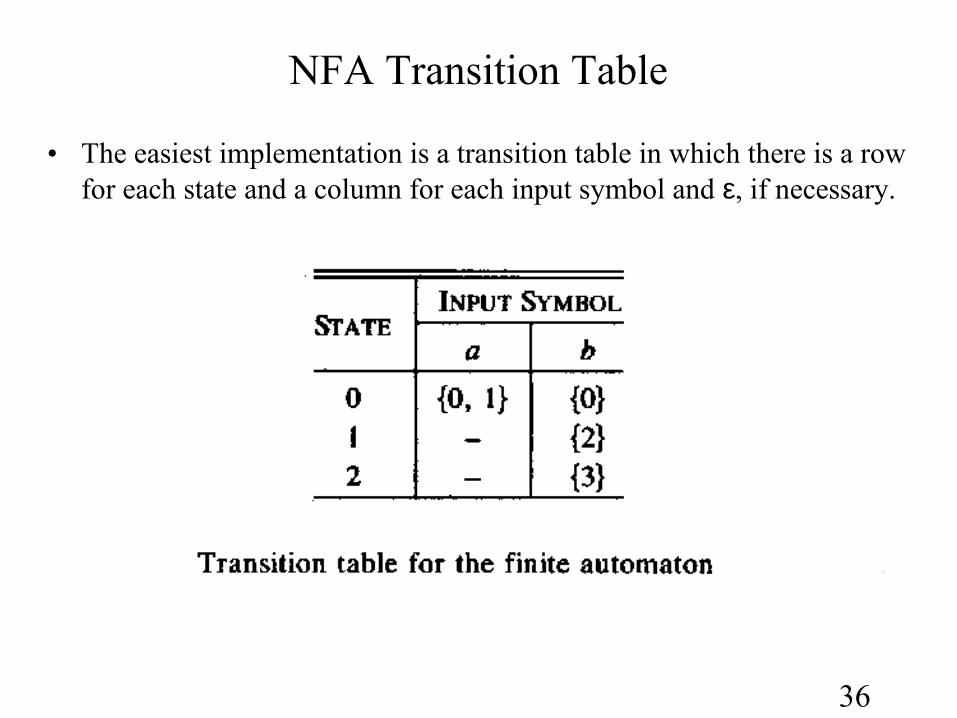
NFA• An NFA can be represented diagrammatically by a labeled directed
graph, called a transition graph, in which the nodes are the states and the labeled edges represent the transition function.
• A nondeterministic finite automaton recognizing the language (a|b)*abb
36
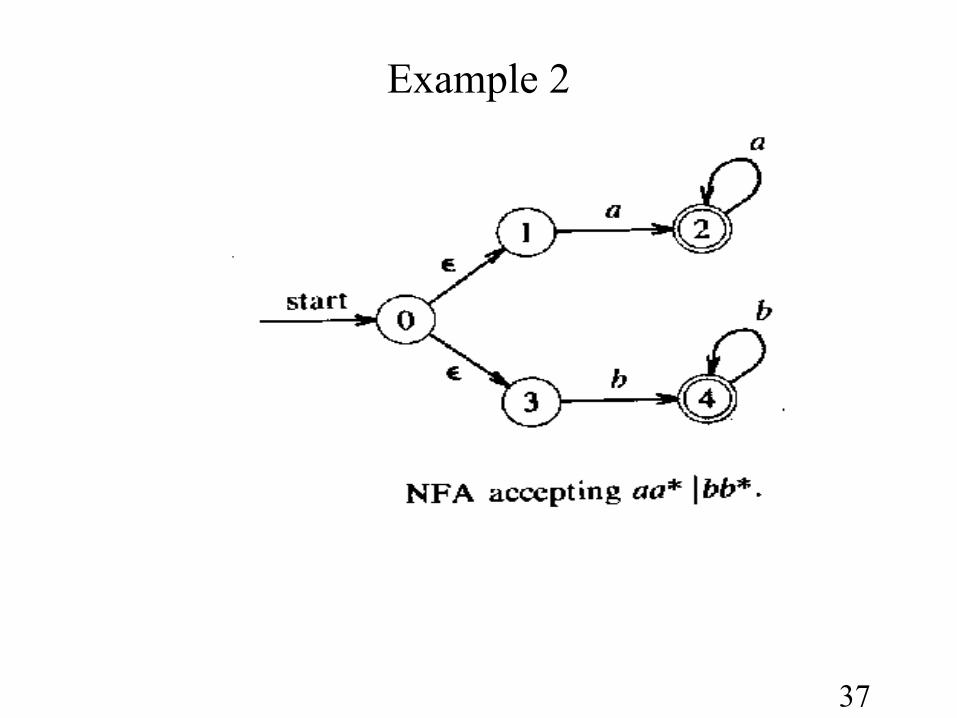
NFA Transition Table
• The easiest implementation is a transition table in which there is a row for each state and a column for each input symbol and ε, if necessary.
37
Example 2

38
Deterministic Finite Automata (DFA)
• A DFA is a special case of a NFA in which
– no state has an ε-transition
– for each state s and input symbol a, there is at most one edge labeled a leaving s.

39
Simulating a DFA
40
DFA Example:

41
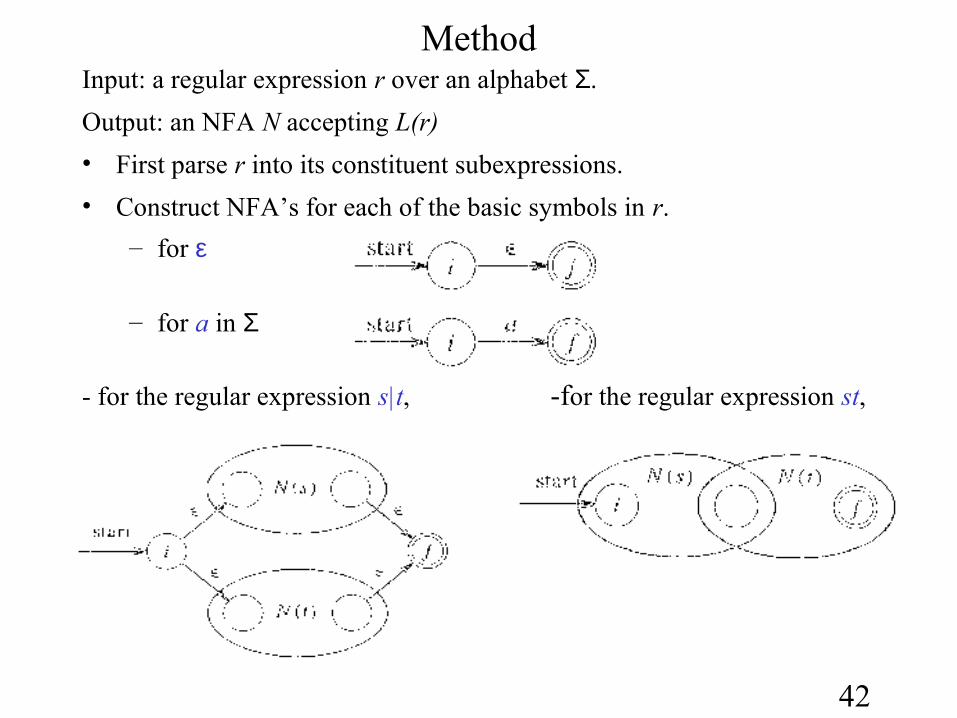
From Regular Expression to NFA
Thompson’s Construction
• This is one way to convert a Regular Expression into a NFA.
• Thomson’s Construction is simple and systematic method.
• It guarantees that the resulting NFA will have exactly one final state, and one start state.
• Construction starts from simplest parts (alphabet symbols).
• To create a NFA for a complex regular expression, NFAs of its sub-expressions are combined to create its NFA,
42
MethodInput: a regular expression r over an alphabet Σ.
Output: an NFA N accepting L(r)
• First parse r into its constituent subexpressions.
• Construct NFA’s for each of the basic symbols in r.
– for ε
– for a in Σ
- for the regular expression s|t, -for the regular expression st,

43
Method...
• For the regular expression s*,
• For the parenthesized regular expression (s), use N(s) itself as the NFA.
• Every time we construct a new state, we give it a distinct name.
44
Example - construct N(r) for r=(a|b)*abb

45
Example (II)

46
Example...

47
Conversion of an NFA into DFA
Subset construction algorithm:
• In the transition table of an NFA, each entry is a set of states; in the transition table of a DFA, each entry is just a single state.
• The general idea behind the NFA-to-DFA construction is that each DFA state corresponds to a set of NFA states.
• The DFA uses its state to keep track of all possible states the NFA can be in after reading each input symbol.

48
Subset Construction - constructing a DFA from an NFA
Input : An NFA N.
Output : A DFA D accepting the same language.
Method:
We construct a transition table Dtran for D. Each DFA state is a set of NFA states and we construct Dtran so that D will simulate “in parallel” all possible moves N can make on a given input string.

49
Subset Construction (II)
s represents an NFA stateT represents a set of NFA states.
∈-Closure(s) : set of NFA states reachable from NFA states s on
∈-transition alone
∈-Closure(T) : Set of NFA states reachable from some NFA
state s in T on ∈-transition alone
move(T,a) : Set of NFA states to which there is a
transition on input ‘a’ from some NFA state s in T
Operations on NFA states

50
The Subset Construction (III)
Initially, ε-closure(s0) is the only state in Dstates and it is unmarkedwhile there is an unmarked state T in Dstates do
mark Tfor each input symbol a ∈ Σ do
U := ε-closure(move(T,a))if U is not in Dstates then
add U as an unmarked state to Dstatesend ifDtran[T,a] := U
end doend do

51
Subset Construction (IV)(ε-closure computation)
push all states in T onto stack;
initialize ∈-closure(T) to T;
while stack is not empty do begin
pop t, the top element, off the stack;
for each state u with edge from t to u labeled ∈ do
if u is not in ∈-closure(T) do begin
add u to ∈-closure(T) ;
push u onto stack
end
end

52
Example

53
Example……
First we calculate: ∈-closure(0)
∈-closure(0) = {0, 1, 2, 4, 7} (all states reachable from 0 on ∈-moves)
Let A={0, 1, 2, 4, 7} be a state of new DFA D
∈-closure(move(A,a)) and ∈-closure (move(A,b))
∈-closure(move(A,a)) = ∈-closure(move({ 0,1,2,4,7},a))} = ∈-closure({3,8}) ( since move(2,a)=3 and move(7,a)=8)
∈-closure({3,8}) = {1,2,3,4,6,7,8}(since 3→6 →1 →4, 6 →7, and 1 →2 all by ∈-moves)
Let B={1,2,3,4,6,7,8} be a new state. Define Dtran[A,a] = B.

54
Example…
b : ∈-closure(move(A,b)) = ∈-closure(move({0,1,2,4,7},b)) = ∈-closure({5})
( since move(4,b)=5)
From this we have : ∈-closure({5}) = {1,2,4,5,6,7}
(since 5→6 →1 →4, 6 →7, and 1 →2 all by ∈-moves)
Let C={1,2,4,5,6,7} be a new state. Define Dtran[A,b] = C.

55
Example ...
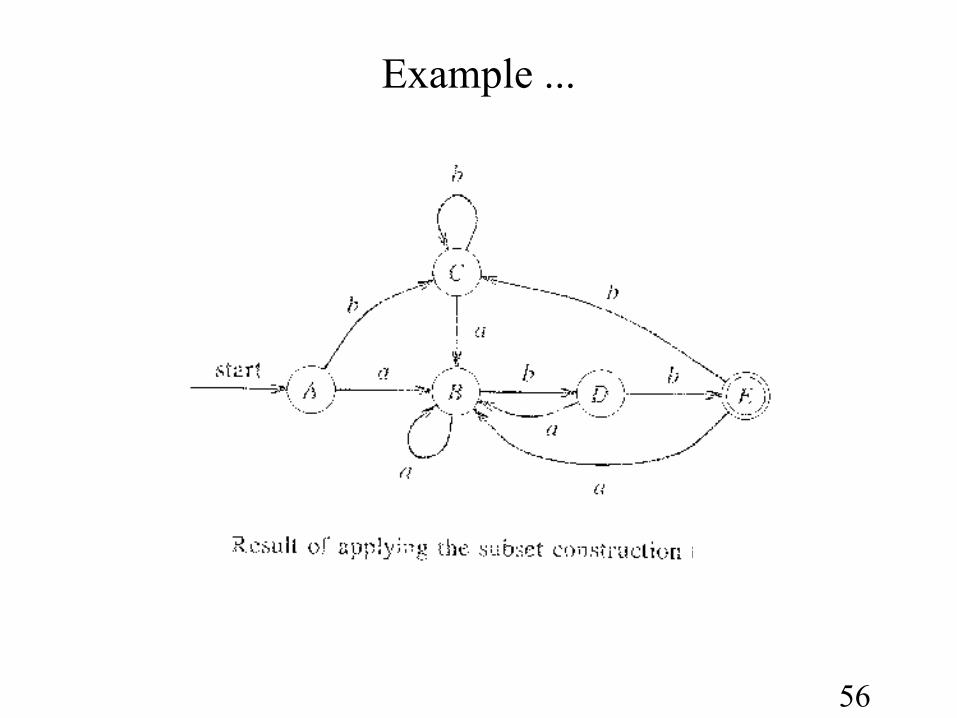
56
Example ...

57
Minimizing the number of states in DFA
• Minimize the number of states of a DFA by finding all groups of states that can be distinguished by some input string.
• Each group of states that cannot be distinguished is then merged into a single state.
• DFA Minimization is a fairly understandable process, and is useful in several areas

58
Minimizing the number of states in DFA (II)

59
Construct New Partition

60
Example
Astart
B
C
D E
b
b
b
b
b
aa
a
a
a
Astart
B D Eb b
a
ab
a
a


















