
2019 富邦人壽管理碩士論文獎 人工智慧情感對話機器人 · 一、研究背景...
21
2019 富邦人壽管理碩士論文獎 人工智慧情感對話機器人 Artificial Intelligence Affective Conversational Robot 摘要 近年來交談機器人 (ChatBot) 已成為各應用領域所廣泛運用的技術。為了與用戶有 更好要互動,提升交談機器人在對話時的溫度,已成為交談機器人重要研究議題。本研 究提出人工智慧情感對話機器人,整合人工智慧深度學習情感分析、生成式與檢索式對 話模型。本研究所發展的情感分析模型使用多層感知機(MLP) 、長短記憶 (LSTM) 與雙 向長短記憶 (BiLSTM)三種模型,並以 Word2Vec 與 Semantic 做為相似度模型的排序比 較基礎。本研究進行深度學習對話模型、情感分析模型與相似度模型三種模型整合比較。 實驗結果顯示情感分析模型使用 BiLSTM,相似度模型使用 Word2Vec,對話模型使用 檢索式模型的對話效果最為出色。本論文主要研究貢獻在於本研究發展人工智慧情感對 話機器人系統,並提出情感對話機器人指數 (Affective Conversational Robot Index; ACR Index) 可做為評估情感對話機器人效能的標準。 關鍵字:對話機器人、情感分析、人工智慧、自然語言、深度學習
Transcript of 2019 富邦人壽管理碩士論文獎 人工智慧情感對話機器人 · 一、研究背景...

2019 富邦人壽管理碩士論文獎
人工智慧情感對話機器人
Artificial Intelligence Affective Conversational
Robot
摘要
近年來交談機器人 (ChatBot) 已成為各應用領域所廣泛運用的技術。為了與用戶有
更好要互動,提升交談機器人在對話時的溫度,已成為交談機器人重要研究議題。本研
究提出人工智慧情感對話機器人,整合人工智慧深度學習情感分析、生成式與檢索式對
話模型。本研究所發展的情感分析模型使用多層感知機(MLP)、長短記憶 (LSTM) 與雙
向長短記憶 (BiLSTM)三種模型,並以 Word2Vec 與 Semantic 做為相似度模型的排序比
較基礎。本研究進行深度學習對話模型、情感分析模型與相似度模型三種模型整合比較。
實驗結果顯示情感分析模型使用 BiLSTM,相似度模型使用 Word2Vec,對話模型使用
檢索式模型的對話效果最為出色。本論文主要研究貢獻在於本研究發展人工智慧情感對
話機器人系統,並提出情感對話機器人指數 (Affective Conversational Robot Index; ACR
Index) 可做為評估情感對話機器人效能的標準。
關鍵字:對話機器人、情感分析、人工智慧、自然語言、深度學習

2019 富邦人壽管理碩士論文獎
壹、 緒論
一、研究背景
隨著人工智慧(Artificial intelligence)技術日漸成熟,交談機器人(Chat Bot)也開
始廣泛運用在各個領域之中。除了基本交談功能外,還提供了解決用戶問題的能
力,來解決企業客服與行銷推廣人力上的缺陷。交談機器人並非是近年才有的技
術和應用。最早於 1966 年麻省理工學院的 Joseph Weizenbaum (1996)開發了名為
ELIZA 的聊天機器人,此交談機器人主要是模擬心理醫生來針對病患做心理諮詢
(Weizenbaum 1966)。之後還有 Wallace, R.所發表的 A.L.I.C.E (Wallace, Tomabechi et
al. 2003),這些都是模擬人類對話行為的交談機器人。隨著人工智慧與自然語言技
術的進步,在 2001 年 IBM Watson 與 2006 年 Apple Siri 相繼推出。這些都已擴大
了交談機器人問答的能力與範圍。近年來交談機器人如雨後春筍般的出現。已不
是只有少數企業能使用的技術,如社交平台臉書(Face Book)、通訊軟體 Line 與微
信(WeChat)都先後提供用戶交談機器人平台,讓用戶可以自製屬於自己專屬的聊天
機器人
二、研究動機
近年來因國內金融科技(Financial technology; 也稱 FinTech)的快速發展,各家
金融業者也為了提供用戶更便利的服務和人力成本,都紛紛發展出屬於自己的交
談機器人。甚至還為這些交談機器人取了名字,如國泰世華銀行的小 Q、中國信
託商業銀行的小 C、富邦銀行的邦妮、玉山銀行的小玉和台新銀行的 Ross,這些
都各有各自已的領域。這些交談機器人,回覆也較為制式甚至有些只會回答特定
領域的問題,讓用戶感覺缺少了溫度與互動。對於情感分析的探討文獻很多,但
有許交談機器人與情感分析結合的研究卻很少。如何讓交談機器人具有感情也是
最近交談機器人一大課題,這也是本研究的動機。
三、研究目的
本研究著重於最原始基本的互動對話同時具有回覆相對應情感的交談機器人。
研究中取得社群網站 170 萬對 POST 文與回文資料數量,透過增加人工智慧技術
加以建模訓練。為了讓交談機器人能分析情感並回覆對應的情感,本研究加入了
情感分析模型,並且將情感細分為五大類「快樂」、「幸福」、「難過」、「生氣」與
「噁心」讓對話的情感更為多元。本研究的具體目的如下:
1. 比較 IR Model 與 LSTM 模型的交談機器人效果。
2. 運用人工智慧技術「MLP」、「LSTM」、「BiLSTM」做情感分析正確率的比
較。
3. 將不同的交談模型與情感分析模型做交叉組合找出效果最佳的組合。

2019 富邦人壽管理碩士論文獎
貳、 文獻探討
一、 交談機器人(ChatBot)
交談機器人(Chat bot)顧名思義就是將文字或語音的對話,透過電腦程式與演
算法做語義分析並給於合適的回答。此技術與概念不是這幾年才新出來的。最早
於 1966 年的 ELIZA (Weizenbaum 1966)和 1975 年的 PARRY,這兩個都是當時極
為有名的交談機器人。Chatter Bot 一詞的是在 1994 年由卡內基梅隆大學的 Mauldin
所開發一個名為「Chatter Bot」的交談機器人(Mauldin 1994)。它能夠與使用者交
談並且能回覆使用者關於導航的相關問題,一直到現在 Chat Bot 以受到大家廣泛
的使用。
二、 對話機器人模型
本章節將介紹在對話機器人有三種最常見的建置模型,分別為模版式模型
(Rule/Template Based Model)、檢索式模型(Information Retrieval Model)與生成式模
型(Generative Based Model)。
2.1 模版式模型
樣版式模型是途述一個基於模版式模型的系統是由多個 if-then 規則組合而成
的。這些單一個的 if-then 規則語句構成完整的條件語句資料庫。
2.2 檢索式模型
訊息檢索(Information Retrieval)一詞最早是 1950 年由 Calvin Mooers 所出。一
開始是利用一定設備和方法,從某種格式的文獻、資料或數據中找到所需要的資
訊。隨著各種資訊型態的產生,資訊檢索的技術也開始有多樣型的發展,來符合
各種型態的資訊。基於檢索式模型的對話機器人,是目前企業較常使用的一種方
式。如微軟的小冰(Little Bing),其使用的原理是收集大量的人類對話語庫做好索
引,在利用用戶的對話句子在語料庫中找尋最適當的回覆。如何選取最適當的方
式有很多種,最常使用的就是找餘弦相似度(cosine similarity),來做為最適當的回
覆(Jurafsky and Martin 2014)。
2.3 生成式模型
生成式學習模型是一種監督式的學習,是一個建立在知識基礎上的學習模型。
Wittrock 於 1974 年首提出次模型後,就開始了一系列的實驗與研究(Jaakkola and
Haussler 1999)。而在對話機器人中,長短期記憶(Long Short Term Memory)是在現
在最常用的生成式模型之一。
三、 自然語言處理
自然語言處理(Natural Language Processing; 簡稱 NLP)為人工智慧學門的一個

2019 富邦人壽管理碩士論文獎
分支。NLP 技術基礎如計算機和信息科學、語言學、數學、電子學、心理學、人
工智慧等,主要是探索如何透過計算機來理解和使用自然語言文於文本與對話上
有更多的應用(Chowdhury 2003)。
自然語言處理在近年來有快速的發展,研究範圍也從簡單的文本分析,到各
式各樣的社交媒體之間。許多研究團體也使用社交媒體數據進行信社群網路分析、
社交媒體分析、社會科學、心理學和語言學的相關研究。也有許多的企業正在社
交媒體上進行留言與評論的研究與分析並且從中受益
四、 情感分析
情感分析(Nasukawa and Yi 2003)又稱為意見探勘(Liu 2012)。是利用自然語言
處理或生物識別技術在透過人工智慧技術。將人們所產出文字或圖片(如社群網站:
微博、FACEBOOK、Twitter 和 Instagram...等)來辨識當下之情感的技術。由於網際
網路的發達,特別是社群網站,是由數百萬個用戶組成。他們在自己的空間發佈
訊息、圖片與視頻,這些訊息往往透露出人們對事物的感情與喜好,情感分析也
變的越來越重要。(Quan and Ren 2009)
一般情感分析的應用大多屬於個人對於商品或事件的喜好研究。但近年來已
有些研究團隊已開始將情感分析做更加細膩的分類且將此與交談機器人結合,嘗
試著讓交談機器人更了解用戶的感受回覆相對應的情感。也有研究指出帶有情感
能力的交談對話系統不只能用戶有趣的情感交流,也能讓企業的滿意度與形像加
分。
五、 本章小節
經由本章節分析探討交談機器人、交談機器人模型、自然語言處理與情緒分
析的文獻探討後,評估本論文的研究可行的方法。本研究主要在讓交談機器人具
有理解情緒與回覆相對情緒的回答。所以我們將使用較成熟與較多文獻嘗試的方
法,來做為本研究的實驗技術與工具,並評估實驗效果。
1. 交談機器人模型:資訊檢索模型、生成模型。
2. 情緒分析模型:MLP,LSTM,BiLSTM。
3. 相似度模型:Word2Vec Similarity,Semantic Similarity。
參、 研究方法與系統架構
一、研究方法
本研究所採用的研究方法為 Nunamaker 等人 (1990) 所提出的系統發展研究
方法論 (System Development Research Methodology) (Nunamaker et al. 1990),此方
法是資訊系統領域的研究方法之一。是以一個系統開發的生命循環週期 (The
Central Nature of System Development in The Research Life Cycle),此循環週期分別

2019 富邦人壽管理碩士論文獎
為建置理論、實驗法、觀察法以及系統開發,分別解釋如下:
1. 建立理論 (Theory Building):是包括系統發展的全新想法、觀念、方式和
演算法的發展與概念框架和模型建置等。
2. 實驗法 (Experimentation):將建置理論中所提出方法進行實驗設計以及模
型實驗,並從實驗結果中提出新的理論以及改善系統
3. 觀察法 (Observation):透過案例分析、個案研究、問卷調查、田野研究與
抽樣調查方法,提供研究者驗證所提出實驗或研究假說。
4. 系統開發 (System Development):系統發展包括了五個階段,分別是概念
設計、建立系統架構、雛形設計、產品發展以及技術轉移。
本研究方法生命週期以系統開發為核心,透過理論建立、實驗法與觀察法來
做系統開發並改善系統,Nunamarker 等人 (1990) 在系統發展研究方法論 (System
Development Research Methodology),提出系統開發的五個重要流程:
1. 建構概念框架(Construct a Conceptual Framework):包含陳述一個有意義的
研究問題、調查系統的功能與需求、解析系統建置的流程與程,及研讀
相關的文獻及學科。
2. 發展系統架構(Develop a System Architecture): 包含發展具擴展性、模組
性的系統架構設計,及定義系統元件的功能與它們之間的相互關係。
3. 分析與設計系統(Analyze & Design the System):包含設計資料庫/智識庫
的架構與實現系統功能的流程,及提出幾個系統發展的解決方案並從其
中擇一實行。
4. 建置系統雛型(Build the Prototype System):從系統建置流程中學習相關的
觀念、架構、設計及深入了解系統的所面臨的問題與複雜度。
5. 觀察與評估系統(Observe & Evaluate the System):透過田野調查或是個案
研究觀察系統、藉由實驗室實驗法或是田野實驗法評估系統,並且基於前述這些
觀察與實驗提出新的理論與模型,最後統整這些學習的經驗。
2019 富邦人壽管理碩士論文獎
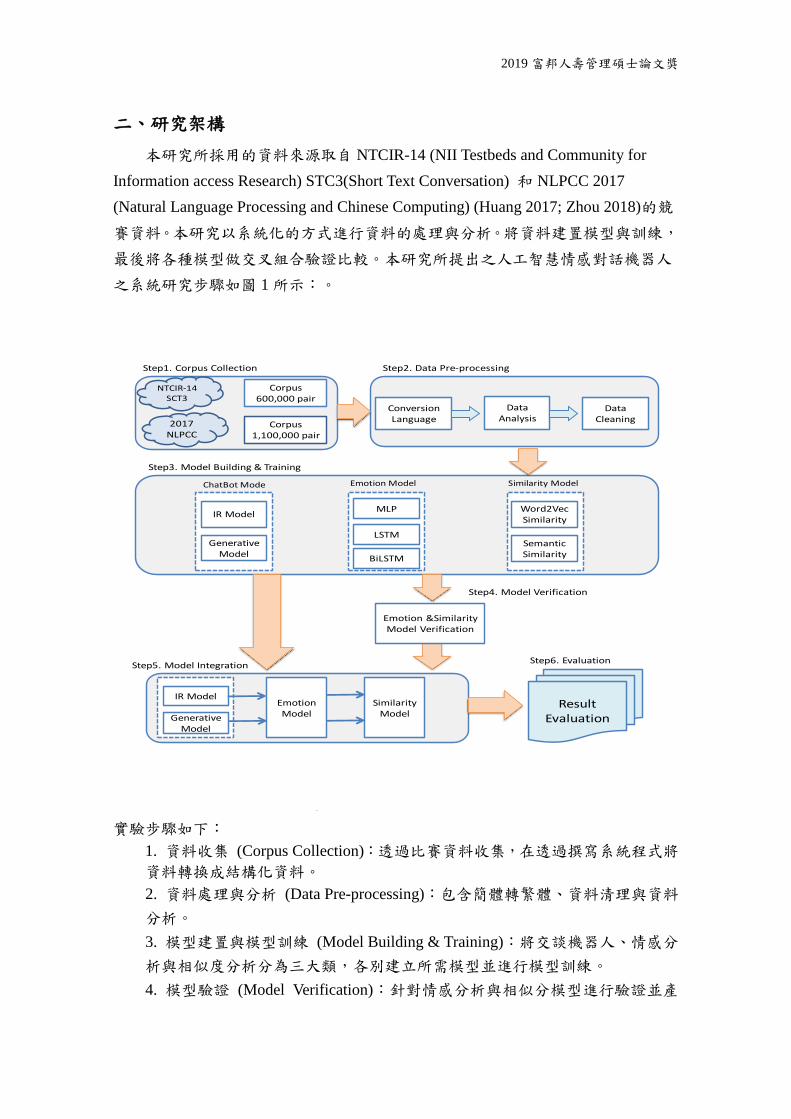
二、研究架構
本研究所採用的資料來源取自 NTCIR-14 (NII Testbeds and Community for
Information access Research) STC3(Short Text Conversation) 和 NLPCC 2017
(Natural Language Processing and Chinese Computing) (Huang 2017; Zhou 2018)的競
賽資料。本研究以系統化的方式進行資料的處理與分析。將資料建置模型與訓練,
最後將各種模型做交叉組合驗證比較。本研究所提出之人工智慧情感對話機器人
之系統研究步驟如圖 1 所示:。
實驗步驟如下:
1. 資料收集 (Corpus Collection):透過比賽資料收集,在透過撰寫系統程式將
資料轉換成結構化資料。
2. 資料處理與分析 (Data Pre-processing):包含簡體轉繁體、資料清理與資料
分析。
3. 模型建置與模型訓練 (Model Building & Training):將交談機器人、情感分
析與相似度分析分為三大類,各別建立所需模型並進行模型訓練。
4. 模型驗證 (Model Verification):針對情感分析與相似分模型進行驗證並產
ResultEvaluation
NTCIR-14 SCT3
2017NLPCC
Corpus600,000 pair
Corpus1,100,000 pair
Conversion Language
Data Analysis
DataCleaning
IR Model
GenerativeModel
MLP
LSTM
BiLSTM
Word2VecSimilarity
SemanticSimilarity
Emotion &Similarity Model Verification
IR Model
GenerativeModel
EmotionModel
SimilarityModel
Step1. Corpus Collection Step2. Data Pre-processing
Step3. Model Building & Training
ChatBot Mode Emotion Model Similarity Model
Step4. Model Verification
Step5. Model IntegrationStep6. Evaluation
圖 1 系統架構(System Architecture)
資料來源 : 本研究整理

2019 富邦人壽管理碩士論文獎
出結果。
5. 模型整合 (Model Integration):將對話模型、情感分析模型與相似度分析模
型透過系統化的方式產出對話結果。
6. 結果評估 (Evaluation):對於產出結果進行人工評估 Response 是否對應 Post
與是否對應情緒,在透過一致性驗證評估結果。
三、語料庫收集
本研究的語料庫取得來至於 NTCIR14-STC3 & 2017NLPCC 這兩個國際短文對
話競賽的資料。NTCIR14-STC3 & 2017NLPCC 語系為簡體中文。此競賽提供相當
大量的語料庫當做訓練資料。故本研究以這兩個語料庫當做主要語料庫的來源。
NTCIR (NII Testbeds and community for information access research) 為日本發
起的一個資訊檢索評估的會議。每年都會有不同國家的研究單位做研究任務的發
佈,吸引不同國家的研究單位一起研究競賽。NTCIR14-STC3 為 2018 年發佈的短
文對話的競賽。此競賽由北京清華大學所舉辦,主要任務是讓對話帶有感情,競
賽也提供了下載語料庫的連結。本研究也將使用此料語庫中情緒分類來當做本研
究情感分類。表 1 分類表。
表 1 情緒分類表
情緒代號 情緒名稱 情緒解譯
1 Like 喜歡
2 Sadness 難過、悲傷
3 Disgust 討厭、厭惡
4 Anger 生氣、憤怒
5 Happiness 幸福
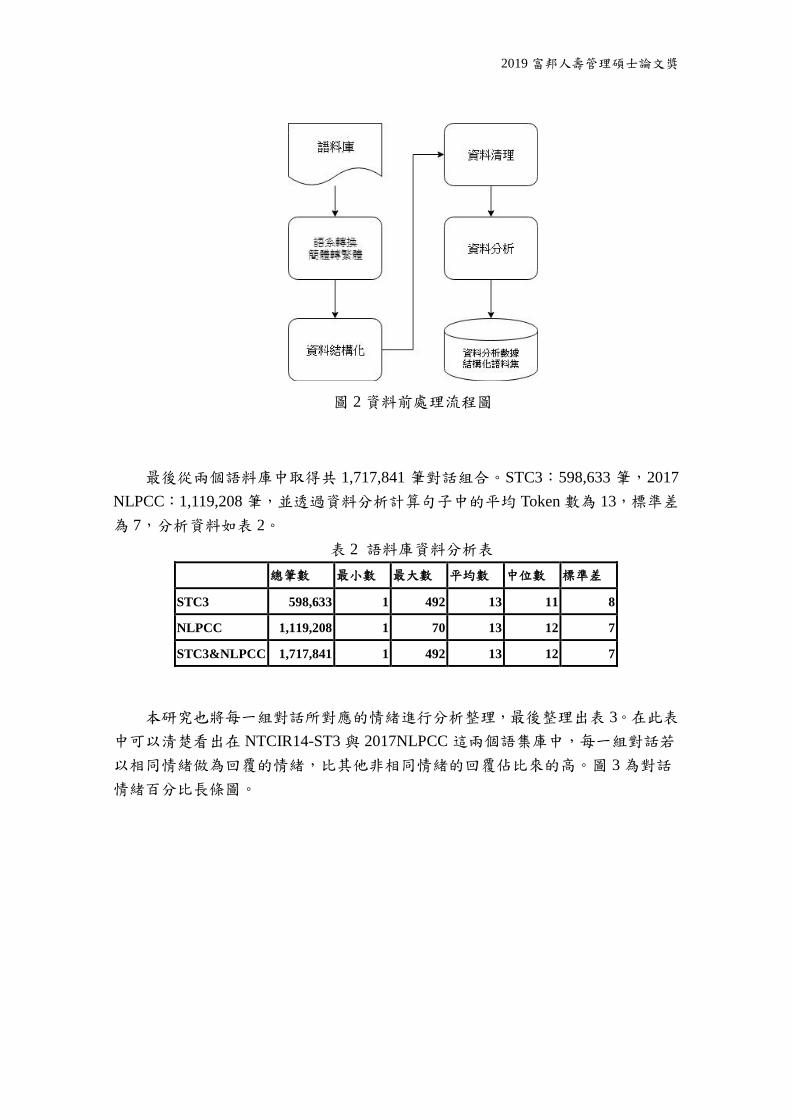
四、資料前處理
本研究的所取得的語料庫屬非結構化的資料,為使資料更能有效的應用,將
進行資料的前處理,本研究以透過編寫 Python 程式語言來進行資料資料處理的自
動化。圖 2 為資料前處理流程圖。
2019 富邦人壽管理碩士論文獎
最後從兩個語料庫中取得共 1,717,841 筆對話組合。STC3:598,633 筆,2017
NLPCC:1,119,208 筆,並透過資料分析計算句子中的平均 Token 數為 13,標準差
為 7,分析資料如表 2。
表 2 語料庫資料分析表
總筆數 最小數 最大數 平均數 中位數 標準差
STC3 598,633 1 492 13 11 8
NLPCC 1,119,208 1 70 13 12 7
STC3&NLPCC 1,717,841 1 492 13 12 7
本研究也將每一組對話所對應的情緒進行分析整理,最後整理出表 3。在此表
中可以清楚看出在 NTCIR14-ST3 與 2017NLPCC 這兩個語集庫中,每一組對話若
以相同情緒做為回覆的情緒,比其他非相同情緒的回覆佔比來的高。圖 3 為對話
情緒百分比長條圖。
圖 2 資料前處理流程圖

2019 富邦人壽管理碩士論文獎
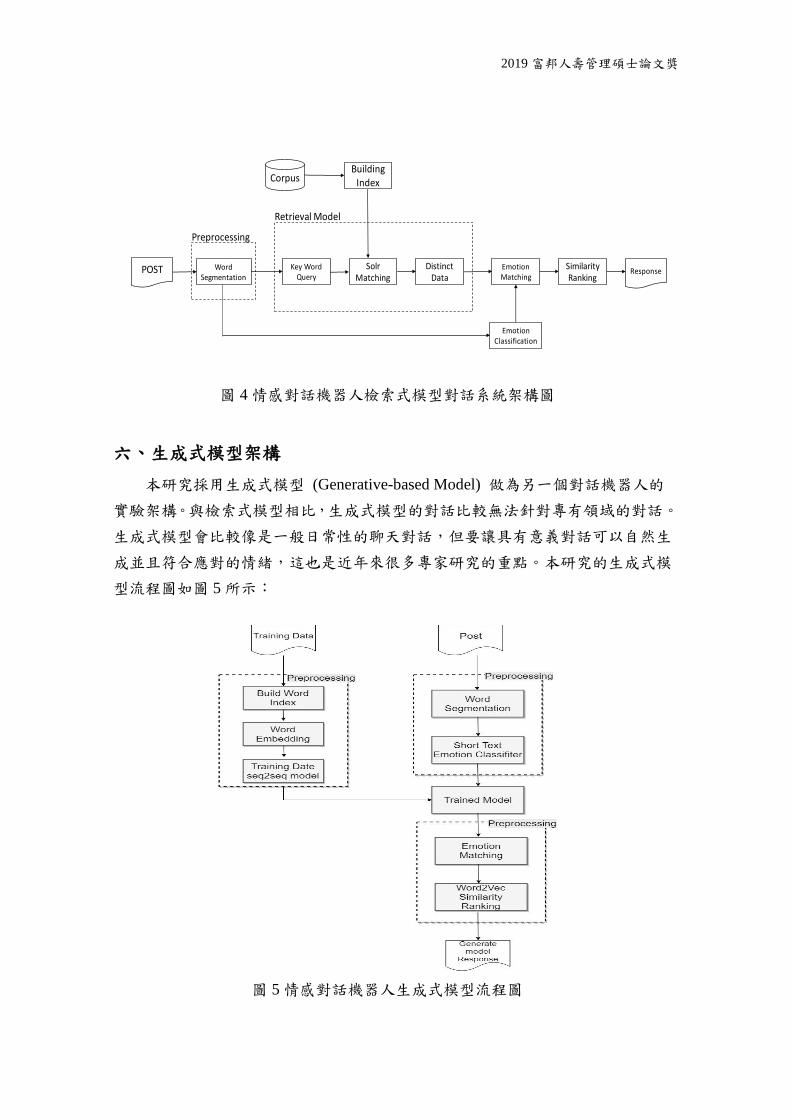
五、檢索式模型架構
本研究使用檢索式模型 (Retrieval-based Model) 當做本研究主要對話模型之
一。檢索式模型的對話都是事先確認好的回覆,這樣子的做法比較不會有語義與
語法上的問題。因此這也是檢索式模型的對話機器人是目前最多企業使用模型的
原因之一。本研究收集了 170 萬筆的大量對話,並且在語料庫中也提供了對應的
情緒,讓檢索式模型的對話系統在一般性對話中也能有不錯的表現。圖 4 為本研
究檢索式模型對話系統架構圖。
表 3 對話情緒分析表
Like Sadness Disgust Anger Happiness
Like 32.16% 15.29% 14.95% 12.80% 20.35%
Sadness 14.76% 26.93% 16.69% 16.73% 16.82%
Disgust 17.43% 22.28% 33.11% 25.46% 17.90%
Anger 9.91% 12.65% 16.38% 24.89% 11.47%
Happiness 25.74% 22.86% 18.88% 20.12% 33.45%
圖 3 對話情緒百分比長條圖
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Like Sadness Disgust Anger Happiness
Happiness
Anger
Disgust
Sadness
Like
2019 富邦人壽管理碩士論文獎
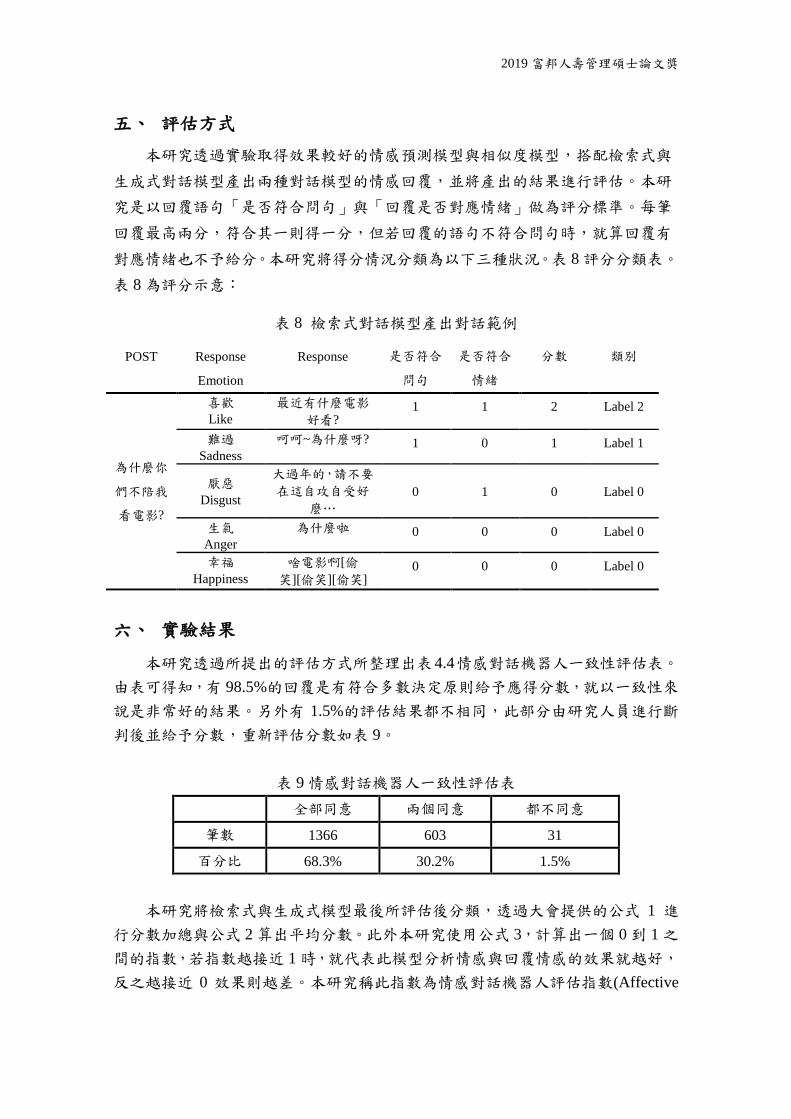
六、生成式模型架構
本研究採用生成式模型 (Generative-based Model) 做為另一個對話機器人的
實驗架構。與檢索式模型相比,生成式模型的對話比較無法針對專有領域的對話。
生成式模型會比較像是一般日常性的聊天對話,但要讓具有意義對話可以自然生
成並且符合應對的情緒,這也是近年來很多專家研究的重點。本研究的生成式模
型流程圖如圖 5 所示:
圖 5 情感對話機器人生成式模型流程圖
CorpusBuilding
Index
Key WordQuery
SolrMatching
DistinctData
EmotionMatching
SimilarityRanking
WordSegmentation
POST Response
EmotionClassification
Retrieval Model
Preprocessing
圖 4 情感對話機器人檢索式模型對話系統架構圖

2019 富邦人壽管理碩士論文獎
七、情感分析模型
本研究的情感分析模型將使用多層感知機(Multilayer Perceptron; MLP)、長短
記憶(Long Short Term Memory; LSTM)與雙向長短記憶(Bi-Directional LSTM;
BiLSTM)做為本研究的情感預測模型,並且將三種預測模型比較其效果。本研究
將會利用對語料庫先將每一個語料做好情緒分類,再以 80%的資料做完訓練資料
另外 20%的資料做為測試模型的測試資料,最後在保存模型。圖 3.5 為本研究情感
分析模型流程圖。
八、相似度模型
在資訊檢索模型 (IR Model) 中,相似度的計算是其模型的核心技術。相似度
分析的好壞也影響最後的答案。在本研究中除了資訊檢索模型使用相似度比較,
在生成式模型最後決定回文時也去比較相似度。此做法是為了研究加入相似度比
較的生成式模型所產出的對話,是否更能增加文字和文意的連貫,包括字句貫
(cohesion)以及語意邏輯連貫(coherence),使而讓加強回覆和問題的關聯性。本研
究使用了 Word2Vec 與 Semantic 兩種不同的相似度計算模型做為比較的工具。
肆、 資料分析與結果
本研究所實驗的各項模型成果,將於本章詳細說明呈現,包含各模型的呈現
與實驗的評估方式。為讓實驗結果據有可信度,本研究也會透過科學評估方式來
評估實驗結果分析最佳的實驗結果。
圖 6 情感預測模型流程圖

2019 富邦人壽管理碩士論文獎
一、 情感預測模型結果
本研究在情感分析實驗中分別使用了多層感知機、長短記憶與雙向長短記憶
這三種深度學習模型來訓練情感分析預測模型。並將實驗成效最好的模型做為本
研究的預測模型。情感分析模型的成效評估方式是以模型預測的準確度(Accuracy)
做為評估指標。預測結果如下圖所示。
從實驗可以得知雙向長短記憶(BiLSTM)情感預測模型的成效最好。此模型的
損失值與準確率都比第二名的長短記憶模型來的好。故本研究將以雙向長短記憶
情感預測模型,做為情感交談機器人的主要情感預測模型。
圖 6 多層感知機各類別準確率的混淆矩陣圖
圖 7 長短記憶模型各類別準確率的混淆矩陣

2019 富邦人壽管理碩士論文獎
二、 相似度分析模型
本實驗使用了 Word2Vec 分析與語義分析(Semantic Similarity)的方式來訓練研
究的相似度模型。語義分析又細分為英文與中文兩種不同之模型,共三種模型進
行比較。因相似度模型較無法用準確率(Accuracy)來做為評估模型的指標,故將訓
練出來的兩種模型並以相似度指數比較找出最佳的相似度模型。
由圖 9 Word2Vec 相似度模型中所分析出詞彙之間的相似度與效果是相當不錯。
套用在語句中相似度分析也是相當好的效果。語意相似度模型為 Tensorflow Hub
平台上開發使用的模型,但英文的語意相似度模型只有訓練英文的語句。本研究
在使用語意相似度模型時,需將中文語句透過 Google Translate API 翻譯成英文在
做相似度分析。
圖 8 雙向長短記憶各類別準確率的混淆矩陣圖
表 4 各情感預測模型損失值與準確率匯總表
訓練模型 Loss 值 準確率
多層感知機(MLP) 0.788 73.91%
長短記憶(LSTM) 0.365 86.4%
雙向長短記憶(BiLSTM) 0.334 87.6%

2019 富邦人壽管理碩士論文獎
圖 9 Word2Vec &語意相似度模型
本實驗使用 170 萬對語料庫對話隨機取出 200 筆進行比較。實驗中我們假設
每個 pair 的回覆都是正確答案,以每一個 pair 透過相似度模型產出分數,相似度
較高者得一分,最後在以總分做為最後評估標準。最後實驗驗證 Word2Vec 相似度
模型取得較高的分數,成效不及 Word2Vec 相似度模型。故本研究則選擇 Word2Vec
相似度模型做為本研究的主要相似度模型。表 5 為相似度模型評分表。圖 10 相似
度模型評分長條圖。
語意相似度模型成效(中文)
語句 1= 承諾,就是一個騙子說給一個傻子聽的
語句 2= 我就是一個開心的傻子
相似度: 0.4201567
====================================== 語句 1= 朋友們,元宵節快樂!
語句 2= 也祝你元宵節快樂
相似度: 0.6462734
====================================== 語句 1= 我愛你
語句 2= 我也愛你啊
相似度: 0.8568930
語意相似度模型成效(英文)
語句 1= 承諾,就是一個騙子說給一個傻子聽的
語句 2= 我就是一個開心的傻子
語句 1 翻譯= A promise is what a cheater says to a
fool 語句 2 翻譯= I'm just happy fool
相似度: 0.34341088
====================================== 語句 1= 朋友們,元宵節快樂!
語句 2= 也祝你元宵節快樂
語句 1 翻譯= Friends, Happy Lantern Festival!
語句 2 翻譯= I wish you a happy Lantern Festival.
相似度: 0.74505186
====================================== 語句 1= 我愛你
語句 2= 我也愛你啊
語句 1 翻譯= I love you
語句 2 翻譯= I love you too
相似度: 0.8866229
Word2Vec 相似度模型成效
A:承諾,就是一個騙子說給一個傻子聽的
B:我就是一個開心的傻子
A: 斷詞: ['承諾', '就是', '一個', '騙子', '說給', '一個', '
傻子', '聽', '的']
B: 斷詞: ['我', '就是', '一個', '開心', '的', '傻子']
相似度: 0.8522515144884826
========================================= A:朋友們,元宵節快樂!
B:也祝你元宵節快樂
A: 斷詞: ['朋友', '們', '元宵', '節快', '樂']
B: 斷詞: ['也', '祝', '你', '元宵', '節快', '樂']
相似度: 0.8695907383644587
========================================= A:我愛你
B:我也愛你啊
A: 斷詞: ['我', '愛', '你']
B: 斷詞: ['我', '也', '愛', '你', '啊']
相似度: 0.9713751676931056

2019 富邦人壽管理碩士論文獎
三、 檢索式對話模型結果
資訊檢索對話模型主要語句的產生是將預先定義好的語料庫,在使用邏輯運
算找出適合的回應。本實驗將實驗語料庫中的 PO 文、回文與對應情緒,輸入到
Solr 中建立檢索式搜尋引擎。在搜尋時則是將對話先使用結巴斷詞,將斷詞的結果
透過布林搜尋法(Boolean Search)搜尋出相關的結果。在以情緒分類做群組,最後
使用實驗中訓練好的 Word2Vec 相似度模型進行相似度的權重計算。本實驗使用
NTCIR-STC3 的比賽題目做為實驗的對話。比賽題目共 200 題,並產出五種不同情
緒的對應回覆,總產出的回覆數為 1,000 題。表 6 檢索式對話模型產出對話範例。
表 5 相似度模型評分表
總分 比率
Word2Vec
相似度模型 191 95.6%
英文語意
相似度模型 4 2%
中文語意
相似度模型 5 2.4%
圖 10 相似度模型評分長條圖
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
英文語意
相似度模型
中文語意
相似度模型
Word2Vec 相似度模型

2019 富邦人壽管理碩士論文獎
表 6 檢索式對話模型產出對話範例
POST Response Emotion Response
為什麼你們不陪我看電影?
喜歡
Like 最近有什麼電影好看?
難過
Sadness 呵呵~為什麼呀?
厭惡
Disgust
大過年的,請不要在這自攻自
受好麼…
生氣
Anger 為什麼啦
幸福
Happiness 啥電影啊[偷笑][偷笑][偷笑]
四、 生成式對話模型結果
本實驗使用長短記憶神經網路(Long Short-Term Memory, LSTM) 來做為生成
式對話的訓練模型。在訓練 LSTM Sequence to Sequence 對話模型前。先需要將訓
練語句做斷詞,並建立詞彙序號(Word Index),最後進行詞向量(Word Vector)。為
了增加生成對話的成效,本實驗分析訓練語料庫的詞彙,計算出詞彙的兩倍標準
差,做為訓練語句的最大詞彙長度。將不足或超過長度的語句進行截長補短的動
作,此做法可統一訓練語句的長度,增加訓練成效。
本實驗將對話模型整合情感預測模型與相似度模型。並用 STC3 的比賽題目做
為實驗的對話,透過系統自動產生的方式將每個題目產出五種不同情緒之回覆,
總共產生 1000 題回覆。表 7 生成式對話模型產出對話。
表 7 檢索式對話模型產出對話範例
POST Response Emotion Response
為什麼你們不陪我看電影?
喜歡
Like 我都不知道啊!
難過
Sadness 快過一節面試…上課幾天啦?
厭惡
Disgust 今天五節麼?
生氣
Anger 多少號玩手機
幸福
Happiness 很久沒看過了啊
2019 富邦人壽管理碩士論文獎
五、 評估方式
本研究透過實驗取得效果較好的情感預測模型與相似度模型,搭配檢索式與
生成式對話模型產出兩種對話模型的情感回覆,並將產出的結果進行評估。本研
究是以回覆語句「是否符合問句」與「回覆是否對應情緒」做為評分標準。每筆
回覆最高兩分,符合其一則得一分,但若回覆的語句不符合問句時,就算回覆有
對應情緒也不予給分。本研究將得分情況分類為以下三種狀況。表 8 評分分類表。
表 8 為評分示意:
表 8 檢索式對話模型產出對話範例
六、 實驗結果
本研究透過所提出的評估方式所整理出表4.4情感對話機器人一致性評估表。
由表可得知,有 98.5%的回覆是有符合多數決定原則給予應得分數,就以一致性來
說是非常好的結果。另外有 1.5%的評估結果都不相同,此部分由研究人員進行斷
判後並給予分數,重新評估分數如表 9。
表 9 情感對話機器人一致性評估表
全部同意 兩個同意 都不同意
筆數 1366 603 31
百分比 68.3% 30.2% 1.5%
本研究將檢索式與生成式模型最後所評估後分類,透過大會提供的公式 1 進
行分數加總與公式 2 算出平均分數。此外本研究使用公式 3,計算出一個 0 到 1 之
間的指數,若指數越接近 1 時,就代表此模型分析情感與回覆情感的效果就越好,
反之越接近 0 效果則越差。本研究稱此指數為情感對話機器人評估指數(Affective
POST Response
Emotion
Response 是否符合
問句
是否符合
情緒
分數 類別
為什麼你
們不陪我
看電影?
喜歡
Like
最近有什麼電影
好看? 1 1 2 Label 2
難過
Sadness
呵呵~為什麼呀? 1 0 1 Label 1
厭惡
Disgust
大過年的,請不要
在這自攻自受好
麼…
0 1 0 Label 0
生氣
Anger
為什麼啦 0 0 0 Label 0
幸福
Happiness
啥電影啊[偷
笑][偷笑][偷笑] 0 0 0 Label 0

2019 富邦人壽管理碩士論文獎
Conversational Robot Index; ACR Index)。表 10 為情感對話機器人評分比較表。計
算公式如下:
Total Score = ∑ 𝑖 ∗ 𝑛𝑢𝑚𝑖
2
𝑖=0
(1)
此公式中的𝑖為 Label 對應的分數,𝑛𝑢𝑚𝑖為被標註 Label 的題目總數。
Average Score = ∑ 𝑖 ∗ 𝑛𝑢𝑚𝑖
2𝑖=0
Nt (2)
此公式中的𝑖為 Label 對應的分數,𝑛𝑢𝑚𝑖為被標註 Label 的題目總數,Nt 則為
所有題目的總數。
ACR Index = ∑ 𝑖 ∗ 𝑛𝑢𝑚𝑖
2𝑖=0
Nt ∗ max (𝑖) (3)
此公式中的𝑖為 Label 對應的分數,𝑛𝑢𝑚𝑖為被標註 Label 的題目總數,Nt 則為
所有題目的總數,max (𝑖)為𝑖的最大值。
表 10 情感對話機器人總評分比較表
Label 0 Label 1 Label 2 Total Score Average
Score ACR Index
檢索式模型 304 209 487 1183 1.183 0.591
生成式模型 875 90 35 160 0.16 0.08
由表 10 中可以得知檢索式模型的情感機器人比生成式模型所產生的效果來的
好。本研究也計算出各種不同情緒的評分,在各別的情緒的評分表中可以得知幸
福情緒預測效果比其他情緒來的好,生氣的緒情預測效果較差。
七、 改善生成式情感對話模型
因本研究所提出之生成式對話模型成效與檢索式模型差距相當大,故針對生
成式對話模型所產出的結果與評分表進行分析。在生成式對話模型所產出的結果
中,我們發現其問句與回覆相似度都偏低,這也會使回覆與問句的關聯式降低,
如圖 11 所示。

2019 富邦人壽管理碩士論文獎
本研究也將三位評分員所評分之結果進行分析並整理出圖 12 生成式模型得分
分佈長條圖。由圖中發現回覆的字句長度落在 6~13 之間得分的機會較高,超過 13
的長度時得分機會就大幅降低。
八、 改善生成式情感對話模型改善方式
針對分析之結果,本研究將對生成式對話模型進行兩部分的改善。第一為提
高回覆與問句的相似度。在現有模型架構下,我們將每一個問句透過生成式對話
模型增加 10000 筆候選的回覆。
另外本實驗針對回覆的長度也進行改善。改善方式為本研究提出一個預期回
覆長度的指數(Expect Response Length Score, ERLS),此為一個 0~1 之間的指數, 公
圖 11 生成式對話模型產生對話圖
圖 12生成式模型得分分佈長條圖
0
5
10
15
20
25
6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
分
數
回覆字句長度

2019 富邦人壽管理碩士論文獎
式如下。透過此公式我們將回覆的長度與預期回覆長度進行計算。當指數越接近 1
時,就越接近預期的回覆長度,反之越接近 0 時,回覆長度就越脫離預期的長度。
𝑬𝑹𝑳𝑺 = 𝐦𝐚𝐱 (𝟎, 𝟏 − (𝑬𝑹𝑳 − 𝑹𝑳
𝑬𝑹𝑳)
𝟐
) (𝟏)
此公式中的𝑬𝑹𝑳為預期的回覆長度,𝑹𝑳為模型產生的回覆長度。
本實驗將計算出來預期長度指數與相似度比分進行加權,加權後在進行排名
選出比分較高的語句做為回覆。
九、 改善生成式情感對話模型改善方式
本實驗透過增加候選名單與加入預期回覆長度係數的改善,並使用候選名單
為 10000 作為實驗結果。進行分數計算前,先將三位評分員所評分資料整理出改
善後的情感對話機器人一致性評估表(此表只針對改善後所產出資料進行分析),由
表可得知,有 92.9%的回覆是有符合多數決定原則給予應得分數,就以一致性來說
是非常好的結果,另外有 7.1%的評估結果都不相同,此部分由研究人員進行判斷
並給予分數。
最後將三位評分員與研究人員所確認之分數整理出表 11,由表中我們可以看
出改善後的生成式對話模型,在 Average Score 從 0.16 提升至 0.428,本研究所提
出之 ACR Index 也從 0.08 提升至 0.214。經由增加候選名單與加入預期回覆長度係
數,在生成式對話成效上有明顯的提升。
表 11 情感對話機器人總評分比較表
Label 0 Label 1 Label 2
Total
Score
Average
Score
ACR
Index
檢索式模型 304 209 487 1183 1.183 0.591
生成式模型 875 90 35 160 0.16 0.08
生成式模型
(改善後) 713 146 141 428 0.428 0.214
伍、 結論與貢獻
一、 結論
本研究提出之人工智慧情感對話機器人的建置方法。透過文獻探討。實驗各
種不同模型並交叉分析驗證,並建置系統自動化,進行語句的情感分析標示出語
句所對應之情感,讓對話機器人能有更為細膩的情感辨識能力。
本研究提出之人工智慧情感對話機器人透過實驗分析與驗證後作出以下結

2019 富邦人壽管理碩士論文獎
論:
1. 以多層感知機、長短記憶和雙向長短記憶三種不同神經網絡方法進行訓
練情感分析模型,並將結果互相比較最後結果顯示,證實雙向長短記憶
模型在情感分析上預測效果最佳。
2. 在檢索式模型與生成式對話模型的評估上,本研究使用一致性評估,評
估顯示在對話上檢索式模型比生成式模型的效果來的出色。
二、 研究貢獻
本研究共有兩項研究貢獻如下:
1) 本研究使用系統發展研究方法,完成了一個具有情感對話機器人的系統雛
型,並提供建置方法與系統架構。此系統實作了情感預測模型與生成式對
話模型的訓練,並將對話模型、情感分析模型與相似度模型整合,並自動
產出多樣的情感回覆。
2) 本研究建置了一種評估情感對話機器人成效的方法,透過一致性與標記評
分兩階段的評估驗證,並且本研究也提出一個名為情感機器人評估指數
(Affective Conversational Robot Index; ACR Index)。此指數可更客觀的評估
情感對話機器人的成效,可讓往後的研究者多一種評估驗證的選擇。
參考文獻
Chowdhury, G. G. (2003). "Natural language processing." Annual review of information
science and technology 37(1): 51-89.
Jaakkola, T. and D. Haussler (1999). Exploiting generative models in discriminative
classifiers. Advances in neural information processing systems.
Jurafsky, D. and J. H. Martin (2014). Speech and language processing, Pearson
London:.
Huang, M., Ye, Z., & Zhou, H. (2017). Overview of the NLPCC 2017 Shared Task:
Emotion Generation Challenge. In National CCF Conference on Natural Language
Processing and Chinese Computing.
Liu, B. (2012). "Sentiment analysis and opinion mining." Synthesis lectures on human
language technologies 5(1): 1-167.
Mauldin, M. L. (1994). Chatterbots, tinymuds, and the turing test: Entering the loebner
prize competition. AAAI.
Nasukawa, T. and J. Yi (2003). Sentiment analysis: Capturing favorability using natural
language processing. Proceedings of the 2nd international conference on
Knowledge capture, ACM.
Nunamaker Jr, J. F., et al. (1990). "Systems development in information systems
research." Journal of management information systems 7(3): 89-106.
Quan, C. and F. Ren (2009). Construction of a blog emotion corpus for Chinese
emotional expression analysis. Proceedings of the 2009 Conference on Empirical
Methods in Natural Language Processing: Volume 3-Volume 3, Association for


















