
2020年度海外留学支援制度(学部学位取得型)募集 …2019/09/13 · 2020 年度海外留学支援制度(学部学位取得型)募集要項 ※この募集は、
Upload
-Category
view
251download
0
第13回 数値流体力学への応用(高度な 適化)
長岡技術科学大学 電気電子情報工学専攻 出川智啓

今回の内容
2015/07/09先端GPGPUシミュレーション工学特論2
拡散方程式
拡散方程式の演算強度
メモリ再利用の考え方
ラプラシアン計算の高度な最適化

これまでのGPU実装
2015/07/09先端GPGPUシミュレーション工学特論3
1スレッドが1点の計算を実行 並列度が最も高い
1点あたりの計算負荷は軽い メモリから読み込むデータのサイズと計算量の比が小さい
演算強度flop/byteが小さい
1スレッドが複数の点を計算することで性能が上がる場合がある 1度メモリから読み込んだデータを極力再利用

拡散方程式
初期条件
境界条件
先端GPGPUシミュレーション工学特論4 2015/07/09
)2.0( 1)2.0( 0
rr
f
1
1x
y r0
nf
n
n
n: 外向き法線ベクトル
jijijiji
jiji
ff
Δxff
Δxff
,,1,1,
,,1
0
0
jijijiji
jiji
ff
Δyff
Δyff
,1,1,,
,1,
0
0
22 yxr

#include<stdlib.h>#include<math.h>
#define Lx (1.0)#define Ly (1.0)#define Nx 128#define Ny 128#define dx (Lx/(Nx‐1))#define dy (Ly/(Ny‐1))#define dt 0.0001#define endT (1.0)#define Nt (int)(endT/dt)#define DIFF (0.01)#define dxdx (dx*dx)#define dydy (dy*dy)#define Nbytes (Nx*Ny*sizeof(double))
void init(double *, double *, double *);void laplacian(double *, double *);void integrate(double *, double *, double *);void update(double *, double *);
int main(void){
double *f,*f_new,*f_lap,x,y;int i,j,n;
f = (double *)malloc(Nx*Ny*sizeof(double));f_new = (double *)malloc(Nx*Ny*sizeof(double));f_lap = (double *)malloc(Nx*Ny*sizeof(double));
init(f, f_lap, f_new);
for(n=0;n<Nt;n++){laplacian(f,f_lap);integrate(f,f_lap,f_new);update(f,f_new);
}return 0;
}
CPUプログラム
2015/07/09先端GPGPUシミュレーション工学特論5
diffusion.c

void init(double *f, double *f_lap, double *f_new){int i,j,ij;double x,y;for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){f [i+Nx*j] = 0.0;f_lap[i+Nx*j] = 0.0;f_new[i+Nx*j] = 0.0;x=i*dx‐Lx/2.0;y=j*dy‐Ly/2.0;if(sqrt(x*x+y*y)<=0.2) f[i+Nx*j] = 1.0;
}}
}
void laplacian(double *f, double *f_lap){int i,j,ij,ip1j,im1j,ijp1,ijm1;for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){ij = i+Nx*j;im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+Nx*j;ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i+Nx*j;ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i+Nx*j;ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i+Nx*j);f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx
+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;}
}}
void integrate(double *f, double *f_lap, double *f_new){
int i,j,ij;for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){ij = i+Nx*j;f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];
}}
}
void update(double *f, double *f_new){int i,j,ij;for(j=0;j<Ny;j++){
for(i=0;i<Nx;i++){ij = i+Nx*j;f[ij] = f_new[ij];
}}
}
CPUプログラム
2015/07/09先端GPGPUシミュレーション工学特論6
diffusion.c

CPUプログラム
差分計算 x方向,y方向偏微分を個別に計算して加算
void laplacian(double *f, double *f_lap){int i,j,ij,ip1j,im1j,ijp1,ijm1;for(j=0;j<Ny;j++){for(i=0;i<Nx;i++){ij = i+Nx*j;im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+Nx*j;ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i+Nx*j;ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i+Nx*j;ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i+Nx*j;
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
}}
}
先端GPGPUシミュレーション工学特論7 2015/07/09
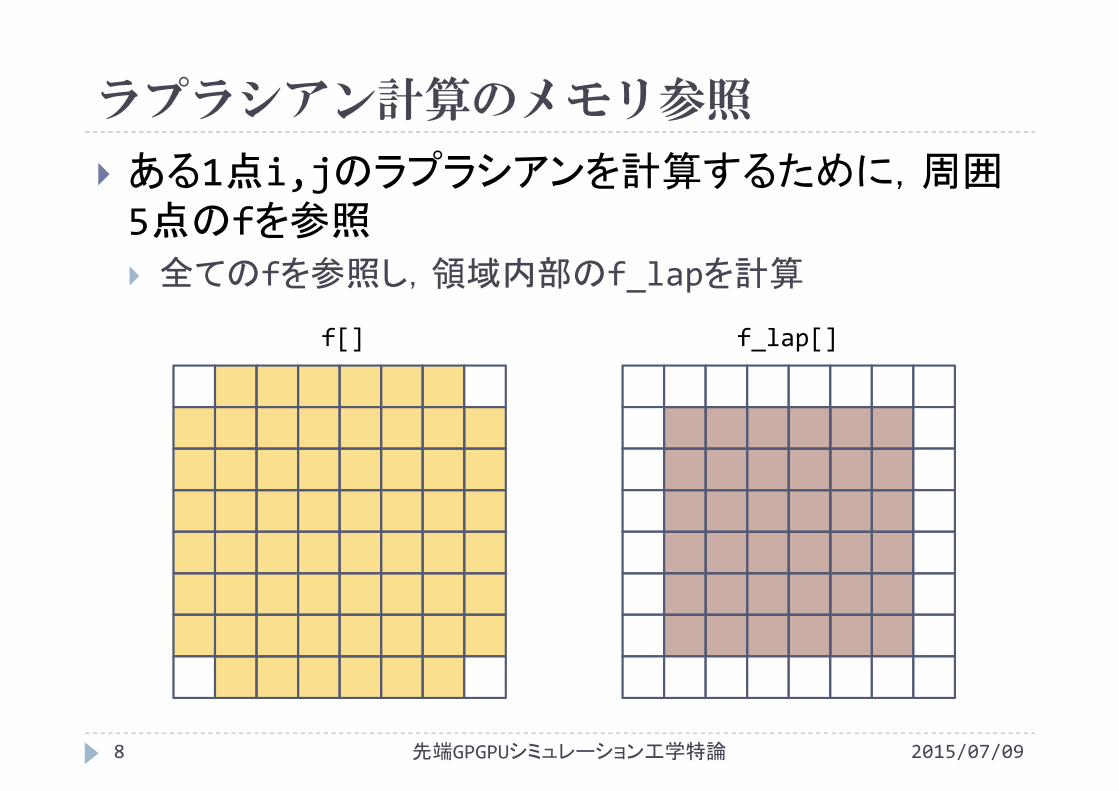
ラプラシアン計算のメモリ参照
ある1点i,jのラプラシアンを計算するために,周囲5点のfを参照 全てのfを参照し,領域内部のf_lapを計算
先端GPGPUシミュレーション工学特論8 2015/07/09
f[] f_lap[]
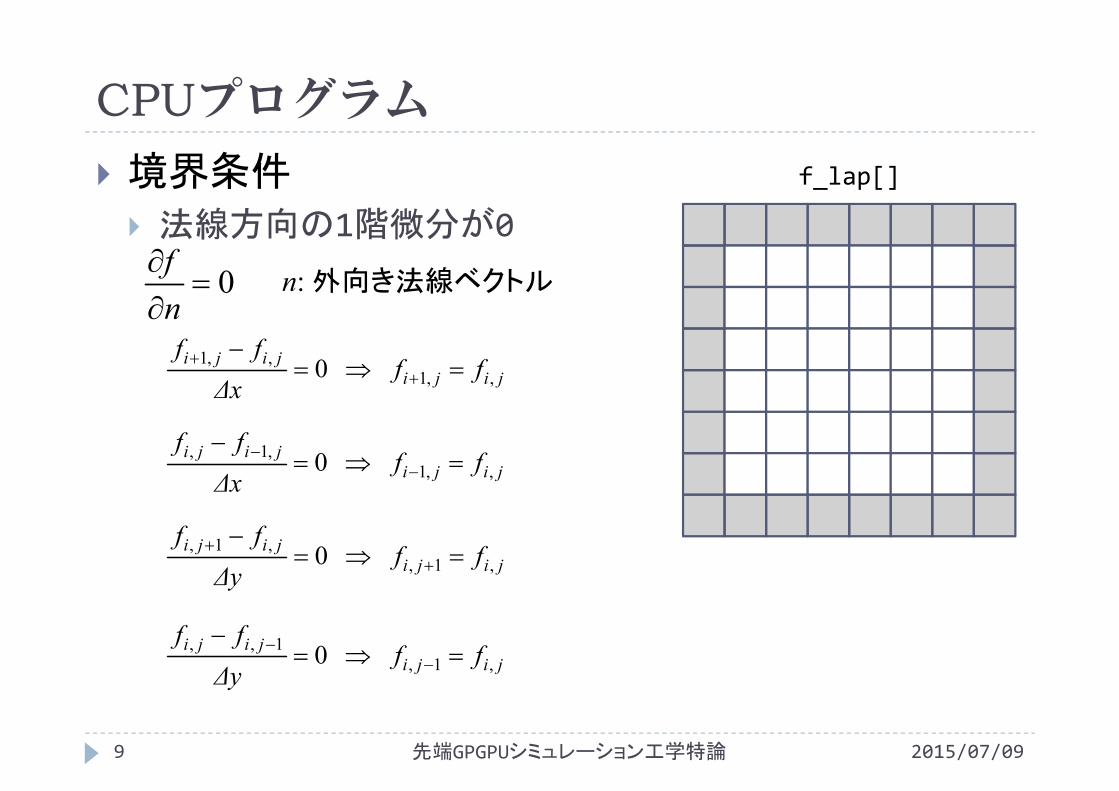
CPUプログラム
境界条件 法線方向の1階微分が0
先端GPGPUシミュレーション工学特論9 2015/07/09
f_lap[]
0nf
n: 外向き法線ベクトル
jijijiji ff
Δxff
,,1,,1 0
jijijiji ff
Δyff
,1,,1, 0
jijijiji ff
Δxff
,,1,1, 0
jijijiji ff
Δyff
,1,1,, 0
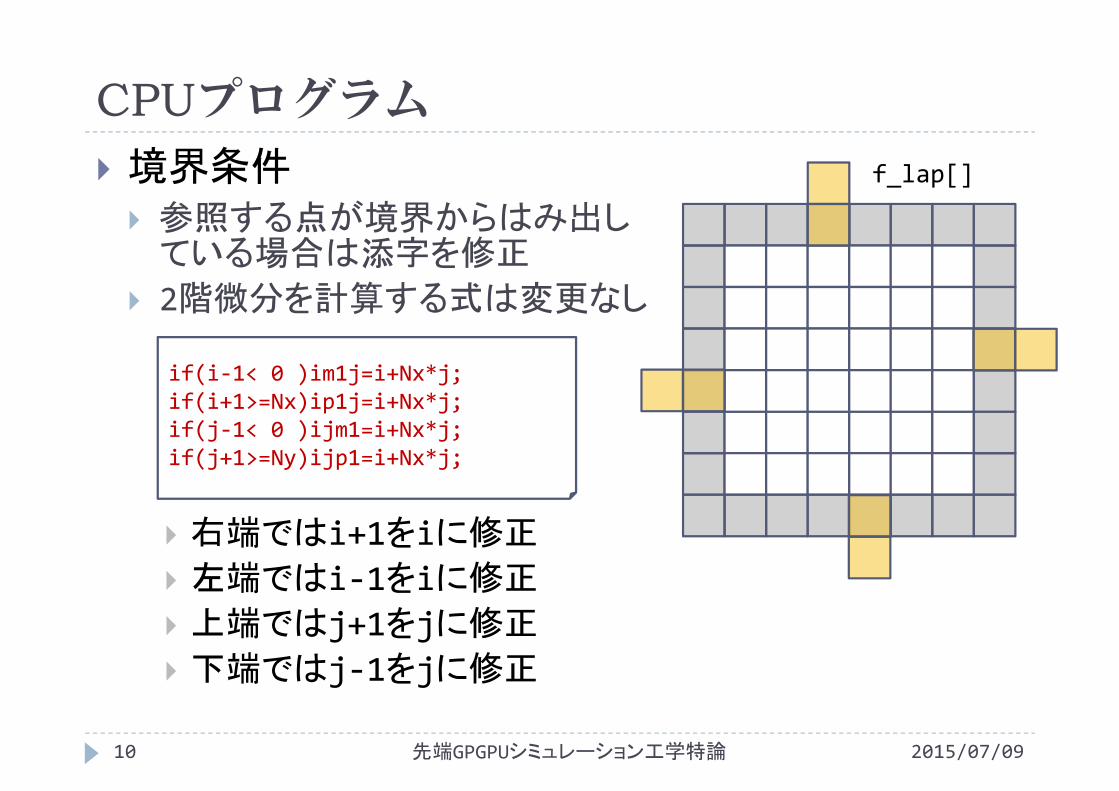
CPUプログラム
境界条件 参照する点が境界からはみ出している場合は添字を修正
2階微分を計算する式は変更なし
右端ではi+1をiに修正
左端ではi‐1をiに修正
上端ではj+1をjに修正
下端ではj‐1をjに修正
先端GPGPUシミュレーション工学特論10 2015/07/09
f_lap[]
if(i‐1< 0 )im1j=i+Nx*j;if(i+1>=Nx)ip1j=i+Nx*j;if(j‐1< 0 )ijm1=i+Nx*j;if(j+1>=Ny)ijp1=i+Nx*j;

CPUプログラム
fの積分
void integrate(double *f, double *f_lap, double *f_new){int i,j,ij;for(j=0;j<Ny;j++){for(i=0;i<Nx;i++){ij = i+Nx*j;f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];
}}
}
先端GPGPUシミュレーション工学特論11 2015/07/09
21,,1,
2,1,,1
,1
,
22Δy
fffΔx
fffΔtff
nji
nji
nji
nji
nji
njin
jinji

CPUプログラム
fの更新 fnからfn+1を計算
fn+1からfn+2を計算
今の時刻から次の時刻を求める
求められた次の時刻を今の時刻と見なし,次の時刻を求める
void update(double *f, double *f_new){int i,j,ij;for(j=0;j<Ny;j++){for(i=0;i<Nx;i++){ij = i+Nx*j;f[ij] = f_new[ij];
}}
}
先端GPGPUシミュレーション工学特論12 2015/07/09
同じアルゴリズム

#include<stdio.h>#include<stdlib.h>#include<math.h>
#define Lx (1.0)#define Ly (1.0)#define Nx 2048#define Ny Nx#define dx (Lx/(Nx‐1))#define dy (Ly/(Ny‐1))#define dt 0.000001#define endT (1.0)#define Nt (int)(endT/dt)#define DIFF (0.01)#define dxdx (dx*dx)#define dydy (dy*dy)#define Nbytes (Nx*Ny*sizeof(double))
int main(void){
int n;double *dev_f,*dev_f_new,*dev_f_lap;dim3 Thread, Block;
if(DIFF*dt/dxdx > 0.5){printf("configuration error¥n");exit(1);
}
cudaMalloc( (void**)&dev_f , Nbytes );cudaMalloc( (void**)&dev_f_new, Nbytes );cudaMalloc( (void**)&dev_f_lap, Nbytes );
Thread = dim3(THREADX,THREADY,1);Block = dim3(BLOCKX ,BLOCKY, 1);init<<<Block, Thread>>>
(dev_f, dev_f_lap, dev_f_new);
for(n=1;n<=Nt;n++){laplacian<<<Block, Thread>>>(dev_f,dev_f_lap);integrate<<<Block, Thread>>>
(dev_f,dev_f_lap,dev_f_new);update<<<Block, Thread>>>(dev_f,dev_f_new);
}
return 0;}
GPUプログラム(CPU処理用共通部分)
2015/07/09先端GPGPUシミュレーション工学特論13
diffusion.cu

#define THREADX 16#define THREADY 16#define BLOCKX (Nx/THREADX)#define BLOCKY (Ny/THREADY)
__global__ void laplacian(double *f, double *f_lap){
int i,j,ij,im1j,ip1j,ijm1,ijp1;i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*blockDim.y + threadIdx.y;
ij =i +Nx* j;im1j=i‐1+Nx* j; if(i‐1< 0 )im1j=i+Nx*j;ip1j=i+1+Nx* j; if(i+1>=Nx)ip1j=i+Nx*j;ijm1=i +Nx*(j‐1);if(j‐1< 0 )ijm1=i+Nx*j;ijp1=i +Nx*(j+1);if(j+1>=Ny)ijp1=i+Nx*j;
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
}
__global__ void integrate(double *f, double *f_lap, double *f_new){
int i,j,ij;i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*blockDim.y + threadIdx.y;ij = i+Nx*j;
f_new[ij] = f[ij] + dt*DIFF*f_lap[ij];}
__global__ void update(double *f, double *f_new){int i,j,ij;i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*blockDim.y + threadIdx.y;ij = i+Nx*j;f[ij] = f_new[ij];
}
__global__ void init(double *f, double *f_lap, double *f_new){
int i,j,ij;double x,y;i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*blockDim.y + threadIdx.y;ij = i+Nx*j;
f [ij] = 0.0;f_lap[ij] = 0.0;f_new[ij] = 0.0;x=i*dx‐Lx/2.0;y=j*dy‐Ly/2.0;if(sqrt(x*x+y*y)<=0.2) f[ij] = 1.0;
}
GPUプログラム(1スレッドが1点を計算)
2015/07/09先端GPGPUシミュレーション工学特論14
diffusion.cu

ラプラシアン計算の演算強度
2015/07/09先端GPGPUシミュレーション工学特論15
演算強度flop/byte 演算7回(加算4回,乗算3回)=>7flop メモリアクセス6回(読込5回,書込1回)=>6*8byte flop/byte = 7/48 ≈ 0.15
メモリアクセスに対して演算が少ない メモリを再利用して実質的な演算強度を高める
f_lap[ij] = (f[ip1j]‐2.0*f[ij]+f[im1j])/dxdx+(f[ijp1]‐2.0*f[ij]+f[ijm1])/dydy;
f_lap[ij] = cx*(f[ip1j]+f[im1j]) //cx = 1.0/dxdx+cy*(f[ijp1]+f[ijm1]) //cy = 1.0/dydy+c*f[ij]; //c=‐2.0*(cx+cy)
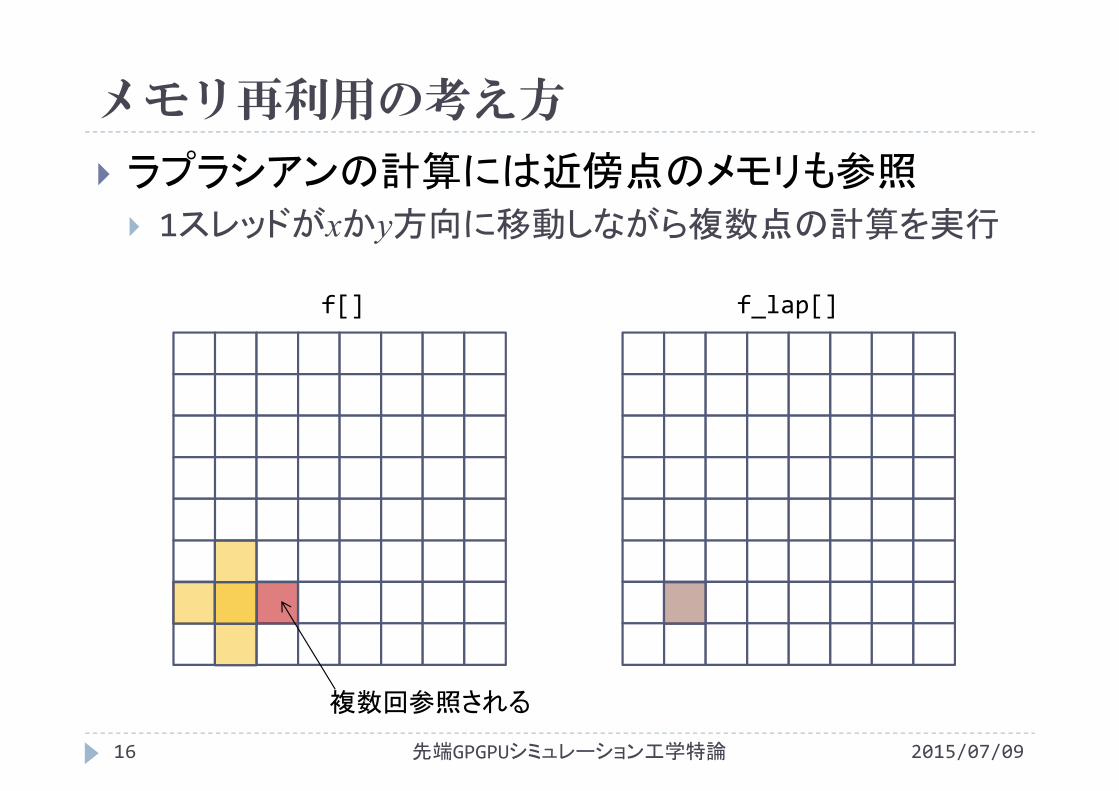
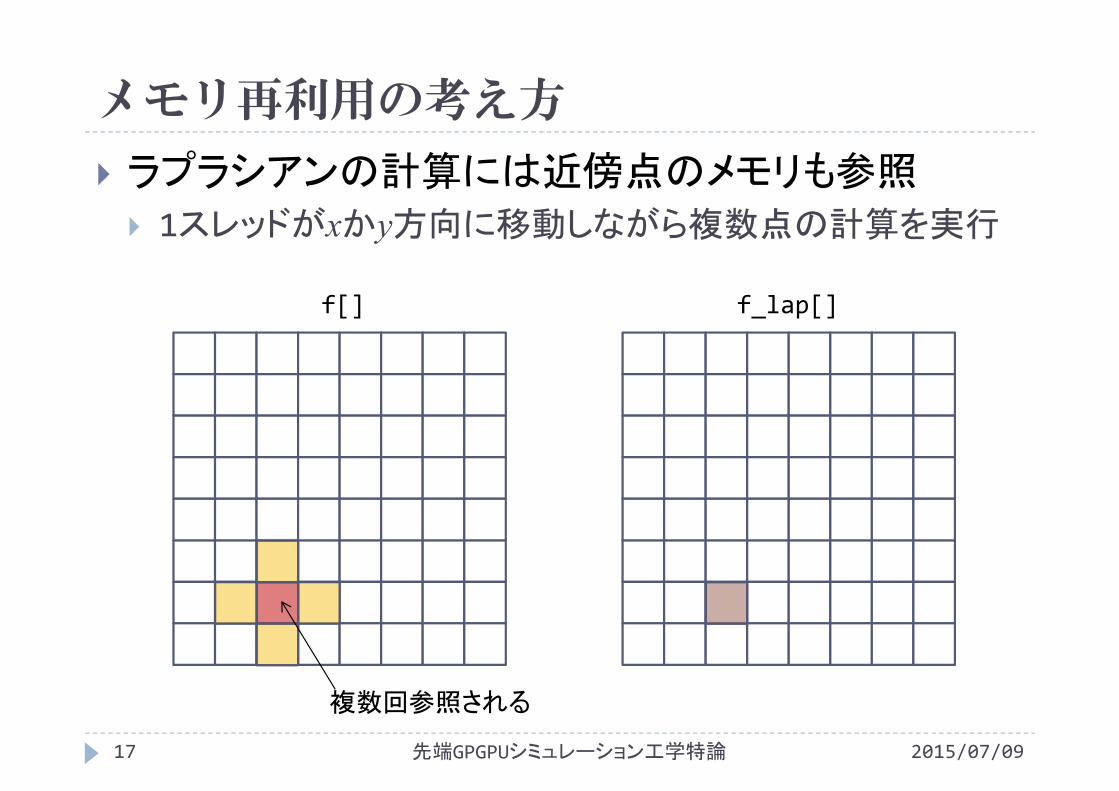
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論16
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される
メモリ再利用の考え方
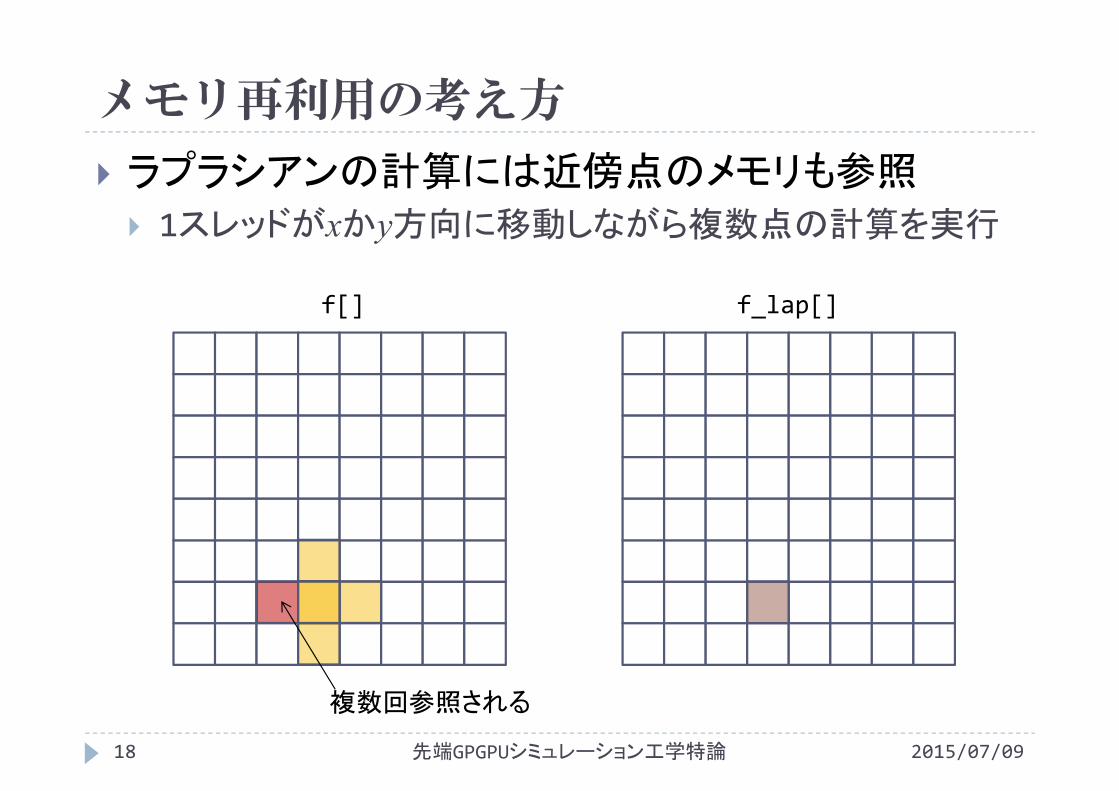
2015/07/09先端GPGPUシミュレーション工学特論17
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論18
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される

メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論19
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される
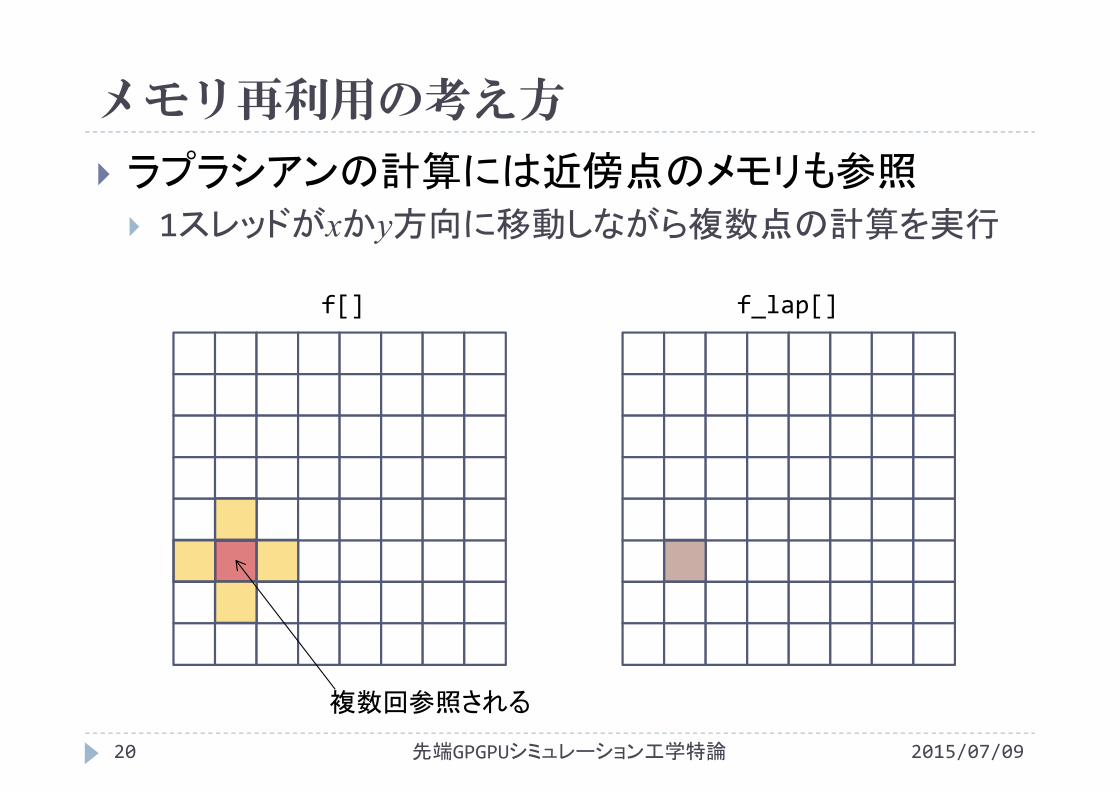
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論20
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される
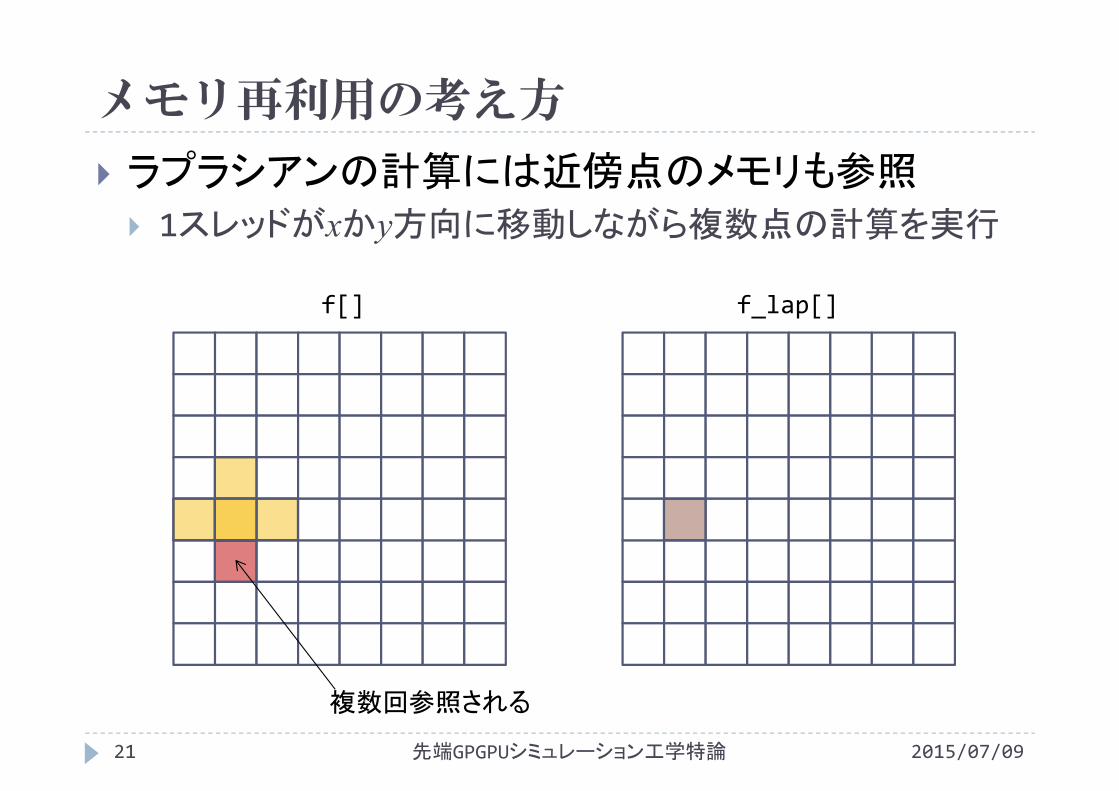
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論21
ラプラシアンの計算には近傍点のメモリも参照 1スレッドがxかy方向に移動しながら複数点の計算を実行
f[] f_lap[]
複数回参照される
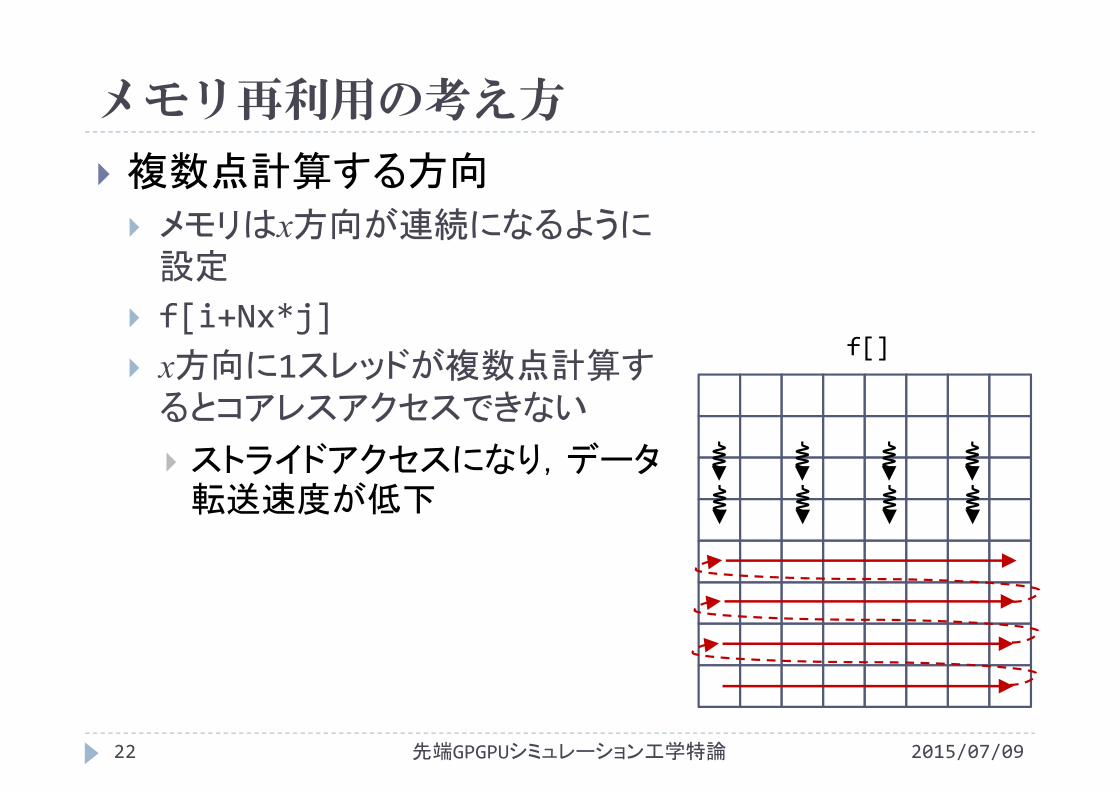
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論22
複数点計算する方向
メモリはx方向が連続になるように設定
f[i+Nx*j] x方向に1スレッドが複数点計算するとコアレスアクセスできない
ストライドアクセスになり,データ転送速度が低下
f[]
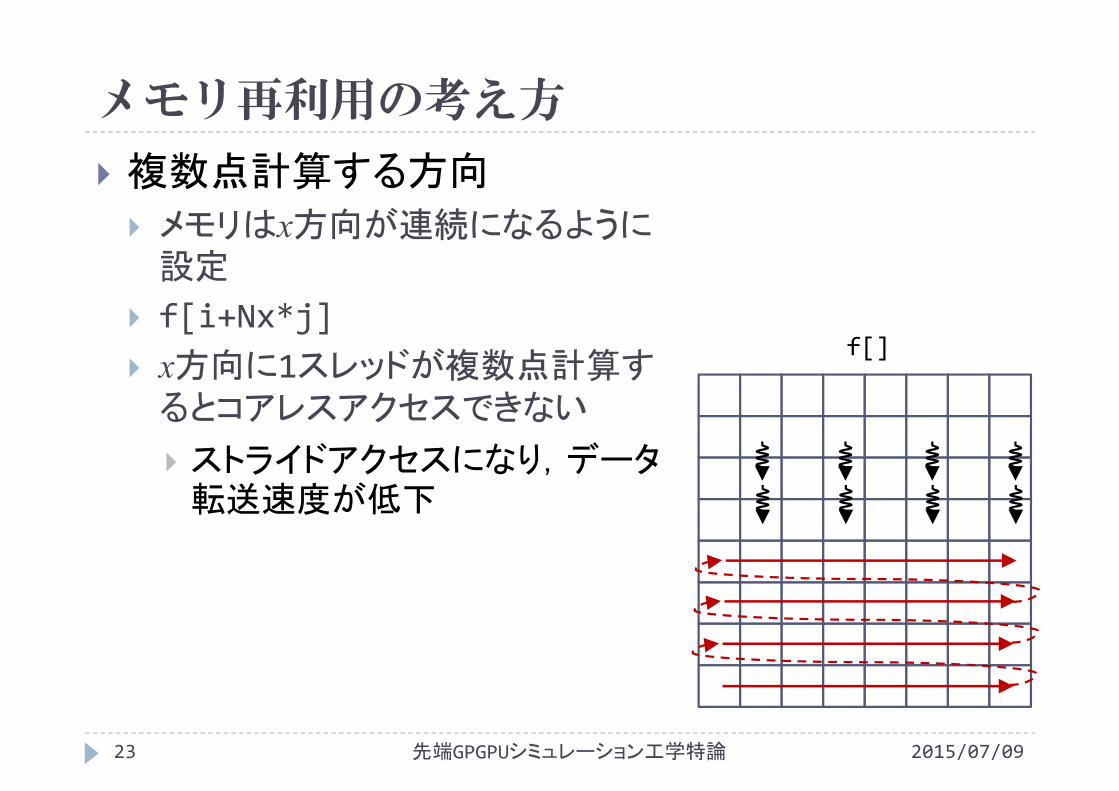
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論23
複数点計算する方向
メモリはx方向が連続になるように設定
f[i+Nx*j] x方向に1スレッドが複数点計算するとコアレスアクセスできない
ストライドアクセスになり,データ転送速度が低下
f[]
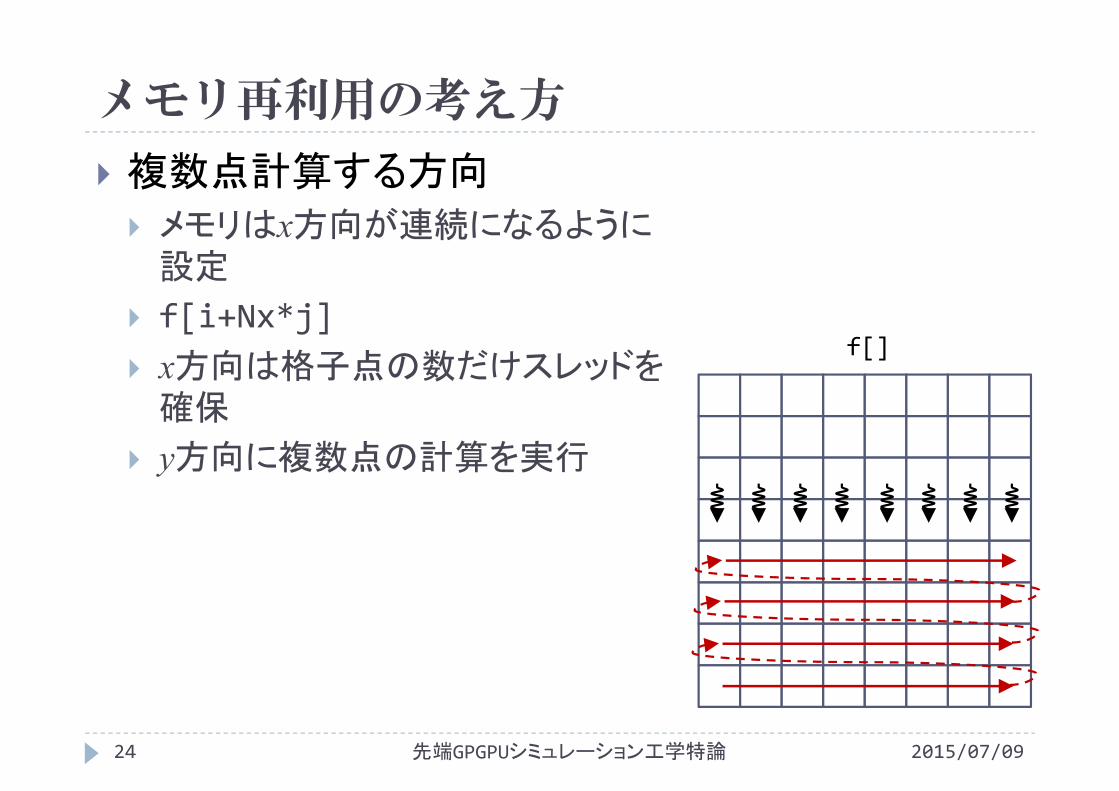
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論24
複数点計算する方向
メモリはx方向が連続になるように設定
f[i+Nx*j] x方向は格子点の数だけスレッドを確保
y方向に複数点の計算を実行
f[]
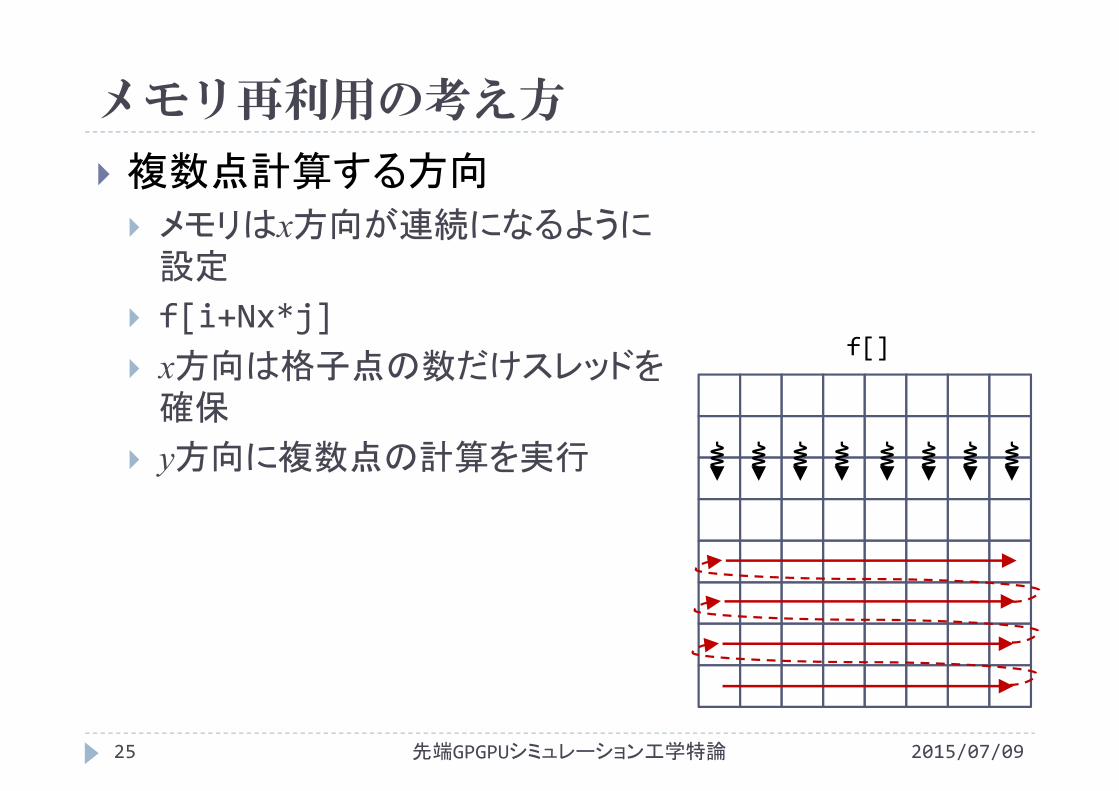
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論25
複数点計算する方向
メモリはx方向が連続になるように設定
f[i+Nx*j] x方向は格子点の数だけスレッドを確保
y方向に複数点の計算を実行
f[]
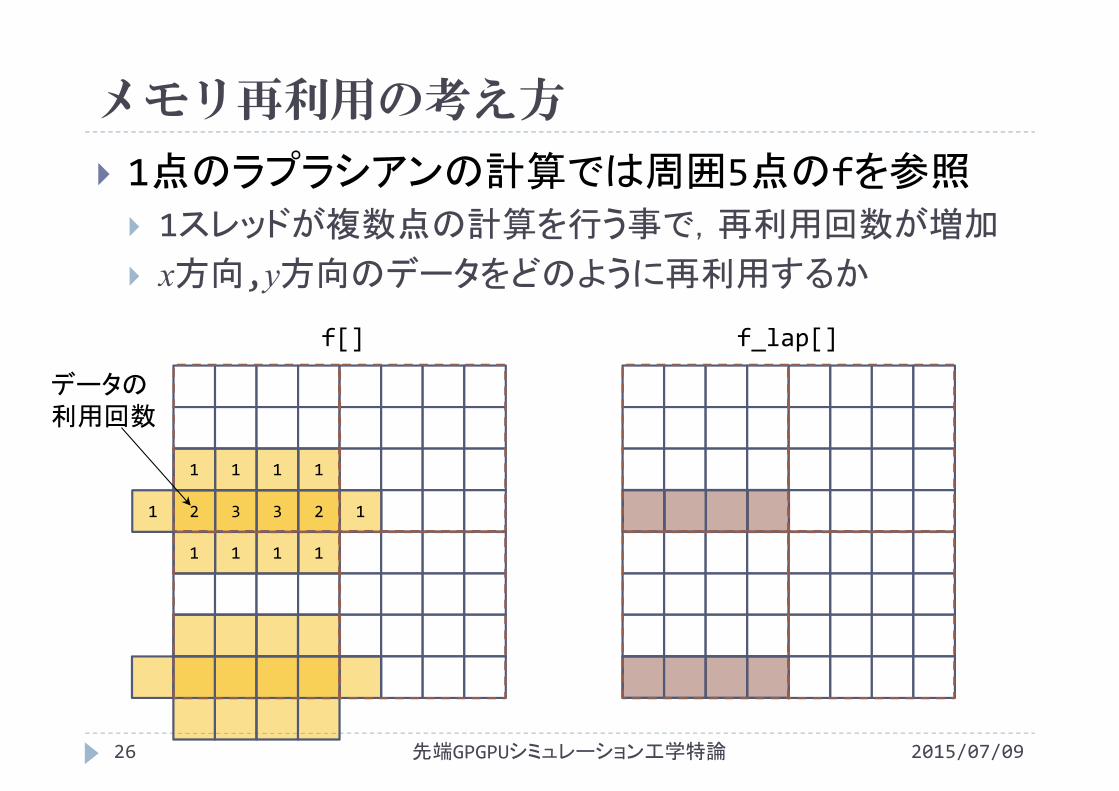
メモリ再利用の考え方
1点のラプラシアンの計算では周囲5点のfを参照 1スレッドが複数点の計算を行う事で,再利用回数が増加
x方向,y方向のデータをどのように再利用するか
先端GPGPUシミュレーション工学特論26 2015/07/09
f[] f_lap[]
11
1 1 1 1
1 1 1 1
2 3 3 2
データの利用回数
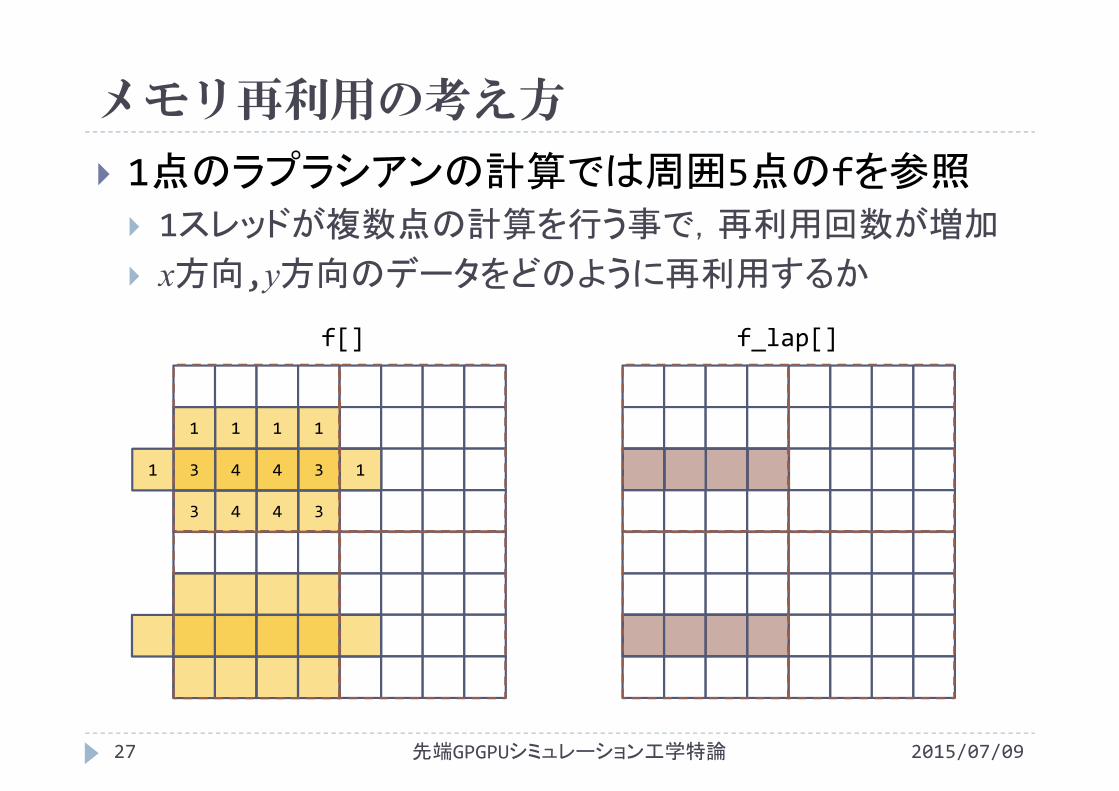
メモリ再利用の考え方
1点のラプラシアンの計算では周囲5点のfを参照 1スレッドが複数点の計算を行う事で,再利用回数が増加
x方向,y方向のデータをどのように再利用するか
先端GPGPUシミュレーション工学特論27 2015/07/09
f[] f_lap[]
11
3 4 4 3
1 1 1 1
3 4 4 3

メモリ再利用の考え方
1点のラプラシアンの計算では周囲5点のfを参照 1スレッドが複数点の計算を行う事で,再利用回数が増加
x方向,y方向のデータをどのように再利用するか
先端GPGPUシミュレーション工学特論28 2015/07/09
f[] f_lap[]
11
4 5 5 4
1 1 1 1
3 4 4 3
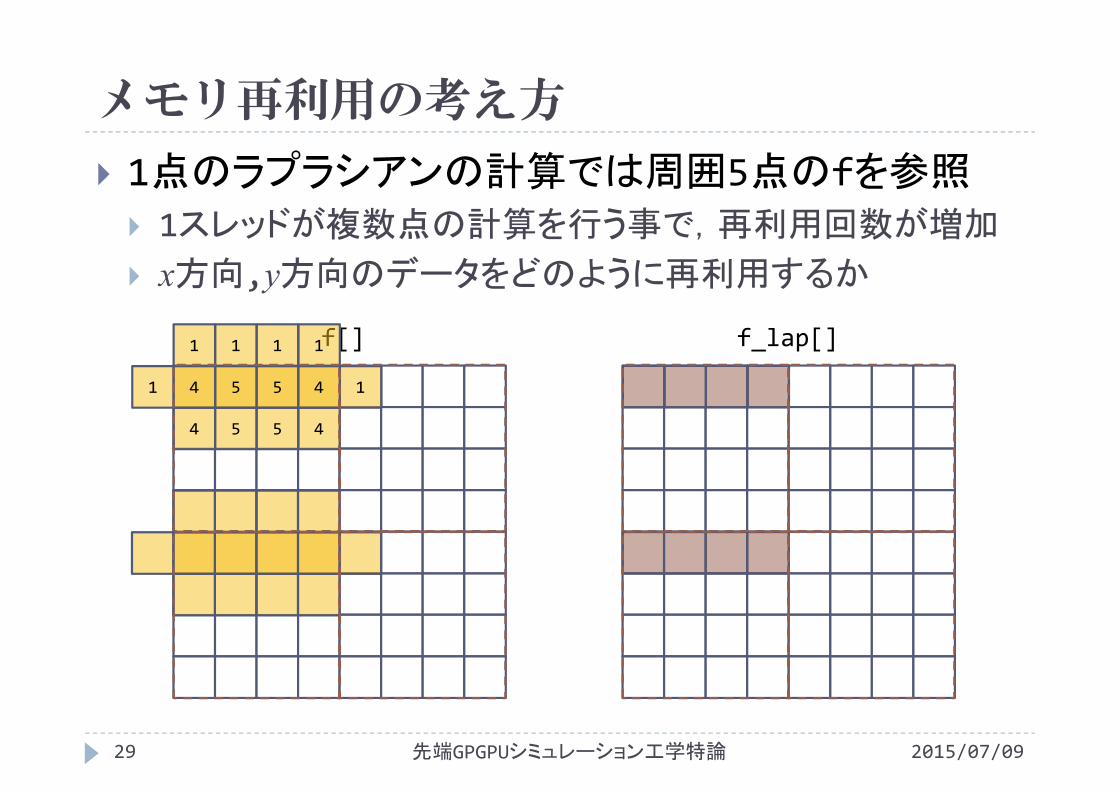
メモリ再利用の考え方
1点のラプラシアンの計算では周囲5点のfを参照 1スレッドが複数点の計算を行う事で,再利用回数が増加
x方向,y方向のデータをどのように再利用するか
先端GPGPUシミュレーション工学特論29 2015/07/09
f[] f_lap[]
11
4 5 5 4
1 1 1 1
4 5 5 4
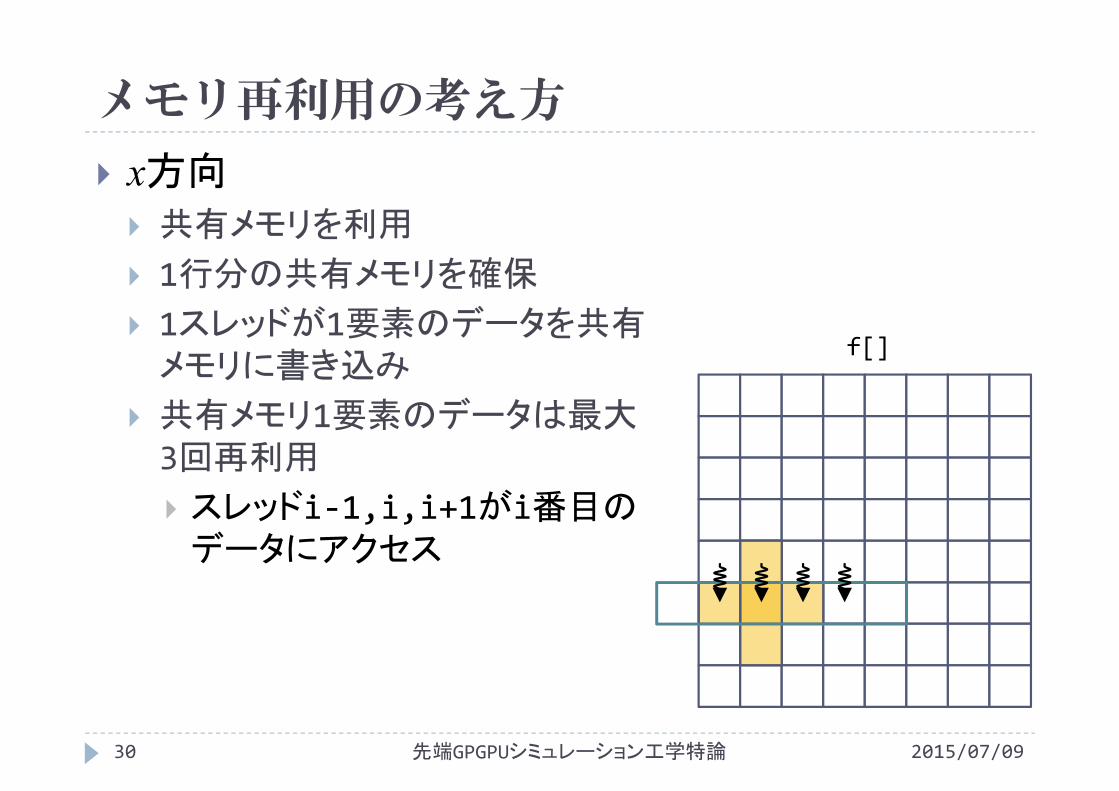
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論30
x方向 共有メモリを利用
1行分の共有メモリを確保
1スレッドが1要素のデータを共有メモリに書き込み
共有メモリ1要素のデータは最大3回再利用
スレッドi‐1,i,i+1がi番目のデータにアクセス
f[]
メモリ再利用の考え方
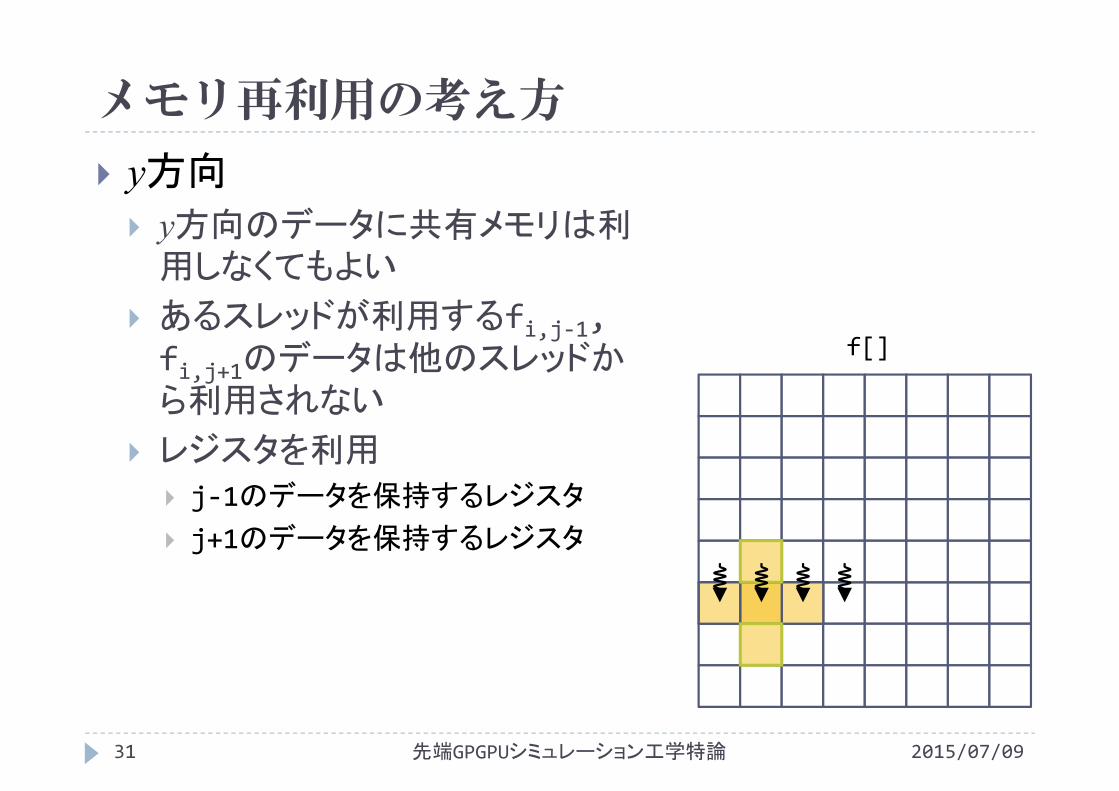
2015/07/09先端GPGPUシミュレーション工学特論31
y方向
y方向のデータに共有メモリは利用しなくてもよい
あるスレッドが利用するfi,j‐1, fi,j+1のデータは他のスレッドから利用されない
レジスタを利用
j‐1のデータを保持するレジスタ
j+1のデータを保持するレジスタ
f[]
f0,5 f1,5 f2,5 f3,5 f4,5 f5,5
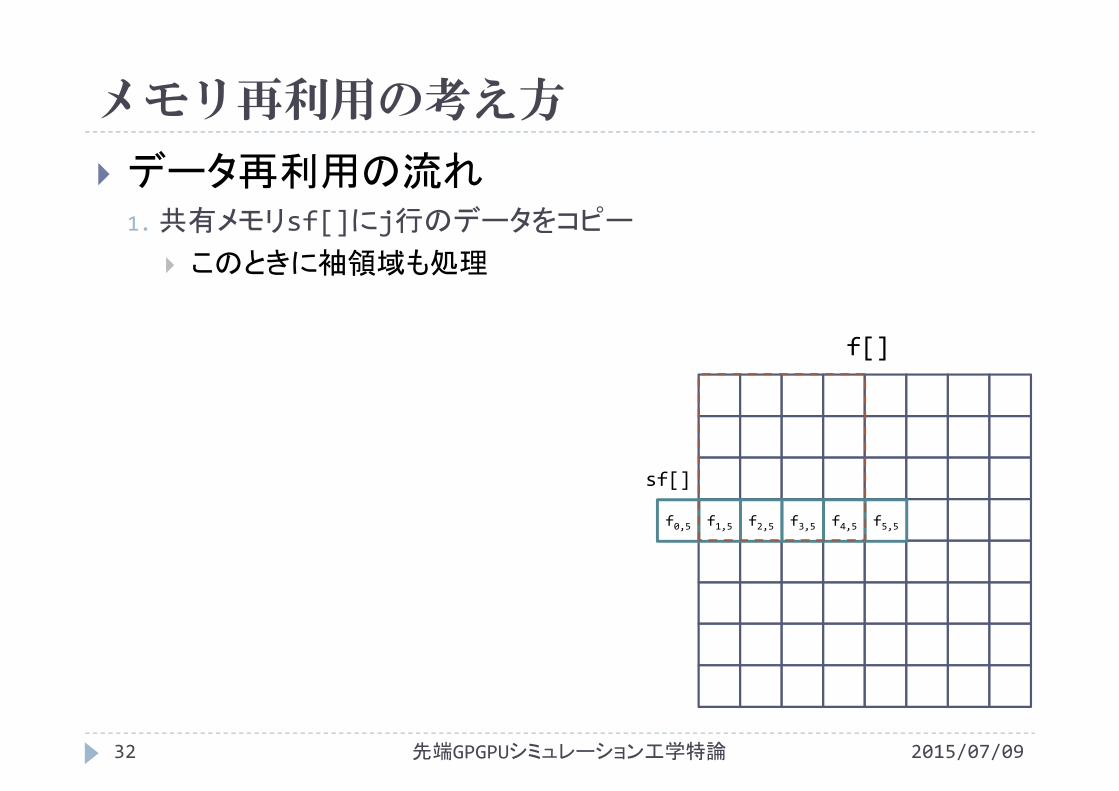
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論32
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
f[]
sf[]
f0,5 f1,5 f2,5 f3,5 f4,5 f5,5
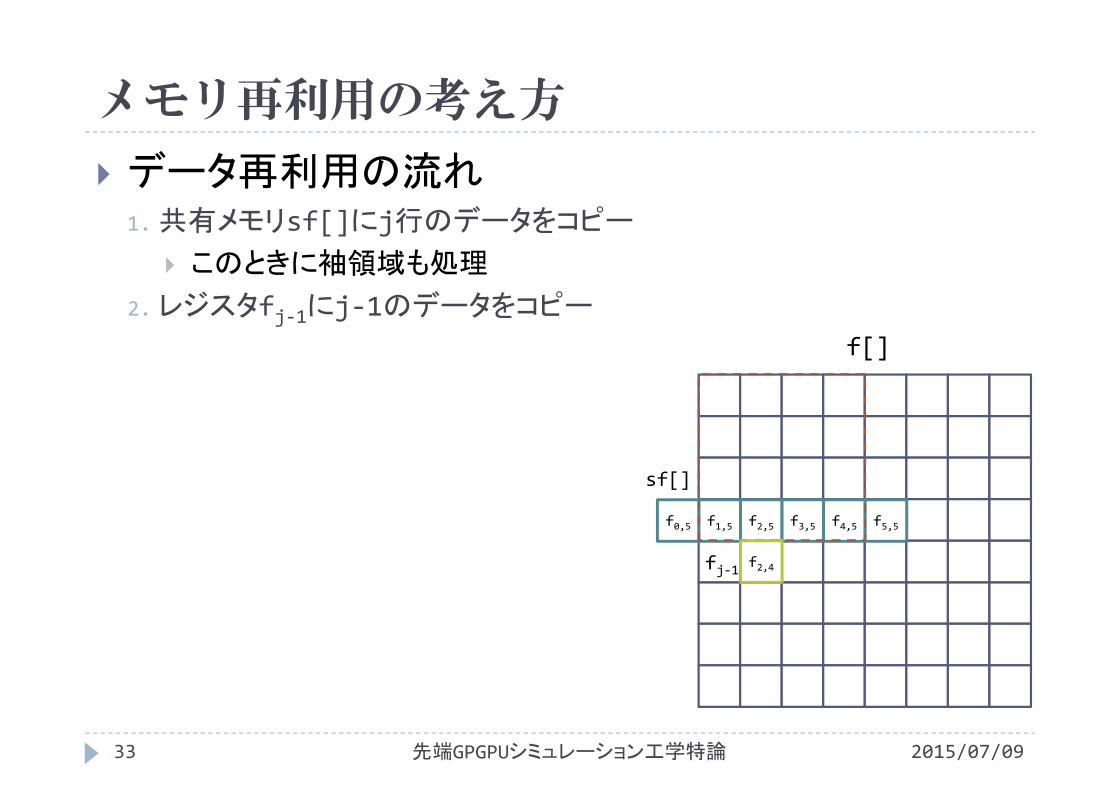
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論33
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
f[]
f2,4
sf[]
fj‐1

f0,5 f1,5 f2,5 f3,5 f4,5 f5,5
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論34
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー f[]
f2,4
f2,6sf[]
fj‐1
fj+1
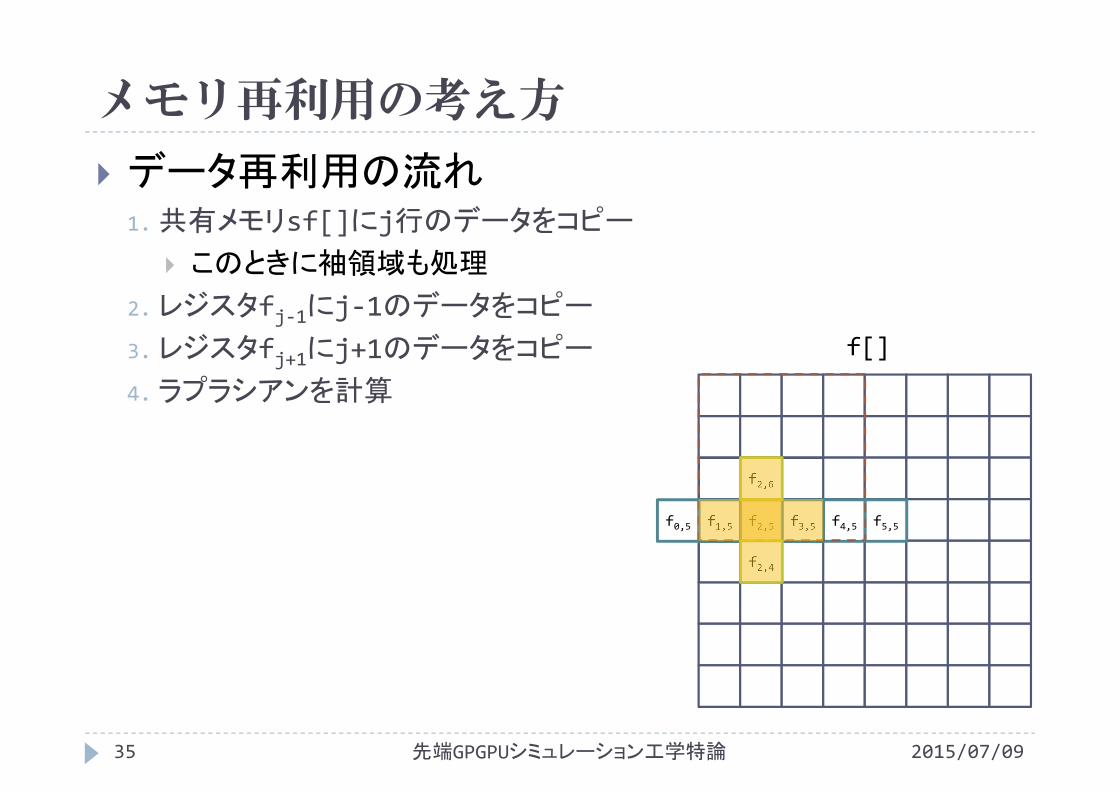
f0,5 f1,5 f2,5 f3,5 f4,5 f5,5
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論35
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー
4.ラプラシアンを計算
f[]
f2,4
f2,6
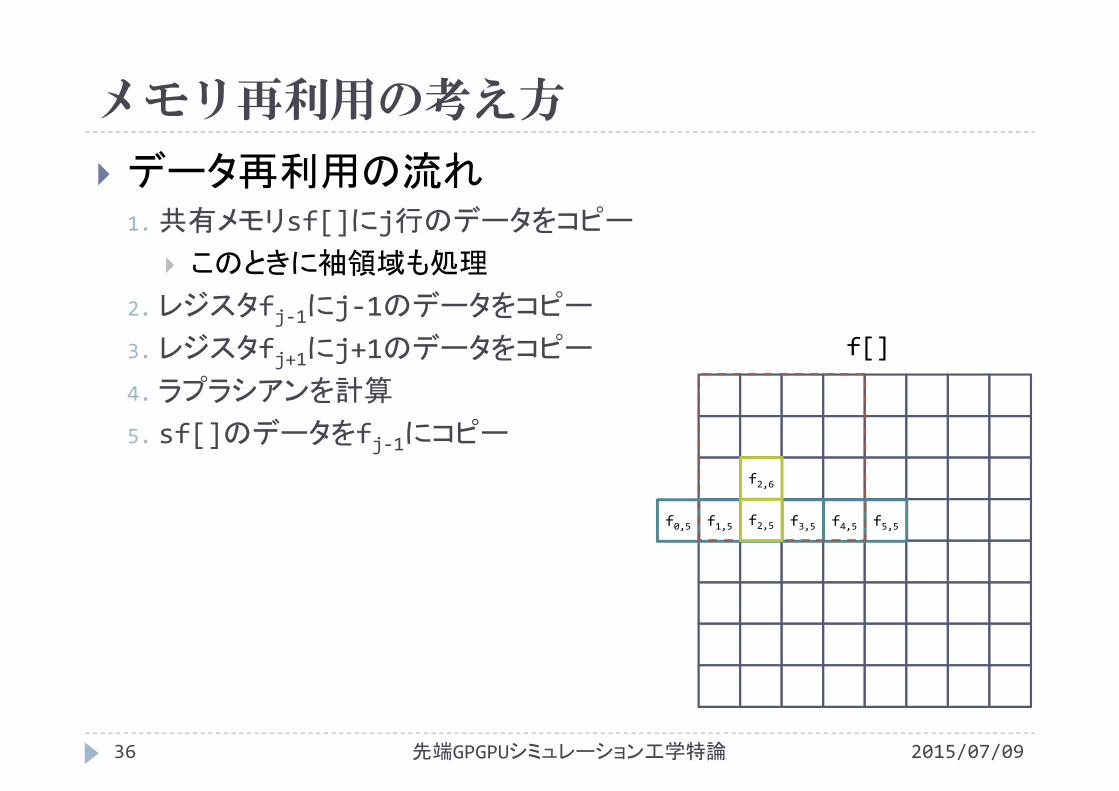
f0,5 f1,5 f2,5 f3,5 f4,5 f5,5
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論36
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー
4.ラプラシアンを計算
5. sf[]のデータをfj‐1にコピー
f[]
f2,5
f2,6
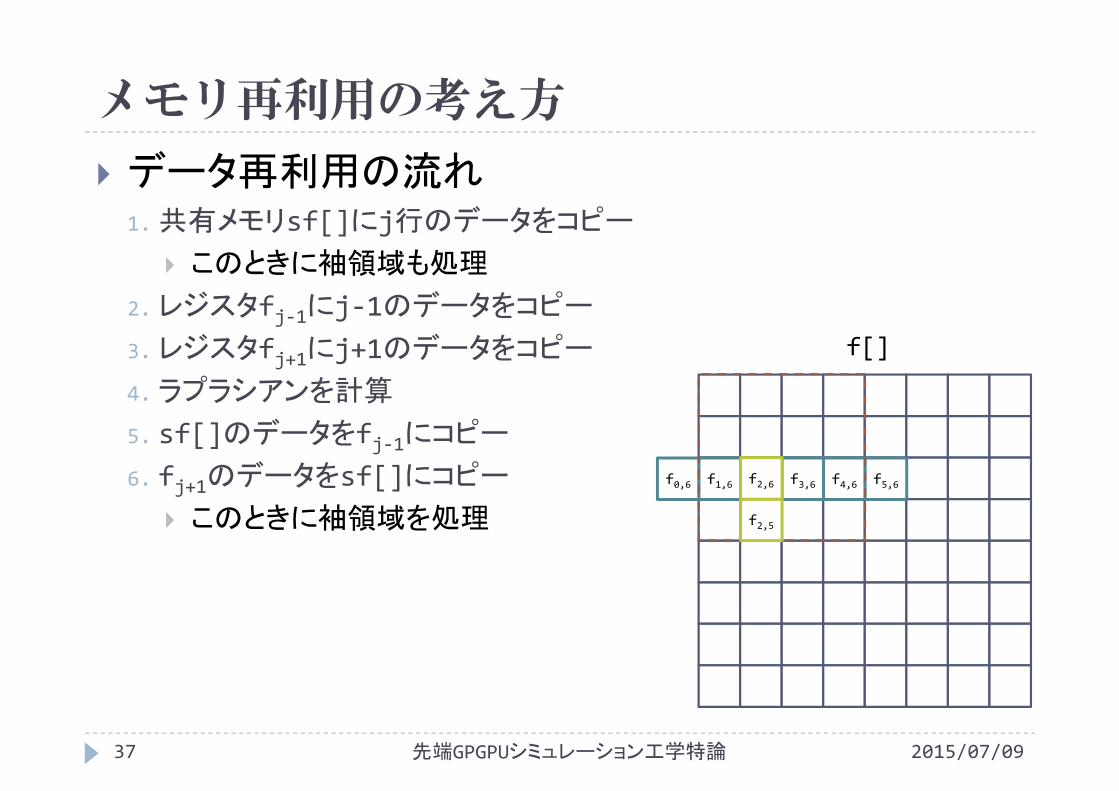
f0,6 f1,6 f2,6 f3,6 f4,6 f5,6
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論37
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー
4.ラプラシアンを計算
5. sf[]のデータをfj‐1にコピー
6. fj+1のデータをsf[]にコピー
このときに袖領域を処理
f[]
f2,5
f2,6
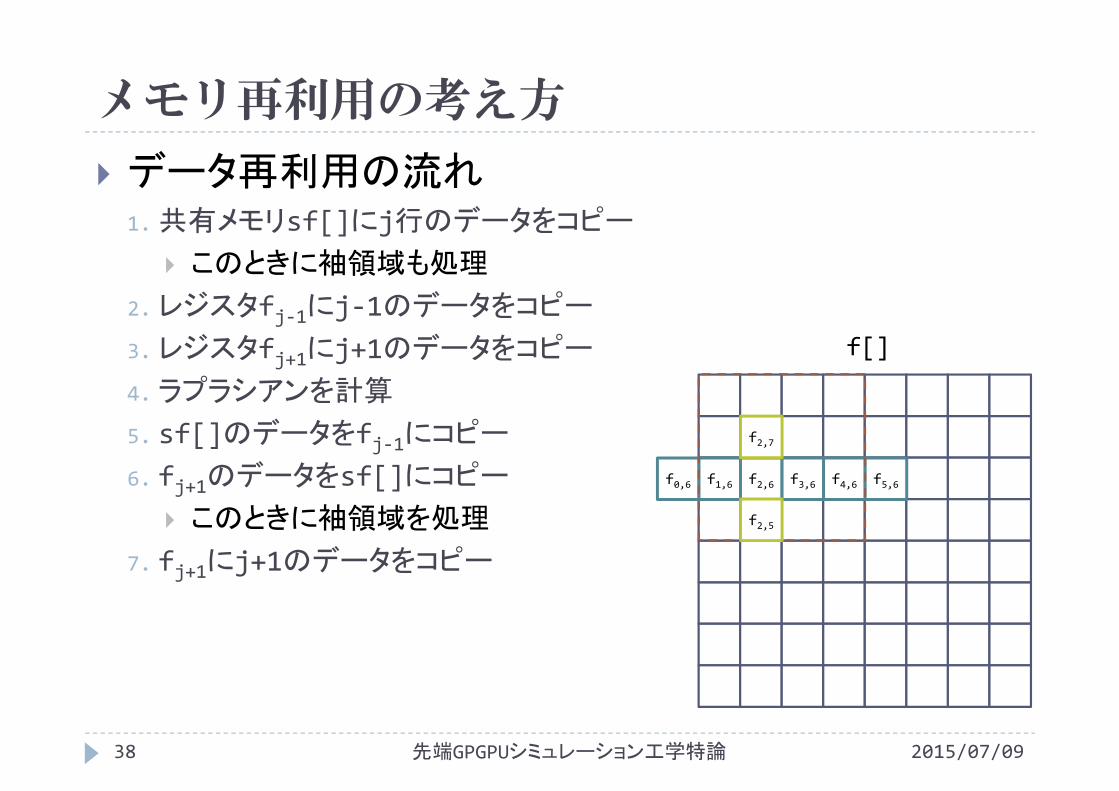
f0,6 f1,6 f2,6 f3,6 f4,6 f5,6
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論38
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー
4.ラプラシアンを計算
5. sf[]のデータをfj‐1にコピー
6. fj+1のデータをsf[]にコピー
このときに袖領域を処理
7. fj+1にj+1のデータをコピー
f[]
f2,5
f2,7
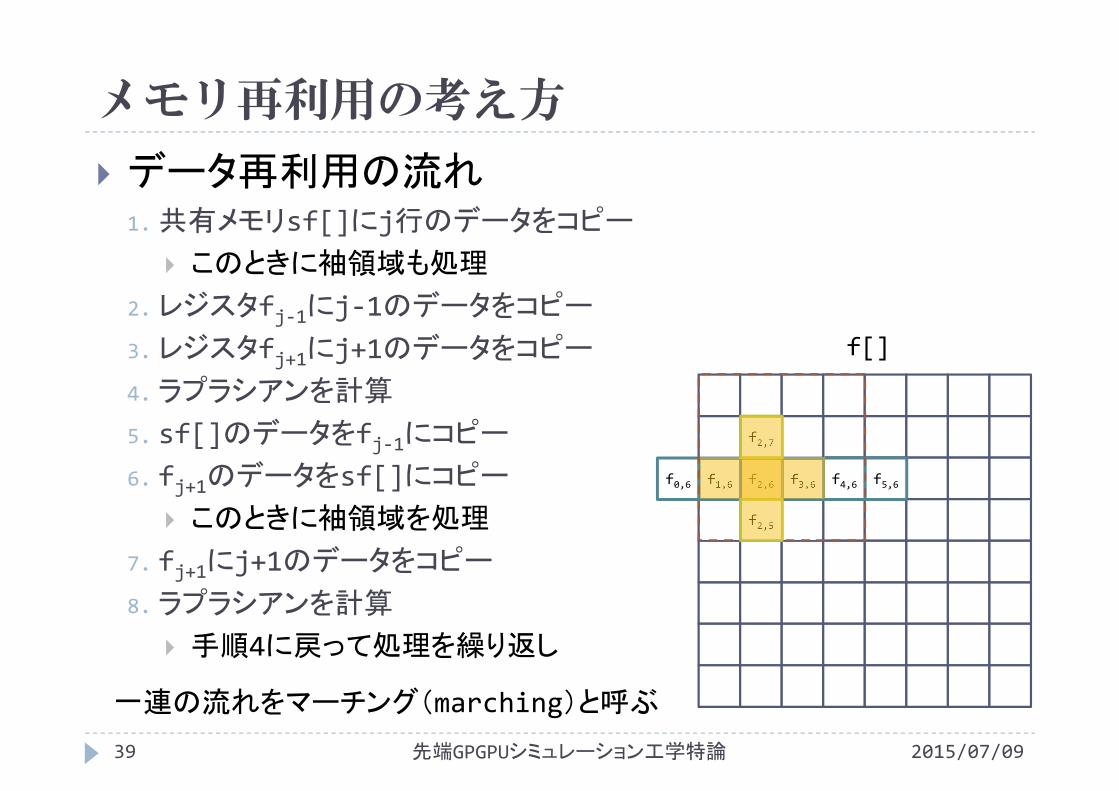
f0,6 f1,6 f2,6 f3,6 f4,6 f5,6
メモリ再利用の考え方
2015/07/09先端GPGPUシミュレーション工学特論39
データ再利用の流れ1.共有メモリsf[]にj行のデータをコピー
このときに袖領域も処理
2.レジスタfj‐1にj‐1のデータをコピー
3.レジスタfj+1にj+1のデータをコピー
4.ラプラシアンを計算
5. sf[]のデータをfj‐1にコピー
6. fj+1のデータをsf[]にコピー
このときに袖領域を処理
7. fj+1にj+1のデータをコピー
8.ラプラシアンを計算
手順4に戻って処理を繰り返し
f[]
f2,5
f2,7
一連の流れをマーチング(marching)と呼ぶ
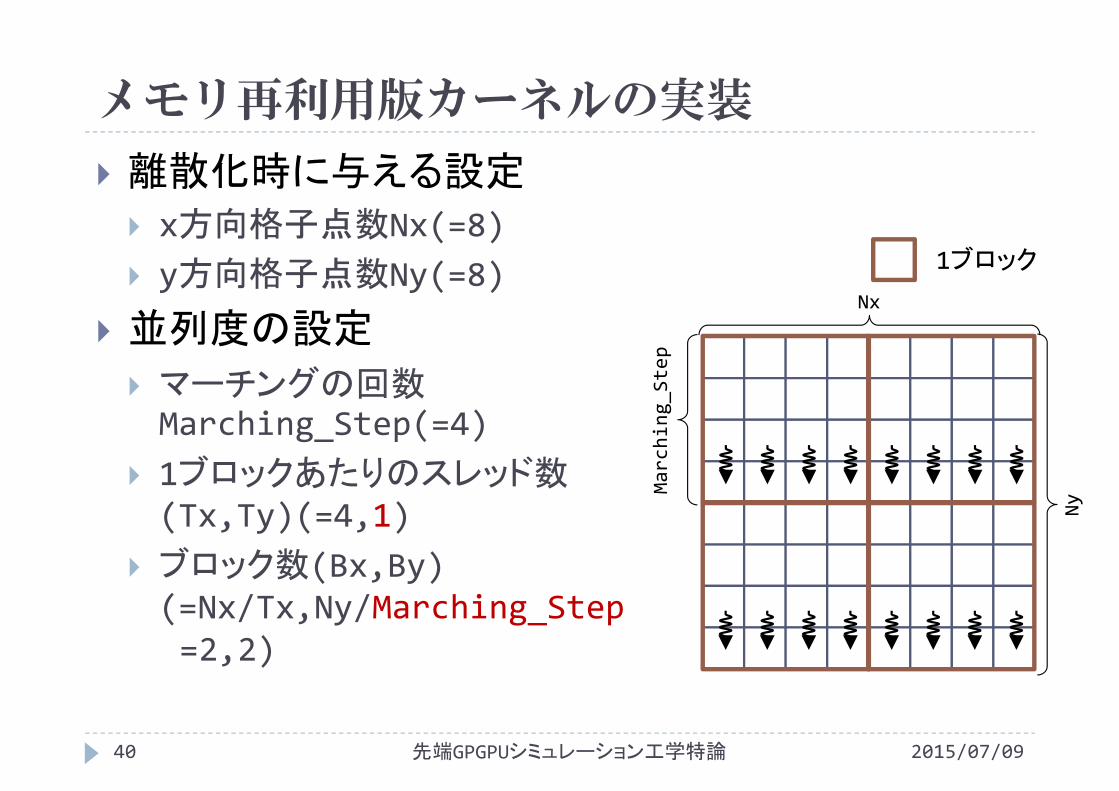
メモリ再利用版カーネルの実装
2015/07/09先端GPGPUシミュレーション工学特論40
離散化時に与える設定 x方向格子点数Nx(=8) y方向格子点数Ny(=8)
並列度の設定
マーチングの回数Marching_Step(=4)
1ブロックあたりのスレッド数(Tx,Ty)(=4,1)
ブロック数(Bx,By) (=Nx/Tx,Ny/Marching_Step=2,2)
Nx
Ny
Marc
hing
_Ste
p
1ブロック
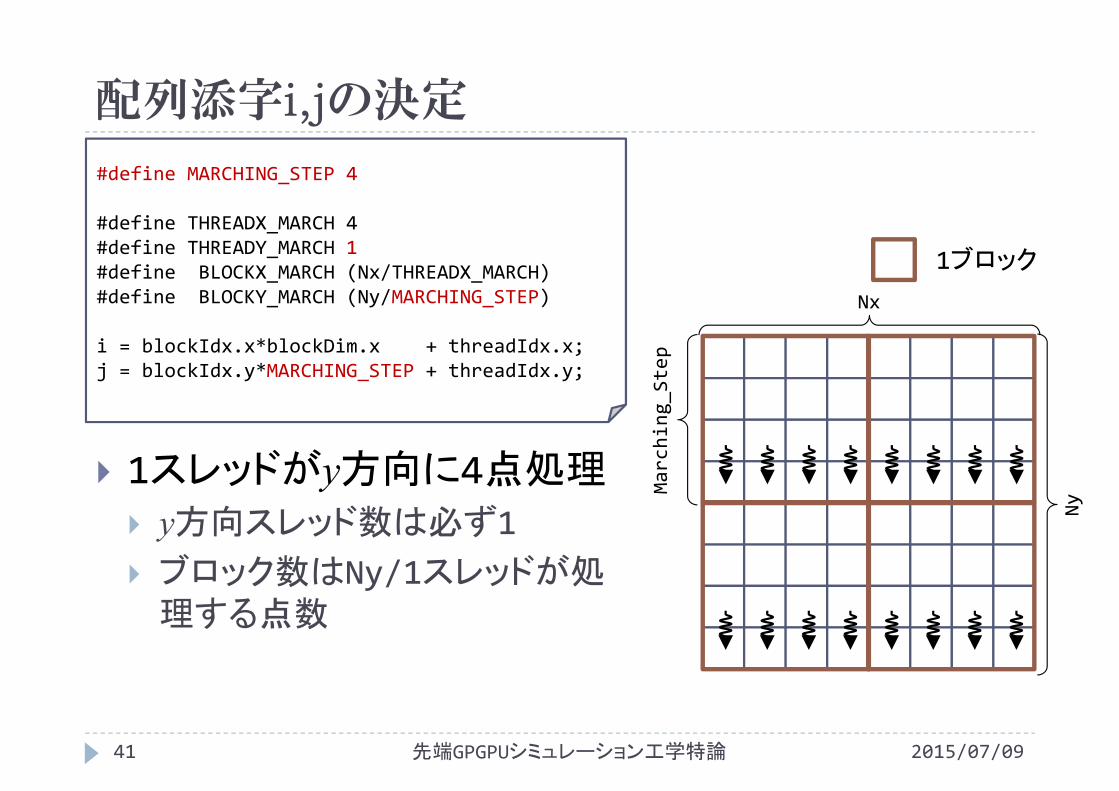
配列添字i,jの決定
2015/07/09先端GPGPUシミュレーション工学特論41
#define MARCHING_STEP 4
#define THREADX_MARCH 4#define THREADY_MARCH 1#define BLOCKX_MARCH (Nx/THREADX_MARCH)#define BLOCKY_MARCH (Ny/MARCHING_STEP)
i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*MARCHING_STEP + threadIdx.y;
Nx
Ny
Marc
hing
_Ste
p
1ブロック
1スレッドがy方向に4点処理 y方向スレッド数は必ず1 ブロック数はNy/1スレッドが処理する点数
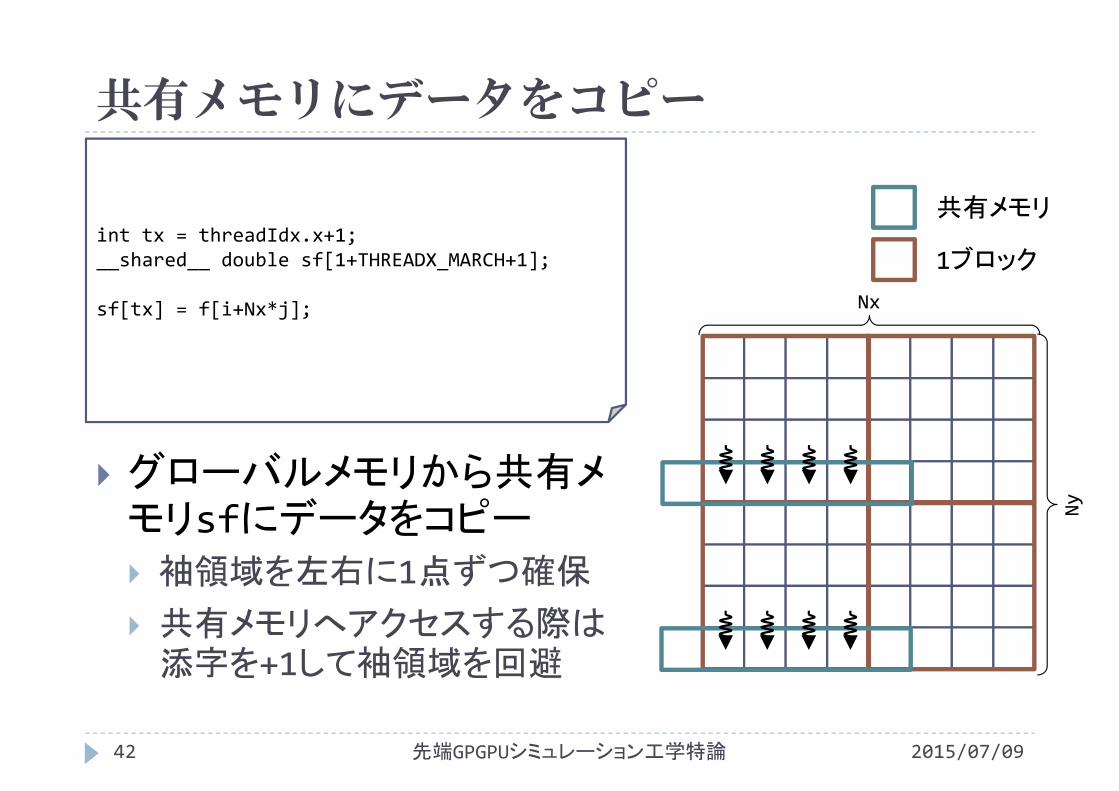
共有メモリにデータをコピー
2015/07/09先端GPGPUシミュレーション工学特論42
int tx = threadIdx.x+1;__shared__ double sf[1+THREADX_MARCH+1];
sf[tx] = f[i+Nx*j];
共有メモリ
Nx
Ny
1ブロック
グローバルメモリから共有メモリsfにデータをコピー 袖領域を左右に1点ずつ確保
共有メモリへアクセスする際は添字を+1して袖領域を回避
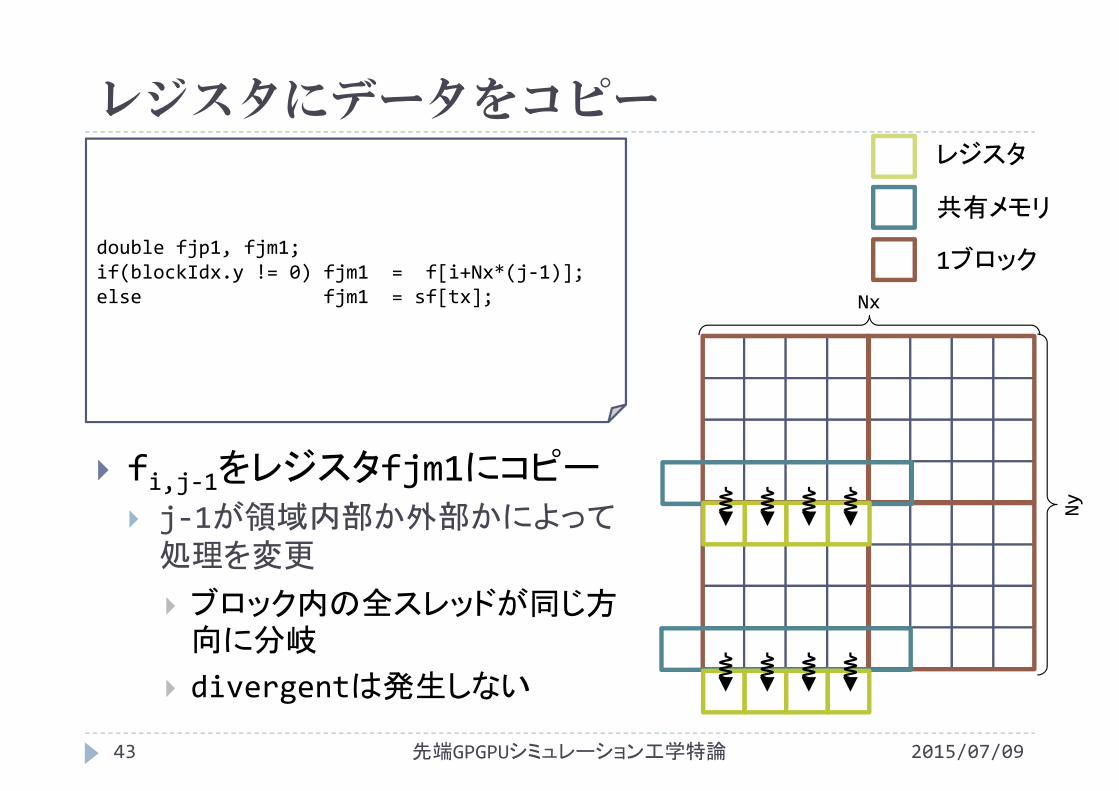
レジスタにデータをコピー
2015/07/09先端GPGPUシミュレーション工学特論43
double fjp1, fjm1;if(blockIdx.y != 0) fjm1 = f[i+Nx*(j‐1)];else fjm1 = sf[tx];
レジスタ
Nx
Ny
fi,j‐1をレジスタfjm1にコピー
j‐1が領域内部か外部かによって処理を変更
ブロック内の全スレッドが同じ方向に分岐
divergentは発生しない
共有メモリ
1ブロック
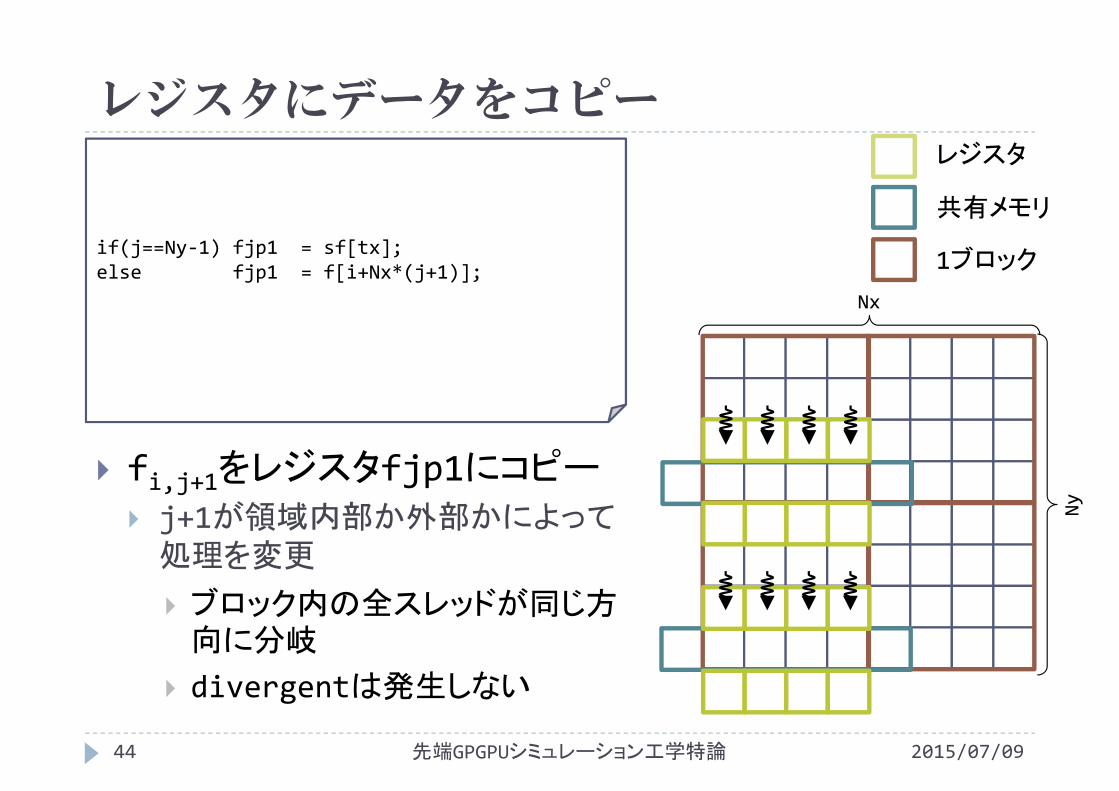
レジスタにデータをコピー
2015/07/09先端GPGPUシミュレーション工学特論44
if(j==Ny‐1) fjp1 = sf[tx];else fjp1 = f[i+Nx*(j+1)];
Nx
Ny
fi,j+1をレジスタfjp1にコピー
j+1が領域内部か外部かによって処理を変更
ブロック内の全スレッドが同じ方向に分岐
divergentは発生しない
レジスタ
共有メモリ
1ブロック
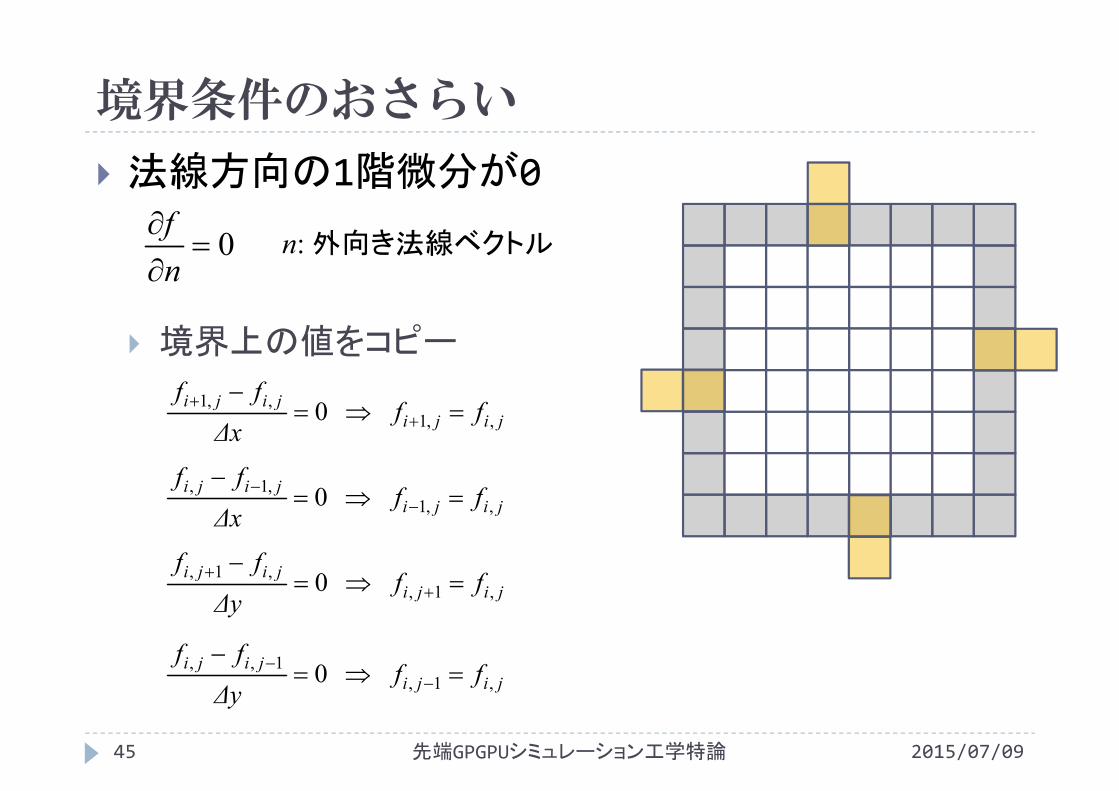
境界条件のおさらい
法線方向の1階微分が0
境界上の値をコピー
先端GPGPUシミュレーション工学特論45 2015/07/09
0nf
n: 外向き法線ベクトル
jijijiji ff
Δxff
,,1,,1 0
jijijiji ff
Δyff
,1,,1, 0
jijijiji ff
Δxff
,,1,1, 0
jijijiji ff
Δyff
,1,1,, 0
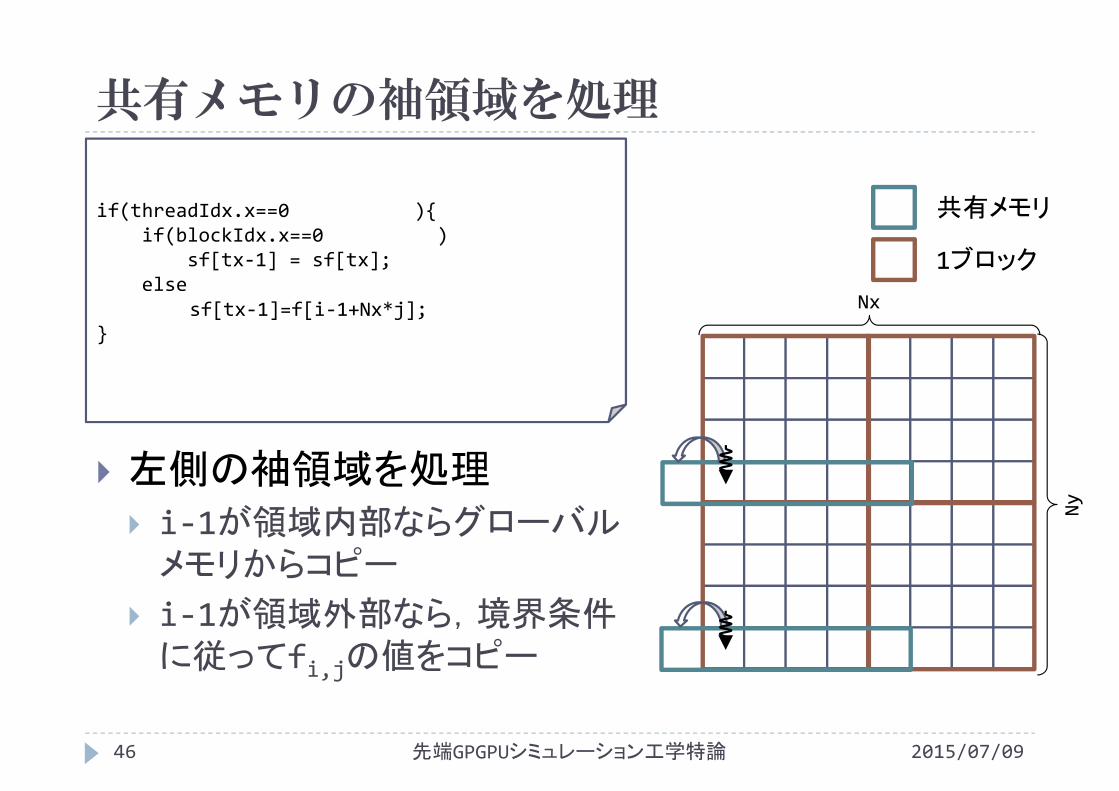
共有メモリの袖領域を処理
2015/07/09先端GPGPUシミュレーション工学特論46
if(threadIdx.x==0 ){if(blockIdx.x==0 )
sf[tx‐1] = sf[tx];else
sf[tx‐1]=f[i‐1+Nx*j];}
Nx
Ny
左側の袖領域を処理 i‐1が領域内部ならグローバルメモリからコピー
i‐1が領域外部なら,境界条件に従ってfi,jの値をコピー
共有メモリ
1ブロック
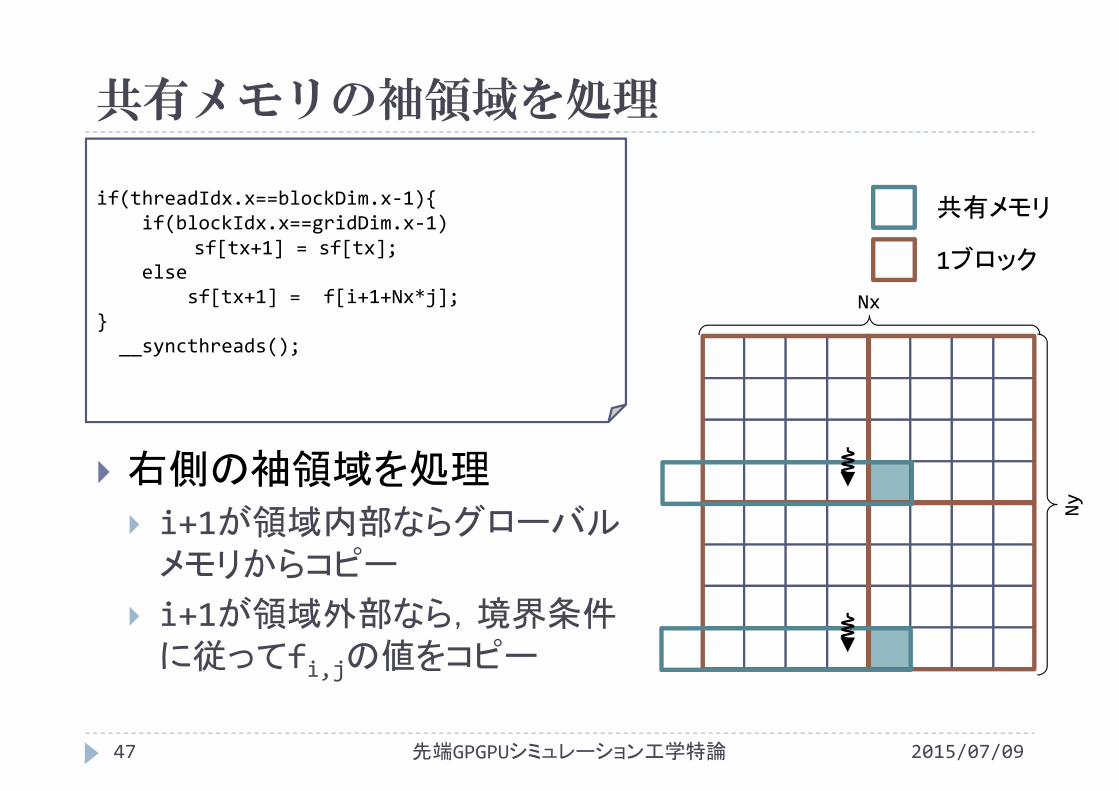
共有メモリの袖領域を処理
2015/07/09先端GPGPUシミュレーション工学特論47
if(threadIdx.x==blockDim.x‐1){if(blockIdx.x==gridDim.x‐1)
sf[tx+1] = sf[tx];else
sf[tx+1] = f[i+1+Nx*j];}
__syncthreads();
Nx
Ny
右側の袖領域を処理 i+1が領域内部ならグローバルメモリからコピー
i+1が領域外部なら,境界条件に従ってfi,jの値をコピー
共有メモリ
1ブロック
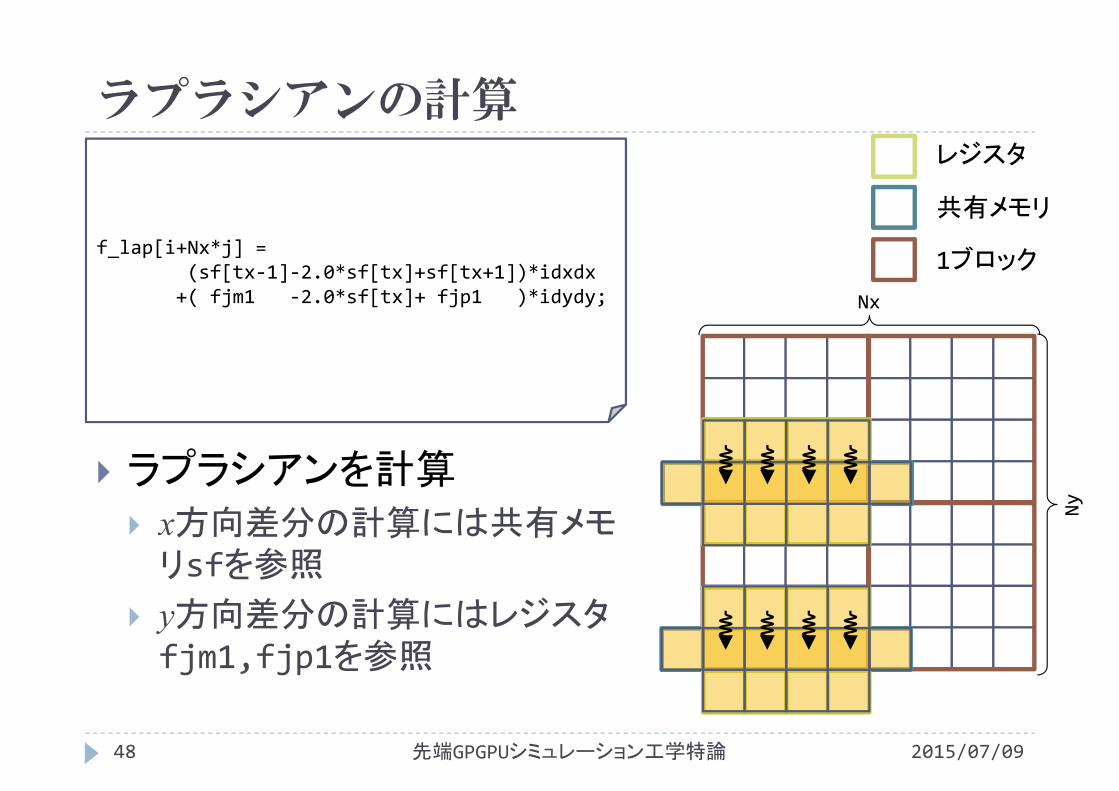
ラプラシアンの計算
2015/07/09先端GPGPUシミュレーション工学特論48
f_lap[i+Nx*j] =(sf[tx‐1]‐2.0*sf[tx]+sf[tx+1])*idxdx
+( fjm1 ‐2.0*sf[tx]+ fjp1 )*idydy; Nx
Ny
ラプラシアンを計算
x方向差分の計算には共有メモリsfを参照
y方向差分の計算にはレジスタfjm1,fjp1を参照
レジスタ
共有メモリ
1ブロック
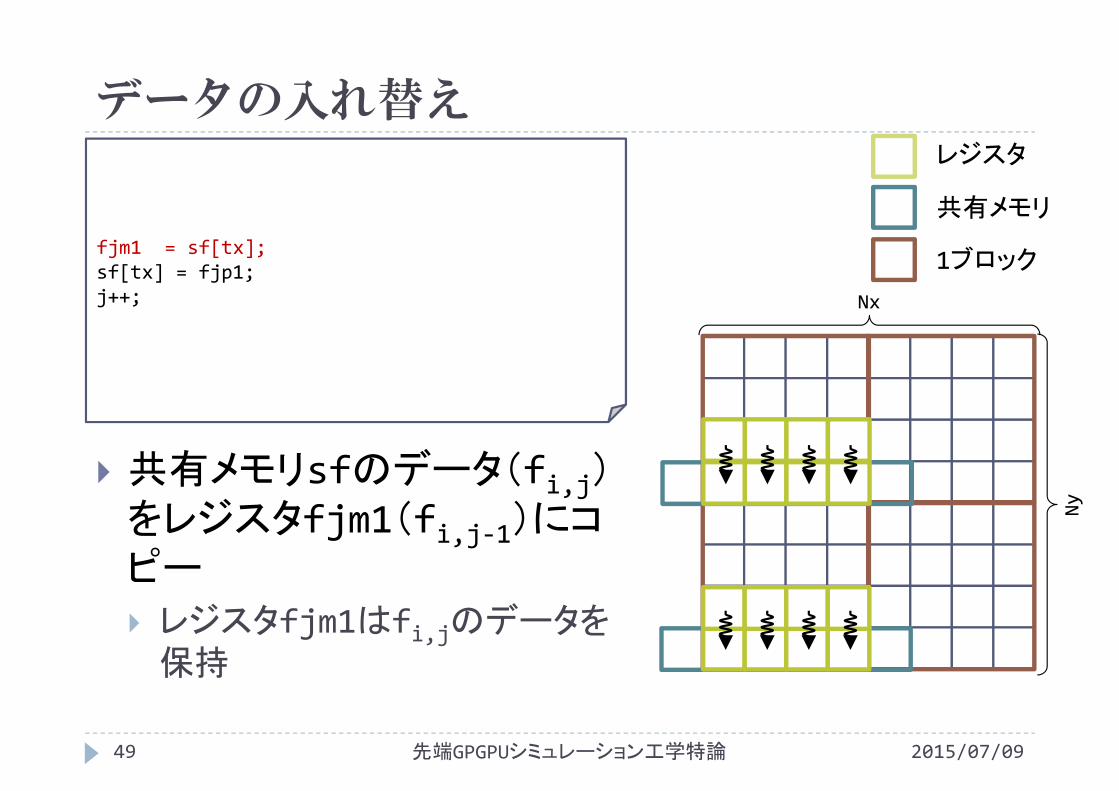
データの入れ替え
2015/07/09先端GPGPUシミュレーション工学特論49
fjm1 = sf[tx];sf[tx] = fjp1;j++; Nx
Ny
レジスタ
共有メモリ
1ブロック
共有メモリsfのデータ(fi,j)をレジスタfjm1(fi,j‐1)にコピー レジスタfjm1はfi,jのデータを保持
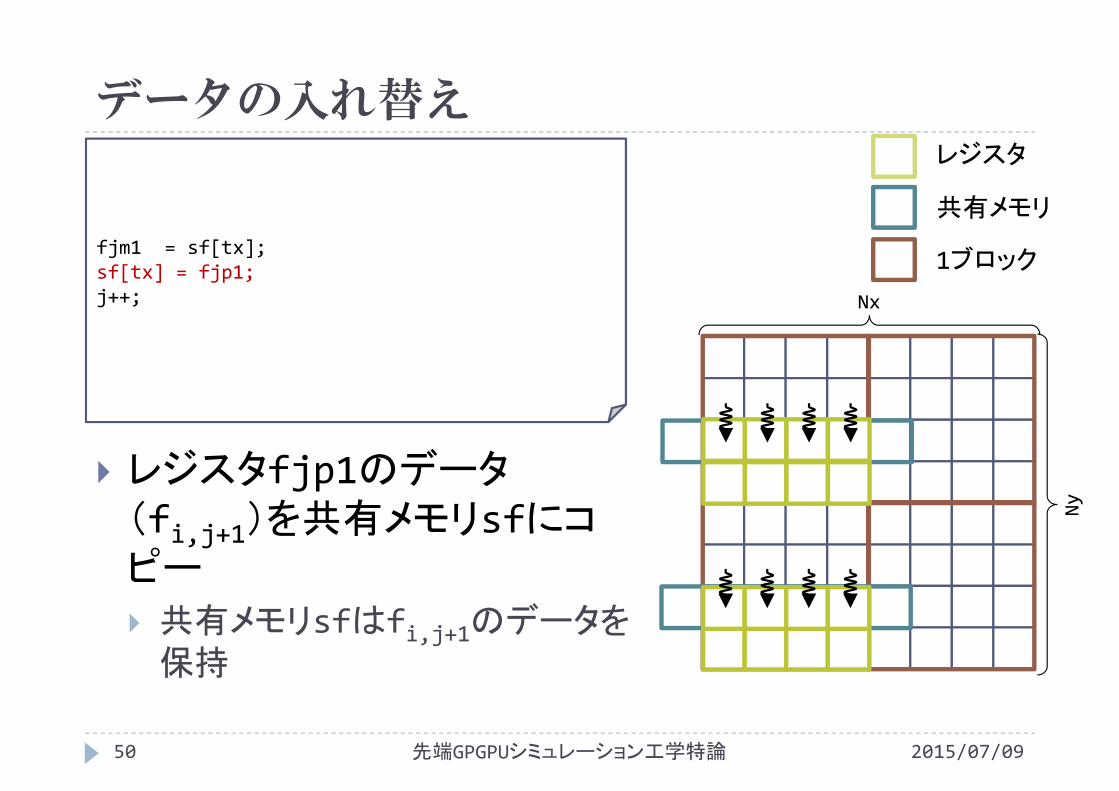
データの入れ替え
2015/07/09先端GPGPUシミュレーション工学特論50
fjm1 = sf[tx];sf[tx] = fjp1;j++; Nx
Ny
レジスタ
共有メモリ
1ブロック
レジスタfjp1のデータ(fi,j+1)を共有メモリsfにコピー 共有メモリsfはfi,j+1のデータを保持
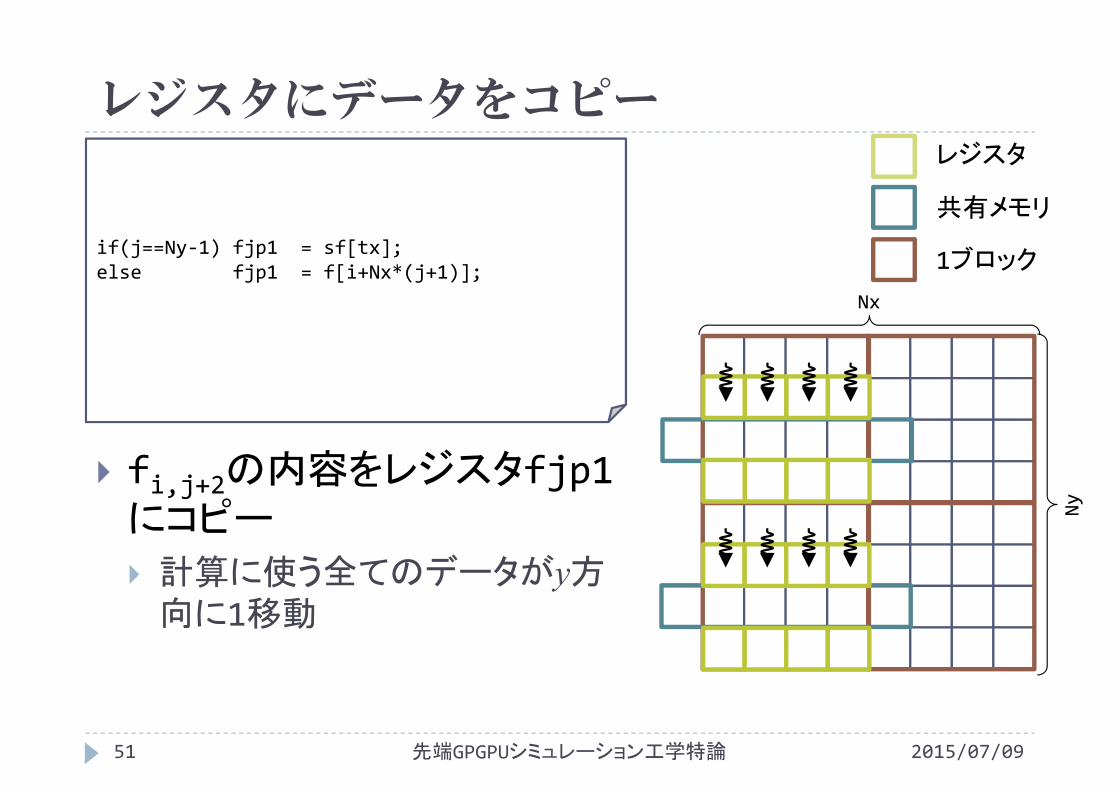
レジスタにデータをコピー
2015/07/09先端GPGPUシミュレーション工学特論51
if(j==Ny‐1) fjp1 = sf[tx];else fjp1 = f[i+Nx*(j+1)];
Nx
Ny
レジスタ
共有メモリ
1ブロック
fi,j+2の内容をレジスタfjp1にコピー
計算に使う全てのデータがy方向に1移動
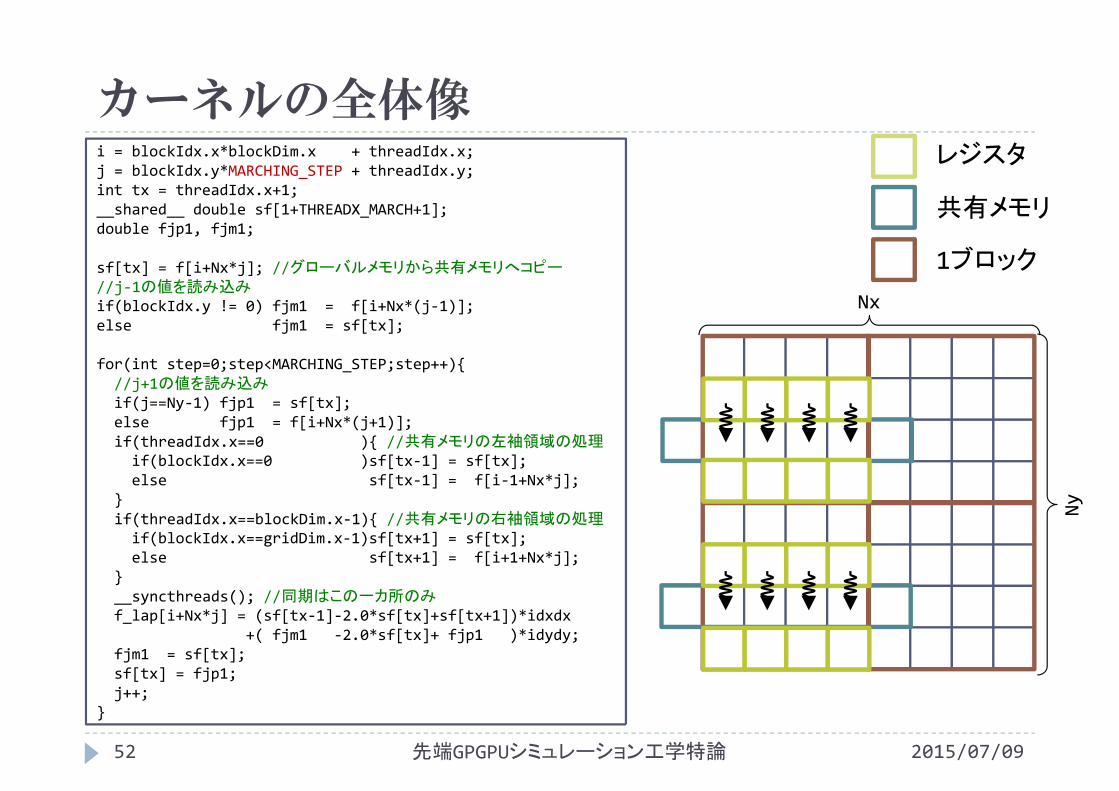
カーネルの全体像
2015/07/09先端GPGPUシミュレーション工学特論52
i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*MARCHING_STEP + threadIdx.y;int tx = threadIdx.x+1;__shared__ double sf[1+THREADX_MARCH+1]; double fjp1, fjm1;
sf[tx] = f[i+Nx*j]; //グローバルメモリから共有メモリへコピー//j‐1の値を読み込みif(blockIdx.y != 0) fjm1 = f[i+Nx*(j‐1)];else fjm1 = sf[tx];
for(int step=0;step<MARCHING_STEP;step++){//j+1の値を読み込みif(j==Ny‐1) fjp1 = sf[tx];else fjp1 = f[i+Nx*(j+1)];if(threadIdx.x==0 ){ //共有メモリの左袖領域の処理if(blockIdx.x==0 )sf[tx‐1] = sf[tx];else sf[tx‐1] = f[i‐1+Nx*j];
}if(threadIdx.x==blockDim.x‐1){ //共有メモリの右袖領域の処理if(blockIdx.x==gridDim.x‐1)sf[tx+1] = sf[tx];else sf[tx+1] = f[i+1+Nx*j];
}__syncthreads(); //同期はこの一カ所のみf_lap[i+Nx*j] = (sf[tx‐1]‐2.0*sf[tx]+sf[tx+1])*idxdx
+( fjm1 ‐2.0*sf[tx]+ fjp1 )*idydy;fjm1 = sf[tx];sf[tx] = fjp1;j++;
}
Nx
Ny
レジスタ
共有メモリ
1ブロック

#include<stdio.h>#include<stdlib.h>#include<math.h>
#define Lx (1.0)#define Ly (1.0)#define Nx 1024#define Ny Nx#define dx (Lx/(Nx‐1))#define dy (Ly/(Ny‐1))#define dt 0.000001#define endT (1.0)#define Nt (int)(endT/dt)#define DIFF (0.01)#define dxdx (dx*dx)#define dydy (dy*dy)#define Nbytes (Nx*Ny*sizeof(double))
int main(void){
int n;double *dev_f,*dev_f_new,*dev_f_lap;dim3 Thread, Block;dim3 Thread_marching, Block_marching
cudaMalloc( (void**)&dev_f , Nbytes );cudaMalloc( (void**)&dev_f_new, Nbytes );
cudaMalloc( (void**)&dev_f_lap, Nbytes );
Thread = dim3(THREADX,THREADY,1);Block = dim3(BLOCKX ,BLOCKY, 1);Thread_marching
=dim3(THREADX_MARCH,THREADY_MARCH,1);Block_marching
=dim3(BLOCKX_MARCH,BLOKCY_MARCH,1);init<<<Block, Thread>>>
(dev_f, dev_f_lap, dev_f_new);
for(n=1;n<=Nt;n++){laplacian3<<<Block_marching, Thread_marching>>>
(dev_f,dev_f_lap);integrate<<<Block, Thread>>>
(dev_f,dev_f_lap,dev_f_new);update<<<Block, Thread>>>(dev_f,dev_f_new);
}
return 0;}
GPUプログラム(CPU処理用共通部分)
2015/07/09先端GPGPUシミュレーション工学特論53
diffusion.cu

#define MARCHING_STEP 2
#define THREADX_MARCH 256#define THREADY_MARCH 1#define BLOCKX_MARCH (Nx/THREADX_MARCH)#define BLOCKY_MARCH (Ny/MARCHING_STEP)
__global__ void laplacian3(double *f, double *f_lap){i = blockIdx.x*blockDim.x + threadIdx.x;j = blockIdx.y*MARCHING_STEP + threadIdx.y;int tx = threadIdx.x+1;__shared__ double sf[1+THREADX_MARCH+1]; double fjp1, fjm1;
sf[tx] = f[i+Nx*j]; //グローバルメモリから共有メモリへコピー
//j‐1の値を読み込みif(blockIdx.y != 0) fjm1 = f[i+Nx*(j‐1)];else fjm1 = sf[tx];
#pragma unrollfor(int step=0;step<MARCHING_STEP;step++){//j+1の値を読み込みif(j==Ny‐1) fjp1 = sf[tx];else fjp1 = f[i+Nx*(j+1)];
//共有メモリの左袖領域の処理
if(threadIdx.x==0 ){ if(blockIdx.x==0 )sf[tx‐1]=sf[tx];else sf[tx‐1]=f[i‐1+Nx*j];
}//共有メモリの右袖領域の処理if(threadIdx.x==blockDim.x‐1){ if(blockIdx.x==gridDim.x‐1)sf[tx+1]=sf[tx];else sf[tx+1]=f[i+1+Nx*j];
}__syncthreads(); //同期はこの一カ所のみ
f_lap[i+Nx*j]= (sf[tx‐1]‐2.0*sf[tx]+sf[tx+1])*idxdx+( fjm1 ‐2.0*sf[tx]+ fjp1 )*idydy;
fjm1 = sf[tx];sf[tx] = fjp1;j++;
}
}
適化されたラプラシアンカーネル
2015/07/09先端GPGPUシミュレーション工学特論54
diffusion.cu
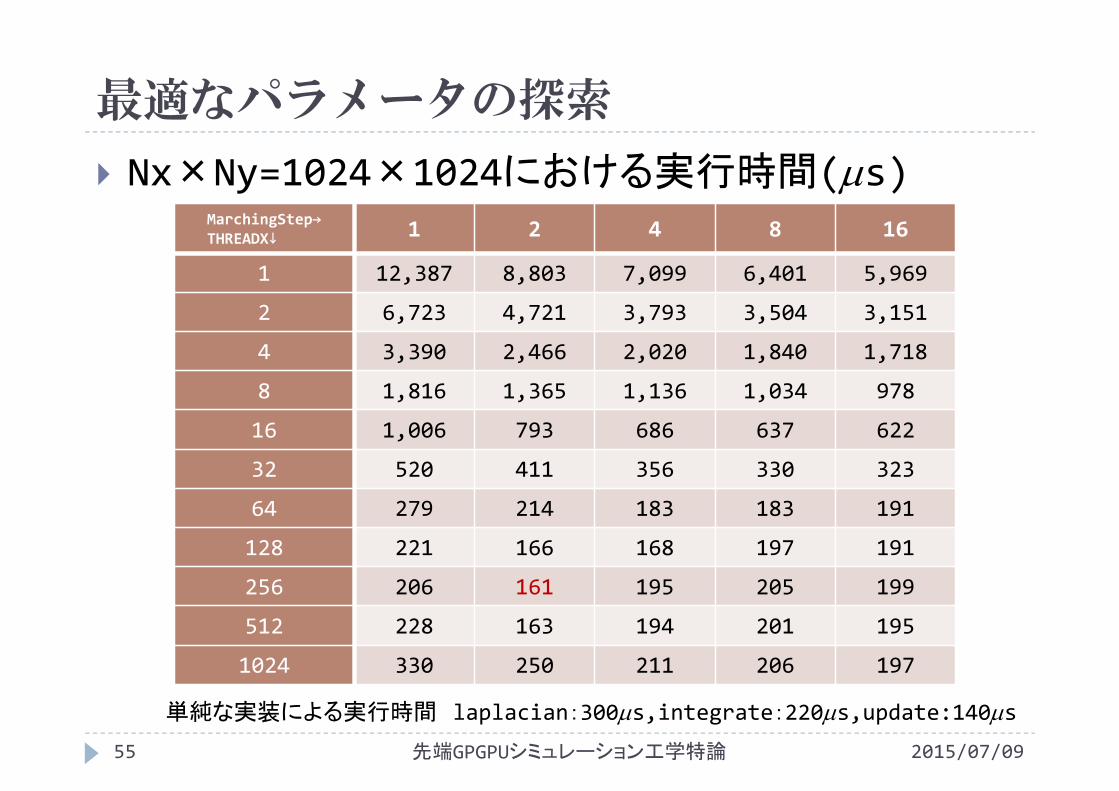
適なパラメータの探索
2015/07/09先端GPGPUシミュレーション工学特論55
MarchingStep→THREADX↓ 1 2 4 8 16
1 12,387 8,803 7,099 6,401 5,969
2 6,723 4,721 3,793 3,504 3,151
4 3,390 2,466 2,020 1,840 1,718
8 1,816 1,365 1,136 1,034 978
16 1,006 793 686 637 622
32 520 411 356 330 323
64 279 214 183 183 191
128 221 166 168 197 191
256 206 161 195 205 199
512 228 163 194 201 195
1024 330 250 211 206 197
Nx×Ny=1024×1024における実行時間(s)
単純な実装による実行時間 laplacian:300s,integrate:220s,update:140s


















![グローバル学部 グローバルコミュニケーション学科...グローバルコミュニケーション学科 -2018年度 学 - 開講表[学科科 ] 2021年度版 必修](https://static.fdocuments.net/doc/165x107/61091bc650709f2960283ca7/ffffef-ffffffffffc-ffffffffffc.jpg)