
理学部物理学科への進学を考えている学生の皆さんへ理学部物理学科への進学を考えている学生の皆さんへ 物理学は、自然の仕組みに対する最善の理解とは何かを追究していく学問です。この
Upload
-Category
view
263download
0
第12回 数値流体力学への応用(GPUへの移植)
長岡技術科学大学 電気電子情報工学専攻 出川智啓

今回の内容
2015/07/02先端GPGPUシミュレーション工学特論2
支配方程式
Cavity流れ
GPUへの移植

数値流体力学
2015/07/02先端GPGPUシミュレーション工学特論3
数値計算を利用して,流体の挙動を計算 Computational Fluid Dynamics(略してCFD)
計算機の性能向上に伴い,必要不可欠な設計ツールとなっている 流体を取り扱う機器の性能評価
流体中を移動する物体が受ける抵抗の評価など
提案された当初はCOLORFUL Fluid Dynamicsと揶揄されていた

支配方程式
2015/07/02先端GPGPUシミュレーション工学特論4
2次元直交(x–y)座標系 x方向速度をu, y方向速度をvと記述
非圧縮性流れ 流体の密度が変化しない
水は圧縮性
一般にマッハ0.3以下では非圧縮と見なす
粘性流れ 流体の粘り気により運動が妨げられる

支配方程式
2015/07/02先端GPGPUシミュレーション工学特論5
連続の式およびNavier‐Stokes方程式 質量と運動量の保存式に対応
運動エネルギの保存は運動量保存式が兼ねる
x, y方向速度u, v,圧力pの3変数を連立
0
yv
xu
2
2
2
2
2
2
2
2
1
1
yv
xv
yp
yvv
xvu
tv
yu
xu
xp
yuv
xuu
tu
連続の式(質量保存式)
Navier‐Stokes方程式(運動量保存式)
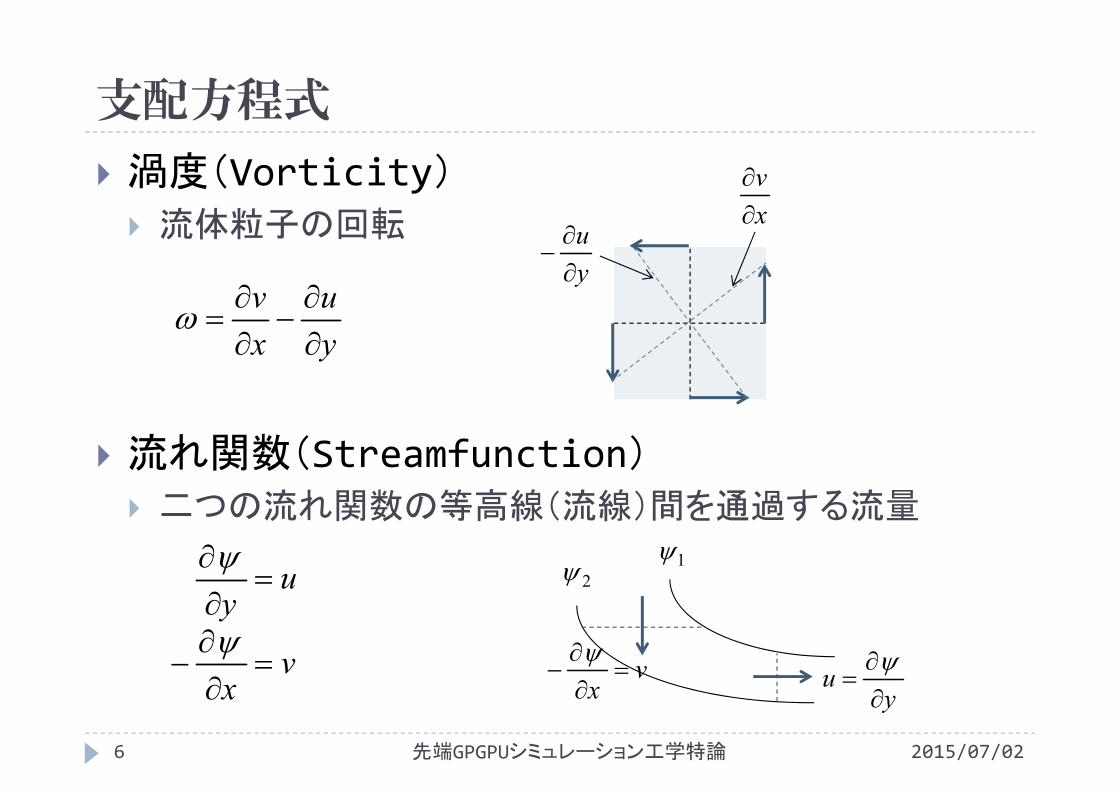
支配方程式
2015/07/02先端GPGPUシミュレーション工学特論6
渦度(Vorticity) 流体粒子の回転
流れ関数(Streamfunction) 二つの流れ関数の等高線(流線)間を通過する流量
yu
xv
vx
uy
xv
yu
12
vx
yu

支配方程式
2015/07/02先端GPGPUシミュレーション工学特論7
渦度方程式 渦度の移流・拡散方程式
流れ関数のPoisson方程式 流れ関数の定義式を渦度の定義式に代入
変数の数が流れ関数,渦度の2個に低減
2
2
2
2
yxyv
xu
t
2
2
2
2
yx
yyxxy
uxv
渦度の移流 渦度の拡散

計算手順
2015/07/02先端GPGPUシミュレーション工学特論8
1. 渦度方程式を計算して渦度を求める
2. 渦度を基に流れ関数のPoisson方程式を解いて流れ関数を求める
3. 流れ関数の定義式から速度を求める
4. 1に戻って計算を繰り返す

渦度方程式の離散化
2015/07/02先端GPGPUシミュレーション工学特論9
時間に前進差分,空間に中心差分を適用
21,,1,
2,1,,1
1,1,,
,1,1,
,1
,
22
22
ΔyΔx
Δyv
Δxu
Δtnji
nji
nji
nji
nji
nji
nji
njin
ji
nji
njin
ji
nji
nji
21,,1,
2,1,,1
1,1,,
,1,1,,
1,
22
22
ΔyΔxΔt
Δyv
ΔxuΔt
nji
nji
nji
nji
nji
nji
nji
njin
ji
nji
njin
jinji
nji

流れ関数のPoisson方程式の離散化
2015/07/02先端GPGPUシミュレーション工学特論10
中心差分による離散化 時刻n+1における流れ関数と渦度の関係
流れ関数の定義式の離散化
1,2
11,
1,
11,
2
1,1
1,
1,1 22
nji
nji
nji
nji
nji
nji
nji
ΔyΔx
Δxv
Δyu
nji
njin
ji
nji
njin
ji
2
21,1
1,11
,
11,
11,1
,
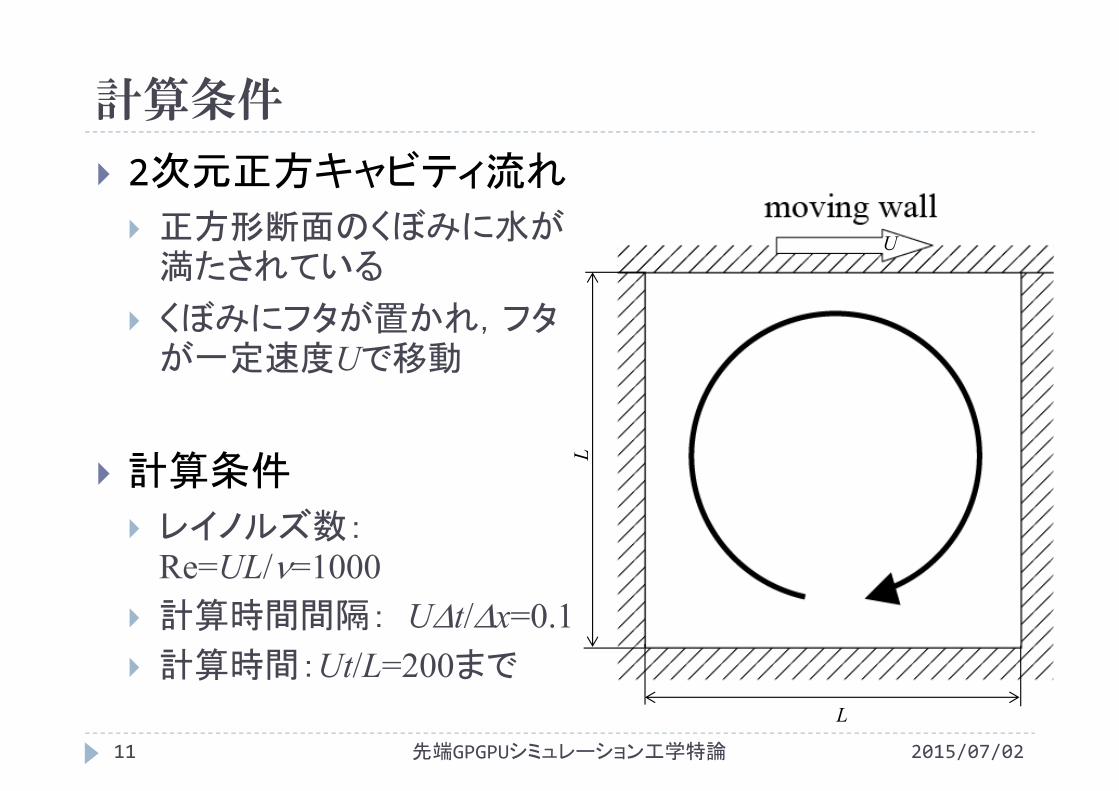
計算条件
2015/07/02先端GPGPUシミュレーション工学特論11
2次元正方キャビティ流れ
正方形断面のくぼみに水が満たされている
くぼみにフタが置かれ,フタが一定速度Uで移動
計算条件
レイノルズ数:Re=UL/=1000
計算時間間隔: Ut/x=0.1 計算時間:Ut/L=200まで
L
U
L
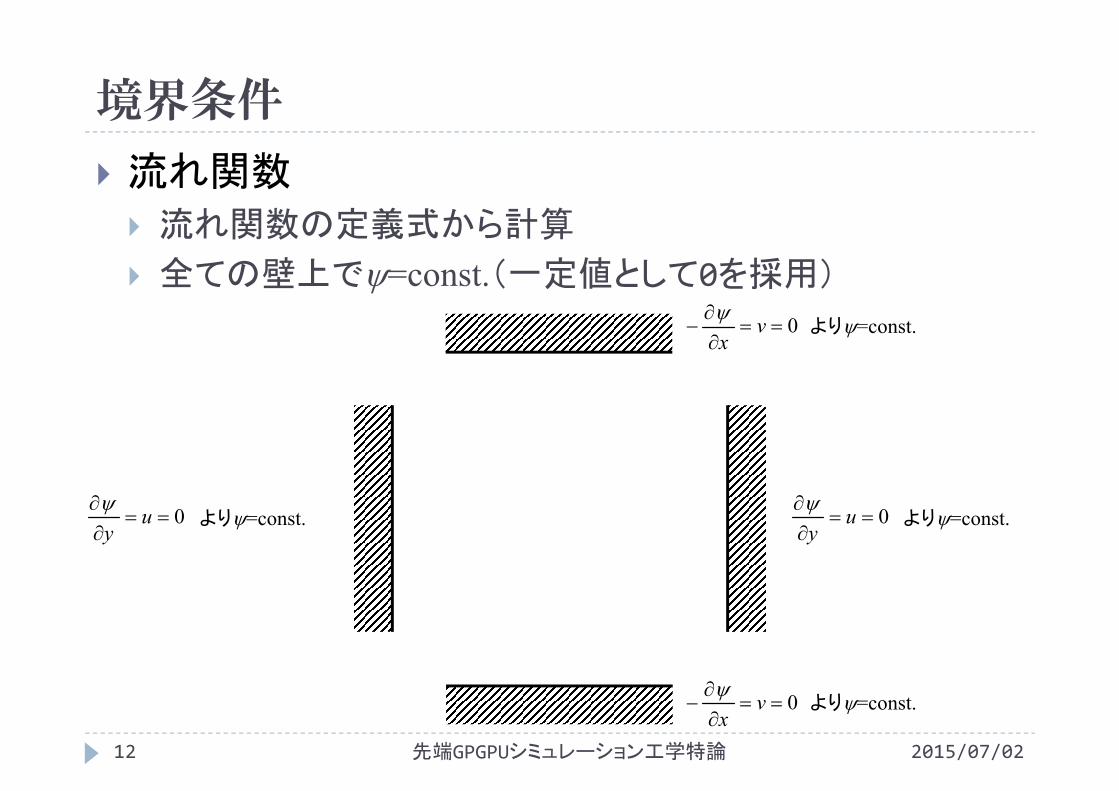
境界条件
2015/07/02先端GPGPUシミュレーション工学特論12
流れ関数 流れ関数の定義式から計算
全ての壁上で=const.(一定値として0を採用)
0
vx
0
vx
0 uy0
uy
より=const.
より=const.
より=const.
より=const.
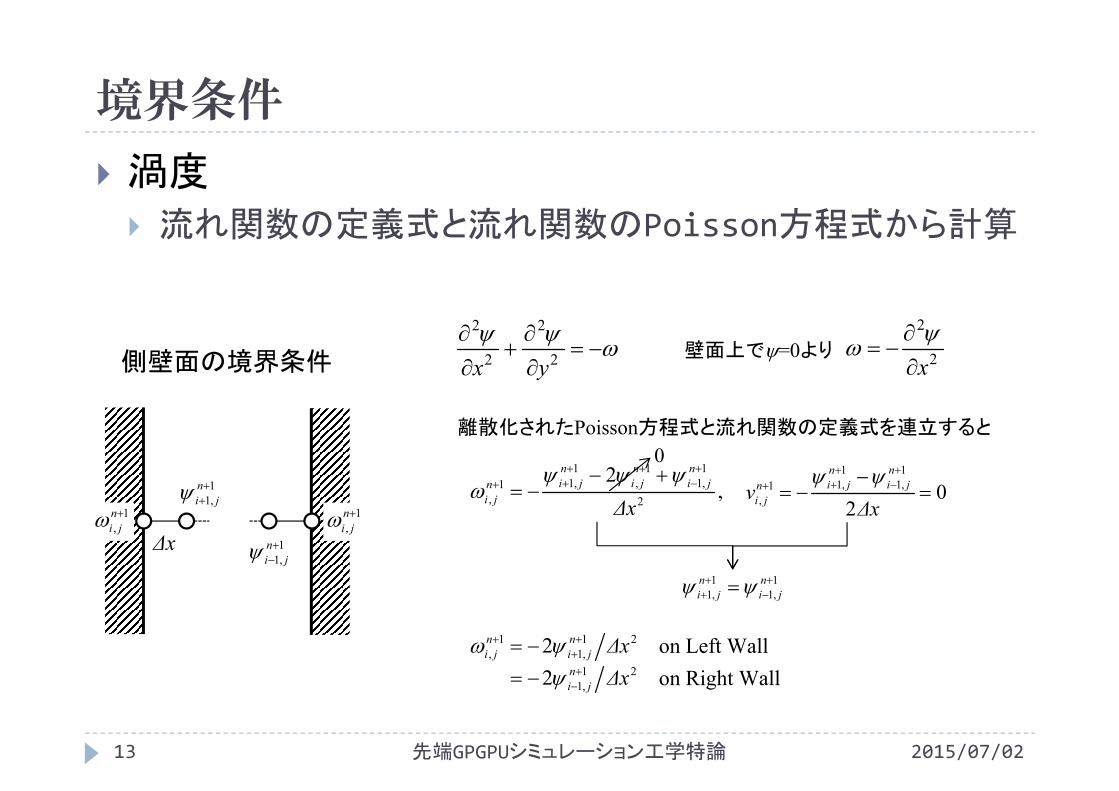
境界条件
2015/07/02先端GPGPUシミュレーション工学特論13
渦度 流れ関数の定義式と流れ関数のPoisson方程式から計算
2
2
2
2
yx 2
2
x
,2
2
1,1
1,
1,11
, Δx
nji
nji
njin
ji
02
1,1
1,11
,
Δxv
nji
njin
ji
1,1
1,1
n
jin
ji
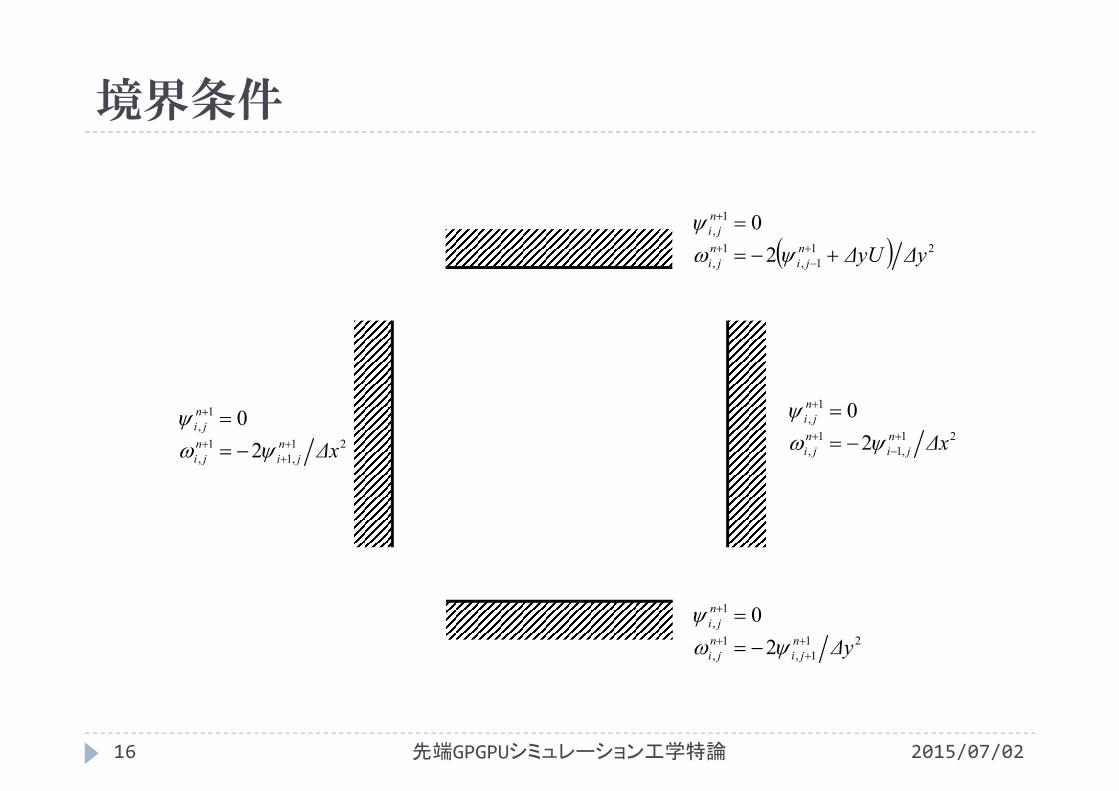
側壁面の境界条件壁面上で=0より
離散化されたPoisson方程式と流れ関数の定義式を連立すると
0
Right Wallon Left Wallon
22
21,1
21,1
1,
ΔxΔx
nji
nji
nji
1,nji
1,1
n
ji
1,1
nji
1,nji
Δx
境界条件
2015/07/02先端GPGPUシミュレーション工学特論14
渦度 流れ関数の定義式と流れ関数のPoisson方程式から計算
2
2
2
2
yx 2
2
y
,2
2
11,
1,
11,1
, Δy
nji
nji
njin
ji
02
11,
11,1
,
Δyu
nji
njin
ji
11,
11,
n
jinji
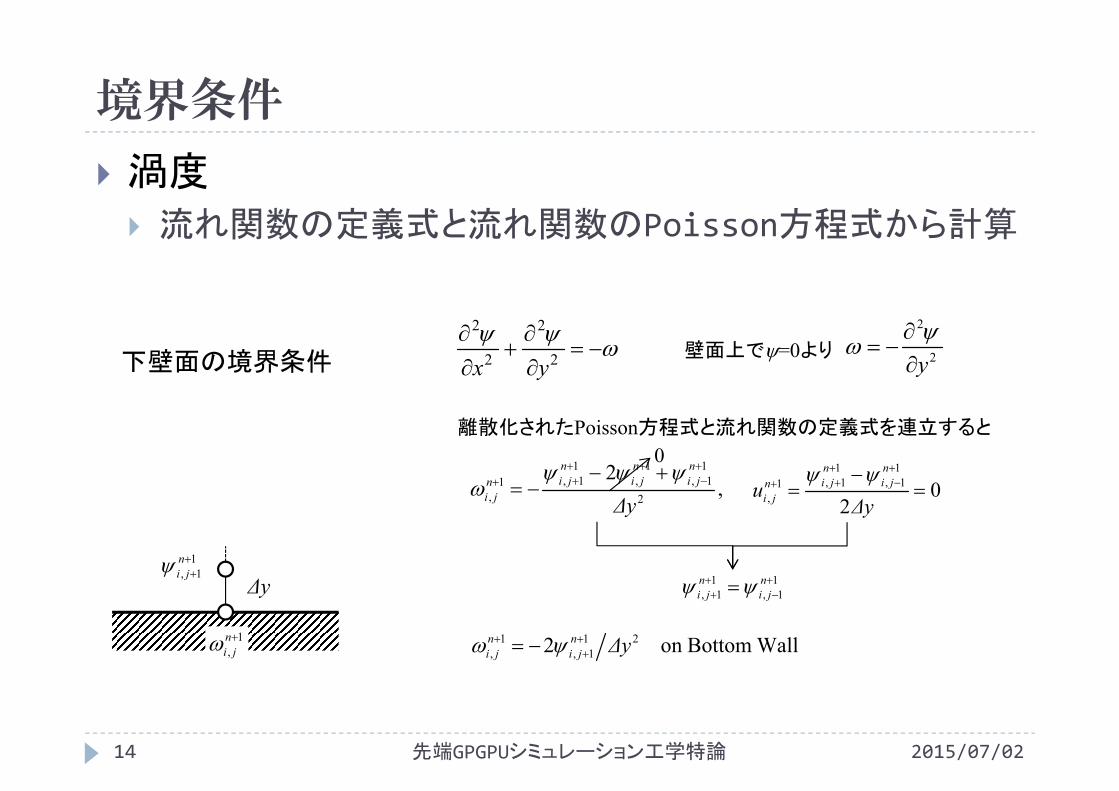
下壁面の境界条件壁面上で=0より
離散化されたPoisson方程式と流れ関数の定義式を連立すると
0
WallBottomon 2 211,
1, Δyn
jinji
1,nji
11,
nji
Δy
境界条件
2015/07/02先端GPGPUシミュレーション工学特論15
渦度 流れ関数の定義式と流れ関数のPoisson方程式から計算
2
2
2
2
yx 2
2
y
,2
2
11,
1,
11,1
, Δy
nji
nji
njin
ji
UΔy
unji
njin
ji
2
11,
11,1
,
11,
11, 2
n
jinji ΔyU
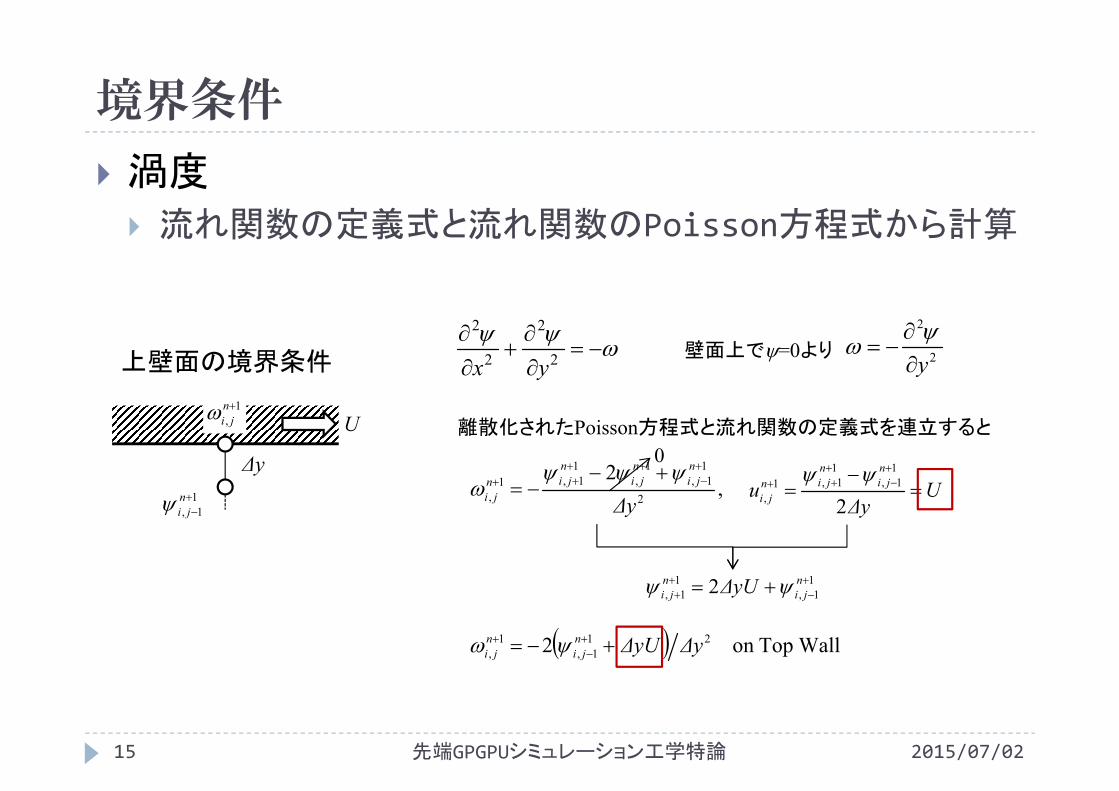
上壁面の境界条件壁面上で=0より
離散化されたPoisson方程式と流れ関数の定義式を連立すると
0
WallTopon 2 211,
1, ΔyΔyUn
jinji
1,nji
11,
nji
Δy
U
境界条件
2015/07/02先端GPGPUシミュレーション工学特論16
211,
1,
1,
20
Δynji
nji
nji
21,1
1,
1,
20
Δxnji
nji
nji
21,1
1,
1,
20
Δxnji
nji
nji
211,
1,
1,
20
ΔyΔyUnji
nji
nji

#include<stdio.h>#include<stdlib.h>#include<math.h>
#define Re 1000 //レイノルズ数#define Lx 0.01 //溝の幅(=高さ)#define Ly Lx#define Uwall 0.1 //移動壁の速度#define Kvisc (Lx*Uwall/Re)#define Nx 81#define Ny Nx#define Nbytes (Nx*Ny*sizeof(double))#define dx (Lx/(Nx‐1))#define dy (Ly/(Ny‐1))
#define dx2 (dx*2.0)#define dy2 (dy*2.0)#define dxdx (dx*dx)#define dydy (dy*dy)#define dxdxdydy (dxdx*dydy)#define dxdy2 (2.0*(dxdx+dydy))
#define ndt (0.1) //CFL条件#define dt (ndt*dx/Uwall) //時間刻み#define endnT (100.0) //終了時間(無次元)#define Nt (int)(endnT/dt*Lx/Uwall)
#define ERR_TOL 1e‐12#define Accel 1.7
パラメータ設定
2015/07/02先端GPGPUシミュレーション工学特論17
cavity.c

void init(double *vrtx, double *stmf, double *u, double *v, double *vrtx_next){
int i,j;for(j=0;j<Ny;j++)for(i=0;i<Nx;i++){
double x = (double)i*dx;double y = (double)j*dy;vrtx[i+Nx*j] = 0.0;stmf[i+Nx*j] = 0.0;v[i+Nx*j] = 0.0;u[i+Nx*j] = 0.0;vrtx_next[i+Nx*j] = 0.0;
}
//速度の境界条件.上壁面に速度Uwallを与えるj=Ny‐1;for(i=0;i<Nx;i++){
u[i+Nx*j] = Uwall;}
}
初期化
2015/07/02先端GPGPUシミュレーション工学特論18
cavity.c

void computeVorticity(double *vrtx, double *stmf, double *u, double *v,double *vrtx_next){
int i,j;int ij,im1j,ip1j,ijm1,ijp1;double conv,visc;
for(j=1;j<Ny‐1;j++){//左壁面i=0;ij = i +Nx*j;ip1j = i+1+Nx*j;vrtx[ij] = ‐2.0*stmf[ip1j]/dxdx;vrtx_next[ij] = vrtx[ij];//右壁面i=Nx‐1;ij = i +Nx*j;im1j = i‐1+Nx*j;vrtx[ij] = ‐2.0*stmf[im1j]/dxdx;vrtx_next[ij] = vrtx[ij];
}
渦度方程式の計算(時間積分)
2015/07/02先端GPGPUシミュレーション工学特論19
21,1
1, 2 Δxn
jinji
21,1
1, 2 Δxn
jinji
cavity.c
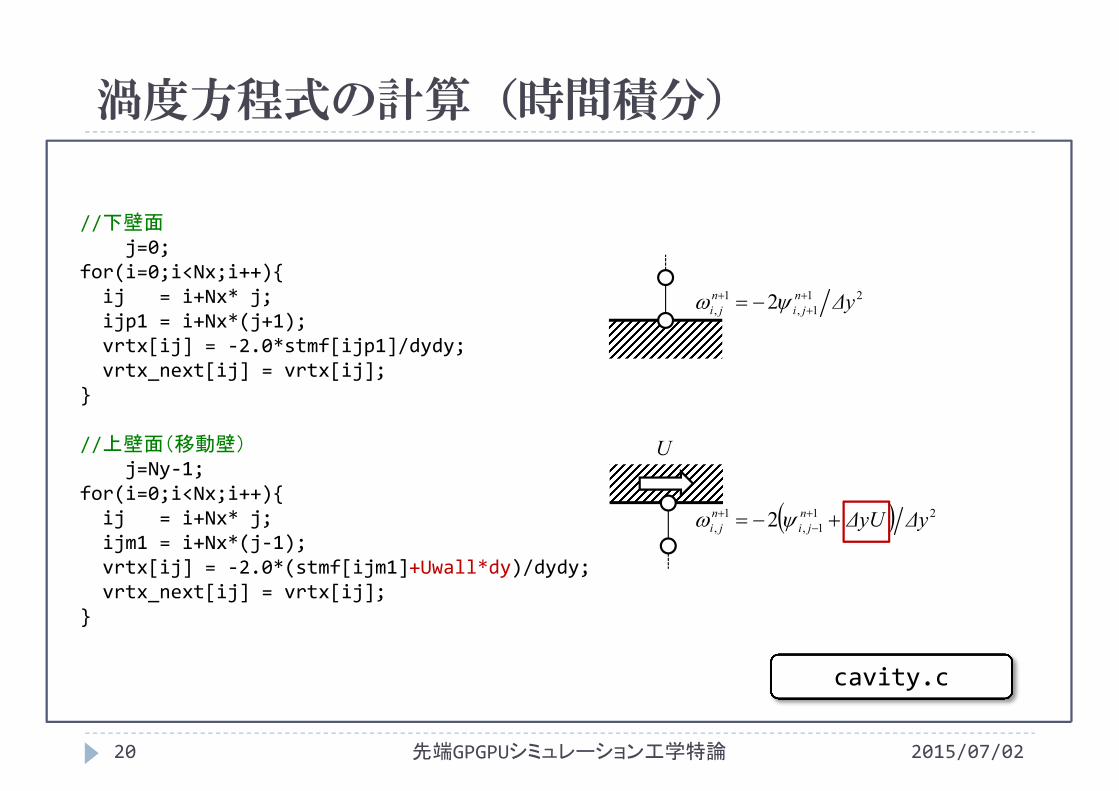
//下壁面j=0;
for(i=0;i<Nx;i++){ij = i+Nx* j;ijp1 = i+Nx*(j+1);vrtx[ij] = ‐2.0*stmf[ijp1]/dydy;vrtx_next[ij] = vrtx[ij];
}
//上壁面(移動壁)j=Ny‐1;
for(i=0;i<Nx;i++){ij = i+Nx* j;ijm1 = i+Nx*(j‐1);vrtx[ij] = ‐2.0*(stmf[ijm1]+Uwall*dy)/dydy;vrtx_next[ij] = vrtx[ij];
}
渦度方程式の計算(時間積分)
2015/07/02先端GPGPUシミュレーション工学特論20
211,
1, 2 Δyn
jinji
211,
1, 2 ΔyΔyUn
jinji
U
cavity.c

//計算領域内部for(j=1;j<Ny‐1;j++)for(i=1;i<Nx‐1;i++){
ij = i +Nx*j;im1j = i‐1+Nx*j;ip1j = i+1+Nx*j;ijm1 = i +Nx*(j‐1);ijp1 = i +Nx*(j+1);//移流項を計算conv = u[ij]*(vrtx[ip1j]‐vrtx[im1j])/dx2 + v[ij]*(vrtx[ijp1]‐vrtx[ijm1])/dy2;//粘性項を計算visc = Kvisc*( (vrtx[im1j]‐2.0*vrtx[ij]+vrtx[ip1j])/dxdx
+(vrtx[ijm1]‐2.0*vrtx[ij]+vrtx[ijp1])/dydy);//時間積分vrtx_next[ij] = vrtx[ij] + dt*(‐conv+visc);
}}
渦度方程式の計算(時間積分)
2015/07/02先端GPGPUシミュレーション工学特論21
cavity.c

void computeVelocity(double *stmf, double *u, double *v){int i,j;int ij,im1j,ip1j,ijm1,ijp1;int im2j,ip2j,ijm2,ijp2;
//境界条件は初期設定の際に設定済み//壁の移動速度は時間で変化しないので何もしなくてよい
for(j=1;j<Ny‐1;j++)for(i=1;i<Nx‐1;i++){
ij = i +Nx*j;im1j = i‐1+Nx*j;ip1j = i+1+Nx*j;ijm1 = i +Nx*(j‐1);ijp1 = i +Nx*(j+1);u[ij] = (stmf[ijp1]‐stmf[ijm1])/dy2;v[ij] =‐(stmf[ip1j]‐stmf[im1j])/dx2;
}
}
プログラム(速度の計算)
2015/07/02先端GPGPUシミュレーション工学特論22
cavity.c
計算結果
2015/07/02先端GPGPUシミュレーション工学特論23
流れ関数 渦度 速度(u, v)
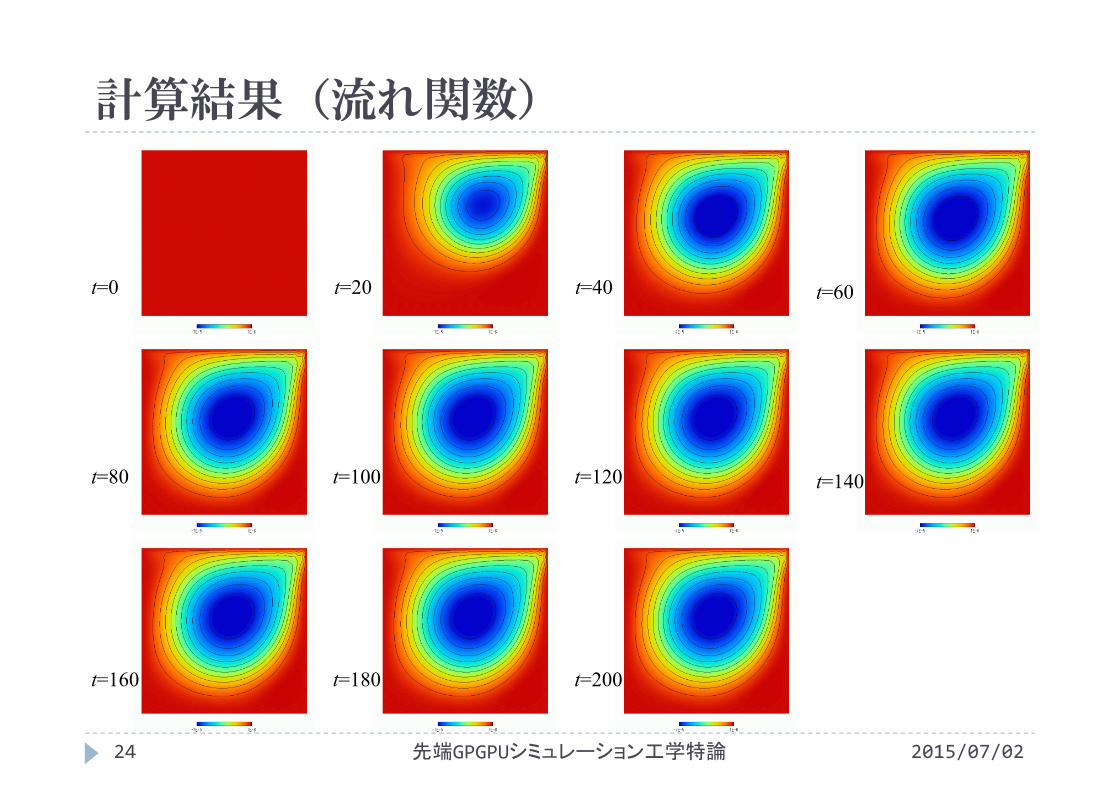
計算結果(流れ関数)
2015/07/02先端GPGPUシミュレーション工学特論24
t=0 t=20 t=40
t=80 t=100 t=120
t=160 t=180 t=200
t=60
t=140
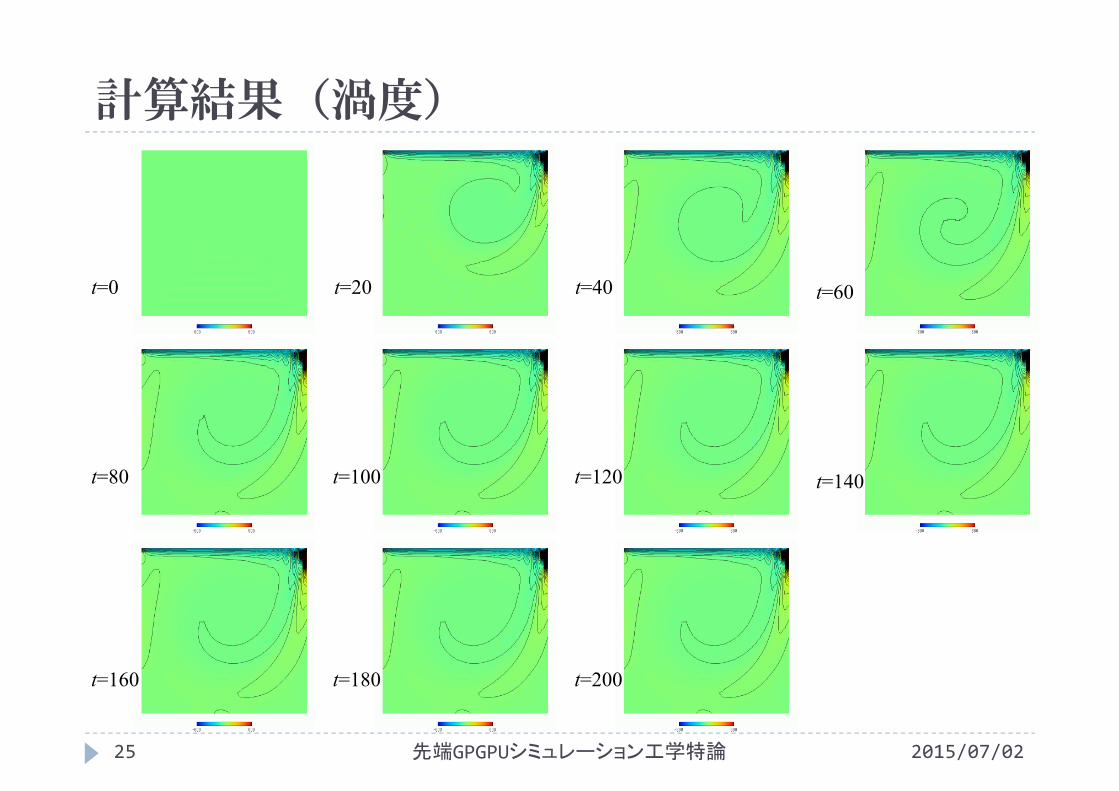
計算結果(渦度)
2015/07/02先端GPGPUシミュレーション工学特論25
t=0 t=20 t=40
t=80 t=100 t=120
t=160 t=180 t=200
t=60
t=140
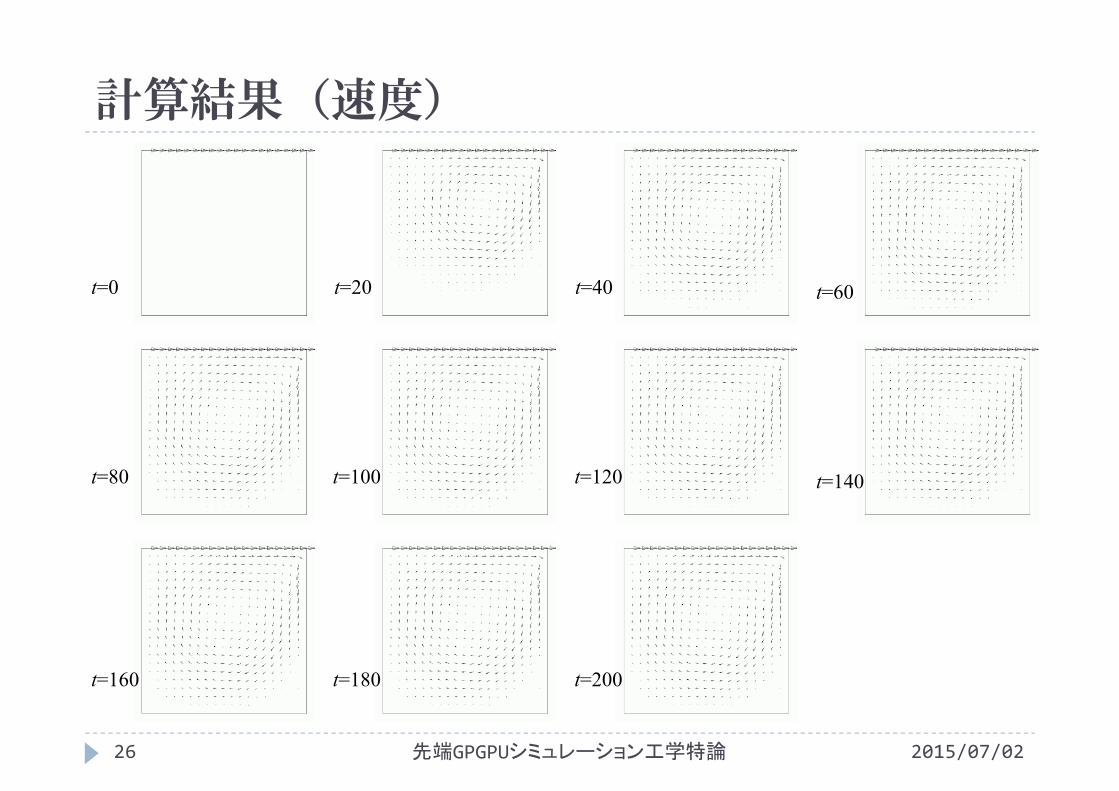
計算結果(速度)
2015/07/02先端GPGPUシミュレーション工学特論26
t=0 t=20 t=40
t=80 t=100 t=120
t=160 t=180 t=200
t=60
t=140
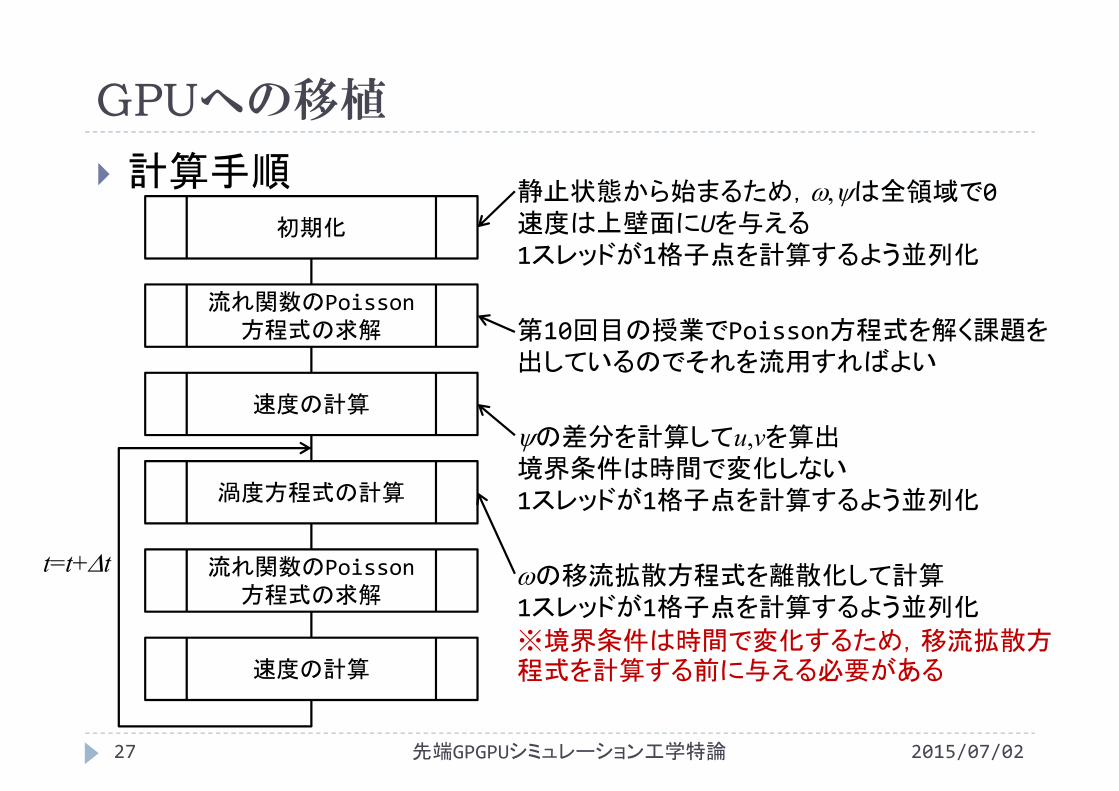
GPUへの移植
2015/07/02先端GPGPUシミュレーション工学特論27
計算手順初期化
流れ関数のPoisson方程式の求解
速度の計算
渦度方程式の計算
流れ関数のPoisson方程式の求解
速度の計算
t=t+t
静止状態から始まるため,は全領域で0速度は上壁面にUを与える1スレッドが1格子点を計算するよう並列化
第10回目の授業でPoisson方程式を解く課題を出しているのでそれを流用すればよい
の差分を計算してu,vを算出境界条件は時間で変化しない1スレッドが1格子点を計算するよう並列化
の移流拡散方程式を離散化して計算1スレッドが1格子点を計算するよう並列化
※境界条件は時間で変化するため,移流拡散方程式を計算する前に与える必要がある
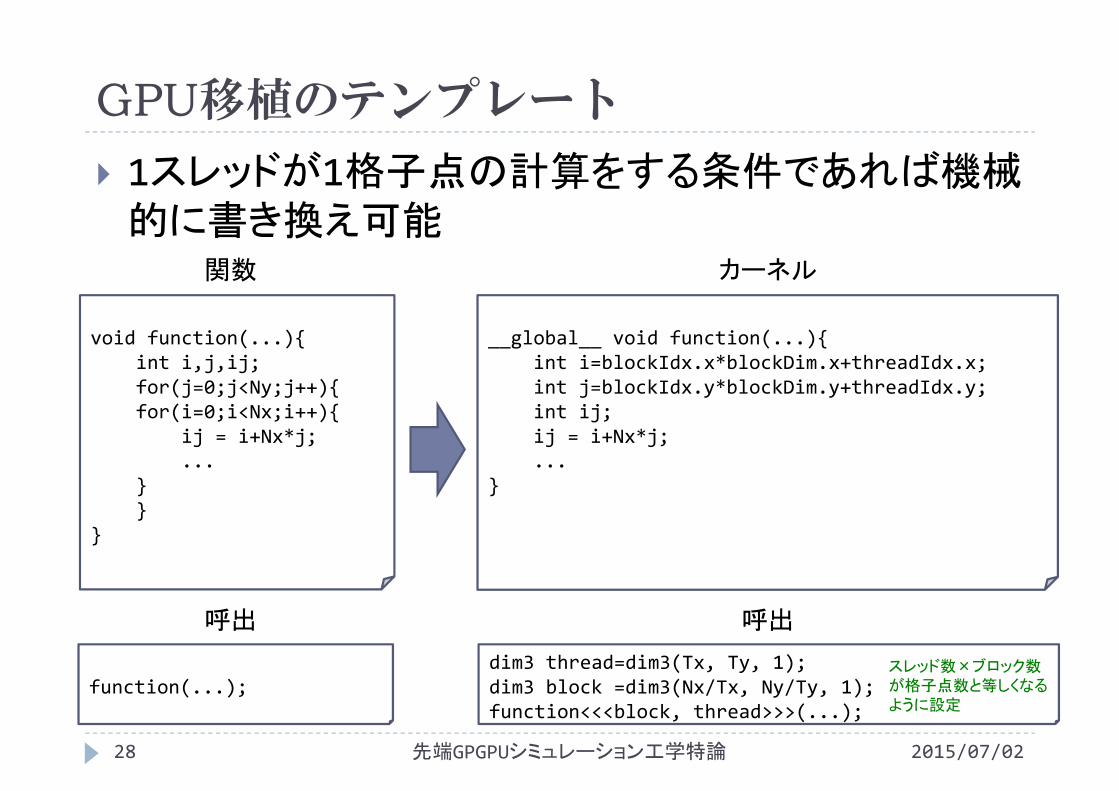
GPU移植のテンプレート
2015/07/02先端GPGPUシミュレーション工学特論28
1スレッドが1格子点の計算をする条件であれば機械的に書き換え可能
void function(...){int i,j,ij;for(j=0;j<Ny;j++){for(i=0;i<Nx;i++){
ij = i+Nx*j;...
}}
}
__global__ void function(...){int i=blockIdx.x*blockDim.x+threadIdx.x;int j=blockIdx.y*blockDim.y+threadIdx.y;int ij;ij = i+Nx*j;...
}
関数 カーネル
function(...);dim3 thread=dim3(Tx, Ty, 1);dim3 block =dim3(Nx/Tx, Ny/Ty, 1);function<<<block, thread>>>(...);
スレッド数×ブロック数が格子点数と等しくなるように設定
呼出 呼出
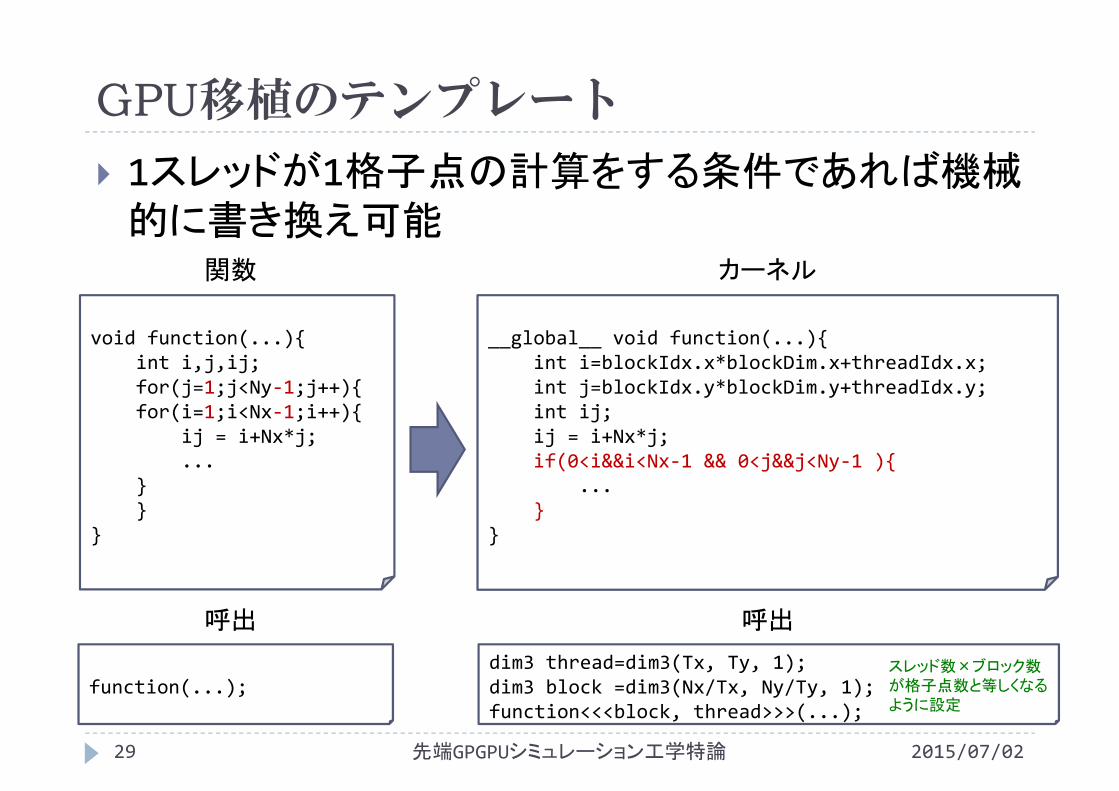
GPU移植のテンプレート
2015/07/02先端GPGPUシミュレーション工学特論29
1スレッドが1格子点の計算をする条件であれば機械的に書き換え可能
void function(...){int i,j,ij;for(j=1;j<Ny‐1;j++){for(i=1;i<Nx‐1;i++){
ij = i+Nx*j;...
}}
}
__global__ void function(...){int i=blockIdx.x*blockDim.x+threadIdx.x;int j=blockIdx.y*blockDim.y+threadIdx.y;int ij;ij = i+Nx*j;if(0<i&&i<Nx‐1 && 0<j&&j<Ny‐1 ){
...}
}
関数 カーネル
function(...);dim3 thread=dim3(Tx, Ty, 1);dim3 block =dim3(Nx/Tx, Ny/Ty, 1);function<<<block, thread>>>(...);
スレッド数×ブロック数が格子点数と等しくなるように設定
呼出 呼出

#define THREADX 16#define THREADY 16#define BLOCKX (Nx/THREADX)#define BLOCKY (Ny/THREADY)
__global__ void init(double *vrtx, double *stmf, double *u, double *v, double *vrtx_next){
int i = blockIdx.x*blockDim.x + threadIdx.x;int j = blockIdx.y*blockDim.y + threadIdx.y;int ij = i + Nx*j;vrtx[ij] = 0.0;stmf[ij] = 0.0;
u[ij] = 0.0;v[ij] = 0.0;
vrtx_next[ij] = 0.0;
if(0<=i&&i<Nx && j==Ny‐1){//Ny‐1の格子点を計算するスレッドが速度の境界条件を計算u[i + Nx*j] = Uwall;
}
}
初期化
2015/07/02先端GPGPUシミュレーション工学特論30
kernel.cu

__global__ void computeVelocity(double *stmf, double *u, double *v){
int i = blockIdx.x*blockDim.x + threadIdx.x;int j = blockIdx.y*blockDim.y + threadIdx.y;int ij = i + Nx*j;int im1j = i ‐ 1 + Nx*j;int ip1j = i + 1 + Nx*j;int ijm1 = i + Nx*(j ‐ 1);int ijp1 = i + Nx*(j + 1);
//境界条件は初期化の際に与えてあるので,計算は内部領域のみif (0 < i&&i < Nx ‐ 1 && 0 < j&&j < Ny ‐ 1){
u[ij] = (stmf[ijp1] ‐ stmf[ijm1])/dy2;v[ij] = ‐(stmf[ip1j] ‐ stmf[im1j])/dx2;
}
}
速度の計算
2015/07/02先端GPGPUシミュレーション工学特論31
kernel.cu

__global__ void computeVorticity(double *vrtx, double *stmf, double *u, double *v,double *vrtx_next){
int i = blockIdx.x*blockDim.x + threadIdx.x;int j = blockIdx.y*blockDim.y + threadIdx.y;int ij = i + Nx*j;int im1j = i ‐ 1 + Nx*j;int ip1j = i + 1 + Nx*j;int ijm1 = i + Nx*(j ‐ 1);int ijp1 = i + Nx*(j + 1);double conv, visc;//計算は内部領域のみ//境界条件は内部領域の計算に影響を及ぼすので,別カーネルを作成if (0 < i&&i < Nx ‐ 1 && 0 < j&&j < Ny ‐ 1){
conv = u[ij]*(vrtx[ip1j]‐vrtx[im1j])/dx2 + v[ij]*(vrtx[ijp1]‐vrtx[ijm1])/dy2;visc = Kvisc*( (vrtx[im1j] ‐ 2.0*vrtx[ij] + vrtx[ip1j])/dxdx
+(vrtx[ijm1] ‐ 2.0*vrtx[ij] + vrtx[ijp1])/dydy);
vrtx_next[ij] = vrtx[ij] + dt*(‐conv + visc);}
}
渦度方程式の計算
2015/07/02先端GPGPUシミュレーション工学特論32
kernel.cu

境界条件を計算するカーネル
2015/07/02先端GPGPUシミュレーション工学特論33
境界条件を計算するカーネルを先に呼び出し,その後内部領域を計算するカーネルを呼び出し 境界の渦度が渦度方程式を通して計算領域内部に影響
計算は境界部分(計算領域外周の点)のみ
計算する点数は概算で2Nx+2Ny
効果的な並列実装は難しいが,計算量自体が少ないのでチューニングを頑張る意味はない

#define BXTHREADX THREADX#define BXTHREADY 1#define BXBLOCKX (Nx/BXTHREADX)#define BXBLOCKY 1__global__ void computeVorticityXBoundary(double *vrtx,double *stmf,double *vrtx_next){
int i = blockIdx.x*blockDim.x + threadIdx.x;int j, ij;
j = 0;ij = i+Nx*j;int ijp1 = i+Nx*(j+1);vrtx[ij] = ‐2.0*stmf[ijp1]/dydy;vrtx_next[ij] = vrtx[ij];
j = Ny‐1;ij = i+Nx*j;int ijm1 = i+Nx*(j‐1);vrtx[ij] = ‐2.0*(stmf[ijm1]+Uwall*dy)/dydy;vrtx_next[ij] = vrtx[ij];
}
x方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論34
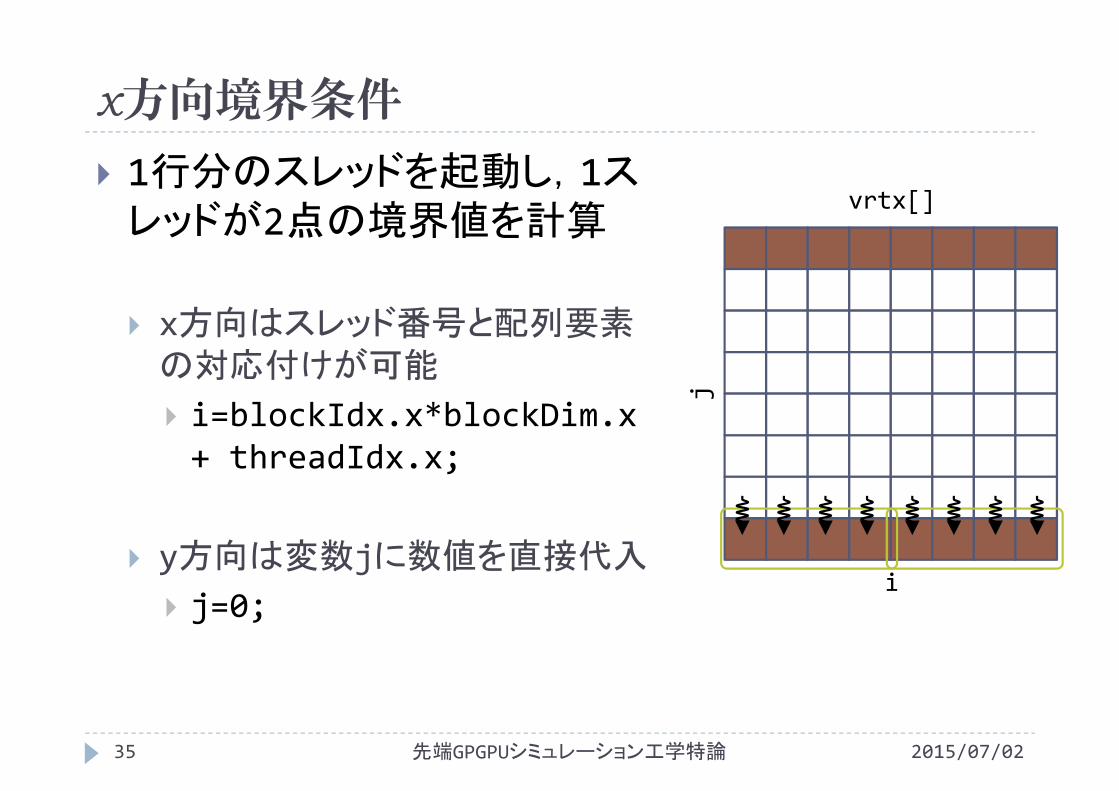
x方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論35
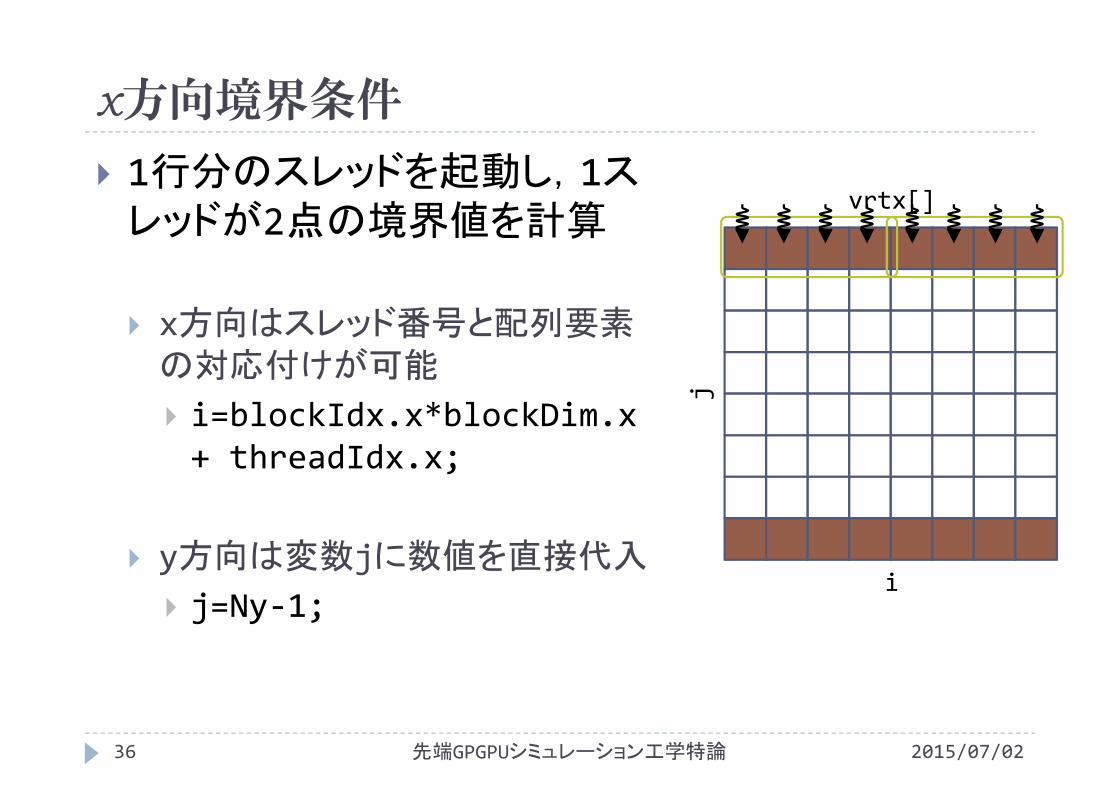
1行分のスレッドを起動し,1スレッドが2点の境界値を計算
x方向はスレッド番号と配列要素の対応付けが可能
i=blockIdx.x*blockDim.x+ threadIdx.x;
y方向は変数jに数値を直接代入
j=0;
vrtx[]
i
j
x方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論36
1行分のスレッドを起動し,1スレッドが2点の境界値を計算
x方向はスレッド番号と配列要素の対応付けが可能
i=blockIdx.x*blockDim.x+ threadIdx.x;
y方向は変数jに数値を直接代入
j=Ny‐1;
vrtx[]
i
j

#define BYTHREADX 1#define BYTHREADY THREADY#define BYBLOCKX 1#define BYBLOCKY (Ny/BYTHREADY)__global__ void computeVorticityYBoundary(double *vrtx,double *stmf,double *vrtx_next){
int j = blockIdx.y*blockDim.y + threadIdx.y;int i, ij;if(0<j&&j<Ny‐1){ //計算領域の4隅はx方向境界条件に従う
i = 0;ij = i+Nx*j;int ip1j = i+1+Nx*j;vrtx[ij] = ‐2.0*stmf[ip1j]/dxdx;vrtx_next[ij] = vrtx[ij];
i = Nx‐1;ij = i+Nx*j;int im1j = i‐1+Nx*j;vrtx[ij] = ‐2.0*stmf[im1j]/dxdx;vrtx_next[ij] = vrtx[ij];
}}
y方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論37
y方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論38
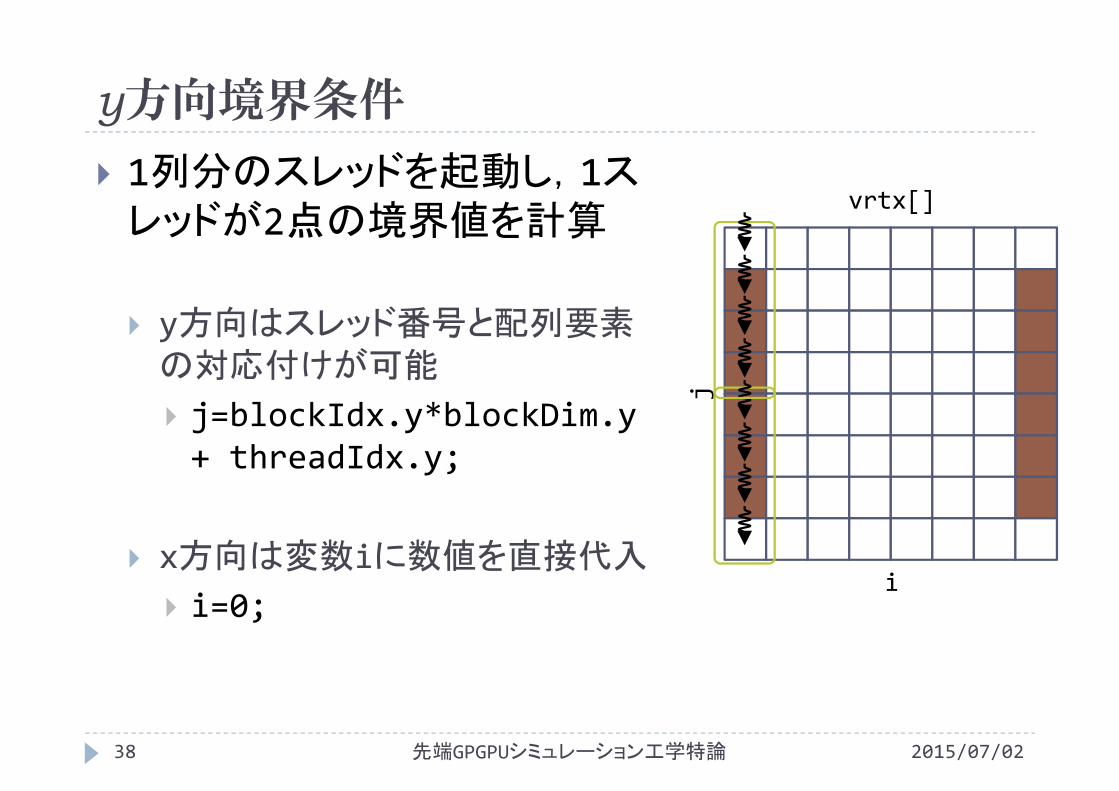
1列分のスレッドを起動し,1スレッドが2点の境界値を計算
y方向はスレッド番号と配列要素の対応付けが可能
j=blockIdx.y*blockDim.y+ threadIdx.y;
x方向は変数iに数値を直接代入
i=0;
vrtx[]
i
j
y方向境界条件
2015/07/02先端GPGPUシミュレーション工学特論39
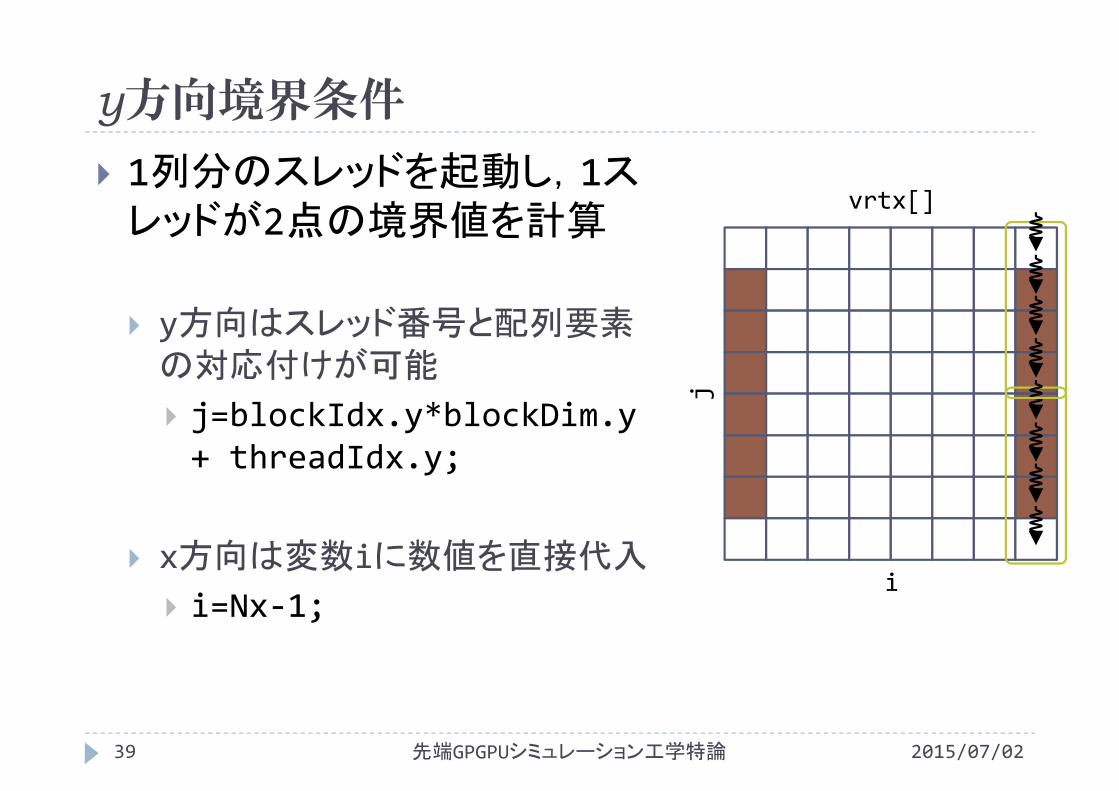
1列分のスレッドを起動し,1スレッドが2点の境界値を計算
y方向はスレッド番号と配列要素の対応付けが可能
j=blockIdx.y*blockDim.y+ threadIdx.y;
x方向は変数iに数値を直接代入
i=Nx‐1;
vrtx[]
i
j

#include<stdio.h>#include<stdlib.h>#include<math.h>
#define Re 1000 //レイノルズ数#define Lx 0.01 //溝の幅(=高さ)#define Ly Lx#define Uwall 0.1 //移動壁の速度#define Kvisc (Lx*Uwall/Re)#define Nx 64#define Ny Nx#define Nbytes (Nx*Ny*sizeof(double))#define dx (Lx/(Nx‐1))#define dy (Ly/(Ny‐1))
#define dx2 (dx*2.0)#define dy2 (dy*2.0)#define dxdx (dx*dx)#define dydy (dy*dy)#define dxdxdydy (dxdx*dydy)#define dxdy2 (2.0*(dxdx+dydy))
#define ndt (0.1) //CFL条件#define dt (ndt*dx/Uwall) //時間刻み#define endnT (100.0) //終了時間(無次元)#define Nt (int)(endnT/dt*Lx/Uwall)
#define ERR_TOL 1e‐12#define Accel 1.7
GPUプログラム(パラメータ設定)
2015/07/02先端GPGPUシミュレーション工学特論40
cavity.cu

#include"kernel.cu"
int main(void){double *dev_vrtx[2], *dev_stmf;double *dev_u, *dev_v;int curr = 0, next = 1;
dim3 Thread = dim3(THREADX, THREADY, 1);dim3 Block = dim3( BLOCKX, BLOCKY, 1);dim3 ThreadBX = dim3(BXTHREADX, BXTHREADY, 1);dim3 BlockBX = dim3(BXBLOCKX, BXBLOCKY, 1);dim3 ThreadBY = dim3(BYTHREADX, BYTHREADY, 1);dim3 BlockBY = dim3(BYBLOCKX, BYBLOCKY, 1);
cudaMalloc((void **)&dev_vrtx[curr], Nbytes);cudaMalloc((void **)&dev_stmf , Nbytes);cudaMalloc((void **)&dev_u , Nbytes);cudaMalloc((void **)&dev_v , Nbytes);cudaMalloc((void **)&dev_vrtx[next], Nbytes);
init<<<Block, Thread>>>(dev_vrtx[curr],dev_stmf,dev_u,dev_v,dev_vrtx[next]);computeStreamfunction_rbsor(dev_stmf,dev_vrtx[curr]);computeVelocity<<<Block, Thread>>>
(dev_stmf,dev_u,dev_v);cudaDeviceSynchronize();
for(int n=1;n<=Nt;n++){printf("%d/%d¥n",n,Nt);computeVorticityXBoundary<<<BlockBX,ThreadBX>>>
(dev_vrtx[curr],dev_stmf, dev_vrtx[next]);computeVorticityYBoundary<<<BlockBY,ThreadBY>>>
(dev_vrtx[curr],dev_stmf, dev_vrtx[next]);computeVorticity<<<Block, Thread>>>(dev_vrtx[curr],
dev_stmf,dev_u,dev_v,dev_vrtx[next]);computeStreamfunction_rbsor
(dev_stmf,dev_vrtx[curr]);computeVelocity<<<Block, Thread>>>
(dev_stmf,dev_u,dev_v);cudaDeviceSynchronize();curr = next; next = 1‐curr;
}
cudaFree(dev_vrtx[curr]);cudaFree(dev_stmf);cudaFree(dev_u);cudaFree(dev_v);cudaFree(dev_vrtx[next]);return 0;
}
GPUプログラム(メイン)
2015/07/02先端GPGPUシミュレーション工学特論41
cavity.cu


















