
20150716 introduction to apache spark v3
43
-
Upload
andrey-vykhodtsev -
Category
Engineering
-
view
174 -
download
5
Transcript of 20150716 introduction to apache spark v3

Presenter : Andrey Vykhodtsev
*collective work, see slide credits

Two meetup groups
Close, but different topics
Ran by me
I don’t have to be a presenter all the time
Propose your agenda

Not a Big Data introduction
Visit our next Big Data Essentials meetup instead http://www.meetup.com/Big-Data-Developers-in-Slovenia/events/223871144/
Not for people without technical background (sorry)
Not a thorough use case discussion
Just a technical overview of technology for beginners

General purpose distributed computing engine suitable for large scale machine learning and data processing tasks

NOT SO GOOD GOOD
Not the first computing engine MapReduce
MPI
Not one of a kind Flink
Not so old (mature)
Developing very fast
Rapidly growing community
Backed by major vendors
Innovation
Designed for iterative data analysis on large scale (supersedes MR)

In-Memory Performance
Ease of Development
Combine Workflows
Unlimited Scale
Enterprise Platform
Wide Range of
Data Formats

A Big Data/DWH developer
A Data Scientist
An Analytics Architect
A CxO of IT company
Statistici
an
Business Analyst
Software Engineer

IT WORDS BUSINESS WORDS
Data processing/Transformation
Machine Learning
Social Network Analysis
Streaming/Microbatching
Segmentation
Campaign response prediction
Churn avoidance
CTR prediction
Behavioral analysis
Genomics
….



Open Source SystemML
Educate One Million Data Professionals
Establish Spark Technology Center
Founding Member of AMPLab
Contributing to the Core
Port many existing applications onto Spark
Develop applications using Spark


Distributed platform for thousands of nodes
Data storage and computation framework
Open source
Runs on commodity hardware
Flexible – everything is loosely coupled

Driving principals
Files are stored across the entire cluster
Programs are brought to the data, not the data to the program
Distributed file system (DFS) stores blocks across the whole cluster
Blocks of a single file are distributed across the cluster
A given block is typically replicated as well for resiliency
Just like a regular file system, the contents of a file is up to the application
Unlike a regular file system, you can ask it “where does each block of my file live?”
FILE BLOCK
S

map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result));
Hello World Bye World
Hello IBM
Content of Input Documents
Reduce (final output):
< Bye, 1> < IBM, 1> < Hello, 2> < World, 2>
Map 1 emits: < Hello, 1> < World, 1> < Bye, 1> < World, 1> Map 2 emits: < Hello, 1> < IBM, 1>

Spark brings two significant value-adds: Bring to Map Reduce the same added value that databases (and
parallel databases) brought to query processing: Let the app developer focus on the WHAT (they need to ask) and let the
system figure out HOW (it should be done).
Enable faster higher level application development through higher level constructs and concepts: (RDD concept)
Let the system deal with performance (as part of the HOW) Leveraging memory (Bufferpools, Caching RDDs in memory)
Maintaining sets of dedicated worker processes ready to go (subagents in DBMS, Executors in Spark)
Enabling interactive processing (CLP, SQL*Plus, spark-shell, etc….)
Be one general purpose engine for multiples types of workloads (SQL, Streaming, Machine Learning, etc…)

Apache Spark is a fast, general purpose, easy-to-use cluster computing system for large-scale data processing Fast
Leverages aggressively cached in-memory distributed computing and dedicated
App Executor processes even when no jobs are running Faster than MapReduce
General purpose Covers a wide range of workloads Provides SQL, streaming and complex
analytics
Flexible and easier to use than Map Reduce Spark is written in Scala, an object oriented,
functional programming language Scala, Python and Java APIs Scala and Python interactive shells Runs on Hadoop, Mesos, standalone or
cloud
Logistic regression in Hadoop and Spark
Spark Stack
val wordCounts = sc.textFile("README.md").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
WordCount

Spark is versatile and flexible:
Can run on YARN / HDFS but also standalone or on MESOS
Spark engine can be exploited from multiple “entry points”: SQL, Streaming, Machine Learning, Graph Processing

Normally you code stuff up in one of the languages
Scala
Python
Java
I like Python, but in some cases it is slower
With DataFrames, no difference (more later)

One of the shells
Scala shell (spark-shell)
Python shell
Code it in the editor and submit with spark-submit
Use “notebook” (Jupyter, Zeppelin)
My preferred method. More later
Enable your IDE to run spark
PyCharm
IntelliJ IDEA


Jupytiter
Zeppelin Scala
Incubated
Many others Spark Notebook
Ispark
DataBricks Cloud
IBM Spark aaS
IBM DataScientist Workbench

Initialize context
Read data
Run stuff
Transformations
Actions
Caching
More later

GOOD STUFF NOT SO GOOD STUFF
Full API exposed
Concise language
Documentation is way better
Faster if you use plain RDDs
Build tools and dependency tracking
Not so many additional libraries compared to Python Pandas
Matplotlib
Harder to run in a “notebook”* *At the moment
Harder to learn

Scala Crash Course
Holden Karau, DataBricks
http://lintool.github.io/SparkTutorial/slides/day1_Scala_crash_course.pdf
Martin Odersky’s “Functional Programming in Scala” course
Books Scala for Impatient
Scala by Example

GOOD STUFF NOT SO GOOD STUFF
Clean & clear language
Easy to learn
Lot of libraries Pandas
Scikit
matplotlib
Easy to run in a “notebook”
Slower Interpreted language
Not all API functions exposed Streaming
Some times behaves differently

I think coding in Java for Spark is terrible
But if you like it messy, there is nobody to stop you


A way to connect to spark engine
Initialized with all runtime parameters
For example, memory parameters

Resilient Distributed Dataset
An abstraction over a generic data collection
Integers
Strings
PairRDD : <key, value> pairs (support additional operations)
Single logical entity but under the hood is a distributed collection
Mokhtar Jacques Dirk
Cindy Dan Susan
Dirk Frank Jacques
Partition 1 Partition 2 Partition 3
Names

You have to pay attention what kind of operation you are running
Transformation
Does not do anything until the action is called
Actions
Kick off computation
Results can be persisted to memory (cache) or to disk (more later)

Three methods for creation Distributing a collection of objects from the driver program
(using the parallelize method of the spark context) val rddNumbers = sc.parallelize(1 to 10) val rddLetters = sc.parallelize (List(“a”, “b”, “c”, “d”)) Loading an external dataset (file)
val quotes = sc.textFile("hdfs:/sparkdata/sparkQuotes.txt")
Transformation from another existing RDD val rddNumbers2 = rddNumbers.map(x=> x+1)

Transformations are lazy evaluations
Returns a pointer to the transformed RDD
Pair RDD (K,V) functions for MapReduce style transformations
Map
Filter
flatMap
reduceByKey
sortByKey
Join
See the doc for full list

Kick off the computation
Transformations are lazily evaluated
Collect()
Count()
Take()
Reduce()
First()
saveAsTextFile()

Each node stores any partitions of the cache that it computes in memory
Reuses them in other actions on that dataset (or datasets derived from it)
Future actions are much faster (often by more than 10x)
Two methods for RDD persistence: persist() and cache()

rdd1.join(rdd2) .groupBy(…) .filter(…)
RDD Objects
build operator DAG
agnostic to operators!
doesn’t know about stages
DAGScheduler
split graph into stages of tasks
submit each stage as ready
DAG
TaskScheduler
TaskSet
launch tasks via cluster manager
retry failed or straggling tasks
Cluster manager
Worker
execute tasks
store and serve blocks
Block manager
Threads
Task
stage failed
DataBricks
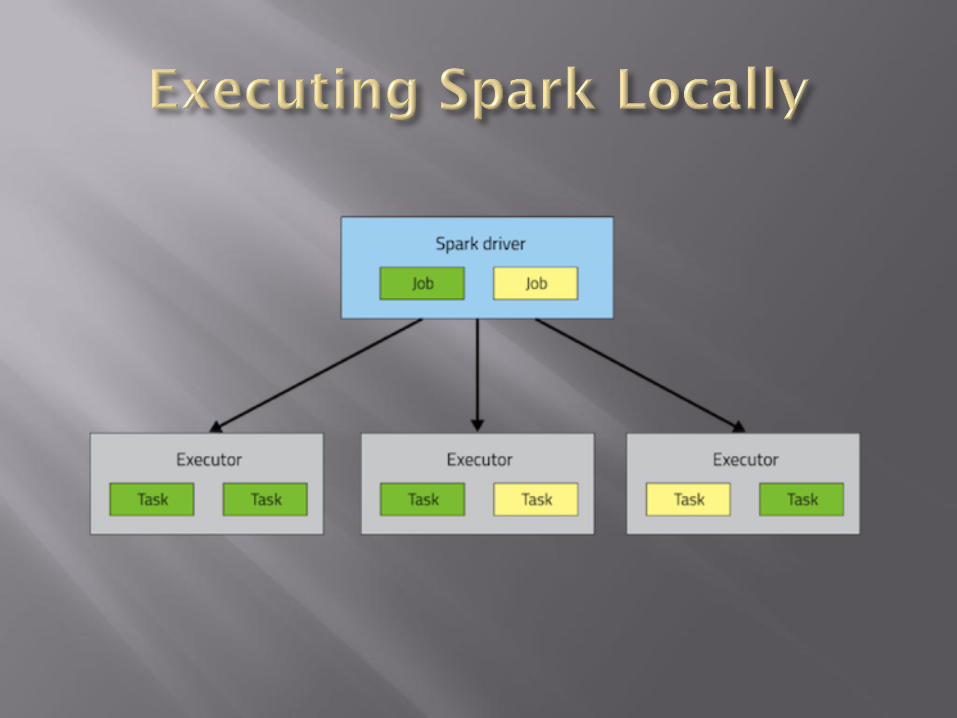
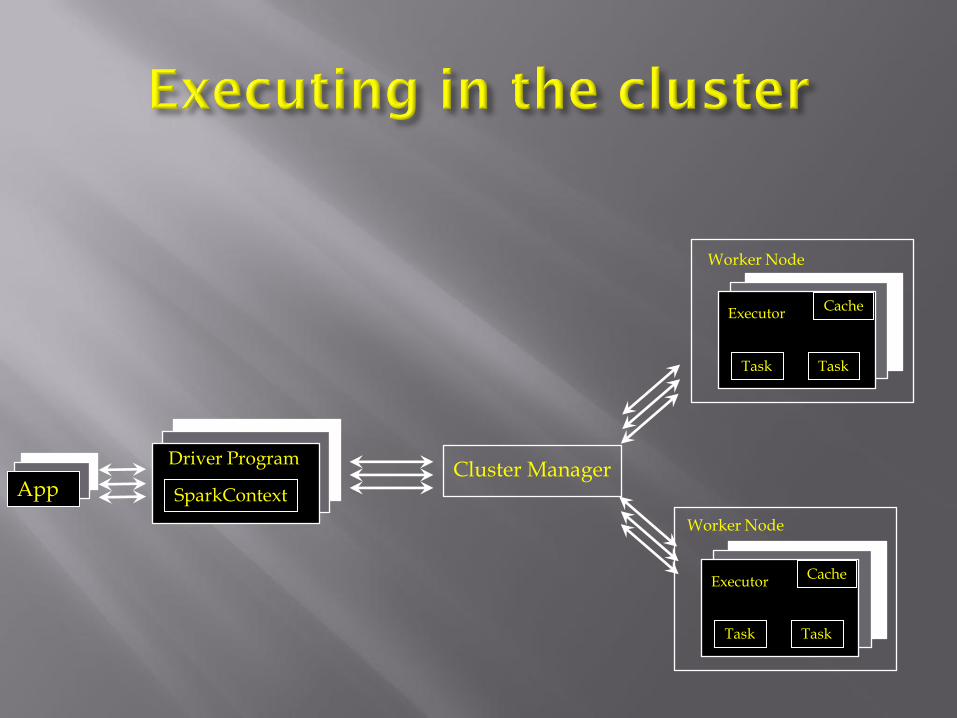
SparkContext
Driver Program Cluster Manager
Worker Node
Executor
Task Task
Cache
Worker Node
Executor
Task Task
Cache
App


MLLib
Distributed machine learning libraries
SparkSQL
DataFrames
GraphX
ML
SparkR
Streaming

Read the Fine Manual
https://spark.apache.org/docs/latest/index.html
Take the course
BigData University https://bigdatauniversity.com/bdu-wp/bdu-course/spark-fundamentals/
edX – edx.org search for Spark
If you’re stuck
Try the user lists : https://spark.apache.org/community.html

Questions?
Topic for the next meetup?
Your experiences?
Want to be a presenter?

Some slide and text graphics were borrowed from the following sources Vincent Poncet, IBM France
Jacques Roy, IBM US
Daniel Kikuchi , IBM US
Mokhtar Kandil , IBM US
DataBricks
Spark Docs
I completely lost track what slides I copied from which source. I apologize.


















