
2011, Manyika, et. all. Big data: The next frontier for innovation, competition, and productivity....
54
Management and algorithms for large data sets. John Freddy Duitama Muñoz U. de A. - UN
-
Upload
shannon-harvey -
Category
Documents
-
view
225 -
download
2
Transcript of 2011, Manyika, et. all. Big data: The next frontier for innovation, competition, and productivity....

Management and algorithms for large data sets.
John Freddy Duitama Muñoz
U. de A. - UN

Big Data Big data refers to datasets whose size
is beyond the ability of typical database software tools to capture, store, manage, and analyze.
Big data is not just about size Find insights from complex, noisy,
heterogeneous, longitudinal and voluminous data.
It aims to answer questions that were previously unanswered. 2011, Manyika, et. all. Big data: The next frontier for innovation, competition, and productivity. McKinsey Global Institute.


Management, analysis and modeling of large data sets
LSH: Locality Sensitive Hashing , S.V.M: Support Vector Machine , I.R: Information Retrieval

Cluster Computing Computer node: CPU, main memory,
cache, and optional local disk.
Computer nodes (8-64) are stored on racks.
Nodes on a single rack are connected by a network (Ethernet)
Racks can be connected by switches.
Fault tolerance. (failures are the norm rather than the exception) then: Files must be stored redundantly.
Computation must be divided into tasks. When one task fails, it can be restarted without affecting other tasks.

Distributed File System DFS for data-intensive applications. Hundreds of terabytes, thousands of disks, thousands of machines. Design assumption.
Fault tolerance. (failures are the norm rather than the exception) Huge files divide into chunks (typically 64 megabytes). Chunks
are replicated (maybe three times) in different computer nodes from different racks.
Files are mutated by appending new data rather than overwriting existing data.
The system must efficiently implement well-defined semantics for multiple clients that concurrently append to the same file.
To find the chunks of a file, the master node is used.

Distributed File System (DFS)
Versions:Google File System, Hadoop File System, CloudStore, Cloudera, etc.
Master Node function:• ACL• Garbage collection• Migration between
chunk servers.• Periodically
communicates with each chunk server

Distributed File System Files are mutated by appending new data rather than overwriting existing
data.
Random writes within a file are practically non-existent.
Once written, the files are only read, and often only sequentially. (data analysis program)
Data streams continuously generated by running applications or archival data.
Intermediate results produced on one machine and processed on another.
Appending becomes the focus of performance optimization and atomicity guarantees.
Map-reduced operation.
sequential read-access to files.
Concurrent record append to the same file

Google File System Architecture
(Ghemawat, 2003, et. al ) The Google File System
The client then sends a request to one of the replicas, most likely the closest one.

Google File System Typical operations: create, delete, open, close, read and write files. New operations: Snapshot and record append. Record append allows multiple clients to append data to the same file concurrently while
guaranteeing the atomicity of each individual client’s append. Master maintains all file system metadata.(namespace, ACI, mapping from files to chunks,
current locations of chunks. The master delegates authority to primary replicas in data mutations
The master periodically communicates with each chunk server.
Clients only interact with the master for metadata operations.
Clients never read and write data through the master.
The log contains a historical record of critical metadata changes.
Chunk replica placement policy: Maximize data reliability and availability, and maximize network bandwidth utilization.
Chunk are spread replicas across racks

Control flow of a write 1. The client asks the master 1. The client asks the master for a
chunk and its replicas. 2. The master replies with the
identity of them.3. The client pushes the data to all
the replicas. (It can do so in any order)
4. The client sends a write request to the primary. The primary assigns serial number.
5. The primary forwards the write request to all secondary replicas.
6. The secondaries all reply to the primary indicating that they have completed the operation.
7. The primary replies to the client.

Google File System – Consistency Model
File namespace mutations are atomic and handled by the master.
File mutation: operation that changes the contents or metadata of a chunk caused by write or append record.
Writing: Data is written at application-specific file offset.
Record Appends. Clients specify only data.
Data is appended atomically even in the presence of concurrent mutations, but at an offset of GFS’s choosing.
Many clients on different machines append to the same file concurrently.
Such files serve as multiple-producer/single consumer queues.

Google File System – Consistency Model
States of file region after a data mutation
Consistent region: all clients will always see the same
data regardless of which replicas they read from. Defined region. If it is consistent and clients will see what the mutation writes
in its entirety. When non-concurrent mutation succeeds, the affected regions are defined. (and by implication consistent) Concurrent successful mutations leave the region undefined but consistent. All clients see the same data, but it may not reflect what any one mutation has written. (region consists of mingled fragments from multiple mutations) Applications can distinguish defined and undefined regions.

Map- Reduce Paradigm A programing model for processing large data sets with a parallel and
distributed algorithm

Motivation To manage immense amounts of data.
Ranking of Web pages.
Searches in social networks.
Map-reduce implementation enables many of the most common calculations of large-scale data to be performed on computing clusters.
When designing map-reduce algorithms, the greatest cost is in the communication.
All you need to write are two function, call Map and Reduce.
The system manages the parallel execution and also deals with possible failures.
Tradeoff: communication cost vs degree of parallelism.

Execution of the map-reduce program
John Freddy Duitama
Cambiar la salida del map sin combiner de la forma (w1,d1), (w1,w1),(w1,d3)

Map-reduce and combiners
Combiner:When the Reduce function is associative and commutative

Matrix -vector multiplication
Matrix M = nxn
Vector V lenght n
mij : matrix element
vj : vector element
mij = 1 link from page j to page i.
0 : otherwise
Matrix representation (i, j, mij)
Vector representation (j, vj)
We move pieces of the sub-vector and chunks of the matrix into the main memory in order to Multiply each sub-vector by each chunk of the matrix.
Map : For each ith stripe.
Reduce:

MATRIX –VECTOR MULTIPLICATION
We move pieces of the sub-vector and chunks of the matrix into the main memory in order to Multiply each sub-vector by each chunk of the matrix.

Relational Algebra and
Map- Reduce Paradigm

Selection
FROM TO
url1 url2
url1 url2
url2 url3
url2 url4.
… …
RelationLinks
Not mandatory

Projection

Projection in MapReduce• Easy!
Map over tuples, emit new tuples with appropriate attributes
Reduce: take tuples that appear many times and emit only one version (duplicate elimination) Tuple t in R: Map(t, t) -> (t’,t’)
Reduce (t’, [t’, …,t’]) -> [t’,t’]
• Basically limited by HDFS streaming speeds
Speed of encoding/decoding tuples becomes important
Relational databases take advantage of compression
Semi structured data? No problem!
Based on slides from Jimmy Lin’s lecture slides (http://www.umiacs.umd.edu/~jimmylin/cloud-2010-Spring/index.html) (licensed under Creation Commons Attribution 3.0 License)

Union

Union, Set Intersection and Set Difference
Similar ideas: the output of each map is the tuple pair (t,t). For union, we output it once, for intersection only when in the reduce we have the entry (t, [t,s])
For Set difference?
Luffi
this does not make sense

Set Difference
Map Function: - For a tuple t in R, produce key-value pair (t, R), - for a tuple t in S, produce key-value pair (t, S).
Reduce Function: - For each key t, do the following.
1. If the associated value list is [R], then produce (t, t).
2. Otherwise, produce nothing
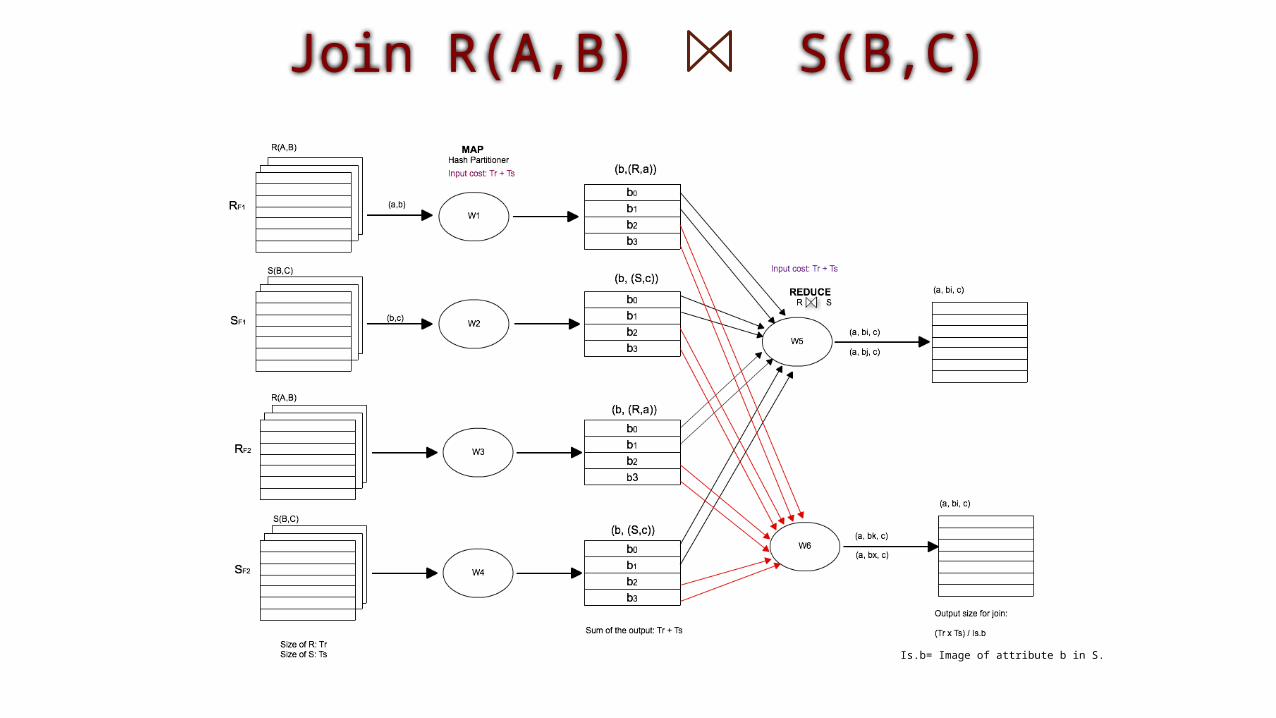
Join R(A,B) S(B,C)
Is.b= Image of attribute b in S.

Group By – Aggregation: ɣA,Ө(B)(R)

Matrix Multiplication
P = M x N
𝑃 𝑖𝑘=∑𝑗=1
𝑛
𝑚𝑖𝑗𝑛 𝑗 𝑘

Example: Matrix Multiplication
x =1 0 2 2 0 2 43 1 2 1 1 7 51 2 1 0 2 4 4
M N P
j=1 j=2 j=3 PM1,j x Nj,1 1x2 0x1 2x0 2M1,j x Nj,2 1x0 0x1 2x2 4M2,j x Nj,1 3x2 1x1 2x0 7M2,j x Nj,2 3x0 1x1 2x2 5M3,j x Nj,1 1x2 2x1 1x0 4M3,j x Nj,2 1x0 2x1 1x2 4
i j k Mi,j x Nj,k1 1 1 1x22 1 1 3x23 1 1 1x22 2 1 1x12 2 2 1x13 2 1 2x13 2 2 2x11 3 2 2x22 3 2 2x23 3 2 1x2
i k Mi,j x Nj,k P1 1 1x2 21 2 2x2 42 1 3x22 1 1x12 2 1x12 2 2x23 1 1x23 1 2x13 2 2x13 2 1x2
7
5
4
4
group by i,k

The Communication Cost Model Computation is described by an acyclic graph of tasks
The communication cost of a task. The size of the input to the task.
Communication cost is a way to measure the algorithm efficiency.
The algorithm executed by each task is simple. It is lineal in the size of its inputs.
The interconnect speed for cluster computing (one gigabit/second) versus CPU speed.
Move data from disk to main memory versus CPU speed.
We count only input size: The output of task T is the input of another task T’
Why do we count only input size? If the output of one task is T, T is input in another task.
The algorithm output is rarely large compared with intermediate data.
Luffi
this sentence needs a verb
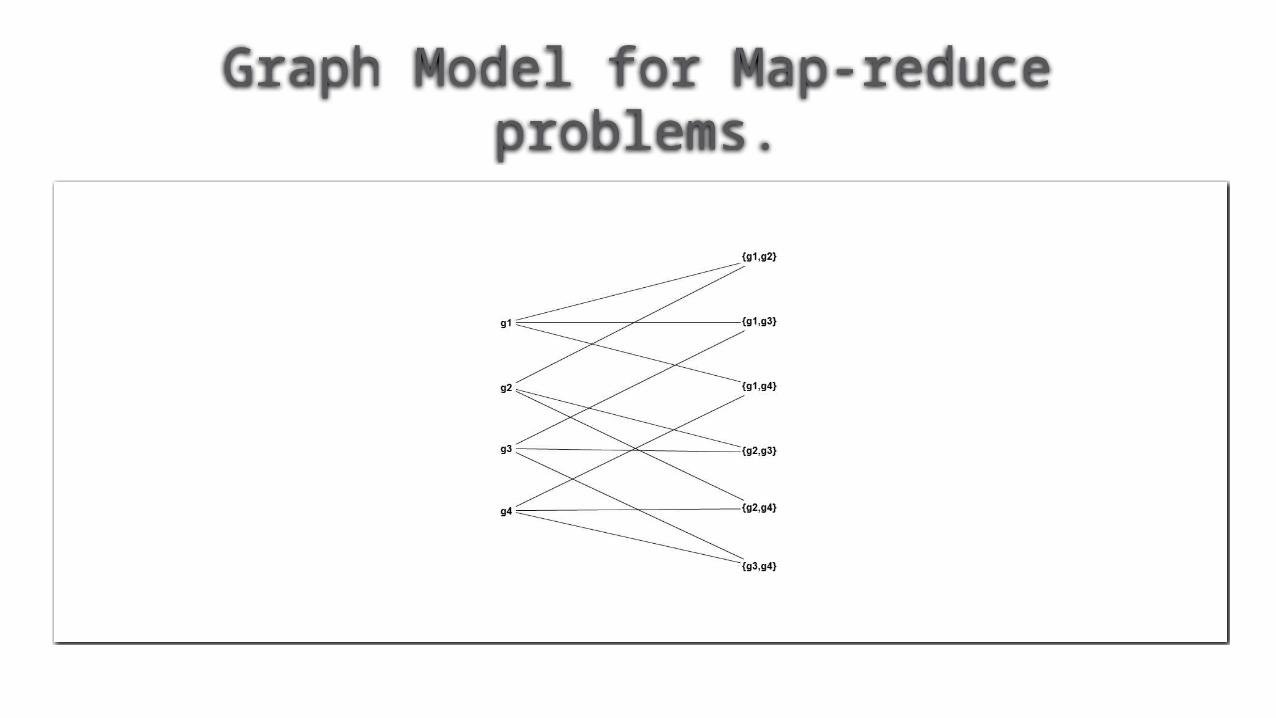
Graph Model for Map-reduce problems.

Cost Communication: Join R(A,B) S(B,C)
Communication Cost of join algorithm: O(Tr + Ts)
The output size for the join can be either larger or smaller than r + s , depending on how likely it is that a given R –tuple joins with a given S –tuple.IS.B = Image of attribute S.B
Eje: R(1,2) (2,(R,1)) S(2,3) (2,(S,3))

R(A,B) S(B,C)
Tr y Ts size (Tuples) of Relations R and S.
Map Task : (Tr + Ts)
Reduce Task : (Tr + Ts)
Cost communication for join algorithm is: O(Tr + Ts).
Output size for join can be either larger or smaller than (Tr + Ts).
(Tr x Ts) x P. Where P: Probability that an R-tuple and an S-Tuple agree on B.
The output size for the join can be either larger or smaller than r + s , depending on how likely it is that a given R –tuple joins with a given S –tuple
Be aware of: Cost communication versus the time taken for a parallel algorithm to
finish.
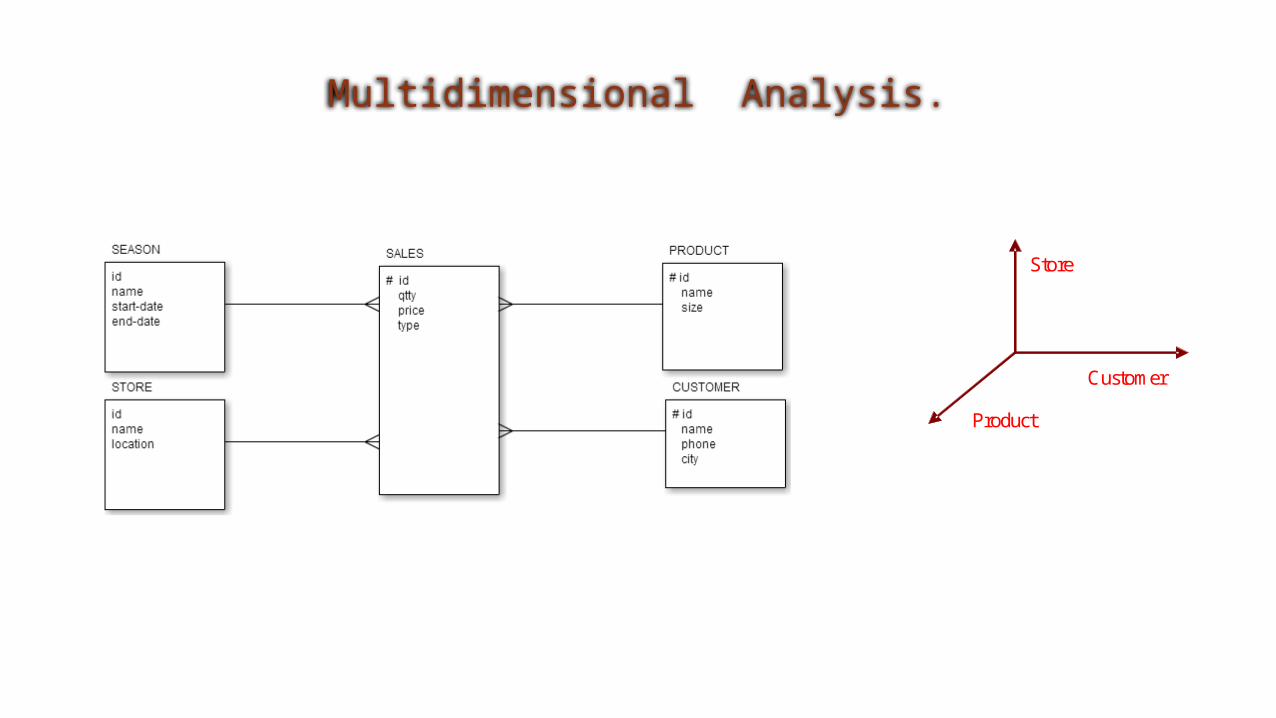
Multidimensional Analysis.
Customer
Product
Store

Multiway Join - Two map-reduce phases.
R(A,B) JOIN S(B,C) JOIN T(C,D)
P: Probability that an R-tuple and an S-Tuple agree on B.
Q: Probability that an S-tuple and an T-Tuple agree on C.
Tr , Ts and Tt size (Tuples) of Relations R, S and T respectively.
First Map-reduce Task R JOIN S : O (Tr + Ts)
Intermediate Join size : (Tr x Ts) x P.
Second Map- Reduce Task : (R JOIN S) JOIN T : O(Tt + (Tr x Ts) x P)
Entire cost communication : O( Tr + Ts + Tt + (Tr x Ts) x P )
Output join size (Tr x Ts x Tt) x P x Q.

Multiway Join (single phase)
Each tuple S(b,c) is sent to one reduce task: (h(b), g(c)).
Each tuple R(a,b) must be sent to b reduce tasks (h(b), x)
Each tuple T(c,d) must be sent to c reduce tasks (g(c),y)

Multiway Join – a Single Map Reduce Job
R(A,B) JOIN S(B,C) JOIN T(C,D)
Map Task :
Tr + Ts + Tt
Reduce Task
Ts to move each tuple S(B,C) once to reducer ( H(B), G(C))
c Tr to move each tuple R(A,B) to the c reducers (H(B), y ) ; y = 1…c
b Tt to move each tuple T(C,D) to the b reducers (y, G(C) ) ; y = 1…b
Cost: Ts + cTr + bTt
Total Communication cost: O(Tr + 2Ts + Tt + cTr + bTt )
Output join size (Tr x Ts x Tt) x P x Q.

How to select b and c?
Minimize f( b, c) = s=Ts, r= Tr and t = Tt
Constraint g (b, c) :
Problem solving using the method of Lagrangean Multipliers
Take derivatives with respect to the two variables b, c
Multiply the two equations:
; ;
Minimum communication cost when : and
Communication Cost

Reducer size and replication rateReducer:
A reducer is a key and its associated values.
There is a reducer for each key. Note: “reducer” != reducer task.
q: reducer size.
Upper bound by the number of values that are allowed to appear in the list associated with a single key.
Premise: reducer size small enough that the computation associated with a single reducer can be executed entirely in main memory.
r: replication rate.
number of key-value pairs produced by all Map tasks / number of inputs.
Remark: the less communication an algorithm uses, the worse it may be in other respects, including wall-clock time and the amount of main memory it requires.

Similarity Join. How similar two elements x and y of set X are?
Output: Pairs whose similarity exceeds a given threshold t .
Reducer size = 2n/g then r = 2n / reducer size
The smaller the reducer size, the larger the replication rate, and therefore the higher the communication.

References[1] S. Ghemawat, H. Gobioff, and S.-T. Leung, “The Google file system,” 19th ACM Symposium on Operating Systems Principles, 2003.
[2] hadoop.apache.org, Apache Foundation.
[3] F. Chang, J. Dean, S. Ghemawat,W.C. Hsieh, D.A.Wallach, M. Burrows, T. Chandra, A. Fikes, and R.E. Gruber, “Bigtable: a distributed storage system for structured data,” ACM Transactions on Computer Systems. 26:2, pp. 1–26, 2008.
[4] Dr. Gautam Shroff. Web Intelligence and Big Data at www.coursera.org. 2013.
[5] A. Rajaraman, Jure Leskovec and J.D. Ullman. Mining of Massive Datasets. Cambridge University Press, UK 2014.
[6] Dean and Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. Communication of the ACM. 2008. Vol.51-1. pp 107-113.
[7] Dean, J. and Ghemawat, S. 2004. MapReduce: Simplified data processing on large clusters. In Proceedings of Operating Systems Design and Implementation (OSDI). San Francisco, CA. 137-150.

End

Graph Model for Map-reduce problems.How to calculate lower bounds on the replication rate as a function of reducer size?
Graph model of problem
A set of inputs
A set of outputs
A many-many relationship between the inputs and outputs.
Mapping schema – reducer size q,
No reducer is assigned more than q inputs.
For every output, there is a least one reducer that is assigned all the inputs required by that output.
Luffi
limits?

A View of Hadoop (from Hortonworks)
Source: “Intro to Map Reduce” -- http://www.youtube.com/watch?v=ht3dNvdNDzI

Comparing: RDBMS vs. Hadoop
Traditional RDBMS Hadoop / MapReduce
Data Size Gigabytes (Terabytes) Petabytes (Hexabytes)
Access Interactive and Batch Batch – NOT Interactive
Updates Read / Write many times Write once, Read many times
Structure Static Schema Dynamic Schema
Integrity High (ACID) Low
Scaling Nonlinear Linear
Query Response Time
Can be near immediate Has latency (due to batch processing)

4.8. RAID.Redundant Arrays of Inexpensive Disk.
Organización de discos múltiples e independientes en un disco lógico.
Data striping: Distribuir los datos transparentemente sobre múltiples discos para que aparezcan como un solo gran disco.
Permite manipulación en paralelo para lograr:
Mayor rata de transferencia ( para grandes volúmenes de datos) Mayor rata de I/O en pequeños datos.Permitir balanceo uniforme de la carga.
RAID -0

RAID. Problema inicial: Tendencia : Mayor distancia velocidad CPU vs. periféricos. Solución: Arreglos de disco.
Nuevo problema: Más Vulnerable a fallas: Arreglo de 100 discos es 100 veces más probable de falla.
MTTF (Mean-time-to-failure).• Si un disco tiene 200.000 horas (23 años)• Arreglo de 100 tiene 2000 horas (3 meses).
Solución: Emplear redundancia en la forma de código corrector de errores. Se logra mayor seguridad. Toda escritura debe actualizar información redundante. Implica un desempeño más pobre que para solo un disco.

RAID.Data Striping.
Granularidad fina: pequeñas unidades de datos. Un requerimiento de I/O, sin importar tamaño, requiere de todos los discos. Solo un I/O lógico simultáneamente. Alta rata de transferencia en todos los pedidos.
Granularidad gruesa : Grandes unidades de datos. Cada I/O requiere de pocos discos. Permite concurrencia de requerimientos lógicos. Grandes requerimientos mantienen alta rata de transferencia.
Objetivos:
· Que cada disco transfiera en cada I/O el máximo de datos útiles.· Usar todos los discos simultáneamente.

RAID 5.
Block interleaved distributed parity. Elimina cuello de botella en disco de paridad. Todo disco maneja datos y paridad.Su mayor debilidad : Pequeñas escrituras son más ineficientes que todos los otros arreglos redundantes.
requieren : READ-MODIFY-WRITE. Se disminuye problema con cache en el dispositivo.
Uso
Tiene el mejor desempeño en pequeñas lecturas, grandes lecturas y grandes escrituras de todos los arreglos redundantes.

RAID.
Throughput por Dólar relativo a RAID -0.
G : número de discos en un grupo de corrección de errores.
Pequeña: I/O que requiere una unidad de striping.
Grande : I/O que requiere una unidad en cada disco del grupo.
Significado:
Una escritura pequeña en RAID 1 cuesta el doble que la misma lectura en RAID-0.
Lectura Pequeña.
Escritura Pequeña
Lectura Grande
Escritura Grande.
Eficiencia almacena.
Raid – 0 1 1 1 1 1 Raid - 1 1 1/2 1 1/2 1/2 Raid - 3 1/G 1/G (G-1)/G (G-1)/G (G-1)/G Raid - 5 1 Max(1/G,1/4) 1 (G-1)/G (G-1)/G

4.10. Particionamiento de tablas.
Ayuda al soporte y desempeño en el manejo de grandes tablas e índices, descomponiendo los objetos en pequeñas piezas.
Part-1 P art-2 Part-3 P art-4
D isk -1 D isk -2 D isk -3 D isk -4
Ind -P 1 Ind -P 2 In d -P3 In d -P4

Particionamiento de tablas.
Ejemplo:
CREATE TABLE sales
( acct_no NUMBER(5),
acct_name CHAR(30),
amount_of_sale NUMBER(6),
week_no INTEGER )
PARTITION BY RANGE ( week_no )
(PARTITION sales1 VALUES LESS THAN ( 4 ) TABLESPACE ts0,
PARTITION sales2 VALUES LESS THAN ( 8 ) TABLESPACE ts1,
...
PARTITION sales13 VALUES LESS THAN ( 52 ) TABLESPACE ts12 );
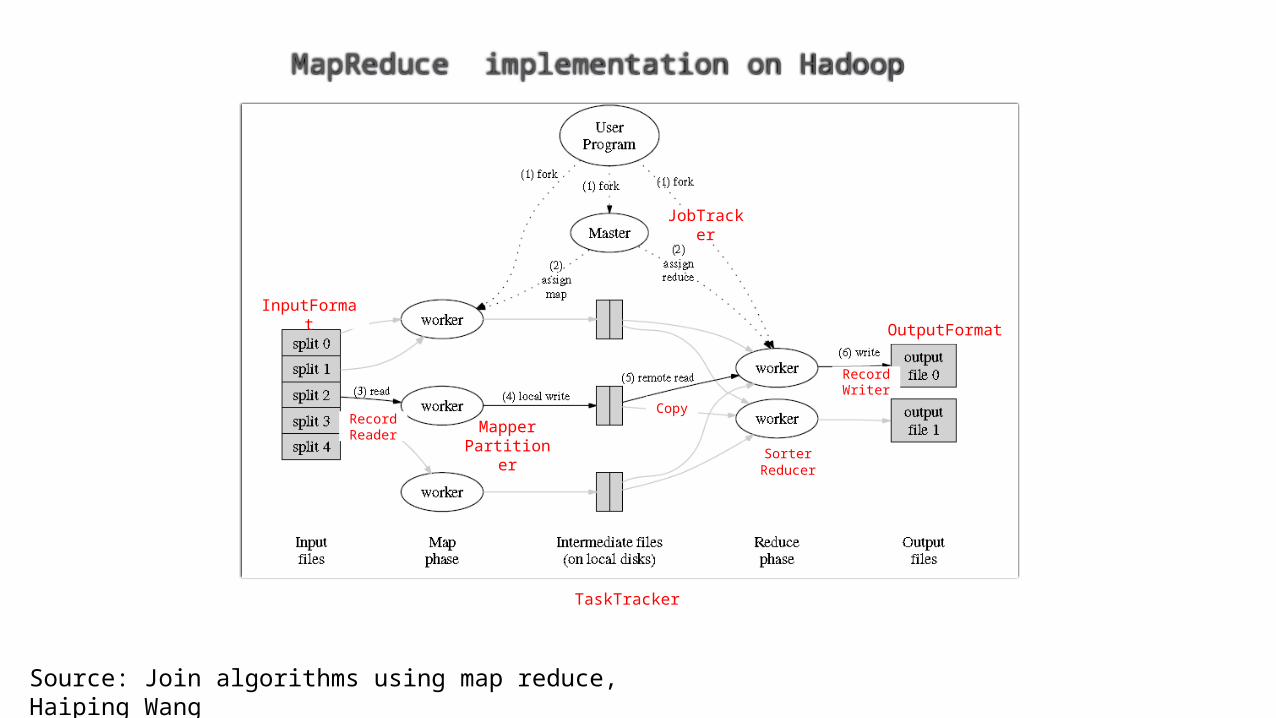
JobTracker
TaskTracker
Record Reader
Record Writer
MapperPartitioner Sorter
Reducer
Copy
InputFormatOutputFormat
MapReduce implementation on Hadoop
Source: Join algorithms using map reduce, Haiping Wang


















