
2004. 8. 24.
18
ETRI 2004. 8. 24. Hyperelliptic Curve Coprocessors On a FPGA HoWon Kim ETRI, Korea
description
Hyperelliptic Curve Coprocessors On a FPGA. 2004. 8. 24. HoWon Kim ETRI, Korea. Contents. Introduction Design Philosophy for Fast HEC coprocessors Parallelism Pipelining Loop unfolding on inversion operation Design Methodology Arithmetic Unit HECC coprocessor Architecture - PowerPoint PPT Presentation
Transcript of 2004. 8. 24.

ETRI
2004. 8. 24.
Hyperelliptic Curve Coprocessors
On a FPGA
HoWon KimETRI, Korea

ETRI Proprietary Ho Won Kim 2
Contents
Introduction Design Philosophy for Fast HEC
coprocessors Parallelism Pipelining Loop unfolding on inversion operation
Design Methodology Arithmetic Unit HECC coprocessor Architecture
Various HECC types : from high performance to low area
Performance Results Conclusions

ETRI Proprietary Ho Won Kim 3
Introduction (1/4)
2
A hyperelliptic curve of g 1 over is the
set of solutions ( , ) to the equation
: ( ) ( ), ( ), ( ) [ ]
with deg { ( )} and ( ) monic with deg { ( )} 2 1x x
C F
x y F F
C y h x y f x h x f x F x
h x g f x f x g
A divisor on is a formal sum of points of , pC P C D m P0The Jacobian of C is defined by ( ) /Jac C Div P
0:divisors of deg. zero, : set of all principal divisorsDiv P
( ) is an abelian group DL systemJac C Each element of ( ) can be represented by a pair of polynomialsJac C
[Mumford representation]

ETRI Proprietary Ho Won Kim 4
Introduction (2/4) Group Cardinality
HEC of genus g over Fq
The cardinality of JC(Fq) is given by Hasse-Weil:
Major implication : group size (field size)g
Don’t choose genus ≥ 4 (5) because of possible attacks [Frey/Rück, Gaudry, Theriault, …]
Group size vs. Field size Group size of 2160 (commercial security level)
ECC (g=1): field size = 160 bit
HECC (g=2): field size = 80 bit
HECC (g=3): field size = 56 bit
HECC (g=4): field size = 52 bit

ETRI Proprietary Ho Won Kim 5
Introduction (3/4)
Explicit Formulae of HECC
t1 = a*e;t1 = a*e;t2 = b*d;t3 = b*f;t4 = c*e;t5 = a*f;t6 = c*d;t7 = sqr(c+f);t8 = sqr(b+e);t9 = (a+d)*(t3+t4);t10= (a+d)*(t5+t6);r =(f+c+t1+t2)*(t7+t9) + t10*(t5+t6) + t8*(t3+t4);t11 = (b+e)*(c+f);inv2 = (t1+t2+c+f)*(a+d)+t8;inv1 = inv2*d + t10 + t11;inv0 = inv2*e + d*(t10+t11) + t9 + t7;t12 = (inv1+inv2)*(k+n+l+o);t13 = (l+o)*inv1;t14 = (inv0+inv2)*(k+n+m+p);t15 = (m+p)*inv0;t16 = (inv0+inv1)*(l+o+m+p);t17 = (k+n)*inv2;rs0 = t15;rs1 = t13+t15+t16;rs2 = t13+t14+t15+t17;rs3 = t12+t13+t17;rs4 = t17;t18 = rs3+rs4*d;s0s = rs0 + f*t18;s1s = rs1 + rs4*f + e*t18;s2s = rs2 + rs4*e + d*t18;w1 = inv(r*s2s);w2 = r*w1;w3 = w1*sqr(s2s);w4 = r*w2;w5 = sqr(w4);
Input: D1 = div(a1,b1), D2 = div(a2,b2)
Output: D3 = D1 + D2 = div(a3,b3)
Composition: d = gcd(a1,a2,b1+b2+h)=s1a1+s2a2+s3(b1+b2+h)
a‘3 = a1a2/d
b‘3 = [s1a1b2+s2a2b1+s3(b1b2+f)]/f mod a‘3
Reduction: WHILE deg(a‘k) > g, DO
a‘k = f – b‘k-1 mod a‘k
b‘k = (-h-b‘k-1) mod a‘k
END WHILE
a3 = a‘k
b3 = b‘k
s0 = w2*s0s;s1 = w2*s1s;s2 = w2*s2s;z0 = s0*c;z1 = s1*c+s0*b;z2 = s0*a+s1*b+c;z3 = s1*a+s0+b;z4 = a+s1;z5 = to_GF2E(1L);t1 = w4*h2;t2 = w4*h3;u3s = d + z4 + s1;u2s = d*u3s + e + z3 + s0 + t2 + s1*z4;u1s = d*u2s + e*u3s + f + z2 + t1 + s1*(z3+t2)
+ s0*z4 + w5;
u0s = d*u1s + e*u2s + f*u3s + z1 + w4*h1 + s1*(z2+t1) + s0*(z3+t2) + w5*(a+f6);
t1 = u3s+z4;v0s = w3*(u0s*t1 + z0) + h0 + m;v1s = w3*(u1s*t1 + u0s + z1) + h1 + l;v2s = w3*(u2s*t1 + u1s + z2) + h2 + k;v3s = w3*(u3s*t1 + u2s + z3) + h3;a3 = f6 + u3s + v3s*(v3s+h3);b3 = u2s + a3*u3s + f5 + v3s*h2 + v2s*h3;c3 = u1s + a3*u2s + b3*u3s + f4 +
v2s*(v2s+h2) + v3s*h1 + v1s*h3;k3 = v2s + (v3s+h3)*a3 + h2;l3 = v1s + (v3s+h3)*b3 + h1;m3 = v0s + (v3s+h3)*c3 + h0;
Explicit formulae (field arithmetic only):
Polynomial arithmetic:
Explicit formulae : ITCC04 [PWP04]
Group doubling: 1inv, 9 mults
Group Addition: 1 inv, 21 mults
Harley’s
explicit method

ETRI Proprietary Ho Won Kim 6
Introduction (4/4) Pros & Cons of the HECC
Pros Short field size : for genus 2 HECC, the size of the
underlying field size is a half of that of ECC– So, It has room to adopt high speed implementation
techniques such as parallelism and loop unfolding Cons
There are many multiplication stages in Explicit formulae
– So, when HECC is implemented as a hardware, its interconnect network and buffer allocation will be complicated
Purpose of this work To check its applicability as a high performance
public key crypto system To check its applicability at the resource
constrained environment such as PDA & Smart Cards from practical point of view

ETRI Proprietary Ho Won Kim 7
Design Philosophy (1/2)
To make HECC coprocessor faster, we have used the following techniques: Parallelism
Multiple number of field operation units to execute the explicit formulae as fast as possible
The number of multipliers is decided by drawing data dependency graph (DDG) for explicit formulae
– For genus-2 HECC explicit formulae, we can see two multipliers are good choice for implementation
– The usage rate of two multipliers is about 90 % group addition operation in affine coord.

ETRI Proprietary Ho Won Kim 8
Design Philosophy (2/2) Pipelining
Field operations(field addition, field squaring) and data copy operation between buffers are performed at the same clock cycle
And can be overlapped with multiplication and inversion
Loop Unfolding “Loop unfolding” is the process of unfolding a loop
so that several iterations(clock cycles) are unrolled into the same iteration(one clock cycle)
Is applied to the MAIA inversion algorithm to boost the performance with reasonable hardware increases

ETRI Proprietary Ho Won Kim 9
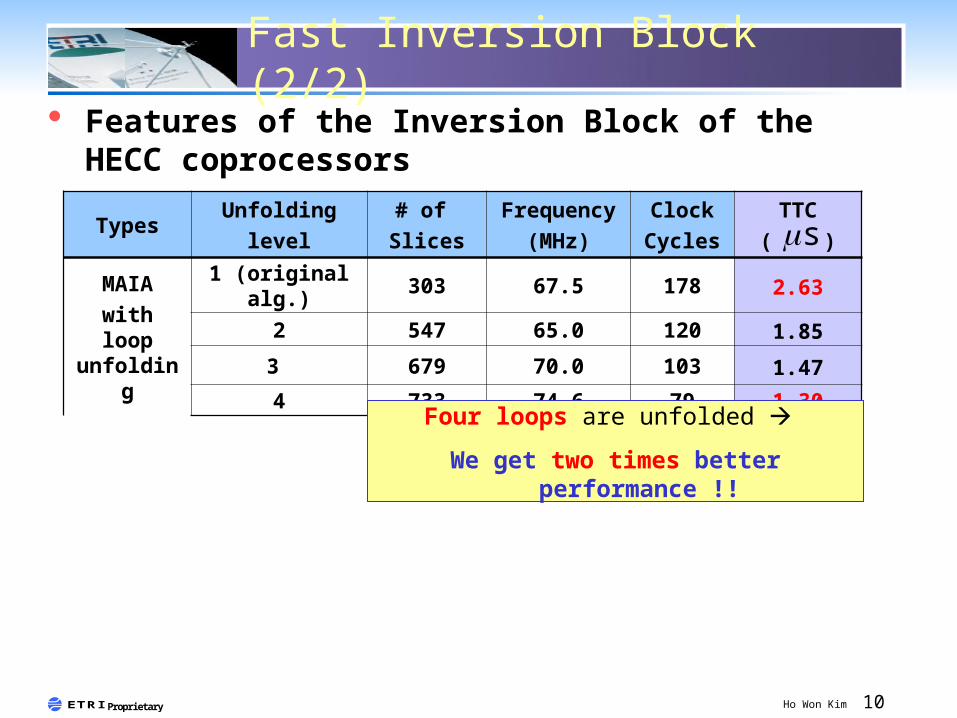
Fast Inversion Block (1/2)
Maximally 4 loops are executed in one clock cycle
MAIA algorithm with 4 loops are unfolded
Can be realized by simple XOR, rewiring
ETRI Proprietary Ho Won Kim 10
Fast Inversion Block (2/2)
TypesUnfolding
level# of Slices
Frequency
(MHz)
ClockCycles
TTC( )
MAIAwith loop
unfolding
1 (original alg.) 303 67.5 178 2.632 547 65.0 120 1.853 679 70.0 103 1.47
4 733 74.6 79 1.30Four loops are unfolded
We get two times better performance !!
Features of the Inversion Block of the HECC coprocessors
s

ETRI Proprietary Ho Won Kim 11
Design Methodology
Design Methodology Architecture design VHDL coding synthesis & implementati
on to FPGA
Main Points toward high performance HECC coprocessor Design Make the H/W complexity of the Interconnect Network as small a
s possible Is done by carefully designed arithmetic units and data path, etc.
Make the number of registers as small as possible Is done by careful buffer allocation
Make efficient AUs By using parallelism, pipelining, loop unfolding techniques, etc.
ETRI Proprietary Ho Won Kim 12
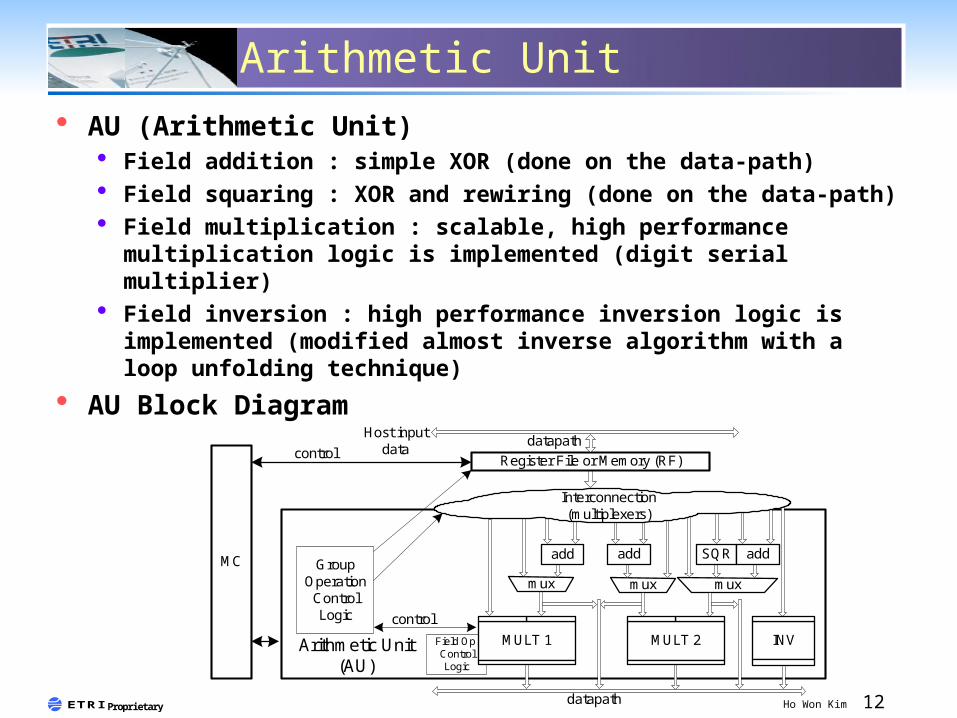
Arithmetic Unit AU (Arithmetic Unit)
Field addition : simple XOR (done on the data-path) Field squaring : XOR and rewiring (done on the data-path) Field multiplication : scalable, high performance
multiplication logic is implemented (digit serial multiplier) Field inversion : high performance inversion logic is
implemented (modified almost inverse algorithm with a loop unfolding technique)
AU Block Diagram
Field Op.ControlLogic
GroupOperation
ControlLogic
Register File or Memory (RF)
Arithmetic Unit(AU)
datapath
control
Host inputdata
MC
control
INVMULT 2MULT 1
mux mux
add add SQR
datapath
mux
add
Interconnection(multiplexers)
ETRI Proprietary Ho Won Kim 13
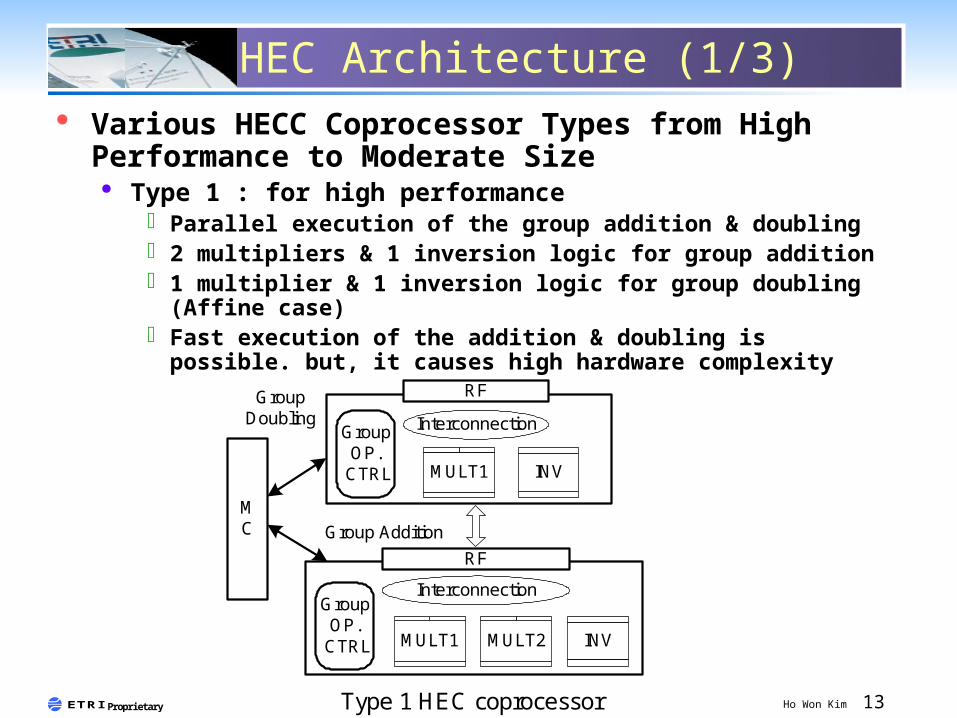
HEC Architecture (1/3) Various HECC Coprocessor Types from High
Performance to Moderate Size Type 1 : for high performance
Parallel execution of the group addition & doubling 2 multipliers & 1 inversion logic for group addition 1 multiplier & 1 inversion logic for group doubling
(Affine case) Fast execution of the addition & doubling is possible.
but, it causes high hardware complexity
INVMULT1
MC
Interconnection
Type 1 HEC coprocessor
Group Addition
GroupDoubling
RF
RF
Interconnection
INVMULT1 MULT2
GroupOP.
CTRL
GroupOP.
CTRL

ETRI Proprietary Ho Won Kim 14
HEC Architecture (2/3) Type 2
Use only registers for RF and multiplexers as an interconnect network
Parallel execution of data read & write is possible. but, it causes high complexity at the interconnect network
Multipliers and inversion logic are shared for group ops. Technology independent design as Type 1 (portable to any
FPGA and ASIC) Type 3 : low hardware complexity
Uses memory to reduce hardware complexity Uses buses to reduce the complexity of interconnect network Incurs more latencies to perform explicit formulae, but, reduces
hardware complexity
INVMULT1 MULT2
Interconnection
Type 2, 3 HEC coprocessor
Group Addition
Group Doubling
MC
RF
GroupOP.
CTRL
MEM
For Type 3
ETRI Proprietary Ho Won Kim 15
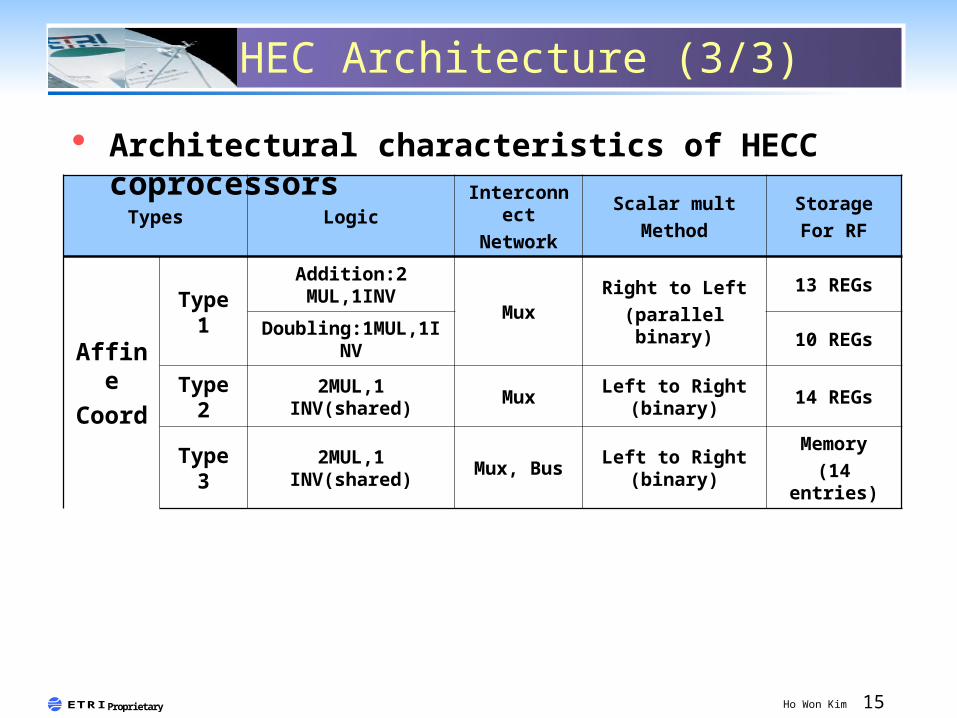
HEC Architecture (3/3)
Types LogicInterconn
ectNetwork
Scalar multMethod
StorageFor RF
AffineCoord
Type 1
Addition:2 MUL,1INV
MuxRight to Left
(parallel binary)
13 REGs
Doubling:1MUL,1INV
10 REGs
Type 2
2MUL,1 INV(shared)
Mux Left to Right (binary)
14 REGs
Type 3
2MUL,1 INV(shared)
Mux, Bus Left to Right (binary)
Memory(14
entries)
Architectural characteristics of HECC coprocessors

ETRI Proprietary Ho Won Kim 16
Performance Results (1/2)
TypesCoord.Type
ScalarMult.
Key size
# Slices Freq. (MHz)
TTC (ms)
Area X Time
Cla03 Projective
Parallel Bin
D=1D=4
166Bits
22,000 - 10.0 50.74
60,000 - 9.0 124.54
Elias GF(2113)
Projective
NAF,D=1NAF,D=4
226bits
21,550 45.6 7.39 36.73
25,271 45.3 2.03 11.83
Type 1, GF(289)
Affine
Parallel Bin,
Binary,Binary
178bits
9,950 62.90 0.436 1.00
Type 2, GF(289)
7,096 50.08 0.791 1.30
Type 3, GF(289)
4,995 50.54 1.020 1.18
Type 1,GF(2113)
Affine
Parallel Bin,
Binary,Binary
226Bits
11,361 59.07 0.722 1.89
Type 2,GF(2113)
8,934 42.43 1.459 3.01
Type 3,GF(2113)
6,436 43.47 1.767 2.62
ECCOrlando et al. 167bit
s1,501 76.7 0.210 -
Gura et al 163bits
11,845 66.4 0.143 0.4
Performance of the HECC coprocessors (scalar mult.)
Target platform : Xilinx FPGA XC2V4000 -6
ETRI Proprietary Ho Won Kim 17
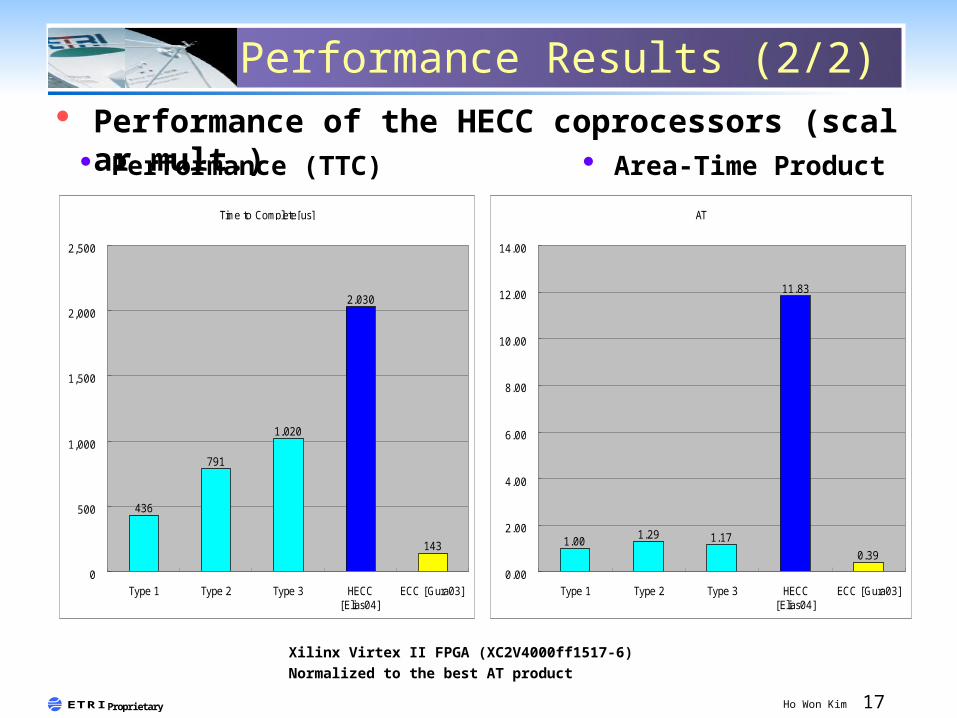
Performance Results (2/2) Performance of the HECC coprocessors (scalar mult.)
Xilinx Virtex II FPGA (XC2V4000ff1517-6)Normalized to the best AT product
Performance (TTC) Area-Time Product
Time to Complete[us]
436
791
1,020
2,030
143
0
500
1,000
1,500
2,000
2,500
Type 1 Type 2 Type 3 HECC[Elias04]
ECC [Gura03]
AT
1.001.29 1.17
11.83
0.39
0.00
2.00
4.00
6.00
8.00
10.00
12.00
14.00
Type 1 Type 2 Type 3 HECC[Elias04]
ECC [Gura03]

ETRI Proprietary Ho Won Kim 18
Conclusions The high performance of the HECC
coprocessor is due to fast inversion algorithm High operating frequency of multiplier in spite of its
large digit size (D=32) Reduced interconnect network latency by using
carefully designed buffer allocation and Arithmetic Units
Parallel execution of field operations Pipelined execution of the field operations and data
movement between register files We can say that HECC coprocessor can be
used at high performance & resource constrained security environments Since the performance is about 0.436 ms with
moderate H/W size (Type 1, GF(289)) However, more research works are still necessary to
surpass the ECC


















