
2 Reguläre Ausdrücke für die Zeichen- kettenverarbeitung ...
51
57 Reguläre Ausdrücke sind ein mächtiges und weit verbreitetes Standard- werkzeug zur effizienten Verarbeitung von zeichenartigen Daten. Die- ses Kapitel bietet eine allgemeine Einführung in reguläre Ausdrücke und beschreibt deren Integration in die ABAP-Welt. Anhand zahlreicher Beispiele wird gezeigt, wie reguläre Ausdrücke die Performance von ABAP-Programmen verbessern können. Ralph Benziger und Björn Mielenhausen 2 Reguläre Ausdrücke für die Zeichen- kettenverarbeitung in ABAP 2.1 Reguläre Ausdrücke in der Textverarbeitung Die Textverarbeitung macht einen großen Teil der Informationsverarbeitung aus, insbesondere im Umfeld typischer SAP-Geschäftsanwendungen. Hier bezieht sich Textverarbeitung nicht nur auf die Arbeit mit Text in natürlicher Sprache, sondern auch auf andere Datentypen, die in einer Textdarstellung gespeichert werden, zum Beispiel Datumsangaben, Währungen oder XML- Daten. Auf solche Informationen zuzugreifen, sie zu analysieren und zu ändern sind häufige Aufgaben in einer ABAP-Entwicklung. Im Allgemeinen lassen sich Textverarbeitungsaufgaben in drei Kategorien glie- dern: Validierung Stimmen Informationen im Hinblick auf syntaktische Eigenschaften mit einer Spezifikation überein? Extraktion Lokalisierung von Informationen in einer größeren Datenmenge, basierend auf dem Kontext, nicht auf der Position Transformation Konvertierung von Informationen in unterschiedliche strukturelle Darstel- lungen Reguläre Ausdrücke sind ein standardisiertes und weit verbreitetes Werkzeug für die effiziente und effektive Verarbeitung von textbasierten Informationen.
Transcript of 2 Reguläre Ausdrücke für die Zeichen- kettenverarbeitung ...

57
Reguläre Ausdrücke sind ein mächtiges und weit verbreitetes Standard-werkzeug zur effizienten Verarbeitung von zeichenartigen Daten. Die-ses Kapitel bietet eine allgemeine Einführung in reguläre Ausdrücke und beschreibt deren Integration in die ABAP-Welt. Anhand zahlreicher Beispiele wird gezeigt, wie reguläre Ausdrücke die Performance von ABAP-Programmen verbessern können.
Ralph Benziger und Björn Mielenhausen
2 Reguläre Ausdrücke für die Zeichen-kettenverarbeitung in ABAP
2.1 Reguläre Ausdrücke in der Textverarbeitung
Die Textverarbeitung macht einen großen Teil der Informationsverarbeitungaus, insbesondere im Umfeld typischer SAP-Geschäftsanwendungen. Hierbezieht sich Textverarbeitung nicht nur auf die Arbeit mit Text in natürlicherSprache, sondern auch auf andere Datentypen, die in einer Textdarstellunggespeichert werden, zum Beispiel Datumsangaben, Währungen oder XML-Daten. Auf solche Informationen zuzugreifen, sie zu analysieren und zu ändernsind häufige Aufgaben in einer ABAP-Entwicklung.
Im Allgemeinen lassen sich Textverarbeitungsaufgaben in drei Kategorien glie-dern:
� ValidierungStimmen Informationen im Hinblick auf syntaktische Eigenschaften miteiner Spezifikation überein?
� ExtraktionLokalisierung von Informationen in einer größeren Datenmenge, basierendauf dem Kontext, nicht auf der Position
� TransformationKonvertierung von Informationen in unterschiedliche strukturelle Darstel-lungen
Reguläre Ausdrücke sind ein standardisiertes und weit verbreitetes Werkzeugfür die effiziente und effektive Verarbeitung von textbasierten Informationen.
1151.book Seite 57 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
58
Vor SAP NetWeaver 7.0 gab es in ABAP aber keine native Unterstützung fürreguläre Ausdrücke, und sie konnten in ABAP-Programmen nur mithilfe vonallerlei Tricks und damit nur sehr eingeschränkt verwendet werden.1
Vor der eingehenden Beschäftigung mit den Details zur Verwendung von regu-lären Ausdrücken werden die genannten Kategorien von Textverarbeitungsauf-gaben, für die sich reguläre Ausdrücke ideal eignen, etwas näher betrachtet.
2.1.1 Drei Typen von Textverarbeitungsaufgaben
Anhand einiger kleiner Beispiele werden die drei Typen von Textverarbei-tungsaufgaben illustriert: Informationen validieren, extrahieren und transfor-mieren. Anschließend wird der erforderliche Aufwand untersucht, um einesdieser Beispiele mit konventionellem ABAP, das heißt ohne die Hilfe von regu-lären Ausdrücken zu lösen.
Informationen validieren
Angenommen, Sie schreiben einen ABAP-basierten Webservice, um Kreditkar-teninformationen als Teil eines E-Commerce-Systems zu verarbeiten. DasDesign der Methode sieht vor, dass die Kreditkartennummer und das Gültig-keitsdatum als Zeichenfolgen übergeben werden. Um ein sicheres Design zugewährleisten, ist es sinnvoll, die Gültigkeit der empfangenen Daten oderzumindest deren Plausibilität zu überprüfen. In diesem Fall soll sichergestelltwerden, dass die Kreditkartennummer eine 15- oder 16-stellige Zahl und dasGültigkeitsdatum eine zweistellige Zahl, gefolgt von einem Schrägstrich undeiner weiteren zweistelligen Zahl, ist:
1234567812345678 02/06 -> akzeptieren123456781234XXXX 03/07 -> ablehnen1234567812345678 04.08 -> ablehnen
Während sich eine solche Validierung der Kreditkartennummer in ABAP pro-blemlos mithilfe des CO-Operators (contains only) und der strlen( )-Funktion(string length) implementieren lässt, erfordert die Überprüfung des Gültig-keitsdatums etwas mehr Aufwand.
Im Allgemeinen gilt: Je flexibler die Spezifikation ist, desto schwieriger wirdes, sie in eine knappe und präzise ABAP-Implementierung umzusetzen. Wenn
1 Ein Beispiel ist der Aufruf von JavaScript aus ABAP heraus, nur um dort einen regulärenAusdruck auszuwerten.
1151.book Seite 58 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke in der Textverarbeitung 2.1
59
die Spezifikation für das Datum beispielsweise einstellige Monatsangabensowie vier- und zweistellige Jahresangaben zulassen würde, würden sich dieAnforderungen an das ABAP-Coding drastisch erhöhen.
Informationen extrahieren
Eine weitere häufige Aufgabe ist das Extrahieren von Informationen aus einergrößeren Datenmenge. Angenommen, Sie erstellen einen Webservice zurBereitstellung von Dokumenten für Benutzer. Das Backend empfängt eine URLvom Frontend, die neben weiteren Informationen die ID des angefordertenDokumentes enthält:
http://docserve.sap.com/serve?user=ralph&docid=NW2004&lang=EN
In diesem Beispiel wird Code zum Extrahieren des Dokumentnamens NW2004aus der Zeichenfolge benötigt. Weitere typische Beispiele sind die Extraktionvon Pfaden und Dateierweiterungen aus Dateinamen oder von E-Mail-Adres-sen aus Headern von E-Mail-Nachrichten.
Informationen transformieren
Bei dieser Aufgabengruppe geht es um die Umwandlung einer strukturellenDarstellung von Informationen in eine andere. Angenommen, in Ihrer Anwen-dung werden Telefonnummern in einem lesbaren Format gespeichert, dasLeerzeichen, Klammern und Bindestriche umfasst:
(800) 123-4567+49 6227 747474
Um die Anwendung mit einer externen Anwendung zu verbinden, die Telefon-nummern als Ziffernfolgen erfordert, müssen Sie Code schreiben, der alle Zei-chen, bei denen es sich nicht um Ziffern handelt, aus den Informationen ent-fernt. Wenn die Anzahl der Zeichen, die keine Ziffern sind, bekannt und geringist, kann diese Aufgabe in ABAP problemlos mithilfe einiger REPLACE-Anwei-sungen ausgeführt werden. Dieser Ansatz wird jedoch schnell mühsam undauch fehleranfällig, wenn die Anzahl der zu testenden Nicht-Ziffern sehr hochist.
Zu weiteren Beispielen für die Informationstransformation zählen das Ersetzenvon mehreren identischen Zeichen durch ein einziges Zeichen oder das Entfer-nen von HTML-Tags (<...>) aus Dokumenten im HTML-Format.
1151.book Seite 59 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
60
2.1.2 Reguläre Ausdrücke als Retter in der Not
Obwohl die aufgeführten Beispiele oft nur sehr kleine Teilaufgaben innerhalbeiner größeren Entwicklung darstellen, erfordern ihre Lösungen unverhältnis-mäßig viel ABAP-Code. Genau für solche Aufgaben können reguläre Ausdrückeoptimal eingesetzt werden.
Um einen ersten Vorgeschmack auf die Vorteile von regulären Ausdrücken zuerhalten, wird eine der beschriebenen einfachen Aufgaben mit ihrer Hilfegelöst. Listing 2.1 zeigt zunächst den traditionellen ABAP-Code, mit dem sämt-liche Tags aus einem HTML-Dokument entfernt werden, das in der Variablenmytext gespeichert ist:
WHILE mytext CS '<'.begin = sy-fdpos.FIND '>' IN SECTION OFFSET begin OF mytext
MATCH OFFSET end.len = end – begin + 1.REPLACE SECTION OFFSET begin LENGTH len OF mytext WITH ``.
ENDWHILE.
Listing 2.1 Traditioneller ABAP-Code
Wie Sie sehen, beinhaltet dieser Code eine Schleife mit zwei Suchvorgängenund eine Anweisung zum Ersetzen, um nur die einfache Aufgabe durchzufüh-ren, alle Elemente zwischen spitzen Klammern sowie diese Klammern selbstauszuwechseln. Dass diese einfache Aufgabe einen derart umfangreichen Codeerfordert, ist sicher nicht zufriedenstellend.
An dieser Stelle soll schon einmal gezeigt werden, wie dieses ABAP-Codefrag-ment durch die Verwendung eines regulären Ausdrucks in einen einzeiligenCode umgewandelt werden kann, der, abhängig von der zu verarbeitendenTextmenge, zudem mindestens eine Größenordnung schneller ist:
REPLACE ALL OCCURRENCES OF REGEX '<[^>]*>' IN mytext WITH ``.
2.2 Einführung in die regulären Ausdrücke in ABAP
Nach einer kurzen Einführung in die Syntax von regulären Ausdrücken undderen Integration in die Sprache ABAP erfahren Sie in diesem Abschnitt, wieSie reguläre Ausdrücke in Ihren eigenen ABAP-Programmen verwenden kön-nen, um die genannten Kategorien der Informationsverarbeitung effizient undeffektiv auszuführen.
1151.book Seite 60 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
61
2.2.1 Grundlagen
Reguläre Ausdrücke, oder kurz Regexe (für Regular Expressions), sind ein Neben-produkt der theoretischen Informatik, das in den 1950er-Jahren vom kanadi-schen Mathematiker Stephen Kleene eingeführt wurde (damals wurde dieInformatik natürlich noch Mathematik genannt). Regexe leisteten nicht nureinen Beitrag in der Mathematik, sondern erfreuten sich auch als Teil desUNIX-Betriebssystems und dessen textorientierten Werkzeugen wie grep, awkund sed größter Beliebtheit.
Heute unterstützen praktisch alle modernen Programmiersprachen, einschließ-lich ABAP, reguläre Ausdrücke entweder nativ oder über zusätzliche Bibliothe-ken. Frühere Versionen von ABAP boten noch keine Unterstützung für regu-läre Ausdrücke und erforderten verschiedene Umwege, um externe Regex-Funktionalität zu nutzen. Ab SAP NetWeaver 7.0 ist die native Regex-Unter-stützung nun aber endlich verfügbar.
Grundlegende Ausdrücke
Ein regulärer Ausdruck ist ein Textmuster, das stellvertretend für eine odermehrere Zeichenfolgen steht. Die Muster regulärer Ausdrücke bestehen aus nor-malen Zeichen (Literalzeichen) sowie einigen speziellen Zeichen, die Operato-ren, Sonder- oder Metazeichen genannt werden:
. * + ? ^ $ ( ) { } [ ] \ |
Der Punktoperator ist beispielsweise ein Platzhalter, der ein beliebiges Einzel-zeichen darstellt. Folglich steht das Muster cat für die Zeichenfolge cat,wohingegen das Muster c.t Zeichenfolgen darstellt, die aus drei Zeichen beste-hen, mit c beginnen und auf t enden. Beachten Sie daher, dass ein Regex ohneOperatoren genau eine Zeichenfolge darstellt, nämlich sich selbst.
Ein regulärer Ausdruck repräsentiert eine Menge von Zeichenfolgen. Wenneine Zeichenfolge eine der von einem Regex repräsentierten Zeichenfolgen ist,wird auch gesagt, dass der Regex mit der Zeichenfolge übereinstimmt oder dassder Regex auf die Zeichenfolge passt (Englisch: matches). Das Ermitteln vonÜbereinstimmungen für Zeichenfolgen ist eine der häufigsten Verwendungenvon Regexen: Um zu überprüfen, ob eine Zeichenfolge zu einer Gruppe vonZeichenfolgen mit einer bestimmten Eigenschaft gehört, wird ermittelt, ob einRegex, der diese Eigenschaft codiert, zur Zeichenfolge passt. Im Beispiel codiertder Regex c.t die Eigenschaft »eine Zeichenfolge aus drei Zeichen, die mit cbeginnt und auf t endet«, sodass der Regex c.t zum Beispiel mit cut, cat undcot übereinstimmt (mit car jedoch nicht).
1151.book Seite 61 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
62
Eine weitere Möglichkeit, um mehr als eine Zeichenfolge über einen regulä-ren Ausdruck zu repräsentieren, besteht darin, sämtliche Alternativen aufzu-listen und diese durch einen Pipe- bzw. Oder-Operator (|) zu trennen. DerRegex ten|(twen|thir)ty passt ausschließlich zu den Zeichenfolgen ten,twenty und thirty. Dieses Beispiel zeigt zudem, dass ähnlich wie in arithme-tischen Ausdrücken runde Klammern zur Strukturierung des Ausdrucks ver-wendet werden können.
Soll eine Übereinstimmung für ein Operatorzeichen ermittelt werden, kanndiesem Zeichen der Rückstrich- bzw. Backslash-Operator vorangestellt werden,um es in ein Literal zu verwandeln. Dieser Vorgang wird als Escaping bezeich-net, und der Rückstrich ist ein Fluchtsymbol. Beispielsweise stimmt der Regex10\.0 mit 10.0 überein. Der Regex 10.0 stimmt mit 10.0 überein, darüber hin-aus jedoch auch mit 1000, 10A0 etc. Das Weglassen des Backslash-Operators vorDezimalpunkten ist ein typischer Anfängerfehler, der häufig unbemerkt bleibt,da der fehlerhafte Regex trotzdem mit dem gewünschten Text übereinstimmt– allerdings nicht nur mit diesem!
Mengen und Klassen
Das ausdrückliche Auflisten zahlreicher Alternativen kann mühsam werden undsich vor allem auch negativ auf die Performance auswirken (siehe Abschnitt 2.4.2,»Performancekontrolle«). Glücklicherweise gibt es als Mengen bezeichnete regu-läre Ausdrücke, um alternative Einzelzeichen kurz und klar zu definieren.
Der Mengenausdruck [abc123.!?] stimmt mit allen innerhalb der eckigenKlammern aufgelisteten Einzelzeichen überein (und nur mit diesen). BeachtenSie, dass alle Metazeichen (Backslash ausgenommen) ihre spezielle Bedeutunginnerhalb von Mengen verlieren, sodass der Punkt in der gezeigten Menge nurmit einem literalen Punkt übereinstimmt, nicht jedoch mit einem beliebigenZeichen.
Darüber hinaus ist die Negation einer Menge möglich, indem der Negations-operator (^) als erstes Zeichen in einer Menge hinzugefügt wird. Eine negierteMenge stimmt mit jedem einzelnen Zeichen außer den in der Menge aufgelis-teten Zeichen überein. Auf diese Weise stimmt der Ausdruck [^0-9a-f] zumBeispiel mit allen Einzelzeichen außer einer hexadezimalen Ziffer überein.Beachten Sie, dass das Winkelzeichen für eine Negation an erster Position ste-hen muss, da es anderenfalls als literales Winkelzeichen interpretiert wird.
Um einen der Mengenoperatoren oder die schließende Klammer selbst zurMenge hinzuzufügen, können Sie einfach, wie beschrieben, den Backslash-Operator als Fluchtsymbol benutzen. Der Ausdruck [\^\-\]] stimmt beispiels-
1151.book Seite 62 Freitag, 9. Januar 2009 4:48 16
Einführung in die regulären Ausdrücke in ABAP 2.2
63
weise mit einem Winkelzeichen, einem Bindestrich oder einer schließendeneckigen Klammer überein.
Ein Bereich bietet eine noch präzisere Möglichkeit, um Mengen zu definieren.Hier müssen die Zeichen nicht einzeln aufgelistet werden, sondern derBereichsoperator (-) wird verwendet, um den Start- und den Endpunkt einesZeichenintervalls festzulegen. Anstelle von [0123456789abcdef] kann so dieeinfachere Schreibform [0-9a-f] verwendet werden, um eine einzelne hexa-dezimale Ziffer zu charakterisieren.
Bereiche sind zwar insbesondere in technischen Domänen sehr nützlich, aber Siesollten dabei immer beachten, dass Bereiche von der Textumgebung abhängigsind! Beispielsweise hängen vom Bereich [ä-ß] abgedeckte Zeichen stark von deraktuellen Codepage ab. Daher ist es schwierig, ABAP-Code zu pflegen, der solcheBereiche verwendet. Glücklicherweise lassen sich die meisten Probleme imZusammenhang mit Bereichen ganz einfach vermeiden, indem Sie vordefinierteZeichenuntermengen benutzen, die als Zeichenklassen bezeichnet werden.
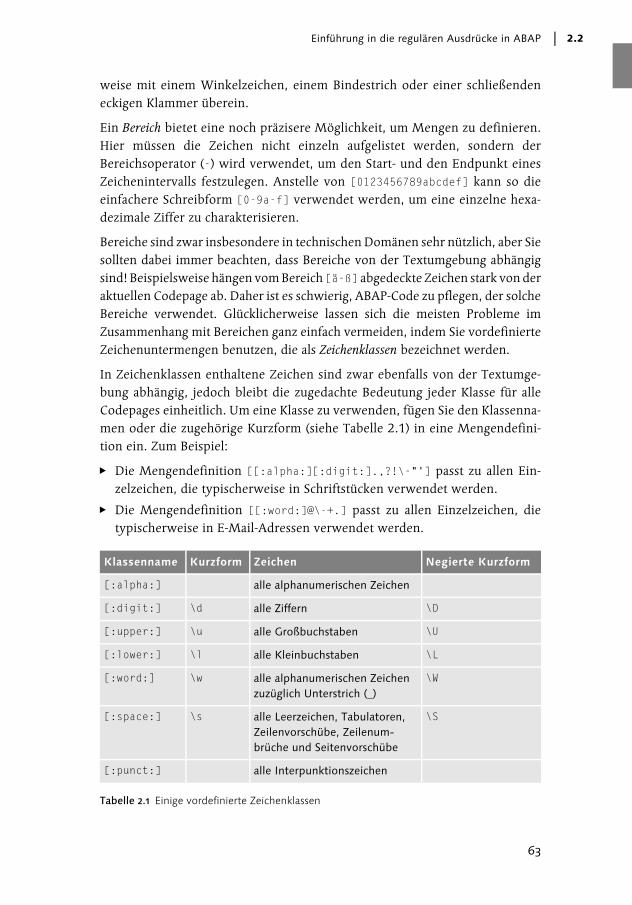
In Zeichenklassen enthaltene Zeichen sind zwar ebenfalls von der Textumge-bung abhängig, jedoch bleibt die zugedachte Bedeutung jeder Klasse für alleCodepages einheitlich. Um eine Klasse zu verwenden, fügen Sie den Klassenna-men oder die zugehörige Kurzform (siehe Tabelle 2.1) in eine Mengendefini-tion ein. Zum Beispiel:
� Die Mengendefinition [[:alpha:][:digit:].,?!\-"'] passt zu allen Ein-zelzeichen, die typischerweise in Schriftstücken verwendet werden.
� Die Mengendefinition [[:word:]@\-+.] passt zu allen Einzelzeichen, dietypischerweise in E-Mail-Adressen verwendet werden.
Klassenname Kurzform Zeichen Negierte Kurzform
[:alpha:] alle alphanumerischen Zeichen
[:digit:] \d alle Ziffern \D
[:upper:] \u alle Großbuchstaben \U
[:lower:] \l alle Kleinbuchstaben \L
[:word:] \w alle alphanumerischen Zeichen zuzüglich Unterstrich (_)
\W
[:space:] \s alle Leerzeichen, Tabulatoren, Zeilenvorschübe, Zeilenum-brüche und Seitenvorschübe
\S
[:punct:] alle Interpunktionszeichen
Tabelle 2.1 Einige vordefinierte Zeichenklassen
1151.book Seite 63 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
64
Die Kurzformen der Zeichenklassen können auch außerhalb von Mengen ver-wendet werden, um die Lesbarkeit der Ausdrücke zu verbessern. Die negiertenKurzformen wie \D entsprechen negierten Zeichenmengen wie [^\d] und kön-nen daher nicht innerhalb von Mengendefinitionen verwendet werden.
Wiederholungen
Bisher wurden lediglich Platzhalter eingeführt, die für Einzelzeichen stehen.Für die Definition von Platzhaltern für mehrere Zeichen steht eine Vielzahl vonWiederholungs- bzw. Verkettungsoperatoren (englisch Quantifiers) zur Verfü-gung (siehe Tabelle 2.2).2 Ein Verkettungsoperator wiederholt den unmittelbarvorangestellten Regex und erzeugt damit Verkettungen dieses Regexes.
Wie bei Alternativen lässt sich mithilfe von Klammern der Bezug von Verket-tungsoperatoren auf größere Unterausdrücke erweitern:
� abc* wiederholt c und stimmt mit ab, abc, abcc, abccc etc. überein.
� a(bc)* wiederholt bc und stimmt mit a, abc, abcbc, abcbcbc etc. überein.
� [abc]* wiederholt [abc] und stimmt mit a, b, c, aa, ab, ac, ba, bb, bc, ca,cb, cc, aaa, aab etc. sowie der leeren Zeichenfolge überein.
Wie im letzten Beispiel gezeigt, wird der quantifizierte Unterausdruck für jedeWiederholung erneut ausgewertet, das heißt, der Unterausdruck stimmt mög-licherweise bei jeder Iteration mit einer anderen Zeichenfolge überein. Folg-lich stimmt [abc]* nicht nur mit Zeichenfolgen überein, die aus identischen
2 Das Arsenal an Verkettungsoperatoren ist umfangreicher als eigentlich notwendig. Bei-spielsweise kann (a+)? anstelle von a* oder aa* anstelle von a+ verwendet werden. Es istsogar zusätzlich a{n,} vorhanden, was a{n}a* entspricht.
Verkettungsoperatoren Bedeutung
a+ mindestens eine Wiederholung des Zeichens a
a* keine oder mehrere Wiederholungen des Zeichens a
a{n} exakt n Wiederholungen des Zeichens a
a{n,m} mindestens n und maximal m Wiederholungen des Zei-chens a
a? ein optionales Zeichen a (das heißt keine oder eine Wie-derholung des Zeichens a)
Tabelle 2.2 Regex-Verkettungsoperatoren für Wiederholungen
1151.book Seite 64 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
65
Zeichen bestehen, sondern auch mit beliebigen Kombinationen aus den Zei-chen a, b und c.
Die richtige Anzahl an Wiederholungen wird für jeden Unterausdruck implizitso bestimmt, dass der gesamte Regex möglichst übereinstimmt, sofern diesüberhaupt möglich ist. Das bedeutet, dass der Verkettungsoperator beimAnwenden des Regexes a*aa auf die Zeichenfolge aaaa eine Übereinstimmungvon a* für die ersten beiden Zeichen a ermittelt und die verbleibenden Zeichena den literalen Zeichen a im Regex vorbehalten bleiben.
2.2.2 Reguläre Ausdrücke für die Validierung
Nach der Einführung der grundlegenden Operatoren für reguläre Ausdrückewenden sich die Ausführungen nun einigen Programmieraufgaben zu. Sie wer-den überrascht sein, wie nützlich bereits die beschriebenen einfachen Regexeeingesetzt werden können.
In diesem Abschnitt sollen Eingaben auf bestimmte Merkmale hin überprüftwerden, indem diese Merkmale in einem regulären Ausdruck codiert werden.Idealerweise stimmt der Regex nur dann mit der Eingabe überein, wenn diesedas hier interessante Merkmal aufweist. Die Probleme beim Schreiben einessolchen regulären Ausdrucks sind entweder falsch positive Ergebnisse (das heißtEingaben, für die selbst dann eine Übereinstimmung ermittelt wird, wenn sienicht das gewünschte Merkmal aufweisen) oder falsch negative Ergebnisse (dasheißt Eingaben, für die selbst dann keine Übereinstimmung ermittelt wird,auch wenn sie das gewünschte Merkmal aufweisen).
Eine bestimmte Anzahl an falsch positiven oder falsch negativen Ergebnissen(jedoch selten beide) ist für zahlreiche Anwendungen sogar akzeptabel. In die-sem Fall ist ein Kompromiss zwischen der Komplexität des nötigen Regexesund seiner Performance einerseits und der Anzahl an akzeptablen falschenÜbereinstimmungen andererseits erforderlich. Damit die in diesem Artikelverwendeten regulären Ausdrücke lesbar bleiben, wird eine bestimmte Anzahlan falsch positiven, jedoch keine falsch negativen Ergebnisse akzeptiert.
Plausibilitätsprüfung von Kreditkartennummern
Bereits in Abschnitt 2.1.1, »Drei Typen von Textverarbeitungsaufgaben«,wurde die Überprüfung von Kreditkartennummern auf Plausibilität hin ange-sprochen. Doch was genau ist eine plausible Kreditkartennummer? Angenom-men, eine Anwendung erfordert, dass keine ungültigen Zeichen in der Num-mer enthalten, aber bestimmte Formatierungen der Nummer zugelassen sind.
1151.book Seite 65 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
66
In diesem Fall kann davon ausgegangen werden, dass eine gültige Kreditkarten-nummer ausschließlich Ziffern, Leerzeichen und Bindestriche enthält. Einregulärer Ausdruck, der ausschließlich mit solchen Kreditkartennummernübereinstimmt, lässt sich problemlos als (\d|\s|-)+ schreiben.
Eine gültige Kreditkartennummer besteht demnach aus einer beliebigen Kom-bination von Ziffern, Leerstellen und Bindestrichen. Um die Gültigkeit eines ineiner Variablen cc gespeicherten Eingabewertes zu überprüfen, muss getestetwerden, ob der reguläre Ausdruck mit dem Inhalt der Variablen cc überein-stimmt. In ABAP lässt sich diese Aufgabe leicht mit der statischen Methodematches( ) der Klasse cl_abap_matcher durchführen (siehe Listing 2.2).3
IF cl_abap_matcher=>matches(pattern = '(\d|\s|-)+'text = cc ) = abap_false.
"invalid credit card numberRETURN.
ENDIF.
Listing 2.2 Statische Methode matches( ) der Klasse cl_abap_matcher
Abhängig von speziellen Anforderungen, soll jetzt möglicherweise die Anzahlan falsch positiven Ergebnissen reduziert werden, indem zusätzlich überprüftwird, ob die Eingabe exakt 15 oder 16 Stellen umfasst. Werden Leerstellen undBindestriche zunächst verboten, genügt der einfache Regex \d{15,16} für diePrüfung, ob die Kartennummer die richtige Anzahl von Ziffern enthält.
Die Kombination beider Ausdrücke, um die richtige Anzahl an Ziffern zu prü-fen und dabei gleichzeitig Leerstellen und Bindestriche zuzulassen, ist nicht soeinfach, wie zunächst vermutet werden könnte. Ein erster trivialer Versuch(\d|\s|-){15,16} ist falsch, da Leerzeichen und Bindestriche hier ebenfalls alsStellen gezählt werden. Dadurch wird zum Beispiel fälschlicherweise eineÜbereinstimmung für eine Zeichenfolge ermittelt, die zehn Ziffern und fünfLeerzeichen umfasst. Dies entspricht jedoch eindeutig nicht dem gewünschtenErgebnis. Um dieses Problem zu lösen, muss die Wirkung des Verkettungsope-rators auf das Teilmuster \d beschränkt werden, während zusätzliche Leerzei-chen und Bindestriche unbegrenzt zulässig sind:
(\s|-)*(\d(\s|-)*){15,16}
3 Mit den Releases 7.0, EhP2 und 7.1/7.2 wurde hierfür sogar eine eingebaute Funktionmatches eingeführt, die direkt einen Wahrheitswert zurückgibt (eine sogenannte Prädikat-funktion). Der logische Ausdruck vereinfacht sich bei ihrer Verwendung zu IF matches(...).
1151.book Seite 66 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
67
Zur Erklärung wird mit dem ursprünglichen Ausdruck \d{15,16} zum Zählender richtigen Anzahl von Ziffern begonnen, in den die hervorgehobenenAbschnitte eingefügt werden, um zusätzliche Leerzeichen und Bindestrichezuzulassen. Jede Position der Kreditkartennummer kann nun eine beliebigeAnzahl an Leerzeichen und Bindestrichen enthalten.
Validierung von Dezimalzahlen
In einem weiteren Beispiel soll gezeigt werden, wie ein Regex erstellt wird, dermit Dezimalzahlen4 übereinstimmt. Generell besteht eine Dezimalzahl ausmehreren Ziffern, denen ein Dezimaltrennzeichen und weitere Ziffern nachge-stellt sind. Es soll jedoch die Möglichkeit berücksichtigt werden, dass einigedieser Abschnitte möglicherweise nicht vorhanden sind (zum Beispiel könntenim englischen Sprachraum die Ziffern vor dem Dezimaltrennzeichen fehlen).Wird dies direkt auf einen Regex übertragen, lautet dieser:
\d*\.?\d*.
Beachten Sie, dass der Backslash-Operator als Fluchtsymbol für den Dezimal-punkt verwendet wird. Ohne diesen Operator behält der Punkt seine Bedeu-tung als Metazeichen bei. Wenngleich der genannte Ausdruck im Allgemeinenfunktioniert, werden auch alleinstehende Dezimalpunkte (.) ermittelt, was zueinem falsch positiven Ergebnis führt. Wenn dieses fehlerhafte Ergebnis ausge-schlossen wird und auch nachgestellte Dezimalpunkte ohne Nachkommastel-len (wie in 10.) nicht zugelassen werden sollen, kann der Regex folgenderma-ßen neu gruppiert werden: \d*(\.\d+)?
Durch das Ändern des zweiten Sternchenoperators in einen Plusoperator wirdsichergestellt, dass dem Dezimalpunkt mindestens eine Ziffer folgt. Indem derFragezeichenoperator an das Ende verschoben wird, werden für den gesamtenAusdruck optional auch Ganzzahlen zugelassen.
Um in ABAP mit großen Zahlen vom Typ p zu arbeiten, sollte möglicherweiseauch eine Unterstützung für Tausendertrennzeichen (,) hinzugefügt werden.Eine nur vermeintliche Lösung wäre eine Lockerung der Zeicheneinschrän-kung für den ganzzahligen Abschnitt des Wertes, indem \d* durch (\d|,)*ersetzt wird. Dadurch stimmt der Ausdruck jedoch mit unsinnigen Zeichenfol-gen, wie zum Beispiel 1,,,.0, überein.
4 Hier wird sich auf die englischsprachige Notation mit Dezimalpunkt und Komma als Tau-sendertrennzeichen bezogen, die in technischen Systemen häufig Anwendung findet.
1151.book Seite 67 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
68
Dies lässt sich vermeiden, wenn eine Eigenschaft für Trennzeichen gefundenwird, die für alle gültigen Ganzzahlen gilt. Gemäß Definition werden Trennzei-chen durch exakt drei Ziffern getrennt. Diese Beschreibung kann weiter verein-facht werden durch die Aussage, dass auf jedes Trennzeichen genau drei Ziffernfolgen. Wird diese Eigenschaft in einem Regex codiert, lautet dieser:
\d{1,3}(,\d{3})*(\.\d+)?
Der Anfangsteil \d{1,3} stimmt mit bis zu drei Ziffern vor dem ersten Trenn-zeichen (falls vorhanden) überein, wohingegen der letzte Unterausdruck(\.\d+)? erneut die Nachkommastellen der Zahl abdeckt (falls vorhanden).
2.2.3 Suchen mit regulären Ausdrücken
Bisher bezogen sich die Erläuterungen auf das Übereinstimmen von regulärenAusdrücken mit Zeichenfolgen, etwa um zu prüfen, ob eine Zeichenfolge einebestimmte Struktur aufweist. In diesem Abschnitt liegt der Schwerpunkt aufeiner weiteren wichtigen Anwendungsmöglichkeit für Regexe: das Finden vonInformationen durch die Suche nach übereinstimmenden Elementen.
Regexe werden im Allgemeinen zum Suchen verwendet, um die Position vonmindestens einer Übereinstimmung für den entsprechenden Regex in einerZeichenfolge zu ermitteln. Trotzdem wird häufig informell die Wendung »nacheinem Regex suchen« verwendet, wenn tatsächlich »nach Übereinstimmungenfür diesen Regex suchen« gemeint ist. Es ist daher wichtig, dass Sie den Unter-schied zwischen Übereinstimmung und Suchen im Kopf behalten, wenn Sie denRest dieses Kapitels lesen. Bedenken Sie zudem, dass in einigen Programmier-sprachen, insbesondere Perl, der Begriff Übereinstimmung (Matching) auch fürSuchvorgänge verwendet wird, was zusätzlich für Verwirrung sorgt.
Erste längste Übereinstimmungen
Was geschieht bei der Suche nach einem Regex (bzw. nach den Übereinstim-mungen für einen Regex) in einem bestimmten Text? Zuerst werden alle mög-lichen Übereinstimmungen des Regexes innerhalb des Textes ermittelt.Anschließend wird in jeder Gruppe aus überlappenden Übereinstimmungendie am weitesten links beginnende Übereinstimmung als Ergebnis zurückgege-ben. Ist die Übereinstimmung nicht eindeutig, so wird die längste zurückgelie-fert. Als Beispiel soll mit dem Regex a[ao]*a in der im Folgenden gezeigtenZeichenfolge gesucht werden:
1151.book Seite 68 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
69
a[ao]*a: ooaooaoaoXoooaaoooooaooaooa (1)aooaoa (2)
aoa (3)aa (4)aaoooooa (5)aoooooa (6)
Die ersten beiden Übereinstimmungen (1 und 2) sind die am weitesten linksbeginnenden Übereinstimmungen in der ersten Gruppe überlappender Über-einstimmungen. Da die zweite Übereinstimmung die längere ist, wird diese alsErgebnis der Suche zurückgegeben. In der zweiten Gruppe handelt es sich beiden Übereinstimmungen 4 und 5 um die am weitesten links ermittelten Über-einstimmungen. Da die zweite Übereinstimmung die längere ist, wird diese alsweiteres Ergebnis der Suche zurückgegeben. Nachdem die Ergebnisse auf dieseWeise eindeutig bestimmt wurden, muss der Benutzer, der die Suche aufgeru-fen hat, ein Ergebnis auswählen (in diesem Fall 2 oder 5). Die meistenSuchschnittstellen geben entweder die erste längste Übereinstimmung vonlinks an oder alternativ alle längsten Übereinstimmungen.5
Die Regel, dass die am weitesten links beginnende (das heißt erste) längsteÜbereinstimmung (Leftmost-longest-Regel) zurückgegeben wird, ist mit dasnatürlichste Verhalten für Suchvorgänge und wurde als POSIX-Standard defi-niert. Es gibt jedoch auch andere Ansätze für die Suche, die kurz in Abschnitt2.4, »Technische Aspekte regulärer Ausdrücke«, erwähnt werden.
Beachten Sie, dass ABAP in Wirklichkeit eine intelligentere Suche durchführtund nicht erst intern alle Übereinstimmungen berechnet, bevor die erstelängste Übereinstimmung zurückgegeben wird. Es ist jedoch hilfreich, sich die-ses Grundprinzip vorzustellen, wenn Sie den Suchprozess gedanklich nachvoll-ziehen wollen.
Da bei der Suche die längste Übereinstimmung als Ergebnis zurückgegebenwird, wird der Vorgang als gierig bezeichnet. Dies gilt nicht nur für den gesam-ten Regex, sondern auch für jeden einzelnen Unterausdruck und macht sich ammeisten bei Wiederholungen bemerkbar. An dieser Stelle spielt diese Tatsachenoch keine besondere Rolle, es muss jedoch auf das Problem zurückgekommenwerden, wenn auf Untergruppen eingegangen wird (siehe Abschnitt 2.3.1,»Arbeiten mit Untergruppen«).
5 Die ABAP-Anweisung FIND macht da keine Ausnahme.
1151.book Seite 69 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
70
Um lediglich zu prüfen, ob eine Übereinstimmung für einen Regex in einembestimmten Text vorhanden ist, kann die statische Methode contains( ) derKlasse cl_abap_matcher verwendet werden (siehe Listing 2.3).6
IF cl_abap_matcher=>contains(pattern = '\d+'text = mytext ) = abap_true.
"match found ...ENDIF.
Listing 2.3 Statische Methode contains( ) der Klasse cl_abap_matcher
In Abschnitt 2.2.4 erfahren Sie, wie Sie detaillierte Informationen zum über-einstimmenden Text erhalten, wie beispielsweise die Position oder die Längeder gefundenen Übereinstimmung.
Anker und Grenzen
Mit einer Handvoll Operatoren, die mit Positionen anstelle von Zeichen über-einstimmen, können Sie zusätzlich steuern, wo Übereinstimmungen in einemText gefunden werden sollen.
Die Anker ̂ und $ entsprechen dem Anfang bzw. dem Ende einer Zeile. Folglichgeben beide Methodenaufrufe in Listing 2.4 den Wert abap_false zurück, da catsich weder am Anfang noch am Ende der Zeichenfolge mytext befindet. Aufgrundihres UNIX-Ursprungs reagieren Anker ebenfalls auf in die Zeichenfolge einge-bettete Zeilenumbrüche. Falls dieses Verhalten nicht erwünscht ist, kann statt-dessen auf die Ankervarianten \A und \z zurückgegriffen werden, die mit demtatsächlichen Anfang bzw. Ende der gesamten Zeichenfolge übereinstimmen.7
mytext = 'the cat sat on the mat'.rc1 = cl_abap_matcher=>contains(
pattern = '^cat'text = mytext ).
rc2 = cl_abap_matcher=>contains(pattern = 'cat$'text = mytext ).
Listing 2.4 Methodenaufrufe für Anker
6 Auch hierfür gibt es seit den Releases 7.0, EhP2 und 7.1/7.2 eine eingebaute Prädikatfunk-tion contains.
7 Die Unterschiede bei der Groß- und Kleinschreibung lassen sich damit erklären, dass esnoch einen weiteren Operator \Z gibt, der fast die gleiche Funktion wie \z erfüllt, jedochalle Zeilenumbrüche am Ende des durchsuchten Textes ignoriert.
1151.book Seite 70 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
71
Die Wortgrenzen \< und \> entsprechen dem Anfang bzw. dem Ende einesWortes:
\<.at: Cathy's cat spat at Matt.at\>: Cathy's cat spat at Matt\<.at\>: Cathy's cat spat at Matt
Technisch gesehen stimmen Wortgrenzen mit Positionen zwischen durch \wund \W darstellbaren Zeichenfolgen überein. Demzufolge ist das Hinzufügenvon Wortgrenzen bei dem oberflächlich sehr sinnvoll erscheinenden Regex\<\w+\> aufgrund der Regel der ersten längsten Übereinstimmung eigentlichredundant.
Es gibt noch einige weitere Begrenzungsoperatoren. Der Operator \b ent-spricht \<|\>, passt also auf Anfang und Ende eines Wortes. Der interessantereOperator \B stimmt mit den Zwischenräumen innerhalb eines Wortes, dasheißt Positionen zwischen zwei aufeinanderfolgenden Zeichen \w, überein.
Kontextbasierte Suche nach Informationen
Ein typischer Anwendungsfall für Regexe ist das kontextbasierte Suchen nachInformationen. Erinnern Sie sich an das Beispiel zur Extraktion von Informati-onen, in dem die Dokument-ID aus einer bestimmten URL extrahiert werdensollte.
Die Position der Informationen wird durch einige Begrenzungsmerkmalegekennzeichnet, das heißt eindeutige Zeichen oder Schlüsselwörter, die dasVorhandensein der gewünschten Informationen eindeutig anzeigen. In diesemBeispiel wird der Wert der Dokument-ID durch das begrenzende Schlüsselwort&docid= auf der linken Seite und das nachfolgende Zeichen & auf der rechtenSeite präzise angezeigt:
http://docserve.sap.com/serve?user=ralph&docid=NW2004&lang=EN
Um diese Informationen schnell zu finden, könnte eine Suche mit dem Regex&docid=\w+& durchgeführt werden, wenn angenommen wird, dass die Doku-ment-ID nur aus Buchstaben, Ziffern und Unterstrichen besteht. Da dies aberkeine Fälle abdeckt, in denen die docid das erste oder letzte Argument in derURL ist, wäre (\?|&)docid=\w+(&|$) eine bessere Lösung.
1151.book Seite 71 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
72
2.2.4 Reguläre Ausdrücke in ABAP-Programmen
Nachdem Sie nun die ersten Regexe für das Abgleichen und die Suche schrei-ben können, wird der Schwerpunkt im Folgenden auf ABAP gelegt undbeschrieben, wie Sie die Vorteile von regulären Ausdrücken in Ihrem ABAP-Code nutzen können.8 Um diesen Erklärungen folgen zu können, ist es hilf-reich, mit den allgemeinen Textverarbeitungstechniken in ABAP vertraut zusein. Um Ihre Kenntnisse diesbezüglich aufzufrischen, können Sie in Kapitel 1,»Effektive Zeichenkettenverarbeitung in ABAP«, nachschlagen.
Suchen und Ersetzen mit FIND und REPLACE
Die wichtigsten Anweisungen für die Textverarbeitung in ABAP sind dieAnweisungen FIND und REPLACE. Ab SAP NetWeaver 7.0 bieten beide Anwei-sungen eine native Unterstützung für reguläre Ausdrücke. Regexe lassen sichdort einfach dadurch verwenden, indem das Schlüsselwort REGEX vor demSuchmuster eingefügt wird.9
Die gefundenen Teilfolgen werden durch die Zusätze MATCH LINE, MATCH OFFSETund MATCH LENGTH zurückgegeben. Um die Übereinstimmungen eines Regexesmypattern in der Zeichenfolge mytext zu finden, wird daher folgender Codeverwendet:
DATA: length TYPE i, offset TYPE i.FIND REGEX mypattern IN mytext
MATCH OFFSET off MATCH LENGTH len. IF sy-subrc = 0.
WRITE: / 'found match of length', len,'at position', off.
ENDIF.
Beachten Sie, dass die Länge des übereinstimmenden Textes (anders als beieiner SUBSTRING-Suche, siehe Kapitel 1, »Effektive Zeichenkettenverarbeitung
8 Eine vollständige Referenz zur Verwendung regulärer Ausdrücke in ABAP sowie die voll-ständige Erklärung der dort erlaubten REGEX-Syntax finden Sie wie gewohnt in der ABAP-Schlüsselwortdokumentation. Sie brauchen nur nach dem Stichwort »regulär« zu suchenoder aus der F1-Hilfe der entsprechenden ABAP-Anweisungen zu den regulären Ausdrü-cken zu navigieren.
9 Die Anweisungen FIND und REPLACE wurden zu Release 7.0 zudem im Hinblick auf die Ver-arbeitung von internen Tabellen und die Harmonisierung von Zusätzen überarbeitet: Ininternen Tabellen mit zeichenartigem Zeilentyp kann über den Zusatz IN TABLE zeilenweisegesucht und ersetzt werden. Zur FIND-Anweisung wurde ein neuer ALL OCCURRENCES OF-Zusatz hinzugefügt, der im Wesentlichen dem gleichlautenden Zusatz der REPLACE-Anwei-sung entspricht.
1151.book Seite 72 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
73
in ABAP«) von der Länge des Suchmusters abweichen kann. Um die tatsächli-che übereinstimmende Zeichenfolge abzurufen, kann der für ABAP typischeOffset-/Längenzugriff verwendet werden:10
DATA text_matched TYPE string.text_matched = mytext+off(len).
Um nach allen Übereinstimmungen innerhalb des Textes zu suchen, kann derZusatz ALL OCCURRENCES OF der FIND-Anweisung verwendet werden. Dann kön-nen Sie mit dem Zusatz MATCH COUNT die Anzahl an ermittelten Übereinstim-mungen abrufen. Mit den anderen Zusätzen MATCH ... werden jedoch nurInformationen zur letzten gefundenen Übereinstimmung zurückgegeben. Dievollständige Liste der Übereinstimmungen kann mit dem Zusatz RESULTS abge-rufen werden, der eine interne Tabelle vom Dictionary-Typ match_result_tabmit dem Zeilentyp match_result füllt (siehe Tabelle 2.3), wobei »Ersetzung«sich auf die Verwendung mit REPLACE bezieht.
Für jede gefundene Übereinstimmung fügt die FIND-Anweisung eine neueZeile vom Dictionary-Typ match_result in die Tabelle ein. Um auf diese Infor-mationen zuzugreifen, wird in der Regel eine LOOP-Anweisung verwendet(siehe Listing 2.5).
DATA res TYPE match_result_tab.FIELD-SYMBOLS <m> TYPE match_result.FIND ALL OCCURRENCES OF REGEX mypattern IN mytext RESULTS res.
10 Oder Sie arbeiten gleich mit Untergruppen (siehe Abschnitt 2.3.1 »Arbeiten mit Unter-gruppen«).
Komponente Typ Bedeutung
line i Zeile der gefundenen Übereinstimmung/durchgeführten Ersetzung in internen Tabellen (anderenfalls 0)
offset i Position der gefundenen Übereinstimmung/durchgeführten Ersetzung
length i Länge der gefundenen Übereinstimmung/durchgeführten Ersetzung
submatches TABLE OF submatch_result
interne Tabelle für Untergruppen (siehe Abschnitt 2.3.1, »Arbeiten mit Untergruppen«)
Tabelle 2.3 Struktur match_result
1151.book Seite 73 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
74
LOOP AT res ASSIGNING <m>.WRITE / mytext+<m>-offset(<m>-length).
ENDLOOP.
Listing 2.5 LOOP-Anweisung für den Zugriff auf Informationen
Der Zusatz RESULTS akzeptiert auch flache Strukturen vom Typ match_result,jedoch bleiben wie auch bei den MATCH ...-Zusätzen lediglich die Informationenzur letzten Übereinstimmung erhalten. Die Verwendung von RESULTS mit Struk-turen ist daher nur dafür vorgesehen, um bei der Verwendung von FIRSTOCCURRENCE auf die Informationen zu Untergruppen zuzugreifen (weitere Infor-mationen hierzu finden Sie in Abschnitt 2.3.1, »Arbeiten mit Untergruppen«).
Der aus Kapitel 1, »Effektive Zeichenkettenverarbeitung in ABAP«, bekannteZusatz ACCEPTING|IGNORING CASE kann natürlich auch mit Regexen verwendetwerden, um bei der Suche in einem Text die Groß- und Kleinschreibung zu berück-sichtigen. Der Zusatz IN BYTE MODE ist bei der Angabe REGEX dagegen ausgeschlos-sen, da binäre Muster von regulären Ausdrücken nicht unterstützt werden.
Alle bisherigen Erklärungen zu FIND gelten gleichermaßen für die REPLACE-Anweisung. In diesem Fall heißen die entsprechenden Zusätze jedochREPLACEMENT LINE, REPLACEMENT OFFSET, REPLACEMENT LENGTH undREPLACEMENT COUNT.
Weitere Informationen zu den Anweisungen FIND und REPLACE sowie einigeEmpfehlungen zur Verwendung mit Zeichenfolgen finden Sie in Kapitel 1.
Reguläre Ausdrücke und ABAP Objects
Für moderne ABAP-Programme wird eine objektorientierte Methodologie alsbevorzugtes Programmiermodell empfohlen. Um Regexe in objektorientiertenProgrammen natürlich verwenden zu können, bietet ABAP die beiden Klassencl_abap_regex und cl_abap_matcher an.
Die Regex-Klasse cl_abap_regex speichert den eigentlichen regulären Aus-druck in einem internen, vorkompilierten Format (weitere Informationen zurRegex-Erstellung finden Sie in Abschnitt 2.4.2, »Performancekontrolle«). DieMatcher-Klasse cl_abap_matcher verknüpft ein cl_abap_regex-Objekt miteinem Text und dient als zentrale Schnittstelle für die weitere Verarbeitung.Insbesondere bietet diese Klasse Methoden zur sequenziellen Suche, Abfrageund Ersetzung einzelner Übereinstimmungen (Match-by-Match).
Um einen Text zu verarbeiten, erstellen Sie zunächst ein Regex-Objekt mit derAnweisung CREATE OBJECT (siehe Listing 2.6).
1151.book Seite 74 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
75
DATA myregex TYPE REF TO cl_abap_regex.CREATE OBJECT myregex
EXPORTINGpattern = 'a*b'ignore_case = abap_true.
Listing 2.6 Regex-Objekt mit CREATE OBJECT erstellen
Der optionale Parameter ignore_case steuert, ob die Groß- und Kleinschrei-bung bei der Ermittlung der Übereinstimmungen berücksichtig werden solloder nicht. Bei fehlender Angabe wird die Groß- und Kleinschreibung berück-sichtigt. Es sind weitere optionale Parameter verfügbar, von denen einige imFolgenden noch beschrieben werden.
Anschließend erstellen Sie ein Matcher-Objekt, um den neuen Regex mit demzu verarbeitenden Text zu verknüpfen (siehe Listing 2.7).
DATA: mytext TYPE string,mymatcher TYPE REF TO cl_abap_matcher.
CREATE OBJECT mymatcherEXPORTING regex = myregex
text = mytext.
Listing 2.7 Matcher-Objekt erstellen
Ein Regex-Objekt kann in beliebig vielen Matcher-Objekten wiederverwendetwerden. Aus Gründen der Performance sollte ein mehrfach verwendeter Regexdeshalb auch eher als Regex-Objekt erzeugt werden, als immer wieder inAnweisungen oder eingebauten Funktionen (ab den Releases 7.0, EhP2 und7.1/7.2) neu kompiliert zu werden.
Alternativ bietet die Matcher-Klasse auch eine Factory-Methode für die hand-liche Erzeugung von Regex und Matcher in einem einzigen Schritt, die dannjedoch keine gemeinsame Nutzung von Regex-Objekten zulässt:
mymatcher = cl_abap_matcher=>create(pattern = 'a*b'text = mytext ).
Das Matcher-Objekt speichert eine interne Kopie des zu verarbeitenden Textes,sodass der Inhalt einer Variablen mytext, die an den Konstruktor übergebenwird, nicht von nachfolgenden Ersetzungsvorgängen geändert wird. Auf dasErgebnis von Ersetzungen muss in diesem Fall über mymatcher->text anstellevon mytext zugegriffen werden. Wenn mytext vom Typ string ist, verursachtdas Kopieren von mytext in das Objekt dabei zunächst kaum Kosten, da hier
1151.book Seite 75 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
76
das aus Kapitel 1, »Effektive Zeichenkettenverarbeitung in ABAP«, bekannteSharing greift. Erst ein Schreibzugriff auf diese Zeichenfolge durch einen Erset-zungsvorgang führt dazu, dass die gemeinsame Verwendung aufgehoben wird,was dann ein potenziell kostenintensiver Vorgang sein kann.
Die Matcher-Klasse bietet eine Vielfalt von Methoden zum Suchen, Abfragenund Ersetzen von Übereinstimmungen (siehe Tabelle 2.4).
Die Interaktion mit einem Matcher-Objekt basiert auf dem Konzept der aktuel-len Übereinstimmung, das heißt der letzten während des Suchvorgangs gefun-denen Übereinstimmung. Eine aktuelle Übereinstimmung wird durch dieMethode find_next( ) bestimmt und von der Methode replace_found( ) zer-stört. Die Abfragemethoden erfordern eine aktuelle Übereinstimmung, habenjedoch keine Auswirkung auf diese.
Anfänglich ist keine aktuelle Übereinstimmung vorhanden, daher musszunächst find_next( ) aufgerufen werden. Sobald eine aktuelle Übereinstim-mung vorhanden ist, können Sie diese mit den Abfragemethoden untersuchen,um zum Beispiel Informationen wie Offset und Länge zu erhalten. Durch daserneute Aufrufen von find_next( ) wird mit der nächsten Übereinstimmungfortgefahren (falls vorhanden). Das Ergebnis des Aufrufs find_next( ) wird alsBoole’scher Wert11 zurückgegeben. Nachdem alle Übereinstimmungen ermit-telt wurden, wird die aktuelle Übereinstimmung invalidiert, und weitere Auf-rufe von find_next( ) schlagen mit dem Wert abap_false fehl. Listing 2.8zeigt, wie dieses Muster verwendet werden kann, um alle Ganzzahlen zu addie-ren, die in einem Text enthalten sind.
DATA: sum TYPE i,mymatch TYPE match_result,mymatcher TYPE REF TO cl_abap_matcher.
Suchmethoden Abfragemethoden Ersetzungsmethoden
find_next( ) get_match( ) replace_found( )
match( ) get_line( ) replace_next( )
get_offset( )
find_all( ) get_length( ) replace_all( )
get_submatch( )
Tabelle 2.4 Methoden von cl_abap_matcher
11 Natürlich in der ABAP-typischen Ausprägung abap_bool.
1151.book Seite 76 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
77
mymatcher = cl_abap_matcher=>create(pattern = '\d+' text = mytext ).
WHILE mymatcher->find_next( ) = abap_true.mymatch = mymatcher->get_match( ).sum = sum + mymatcher->text+mymatch-offset(mymatch-length).
ENDWHILE.
Listing 2.8 Summierung aller in einem Text enthaltenen Ganzzahlen
Jedes Mal, wenn der Matcher eine aktuelle Übereinstimmung gespeichert hat,kann die Methode replace_found( ) aufgerufen werden, um diese aktuelleÜbereinstimmung durch einen neuen Text zu ersetzen. Dadurch wird die aktu-elle Übereinstimmung zerstört, sodass alle darauffolgenden Aufrufe einerAbfragemethode eine Ausnahme auslösen. Durch das erneute Aufrufen vonfind_next( ) wird jedoch die nächste nicht verarbeitete Übereinstimmungermittelt und als aktuelle Übereinstimmung gesetzt.
Indem Sie abwechselnd find_next( ) und replace_found( ) aufrufen, könnenSie die Übereinstimmungen im Text problemlos durchlaufen und für die ein-zelnen Übereinstimmungen Aktionen ausführen. Dadurch haben Sie die Mög-lichkeit, zum Beispiel sämtliche Ganzzahlen in einem Textdokument um denWert 1 zu erhöhen, da der Ersetzungstext berechnet werden kann, nachdem dieÜbereinstimmung ermittelt wurde (siehe Listing 2.9).
DATA: value TYPE i,value_text TYPE string,mymatch TYPE match_result,mymatcher TYPE REF TO cl_abap_matcher.
mymatcher = cl_abap_matcher=>create(pattern = '\ d+' text = mytext ).
WHILE mymatcher->find_next( ) = abap_true.mymatch = mymatcher->get_match( ).value = mymatcher->text+mymatch-offset(mymatch-length) + 1.value_text = value.mymatcher->replace_found( value_text ).
ENDWHILE.
Listing 2.9 Erhöhen aller Ganzzahlen in einem Text um den Wert 1
Abbildung 2.1 zeigt die Statusänderungen eines Matcher-Objektes währendeines typischen Nutzungszyklus.
Die Matcher-Klasse bietet zum Suchen und Ersetzen noch einige weitereMethoden an. Die Methode replace_next( ) ist eine Kurzform von find_next( ), unmittelbar gefolgt von replace_found( ). Die Methode erfordertdaher keine aktuelle Übereinstimmung.
1151.book Seite 77 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
78
Abbildung 2.1 Typische Verwendung eines cl_abap_matcher-Objektes
Die Methoden find_all( ) und replace_all( ) werden für alle noch übrigenÜbereinstimmungen im Text ausgeführt. Die Aufrufe beider Methoden invali-dieren zudem die aktuelle Übereinstimmung. Die Methode match( ) vergleichtden Regex mit dem übrigen Text, der noch nicht verarbeitet wurde. Zwar wirddie Methode match( ) in der Regel unmittelbar nach der Erzeugung des Mat-chers aufgerufen, um eine Übereinstimmung für den gesamten Text zu ermit-teln, jedoch ist dies nicht zwingend erforderlich.
Statische Methoden
Die statischen Methoden matches( ) und contains( ) wurden bereits in derEinführung in reguläre Ausdrücke erwähnt. Beide statischen Methoden sindfür die Verwendung in bedingten Anweisungen als Ersatz für Zeichenfolgen-operatoren wie CS und CP bestimmt.
Sehr häufig wird lediglich die Information benötigt, ob für einen Regex über-haupt Übereinstimmungen in einem Text vorhanden sind. Es ist jedoch auchmöglich, weitere Informationen zu dieser Übereinstimmung abzurufen, wie esauch bei der älteren Vorgehensweise mit Operatoren wie CS durch Verwen-dung von sy-fdpos möglich war. Hierzu rufen Sie die statische Methode get_object( ) auf, um ein Matcher-Objekt zu erhalten, das den Status der vorher-gehenden Operation matches( ) oder contains( ) darstellt. Anschließend kön-nen Sie ganz normal die eingeführten Abfragemethoden einsetzen, um weitereInformationen zu diesem Objekt zu erhalten (siehe Listing 2.10).
cl_abap_matcher
find_next( )
replace_found( )
Aktuelle gespeicherte Übereinstimmung
Keine aktuelle Übereinstimmung
cl_abap_matcherget_match( )find_next( )
text
text match
1151.book Seite 78 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
79
IF cl_abap_matcher=>contains(pattern = mypatterntext = mytext ) = abap_true.
mymatcher =cl_abap_matcher=>get_object( ).
off = mymatcher->get_offset( ).WRITE: / 'found match at offset', off.
ENDIF.
Listing 2.10 Informationen zum Objekt abfragen
Theoretisch ist es sogar möglich, die Methoden zum Suchen und Ersetzen fürdieses so erhaltene Objekt aufzurufen. Diese Vorgehensweise wird allerdingsals schlechter Programmierstil angesehen und deshalb nicht empfohlen.
2.2.5 Reguläre Ausdrücke außerhalb von ABAP-Programmen
Reguläre Ausdrücke können auch außerhalb von ABAP-Programmen getestetund verwendet werden. Ab SAP NetWeaver 7.0 bietet der neue ABAP Debug-ger in zahlreichen Suchdialogfenstern Unterstützung für Regexe. Die Unter-stützung in weiteren Werkzeugen ist für zukünftige Releases geplant.
Im Folgenden werden das Regex Toy und der Code Inspector als zwei Beispielevorgestellt, die nützliche Regex-Funktionalität bieten.
Regexe testen mit dem Regex Toy
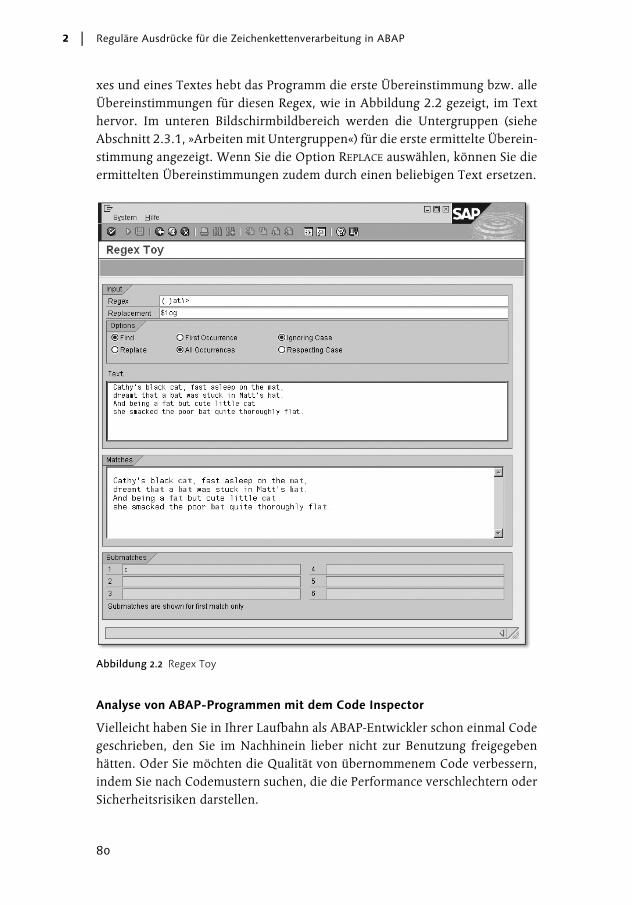
SAP NetWeaver 7.0 bietet ein nützliches kleines Programm namens DEMO_REGEX_TOY, mit dem Entwickler ihre regulären Ausdrücke schnell und mühe-los testen können.12 Das interaktive Regex Toy zeigt an, ob und an welchen Posi-tionen Übereinstimmungen für reguläre Ausdrücke in einem vom Benutzerinteraktiv bereitgestellten Text gefunden werden. Nach der Eingabe eines Rege-
Hinweis
Ab den Releases 7.0, EhP2 und 7.1/7.2 enthält ABAP einen großen Satz eingebauterZeichenkettenfunktionen. Von diesen Funktionen nehmen wiederum viele Regexe alsParameter entgegen. Beispiele sind matches, contains, find, replace und match.Diese Funktionen können statt der Methoden der genannten Klassen verwendet wer-den, wenn es um einzelne kontextfreie Abgleiche geht, in denen die sonstige hier auf-geführte Funktionalität nicht benötigt wird.
12 Falls dieses Programm in Ihrer Installation nicht vorhanden ist, müssen Sie das System aufdas Support Package 7 aktualisieren. Ab den Releases 7.0, EhP2 und 7.1/7.2 gibt es auchein kleineres Programm DEMO_REGEX, das für einfache Abgleiche ausreichend ist.
1151.book Seite 79 Freitag, 9. Januar 2009 4:48 16
Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
80
xes und eines Textes hebt das Programm die erste Übereinstimmung bzw. alleÜbereinstimmungen für diesen Regex, wie in Abbildung 2.2 gezeigt, im Texthervor. Im unteren Bildschirmbildbereich werden die Untergruppen (sieheAbschnitt 2.3.1, »Arbeiten mit Untergruppen«) für die erste ermittelte Überein-stimmung angezeigt. Wenn Sie die Option REPLACE auswählen, können Sie dieermittelten Übereinstimmungen zudem durch einen beliebigen Text ersetzen.
Abbildung 2.2 Regex Toy
Analyse von ABAP-Programmen mit dem Code Inspector
Vielleicht haben Sie in Ihrer Laufbahn als ABAP-Entwickler schon einmal Codegeschrieben, den Sie im Nachhinein lieber nicht zur Benutzung freigegebenhätten. Oder Sie möchten die Qualität von übernommenem Code verbessern,indem Sie nach Codemustern suchen, die die Performance verschlechtern oderSicherheitsrisiken darstellen.
1151.book Seite 80 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
81
Für die LOOP AT-Anweisung gibt es beispielsweise zwei Hauptvarianten, die dieZusätze INTO wa und ASSIGNING <fs> verwenden. Die Letztgenannte ist im All-gemeinen vorzuziehen, da der Zugriff auf die aktuelle Zeile der durchlaufenenTabelle nicht über einen Wertetransport, sondern effizient über eine Referenzerfolgt. Die Aufrufe von Systemfunktionen über CALL name können dagegen zuSicherheitsproblemen führen, wenn sie nicht ordnungsgemäß durch ABAP-Code mit entsprechenden Authentifizierungsprüfungen geschützt werden.
Angenommen, Sie möchten nun anhand dieser Informationen Ihren Code ver-bessern und eine einfache Codeprüfung durchführen – wie sollten Sie vorge-hen, um die relevanten Anweisungen zu finden? Der einfache Suchdialog desklassischen ABAP Editors weist diverse Einschränkungen auf, die den Nutzendieses Dialogs für die vorliegende Aufgabe erheblich reduzieren:
� Die Suche erfolgt zeilenweise, sodass bei der Suche nach dem MusterLOOP*INTO keine mehrzeiligen LOOP-Anweisungen ermittelt werden.
� Doppelpunkt-Komma-Ausdrücke ändern den syntaktischen Aufbau vonAnweisungen, sodass geschachtelte LOOP-Anweisungen hinter einem LOOPAT: nicht gefunden werden.
� Kommentare und Zeichenliterale enthalten möglicherweise die Suchbe-griffe, was zu falsch positiven Ergebnissen führt.
� Negative Suchvorgänge das heißt eine Suche nach Wörtern, die nicht miteinem bestimmten Suchbegriff übereinstimmen, werden nicht unterstützt.Dies ist jedoch im zweiten Beispiel erforderlich (CALL name), um Anweisun-gen wie CALL SCREEN, CALL FUNCTION oder CALL METHOD auszuschließen, diein der Regel keine Gefahren darstellen.13
Der Code Inspector ist ein mächtiges Werkzeug zur Quellcodeanalyse undgenau richtig für diese Art von Aufgabe. Das Programm ist im Lieferumfangsämtlicher Releases von SAP NetWeaver enthalten und löst ältere Werkzeugewie die ohnehin nur zur internen Verwendung vorgesehene TransaktionSAMT ab. Der Code Inspector ist von keinem der genannten Probleme betrof-fen: Er verarbeitet die Anweisungen in einem normalisierten Quellcode nach-einander, das heißt mit aufgelösten Doppelpunkt-Komma-Ausdrücken, undermöglicht den Ausschluss von Kommentaren. Eine ausführliche Einführung indas Werkzeug Code Inspector ist an dieser Stelle nicht möglich (siehe hierzuKapitel 10, »Qualitätsüberprüfung mit dem Code Inspector« in Band 1 vonABAP – Fortgeschrittene Techniken und Tools), doch soll trotzdem anhand eines
13 Beachten Sie, dass bei der klassischen Suche nach CALL ' zwar Systemaufrufe ermitteltwerden, ohne über CALL SCREENS und ähnliche Elemente zu stolpern; durch Variablenoder Konstanten definierte Systemaufrufe werden allerdings möglicherweise übersehen.
1151.book Seite 81 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
82
vollständigen Beispiels gezeigt werden, wie Sie sich dort ab den Releases 7.0,EhP2 und 7.1/7.2 Regexe zunutze machen können.
Nachdem Sie den Code Inspector mit Transaktion SCI oder über den Menüeintragim ABAP Editor gestartet haben, definieren Sie zunächst einen neuen ObjektsatzREGEX_DEMO, der sämtliche Programme enthält, die Sie untersuchen möchten.Anschließend erstellen Sie eine neue Prüfvariante, mit der alle Objekte innerhalbdieses Objektsatzes durchsucht werden (siehe Abbildung 2.3).
Abbildung 2.3 Erstellen einer neuen Inspektion im Code Inspector
Es stehen zahlreiche vordefinierte Analysen zur Auswahl.14 Zum Zweck diesereinmaligen Ausführung entscheiden Sie sich jedoch für eine temporäre Defini-tion.15 Nachdem Sie den Teilbaum SUCHFUNKTIONEN aufgeklappt haben, klicken
14 Dank der umfangreichen vorhandenen Analysen ist es nur selten erforderlich, von Grundauf neue Analysen für den Code Inspector zu schreiben. Bei speziellen Anforderungen fin-den Sie in der Dokumentation zum Code Inspector weitere Informationen.
15 Hierfür müssen Sie im Einstiegsbild des Code Inspectors das Eingabefeld für den Namender Inspektion leer lassen und ANLEGEN auswählen.
1151.book Seite 82 Freitag, 9. Januar 2009 4:48 16

Einführung in die regulären Ausdrücke in ABAP 2.2
83
Sie auf den kleinen Pfeil neben dem seit den Releases 7.0, EhP2 und 7.1/7.2vorhandenen Element Suche von ABAP-Anweisungen mit regulären Aus-
drücken, um das in Abbildung 2.4 gezeigte Dialogfenster für die Regex-Suchezu öffnen.
Abbildung 2.4 Dialogfenster für die Regex-Suche
Stellen Sie sicher, dass die Option SUCHE IN ANWEISUGNEN aktiviert ist, undgeben Sie den folgenden Regex in das Texteingabefeld ein:
(\<LOOP\s+AT\>(?!.+\<ASSIGNING\>))|(\<CALL\s+(?!FUNCTION|METHOD|SCREEN))
Dieses Muster sucht nach LOOP- und CALL-Anweisungen, die auf die Beschrei-bung der fraglichen Programmierkonstrukte passen. Um die Genauigkeit derÜbereinstimmungen zu erhöhen, werden viele Wortgrenzen und Leerzeichen-mengen verwendet. Der neue Operator (?!...), der hier bereits integriertwurde, wird als negative Vorausschaubedingung bezeichnet. Dieser Operatorermittelt eine Übereinstimmung, wenn der Text, der von dem in den Klam-mern angegebenen Teilausdruck repräsentiert wird, nicht gefunden wird. Die-ser nützliche Operator wird in Abschnitt 2.3.2, »Weitere Operatoren undzukünftige Erweiterungen«, detailliert beschrieben. Das Regex-Eingabefeldkann erweitert werden, um Ausnahmen und Alternativen anzugeben. Abgese-hen von einer verbesserten Lesbarkeit, wird dadurch jedoch keine neue Funk-tionalität zur Suche hinzugefügt, da diese Kombination von Regexen bereitsdurch Regexe selbst ausgedrückt werden kann.
Nachdem Sie das Dialogfenster über den Eingabeknopf ( ) geschlossenhaben, kann der Inspektionslauf gestartet werden. Wenn Sie im oberen Bild-schirmbildbereich auf den Knopf zum Ausführen klicken oder die Taste (F8)drücken, führt das System den Lauf durch. Nach kurzer Zeit sollten eine Mel-dung über die erfolgreiche Ausführung und ein neuer Knopf zur Anzeige derErgebnisse erscheinen (siehe Abbildung 2.5).
1151.book Seite 83 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
84
Abbildung 2.5 Ergebnisse der Inspektion
In diesem Beispiellauf hat der Code Inspector zwei Codezeilen ermittelt, diemit den Suchkriterien übereinstimmen. Durch Doppelklicken auf die Ergebnis-zeilen lässt sich der Quellcode anzeigen, um zu überprüfen, ob und wie sichder Code verbessern lässt.
2.3 Fortgeschrittene Eigenschaften regulärer Ausdrücke
Nach der vorangegangenen Einführung in die elementaren Eigenschaften vonregulären Ausdrücken und ihre Verwendung sowohl in ABAP-Programmen alsauch in Werkzeugen des SAP NetWeaver Application Servers ABAP wird nunauf einige fortgeschrittene Aspekte dieses mächtigen Konzeptes eingegangen.
2.3.1 Arbeiten mit Untergruppen
Untergruppen gehören zu den nützlichsten Aspekten von regulären Ausdrü-cken überhaupt. Um reguläre Ausdrücke effektiv zu nutzen, müssen Sie mitdem Konzept der Untergruppen vertraut sein.
Um die wichtigsten Eigenschaften von Untergruppen kurz vorwegzunehmen:Die bereits bekannten runden Klammern strukturieren nicht nur Ihren Regex,sondern speichern zudem eine interne Kopie der Unterfolge, die mit dem ein-geklammerten regulären Ausdruck übereinstimmt, intern ab. Diese sogenann-ten Untergruppen können anschließend verwendet werden, um Teile der unter-suchten Zeichenfolge
1151.book Seite 84 Freitag, 9. Januar 2009 4:48 16

Fortgeschrittene Eigenschaften regulärer Ausdrücke 2.3
85
� kontextbasiert zu extrahieren oder
� wertebasiert zu transformieren.
Informationen zu den abgespeicherten Untergruppen können mit den Anwei-sungen FIND und REPLACE sowie mit cl_abap_matcher abgefragt werden. Dar-über hinaus kann sowohl in regulären Ausdrücken als auch in Ersetzungstextenauf diese Untergruppen zugegriffen werden.
Untergruppen
Mithilfe von Klammern lassen sich reguläre Ausdrücke in Unterausdrückenstrukturieren. Diese Unterausdrücke werden von links nach rechts nummeriert(einsetzend mit 1) und beginnen mit einer öffnenden Klammer. Auch eineSchachtelung ist möglich:
a+(b+)(c(e+)|d(e+))f<––><–––––––––––>1 2
<––> <––>3 4
Wenn Sie Übereinstimmungen für diesen Regex innerhalb des Textesaabbbdeef ermitteln, erhalten Sie als Ergebnis die folgenden Übereinstimmun-gen:
Text: ...aabbbdeef...Übereinstimmung: aabbbdeefUntergruppe 1: bbbUntergruppe 2: deeUntergruppe 3: (leer)Untergruppe 4: ee
Die Übereinstimmungen mit den Unterausdrücken werden als Untergruppenabgespeichert. Um auf diese Untergruppen zuzugreifen, kann der ZusatzSUBMATCHES der Anweisung FIND verwendet werden:
FIND REGEX 'a+(b+)(c(e+)|d(e+))f'IN 'aabbbdeef'SUBMATCHES s1 s2 s3 s4 s5.
Diese Anweisung speichert die Werte bbb, dee und ee in den Variablen s1, s2und s4 und initialisiert die Variablen s3 und s5.
1151.book Seite 85 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
86
Der Zusatz SUBMATCHES füllt somit alle angegebenen Variablen mit der entspre-chenden Zeichenfolge der Untergruppe. Falls weniger Unterausdrücke als Vari-ablen vorhanden sind, werden die überzähligen Variablen initialisiert (wie s5im Beispiel). Das Gleiche gilt für Variablen, für deren Unterausdrücke keineÜbereinstimmungen gefunden wurden (wie s3 im Beispiel).
Um weitergehende Informationen zu erhalten, können Sie den Zusatz RESULTSverwenden, der, wie bereits in Abschnitt 2.2.4, »Reguläre Ausdrücke in ABAP-Programmen«, erwähnt, Ergebnisse der Typen match_result oder match_result_tab zurückgibt und auf deren Komponente submatches zugreift. DieseKomponente ist eine interne Tabelle vom Dictionary-Typ submatch_result_tab, deren Zeilen vom Typ submatch_result den Offset und die Länge für jedeUntergruppe enthalten.
Alternativ kann auch wieder die Klasse cl_abap_matcher aus Abschnitt 2.2.4,»Reguläre Ausdrücke in ABAP-Programmen«, mit ihren Abfragemethoden ein-gesetzt werden, um dieselben Informationen zu erhalten (siehe Listing 2.11).
DATA: mymatcher TYPE REF TO cl_abap_matcher,str TYPE string,off TYPE i,len TYPE i.
mymatcher =cl_abap_matcher=>create_matcher(
pattern = 'a+(b+)(c(e+)|d(e+))f'text = 'aabbbdeef' ).
mymatcher->find_next( ).str = mymatcher->get_submatch( 1 ).off = mymatcher->get_offset( 2 ).len = mymatcher->get_length( 4 ).
Listing 2.11 Klasse cl_abap_match
Die Methode get_submatch( ) gibt ähnlich wie der Zusatz SUBMATCHES einfachdie Zeichenfolge der nten Untergruppe zurück. Wenn Sie eine leere Unter-gruppe angeben, wird auch eine leere Zeichenfolge zurückgegeben. ÜbergebenSie jedoch den Index einer nicht vorhandenen Gruppe, wird der Ausnahmefeh-ler cx_sy_invalid_submatch ausgelöst. Der spezielle Index 0 bezieht sich aufdie gesamte Übereinstimmung, sodass über get_submatch( 0 ) der Text dergesamten Übereinstimmung abgerufen werden kann.
Die übrigen Abfragemethoden aus vorangegangener Tabelle 2.4 unterstützenebenfalls einen optionalen index-Parameter, der die Zeile, den Offset oder dieLänge der entsprechenden Untergruppe zurückgibt.
1151.book Seite 86 Freitag, 9. Januar 2009 4:48 16

Fortgeschrittene Eigenschaften regulärer Ausdrücke 2.3
87
Wenngleich das Konzept der Untergruppen bisher recht unkompliziert ist, gibtes einige nennenswerte Feinheiten bei deren Verwendung innerhalb von Wie-derholungen. Genau wie die wiederholten Unterausdrücke in jeder Iterationneu angewendet werden, wird auch jede potenzielle Untergruppe bei jeder Ite-ration neu gefüllt. Bei der Anwendung des Regexes
(([ab])|([cd])|([ef]))*<––––––––––––––––––––>1<––––> <––––> <––––>2 3 4
auf den Text aebe werden zum Beispiel für die Untergruppen 1 bis 4 die Über-einstimmungen e, b, (empty) bzw. e zurückgegeben, da jede Gruppe den letz-ten übereinstimmenden Zeichenfolgenwert beibehält.
Ein weiterer interessanter Aspekt von Untergruppen betrifft die »Gierigkeit«von regulären Ausdrücken, die auch für Unterausdrücke gilt. Während dieRegel zur ersten längsten Übereinstimmung (siehe Abschnitt 2.2.3, »Suchenmit regulären Ausdrücken«) die zurückzugebende Übereinstimmung bei derSuche nach Regexen eindeutig definiert, bleibt zunächst unklar, wie Unter-gruppen bestimmt werden sollen. Betrachten Sie zum Beispiel folgende Anwei-sung:
FIND REGEX '([ab]+)([bc]+)' IN 'ooaabbccoo'SUBMATCHES s1 s2.
Die Regel für die erste längste Übereinstimmung legt nicht fest, ob s1 der Wertaa, aab oder aabb zugewiesen wird. Da die Gierigkeit jedoch auch für Unter-ausdrücke, und zwar von links nach rechts, gilt, wird der Variablen s1 der Wertaabb zugeordnet, und s2 erhält den Restwert cc. Es ist jedoch wichtig zu ver-stehen, dass trotz gieriger Unterausdrücke primär der gesamte Regex überein-stimmen muss. Vergleichen Sie das vorhergehende Beispiel mit dem folgenden:
FIND REGEX '(a+)(ab)' IN 'ooaaboo'SUBMATCHES s1 s2.
Hier erhält trotz Gierigkeit s1 nicht aa zugewiesen, da sonst der gesamte Regexnicht mehr übereinstimmen würde. Tatsächlich erfordert die einzige möglicheÜbereinstimmung für den gesamten Regex, dass s1 den Wert a und s2 denWert ab erhält.
1151.book Seite 87 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
88
Diese Analyse mag Ihnen zunächst recht theoretisch erscheinen. Es ist aber hilf-reich, an dieses Verhalten zu denken, wenn Sie Untergruppen zum Extrahierenvon Informationen verwenden, was im Folgenden vorgestellt wird.
Extrahieren von Teilinformationen mit Untergruppen
Im ersten Teil dieses Kapitels wurde gezeigt, wie Sie reguläre Ausdrücke für diekontextbasierte Suche nach Informationen verwenden (siehe Abschnitt 2.2.3,»Suchen mit regulären Ausdrücken«). Häufig sind diese Informationen jedochzusätzlich unterstrukturiert und lediglich bestimmte Teile von ihnen interessant.
Im Folgenden wird dies wieder anhand eines Beispiels gezeigt: Angenommen,Sie schreiben eine Webanwendung, die eine URL wie die folgende mit denAnmeldeinformationen des Benutzers erhält:16
http://sap.com/handler?sess=1&login=ralph@geheim&lang=EN
Die Anmeldeinformationen werden über den login-Parameter angegeben, derBenutzername und Kennwort enthält, die durch ein @-Zeichen getrennt sind.Diese Informationen lassen sich problemlos mithilfe von FIND REGEX finden(siehe Listing 2.12).
DATA: login TYPE string,user TYPE string,pass TYPE string.
FIND REGEX '&login=\ w+@\ w+' IN urlMATCH OFFSET off MATCH LENGTH len.
CHECK sy-subrc = 0.login = url+off(len).
Listing 2.12 Anmeldeinformationen mit FIND REGEX ermitteln
Die Unterfolge &login=ralph@geheim mit den Anmeldeinformationen ist nunin der Variablen login gespeichert. Um den Benutzernamen und das Kennwortzu extrahieren, überspringen Sie zunächst den Namen des Parameters, indemSie auf login+7 verweisen und anschließend die restliche Zeichenfolge beimTrennzeichen abtrennen:
SPLIT login+7 AT '@' INTO user pass.
Dieser Code ist noch etwas umständlich, da Sie die Anzahl der zu übersprin-genden Zeichen selbst zählen müssen. Darüber hinaus müssen Sie einige der
16 Dieses konkrete Anwendungsbeispiel dient ausdrücklich nur zur Illustration und ist auf-grund seiner Sicherheitsmängel nicht für den Produktivbetrieb geeignet.
1151.book Seite 88 Freitag, 9. Januar 2009 4:48 16

Fortgeschrittene Eigenschaften regulärer Ausdrücke 2.3
89
Eingaben zweimal durchsuchen, um an die interessanten Teile zu gelangen.Mithilfe von Untergruppen können Sie dieses Verfahren auf einen einzigenVorgang reduzieren, der zudem weniger anfällig für Änderungen an der URL-Syntax ist:
FIND REGEX '&login=(\w+)@(\w+)' IN urlSUBMATCHES user pass.
CHECK sy-subrc = 0.
Die erste Untergruppe des Regexes speichert den in der URL enthaltenenBenutzernamen und die zweite Untergruppe das Kennwort. Die Schlüsselwör-ter und Begrenzungszeichen, die zur Suche nach den Informationen eingesetztwerden, werden zwar für die tatsächliche Übereinstimmung benötigt, jedochnicht als Teil des Ergebnisses zurückgegeben. Dies ist einer der entscheidendenVorteile bei der Verwendung von Untergruppen.
Als weiteres, etwas kompliziertes Beispiel sollen Sie nun einen Pfadnamen wie/usr/sap/work/profile.txt in Verzeichnis, Basisname und Erweiterung unterteilen:
FIND REGEX '(.*/)?([^.]*)(\..*)?' IN pathSUBMATCHES dir base ext.
Den ersten Teil des Pfadnamens bildet das Verzeichnis, zu dem auch der letzteSchrägstrich (/) zählt. Die Erweiterung ist der letzte Teil des Pfades und beginntmit dem ersten Punkt (.) von links, der nicht zum Verzeichnis gehört. Derübrige Teil zwischen dem Verzeichnis und der Erweiterung ist der Basisname.Jeder dieser Teile kann leer sein.
Der erste Unterausdruck (.*/)? stimmt mit dem Teil des Pfadnamens bis zumletzten Schrägstrich überein (sofern vorhanden, anderenfalls bleibt die zugehö-rige Untergruppe leer). Dieses Ergebnis entspricht dem Verzeichnisteil.Anschließend wird der Text bis zum ersten Punkt ermittelt, der dem Basisna-men der Datei entspricht. Falls kein Punkt vorhanden ist, handelt es sich beidem übrigen Abschnitt des Pfades um den Basisnamen. Auch hier gilt, dass derBasisname leer sein kann. Zuletzt wird eine Übereinstimmung für den Punkt(falls vorhanden) und den übrigen Teil des Pfades ermittelt, der für die Erwei-terung des Pfades steht.
In Fällen wie in diesem Beispiel, in denen Sie Informationen eigentlich nurunterteilen anstatt suchen wollen, sollten Sie einen Abgleich statt einer Suchedurchführen, um auszuschließen, dass Sie falsch positive Ergebnisse für einepassende Teilfolge erhalten. Wenn Sie für diese Aufgabe nicht direkt ein Mat-
1151.book Seite 89 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
90
cher-Objekt verwenden möchten, können Sie für die FIND-Anweisung dasDurchführen eines Abgleiches erzwingen, indem Sie den Regex in Zeilenanker^ ... $ einschließen. In diesem Beispiel mit dem Pfadnamen ist dies allerdingsnicht erforderlich, da der verwendete Regex so gierig ist, dass er stets entwedermit dem gesamten Text oder gar nicht übereinstimmt.
Ersetzen von Übereinstimmungen
Ein weiterer nützlicher Aspekt von Untergruppen ist, dass Sie innerhalb einesErsetzungstextes17 auf Untergruppen verweisen können. Sowohl die Anwei-sung REPLACE als auch die replace-Methoden kennen das spezielle Konstrukt$n, das die nte Untergruppe der aktuellen Übereinstimmung mit einem Regexbezeichnet.18 Dies ist sehr hilfreich, um mit einer einzigen Anweisung Informa-tionen hinzuzufügen oder vorhandene Inhalte zu transformieren.
Angenommen, Sie möchten Datumsangaben im amerikanischen FormatMM/DD/YY in das europäische Datumsformat DD.MM.YY konvertieren. Mit demrichtigen Regex wird hierfür lediglich eine Zeile benötigt:
REPLACE ALL OCCURRENCES OF REGEX '(\d+)/(\d+)/'IN mytext WITH '$2.$1.'.
Zunächst wird nach den Datumsangaben im amerikanischen Format anhandder begrenzenden Schrägstriche gesucht, und die relevanten Teile mit denMonats- und Tagesdaten werden in Untergruppen extrahiert. Dann werden diealten Datumsangaben durch das neue Format ersetzt, bei dem die Reihenfolgevon Tag und Monat umgekehrt ist und Punkte anstelle von Schrägstrichen ver-wendet werden.
Es ist sogar möglich, in einem Schritt Datumsangaben vom amerikanischen indas japanische Format (YY-MM-DD) und umgekehrt zu konvertieren, indem Sievon der Eigenschaft profitieren, dass Untergruppen ohne Übereinstimmungleer bleiben:
REPLACE ALL OCCURRENCES OFREGEX '(\d+)/(\d+)/(\d+)|(\d+)-(\d+)-(\d+)'IN mytext WITH '$2$6.$1$5.$3$4'.
17 Das ist der Text, der in der Anweisung REPLACE hinter WITH angegeben wird.18 Für die ab den Releases 7.0, EhP2 und 7.1/7.2 verfügbaren eingebauten replace-Funkti-
onen gilt das natürlich genauso.
1151.book Seite 90 Freitag, 9. Januar 2009 4:48 16

Fortgeschrittene Eigenschaften regulärer Ausdrücke 2.3
91
Die Verarbeitung dieses Codes ist sogar etwas schneller als die Verwendungvon zwei separaten REPLACE-Anweisungen für jeweils eine Umwandlungsrich-tung.
Wie in der Einführung zu Untergruppen bereits beschrieben, steht die Unter-gruppe mit dem Index 0 gemäß Konvention für die gesamte Übereinstimmung.Daher können Sie auch $0 verwenden, um die gesamte aktuelle Übereinstim-mung in den Ersetzungstext aufzunehmen. Dies ist insbesondere für das Hin-zufügen von Informationen zum ursprünglichen Text hilfreich. Nehmen Siebeispielsweise an, dass die Fettschrift-Tags <b> und </b> zu allen Zahlen ineinem HTML-Dokument hinzugefügt werden sollen. So einfach sieht das dannaus:
REPLACE ALL OCCURRENCES OF REGEX '\d+'IN mytext WITH '<b>$0</b>'.
Beachten Sie, dass die $n-Operatoren ausschließlich in Ersetzungstext verwen-det werden können. Sie sind zwar nicht Teil der Regex-Syntax, es ist aber eineenge Verknüpfung vorhanden. So führt eine ungültige Angabe für Untergrup-pen, wie zum Beispiel $*, zum Ausnahmefehler cx_sy_invalid_regex_format.Wenn Sie ein literales Dollarzeichen in die Ersetzungstexte einfügen müssen,können Sie einfach das für Regexe übliche Fluchtsymbol verwenden: \$.
Um den Abschnitt über Ersetzungen abzuschließen, sollen Sie sich nochmals anKapitel 1 erinnern: Beachten Sie beim Arbeiten mit REPLACE, dass die vonREPLACE zurückgegebenen Informationen sich anders als bei FIND nicht auf diegefundenen Übereinstimmungen, sondern immer auf die eingefügte Zeichen-folge beziehen:
mytext = '-x-x-'.REPLACE ALL OCCURRENCES OF REGEX '\w+'
IN mytext WITH 'ooo’REPLACEMENT COUNT cnt REPLACEMENT OFFSET final_off.
WRITE: / mytext, cnt, final_off.
Als Ergebnis wird -ooo-ooo- 2 5 ausgegeben – das heißt, final_off weist beider Fertigstellung den Wert 5 und nicht 3 auf.
Rückwärtsreferenzen
Ein weiterer recht ausgefeilter, jedoch eher selten verwendeter Operator fürUntergruppen ist der Rückwärtsreferenzoperator (\n), mit dem auf die nte unter-
1151.book Seite 91 Freitag, 9. Januar 2009 4:48 16

Reguläre Ausdrücke für die Zeichenkettenverarbeitung in ABAP2
92
geordnete Übereinstimmung im Regex selbst verwiesen werden kann. Odermit anderen Worten: Jeder Untergruppe ist ein Operator \1, \2, \3 ... zugeord-net, der hinter dem entsprechenden Unterausdruck angegeben werden kannund rückwärts auf die Untergruppe verweist. Er wirkt also im Regex als Platz-halter für die Zeichenfolge der Untergruppe. Dies mag zunächst seltsam klin-gen, aber nehmen Sie zum Beispiel an, dass Sie über eine einfache Datenbankmit Benutzernamen und Passwörtern verfügen, die als Zeilen aus user:pass-Ein-trägen in einer internen Tabelle userdata gespeichert sind. Dann können Siedie Anweisung
FIND ALL OCCURRENCES OF REGEX '^(\w+):\1$' IN TABLE userdataRESULTS res.
verwenden, um alle nachlässigen Benutzer zu ermitteln, deren Kennwort mitdem Anmeldenamen übereinstimmt.
An dieser Stelle ist es nochmals wichtig, den grundlegenden Unterschied zwi-schen nicht übereinstimmenden und nicht vorhandenen Untergruppen herauszu-stellen. Eine Rückwärtsreferenz auf eine Untergruppe ohne Übereinstimmungist möglich und steht für eine leere Zeichenfolge, das heißt, dass sie praktischignoriert wird. Der Regex
regex: (['"])?\w+\1found here: This "is" 'not" 'it'!
stimmt beispielsweise mit Wörtern überein, die auch in Anführungszeichenstehen können. Dabei müssen die Anführungszeichen jedoch konsistent sein.Wird der Fragezeichenoperator innerhalb des Unterausdrucks platziert, ändertsich zwar die Funktionsweise innerhalb dieses Ausdrucks geringfügig, dies hatallerdings keine Auswirkungen auf das Endergebnis der Übereinstimmung.
Das Verweisen auf nicht vorhandene Untergruppen oder auf Gruppen, die ersthinter dem Rückwärtsreferenzoperator kommen, ist allerdings nicht zulässigund löst die Ausnahme cx_sy_invalid_regex aus. Als Faustregel gilt, dass Siestets überprüfen sollten, ob der nten Rückwärtsreferenz mindestens n schlie-ßende Klammern nachgestellt sind.
Im Gegensatz zu den meisten anderen Regex-Implementierungen ist dieAnzahl an Rückwärtsreferenzen in ABAP nicht auf \1 bis \9 begrenzt. Stattdes-sen ist eine beliebige Anzahl von Referenzen, wie zum Beispiel \69, zulässig. Inanderen Sprachen ist dies nicht möglich, da solche Ausdrücke in der Regel alsSteuerungscodes für ASCII-Zeichen interpretiert werden.
1151.book Seite 92 Freitag, 9. Januar 2009 4:48 16

565
Index
.NET Connector 204
A
ABAPDebugging 373Programmierfehler 345Remote Communication 199Serialization XML 120Webservice 125XML-Mapping 113, 125
ABAP Debugger 177, 178, 179, 307, 335, 336, 337, 338, 343, 369, 374, 377, 392, 406, 460, 467, 470, 525Fehlermeldung 391Interface � ADINachteil 406Neuer ABAP Debugger � Neuer ABAP
DebuggerStarten 375, 380, 383
ABAP Dictionary 352, 353, 354, 538Datentyp 354Element 548
ABAP Editor 334Programmeigenschaft 381
ABAP Serialization XML � asXMLABAP Shared Objects 157, 158, 169
Administration 164erweiterte Programmiertechnik 179Programmiermodell 160Shared Objects Monitor 164, 167, 168,
169Zugriffsmodell 163
ABAP Test Cockpit � ATCABAP Unit 309, 311, 323, 325, 477,
479, 500Browser 326Delegation 496Detailsicht 494Ergebnisanzeige 492Hierarchiedarstellung 492Massentest 501Testisolation 497Vorgehen 324
ABAP-Checkpoint 443
ABAP-Code 548ABAP-Dump 390ABAP-Dumpanalyse 337, 340, 342, 344,
347ABAP-Laufzeitanalyse 336, 337, 355,
358, 365Verwenden 364
ABAP-Laufzeitfehler 264, 345ABAP-Modultest 308ABAP-Programm 316
Testen 308ABAP-Trace 355, 356, 358, 368, 376,
380Ergebnis 360paralleler Modus 365Starten 364Tipp 362Variante 363, 368
ABAP-Verbindung 238, 242, 303Abdeckungsdaten 332abgebrochener Job 338Ablauflogik 553Abnahmetest 479ABORT 470ACCEPTING CASE 74Add-on 549ADI 409aktivierbare Assertion 447aktivierbarer Breakpoint 461Aktivierung
benutzerspezifische 452Einstellung 451, 459, 467globale 452globale Variante 472gruppenspezifische 451programmspezifische 451, 456serverspezifische 452Variante 457
Aktualparameter 425ALE 199ALL OCCURRENCES 48ALL OCCURRENCES OF 73ALL_ABORT_ABORT 472ALL_BREAK_ABORT 472ALL_BREAK_LOG 472
1151.book Seite 565 Freitag, 9. Januar 2009 4:48 16

566
Index
ALL_LOG_LOG 472Alternative 62Analyse
Post-Mortem-Analyse 338Analysewerkzeug 307Änderungssperre 193Anker 70Anmeldebild 244Anmeldeinformation 205anonymes Datenobjekt 508Ansatz
Inside-Out 119Outside-In 118
Anweisung 395deklarative 444operative 444
Anwendungsprotokoll 261, 299Anzeigefilter 363Append 547Application Link Enabling � ALEApplication Log 261, 299, 462ArchiveLink 199AS ABAP 201, 224ASSERT 444, 446ASSERT CONDITION 448ASSERT FIELDS 472ASSERT ID 448ASSERT SUBKEY 472Assertion 445, 470, 474
aktivierbare 447Bedingung 447, 453, 470, 474Protokoll 470
ASSERTION_FAILED 446, 450, 470Assert-Methode 325, 481, 494
abort 484assert_... 484assert_bound 487assert_differs 487assert_equals 484assert_initial 487assert_not_bound 487assert_not_initial 487assert_subrc 487assert_that 488fail 483Parameter 483spezialisierte 484
asXML 120, 127, 235asynchroner RFC � RFC
ATC 322, 502Atomic 267Aufruf 357
zustandsloser 210Aufrufebene 360, 361Aufrufhierarchie 360, 367Aufrufstack 419, 422Ausführungskontext 452Ausführungszeitpunkt 226Ausgabeparameter 226, 227Ausnahme 396
vordefinierte 261Ausnahmebehandlung
Zusichern 488Ausnahmefehler 493Automaten-Cache 107automatischer Gebietsaufbau 185
B
Background RFC � bgRFCBackslash-Operator 62Backtracking 103, 110BAdI 540, 542, 543, 546, 549basXML 234, 235, 236, 238, 246, 250,
259, 292bedingter Checkpoint 447Befehlstyp 383Begrenzung 99Begrenzungsoperator 71Begrenzungszeichen 97Benutzer 245Benutzergruppe 243Benutzerkontext 366Benutzersitzung 202benutzerspezifische Aktivierung 452Benutzerstammsatz 21Benutzerwechsel 226, 227Berechtigungsobjekt 211Berechtigungsprüfung 237Berechtigungstest 245Bereichsoperator 63bestimmte Einheit 368Betriebsart 452, 469bgRFC 265, 291
ACID 267API 280Destination 268, 272Destination konfigurieren 292
1151.book Seite 566 Freitag, 9. Januar 2009 4:48 16

567
Index
bgRFC (Forts.)Framework 266, 292Inbound 271, 281Outbound 270, 281Out-Inbound 273, 281, 290Programmieren 282Scheduler 270, 273, 283, 289Scheduler konfigurieren 300Szenario 269Unit 266, 274, 278, 279, 283, 284,
300Unit überwachen 295Verarbeiten 299Verbuchen 288
Big Endian 250Binärdaten 19
Typ 25Binärmodus 25Boyer-Moore-Algorithmus 50Branchenerweiterung 538Branchenlösung 535, 537, 539, 549branchenspezifische Funktionalität 549BREAK 470BREAK-POINT 393, 426, 444, 460Breakpoint 370, 384, 392, 400, 419,
422, 434, 460, 470aktivierbarer 461Anlegen 428Debugger-Breakpoint 393, 394, 426,
428dynamischer 395Externer Breakpoint 394, 426, 428flüchtiger 461Session-Breakpoint 426Setzen 426Symbol 427Typ 427Typ ändern 430Werkzeug 467Wertehilfe 429Zeilen-Breakpoint 394
BREAK-POINT ID 461Breakpoints
Session-Breakpoint 393Broker-Klasse 194Buffer
Exclusive Buffer 160Business Add-in � BAdIBusiness Function 554
Business Function Set 547BYTE MODE 25, 50BYTE-CA 53BYTE-CN 53BYTE-CO 53Bytecode 355BYTE-CS 53Bytefolge 19BYTE-NA 53Bytereihenfolge 250
C
CA 52CALL FUNCTION 208CALL TRANSFORMATION 121, 123,
125, 146, 152, 153Callback 212
Destination 248Mechanismus 227
Castingimplizites 30
CATT 329CFW 204Checkpoint 393, 443
bedingter 447Gruppe 448
cl_abap_char_utilities 22, 46cl_abap_conv_in_ce 46cl_abap_conv_out_ce 46cl_abap_conv_x2x_ce 46cl_abap_matcher 70, 74, 86, 108cl_abap_memory_utilities 528cl_abap_regex 74, 108cl_abap_string_utilities 46cl_abap_weak_reference 518cl_aunit_assert 481cl_sxml_string_reader 153Class Builder 491, 500Class-Pool 491
Testmethode 492CLEAR 511clike 36CN 52CO 52Code Inspector 80, 308, 309, 315, 321,
334, 480, 502Codepage 21, 63, 251, 253
Umgebungs-Codepage 252, 258
1151.book Seite 567 Freitag, 9. Januar 2009 4:48 16

568
Index
Codepage (Forts.)verwendete 255
COMMIT WORK 218, 440Component under Test � CUTCONCATENATE 40CONDENSE 45Consistency 267contains 52, 78, 79Control 204Copy-on-Detach 195Copy-on-Write 35, 195, 509Coverage Analyzer 309, 310, 330, 332,
334Anzeige 334
CP 54, 78CREATE DATA 521CREATE OBJECT 521CS 53, 78csequence 36Customer-Exit 540, 544Customizing 540Customizing-Anpassung 549CUT 489, 494cx_st_error 154cx_sy_range_out_of_bounds 39cx_transformation_error 154cx_xslt_exception 154
D
Data Explorer 406, 420, 425Data-Dictionary-Objekt 308Dateizugriff 357Datenbank
Commit 219Datenbankzugriff 357Datenobjekt 423
Analysieren 423anonymes 508
Datenreferenz 508Vergleich 487
Datentypgenerischer 36
Datumsfeld 28Debuggee 409Debugger Engine 409Debugger-Breakpoint 393, 394, 426,
428
Debugger-Variante 417Sichern 418
Debugging 226, 295, 375, 432Einstellung 412Gebietsinstanz 170, 177Hintergrundjob 385Layer-aware Debugging 388Szenario 433
Debugging-Modus 375, 378, 379, 387exklusiver 441nicht exklusiver 440
Definitionglobale 321lokale 321
deklarative Anweisung 444Delegation 496DEMO_REGEX_TOY 79Deserialisierung 118, 126, 249Desktop 413DESTINATION 208Destination 210, 238, 268, 285, 295,
297Destinationskennung 249dynamische 205Sperren 298Supervisor-Destination 303vordefinierte 247
Dezimalzahlgültige 67
Dialoginteraktion 226, 227, 228, 229Dialogtransaktion 380Dialogverarbeitung 384Dialog-Workprozess 202Difftool 406, 411, 420, 436, 437Dispatcher 201Dispatcher-Queue 291Document Object Model � DOMDocument Type Declaration � DTDDOM 113, 116, 124DTD 153Dumpanalyse 374, 384Dumpkontext 344Durable 267dynamische Destination 205dynamischer Breakpoint 395dynamisches Speicherobjekt 507, 508Dynpro 228, 538Dynproanalyse 420Dynpro-Element 547, 548
1151.book Seite 568 Freitag, 9. Januar 2009 4:48 16

569
Index
E
eCATT 309, 310, 323, 328Vorteile 329
Edit Control 421Einheit
bestimmte 368Einsatz von Analysewerkzeugen 335Einzelanzeige 435Einzelfeld 420Einzelschritt 400Endlosschleife
temporäre 386Enhancement Framework 544, 545, 547Enhancement Spot 545ENHANCEMENT-POINT 545ENHANCEMENT-SECTION 545Enqueue-Workprozess 202Entwicklertest 479Entwicklungsobjekt 546
Typ 548Ergebnis
falsch negatives 65falsch positives 65
Ergebnisanzeige 492erste längste Übereinstimmung 68erweiterte Programmprüfung 308, 309,
312Erweiterung 554
Implementierung 545konsolidierte 535verfügbare 556
Erweiterungspunkt 554, 556Erweiterungstechnologie
klassische 542Exactly Once 216, 226Exactly Once In Order 216, 226Exchange Infrastructure � SAP NetWea-
ver Process IntegrationExclusive Buffer 160extended Computer Aided Test Tool �
eCATTExtensible Markup Language � XMLExtensible Stylesheet Language Transfor-
mations � XSLTExterner Breakpoint 394, 426, 428externer Fehler 346Extreme Programming 328
F
Factory-Klasse 273Factory-Methode 271, 273, 286falsch negatives Ergebnis 65falsch positives Ergebnis 65falsche Kommunikationsart 254Fehler
externer 346interner 345
Fehleranalyse 348, 485Fehlerliste 493Fehlermeldung 212
ABAP Debugger 391Fehlerursache
Ermitteln 347, 348Feld 352
Inhalt überprüfen 351vorbelegtes 375
Feldattribut 553Feldsymbol 36feste Länge 20FIFO 275
Pipe 275, 276FIND 46, 47, 72, 85, 107find 79First In, First Out � FIFOFixture 494, 497flüchtiger Breakpoint 461Fluchtsymbol 53, 99Formalparameter 36Formatierung 43
Regel 44Framework 373FREE 511, 519Function Builder 204, 425, 556funktionale Methode 474funktionaler Methodenaufruf 474Funktionalität
branchenspezifische 549Funktionsbaustein 199, 228, 288, 396
Aufrufen 207, 217remotefähiger � RFM 233
Funktionsgruppe 236
G
Garbage Collector 425, 507, 512Gateway 201
1151.book Seite 569 Freitag, 9. Januar 2009 4:48 16

570
Index
Gebietmandantenabhängiges 189
Gebietsaufbauautomatischer 185
Gebietshandle 174, 193Gebietsinstanz 160, 163, 179
Aktualisieren 170, 174Aktualisierungszeit 188Debugging 170, 177Erzeugen 170, 171Fehler behandeln 170, 176Lebensdauer 188Leerlaufzeit 188Objekt lokaler Klasse 175Speichern von Daten 170Sperren 161transaktionale 191Verfallszeit 188Versionierung 180Wurzelobjekt 161Zugreifen 170, 173
Gebietsklasse 164Gebietskonstruktor 186
Implementieren 187generischer Datentyp 36genügsame Übereinstimmung 97gierige Übereinstimmung 69, 96Gierigkeit 87Gleitkommazahl
Vergleich 486globale Aktivierung 452globale Definition 321globale Testklasse 498globale Testmethode 499globale Variable 424Graph 512
gerichteter 512Gruppe
Logon-Gruppe 240RFC-Servergruppe 240
GUI-Verknüpfung 382Erstellen 382
gültige Dezimalzahl 67gültige Kreditkartennummer 66Gültigkeitsbereich 451, 456
H
Hash-Tabelle 436Hauptmodus 232Haupt-Template 147Header 34heterogene Kommunikation 253, 254,
256, 257Hexadezimalwert 25Hierarchiedarstellung 492Hilfsmethode
Testklasse 497Hintergrundjob 383, 388
Debuggen 385im Debugging-Modus starten 387
Hintergrundprozess 367Hintergrundverarbeitung 460, 461Hintergrund-Workprozess 202hmusa 528homogene Kommunikation 253, 254,
256Hook 540HTML
Tag 99HTTP-Service 462
I
ICM 201IDoc 199id-Transformation 121IGNORING CASE 50, 74, 111implizite Methode 495IN TABLE 48Inbound-Destination 293, 294Inbound-Scheduler 221, 290Inbound-Szenario 272, 281Inbound-Unit
Erstellen 282Typ Q 285Typ T 283
Include-Programm 316, 348INITIAL SIZE 519Initialisierungsfehler 325Inkonsistenz
Feststellen 353Inside-Out-Ansatz 119Inspektion 316
Anlegen 320
1151.book Seite 570 Freitag, 9. Januar 2009 4:48 16

571
Index
Inspektion (Forts.)Ausführen 320Starten 320
Inspektionslauf 321Installationsfehler 346Instanzattribut 434Instanzkonstruktor 436Instanzmethode 500
parameterlose 480Integrationstest 328Intermediate Document � IDocinterne Tabelle 236, 357, 403, 414
Vergleich 485interne Verbindung 248interner Fehler 345interner Modus 237, 467, 518Internet Communication Manager �
ICMINTO TABLE 41Isolation 267iXML
Bibliothek 116Parser 152
J
Java Connector 204Job
abgebrochener 338Job-Log 384Jobübersicht 339, 387
K
kanonische XML-Darstellung 119Kante 512Knoten 512Kommentar 443Kommunikation
heterogene 253, 254, 256, 257homogene 253, 254, 256
Kommunikationsart 246, 254falsche 254
Kommunikationsfehler 216, 260kontextbasierte Suche 71Kontextknoten 129Kontrollbereich 413Kontrollblock 402
Konvertierung 29Exit 44Regel 29
Kreditkartennummergültige 66
Kurzdump 263, 342, 370, 390Entsperren 343Navigation 346Sperren 343
KurzdumpanzeigeKategorie 345
Kurzdumptext 347
L
Längefeste 20variable 20
Lastausgleich 269, 302Lastverteilung 239, 241Laufzeitanalyse 361Laufzeitfehler 342, 353, 384, 493Laufzeitprüfung 309, 310, 311Layer-aware Debugging 388Leerzeichen
schließendes 23, 33, 38Leftmost-longest-Regel 69Legacy-Framework 292LENGTH 23, 26, 48Lesehandle 174Lesesperre 184Literaloperator 22, 95, 99Little Endian 250Loader-Klasse 194LOG 470Logical Unit of Work � LUWlogische Verbindung 302logisches System 203Logon-Gruppe 240, 241LOG-POINT 444, 463
FIELDS 464ID 463SUBKEY 466
Logpoint 462, 470lokale Definition 321lokale Testklasse 490Loopback-Destination 248
1151.book Seite 571 Freitag, 9. Januar 2009 4:48 16

572
Index
LösungAusarbeiten 353
LUW 203, 215, 219, 267, 283, 288, 440
M
mandantenabhängiges Gebiet 189Mapping-Liste 134Massentest 316, 480match 79MATCH COUNT 73MATCH LENGTH 47, 72MATCH LINE 72MATCH OFFSET 47, 72MATCH_RESULT_TAB 49, 73Matcher-Klasse 75Matcher-Objekt 75matches 52, 78, 79Matching-Operation 104MDMP 252
System 21, 252, 255, 258Mehrfachverwendung 34Meldungsart 493Memory Inspector 420, 506, 519, 525Mengenausdruck 62Menüelement 548MESSAGE 262Message-Server 241Metazeichen 53, 61Methode 396
Assert-Methode 325funktionale 474implizite 495statische 496
Methodenaufruffunktionaler 474
Methodendefinition 488Modifikation 542Modifikationsassistent 541Modultest 311, 323, 326, 328, 477, 478,
479, 481, 489, 497Ablauf 494Ablaufdiagramm 498globale Klasse 489Implementieren 491
Modusinterner 237, 467, 518
Modusnummer 412Modustyp 412
MOVE 29, 510Multibyte-Codepage 21, 25Multi-Display, Multi-Processing-System
� MDMPMuster 53
N
NA 52Nachricht
Senden 433Typ 263
Negationsoperator 62negativer Vorausschauoperator 93Neuer ABAP Debugger 405
Benutzeroberfläche 410, 414Detailsicht 419, 424Einstellen 408Prozessinformation 412Variante 417Werkzeug 419Zwei-Prozess-Architektur 408
nicht vorhandenes Programm 356Nicht-Unicode-System 252, 255numerischer Text 27
O
Oberklasse 397Object Navigator 545Objekt 420, 508
Referenz 508Objektliste 554Objektmenge 316, 334
Definieren 317Objektreferenz 283, 284, 286, 403
Vergleich 487Objektsicht 435OFFSET 48Offset-/Längenzugriff 38operative Anweisung 444Outbound-Destination 271, 292Outbound-Queue 286Outbound-Scheduler 221, 273, 290Outbound-Szenario 271, 281Outbound-Unit
Erstellen 285, 287Sperre aufheben 286Typ Q 287
1151.book Seite 572 Freitag, 9. Januar 2009 4:48 16

573
Index
Typ T 285Out-Inbound-Szenario 281, 290, 291Out-Inbound-Unit 287
queued 287Outside-In-Ansatz 118
P
Paket 546Paketzuordnung 542paralleler RFC � RFCParallelisierung 222, 225, 275Parameter
tiefer 236parameterlose Instanzmethode 480Passwort 245Performanceassistent 377Perl 103, 106Personalisierung 540Pipe-Operator 62Plausibilitätsprüfung 65Plusoperator 99Positionsdetail 550POSIX 103
Standard 69, 106Post-Mortem-Analyse 338Produktivbetrieb 460Produktivsystem 460, 536Profilparameter 328, 357Program Execution Area � PXAProgramm
nicht vorhandenes 356Programmablauf
Analysieren 375Programmprüfung
erweiterte 308, 309, 312Programmzustand 445Protokoll
Eintrag 463, 470Speicher 463
Prozessübersicht 385, 442Prüffehler 493Prüfung
statische 309, 312Prüfvariante 316
Definieren 319Pseudokommentar 315Punktoperator 61PXA 161
Q
QoS 266, 270, 273Typ 270
QoS BE 271, 272QoS EO 270, 271, 272, 274, 282QoS EOIO 270, 271, 274, 275, 278, 281qRFC-Scheduler 220Quality of Service Best Effort � QoS BEQuality of Service Exactly Once In Order
� QoS EOIOQuality of Service Exactly Once � QoS
EOQuality of Service � QoSQuelltext 419
Überprüfen 348Quelltextanzeige 314, 422, 437Quelltextebene 309Quelltexterweiterung 543Quelltextinformation 413Quelltext-Plug-in 543, 545Quelltextposition 392Queue
Präfix 294Sperre löschen 298Statusanzeige 297virtuelle 280
queued RFC � RFC
R
Rangliste 520Realtime Information and Billing System
� RIVARECEIVE RESULTS 213Referenz
Anzeigen 425schwache 518Semantik 508Zähler 513
Referenzvariable 435REFRESH 511REGEX 72Regex 57, 61
Erstellung 107Klasse 74Muster 101Objekt 74Performance 107
1151.book Seite 573 Freitag, 9. Januar 2009 4:48 16

574
Index
Regex (Forts.)Regex Toy 79Ressource 101
Regressionstest 308, 501regulärer Ausdruck � RegexReliable Messaging 272, 274Remote Function Call � RFCRemote-enabled Function Module �
RFMremotefähiger Funktionsbaustein � RFMRemote-Generierung 442Remote-System 295REPLACE 46, 51, 72, 90, 107replace 79REPLACEMENT COUNT 74REPLACEMENT LENGTH 51, 74REPLACEMENT LINE 74REPLACEMENT OFFSET 51, 74Representational State Transfer � REST
ParadigmaRESPECTING CASE 50Ressourcenengpass 346Ressourcenmanagement 289REST
Paradigma 114RESULTS 49RFC 199, 265
Aktion im Workprozess 206asynchroner RFC (aRFC) 210, 212, 223,
228, 231asynchroner RFC (aRFC) mit Antwort
212asynchroner RFC (aRFC) ohne Antwort
210Ausnahmebehandlung 249, 260Auswahl 225Basistyp 215Benutzer 202Bibliothek 209binäres Protokoll 249Client 203Datenübertragung 249Destination 238, 253Eigenschaft 226Einschränkung 265Fehlerprotokoll 263Grundlagen 200Kommunikation 241, 256, 257Kommunikationsfehler 260
RFC (Forts.)Kommunikationsprozess 204Nachricht 262paralleler RFC (pRFC) 222, 223, 224,
229Protokoll 235Prozess 205qRFC-Scheduler 220queued RFC (qRFC) 215, 220, 229, 248Schnittstellendaten 206Server 203Servergruppe 240, 294Sitzung 206synchroner RFC (sRFC) 208, 212, 228Systemfehler 261Trace 246transaktionaler RFC (tRFC) 215, 218,
229, 248Variante 207Workprozess-Ablauf 207
RFM 200, 204, 231, 232, 233Anlegen 233asynchroner RFM 212Ausführen 211Debugging 389Performance 235Robustheit 237Sicherheit 236
RIGHT-JUSTIFIED 44RIVA 538ROLLBACK WORK 218Rollbereich 467Rollbereichsende 409Roll-In 203Roll-Out 203Round-Robin-Verfahren 276Rückgabewert 212, 350Rückwärtsreferenzoperator 91
S
S_MEMORY_INSPECTOR 529SAP Control Framework � CFWSAP Core System 535SAP ERP 6.0 535SAP LUW � LUWSAP NetWeaver 535, 537SAP NetWeaver Application Server ABAP
� AS ABAP
1151.book Seite 574 Freitag, 9. Januar 2009 4:48 16

575
Index
SAP NetWeaver Process Integration 114, 125
SAP Simple Transformations � STSAP-Server 393SAPshortcut 381SAP-Spool-System 387Schalter 543, 546, 552Scheduler
Benutzer 300, 304Schleifenzähler 405schließendes Leerzeichen 23, 33, 38Schnittoperator 106schwache Referenz 518Screen Painter 536, 552SEARCH 46Secure Network Communications � SNCSEPARATED BY 40Serialisierung 113, 118, 126, 249
Standardserialisierung 139Servergruppe 272
Pflegen 294serverspezifische Aktivierung 452Servicebenutzer 300Session-Breakpoint 393, 426SET COUNTRY 43Shared Buffer 159Shared Memory 157, 160, 332
Aufbau 160Überwachung 164Verwaltung 164Werkzeug 164
Shared Objects Monitor 164, 167, 168, 169
Sharing 34, 37, 509SHIFT 42Simple Transformations � STSingle Sign-on 243Single-Byte-Codepage 25SNC 244Software-Lebenszyklus 311Softwarequalität 443Sortierung
topologische 277, 279space 24Speicher
Abzug 528, 529allokierter 515Analyse 525benutzter 515
Speicher (Forts.)gebundener 514Problem 505referenzierter 514Speicherleck 506, 518Verbrauch 507, 514Verwalten 506
Speicheranalyse 420Speichergrenze 192Speicherobjekt
dynamisches 507, 508statisches 507
Speicherverbrauch 359Sperre 179Sperren
mit Versionierung 182ohne Versionierung 181
SPLIT 41Spool-Workprozess 202Sprache 244SQL Trace 337, 433ST 125
Anweisung 129Programm 128, 150Wurzel 129
stabile Struktur 237Standardnotation 279Standardprüfvariante 321starke Zusammenhangskomponente
522, 523statische Methode 496statische Prüfung 309, 312statischer Test 311statisches Speicherobjekt 507Statusanzeige
Queue 297Steueroperation 104Steuerzeichen 22String 32, 195, 237, 508
Literal 32Referenz 508
Struktur 30, 420Komponente 30stabile 237tiefe 36
Strukturkomponente 397, 399Strukturkomponenten-Selektor 30SUBMATCHES 85SUBSTRING 47
1151.book Seite 575 Freitag, 9. Januar 2009 4:48 16

576
Index
Suche 68kontextbasierte 71
Suchergebnis 361Supervisor-Destination 303Support Package 541Switch Framework 546, 547
Architektur 547Switch � SchalterSwitch und Enhancement Framework
535, 536, 558Einführung 542Einsatz 550Funktionsweise 543Integration 536Vorteile 536
symmetrische Transformation 126synchroner RFC � RFCSynchronisation 289Syntaxprüfung 312System
Debugging 461logisches 203Programm 461Protokoll 461, 462
SYSTEM_NO_ROLL 505Systembefehl 383Systembereich 420Systembereichsanzeige 505System-Exception 396Systemfehler 261Systemfeld 349, 402, 413Systemmodul 380Systemprotokoll 337, 339, 340, 384
Ausgeben 340Dateigröße 341Spalte 341
T
T005X 43Tabelle 420, 538
Hash-Tabelle 436Header 404interne 195, 236, 357, 403, 414
Tabellenkörper 508Tabellenreferenz 508Tabellenvergleich 485Taskhandler 289TDD 490
Template 129Haupt-Template 147Unter-Template 148
temporäre Endlosschleife 386temporäres Testprogramm 479Test 477
einrichten 310statischer 311Wiederverwenden 498
TestannahmeÜberprüfen 481
Test-Driven Development � TDDTest-Fixture 326testgetriebene Entwicklung � TDDTestgruppe 331Testhierarchie 492Testisolation 497Testklasse 480, 492
globale 498Hilfsmethode 497lokale 490Vererben 501
Testlauf 316Testlogik 480Testmethode 326, 480, 492, 496, 500
Ausnahmebehandlung 488globale 499
Testperformance 310Testprogramm
temporäres 479Teststrategie 311Testwerkzeug 307
Software-Lebenszyklus 311Überblick 309Verwenden 334
Textextrahieren 59Muster 61numerischer 27transformieren 59validieren 58verarbeiten 57
Textfeldliteral 22Textsprache 258, 260Textübersetzung 425Textumgebung 21Thread 277tiefe Struktur 36Tiefenanalyse 373
1151.book Seite 576 Freitag, 9. Januar 2009 4:48 16

577
Index
tiefer Parameter 236topologische Sortierung 277, 279Trace 246Trace-Ergebnis 361Trace-Variante 359Tracing 357, 368Transaktion
PFCG 300RZ11 207RZ12 224, 321SAAB 449, 463SBGRFCCONF 282, 293, 305SBGRFCMON 295SCI 308, 315, 480, 502SCOV 309, 331SE09 375, 398, 402SE24 325SE30 336, 355, 358SE37 425SE93 378, 398SECATT 309SFW5 548SHMA 164, 188SHMM 164, 167SLG1 299SLIN 308, 313SM21 339SM37 338, 387SM50 385SM51 393SM58 216, 219, 255SM59 205, 239, 292SMLG 241, 294SMQ2 227SMQS 222SMT2 242ST05 433ST11 263ST22 340, 342VA01 442
Transaktion SM37 339transaktionaler RFC � RFCTransaktionskennung 216Transaktionspflege 378, 398Transformation 125
id-Transformation 121symmetrische 126Transformationsrichtung 118umkehrbare 126
TRANSLATE 45Transport Organizer 375, 398, 402Trusted System 242TSV_TNEW_PAGE_ALLOC_FAILED 505tt:apply 148tt:assign 144tt:attribute 132tt:call 149tt:clear 144tt:cond 138tt:context 148tt:copy 135tt:deserialize 137tt:group 142tt:include 149tt:lax 143tt:loop 136tt:parameter 146tt:read 145tt:ref 129tt:root 129tt:serialize 137tt:skip 137tt:switch 138tt:switch-var 146tt:template 129tt:text 132tt:transform 128tt:value 130, 132tt:value-ref 130tt:variable 146tt:with-parameter 149tt:with-root 148tt:write 145TYPE REF TO 509
U
Übereinstimmungerste längste 68genügsame 97gierige 69, 96unerwünschte 98
Übertragungsprotokoll 235, 246, 292Überwachung 226, 227Umfeldmethode 496Umgebungs-Codepage 252, 258umkehrbare Transformation 126unerwünschte Übereinstimmung 98
1151.book Seite 577 Freitag, 9. Januar 2009 4:48 16

578
Index
ungültiger Wert 26Unicode 21Unicode-System 251, 252, 254, 255Uniform Resource Locator � URLUnit 278, 289, 478
Detail 298ID 298Objekt 273Referenz 284, 285Typ 295
Unit Browser 502Unterausdruck 85
ohne Registrierung 108Untergruppe 84Unterprogramm 396Unter-Template 148Update-Prozess 537URL 88User Exit 540
V
VariableAnzeigen 423globale 424
variable Länge 20Variante
Aktivieren 457Deaktivieren 459Pflege 458
Verarbeitungsart 226Verbindung
interne 248logische 302
Verbindungsparameter 205Verbuchung 460
Debugging 461Verbuchungs-Task 271, 288Verbuchungs-Workprozess 202Verdrängbarkeit 192Vererbung 543Vererbungshierarchie
Anzeigen 435verfügbare Erweiterung 556Vergleich
interne Tabelle 485Verkettungsoperator 64Versionierung
Gebietsinstanz 180
Versionierung (Forts.)lange Sperrzeit 185
Verwendungsnachweis 475Verzweigungspunkt 105virtuelle Queue 280Voraballokation 517Vorausschauoperator 93
negativer 93vorbelegtes Feld 375vordefinierte Ausnahme 261vordefinierte Destination 247
W
W3C 122Warnung 493Wartung 446Watchpoint 397, 399, 402, 430, 437
Anlegen 398, 400, 430für interne Tabelle 431Tabellen-Header 404Tipp 432Variable 402Wertevergleich 437
Webservice 114ABAP 125
Werkzeug 413Wert
ungültiger 26, 29Untersuchen 349Vergleich 484
WertehilfeBreakpoint 429
Wertesemantik 508Wertevergleich 437Workprozess 201, 268, 291, 304, 365,
366, 441Dialog-Workprozess 202Enqueue-Workprozess 202Hintergrund-Workprozess 202Spool-Workprozess 202Verbuchungs-Workprozess 202
World Wide Web Consortium � W3CWortgrenze 71WRITE TO 43WRITE_MEMORY_CONSUMPTION_FIL
E 528Wurzelmenge 512Wurzelobjekt 161
1151.book Seite 578 Freitag, 9. Januar 2009 4:48 16

579
Index
X
XHTML 127XI � SAP NetWeaver Process IntegrationXML 113, 115, 235
Infoset 115kanonische Darstellung 119Kommunikation 117Parser 116Schema 117Stream-Reader 126, 152Tag 115
XML Browser 425XPath 124xRFC 249xsequence 36XSLT 122
Programm 123xstring 33
Z
Zeichendarstellung 251Zeichendatentyp 21Zeichenfolge 19Zeichenkette
Vergleich 485Zeichenketten-Template 43Zeichenklasse 63Zeichenkonvertierung 247Zeichenliteral 22Zeichenmodus 25Zeilen-Breakpoint 394Zeitfeld 28Zusammenhangskomponente 522
starke 522, 523zustandsloser Aufruf 210Zuweisung 29Zwei-Phasen-Commit 219
1151.book Seite 579 Freitag, 9. Januar 2009 4:48 16


![Reguläre Ausdrücke / regular expression. P. Brezany2 =~ m/^[\w\-]+@[\.\w\-]+$](https://static.fdocuments.net/doc/165x107/570491c61a28ab14218daf34/regulaere-ausdruecke-regular-expression-p-brezany2-mw-w-.jpg)















