
12. NoSQL - swl.htwsaar.deswl.htwsaar.de/lehre/ws16/dbs/slides/2016-vl-dbs-kap12-nosql.pdf · 2...
32
12. NoSQL
Transcript of 12. NoSQL - swl.htwsaar.deswl.htwsaar.de/lehre/ws16/dbs/slides/2016-vl-dbs-kap12-nosql.pdf · 2...

12. NoSQL

2
Inhalt§ 12.1 NoSQL?
§ 12.2 MapReduce & Co
§ 12.3 Key-Value Stores
§ 12.4 Extensible Record Stores
§ 12.5 Dokumentorientierte Datenbanken
§ 12.6 Graphdatenbanken
Datenbanken / Kapitel 11: Datenbankschnittstellen

3
12.1 NoSQL?§ Relationale Datenbanksysteme (RDBMSs) bieten u.a.
§ konzeptuellen Entwurf mit Schema in Normalform (3NF)zur redundanzfreien Speicherung der Daten
§ eine deklarative Anfragesprache SQL, d.h. Anfragen spezifizieren nur das Ergebnis, jedoch nichtwie es ermittelt werden soll
§ ACID-Transaktionen, deren Implementierung Mechanismenwie Sperren und Verlaufsprotokolle benötigt
§ Sicherung der Datenintegrität mittels Constraints(z.B. Fremdschlüssel, UNIQUE, CHECK)
§ Benutzerverwaltung und Berechtigungen
Datenbanken / Kapitel 11: Datenbankschnittstellen

4
NoSQL?§ Konzeptueller Entwurf nimmt an, dass der abzubildende
Abschnitt der Realität feststeht; späteres Hinzufügenoder Entfernen von Attributen ist nicht vorgesehen
§ ACID-Transaktionen sind nützlich, aber mit Kosten zur Laufzeit verbunden; nicht alle Anwendungen benötigen sie
§ Deklarative Anfragesprache unterbindet Einflussnahmedurch Entwickler auf die Anfragebearbeitung
§ Heutige Datenmengen lassen sich häufig nicht auf einemleistungsstarken Rechner verwalten, sondern müssenüber viele Rechner verteilt werden
Datenbanken / Kapitel 11: Datenbankschnittstellen

5
NoSQL?§ Das Schlagwort NoSQL fasst verschiedene Entwicklungen
seit Mitte der 2000er Jahre zusammen, z.B.
§ Alternativen zum relationalen Modell (z.B. Modellierung der Daten in Form von Dokumenten oder eines Graphs)
§ Unterstützung flexibler Schema (d.h. Attribute können ohne Einbußen hinzugefügt oder entfernt werden)
§ Verzicht auf deklarative Anfragesprache zu Gunsten von Implementierung der Anfragebearbeitung durch Entwickler
§ Speicherung und Verarbeitung der Daten erfolgt oft verteiltauf viele herkömmliche Rechner, anstatt auf einem oder wenigen sehr leistungsstarken Rechner
Datenbanken / Kapitel 11: Datenbankschnittstellen

6
12.2 MapReduce & Co§ MapReduce [3] ist eine bei Google von Jeff Dean und
Sanjay Ghemawat entwickelte Plattform zur verteilen Speicherung und Bearbeitung großer Datenmengen
§ Bestandteile:
§ verteiltes Dateisystem GFS (HDFS bei Hadoop)
§ MapReduce Programmiermodell
§ Herausforderungen:
§ Lastbalancierung
§ Fehlertoleranz
§ Benutzerfreundlichkeit
Datenbanken / Kapitel 11: Datenbankschnittstellen
Jeff Dean
Sanjay Ghemawat

7
Jeff Dean Facts§ When Jeff Dean designs software, he first codes the binary
and then writes the source as documentation.
§ Compilers don’t warn Jeff Dean. Jeff Deanwarns compilers.
§ Jeff Dean's keyboard has two keys: 1 and 0.
§ When Graham Bell invented the telephone, he saw a missed call from Jeff Dean.
§ Jeff Dean's PIN is the last 4 digits of pi
§ http://www.quora.com/Jeff-Dean/What-are-all-the-Jeff-Dean-facts
Datenbanken / Kapitel 11: Datenbankschnittstellen
8
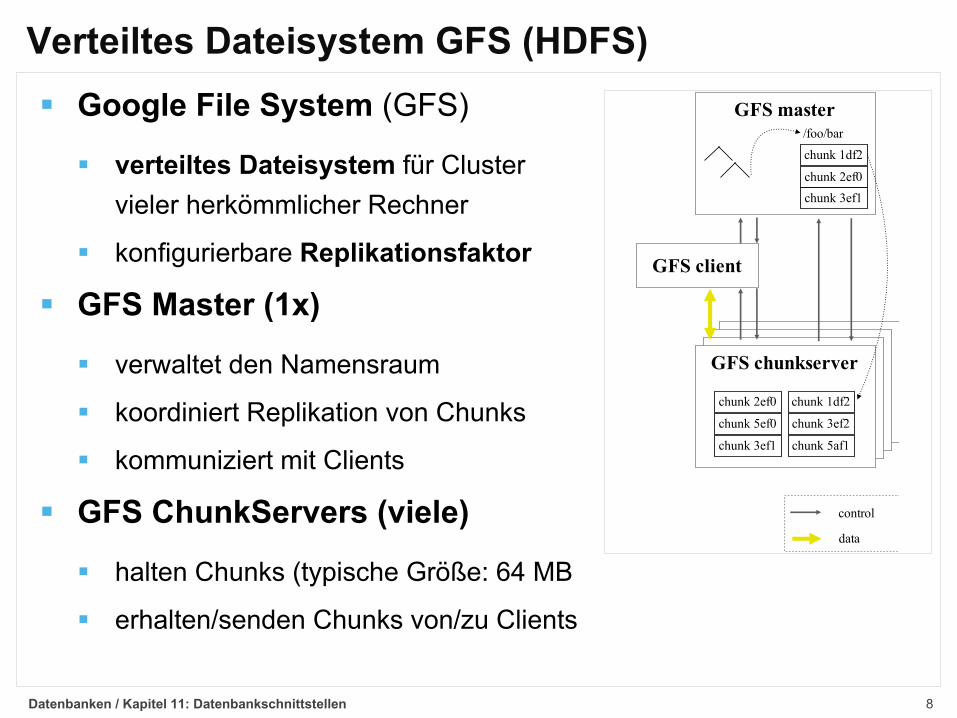
Verteiltes Dateisystem GFS (HDFS)
Datenbanken / Kapitel 11: Datenbankschnittstellen
§ Google File System (GFS)
§ verteiltes Dateisystem für Clustervieler herkömmlicher Rechner
§ konfigurierbare Replikationsfaktor
§ GFS Master (1x)
§ verwaltet den Namensraum
§ koordiniert Replikation von Chunks
§ kommuniziert mit Clients
§ GFS ChunkServers (viele)
§ halten Chunks (typische Größe: 64 MB
§ erhalten/senden Chunks von/zu Clients
GFS master
chunk 1df2
chunk 2ef0
chunk 3ef1
/foo/bar
GFS chunkserver
chunk 2ef0
chunk 5ef0
chunk 3ef1
chunk 1df2
chunk 3ef2
chunk 5af1
GFS client
control
data

9
MapReduce als Plattform
Datenbanken / Kapitel 11: Datenbankschnittstellen
§ MapReduce (MR)
§ Plattform zur verteiltenDatenverarbeitung
§ Berechnungen werden zuden Daten bewegt
§ kann Ausfälle von Rechnernin Maßen kompensieren
§ MR Master (1x)
§ koordiniert Ausführung eines Jobs
§ verteilt Aufgaben auf Clients
§ MR Workers (viele)
§ führen zugewiesene Aufgaben aus
GFS chunkserver
MR worker
GFS chunkserver
MR worker
GFS chunkserver
MR worker
GFS chunkserver
MR worker
MR master
control
MR client
assign tasks
report progress

10
MapReduce als Programmiermodell§ MapReduce setzt auf ein einfaches Programmiermodell,
welches von funktionalen Programmiersprachen(z.B. ML und Haskell) inspiriert ist
§ Daten als Schlüssel-Wert-Paare (key-value pairs)
§ Aufgabe in Form von zwei Funktionen ausgedrückt
§ map() : (k1, v1) => list(k2, v2) liest die Eingabedaten alsSchlüssel-Wert-Paare (k1, v1) und produziert für jedeseinen oder mehrere Schlüssel-Wert-Paare (k2, v2)
§ reduce() : (k2, list(v2)) => list(k3, v3) liest Ausgabe von map() gruppiert und sortiert nach Schlüssel k2 und gibt für jede Gruppe ein oder mehrere Schlüssel-Wert-Paare (k3, v3) aus
Datenbanken / Kapitel 11: Datenbankschnittstellen

11
MapReduce als Programmiermodell§ Funktion map() wird verteilt auf den Eingabedaten im GFS
ausgeführt; jeder MR Worker soll die Funktion lokalauf den bei ihm gespeicherten Daten ausführen
§ Zwischen Ausführung der Funktionen map() und reduce()werden die Daten nach den Werten der Schlüssel k2gruppiert und sortiert; alle Schlüssel-Wert-Paare mit bestimmtem Wert k2 landen auf einem Rechner
§ Funktion reduce() wird verteilt auf gruppierten und sortierten Schlüssel-Wert-Paaren (k2, list(v2)) ausgeführt und schreibt Ausgabe ins GFS
Datenbanken / Kapitel 11: Datenbankschnittstellen

12
Wörter Zählen mit MapReduce§ Problem: Zähle wie oft jedes Wort in einer sehr großen
Dokumentensammlung vorkommt
Datenbanken / Kapitel 11: Datenbankschnittstellen
1 map(long did , String content ) {
2 for( String word : content .split ()) {
3 emit(word , 1);
4 }
5 }
1 reduce ( String word , List <long > counts ) {
2 int total = 0;
3 for(long count : counts ) {
4 sum += count;
5 }
6 emit(word , total );
7 }

13
Ausführung in MapReduce
Datenbanken / Kapitel 11: Datenbankschnittstellen
d123a x bb a y
d242b y ax a b
(a,4)(b,4)
…
(x,2)(y,2)
…
Map
M1
Mn
(a,d123),(x,d242),
…
(b,d123),(y,d242),
…
map()
Reduce
R1
Rm
(a,d123),(a,d242),
…
(x,d123),(x,d242),
…
reduce()
Sort1
m
1
m
1
m
1
m
partition()compare()

14
Apache Hadoop§ Open-Source Implementierung von MapReduce§
§ Hadoop File System (HFS)
§ name node (master)
§ data node (chunkserver)
§ Hadoop MapReduce
§ job tracker (master)
§ task tracker (worker)
§ Produktiver Einsatz auf Clustern mit > 10.000 Rechnernbei Unternehmen wie Yahoo!, Ebay, etc.
§ https://hadoop.apache.orgDatenbanken / Kapitel 11: Datenbankschnittstellen
Doug Cutting

15
Apache Hive§ Apache Hive bietet eine an SQL
angelehnte Anfragesprache(Selektion, Projektion, Join)zum Verarbeiten im HDFSgespeicherter Daten(z.B. als CSV-Datei)
§ Anfragen werden automatisch in einen oder mehrere MapReduce-Jobs übersetzt und dannverteilt auf den Daten ausgeführt
§ https://hive.apache.org
Datenbanken / Kapitel 11: Datenbankschnittstellen

16
Apache PIG§ Apache Pig bietet eine Programmiersprache,
die Ideen von SQL und prozeduralerProgrammiersprachen vereint
§ Programme werden automatisch inein oder mehrere MapReduce-Jobsübersetzt und dann verteilt aufden Daten ausgeführt
§ https://pig.apache.org
Datenbanken / Kapitel 11: Datenbankschnittstellen

17
Beispiel Apache Pig
Datenbanken / Kapitel 11: Datenbankschnittstellen
1 USERS = load ’data/users ’ using PigStorage (’\t’)2 as (id:int , email :chararray , language :chararray , location : chararray );3
4 TRANSACTIONS = load ’data/ transactions ’ using PigStorage (’\t’)5 as (id:int , product :int , user:int , purchase_amount :double , description : chararray );6
7 A = JOIN TRANSACTIONS by user LEFT OUTER , USERS by id;8
9 B = GROUP A by product ;10
11 C = FOREACH B {12 LOCS = DISTINCT A. location ;13 GENERATE group , COUNT(LOCS) as location_count ;14 };15 DUMP C;

18
Apache Drill und Cloudera Impala§ Apache Drill und Cloudera Impala
erlauben SQL Anfragen fürDaten, die z.B. in HDFSgespeichert sind
§ Im Gegensatz zu Apache Hiveund Apache Pig werden dieAnfragen selbst bearbeitetund nicht in MapReduce-Jobsübersetzt
§ https://drill.apache.org
§ http://impala.ioDatenbanken / Kapitel 11: Datenbankschnittstellen

19
Distributionen von Hadoop & Co§ Hadoop, Hive, Pig, etc. sind Open-Source Projekte
mit großer Unterstützung namhafter Unternehmen;sie entwickeln sich mit unterschiedlicher Geschwindigkeitund es ist nicht garantiert, dass die neuesten Versionender Projekte miteinander kompatibel sind
§ Distributoren stellen zueinander kompatible Versionender Projekte mit Dokumentation und zusätzlichenWerkzeugen (z.B. zur Installation) zur Verfügung
§ http://www.cloudera.com
§ http://hortonworks.com
§ http://mapr.com
Datenbanken / Kapitel 11: Datenbankschnittstellen

20
12.3 Key-Value Stores§ Key-Value Stores speichern Schlüssel-Wert-Paare
wie (37821, „Max Müller“) und bieten zumindestfolgende Methoden zum Zugriff
§ set(key, value) legt Wert zu Schlüssel ab
§ get(key) holt Wert zu Schlüssel
sofern die zugrundeliegende Datenstruktur die Ordnung derWerte beibehält, gibt es zudem Bereichsanfragen
§ range(low, high) holt Werte mit Schlüsseln im Bereich
§ Schlüssel und Werte sind intern meist byte[], Entwickler muss sich um Serialisierung/Deserialisierung kümmern
Datenbanken / Kapitel 11: Datenbankschnittstellen

21
BerkeleyDB§ BerkeleyDB ist ein Key-Value-Store zum Betrieb auf
einem Rechner, der zudem (ähnlich SQLite) in Anwendungen eingebettet werden kann
§ BerkeleyDB basiert auf einem B+-Baum als Datenstrukturund unterstützt somit auch Bereichsanfragen
§ BerkeleyDB Java Edition bietet sogenannte StoredCollections; diese implementieren die von Javabekannten Interfaces List und Map und lagernDaten transparent im Sekundärspeicher aus
§ http://www.oracle.com/us/products/database/berkeley-db/overview/index.html
Datenbanken / Kapitel 11: Datenbankschnittstellen

22
Redis§ Redis ist ein verteilter Key-Value Store,
der Daten im Hauptspeicher derRechner hält, sofern keineDauerhaftigkeit sichergestelltwerden muss
§ Replikation (d.h. die gleichen Daten werden mehrfachgehalten) erlaubt zudem eine Skalierungbei Wachstum der Anfragelast
§ http://redis.io
Datenbanken / Kapitel 11: Datenbankschnittstellen

23
12.4 Extensible Record Stores§ Extensible Record Stores erweitern die Idee von Key-
Value Stores, indem sie für den Wert eine Struktur(ähnlich dem Schema einer Tabelle) zulassen
§ Schlüssel ist weiterhin z.B. ein byte[]
§ Wert besteht aus Paaren von Spaltenname und -wert
§ Im Gegensatz zum relationalen Modell gibt es kein fixes Schema und das System ist für dünnbesetzte Datenoptimiert, d.h. Spalten für die meisten Daten unbekannt
§ BigTable als ein bei Google entwickeltes System war Vorreiter der Extensible Record Stores
Datenbanken / Kapitel 11: Datenbankschnittstellen

24
Hbase & Co§ Open-Source Implementierung
von Google‘s BigTable [4]
§ Daten werden im verteilten DateisystemHDFS von Hadoop gespeichert undrepliziert zur Lastverteilung undAusfallsicherheit
§ Transaktionen nur für Zugriff auf einzelne Schlüssel
§ https://hbase.apache.org
§ Ähnliches Projekt: http://cassandra.apache.org
Datenbanken / Kapitel 11: Datenbankschnittstellen

25
12.5 Dokumentorientierte Datenbanken§ Dokumentenorientierte Datenbanken (document
databases) modellieren die Daten als Dokumente in einem Format wie JSON (JavaScript Object Notation)
§ Beispiel: Student als JSON-Dokument
Datenbanken / Kapitel 11: Datenbankschnittstellen
1 {
2 " matrnr " : 37821 ,
3 "name" : "Max",
4 " vorname " : "M
¨
uller",
5 " semester " : 9,
6 " anschrift " : {
7 " strasse " : " hauptstra ße",
8 " hausnummer " : 34,
9 "plz" : 66117 ,
10 "stadt" : " saarbr
¨
ucken"
11 }
12 " vorlesungen " : [" Datenbanken "," Programmierung 2"]
13 }

26
Dokumentenorientierte Datenbanken§ Zugriff auf so gespeicherte Daten dann mittels
Anfrageprädikaten z.B.
§ Systeme bieten teilweise zusätzliche Funktionalität
§ Gruppierung und Aggregation (MongoDB)
§ MapReduce zur Anfrageformulierung (CouchDB)
§ Indizes auf ausgewählten Attributen (MongoDB, CouchDB)
§ Verteilung und Replikation zur Skalierung bei großen Datenmengen und/oder hoher Anfragelast
Datenbanken / Kapitel 11: Datenbankschnittstellen
1 {name:"Max", semester :9}

27
MongoDB & CouchDB§ MongoDB erwartet Dokumente
im JSON-Format; erlaubtAnfrageterminologie anSQL angelehnt
§ https://www.mongodb.org
§ CouchDB erwartet Dokumenteim JSON-Format; erlaubtImplementierung vonAnfragen in MapReduce
§ http://couchdb.apache.org
Datenbanken / Kapitel 11: Datenbankschnittstellen

28
12.6 Graphdatenbanken§ Graphdatenbanken (graph databases) modellieren die
Daten als einen gerichteten Graphen mitBeschriftungen an Knoten und Kanten
Datenbanken / Kapitel 11: Datenbankschnittstellen
MatrNr: 37821Vorname : „Max“Name : „Müller“Semester : 9
VorlNr: 1303Titel : „Datenbanken“SWS : 4
ProfNr: 22Vorname : „Donald“Name : „Knuth“
hörtliest

29
Graphdatenbanken§ Festes Schema, wie beim relationalen Modell, ist meist
nicht erforderlich, d.h. neue Beschriftungen fürKanten und Knoten können hinzugefügt werden
§ Triple Stores für Daten im Semantic-Web Format RDFmit Anfragesprache SPARQL sind Spezialfall von Graphdatenbanken (vgl. Vlen zu Linked Open Data)
§ Anfragen als Pfadausdrücken formuliert, z.B.
findet Studenten, die Vorlesung beim Professor hören,der (auch) Datenbanken liest
Datenbanken / Kapitel 11: Datenbankschnittstellen
1 (?s) = h
¨
ort => v <= liest ( ) => liest (titel : " Datenbanken ")

30
Neo4J§ Neo4J zum Betrieb auf einem
Rechner; bietet mit Cypher eineeigene Anfragesprache, dieauch Graphoperationen wiekürzeste Pfade unterstützt
§ http://neo4j.com
§ OrientDB zum Betrieb auf mehrerenRechnern; unterstützt SQL alsAnfragesprache
§ http://orientdb.com
Datenbanken / Kapitel 11: Datenbankschnittstellen

31
Zusammenfassung§ NoSQL bieten Alternativen zu RDBMSs für Anwendungen,
die z.B. keine ACID-Transaktionen benötigen, keinrigides Schema festlegen können oder ihre Daten aufviele herkömmliche Rechner verteilen müssen
§ Bei rudimentären Systemen (z.B. Key-Value Stores) müssen Entwickler vieles, was bei einem RDBMS gegeben ist, beispielsweise Joins, selbst implementieren
§ SQL als Anfragesprache spielt auch in NoSQL-Systemeneine Rolle und wird zunehmend „nachgerüstet“(z.B. Apache Drill und Cloudera Impala)
Datenbanken / Kapitel 11: Datenbankschnittstellen

32
Literatur[1] A. Kemper und A. Eickler: Datenbanksysteme – Eine
Einführung, De Gruyter Oldenbourg, 2015 (Kapitel 21)
[2] L. Wiese: Advanced Data Management for SQL, NoSQL, Cloud and Distributed Databases,DeGruyter, 2015
[3] J. Dean und S. Ghemawat: MapReduce: a flexible dataprocessing tool, OSDI 2004
[4] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, R. E. Gruber: Bigtable: A Distributed Storage System forStructured Data, ACM TODS 26(2), 2008
Datenbanken / Kapitel 11: Datenbankschnittstellen


















