
1 Recap (Pipelining). 2 What is Pipelining? A way of speeding up execution of tasks Key idea :...
31
1 Recap Recap (Pipelining) (Pipelining)
-
date post
20-Dec-2015 -
Category
Documents
-
view
222 -
download
3
Transcript of 1 Recap (Pipelining). 2 What is Pipelining? A way of speeding up execution of tasks Key idea :...

1
RecapRecap(Pipelining)(Pipelining)

2
What is Pipelining?• A way of speeding up execution of tasks
• Key idea:
overlap execution of multiple taks

3
Automobile Manufacturing1. Build frame. 60 min.
2. Add engine. 50 min.
3. Build body. 80 min.
4. Paint. 40 min.
5. Finish. 45 min.
275 min.
Latency: Time from start to finish for one car.
Throughput: Number of finished cars per time unit.
1 car/275 min = 0.218 cars/hour
275 minutes per car.
Issues: How can we make the process better by adding?
(smaller is better)
(larger is better)

4
An Assembly line
1
1
1
1
1
2
2
2
2
2
3
3
3
3
3
4
4
4
4
4
60 50 80 40 45
First two stagescan’t produce faster thanone car/80 min or a backlog will occurat third stage.
80 80
Last two stages only receive onecar/80 min to work on.
80 80
Latency: 400 min/carThroughput: 4 cars/640 min (1 car/160 min)
time
Will approach 1 car/80 min as time goes on

5
Pipelining a Digital System
• Key idea: break big computation up into pieces
Separate each piece with a pipeline register
1ns
200ps 200ps 200ps 200ps 200ps
PipelineRegister
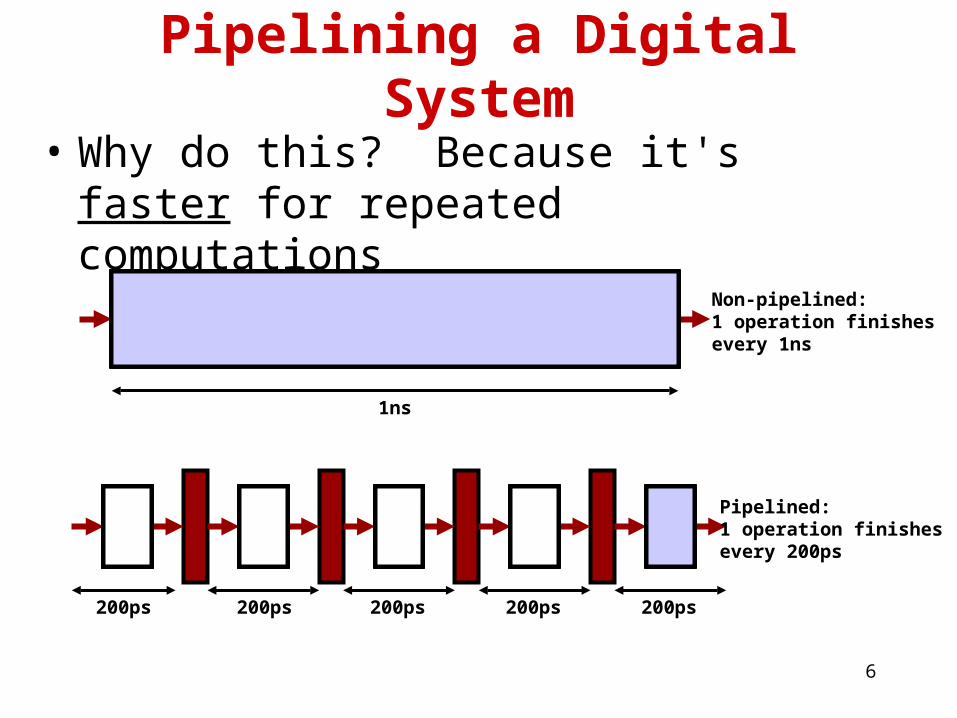
6
Pipelining a Digital System
• Why do this? Because it's faster for repeated computations
1ns
Non-pipelined:1 operation finishesevery 1ns
200ps 200ps 200ps 200ps 200ps
Pipelined:1 operation finishesevery 200ps

7
Comments about pipelining
• Pipelining increases throughput, but not latency
– Answer available every 200ps, BUT
– A single computation still takes 1ns
• Limitations:
– Computations must be divisible into stages of equal sizes
– Pipeline registers add overhead
8
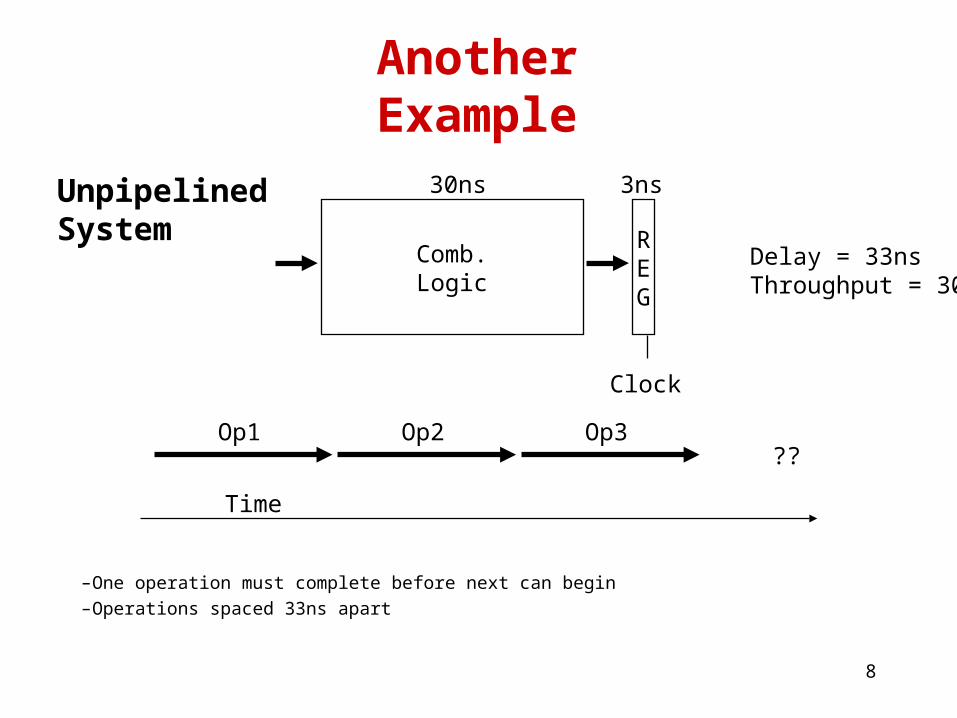
Another Example
Comb.Logic
REG
30ns 3ns
Clock
Delay = 33nsThroughput = 30MHz
Time
UnpipelinedSystem
Op1 Op2 Op3??
– One operation must complete before next can begin– Operations spaced 33ns apart

9
3 Stage Pipelining
– Space operations 13ns apart
– 3 operations occur simultaneously
REG
Clock
Comb.Logic
REG
Comb.Logic
REG
Comb.Logic
10ns 3ns 10ns 3ns 10ns 3ns
Delay = 39nsThroughput = 77MHz
Time
Op1
Op2
Op3
Op4
10
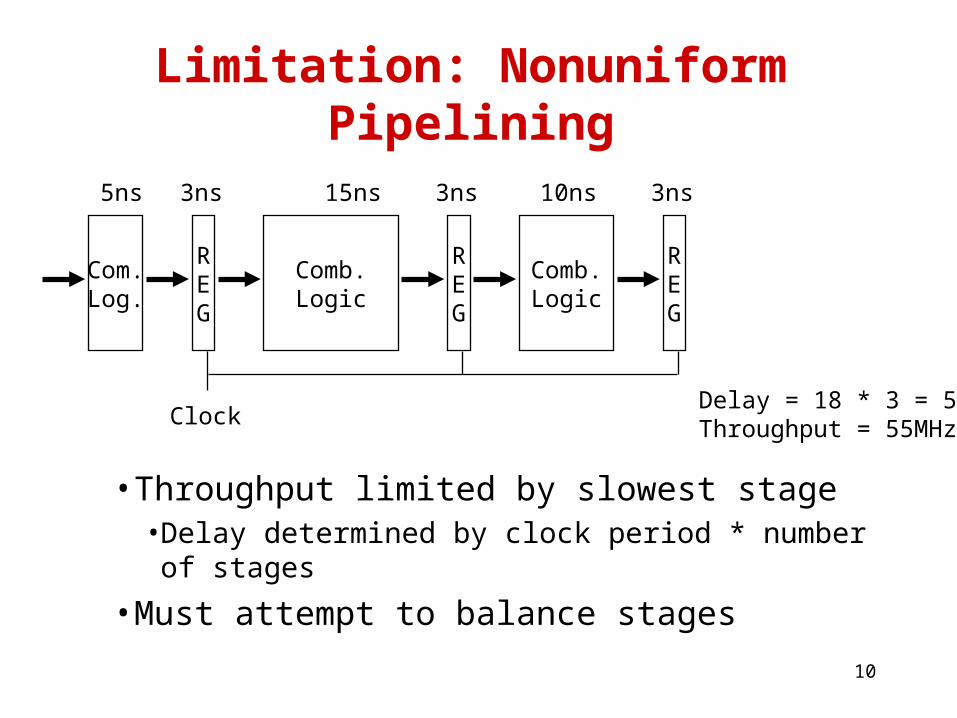
Limitation: Nonuniform Pipelining
Clock
REG
Com.Log.
REG
Comb.Logic
REG
Comb.Logic
5ns 3ns 15ns 3ns 10ns 3ns
Delay = 18 * 3 = 54 nsThroughput = 55MHz
• Throughput limited by slowest stage• Delay determined by clock period * number of stages
• Must attempt to balance stages
11
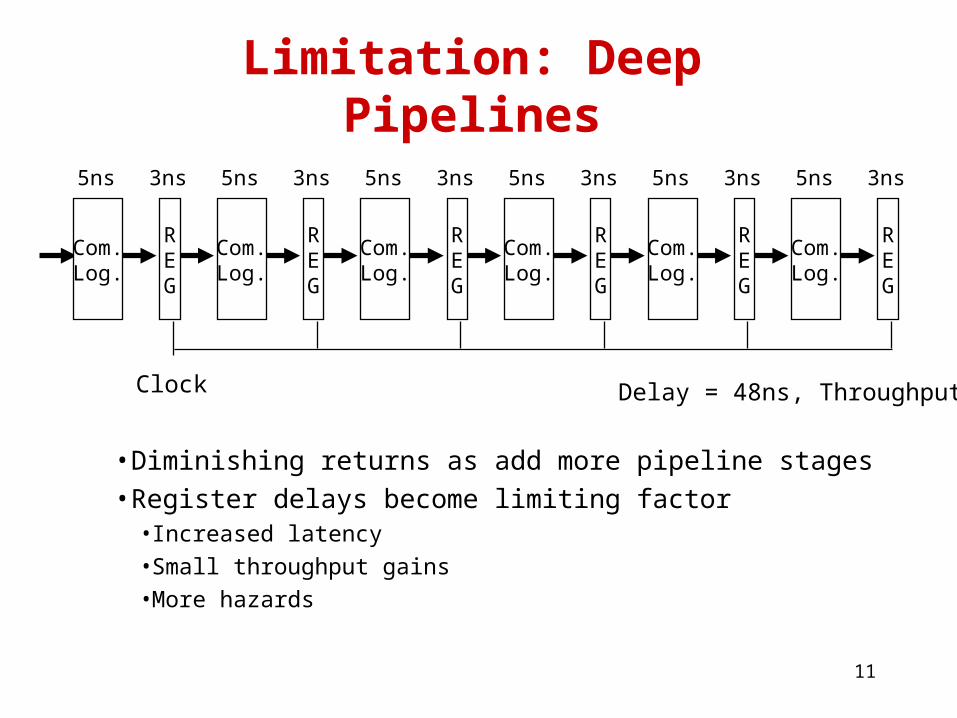
Limitation: Deep Pipelines
• Diminishing returns as add more pipeline stages• Register delays become limiting factor
• Increased latency• Small throughput gains• More hazards
Delay = 48ns, Throughput = 128MHzClock
REG
Com.Log.
5ns 3ns
REG
Com.Log.
5ns 3ns
REG
Com.Log.
5ns 3ns
REG
Com.Log.
5ns 3ns
REG
Com.Log.
5ns 3ns
REG
Com.Log.
5ns 3ns

12
MIPSPipeliningPipelining

13
MIPS 5-stage pipelineMIPS 5-stage pipeline• The MIPS processor needs 5 stages to execute instructions
• Pipelining stages:– IF - Instruction Fetch
– ID - Instruction Decode
– EX - Execute / Address Calculation
– MEM - Memory Access (read / write)
– WB - Write Back (results into register file)
• Not all instructions need all the stages (e.g., add instruction does not need the MEM stage)
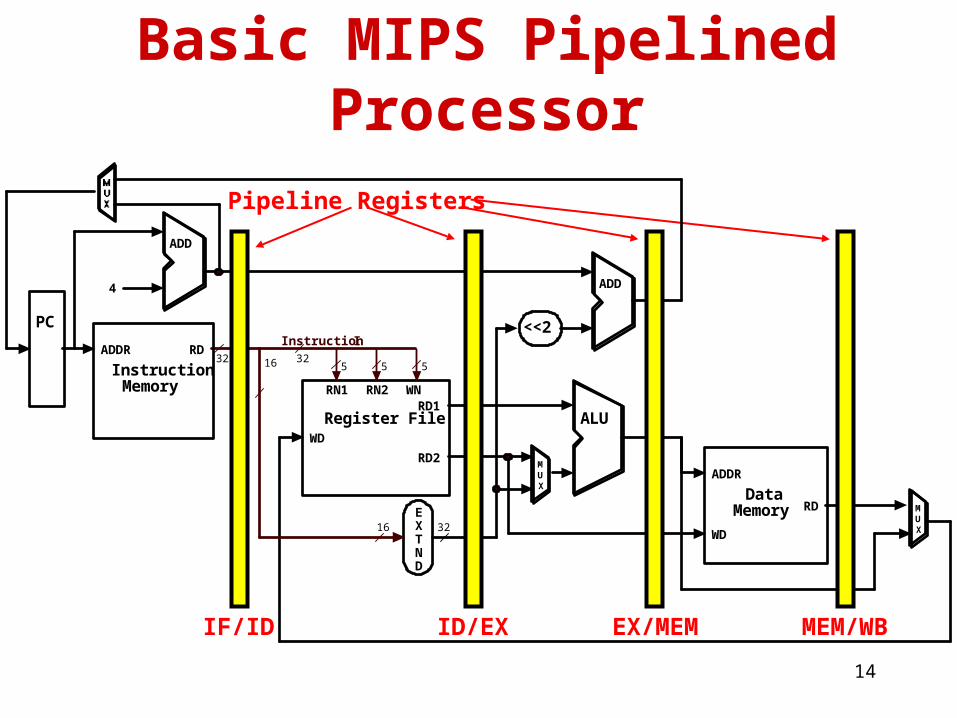
14
Basic MIPS Pipelined Processor
IF/ID
Pipeline Registers
5 516
RD1
RD2
RN1 RN2 WN
WD
Register File ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
5
Instruction I32
MUX
<<2RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
32
ID/EX EX/MEM MEM/WB

15
Pipelined Example - Executing Multiple Instructions
• Consider the following instruction sequence:
lw $r0, 10($r1)
sw $sr3, 20($r4)
add $r5, $r6, $r7
sub $r8, $r9, $r10
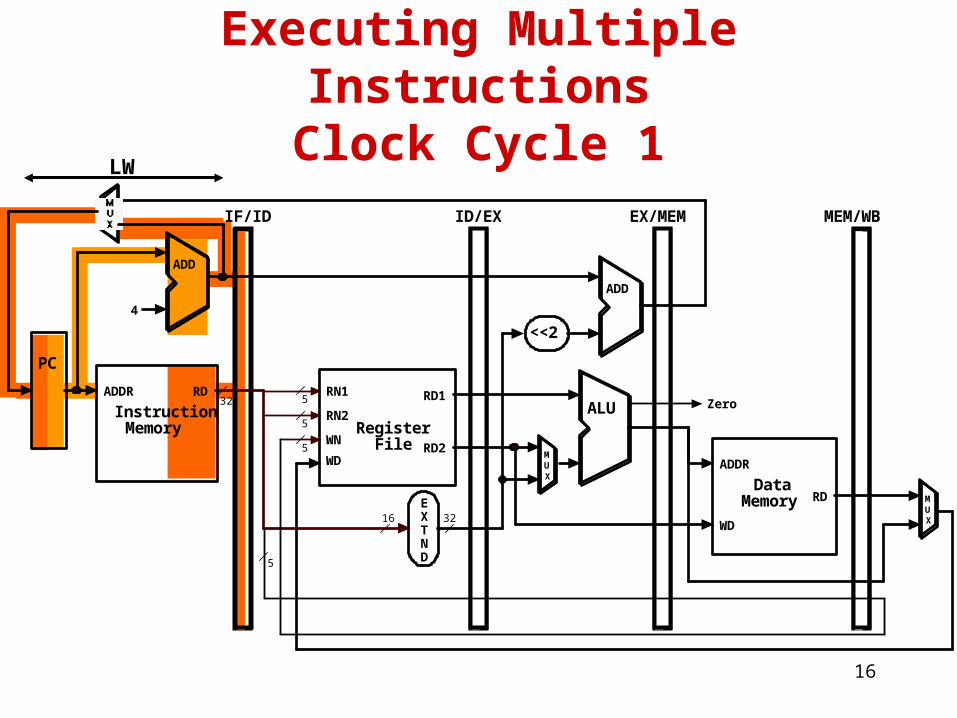
16
Executing Multiple InstructionsClock Cycle 1
LW
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
17
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
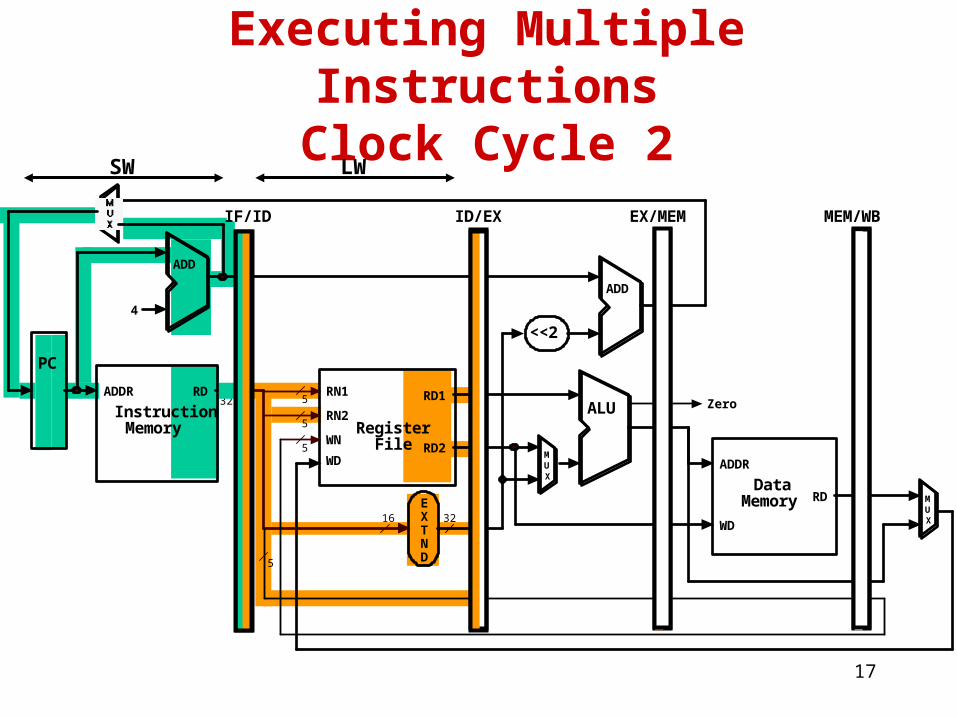
Executing Multiple InstructionsClock Cycle 2
LWSW
18
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
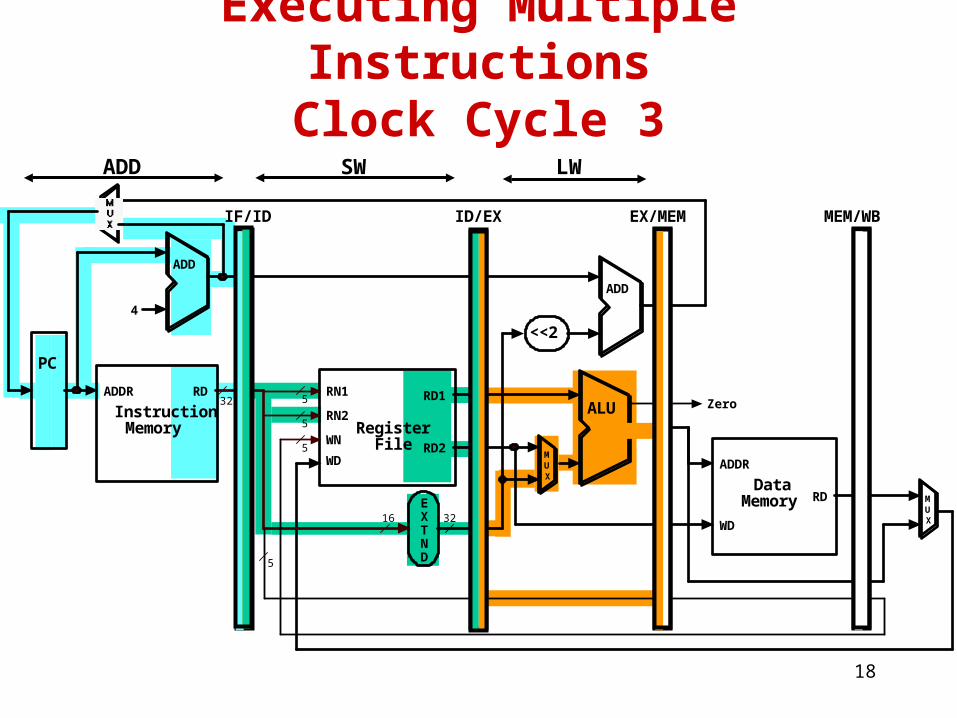
Executing Multiple InstructionsClock Cycle 3
LWSWADD
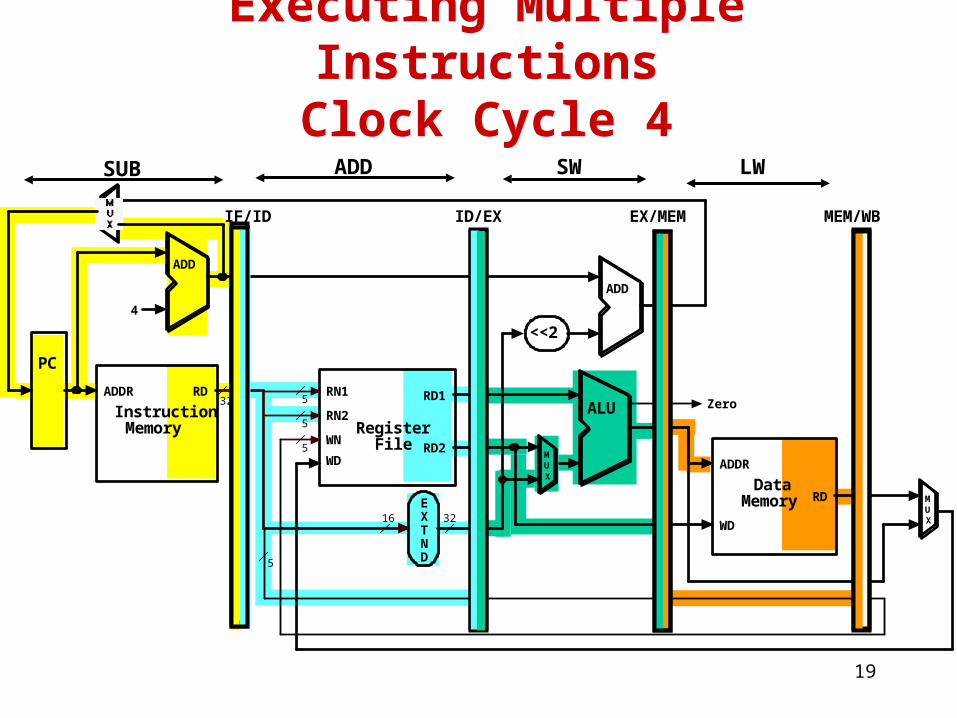
19
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
Executing Multiple InstructionsClock Cycle 4
LWSWADDSUB
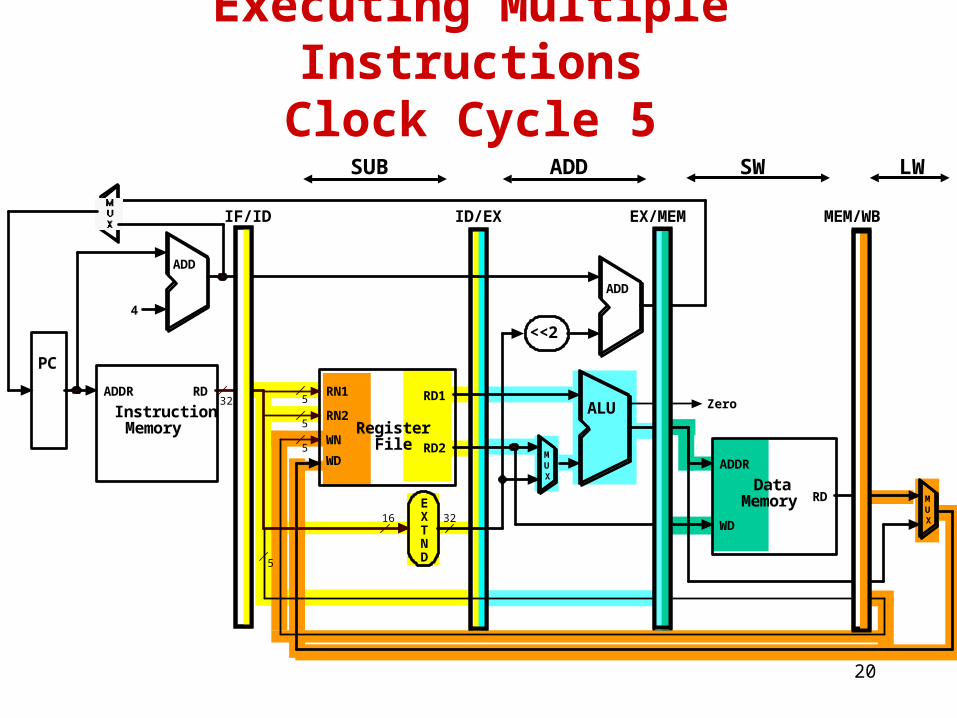
20
Executing Multiple InstructionsClock Cycle 5
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
LWSWADDSUB
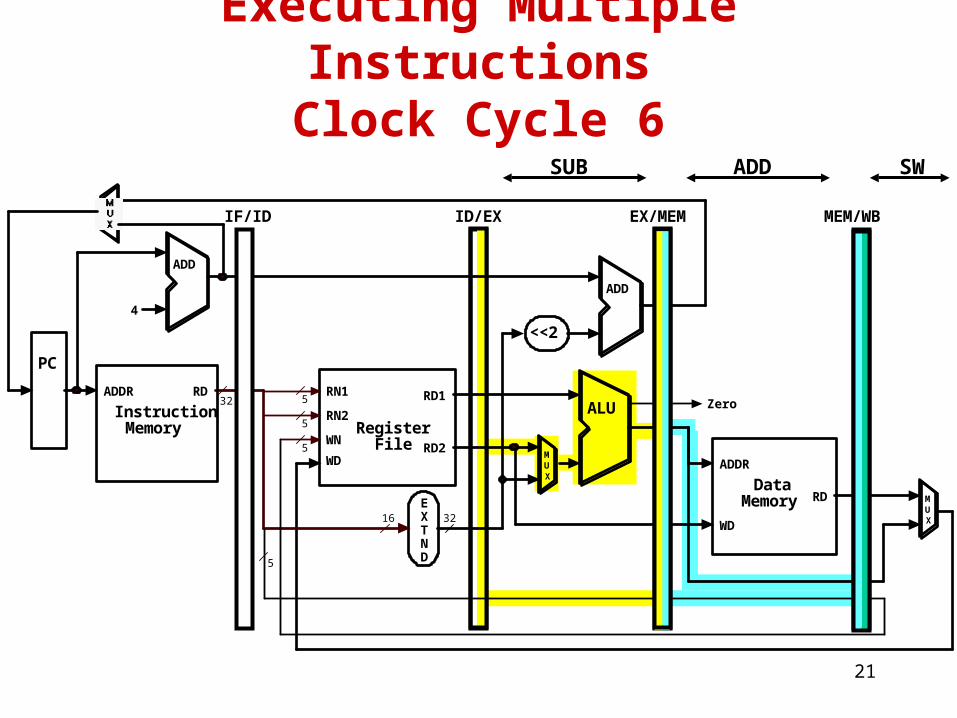
21
Executing Multiple InstructionsClock Cycle 6
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
SWADDSUB

22
Executing Multiple InstructionsClock Cycle 7
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
ADDSUB
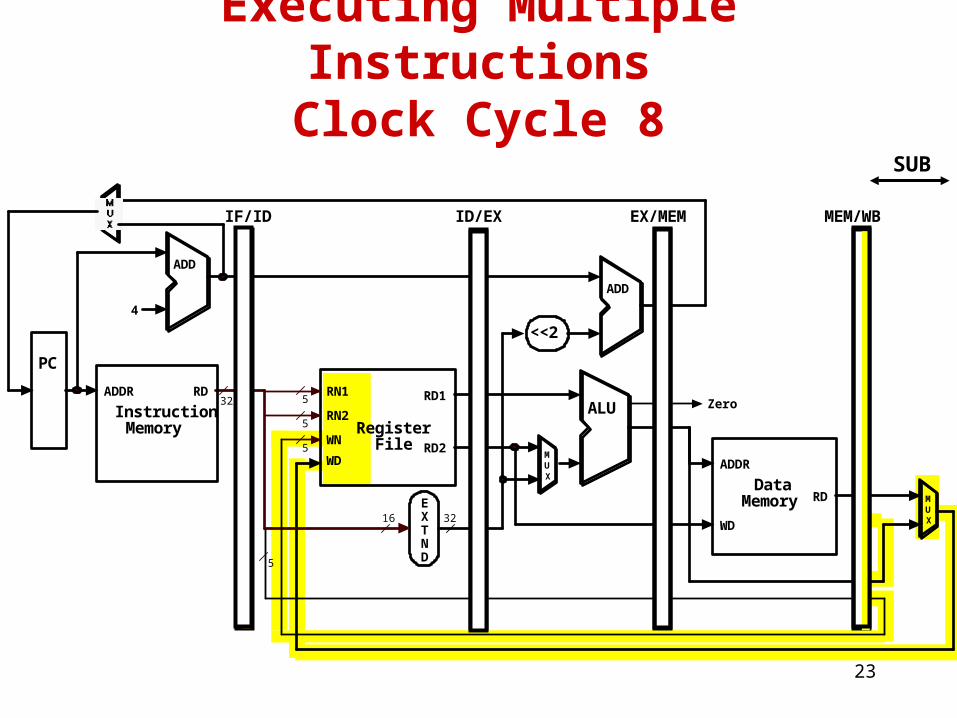
23
Executing Multiple InstructionsClock Cycle 8
5
RD1
RD2
RN1
RN2
WN
WD
RegisterFile
ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
32
MUX
<<2
RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
5
5
5
IF/ID ID/EX EX/MEM MEM/WB
Zero
SUB
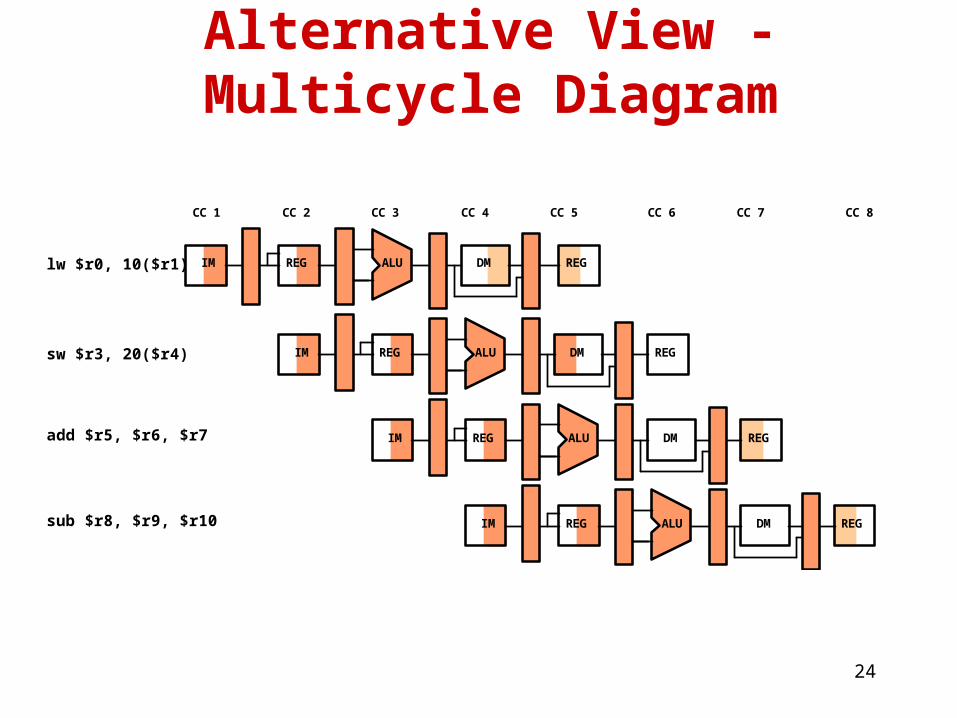
24
Alternative View - Multicycle Diagram
IM REG ALU DM REGlw $r0, 10($r1)
sw $r3, 20($r4)
add $r5, $r6, $r7
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7
IM REG ALU DM REG
IM REG ALU DM REG
sub $r8, $r9, $r10 IM REG ALU DM REG
CC 8

25
Processor Pipelining
• There are two ways that pipelining can help:
1. Reduce the clock cycle time, and keep the same CPI
2. Reduce the CPI, and keep the same clock cycle time
CPU time = Instruction count * CPU time = Instruction count * CPICPI * * Clock cycle timeClock cycle time

26
Reduce the clock cycle time, and keep Reduce the clock cycle time, and keep the same CPIthe same CPI
5 516
RD1
RD2
RN1 RN2 WN
WD
Register File ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
5
Instruction I32
MUX
<<2RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
32
CPI = 1CPI = 1
Clock = X HzClock = X Hz
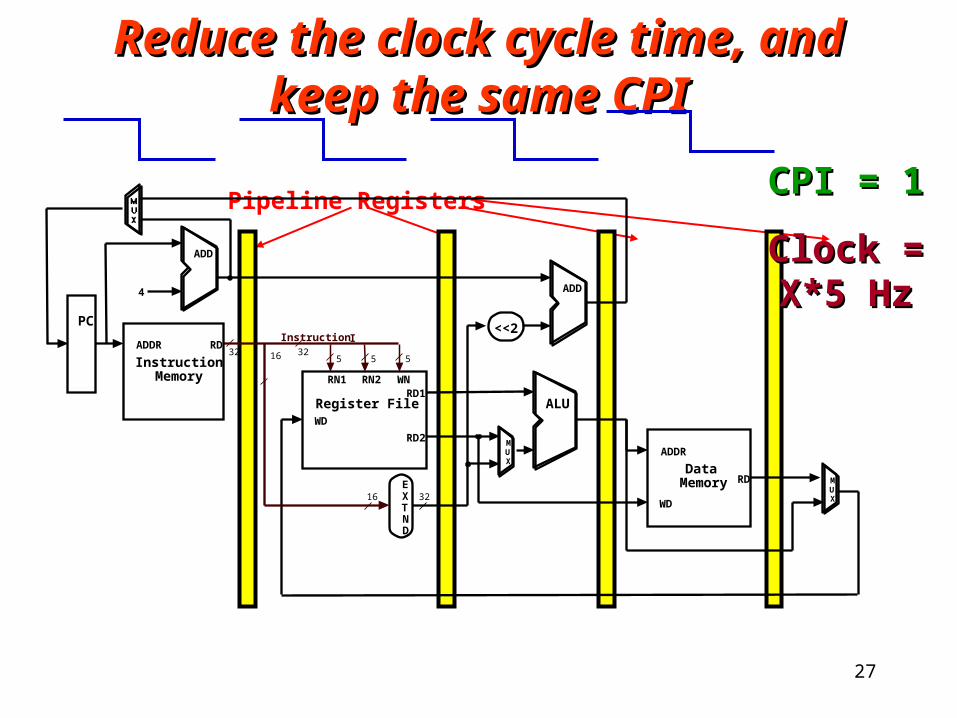
27
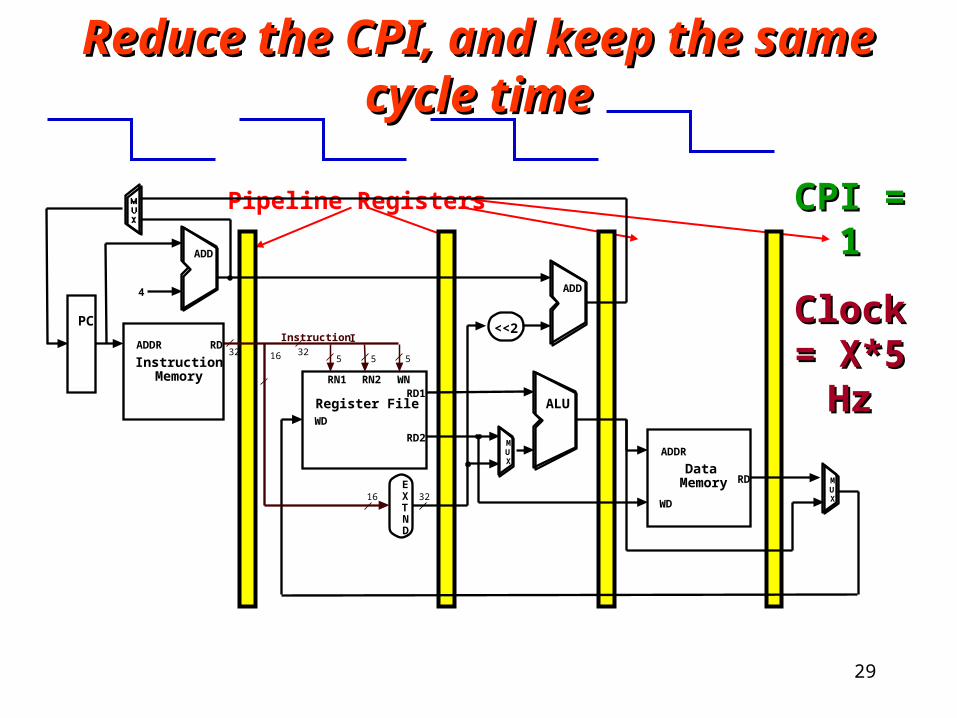
Reduce the clock cycle time, and keep Reduce the clock cycle time, and keep the same CPIthe same CPI
Pipeline Registers
5 516
RD1
RD2
RN1 RN2 WN
WD
Register File ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
5
Instruction I32
MUX
<<2RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
32
CPI = 1CPI = 1
Clock = Clock = X*5 HzX*5 Hz
28
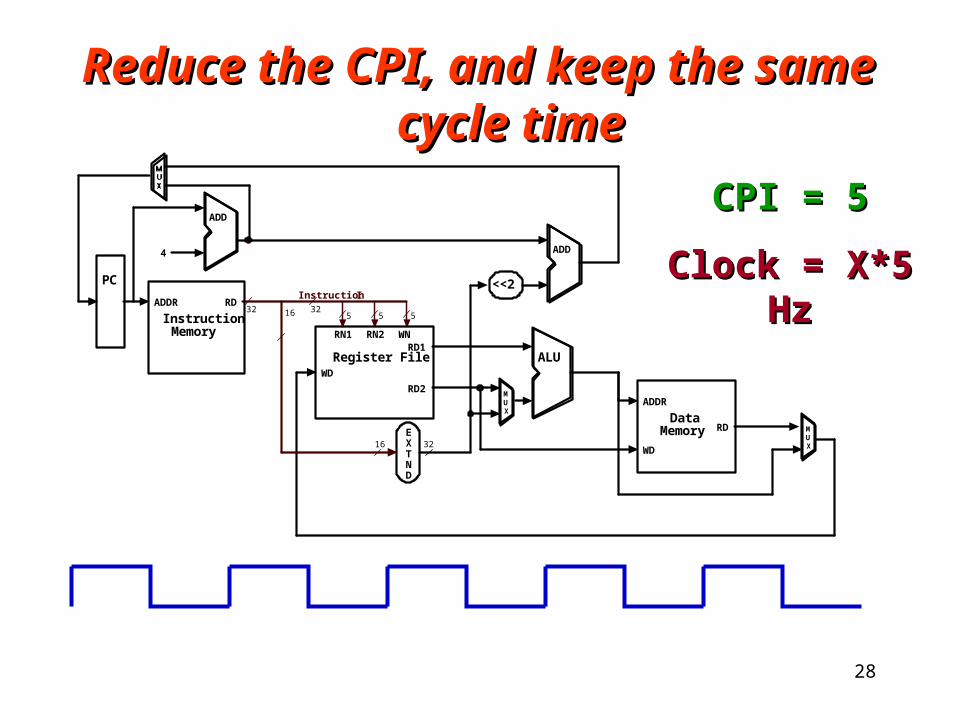
Reduce the CPI, and keep the same Reduce the CPI, and keep the same cycle timecycle time
5 516
RD1
RD2
RN1 RN2 WN
WD
Register File ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
5
Instruction I32
MUX
<<2RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
32
CPI = 5CPI = 5
Clock = X*5 HzClock = X*5 Hz
29
Reduce the CPI, and keep the same Reduce the CPI, and keep the same cycle timecycle time
Pipeline Registers
5 516
RD1
RD2
RN1 RN2 WN
WD
Register File ALU
EXTND
16 32
RD
WD
DataMemory
ADDR
5
Instruction I32
MUX
<<2RD
InstructionMemory
ADDR
PC
4
ADD
ADD
MUX
32
CPI = 1CPI = 1
Clock = Clock = X*5 HzX*5 Hz

30
Pipeline performancePipeline performance
• Ideally we get a speedup (by reducing clock cycle or reducing the CPI) equal to the number of stages.
• In practice, we do not achieve that – but we get close:
– Pipelining has additional overhead (e.g., pipeline registers)
– Pipeline hazards

31
Pipeline HazardsPipeline Hazards• Hazards are situations in pipelining which
prevent the next instruction in the instruction stream from executing during the designated clock cycle.
• Hazards reduce the ideal speedup gained from pipelining (e.g., CPI =1) and are classified into three classes:
– Structural hazards
– Data hazards
– Control hazards


















