
1 Lecture 7: Out-of-Order Processors Today: out-of-order pipeline, memory disambiguation, basic...
25
1 ecture 7: Out-of-Order Processors day: out-of-order pipeline, memory disambiguation, asic branch prediction (Sections 3.4, 3.5, 3.7)
-
date post
20-Dec-2015 -
Category
Documents
-
view
220 -
download
0
Transcript of 1 Lecture 7: Out-of-Order Processors Today: out-of-order pipeline, memory disambiguation, basic...

1
Lecture 7: Out-of-Order Processors
• Today: out-of-order pipeline, memory disambiguation, basic branch prediction (Sections 3.4, 3.5, 3.7)

2
An Out-of-Order Processor Implementation
Branch predictionand instr fetch
R1 R1+R2R2 R1+R3
BEQZ R2R3 R1+R2R1 R3+R2
Instr Fetch Queue
Decode &Rename
Instr 1Instr 2Instr 3Instr 4Instr 5Instr 6
T1T2T3T4T5T6
Reorder Buffer (ROB)
T1 R1+R2T2 T1+R3
BEQZ T2T4 T1+T2T5 T4+T2
Issue Queue (IQ)
ALU ALU ALU
Register FileR1-R32
Results written toROB and tags
broadcast to IQ

3
Design Details - I
• Instructions enter the pipeline in order
• No need for branch delay slots if prediction happens in time
• Instructions leave the pipeline in order – all instructions that enter also get placed in the ROB – the process of an instruction leaving the ROB (in order) is called commit – an instruction commits only if it and all instructions before it have completed successfully (without an exception)
• To preserve precise exceptions, a result is written into the register file only when the instruction commits – until then, the result is saved in a temporary register in the ROB

4
Design Details - II
• Instructions get renamed and placed in the issue queue – some operands are available (T1-T6; R1-R32), while others are being produced by instructions in flight (T1-T6)
• As instructions finish, they write results into the ROB (T1-T6) and broadcast the operand tag (T1-T6) to the issue queue – instructions now know if their operands are ready
• When a ready instruction issues, it reads its operands from T1-T6 and R1-R32 and executes (out-of-order execution)
• Can you have WAW or WAR hazards? By using more names (T1-T6), name dependences can be avoided

5
Design Details - III
• If instr-3 raises an exception, wait until it reaches the top of the ROB – at this point, R1-R32 contain results for all instructions up to instr-3 – save registers, save PC of instr-3, and service the exception
• If branch is a mispredict, flush all instructions after the branch and start on the correct path – mispredicted instrs will not have updated registers (the branch cannot commit until it has completed and the flush happens as soon as the branch completes)
• Potential problems: ?

6
Managing Register Names
LogicalRegistersR1-R32
PhysicalRegistersP1-P64
R1 R1+R2R2 R1+R3
BEQZ R2R3 R1+R2
P33 P1+P2P34 P33+P3
BEQZ P34P35 P33+P34
At the start, R1-R32 can be found in P1-P32Instructions stop entering the pipeline when P64 is assigned
What happens on commit?
Temporary values are stored in the register file and not the ROB

7
The Commit Process
• On commit, no copy is required
• The register map table is updated – the “committed” value of R1 is now in P33 and not P1 – on an exception, P33 is copied to memory and not P1
• An instruction in the issue queue need not modify its input operand when the producer commits
• When instruction-1 commits, we no longer have any use for P1 – it is put in a free pool and a new instruction can now enter the pipeline for every instr that commits, a new instr can enter the pipeline number of in-flight instrs is a constant = number of extra (rename) registers
8
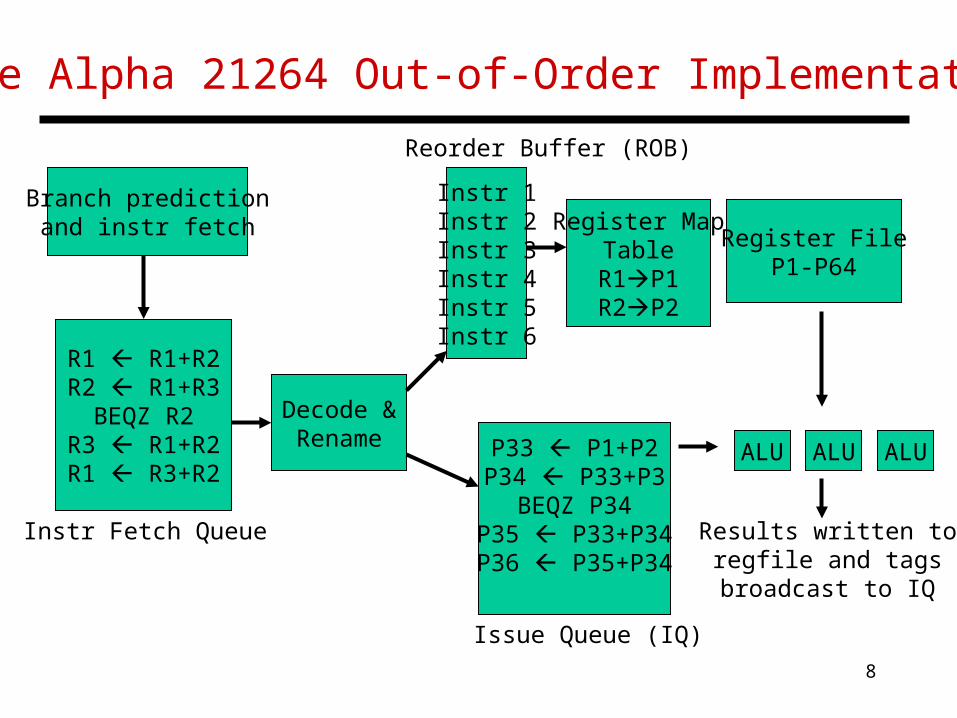
The Alpha 21264 Out-of-Order Implementation
Branch predictionand instr fetch
R1 R1+R2R2 R1+R3
BEQZ R2R3 R1+R2R1 R3+R2
Instr Fetch Queue
Decode &Rename
Instr 1Instr 2Instr 3Instr 4Instr 5Instr 6
Reorder Buffer (ROB)
P33 P1+P2P34 P33+P3
BEQZ P34P35 P33+P34P36 P35+P34
Issue Queue (IQ)
ALU ALU ALU
Register FileP1-P64
Results written toregfile and tagsbroadcast to IQ
Register MapTable
R1P1R2P2

9
Out-of-Order Loads/Stores
Ld R1 [R2]
Ld
St
Ld
Ld
What if the issue queue also had load/store instructions? Can we continue executing instructions out-of-order?
R3 [R4]
R5 [R6]
R7 [R8]
R9[R10]

10
Memory Dependence Checking
Ld 0x abcdef
Ld
St
Ld
Ld 0x abcdef
St 0x abcd00
Ld 0x abc000
Ld 0x abcd00
• The issue queue checks for register dependences and executes instructions as soon as registers are ready
• Loads/stores access memory as well – must check for RAW, WAW, and WAR hazards for memory as well
• Hence, first check for register dependences to compute effective addresses; then check for memory dependences

11
Memory Dependence Checking
Ld 0x abcdef
Ld
St
Ld
Ld 0x abcdef
St 0x abcd00
Ld 0x abc000
Ld 0x abcd00
• Load and store addresses are maintained in program order in the Load/Store Queue (LSQ)
• Loads can issue if they are guaranteed to not have true dependences with earlier stores
• Stores can issue only if we are ready to modify memory (can not recover if an earlier instr raises an exception)

12
The Alpha 21264 Out-of-Order Implementation
Branch predictionand instr fetch
R1 R1+R2R2 R1+R3
BEQZ R2R3 R1+R2R1 R3+R2
Instr Fetch Queue
Decode &Rename
Instr 1Instr 2Instr 3Instr 4Instr 5Instr 6
Reorder Buffer (ROB)
P33 P1+P2P34 P33+P3
BEQZ P34P35 P33+P34P36 P35+P34
Issue Queue (IQ)
ALU ALU ALU
Register FileP1-P64
Results written toregfile and tagsbroadcast to IQ
Register MapTable
R1P1R2P2
P37 [P34 + 4]P35 [P36 + 4]
LSQ
ALU
D-Cache

13
Control Hazards
• In the 5-stage in-order processor: assume always taken or assume always not taken; if the branch goes the other way, squash mis-fetched instructions
• Modern out-of-order processors: dynamic branch prediction
• Branch predictor: a cache of recent branch outcomes

14
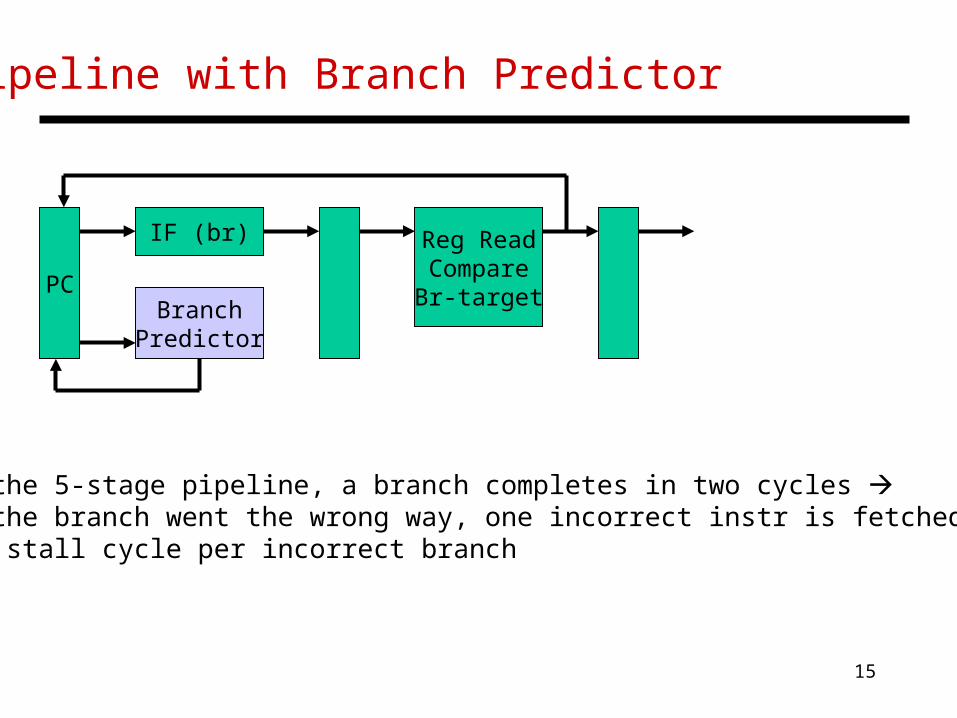
Pipeline without Branch Predictor
IF (br)
PC
Reg ReadCompareBr-target
PC + 4
In the 5-stage pipeline, a branch completes in two cycles If the branch went the wrong way, one incorrect instr is fetched One stall cycle per incorrect branch
15
Pipeline with Branch Predictor
IF (br)
PC
Reg ReadCompareBr-target
In the 5-stage pipeline, a branch completes in two cycles If the branch went the wrong way, one incorrect instr is fetched One stall cycle per incorrect branch
BranchPredictor

16
Branch Mispredict Penalty
• Assume: no data or structural hazards; only control hazards; every 5th instruction is a branch; branch predictor accuracy is 90%
• Slowdown = 1 / (1 + stalls per instruction)
• Stalls per instruction = % branches x %mispreds x penalty = 20% x 10% x 1 = 0.02
• Slowdown = 1/1.02 ; if penalty = 20, slowdown = 1/1.4

17
1-Bit Prediction
• For each branch, keep track of what happened last time and use that outcome as the prediction
• What are prediction accuracies for branches 1 and 2 below:
while (1) { for (i=0;i<10;i++) { branch-1 … } for (j=0;j<20;j++) { branch-2 … } }

18
2-Bit Prediction
• For each branch, maintain a 2-bit saturating counter: if the branch is taken: counter = min(3,counter+1) if the branch is not taken: counter = max(0,counter-1)
• If (counter >= 2), predict taken, else predict not taken
• Advantage: a few atypical branches will not influence the prediction (a better measure of “the common case”)
• Especially useful when multiple branches share the same counter (some bits of the branch PC are used to index into the branch predictor)
• Can be easily extended to N-bits (in most processors, N=2)

19
Correlating Predictors
• Basic branch prediction: maintain a 2-bit saturating counter for each entry (or use 10 branch PC bits to index into one of 1024 counters) – captures the recent “common case” for each branch
• Can we take advantage of additional information? If a branch recently went 01111, expect 0; if it recently went 11101, expect 1; can we have a separate counter for each case? If the previous branches went 01, expect 0; if the previous branches went 11, expect 1; can we have a separate counter for each case?
Hence, build correlating predictors

20
Local/Global Predictors
• Instead of maintaining a counter for each branch to capture the common case,
Maintain a counter for each branch and surrounding pattern If the surrounding pattern belongs to the branch being predicted, the predictor is referred to as a local predictor If the surrounding pattern includes neighboring branches, the predictor is referred to as a global predictor

21
Global Predictor
A single register that keeps trackof recent history for all branches
00110101
Branch PC
8 bits6 bits
Table of16K entries
of 2-bitsaturatingcounters
Also referred to as a two-level predictor
22
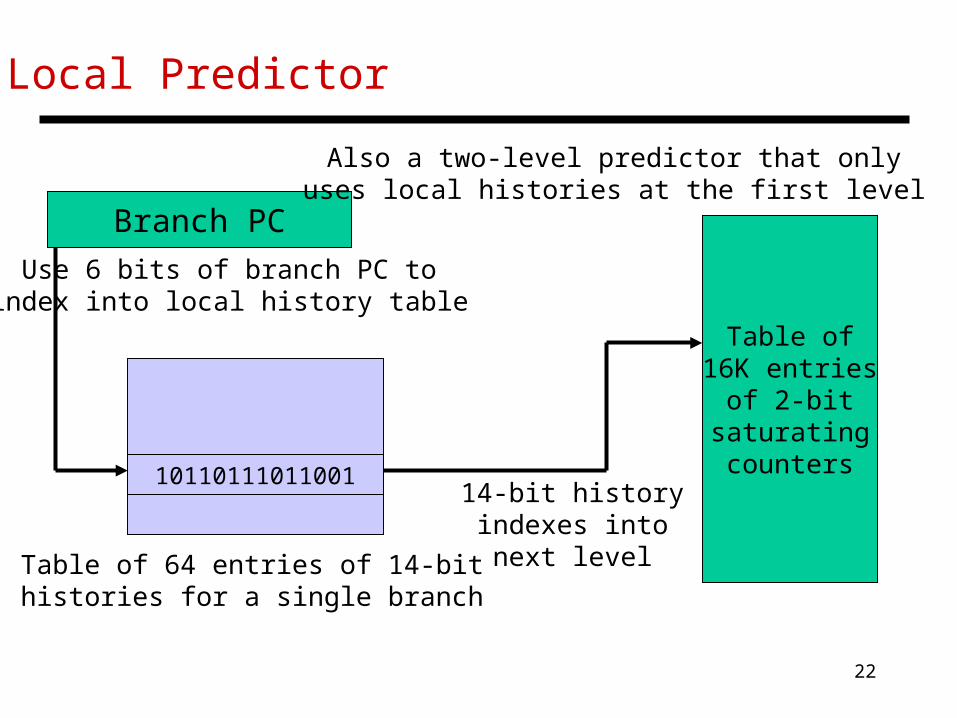
Local Predictor
Branch PC
Table of16K entries
of 2-bitsaturatingcounters
Table of 64 entries of 14-bithistories for a single branch
10110111011001
Use 6 bits of branch PC toindex into local history table
14-bit historyindexes into
next level
Also a two-level predictor that onlyuses local histories at the first level

23
Tournament Predictors
• A local predictor might work well for some branches or programs, while a global predictor might work well for others
• Provide one of each and maintain another predictor to identify which predictor is best for each branch
TournamentPredictor
Branch PC
Table of 2-bitsaturating counters
LocalPredictor
GlobalPredictor
MUX
Alpha 21264:Local:1K entries in level-11K entries in level-2Global:4K entries12-bit global historyTournament:4K entries
Total capacity: ?

24
Branch Target Prediction
• In addition to predicting the branch direction, we must also predict the branch target address
• Branch PC indexes into a predictor table; indirect branches might be problematic
• Most common indirect branch: return from a procedure – can be easily handled with a stack of return addresses

25
Title
• Bullet


















