
Accenture Competitive Pricing Harnessing Power Waterfall Model

1. Introduction
1.1 Problem Statement
Chrobis Web Designs (CWD) is a small, independent web design company run by IT
consultant Rob Moriarty, which produces custom web sites and underlying
supporting systems for a range of clients. Given the bespoke nature of their work,
CWD uses a small team of in-house programmers and a number of external
contractors in order to produce its products. The products themselves range widely
in terms of technology; PHP, XHTML, CSS, Java, JavaScript, Python, Perl, XML and
Ruby are some of the many programming languages used to create often complex
systems, with tens of thousands of lines of code typically found in even the
relatively smaller projects.
It is a requirement of CWD that all code on their projects is produced from scratch
or from pre-existing CWD code; on occasions where this is not practical, non-native
CWD code must clearly be marked as so to the project manager (typically Mr
Moriarty himself). Mr Moriarty feels that this ensures his programmers are fully
conversant with every system and can thus more easily diagnose problems and
bugs, and that production of their own code gives them the ability to better more
commonly-used code libraries, interfaces and widgets; thus, giving them a
commercial edge. In addition, CWD frequently releases older components under the
GNU General Public Licence (GPL) as part of the company's ethos of giving back to
the community. It is therefore essential on all of these counts that CWD can be
certain the code is the original work of its employees.
Recently the company was threatened with legal action when code belonging to
programmer who was not an employee of CWD was found in one of its products. A
code review taken shortly thereafter revealed a number of instances where this had
occurred. CWD is anxious to ensure that this does not occur in future. The company
currently uses an existing commercial web-based anti-plagiarism system, but this
has failed to highlight any of the aforementioned cases.
This problem is in itself part of a much larger problem – proving that any given file
of source code was indeed produced by the claimed author. Further research (see
section 3.3) has concluded that present systems and approaches are largely
1

inadequate, relying principally on comparing a specimen against other matching
code (which may not be locatable or even exist). An approach is needed whereby
authorship of a file can be inferred by close examination of its characteristics.
1.2 Project Aim and Objectives
The aim of this project is to design, develop and implement a system which
establishes a “digital fingerprint” for a given programmer - a collection of
regularly-occurring idiosyncrasies in the style and design choices made by the
author in the creation of his/her source code files, which can be used to verify
future work by that author.
This can be broken into a number of smaller objectives:
● To research any previous work in the field of digital fingerprinting, systems
for establishing authorship and related anti-plagiarism work.
● To determine why existing systems and past efforts are insufficient.
● To catalogue a full list of known design and stylistic choices a programmer
can make in the creation of source code in a particular language, which do
not affect the functionality of the end program.
● To develop a system which recognises sufficient numbers of these to
establish a regular pattern (“digital fingerprint”) common to every file from a
given author written in a particular programming language
● To be able to use the system to precisely support or refute an author's claim
to a given file of source code
● To compare, where data is available, the success rate of the system when
compared with other systems designed for similar purposes.
1.3 Minimum Requirements of Project
The minimum requirements for the successful completion of the project are:
1. Product a comprehensive list of individual decisions a programmer may
make in writing source code that do not affect the overall functionality;
2. Create a system which identifies a sufficient number of these decisions
within a given set of source code files by a particular author to be able to
stereotype the author's style, distinct from that of others;
3. Create a system which can compare a source code file asserted to belong to
an given author with the author's established previous work, and accurately
2

predict whether the source code file was written by the author in question
1.4 Potential Extensions to Project
There are a variety of potential extensions to the minimum requirements which
could be considered. Some or all of these may potentially be incorporated if the
project successfully delivers on its minimum requirements.
● The ability to read and establish authorship in multiple programming
languages
● The ability to spot programming patterns carried across different languages
by the same programmer
● A scripting/plug-in system such that support for additional languages or
tests can be easily added
● A graphical user interface
● A submission system for authors to submit their own code for checking
● The ability to deactivate tests for particular idiosyncrasies that are overruled
by corporate style guidelines
● The ability to detect if only certain sections of a programmer's code deviate
from his/her digital fingerprint
1.5 Relevance to Degree Programme
This project is the specialist project for a BSc Computing with Industry, and reflects
the following objectives for that programme as outlined in Fores (2007):
● Demonstrates the potential of technological developments in hardware and
software for supporting and improving the efficiency and effectiveness of
systems.
● Utilises good engineering practice in the design and construction of software
and information systems.
● Demonstrates an understanding of the mathematical, theoretical and
conceptual foundations of information and software engineering.
● Demonstrates analytic, design, engineering and evaluation skills necessary to
specify, develop, test and implement information and software systems.
● Shows high competency in computer programming.
The following course modules are deemed in particular to be essential prerequisites
for the work being undertaken:
3

● COMP2680 – Application of practical software development
● COMP3470 – An understanding of the people issues involved in the
implementation of such a system
● COMP3410 – Technologies for knowledge management will undoubtedly
come into play in terms of data mining from the original source
1.6 Deliverables
● A list detailing the style and design choices a programmer can make which
do not affect the overall functionality of the program, some of which can be
used to create a “digital fingerprint”
● A computer program that can infer a programmer's style given a set of
source code files written by that programmer; and either verify or refute the
authorship of the programmer when given an additional file.
1.7. Changes from Mid-Project Report
The project as proposed in the mid-project report (having replaced a previously
unworkable project idea) was deemed ultimately not workable, mainly due to the
lack of a direct problem owner and a great number of other papers produced on the
topic suggested. Whilst some of the background reading and ideas regarding
plagiarism from the mid-project report are still applicable, the project is radically
different in aim, objectives and scheduling from what was presented there. The
final project idea was confirmed on 13/02/08, and the project schedule thus
reflects both a late start as well as a much compressed research period, given that
much of the background reading and research from the previous project idea was
still applicable.
4

2. Project Management
2.1 Initial Project Schedule
A number of factors must be taken into consideration when drafting the initial
project schedule:
● Given that the start date is February 13th (see section 1.7) and the due date is
March 23rd, a highly compressed project schedule must be put together. It
has to be assumed that weekends will be included to allow sufficient time for
tasks to be completed.
● Some items are still tentative: the progress meeting has yet to be scheduled,
and given the delayed start to the project an extension to the final deadline
may ultimately be appropriate.
● The project methodology has yet to be finalised; hence design and
implementation tasks and their projected lengths may be subject to change.
This final report will however be written in parts as each stage progresses,
reducing the overall workload after the software has been produced.
Based on the above, an initial project schedule Gantt chart has been put together
and can be seen in Appendix B; a HTML-browsable version of the schedule is
available on the accompanying project CD. A brief summary of the primary
milestones follows:
Date Milestone
February 13th Submit revised aim and minimum requirements
February 17th Project methodology selection made
February 20th Programming languages (to be read, and to be used in system construction) are selected
February 29th Completion of research; design commences
March 6th Completion of design; implementation commences
March 14th Progress meeting
March 27th Completion of implementation; evaluation and testing commences
April 5th Completion of evaluation and testing; possible extensions commence
April 12th Extensions completed; final report collation and writing commences
April 23rd Report produced and submitted
April 25th Electronic copy of report submitted
5

2.2 Researching Project Methodologies
Any software project methodology contains two key elements: a development
process, and a modelling language to articulate the software being produced [2].
Before the project can commence, an appropriate development process must be
selected and tailored to this project's specific needs; as well as the most relevant
and useful modelling language to the task at hand.
2.2.1 - Researching a development process
The key criteria in choosing a development process for this project are that it is
known to be fast (given the compressed schedule, a major consideration) and
suitable to software engineering (given the main focus on the software deliverable).
It will need to encompass the whole project lifecycle (on this basis, Structured
Systems Analysis and Design Method (SSADM) was discounted as a framework as it
only covers system analysis and design), and take into account there there is only
one person running the project (on this basis, XP (Extreme Programming) was
discounted as it is typically team and pair-programming focussed).
Four methodologies met these criteria and were sufficiently well-documented, with
numerous examples of successful usage. The following sections detail the relevant
development processes, and the merits of utilising each in this project.
2.2.1.1 – The Waterfall model
The Waterfall model was the first known software life-cycle model expressly
articulated in 1970 by Dr Winston Royce as a flawed method for development, but
its simple, linear and modular nature ensured it gained a huge following in systems
development (Royce, 1970). In Royce's original model, seven basic stages were
proposed:
i. Requirements specification: the capturing and statement of system requirements
ii. Design: including modelling, interface design etc.iii. Construction: of the proposed system in full.iv. Integration: of the components of the system.v. Testing and debugging: validating the system against the requirements
specificationvi. Installation: of the proposed system into the target environmentvii. Maintenance
At each stage a final, discrete product is created which should be sufficiently
6

articulated that a different team could start the next stage with no prior knowledge.
A diagram showing this can be seen in Appendix C. The emphasis is placed on tying
up each stage concretely and producing large quantities of documentation charting
the progress.
The model has been criticised for its failure to account for changing needs and has
been supplemented by a variety of modified waterfall models that advocate part
iteration or slightly different stages. These offshoots include a further-refined
waterfall from Dr Royce himself; the Sashimi Model (DeGrace, 1990) and the Iterfall
Model; and indirectly the Spiral Model (Boehm, 1988). Most of these simply adapt
the existing model with some added iteration or overlap.
Advantages: The waterfall's simplicity and linear nature makes for a very
straightforward run through the project, and as the most widely-used methodology
to date there exist innumerable examples of its use and documentation. The
principle of a single run through the development is appealing in terms of speed
and reduced complication – if it is done correctly.
Disadvantages: The high focus on discrete standalone products at the end of each
stage may be far too bureaucratic and unnecessary for a project of this size. Whilst
there is always the temptation to make a single, ostensibly infallible run through
the lifecycle, even the most experienced developers will note that there are nearly
always flaws, changes in requirements and extra considerations which occur late in
development in this model.
2.2.1.2 – Rapid Application Development (RAD) methodology (including DSDM)
Rapid Application Development (RAD) was developed at IBM in the 1980s as an
alternative to the traditional waterfall model (Martin, 1991). First formally
published by Dr James Martin in 1991, this methodology seeks to vastly accelerate
the speed and reduce the costs of a project, with a much higher emphasis on the
software deliverables rather than extensive paperwork. The mantra is “there is
nothing so wasteful as doing with great efficiency that which doesn’t need to be
done” - instead of spending a long time documenting and implementing features
which may be wrong or unnecessary (or which have changed since the
specification), RAD attempts to capture and verify requirements as early as
7

possible.
Sequentially more-functional prototypes are produced iteratively, on the 80:20
principle that 80% of the functionality can often be produced in 20% of the
development time (Arthur, 1997). As a prototype meeting minimum requirements is
produced early, the likelihood of the end-user changing the requirements by the
time implementation starts is reduced. This is often a symptom of protracted
design and development phases in the waterfall model where a working product is
not seen by the end-user; if the resulting implementation then does not meet
requirements, a large amount of time has been wasted. RAD has been criticised as
“Rough And Dirty” by some industry users as the trade-off of a high speed
schedule has seen sometimes lower-quality end products (Howard, 2002); but it has
notably produced large-scale applications in periods of 60 to 90 days. A diagram
showing RAD strategy can be seen in Appendix C.
RAD lacked a formal specification at the time of its creation, so an offshoot named
Dynamic Systems Development Method (DSDM) was developed by a non-profit
consortium of organisations with a vested interest in speedy project delivery, often
under tight financial and time constraints (Stapleton, 1999). DSDM consists of three
phases: Pre-Project (projects, identified, funding sourced and commitment made),
Project Life Cycle (the development itself) and Post-Project (ongoing maintenance
and improvement of the project, often returning to phase two). The first and third
phases are fairly self-explanatory, but the meat of the method is contained in the
middle phase, which has five stages:
i. Feasibility study: is the project likely to meet the end-user needs? Is DSDM
suitable to the task? What risks are inherent?
ii. Business study: requirements of the system discussed and produced usually
under MoSCoW principles, and a suitable time boxed project plan is
produced.
iii. Functional model iteration: priority functionalities are used to generate a
functional prototype and model for review. Ongoing testing occurs.
iv. Design and build iteration: the functional model is combined with feedback
and non-functional requirements into a working design prototype; ongoing
testing continues.
8

v. Implementation: end-users are given the full design prototype and
documentation; if successful it forms the delivered system; if not, the
process loops back to previous stages.
Advantages: RAD in the form of DSDM would greatly benefit the project due to the
tight schedule by accelerating development and ensuring that mostly-functional
software is produced early, ensuring that in the event of a delay there is at least a
prototype with 80% of the functionality.
Disadvantages: The problem owner for this project (CWD) desires minimal input
into the system, seeing the primary goal as largely self-explanatory; as a technical
audience, the problem owner is more concerned with seeing a system that works
quickly than with his input into this. Many of the early stages may be unnecessary.
2.2.1.3 – The Spiral model
Despite being officially published prior to RAD, the Spiral model is essentially a
combination of the waterfall method with prototyping methods (precursors to RAD)
(Boehm, 1988). Created in 1988 by Dr Barry Boehm, the Spiral model was the first
model to advocate the importance of an iterative approach to development. Four
stages are cyclically repeated in the model:
i. Determine objectives: both initially, and following each cycle of the model
ii. Identify and resolve risks: problems in achieving the objectives are mitigated,
and a working prototype (of either documentation of software) is created.
iii. Development and test: the prototype is expanded into a working system and
thoroughly tested. If there is further work to be done, the cycle moves to
stage four (or else, finishes).
iv. Plan the next iteration.
This approach produces regular prototypes and documentation, and constantly
feeds back risks and results into the process. The incremental development catches
risks at an earlier stage. Most notably, it tends to be used in the development of
very large and complicated systems.
Advantages: The core of the project is produced earlier as in RAD again helping if
the project is cut short soon; the constant focus on risks and problems is
9

comprehensive and thorough, and this in turn helps estimates of scheduling, which
is vital to the project.
Disadvantages: The frequent use for larger projects is not accidental; the constant
emphasis on prototyping everything (including the requirements and development
plan) are undoubtedly a paperwork overkill for a project of this size and scope.
2.2.1.4 – Unified Processes
The Unified Process is best described as a repeating series of mini-waterfalls, with
the components of each waterfall growing or shrinking in importance with each
iteration. The first incarnation of this process put forward was Rational Unified
Process (RUP) created by Rational Software (Kruchten, 2003). It was released under
the current name in 1998 but its precursors were developed over the preceding
decade (Jacobson, 1999). Aside from RUP, common offshoots include the Agile
Unified Process (AUP) and the Open Unified Process (OpenUP) amongst many
others.
There are a succession of waterfalls composed of identical stages in each model,
e.g.:
RUP: Business Modelling, Requirements, Analysis and Design, Implementation, Test,
Deployment
AUP: Model, Implementation, Test, Deployment, Configuration Management, Project
Management, Environment
There are four phases (Inception, Elaboration, Construction, Transition) which may
each contain one or more waterfalls (see Appendix C), and which lend different
emphasis to each of the stages. Full charts showing the relevant stages and cycles
can be found in Appendix C. As UML sprang from the same background as the
original Unified Process, RUP, most forms of the process are associated with UML
and adhere closely to use cases and modelling, most of which is often done using
UML.
Advantages: A widely popular set of processes, the various Unified Processes
harness the simplicity and power of use cases to keep development focussed;
various incarnations also add great emphasis on agility, which could keep the
10

project short. A clear mantra on the relative lengths of each stage and on iteratively
capturing information should help avoid problems with the final product and
ensure stages do not overrun.
Disadvantages: Six or seven stages across four phases makes for between 24 and
28 discrete phases to keep track of. The heavily use case-driven nature may be
unnecessary for a project tackling this particular challenge of software engineering
which has far less focus on a user experience.
2.2.2 – Researching a modelling language
The modelling language is the format in which the concept and design of the
system will be expressed. An appropriate modelling language will convey the
pertinent details in a simple, easily-understandable format; be appropriate to the
discipline of software engineering; and in keeping with the necessary speed of the
project as outlined in the project schedule (Appendix B), be easy to grasp and use
as well as portray the stages of the project.
2.2.2.1 – Fundamental Modelling Concepts
Fundamental Modelling Concepts (FMC) is a specification and doctrine of modelling
that is oriented towards more software-intensive systems; accordingly, there are a
significant number of symbols and entities used to represent the low-level
fundamentals of a software system such as read/write access, processes,
communication channels etc. It can be abstracted to show higher or lower level
views, but is clearly geared towards lower-level representation (Knoepfel, 2005).
FMC is comprised of three types of diagram:
1. Block Diagrams: depicts the composition structure of static systems, showing
the connections, interactions and relationships between the agents in a
system whether they be human, servers both hardware and software or
processes.
2. Petri Nets: show dynamic systems in transition; whether this be changes in
running processes or values passed through a program at low levels.
3. Entity Relationships: show the composition of attributes into entities within
the system and the relationships between each.
11

Advantages: The extremely software-oriented nature of these diagrams lends
themselves to a very detailed description of an overall system, presumably much
reducing implementation time by being explicit at very low levels.
Disadvantages: The diagrams seem complex and would undoubtedly form a steep
learning curve. This approach may be incompatible with the more agile and iterative
development processes listed in the previous section as they tend to emphasise
high-level detail first which is fleshed out; FMC seems to encourage mapping
systems out extremely explicitly at a lower level first. This may be too time-
consuming an approach. There appears also to be little support for areas of system
analysis (such as requirements capture).
2.2.2.2 – Unified Modelling Language
The Unified Modelling Language (UML) was first published in 1996 by employees of
Rational Software. It was an amalgamation of previous modelling strategies and
since release 1.0 has been specified by the not-for-profit Object Management
Group, a consortium of interested parties. Relatively recently it reached revision 2.0,
and is widely used across a number of industries due to its great flexibility. Its
history is closely linked the the Unified Process (Quatrani, 2005).
UML specifies thirteen different types of diagram, which can be loosely grouped
into three classes:
1. Structure diagrams (class, component, composite structure, deployment,
object, package): items that must be present within the system and the
relationships between them. This can for example be classes and their
attributes/methods and inheritance; or the components of software and
hardware interacting.
2. Behaviour diagrams (use case, activity, state machine): what must actually
happen in the overall system either from a user perspective, a task-oriented
perspective or a process perspective.
3. Interaction diagrams (communication, interaction overview, sequence, timing):
these show the sequence and flow of information, communication and
message passing and control through the system at various levels.
12

Advantages: A highly-adopted and widely-used industry standard, UML is widely
recognised and understood. Many of the diagrams are extremely simple and quick
to produce but convey useful information succinctly, such as the famous Use Case
diagrams. The flexibility of the UML schema makes it easily adaptable to the
project. Consistent symbols throughout all the diagram aid in quick production.
Disadvantages: Care must be taken to ensure that only those diagrams which are
needed are used; there is a very wide field to choose from. Upon investigation, UML
is not quite as specially suited to producing detailed descriptions of low-level
software processes as FMC – it is far less succinct, though the same nature makes it
more easily comprehensible.
2.2.2.3 – Systems Modelling Language
A highly-specialised and adapted form of UML, Systems Modelling Language
(SysML) aims to be more specifically tailored to systems engineering than the more
generic UML [14]. It has a much reduced number of diagrams (seven to UML's
thirteen). Upon further examination of the language however, it appears to remove
most of the software-centric features of UML (which its proponents criticise as
having a “software bias”) whilst using the same notation and introducing non-
software related diagrams such as the Parametric diagram, which is geared towards
examining the constraints of structural elements in a physical system.
Whilst the methodology purports to be applicable to all manner systems
engineering purposes, it seems instantly obvious that an approach with a similar
learning curve of notation to UML but with less software-oriented features (and
more redundant physical systems diagrams) is instantly inferior to UML. The other
major diagram addition (a requirements diagram) causes overlap with the Use Case
diagram but seems designed for more detailed cases; this in itself would seem to
defeat the objective of having simple, easily-constructed diagram in UML. This
modelling language therefore can be appropriately disregarded as forming, in terms
of this project, a less useful version of UML.
2.3 Chosen Project Methodology
The selected project methodology will follow a modified DSDM methodology (in the
RAD tradition), using UML to model the system.
13

The Waterfall model was proposed as flawed by its creator upon inception; and
whilst there is a temptation to breeze through the stages sequentially without
revisiting any of them for the sake of speed, this has almost universally proved
fatal to even small projects. The excessive documentation and defined specification
produced at the end of this stage negates the usefulness of even more iterative
incarnations of this methodology.
The Spiral model as noted again seems geared towards constant reassurance and
risk mitigation of the numerous problems found in very large-scale projects, which
this is not. Again it seems to rely on extensive production of documentation,
verification of that documentation and consultation on it by the end-users; the
problem owner in this case desires minimal input and only that documentation
which is fundamentally necessary (i.e. to this report) must therefore be produced.
The Unified Process family seems to cut down on much of this – however the very
user-driven nature of it combined with the administrative complexity of the
process (multiple phases of multiple stages) makes it less appealing than the final
choice.
SysML was discarded early due to the reasons stated in it being fundamentally
similar to UML but less software-focussed and more physical-system/business
focussed; it was therefore always an inferior choice to UML in this regard. Between
UML and FMC, UML offered the greatest and most flexible range of diagrams to
cover this project; FMC has little support for dealing with requirements and is
geared towards a level of low-level system detail which would not feasibly be
producible in the allotted timespan for the project.
UML's flexibility and simplicity makes it the perfect choice- quick to produce and
master, easy to understand. While the first and final phases of DSDM (pre-project
and post-project) as well as the first stage of the middle phase (the “feasibility
study”) seem redundant to this particular project, the mentality of producing a
prototype with the majority of essential functionality early in the project makes for
an excellent methodological choice. If the project overruns the eye-wateringly tight
schedule, development can be cut short with hopefully a still mostly-usable and
useful product already produced. The consistent prototyping involved will also
14

expose programming difficulties and required modifications that will undoubtedly
be thrown up by a programming challenge of this nature. Most languages
(programming or human) have numerous exceptions, irregularities and esoteric
terminology and syntax alongside their more mainstream uses; given the number of
problems thus likely to incur in testing, an approach which provides early
prototypes with frequent revision is the most rational choice. The project schedule
has thus been updated to better reflect this adapted DSDM methodology.
15

3. Background Research
3.1 Searching Relevant Literature
To better understand the nature of the problem, examine the merits of any
previously-attempted solutions and devise a method of solving the problem, a
literature search will be conducted.
The topics of search will be authorship as a concept, and the methods of
establishing it both manually and with the aid of computer technology; the concept
a unique “fingerprint” in text or source code; the history of attempts to produce
automated tools to prove or disprove authorship; and what programming language
and tools would best be suited to producing a tool that could determine authorship.
In addition, a comparison of programming languages in use by the project owner
will be made to determine which would be the most suitable to analyse in this
project; the chosen language will then be researched to determine what individual
choices programmers utilising it can make which might uniquely identify their
“style”.
Sources to search will include the University of Leeds Library; electronic resources
from other libraries and repositories; previous dissertation or final year project
work on similar areas of research; holdings of the British Library via their document
supply centre in the case of rare papers or extracts; and use of public Internet
resources and information for providing general overviews, definitions and to
supplement other more established sources where appropriate.
Main keywords: stylometrics, authorship, authorship attribution, digital
fingerprinting, textual fingerprinting, identifying authors.
3.2 Defining Authorship
Authorship, as defined by the Chambers 21st Century Dictionary, is “the origin or
originator of a particular piece of writing” (Harrap, 2003). This is by no means a
new field of study – work into determining the author of a work of unknown
original has been happening at least as long as historians and religious academics
have made attempts to attribute portions of the Bible (Baayen et. al, 2002). An
author lends by their nature a credence to their work; many authors have attempted
16

to remain anonymous to avoid personal criticism and shunning (White, 1994),
whereas in modern academia, the citing of recognised authors and works forms the
basis for academic acceptance of a work.
Applications for the process are wide; everything from counter-terrorism (Chen,
2005) to attribution of ancient Biblical texts (Person, 1997), which can be of huge
cultural and religious importance. More recently the process of determining an
author has been referred as “stylometrics” or “authorship attribution studies”
(Somers, 2003), and forms a key branch in the field of linguistics.
There is good reason to examine the historical development and use of authorship
attribution – as a science that has been refined over hundreds of years, the
techniques it employs are mature and well-established, due to the importance of
accuracy when authorship is used in legal cases or criminal detection. Whilst this
project deals with more formulaic works of source code rather than freely-written
prose, there are undoubtedly techniques used on prose which can be readily
adapted to work on source code.
3.2 Learning from Modern Principles of Authorship Attribution
The most basic principle of authorship attribution is that each author
unconsciously develops a style; habitual ways of writing that are consistent through
different works and can potentially be measured. Schommer and Uhde refer to a
“text fingerprint” or “linguistic fingerprint” left by each and every author, even
when that author consciously attempts to modify their style (Schommer, 2008).
Laan observes that the ideas that style can both change and remain the same are
not necessarily conflicting; and that style may be said to have two components –
one which remains consistent, and one which varies through time and given the
nature of the work (Laan, 1995). Filtering out the differences is the primary work of
authorship identification.
Over the course of time the process of author attribution has moved from the more
subjective field of literary criticism and commentary to the more objective fields of
natural language processing and statistical testing. The first landmark example of
this was Mosteller and Wallace's 1964 paper analysing the Federalist Papers,
documents written at the time of the creation of the American Constitution and
17

supporting its ratification (Mosteller, 1963). This approach used the fairly simple
measure of statistical testing for the frequency of a small set of function words
such as “the”, “of”, “upon”, “about” etc. The results differentiated between authors
significantly – papers known to be written by Founding Father James Madison used
the word “upon” an average of 0.23 times per 1000 words; but by sharp contrast,
Founding Father Alexander Hamilton averaged 3.24 uses per 1000 words. By
showing statistical patterns of word usage unique to each man, the Mosteller and
Wallace could infer the authorship of works whose author was not conclusively
known. The idea that frequent usage of certain functional words could easily
translate to programming – decisions regarding preferred control or loop structures
could for example reveal a preference for one particular type (even though many
can used interchangeably), analogous to the word frequencies of Mosteller and
Wallace.
Subsequent approaches in identifying the authorship of the Federalist Papers as
well as many other works built on this success by analysing multiple metrics of
style (Hoover, 2003). Frequently occurring metrics in works include the extent of
vocabulary (or number of unique words in the text) (Madigan, 2005); the
aforementioned frequency of words or “lexical repetition” (Stamatatos, 2001);
frequency of categories of words (e.g. frequency of adjectives vs frequency of
nouns, for example) (Argamon, 2003); analysis in choices of syntax and sentence
construction, including grammatical errors (Madigan, 2005); “collocations” of
words, that is, groups of words whose members indicate the nearby presence of
other group members when found in text (Smadja, 1989); chosen lengths of words,
clauses, sentences and paragraphs; and use of more esoteric and rare words seldom
found elsewhere.
Some of these techniques when properly examined suggest analogous statistical
tests that could be performed on source code. Stamatatos et. al (Stamatatos, 2001)
note the simple simplest measure of vocabulary, V/N – where V is the size of the
vocabulary, and N is the number of total words. Given that the Longman Dictionary
of Contemporary English can define the majority of everyday English using only
2000 words [29], it is clear that the vocabulary of any language often features a
degree of redundancy. The presumed unconscious preferences and habits of the
author therefore determine this to an extent. As aforementioned, choices in control
18

or loop structure, data structure or numbers of unique variable names could be an
analogous programming concept.
Argamon et. al (Argamon, 2003) note that word class frequencies (e.g. pronouns vs.
noun specifiers) successfully showed a distinction between male and female
authors. In programming, authors often have a choice in determining the numbers
of methods, variables or parameters used amongst others; better programmers can
often express things more succinctly, and personal preference may affect the
decision of whether to pass a data structure as a single parameter, or else declare
separate parameters for each item of data. Contrastingly however, Smadja's concept
of word collocation (Smadja, 198) may not be as germane to the domain of
computer programming – most languages strictly prescribe the components of a
programming statement. There may still however be instances – some programmers
will declare variables up front but only initialise when needed, whereas others will
declare and initialise simultaneously. In this case, a limited amount of collocation
might be observed in that early assignment statements in one style incorporate a
value; whereas in another, this is absent.
Word, sentence, clause and paragraph lengths have featured almost as standard in
the most of the papers reviewed so far to some success; and these have
counterparts in source code (length of identifiers, statements, statement blocks).
Testing for occurrences of esoteric and idiosyncratic terms may also have a direct
counterpart in software; indeed one experienced Java programmer contacted for
source code later in the project observed that “older generations of programmers
tend to use the dollar sign in variables and underscores” more frequently, which are
considered more esoteric in modern programming languages. Less regularly-used
features of programming languages may therefore act as very clear signposts in
testing for authorship.
One area that may contrastingly have little application to this project is the
identification of grammatical errors. Whilst grammatical errors can be an
idiosyncratic style in themselves, it is necessary to take the viewpoint that this
project will examine completed source code files, which therefore would be unlikely
to contain idiosyncratic errors that would have been removed during the debugging
process. In this regard, source code is much stricter in prescribing a set syntax than
19

the freer choices available in written prose; there may however exist some limited
choices in syntax which would be measured.
In conclusion, there are a number of ideas that have formed the backbone of
authorship identification in written text that can potentially be translated to the
identification of authorship in source code. The next step is to find any notable
previous attempts at identifying the authorship of source code itself.
3.3 Verifying Authorship with Digital Fingerprinting
A notable piece work in extolling the use authorship of source code by Sallis et. al
(Sallis, 1997) made reference to an emerging scientific field of “software forensics”.
It was proposed that with an increasing rise in computer security threats, there
would be an increasing need for establishing an author's identity, particularly in
criminal cases. This turned out to be particularly prescient – in the intervening
years, an increasing number of examples abound where the work of virus-writers
has been tested for authorship (Longstaff, 1993), or where authorship is disputed in
cases of alleged plagiarism (Vitoria, 2006).
The paper drew on previous works of studies into anti-plagiarism which had
attempted to categorise programming style as means of positively identifying a
work as belonging to a known author other than the claimed creator, and studies
into identifying the authorship of malicious code. Notably, however, it failed to
make any reference to the well-established tradition of detecting authorship in text
and referred to an authorship detection tool in development, though did not
showcase this. A later paper by MacDonell et al (MacDonell, 1997) showed a
screenshot of the tool and identified it as working, but provided no data to
corroborate this, and the tool does not appear to have gained any widespread
acceptance and usage.
By contrast, Spafford and Weeber (Spafford, 1993) in their piece, although making a
fairly specious argument about handwriting styles (which seem to have little
relevance to the subject matter), did acknowledge and discuss the use of written
authorship techniques and noted that many of the statistical tests and feature-
spotting could be applied to source code. They noted the following characteristics
20

of source code which could vary in style:
● Choice of language
● Code formatting
● Special features that might indicate a choice of compiler
● Commenting style
● Variable naming conventions
● Spelling and grammar
● Choices of language features
● Preference in scope of variables (global, local etc)
● Errors (reproduction of similar errors across work)
This work well encapsulated the basis for authorship testing and possible metrics,
whilst not producing a direct tool. One of the most notable first attempts at using
such metrics (albeit in what appears to be a fairly casual observational fashion
rather than by empirical research) was in the work of Longstaff and Schultz
(Longstaff, 2003). They analysed the work of two related computer worms: WANK
and OILZ, which propagated in 1989 and were the first examples of worms
spreading with a political agenda. Particularly they noted that there appeared to be
from style variations three different authors -
1. Author A, who wrote the parts of the code used in proliferation.
Characterised by descriptive and lower-case variable names, use of variables
and GOTO sequences for flow control, convoluted execution flow and
evidence of a deep understanding of networking concepts.
2. Author B, who wrote the malicious parts of the code. Characterised by
frequent use of profanity, capitalisation in variable names, a straightforward
execution flow, and frequent misuse of a language routine.
3. Author C, who assembled the code. Characterised by mixed-use of upper
and lower case characters in method and variable names, single character
variable names, similarities to BASIC programming and attempts to unite
code from the previous two authors.
Such wide variations in style, errors and flow seem almost certainly the work of
different individuals and highlight how radically different code can look; whilst the
individuals responsible were never positively identified, the paper makes a very
convincing argument for the technique used.
21

Whilst any number of attempts have been made to develop anti-plagiarism
software, there appears to have been little progress made in the way of positive
authorship confirmation. It is important here to draw a distinction between the two
– detecting plagiarism frequently involves attempting to prove that an author did
not create a work asserted to be theirs because the work bears strong resemblance
to other existing work. By contrast, authorship identification is concerned with
establishing that a piece of work fits an individuals established style and is indeed
theirs.
Previous efforts in anti-plagiarism have been mainly intra-corpal (comparing items
within a submitted set), or extra-corpal (comparing items with an large external
catalogue) (Helmore, 2005). These terms are both limited in that no database can
ever hold the all other works in existence; and indeed the work itself may be
entirely novel, but not developed by the author in question. Detecting plagiarism
has its place where wholesale reproduction is concerned; but has considerable
limitations. The ability to actively associate code produced with the author by
testing for a defined style however is limited only by the accuracy of the test-
increased refinements should therefore be able to prove authorship or else disprove
it, without needing an incomplete database of other works.
Whilst the detection using statistical tests of style has been coined as “stylometrics”
in the linguistic domain, in the domain of source code this project will use the term
“digital fingerprint” to refer to the unique style detectable in code, and
subsequently used to prove or disprove authorship. The research material covered
here, along with the reasons cited together make a clear case for the need for a
digital fingerprinting tool.
3.4 Choosing a Programming Language to Analyse
The most frequent languages as used by the problem owner (CWD) referenced in
the introduction to this report were PHP, XHTML, CSS, Java, JavaScript, Python, Perl,
XML and Ruby. In choosing which to analyse, considerations should be made as to
the degree of flexibility of the language (i.e. how many stylistic choices can be
made); the ease of reading it and parsing the contents; and how well-supported it is
with documentation to facilitate an understanding of its working necessary for this
22

project.
3.4.1 Markup languages (CSS, XHTML, XML)
Markup languages specify how to structure, format and display text. CWD utilises a
large number of XHTML samples and there are ample examples of this technology
frequently available on the web. The advantages of analysing a markup language
are:
● Whitespace-agnostic, so indents and whitespace are programmer decisions
● Large numbers of samples are easily found on the Internet
● Deprecated tags make for potential esoteric styles that can be analysed.
There appear to be considerable disadvantages however:
● Many files are automatically generated via WYSIWYG tools, removing
programmer variance
● A very limited number of tags, and no usual programming constructs on
which to examine as per previous work in this field (e.g. variables, methods
etc).
● CSS is far too basic; XHTML is too prescribed and XML schemes vary too
much.
3.4.2 Scripting languages (PHP, JavaScript, Python, Perl, Ruby)
These languages are far more representative of normal programming constructs
than markup languages. Scripting languages by and large (although some of the
above can also run as executable programs) do not execute independently but work
to control or modify other applications. The advantages are:
● Again owing to web technologies, samples of many of these are freely found
on the Internet
● The syntax in some cases is slightly simpler than more established
programming languages designed for independent execution, making for an
easier learning curve parsing them.
Conversely however:
23

● The lack of standalone execution means that other programming languages
or accompanying applications may be needed (e.g. HTML in the case of PHP,
Ruby and JavaScript)
● The fact that most of them have object-oriented components as an optional
paradigm will add confusion and possibly duplicate the work (the system
would have to treat files written from different paradigms separately).
● Little formal documentation available on some (such as Ruby); others such as
Perl have considerably less documentation than more modern programming
languages as they have fallen out of favour compared to modern alternatives.
3.4.3 Standalone Programming Language (Java)
Java is the only “standalone” language used by CWD. Developed by Sun
Microsystems, it is ranked the most used programming language in the world
according to TIOBE Programming Community Index[36]. Advantages are:
● Enforcing of a single paradigm in the code will make analysis much simpler
● Very extensive official and unofficial documentation available
● The prevalence of Java will make a software tool that detects authorship in
Java automatically more useful than that of another language
Disadvantages:
● The enforced structures (e.g. every file must declare a class, file names must
be the class) put some limits on creative freedom and hence style
● Strict Java runtime and compile-time checking removes most serious bugs,
so detecting frequently recurring errors will not form part of the authorship
profiling.
In the end, Java has been chosen as the best candidate to analyse. Its prevalence,
the use of documentation, and even its overly verbose nature (compared to more
succinct languages such as Python and Ruby particularly) and complexity will be
useful in producing overall longer files with more constructs that will be easier to
analyse for style.
24

3.5 Choosing a Programming Language to Perform the Analysis
Having chosen to analyse Java source code files, a programming language in which
to write the project had to be selected. Python, Perl, Java and C all have significant
text-processing features, which would form the core of this work. The potential
extension of a GUI would be simplest to implement in Java or C if it were
standalone; in Python or Perl if it were web-based. However the instant deciding
factor was Python's minimalist approach – for example, the “Hello, world” program
can be written in 1 line, compared to C and Java's 7 [37]. The very easy-to-learn,
simple and easy-to-debug syntax of Python, combined with extensive
documentation and inbuilt text-processing capacity, made this ultimately an easy
winner. As a result, the programme will be implemented in Java.
The next step is to obtain a selection of source code files to perform the initial
analysis, and to identify the markers of style that can be found in Java. The next
chapter will address the collection of source code and the style measures that will
be analysed.
25

4. Data Collection and Analysis Overview
This section is mainly concerned with the collection of Java source code files
required for the project; and a summary of all the potential criteria that may be
used in the context of the Java language to differentiate programmer styles,
drawing on ideas from the previous section in the fields of textual authorship,
plagiarism detection and the limited forays made into source-code authorship –
establishing of the “digital fingerprint”.
4.1 Individual Programmer Choices in Java
Having chosen Java to analyse, the official documentation for Java [38] was
examined to determine what possible variations in style were possible. The goal was
to break down the language into its main components, and see how those
components could be used or omitted, and where they were interchangeable. The
results will be used to specify the broad criteria that may be tested for in individual
Java files which could be indicative of a given programmer's style.
4.1.1 Broad categories of Java Tokens
Tokens in every Java program can be broken down into seven broad categories:
whitespace, identifiers, operators, keywords, values, symbols and comments. Each
of these has unique properties which allow for individual style.
Whitespace is mostly completely at the programmer's discretion in Java. Whilst it is
not allowed to break up the five of the other symbols (the exception is comments),
it can appear between them in any amount and in any fashion. Both of the following
are legal Java:
int c =0;int h=1;int r=2; int
c
=
2;
int h = 1;
int r = 2;
Applications to examine include the placing of whitespace at different locations in
the program; choices in indentation length and indentation of specific tokens
26

Identifiers are the names assigned to memory spaces in which Java holds data; they
can identify primitive types (such as integers or boolean values), or complex objects
(classes, interfaces). The rules governing identifiers are:
● The identifier's name must start with a dollar sign ($), underscore (_) or an
alphabetic character (A-Z, a-z).
● The remainder of the identifier may be made up of any of the above three
items and additionally, numbers.
● The identifier may be delineated at the start and end by whitespace, symbols,
operators or comments, but not values or keywords.
● The identifier of the primary class or interface must match the name of the
file.
Applications to examine are choices in length of identifiers; choices of naming in
identifiers; and whether identifiers assigned to different items (e.g. primitive types
vs parameters vs instances) sport different styles of name.
Operators are a subset of symbols used for performing some kind of operation on
the data, such as mathematical or boolean operators. Many are required in different
places (assignment statements require the “=” operator; control structures require
one of the many boolean operators to check conditions), but broadly speaking they
may appear anywhere. A list of operators and the conditions in which they must
appear as well as the order in which they take precedence can be found in some
appendix.
Linking back to the authorship tests looking at the frequency of function words
such as “the”, “of”, “about” etc, it could be said that operators are as close to
analogous of these connecting words as any other component. In this vein,
applications could include testing the frequency of symbols or certain types. It
should be noted however that in textual linguistics this was shown only to be stable
above a certain threshold – in the case of text, 1000 words or more. Since
programming is much more prescribed than free prose, this may be considerably
higher.
Keywords are numerous in Java and perform many different functions and have
different uses. Some notable highlights:
27

● Loop structures: there are four types of loop – 'for', 'foreach', 'while' and 'do
while'. Each can be rewritten into the style of the other with minor
modifications, so greater preference for one or more over the others might
be reflected in style. The 'break' keyword is in itself also a choice as a
method of exit from a loop.
● Decision structures: the most prevalent of these is the “if” keyword, which
can be optionally extended with “else”, and instances of “else if”. Since only
the 'if' keyword itself is truly required for decisions, the choice of partnering
it with 'else' statements, or adding in 'else... if' is entirely at the
programmer's discretion. The 'switch' keyword is a less commonly-used
alternative to this, and again frequency may show style.
● Import: utilising the power of other code is generally managed through
import statements. The writing of these is flexible however; a programmer
may import a whole library, packages from within a library or specific classes
from within the package. Any of these would put the required classes at the
programmer's disposal, so this is another area of style.
● Class machinery: a number of keywords expose choices in object-orientation
– 'static' marks class variables and methods, the numbers of which when
compared with their instance counterparts could reveal a limited preference
(i.e. the decision to place common data and methods in a single location).
The keywords 'this' and 'super' also act as optional shortcuts for referencing
objects.
Values are fairly less revealing; though the type of variable or structure they are
held in can be very revealing. Java's primitive types can sometimes be used
interchangeably for certain things - indiscriminate use of 'float' and 'double'; 'long'
and 'int' for example, to represent the same numbers. Again when looking at
frequency of occurrence of tokens in authorship, it may simply be the numbers of
values held and their types that reveal the most about style; does an author prefer a
single array or multidimensional arrays, for example.
Symbols can mostly be used for determining other things – since a semi-colon
denotes the end of statement, for example, they could be used in measuring
statement lengths. Parenthesis can be used to make the intent of mathematical
expressions clearer, so redundant parenthesis are probably also indicative of a
28

choice.
Comments are entirely optional, making them completely programmer-determined.
Two types of comments (multi-line and single-line) can be used interchangeably
(single-line comments can be stacked on successive lines; so-called 'multi-line'
comments can be opened and terminated within a statement). The positioning,
length, relative length to the program and verbosity of these items are just a few of
the measures of style that could be applied.
4.1.2 Table of choices
The following is the final table of choices a programmer can employ when writing a
single file of Java source code. Multi-file programs add additional complexity which
will not be tackled in the minimum requirements of this project (such as
proportional sizes of files, numbers of files per program etc) but which may be
revisited later on as an optional extension. This fulfils the first minimum
requirement set out in the project introduction.
ID Category Item Choice
C1 Whitespace
Indentation Indentation is optional in Java; its presence and any regularly repeating pattern (indents of three spaces, four spaces etc)
C2 Whitespace
Symbols Amounts of whitespace separating different types of symbol in Java are optional. ( int x = 5 ) ; is equivalent to (int x=5);
C3 Whitespace
Blank lines Usage of blank lines between statements and statement blocks is a programmer choice
C4 Whitespace
New lines The decision to put certain elements on the next line (e.g. the right hand side of an assignment, or the opening brace of a statement block)
C5 Whitespace
Characters Whitespace “characters” (\t, \r, \n) can be determined by the programming editor or IDE; tabs can be used for indentation rather than spaces, new-line and carriage return use may vary
C6 Comments Type Either multi-line comments or single-line comments may be used
C7 Comments Frequency This can be measured in total occurrences, or as a ratio against code
C8 Comments Length Either length of lines in the case of multi-line comments, or number of characters
C9 Comments Position Can be positioned at different places in a file; before a statement, after it, at the start, at the end, on line of code etc
29

C10 File Length File lengths will naturally vary, but overall some programmers will produce smaller files (due to a desire for smaller files, lack of extraneous whitespace and comments or simply efficient programming) and other will produce generally longer files
C11 Code Lines The actual lines of code in a file as a ratio against whitespace and comment
C12 Identifiers Length The character length of all identifiers or of categories of identifier (parameter, local, class, instance etc)
C13 Identifiers Characters Use of whitespace, numbers, digits or alphabetical characters
C14 Statements Import As aforementioned, programmers can choose to import whole packages, subsets, classes etc
C15 Statements Length The average length of statements
C16 Statements Dot notation A user can choose to frequently use length dot notation (this.that.the.other), or else assign such imported methods and variables to new, shorter names. The prevalence of dot notation usage is thus a programming choice
C17 Keywords Overall The presence and choice of all keywords can be measured as proportions of the file's tokens
C18 Symbols Overall The presence and choice of all symbols can be measured as proportions of the file's tokens
C19 Keywords Loops The proportions of loops categorised as one of the four options is a programmer choice (as indeed is their presence; see Keywords > Overall)
C20 Variables Declaration Proportions of variables initialised at point of declaration
C21 Variables Not assigned Proportions of variables that are not assigned values at any points
C22 Variables Reassignments
Numbers of variable reassignments after initial use
C23 Parameters Number Average numbers of parameters passed to a method
C24 Methods Overloading Incidence and numbers of overloaded methods and constructors
C25 Scope Braces Average number of scope levels, i.e. highest number of containing braces for any given item. May be compared with file length.
This covers all of the known fundamental choices a programmer can make. Many of
these criteria lend themselves to multiple tests – for example, C17 would
30

presumably incorporate tests for each and every known keyword. The level to which
these tests could be broken down is unknown – combinations and derivatives of
these tests could stretch into hundreds or even thousands, in an attempt to catch
the most esoteric of styles. For example – what if a programmer typically puts no
spaces between operators and operands, except around mathematical signs ( +, -, /,
*)? Example like this are extreme, but the sheer flexibility of Java and the choices it
permits allow for such styles. The more detailed and numerous the tests created,
the more conclusive the results would be (assuming tests with inconclusive results
are discarded from the analysis process); such a case as mentioned would
presumably, in combination with other tests, be so conclusive as to make the faith
in the authorship identification very high.
The key to creating an initial system therefore is to create those tests which the
simplest and most generic and yet manage to differentiate between most styles.
Failure to differentiate accurately will unlikely disprove the notion that authorship
can be attributed via source code; rather suggest only that the level of testing and
the specificity of the tests may need to be increased.
4.2 Collection of Data for Analysis
4.2.1 Concerns and Choices in Data Needed
Having established the choice of language, development methodology and broad
criteria to look for, it is necessary to gather the material to be analysed. When doing
this, the following must be considered:
● How many known authors need provide work whose style can be analysed
for authorship to prove the system works?
● How many source code files from each author would the system need to
“learn the style”, before it could be effective?
● What is the minimum length of a file required to be useful to stylistic
analysis?
● Are there types of source code file that are unusable for reasons other than
length?
One further issues needs resolution: in the previous section, reference was made to
the fact that levels of testing could go on to great depths in an attempt to establish
esoteric styles, with each tests searching for very specific style data on one of the
programmer choices (C1 to C25 as in Table 4.1.2; the quoted example mentioned
31

spacing around operators). The scope of this project is not great enough to examine
every potential style, so a sensible number of tests that differentiate most styles is
needed.
To ascertain the latter issue, it is apparent that the most logical approach is to have
two data sets:
1. A “training” data set, made up of as many individual source code files from
different authors as possible. This can be used to try and spot the major
differences in style, which can be used to determine which tests are the most
applicable and useful. The eclectic range of authors and styles contained
should ensure that when the program is trained on this data, problems with
item recognition, production of statistics and tokenising are all ironed out.
2. A more detailed “proof of concept” data set. This would be composed of a
much smaller number of authors, each of whom would be required to submit
multiple files. After the first set had been used to determine what tests
should be run, and that the tokenising and item recognition processes work
correctly, this set would be used to actually “learn” the style from files by
each author, identify a digital fingerprint, and then accurately attribute
authorship to further source code file from each author.
This approach avoids the need to collect multiple files from many different authors
(which may be problematic) but ensures that there is still a small selection of styles
to identify, once the initial construction is complete and fully tested on the training
data.
Given this, data will be collected to fill the sets as follows:
Set 1 - “Training”: Unlimited requests will be made for a one week period for
individual files from authors. These will be anonymised and no tracking of the
authorship of each file will be made. The files will be pooled into the training data
set and analysed to spot style differences that often occur. Length and content of
these, provided they are Java files, is unimportant.
Set 2- “Proof of concept”: Having briefly analysed data received for Set 1, a small
number of requests will be made for willing programmers to donate multiple files.
32

The number of files needed from each and any other criteria they must meet will
need to be determined after a working prototype has analysed the training set, and
concrete methods for style detection have been produced that inform these
minimum criteria.
4.2.2 Initial Data Collected
Requests were sent out to known colleagues, students, lecturers and professional
programmers for source code files for the Training dataset. A few publicly available
files of Java code were added into the mix; whilst these will never be used for
production purposes, care was taken to ensure that no rights were infringed. Each
file was anonymised and can be found in the initial data set folder on the
accompanying CD. A total of 72 source code files were obtained for the Training
dataset.
Clearly, the call for the proof-of-concept dataset cannot be made until the
requirements of the digital fingerprint detection process are known. This will be
detailed in the next section and a prototype implemented; after which the requests
will be made for the data. This will be detailed in a later section.
33

5. Modelling and Design
The selected methodology (a modified DSDM development process, utilising UML
2.0 notation) involves the production of prototypes iteratively and incrementally. In
modifying the DSDM, the pre- and post-project phases were removed, as was the
first stage of the remaining phase (Feasibility; which is by and large covered by
background research). A partial stage two will be followed establishing the user
needs, and the prioritised requirements of the system. Following this, successive
iterations of design will be shown in this section, with successive iterations of
implementation shown in Section 6.
5.1 User Needs
In figure 5.1 below, the system's top-level user requirements are shown using a Use
Case Diagram:
The diagram clearly shows that in terms of interaction with the system, users must
be able to submit source code files, which are checked for authorship and/or used
to build up the digital fingerprint. The owner of CWD must be able to see the
results – a report confirming or questioning the authorship of each file.
34

Given these clear needs and taking into account the project's minimum
requirements, we can use the MoSCoW analysis (a frequent feature of DSDM) to
produce a list of requirements. MoSCoW categorises the system into four sets of
requirements – must have (definitely, should have (preferably), could have
(optionally), would have (in ideal conditions):
Must Have
● The ability to input Java files
● The capacity to identify tokens within the Java file
● To be able to produce simple counts of tokens, and know their location
● To produce the minimal needed statistics on each file
● To compare these against previous, known files from that author
● To establish a “digital fingerprint” - commonalities, the combination of
which can be reasonably believed to be very likely indicative of the author
● To report established or disprove authorship
Should Have
● A way of expressing confidence in the digital fingerprint (how reliable is it?)
and subsequent authorship predictions.
● To adaptively choose which tests are generating useful data for any given
user, and discard unimportant results
● To improve the digital fingerprint with successive data.
● A basic submission system and graphical interface
Could Have
● The ability to turn tests on and off to reflect potential corporate style
guidelines
● The ability to accept multiple files as a single “program”
● A more detailed level of statistical data to capture esoteric styles and
increase digital fingerprint accuracy
● Flag up significant variations in the fingerprint in sections of a file
Would Have
● A scripting/plug-in system to allow extra languages and tests to be added
● In-built support for additional programming languages
● The ability to build a digital fingerprint that identified style over multiple
languages
35
The first iteration will tackle the Should Haves. Following the 80:20 principle in
RAD that 80% of the functionality will be achieved by 20% of the work, it is likely
that majority of the Should Haves can be completed relatively easily for first
iteration – the Functional Model.
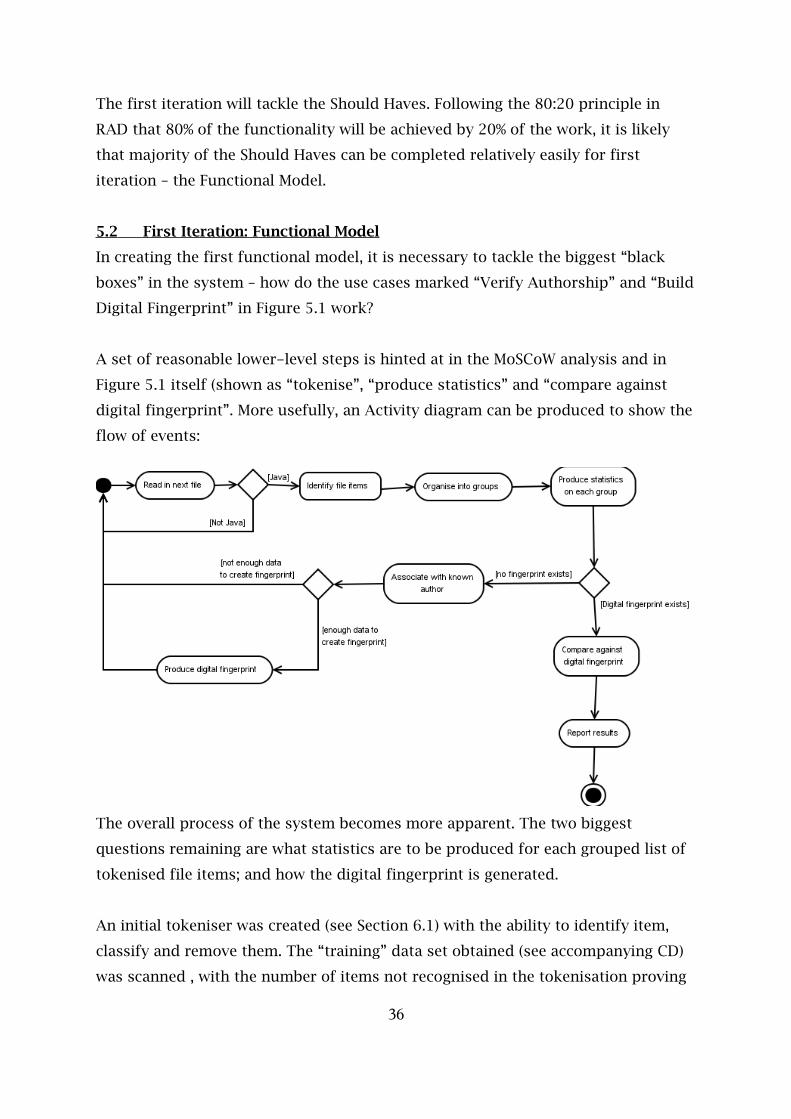
5.2 First Iteration: Functional Model
In creating the first functional model, it is necessary to tackle the biggest “black
boxes” in the system – how do the use cases marked “Verify Authorship” and “Build
Digital Fingerprint” in Figure 5.1 work?
A set of reasonable lower-level steps is hinted at in the MoSCoW analysis and in
Figure 5.1 itself (shown as “tokenise”, “produce statistics” and “compare against
digital fingerprint”. More usefully, an Activity diagram can be produced to show the
flow of events:
The overall process of the system becomes more apparent. The two biggest
questions remaining are what statistics are to be produced for each grouped list of
tokenised file items; and how the digital fingerprint is generated.
An initial tokeniser was created (see Section 6.1) with the ability to identify item,
classify and remove them. The “training” data set obtained (see accompanying CD)
was scanned , with the number of items not recognised in the tokenisation proving
36

to be around 2% of the file's items, which was considered to be acceptable for the
first iteration. Output was printed to text files as a list of items organised by
position in file, and then shown again organised by type. The input files and the
lists of tokenised items were then examined and compared against the choices table
(4.1.2), to see which variations were most prevalent and produce appropriate tests.
The most notable style variations, categorised by the choices table, were as
observed and written. The observations follow:
C1: Indentation lengths vary highly; are not always consistent
C2: Significant variations in spacing around operators; spacing choices seem to vary
between types of operator (e.g. assignment, mathematics etc) or even whether it was
before or after the operator.
C5: Mainly positioning of braces seems to determine new lines – different styles
show opening and closing braces either on their own lines or own separate lines (or
mixed).
C6: Preference of multi-line and single-line comments vary greatly
C7: Numbers of types of comments and overall numbers vary
C8: Line-span of multi-line comments, length in characters vary
C9: Main preference seems to be choice of positioning comments on/in lines of
code or on their own lines
C10: File lengths naturally vary
C11: Number of lines of code as proportion of file seem wildly different
C12: Length of identifiers varies, particular depending on type (e.g. many choose
shorter names for parameters)
C13: Some styles use underscores; others capitalised letters to start words.
Occasional use of all caps, all lower and some number/dollar usage; seems
idiosyncratic and relatively consistent.
C15: Length of statement blocks most notable
C16: Number of dot-separated names more prevalent and lengthy in some files
C17: Most notable variations in proportions of variables, parameter and method
usage (some files many methods; some with lots of parameters; some with very few
recycled variable names)
C19: Loop choices vary considerably
C25: Number of levels of brace seem indicative in given files.
37

One particularly noticeable variation that did not come properly under the headings
above was the distribution and use of braces. Some programmers seemed to like to
cram them on one line; some seemed to try and match up the column index of
matching braces; some insisted on putting braces in when they were not required
(e.g. an 'if' or “else” with one statement) and others omitted them in this case. This
information and the list above was combined to generate a set of token statistics
(discussed in Section 6.1) that attempted to capture these style variations.
During the production of the statistics it was determined that given time
constraints, it was important to tie up the system and deliver the tokenising and
statistic-producing system as a first functional prototype, as considerable extra
design and implementation would be needed to generate the digital fingerprint.
This process comprised the second iteration.
5.3 Second Iteration: Increased Functionality Prototype
The first iteration did not fully meet the functional requirements of the system and
required extra design work, owing to the decision to complete the prototype's
tokenising and statistic-producing functionalities. One of the rationales behind
choosing DSDM as a development process was the knowledge that there were
severe limitations on project time (10 weeks in total) and thus the production of
successively-functional prototypes in quick succession ensured that if development
had to be cut short, some software model representative of the project aims was
still produced. At this point in the project, implementation of the tokenising system
(the complexities of which produced a number of obvious bugs and exceptions
which needed to be fixed/accounted for) was protracted, leaving a very short
amount of time left. Given the need to finalise the project report, an extension of
seven days to the deadline was negotiated. This left time to produce the report,
plus a few extra days. This extra time would be used for a second iteration, which
would aim to complete the digital fingerprinting functionality and thus the final
project minimum requirement remaining.
When examining solely the question of adding the digital fingerprint functionality
to the system - both ability to “learn” one from a set of files from a known author,
and ability to verify a future files – it seems that the final three Must Have
objectives and the first three Should Haves can be collectively approach as
comprising one overall problem, which will be the subject of this second iteration.
38

5.3.1 Normalising the existing results
The first problem is to “normalise” the statistics, which are measured on a variety
of scales. Putting some uniformity into the scales so that each file can be compared
like-for-like is a necessary step before any comparisons between files can made.
The decision was taken to attempt where possible to put this on a scale of 100 – for
example, items found per 100 lines, proportions of one item versus another in
terms of percentage, items found per 100 words, etc.
There are some statistics which cannot be normalised within reason – things like
file length and word count must be judged in terms of their original numbers.
Clearly therefore, methods of analysing the statistics will be needed which
compensates for the fact that some items are compared on a scale of 0 to 100, and
others have no set scale or boundaries. The final list of statistics, and which were
normalised to a scale of 100, can be seen in Appendix D. Details on the
normalisation can be found in Section 6.2
5.3.2 Weighting and Confidence
The activity diagram shown in section 5.2 illustrates that a set of known
submissions must be received for an author whose identity is known before a
digital fingerprint can be created for that author; once created, submissions can be
verified against the original. Looking at the first three “Should Have” criteria, it
seems logical to suggest that the work of creating a digital fingerprint that
conforms to these ideas can only be facilitated by some kind of weighting system
that gives greater or lesser importance to each set of tests performed on the initial,
verified submissions.
This could only be determined by a formula that analysed the initial set and
determined which tests produced the most uniform data, and which were more
disparate; thus making for any given author tests that show consistent data more
important and removing emphasis on tests where the author's work was shown to
have little consistency. This would form the initial digital fingerprint. When
comparing against a new file to establish authorship, each relevance-weighted test
would then be performed on the new file's data; some kind of confidence value
would be needed that expressed how closely the new file's data conformed to
39

previous data.
Thus, for the purposes of this project, the digital fingerprint is expressed as “the
average values produced by a series of weighted tests, where weights make some
averages more important than others”. Conformance to a digital fingerprint can be
expressed as “values which most closely conform to a given set of tests, with the
importance of each match determined by the weight of the test and the proximity
to the average set of results”.
Methods of weighting and confidence are shown below:
Weighting 100 - (standard deviation of results x 100 )
mean of results
Confidence If within standard deviation range: 100 – 1% for each 1% of difference from average; otherwise, 2% for each 1% difference from average
The weighting gives higher confidence to those tests for which the standard
deviation is a smaller percentage of the mean; for a test where the standard
deviation was zero (I.e. all observed items were identical in result) this would result
in 100% weighting; tests where the standard deviation exceeded the average result
would be given 0% weighting.
In terms of the confidence of whether a tested item matches the established
fingerprint, the confidence is lowered by 1% for each percentage distance it is from
the average – for example, if the average is “100”, a value of 93 would be 7%
distance away, and thus have a 93% confidence rating as matching the fingerprint.
This increases to 2% if it crosses the standard deviation range; in the above
example, if the standard deviation was 3, then the confidence lost would be 1% x 3
(100 to 97) and then 2% x 4 (97 to 93), making for 89% confidence. The effectiveness
of both of these sums will be tested upon the system's implementation.
Finally, a “proof-of-concept” data set was needed. The criteria set for these
datasets (the importance of which is noted in Section 4.2.1) was defined as:
40

● Minimum of four files needed. This assumes that the bare minimum needed
to establish a digital fingerprint is three, so that in each test, if an anomalous
result is found, the other two results will ensure the test is still kept
relatively applicable. The fourth file would be tested against the established
fingerprint.
● No abstract classes or interfaces. These are Java construct where the file
structure differs considerably from standard class files; support for these
can be added later, but for now they may confuse the results
● Minimum of 50 lines – this allows for huge variations in length, but ensures
we have a fairly minimal sample that has room for a couple of methods and
control structures as needed.
This answers most of the concerns raised in 4.2.1. Ultimately seven authors happily
donated code which met the above requirements, which it is believed is sufficient to
establish a small set of differing styles and test for authorship. Authorship testing,
owing to the above confidence and weighting, will be expressed as a percentage
probability that is an average of the confidences for each test, skewed by test
weight. Section 6.2 of the implementation documents the work done to implement
these design ideas.
41

6. Implementation
Using the DSDM development process means multiple iterations of rapid design
and implementation of prototypes. Where sections here are linked to a design
iteration it will be clearly marked.
6.1 First Iteration: Functional Model
The design objectives for iteration one were to tackle most the the Should Haves
from the MoSCoW analysis. The first steps were accepting Java files as input;
tokenising them and producing output lists of tokens. From the beginning Python
demonstrated its worth; the code to take all filenames from a directory is as
follows:
home_dir = os.getcwd() # program directoryresults_dir = (os.getcwd() + "/results")os.chdir(home_dir + "/input")input_dir = os.getcwd() # location of files to be processedinput_files = os.listdir(input_dir)
This short snippet takes the current program directory; sets a directory to print
results to and one to read input from; and produces a list of input files (input_files).
The simplicity of Python's 'for' loop structure then allows iteration over the files by
writing:
for selected_file in input_files:
Some method of verification was needed to ensure the input files were standard
Java class files. To remove complications, it was decided that the simplest way to
achieve this was to check for the presence of the file extension “.java” at the end.
Here Python's text comprehension and manipulation capabilities came in to effect
with the use of 'slices', a construct which easily allows substrings to be produced.
The following code, placed immediately after the opening 'for' loop, effectively
vetoes non-.java files using this method:
if selected_file[-5:] == ".java":
The next task was considerably more challenging – the identification of tokens in a
Java file. One idea was to use and adapt an existing Java compiler; however this was
quickly dismissed for two reasons. First, there are no known compilers written in
Python and translation into Python would take longer than the time allotment for
this project. Secondly, a quick examination of the regular javac compiler (presumed
42

representative of Java compilers) showed a program composed over hundreds of
files of source code, with considerable complexity. Compilers are designed to
understand each reference and word, and perform a level of checking,
comprehension and memory management (not to mention actual compilation). As a
result the effort required to remove any useful tokenising code seemed more
extensive than writing a simple tokeniser from scratch.
Context matters heavily in Java as in all programming languages – the word
“automobile” might be an identifier; but if immediately preceded by “//” it is a
comment; if encased in quotes, a string. The following three items were identified
as “blocking” elements – the state of being “inside” them overrode all other
considerations:
Multi-line comments Delineated by “/*” and “*/”
Single-line comments
Delineated by “//” and end of line
Strings Delineated by single or double quotation marks
Therefore it seemed sensible to remove these items first, so a tokeniser could more
positively identify the remaining items. What is important to note that is that these
“blocking” items, which “block” the normal use of other words, also block each
other. A sentence surrounded by quotation marks is NOT a valid Java string if it is
inside a comment; if a single-line comment has been declared, any number of
multi-line delineators written on the rest of that line do not comprise valid
comments in their own right. Furthermore it was necessary to be able to identify
these blocking items if they stretched across multiple lines, ensuring that their full
length was identified and removed from the parsing process.
The simplest solution is to test for the presence of all three opening delineators
(quotation marks, “//” or “/*”) - the one with the lowest index on the line is
accepted to take precedence, and initiates its blocking item until it is closed off. The
indices inside the blocking element are removed from the checking process which
continues until there are no blocking elements left on the line. In the code, this was
implemented as follows:
string_found = current_modifieds[line_number].find("\"")mlc_found = current_modifieds[line_number].find("/*")
43

slc_found = current_modifieds[line_number].find("//")
while (string_found > -1) | (mlc_found > -1) | (slc_found > -1):lowest_result = tests.lowest_index([string_found, mlc_found, slc_found])if lowest_result == mlc_found:
// some code elif (lowest_result == slc_found):
// some code elif (lowest_result == string_found):
// some code
This basic algorithm demonstrates the premise. A separate module “tests” was set
up in order to perform basic tests on the input data (such as the above, “find me
the lowest item of these three, and report its name”), including the tests for
particular token types.
Because of the importance of context in Java, it was decided three copies of a
source code file's data should be kept, to track which items had been tokenised and
where they were placed. The three types and their uses are outlined below:
Name Contents Rationale
current_lines Exact replicas of each file's lines
Kept completely unmodified to verify original state of lines
current_nonblocking
Exact replica of file lines with blocking items (strings and comments) removed
When tokenising anything other than strings and comments, the surrounding context of a word or symbol can be checked without accidentally including anything blocked by a comment or string
current_modifieds Replica of file lines with currently-recognised items removed
Used to determine what still needs to be tokenised in a file
In order to meet the rest of the Should Have criteria, a number of tests were then
added in to systematically find recognisable tokens, remove them from the
“current_modifieds” set and collate them. A “data_store” array was set up to keep
track of the various items discovered, and arrays of normal Java keywords and
symbols were created to be scanned for in the file. Context-sensitive tests were
created which took the known keywords and symbols and used their position to
infer the position of other file items. Overall, the following tests were added:
Test Function
whitespace_check Locate tabs, indents, whitespace characters
44

keyword_finder Used to locate initial Java keywords; and once it has identified user-defined keywords (such as class names), locates these also
dot_notation Identifies class, packages etc referred to via dots (i.e. that.that.theother().method)
constructor_finder Locates constructors – primarily used to identify names of external classes used, to then locate other references to these classes
class_finder Given a list of class names identified, scans file for other references to these class names
name_finder Locates the first-time use of an identifier (variable or method declaration or parameter, e.g)
repeat_identifiers Locates subsequent references to identifiers
symbol_finder Locates all symbols including operators
number_finder Locates literal numerical values in the file
Collectively these tests scored around 98% of file items recognised (varying on
which files were input) when run. The full coding and structure of the tests can be
seen in the source code files on (the accompanying project CD). Finally, the results
were output to files (corresponding results for each file can be found in the
“results” folder of the project). An early work in progress of the tokenisation and
results-production components was successfully demonstrated at the project
progress meeting (shown in the project schedule).
As discussed in section 5.2, the results files and their corresponding input files
were then examined to find the most obvious style differences, which were found
and listed in the aforementioned section. Using these as guidelines, a
“stats_generator” module was produced to generate appropriate statistics and print
the results to results files. The “generate” method in the module does just this –
items are counted from the results lists and a second corresponding “stats” file is
produced in the “stats” directory of the source tree.
The first four Should Haves were thus completed. The system produced raw data
necessary for the detection of style and creation of a digital fingerprint, but it was
as yet unclear how the data would be manipulated to do this. The decision was
made to consider this prototype a proof-of-concept of the tokenisation and
statistic-producing parts of the system, and to back to modelling and design to
45

plan a second iteration with the capacity to manipulate the statistics and produce a
detectable digital fingerprint. This early functional prototype fulfilled most of the
second minimum requirement for the project, in that it produced enough data to
identify a distinctive style for a given author; the actual identification process
though (mostly covered by the final minimum requirement) will be covered by the
next iteration.
6.2 Second Iteration.
The first task was to perform the statistic normalisation. An extra function in the
stats_generator module was added to normalise the existing statistics on to scales
where possible, and produce the results as CSV files. As a sample, sets of five files
from five of the authors were put through this process. The results were collected
and averages and standard deviations added, ready for the weighting and
confidence. The collated results from this can be seen in the “Stats test”
spreadsheet on the project CD.
Unfortunately at this stage, the implementation had begun to overrun its timebox,
and emphasis had to be placed on a completed project report. Observations on this
and whether or not the inability to produce the digital fingerprint from the collated
statistics constitutes a failure of the project can be read in Appendix A.
46

Bibliography
1. Fores, S. (2007). School Taught Student Handbook for Returning Students
2007-2008, School of Computing, University of Leeds, page 18.
2. Jimack, P., Efford, N., Fores, S., Clark, M. (2007). Project Topics, School of
Computing, University of Leeds,
http://www.comp.leeds.ac.uk/tsinfo/projects/software_g.html [April 2008]
3. Royce, W. (1970). Managing the Development of Large Software Systems,
Proceedings of IEEE WESCON vol. 26, pp1-9.
4. DeGrace, P., Hulet Stahl, L. (1990). Wicked Problems, Righteous Solutions: A
Catalog of Modern Software Engineering Paradigms, Prentice Hall
5. Boehm, B.(1988). A Spiral Model of Software Development and Enhancement,
IEEE Computer magazine vol. 21, issue 5
6. Martin, J. (1991). Rapid application development, Macmillan Publishing Co.
7. Arthur, L. J., (1997). Quantum improvements in software system quality,
Communications of the ACM vol. 40, issue 6
8. Howard, A. (2002). Rapid application development: rough and dirty or value-
for-money engineering?, Communications of the ACM vol. 45, issue 10
9. Stapleton, J. (1999). DSDM: Dynamic Systems Development Method,
Proceedings of Technology of Object-Oriented Languages and Systems, 1999,
British Computer Society.
10.Kruchten, P. (2003). The Rational Unified Process: An Introduction, Addison
Wesley
11.Jacobson, I. (1999). The unified software development process, Addison
Wesley
12.Knoepfel, A., Groene, B., Tabeling, P. (2005). Fundamental modeling concepts
– effective communication of IT systems, Wiley
13. Quatrani, T. (2005). Introduction to UML 2.0, Object Management Group,
http://www.omg.org/news/meetings/workshops/MDA-SOA-WS_Manual/00-
T4_Matthews.pdf [April 2008]
14. www.sysml.org [April 2008]
15. Harrap, C. (2003). Chamber 21st Century Dictionary, Harrap Publishers
16.Baayen, H., Neijt, A., Tweedie, J. (2002). An experiment in author attribution,
Proceedings of the JADT, University of Paris
47

17. White, J.W., Kowalski, R.M. (1994). A Feminist Analysis, Psychology of Women
Quarterly, Blackwell Synergy
18. Chen, H. (2005). Artificial Intelligence for Homeland Security, Intelligent
Systems, IEEE vol 20. issue 5
19. Person, R. F. (1997). The Kings-Isaiah and Kings-Jeremiah, Walter de Gruyter
20. Somers, H., Tweedie, F. (2003). Authorship Attribution and Pastiche, Springer
21. Schommer, C., Uhde, C. (2008). Textual Fingerprinting with Texts from Parkin,
Bassewitz, and Leander, Arxiv Pre-Print
22. Laan, N. (1995). Stylometry and Method. The Case of Euripides, Literary and
Linguistic Computing 1995 10(4): 271-278
23. Mosteller, F., Wallace, D.L. (1963). Inference in an Authorship Program,
Journal of the American Statistical Association
24. Hoover, D.L. (2003). Multivariate Analysis and the Study of Style Variation, Literary and Linguistic Computing 2003 18(4):341-360
25.Madigan, D., Genkin, A., Lewis, D.D., Argamon, S., Fradkin, D., Ye, L. (2005). Authorship Identification on the Large Scale, Rutgers University Press
26. Stamatatos, E., Fakotakis, N., Kokkinakis, G. (2000). Automatic Text Categorization in Terms of Genre and Author, Computational Linguistics 2000, vol 26. issue 4, pp 471-495
27. Argamon, S., Koppel, M., Fine, J., Shimoni, A.R. (2003). Gender, genre, and
writing style in formal written texts. Text-Interdisciplinary Journal for the
Study of Discourse, Walter de Gruyter
28. Smadja, F. A. (1989). Lexical Co-occurence: The Missing Link, Oxford
University Press
29. www.ldoce.com [April 2008]
30. Longstaff, T.A., Schultz, E.E. (1993). Beyond preliminary analysis of the WANK
and OILZ worms: a case study of malicious code, Computers and Security, vol.
12 issue 1
31. Spafford, E.H., Weeber, S.A. (1993). Software forensics: Can we track code to
its authors?, Computers and Security, vol 12, pp 585-595
32. Vitoria, M. (2006). Navitare Inc. v Easy Jet Airline Co Ltd., Crown Publishings
33. Sallis, P., Gray, A., MacDonnell, S. (1997). Software Forensics: Extending
Authorship Analysis Techniques to Computer Programs, Proceedings of the
3rd Biannual Conference of the IAFL, 1997 1-8
34. MacDonnell, S., MacLennan, G., Kilgour, R., Gray, A., Sallis, P. (1997).
48

IDENTIFIED: Software Authorship Analysis with Case-Based Reasoning,
Proceedings of the Addendum Session of the 1997 International Conference
on Neural Information Processing and Intelligent Information Systems.
35. Helmore, S. (2005). Detecting Bought Programming Coursework Solutions,
School of Computing, University of Leeds
36. http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html [April
2008]
37. http://en.wikibooks.org/wiki/List_of_hello_world_programs [April 2008]
38. http://java.sun.com/reference/docs/ [April 2008]
49

Appendix AReflections on Project Experience
In summary the project was, I feel, a worthwhile experience and one I would happily do again, incorporating lessons I have learned during this project.
One of the great joys of the project was the research. The opportunity to read into very specific areas in depth was a fantastic learning experience in particular; a great opportunity to become “an expert” in a very specific field, such that one can write knowledgeably about it. To ensure the project can make a germane contribution to that particular field, it is necessary to read decades' worth of papers on the subject, giving an insight into both the development of the technology and the thought processes of some of computing's leading thinkers. The resulting solution very much feels to the creator as though he/she has stood on the back of giants and worked on topics that have been grappled with by such brilliant minds; this is in itself very fulfilling.
I would highly recommend to students attempting projects that they send a great deal of time at the start of their project familiarising themselves with the expectations the School places on such projects and what they are expected to deliver. Whilst projects posted on News are always valid, the student needs to make them applicable to the framework of a final-year project. In my own case, failure to properly grasp the expectations of a final-year project led to a number of poor choices of project and/or proposed solutions; ultimately therefore the choice of project went through many revisions. This led to a very short timescale within which to produce the solution and report, which undoubtedly caused the project to suffer both in terms of lack of time to produce the solution (implementation had to stop before full realisation of the solution could be made) and lack of time to finalise the report. This clearly emphasises the need to resolve such teething problems early; the project schedule is clearly designed with an adequate amount of time for completion, and delays are likely to hinder progress and deliver poorer final results.
This project does not however constitute a failure to my mind; the substantial research and theoretical reasoning behind the proposed system along with a partial proof-of-concept, I believe demonstrate sound work and a platform for future work to be built upon. Completion of the implementation could be taken up by anyone with access to the source code and this paper; and whilst the implementation is incomplete it is my judgement that the theories are sound and backed up by exhaustive research.
Students attempting this area of research in future should consider the theories put forward and examine the source code of the implementation as it stands, as a possible way forward. The bibliography, in conjunction with the research section, sets out a wide number of resources from the fields of linguistics, natural language processing, plagiarism detection and computing in general. I would advise that future endeavours into this field continue to examine all of these areas to gain the maximum advantages offered by all of these areas of research.
50

In conclusion my thanks go to my long-suffering project supervisor; and I would again exhort participating students to full utilise the wealthy mine of information and resources that supervisors offer; and I hope that this paper can have contributed at least in a small way into the thinking and design of digital fingerprinting systems.
51

Appendix B
52
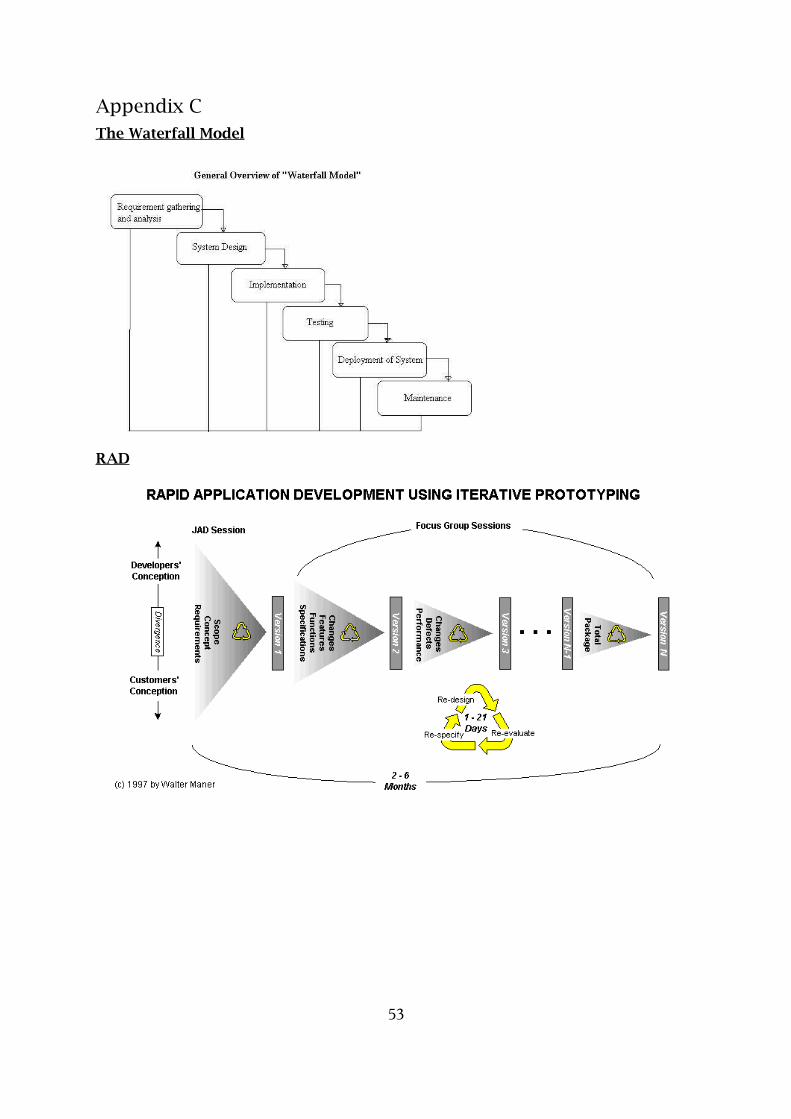
Appendix CThe Waterfall Model
RAD
53

DSDM
The Spiral Model
54

Unified Process
55

Appendix D
The above represents a sample; the full spreadsheet (at 76 columns) can be seen on the attached project CD
56
La
be
l
comments_mlc_count
comments_slc_count
comments_mlc_linespan
comments_slc_chars
comments_mlc_chars
comments_mlc_total_char
comments_slc_total_char
comments_total_char
comments_mlc_proportion
comments_slc_proportion
comments_num_lines
comments_mixed_lines
code_all_lines
code_lines
code_exclusive_lines
Programmer A6.85 2.74 4.8 27 143 717 55 772 92.88 7.12 75.34 1.82 73 53.42 97.444.92 4.92 8.67 57 313 939 171 1110 84.59 15.41 280.33 0 61 47.54 1006.74 6.74 5.67 47 169 1015 282 1297 78.26 21.74 316.85 0.35 89 47.19 97.624.15 5.7 4.13 35 106 1696 790 2486 68.22 31.78 204.66 0.38 386 63.21 98.778.77 0 5.6 0 175 878 0 878 100 0 0 0 57 43.86 100
Av 6.29 4.02 5.77 33.2 181.2 1049 259.6 1308.6 84.79 15.21 175.44 0.51 133.2 51.05 98.77Std 1.81 2.68 1.74 21.8 78.54 377.93 315.8 689.06 12.39 12.39 134.77 0.75 141.87 7.62 1.24
Programmer B0.22 6.67 2 31 75 75 931 1006 7.46 92.54 206.89 1.18 450 77.11 96.833.64 3.64 6 52 151 303 104 407 74.45 25.55 189.09 0 55 50.91 1001.72 0 6 0 153 153 0 153 100 0 0 0 58 65.52 1001.49 0 6 0 156 312 0 312 100 0 0 0 134 69.4 1000.77 7.69 7 40 150 150 403 553 27.12 72.88 310 0.25 130 65.38 98.82
Av 1.57 3.6 5.4 24.6 137 198.6 287.6 486.2 61.81 38.19 141.2 0.29 165.4 65.66 99.13Std 1.3 3.61 1.95 23.66 34.73 104.26 395.73 324.92 42.53 42.53 136.91 0.51 163.52 9.52 1.38
Programmer C8.24 2.35 5.43 2 169 1184 4 1188 99.66 0.34 4.71 0 85 40 1001.37 12.33 6 3 110 110 27 137 80.29 19.71 36.99 0 73 75.34 1003.85 6.41 5.33 5 175 527 29 556 94.78 5.22 37.18 0 78 60.26 1004.47 3.35 7.13 6 285 2282 37 2319 98.4 1.6 20.67 0 179 54.75 1003.97 0.32 6.32 45 261 6530 91 6621 98.63 1.37 14.44 1.1 630 57.94 99.73
Av 4.38 4.95 6.04 12.2 200 2126.6 37.6 2164.2 94.35 5.65 22.8 0.22 209 57.66 99.95Std 2.47 4.67 0.73 18.4 71.82 2594.61 32.28 2623.73 8.07 8.07 14.23 0.49 239.36 12.65 0.12
Programmer D10.71 3.57 3.33 45.5 92.5 555 91 646 85.91 14.09 162.5 0 56 48.21 1006.25 10.94 3.75 39.43 69.25 277 276 553 50.09 49.91 431.25 0.36 64 51.56 96.973.45 4.6 4 23 109 327 92 419 78.04 21.96 105.75 0 87 64.37 1006.67 0 7 0 268 1072 0 1072 100 0 0 0 60 46.67 1005.04 3.36 3.33 42 93.67 562 168 730 76.99 23.01 141.18 0 119 62.18 100
Av 6.42 4.49 4.28 29.99 126.48 558.6 125.4 684 78.21 21.79 168.13 0.07 77.2 54.6 99.39Std 2.7 4 1.55 18.86 80.37 314.86 103.1 245.71 18.21 18.21 159.8 0.16 26.28 8.15 1.36
Programmer E0 8.09 0 17.64 0 0 247 247 0 100 142.77 5.67 173 73.41 88.980 3.39 0 24.25 0 0 97 97 0 100 82.2 4.12 118 79.66 95.740 3.54 0 23 0 0 92 92 0 100 81.42 4.35 113 74.34 95.240 2.61 0 29 0 0 116 116 0 100 75.82 3.45 153 72.55 96.40 3.88 0 23.25 0 0 93 93 0 100 90.29 4.3 103 70.87 94.52
Av 0 4.3 0 23.43 0 0 129 129 0 100 94.5 4.38 132 74.17 94.18Std 0 2.17 0 4.04 0 0 66.67 66.67 0 0 27.48 0.81 29.66 3.33 2.99


















