
1 I256 Applied Natural Language Processing Fall 2009 Sentence Structure Barbara Rosario.
45
1 I256 Applied Natural Language Processing Fall 2009 Sentence Structure Barbara Rosario
-
date post
22-Dec-2015 -
Category
Documents
-
view
219 -
download
0
Transcript of 1 I256 Applied Natural Language Processing Fall 2009 Sentence Structure Barbara Rosario.

1
I256
Applied Natural Language Processing
Fall 2009
Sentence Structure
Barbara Rosario

2
Resources for IR
• Excellent resources for IR:– Course syllabus of Stanford course:
Information Retrieval and Web Search (CS 276 / LING 286)• http://www.stanford.edu/class/cs276/cs276-2009-
syllabus.html
– Book: Introduction to Information Retrieval (http://informationretrieval.org/)

3
Outline• Sentence Structure• Constituency• Syntactic Ambiguities• Context Free Grammars (CFG)• Probabilistic CFG (PCFG)• Main issues
– Designing grammars– Learning grammars– Inference (automatic parsing)
• Lexicalized Trees• Review
Acknowledgments: Some slides are adapted and/or taken from Klein’s CS 288 course

4
Analyzing Sentence Structure
• Key motivation is natural language understanding. – How much more of the meaning of a text can
we access when we can reliably recognize the linguistic structures it contains?
– With the help of the sentence structure, can we answer simple questions about "what happened" or "who did what to whom"?

5
Phrase Structure Parsing
• Phrase structure parsing organizes syntax into constituents or brackets
new art critics write reviews with computers
PP
NP
NP
N’
NP
VP
S

6
Example Parse
Hurricane Emily howled toward Mexico 's Caribbean coast on Sunday packing 135 mph winds and
torrential rain and causing panic in Cancun , where frightened tourists squeezed into musty shelters .

7
Analyzing Sentence Structure
• How can we use a formal grammar to describe the structure of an unlimited set of sentences?
• How can we “discover” / design such a grammar?

8
Constituency Tests
• Words combine with other words to form units. • How do we know what nodes go in the tree?
– What is the evidence of being a unit?
• Classic constituency tests:– Substitution– Question answers– Semantic grounds
• Coherence• Reference• Idioms
– Dislocation– Conjunction

9
Constituent structure: Substitution
• Substitutability: a sequence of words in a well-formed sentence can be replaced by a shorter sequence without rendering the sentence ill-formed.– The little bear saw the fine fat trout in the brook.
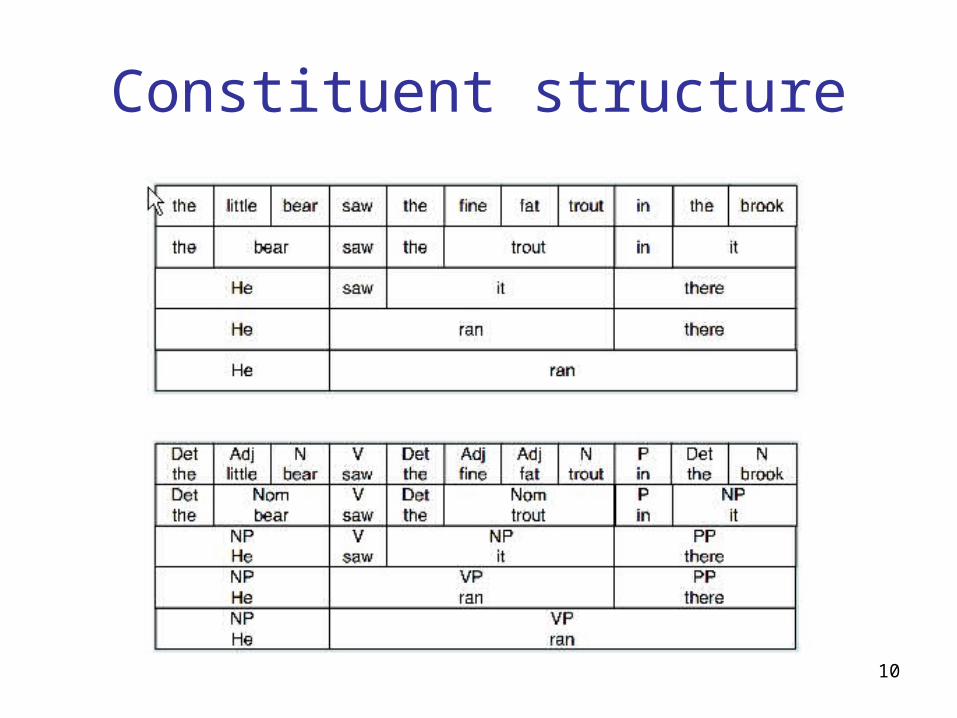
10
Constituent structure

11
Constituent structure
• Each node in this tree (including the words) is called a constituent. – The immediate constituents of S are NP and VP.
12
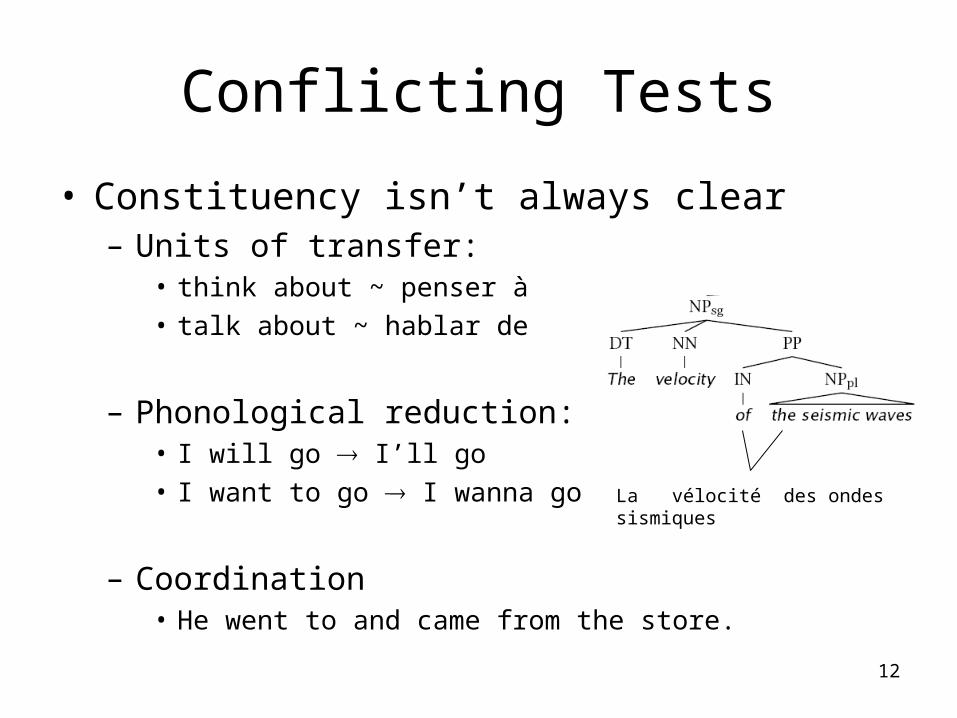
Conflicting Tests
• Constituency isn’t always clear– Units of transfer:
• think about ~ penser à• talk about ~ hablar de
– Phonological reduction:• I will go I’ll go• I want to go I wanna go
– Coordination• He went to and came from the store.
La vélocité des ondes sismiques

13
PP Attachment
I cleaned the dishes from dinnerI cleaned the dishes with detergentI cleaned the dishes in my pajamasI cleaned the dishes in the sink

14
PP Attachment

15
Syntactic Ambiguities• Prepositional phrases:
They cooked the beans in the pot on the stove with handles.
• Particle vs. preposition:The puppy tore up the staircase.
• Gerund vs. participial adjectiveVisiting relatives can be boring.Changing schedules frequently confused passengers.
• Modifier scope within NPsimpractical design requirementsplastic cup holder
• Coordination scope:Small rats and mice can squeeze into holes or cracks in the wall.
• And others…

16
Context Free Grammar (CFG)
• Write symbolic or logical rules:
Grammar (CFG) Lexicon
ROOT S
S NP VP
NP DT NN
NP NN NNS
NN interest
NNS raises
VBP interest
VBZ raises
…
NP NP PP
VP VBP NP
VP VBP NP PP
PP IN NP

17
Context Free Grammar (CFG)
• NLTK, context-free grammars are defined in the nltk.grammar module.
• Define a grammar (you can write your own grammars)

18
CFG: formal definition
• A context-free grammar is a tuple <N, T, S, R>– N : the set of non-terminals
• Phrasal categories: S, NP, VP, ADJP, etc.• Parts-of-speech (pre-terminals): NN, JJ, DT, VB
– T : the set of terminals (the words)– S : the start symbol
• Often written as ROOT or TOP
– R : the set of rules• Of the form X Y1 Y2 … Yk, with X, Yi N
• Examples: S NP VP, VP VP CC VP• Also called rewrites, productions, or local trees

19
CFG: parsing
• Parse a sentence admitted by the grammar
• Use deduction systems to prove parses from words– Simple 10-rule grammar: 592 parses– Real-size grammar: many millions of parses!
• This scales very badly, didn’t yield broad-coverage tools

20
Treebank
• Access Treebank to develop broad-coverage grammars.

21
PLURAL NOUN
NOUNDETDET
ADJ
NOUN
NP NP
CONJ
NP PP
Treebank Grammar Scale• Treebank grammars can be enormous
– The raw grammar has ~10K states, excluding the lexicon– Better parsers usually make the grammars larger, not smaller
• Solution?

22
Probabilistic Context Free Grammar (PCFG)
• Context free grammar that associates a probability with each of its productions.
– P(Y1 Y2 … Yk | X)
• The probability of a parse generated by a PCFG is simply the product of the probabilities of the productions used to generate it.

23
Outline• Sentence Structure• Constituency• Syntactic Ambiguities• Context Free Grammars (CFG)• Probabilistic CFG (PCFG)• Main issues
– Designing grammars– Learning grammars (learn the set of rules
automatically)– Parsing (inference: analyze a sentence and
automatically build a syntax tree)
• Lexicalized Trees

24
The Game of Designing a Grammar
Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson ’98]

25
Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson ’98] Head lexicalization [Collins ’99, Charniak ’00]
The Game of Designing a Grammar

26
Annotation refines base treebank symbols to improve statistical fit of the grammar Parent annotation [Johnson ’98] Head lexicalization [Collins ’99, Charniak ’00] Automatic clustering
The Game of Designing a Grammar

27
Learning
• Many complicated learning algorithms…– Another time )-;– Or take CS 288 spring 2010 (recommended!)

28
Parsing with Context Free Grammar
• A parser processes input sentences according to the productions of a grammar, and builds one or more constituent structures that conform to the grammar. (Inference)– It is a procedural interpretation of the
grammar. – It searches through the space of trees
licensed by a grammar to find one that has the required sentence along its fringe.

29
Parsing algorithms
• Top-down method (aka recursive descent parsing)
• Bottom-up method (aka shift-reduce parsing)
• Left-corner parsing
• Dynamic programming technique called chart parsing.
• Etc…

30
• Bottom up parser: Begins with a tree consisting of the node S• At each stage it consults the grammar to find a production that can be used
to enlarge the tree• When a lexical production is encountered, its word is compared against the
input• After a complete parse has been found, the parser backtracks to look for
more parses.

31
Issues
• Memory requirements
• Computation time

32
Runtime: Practice
• Parsing with the vanilla treebank grammar:
• Why’s it worse in practice?– Longer sentences “unlock” more of the grammar– All kinds of systems issues don’t scale
~ 20K Rules
(not an optimized parser!)
Observed exponent:
3.6
33
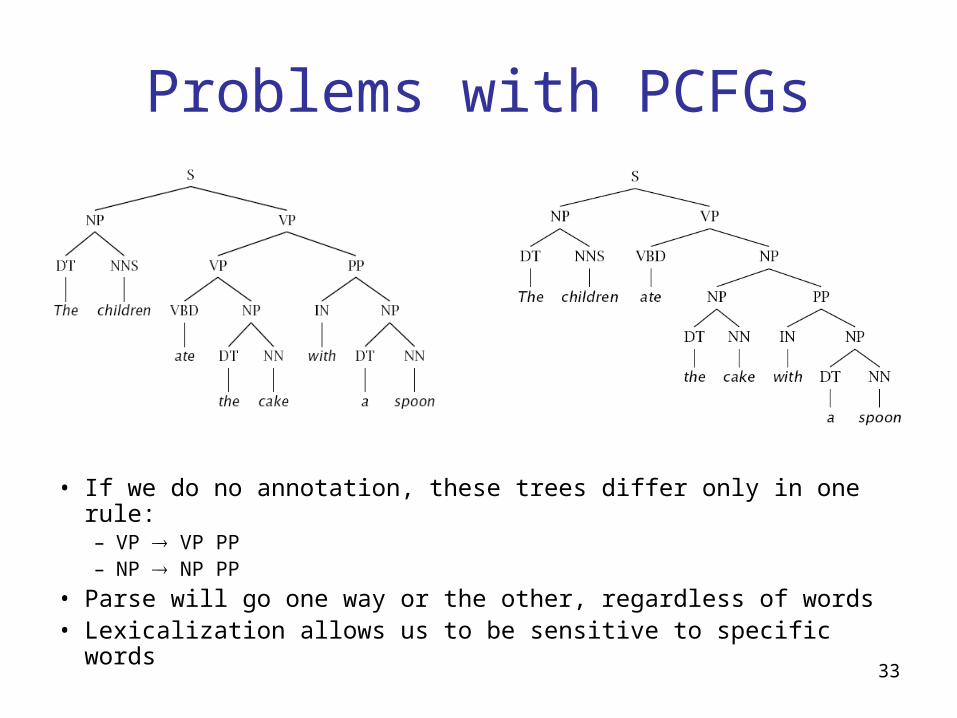
Problems with PCFGs
• If we do no annotation, these trees differ only in one rule:– VP VP PP– NP NP PP
• Parse will go one way or the other, regardless of words• Lexicalization allows us to be sensitive to specific words

34
Lexicalized Trees
• Add “headwords” to each phrasal node– Syntactic vs. semantic
heads– Headship not in (most)
treebanks– Usually use head rules,
e.g.:• NP:
– Take leftmost NP– Take rightmost N*– Take rightmost JJ– Take right child
• VP:– Take leftmost VB*– Take leftmost VP– Take left child

35
Lexicalized PCFGs?
• Problem: we now have to estimate probabilities like
• Never going to get these atomically off of a treebank
• Solution: break up derivation into smaller steps

36
Resources
• Foundation of Stat NLP (chapter 12) • Dan Klein’s group (and his class cs 288)
– http://www.cs.berkeley.edu/~klein– http://nlp.cs.berkeley.edu/Main.html#Parsing
• Speech and Language processing. Jurafsky and Martin (chapters 12, 13, 14)
• Software:– Berkeley parser (Klein group) http://
code.google.com/p/berkeleyparser/– Michael Collins parser:
http://people.csail.mit.edu/mcollins/code.html

37
Dependency grammars
• Phrase structure grammar is concerned with how words and sequences of words combine to form constituents.
• A distinct and complementary approach, dependency grammar, focuses instead on how words relate to other words
• Dependency is a binary asymmetric relation that holds between a head and its dependents.

38
Dependency grammars
• Dependency graph: labeled directed graph– nodes are the lexical items– labeled arcs represent dependency relations
from heads to dependents
• Can be used to directly express grammatical functions as a type of dependency.

39
Dependency grammars
• Dependency structure gives attachments.
• In principle, can express any kind of dependency
• How to find the dependencies?
Shaw Publishing acquired 30 % of American City in March
WHAT
WHEN
WHO

40
• Link up pairs with high mutual information– Mutual information measures how much one word
tells us about another. – The doesn’t tell us much about what follows
• I.e. “the” and “red” have small mutual information– United ?
Idea: Lexical Affinity Models
congress narrowly passed the amended bill

41
Problem: Non-Syntactic Affinity
• Words select other words (also) on syntactic grounds
• Mutual information between words does not necessarily indicate syntactic selection.
a new year begins in new york
expect brushbacks but no beanballs
congress narrowly passed the amended bill

42
Idea: Word Classes
• Individual words like congress are entwined with semantic facts about the world.
• Syntactic classes, like NOUN and ADVERB are bleached of word-specific semantics.
• Automatic word classes more likely to look like DAYS-OF-WEEK or PERSON-NAME.
• We could build dependency models over word classes. [cf. Carroll and Charniak, 1992]
congress narrowly passed the amended bill
NOUN ADVERB VERB DET PARTICIPLE NOUN

43
Review• Python and NLTK• Lower level text processing (stemming
segmentation…)
• Grammar– Morphology– Part-of-speech (POS)– Phrase level syntax (PCFG, parsing)
• Semantics– Word sense disambiguation (WSD)– Lexical acquisition

44
Review• “Higher level” apps
– Information extraction– Machine translation– Summarization– Question answering– Information retrieval
• Intro to probability theory and graphical models (GM)– Example for WSD– Language Models (LM) and smoothing
• Corpus-based statistical approaches to tackle NLP problems– Data (corpora, labels, linguistic resources)– Feature extractions – Statistical models: Classification and clustering

45
Review• What I hope we achieved:• Given a language problem, know how to frame it in
NLP language, and use the appropriate algorithms to tackle it
• Overall idea of linguistic problems • Overall understanding of NLP tasks, both lower
level and higher level application• Basic understanding of Stat NLP
– Corpora & annotation– Classification, clustering – Sparsity problem
• Familiarity with Python and NLTK


















