
1 FT 101 FT 101 Jim Gray Microsoft Research gray/Talks/ 80% of slides are not shown (are hidden) so...
62
1 FT 101 FT 101 Jim Gray Microsoft Research http://research.microsoft.com/~gray/Talks/ 80% of slides are not shown (are hidden) so view with PPT to see them all Outline • Terminology and empirical measures •General methods to mask faults. •Software-fault tolerance •Summary
-
date post
21-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of 1 FT 101 FT 101 Jim Gray Microsoft Research gray/Talks/ 80% of slides are not shown (are hidden) so...

1
FT 101FT 101 Jim Gray Microsoft Research
http://research.microsoft.com/~gray/Talks/80% of slides are not shown (are hidden) so view with PPT to see them all
Outline• Terminology and empirical measures
• General methods to mask faults.• Software-fault tolerance
• Summary

2
Dependability: The 3 ITIES
• Reliability / Integrity: does the right thing. (Also large MTTF)
• Availability: does it now. (Also small MTTR
MTTF+MTTRSystem Availability:if 90% of terminals up & 99% of DB up?
(=>89% of transactions are serviced on time).
• Holistic vs. Reductionist view
SecurityIntegrityReliability
Availability

3
High Availability System ClassesGoal: Build Class 6 Systems
Availability
90.%
99.%
99.9%
99.99%
99.999%
99.9999%
99.99999%
System Type
Unmanaged
Managed
Well Managed
Fault Tolerant
High-Availability
Very-High-Availability
Ultra-Availability
Unavailable(min/year)
50,000
5,000
500
50
5
.5
.05
AvailabilityClass
1234567
UnAvailability = MTTR/MTBFcan cut it in ½ by cutting MTTR or MTBF

4
Demo: looking at some nodes• Look at http://uptime.netcraft.com/ • Internet Node availability:
92% mean, 97% median
Darrell Long (UCSC) ftp://ftp.cse.ucsc.edu/pub/tr/– ucsc-crl-90-46.ps.Z "A Study of the Reliability of Internet Sites" – ucsc-crl-91-06.ps.Z "Estimating the Reliability of Hosts Using
the Internet" – ucsc-crl-93-40.ps.Z "A Study of the Reliability of Hosts on the
Internet" – ucsc-crl-95-16.ps.Z "A Longitudinal Survey of Internet Host
Reliability"

5
Sources of FailuresMTTF MTTR
Power Failure: 2000 hr 1 hr
Phone LinesSoft >.1 hr .1 hrHard 4000 hr 10 hr
Hardware Modules: 100,000hr 10hr (many are transient)
Software:1 Bug/1000 Lines Of Code (after vendor-user testing)
=> Thousands of bugs in System! Most software failures are transient: dump & restart system.
Useful fact: 8,760 hrs/year ~ 10k hr/year

6
Case Study - Japan"Survey on Computer Security", Japan Info Dev Corp., March 1986. (trans: Eiichi Watanabe).
Vendor (hardware and software) 5 MonthsApplication software 9 MonthsCommunications lines 1.5 YearsOperations 2 YearsEnvironment 2 Years
10 Weeks1,383 institutions reported (6/84 - 7/85)7,517 outages, MTTF ~ 10 weeks, avg duration ~ 90 MINUTES
To Get 10 Year MTTF, Must Attack All These Areas
42%
12%
25%9.3%
11.2%
Vendor
Environment
OperationsApplication
Software
Tele Comm lines

7
Case Studies - Tandem Trends Reported MTTF by Component
0
50
100
150
200
250
300
350
400
450
1985 1987 1989
software
hardware
maintenance
operations
environment
total
Mean Time to System Failure (years) by Cause
1985 1987 1990SOFTWARE 2 53 33 YearsHARDWARE 29 91 310 YearsMAINTENANCE 45 162 409 YearsOPERATIONS 99 171 136 YearsENVIRONMENT 142 214 346 Years
SYSTEM 8 20 21 YearsProblem: Systematic Under-reporting

8
Many Software Faults are SoftAfter Design Review
Code InspectionAlpha TestBeta Test10k Hrs Of Gamma Test (Production)
Most Software Faults Are TransientMVS Functional Recovery Routines 5:1Tandem Spooler 100:1Adams >100:1
Terminology:Heisenbug:Heisenbug: Works On RetryBohrbug:Bohrbug: Faults Again On Retry
Adams: "Optimizing Preventative Service of Software Products", IBM J R&D,28.1,1984Gray: "Why Do Computers Stop", Tandem TR85.7, 1985Mourad: "The Reliability of the IBM/XA Operating System", 15 ISFTCS, 1985.

9
Summary of FT Studies• Current Situation: ~4-year MTTF =>
Fault Tolerance Works.• Hardware is GREAT (maintenance and MTTF).• Software masks most hardware faults.• Many hidden software outages in operations:
– New Software.– Utilities.
• Must make all software ONLINE.• Software seems to define a 30-year MTTF ceiling.
• Reasonable Goal: 100-year MTTF. class 4 today => class 6 tomorrow.

10
Fault Tolerance vs Disaster Tolerance
• Fault-Tolerance: mask local faults– RAID disks– Uninterruptible Power Supplies– Cluster Failover
• Disaster Tolerance: masks site failures– Protects against fire, flood, sabotage,..– Redundant system and service at remote site.– Use design diversity

11
Outline
• Terminology and empirical measures
• General methods to mask faults.• Software-fault tolerance
• Summary

12
Fault Model• Failures are independent
So, single fault tolerance is a big win
• Hardware fails fast (blue-screen)
• Software fails-fast (or goes to sleep)
• Software often repaired by reboot:– Heisenbugs
• Operations tasks: major source of outage– Utility operations
– Software upgrades

13
Fault Tolerance Techniques• Fail fast modules: work or stop
• Spare modules : instant repair time.
• Independent module fails by designMTTFPair ~ MTTF2/ MTTR (so want tiny MTTR)
• Message based OS: Fault Isolationsoftware has no shared memory.
• Session-oriented comm: Reliable messagesdetect lost/duplicate messagescoordinate messages with commit
• Process pairs :Mask Hardware & Software Faults
• Transactions: give A.C.I.D. (simple fault model)

14
Example: the FT Bank
Modularity & Repair are KEY: vonNeumann needed 20,000x redundancy in wires and switches
We use 2x redundancy.Redundant hardware can support peak loads (so not redundant)
Fault Tolerant Computer Backup System
System MTTF >10 YEAR (except for power & terminals)

15
Fail-Fast is Good, Repair is Needed
Improving either MTTR or MTTF gives benefit
Simple redundancy does not help much.
Fault Detect
Repair
Return
Lifecycle of a moduleLifecycle of a modulefail-fast gives fail-fast gives short fault latencyshort fault latency
High Availability High Availability
is low UN-Availabilityis low UN-Availability
Unavailability Unavailability MTTRMTTR MTTFMTTF

16
Hardware Reliability/Availability (how to make it fail fast)
Comparitor Strategies:Duplex: Fail-Fast: fail if either fails (e.g. duplexed cpus)
vs Fail-Soft: fail if both fail (e.g. disc, atm,...)Note: in recursive pairs, parent knows which is bad.
Triplex: Fail-Fast: fail if 2 fail (triplexed cpus) Fail-Soft: fail if 3 fail (triplexed FailFast cpus)
Basic FailFast DesignsPair Triplex
Recursive Designs
Recursive Availability Designs
Pair & Spare + + Triple Modular Redundancy

17
Redundant Designs have Worse MTTF!
THIS IS NOT GOOD: Variance is lower but MTTF is worse
Simple redundancy does not improve MTTF (sometimes hurts).
This is just an example of the airplane rule.
3 work
2 work
1 work
0 work
mttf/3 mttf/2
mttf/1
3 work
2 work
1 work
0 work
mttf/3 mttf/2
5/6*mttf
11/6*mttf
TMR: fail fast
TMR: fail soft
2 work
1 work
0 work
mttf/2
mttf/1
2 work
1 work
0 work
mttf/2
mttf/2
1.5*mttf
Duplex: fail fast
Duplex: fail soft
mttf/1
3 work
2 work
1 work
0 work
0 mttf/2
3/4*mttfPair & Spare: fail fast
4 work
mttf/4
mttf
3 work
2 work
1 work
0 work
mttf/2
~2.1*mttfPair & Spare: fail soft
4 work
mttf/4 mttf/3
mttf/1 mttf/1
The Airplane Rule:
A two-engine airplane has twice as many engine
problems as a one engine plane.

18
Add Repair: Get 104 Improvement
Availability estimates1 year MTTF modules
12-hour MTTR
MTTF EQUATION COST
SIMPLEX 1 year MTTF 1DUPLEX:FAIL FAST
~0.5years
MTTF/2 2+
DUPLEX: FAILSOFT
~1.5years
MTTF(3/2) 2+
TRIPLEX:FAIL FAST
.8 year MTTF(5/6) 3+
TRIPLEX:FAIL SOFT
1.8year
1.8MTTF 3+
Pair and spare:FAIL-FAST
~.7year
MTTF(3/4) 4+
TRIPLEX WITHREPAIR
>105years
MTTF3/3MTTR2
3+
Duplex fail soft +REPAIR
>104years
MTTF2/2MTTR 4+
3 work
2 work
1 work
0 work
mttf/3
TMR: fail fast
2 work
1 work
0 work
mtbf/2
Duplex: fail fast: mttf/2
mttrmttr mttr mttr mttr
10 mttf4
mttf/1
3 work
2 work
1 work
0 work
mttf/3 mttf/2
TMR: fail soft
mttf/1
2 work
1 work
0 work
Duplex: fail soft
mttrmttrmttrmttrmttr
10 mttf5
10 mttf4
mttf/1 mttf/2
mttf/2
mttf/2

19
When To Repair?
Chances Of Tolerating A Fault are 1000:1 (class 3)A 1995 study: Processor & Disc Rated At ~ 10khr MTTF
Computed Single Observed Failures Double Fails Ratio
10k Processor Fails 14 Double ~ 1000 : 1 40k Disc Fails, 26 Double ~ 1000 : 1
Hardware Maintenance:On-Line Maintenance "Works" 999 Times Out Of 1000.
The chance a duplexed disc will fail during maintenance?1:1000
Risk Is 30x Higher During Maintenance=> Do It Off Peak Hour
Software Maintenance:Repair Only Virulent BugsWait For Next Release To Fix Benign Bugs

20
OK: So FarHardware fail-fast is easyRedundancy plus Repair is great (Class 7 availability) Hardware redundancy & repair is via modules.How can we get instant software repair?We Know How To Get Reliable Storage
RAID Or Dumps And Transaction Logs.We Know How To Get Available Storage
Fail Soft Duplexed Discs (RAID 1...N).
? ? How do we get reliable execution?How do we get reliable execution?? How do we get available execution?? How do we get available execution?

21
Outline
• Terminology and empirical measures
• General methods to mask faults.
• Software-fault tolerance• Summary

22
Key Idea Architecture Hardware Faults Software Masks Environmental Faults Distribution Maintenance • Software automates / eliminates operators So, • In the limit there are only software & design faults.
Software-fault tolerance is the key to dependability.
INVENT IT!
} { }{

23
Software Techniques: Learning from Hardware
Recall that most outages are not hardware. Most outages in Fault Tolerant Systems are SOFTWAREFault Avoidance Techniques: Good & Correct design.After that: Software Fault Tolerance Techniques:
Modularity (isolation, fault containment) Design diversity N-Version Programming: N-different implementations Defensive Programming: Check parameters and data Auditors: Check data structures in backgroundTransactions: to clean up state after a failure
Paradox: Need Fail-Fast Software

24
Fail-Fast and High-Availability ExecutionSoftware N-Plexing: Design Diversity
N-Version ProgrammingWrite the same program N-Times (N > 3)Compare outputs of all programs and take majority vote
Process Pairs: Instant restart (repair)Use Defensive programming to make a process fail-fastHave restarted process ready in separate environment Second process “takes over” if primary faultsTransaction mechanism can clean up distributed state
if takeover in middle of computation.SESSION
PRIMARYPROCESS
BACKUPPROCESS
STATEINFORMATION
LOGICAL PROCESS = PROCESS PAIR

25
What Is MTTF of N-Version Program?First fails after MTTF/NSecond fails after MTTF/(N-1),...
so MTTF(1/N + 1/(N-1) + ... + 1/2)harmonic series goes to infinity, but VERY slowly
for example 100-version programming gives ~4 MTTF of 1-version programming
Reduces variance
N-Version Programming Needs REPAIRIf a program fails, must reset its state from other programs.=> programs have common data/state representation.How does this work for Database Systems?
Operating Systems?Network Systems?
Answer: I don’t know.

26
Why Process Pairs Mask Faults:Many Software Faults are Soft
After Design Review
Code InspectionAlpha TestBeta Test10k Hrs Of Gamma Test (Production)
Most Software Faults Are TransientMVS Functional Recovery Routines 5:1Tandem Spooler 100:1Adams >100:1
Terminology:Heisenbug: Works On RetryBohrbug: Faults Again On Retry
Adams: "Optimizing Preventative Service of Software Products", IBM J R&D,28.1,1984Gray: "Why Do Computers Stop", Tandem TR85.7, 1985Mourad: "The Reliability of the IBM/XA Operating System", 15 ISFTCS, 1985.

27
Heisenbugs:Heisenbugs: A Probabilistic Approach to AvailabilityA Probabilistic Approach to AvailabilityThere is considerable evidence that (1) production systems have about one bug per thousand lines of code (2) these bugs manifest themselves in stochastically: failures are due to confluence of rare events, (3) system mean-time-to-failure has a lower bound of a decade or so. To make highly available systems, architects must tolerate these failures by providing instant repair (un-availability is approximated by repair_time/time_to_fail so cutting the repair time in half makes things twice as good. Ultimately, one builds a set of standby servers which have both design diversity and geographic diversity. This minimizes common-mode failures.
28
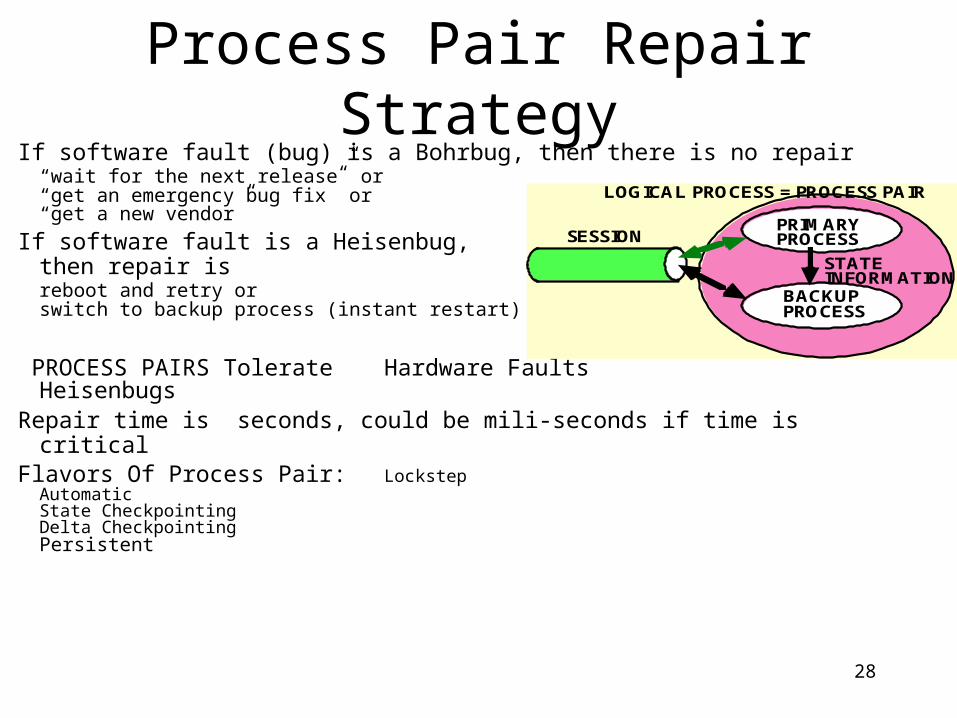
Process Pair Repair StrategyIf software fault (bug) is a Bohrbug, then there is no repair
“wait for the next release” or “get an emergency bug fix” or“get a new vendor”
If software fault is a Heisenbug, then repair is
reboot and retry orswitch to backup process (instant restart)
PROCESS PAIRS Tolerate Hardware Faults
HeisenbugsRepair time is seconds, could be mili-seconds if time is criticalFlavors Of Process Pair: Lockstep
AutomaticState CheckpointingDelta CheckpointingPersistent
SESSIONPRIMARYPROCESS
BACKUPPROCESS
STATEINFORMATION
LOGICAL PROCESS = PROCESS PAIR

29
How Takeover Masks Failures
Server Resets At Takeover But What About Application State?
Database State?
Network State?
Answer: Use Transactions To Reset State!
Abort Transaction If Process Fails.
Keeps Network "Up"
Keeps System "Up"
Reprocesses Some Transactions On Failure
SESSIONPRIMARYPROCESS
BACKUPPROCESS
STATEINFORMATION
LOGICAL PROCESS = PROCESS PAIR

30
PROCESS PAIRS - SUMMARYTransactions Give Reliability
Process Pairs Give Availability
Process Pairs Are Expensive & Hard To Program
Transactions + Persistent Process Pairs
=> Fault Tolerant Sessions &Execution
When Tandem Converted To This Style
Saved 3x Messages
Saved 5x Message Bytes
Made Programming Easier

31
SYSTEM PAIRSFOR HIGH AVAILABILITY
Programs, Data, Processes Replicated at two sites.Pair looks like a single system.System becomes logical conceptLike Process Pairs: System Pairs.Backup receives transaction log (spooled if backup down).If primary fails or operator Switches, backup offers service.
Primary Backup

32
SYSTEM PAIR CONFIGURATION OPTIONS
Mutual Backup:
each has1/2 of Database & Application
Hub:
One site acts as backup for many others
In General can be any directed graph
Stale replicas: Lazy replication
Primary Backup
Primary Backup
Primary
Primary
Primary Backup
Copy
Copy Copy

33
SYSTEM PAIRS FOR: SOFTWARE MAINTENANCE
Similar ideas apply to:Database ReorganizationHardware modification (e.g. add discs, processors,...)Hardware maintenanceEnvironmental changes (rewire, new air conditioning)Move primary or backup to new location.
V2
(Pr imary)
(Backup )
V1 V1
(Pr imary)
(Backup)
V1 V2
St ep 1: Bot h systems are running V1. Step 2: Backup is cold-loaded as V2.
(Backup)
(Pr imary)
V1 V2
(Backup )
(Pr imary)
V2
Step 3: SWITCH to Backup. Step 4: Backup is cold-loaded as V2 D30.

34
SYSTEM PAIR BENEFITSProtects against ENVIRONMENT: weather
utilitiessabotage
Protects against OPERATOR FAILURE: two sites, two sets of operators
Protects against MAINTENANCE OUTAGESwork on backupsoftware/hardware install/upgrade/move...
Protects against HARDWARE FAILURESbackup takes over
Protects against TRANSIENT SOFTWARE ERRORR
Allows design diversity
different sites have different software/hardware)

35
Key Idea Architecture Hardware Faults Software Masks Environmental Faults Distribution Maintenance • Software automates / eliminates operators So, • In the limit there are only software & design faults.
Many are Heisenbugs
Software-fault tolerance is the key to dependability.
INVENT IT!
} { }{

36
ReferencesAdams, E. (1984). “Optimizing Preventative Service of Software Products.” IBM Journal of
Research and Development. 28(1): 2-14.0Anderson, T. and B. Randell. (1979). Computing Systems Reliability. Garcia-Molina, H. and C. A. Polyzois. (1990). Issues in Disaster Recovery. 35th IEEE
Compcon 90. 573-577.Gray, J. (1986). Why Do Computers Stop and What Can We Do About It. 5th Symposium on
Reliability in Distributed Software and Database Systems. 3-12.Gray, J. (1990). “A Census of Tandem System Availability between 1985 and 1990.” IEEE
Transactions on Reliability. 39(4): 409-418.Gray, J. N., Reuter, A. (1993). Transaction Processing Concepts and Techniques. San Mateo,
Morgan Kaufmann.Lampson, B. W. (1981). Atomic Transactions. Distributed Systems -- Architecture and
Implementation: An Advanced Course. ACM, Springer-Verlag.Laprie, J. C. (1985). Dependable Computing and Fault Tolerance: Concepts and Terminology.
15’th FTCS. 2-11.Long, D.D., J. L. Carroll, and C.J. Park (1991). A study of the reliability of Internet sites. Proc
10’th Symposium on Reliable Distributed Systems, pp. 177-186, Pisa, September 1991.Darrell Long, Andrew Muir and Richard Golding, ``A Longitudinal Study of Internet Host
Reliability,'' Proceedings of the Symposium on Reliable Distributed Systems, Bad Neuenahr, Germany: IEEE, September 1995, pp. 2-9

37

38
Scaleable Replicated Databases
Jim Gray (Microsoft)
Pat Helland (Microsoft)
Dennis Shasha (Columbia)
Pat O’Neil (U.Mass)

39
Outline• Replication strategies– Lazy and Eager– Master and Group
• How centralized databases scale– deadlocks rise non-linearly with
• transaction size
• concurrency
• Replication systems are unstable on scaleup
• A possible solution
40
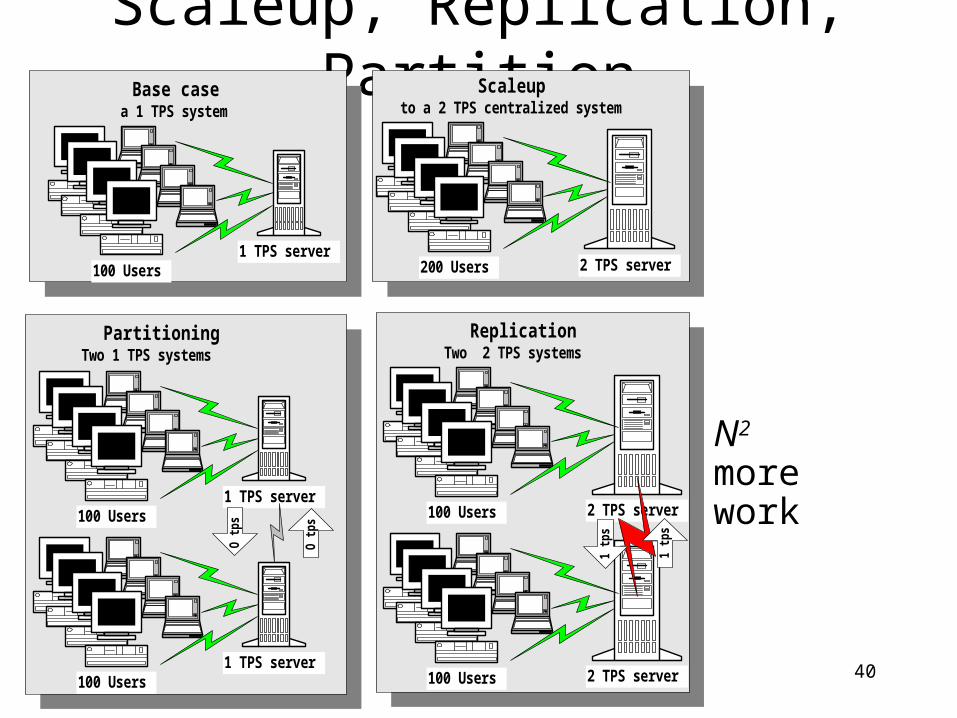
Scaleup, Replication, Partition
• N2 more work
PartitioningTwo 1 TPS systems
ReplicationTwo 2 TPS systems
2 TPS server1 TPS server
100 Users
1 TPS server100 Users
O tp
s
O tp
s
100 Users
2 TPS server100 Users
1 tp
s
1 tp
s
1 TPS server100 Users
Base casea 1 TPS system
2 TPS server200 Users
Scaleupto a 2 TPS centralized system

41
Why Replicate Databases?• Give users a local copy for
– Performance– Availability– Mobility (they are disconnected)
• But... What if they update it?
• Must propagate updates to other copies

42
Propagation Strategies• Eager: Send update right away
– (part of same transaction)– N times larger transactions
• Lazy: Send update asynchronously– separate transaction– N times more transactions
• Either way– N times more updates per second per node– N2 times more work overall
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit

43
Update Control Strategies
• Master – Each object has a master node– All updates start with the master– Broadcast to the subscribers
• Group– Object can be updated by anyone– Update broadcast to all others
• Everyone wants Lazy Group:– update anywhere, anytime, anyway

44
Quiz Questions: Name One• Eager – Master: N-Plexed disks– Group: ?
• Lazy – Master: Bibles, Bank accounts, SQLserver– Group: Name servers, Oracle, Access...
• Note: Lazy contradicts Serializable– If two lazy updates collide, then ... reconcile
• discard one transaction (or use some other rule)• Ask for human advice
• Meanwhile, nodes disagree =>– Network DB state diverges: System Delusion

45
Anecdotal Evidence
• Update Anywhere systems are attractive
• Products offer the feature
• It demos well
• But when it scales up– Reconciliations start to cascade– Database drifts “out of sync” (System Delusion)
• What’s going on?

46
Outline
• Replication strategies– Lazy and Eager– Master and Group
• How centralized databases scale– deadlocks rise non-linearly
• Replication is unstable on scaleup
• A possible solution

47
Simple Model of Waits
• TPS transactions per second• Each
– Picks Actions records uniformly from set of DBsize records
– Then commits• About Transactions x Actions/2 resources locked • Chance a request waits is• Action rate is TPS x Actions
• Active Transactions TPS x Actions x Action_Time
• Wait Rate = Action rate x Chance a request waits
• =
• 10x more transactions, 100x more waits
DBsizeDBsize recordsrecords
TransctionsTransctionsxxActionsActions22
TPSTPS22 xx Actions Actions33 xx Action_Time Action_Time
2 2 xx DB_size DB_size
Transactions Transactions xx Actions Actions2 2 xx DB_size DB_size

48
Simple Model of Deadlocks
TPSTPS22 xx Actions Actions33 xx Action_Time Action_Time
2 2 xx DB_size DB_size
TPS TPS xx Actions Actions33xx Action_Time Action_Time
2 2 xx DB_size DB_size
TPS x Actions x Action_Time
TPSTPS22 xx Actions Actions55 xx Action_Time Action_Time
4 4 xx DB_size DB_size22
• A deadlock is a wait cycle• Cycle of length 2:
– Wait rate x Chance Waitee waits for waiter
– Wait rate x (P(wait) / Transactions)
• Cycles of length 3 are PW3, so ignored.•
10x bigger trans = 100,000x more deadlocks

49
Summary So Far• Even centralized systems unstable
• Waits:– Square of concurrency– 3rd power of transaction size
• Deadlock rate– Square of concurrency– 5th power of transaction size
Tra
ns S
ize
Tra
ns S
ize
Concu
rrenc
y
Concu
rrenc
y

50
Outline
• Replication strategies
• How centralized databases scale
• Replication is unstable on scaleup• Eager (master & group)
• Lazy (master & group & disconnected)
• A possible solution

51
Eager Transactions are FAT
• If N nodes, eager transaction is Nx bigger– Takes Nx longer– 10x nodes, 1,000x deadlocks– (derivation in paper)
• Master slightly better than group• Good news:
– Eager transactions only deadlock– No need for reconciliation
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit

52
Lazy Master & Group
• Use optimistic concurrency control– Keep transaction timestamp with record– Updates carry old+new timestamp– If record has old timestamp
• set value to new value• set timestamp to new timestamp
– If record does not match old timestamp• reject lazy transaction
– Not SNAPSHOT isolation (stale reads)
• Reconciliation:– Some nodes are updated
– Some nodes are “being reconciled”
New New TimestampTimestamp
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
Write A
Write B
Write C
Commit
OID, old time, new valueOID, old time, new value
TRID, TimestampTRID, TimestampA Lazy TransactionA Lazy Transaction

53
Reconciliation
• Reconciliation means System Delusion– Data inconsistent with itself and reality
• How frequent is it?• Lazy transactions are not fat
– but N times as many
– Eager waits become Lazy reconciliations
– Rate is:
– Assuming everyone is connected
TPSTPS22 xx (Actions (Actions xx Nodes) Nodes)33 xx Action_Time Action_Time
2 2 xx DB_size DB_size

54
Eager & Lazy: Disconnected• Suppose mobile nodes disconnected for a day
• When reconnect:
– get all incoming updates
– send all delayed updates
• Incoming is Nodes x TPS x Actions x disconnect_time
• Outgoing is: TPS x Actions x Disconnect_Time
• Conflicts are intersection of these two sets
Action_Time Action_Time
Action_Time Action_Time
Disconnect_Time Disconnect_Time xx ( (TPS TPS xxActions Actions xx Nodes) Nodes)22
DB_sizeDB_size

55
Outline• Replication strategies (lazy & eager, master & group)
• How centralized databases scale• Replication is unstable on scaleup• A possible solution
– Two-tier architecture: Mobile & Base nodes– Base nodes master objects– Tentative transactions at mobile nodes
• Transactions must be commutative
– Re-apply transactions on reconnect– Transactions may be rejected

56
Safe Approach• Each object mastered at a node
• Update Transactions onlyread and write master items
• Lazy replication to other nodes
• Allow reads of stale data (on user request)
• PROBLEMS: – doesn’t support mobile users– deadlocks explode with scaleup
• ?? How do banks work???

57
Two Tier Replication
• Two kinds of nodes:– Base nodes always connected, always up– Mobile nodes occasionally connected
• Data mastered at base nodes
• Mobile nodes – have stale copies– make tentative updates Base
Node
Mobile

58
Mobile Node Makes Tentative Updates
• Updates local database while disconnected• Saves transactions • When Mobile node reconnects:
Tentative transactions re-done as Eager-Master (at original time??)
• Some may be rejected– (replaces reconciliation)
• No System Delusion.
tentativetransactions
base updates &failed base transactions
BaseNode
Mobile

59
Tentative Transactions• Must be commutative with others– Debit 50$ rather than Change 150$ to 100$.
• Must have acceptance criteria– Account balance is positive– Ship date no later than quoted– Price is no greater than quoted
TentativeTentative TransactionsTransactions at local DBat local DB Updates & RejectsUpdates & Rejects
TransactionsTransactionsFrom From OthersOtherssend Tentative Xacts
send Tentative Xacts

60
Refinement: Mobile Node Can Master Some Data
• Mobile node can master “private” data– Only mobile node updates this data– Others only read that data
• Examples:– Orders generated by salesman– Mail generated by user– Documents generated by Notes user.

61
Virtue of 2-Tier Approach
• Allows mobile operation
• No system delusion • Rejects detected at reconnect (know right away)
• If commutativity works, – No reconciliations– Even though work rises as (Mobile + Base)2

62
Outline
• Replication strategies (lazy & eager, master & group)
• How centralized databases scale• Replication is unstable on scaleup• A possible solution (two-tier architecture)
– Tentative transactions at mobile nodes– Re-apply transactions on reconnect– Transactions may be rejected & reconciled
• Avoids system delusion


















