
1 CSE 45432 SUNY New Paltz Chapters 8 Interfacing Processors and Peripherals.
22
1 CSE 45432 SUNY New Paltz Chapters 8 Interfacing Processors and Peripherals Main m emory I/O controller I/O controller I/O controller Disk G raphics output Netw ork M em ory– I/O bus P rocessor C ache Interrupts Disk
-
date post
20-Dec-2015 -
Category
Documents
-
view
229 -
download
1
Transcript of 1 CSE 45432 SUNY New Paltz Chapters 8 Interfacing Processors and Peripherals.
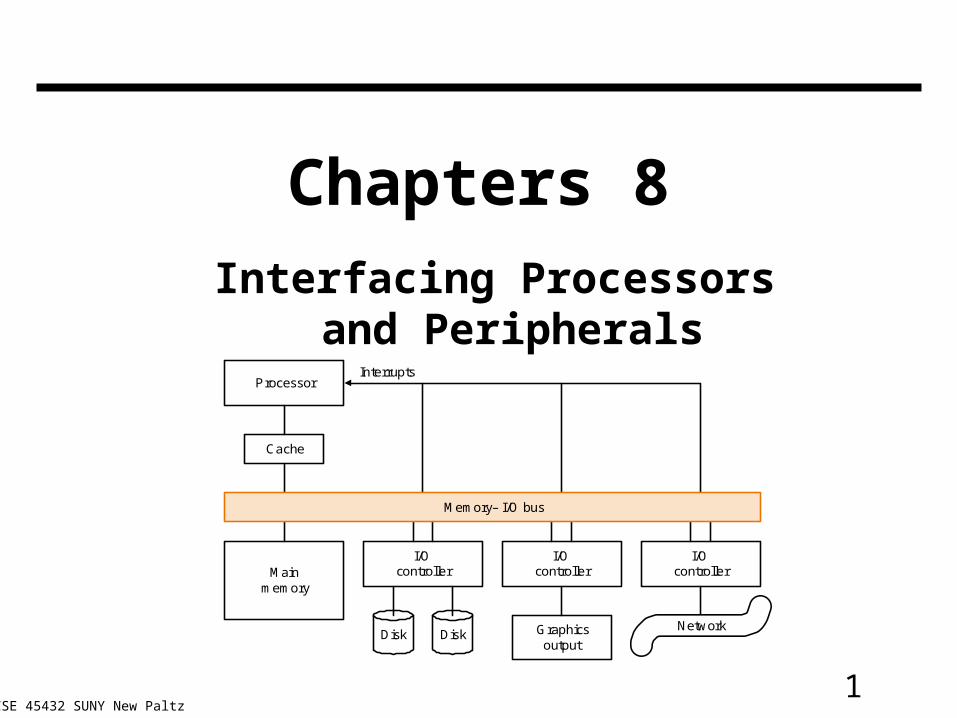
1CSE 45432 SUNY New Paltz
Chapters 8Interfacing Processors and
Peripherals
Mainmemory
I/Ocontroller
I/Ocontroller
I/Ocontroller
Disk Graphicsoutput
Network
Memory– I/O bus
Processor
Cache
Interrupts
Disk
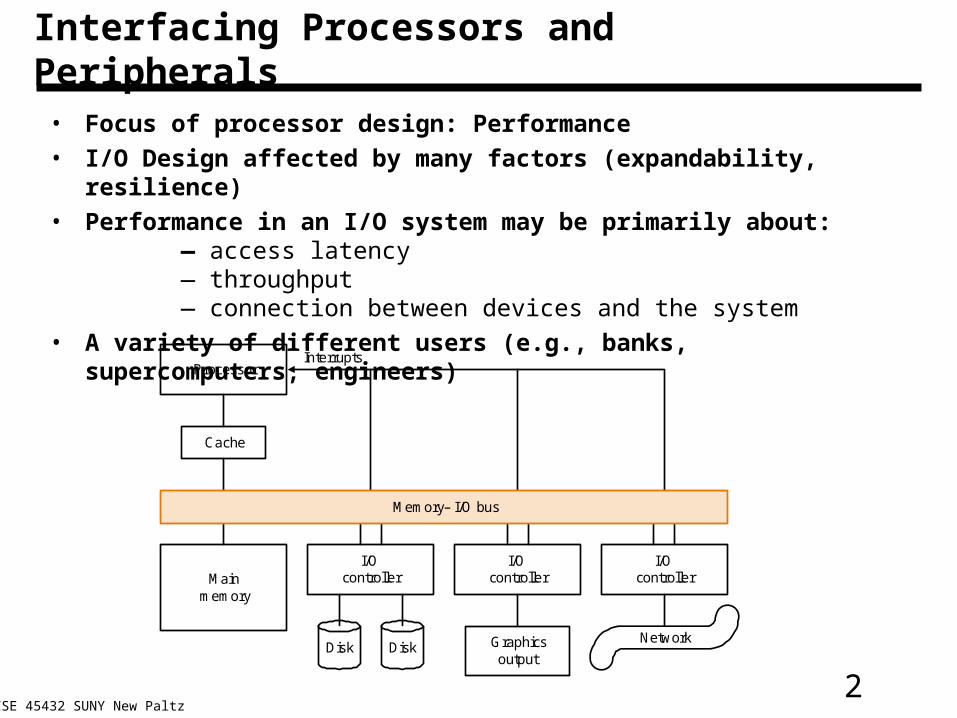
2CSE 45432 SUNY New Paltz
Interfacing Processors and Peripherals
• Focus of processor design: Performance
• I/O Design affected by many factors (expandability, resilience)
• Performance in an I/O system may be primarily about:— access latency — throughput— connection between devices and the system
• A variety of different users (e.g., banks, supercomputers, engineers)
Mainmemory
I/Ocontroller
I/Ocontroller
I/Ocontroller
Disk Graphicsoutput
Network
Memory– I/O bus
Processor
Cache
Interrupts
Disk

3CSE 45432 SUNY New Paltz
Impact of I/O on System Performance
• Example:
Suppose we have a benchmark that executes in 100 seconds of elapsed time, where 90 seconds is CPU time and the rest is I/O time. If CPU time improves by 50% per year for the next 5 years but I/O time does not improve, how much faster will our program run at the end of five years?
• I/O may become a bottleneck, especially with fast CPUs
• I/O performance may be
– How much data can we move through the system in a certain time?
– How many I/O operations can we do per unit of time?
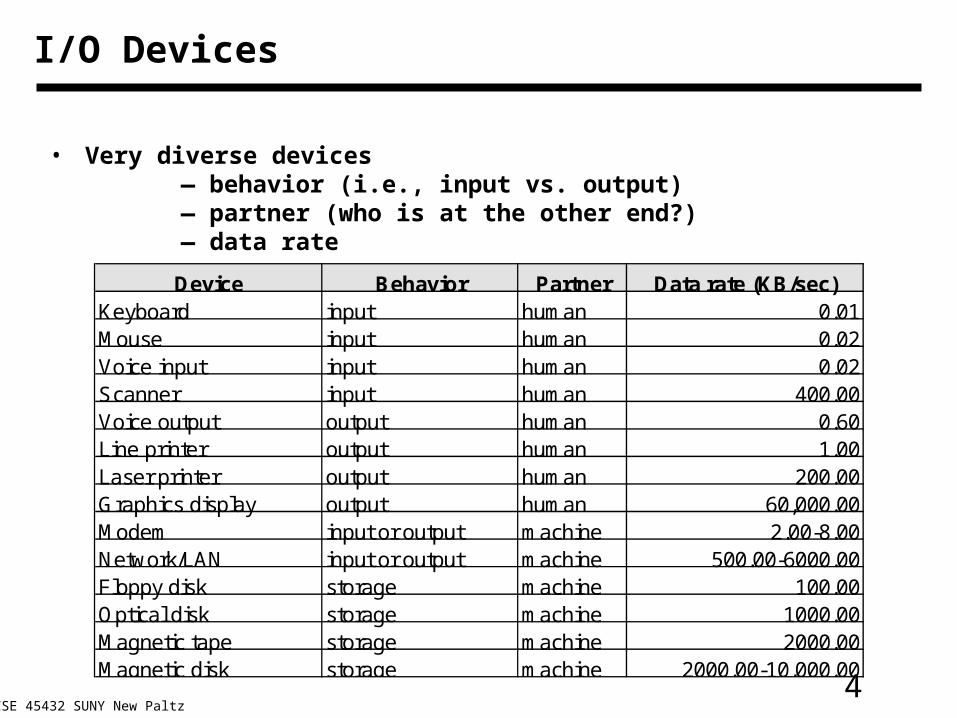
4CSE 45432 SUNY New Paltz
I/O Devices
• Very diverse devices— behavior (i.e., input vs. output)— partner (who is at the other end?)— data rate
Device Behavior Partner Data rate (KB/sec)Keyboard input human 0.01Mouse input human 0.02Voice input input human 0.02Scanner input human 400.00Voice output output human 0.60Line printer output human 1.00Laser printer output human 200.00Graphics display output human 60,000.00Modem input or output machine 2.00-8.00Network/LAN input or output machine 500.00-6000.00Floppy disk storage machine 100.00Optical disk storage machine 1000.00Magnetic tape storage machine 2000.00Magnetic disk storage machine 2000.00-10,000.00
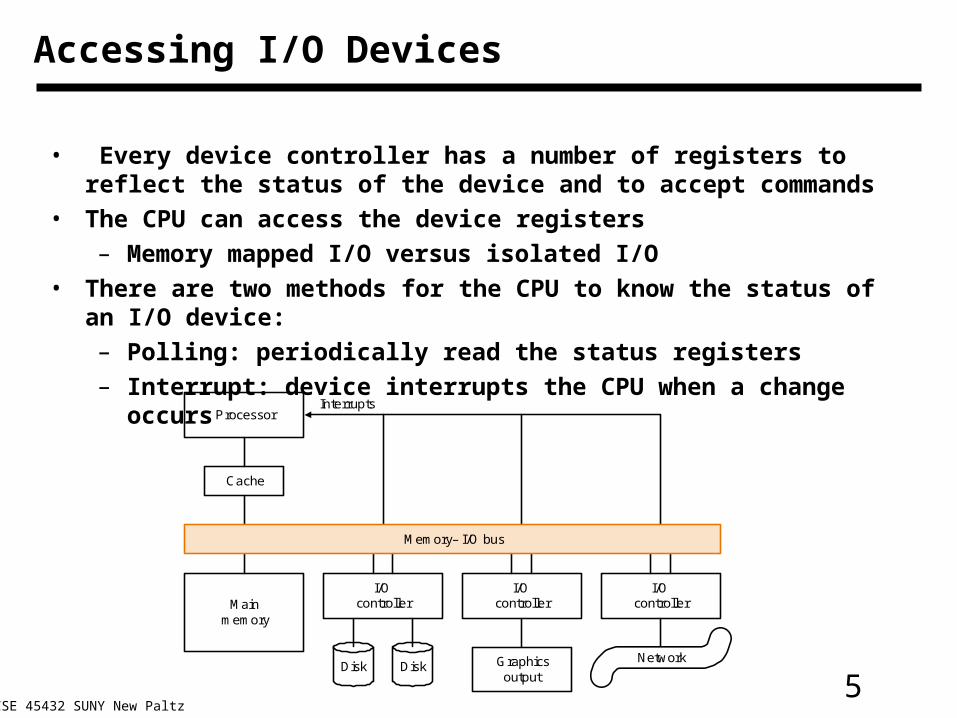
5CSE 45432 SUNY New Paltz
Accessing I/O Devices
• Every device controller has a number of registers to reflect the status of the device and to accept commands
• The CPU can access the device registers
– Memory mapped I/O versus isolated I/O
• There are two methods for the CPU to know the status of an I/O device:
– Polling: periodically read the status registers
– Interrupt: device interrupts the CPU when a change occurs
Mainmemory
I/Ocontroller
I/Ocontroller
I/Ocontroller
Disk Graphicsoutput
Network
Memory– I/O bus
Processor
Cache
Interrupts
Disk
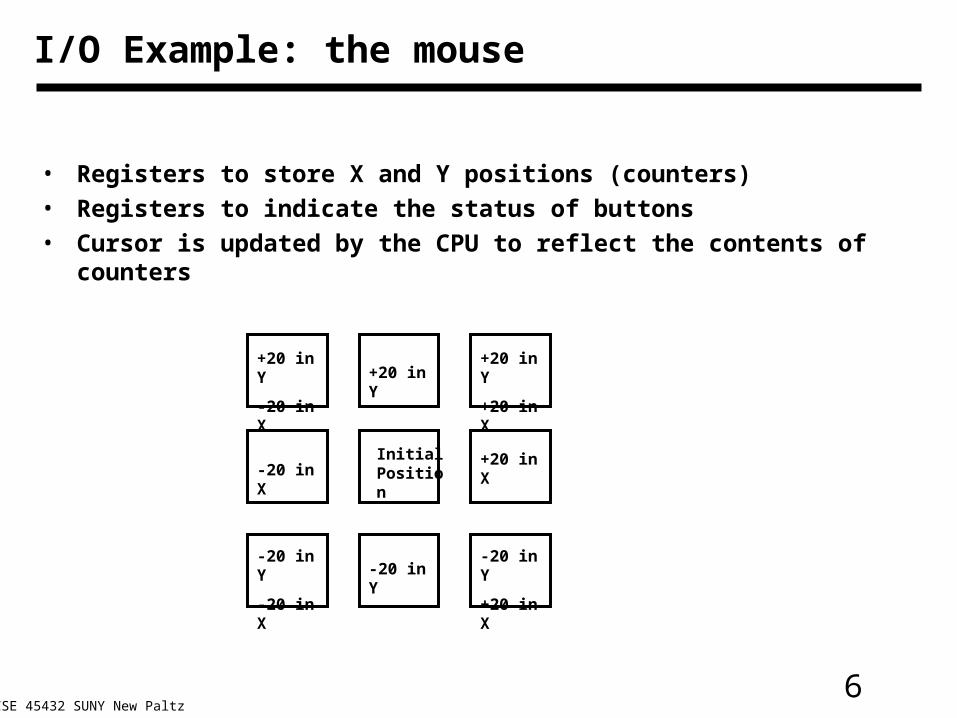
6CSE 45432 SUNY New Paltz
I/O Example: the mouse
• Registers to store X and Y positions (counters)
• Registers to indicate the status of buttons
• Cursor is updated by the CPU to reflect the contents of counters
Initial Position
+20 in Y
-20 in X
+20 in Y
+20 in X
-20 in X
+20 in Y
-20 in Y
-20 in X-20 in Y
+20 in X
-20 in Y
+20 in X
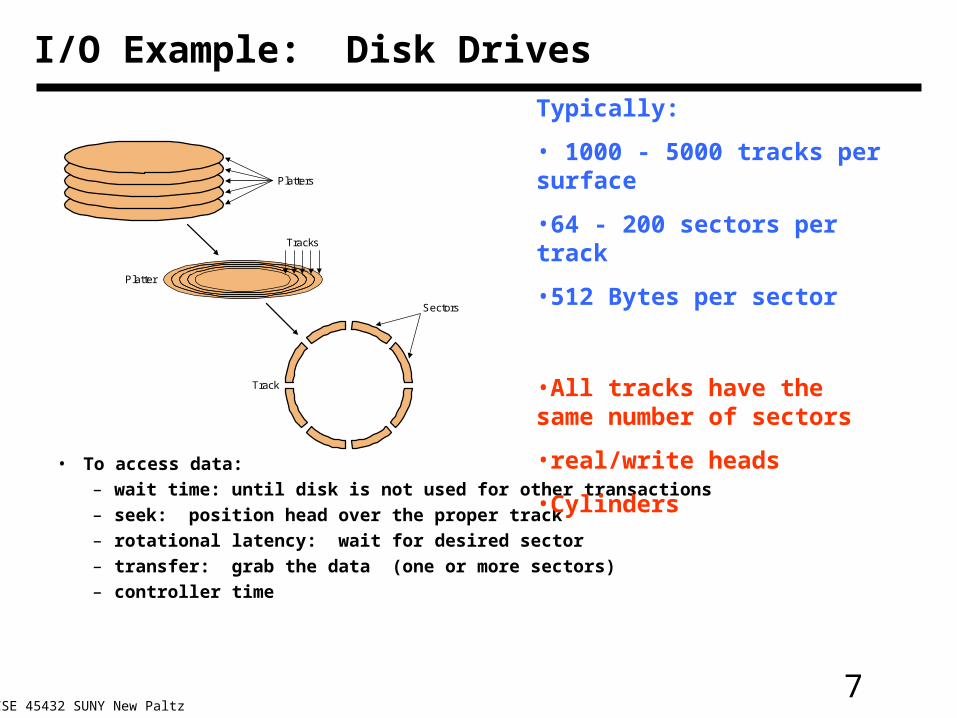
7CSE 45432 SUNY New Paltz
I/O Example: Disk Drives
• To access data:– wait time: until disk is not used for other transactions– seek: position head over the proper track – rotational latency: wait for desired sector – transfer: grab the data (one or more sectors) – controller time
Platter
Track
Platters
Sectors
Tracks
Typically:
• 1000 - 5000 tracks per surface
•64 - 200 sectors per track
•512 Bytes per sector
•All tracks have the same number of sectors
•real/write heads
•Cylinders

8CSE 45432 SUNY New Paltz
I/O Example: Disk Drives
Typical specification:• 3600 - 7200 RPM ( approximately 16 - 8 ms per revolution)• Sector address = plate #, track #, sector #• A file is physically stored as an ordered list of sectors
• Average seek time over all possible seeks (8 - 20 ms)
• Rotation latency = 0.5 * time for a full rotation (1/RPM) = 4.2 to 8.3 ms• Transfer rate = 2 to 15 MB/sec -- may improve by adding caches on disk
• Example: 512 bytes / sector, 5400 RPM, average seek time = 12 ms, Controller delay = 2 ms, transfer rate = 5 MB/sec. What is average disk access time? Assume disk is idle so that there is no waiting time.

9CSE 45432 SUNY New Paltz
I/O Example: Networks
• Major medium used to communicate between computers• Point to point networks:
– Example: RS232: 0.3 - 19.2 Kb/sec over short distances
• Local area networks (LAN)– Example: Ethernet: a bus with multiple masters– 10 - 100 Mb/sec over hundreds of meters
• Long-haul networks: usually switch networks– packet switch– usually uses a stack of protocols – example TCP/IP (Transmission Control Protocol /Internet Protocol)– 100 Mb/sec - 1Gb/sec – Another example: ATM (Asynchronous Transfer Method)– 155 Mb/sec - 2.5 Gb/sec
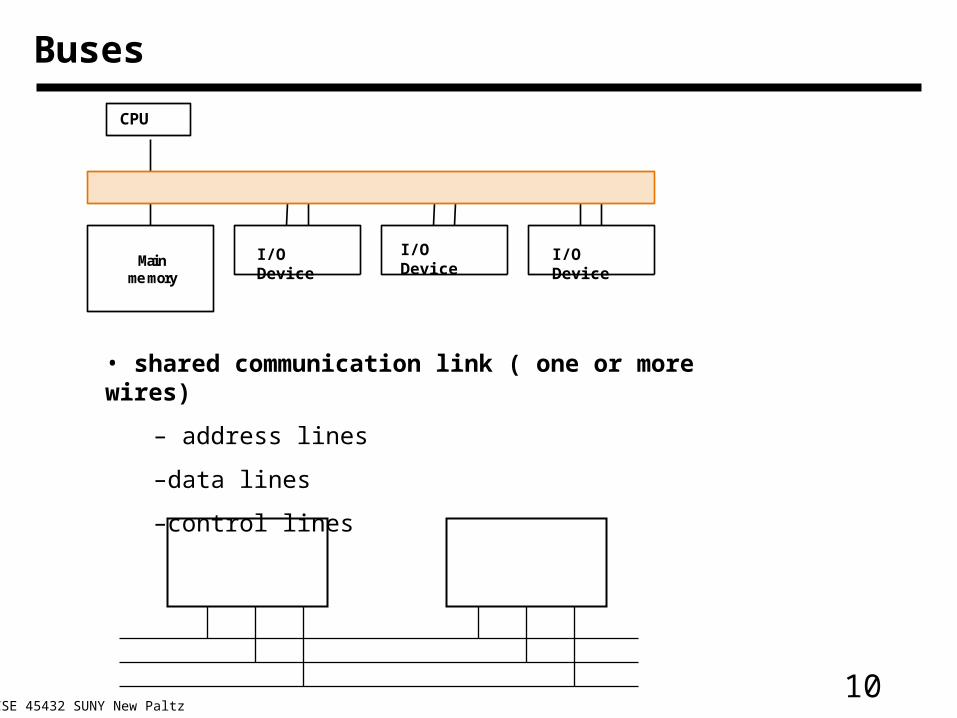
10CSE 45432 SUNY New Paltz
Buses
Mainmemory
CPU
I/O Device I/O Device I/O Device
• shared communication link ( one or more wires)
– address lines
–data lines
–control lines

11CSE 45432 SUNY New Paltz
Advantages and disadvantages of Buses
Advantages:
• Versatility
– New devices can be added easily
– Peripherals can be moved between computers that use the same bus standard
• Low cost: a single set of wires is shared in multiple ways
• Mange complexity by partitioning the design
Disadvantage
• Creates communication bottleneck
• The maximum bus speed is largely limited by
– Length of the bus
– The number of devices on the bus
– the need to support a range of devices with varying latencies and transfer rates

12CSE 45432 SUNY New Paltz
Master Versus Slave
• A bus transaction includes two parts:– Issuing the command ( and address) - request– Transferring the data - action
• Master is the one who starts the bus transaction by:– Issuing the command (and address)
• Slave is the one who responds by:– Sending data to the master if master asks for data– Receiving data from the master if the master wants to send data
• A bus may only have one master device -- all other devices are slaves• A bus may have more than one possible master
– Need some arbitration to determine the master at any given time

13CSE 45432 SUNY New Paltz
Types of Buses
• Processor-Memory Bus ( design specific)
– short and high speed
– Only need to match the memory system
– Connects directly to the processor
• I/O Bus (industry standard)
– Usually lengthy and slower– Need to match a wide range of I/O devices
– Connects to the processor-memory bus or the backplane bus
• Backplane Bus (standard or proprietary)
– An interconnection structure within the chassis– Allows processor, memory, and I/O devices to coexist
– Cost advantage: one bus for all components
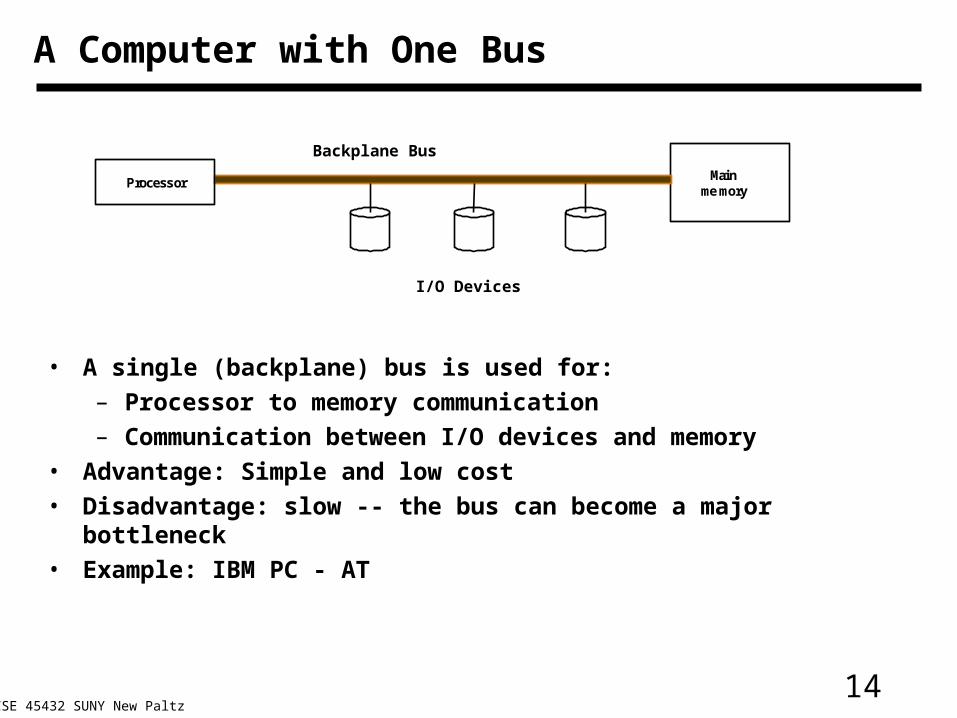
14CSE 45432 SUNY New Paltz
A Computer with One Bus
• A single (backplane) bus is used for:
– Processor to memory communication
– Communication between I/O devices and memory
• Advantage: Simple and low cost
• Disadvantage: slow -- the bus can become a major bottleneck
• Example: IBM PC - AT
Mainmemory
Proces sor
I/O Devices
Backplane Bus
15CSE 45432 SUNY New Paltz
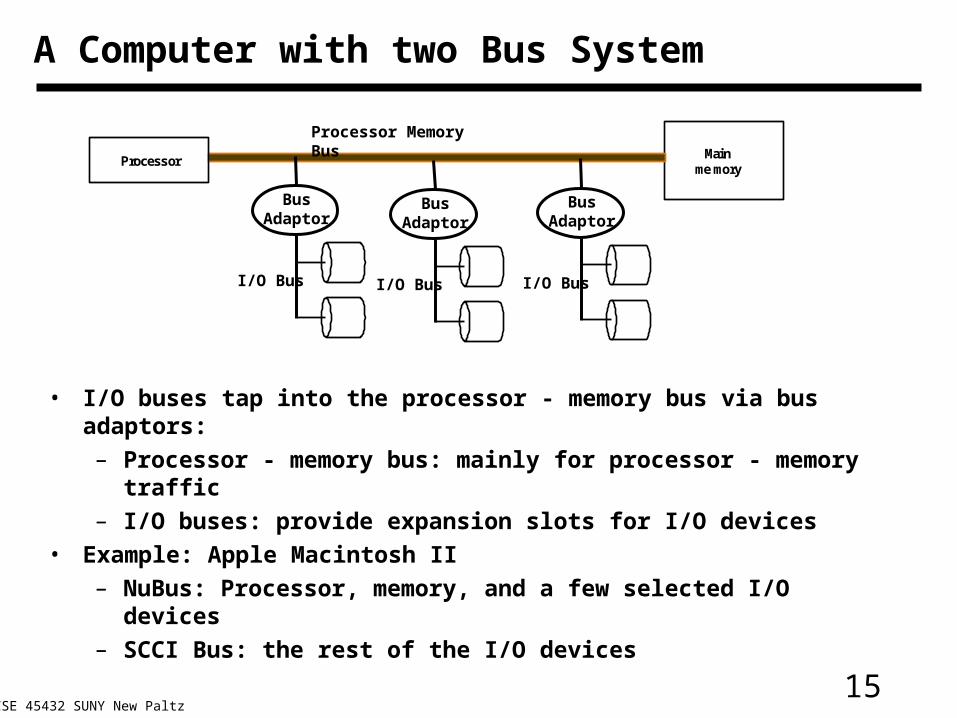
A Computer with two Bus System
• I/O buses tap into the processor - memory bus via bus adaptors:
– Processor - memory bus: mainly for processor - memory traffic
– I/O buses: provide expansion slots for I/O devices
• Example: Apple Macintosh II
– NuBus: Processor, memory, and a few selected I/O devices
– SCCI Bus: the rest of the I/O devices
Mainmemory
Proces sor
Processor Memory Bus
I/O Bus
Bus Adaptor
I/O Bus
Bus Adaptor
I/O Bus
Bus Adaptor
16CSE 45432 SUNY New Paltz
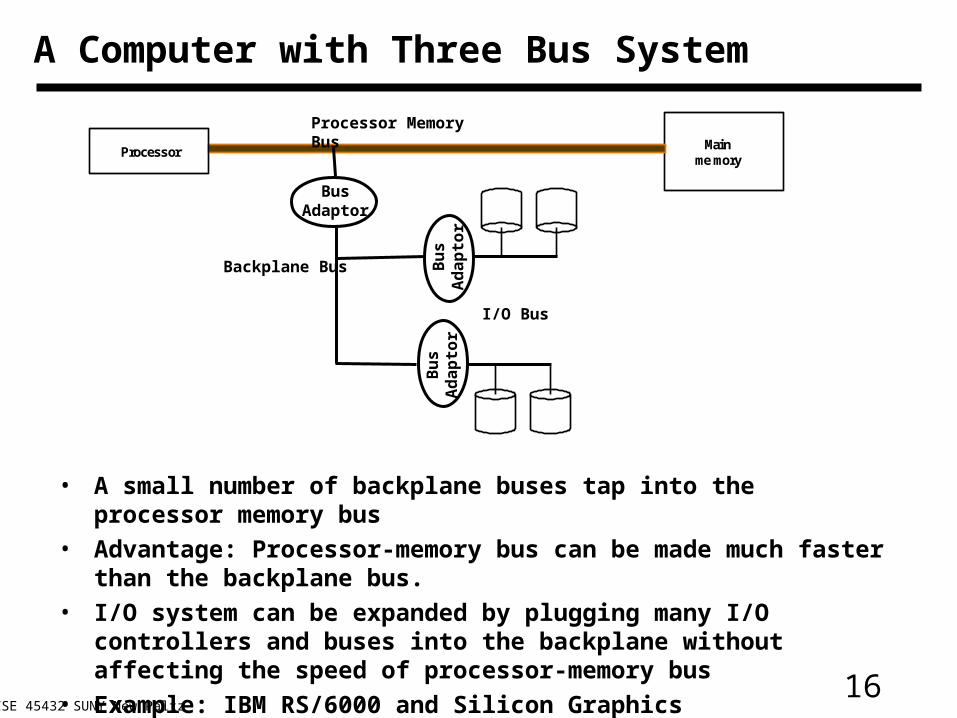
A Computer with Three Bus System
• A small number of backplane buses tap into the processor memory bus
• Advantage: Processor-memory bus can be made much faster than the backplane bus.
• I/O system can be expanded by plugging many I/O controllers and buses into the backplane without affecting the speed of processor-memory bus
• Example: IBM RS/6000 and Silicon Graphics Multiprocessors
Mainmemory
Proces sor
Processor Memory Bus
I/O Bus
Bu
s A
dap
tor
Bu
s A
dap
tor
Backplane Bus
Bus Adaptor

17CSE 45432 SUNY New Paltz
Synchronous vs. Asynchronous
• Synchronous Bus
– use a clock in the control lines
– A fixed protocol for communication that is relative to the clock
• T1: Transmit address and read command
• T2: Memory responds – Advantage: involves very little logic and can run very fast
– Disadvantage: every device must operate at same rate and clock skew requires the bus to be short
• Asynchronous Bus:
– It is not clocked
– It can accommodate a wide rage of devices
– It can be lengthened without worrying about clock shew
– It requires a handshaking protocol
18CSE 45432 SUNY New Paltz
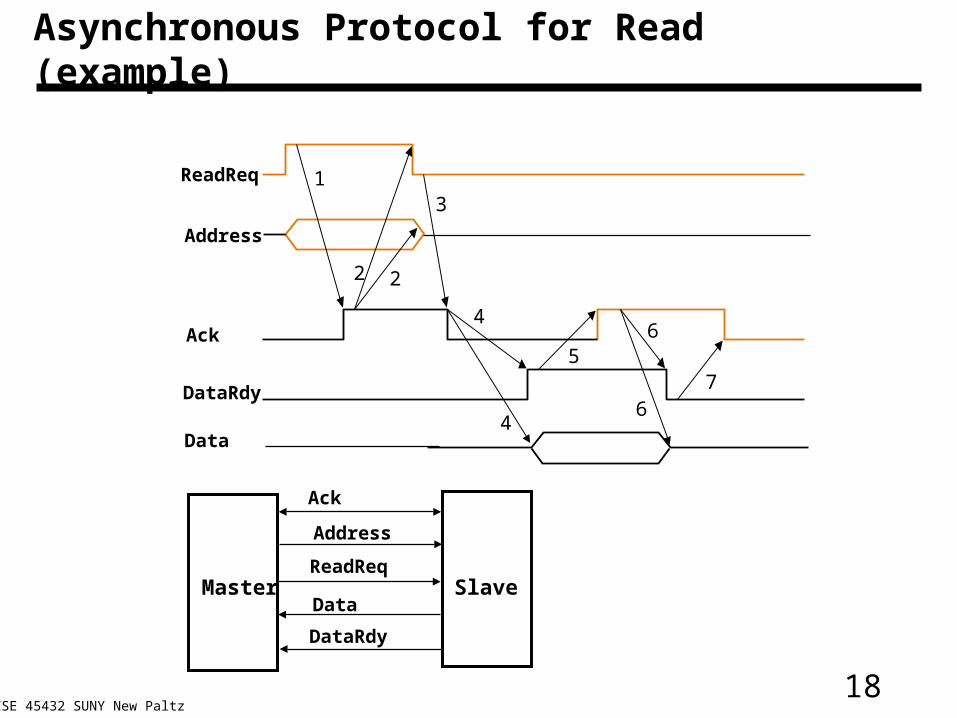
Asynchronous Protocol for Read (example)
13
4
57
64
2 2
6
ReadReq
Address
Ack
DataRdy
Data
Master SlaveReadReq
Address
Ack
DataRdy
Data
19CSE 45432 SUNY New Paltz
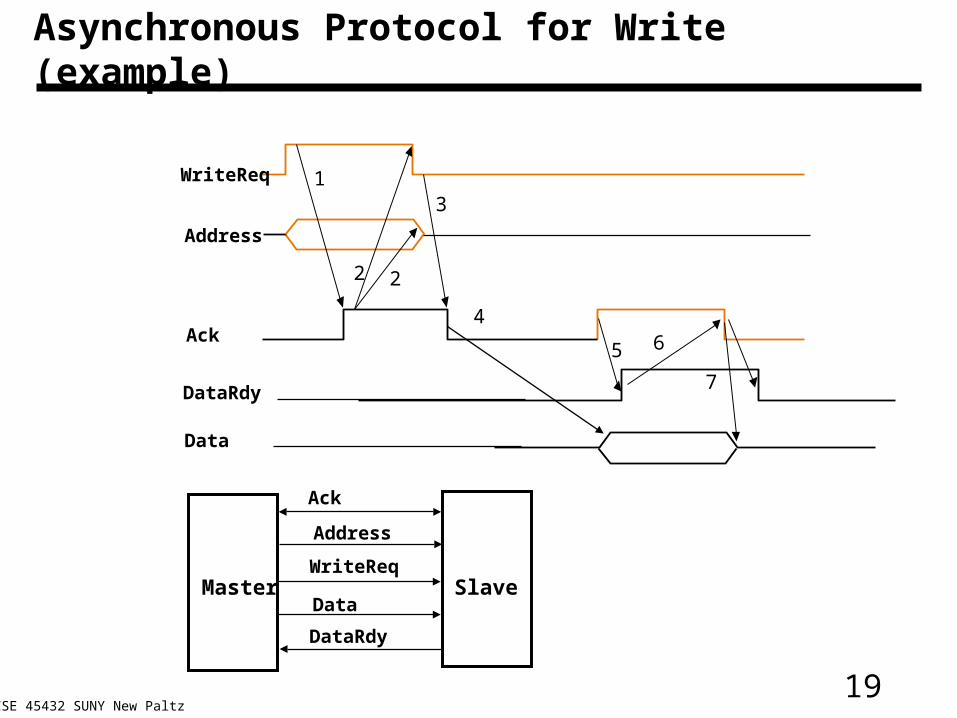
Asynchronous Protocol for Write (example)
13
4
5
7
2 2
6
WriteReq
Address
Ack
DataRdy
Data
Master SlaveWriteReq
Address
Ack
DataRdy
Data

20CSE 45432 SUNY New Paltz
Arbitration: Obtaining Access to the Bus
• One of the most important issues in bus design
– How is the bus reserved by a device that wishes to use it?
• Chaos is avoided by a master-slave arrangement:
– Only the bus master can control access to the bus:
it initiates and control all bus requests
– A slave responds to read and write requests
• The simplest system:
– Processor is the only bus master
– All bus requests must be controlled by the processor
– Major drawback: the processor is involved in every transaction

21CSE 45432 SUNY New Paltz
Multiple Potential Masters: Need for Arbitration
• Bus arbitration scheme:
– A bus master wanting to use the bus asserts the bus request
– A bus master cannot use the bus until its request is granted
– A bus master must signal to the arbiter after it finishes using the bus
• Try to balance two factors
– Bus priority: the highest priority device should be serviced first
– Fairness: even the lowest priority device should eventually get served
• Bus arbitration can be divided into four broad classes:
– Daisy chain arbitration: single device with all request lines
– centralized, Parallel arbitration (requires an arbiter), e.g., PCI
– Distributed arbitration by self selection, e.g., NuBus used in Macintosh
– Distributed arbitration by collision detection, e.g., Ethernet

22CSE 45432 SUNY New Paltz
Multiple Potential Masters: Need for Arbitration• Bus Overview • What is it? - shared communication line between subsystems. (PH Figure 8.1) • Design factors: • Speed is limited by length and number of devices. • Must support a range of latencies and data rates. • Structure: • Data lines - carry information • Address lines - carry address (sometimes multiplexed on data lines) • Control lines - signal request and acknowledgement • Types: (PH Figure 8.9) • Processor-memory - short, high-speed • I/O buses - long, many devices, usually don't connect directly to memory • Backplane - balance I/O - memory with CPU-memory communication
• • Asynchronous bus: • Not clocked • Uses handshaking protocol (look at PH Figures 8.10 and 8.11) with control lines (e.g.• ReadReq, DataReq and Acq) • Performance: - synchronous buses are faster (discuss the comparison on PH pp. 662-663)
• Read PH Section 8.5
• Bus Arbitration: (e.g. how devices acquire access to the bus) • Overview: • A bus master initiates and controls a bus request. • A slave (such as memory) responds to the request of a master. • Need arbitration when more than one possible master. • A master signals a bus request. • The arbiter grants the request. • Bus arbitration schemes: • Daisy-chain (PH Figure 8.13) - simple and cheap but not fair or fast.• Signal request line. • Wait for transition on grant line from low to high. • Intercept grant signal • Stop asserting request line. • Use bus. • Assert release line. • Centralized, parallel arbitration - needs multiple request lines, used by PCI • Distributed arbitration by self-selection - multiple request lines, each device puts its code• on the bus and determines whether it was the highest. Used by NuBus on Machintosh II's. • Distributed arbitration by collision detection - Ethernet.
• Read PH Section 8.5
• PCI bus (continued from last time)• Reference: The Indispensable PC Hardware bBook by Messmer • Refer to class handout. • Current high-end PC bus • Synchronous: • Address in the first cycle • Write data in second cycle • Read data in the third cycle • So read access is 44 Mbytes/second and write access is 66 Mbytes/sec for 32-bit width. Also• comes in a 64-bit width. Maximum rate in burst mode is 133Mbytes/sec. • PCI Bridge combines independent references into bursts. So a processor access to video ram will• be combined even though the processor can't do it. • Has three address areas: • Memory • I/O • Configuration addresses: • 256 bytes for each PCI unit - 64 registers of 32 bits • 64 byte header • 192 bytes are unit dependent. • PC terminology • Master = initiator • Slave = target
• Basic protocol: • initiator starts with NOT FRAME • target signals NOT TRDY to indicate ready • initiator does NOT IRDY to signal its ready to bridge • C/NOT BEX are transfer byte signals • Bus arbitration is done separately by a centralized arbiter while the previous bus access is still• going on. • I/O Programming • Characteristics of I/O systems: • Shared by multiple programs • Use interrupts which cause a trap to kernel mode • Complex low-level control involving concurrent events
• Role of the operating system: • Guarantee security and access • Provide device abstraction • Handle resources • Be fair
• Approaches: • Memory mapped I/O versus I/O instructions • Polling versus interrupts • Direct memory access: (DMA) • Uses specialized controller • Process sets up by giving • Identity of the device • Operation • Starting address • Number of bytes to transfer • DMA controller starts operation and arbitrates the bus. • DMA controller interrupts the processor to signal completion. • If time a look at the 8237A DMA chip


















