
1 COMM 301: Empirical Research in Communication Lecture 15 – Hypothesis Testing Kwan M Lee.
36
1 COMM 301: Empirical Research in Communication Lecture 15 – Hypothesis Testing Kwan M Lee
-
Upload
monique-kayes -
Category
Documents
-
view
215 -
download
1
Transcript of 1 COMM 301: Empirical Research in Communication Lecture 15 – Hypothesis Testing Kwan M Lee.

1
COMM 301:Empirical Research in
Communication
Lecture 15 – Hypothesis Testing
Kwan M Lee

2
Things you should know by the end of the lecture
• Structure and logic of hypothesis testing– Differentiate means and standard deviations of population,
sample, and sampling distributions.
– What is a null hypothesis? What is an alternative hypothesis? Know how to set up these hypotheses.
– Know the meaning of significance level
– Know the decision rules for rejecting the null hypothesis: • Comparing observed value versus critical value (check z
statistic example)• Comparing p-value versus significance level.
– Know the limitations of statistical significance.
– Know Type 1 error, Type 2 error, power, and the factors that affect them.

3
Structure and logic of hypothesis testing
• Research question• Hypothesis: a testable statement regarding the
difference between/among groups or about the relationship between/among variables we ONLY talked Hr (research H) [aka Ha (alternative H)]
• Data Gathering (you have done!)• Analysis
– Descriptive• Measure of Central Tendency• Measure of Dispersion
– Inferential• We will test H0 (null hypothesis) in order to test Hr

4
Cf. Normal Distribution• A continuous random variable Y has a normal
distribution if its probability density function is – Don’t worry about this formula!
• The normal probability density function has two parameters – mean (mu) and standard deviation (sigma)
• Mu and sigma changes particular shapes of a normal distribution (see next graphs)– Remember standard deviation is how far away “on
average” scores are away from the mean of a set of data

5

6
Cf. Standard Normal Distribution
• Standard normal distribution is a normal distribution with mu = 0 and sigma = 1
• z distribution = distribution of a standard normal distribution
• z transformation

7
Population Distribution:Sample Distribution:
& Sampling Distribution
• See SPSS example! (lect 15_2)
• Very important to know the difference!
• Central limit theorem– With large sample size and limitless sampling,
sampling distribution will always show normal distribution.

8
Two Hypotheses in Data Analyses
• Null hypothesis, H0
• Alternative hypothesis, Ha (this is your Research H)
• H0 and Ha are logical alternative to each other
• Ha is considered false until you have strong evidence to refute H0

9
Null hypothesis
– A statement saying that there is no difference between/among groups or no systematic relationship between/among variables
– Example: Humor in teaching affects learning.R M1 X M2R M3 M4
• Learning measured by standardized tests• H0 : M2 = M4, meaning that …?• Equivalent way of stating the null hypothesis:
– H0 : M2 - M4 = 0

10
Alternative hypothesis
• Alternative H (Ha) = Research H (Hr)
– A statement saying that the value specified H0 is not true.
– Usually, alternative hypotheses are your hypotheses of interest in your research project
• An alternative hypothesis can be bi-directional (non-directional) or uni-directional (directional).
• Bi-directional H1 (two-tailed test)
• H1: M2 - M4 0 (same as M2 M4)– I am not sure if humor in teaching improves learning or
hampers learning. So I set the above alternative hypothesis.

11
Alternative hypothesis (cont.)
• Uni-directional or Directional Ha (one-tailed test)• You set a uni-directional Ha when you are sure which
way the independent variable will affect the dependent variable.
• Example: Humor in teaching affects learning.R M1 X M2R M3 M4
• I expect humor in teaching improves learning. So I set the alternative hypothesis as– M2 > M4
– Then, H0 becomes: M2 “< or =“ M4

12
Comparing two values
• Okay, so we have set up H0 and Ha.
• The key questions then become: Is H0 correct or is Ha correct?
• How do we know?• We know by comparing 2 values against each
other (when using stat tables): – observed value (calculated from the data you have
collected), against
– critical value (a value set by you, the researcher)
• Or simply by looking alpha value in SPSS output

13
Finding observed values
• How do we find the observed value?• Observed values are calculated from the data
you have collected, using statistical formulas– E.g. z; t; r; chi-square etc.
• Do you have to know these formulas? – Yes and No: for the current class, we will test only chi-
square ( we will learn it later)– Most of the time, you need to know where to look for
the observed value in a SPSS output, or to recognize it when given in the examination question.
diffS
XXt
2
__
1
__

14
Determining the critical value
• How to determine the critical value?• four factors
– Type of distribution used as testing framework– Significance levels
– Uni-directional or bi-directional H1 (one-tailed or two-tailed test)
– Degree of freedom

15
Determining critical values
• Type of distribution– Recall that data form distributions– Certain common distributions are used as a framework to test
hypotheses:• z distribution• t distribution• chi-square distribution• F distribution
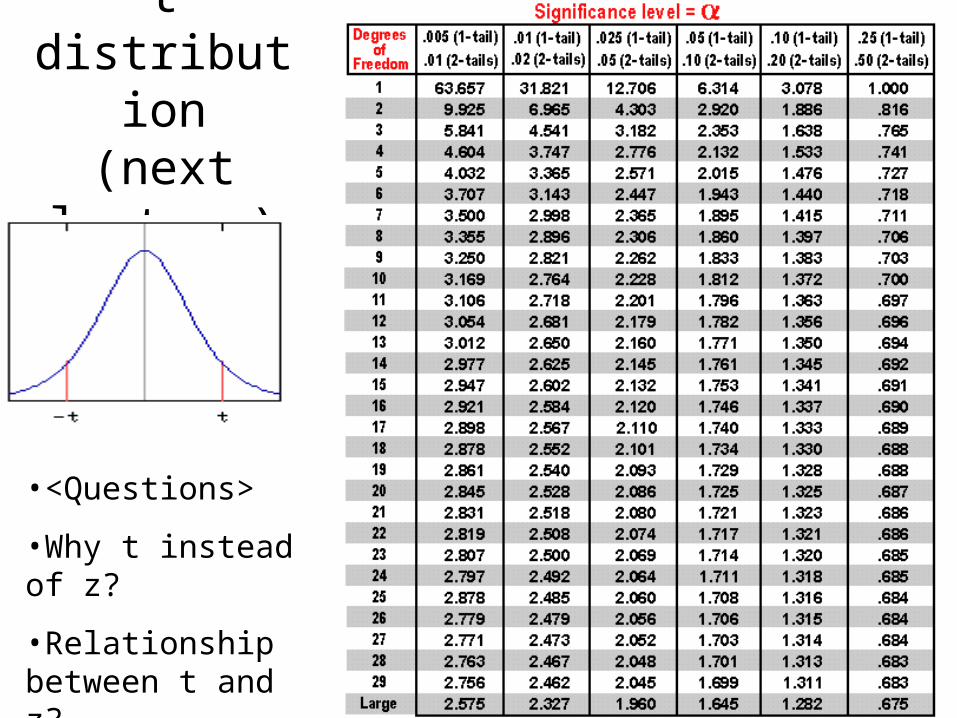
– Key skill: reading the correct critical values off printed tables of critical values.
– Table example • t-distribution see next slide• Also compare it with z distribution (what’s the key difference? z is
when you know population parameters; t is when you don’t know population parameters)

16
z distribution
• Remember the standard normal distribution!
17
t distribution(next
lecture)
•<Questions>
•Why t instead of z?
•Relationship between t and z?

18
p
df .05 .01
1 3.84 6.63
2 5.99 9.21
3 7.81 11.34
4 9.49 13.28
5 11.07 15.09
6 12.59 16.81
7 14.07 18.48
8 15.51 20.09
9 16.92 21.67
10 18.31 23.21
11 19.68 24.72
12 21.03 26.22
13 22.36 27.69
14 23.68 29.14
15 25.00 30.58
16 26.30 32.00
17 27.59 33.41
18 28.87 34.81
19 30.14 36.19
20 31.41 37.57
21 32.67 38.93
… … …
100 124.3 135.8
chi-squaredistribution
(next lecture)

19
Determining critical values
• Significance level (alpha level)– A percentage number set by you, the researcher.– Typically 5% or 1%.– The smaller the significance level, the stricter the test.

20
Determining critical values
• One-tailed or two-tailed tests– One-tailed tests (uni-directional H1, e.g. M2 - M4 > 0)
use the whole significance level.
– Two-tailed tests (bi-directional H1, e.g. M2 - M4 0) use the half the significance level.
– Applies to certain distributions and tests only, in our case, the t-distributions and t-tests

21
Determining critical values
• Degree of freedom– How many scores are free to vary in a group of
scores in order to obtain the observed mean– Df = N – 1– In two sample t-test, it’s N (total sample numbers)-2.
Why?

22
Accept or reject H0?
• Next, you compare the observed value (calculated from the data) against the critical value (determined by the researcher), to find if H0 is true or H1 is true.
• The key decision to make is: Do we reject H0 or not?• We reject H0 when the observed value (z: t; r; chi-
square; etc.) is more extreme than the critical value. • If we reject H0, it means, we accept H1.• H1 is likely to be true at 5% (or 1%) significance level.• We are 95% (or 99%) sure that H1 is true.

23
Cf. Hypothesis testing with z
• When you know mu and sigma of population (this is a rare case), you conduct z test
• Example. After teaching Comm301 to all USC undergrads (say, 20000), I know that the population distribution of Comm301 scores of all USC students is a normal distribution with mu =82 and sigma = 6
• In my current class (say 36 students), the mean for the final is 86.
• RQ: Is the students in my current class (i.e., my current sample) significantly different from the whole USC students (the population)?

24
Cf. Hypothesis testing with z (cont)
• Step 1: State H0 = “mean = 82” and Ha• Step 2: Calculate z statistic of sampling distribution
(distribution of sample means: you are testing whether this sample is drawn from the same population)
= = 4
– Notice that for the z statistic here, we are using the sigma of the sampling distribution, rather than the sigma of the population distribution.
– It’s because we are testing whether the current mean score is the result of a population difference (i.e., the current students are from other population: Ha) or by chance (i.e., students in my current class happened to be best USC students; difference due to chances caused by sampling errors or other systematic and non-systematic errors)
36
68286

25
Cf. Hypothesis testing with z (cont)
• Step 3: Compare test statistic with a critical value set by you (if you set alpha at 0.05, the critical value is 2 [more precisely it’s 1.96]) see the previous standard normal distribution graph (z-distribution graph)
• Step 4: Accept or Reject H0– Since the test statistic (observed value) is lager than
the critical value, you reject H0 and accept Ha• Step 5: Make a conclusion
– My current students (my current samples) are significantly different from other USC students (the population) with less than 5% chance of being wrong in this decision.
• But still there is 5% of chance that your decision is wrong

26
Another way to decide: Simply look at p-value in SPSS output
• Area under the curve of a distribution represents probabilities.
• This gives us another way to decide whether to reject H0.
• The way is to look at the p-value.• There is a very tight relationship between the p-value
and the observed value: the larger the observed value, the smaller the p-value.
• The p-value is calculated by SPSS. You need to know where to look for it in the output.

27
Another way to decide: p-value
• So what is the decision rule for the p-value to see if we reject H0 or not?
• The decision rule is this:– We reject H0, if the p-value is smaller than the
significance level set by us (5% or 1% significance level).
• Caution: P-values in SPSS output are denoted as “Sig.” or “Sig. level”.

28
The meaning of statistical significance
– Example: Humor in teaching affects learning.R M1 X M2
R M3 M4– H1: M2 - M4 0; H0: M2 - M4 = 0.– Assume that p-value calculated from our data is
0.002, i.e. 0.2% meaning that, assuming H0 is true (there is no relationship between humor in teaching and learning), the chance that M2 - M4 = 0 is very, very small, less than 1% (actually 0.2%).
– If the chance that H0 is true is very very small, we have more probability that H1 is true (actually, 99.8%).
– Key point: The conclusion is a statement based on probability!

29
The meaning of statistical significance (cont.)
• When we are able to reject H0, we say that the test is statistically significant.
• It means that there is very likely a relationship between the independent and dependent variables; or two groups that are being compared are significantly different.
• However, a statistically significant test does not tell us whether that relationship is important.

30
The meaning of statistical significance (cont)
• Go back to the previous example.– So, we have a p-value of 0.002. The test is significant, the
chance that M2 - M4 = 0 is very very small. – M2 - M4 > 0 is very likely true. But
it could mean M2 - M4 = 5 point (5 > 0), or M2 - M4 = 0.5 points (0.5 > 0).
• One key problem with statistical significance is that it is affected by sample size.– The larger the sample, the more significant the result.– So, I could have M2 - M4 = 0.5 (0.5 > 0, meaning that my
treatment group on average performs 0.5 point better than my control group), and have statistical significance if I run many many subjects.

31
Need to consider “Effect Size”
• Then, should I take extra time to deliver jokes during the class for the 0.5 point improvement?
• So, beyond statistical significance, we need to see if the difference (or the relationship) is substantive.
• You can think of it this way: an independent variable having a large impact on a dependent variable is substantive.
• The idea of a substantive impact is called effect size.• Effect size is measured in several ways (omega square,
eta square, r square [coefficient of determination]). You will meet one later: r2

32
Type 1 error
• At anytime we reject the null hypothesis H0, there is a possibility that we are wrong:
H0 is actually true, and should not be rejected.
• By random chance, the observed value calculated from the data is large enough to reject H0. = By random chance, the p-value calculated from the data is small enough to reject H0.
• This is the Type 1 error: wrongly rejecting H0 when it is actually true.

33
Type 1 error (cont)
• The probability of committing a Type 1 error is equal to the significance level set by you, 5% or 1%. Type 1 error = alpha
• As a researcher, you control the chance of a Type 1 error.
• So, if we want to lower the chance of committing a Type 1 error, what can we do?

34
Type 1, Type 2 errors, and Power

35
Type 2 error and Power
• When we lower the chance of committing a Type 1 error, we increase the chance of committing another type of error, a Type 2 error (holding other factors constant).
• A Type 2 error occurs when we fail to reject H0 when it is false.
• Type 2 error is also known as beta. • From Type 2 error, we get an important concept:
How well can a test reject H0 when it should be rejected? This is the power of a test.
• Power of a test is calculated by (1 - beta). • You don’t have to know how to calculate beta; it will be
given or set by you.

36
Factors affecting power of a test
– Effect size: • The larger the effect size, the smaller beta, and hence the
larger the power (holding alpha (significance level) and sample size constant).
– Sample size:• The larger the sample size, the smaller the beta, and hence
the larger the power (holding alpha and effect size constant)
– Measurement errors• The less measurement errors the more power


















