
1 Cloudera Impala and improvements in HDFS for real-time queries Todd Lipcon Software Engineer,...
49
1 Cloudera Impala and improvements in HDFS for real-time queries Todd Lipcon Software Engineer, Cloudera
-
Upload
mercy-watkins -
Category
Documents
-
view
220 -
download
0
Transcript of 1 Cloudera Impala and improvements in HDFS for real-time queries Todd Lipcon Software Engineer,...

1
Cloudera Impala and improvements in HDFS for real-time queriesTodd LipconSoftware Engineer, Cloudera

你好 !
• Todd Lipcon• Email: [email protected] / [email protected]• Twitter: @tlipcon
• Software Engineer at Cloudera since 2009• Hadoop and HBase PMC Member / Committer at
Apache Software Foundation• Primarily work on HDFS and other Storage projects
• Best known for writing about 80% of HDFS HA support• …but also know a lot about the Impala code
2

Outline
• Cloudera and the Enterprise Data Hub (less technical)• Impala introduction/architecture (medium technical)• New requirements for HDFS (very technical)
• Block replica / disk placement info• In-memory caching for hot files• Short-circuit reads, reduced copy overhead
• Performance benchmarks
3

Ask Bigger Questions
Cloudera and theEnterprise Data Hub
5
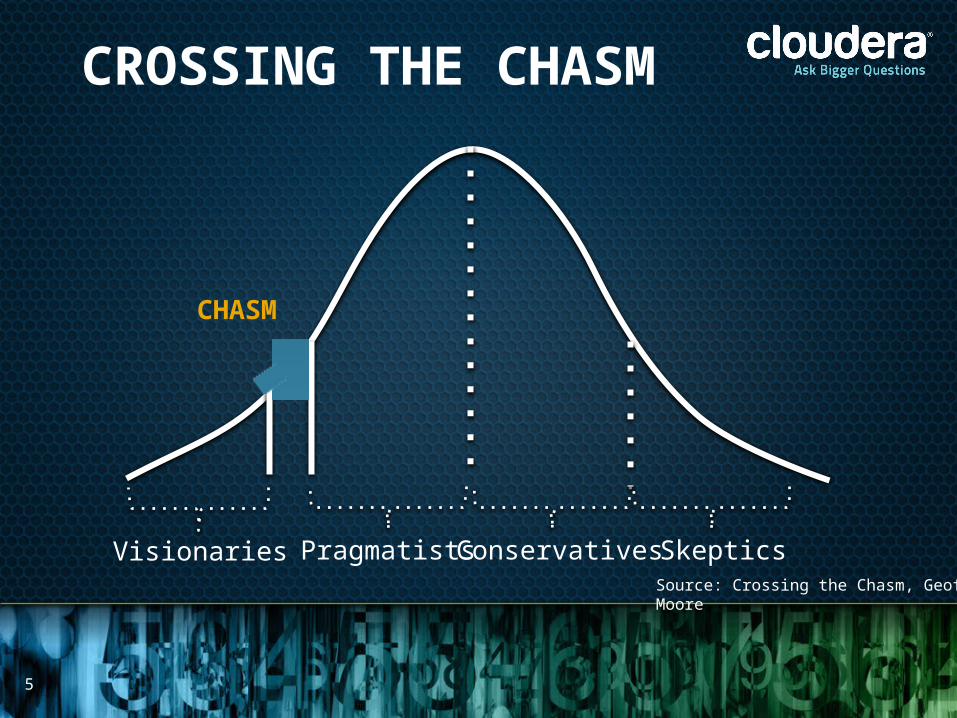
CROSSING THE CHASM
CHASM
Source: Crossing the Chasm, Geoff Moore
Visionaries Pragmatists Conservatives Skeptics

6
Hadoop has matured
• Hadoop 2 with HDFS HA and YARN• Security with Apache Sentry• Data Governance with emphasis on metadata,
discovery, auditing and most importantly lineage• Reliability with Backup and Disaster Recovery• Most importantly open both in Source and Platform.

7
The Future for Data
is Hadoop
Hadoop is moving to the Center of IT

8
The Future for Data
is Hadoop
The Enterprise Data Hub: One Unified System
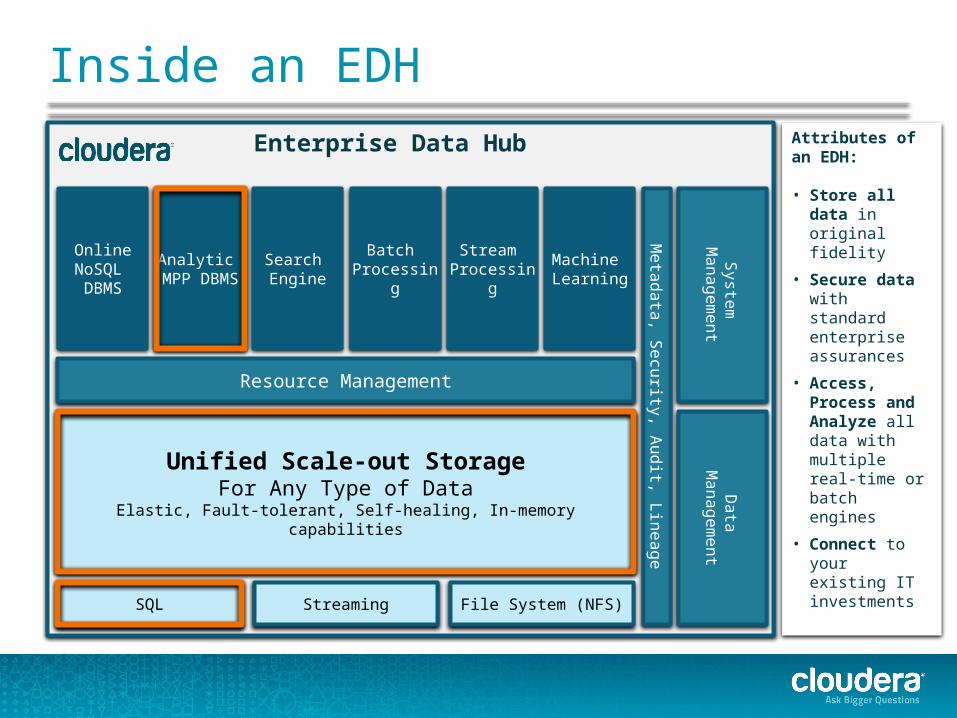
Enterprise Data Hub
Inside an EDH
Unified Scale-out StorageFor Any Type of Data
Elastic, Fault-tolerant, Self-healing, In-memory capabilities
Resource Management
Online NoSQL DBMS
Analytic MPP DBMS
Search Engine
Batch Processing
Stream Processing
Machine Learning
SQL Streaming File System (NFS)
System
Managem
entD
ata M
anagement
Metadata, Security, Audit, Lineage
Attributes of an EDH:
• Store all data in original fidelity
• Secure data with standard enterprise assurances
• Access, Process and Analyze all data with multiple real-time or batch engines
• Connect to your existing IT investments

IMPALA INTRODUCTION

11
Cloudera Impala
Interactive SQL for Hadoop Responses in seconds or milliseconds Nearly ANSI-92 standard SQL. Fully compatible with Hive QL
Native MPP Query Engine Built for low-latency queries Separate runtime from MapReduce Designed as part of the Hadoop ecosystem
Open Source Apache-licensed, C++ and Java code base http://github.com/cloudera/impala

12
Not All SQL On Hadoop Is Created Equal
Batch MapReduceMake MapReduce faster
Slow, still batch
Remote QueryPull data from HDFS over the network to the DW
compute layer
Slow, expensive
Separate DBMSLoad data into a
proprietary database file
Rigid, separate data,slow ETL
ImpalaNative MPP query engine
that’s integrated into Hadoop
Fast, flexible, cost-effective
$

IMPALA ARCHITECTURE
14
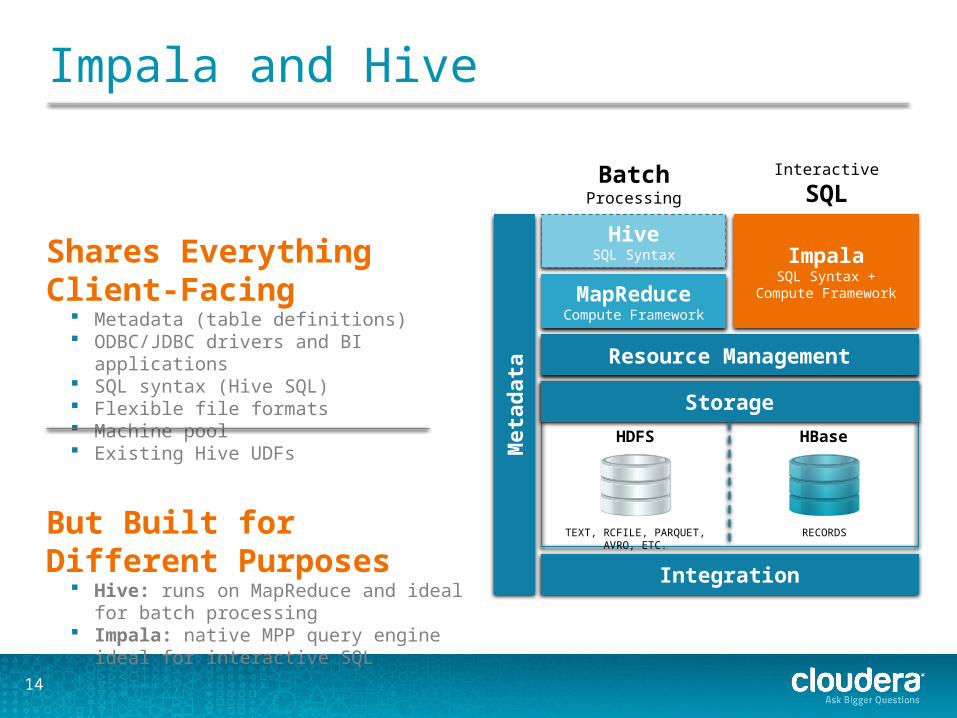
Impala and Hive
Shares Everything Client-Facing Metadata (table definitions) ODBC/JDBC drivers and BI applications SQL syntax (Hive SQL) Flexible file formats Machine pool Existing Hive UDFs
But Built for Different Purposes Hive: runs on MapReduce and ideal for batch
processing Impala: native MPP query engine ideal for
interactive SQL
Storage
Integration
Resource Management
Met
adat
a
HDFS HBase
TEXT, RCFILE, PARQUET, AVRO, ETC. RECORDS
HiveSQL Syntax Impala
SQL Syntax +Compute FrameworkMapReduce
Compute Framework
BatchProcessing
Interactive
SQL

15
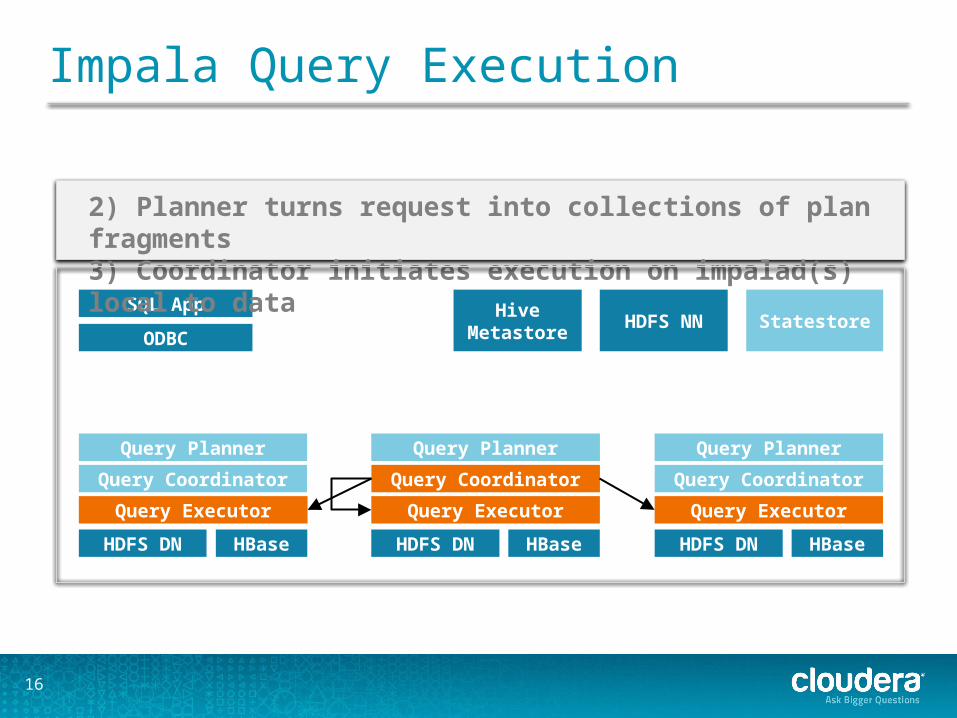
Impala Query Execution
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
SQL App
ODBCHive
Metastore HDFS NN Statestore
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
SQL request
1) Request arrives via ODBC/JDBC/Beeswax/Shell
16
Impala Query Execution
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
SQL App
ODBCHive
Metastore HDFS NN Statestore
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
2) Planner turns request into collections of plan fragments3) Coordinator initiates execution on impalad(s) local to data

17
Impala Query Execution
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
SQL App
ODBCHive
Metastore HDFS NN Statestore
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
Query Planner
Query Coordinator
Query Executor
HDFS DN HBase
4) Intermediate results are streamed between impalad instances5) Query results are streamed back to client
Query results

18
What makes Impala fast?
• LLVM based Just-In-Time (JIT) code generation• Query execution at maximum CPU speed, optimized for
modern processors (SSE4.2, etc)• Low query startup overhead
• Always-on service (no JVM launch overhead)• Cached table metadata
• Efficient file formats and I/O scheduling• Use full disk speed from all available disks
• HDFS developments specifically for Impala performance

HDFS IMPROVEMENTS MOTIVATED BY IMPALA

HDFS Improvements: Motivation
• HDFS originally built for large batch jobs (MR)• Impala is concerned with very low latency queries
• Need to make best use of available aggregate disk throughput and CPU resources
• Impala’s more CPU-efficient execution engine is far more likely to be I/O bound as compared to Hive• For many queries the best performance improvement will
be from improved I/O• How can we improve HDFS’s raw bytes/second and
bytes/cycle throughput?
20

HDFS Improvements: Outline
• Reducing disk contention with I/O scheduling• In-memory caching of hot tables/files• Reduced copies during reading, short-circuit reads
21

Reducing I/O contention on disks
• The problem: many plan fragments run concurrently, and may contend with each other on spinning disks.
• Impala wants to make sure that concurrent plan fragments operate on data on separate disks• Avoid disk contention and seeks• Maximize aggregate available disk throughput
22

23
Scheduling without disk awareness
CPU Core 1
CPU Core 2
CPU Core 3
CPU Core 4
Block 1Block 2Block 3Block 4Block 5Block 6Block 7Block 8Block 9
Block 10Block 11Block 12
Query fragments
Block 7
Block 10
Block 1Block 2
Block 4
Block 5
Block 6Block 8
Block 9
Block 11
Block 12
Disk 1
Disk 2
Disk 3
Disk 4
Block 3
Query arrives, which must process 12 blocks
These blocks are randomly
distributed across 4 disks
Blocks are assigned in FIFO order to CPU cores
Disks 1 and 2 are overloaded. Disks 3 and 4 are wasted!
50% waste

Block Replica Disk Location Data
• The solution: add new API to return which disks each replica is stored on
• During query planning phase, impalad…• Determines all DNs data for query is stored on• Queries those DNs to get volume information
• During query execution phase, impalad…• Queues disk reads to per-disk queues so that each disk
always has one active reader
• (included in CDH4 and Apache Hadoop 2.x)
24
25
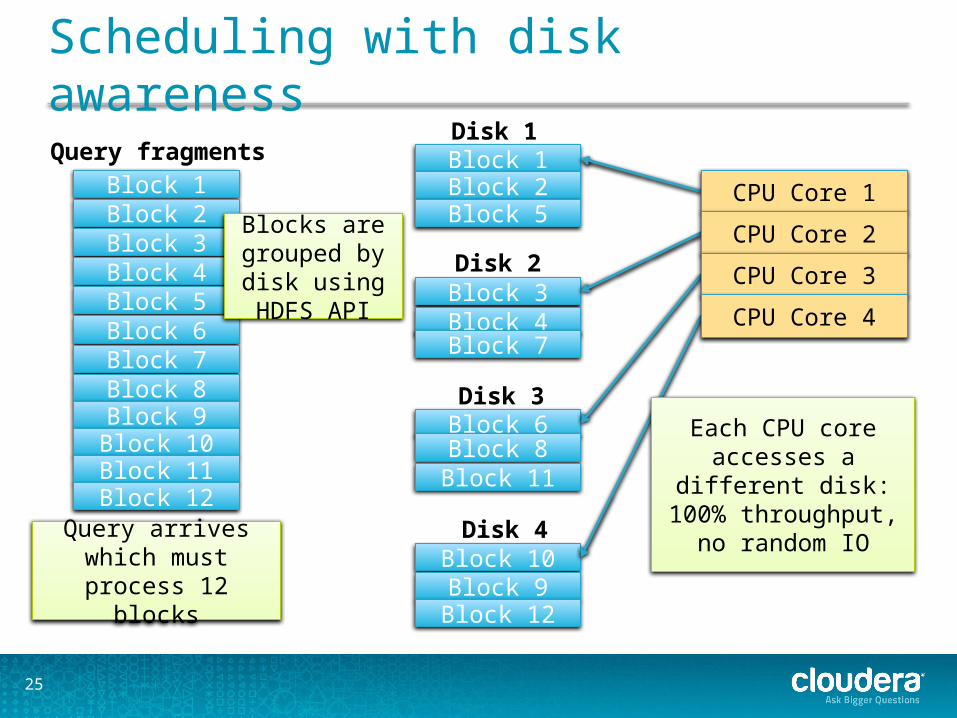
Scheduling with disk awareness
Block 1Block 2Block 3Block 4Block 5Block 6Block 7Block 8Block 9
Block 10Block 11Block 12
Query fragments
Query arrives which must process 12 blocks
Blocks are grouped by disk using HDFS API
Block 10
Block 1Block 2
Block 3Block 4
Block 5
Block 6
Block 7
Block 8
Block 9
Block 11
Block 12
Disk 1
Disk 2
Disk 3
Disk 4
Each CPU core accesses a different disk:
100% throughput,no random IO
CPU Core 1
CPU Core 2
CPU Core 3
CPU Core 4

In-memory Caching
• The problem: Impala queries are often bottlenecked at maximum disk throughput (~1GB/sec for 10 disks)
• Memory throughput is much higher (~25GB/sec)• Memory is getting cheaper/denser
• Slave nodes with 96+GB of RAM• If you put a table in RAM, we want to give a 25x
speed boost.• How do we give users this 25x speed boost?
26

In-memory Caching
• The solution: Let HDFS explicitly mlock specific files into memory
• Allows Impala to query data at full memory bandwidth speeds (25+ GB/s/node)
• Give cluster operator control over which files/tables should be kept in RAM• For example, “cache all data in the table partitions for this
week”• Later, we will add LRU/LFU policies
• Upcoming in Hadoop 2.3 / CDH5
27

Fewer Copies/Short-circuit Reads
• The problem: A typical read in HDFS resulted in many extra memory copies, wasting CPU.• Buffer cache -> Network socket (sendfile())• Network socket -> JVM buffer (read() syscall)• JVM buffer -> byte[] (Java InputStream.read())• For C clients: byte[] -> char* (libhdfs hdfsRead())
• Competition: Traditional RDBMS engines have no copies in data path
28

Fewer Copies/Short-circuit Reads
• The solution: Allow for reads to be performed directly on local files, with fewer copies
• Short circuit reads: Added facility to HDFS to allow for reads to completely bypass DataNode when client co-located with block replica files
• Direct read API: Added API in libhdfs to supply direct “char*” buffers to HDFS read operations• reduces number of copies to bare minimum (1-copy)
• Zero-copy read API: Added API in libhdfs which returns a buffer of cached data (zero-copy/mmap)
• All available in Hadoop 2.x29

• This can also benefit apps like HBase and MR• mmap-based zero-copy read for cached files is “infinitely fast” (just char*
pointer assignment)
libhdfs “direct read” support (HDFS-2834)
30

You might be surprised
ResultsJust how fast is Impala?
31
32
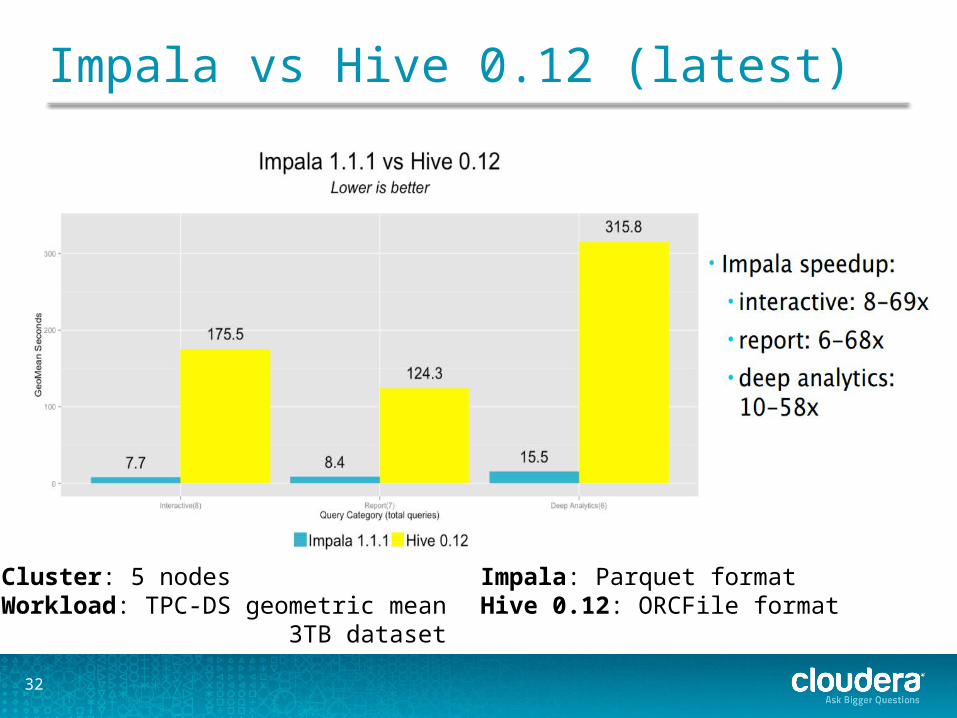
Impala vs Hive 0.12 (latest)
Cluster: 5 nodesWorkload: TPC-DS geometric mean 3TB dataset
Impala: Parquet formatHive 0.12: ORCFile format

Impala vs commercial MPP RDBMS
33
“DeWitt Clause” prohibitsusing DBMS vendor name

Test drive Impala
• Impala Community:• Download: http://cloudera.com/impala• Github: https://github.com/cloudera/impala• User group: impala-user on groups.cloudera.org
34
Copyright © 2013 Cloudera Inc. All rights reserved.
35

36
谢谢 !

37
BACKUP SLIDES

38
Parquet File Format
Open source, columnar Hadoop file format developed by Cloudera & Twitter
Organizes data from the same column together in the file
Read only the columns which are required for a query
Efficient encodings for each type (RLE, Dictionary, etc)
Supports fully nested data
Supports index pages for fast lookup

Why use Parquet Columnar Format for HDFS?•Well defined open format - http://parquet.io/
• Works in Impala, Pig, Hive & Map/Reduce• I/O reduction by only reading necessary columns•Columnar layout compresses/encodes better•Supports nested data by shredding columns
• Uses techniques used by Google’s ColumnIO • Impala loads use Snappy compression by default
• Gzip available: set PARQUET_COMPRESSION_CODEC=gzip;•Quick word on Snappy vs. Gzip
39

Quick Note on Compression
•Snappy• Faster compression/decompression speeds• Less CPU cycles•Lower compression ratio
•Gzip/Zlib• Slower compression/decompression speeds • More CPU cycles•Higher compression ratio
• It’s all about trade-offs
40

It’s all about the compression codec
Compressed with Snappy
Compressed with Gzip
Hortonworks graphic fails to call out that different codecs are
used. Gzip compresses better than Snappy, but
we all knew that.
41
Source: http://hortonworks.com/blog/orcfile-in-hdp-2-better-compression-better-performance/
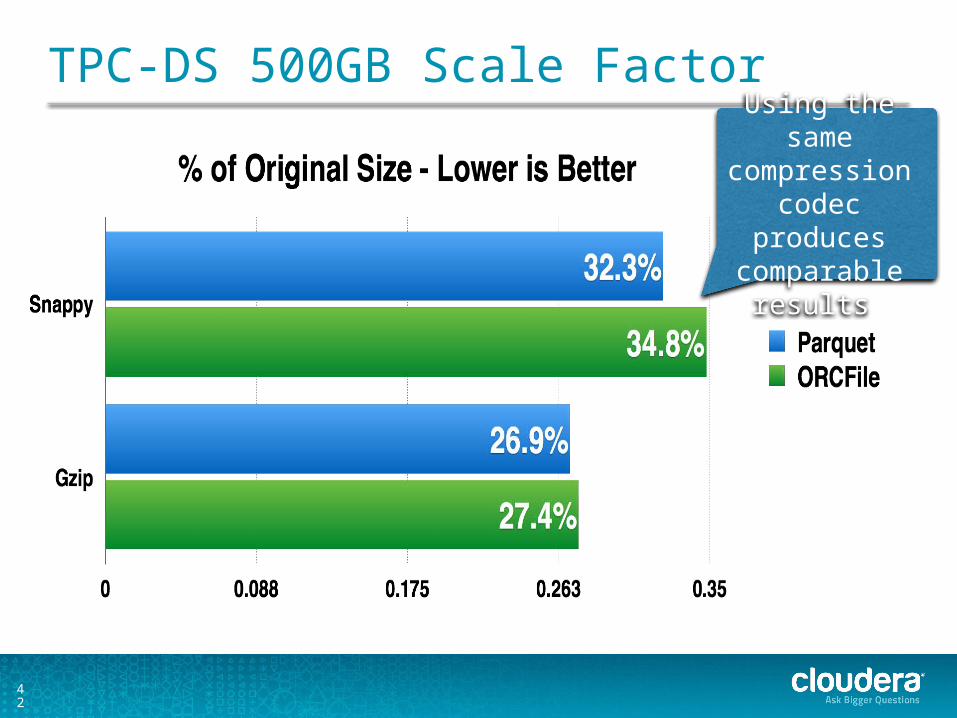
TPC-DS 500GB Scale Factor
42
Using the same compression codec
produces comparable results

HDFS INTRODUCTION

HDFS Introduction
• HDFS is the Hadoop Distributed File System• Append-only distributed file system• Intended to store many very large files
• Block sizes usually 64MB – 512MB• Files composed of several blocks• Scalable to 100+ PB
• Write a file once during ingest• Read a file many times for analysis
44

HDFS Introduction (continued)
• HDFS originally designed specifically for Map/Reduce• Each MR task typically operates on one HDFS block• MR tasks run co-located on HDFS nodes• Data locality: move the code to the data
• Each block of each file is replicated 3 times• For reliability when machines or drives fail• Provide a few options for data locality during processing
45

HDFS ARCHITECTURE

HDFS Architecture
• Each cluster has…• A single Name Node (with High Availability failover)
• Stores file system metadata• Stores “Block ID” -> Data Node mapping
• Many Data Nodes• Store actual file data on local filesystem (eg ext4)
• Clients of HDFS…• Communicate with Name Nodes to browse file system, get block
locations for files• Communicate directly with Data Nodes to read/write files
47
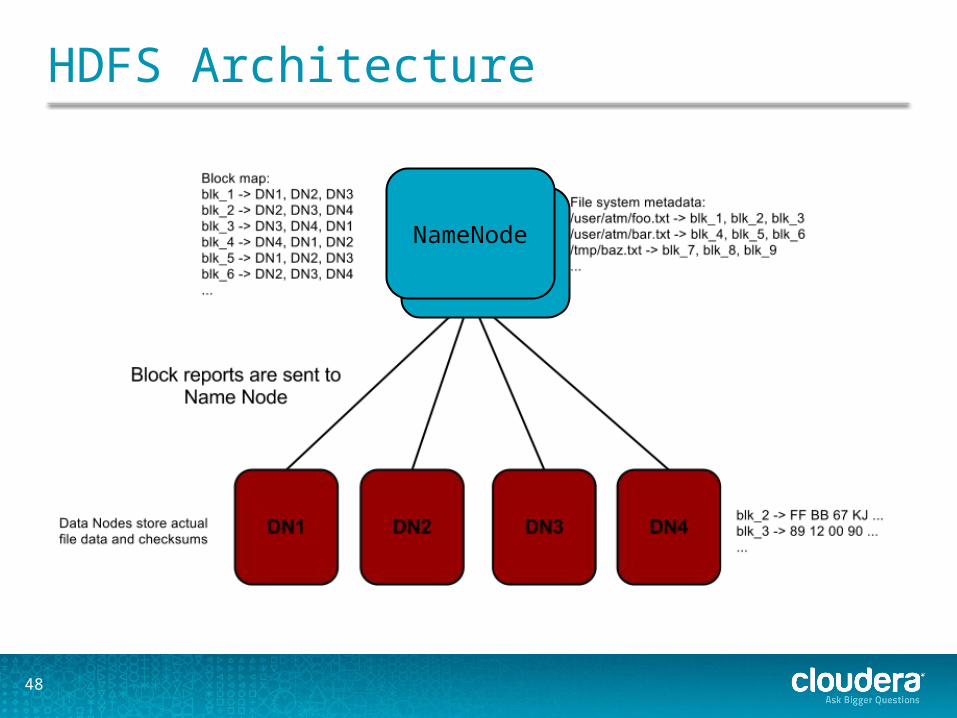
HDFS Architecture
48
NameNodeNameNode

Cloudera’s Enterprise Data Hub
Improve IT Operations• ETL Acceleration• EDW Rationalization• Mainframe Offload
Powerful Security Solution• Risk Analysis• Fraud Prevention• Compliance
Advanced Analytics Engine• 360° Customer View• Recommendation Engines• Processing & Analytics
Infinite Analytic Storage• Multi-Structured Data• In-place Analytics• Active Archive
Integration with Over 200 ISVs• Self-Service BI• Data Exploration• Visualization
Flexible Deployment Options• On-Premise or Cloud• Appliances• Engineered Systems
Enterprise Data Hub


















